1. Introduction
With the substantial progress of remote sensing technology, the automatic interpretation of remote sensing images (RSIs) has significantly improved [
1,
2]. Higher resolution and large-scale data give impetus to the development of RSI interpretation systems in scene classification [
3,
4], object detection [
5,
6], and semantic segmentation [
7,
8,
9,
10,
11]. Automated RSI interpretation with robustness and high accuracy can lead to significant economic benefits. Object detection performance, which is the cornerstone of the RSI interpretation system, is especially crucial. With the development of deep learning theory and computer hardware technology, especially the success of convolutional neural networks (CNNs), significant breakthroughs have been made in object detection [
12,
13]. Intuitively, many excellent detection algorithms [
14,
15] have been introduced to the RSI interpretation system. These RSI detection models outperform traditional detectors in terms of accuracy and efficiency, which is inseparable from CNN’s excellent feature extraction capabilities.
However, many CNN-based models exhibit a lack of stability with regard to specially designed “small” perturbations to the signal input space [
16]. These “small” disturbances keep the signal content perceived by humans unchanged while causing fundamental changes in the output of the CNN-based model. The CNN-based model has poor resistance to these specially designed disturbances and is fragile. Images containing such disturbances are usually referred to as adversarial examples. The concept of adversarial examples was introduced in the field of image classification by Szegedy et al. [
17]. In recent years, adversarial samples for classification tasks have been widely used in RSIs [
18,
19].
The object detection task is another critical problem in RSI understanding. It combines multitarget localization and multitarget classification problems simultaneously. The candidate regions generated in the object detection task are more challenging than image classification alone. Most existing research on adversarial attacks focuses on image classification problems, while little attention is given to object detectors. The first adversarial attack model for object detection was proposed by Lu et al. [
20], who suggested adding perturbations to traffic signs and human faces in images to mislead detectors. Then, a series of studies were conducted on adversarial attacks for object detection.
Nevertheless, most of these adversarial attacks for object detection directly adopt gradient attacks designed for classification tasks and use random adoption for gradient initialization [
21,
22,
23]. This unreasonable approach leads to compromised attack performance. In fact, the diversity of the input space cannot be directly converted into the diversity of the output space. If only the input is initialized randomly, the initialization of the output space cannot be guaranteed to be completely random. Although this has little impact on classification tasks, it is crucial for object detection tasks. For object detection, the complexity of the output space is far greater than image classification. Specifically, the classification output is a vector representing the probability of each category. In contrast, the detection output is a high-dimensional tensor containing the target’s location, category, and confidence score. If the diversity of the detector’s outputs is not maximized, the gradient attack may fall into the suboptimal solution. This limits the performance of adversarial attack methods in object detection tasks.
According to the range of modification to the detected target pixels, adversarial attacks for object detection can generally be classified into global attacks [
20,
24,
25,
26,
27] and patch-based attacks [
28,
29,
30]. A global attack modifies the entire image’s pixels when adversarial examples are generated. Unlike the global attack, the patch-based attack only adds a perturbation in a specific area of the original image so that the perturbation in this area can affect the whole image and deceive the detector. Note that the targets in RSIs usually have different sizes and uneven distributions. Hence, it is difficult for a local perturbation attack to exert the same effect on all targets. However, the gradient attack algorithms adopted by these models are all designed for classified tasks and are unsuitable for object detection tasks.
However, both global attacks and patch-based attacks are easily detected by the naked eye [
31,
32]. Global attacks are unsuitable for the RSI’s object detection because the target only occupies a small area in the RSI [
33]. This means the perturbation generated in the background area usually does not improve the attack effect but may add the perturbed pixels and weaken the invisibility. For patch-based attacks, humans can easily perceive attacks due to the large contrast between patch pixels and image pixels, which is not conducive to the camouflage of targets [
34]. These patches usually have a large average gradient, so some defense measures can even detect the location of the target by detecting patch-based attacks [
35].
To overcome these problems, we propose a target camouflage network based on the adversarial attack for RSIs, named CamoNet. In the natural world, camouflage is one of the essential anti-predator defenses that prevent prey from being recognized by predators [
36]. Inspired by this, we limit the perturbation to the target itself with a mask and propose a detection space initialization (DSI) strategy. Moreover, we integrate a key pixel distillation (KPD) module into CamoNet. It can further reduce the pixels of disturbance while ensuring the attack effect, making the attack more concealed and imperceptible to the naked eye.
Next we summarize the main contributions of this work as follows:
(i) This paper proposes a target camouflage network based on the adversarial attack for RSIs, named CamoNet, which provides a new view instead of traditional target camouflage. We propose a new initialization strategy, to maximize diversity in the detector’s outputs among the generated samples. It can boost the performance of the gradient attack algorithms designed for classification in the object detection task.
(ii) Inspired by the anti-predator defense mechanism in the natural world, the KPD module is employed for the target camouflage network. It can make the attack more concealed and imperceptible to the naked eye without weakening the attack effect.
(iii) The experimental results of the DOTA and DIOR datasets validate the effectiveness of CamoNet. The ablation experiment demonstrates each component’s effectiveness. At the same time, we further explore the network’s generality and transferability.
The rest of the paper is organized as follows. Related work is introduced in
Section 2. In
Section 3, CamoNet is proposed, the validation experiment results of which are shown in
Section 4. Finally, the conclusions are presented in
Section 5.
