Figure 1.
Technical flowchart.
Figure 1.
Technical flowchart.
Figure 2.
Image transformation: (a) original image; (b) cut-out images; (c) adding salt and pepper noise; (d) adding Gaussian noise; (e) adding salt and pepper and Gaussian noise; (f,g,h) rotating 90°, 180°, 270° anticlockwise; (i) horizontal flip; (j) vertical flip.
Figure 2.
Image transformation: (a) original image; (b) cut-out images; (c) adding salt and pepper noise; (d) adding Gaussian noise; (e) adding salt and pepper and Gaussian noise; (f,g,h) rotating 90°, 180°, 270° anticlockwise; (i) horizontal flip; (j) vertical flip.
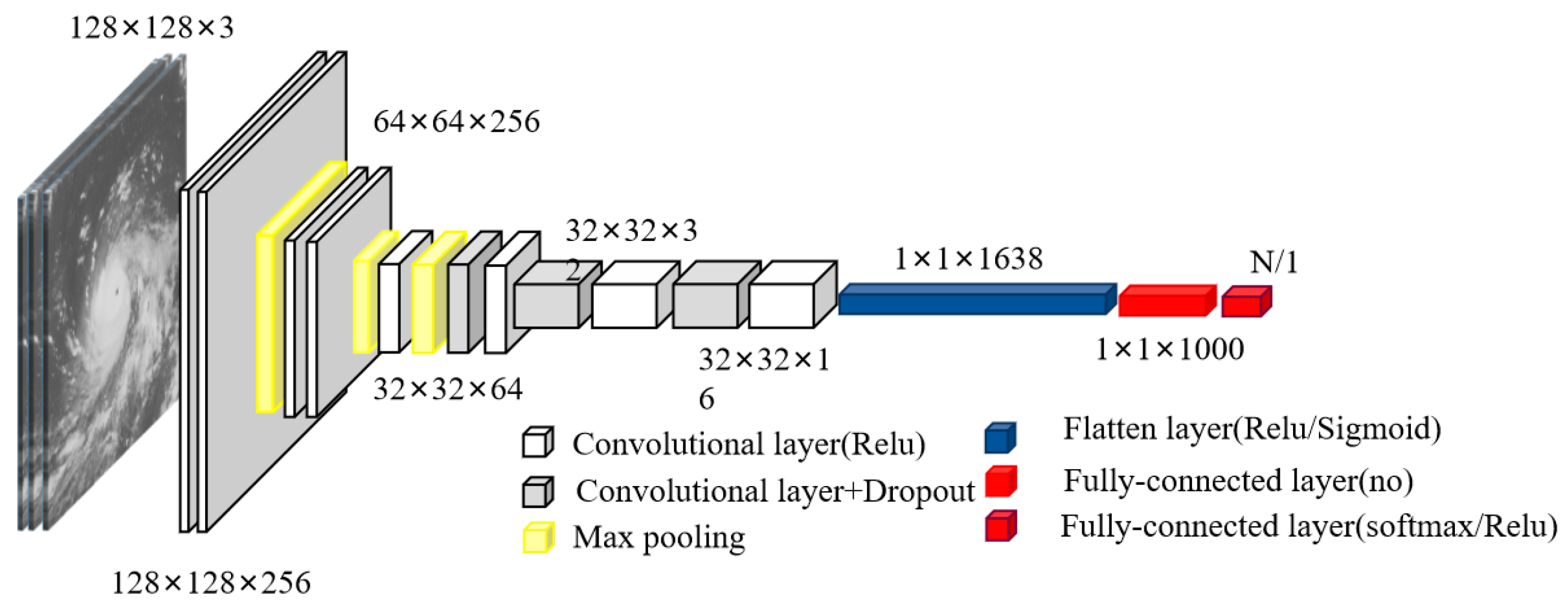
Figure 3.
Structures of the DCNN network.
Figure 3.
Structures of the DCNN network.
