
Classification of Coniferous and Broad-Leaf Forests in China Based on High-Resolution Imagery and Local Samples in Google Earth Engine

 ,
,
Abstract
:1. Introduction
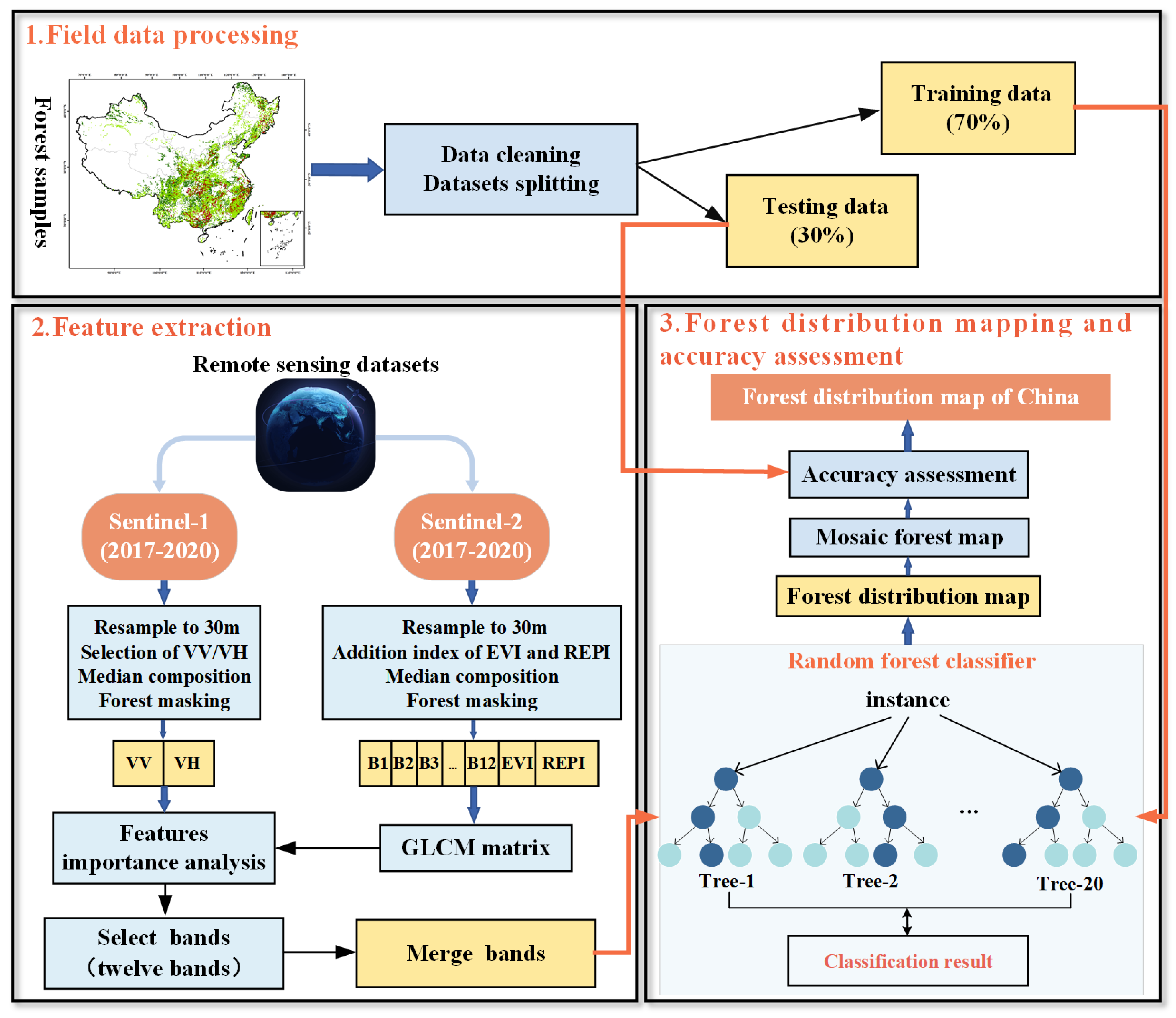
2. Materials and Methods
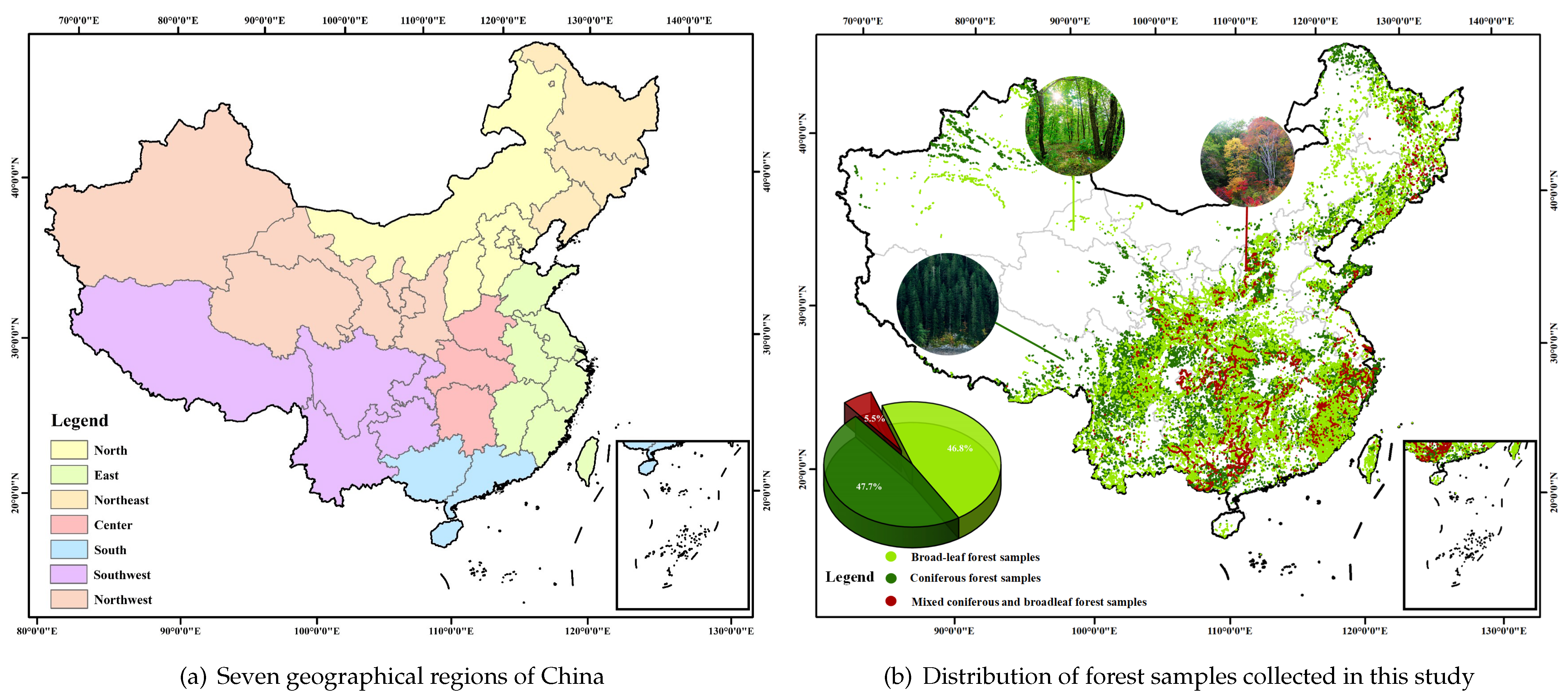
2.1. Field Data
2.2. Remote Sensing Datasets
2.2.1. Sentinel-1
2.2.2. Sentinel-2
2.2.3. Auxiliary Data
2.3. Methodology
2.3.1. Structural and Spectral Feature Analysis
2.3.2. Texture Features Analysis
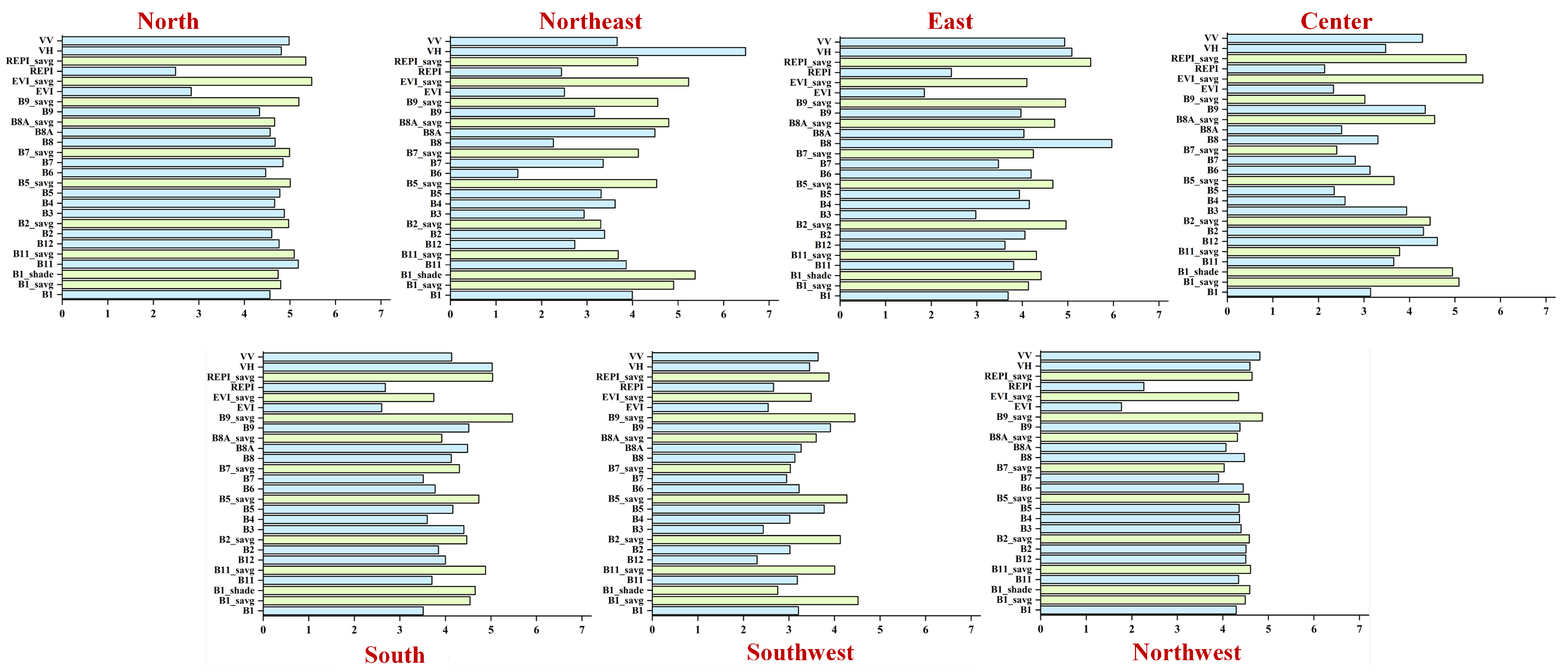
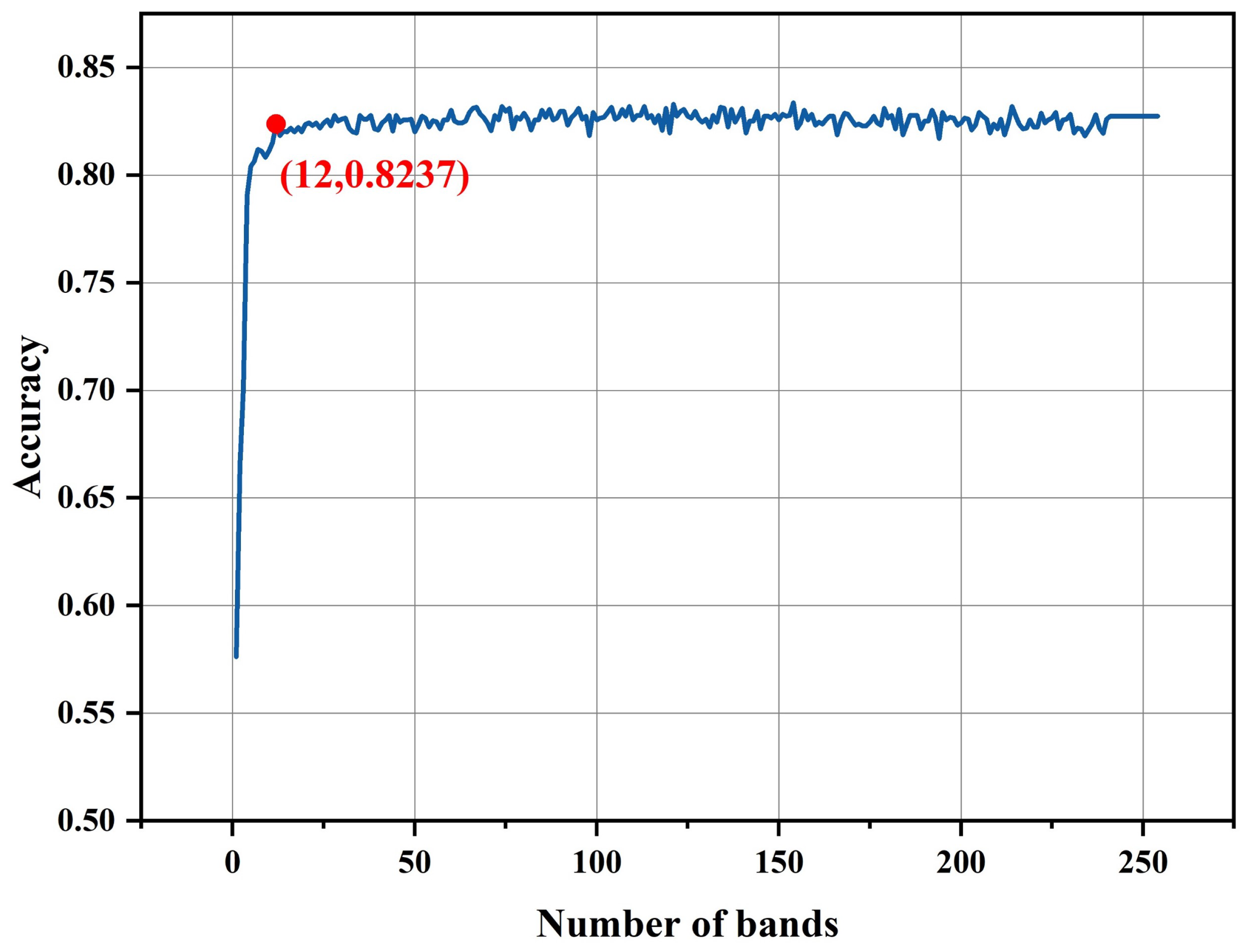
2.3.3. Feature Importance Analysis
2.3.4. Classification
2.4. Accuracy Assessment
2.4.1. Comparison with Field Data
2.4.2. Comparison with National Vegetation Map
3. Results
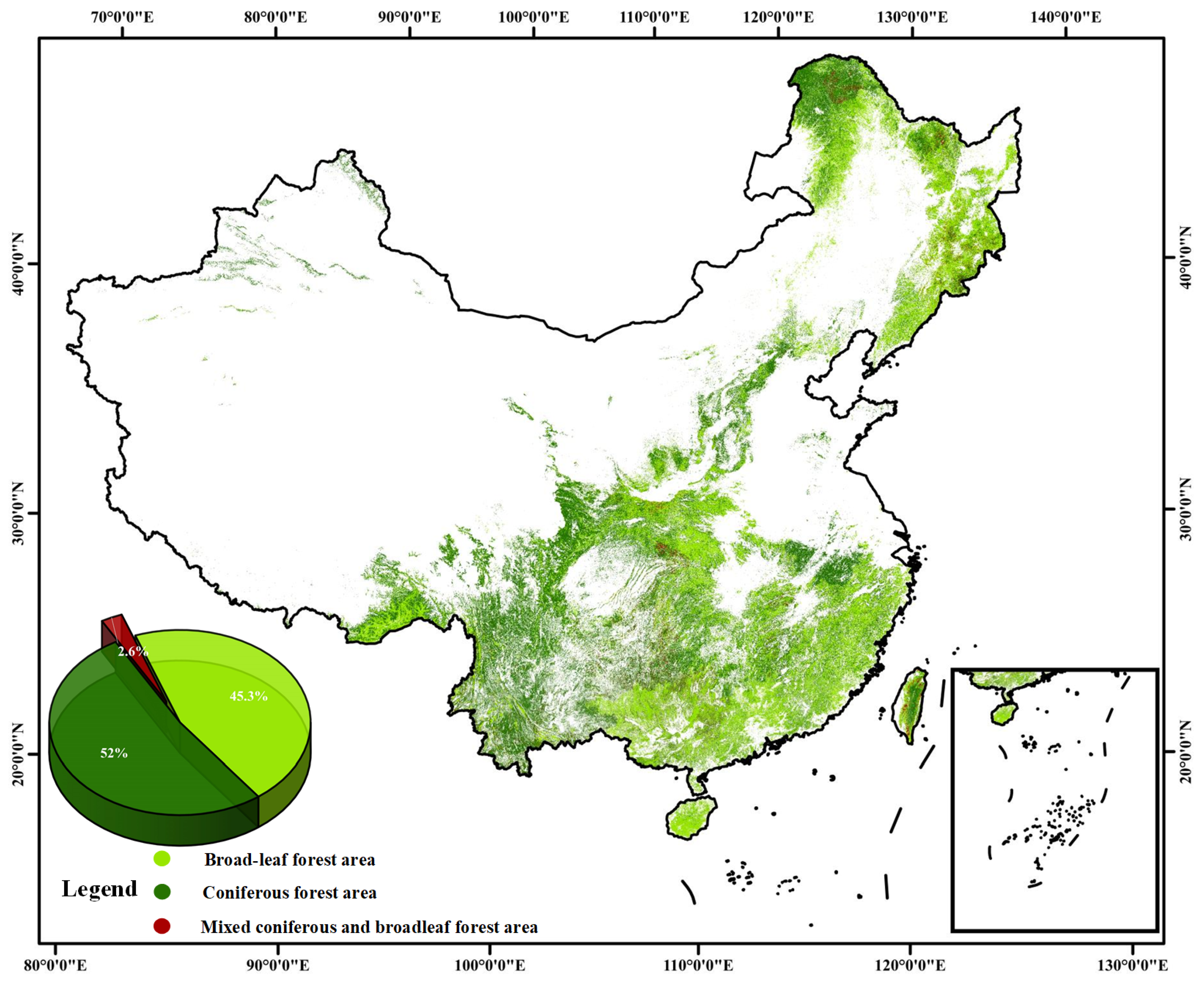
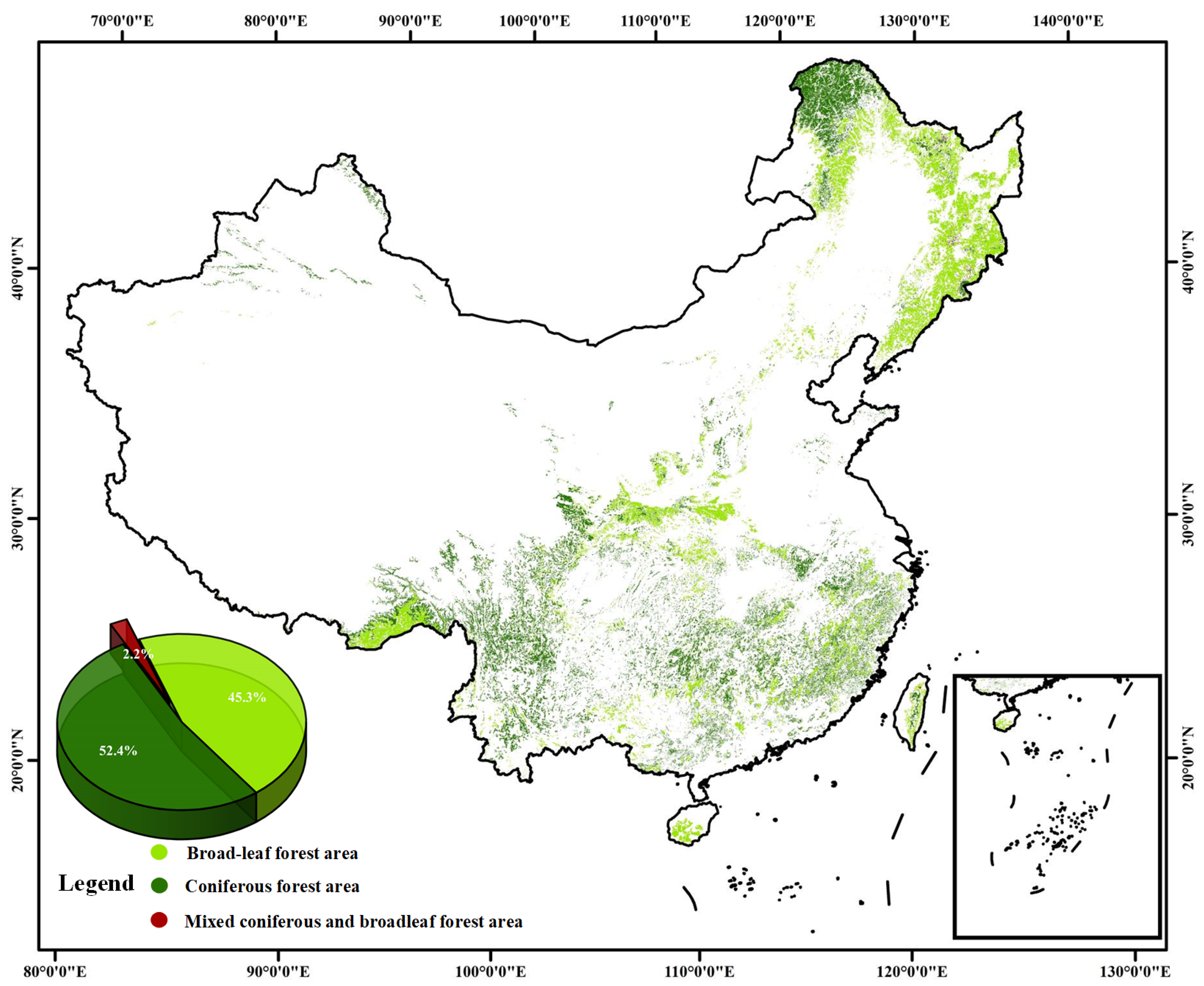
3.1. Distribution of China’s Forests in 2020
3.2. Accuracy Assessment
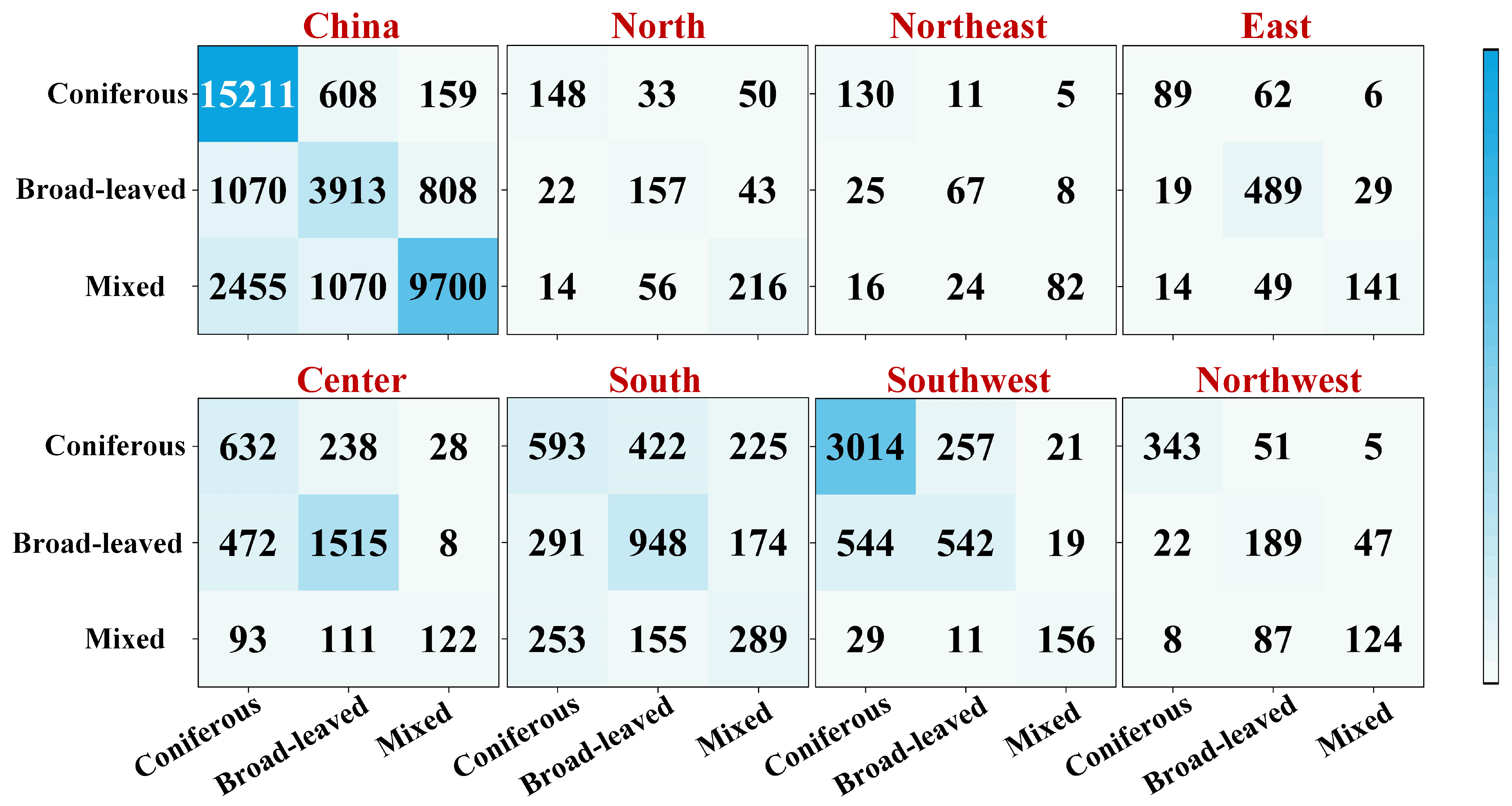
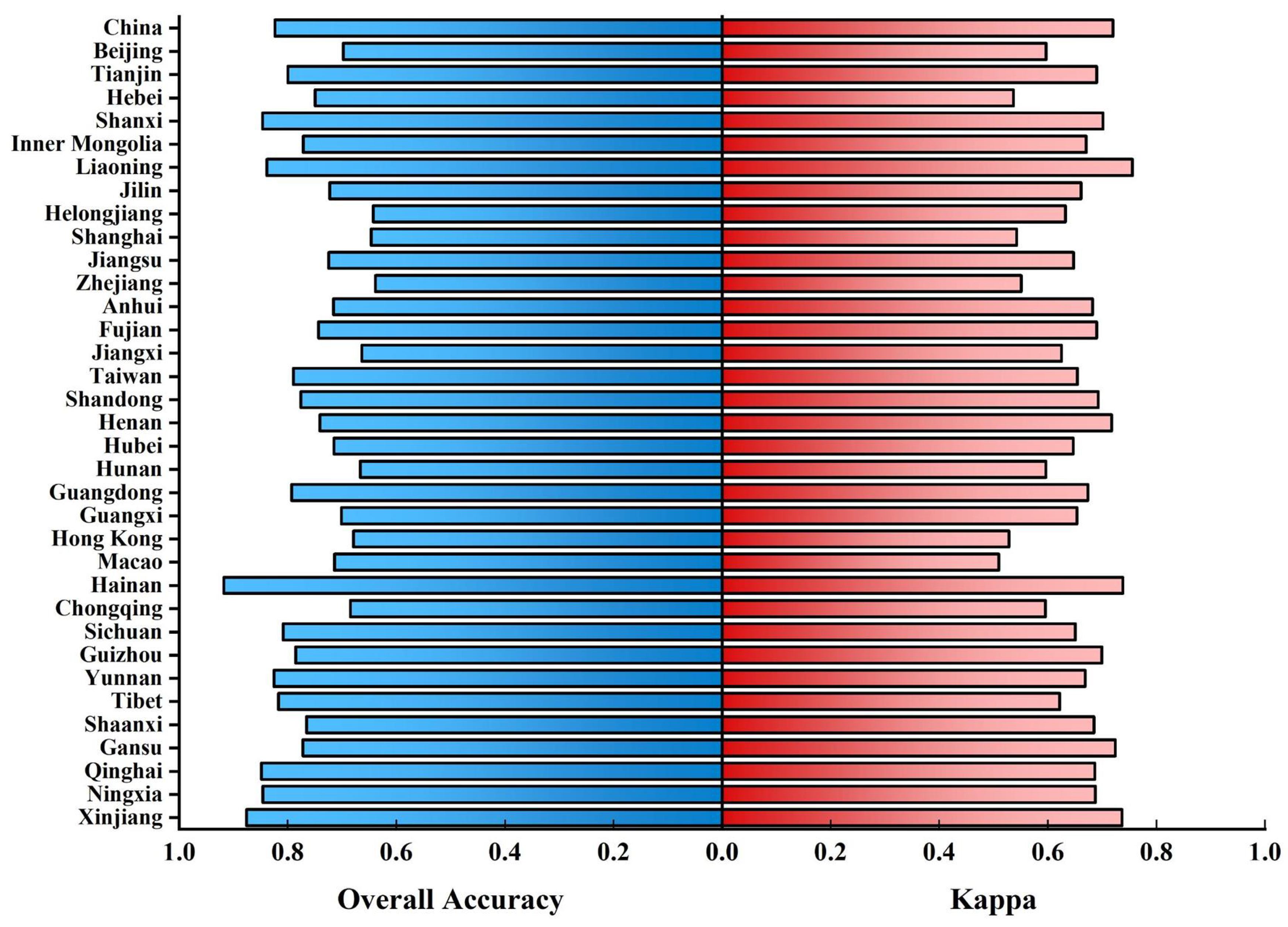
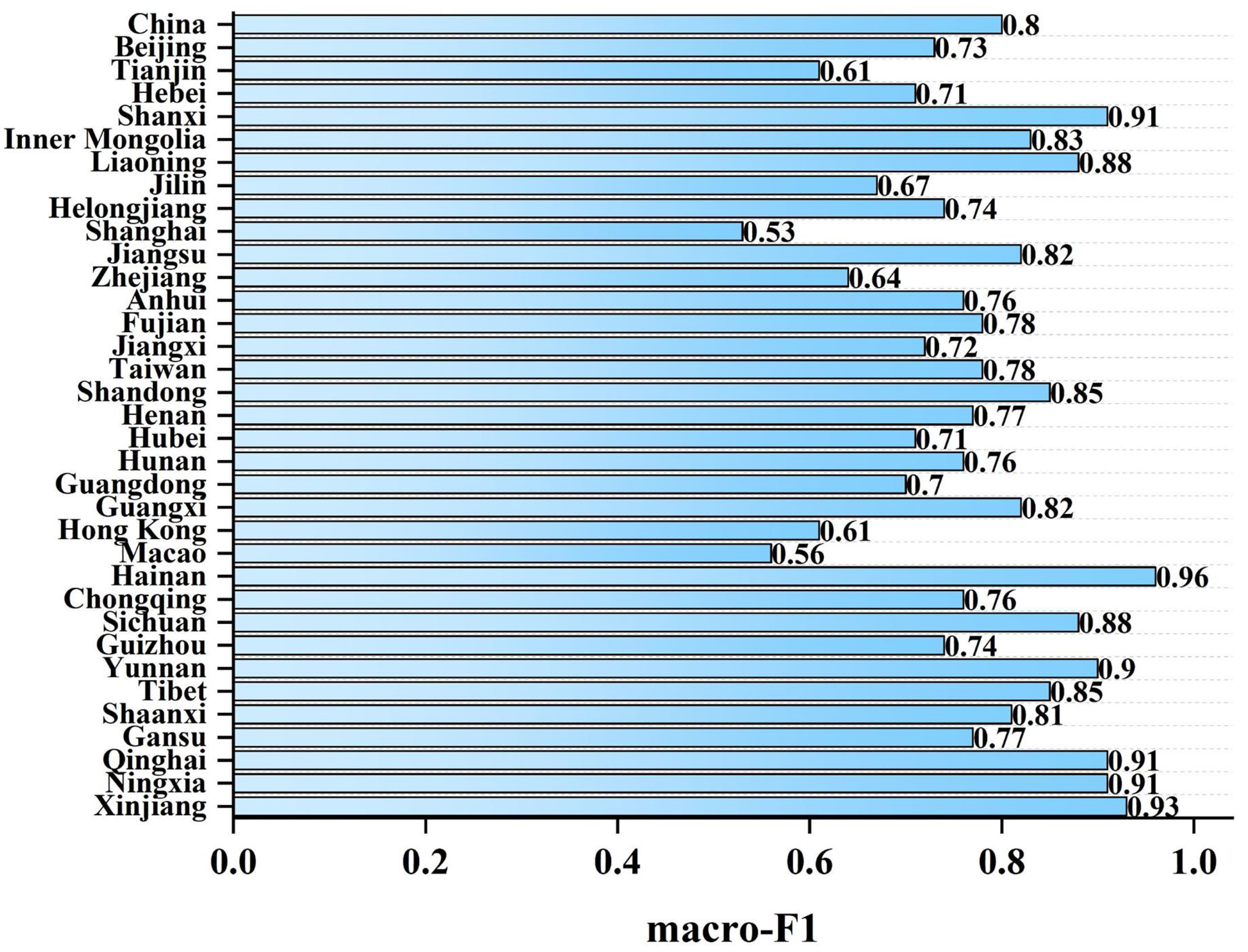
3.2.1. Comparison with Field Data
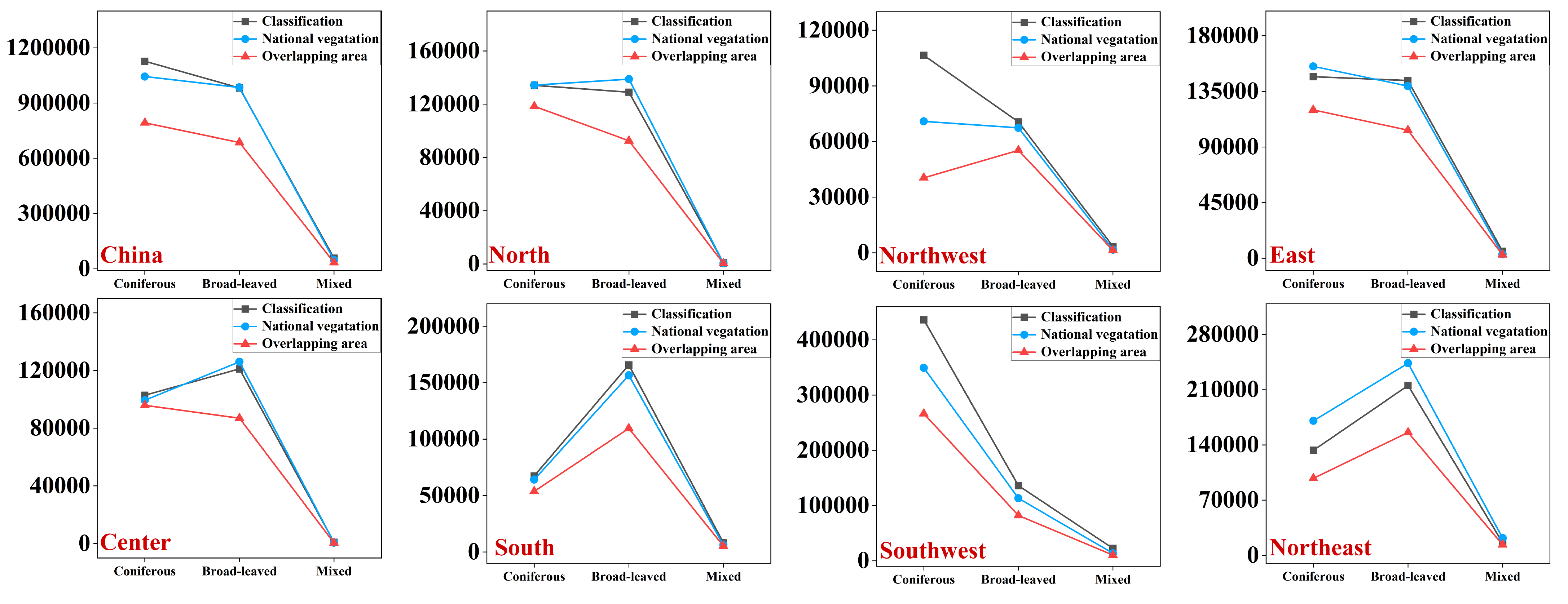
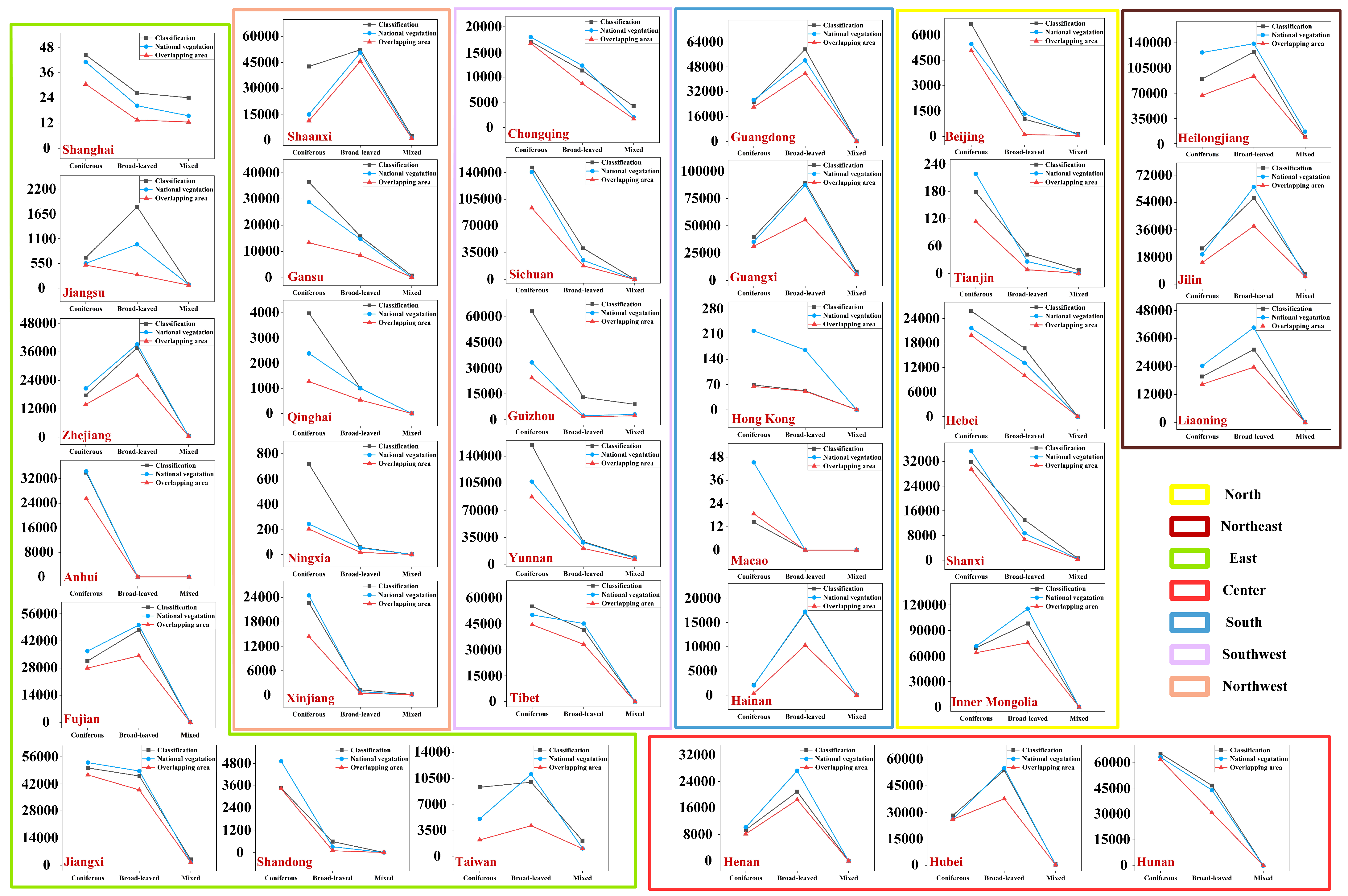
3.2.2. Comparison with National Vegetation Map
3.3. Uncertainties of the Forest Classification Forest Map
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Band | Center Wavelength/nm | Resolution/m | Description |
|---|---|---|---|
| B1 | 443 | 60 | Aerosols |
| B2 | 490 | 10 | Blue |
| B3 | 560 | 10 | Green |
| B4 | 665 | 10 | Red |
| B5 | 705 | 20 | Red Edge 1 |
| B6 | 740 | 20 | Red Edge 2 |
| B7 | 783 | 20 | Red Edge 3 |
| B8 | 842 | 10 | NIR |
| B8A | 865 | 20 | Red Edge 4 |
| B9 | 940 | 60 | Water vapor |
| B11 | 1610 | 20 | SWIR 1 |
| B12 | 2190 | 20 | SWIR 2 |
| QA10 | 10 | ||
| QA20 | 20 | ||
| QA60 | 60 | Cloud Mask | |
| AOT | Aerosol Optical Thickness |
Appendix A.2

Appendix A.3

References
- Romijn, E.; Lantican, C.B.; Herold, M.; Lindquist, E.; Ochieng, R.; Wijaya, A.; Murdiyarso, D.; Verchot, L. Assessing change in national forest monitoring capacities of 99 tropical countries. For. Ecol. Manag. 2015, 352, 109–123. [Google Scholar] [CrossRef]
