
A Task-Risk Consistency Object Detection Framework Based on Deep Reinforcement Learning



Abstract
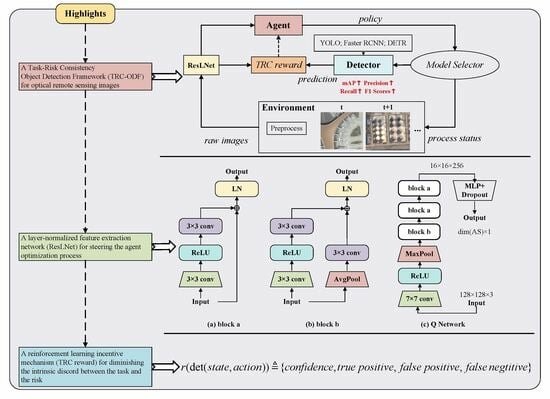
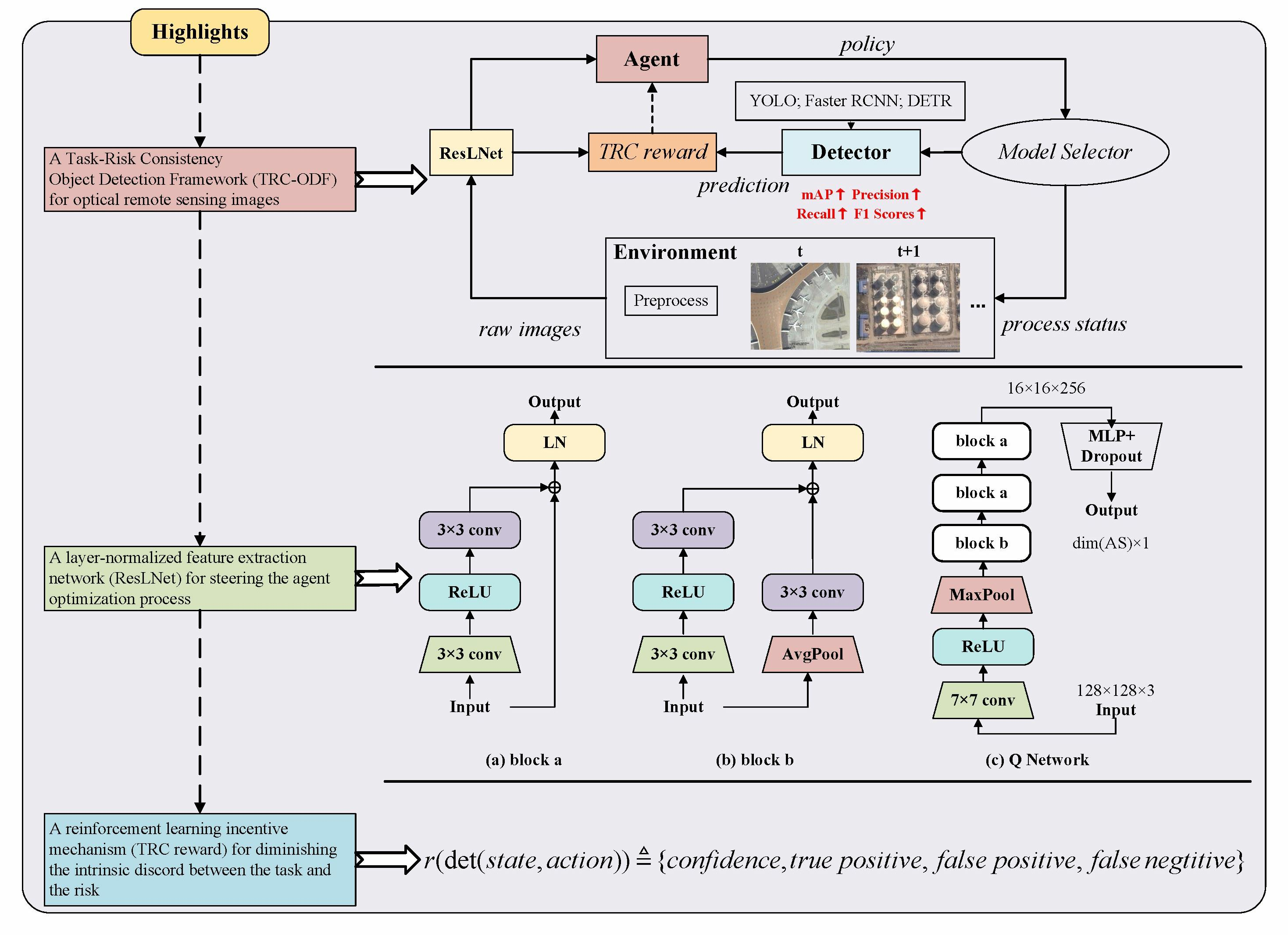
:
1. Introduction
2. Related Works
2.1. Object Detection
2.2. Deep Reinforcement Learning
2.3. Deep Reinforcement Learning in Object Detection
3. Methodology
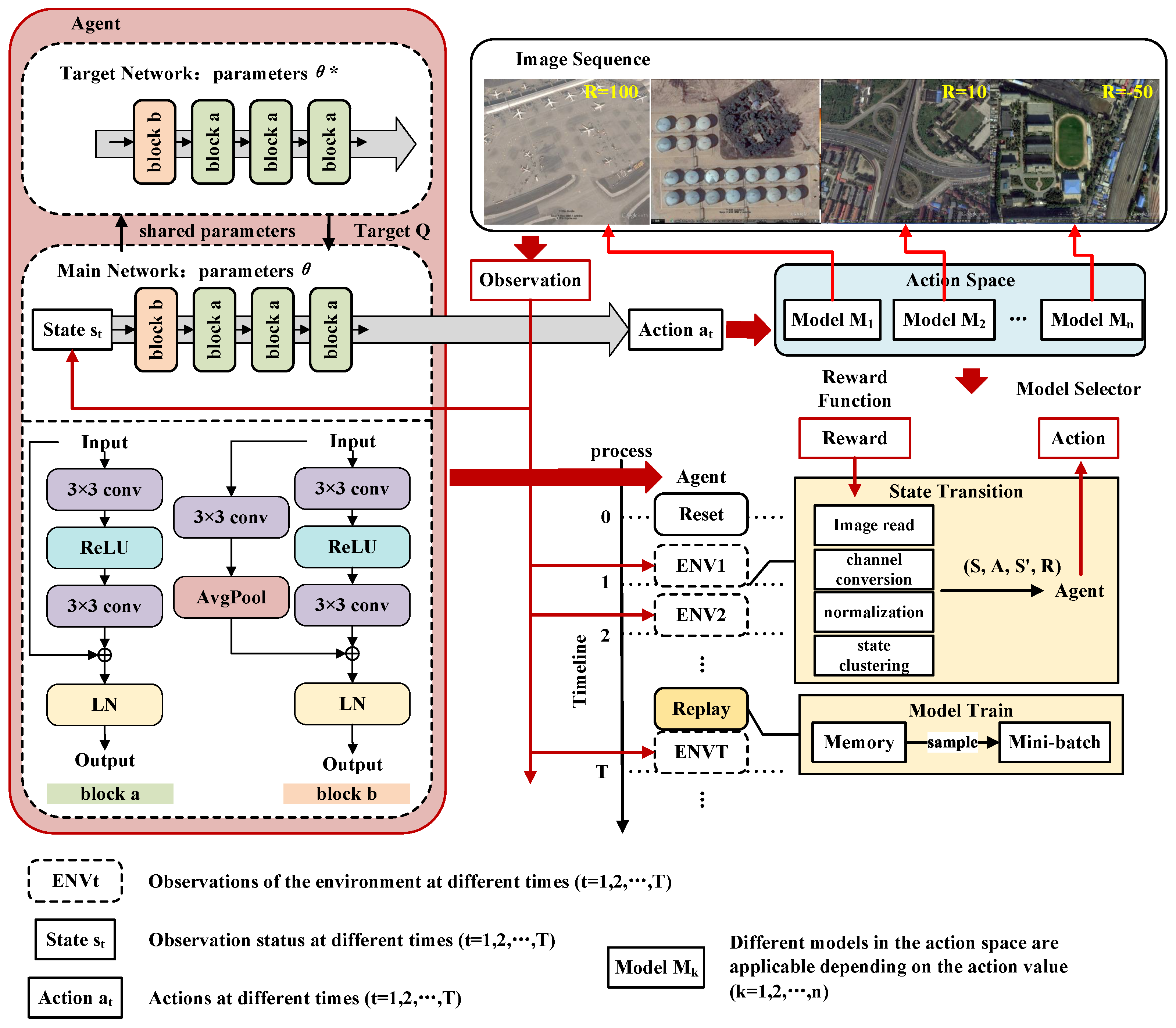
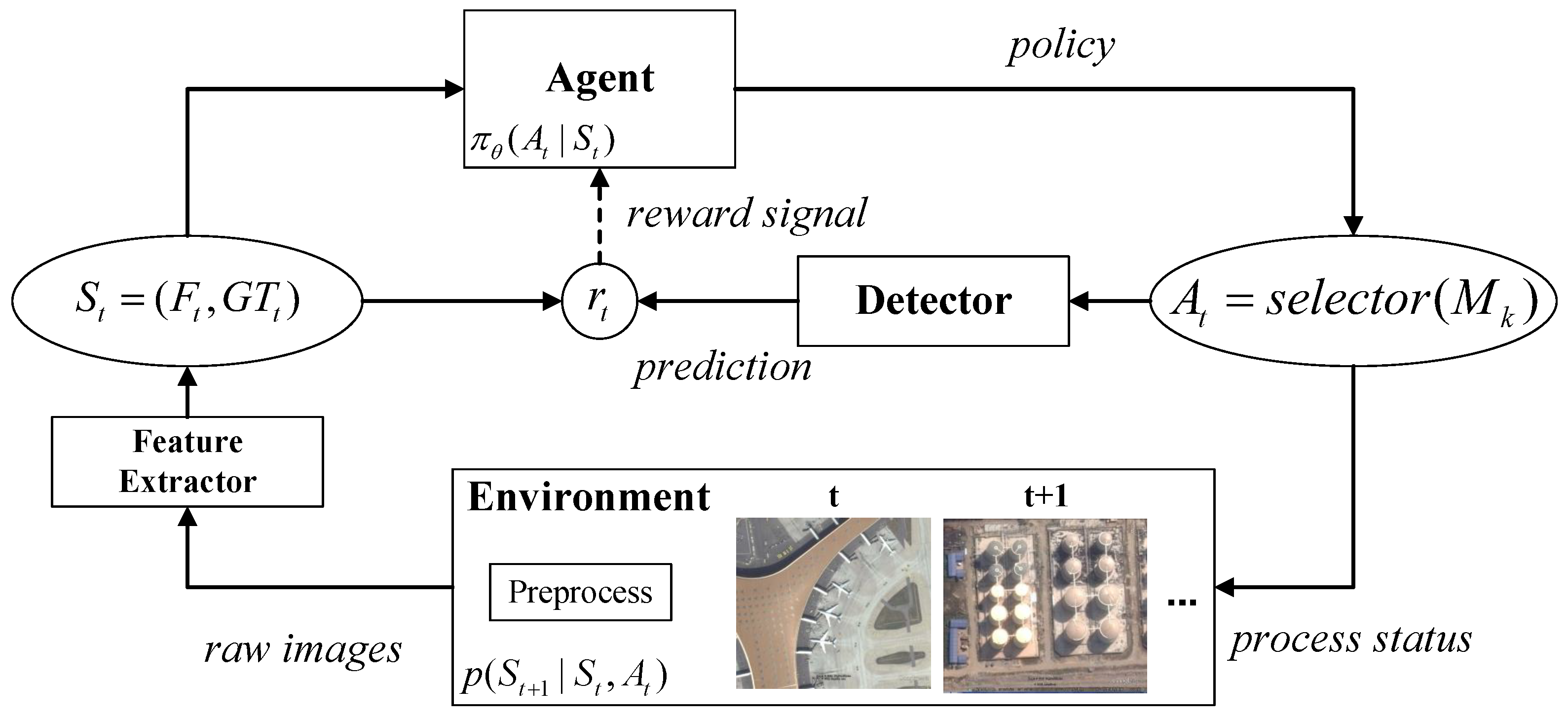
3.1. The Framework of Object Detection Based on Deep Reinforcement Learning
3.1.1. Problem Formulation
3.1.2. Framework Details
3.2. The Model-Free Reinforcement Learning Algorithm Based on Value Function
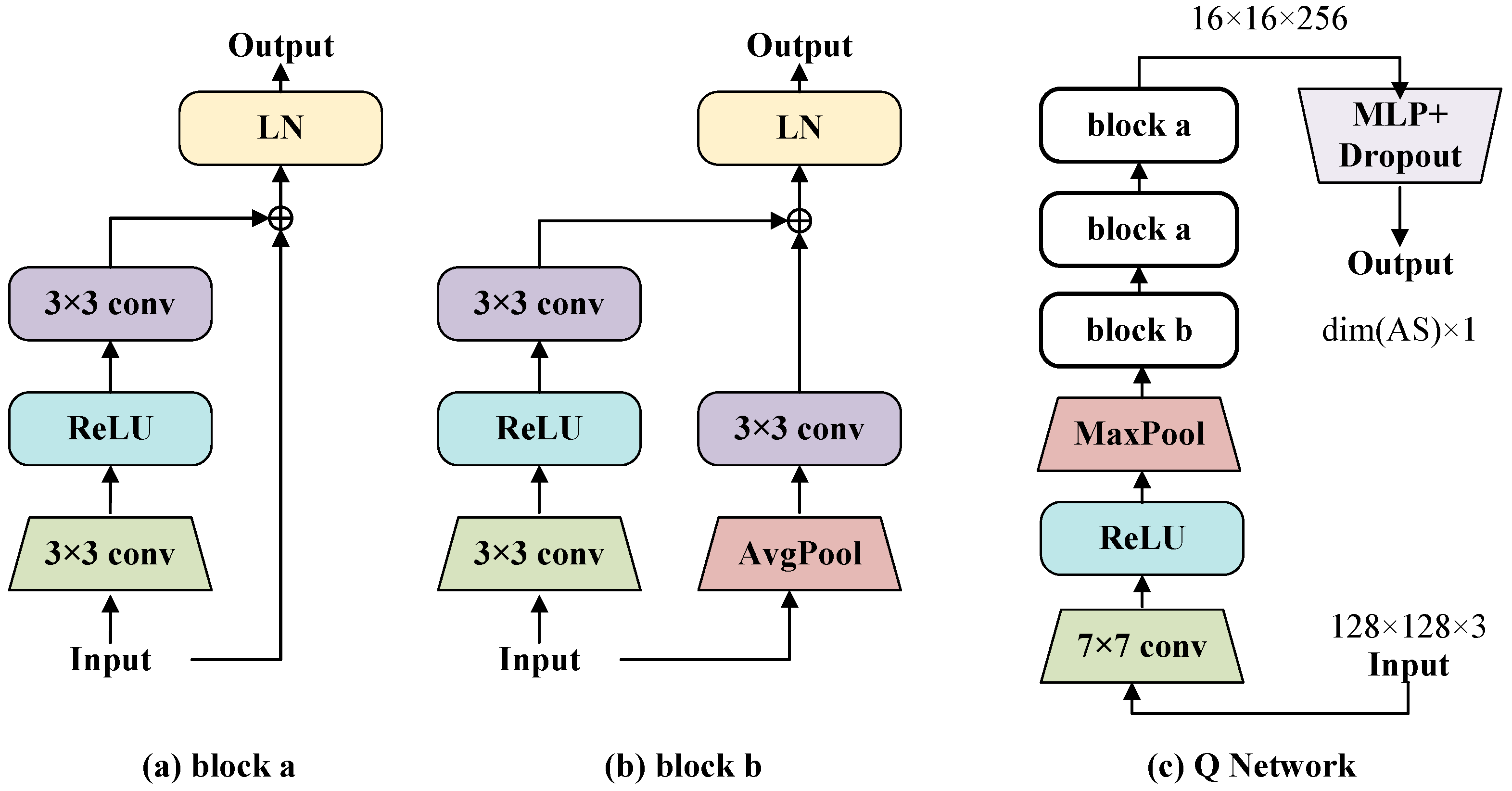
3.2.1. Network Architecture
3.2.2. Policy Optimization
| Algorithm 1: Optimization process. |
 |
3.3. The Reward Mechanism for Task-Risk Consistency
4. Experimental Settings
4.1. Parameter Setup
4.1.1. Object Detection Network Training Parameter Settings
4.1.2. Reinforcement Learning Agent Training Parameter Settings
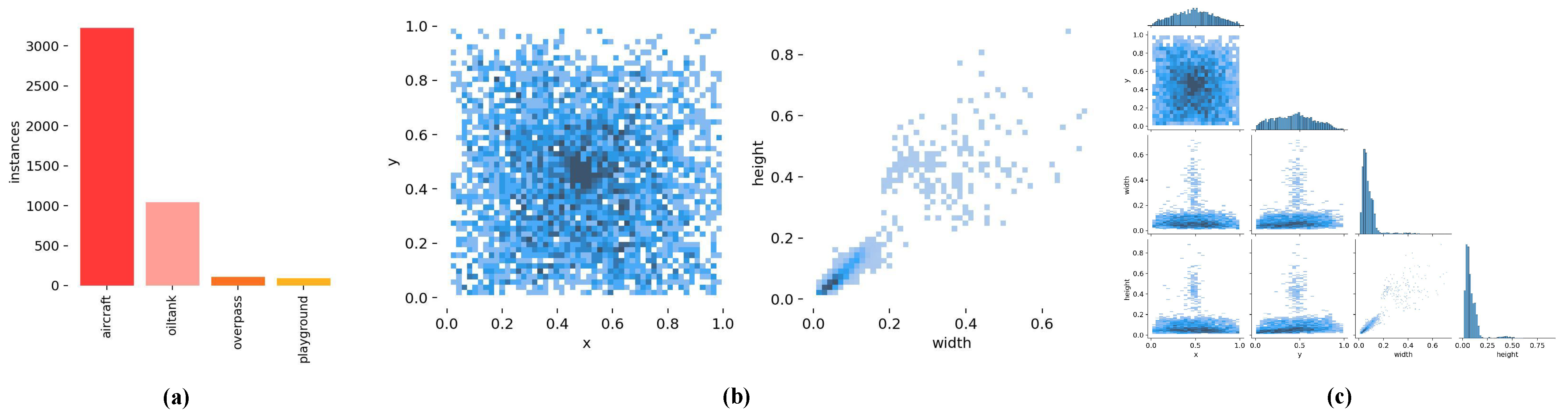