Figure 4.
Analysis of the overall structure of ViT.
Figure 4.
Analysis of the overall structure of ViT.
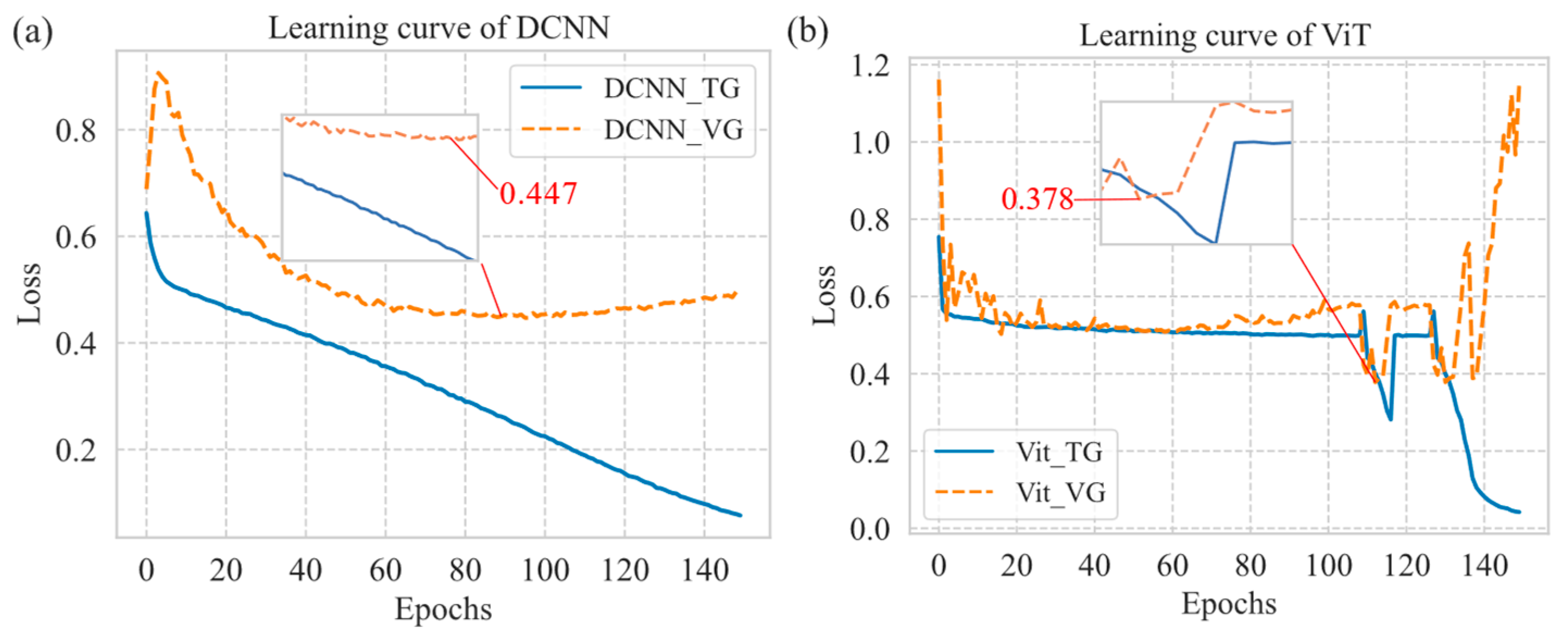
Figure 5.
TC intensity regression model learning curves: (a) DCNN; (b) ViT.
Figure 5.
TC intensity regression model learning curves: (a) DCNN; (b) ViT.
Figure 6.
Estimations from validating (Val) and testing (test) processes of DCNN and ViT for the one-stage strategy, compared with best-track data. Red line denotes linear fit of estimation in function of best-track data: (a) DCNN validation, (b) ViT validation, (c) DCNN testing, and (d) ViT testing.
Figure 6.
