
Your Input Matters—Comparing Real-Valued PolSAR Data Representations for CNN-Based Segmentation

 ,
,
Abstract
:1. Introduction
- The direct use of the coherency matrix elements represented by nine real values;
- The use of the six-dimensional feature vector proposed in [20];
- The use of physically interpretable features based on polarimetric target decomposition; or
- The use of a combination of coherency matrix elements and various polarimetric features.
2. Methods
2.1. Real-Valued PolSAR Data Representations
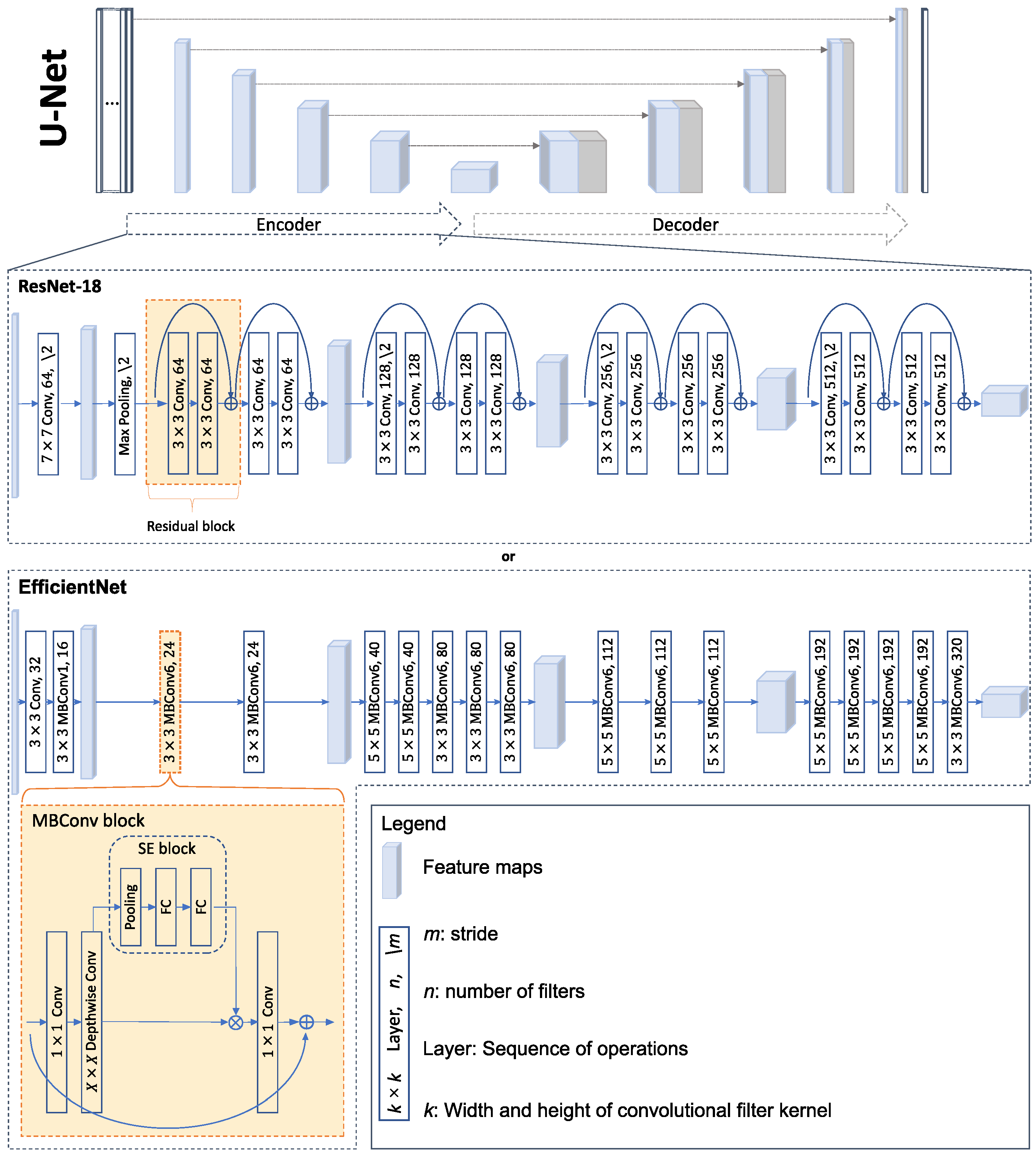
2.2. CNN Segmentation Models
3. Experimental Setup
3.1. Dataset
3.2. Model Training
4. Results
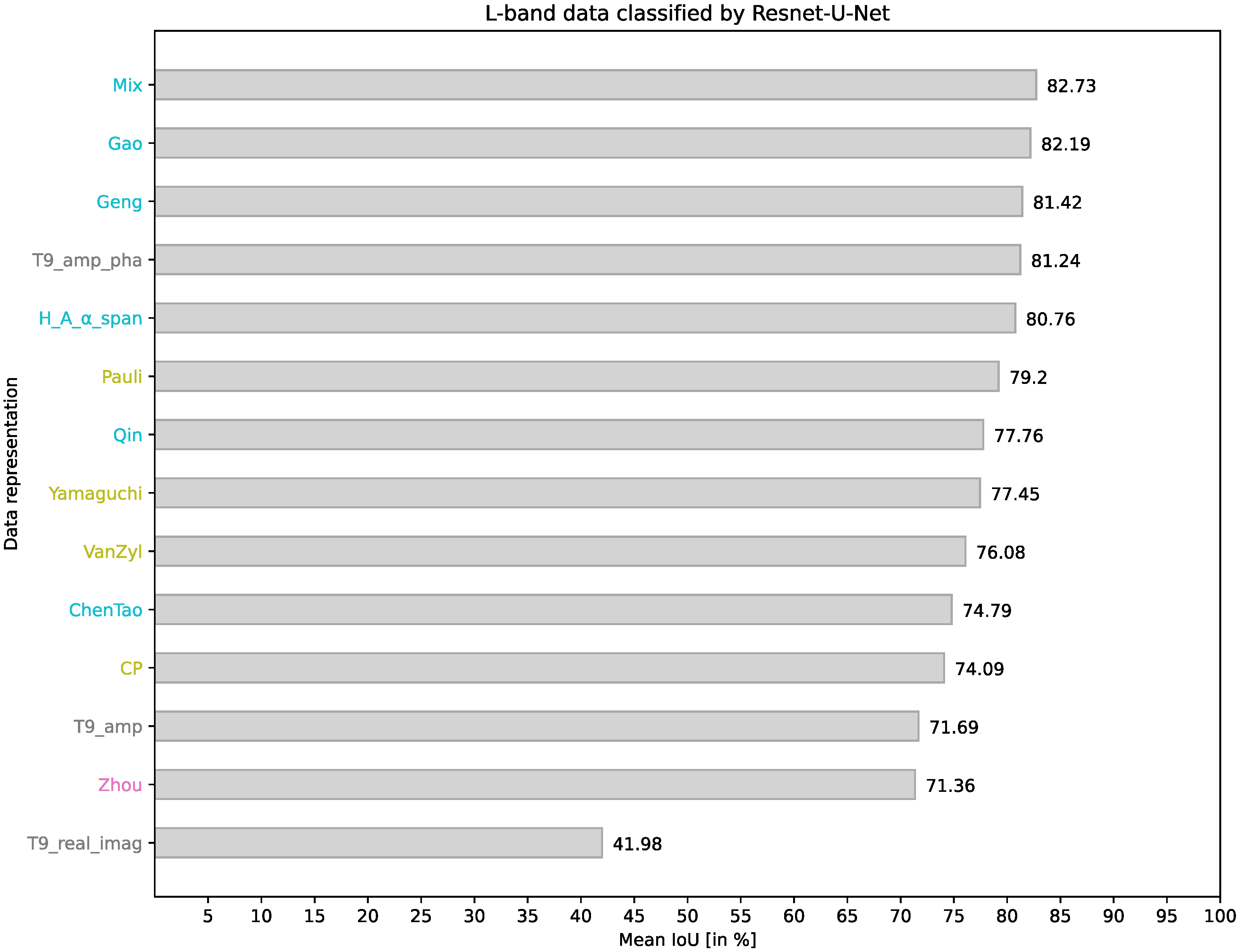
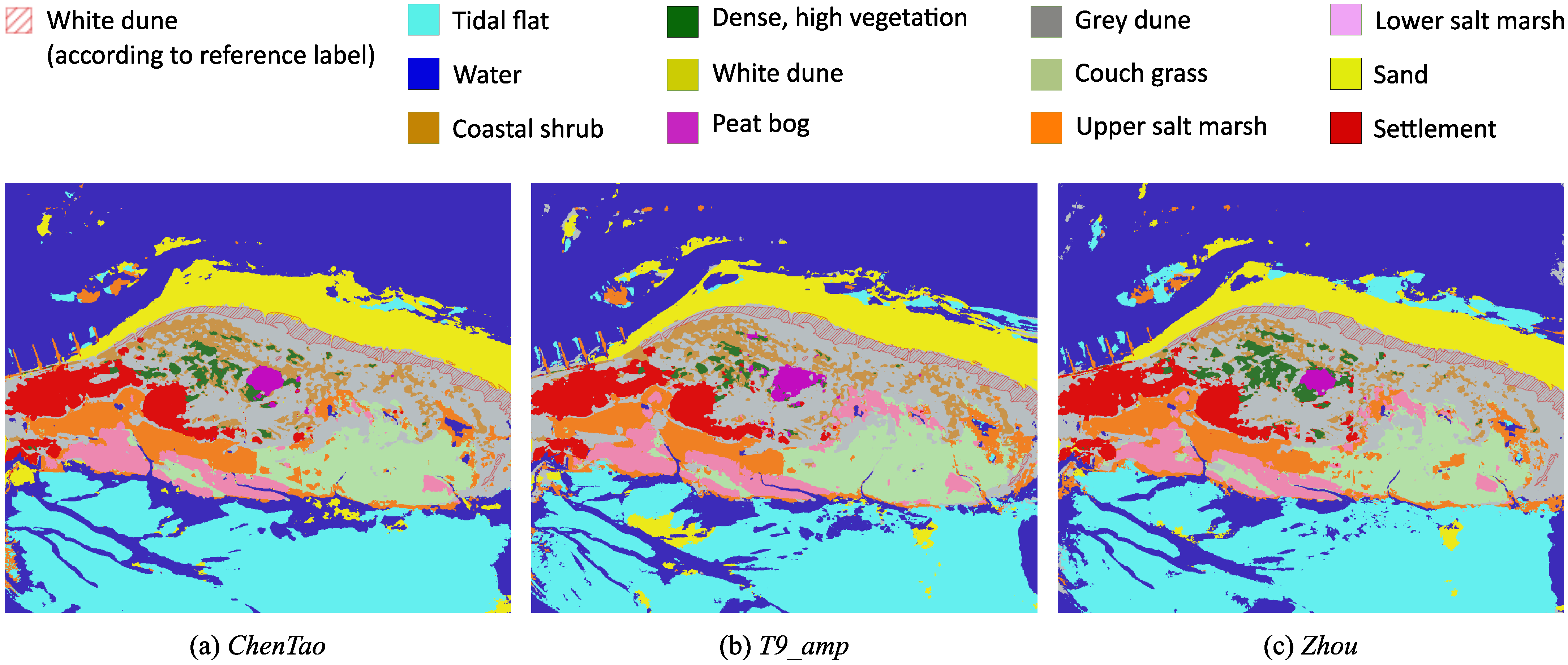
4.1. ResNet-U-Net on L-Band Data
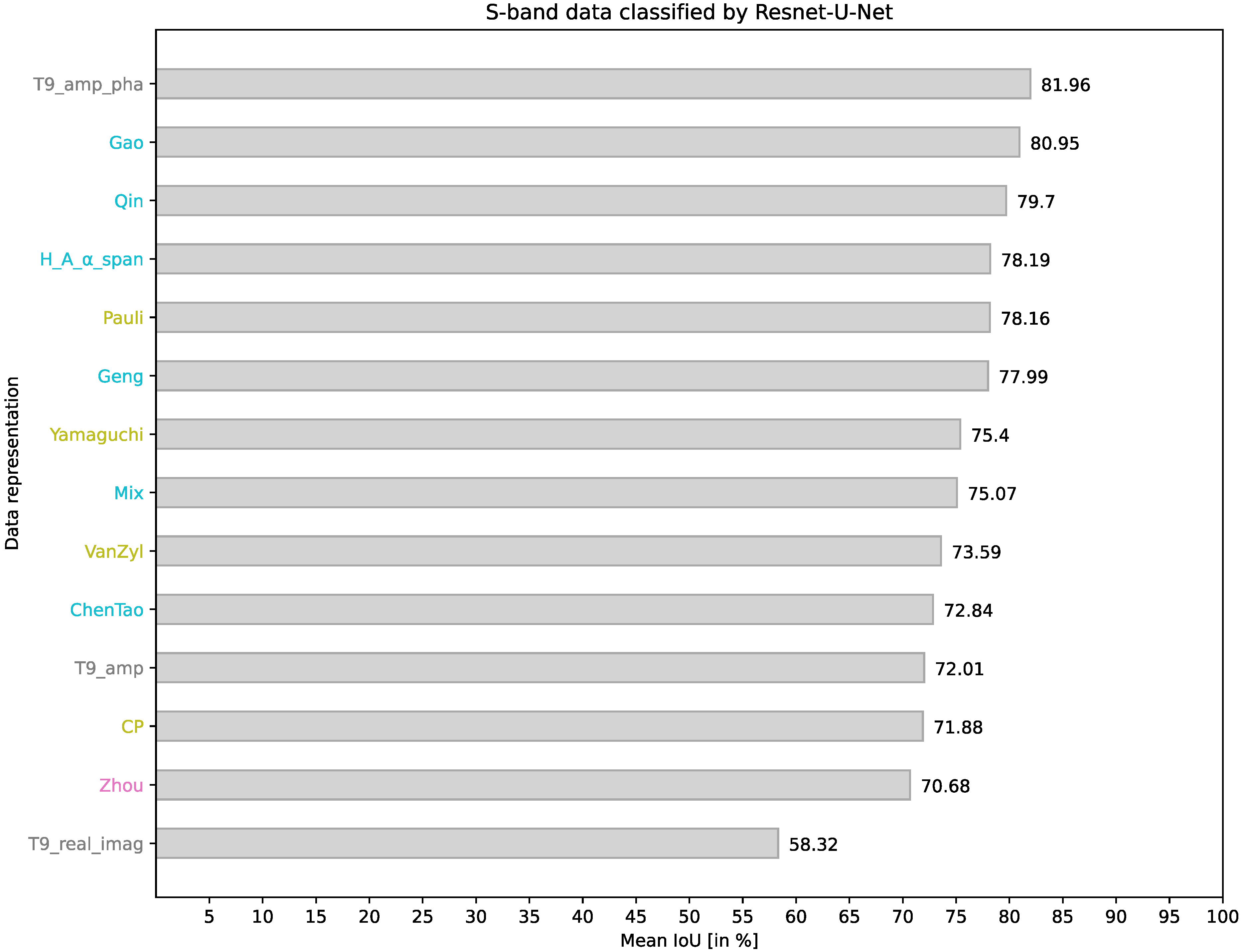
4.2. ResNet-U-Net on S-Band Data
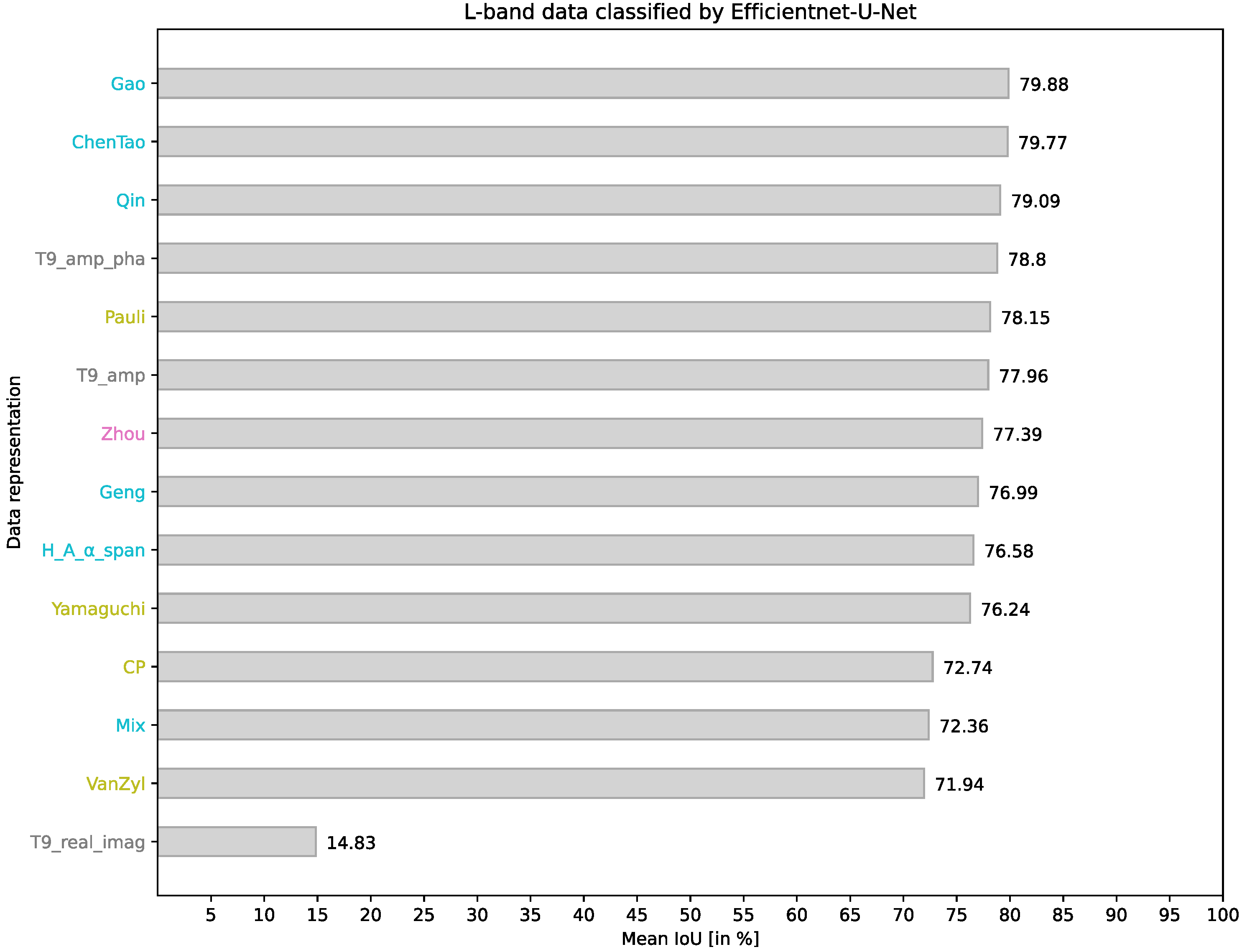
4.3. EfficientNet-U-Net on L-Band Data
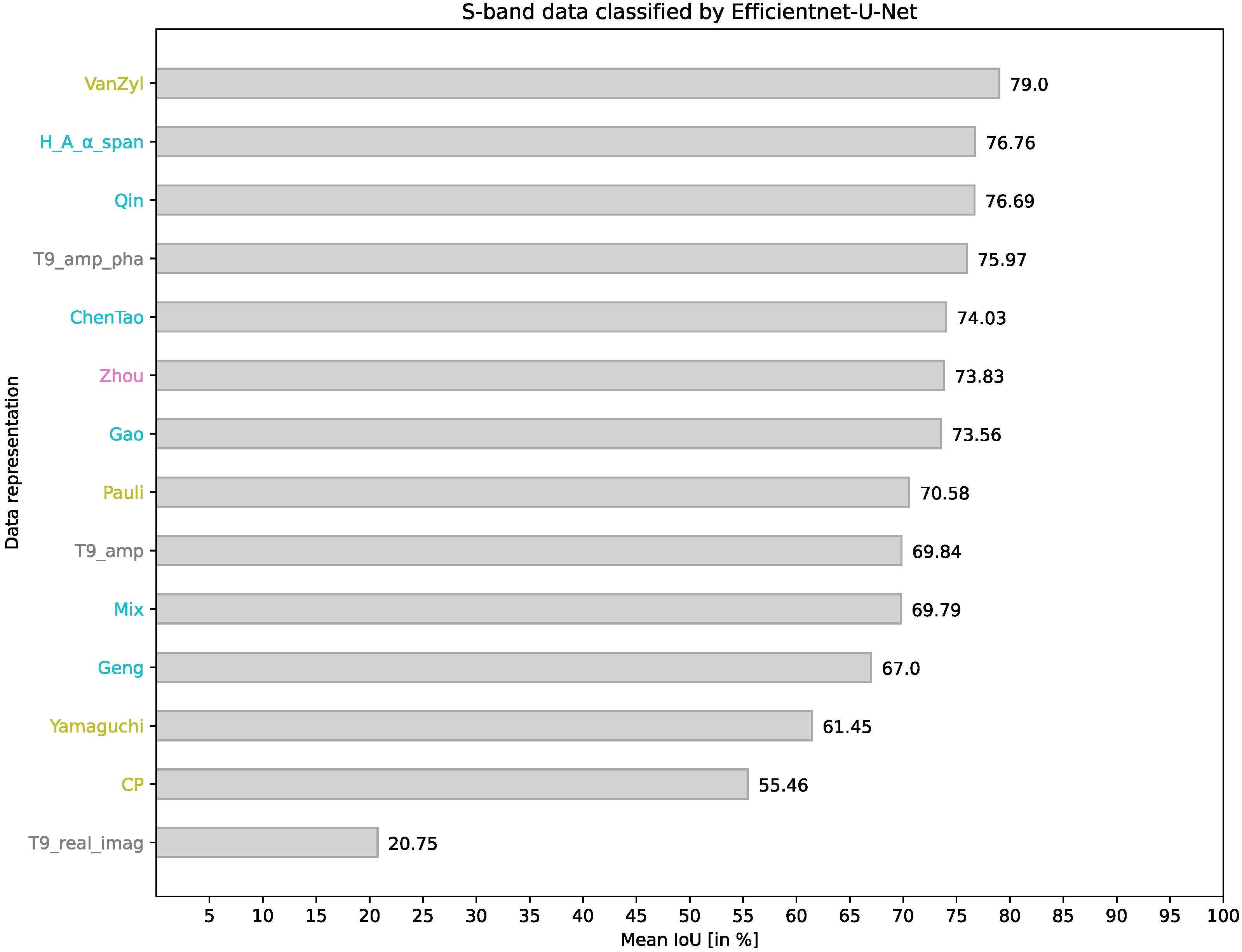
4.4. EfficientNet-U-Net on S-Band Data
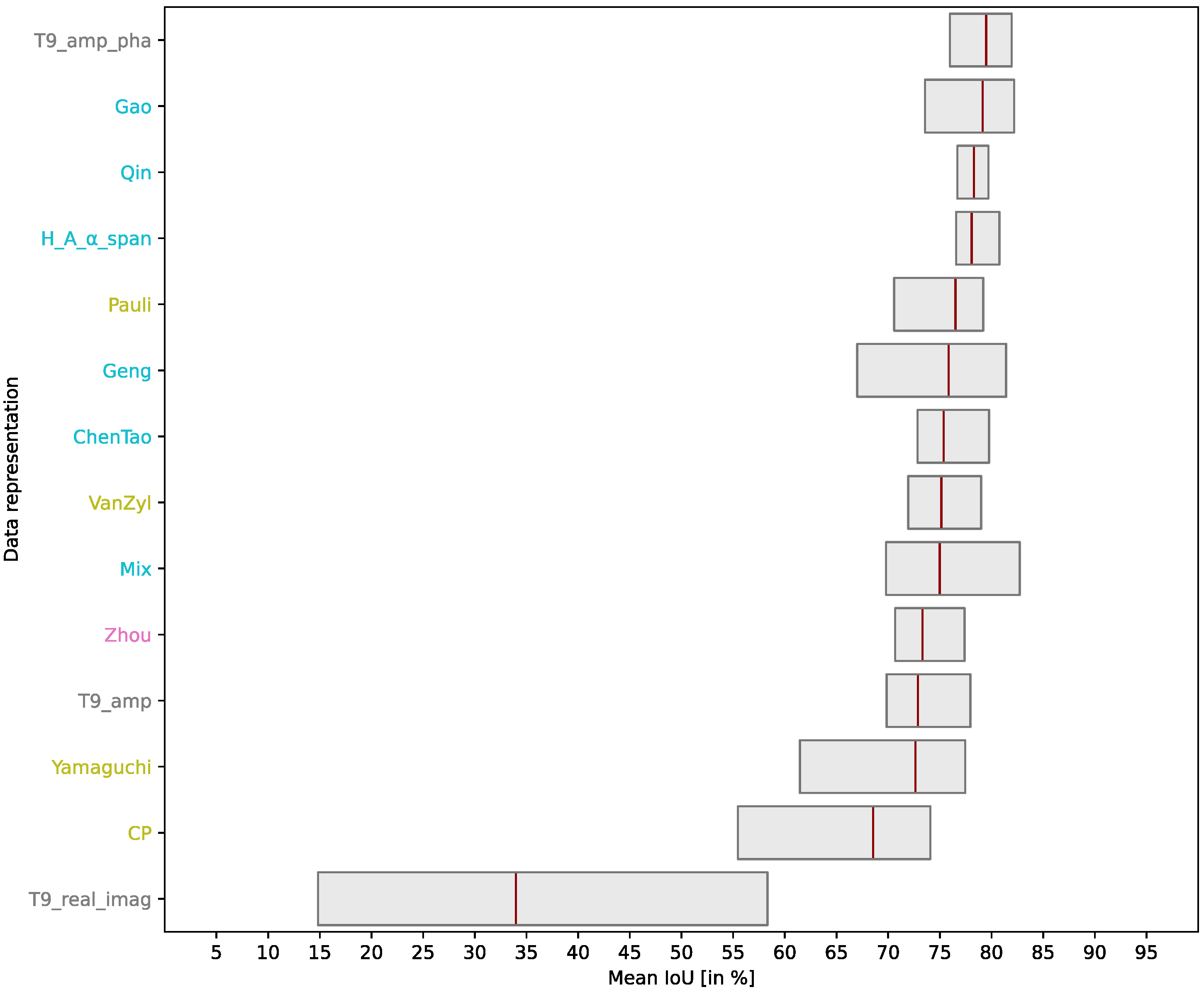
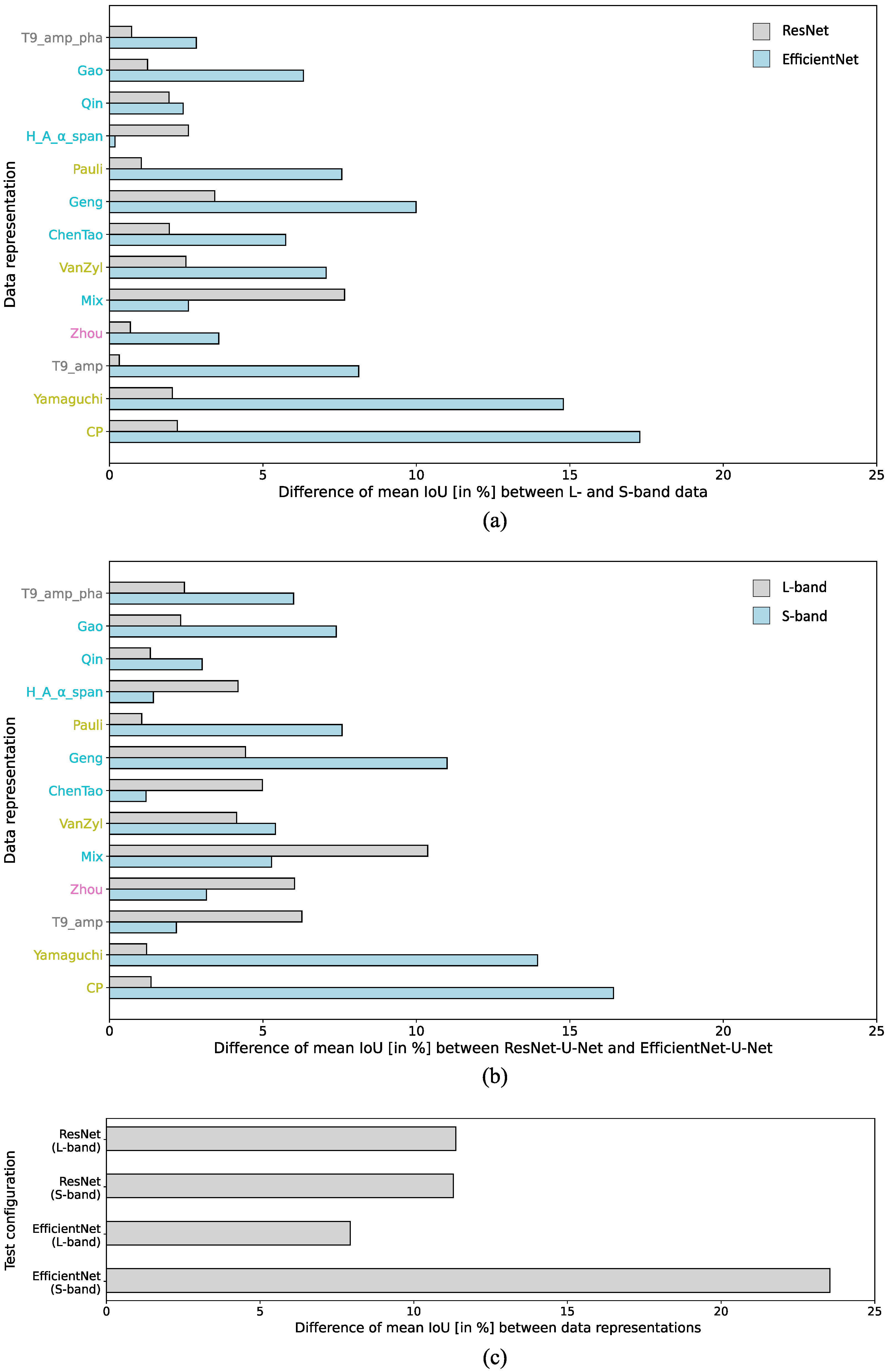
4.5. Comprehensive Results Evaluation
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hajnsek, I.; Jagdhuber, T.; Schon, H.; Papathanassiou, K.P. Potential of estimating soil moisture under vegetation cover by means of PolSAR. IEEE Trans. Geosci. Remote Sens. 2009, 47, 442–454. [Google Scholar] [CrossRef]
- He, L.; Panciera, R.; Tanase, M.A.; Walker, J.P.; Qin, Q. Soil moisture retrieval in agricultural fields using adaptive model-based polarimetric decomposition of SAR data. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4445–4460. [Google Scholar] [CrossRef]
- Park, S.E.; Moon, W.M.; Kim, D.j. Estimation of surface roughness parameter in intertidal mudflat using airborne polarimetric SAR data. IEEE Trans. Geosci. Remote Sens. 2009, 47, 1022–1031. [Google Scholar] [CrossRef]
- Babu, A.; Baumgartner, S.V.; Krieger, G. Approaches for Road Surface Roughness Estimation Using Airborne Polarimetric SAR. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 3444–3462. [Google Scholar] [CrossRef]
- Mohammadimanesh, F.; Salehi, B.; Mahdianpari, M.; Gill, E.; Molinier, M. A new fully convolutional neural network for semantic segmentation of polarimetric SAR imagery in complex land cover ecosystem. ISPRS J. Photogramm. Remote Sens. 2019, 151, 223–236. [Google Scholar] [CrossRef]
- Duguay, Y.; Bernier, M.; Lévesque, E.; Domine, F. Land cover classification in subarctic regions using fully polarimetric RADARSAT-2 data. Remote Sens. 2016, 8, 697. [Google Scholar] [CrossRef]
