
Double Deep Q-Network for Hyperspectral Image Band Selection in Land Cover Classification Applications



Abstract
:1. Introduction
2. Methods
2.1. Reward Functions
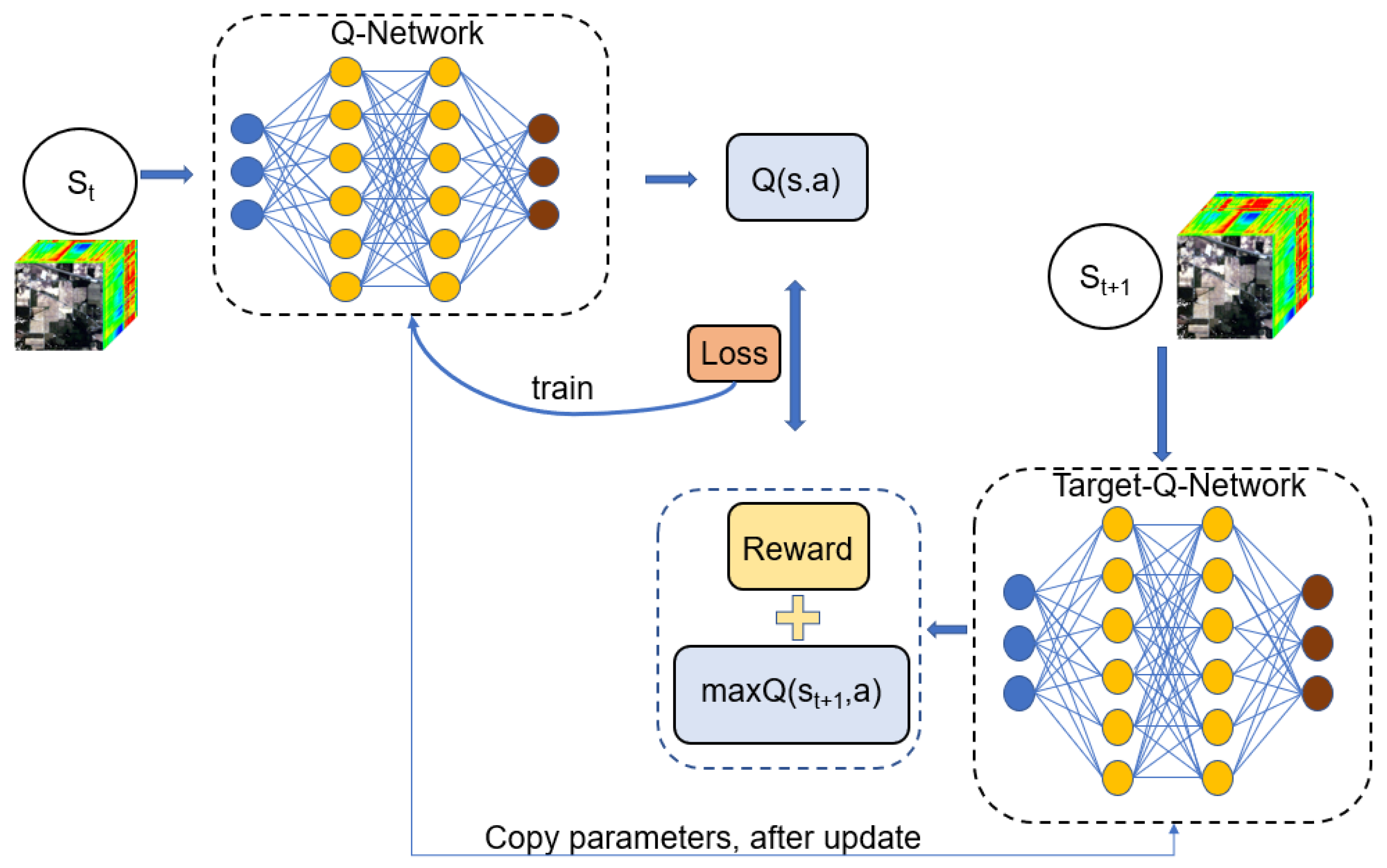
2.2. Double Deep Q Network (DDQN)
| Algorithm 1 Double DQN |
| 1: Input: randomly initialize Q-network weights θ, copy θ to θ’; initialize replay memory M; initialize the complete set of all actions A; load reward table R; 2: for do 3: initialize state: s 4: empty the set of chosen bands: B 5: do 6: compute the actual set of actions, simulate one step with the ε-greedy policy; 7: choose action a; 8: ; 9: ) into M; 10: ; 11: end for 12: randomly sample a mini-batch Bc from M; 13: for do 14: calculate the learning target according to Equation (11) 15: 16: end for 17: carry out a gradient descent step on L, according to Equation (10) 18: 19: 20: end for |
2.3. The Proposed DDQN Based BS Method
3. Datasets
- (A)
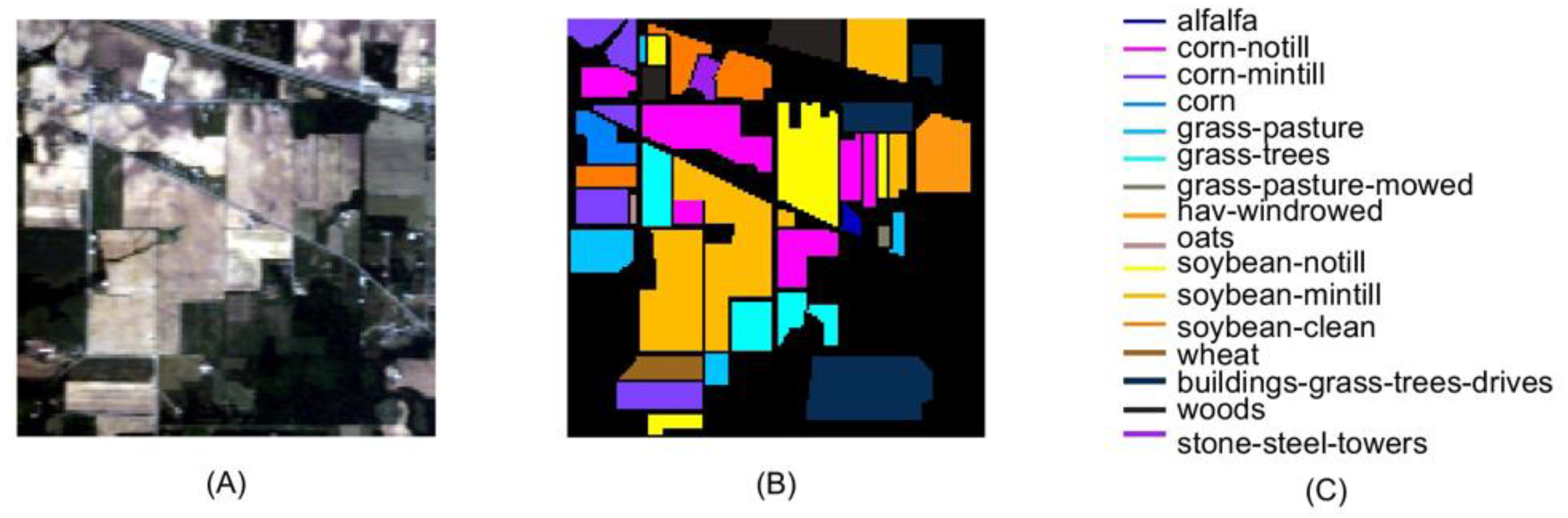
- AVIRIS dataset: to validate the proposed BS method and compare it with other BS methods, a publicly available hyperspectral image dataset acquired using NASA’s Airborne Visible-Infrared Imaging Spectrometer sensor (AVIRIS) on 12 June 1992 was used. This particular dataset (the Indian Pines) was chosen because it has ground truth information captured through field observations and pixel-by-pixel labelled. It covers a geographical area in the northwest of Indiana in the United States as shown in Figure 2. The dataset includes pixels, with pixel spatial resolution of 20 m. There are 220 bands in total, and the wavelength range is between 400–2500 nm. The data provided 16 types labelled data, most of which are crops and are they are in different growth stages. Before applying the BS methods, 20 bands (104–108, 150–163 and 220), all of which are water absorption bands, are removed. A total of 200 spectral bands are used as the input data.