Throughout the paper, matrices, vectors, and scalars are represented by bold uppercase letters , bold lowercase letters , and regular letters x, respectively. Superscripts and represent the transpose and inverse, respectively. We use , , and to denote the , , and norms, respectively.
2. Related Work
In recent years, a batch of excellent work has emerged in the field of remote sensing object detection. Lu et al. [
37] proposed adaptively placing counter patches of different sizes according to the size of the aircraft, which can effectively improve the success rate of patch-based attacks on RSIs. Zhang et al. [
38] raised a scale factor to generate adversarial patches that adapt to multiscale objects. Zhang et al. [
32] designed an IoU-based objective function specific for patch attacks, which can push the detected boxes far from the initial ones. Tang et al. [
39] proposed a novel natural weather-style patch attack, which is more natural and stealthy. Due to the threat posed by adversarial attacks to remote sensing detectors, Li et al. [
40] began researching remote sensing target detectors that are robust to adversarial attacks.
In summary, their modifications to the algorithm mainly focus on the design of gradient attack vectors and objective functions. In the following parts of this section, we first introduce several classical gradient attack methods in the field of adversarial attacks. Then, we introduce two adversarial attack objective functions designed for object detection tasks. Finally, we introduce two remote sensing image object detection datasets used in the experimental part of this article.
2.1. Gradient Attacks
Gradient attacks are input samples formed by intentionally adding subtle pixels to the data. The disturbed input makes the model give an incorrect output with high confidence. In this subsection, several representative gradient-based attacks used in the experiments of this article are briefly shown.
The fast Gradient Notation Method (FGSM) [
21] is a gradient-based attack. At the same time, it is also a non-iterative attack because it computes the gradient only once for each image. However, FGSM does not match the reality by assuming that DCNN is linear. The activation functions in DCNN make them not strictly linear.
Given an image
and its true label
, the adversarial example
can be calculated as
where
calculates the gradients of the loss function
with respect to the input sample
,
denotes the sign function, and
clips the pixel values in the image. In addition, with different values of
, we can obtain adversarial examples with different attack strengths.
For the gradient-based attack, project gradient descent (PGD) [
22] can be considered an iterative version of FGSM. At each iteration, the adversarial example can be updated as follows:
where
is the step size. We can obtain adversarial examples with different attack strengths by setting the parameters
and the iterations of PGD.
MI-FGSM [
23] is also an iterative version of FGSM, which applies the idea of momentum to generate adversarial examples. At each iteration, the adversarial example can be updated as follows:
where
is the accumulated gradient, which is updated by accumulating the velocity vector in the gradient direction.
2.2. Objective Functions
Object detection’s objective function is more complex than the classification task’s objective function. Given an RSI , the object detector first detects a large number of S proposals , where is a proposal centered at having a dimension with a confidence score of , and K-class probabilities . Because in actual application scenarios it is often difficult to obtain the annotations of the attacked image, this paper only studies two objective functions that do not need the true label .
DAG (dense adversary generation) [
24] was the first model to propose the object-mislabeling loss in object detection. Its objective function is as follows
where
, which is the predicted label of the
ith bounding box.
S is the total number of bounding boxes predicted by the model.
is the cross-entropy (CE), and
is the wrong label randomly generated for the
ith bounding box. The objective function is designed to narrow the score gap between the correct and wrong labels predicted by the model. However, this objective function does not consider the attack on regression loss, resulting in many candidate boxes with incorrect category prediction in the final result.
The object-vanishing loss without labels was first proposed in RPAttack [
41]. The confidence score of each bounding box should be reduced to hide the objects from the detector. Based on this, the objective function is defined as
where
is the mean square error (MSE) and
is the confidence score of the
ith bounding box. Notably, this objective function can achieve the effect of target camouflage. Since object-vanishing loss is closest to our target camouflage requirements, we use this loss as the default objective function in the following.
3. Methodology
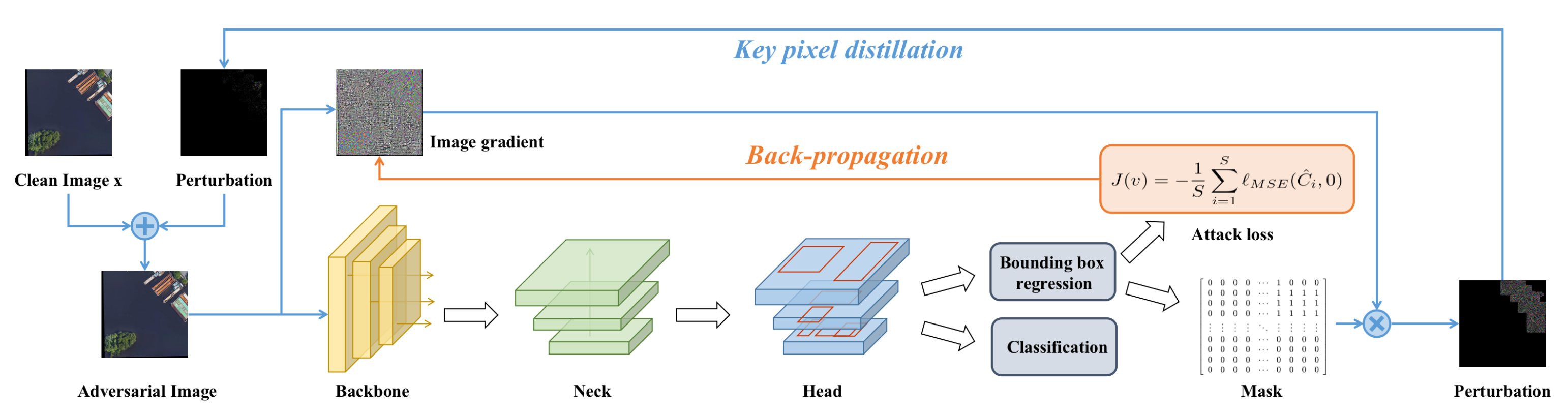
The proposed CamoNet for RSI target camouflage is introduced in this section, which mainly consists of two parts. First, we performed the gradient attack on the detector to obtain a perturbation of the same size as the input image. Then, we eliminated the meaningless perturbation in the RSI’s background region through postprocessing. The pipeline of CamoNet is shown in
Figure 1. We introduce these two phases in detail in the following subsections.
