




Optimal Sample Size and Composition for Crop Classification with Sen2-Agri’s Random Forest Classifier
 , , and
, , and
Abstract
:1. Introduction
- Does a proportional or equal representation of each crop type in the training data generate better classification results?
- What is the optimal number of training fields?
- How does classification accuracy change with time across the season?
- What kind of accuracies can be achieved with a binary classification, in which one focuses just on one crop vs. “everything else”?
2. Materials and Methods
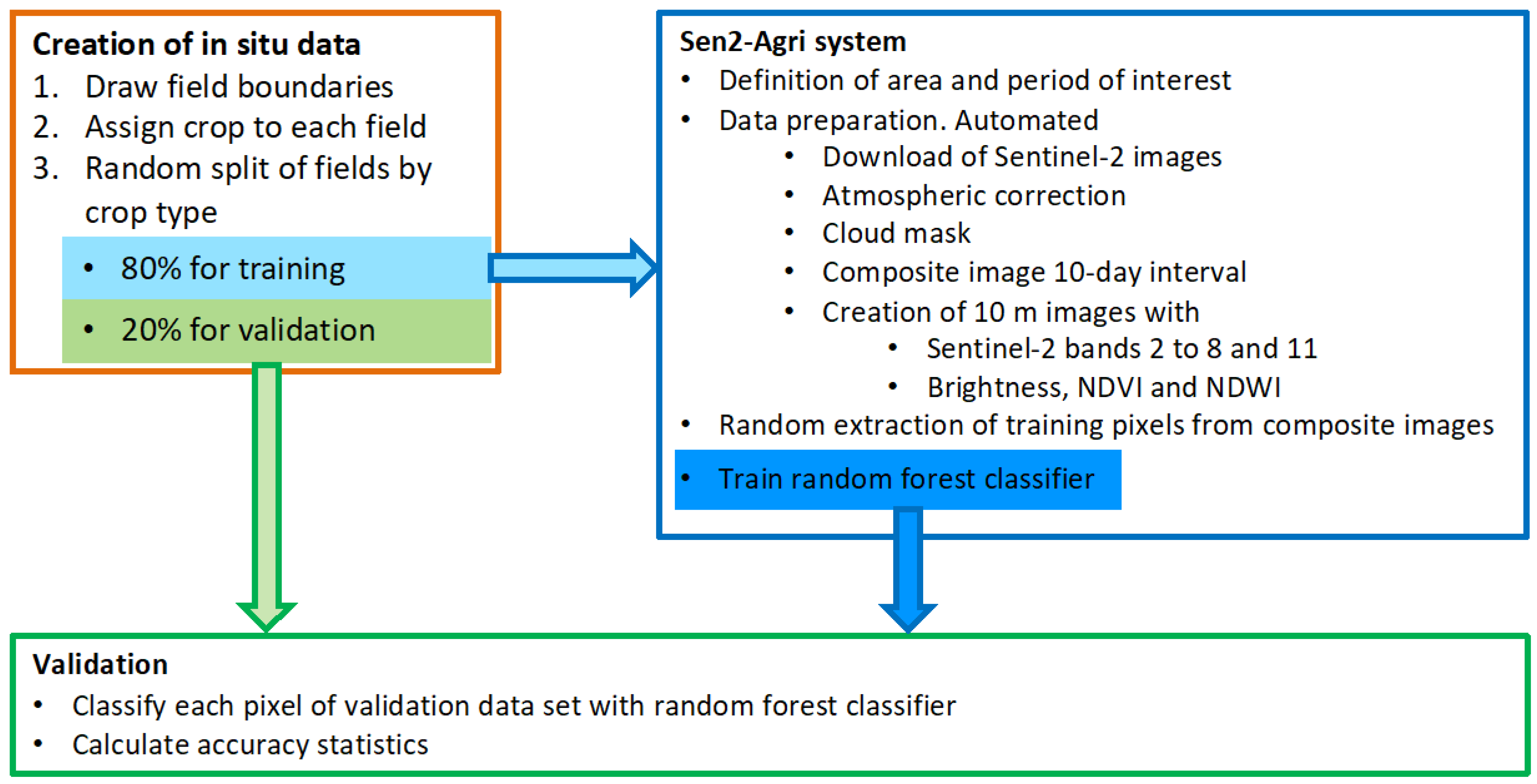
2.1. Overall Workflow
- Creation of the in situ data set consisting of more than 6000 crop fields.
- Running of the Sen2-Agri system to access and process the Sentinel-2 data from the Copernicus Open Access Hub. The RF classifier of Sen2-Agri was then trained with specific input data for the various scenarios described in Section 2.4.
- Application of the RF classifier to the validation data set to calculate classification accuracies.