- Woodwell, G.M.; Whittaker, R.; Reiners, W.; Likens, G.E.; Delwiche, C.; Botkin, D. The Biota and the World Carbon Budget: The terrestrial biomass appears to be a net source of carbon dioxide for the atmosphere. Science 1978, 199, 141–146. [Google Scholar] [CrossRef] [PubMed]
- Martin, P.A.; Newton, A.C.; Bullock, J.M. Carbon pools recover more quickly than plant biodiversity in tropical secondary forests. Proc. R. Soc. B Biol. Sci. 2013, 280, 20132236. [Google Scholar] [CrossRef]
- Huang, W.; Liu, J.; Wang, Y.P.; Zhou, G.; Han, T.; Li, Y. Increasing phosphorus limitation along three successional forests in southern China. Plant Soil 2013, 364, 181–191. [Google Scholar]
- Xiang, W.; Liu, S.; Lei, X.; Frank, S.C.; Tian, D.; Wang, G.; Deng, X. Secondary forest floristic composition, structure, and spatial pattern in subtropical China. J. For. Res. 2013, 18, 111–120. [Google Scholar]
- Zhou, G.; Peng, C.; Li, Y.; Liu, S.; Zhang, Q.; Tang, X.; Liu, J.; Yan, J.; Zhang, D.; Chu, G. A climate change-induced threat to the ecological resilience of a subtropical monsoon evergreen broad-leaved forest in Southern China. Glob. Chang. Biol. 2013, 19, 1197–1210. [Google Scholar]
- Cao, S.; Chen, L.; Shankman, D.; Wang, C.; Wang, X.; Zhang, H. Excessive reliance on afforestation in China’s arid and semi-arid regions: Lessons in ecological restoration. Earth-Sci. Rev. 2011, 104, 240–245. [Google Scholar]
- Liu, J.; Li, S.; Ouyang, Z.; Tam, C.; Chen, X. Ecological and socioeconomic effects of China’s policies for ecosystem services. Proc. Natl. Acad. Sci. USA 2008, 105, 9477–9482. [Google Scholar]
- Paquette, A.; Messier, C. The role of plantations in managing the world’s forests in the Anthropocene. Front. Ecol. Environ. 2010, 8, 27–34. [Google Scholar]
- Farooq, T.H.; Shakoor, A.; Wu, X.; Li, Y.; Rashid, M.H.U.; Zhang, X.; Gilani, M.M.; Kumar, U.; Chen, X.; Yan, W. Perspectives of plantation forests in the sustainable forest development of China. iForest-Biogeosci. For. 2021, 14, 166–174. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Bowditch, E.; Santopuoli, G.; Binder, F.; Del Rio, M.; La Porta, N.; Kluvankova, T.; Lesinski, J.; Motta, R.; Pach, M.; Panzacchi, P.; et al. What is Climate-Smart Forestry? A definition from a multinational collaborative process focused on mountain regions of Europe. Ecosyst. Serv. 2020, 43, 101113. [Google Scholar]