3.1. Gradient Attack Phase
In the gradient attack stage, the attack, which works well in image classification, is migrated to the object detection task. The gradient attack can be simply summarized as calculating the gradient of the objective function for each pixel of the input image of the model and then adding the gradient to the input image as a disturbance to obtain an adversarial sample, which can invalidate the model. The attack goal for the object detection task is to make the detector unable to detect any targets. It should minimize the confidence of each bounding box because the confidence of a bounding box indicates whether it contains objects and the degree of accuracy. To achieve the effect of target camouflage, we choose as our objective function, which is calculated according to the confidence score of the bounding boxes output by the detector. Attacks in most image classification tasks can be directly used in CamoNet. The performance of these attacks in target camouflage is quantitatively analyzed in the experiment section.
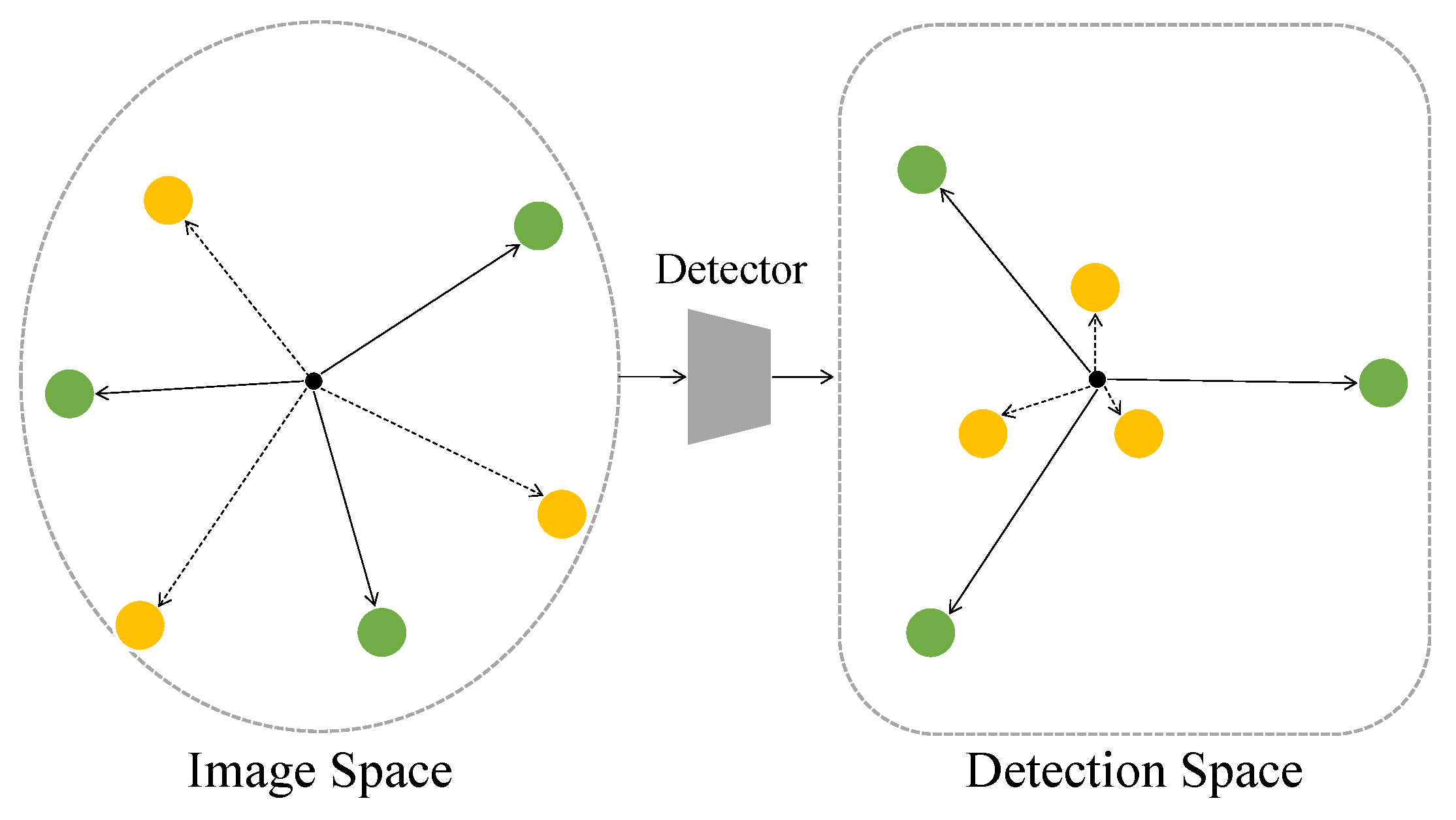
As intuitively presented in
Figure 2, random initialization in the image space does not necessarily produce initialization with high diversity as measured in the detection space. To address this problem, we propose a DSI strategy to maximize diversity in the detector’s outputs among the generated samples (green points in
Figure 2). It can boost the performance of the gradient attack algorithms designed for classification in the object detection task. DSI can be incorporated into most adversarial attack methods. One strong and popular example is the PGD attack, called DSI-PGD.