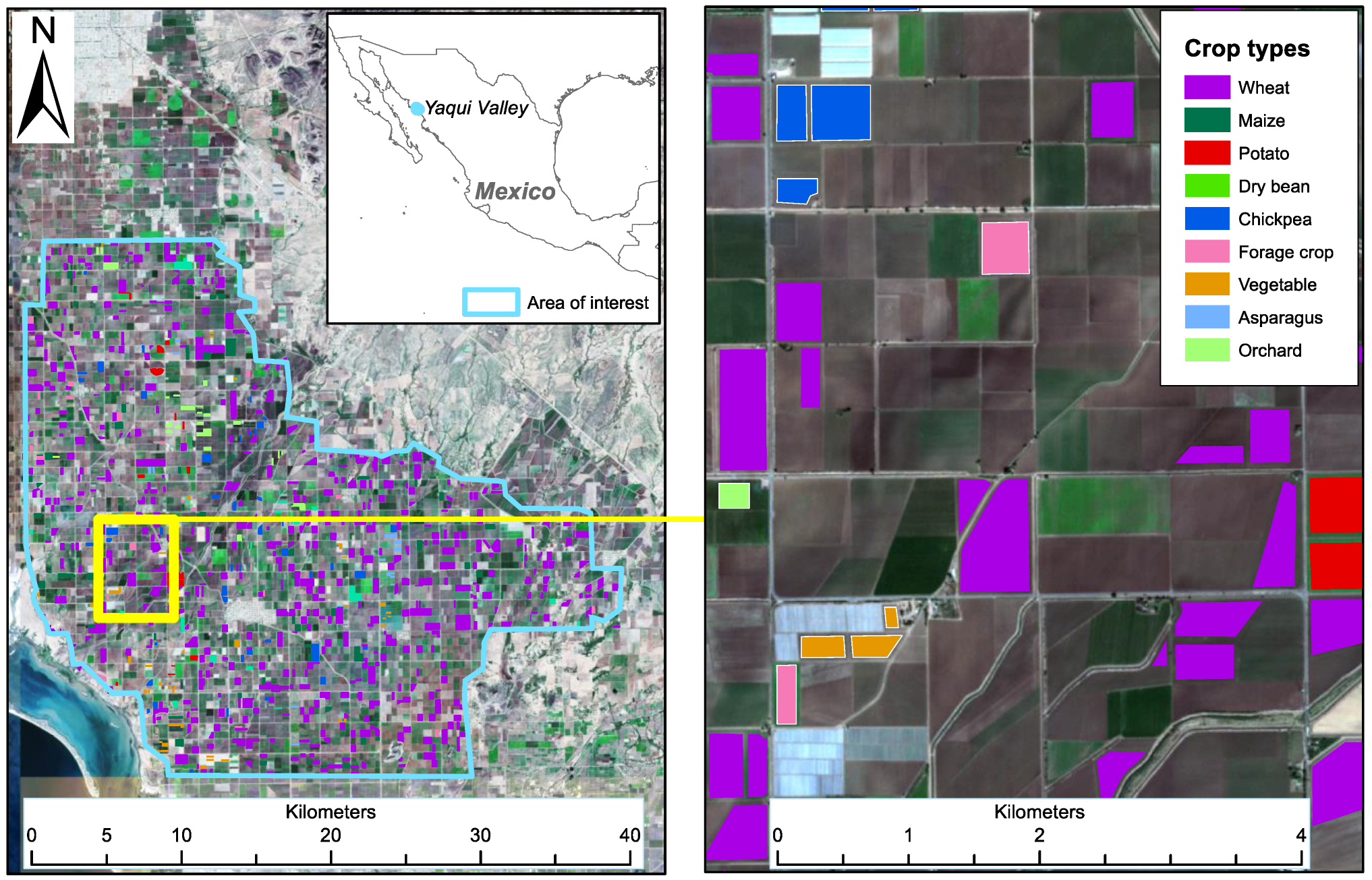
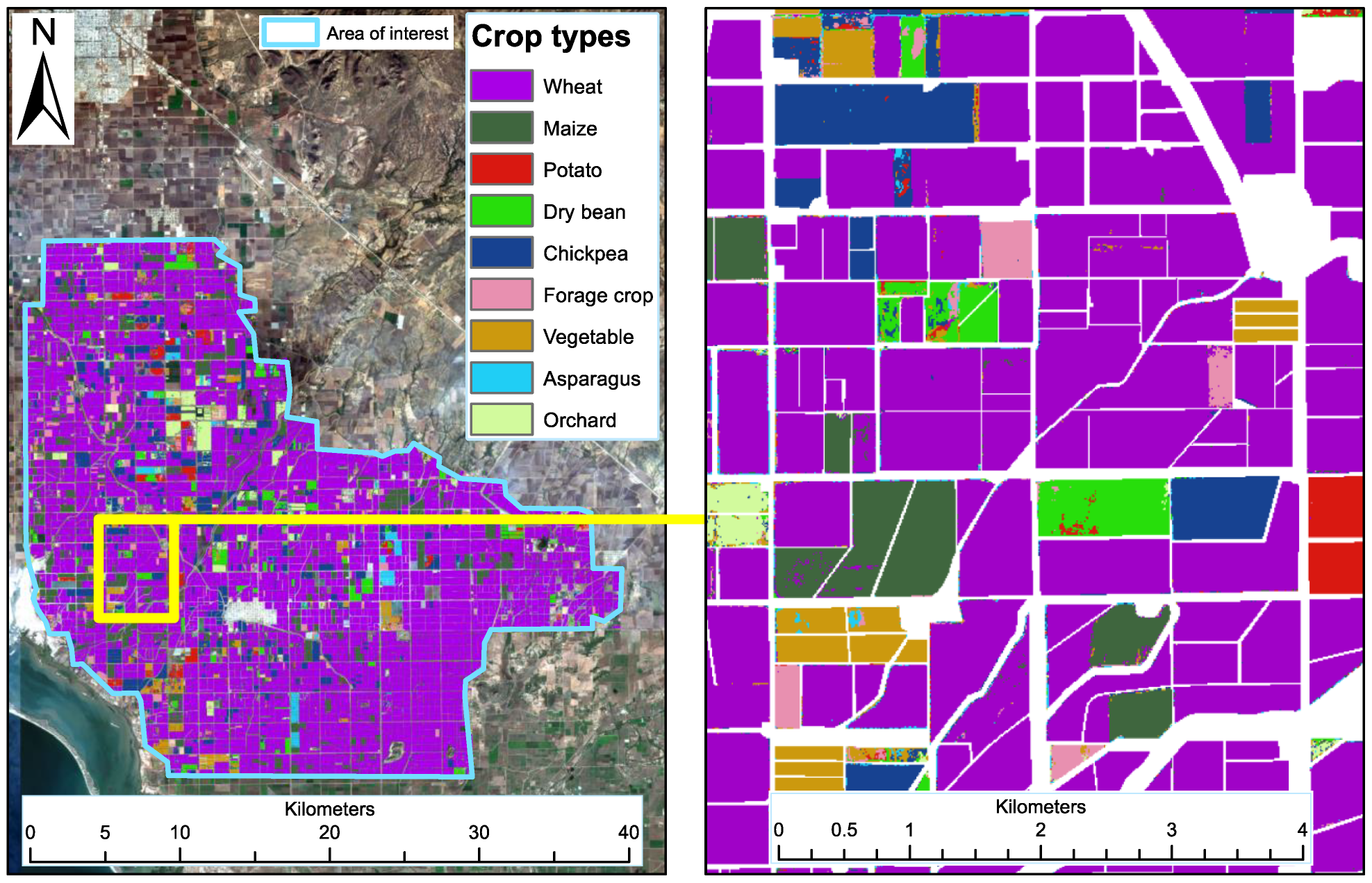
2.2. Characteristics of the Study Region and In Situ Data Preparation
2.3. Sen2-Agri Crop Classification System
2.4. Scenarios
2.5. Nomenclature and Statistical Analyses
3. Results
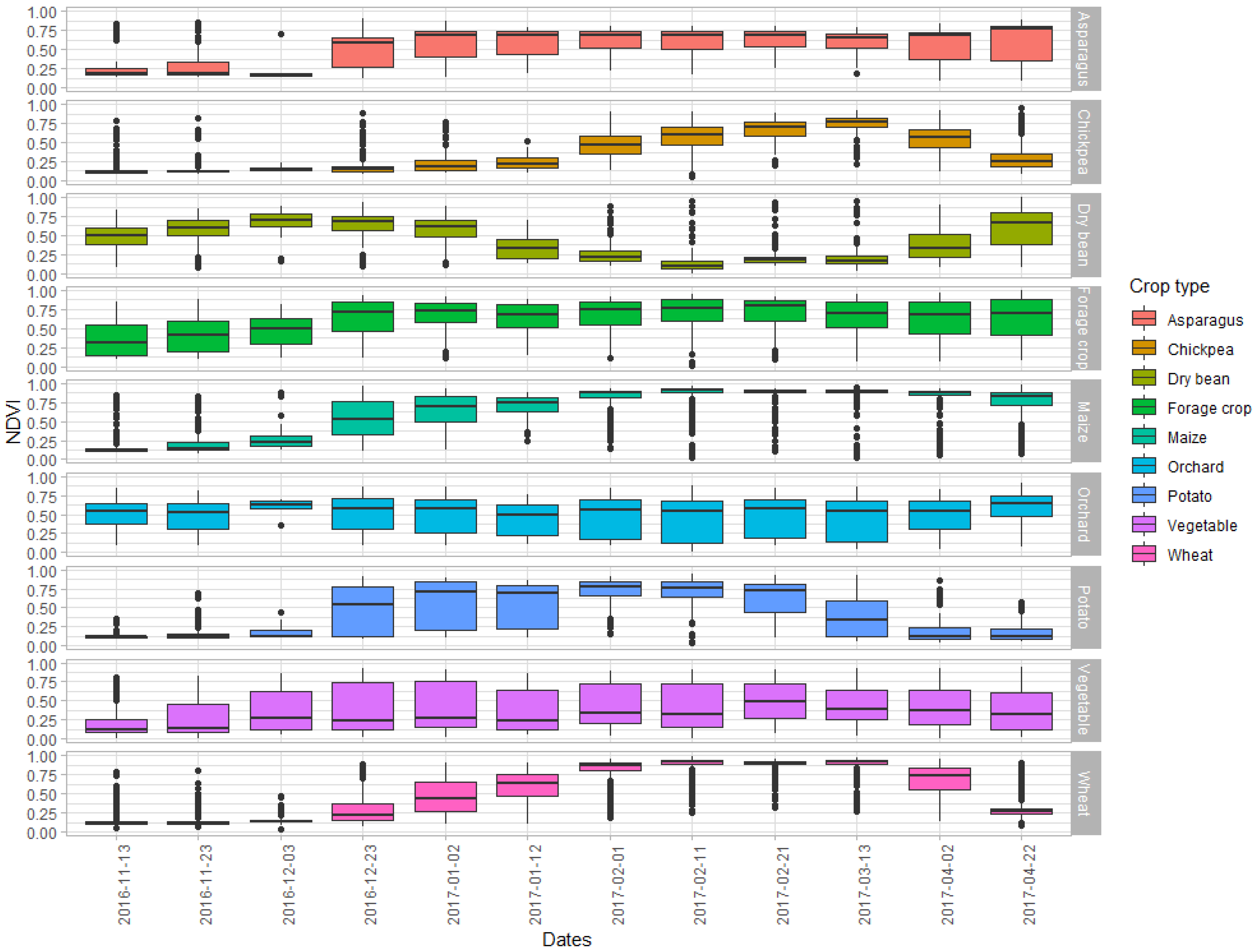
3.1. Evolution and Dispersion of Crop-Specific NDVI over Time
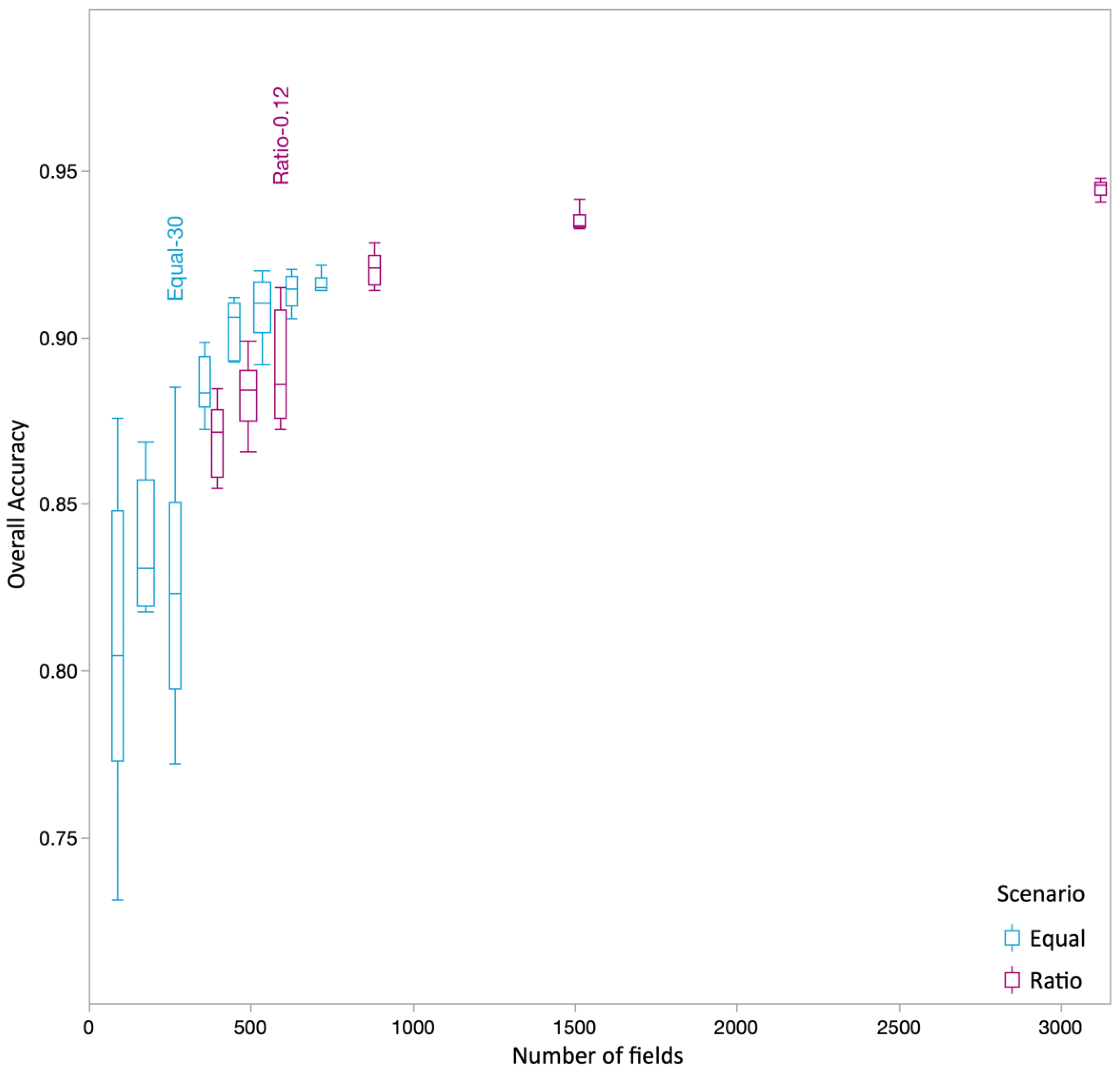
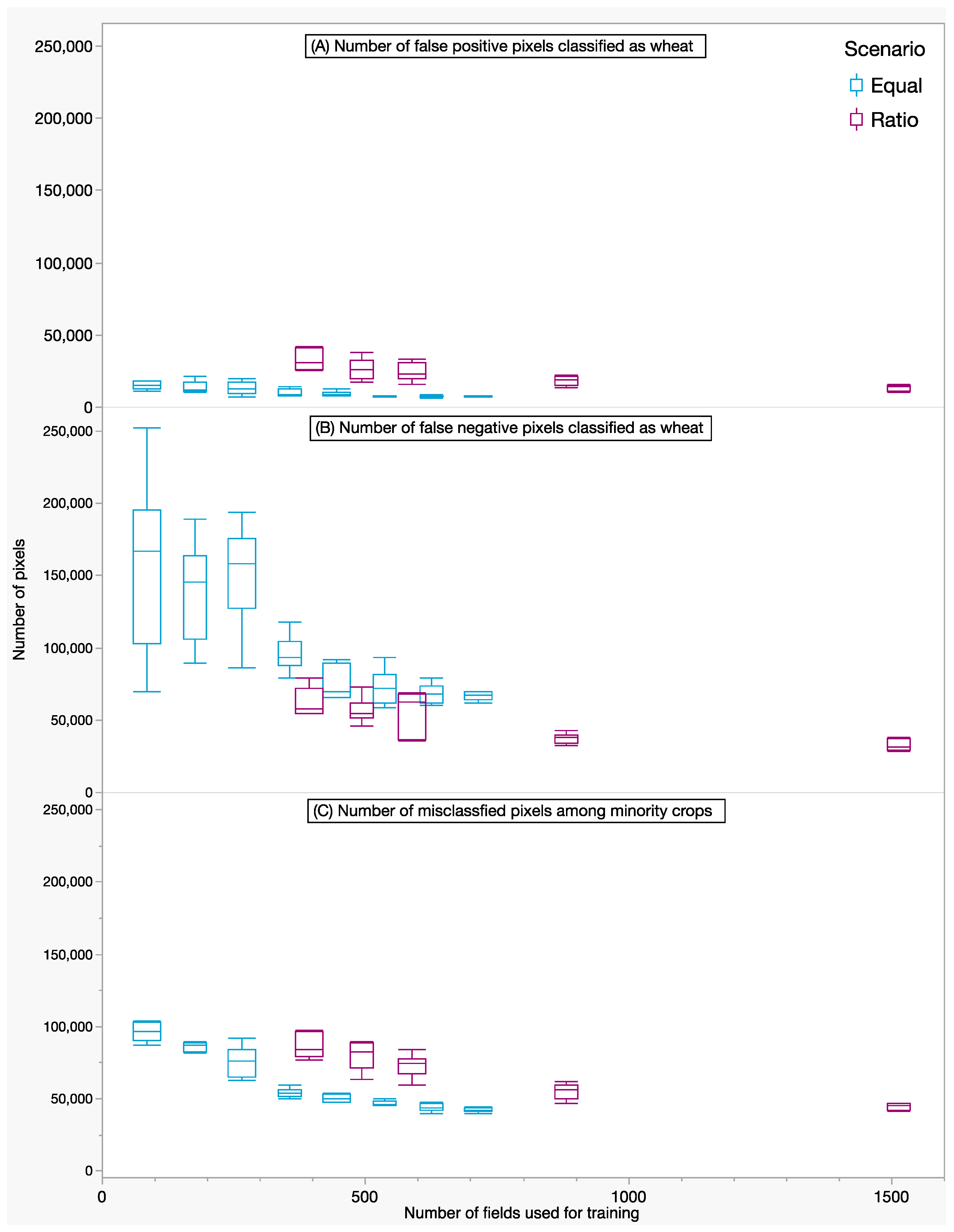