- (B)
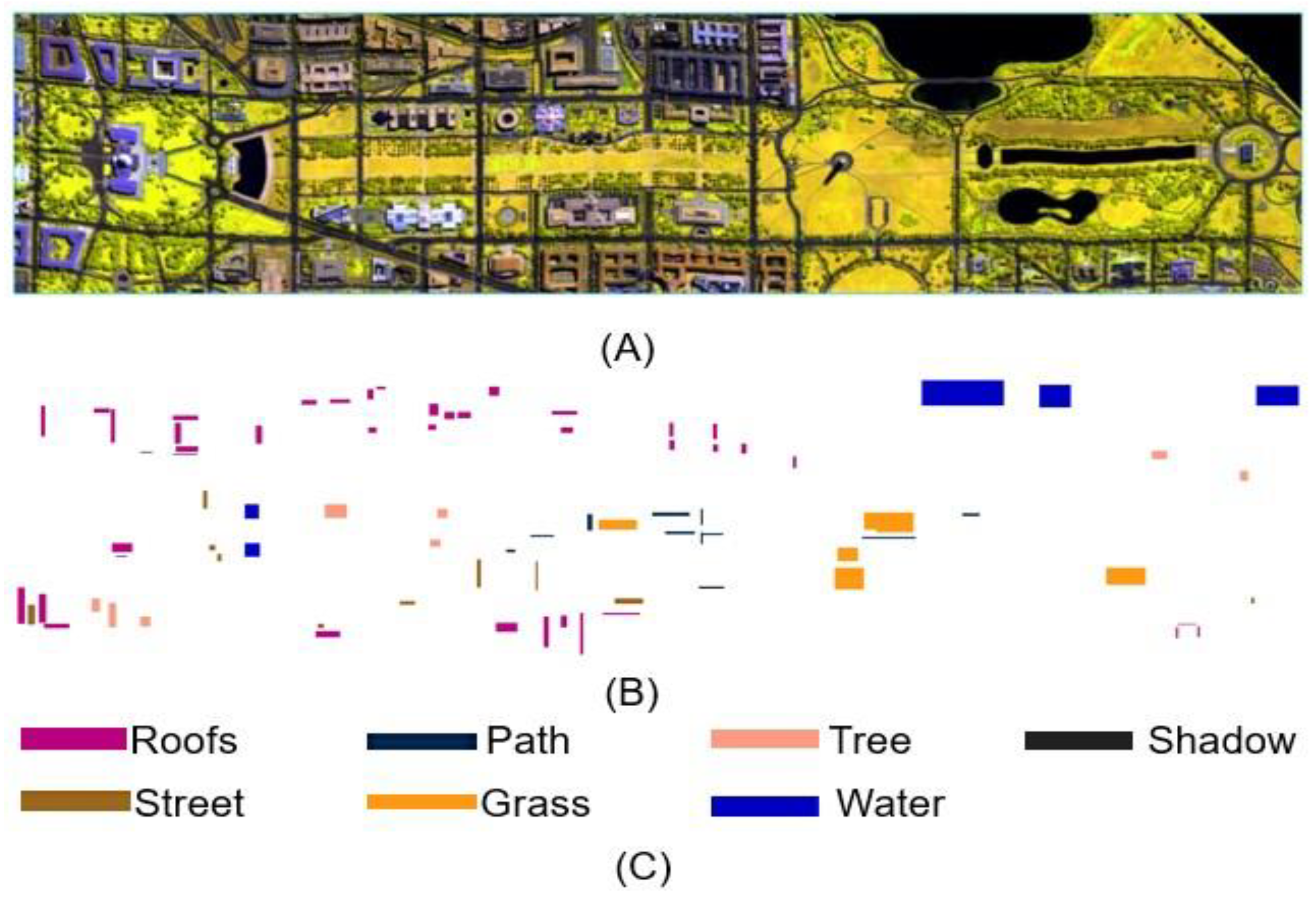
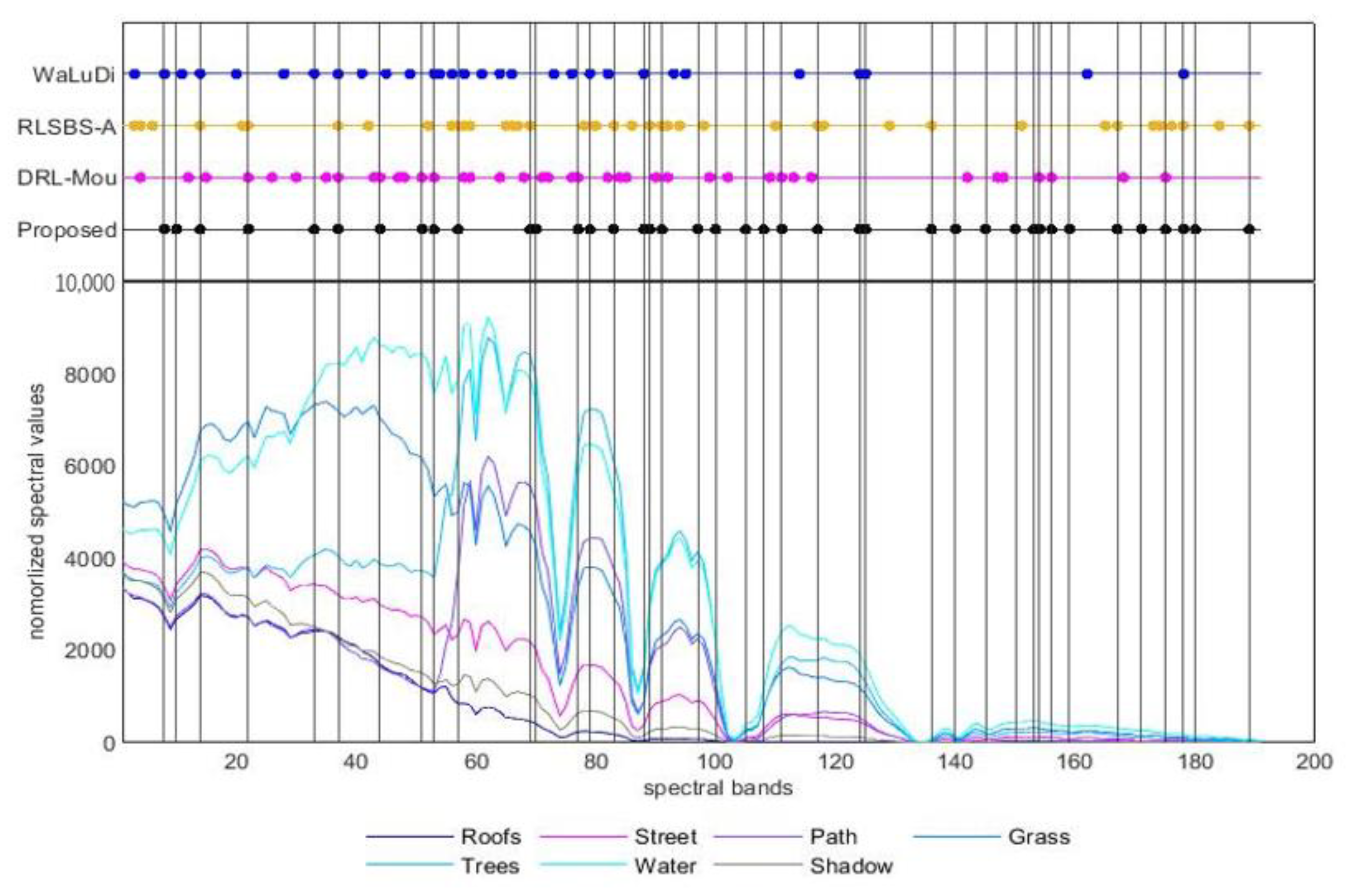
- HYDICE dataset: the Washington District of Columbia (Washington DC) Mall dataset was captured using Hyperspectral Digital Imagery Collection Experiment (HYDICE) sensor over the urban region Washington DC Mall in 1995. HYDICE has 191 bands, and 0.4 µm to 2.4 µm spectral range. The image (only shows three bands), the ground truth and mapping classes are shown in Figure 3. This data set contains 1208 scan lines with 307 pixels in each scan line. It has seven classes (roofs, street, path, grass, trees, water, and shadow).