Given the direction of diversification
, the normalized perturbation vector of DSI can be defined as follows:
where
is sampled from the uniform distribution over
.
In CamoNet, we utilize DSI to generate output-diversified starting points. Given an original input
and the direction for DSI
, we try to find a restart point
that is as far away from
as possible by maximizing
via the following iterative update:
where
,
is the set of allowed perturbations and
is a step size. After some steps of DSI, the PGD attack can restart from
obtained by DSI. One step of ODI costs roughly the same time as one iteration of the PGD attack.
3.2. Postprocessing Phase
To further reduce the perturbation rate, the network performs a postprocessing operation. First, the network generates a mask according to the bounding box output by the detection model, which is a matrix with the same shape as the original image. At the position within the bounding box, the value of the mask matrix is 1, and the value at the remaining positions is 0. Then, the product of the mask and the gradient map is used as the initial perturbation applied to the original image. The mask can control the perturbation around the targets and does not involve the background area. The network repeats the above gradient attack and postprocessing until it reaches the maximum number of attack rounds.
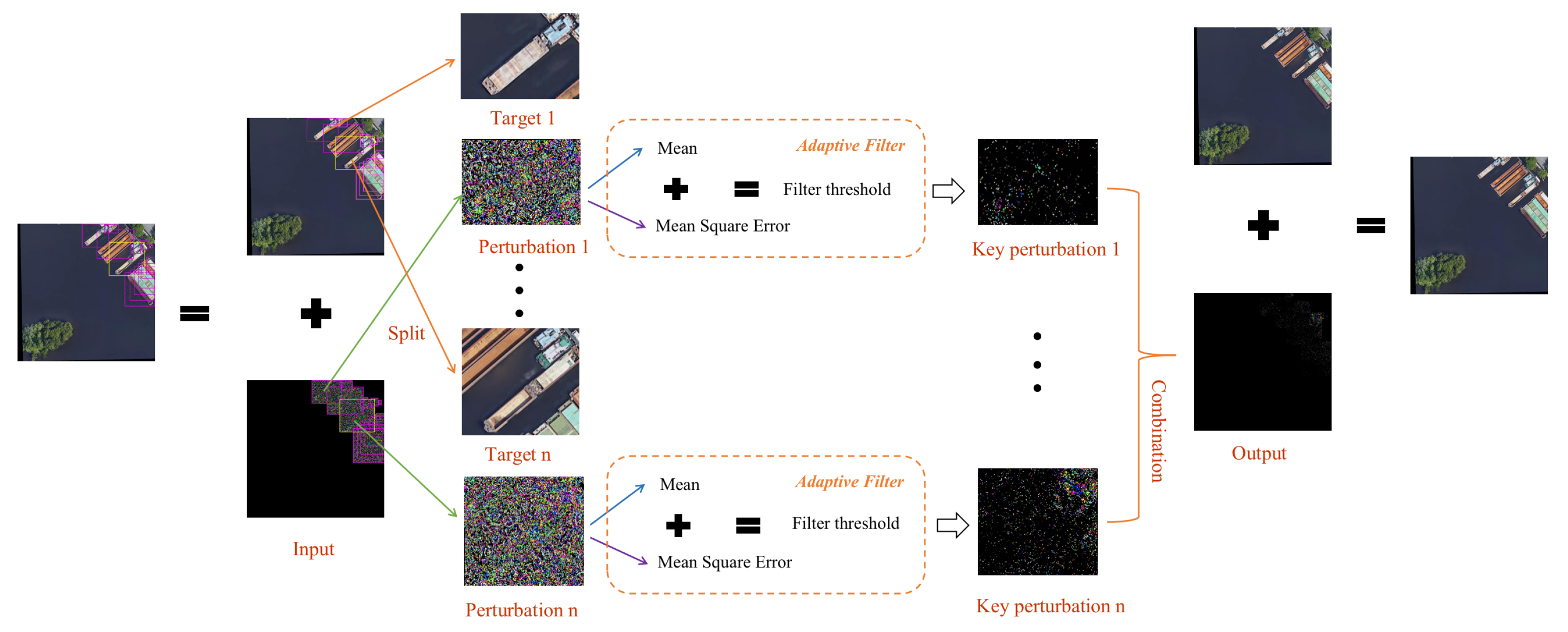
The purpose of target camouflage is to deceive the detector and make the intelligent interpretation system fail. However, if there are many modified pixels in the image, the attack may be detected by humans. Only when the perturbation rate is as low as possible can the naked eye be deceived. To further reduce the perturbation rate, we introduced KPD to extract the most critical pixels. It adaptively filters the unimportant pixels in each patch according to their mean value and mean square error. The details of KPD are shown in
Figure 3. It can further reduce the pixels of disturbance while ensuring the attack effect, making the attack more concealed and imperceptible to the naked eye.