3.2. Classification Results for Ratio and Equal
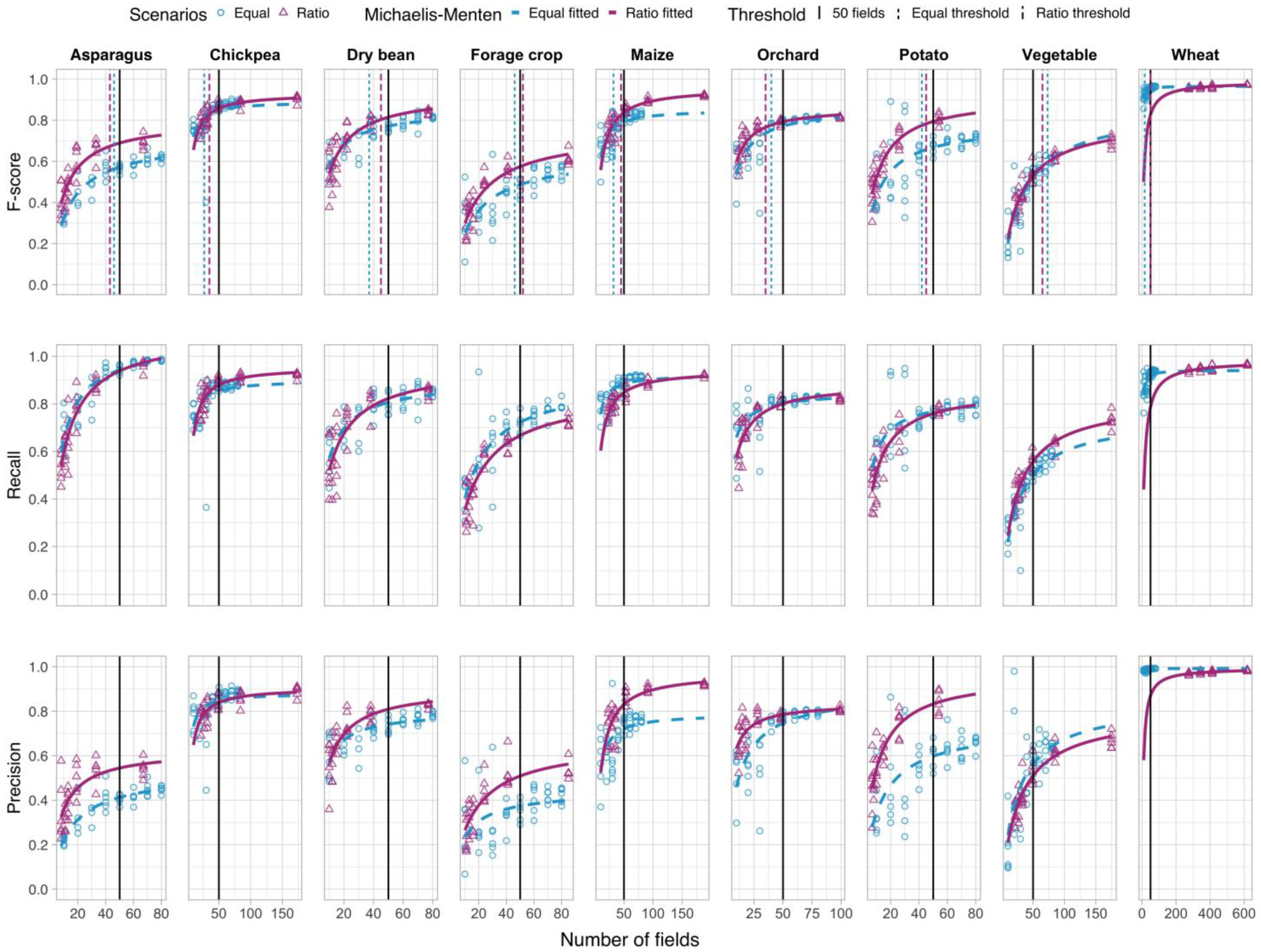
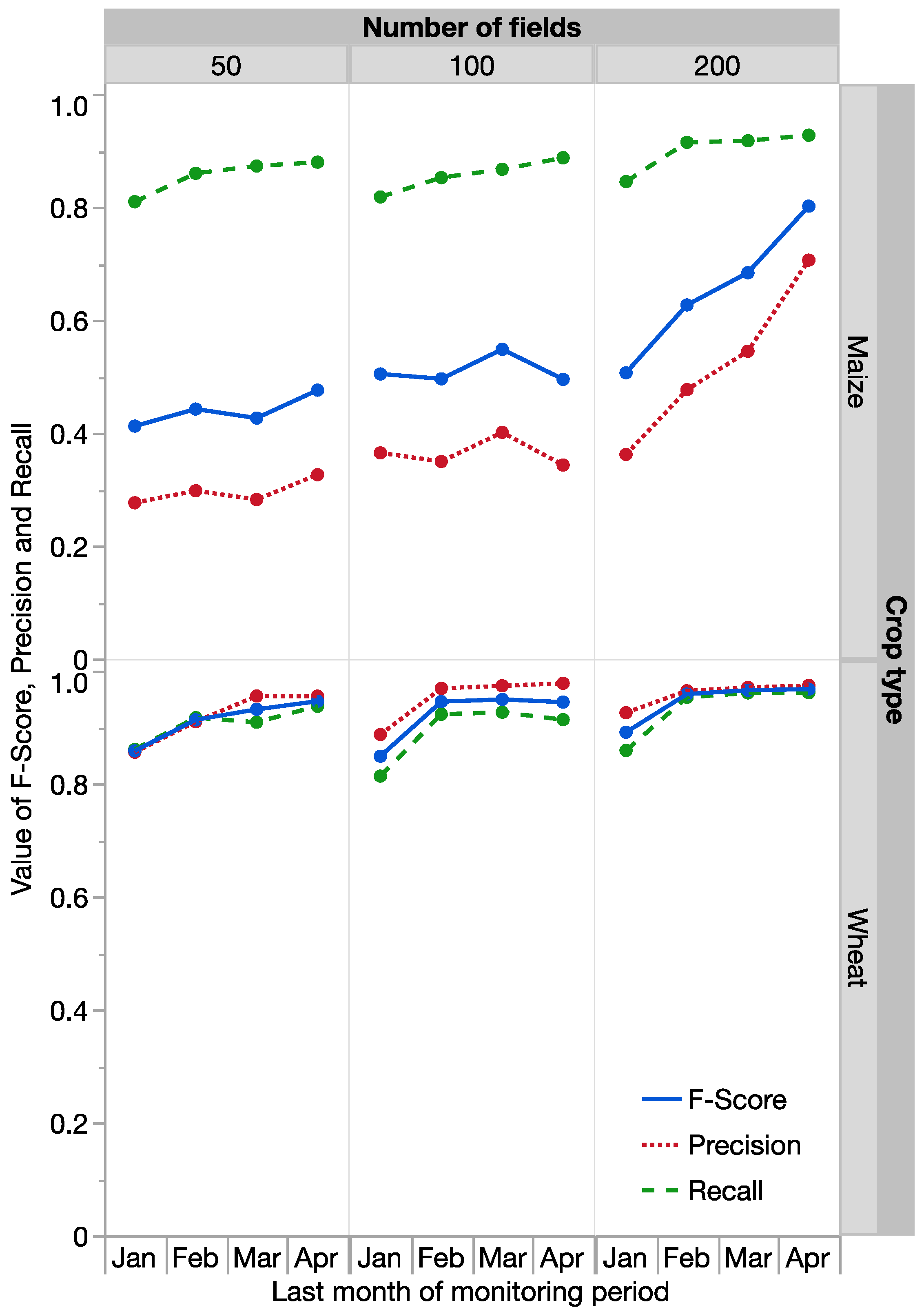
3.3. How Many Fields Are Needed for Training?
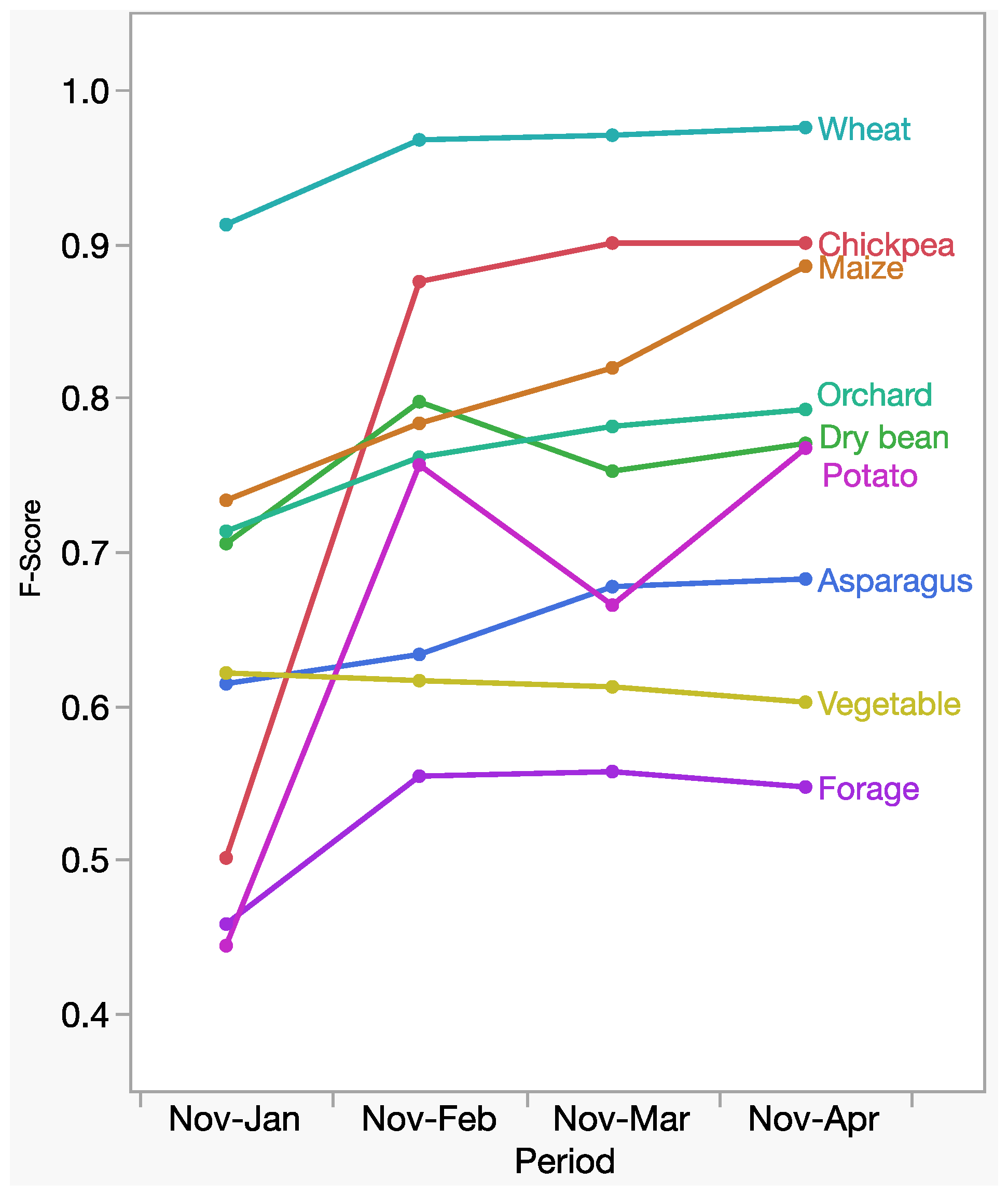
3.4. Change of Classification Accuracy across the Season
3.5. Binary In-Season Classification
4. Discussion
4.1. Validity of the Study
4.2. Does Equal or Proportional Representation Produce Better Classification Results?
4.3. How Many Fields Are Needed?