- (C)
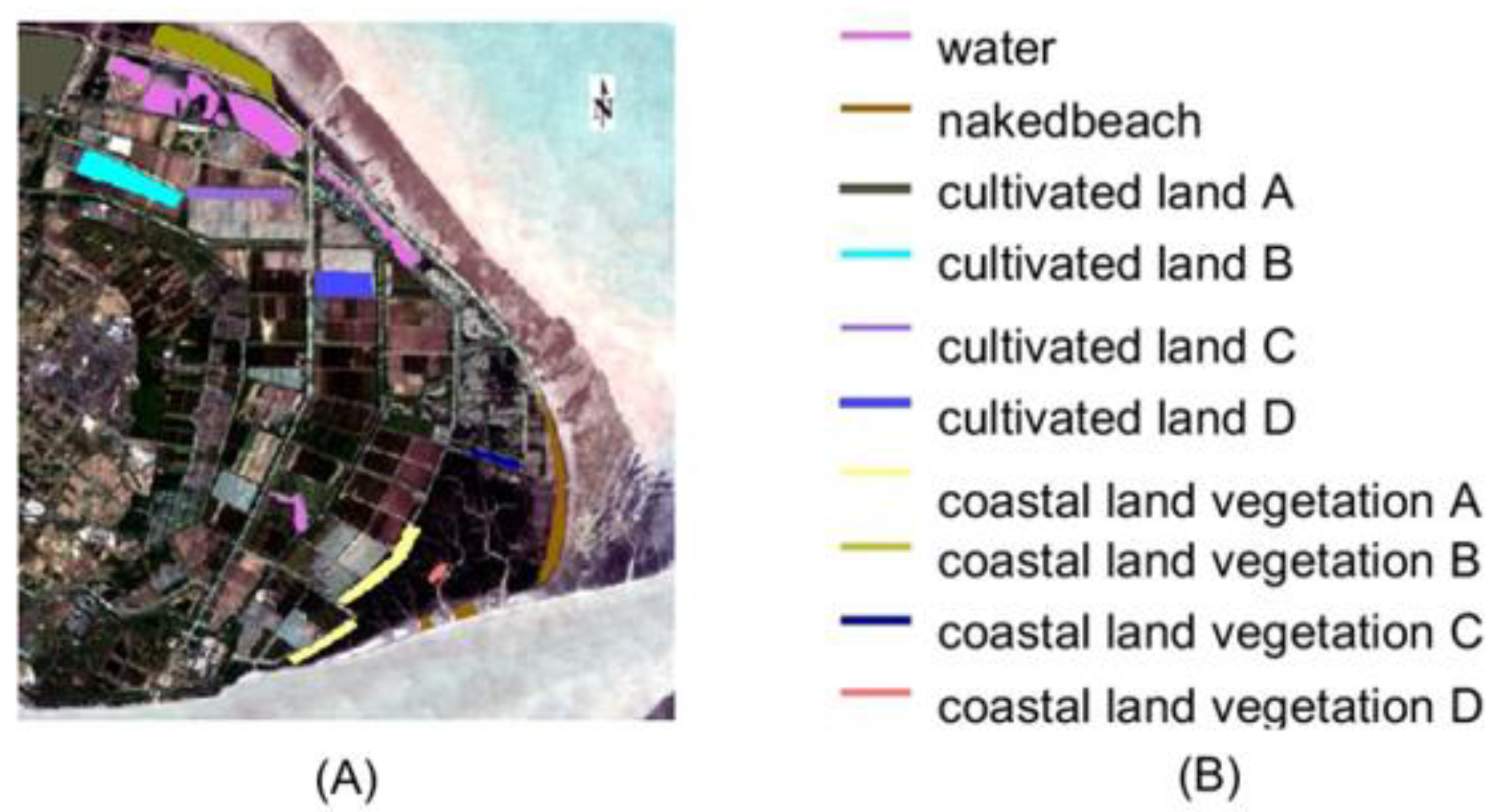
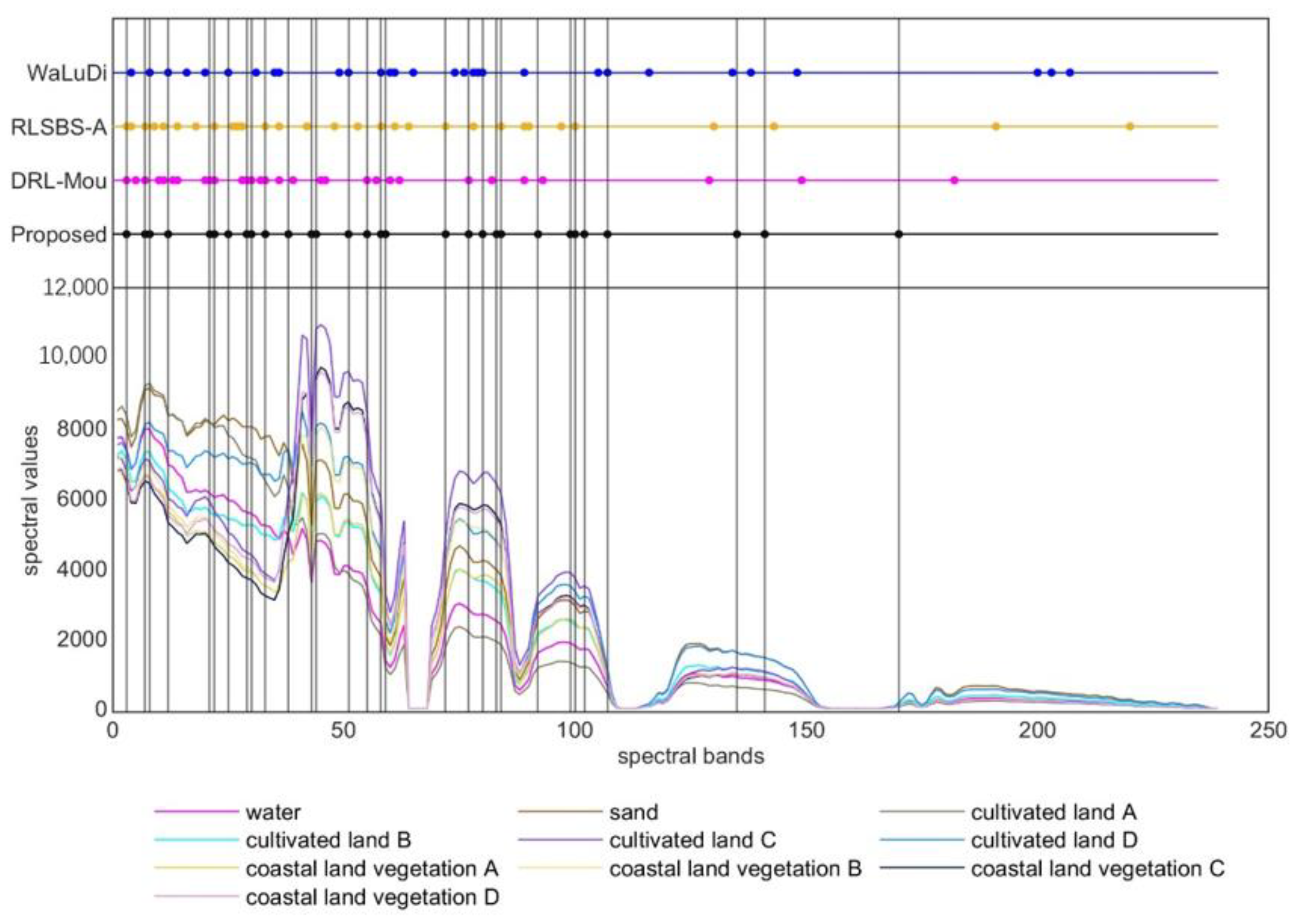
- PRISMA dataset: PRISMA is a small satellite hyperspectral imaging sensor, managed and operated by the Italian Space Agency. It has a total of 239 spectral bands that acquire images at a 30 m spatial resolution and at a 10 nm spectral resolution. The entire hyperspectral range of bands in a PRISMA scene is from 400 nm to 2505 nm. Among 239 bands, 66 are in the visible and near infrared range (VNIR) and 173 are in the short-wave infrared range (SWIR). The Level 1 product was used for experiment. Chongming Island data from PRISMA was acquired on 8 May 2022. After evaluating Chongming Island PRISMA data, it was found that there are three empty bands in VNIR and 2 in SWIR. Ten types of common land cover types were manually sampled, including water body, bare sand, four types of coast bush vegetation, four types of cultivated land cover, there are 4775 sample pixels in total (Figure 4). The Indian Pines and Washington