- Salehi, M.; Sahebi, M.R.; Maghsoudi, Y. Improving the accuracy of urban land cover classification using Radarsat-2 PolSAR data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 7, 1394–1401. [Google Scholar] [CrossRef]
- Cloude, S.; Pottier, E. A review of target decomposition theorems in radar polarimetry. IEEE Trans. Geosci. Remote Sens. 1996, 34, 498–518. [Google Scholar] [CrossRef]
- Freeman, A.; Durden, S. A three-component scattering model for polarimetric SAR data. IEEE Trans. Geosci. Remote Sens. 1998, 36, 963–973. [Google Scholar] [CrossRef]
- Yamaguchi, Y.; Sato, A.; Boerner, W.M.; Sato, R.; Yamada, H. Four-Component Scattering Power Decomposition With Rotation of Coherency Matrix. IEEE Trans. Geosci. Remote Sens. 2011, 49, 2251–2258. [Google Scholar] [CrossRef]
- Singh, G.; Yamaguchi, Y. Model-based six-component scattering matrix power decomposition. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5687–5704. [Google Scholar] [CrossRef]
- Han, W.; Fu, H.; Zhu, J.; Wang, C.; Xie, Q. Polarimetric SAR Decomposition by Incorporating a Rotated Dihedral Scattering Model. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4005505. [Google Scholar] [CrossRef]
- Quan, S.; Zhang, T.; Wang, W.; Kuang, G.; Wang, X.; Zeng, B. Exploring Fine Polarimetric Decomposition Technique for Built-Up Area Monitoring. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5204719. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I.H. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef]
- Zhang, X.; Xu, J.; Chen, Y.; Xu, K.; Wang, D. Coastal Wetland Classification with GF-3 Polarimetric SAR Imagery by Using Object-Oriented Random Forest Algorithm. Sensors 2021, 21, 3395. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Yang, X.; Li, X.; Chen, K.; Liu, G.; Li, Z.; Gade, M. A Fully Polarimetric SAR Imagery Classification Scheme for Mud and Sand Flats in Intertidal Zones. IEEE Trans. Geosci. Remote Sens. 2017, 55, 1734–1742. [Google Scholar] [CrossRef]
- Gou, S.; Li, X.; Yang, X. Coastal Zone Classification with Fully Polarimetric SAR Imagery. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1616–1620. [Google Scholar] [CrossRef]
- Mohammadimanesh, F.; Salehi, B.; Mahdianpari, M.; Brisco, B.; Gill, E. Full and Simulated Compact Polarimetry SAR Responses to Canadian Wetlands: Separability Analysis and Classification. Remote Sens. 2019, 11, 516. [Google Scholar] [CrossRef]