Estimations from validating (Val) and testing (test) processes of DCNN and ViT for the one-stage strategy, compared with best-track data. Red line denotes linear fit of estimation in function of best-track data: (a) DCNN validation, (b) ViT validation, (c) DCNN testing, and (d) ViT testing.
Figure 7.
Geographic distribution of estimation errors for DCNN and ViT from one-state strategy: (a) RMSE for DCNN, (b) RMSE for ViT, (c) MAPE for DCNN, and (d) MAPE for ViT.
Figure 7.
Geographic distribution of estimation errors for DCNN and ViT from one-state strategy: (a) RMSE for DCNN, (b) RMSE for ViT, (c) MAPE for DCNN, and (d) MAPE for ViT.
Figure 8.
Geographic distribution of appearance probability of: (a) TCs, (b) TC genesis, (c) TCs with MSW > 65 kt, and (d) TCs with MSW > 80 kt.
Figure 8.
Geographic distribution of appearance probability of: (a) TCs, (b) TC genesis, (c) TCs with MSW > 65 kt, and (d) TCs with MSW > 80 kt.
Figure 9.
Learning curves of classification models: (a) DCNN; (b) ViT.
Figure 9.
Learning curves of classification models: (a) DCNN; (b) ViT.
Figure 10.
Boxplots of estimation bias for different models via two-stage strategies: (a) DCNN_DCNN, (b) DCNN_Vit, (c) ViT_ViT, and (d)ViT_DCNN.
Figure 10.
Boxplots of estimation bias for different models via two-stage strategies: (a) DCNN_DCNN, (b) DCNN_Vit, (c) ViT_ViT, and (d)ViT_DCNN.
Figure 11.
Geographic distribution of estimation errors from two two-state strategies: (a) RMSE for ViT_DCNN, (b) RMSE for ViT_ViT, (c) MAPE for ViT_DCNN, and (d) MAPE for ViT_ViT.
Figure 11.