4.2. The Description of the Datasets
4.3. Evaluation Metrics
5. Results
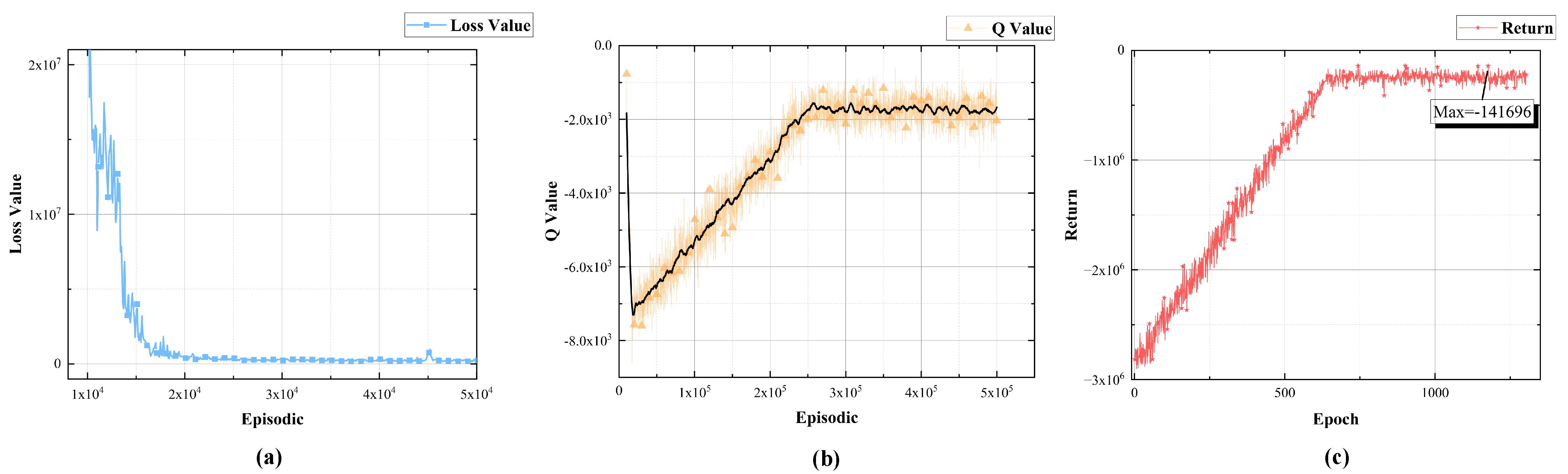
5.1. Experimental Result and Analysis of the Rationality of the Proposed Framework
5.2. Experimental Results and Analysis of Different Scale Detectors
6. Discussion
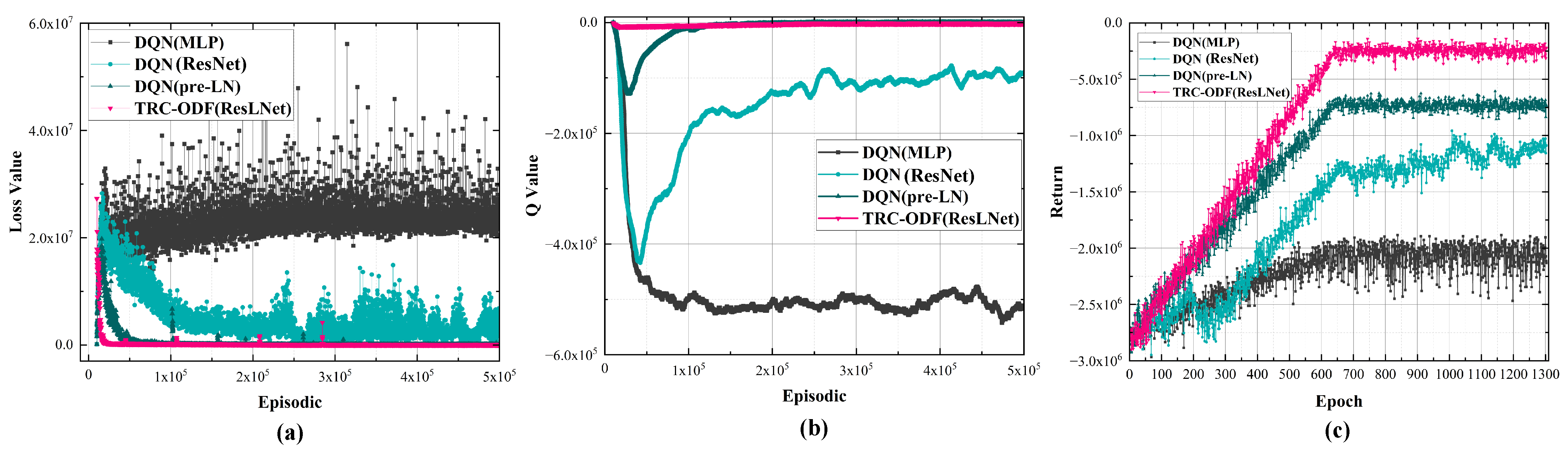
6.1. Effectiveness of the Agent Feature Extractor
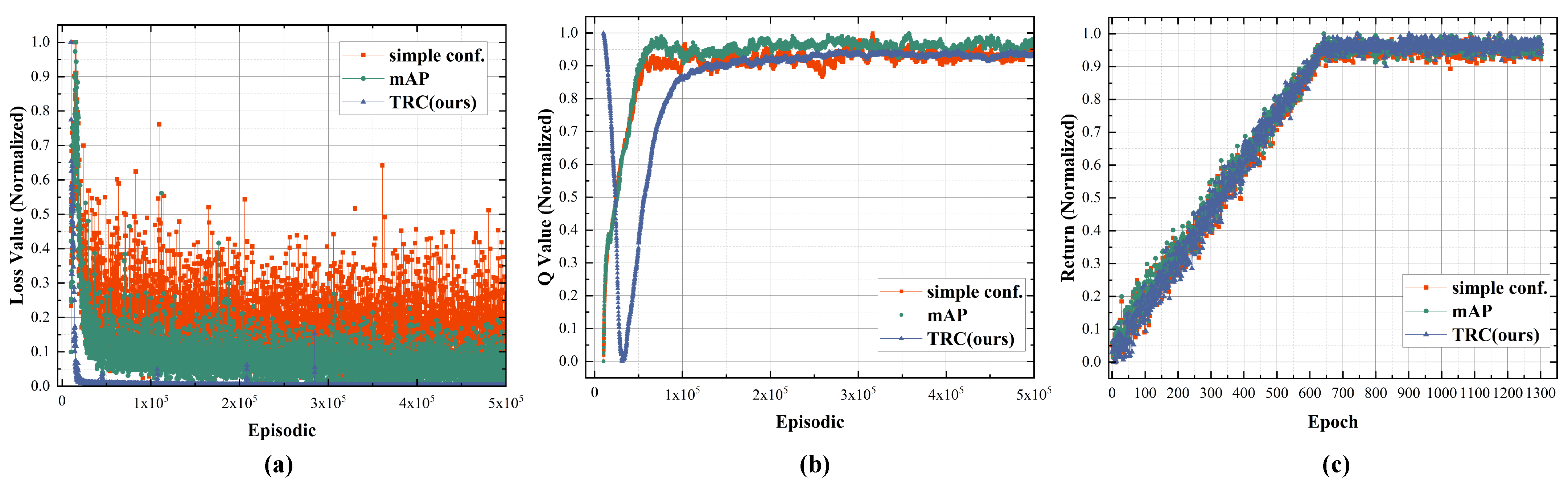
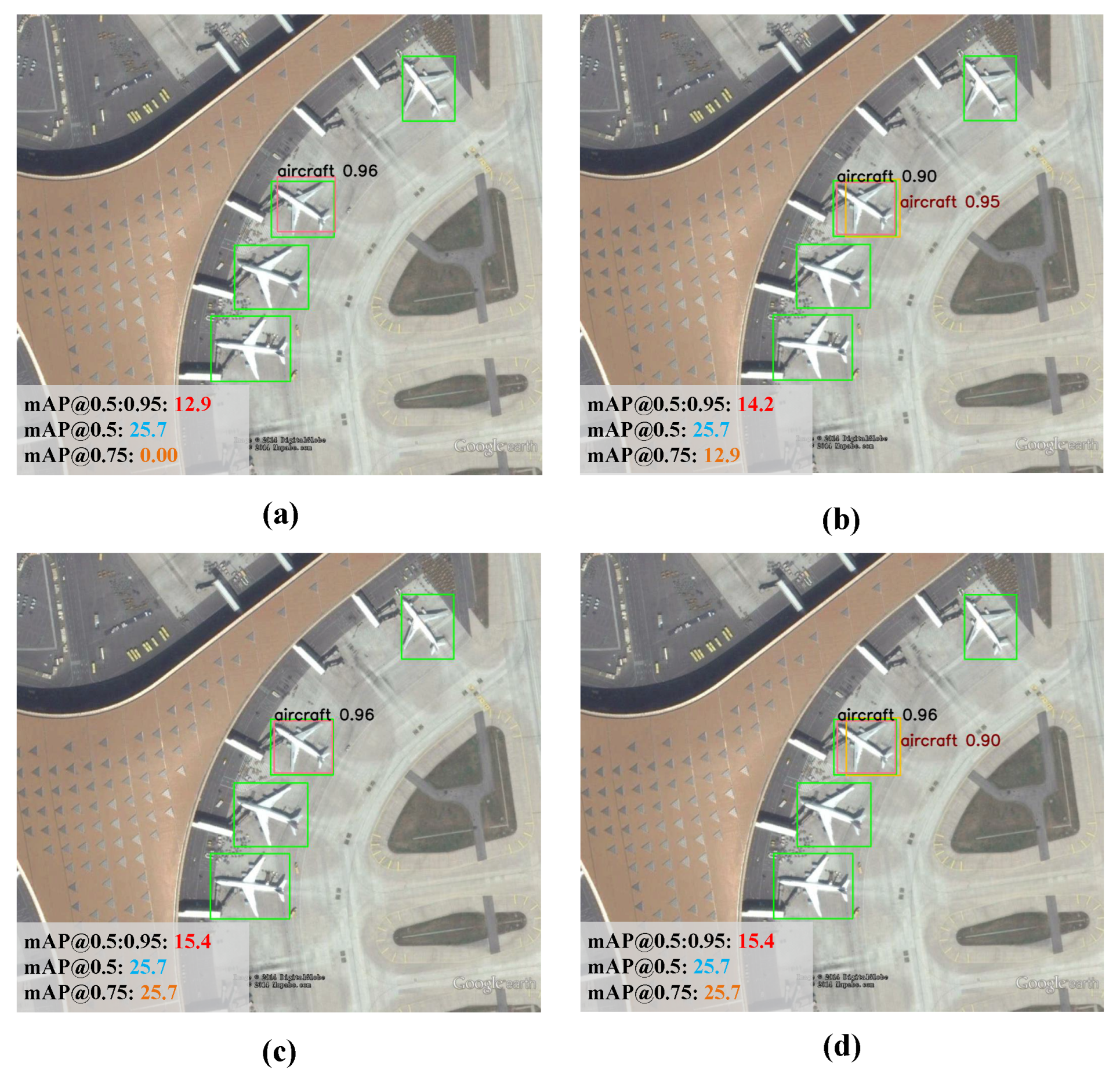
6.2. Effectiveness of the Reward Function Based on Task-Risk Consistency
6.3. Computational Time Analysis
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote. Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L.; Xu, M. Weakly Supervised Learning Based on Coupled Convolutional Neural Networks for Aircraft Detection. IEEE Trans. Geosci. Remote. Sens. 2016, 54, 5553–5563. [Google Scholar] [CrossRef]
- Aposporis, P. Object Detection Methods for Improving UAV Autonomy and Remote Sensing Applications. In Proceedings of the 2020 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), The Hague, The Netherlands, 7–10 December 2020; pp. 845–853. [Google Scholar] [CrossRef]
