

We Need to Communicate: Communicating Attention Network for Semantic Segmentation of High-Resolution Remote Sensing Images

Abstract
:
1. Introduction
- (1)
- To bridge the gap between high-level and low-level features in terms of spatial distribution and physical content, we introduce two attention modules, CMA and CSA. These modules enhance the model’s ability to capture fine targets while maintaining the global semantic modeling capability.
- (2)
- We propose the CANet model for semantic segmentation of high-resolution remote sensing images. The model improves the accuracy of semantic segmentation in urban areas by fusing output features of different scales and levels from the CNN in the encoding stage using the attention mechanism.
2. Related Work
2.1. Semantic Segmentation of Remote Sensing Images
2.2. Attention Mechanism
2.3. Multi-Scale Feature Fusion
3. Materials and Methods
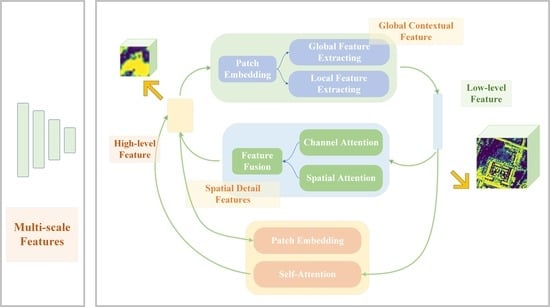
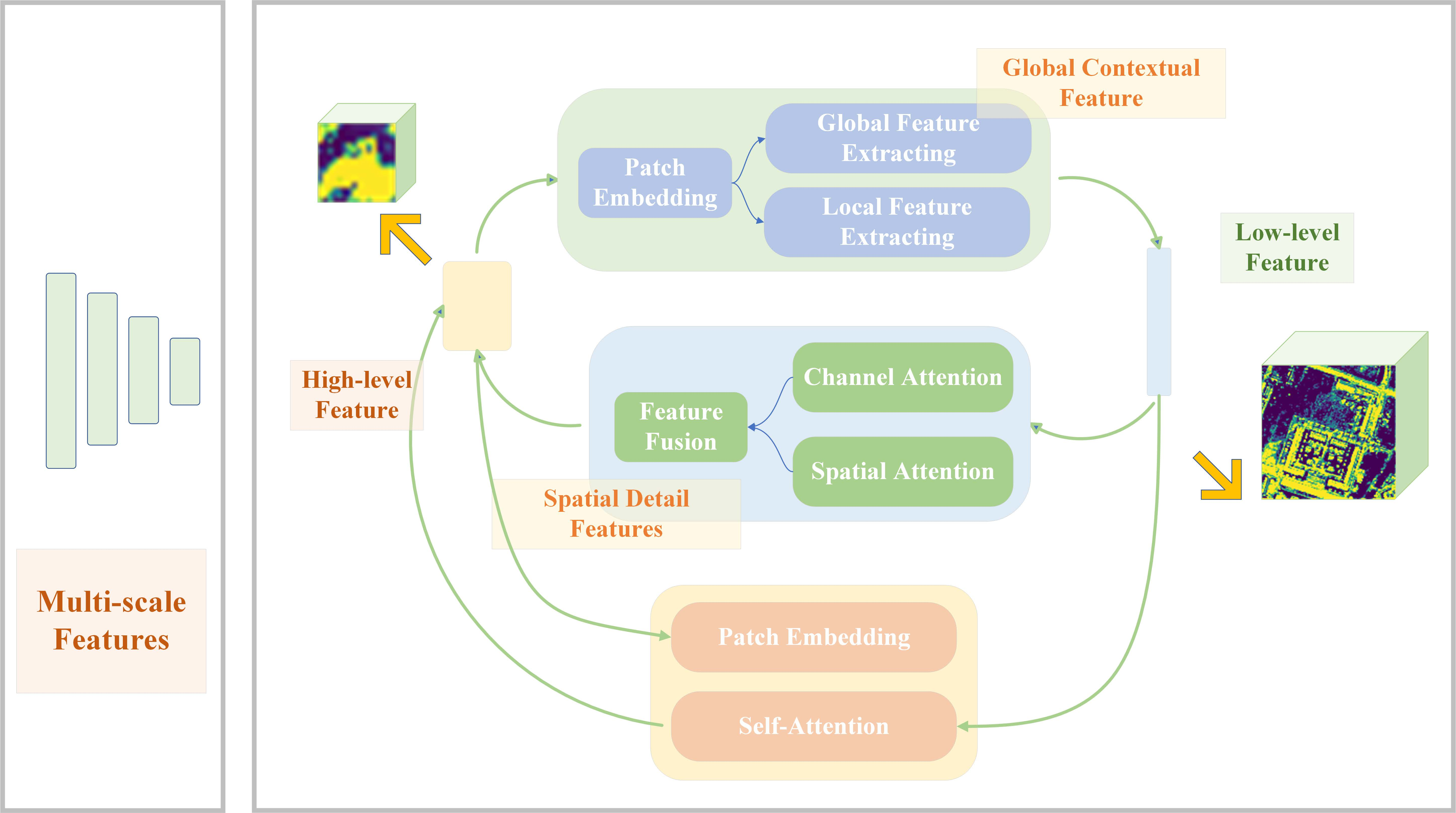
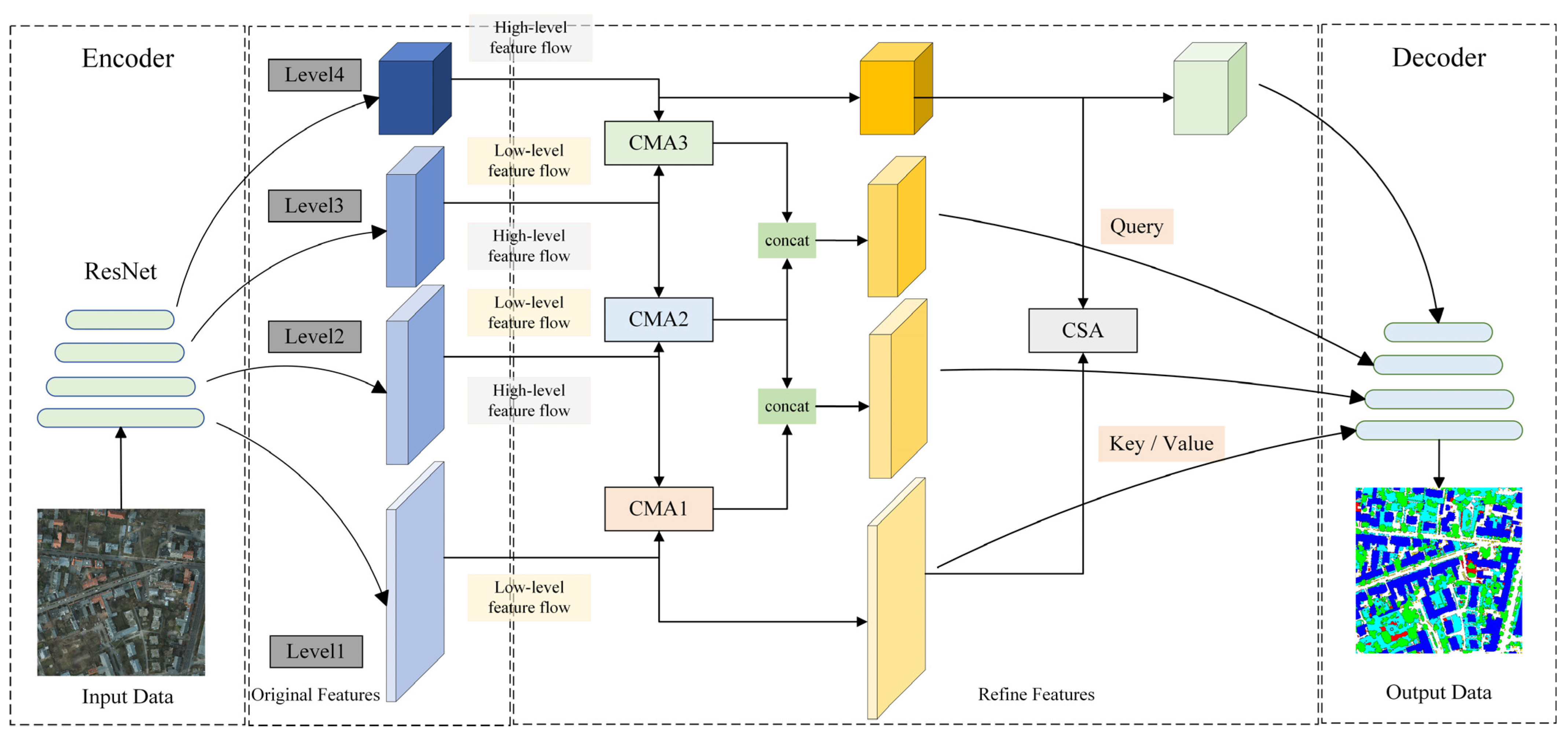
3.1. Approach Overview
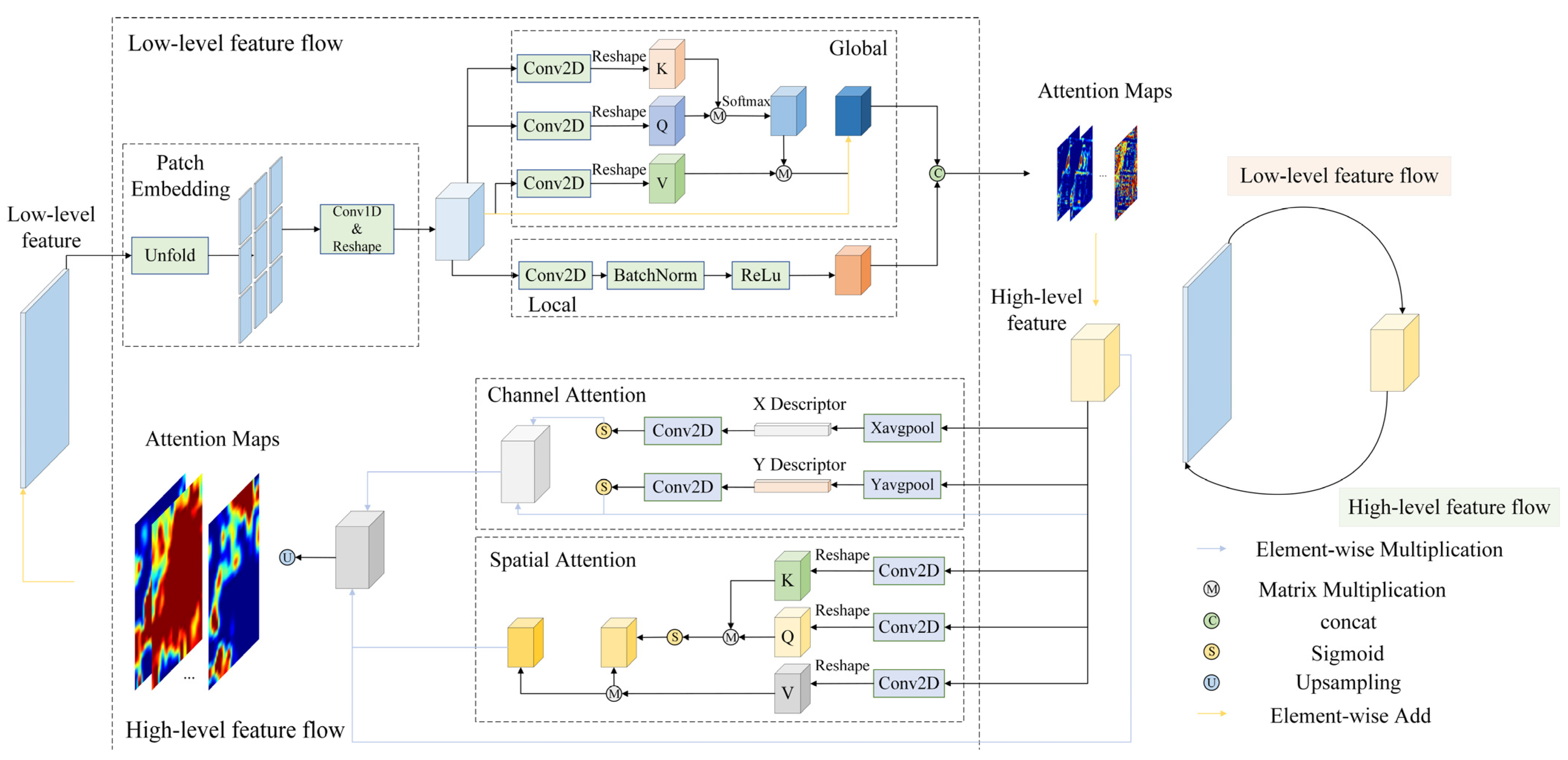
3.2. Communicating Mutual Attention (CMA)
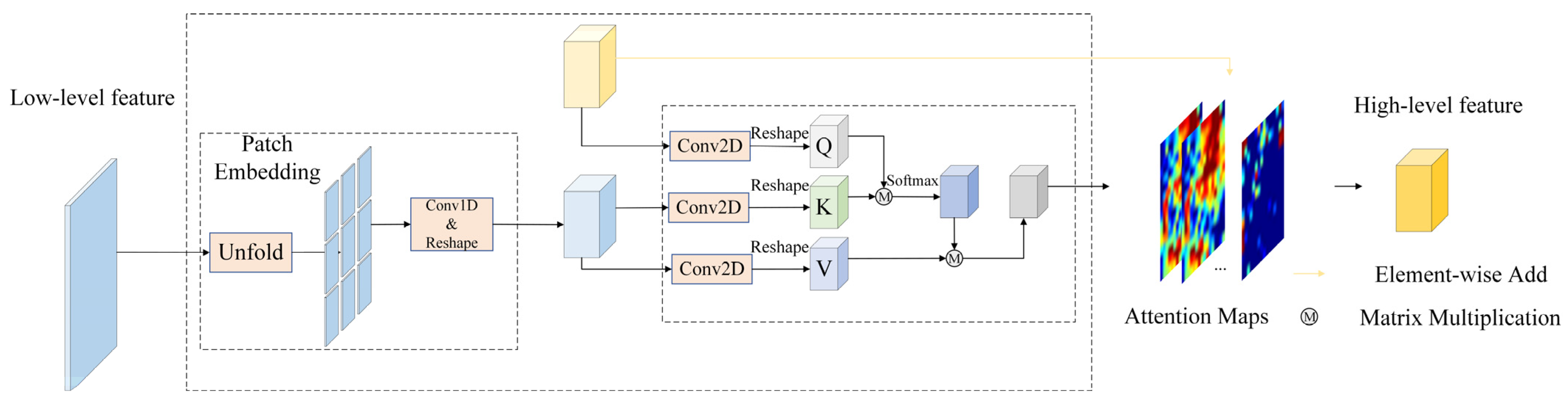
3.3. Communicating Self Attention (CSA)
3.4. Communicating Attention Network (CANet)
| Algorithm 1 The algorithm implementation process of CANet (Vaihingen dataset) |