- Bowditch, E.; Santopuoli, G.; Neroj, B.; Svetlik, J.; Tominlson, M.; Pohl, V.; Avdagić, A.; del Rio, M.; Zlatanov, T.; Maria, H.; et al. Application of climate-smart forestry–Forest manager response to the relevance of European definition and indicators. Trees For. People 2022, 9, 100313. [Google Scholar] [CrossRef]
- Klerkx, L.; Jakku, E.; Labarthe, P. A review of social science on digital agriculture, smart farming and agriculture 4.0: New contributions and a future research agenda. NJAS-Wagening. J. Life Sci. 2019, 90, 100315. [Google Scholar]
- Moore, M.M.; Bauer, M.E. Classification of forest vegetation in north-central Minnesota using Landsat Multispectral Scanner and Thematic Mapper data. For. Sci. 1990, 36, 330–342. [Google Scholar]
- Walsh, S.J. Coniferous tree species mapping using Landsat data. Remote Sens. Environ. 1980, 9, 11–26. [Google Scholar]
- Mallinis, G.; Koutsias, N.; Tsakiri-Strati, M.; Karteris, M. Object-based classification using Quickbird imagery for delineating forest vegetation polygons in a Mediterranean test site. ISPRS J. Photogramm. Remote Sens. 2008, 63, 237–250. [Google Scholar]
- Zhang, C.; Qiu, F. Mapping individual tree species in an urban forest using airborne lidar data and hyperspectral imagery. Photogramm. Eng. Remote Sens. 2012, 78, 1079–1087. [Google Scholar]
- Feng, W.; Dauphin, G.; Huang, W.; Quan, Y.; Bao, W.; Wu, M.; Li, Q. Dynamic synthetic minority over-sampling technique-based rotation forest for the classification of imbalanced hyperspectral data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2159–2169. [Google Scholar] [CrossRef]
- Pant, P.; Heikkinen, V.; Hovi, A.; Korpela, I.; Hauta-Kasari, M.; Tokola, T. Evaluation of simulated bands in airborne optical sensors for tree species identification. Remote Sens. Environ. 2013, 138, 27–37. [Google Scholar]
- Descals, A.; Wich, S.; Meijaard, E.; Gaveau, D.L.; Peedell, S.; Szantoi, Z. High-resolution global map of smallholder and industrial closed-canopy oil palm plantations. Earth Syst. Sci. Data 2021, 13, 1211–1231. [Google Scholar]