Geographic distribution of estimation errors from two two-state strategies: (a) RMSE for ViT_DCNN, (b) RMSE for ViT_ViT, (c) MAPE for ViT_DCNN, and (d) MAPE for ViT_ViT.
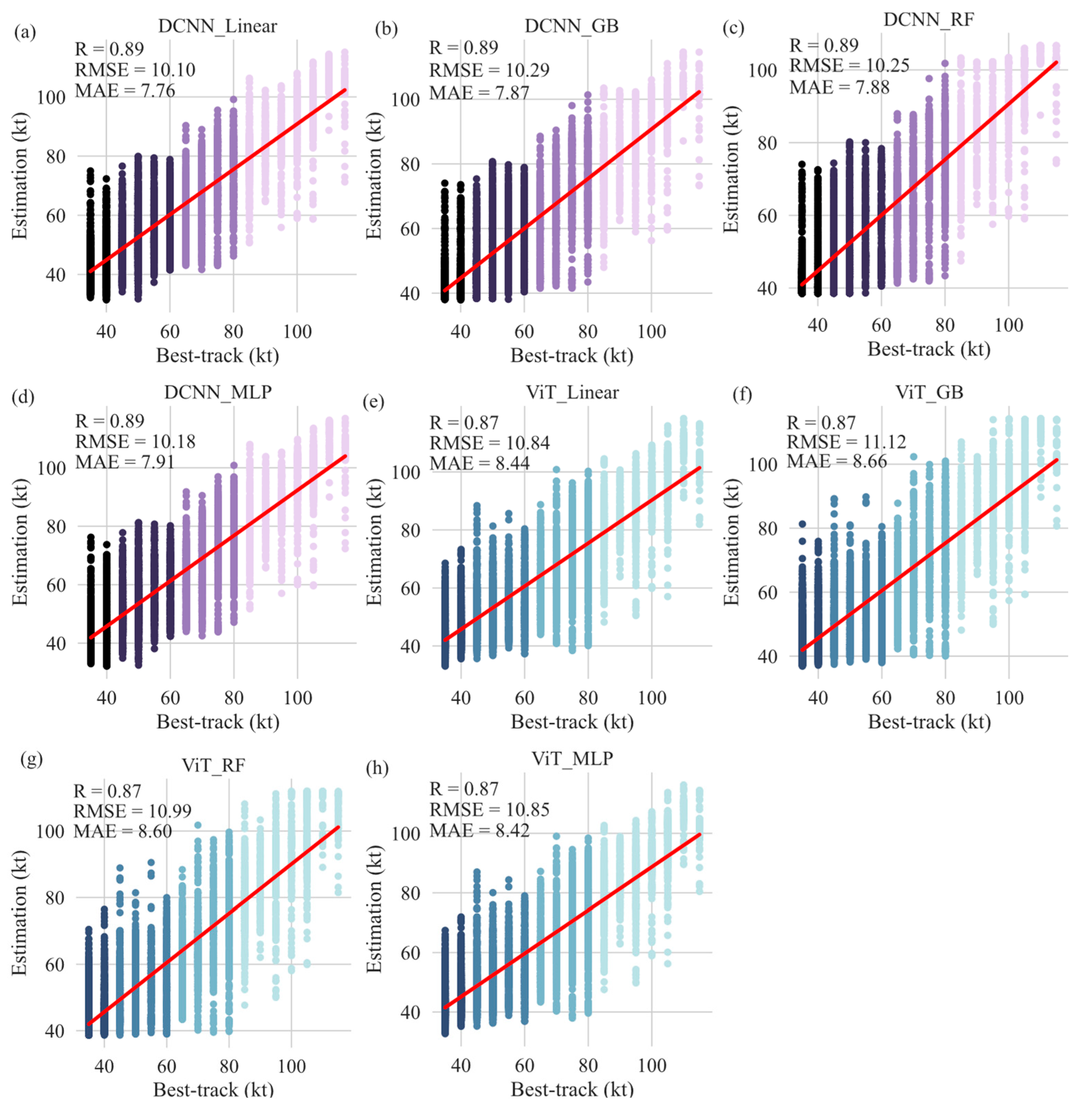
Figure 12.
Smoothed estimations from testing process of DCNN and ViT for the one-stage strategy via different smoothing methods: (a,e) using linear weighting; (b,f) using GB; (c,g) using RF; (d,h) using MLP, compared with best-track data.
Figure 12.
Smoothed estimations from testing process of DCNN and ViT for the one-stage strategy via different smoothing methods: (a,e) using linear weighting; (b,f) using GB; (c,g) using RF; (d,h) using MLP, compared with best-track data.
Figure 13.
Geographic distribution of smoothed estimation errors for DCNN_Linear and ViT_MLP from one-state strategy: (a) RMSE for DCNN_Linear, (b) RMSE for ViT_MLP, (c) MAPE for DCNN_Linear, and (d) MAPE for ViT_MLP.
Figure 13.
Geographic distribution of smoothed estimation errors for DCNN_Linear and ViT_MLP from one-state strategy: (a) RMSE for DCNN_Linear, (b) RMSE for ViT_MLP, (c) MAPE for DCNN_Linear, and (d) MAPE for ViT_MLP.
Figure 14.
Geographic distribution of smoothed estimation errors for V_D_Linear and V_D_MLP from two-state strategy: (a) RMSE for V_D_Linear, (b) RMSE for V_D_MLP, (c) MAPE for V_D_Linear, and (d) MAPE for V_D_MLP.
Figure 14.
Geographic distribution of smoothed estimation errors for V_D_Linear and V_D_MLP from two-state strategy: (a) RMSE for V_D_Linear, (b) RMSE for V_D_MLP, (c) MAPE for V_D_Linear, and (d) MAPE for V_D_MLP.