DC Mall datasets are from airborne hyperspectral sensors (ARIVIS and HYDICE, respectively). In order to further verify the performance of the proposed BS method, a recently available PRISMA satellite hyperspectral scene in a coast region (Chongming Island Shanghai China) was utilized.
- (D)
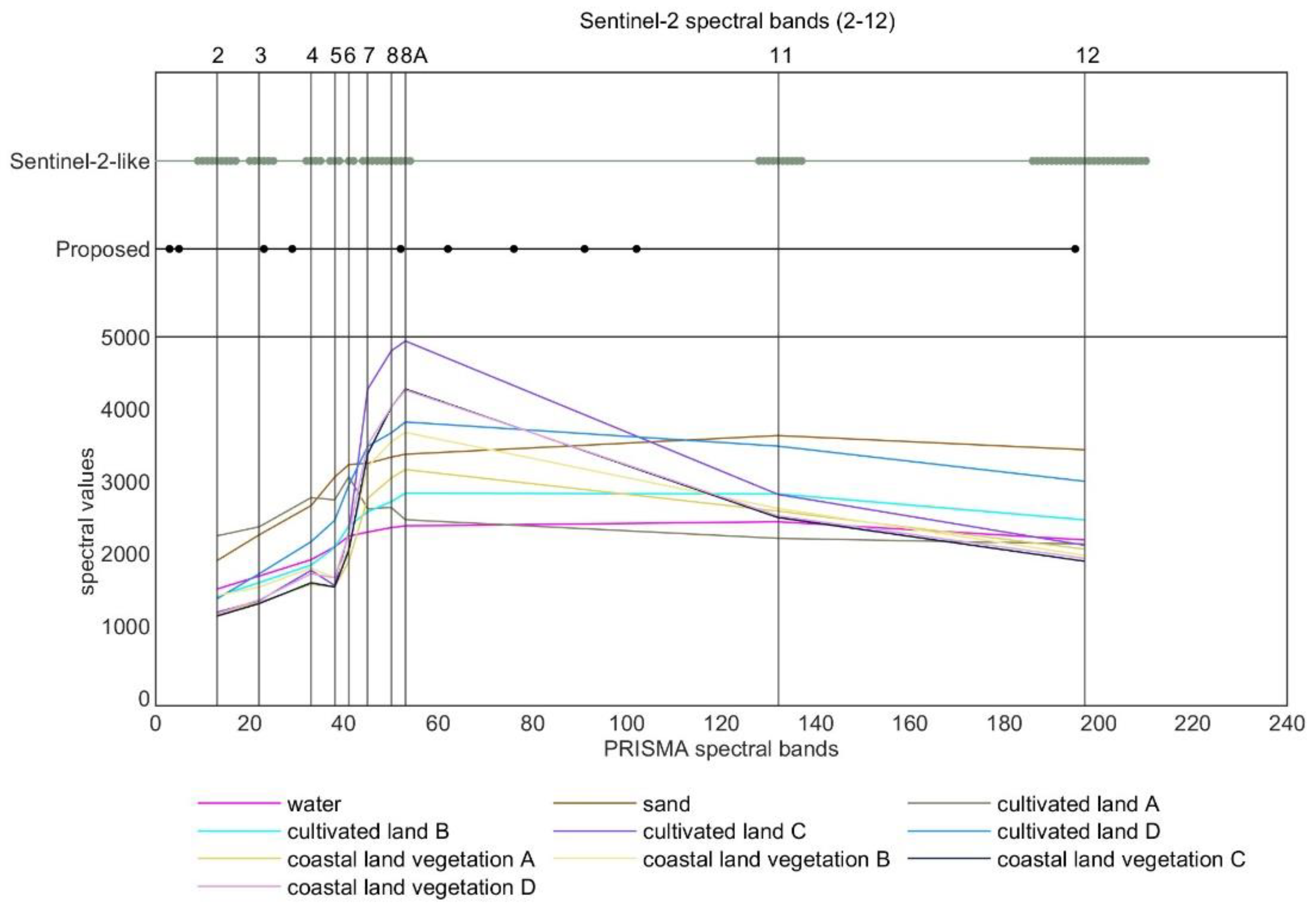
- Sentinel-2 MRS: the Sentinel-2 multispectral data of Chongming Island was acquired at 02:35 (UTC time) on 8 May 2022 (by satellite Sentinel-2A), which is just 10 min apart from PRISMA data which was acquired at 02:45 (UTC time) on the same day, therefore it was a rare opportunity to compare hyperspectral and multispectral data performance on classification applications. Sentinel-2 is a high-resolution multispectral imaging satellite. The resolution of Bands 2, 3, 4, and 8 is 10 m. The resolution of bands 5, 6, 7, 8a, 11, and 12 is 20 m. In order to compare with PRISMA data, the Sentinel-2 data was resampled to 30 m. The corresponding band’s spectral range is as Table 1.