| Input: (NIR, R, G, DSM) Output: (Prediction results of semantic segmentation) // Step1: Extracting multi-level feature maps from the encoder = // Step2: CMA and CSA performs characteristic aggregation of multi-level features for i in {1, 2, 3} do = end = // Step3: Skip connection of refine features to decoders for i in {1, 2, 3, 4} do = + end // Step4: Output prediction results = end |
3.5. Loss Function
3.6. Dataset
3.7. Data Pre-Processing and Experimental Setting
3.8. Accuracy Evaluation
4. Results
4.1. Ablation Study
4.2. Quantitative Comparison of Various Modules
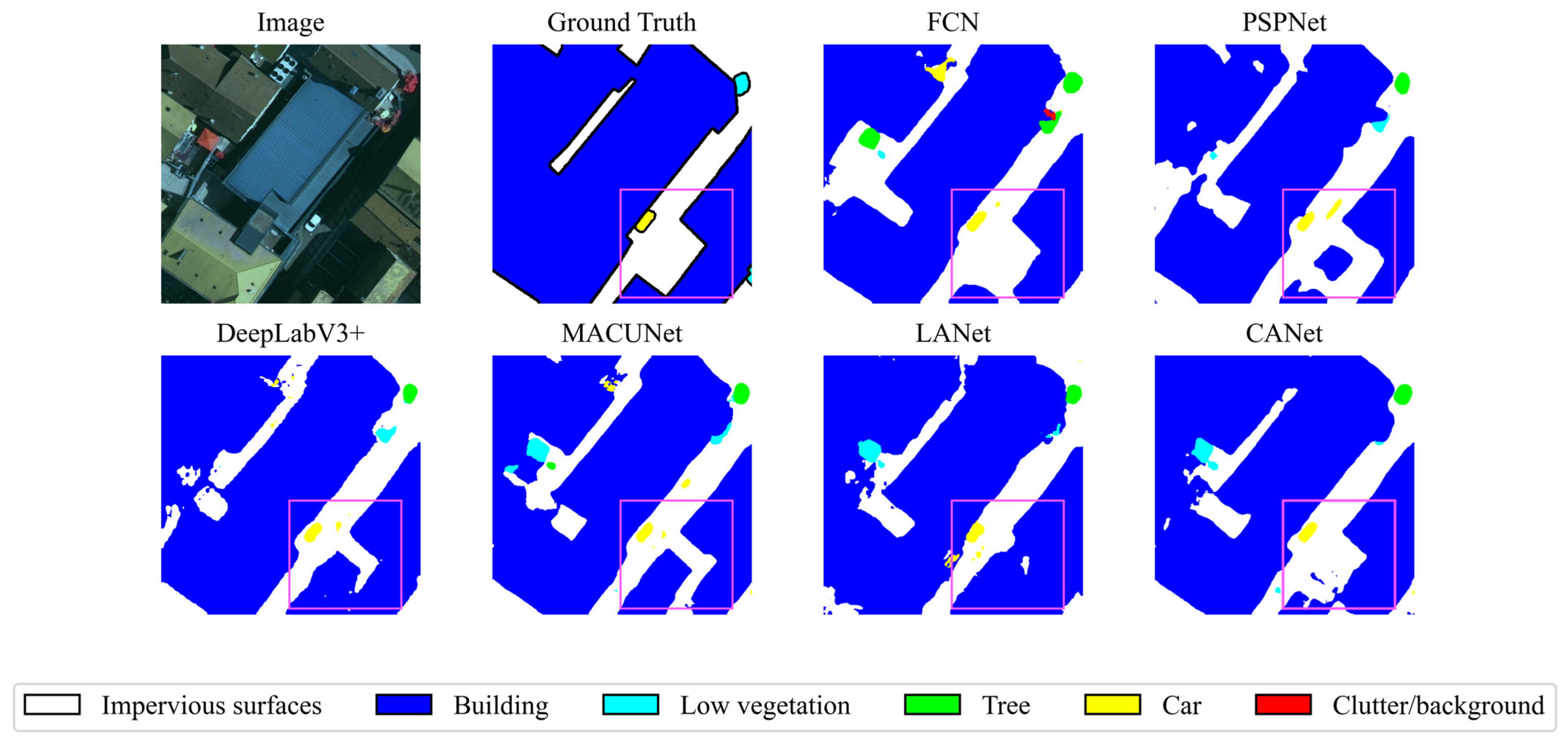
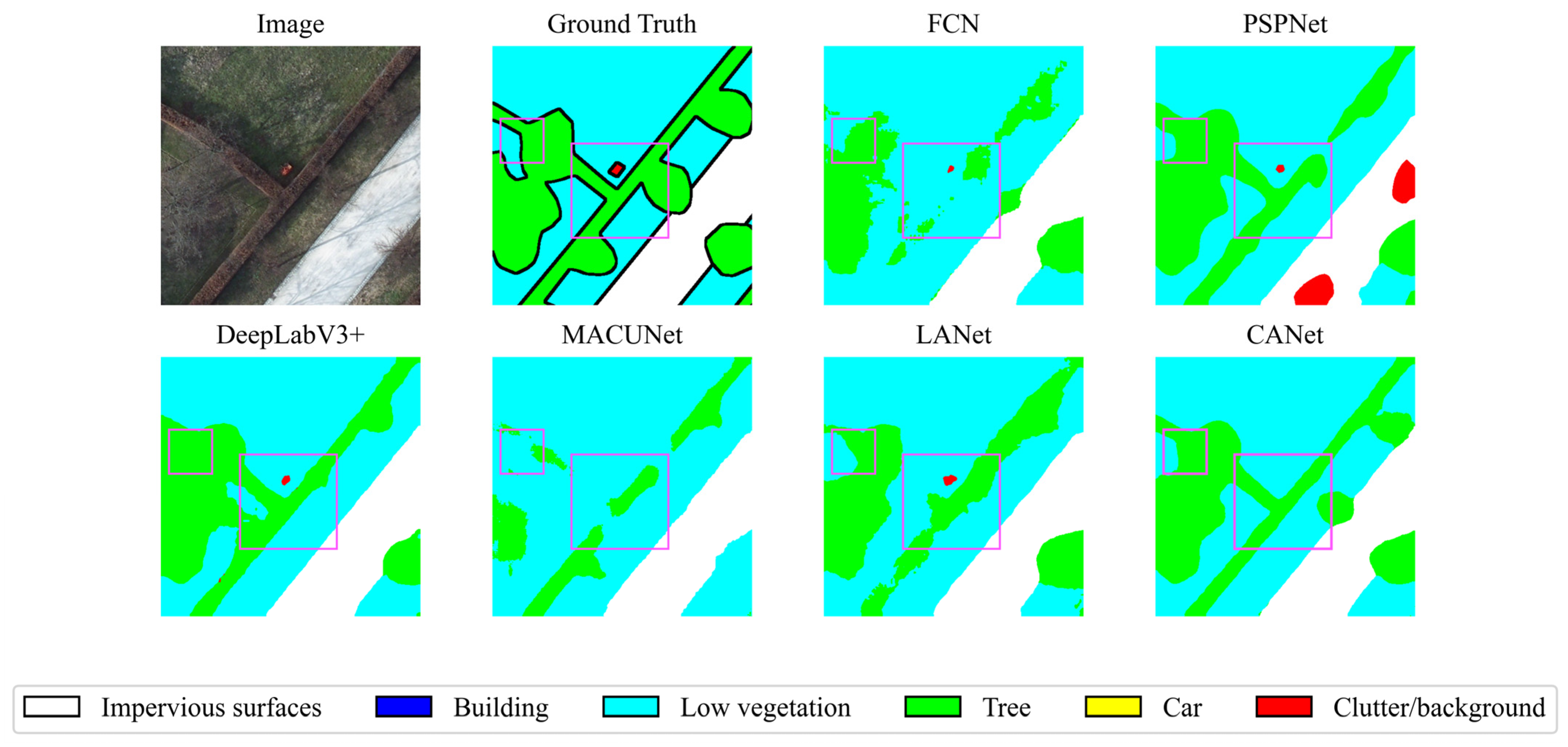
4.3. Quantitative Comparison of Various Models
5. Discussion
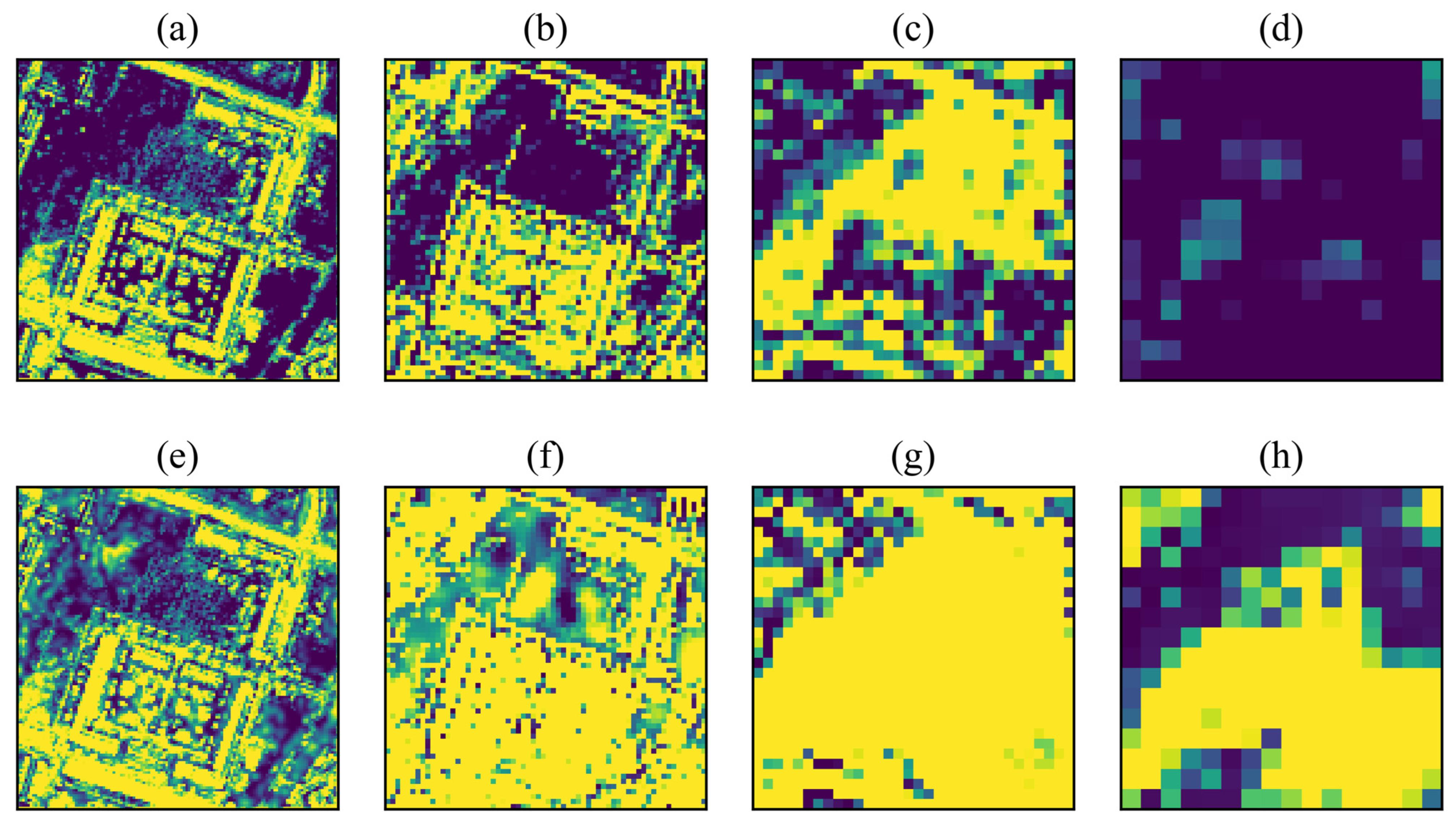
5.1. Interaction of High-Level and Low-Level Features
5.2. Number of High-Level and Low-Level Feature Cycles
5.3. Computational Complexity of the Algorithm
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yuan, X.; Shi, J.; Gu, L. A review of deep learning methods for semantic segmentation of remote sensing imagery. Expert Syst. Appl. 2021, 169, 114417. [Google Scholar] [CrossRef]
- Kemker, R.; Salvaggio, C.; Kanan, C. Algorithms for semantic segmentation of multispectral remote sensing imagery using deep learning. ISPRS J. Photogramm. Remote Sens. 2018, 145, 60–77. [Google Scholar] [CrossRef] [Green Version]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Chen, W.; Xie, S.M.; Azzari, G.; Lobell, D.B. Weakly supervised deep learning for segmentation of remote sensing imagery. Remote Sens. 2020, 12, 207. [Google Scholar] [CrossRef] [Green Version]