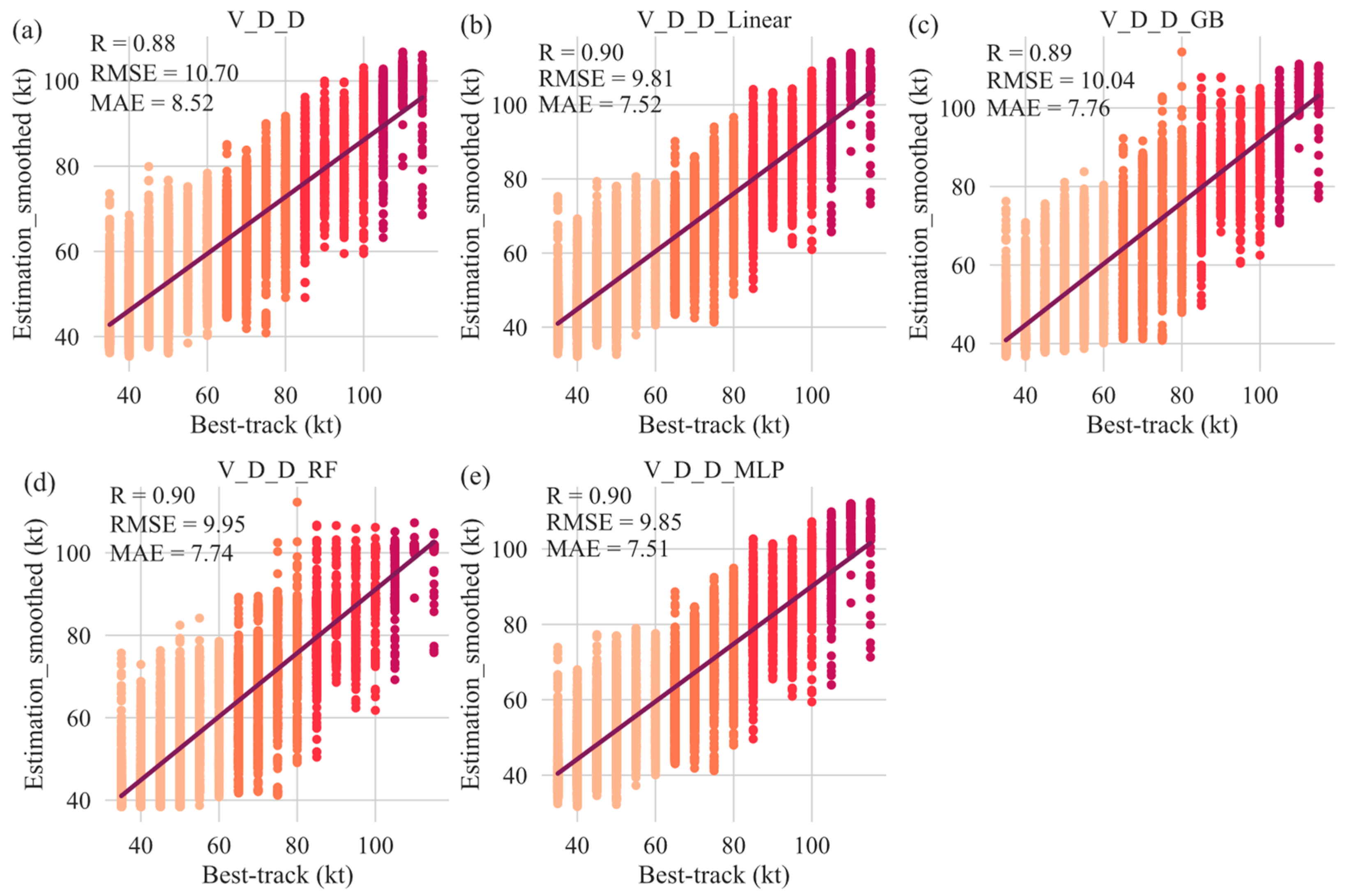
Figure 15.