4. Experimental Design
- (A)
- PCA [11]: the most popular dimensionality reduction technology, which is widely used in many fields.
- (B)
- mvPCA [12]: a ranking-based BS method that uses an eigen analysis-based criterion to prioritize spectral bands.
- (C)
- ICA [14]: a method that compares mean absolute independent component analysis coefficients of individual spectral bands and picks independent ones including the maximum information. The stated three methods are feature extraction methods.
- (D)
- WaLuDi [37]: a BS method based on hierarchical clustering, which uses Kullback-Leibler divergence as the standard for clustering.
- (E)
- DRL-Mou [45]: a DRL (DQN based) BS method based on value function, also uses information entropy and/or band correlation as the reward function.
- (F)
- RLSBS-A [26]: a DRL (A3C based) BS method was used for BS, based on the mixture of policy and value function, also uses the loss function of the deep neural network based on semi-supervised classification as the reward function.
5. Experimental Results
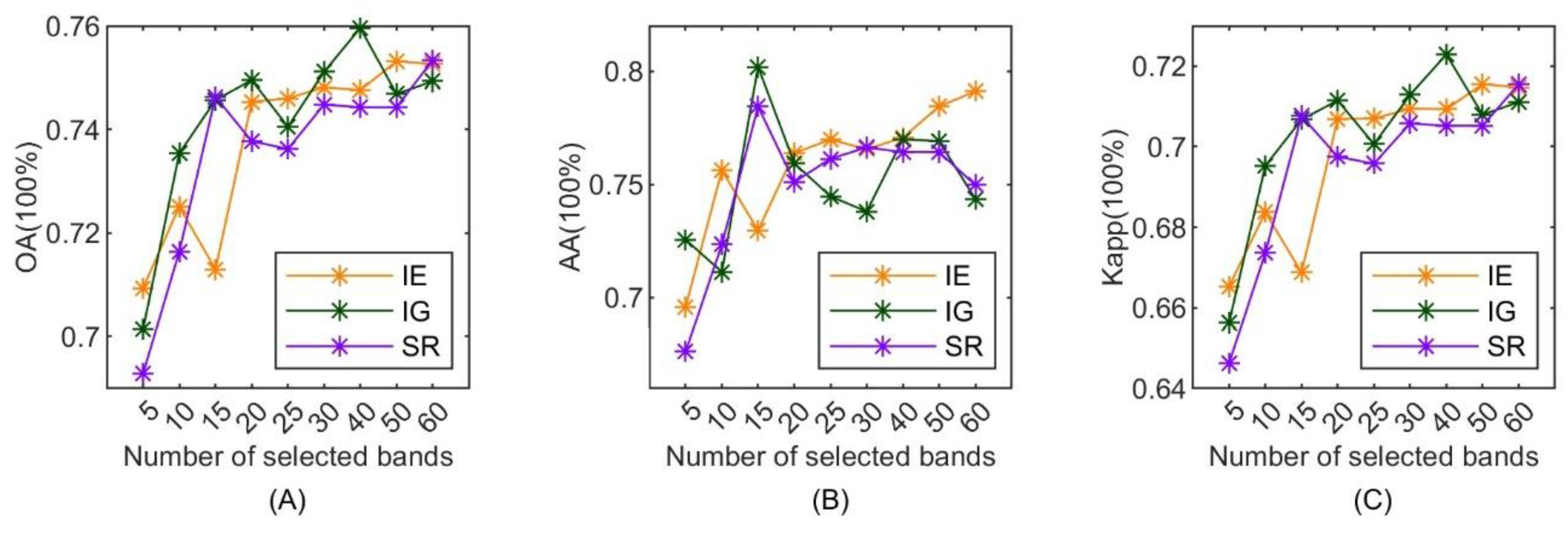
5.1. The Results of Reward Functions
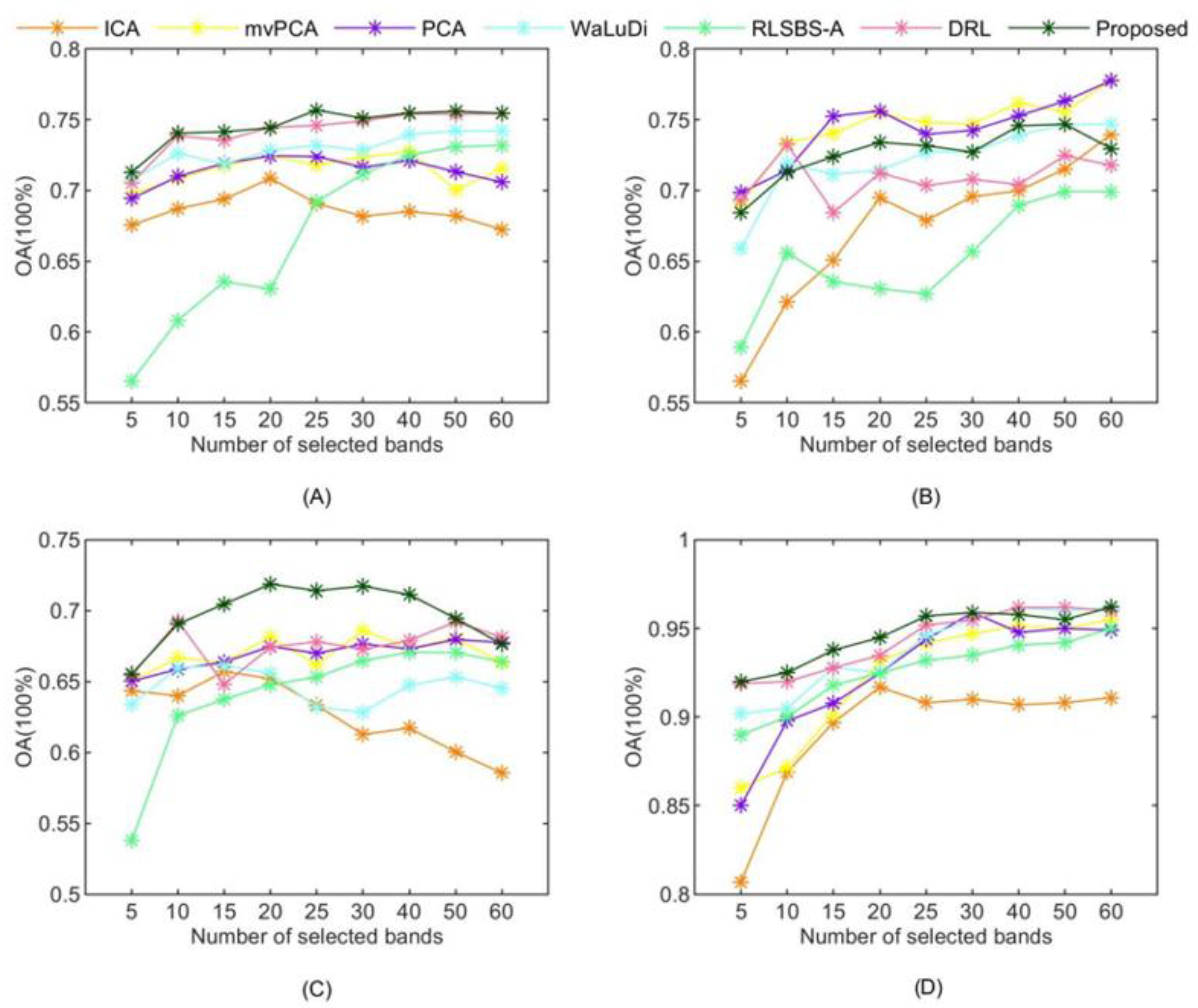
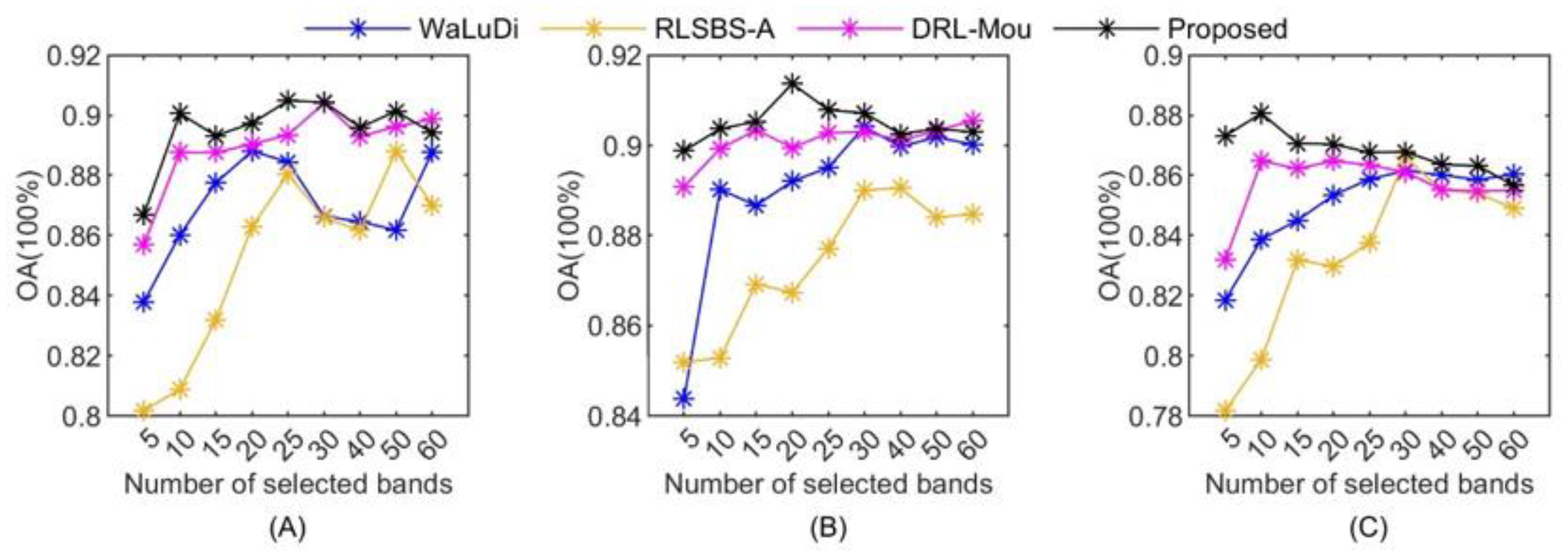
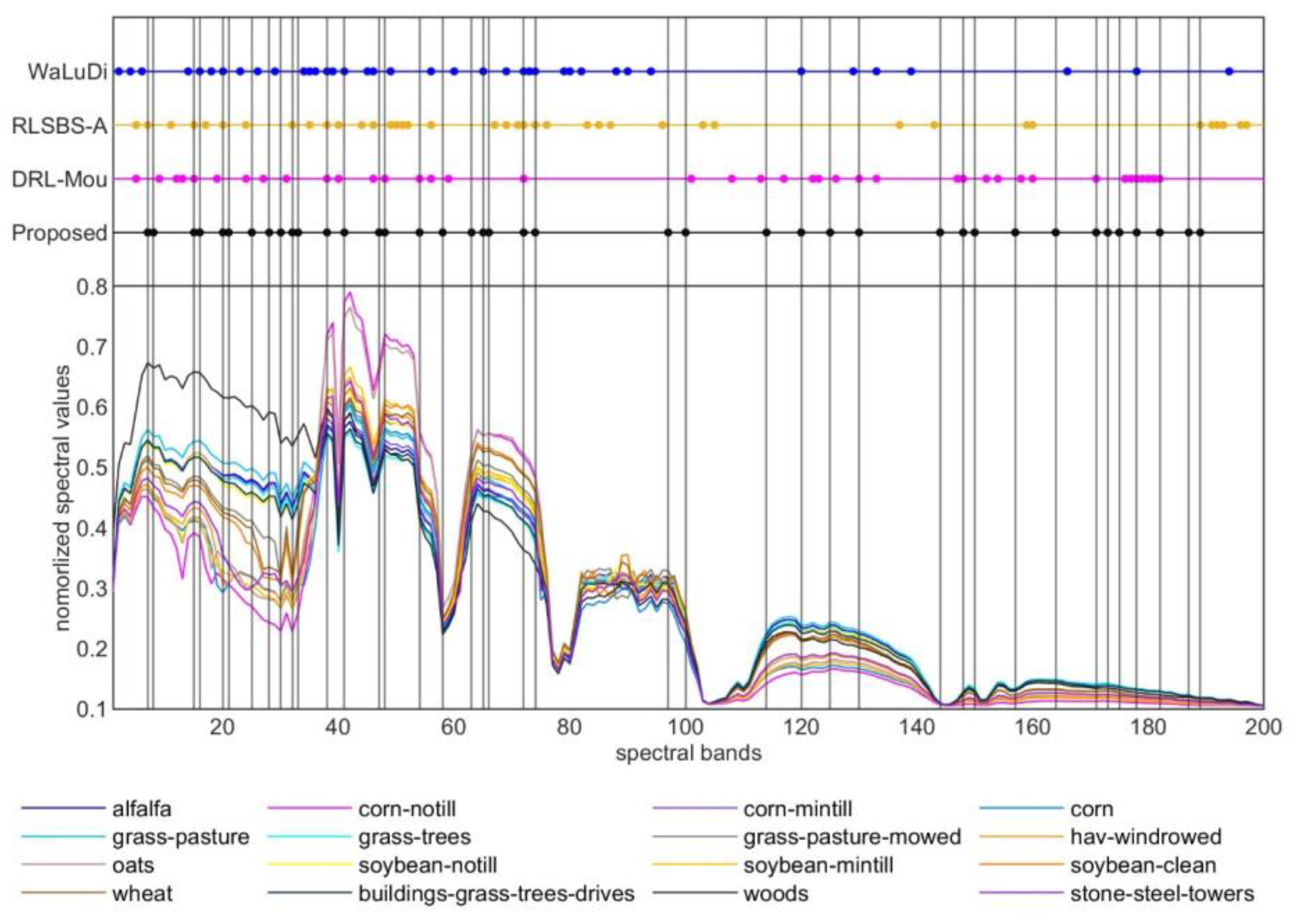
5.2. The Comparison of Different BS Methods
6. Discussions




7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yan, Y.; Liying, L.; Wang’e, X. Mechanical Structure Design for Hyperspectral Imager of HJ-1A Satellite. Spacecr. Eng. 2009, 18, 97–105. [Google Scholar]
- Zhan, H. The First Two Satellites OVS-1A/1B of Zhuhai-1 Remote-sensing Micro/Nano Satellites Constellation Launched Successfully. Space Int. 2017, 462, 1674–9030. [Google Scholar]
- Shanshan, M. Gaofen 5 and Gaofen 6 Satellites Put into Operation. Aerosp. China 2019, 20, 58. [Google Scholar]
- Kerr, G.; Avbelj, J.; Carmona, E.; Eckardt, A.; Gerasch, B.; Graham, L.; Günther, B.; Heiden, U.; Krutz, D.; Krawczyk, H.; et al. The hyperspectral sensor DESIS on MUSES: Processing and applications. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 268–271. [Google Scholar]
- Pignatti, S.; Palombo, A.; Pascucci, S.; Romano, F.; Santini, F.; Simoniello, T.; Umberto, A.; Vincenzo, C.; Acito, N.; Diani, M.; et al. The PRISMA hyperspectral mission: Science activities and opportunities for agriculture and land monitoring. In Proceedings of the 2013 IEEE International Geoscience and Remote Sensing Symposium-IGARSS, Melbourne, VIC, Australia, 21–26 July 2013; pp. 4558–4561. [Google Scholar]
- Guanter, L.; Kaufmann, H.; Segl, K.; Foerster, S.; Rogass, C.; Chabrillat, S.; Küster, T.; Hollstein, A.; Rossner, G.; Chlebek, C.; et al. The EnMAP Spaceborne Imaging Spectroscopy Mission for Earth Observation. Remote Sens. 2015, 7, 8830–8857. [Google Scholar] [CrossRef] [Green Version]
- Landgrebe, D. Hyperspectral image data analysis. IEEE Signal Process. Mag. 2002, 19, 17–28. [Google Scholar] [CrossRef]
- Chang, C.-I.; Wang, S. Constrained band selection for hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2006, 44, 1575–1585. [Google Scholar] [CrossRef]
- Jimenez-Rodriguez, L.O.; Arzuaga-Cruz, E.; Velez-Reyes, M. Unsupervised Linear Feature-Extraction Methods and Their Effects in the Classification of High-Dimensional Data. IEEE Trans. Geosci. Remote Sens. 2007, 45, 469–483. [Google Scholar] [CrossRef]