KPD mainly screens and retains disturbances at positions with large gradients by setting a threshold. The positions that have a large impact on the gradient are the key positions for generating effective adversarial samples. Retaining the perturbation at key positions and clearing perturbation at positions that have little influence on the gradient can achieve the purpose of reducing the perturbation rate while ensuring the attack effect. Choosing the appropriate threshold is the core of module design. We tried a variety of threshold selection methods. Compared with using fixed hyperparameters to set the threshold, adaptively selecting the threshold according to the gradient obtained in each attack round can make the model more robust and not affect the attack effect due to the selection of different hyperparameters. We use the mean plus standard deviation as the threshold. The locations where the gradient is higher than the threshold are selected to retain the perturbation, and the locations where it is below the threshold are not added to the perturbation. The mean value indicates the overall contribution of the gradients of all locations in the current area to the detection results. Positions with a gradient greater than the mean are more important, and positions with a gradient less than the mean are less important. Therefore, the preliminary screening retains the positions with a gradient greater than the mean. Then the standard deviation is used to further screen the positions that retain disturbances. The standard deviation indicates the difference in the degree of influence of the gradient of each position in the current area on the detection results. A high standard deviation indicates that the gradient distribution of these positions is uneven, and the importance varies greatly. Most of the contributions to the detection results are concentrated in a small number of positions with high gradients, so a higher threshold screening is needed. A low standard deviation indicates that the gradient distribution of these important positions is relatively average, and the importance of each position is not very different. That is, the contribution of these positions to the detection results is not very different. At this time, a lower threshold is used to retain the disturbance of more positions.
To ensure that the gradient attack achieves the best effect, KPD is triggered when the adversarial example obtained by the gradient attack makes the detection model unable to detect any target. The detail of the whole algorithm is shown in Algorithm 1.
| Algorithm 1 CamoNet and key pixel distillation |
Input: Objective function J; an input image ; a perturbation of image ; bounding boxes ; maximum iterations T; warm up iterations W; score threshold t; step ; direction of diversification ; normalized perturbation vector ; warm up step ; postprocessing function ; iterations to recover the last mask Z. Output: the adversarial example - 1:
generate mask by taking as the masks. - 2:
- 3:
while
and do - 4:
- 5:
if then - 6:
- 7:
else - 8:
- 9:
end if - 10:
- 11:
number of bounding boxes - 12:
- 13:
- 14:
if then - 15:
- 16:
- 17:
- 18:
end if - 19:
if and then - 20:
- 21:
- 22:
end if - 23:
- 24:
end while return
|
3.3. Dataset
DOTA [
42] is a large-scale remote sensing dataset for oriented object detection in RSIs, comprising 15 different object categories.
Figure 4 shows the visualization results of the DOTA dataset. This dataset contains 2806 multiresolution RSIs obtained from different optical satellites. In the experiments, the original images in the DOTA dataset are cropped into
patches with an overlap of 256 pixels because the original images are of different and large sizes, which are unsuitable for training the object detector.
DIOR [
43] is another large-scale open-source dataset in RSI, which consists of 20 different object categories.
Figure 5 shows the visualization results of the DIOR dataset. This dataset contains 23,463 aerial images obtained from different sensors and platforms with multiple resolutions. All the shapes of the images are 800 × 800 pixels.
Table 1 shows the specific details of the two datasets. It is worth mentioning that this paper only uses horizontal box annotation.
3.4. Evaluation Metrics
We use average precision (AP) to quantitatively evaluate the detection performance. The detection result is true if the IoU overlap ratio between the ground truth and the prediction box is greater than 0.5. Otherwise, the prediction box is considered a false positive. In addition, if multiple prediction boxes overlap with the same ground truth, only one box with the highest score is considered a true positive, while the other boxes are false positives. Precision measures the proportion of true positive detections, and recall measures the detection coverage of the detector for all the targets to be detected.
where
represents the total number of predicted boxes,
is the number of targets correctly detected, and
denotes the actual number of targets.
As soon as the threshold of IoU is determined, we can draw the model’s precision–recall curve (PRC). The AP metric quantitatively evaluates the combined detection performance of the detector by calculating the area under the PRC as follows:
the higher the AP value is, the better the performance, and vice versa.
For a fair quantitative comparison, PSNR [
44] is used for object-vanishing attack assessment. The evaluation indicator is calculated as follows:
where
x and
y are images of size
and the corresponding adversarial example, respectively, and
is the maximum pixel value of the image. The higher the value of PSNR, the lower the image noise. In the field of image compression and reconstruction, it is believed that when PSNR is close to 50, the image error is very small. When PSNR is between 30 and 50, it is difficult for human eyes to detect the image difference.
4. Experimental Results
In the experiments, ImageNet pretrained weights are used to initialize the backbone. Most models are trained in 12 periods with a batch size of 2. RTMDet [
45] is trained in 36 epochs. This paper uses stochastic gradient descent (SGD) as the default optimizer. The weight decay and momentum of SGD are
and 0.9, respectively. The initial learning rate is set to
. The learning rate decays by a factor of 0.1 at 8 and 11 epochs. Our experiments are carried out on an Ubuntu system with one Tesla V100 GPU.
4.1. Objective Function Studies
In this part of the experiment, we use different objective functions to attack the Faster R-CNN object detectors trained on the DOTA training set and then compare and evaluate their attack performance on 100 images selected from the DOTA verification set.