- Zhao, Y.; Zhu, W.; Wei, P.; Fang, P.; Zhang, X.; Yan, N.; Liu, W.; Zhao, H.; Wu, Q. Classification of Zambian grasslands using random forest feature importance selection during the optimal phenological period. Ecol. Indic. 2022, 135, 108529. [Google Scholar]
- Nguyen, Q.P.; Lim, K.W.; Divakaran, D.M.; Low, K.H.; Chan, M.C. GEE: A gradient-based explainable variational autoencoder for network anomaly detection. In Proceedings of the 2019 IEEE Conference on Communications and Network Security (CNS), Washington, DC, USA, 10–12 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 91–99. [Google Scholar]
- Torres, R.; Snoeij, P.; Geudtner, D.; Bibby, D.; Davidson, M.; Attema, E.; Potin, P.; Rommen, B.; Floury, N.; Brown, M.; et al. GMES Sentinel-1 mission. Remote Sens. Environ. 2012, 120, 9–24. [Google Scholar] [CrossRef]
- Vollrath, A.; Mullissa, A.; Reiche, J. Angular-based radiometric slope correction for Sentinel-1 on google earth engine. Remote Sens. 2020, 12, 1867. [Google Scholar]
- Phiri, D.; Simwanda, M.; Salekin, S.; Nyirenda, V.R.; Murayama, Y.; Ranagalage, M. Sentinel-2 data for land cover/use mapping: A review. Remote Sens. 2020, 12, 2291. [Google Scholar]
- Cheng, K.; Su, Y.; Guan, H.; Tao, S.; Ren, Y.; Hu, T.; Ma, K.; Tang, Y.; Guo, Q. Mapping China’s planted forests using high resolution imagery and massive amounts of crowdsourced samples. ISPRS J. Photogramm. Remote Sens. 2023, 196, 356–371. [Google Scholar]
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X.; He, C.; Han, G.; Peng, S.; Lu, M.; et al. Global land cover mapping at 30 m resolution: A POK-based operational approach. ISPRS J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar]
- Torbick, N.; Ledoux, L.; Salas, W.; Zhao, M. Regional mapping of plantation extent using multisensor imagery. Remote Sens. 2016, 8, 236. [Google Scholar] [CrossRef]
- Testa, S.; Soudani, K.; Boschetti, L.; Mondino, E.B. MODIS-derived EVI, NDVI and WDRVI time series to estimate phenological metrics in French deciduous forests. Int. J. Appl. Earth Obs. Geoinf. 2018, 64, 132–144. [Google Scholar]