- Shafique, A.; Cao, G.; Khan, Z.; Asad, M.; Aslam, M. Deep learning-based change detection in remote sensing images: A review. Remote Sens. 2022, 14, 871. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Lei, L.; Zou, H. Multi-scale object detection in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2018, 145, 3–22. [Google Scholar] [CrossRef]
- Carvalho, O.L.F.D.; de Carvalho Júnior, O.A.; Albuquerque, A.O.D.; Bem, P.P.D.; Silva, C.R.; Ferreira, P.H.G.; Moura, R.D.S.D.; Gomes, R.A.T.; Guimaraes, R.F.; Borges, D.L. Instance segmentation for large, multi-channel remote sensing imagery using mask-RCNN and a mosaicking approach. Remote Sens. 2020, 13, 39. [Google Scholar] [CrossRef]
- Chen, M.; Wu, J.; Liu, L.; Zhao, W.; Tian, F.; Shen, Q.; Zhao, B.; Du, R. DR-Net: An improved network for building extraction from high resolution remote sensing image. Remote Sens. 2021, 13, 294. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional neural networks for large-scale remote-sensing image classification. IEEE Trans. Geosci. Remote Sens. 2016, 55, 645–657. [Google Scholar] [CrossRef] [Green Version]
- Ali, M.; Clausi, D. Using the Canny edge detector for feature extraction and enhancement of remote sensing images. In Proceedings of the IGARSS 2001. Scanning the Present and Resolving the Future. Proceedings. IEEE 2001 International Geoscience and Remote Sensing Symposium (Cat. No. 01CH37217), Sydney, NSW, Australia, 9–13 July 2001; pp. 2298–2300. [Google Scholar]