- Xie, H.; Wang, S.; Liu, K.; Lin, S.; Hou, B. Multilayer feature learning for polarimetric synthetic radar data classification. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 2818–2821. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, H.; Xu, F.; Jin, Y.Q. Polarimetric SAR Image Classification Using Deep Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1935–1939. [Google Scholar] [CrossRef]
- Chen, S.W.; Tao, C.S. PolSAR Image Classification Using Polarimetric-Feature-Driven Deep Convolutional Neural Network. IEEE Geosci. Remote Sens. Lett. 2018, 15, 627–631. [Google Scholar] [CrossRef]
- Liu, X.; Jiao, L.; Tang, X.; Sun, Q.; Zhang, D. Polarimetric Convolutional Network for PolSAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3040–3054. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18, 2015. pp. 234–241. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Wang, Y.; He, C.; Liu, X.; Liao, M. A hierarchical fully convolutional network integrated with sparse and low-rank subspace representations for PolSAR imagery classification. Remote Sens. 2018, 10, 342. [Google Scholar] [CrossRef]
- Li, Y.; Chen, Y.; Liu, G.; Jiao, L. A novel deep fully convolutional network for PolSAR image classification. Remote Sens. 2018, 10, 1984. [Google Scholar] [CrossRef]
- Wu, W.; Li, H.; Li, X.; Guo, H.; Zhang, L. PolSAR image semantic segmentation based on deep transfer learning—Realizing smooth classification with small training sets. IEEE Geosci. Remote Sens. Lett. 2019, 16, 977–981. [Google Scholar] [CrossRef]
- He, C.; Tu, M.; Xiong, D.; Liao, M. Nonlinear Manifold Learning Integrated with Fully Convolutional Networks for PolSAR Image Classification. Remote Sens. 2020, 12, 655. [Google Scholar] [CrossRef]
- Zhang, R.; Chen, J.; Feng, L.; Li, S.; Yang, W.; Guo, D. A refined pyramid scene parsing network for polarimetric SAR image semantic segmentation in agricultural areas. IEEE Geosci. Remote Sens. Lett. 2021, 19, 4014805. [Google Scholar] [CrossRef]
- Ding, L.; Zheng, K.; Lin, D.; Chen, Y.; Liu, B.; Li, J.; Bruzzone, L. MP-ResNet: Multipath residual network for the semantic segmentation of high-resolution PolSAR images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 4014205. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, H.; Xu, F.; Jin, Y.Q. Complex-Valued Convolutional Neural Network and Its Application in Polarimetric SAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7177–7188. [Google Scholar] [CrossRef]
- Mullissa, A.G.; Persello, C.; Stein, A. PolSARNet: A deep fully convolutional network for polarimetric SAR image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 5300–5309. [Google Scholar] [CrossRef]