- Frampton, W.J.; Dash, J.; Watmough, G.; Milton, E.J. Evaluating the capabilities of Sentinel-2 for quantitative estimation of biophysical variables in vegetation. ISPRS J. Photogramm. Remote Sens. 2013, 82, 83–92. [Google Scholar] [CrossRef]
- Liang, J.; Zheng, Z.; Xia, S.; Zhang, X.; Tang, Y. Crop recognition and evaluationusing red edge features of GF-6 satellite. Yaogan Xuebao/J. Remote Sens. 2020, 24, 1168–1179. [Google Scholar] [CrossRef]
- Hong, D.; Yokoya, N.; Chanussot, J.; Zhu, X.X. An augmented linear mixing model to address spectral variability for hyperspectral unmixing. IEEE Trans. Image Process. 2018, 28, 1923–1938. [Google Scholar] [CrossRef]
- Tassi, A.; Vizzari, M. Object-oriented lulc classification in google earth engine combining snic, glcm, and machine learning algorithms. Remote Sens. 2020, 12, 3776. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I.H. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 1973, 610–621. [Google Scholar] [CrossRef]
- Conners, R.W.; Trivedi, M.M.; Harlow, C.A. Segmentation of a high-resolution urban scene using texture operators. Comput. Vision Graph. Image Process. 1984, 25, 273–310. [Google Scholar]
- Wang, S.; Feng, W.; Quan, Y.; Li, Q.; Dauphin, G.; Huang, W.; Li, J.; Xing, M. A heterogeneous double ensemble algorithm for soybean planting area extraction in Google Earth Engine. Comput. Electron. Agric. 2022, 197, 106955. [Google Scholar] [CrossRef]
- Feng, W.; Dauphin, G.; Huang, W.; Quan, Y.; Liao, W. New margin-based subsampling iterative technique in modified random forests for classification. Knowl.-Based Syst. 2019, 182, 104845. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Feng, W.; Quan, Y.; Dauphin, G.; Li, Q.; Gao, L.; Huang, W.; Xia, J.; Zhu, W.; Xing, M. Semi-supervised rotation forest based on ensemble margin theory for the classification of hyperspectral image with limited training data. Inf. Sci. 2021, 575, 611–638. [Google Scholar]
- Oreti, L.; Giuliarelli, D.; Tomao, A.; Barbati, A. Object oriented classification for mapping mixed and pure forest stands using very-high resolution imagery. Remote Sens. 2021, 13, 2508. [Google Scholar]