- Jimenez, L.O.; Landgrebe, D.A. Supervised classification in high-dimensional space: Geometrical, statistical, and asymptotical properties of multivariate data. IEEE Trans. Syst. Man Cybern. Part C 1998, 28, 39–54. [Google Scholar] [CrossRef]
- Elghazawi, T.; Kaewpijit, S.; Moigne, J.L. Parallel and Adaptive Reduction of Hyperspectral Data to Intrinsic Dimensionality. IEEE Int. Conf. Clust. Comput. 2001, 107, 215–224. [Google Scholar]
- Chang, C.I.; Qian, D.; Sun, T.L.; Althouse, M.L.G. A joint band prioritization and band-decorrelation approach to band selection for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 1999, 37, 2631–2641. [Google Scholar] [CrossRef] [Green Version]
- Bruce, L.M.; Koger, C.H. Dimensionality reduction of hyperspectral data using discrete wavelet transform feature extraction. IEEE Trans. Geosci. Remote Sens. 2002, 40, 2331–2338. [Google Scholar] [CrossRef]
- Lennon, M.; Mercier, G.; Mouchot, M.-C.; Hubert-Moy, L. Independent component analysis as a tool for the dimensionality reduction and the representation of hyperspectral images. In Proceedings of the IGARSS 2001. Scanning the Present and Resolving the Future. Proceedings. IEEE 2001 International Geoscience and Remote Sensing Symposium (Cat. No.01CH37217), Sydney, NSW, Australia, 9–13 July 2001; Volume 6, pp. 2893–2895. [Google Scholar] [CrossRef] [Green Version]
- Maji, B.; Swain, M. Advanced Fusion-Based Speech Emotion Recognition System Using a Dual-Attention Mechanism with Conv-Caps and Bi-GRU Features. Electronics 2022, 22, 1328. [Google Scholar] [CrossRef]
- Bruzzone, L. An extension of the Jeffreys-Matusita distance to multiclass cases for feature selection. IEEE Trans. Geosci. Remote Sens. 1995, 33, 1318–1321. [Google Scholar] [CrossRef]
- Serpico, S.B.; Bruzzone, L. A new search algorithm for feature selection in hyperspectral remote sensing images. IEEE Trans. Geosci. Remote Sens. 2001, 39, 1360–1367. [Google Scholar] [CrossRef]
- Yang, H.; Du, Q.; Su, H.; Sheng, Y. An Efficient Method for Supervised Hyperspectral Band Selection. IEEE Geosci. Remote Sens. Lett. 2011, 8, 138–142. [Google Scholar] [CrossRef]
- Cao, X.; Tao, X.; Jiao, L. Supervised Band Selection Using Local Spatial Information for Hyperspectral Image. IEEE Geosci. Remote Sens. Lett. 2016, 13, 329–333. [Google Scholar] [CrossRef]
- Tang, Y.; Fan, E.; Yan, C.; Bai, X.; Zhou, J. Discriminative weighted band selection via one-class SVM for hyperspectral imagery. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 2765–2768. [Google Scholar] [CrossRef] [Green Version]
- Feng, S.; Itoh, Y.; Parente, M.; Duarte, M.F. Hyperspectral Band Selection From Statistical Wavelet Models. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2111–2123. [Google Scholar] [CrossRef]
- Li, H.; Wang, Y.; Duan, J.; Xiang, S.; Pan, C. Group sparsity based semi-supervised band selection for hyperspectral images. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, VIC, Australia, 15–18 September 2013; pp. 3225–3229. [Google Scholar]
- Feng, J.; Jiao, L.; Liu, F.; Sun, T.; Zhang, X. Mutual-Information-Based Semi-Supervised Hyperspectral Band Selection with High Discrimination, High Information, and Low Redundancy. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2956–2969. [Google Scholar] [CrossRef]