- Wang, L.; Xu, X.; Dong, H.; Gui, R.; Pu, F. Multi-pixel simultaneous classification of PolSAR image using convolutional neural networks. Sensors 2018, 18, 769. [Google Scholar] [CrossRef] [PubMed]
- Song, D.; Zhen, Z.; Wang, B.; Li, X.; Gao, L.; Wang, N.; Xie, T.; Zhang, T. A novel marine oil spillage identification scheme based on convolution neural network feature extraction from fully polarimetric SAR imagery. IEEE Access 2020, 8, 59801–59820. [Google Scholar] [CrossRef]
- Dong, H.; Zhang, L.; Zou, B. PolSAR image classification with lightweight 3D convolutional networks. Remote Sens. 2020, 12, 396. [Google Scholar] [CrossRef]
- Shang, R.; He, J.; Wang, J.; Xu, K.; Jiao, L.; Stolkin, R. Dense connection and depthwise separable convolution based CNN for polarimetric SAR image classification. Knowl.-Based Syst. 2020, 194, 105542. [Google Scholar] [CrossRef]
- Wang, H.; Xing, C.; Yin, J.; Yang, J. Land Cover Classification for Polarimetric SAR Images Based on Vision Transformer. Remote Sens. 2022, 14, 4656. [Google Scholar] [CrossRef]
- Xie, W.; Wang, R.; Yang, X.; Hua, W. Depthwise Separable Residual Network Based on UNet for PolSAR Images Classification. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 1039–1042. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, S.; Zou, B.; Dong, H. Unsupervised deep representation learning and few-shot classification of PolSAR images. IEEE Trans. Geosci. Remote Sens. 2020, 60, 5100316. [Google Scholar] [CrossRef]
- Yang, R.; Hu, Z.; Liu, Y.; Xu, Z. A novel polarimetric SAR classification method integrating pixel-based and patch-based classification. IEEE Geosci. Remote Sens. Lett. 2019, 17, 431–435. [Google Scholar] [CrossRef]
- Zuo, Y.; Guo, J.; Zhang, Y.; Hu, Y.; Lei, B.; Qiu, X.; Ding, C. Winner takes all: A superpixel aided voting algorithm for training unsupervised PolSAR CNN classifiers. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1002519. [Google Scholar] [CrossRef]
- Zhao, F.; Tian, M.; Xie, W.; Liu, H. A new parallel dual-channel fully convolutional network via semi-supervised FCM for PolSAR image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4493–4505. [Google Scholar] [CrossRef]
- Barrachina, J.A.; Ren, C.; Morisseau, C.; Vieillard, G.; Ovarlez, J.P. Comparison between equivalent architectures of complex-valued and real-valued neural networks-Application on polarimetric SAR image segmentation. J. Signal Process. Syst. 2023, 95, 57–66. [Google Scholar] [CrossRef]