- Su, Y.; Guo, Q.; Hu, T.; Guan, H.; Jin, S.; An, S.; Chen, X.; Guo, K.; Hao, Z.; Hu, Y.; et al. An updated vegetation map of China (1: 1000000). Sci. Bull. 2020, 65, 1125–1136. [Google Scholar] [CrossRef] [PubMed]
- Dong, J.; Xiao, X.; Menarguez, M.A.; Zhang, G.; Qin, Y.; Thau, D.; Biradar, C.; Moore III, B. Mapping paddy rice planting area in northeastern Asia with Landsat 8 images, phenology-based algorithm and Google Earth Engine. Remote Sens. Environ. 2016, 185, 142–154. [Google Scholar] [CrossRef] [PubMed]
- Chen, B.; Xiao, X.; Li, X.; Pan, L.; Doughty, R.; Ma, J.; Dong, J.; Qin, Y.; Zhao, B.; Wu, Z.; et al. A mangrove forest map of China in 2015: Analysis of time series Landsat 7/8 and Sentinel-1A imagery in Google Earth Engine cloud computing platform. ISPRS J. Photogramm. Remote Sens. 2017, 131, 104–120. [Google Scholar] [CrossRef]
- Teluguntla, P.; Thenkabail, P.S.; Oliphant, A.; Xiong, J.; Gumma, M.K.; Congalton, R.G.; Yadav, K.; Huete, A. A 30-m landsat-derived cropland extent product of Australia and China using random forest machine learning algorithm on Google Earth Engine cloud computing platform. ISPRS J. Photogramm. Remote Sens. 2018, 144, 325–340. [Google Scholar] [CrossRef]
- Li, Z.; He, W.; Cheng, M.; Hu, J.; Yang, G.; Zhang, H. SinoLC-1: The first 1-meter resolution national-scale land-cover map of China created with the deep learning framework and open-access data. Earth Syst. Sci. Data Discuss. 2023, 2023, 1–38. [Google Scholar]













| Region | Province | Number of Samples | Total |
|---|---|---|---|
| North | Beijing | 497 | 20,123 |
| Tianjin | 45 | ||
| Hebei | 1346 | ||
| Shanxi | 15,006 | ||
| Inner Mongolia | 3229 | ||
| Northeast | Liaoning | 5880 | 18,326 |
| Jilin | 3904 | ||
| Heilongjiang | 8542 | ||
| East | Shanghai | 1281 | 85,861 |
| Jiangsu | 3535 | ||
| Zhejiang | 11,459 | ||
| Anhui | 4936 | ||
| Fujian | 21,804 | ||
| Jiangxi | 18,742 | ||
| Taiwan | 1823 | ||
| Shandong | 22,381 | ||
| Center | Henan | 3873 | 45,681 |
| Hubei | 16,443 | ||
| Hunan | 25,365 | ||
| South | Guangdong | 2558 | 26,680 |
| Guangxi | 23,844 | ||
| Hong Kong | 30 | ||
| Macao | 7 | ||
| Hainan | 241 | ||
| Southwest | Chongqing | 13,635 | 75,381 |
| Sichuan | 41,666 | ||