Smoothed estimations from testing process of hybrid strategy models, compared with best-track data: (a) V_D_D, (b) V_D_D_Linear, (c) V_D_D_GB, (d) V_D_D_RF, and (e) V_D_D_MLP.
Figure 15.
Smoothed estimations from testing process of hybrid strategy models, compared with best-track data: (a) V_D_D, (b) V_D_D_Linear, (c) V_D_D_GB, (d) V_D_D_RF, and (e) V_D_D_MLP.
Figure 16.
Geographic distribution of smoothed estimation errors for V_D_D_Linear and V_D_D_MLP from one-state strategy: (a) RMSE for V_D_D_Linear, (b) RMSE for V_D_D_MLP, (c) MAPE for V_D_D_Linear, and (d) MAPE for V_D_D_MLP.
Figure 16.
Geographic distribution of smoothed estimation errors for V_D_D_Linear and V_D_D_MLP from one-state strategy: (a) RMSE for V_D_D_Linear, (b) RMSE for V_D_D_MLP, (c) MAPE for V_D_D_Linear, and (d) MAPE for V_D_D_MLP.
Figure 17.
Histogram of errors obtained via different techniques: (a) RMSE, (b) MAE, (c) MAPE, and (d) R coefficient.
Figure 17.
Histogram of errors obtained via different techniques: (a) RMSE, (b) MAE, (c) MAPE, and (d) R coefficient.
Figure 18.
Boxplots of estimation bias for different techniques: (a) for TY intensity samples, (b) for STY intensity samples, (c) for VSTY intensity samples, and (d) for VTY intensity samples.
Figure 18.
Boxplots of estimation bias for different techniques: (a) for TY intensity samples, (b) for STY intensity samples, (c) for VSTY intensity samples, and (d) for VTY intensity samples.
Figure 19.
Comparison of estimations via varied methods for four TCs: (a) Mangkhut in 2018, (b) Yutu in 2018, (c) Wutip in 2019, and (d) Hagibis in 2019.
Figure 19.
Comparison of estimations via varied methods for four TCs: (a) Mangkhut in 2018, (b) Yutu in 2018, (c) Wutip in 2019, and (d) Hagibis in 2019.
Figure 20.
Estimation errors for 4 TCs at varied developing stages (A, B, C represent the formation, mature, and dissipation stage): (a) Mangkhut in 2018; (b) Yutu in 2018; (c) Wutip in 2019; (d) Hagibis in 2019.
Figure 20.
Estimation errors for 4 TCs at varied developing stages (A, B, C represent the formation, mature, and dissipation stage): (a) Mangkhut in 2018; (b) Yutu in 2018; (c) Wutip in 2019; (d) Hagibis in 2019.
Table 1.
The number of samples.
Table 1.
The number of samples.
| | Years | TCs | SCI Samples |
|---|
| Train | 2000–2013 | 330 | 158,260 |
| Validation | 2014–2017 | 113 | 52,032 |
| Test | 2018–2021 | 103 | 11,920 |
Table 2.
Confusion matrix of parameters for calculating PRF values.
Table 2.
Confusion matrix of parameters for calculating PRF values.
| Confusion Matrix | Predicted |
| Positive | Negative |
| Actual | Positive | NTP | NFN |
| Negative | NFP | NTN |
Table 3.
Performance of regression model during testing process.
Table 3.
Performance of regression model during testing process.
| Model | Dataset | RMSE | MAE | MAPE | R |
|---|
| DCNN | Validation | 12.02 | 9.47 | 0.16 | 0.83 |
| Testing | 11.18 | 8.57 | 0.16 | 0.86 |
| ViT | Validation | 12.95 | 10.01 | 0.18 | 0.80 |
| Testing | 12.60 | 9.42 | 0.17 | 0.82 |
Table 4.
Overall performance of the DCNN and ViT classification models.
Table 4.