- Fang, Z.; Zhang, G.; Dai, Q.; Xue, B.; Wang, P. Hybrid Attention-Based Encoder–Decoder Fully Convolutional Network for PolSAR Image Classification. Remote Sens. 2023, 15, 526. [Google Scholar] [CrossRef]
- Zhang, L.; Dong, H.; Zou, B. Efficiently utilizing complex-valued PolSAR image data via a multi-task deep learning framework. ISPRS J. Photogramm. Remote Sens. 2019, 157, 59–72. [Google Scholar] [CrossRef]
- Geng, J.; Wang, R.; Jiang, W. Polarimetric SAR Image Classification Based on Feature Enhanced Superpixel Hypergraph Neural Network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5237812. [Google Scholar] [CrossRef]
- Bi, H.; Sun, J.; Xu, Z. A graph-based semisupervised deep learning model for PolSAR image classification. IEEE Trans. Geosci. Remote Sens. 2018, 57, 2116–2132. [Google Scholar] [CrossRef]
- Bi, H.; Xu, F.; Wei, Z.; Xue, Y.; Xu, Z. An active deep learning approach for minimally supervised PolSAR image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9378–9395. [Google Scholar] [CrossRef]
- Ai, J.; Wang, F.; Mao, Y.; Luo, Q.; Yao, B.; Yan, H.; Xing, M.; Wu, Y. A fine PolSAR terrain classification algorithm using the texture feature fusion-based improved convolutional autoencoder. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5218714. [Google Scholar] [CrossRef]
- Hua, W.; Zhang, C.; Xie, W.; Jin, X. Polarimetric SAR Image Classification Based on Ensemble Dual-Branch CNN and Superpixel Algorithm. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 2759–2772. [Google Scholar] [CrossRef]
- Yu, L.; Zeng, Z.; Liu, A.; Xie, X.; Wang, H.; Xu, F.; Hong, W. A lightweight complex-valued DeepLabv3+ for semantic segmentation of PolSAR image. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 930–943. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, C.; Zhang, H. Integrating H-A-α with fully convolutional networks for fully PolSAR classification. In Proceedings of the 2017 International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 18–21 May 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Garg, R.; Kumar, A.; Bansal, N.; Prateek, M.; Kumar, S. Semantic segmentation of PolSAR image data using advanced deep learning model. Sci. Rep. 2021, 11, 15365. [Google Scholar] [CrossRef] [PubMed]
- Qin, R.; Fu, X.; Lang, P. PolSAR Image Classification Based on Low-Frequency and Contour Subbands-Driven Polarimetric SENet. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4760–4773. [Google Scholar] [CrossRef]