- Wang, Z.; Jensen, J.R.; Im, J. An automatic region-based image segmentation algorithm for remote sensing applications. Environ. Model. Softw. 2010, 25, 1149–1165. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Alam, M.; Wang, J.-F.; Guangpei, C.; Yunrong, L.; Chen, Y. Convolutional neural network for the semantic segmentation of remote sensing images. Mob. Netw. Appl. 2021, 26, 200–215. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ghassemian, H. A review of remote sensing image fusion methods. Inf. Fusion 2016, 32, 75–89. [Google Scholar] [CrossRef]
- Ding, L.; Tang, H.; Bruzzone, L. LANet: Local attention embedding to improve the semantic segmentation of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 426–435. [Google Scholar] [CrossRef]
- Yang, M.Y.; Kumaar, S.; Lyu, Y.; Nex, F. Real-time semantic segmentation with context aggregation network. ISPRS J. Photogramm. Remote Sens. 2021, 178, 124–134. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Wang, L.; Atkinson, P.M. ABCNet: Attentive bilateral contextual network for efficient semantic segmentation of Fine-Resolution remotely sensed imagery. ISPRS J. Photogramm. Remote Sens. 2021, 181, 84–98. [Google Scholar] [CrossRef]
- Ju, J.; Gopal, S.; Kolaczyk, E.D. On the choice of spatial and categorical scale in remote sensing land cover classification. Remote Sens. Environ. 2005, 96, 62–77. [Google Scholar] [CrossRef]