Overall performance of the DCNN and ViT classification models.
| Model | Category | Validation Accuracy | Testing Accuracy | Precision | Recall Ratio | F1-Score |
|---|
| DCNN | TY | 0.805 | 0.834 | 0.875 | 0.864 | 0.870 |
| STYS | 0.762 | 0.780 | 0.771 |
| ViT | TY | 0.831 | 0.854 | 0.885 | 0.887 | 0.886 |
| STYS | 0.797 | 0.795 | 0.796 |
Table 5.
Confusion matrix of predictions from the DCNN classification model.
Table 5.
Confusion matrix of predictions from the DCNN classification model.
| DCNN | True Label |
|---|
| TY | STYS | Sum |
|---|
| STY | VSTY | VTY |
|---|
| Predicted label | TY | 6600 | 768 | 150 | 22 | 7540 |
| STYS | 1041 | 1486 | 1326 | 527 | 4380 |
| Sum | 7641 | 2254 | 1476 | 549 | 11920 |
Table 6.
Confusion matrix of predictions from the ViT classification model.
Table 6.
Confusion matrix of predictions from the ViT classification model.
| ViT | True Label |
|---|
| TY | STYS | Sum |
|---|
| STY | VSTY | VTY |
|---|
| Predicted label | TY | 6775 | 729 | 130 | 17 | 7651 |
| STYS | 866 | 1525 | 1346 | 532 | 4269 |
| Sum | 7641 | 2254 | 1476 | 549 | 11920 |
Table 7.
Performance of four scenarios for the two-stage strategy.
Table 7.
Performance of four scenarios for the two-stage strategy.
| Scenario | RMSE | MAE | MAPE | R |
|---|
| DCNN_DCNN | 12.82 | 9.37 | 0.17 | 0.81 |
| DCNN_ViT | 13.45 | 10.00 | 0.18 | 0.79 |
| ViT_ViT | 12.70 | 9.63 | 0.17 | 0.82 |
| ViT_DCNN | 11.78 | 8.88 | 0.16 | 0.84 |
Table 8.
Overall performance of the two-state strategy smoothed models.
Table 8.
Overall performance of the two-state strategy smoothed models.
| Model | RMSE (kt) | MAE (kt) | MAPE | R |
|---|
| D_D_Linear | 12.07 | 9.16 | 0.16 | 0.84 |
| D_D_GB | 12.05 | 9.17 | 0.16 | 0.84 |
| D_D_RF | 12.00 | 9.15 | 0.16 | 0.84 |
| D_D_MLP | 12.13 | 9.15 | 0.16 | 0.84 |
| V_D_Linear | 10.64 | 8.10 | 0.15 | 0.88 |
| V_D_GB | 10.90 | 8.29 | 0.15 | 0.87 |
| V_D_RF | 10.85 | 8.30 | 0.15 | 0.87 |
| V_D_MLP | 10.65 | 8.09 | 0.15 | 0.88 |
Table 9.
Comparison of the best estimation performance in this study with those in references.
Table 9.
Comparison of the best estimation performance in this study with those in references.
| Model | RMSE (kt) | MAE (kt) | TC Year | Reference |
|---|
| ADT9.0 | 11.24 | 8.67 | 2018 | Olander et al. [4] |
| DAV-T | 14.3 | - | 2007–2011 | Ritchie et al. [37] |
| SATCON | 8.9 | 7.70 | 2008–2010 | Velden and Herndon [12] |
| TCIENet | 10.12 | 7.94 | 2017 | Zhang and Liu [25] |
| CNN-TC | 12.25 | - | 2015–2016 | Chen et al. [23] |
| VGG19 | 13.23 | - | 2015–2016 | Combinido et al. [21] |
| CNN 1 | 10.19 | - | 2015–2018 | Wang et al. [24] |
| V_D_D_Linear | 9.81 | 7.52 | 2018–2019 | This study |
| V_D_D_MLP | 9.85 | 7.51 |


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}