- Dong, H.; Zhang, L.; Zou, B. Exploring Vision Transformers for Polarimetric SAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5219715. [Google Scholar] [CrossRef]
- Wu, Q.; Hou, B.; Wen, Z.; Ren, Z.; Jiao, L. Cost-sensitive latent space learning for imbalanced PolSAR image classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4802–4817. [Google Scholar] [CrossRef]
- Zhang, J.; Feng, H.; Luo, Q.; Li, Y.; Wei, J.; Li, J. Oil spill detection in quad-polarimetric SAR Images using an advanced convolutional neural network based on SuperPixel model. Remote Sens. 2020, 12, 944. [Google Scholar] [CrossRef]
- van Zyl, J.J. Application of Cloude’s target decomposition theorem to polarimetric imaging radar data. Proc. Radar Polarim. 1993, 1748, 184–191. [Google Scholar] [CrossRef]
- Gao, F.; Huang, T.; Wang, J.; Sun, J.; Hussain, A.; Yang, E. Dual-Branch Deep Convolution Neural Network for Polarimetric SAR Image Classification. Appl. Sci. 2017, 7, 447. [Google Scholar] [CrossRef]
- Geng, J.; Ma, X.; Fan, J.; Wang, H. Semisupervised Classification of Polarimetric SAR Image via Superpixel Restrained Deep Neural Network. IEEE Geosci. Remote Sens. Lett. 2018, 15, 122–126. [Google Scholar] [CrossRef]
- Ince, T.; Ahishali, M.; Kiranyaz, S. Comparison of polarimetrie SAR features for terrain classification using incremental training. In Proceedings of the 2017 Progress in Electromagnetics Research Symposium—Spring (PIERS), St. Petersburg, Russia, 22–25 May 2017; pp. 3258–3262. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Hochstuhl, S.M.; Pfeffer, N.; Thiele, A.; Hinz, S.; Amao-Oliva, J.; Scheiber, R.; Reigber, A.; Dirks, H. Pol-InSAR-Island-A Benchmark Dataset for Multi-frequency Pol-InSAR Data Land Cover Classification (Version 2). Isprs Open J. Photogramm. Remote Sens. 2023, 10, 100047. [Google Scholar] [CrossRef]
- Liu, X.; Jiao, L.; Liu, F.; Zhang, D.; Tang, X. PolSF: PolSAR image datasets on san Francisco. In Proceedings of the International Conference on Intelligence Science, Xi’an, China, 28–31 October 2022; pp. 214–219. [Google Scholar] [CrossRef]
- Horn, R.; Nottensteiner, A.; Reigber, A.; Fischer, J.; Scheiber, R. F-SAR—DLR’s new multifrequency polarimetric airborne SAR. In Proceedings of the 2009 IEEE International Geoscience and Remote Sensing Symposium, Cape Town, South Africa, 12–17 July 2009; pp. II-902–II-905. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Wightman, R. PyTorch Image Models. 2019. Available online: https://github.com/rwightman/pytorch-image-models (accessed on 24 February 2023).