4.4. Change of Classification Accuracy across the Season
4.5. Binary In-Season Classification
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Immitzer, M.; Vuolo, F.; Atzberger, C. First Experience with Sentinel-2 Data for Crop and Tree Species Classifications in Central Europe. Remote Sens. 2016, 8, 166. [Google Scholar] [CrossRef]
- European Space Agency Sentinel-2 MSI. Available online: https://earth.esa.int/web/sentinel/user-guides/sentinel-2-msi (accessed on 11 December 2022).
- Vuolo, F.; Neuwirth, M.; Immitzer, M.; Atzberger, C.; Ng, W.-T. How Much Does Multi-Temporal Sentinel-2 Data Improve Crop Type Classification? Int. J. Appl. Earth Obs. Geoinf. 2018, 72, 122–130. [Google Scholar] [CrossRef]
- Sentinel-2 for Agriculture. Available online: http://www.esa-sen2agri.org (accessed on 13 December 2022).
- Defourny, P.; Bontemps, S.; Bellemans, N.; Cara, C.; Dedieu, G.; Guzzonato, E.; Hagolle, O.; Inglada, J.; Nicola, L.; Rabaute, T.; et al. Near Real-Time Agriculture Monitoring at National Scale at Parcel Resolution: Performance Assessment of the Sen2-Agri Automated System in Various Cropping Systems around the World. Remote Sens. Environ. 2019, 221, 551–568. [Google Scholar] [CrossRef]
- The Sentinels for Common Agricultural Policy-Sen4CAP. Available online: http://esa-sen4cap.org (accessed on 11 December 2022).