- Guo, Z.; Xiao, B.; Zhang, Z.; Zhou, J. A hypergraph based semi-supervised band selection method for hyperspectral image classification. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, VIC, Australia, 15–18 September 2013. [Google Scholar]
- Su, H.; Yong, B.; Qian, D. Hyperspectral Band Selection Using Improved Firefly Algorithm. IEEE Geosci. Remote Sens. Lett. 2015, 13, 68–72. [Google Scholar] [CrossRef]
- Feng, J.; Li, D.; Gu, J.; Cao, X.; Jiao, L. Deep Reinforcement Learning for Semisupervised Hyperspectral Band Selection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–19. [Google Scholar] [CrossRef]
- Sui, C.; Yan, T.; Xu, Y.; Yong, X. Unsupervised Band Selection by Integrating the Overall Accuracy and Redundancy. IEEE Geosci. Remote Sens. Lett. 2015, 12, 185–189. [Google Scholar]
- Zhang, M.; Ma, J.; Gong, M. Unsupervised Hyperspectral Band Selection by Fuzzy Clustering with Particle Swarm Optimization. IEEE Geosci. Remote Sens. Lett. 2017, 14, 773–777. [Google Scholar] [CrossRef]
- Chang, C. Hyperspectral Data Exploitation: Theory and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2007. [Google Scholar]
- Guo, B.; Gunn, S.R.; Damper, R.I.; Nelson, J. Band Selection for Hyperspectral Image Classification Using Mutual Information. IEEE Geosci. Remote Sens. Lett. 2006, 3, 522–526. [Google Scholar] [CrossRef]
- Jia, S.; Tang, G.; Zhu, J.; Li, Q. A Novel Ranking-Based Clustering Approach for Hyperspectral Band Selection. IEEE Trans. Geosci. Remote Sens. 2016, 54, 88–102. [Google Scholar] [CrossRef]
- Wang, Q.; Zhang, F.; Li, X. Optimal Clustering Framework for Hyperspectral Band Selection. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5910–5922. [Google Scholar] [CrossRef] [Green Version]
- Qian, Y.; Yao, F.; Jia, S. Band selection for hyperspectral imagery using affinity propagation. IET Comput. Vis. 2008, 3, 213–222. [Google Scholar] [CrossRef]
- Sun, K.; Geng, X.; Ji, L. Exemplar Component Analysis: A Fast Band Selection Method for Hyperspectral Imagery. IEEE Geosci. Remote Sens. Lett. 2015, 12, 998–1002. [Google Scholar]
- Ahmad, M.; Haq, I.U.; Mushtaq, Q.; Sohaib, M. A New Statistical Approach for Band Clustering and Band Selection Using K-Means Clustering. Int. J. Eng. Technol. 2011, 3, 606–614. [Google Scholar]
- Ding, Y.; Yuan, X.; Di, Z.; Dong, L.; An, Z. Feature representation and selection in malicious code detection methods based on static system calls. Comput. Secur. 2011, 30, 514–524. [Google Scholar]
- Martinez-Uso, A.; Pla, F.; Sotoca, J.M.; García-Sevilla, P. Clustering-Based Hyperspectral Band Selection Using Information Measures. IEEE Trans. Geosci. Remote Sens. 2007, 45, 4158–4171. [Google Scholar] [CrossRef]
- Duan, P.; Kang, X.; Li, S.; Ghamisi, P. Multichannel Pulse-Coupled Neural Network-Based Hyperspectral Image Visualization. IEEE Trans. Geosci. Remote Sens. 2019, 58, 2444–2456. [Google Scholar] [CrossRef]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep Learning for Hyperspectral Image Classification: An Overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Li, Q.; Li, X. Hyperspectral Band Selection via Adaptive Subspace Partition Strategy. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 4940–4950. [Google Scholar] [CrossRef]