- Abraham, N.; Khan, N.M. A Novel Focal Tversky Loss Function with Improved Attention U-Net for Lesion Segmentation. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 683–687. [Google Scholar] [CrossRef]
- Jadon, S. A survey of loss functions for semantic segmentation. In Proceedings of the 2020 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Via del Mar, Chile, 27–29 October 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Dong, H.; Zhang, L.; Lu, D.; Zou, B. Attention-Based Polarimetric Feature Selection Convolutional Network for PolSAR Image Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4001705. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. arXiv 2018, arXiv:1807.06521. [Google Scholar]
- Yang, Z.; Zhang, Q.; Chen, W.; Chen, C. PolSAR Image Classification Based on Resblock Combined with Attention Model. In Proceedings of the 2021 IEEE 6th International Conference on Signal and Image Processing (ICSIP), Nanjing, China, 22–24 October 2021; pp. 340–344. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Description | Components | Related Publications |
|---|---|---|---|
| -elements | T9_real_imag | , , , , , , , , | [35,36,37,38,39,40,41,42,43,44,45,46] |
| T9_amp_pha | , , , ||, , ||, , ||, | [47] | |
| T9_amp | , , , ||, ||, || | [58] | |
| -feature vector | Zhou | , , , , , | [20,48,49,50,51,52,53] |
| Target decomposition | Pauli | , , | [31] |
| Yamaguchi | , , | [59] | |
| VanZyl | , , | [60] | |
| CP | H, A, | [54,59] | |
| Combination | Gao | , , , , , , , , | [61] |
| Geng | , , , ||, ||, ||, , , | [62] | |
| ChenTao | H, A, , span, , | [21] | |
| H_A__span | H, A, , span | [63] | |
| Qin | , , , ||, , ||, , ||, , , A, , , , , | [56] | |
| Mix | H, A, , span, , , , , , ||, , ||, , ||, , , , , , , , , | - |
| TF | W | CS | DV | WD | PB | GD | CG | US | LS | S | SE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Training | 7.09 | 17.98 | 5.29 | 2.04 | 6.72 | 0.87 | 17.78 | 8.17 | 8.01 | 5.85 | 14.92 | 5.28 |
| Test | 8.07 | 17.31 | 3.65 | 1.43 | 6.44 | 1.15 | 19.88 | 7.56 | 9.51 | 4.75 | 14.62 | 5.63 |
| Input | TF | W | CS | DV | WD | PB | GD | CG | US | LS | S | SE | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T9_real_imag | 13.42 | 78.50 | 56.10 | 36.61 | 7.70 | 79.30 | 38.79 | 20.76 | 1.54 | 29.48 | 49.07 | 92.53 | 41.98 |
| T9_amp_pha | 98.22 | 97.73 | 69.66 | 56.44 | 78.61 | 92.84 | 78.07 | 66.47 | 64.26 | 83.74 | 97.06 | 91.81 | 81.24 |
| T9_amp | 91.87 | 95.49 | 64.89 | 49.91 | 0.00 | 83.83 | 64.60 | 75.33 | 70.25 | 76.41 | 95.68 | 91.99 | 71.69 |
| Pauli | 90.07 | 94.93 | 67.01 | 62.48 | 67.90 | 87.39 | 75.66 | 73.56 | 65.47 | 77.15 | 97.08 | 91.70 | 79.20 |
| Zhou | 96.59 | 95.17 | 57.75 | 46.36 | 0.00 | 91.52 | 64.59 | 75.51 | 61.20 | 79.01 | 97.12 | 91.49 | 71.36 |
| Gao | 97.80 | 95.24 | 70.34 | 58.03 | 82.30 | 87.34 | 79.33 | 77.68 | 63.65 | 84.46 | 98.01 | 92.14 | 82.19 |
| CP | 94.36 | 95.13 | 57.58 | 44.87 | 65.20 | 79.40 | 76.18 | 56.03 | 73.00 | 58.48 | 94.64 | 94.18 | 74.09 |
| Yamaguchi | 93.11 | 96.36 | 66.09 | 52.19 | 74.33 | 86.30 | 75.78 | 68.02 | 58.03 | 72.19 | 99.00 | 87.95 | 77.45 |
| VanZyl | 89.66 | 96.22 | 61.88 | 46.61 | 64.30 | 96.43 | 72.15 | 71.80 | 58.88 | 70.70 | 94.31 | 90.02 | 76.08 |
| ChenTao | 97.55 | 98.50 | 64.43 | 51.62 | 0.00 | 91.91 | 66.78 | 76.42 | 73.67 | 86.53 | 97.74 | 92.29 | 74.79 |
| H_A__span | 92.08 | 97.51 | 67.78 | 59.37 | 69.22 | 92.57 | 77.38 | 74.60 | 70.65 | 76.13 | 98.89 | 92.97 | 80.76 |
| Geng | 94.70 | 96.36 | 70.47 | 54.91 | 80.45 | 85.69 | 77.77 | 75.30 | 66.11 | 83.17 | 97.53 | 94.53 | 81.42 |
| Qin | 92.83 | 92.02 | 60.69 | 44.37 | 78.88 | 83.46 | 78.16 | 73.69 | 67.47 | 84.01 | 92.33 | 85.26 | 77.76 |
| Mix | 90.57 | 96.26 | 67.66 | 63.65 | 76.32 | 95.90 | 78.59 | 72.65 | 70.53 | 88.57 | 98.75 | 93.31 | 82.73 |
| Input | TF | W | CS | DV | WD | PB | GD | CG | US | LS | S | SE | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T9_real_imag | 72.05 | 86.54 | 57.45 | 27.62 | 2.69 | 72.25 | 52.98 | 41.32 | 45.25 | 61.07 | 91.55 | 89.03 | 58.32 |
| T9_amp_pha | 94.72 | 97.86 | 64.64 | 53.73 | 70.77 | 95.30 | 77.27 | 80.77 | 73.32 | 87.10 | 97.50 | 90.59 | 81.96 |
| T9_amp | 93.19 | 95.81 | 57.84 | 53.53 | 0.00 | 94.35 | 62.56 | 77.30 | 64.25 | 78.69 | 97.27 | 89.39 | 72.01 |
| Pauli | 86.33 | 95.49 | 60.53 | 51.11 | 59.78 | 95.01 | 74.00 | 75.48 | 65.81 | 82.66 | 97.39 | 94.29 | 78.16 |
| Zhou | 77.27 | 90.11 | 62.71 | 40.84 | 0.00 | 91.84 | 66.05 | 77.36 | 72.24 | 82.57 | 95.49 | 91.67 | 70.68 |
| Gao | 92.27 | 95.98 | 68.83 | 60.23 | 69.15 | 88.78 | 75.34 | 76.57 | 67.76 | 87.02 | 96.21 | 93.23 | 80.95 |
| CP | 83.12 | 89.85 | 58.47 | 53.46 | 72.55 | 93.34 | 73.49 | 56.00 | 62.31 | 50.20 | 76.53 | 93.22 | 71.88 |
| Yamaguchi | 78.27 | 93.46 | 61.28 | 40.17 | 66.50 | 92.94 | 73.45 | 68.93 | 61.81 | 84.15 | 93.08 | 90.78 | 75.40 |
| VanZyl | 86.10 | 95.71 | 62.26 | 0.00 | 61.52 | 95.39 | 73.73 | 74.82 | 63.20 | 82.38 | 95.13 | 92.87 | 73.59 |