- Barrett, E.C. Introduction to Environmental Remote Sensing; Routledge: New York, NY, USA, 1999. [Google Scholar]
- Kamusoko, C. Importance of Remote Sensing and Land Change Modeling for Urbanization Studies. In Urban Development in Asia and Africa: Geospatial Analysis of Metropolises; Murayama, Y., Kamusoko, C., Yamashita, A., Estoque, R.C., Eds.; Springer: Singapore, 2017; pp. 3–10. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote. Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Li, C.; Cheng, G.; Wang, G.; Zhou, P.; Han, J. Instance-Aware Distillation for Efficient Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote. Sens. 2023, 61, 1–11. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Zhu, P.; Jia, X.; Tang, X.; Jiao, L. Generalized few-shot object detection in remote sensing images. ISPRS J. Photogramm. Remote. Sens. 2023, 195, 353–364. [Google Scholar] [CrossRef]
- Chen, S.; Zhao, J.; Zhou, Y.; Wang, H.; Yao, R.; Zhang, L.; Xue, Y. Info-FPN: An Informative Feature Pyramid Network for object detection in remote sensing images. Expert Syst. Appl. 2023, 214, 119132. [Google Scholar] [CrossRef]
- Zhou, H.; Ma, A.; Niu, Y.; Ma, Z. Small-Object Detection for UAV-Based Images Using a Distance Metric Method. Drones 2022, 6, 308. [Google Scholar] [CrossRef]
- Liu, H.; Yu, Y.; Liu, S.; Wang, W. A Military Object Detection Model of UAV Reconnaissance Image and Feature Visualization. Appl. Sci. 2022, 12, 12236. [Google Scholar] [CrossRef]
- Kreutzer, J.; Khadivi, S.; Matusov, E.; Riezler, S. Can Neural Machine Translation be Improved with User Feedback? arXiv 2018, arXiv:cs.CL/1804.05958. [Google Scholar]
- Stiennon, N.; Ouyang, L.; Wu, J.; Ziegler, D.; Lowe, R.; Voss, C.; Radford, A.; Amodei, D.; Christiano, P.F. Learning to summarize with human feedback. Adv. Neural Inf. Process. Syst. 2020, 33, 3008–3021. [Google Scholar]