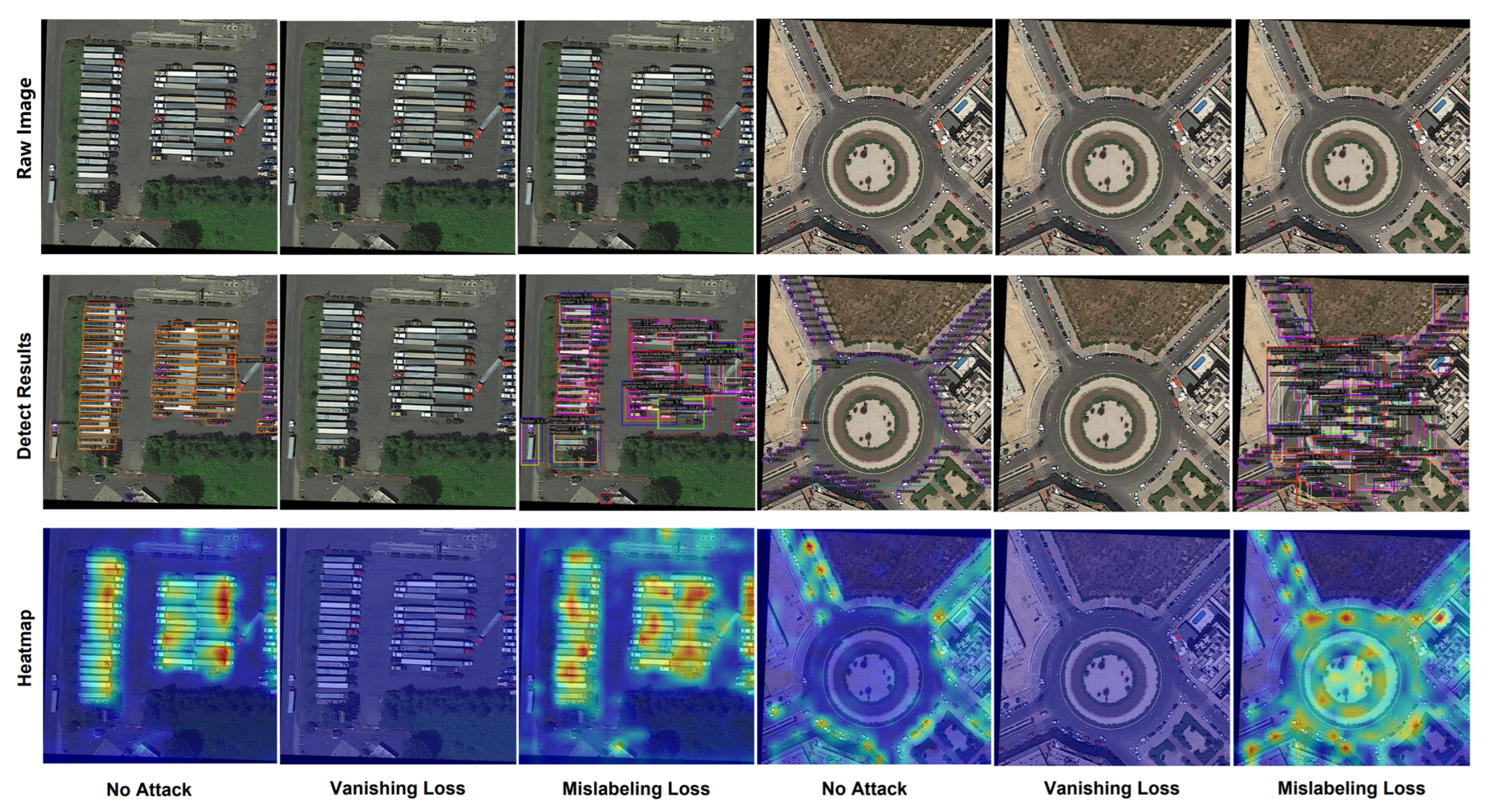
Figure 6 provides an illustration to intuitively show the difference between the two objective functions. The first row show the raw images, the second row is the visualization of the detection results, and the third row is the heatmaps obtained by AblationCAM. The vanishing loss eliminates the ability to recognize the target the victim model should have. The mislabeling loss fools the detector into mislabeling detected objects. It can be seen from the heatmaps that the model’s attention after the vanishing loss completely disappears so that the model cannot detect any target. After the mislabeling loss, the model’s attention is distracted, resulting in many false alarms.
The quantitative results are shown in
Table 2. It turns out that mislabeling and vanishing losses drastically reduce the
of the victim detector. The
of mislabeling loss reaches a score of 21.2 (decreased by 69.4%). It is worth noting that the vanishing loss breaks down the detection capability of the victim detector by reducing
from 69.3% to 0.6% (decreased by 99.1%). It also shows that when mislabeling and vanishing loss are applied simultaneously, the result can be worse than using vanishing loss alone. This is because the two objective functions are mutually exclusive. Compared with the perfect detection results under no attack, the vanishing loss removes the victim’s ability to recognize any object. The mislabeling loss fools the detector into mislabeling detected objects (e.g., a vehicle as an airplane). Since vanishing loss is more suitable for camouflage and hiding targets, the following experiments use vanishing loss as the default object function.