| ChenTao | 95.16 | 97.00 | 60.31 | 58.23 | 0.00 | 93.75 | 66.12 | 72.57 | 71.48 | 75.43 | 94.44 | 89.63 | 72.84 |
| H_A__span | 96.66 | 96.91 | 63.41 | 52.54 | 61.70 | 92.21 | 70.36 | 73.96 | 57.87 | 85.64 | 95.81 | 91.24 | 78.19 |
| Geng | 95.40 | 96.08 | 66.69 | 46.04 | 67.06 | 88.01 | 73.53 | 77.35 | 55.97 | 82.70 | 96.28 | 90.80 | 77.99 |
| Qin | 97.38 | 97.41 | 61.34 | 49.81 | 52.51 | 97.21 | 74.37 | 80.51 | 69.04 | 88.58 | 96.18 | 92.10 | 79.70 |
| Mix | 98.46 | 97.73 | 64.82 | 51.21 | 0.00 | 94.44 | 66.77 | 76.12 | 71.1 | 89.62 | 96.05 | 94.56 | 75.07 |
| Input | TF | W | CS | DV | WD | PB | GD | CG | US | LS | S | SE | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T9_real_imag | 0.00 | 32.32 | 37.58 | 27.43 | 0.00 | 0.00 | 27.34 | 0.00 | 0.00 | 0.00 | 1.22 | 52.00 | 14.83 |
| T9_amp_pha | 96.59 | 96.91 | 64.81 | 49.09 | 74.06 | 80.02 | 77.67 | 68.72 | 68.09 | 81.91 | 95.97 | 91.81 | 78.80 |
| T9_amp | 86.51 | 95.21 | 64.11 | 49.82 | 83.10 | 71.81 | 78.60 | 72.88 | 67.71 | 76.50 | 97.27 | 92.03 | 77.96 |
| Pauli | 82.62 | 92.83 | 66.89 | 61.81 | 75.03 | 91.25 | 75.80 | 67.46 | 62.21 | 73.31 | 94.69 | 93.93 | 78.15 |
| Zhou | 89.13 | 94.73 | 69.45 | 48.77 | 80.18 | 75.49 | 75.84 | 69.08 | 68.40 | 71.91 | 96.06 | 89.67 | 77.39 |
| Gao | 89.62 | 95.08 | 67.22 | 55.90 | 85.86 | 88.43 | 79.41 | 72.05 | 66.58 | 70.17 | 97.89 | 90.32 | 79.88 |
| CP | 90.22 | 91.96 | 53.68 | 47.09 | 75.61 | 81.45 | 69.03 | 55.85 | 65.42 | 58.84 | 90.86 | 92.87 | 72.74 |
| Yamaguchi | 84.64 | 92.48 | 64.41 | 53.88 | 75.25 | 85.07 | 75.93 | 63.56 | 60.80 | 73.02 | 98.50 | 87.34 | 76.24 |
| VanZyl | 93.37 | 93.61 | 53.00 | 36.12 | 68.77 | 71.23 | 72.70 | 67.81 | 55.86 | 67.68 | 92.03 | 91.12 | 71.94 |
| ChenTao | 98.67 | 95.89 | 67.03 | 55.43 | 72.41 | 86.90 | 75.91 | 65.49 | 67.34 | 84.76 | 94.03 | 93.32 | 79.77 |
| H_A__span | 85.42 | 91.73 | 62.94 | 49.29 | 79.01 | 83.05 | 77.99 | 68.71 | 64.04 | 69.33 | 94.60 | 92.82 | 76.58 |
| Geng | 81.70 | 92.82 | 67.64 | 56.80 | 83.05 | 81.04 | 77.28 | 64.39 | 60.87 | 70.83 | 96.65 | 90.75 | 76.99 |
| Qin | 96.37 | 96.16 | 61.77 | 52.49 | 80.90 | 86.53 | 75.58 | 61.88 | 62.78 | 84.23 | 97.45 | 92.94 | 79.09 |
| Mix | 95.27 | 95.62 | 52.79 | 30.20 | 63.70 | 78.31 | 71.90 | 60.36 | 63.12 | 73.68 | 97.04 | 86.34 | 72.36 |
| Input | TF | W | CS | DV | WD | PB | GD | CG | US | LS | S | SE | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T9_real_imag | 0.00 | 0.10 | 41.78 | 20.21 | 0.00 | 55.65 | 20.37 | 7.65 | 1.45 | 38.17 | 0.00 | 63.60 | 20.75 |
| T9_amp_pha | 94.11 | 96.95 | 60.05 | 40.22 | 49.04 | 91.45 | 75.50 | 70.65 | 74.67 | 74.95 | 94.53 | 89.45 | 75.97 |
| T9_amp | 70.89 | 88.26 | 49.66 | 37.47 | 51.37 | 90.10 | 70.96 | 61.03 | 63.02 | 67.20 | 96.55 | 91.53 | 69.84 |
| Pauli | 88.23 | 96.62 | 60.31 | 37.06 | 0.00 | 91.74 | 65.89 | 73.98 | 64.73 | 84.22 | 94.05 | 90.08 | 70.58 |
| Zhou | 86.74 | 92.23 | 54.86 | 36.42 | 65.09 | 84.80 | 71.91 | 72.47 | 63.96 | 74.46 | 92.15 | 90.92 | 73.83 |
| Gao | 83.19 | 93.54 | 63.58 | 36.07 | 53.84 | 77.35 | 70.66 | 68.89 | 66.15 | 80.26 | 96.15 | 93.05 | 73.56 |
| CP | 64.28 | 81.20 | 46.50 | 49.39 | 24.87 | 46.83 | 62.84 | 48.14 | 55.67 | 48.26 | 49.69 | 87.89 | 55.46 |
| Yamaguchi | 41.30 | 70.80 | 55.79 | 41.74 | 36.08 | 74.49 | 65.31 | 61.70 | 55.93 | 76.25 | 72.69 | 85.35 | 61.45 |
| VanZyl | 89.28 | 94.94 | 63.31 | 52.26 | 54.03 | 96.47 | 74.24 | 78.16 | 72.33 | 85.71 | 94.54 | 92.74 | 79.00 |
| ChenTao | 95.62 | 94.83 | 54.58 | 47.37 | 70.48 | 84.70 | 76.67 | 59.77 | 71.99 | 47.83 | 93.72 | 90.83 | 74.03 |
| H_A__span | 93.72 | 96.42 | 64.01 | 40.29 | 63.57 | 93.36 | 71.18 | 70.92 | 59.78 | 83.40 | 94.10 | 90.44 | 76.76 |
| Geng | 79.86 | 92.22 | 58.31 | 31.66 | 33.71 | 68.37 | 61.75 | 68.39 | 54.81 | 73.23 | 91.79 | 89.85 | 67.00 |
| Qin | 84.71 | 93.59 | 59.03 | 50.62 | 64.54 | 75.20 | 78.03 | 74.58 | 75.24 | 76.84 | 93.26 | 94.61 | 76.69 |
| Mix | 95.44 | 93.58 | 39.03 | 33.07 | 59.65 | 78.36 | 69.06 | 59.98 | 65.42 | 66.90 | 90.80 | 86.18 | 69.79 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hochstuhl, S.; Pfeffer, N.; Thiele, A.; Hammer, H.; Hinz, S. Your Input Matters—Comparing Real-Valued PolSAR Data Representations for CNN-Based Segmentation. Remote Sens. 2023, 15, 5738. https://doi.org/10.3390/rs15245738
Hochstuhl S, Pfeffer N, Thiele A, Hammer H, Hinz S. Your Input Matters—Comparing Real-Valued PolSAR Data Representations for CNN-Based Segmentation. Remote Sensing. 2023; 15(24):5738. https://doi.org/10.3390/rs15245738
Chicago/Turabian StyleHochstuhl, Sylvia, Niklas Pfeffer, Antje Thiele, Horst Hammer, and Stefan Hinz. 2023. "Your Input Matters—Comparing Real-Valued PolSAR Data Representations for CNN-Based Segmentation" Remote Sensing 15, no. 24: 5738. https://doi.org/10.3390/rs15245738
APA StyleHochstuhl, S., Pfeffer, N., Thiele, A., Hammer, H., & Hinz, S. (2023). Your Input Matters—Comparing Real-Valued PolSAR Data Representations for CNN-Based Segmentation. Remote Sensing, 15(24), 5738. https://doi.org/10.3390/rs15245738