- Pinto, A.S.; Kolesnikov, A.; Shi, Y.; Beyer, L.; Zhai, X. Tuning computer vision models with task rewards. arXiv 2023, arXiv:2302.08242. [Google Scholar]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. Adv. Neural Inf. Process. Syst. 2022, 35, 27730–27744. [Google Scholar]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-Train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing. ACM Comput. Surv. 2023, 55, 1–35. [Google Scholar] [CrossRef]
- Uzkent, B.; Yeh, C.; Ermon, S. Efficient Object Detection in Large Images Using Deep Reinforcement Learning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1824–1833. [Google Scholar]
- Jie, Z.; Liang, X.; Feng, J.; Jin, X.; Lu, W.; Yan, S. Tree-Structured Reinforcement Learning for Sequential Object Localization. Adv. Neural Inf. Process. Syst. 2016, 29, 29. [Google Scholar]
- Wang, Y.; Zhang, L.; Wang, L.; Wang, Z. Multitask Learning for Object Localization With Deep Reinforcement Learning. IEEE Trans. Cogn. Dev. Syst. 2019, 11, 573–580. [Google Scholar] [CrossRef]
- Pirinen, A.; Sminchisescu, C. Deep Reinforcement Learning of Region Proposal Networks for Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6945–6954. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Yan, J.; Lei, Z.; Wen, L.; Li, S.Z. The Fastest Deformable Part Model for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2497–2504. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–25 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2019; pp. 2980–2988. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. 2020. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; NanoCode012; Kwon, Y.; Michael, K.; TaoXie; Fang, J.; Imyhxy; et al. ultralytics/yolov5: v7.0—YOLOv5 SOTA Realtime Instance Segmentation. Zenodo, 2022. Available online: https://zenodo.org/records/7347926 (accessed on 15 May 2020).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. 2022. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 January 2023; pp. 7464–7475. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. YOLO by Ultralytics. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 12 March 2023).