4.2. Gradient Attack Studies
In this part of the experiment, we use different adversarial attack methods to attack the Faster R-CNN object detectors trained on the DOTA training set and then compare and evaluate their attack performance on 100 images selected from the DOTA verification set. Since the object detection attack framework is based on the gradient, these gradient-based adversarial attack methods widely used in classification tasks can be directly used. The results are shown in
Table 3. PGD and DIS-PGD obviously decrease the
index. The
of PGD reaches a score of 0.6, and the
of DIS-PGD reaches a score of 0.2. Compared with PGD, DIS-PGD sacrifices PSNR but has a faster attack speed. However, the PSNR is high enough to make it difficult for human eyes to detect differences in images. Although FGSM has a much higher PSNR and attack speed than other methods, its attack success rate is low. The attack speed of MI-FGSM is the slowest among the four methods. Given the priority of the attack success rate, DIS-PGD is chosen as the default adversarial attack method in the following experiments.
4.3. Postprocessing Studies
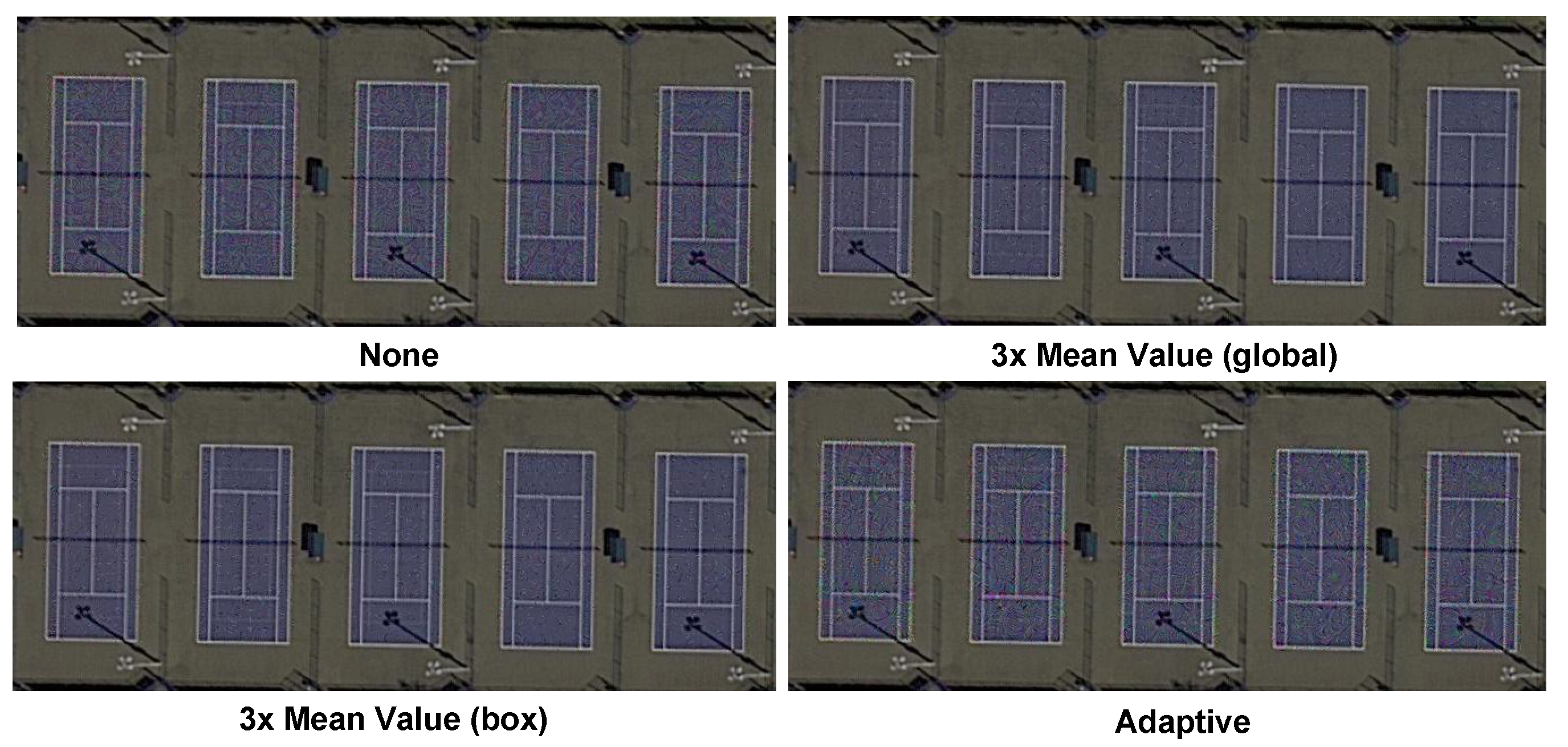
To further improve the success rate of ground target camouflage, the KPD module is introduced, which can reduce the disturbance rate and make camouflage more difficult to detect. To explore different postprocessing strategies, the proposed target camouflage network is applied to the DOTA dataset. The results are shown in
Table 4. The entire bounding box areas are taken as masks when no postprocessing strategy is specified. It has the highest pixel perturbation rate of 9.2%. When postprocessing operations are performed, the model selects these critical pixels, and the disturbance rate further decreases. A 3× mean value (global) means that the model retains pixels larger than the 3× mean value of all mask pixels. A 3× mean value (box) means the model retains pixels larger than the 3× mean value of mask pixels of the current bounding box. Therefore, the latter has a higher time complexity and slower speed than the former. Adaptive indicates that the model adaptively retains pixels larger than the sum of the mean and mean square error of the mask pixels of the current bounding box, which has a dynamic threshold. Surprisingly, although the three strategies reduce the perturbation rate, they do not increase
, which means that the attack success rate is not affected.