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Belgiu, M.; Drăguţ, L. Random Forest in Remote Sensing: A Review of Applications and Future Directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Sheykhmousa, M.; Mahdianpari, M.; Ghanbari, H.; Mohammadimanesh, F.; Ghamisi, P.; Homayouni, S. Support Vector Machine Versus Random Forest for Remote Sensing Image Classification: A Meta-Analysis and Systematic Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 6308–6325. [Google Scholar] [CrossRef]
- Ghassemi, B.; Dujakovic, A.; Żółtak, M.; Immitzer, M.; Atzberger, C.; Vuolo, F. Designing a European-Wide Crop Type Mapping Approach Based on Machine Learning Algorithms Using LUCAS Field Survey and Sentinel-2 Data. Remote Sens. 2022, 14, 541. [Google Scholar] [CrossRef]
- Elmes, A.; Alemohammad, H.; Avery, R.; Caylor, K.; Eastman, J.R.; Fishgold, L.; Friedl, M.A.; Jain, M.; Kohli, D.; Laso Bayas, J.C.; et al. Accounting for Training Data Error in Machine Learning Applied to Earth Observations. Remote Sens. 2020, 12, 1034. [Google Scholar] [CrossRef] [Green Version]
- Congalton, R.G. A Review of Assessing the Accuracy of Classifications of Remotely Sensed Data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Hay, A.M. Sampling Designs to Test Land-Use Map Accuracy. Photogramm. Eng. 1979, 5, 529–533. [Google Scholar]
- Mather, P.M.; Koch, M. Computer Processing of Remotely-Sensed Images: An Introduction; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Van Niel, T.; Mcvicar, T.; Datt, B. On the Relationship between Training Sample Size and Data Dimensionality: Monte Carlo Analysis of Broadband Multi-Temporal Classification. Remote Sens. Environ. 2005, 98, 468–480. [Google Scholar] [CrossRef]
- Waldner, F.; Jacques, D.C.; Löw, F. The Impact of Training Class Proportions on Binary Cropland Classification. Remote Sens. Lett. 2017, 8, 1122–1131. [Google Scholar] [CrossRef] [Green Version]
- Johnson, D.M. Using the Landsat Archive to Map Crop Cover History across the United States. Remote Sens. Environ. 2019, 232, 111286. [Google Scholar] [CrossRef]
- Krupnik, T.J.; Schulthess, U.; Ahmed, Z.U.; McDonald, A.J. Sustainable Crop Intensification through Surface Water Irrigation in Bangladesh? A Geospatial Assessment of Landscape-Scale Production Potential. Land Use Policy 2017, 60, 206–222. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schulthess, U.; Timsina, J.; Herrera, J.M.; McDonald, A. Mapping Field-Scale Yield Gaps for Maize: An Example from Bangladesh. Field Crops Res. 2013, 143, 151–156. [Google Scholar] [CrossRef] [Green Version]
- Waldner, F.; Chen, Y.; Lawes, R.; Hochman, Z. Needle in a Haystack: Mapping Rare and Infrequent Crops Using Satellite Imagery and Data Balancing Methods. Remote Sens. Environ. 2019, 233, 111375. [Google Scholar] [CrossRef]
- Millard, K.; Richardson, M. On the Importance of Training Data Sample Selection in Random Forest Image Classification: A Case Study in Peatland Ecosystem Mapping. Remote Sens. 2015, 27, 8489–8515. [Google Scholar] [CrossRef] [Green Version]
- Mellor, A.; Boukir, S.; Haywood, A.; Jones, S. Exploring Issues of Training Data Imbalance and Mislabelling on Random Forest Performance for Large Area Land Cover Classification Using the Ensemble Margin. ISPRS J. Photogramm. Remote Sens. 2015, 105, 155–168. [Google Scholar] [CrossRef]
- Whang, S.E.; Lee, J.-G. Data Collection and Quality Challenges for Deep Learning. Proc. VLDB Endow. 2020, 13, 3429–3432. [Google Scholar] [CrossRef]
- Eichler, S.E.; Kline, K.L.; Ortiz-Monasterio, I.; Lopez-Ridaura, S.; Dale, V.H. Rapid Appraisal Using Landscape Sustainability Indicators for Yaqui Valley, Mexico. Environ. Sustain. Indic. 2020, 6, 100029. [Google Scholar] [CrossRef]
- Rouse, J.W.; Haas, R.H.; Scell, J.A.; Deering, D.W.; Harlan, J.C. Monitoring the Vernal Advancement of Retrogradiation of Natural Vegetation; NASA/GSFC Type III: Greenbelt, MD, USA, 1974; p. 371. [Google Scholar]
- Hagolle, O.; Huc, M.; Desjardins, C.; Auer, S.; Richter, R. MAJA Algorithm Theoretical Basis Document; CNES: Paris, France; CESBIO: Toulouse, France; DLR: Cologne, France, 2017. [Google Scholar] [CrossRef]
- Gao, B. NDWI--A Normalized Difference Water Index for Remote Sensing of Vegetation Liquid Water from Space. Remote Sens. Environ. 1996, 58, 257–266. [Google Scholar] [CrossRef]
- Foody, G.M. Status of Land Cover Classification Accuracy Assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Michaelis, L.; Menten, M.L. Die Kinetik Der Invertinwirkung. Biochem Z 1913, 49, 352. [Google Scholar]
- Foody, G.M. Impacts of Ignorance on the Accuracy of Image Classification and Thematic Mapping. Remote Sens. Environ. 2021, 259, 112367. [Google Scholar] [CrossRef]
- Orynbaikyzy, A.; Gessner, U.; Conrad, C. Spatial Transferability of Random Forest Models for Crop Type Classification Using Sentinel-1 and Sentinel-2. Remote Sens. 2022, 14, 1493. [Google Scholar] [CrossRef]
- Jin, H.; Stehman, S.V.; Mountrakis, G. Assessing the Impact of Training Sample Selection on Accuracy of an Urban Classification: A Case Study in Denver, Colorado. Int. J. Remote Sens. 2014, 35, 2067–2081. [Google Scholar] [CrossRef]
- Fowler, J.; Waldner, F.; Hochman, Z. All Pixels Are Useful, but Some Are More Useful: Efficient in Situ Data Collection for Crop-Type Mapping Using Sequential Exploration Methods. Int. J. Appl. Earth Obs. Geoinf. 2020, 91, 102114. [Google Scholar] [CrossRef]