- Pham, H.M.; Yamaguchi, Y.; Bui, T.Q. A case study on the relation between city planning and urban growth using remote sensing and spatial metrics. Landsc. Urban Plan. 2011, 100, 223–230. [Google Scholar] [CrossRef]
- Li, J.; Pei, Y.; Zhao, S.; Xiao, R.; Sang, X.; Zhang, C. A review of remote sensing for environmental monitoring in China. Remote Sens. 2020, 12, 1130. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. pp. 234–241. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Lv, Z.; Zhang, P.; Sun, W.; Benediktsson, J.A.; Li, J.; Wang, W. Novel Adaptive Region Spectral-Spatial Features for Land Cover Classification with High Spatial Resolution Remotely Sensed Imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5609412. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2015; Volume 28. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Su, J.; Wang, L.; Atkinson, P.M. Multiattention network for semantic segmentation of fine-resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Li, X.; Lei, L.; Sun, Y.; Li, M.; Kuang, G. Collaborative attention-based heterogeneous gated fusion network for land cover classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 3829–3845. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Zhang, T.; Qi, G.-J.; Xiao, B.; Wang, J. Interleaved group convolutions. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4373–4382. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Ding, L.; Lin, D.; Lin, S.; Zhang, J.; Cui, X.; Wang, Y.; Tang, H.; Bruzzone, L. Looking outside the window: Wide-context transformer for the semantic segmentation of high-resolution remote sensing images. arXiv 2021, arXiv:2106.15754. [Google Scholar] [CrossRef]
- Li, R.; Duan, C.; Zheng, S.; Zhang, C.; Atkinson, P.M. MACU-Net for semantic segmentation of fifine-resolution remotely sensed images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Imp. Surf. | Building | Low Veg. | Tree | Car | Mean F1 | OA | mIoU |
|---|---|---|---|---|---|---|---|---|
| FCN [24] | 89.05 | 91.54 | 79.01 | 87.10 | 84.22 | 86.18 | 87.0 | 75.97 |
| FCN + CMA1 | 91.30 | 94.69 | 81.20 | 88.11 | 86.50 | 88.36 | 89.12 | 79.44 |
| FCN + CMA2 | 92.21 | 94.96 | 82.29 | 88.51 | 86.75 | 88.95 | 89.79 | 80.38 |
| FCN + CMA3 | 91.35 | 94.37 | 81.10 | 87.87 | 87.77 | 88.49 | 89.0 | 79.64 |
| FCN + CMA123 | 91.67 | 94.58 | 83.31 | 88.94 | 87.84 | 89.27 | 89.83 | 80.83 |
| FCN + CSA | 90.82 | 94.44 | 80.56 | 87.95 | 86.48 | 88.05 | 88.80 | 78.96 |
| CANet | 92.49 | 95.26 | 83.34 | 89.18 | 87.75 | 89.61 | 90.33 | 81.41 |
| Dataset | Method | Mean F1 | OA | mIoU |
|---|---|---|---|---|
| Vaihingen | FCN [24] | 86.18 | 87.0 | 75.97 |
| FCN + SE [32] | 87.23 | 89.71 | 77.89 | |
| FCN + CBAM [33] | 88.19 | 89.96 | 79.61 | |
| FCN + PPM [40] | 86.47 | 89.36 | 76.78 | |
| FCN + ASPP [27] | 86.77 | 89.12 | 77.12 | |