To show the differences between different postprocessing strategies more intuitively, the enlarged visible results are shown in
Figure 7. The PSNR of the 3× mean value (box) is the highest among the three postprocessing methods, and is 44.7. It is difficult for the naked eye to find the added disturbance of the 3× mean value (box). Although KPD reduces the pixel perturbation rate, its disturbance seems more obvious than that without adding a postprocessing module. It is worth mentioning that these disturbances are so subtle that it is difficult to find them directly from large RSIs.
To further verify the generality of the KPD module, the proposed target camouflage network is also applied to the DIOR datasets. The results are shown in
Table 5. We also visualize the enlarged results on the DIOR dataset in
Figure 8 and find that the rules are consistent with those on the DOTA dataset. The PSNR of the 3× mean value (global) is the highest among the three postprocessing methods, and is 38.6. It is worth mentioning that the KPD strategy reduces the perturbation rate and
, while the 3× mean value strategy improves
. This may be because the filter threshold of the 3× mean value strategy is fixed, and parameters need to be adjusted based on different datasets. However, the filter threshold of the adaptive strategy is automatically adjusted so it has stronger generality.
4.4. Image Forensics Studies
As shown in
Figure 9 We applied four traditional image forensic techniques [
46] to the attacked images to check if they can detect changes in the image. They include clone detection, error level analysis, noise analysis, and principal component analysis. The following is a brief introduction to these four methods:
Clone Detection—The clone detector highlights copied regions within an image. These can be a good indicator that a picture has been manipulated.
Error Level Analysis—This tool compares the original image to a recompressed version. This can make manipulated regions stand out in various ways. For example, they can be darker or brighter than similar regions that have not been manipulated.
Noise Analysis—This tool is basically a reverse denoising algorithm. Rather than removing the noise, it removes the rest of the image. It uses a super simple separable median filter to isolate the noise. It can be useful for identifying manipulations of the image such as airbrushing, deformations, warping, and perspective-corrected cloning.
Principal Component Analysis—This tool performs principal component analysis on the image. This provides a different angle to view the image data, which makes discovering certain manipulations and details easier.
By comparing the results of the attacked images and the raw images, we found that the images with the added “small” disturbance only differ from the original images in error level analysis and noise analysis, but still cannot determine whether the image has been modified. This indicates that these traditional forensic techniques cannot detect attacks generated by CamoNet.
5. Discussion
In this section, we discuss the transferability of CamoNet. Specifically, we use a target camouflage network to attack different object detectors trained on the DOTA training set and then compare and evaluate their attack performance on the full DOTA verification set. Specifically, the target camouflage network is applied to three dominant detection algorithms (RetinaNet, Faster R-CNN, and RTMDet) and three backbones (ResNet-50, swin-t, and CSPNext-t). The results are shown in
Table 6.
equals
minus
, which can measure the effect of target camouflage. Compared to the clean
, the target camouflage network drastically reduces the attack
of all victim detectors. For instance, vanishing attacks break down the detection capability of the four detectors: RetinaNet (ResNet-50), Faster R-CNN (ResNet-50), Faster R-CNN (swin-t), and RTMDet (CSPNext-t), by reducing their mAP from 60.5%, 66.0%, 68.9%, and 64.4% to 0.7%, 1.1%, 0.5%, and 0.0%, respectively. Faster R-CNN has a faster attack speed and higher PSNR than RetinaNet. Swin-t has a faster attack speed and lower
than ResNet-50. It is worth mentioning that the
of RTMDet can reach 0, which means the attack success rate is 100%. The experimental results show that our method can work on various types of detectors and verify the generality of the target camouflage network.
To study the transferability, we use the adversarial examples generated by the attack detector to attack different victim detectors. Both victim detectors and attack detectors are trained on the DOTA training set and evaluated on the DOTA verification set. The results are shown in
Table 7. When the victim detector is the attack detector, which is usually called a white-box attack in the field of adversarial attack, the effect of target camouflage is the best. When the victim detector and the attack detector are different, which is usually called a black-box attack, the ability of target camouflage declines. After the attack of four different detectors, the minimum value of
of the victim detector is 26.4%, 21.7%, 18.5%, and 21.1%, respectively, which means that the target camouflage network does not completely fail even under the black-box attack.
In addition, we study the transferability of different postprocessing strategies on the DOTA dataset. The results are shown in
Table 8. We use the adversarial examples generated by the Faster R-CNN detector to attack different victim detectors and apply postprocessing strategies to them.
indicates the
of the victim detector after the postprocessing strategy is adopted.
equals
minus
, which can measure the effectiveness of the postprocessing strategy. Total
equals the sum of four victim detectors’
values, which can measure the transferability of the postprocessing strategy. The 3× mean value strategies have negative
. This means that although they reduce the perturbation rate, they also weaken the effect of target camouflage. In contrast, adaptive strategy has a positive
. The
of RetinaNet, Faster R-CNN (r50), Faster R-CNN (swin-t), and RTMDet are 1.9%, 0.0%, 1.7%, and 0.9%, respectively. This means that the KPD strategy reduces the perturbation rate and enhances the transferability of the target camouflage network.
However, CamoNet inevitably has some disadvantages that need to be addressed. In the gradient attack phase, when using adversarial samples generated by a certain model to attack other models, the success rate of the attack decreases significantly. In the postprocessing phase, although adaptive strategies have better mobility, their disturbance rate is higher than strategies with fixed thresholds. This means that this postprocessing strategy is more easily visible to the naked eye.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}