- Gilcher, M.; Ruf, T.; Emmerling, C.; Udelhoven, T. Remote Sensing Based Binary Classification of Maize. Dealing with Residual Autocorrelation in Sparse Sample Situations. Remote Sens. 2019, 11, 2172. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Croptype | Number of Fields | Area | Season | Remarks | ||
|---|---|---|---|---|---|---|
| ha | Std | Start | End | |||
| Wheat | 4291 | 12.4 | 8.6 | November | April/May | |
| Maize | 366 | 13.8 | 9.7 | October/January | April/June | Anytime (>120 day crop) |
| Potato | 105 | 11.3 | 9.5 | November | March | |
| Dry bean | 151 | 11.1 | 9.0 | October | May | Anytime (90 day crop) |
| Chickpea | 338 | 11.9 | 8.9 | January | May | |
| Forage crop | 166 | 7.3 | 6.2 | Perennial | ||
| Vegetable | 343 | 4.6 | 2.8 | October | May | Anytime (~90 day crop) |
| Asparagus | 131 | 5.3 | 2.6 | Perennial | ||
| Orchard | 193 | 8.8 | 7.1 | Perennial | ||
| Total | 6084 | |||||
| Crop | Total Number of Fields | 20% for Validation | 80% for Calibration | Ratio | |||||
|---|---|---|---|---|---|---|---|---|---|
| 0.64 | 0.31 | 0.18 | 0.12 | 0.1 | 0.08 | ||||
| Wheat | 4291 | 858 | 3433 | 2128 | 1064 | 618 | 412 | 343 | 275 |
| Maize | 366 | 73 | 293 | 182 | 91 | 53 | 35 | 29 | 23 |
| Potato | 105 | 21 | 84 | 52 | 26 | 15 | 10 | 8 | 7 |
| Dry bean | 151 | 30 | 121 | 75 | 37 | 22 | 14 | 12 | 10 |
| Chickpea | 338 | 68 | 270 | 168 | 84 | 49 | 32 | 27 | 22 |
| Forage crop | 166 | 33 | 133 | 82 | 41 | 24 | 16 | 13 | 11 |
| Vegetable | 343 | 69 | 274 | 170 | 85 | 49 | 33 | 27 | 22 |
| Asparagus | 131 | 26 | 105 | 65 | 32 | 19 | 13 | 10 | 8 |
| Orchard | 193 | 39 | 154 | 96 | 48 | 28 | 19 | 15 | 12 |
| Total | 6084 | 1217 | 4867 | 3018 | 1509 | 876 | 584 | 487 | 389 |
| Use of 18% of Fields of Each Crop Type for Training (Ratio-0.18) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Classified | Reference | Total Pixels | Precision | ||||||||
| Wheat | Maize | Potato | Dry Bean | Chickpea | Forage Crop | Vegetable | Asparagus | Orchard | |||
| Wheat | 1,021,798 | 11,940 | 1108 | 302 | 1041 | 2422 | 1341 | 73 | 126 | 1,040,150 | 0.98 |
| Maize | 11,602 | 84,461 | 27 | 104 | 163 | 709 | 479 | 170 | 33 | 97,748 | 0.86 |
| Potato | 2708 | 104 | 12,139 | 961 | 1280 | 580 | 1694 | 136 | 47 | 19,647 | 0.62 |
| Dry bean | 743 | 694 | 2969 | 23,712 | 180 | 573 | 2295 | 459 | 418 | 32,043 | 0.74 |
| Chickpea | 6752 | 628 | 1206 | 733 | 77,545 | 1133 | 2787 | 446 | 942 | 92,171 | 0.84 |
| Forage crop | 5310 | 650 | 1374 | 1430 | 1172 | 11,908 | 1732 | 653 | 2965 | 27,193 | 0.44 |
| Vegetable | 4623 | 711 | 1499 | 1897 | 1855 | 1206 | 15,193 | 471 | 1605 | 29,060 | 0.52 |
| Asparagus | 3850 | 619 | 79 | 2016 | 1272 | 710 | 760 | 10,702 | 2208 | 22,215 | 0.48 |
| Orchard | 1757 | 251 | 55 | 1659 | 1971 | 1001 | 856 | 407 | 27,067 | 35,024 | 0.77 |
| Total pixels | 1,059,143 | 100,059 | 20,456 | 32,813 | 86,478 | 20,242 | 27,135 | 13,515 | 35,410 | 1,395,251 | |
| Recall | 0.96 | 0.84 | 0.59 | 0.72 | 0.90 | 0.59 | 0.56 | 0.79 | 0.76 | ||
| Overall Accuracy: 0.92 | |||||||||||
| Use of 80 Fields of Each Crop Type for Training (Equal-80) | |||||||||||
| Classified | Reference | Total Pixels | Precision | ||||||||
| Wheat | Maize | Potato | Dry Bean | Chickpea | Forage Crop | Vegetable | Asparagus | Orchard | |||
| Wheat | 992,355 | 5212 | 512 | 77 | 479 | 808 | 688 | 0 | 100 | 1,000,229 | 0.99 |
| Maize | 27,556 | 91,312 | 4 | 40 | 39 | 720 | 244 | 0 | 1 | 119,915 | 0.76 |
| Potato | 2846 | 88 | 16,113 | 580 | 3082 | 287 | 1547 | 1 | 41 | 24,583 | 0.66 |
| Dry bean | 643 | 654 | 2923 | 27,746 | 192 | 231 | 2575 | 24 | 410 | 35,396 | 0.78 |
| Chickpea | 6631 | 371 | 228 | 216 | 76,386 | 124 | 2055 | 41 | 79 | 86,131 | 0.89 |
| Forage crop | 14,787 | 1120 | 425 | 1085 | 1360 | 16,052 | 2380 | 73 | 639 | 37,921 | 0.42 |
| Vegetable | 5848 | 295 | 93 | 291 | 1511 | 387 | 15,761 | 24 | 391 | 24,600 | 0.64 |
| Asparagus | 6424 | 857 | 125 | 1223 | 1431 | 736 | 1027 | 13,267 | 4391 | 29,480 | 0.45 |
| Orchard | 2055 | 152 | 34 | 1557 | 1999 | 897 | 860 | 85 | 29,359 | 36,996 | 0.79 |
| Total pixels | 1,059,143 | 100,059 | 20,456 | 32,813 | 86,478 | 20,242 | 27,135 | 13,515 | 35,410 | 1,395,251 | |
| Recall | 0.94 | 0.91 | 0.79 | 0.85 | 0.88 | 0.79 | 0.58 | 0.98 | 0.83 | ||
| Overall Accuracy: 0.92 | |||||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schulthess, U.; Rodrigues, F.; Taymans, M.; Bellemans, N.; Bontemps, S.; Ortiz-Monasterio, I.; Gérard, B.; Defourny, P. Optimal Sample Size and Composition for Crop Classification with Sen2-Agri’s Random Forest Classifier. Remote Sens. 2023, 15, 608. https://doi.org/10.3390/rs15030608
Schulthess U, Rodrigues F, Taymans M, Bellemans N, Bontemps S, Ortiz-Monasterio I, Gérard B, Defourny P. Optimal Sample Size and Composition for Crop Classification with Sen2-Agri’s Random Forest Classifier. Remote Sensing. 2023; 15(3):608. https://doi.org/10.3390/rs15030608
Chicago/Turabian StyleSchulthess, Urs, Francelino Rodrigues, Matthieu Taymans, Nicolas Bellemans, Sophie Bontemps, Ivan Ortiz-Monasterio, Bruno Gérard, and Pierre Defourny. 2023. "Optimal Sample Size and Composition for Crop Classification with Sen2-Agri’s Random Forest Classifier" Remote Sensing 15, no. 3: 608. https://doi.org/10.3390/rs15030608
APA StyleSchulthess, U., Rodrigues, F., Taymans, M., Bellemans, N., Bontemps, S., Ortiz-Monasterio, I., Gérard, B., & Defourny, P. (2023). Optimal Sample Size and Composition for Crop Classification with Sen2-Agri’s Random Forest Classifier. Remote Sensing, 15(3), 608. https://doi.org/10.3390/rs15030608