| FCN + PAM and AEM [18] | 88.09 | 89.83 | - | |
| CANet | 89.61 | 90.33 | 81.41 | |
| FCN [24] | 88.05 | 88.02 | 81.41 | |
| Potsdam | FCN + SE [32] | 91.39 | 89.60 | 85.38 |
| FCN + CBAM [33] | 91.73 | 89.89 | 85.65 | |
| FCN + PPM [40] | 89.98 | 90.14 | 81.99 | |
| FCN + ASPP [27] | 90.86 | 89.18 | 84.24 | |
| FCN + PAM and AEM [18] | 91.95 | 90.84 | - | |
| CANet | 92.60 | 91.44 | 86.48 |
| Method | Imp.Surf. | Building | Low Veg. | Tree | Car | Mean F1 | OA | mIoU |
|---|---|---|---|---|---|---|---|---|
| FCN [24] | 89.05 | 91.54 | 79.01 | 87.10 | 84.22 | 86.18 | 87.0 | 75.97 |
| PSPNet [40] | 90.83 | 94.48 | 80.51 | 88.28 | 84.14 | 87.65 | 88.83 | 78.35 |
| DeepLabV3+ [27] | 90.41 | 94.05 | 80.27 | 88.31 | 78.64 | 86.34 | 88.50 | 76.44 |
| MACUNet [47] | 91.66 | 93.67 | 80.76 | 87.78 | 83.66 | 87.51 | 88.80 | 78.11 |
| LANet [18] | 92.41 | 94.90 | 82.89 | 88.92 | 81.31 | 88.09 | 89.83 | - |
| CANet | 92.49 | 95.26 | 83.34 | 89.18 | 87.75 | 89.61 | 90.33 | 81.41 |
| Method | Imp.Surf. | Building | Low Veg. | Tree | Car | Mean F1 | OA | mIoU |
|---|---|---|---|---|---|---|---|---|
| FCN [24] | 92.24 | 95.35 | 84.29 | 83.12 | 94.53 | 89.19 | 88.60 | 82.06 |
| PSPNet [40] | 90.80 | 95.17 | 85.76 | 86.99 | 91.14 | 89.97 | 88.82 | 81.94 |
| DeepLabV3+ [27] | 91.59 | 96.03 | 86.09 | 86.50 | 94.23 | 90.59 | 89.41 | 83.54 |
| MACUNet [47] | 92.64 | 97.00 | 86.30 | 87.49 | 95.14 | 91.71 | 90.36 | 84.97 |
| LANet [18] | 93.05 | 97.19 | 87.30 | 88.04 | 94.19 | 91.95 | 90.84 | - |