| Guizhou | 6071 | ||
| Yunnan | 11,478 | ||
| Tibet | 2531 | ||
| Northwest | Shaanxi | 17,825 | 39,738 |
| Gansu | 15,519 | ||
| Qinghai | 1083 | ||
| Ningxia | 551 | ||
| Xinjiang | 4760 | ||
| 311,890 |
| Band | Importance | Band | Importance | Band | Importance |
|---|---|---|---|---|---|
| B1_savg | 18.958 | B9_savg | 15.711 | B3_prom | 15.226 |
| B2_savg | 17.409 | VV | 15.678 | B5_dvar | 14.991 |
| B1_shade | 17.241 | B8A_savg | 15.550 | B1_idm | 14.853 |
| B7_savg | 16.934 | REPI_savg | 15.435 | EVI_shade | 14.839 |
| B5_savg | 16.044 | VH | 15.389 | B6_idm | 14.741 |
| EVI_savg | 15.912 | B11_savg | 15.373 | B5_shade | 14.617 |
| Region | Province | Coniferous/km | Broad-Leaf/km | Mixed/km | Total//km | Percent/% |
|---|---|---|---|---|---|---|
| North | Beijing | 6,661.91 | 1,018.35 | 166.29 | 7,846.55 | 0.36 |
| Tianjin | 178.22 | 41.26 | 7.5 | 226.98 | 0.01 | |
| Hebei | 25,865.77 | 16,725.32 | 1.05 | 42,592.14 | 1.97 | |
| Shanxi | 31,775.18 | 13,045.02 | 593.34 | 45,413.54 | 2.10 | |
| Inner Mongolia | 69,728.81 | 98,247.58 | 6.7 | 167,983.09 | 7.75 | |
| 264,062.3 | 12.19 | |||||
| Northeast | Liaoning | 19,660.41 | 31,282.36 | 38.49 | 50,981.26 | 2.35 |
| Jilin | 23,627.01 | 56,882.8 | 7,011.02 | 87,520.83 | 4.04 | |
| Heilongjiang | 89,905.14 | 127,198.53 | 8,996.01 | 226,099.68 | 10.44 | |
| 364,601.77 | 16.83 | |||||
| East | Shanghai | 44.47 | 26.36 | 24.09 | 94.92 | 0.00 |
| Jiangsu | 678.6 | 1,806.63 | 76.82 | 2,562.05 | 0.12 | |
| Zhejiang | 17,637.16 | 37,665.23 | 601.8 | 55,904.19 | 2.58 | |
| Anhui | 34,004.67 | 5.72 | 0.09 | 34,013.48 | 1.57 | |
| Fujian | 31,548.95 | 47,649.96 | 15.7 | 79,214.61 | 3.66 | |
| Jiangxi | 50,174.06 | 46,016.37 | 2919.94 | 99,110.37 | 4.58 | |
| Taiwan | 9,303.47 | 9,977.72 | 2,092.07 | 21,373.26 | 0.99 | |
| Shandong | 3,470.8 | 590.32 | 0.12 | 4,061.24 | 0.19 | |
| 296,334.12 | 13.68 | |||||
| Center | Henan | 9,415.18 | 20,921 | 6.42 | 30,342.6 | 1.40 |
| Hubei | 28,330.9 | 53,717.53 | 697.47 | 82,745.9 | 3.82 | |
| Hunan | 65,070.74 | 46,516.89 | 164.52 | 111,752.15 | 5.16 | |
| 224,840.65 | 10.38 | |||||
| South | Guangdong | 25,592.29 | 59,261.58 | 43.9 | 84,897.77 | 3.92 |