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2010, arXiv:2010.04159. [Google Scholar]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep Reinforcement Learning: A Brief Survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- van Hasselt, H.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar] [CrossRef]
- Wang, Z.; Schaul, T.; Hessel, M.; Hasselt, H.; Lanctot, M.; Freitas, N. Dueling Network Architectures for Deep Reinforcement Learning. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1995–2003. [Google Scholar]
- Williams, R.J. Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning. In Reinforcement Learning; Sutton, R.S., Ed.; Springer US: Boston, MA, USA, 1992; pp. 5–32. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. 2017. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous Methods for Deep Reinforcement Learning. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1928–1937. [Google Scholar]
- Babaeizadeh, M.; Frosio, I.; Tyree, S.; Clemons, J.; Kautz, J. Reinforcement Learning through Asynchronous Advantage Actor-Critic on a GPU. arXiv 2017, arXiv:cs.LG/1611.06256. [Google Scholar]
- Holliday, J.B.; Le, T.N. Follow then Forage Exploration: Improving Asynchronous Advantage Actor Critic. In Proceedings of the Computer Science & Information Technology; AIRCC Publishing Corporation: Tamil Nadu, India, 2020; pp. 107–118. [Google Scholar] [CrossRef]
- Caicedo, J.C.; Lazebnik, S. Active Object Localization with Deep Reinforcement Learning. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2488–2496. [Google Scholar]
- Mathe, S.; Pirinen, A.; Sminchisescu, C. Reinforcement Learning for Visual Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2894–2902. [Google Scholar]
- Bueno, M.B.; Nieto, X.G.i.; Marqués, F.; Torres, J. Hierarchical object detection with deep reinforcement learning. Deep. Learn. Image Process. Appl. 2017, 31, 3. [Google Scholar]
- Ayle, M.; Tekli, J.; El-Zini, J.; El-Asmar, B.; Awad, M. BAR—A Reinforcement Learning Agent for Bounding-Box Automated Refinement. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 2561–2568. [Google Scholar] [CrossRef]
- Navarro, F.; Sekuboyina, A.; Waldmannstetter, D.; Peeken, J.C.; Combs, S.E.; Menze, B.H. Deep Reinforcement Learning for Organ Localization in CT. In Proceedings of the Third Conference on Medical Imaging with Deep Learning, Montreal, QC, Canada, 6–8 July 2020; pp. 544–554. [Google Scholar]
- Bhatt, A.; Argus, M.; Amiranashvili, A.; Brox, T. CrossNorm: Normalization for Off-Policy TD Reinforcement Learning. arXiv 2019, arXiv:cs.LG/1902.05605. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous Control with Deep Reinforcement Learning. arXiv 2019, arXiv:cs.LG/1509.02971. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate Object Localization in Remote Sensing Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote. Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote. Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Cramer, M. The DGPF-Test on Digital Airborne Camera Evaluation Overview and Test Design; Photogrammetrie-Fernerkundung-Geoinformation Schweizerbart Science Publishers: Stuttgart, Germany, 2010; pp. 73–82. [Google Scholar] [CrossRef]
- Padilla, R.; Netto, S.L.; da Silva, E.A.B. A Survey on Performance Metrics for Object-Detection Algorithms. In Proceedings of the 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), Niteroi, Brazil, 1–3 July 2020; pp. 237–242. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Model | Return | [email protected] | [email protected]:0.95 | Precision | Recall | F1 Score | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RSOD | Multi- Class | A 1 | −91,562.8 | −2339.5 | 90.8 | 90.6 | 64.7 | 64.2 | 94.3 | 97.8 | 92.3 | 87.3 | 93.3 |
| B | 3862.7 | 97.6 | 78.3 | 96.1 | 97.7 | ||||||||
| C | −98,131.5 | 74.9 | 34.0 | 84.7 | 84.9 | ||||||||
| D | 5045.4 | 99.9 | 82.4 | 98.5 | 99.3 | ||||||||
| TRC-ODF (ours) | A | 9058.2 | −5699.5 | 96.2 | 87.9 | 67.4 | 62.1 | 95.4 | 96.2 | 93.9 | 89.9 | 94.6 | |
| B | 4160.5 | 97.6 | 79.3 | 97.0 | 98.0 | ||||||||
| C | 4797.0 | 99.5 | 42.6 | 88.4 | 87.7 | ||||||||
| D | 5045.4 | 99.9 | 85.7 | 100.0 | 100.0 | ||||||||
| NWPU VHR-10 | Multi- Class | a 2 | - | - | 94.5 | 99.5 | 66.9 | 72.5 | 94.8 | 99.1 | 87.1 | 100.0 | 90.8 |
| b | - | 95.4 | 67.7 | 91.9 | 87.4 | ||||||||
| c | - | 81.4 | 45.7 | 81.9 | 81.0 | ||||||||
| d | - | 99.0 | 79.2 | 97.6 | 96.7 | ||||||||
| e | - | 96.7 | 72.7 | 96.7 | 82.4 | ||||||||
| f | - | 97.0 | 74.7 | 96.6 | 96.2 | ||||||||
| g | - | 99.9 | 85.7 | 100.0 | 98.2 | ||||||||
| h | - | 97.3 | 66.6 | 95.4 | 86.9 | ||||||||
| i | - | 83.8 | 37.2 | 94.5 | 57.6 | ||||||||
| j | - | 95.4 | 62.5 | 94.4 | 84.9 | ||||||||
| TRC-ODF (ours) | a | - | - | 96.2 | 99.5 | 68.9 | 75.3 | 95.2 | 99.3 | 93.4 | 100.0 | 94.3 | |