| CANet | 93.91 | 97.22 | 87.59 | 88.23 | 96.07 | 92.60 | 91.44 | 86.48 |
| Cycle Number | Imp.Surf. | Building | Low Veg. | Tree | Car | Mean F1 | OA | mIoU |
|---|---|---|---|---|---|---|---|---|
| 1 | 92.49 | 95.26 | 83.34 | 89.18 | 87.75 | 89.61 | 90.33 | 81.41 |
| 2 | 92.41 | 95.02 | 82.82 | 88.91 | 87.12 | 89.26 | 90.07 | 80.86 |
| 3 | 91.75 | 94.57 | 82.54 | 88.27 | 86.04 | 88.64 | 89.55 | 79.85 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meng, X.; Zhu, L.; Han, Y.; Zhang, H. We Need to Communicate: Communicating Attention Network for Semantic Segmentation of High-Resolution Remote Sensing Images. Remote Sens. 2023, 15, 3619. https://doi.org/10.3390/rs15143619
Meng X, Zhu L, Han Y, Zhang H. We Need to Communicate: Communicating Attention Network for Semantic Segmentation of High-Resolution Remote Sensing Images. Remote Sensing. 2023; 15(14):3619. https://doi.org/10.3390/rs15143619
Chicago/Turabian StyleMeng, Xichen, Liqun Zhu, Yilong Han, and Hanchao Zhang. 2023. "We Need to Communicate: Communicating Attention Network for Semantic Segmentation of High-Resolution Remote Sensing Images" Remote Sensing 15, no. 14: 3619. https://doi.org/10.3390/rs15143619
APA StyleMeng, X., Zhu, L., Han, Y., & Zhang, H. (2023). We Need to Communicate: Communicating Attention Network for Semantic Segmentation of High-Resolution Remote Sensing Images. Remote Sensing, 15(14), 3619. https://doi.org/10.3390/rs15143619