| Guangxi | 39,644.76 | 89,432.19 | 8,058.34 | 137,135.29 | 6.33 | |
| Hong Kong | 68.83 | 52.64 | 0 | 121.47 | 0.01 | |
| Macao | 14.32 | 0 | 0 | 14.31 | 0.00 | |
| Hainan | 2,056.5 | 17,033.53 | 0 | 19,090.03 | 0.88 | |
| 241,258.87 | 11.14 | |||||
| Southwest | Chongqing | 17,029.21 | 11,295.87 | 4,219.55 | 32,544.63 | 1.50 |
| Sichuan | 146,670.31 | 40,738.02 | 81.56 | 187,489.89 | 8.65 | |
| Guizhou | 62,969.38 | 13,024.96 | 8,981.37 | 84,975.71 | 3.92 | |
| Yunnan | 154,402.04 | 29,265.63 | 9,060.16 | 192,727.83 | 8.90 | |
| Tibet | 55,258.38 | 41,689.71 | 20.69 | 96,968.78 | 4.48 | |
| 594,706.84 | 27.45 | |||||
| Northwest | Shaanxi | 42,740.64 | 52,406.42 | 2,406.09 | 97,553.15 | 4.50 |
| Gansu | 36,428 | 15,813.78 | 829.29 | 53,071.07 | 2.45 | |
| Qinghai | 3,978.6 | 1,002.57 | 0.02 | 4,981.19 | 0.23 | |
| Ningxia | 716.66 | 55.99 | 0.08 | 772.73 | 0.04 | |
| Xinjiang | 22,640.06 | 1,283.14 | 155.28 | 24,078.48 | 1.11 | |
| 180,456.62 | 8.33 | |||||
| 2,166,261.2 | 100 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, X.; Liang, Y.; Feng, W.; Li, J.; Ren, H.; Han, S.; Liu, M. Classification of Coniferous and Broad-Leaf Forests in China Based on High-Resolution Imagery and Local Samples in Google Earth Engine. Remote Sens. 2023, 15, 5026. https://doi.org/10.3390/rs15205026
Yuan X, Liang Y, Feng W, Li J, Ren H, Han S, Liu M. Classification of Coniferous and Broad-Leaf Forests in China Based on High-Resolution Imagery and Local Samples in Google Earth Engine. Remote Sensing. 2023; 15(20):5026. https://doi.org/10.3390/rs15205026
Chicago/Turabian StyleYuan, Xiaoguang, Yiduo Liang, Wei Feng, Junhang Li, Hongtao Ren, Shuo Han, and Mengqi Liu. 2023. "Classification of Coniferous and Broad-Leaf Forests in China Based on High-Resolution Imagery and Local Samples in Google Earth Engine" Remote Sensing 15, no. 20: 5026. https://doi.org/10.3390/rs15205026
APA StyleYuan, X., Liang, Y., Feng, W., Li, J., Ren, H., Han, S., & Liu, M. (2023). Classification of Coniferous and Broad-Leaf Forests in China Based on High-Resolution Imagery and Local Samples in Google Earth Engine. Remote Sensing, 15(20), 5026. https://doi.org/10.3390/rs15205026