| b | - | 93.8 | 68.3 | 91.1 | 89.2 | ||||||||
| c | - | 93.7 | 43.3 | 94.5 | 92.7 | ||||||||
| d | - | 98.9 | 81.6 | 98.2 | 98.4 | ||||||||
| e | - | 97.0 | 71.9 | 92.8 | 94.4 | ||||||||
| f | - | 99.3 | 81.3 | 92.9 | 100.0 | ||||||||
| g | - | 99.5 | 92.6 | 100.0 | 99.6 | ||||||||
| h | - | 97.9 | 68.6 | 98.3 | 94.9 | ||||||||
| i | - | 86.2 | 38.6 | 91.9 | 75.9 | ||||||||
| j | - | 95.9 | 67.2 | 93.5 | 89.3 | ||||||||
| DIOR | Multi- Class | 1–5 3 | - | - | 81.8 | 88.3 | 61.0 | 69.1 | 86.1 | 91.8 | 74.1 | 78.9 | 79.7 |
| 6–10 | - | 79.7 | 62.2 | 84.8 | 73.0 | ||||||||
| 11–15 | - | 79.5 | 59.6 | 82.7 | 73.0 | ||||||||
| 15–20 | - | 79.5 | 53.0 | 85.1 | 71.6 | ||||||||
| TRC-ODF (ours) | 1–5 | - | - | 82.6 | 89.0 | 61.7 | 69.5 | 87.8 | 91.9 | 74.7 | 79.7 | 80.7 | |
| 6–10 | - | 79.9 | 62.6 | 85.6 | 74.3 | ||||||||
| 11–15 | - | 80.4 | 59.8 | 85.2 | 73.1 | ||||||||
| 16–20 | - | 80.9 | 54.7 | 88.4 | 71.6 | ||||||||
| Model | Selected Percentage | [email protected] | [email protected]:0.95 | Precision | Recall | F1 Score | |
|---|---|---|---|---|---|---|---|
| Single Model | YOLOv8-n | - | 87.1 | 53.7 | 90.5 | 87.7 | 89.1 |
| YOLOv8-s | - | 90.8 | 64.7 | 94.3 | 92.3 | 93.3 | |
| YOLOv8-m | - | 94.5 | 72.4 | 96.0 | 93.2 | 94.6 | |
| YOLOv8-l | - | 96.8 | 76.3 | 96.6 | 94.8 | 95.7 | |
| YOLOv8-x | - | 98.7 | 77.7 | 98.1 | 95.7 | 96.9 | |
| Multimodel (RL) | YOLOv8-n | 0.0% | 98.9 | 80.1 | 98.3 | 96.6 | 97.4 |
| YOLOv8-s | 0.0% | ||||||
| YOLOv8-m | 1.9% | ||||||
| YOLOv8-l | 2.8% | ||||||
| YOLOv8-x | 95.3% | ||||||
| Single Model | Faster R-CNN | - | 94.9 | 68.0 | 95.9 | 91.7 | 93.8 |
| DETR | - | 95.5 | 69.4 | 96.5 | 93.5 | 95.0 | |
| Multimodel (RL) | Faster R-CNN | 90.0% | 96.5 | 68.6 | 97.4 | 92.9 | 95.1 |
| DETR | 90.1% | 97.4 | 69.8 | 97.9 | 95.9 | 96.9 | |
| Network | Return | [email protected] | [email protected]:0.95 | Precision | Recall | F1 Score | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DQN (MLP) | Class A | −6046.4 | −6046.4 | 22.0 | 87.9 | 15.5 | 62.1 | 24.1 | 96.2 | 22.5 | 89.9 | 23.2 |
| Class B | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | |||||||
| Class C | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | |||||||
| Class D | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | |||||||
| DQN (ResNet) | Class A | 942.6 | −6475.7 | 59.7 | 81.0 | 45.7 | 57.7 | 98.1 | 97.9 | 59.9 | 81.7 | 74.4 |
| Class B | 4242.0 | 97.6 | 79.3 | 94.4 | 98.8 | |||||||
| Class C | 925.3 | 20.8 | 10.8 | 100.0 | 20.0 | |||||||
| Class D | 2251.1 | 39.6 | 35.1 | 100.0 | 39.1 | |||||||
| DQN (pre-LN) | Class A | 3616.4 | −6046.4 | 69.1 | 87.9 | 54.4 | 62.1 | 96.1 | 96.2 | 70.4 | 89.9 | 81.3 |
| Class B | 4153.0 | 95.6 | 77.4 | 94.5 | 96.3 | |||||||
| Class C | 86.9 | 2.0 | 1.6 | 100.0 | 1.7 | |||||||
| Class D | 5422.9 | 91.0 | 76.4 | 93.8 | 93.8 | |||||||
| TRC-ODF (ResLNet) | 9058.2 | 96.2 | 67.4 | 95.4 | 93.9 | 94.6 | ||||||
| Reward Model | Select Accuracy | [email protected] | [email protected]:0.95 | Precision | Recall | F1 Score | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Simple conf. | Class A | 95.3% | 99.4% | 87.1 | 87.0 | 60.4 | 62.0 | 97.8 | 95.3 | 88.3 | 87.9 | 91.7 |
| Class B | 100.0% | 97.6 | 79.3 | 94.1 | 98.8 | |||||||
| Class C | 93.1% | 89.3 | 37.6 | 93.1 | 90.0 | |||||||
| Class D | 80.0% | 74.5 | 62.5 | 96.1 | 76.6 | |||||||
| mAP | Class A | 96.1% | 100.0% | 88.2 | 87.9 | 61.3 | 62.1 | 96.2 | 97.8 | 89.1 | 88.1 | 92.5 |
| Class B | 100.0% | 97.6 | 79.3 | 94.1 | 98.8 | |||||||
| Class C | 91.4% | 87.9 | 37.1 | 96.4 | 88.3 | |||||||
| Class D | 85.0% | 79.5 | 66.6 | 96.3 | 81.3 | |||||||
| TRC (ours) | Class A | 99.7% | 100.0% | 96.2(+9.1, +8.0) | 67.4(+7.0, +6.1) | 95.4 | 93.9(+5.6, +4.8) | 94.6(+2.1, +2.9) | ||||
| Class B | 100.0% | |||||||||||
| Class C | 98.3% | |||||||||||
| Class D | 100.0% | |||||||||||
| Model | Size | Parameters | GFLOPs | Delay |
|---|---|---|---|---|
| TRC-ODF | 12.2 MB | 3.04 M | 1.84 | 13.2 ms |
| YOLOv8-s | 22.6 MB | 11.20 (+8.16) M | 28.60 (+26.76) | 3.5 (−9.7) ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wen, J.; Liu, H.; Li, J. A Task-Risk Consistency Object Detection Framework Based on Deep Reinforcement Learning. Remote Sens. 2023, 15, 5031. https://doi.org/10.3390/rs15205031
Wen J, Liu H, Li J. A Task-Risk Consistency Object Detection Framework Based on Deep Reinforcement Learning. Remote Sensing. 2023; 15(20):5031. https://doi.org/10.3390/rs15205031
Chicago/Turabian StyleWen, Jiazheng, Huanyu Liu, and Junbao Li. 2023. "A Task-Risk Consistency Object Detection Framework Based on Deep Reinforcement Learning" Remote Sensing 15, no. 20: 5031. https://doi.org/10.3390/rs15205031
APA StyleWen, J., Liu, H., & Li, J. (2023). A Task-Risk Consistency Object Detection Framework Based on Deep Reinforcement Learning. Remote Sensing, 15(20), 5031. https://doi.org/10.3390/rs15205031