- Roy, S.K.; Chatterjee, S.; Bhattacharyya, S.; Chaudhuri, B.B.; Platos, J. Lightweight Spectral-Spatial Squeeze-and-Excitation Residual Bag-of-Features Learning for Hyperspectral Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5277–5290. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 7132–7141. [Google Scholar] [CrossRef] [Green Version]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar]
- Cai, Y.; Liu, X. BS-Nets: An End-to-End Framework for Band Selection of Hyperspectral Image. IEEE Trans. Geosci. Remote Sens. 2020, 58, 1969–1984. [Google Scholar] [CrossRef]
- Mou, L.; Saha, S.; Hua, Y.; Bovolo, F.; Bruzzone, L.; Zhu, X.X. Deep Reinforcement Learning for Band Selection in Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep reinforcement learning: A brief survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2012, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M.A. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Van Hasselt, H. Double Q-learning. In Advances in Neural Information Processing Systems 23 (NIPS 2010), Proceedings of the 24th Annual Conference on Neural Information Processing Systems 2010, Vancouver, BC, Canada, 6–9 December 2010; Curran Associates, Inc.: Red Hook, NY, USA, 2010; pp. 2613–2621. [Google Scholar]
- Hasselt, H.V.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-learning. arXiv 2015, arXiv:1509.06461. [Google Scholar] [CrossRef]
- Hellman, M.E. The Nearest Neighbor Classification Rule with a Reject Option. IEEE Trans. Syst. Sci. Cybern. 1970, 6, 179–185. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Hearst, M.A.; Dumais, S.T.; Osman, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef] [Green Version]
- Swami, A.; Jain, R. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2013, 12, 2825–2830. [Google Scholar]
- Jia, J.; Chen, J.; Zheng, X.; Wang, Y.; Guo, S.; Sun, H.; Jiang, C.; Karjalainen, M.; Karila, K.; Duan, Z.; et al. Tradeoffs in the Spatial and Spectral Resolution of Airborne Hyperspectral Imaging Systems: A Crop Identification Case Study. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sentinel-2 Band | Center Wavelength | Bandwidth | PRISMA Bands |
|---|---|---|---|
| 1-Coastal aerosol | 442.3 | 21 | 5–8 |
| 2-Blue | 492.1 | 66 | 9–17 |
| 3-Green | 559 | 36 | 20–25 |
| 4-Red | 665 | 31 | 32–35 |
| 5-Vegetation red edge | 703.8 | 16 | 37–39 |
| 6-Vegetation red edge | 739.1 | 15 | 41–42 |
| 7-Vegetation red edge | 779.7 | 20 | 44–46 |
| 8-NIR | 833 | 106 | 47–52 |
| 8A-Narrow NIR | 864 | 22 | 53–54 |
| 9-Water vapour | 943 | 21 | 60–61 |
| 10-SWIR-Cirrus | 1376.9 | 30 | 109–112 |
| 11-SWIR | 1610.4 | 94 | 128–137 |
| 12-SWIR | 2185.7 | 185 | 186–209 |
| Types | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | SN |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 888 | 19 | 7 | 2 | 6 | 0 | 82 | 255 | 26 | 0 | 0 | 4 | 1 | 0 | 0 | 0 | 1290 |
| 2 | 115 | 369 | 16 | 0 | 2 | 0 | 8 | 187 | 53 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 750 |
| 3 | 62 | 14 | 58 | 3 | 5 | 0 | 4 | 30 | 32 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 210 |
| 4 | 0 | 2 | 1 | 366 | 12 | 10 | 5 | 2 | 2 | 0 | 36 | 6 | 0 | 1 | 4 | 0 | 447 |
| 5 | 0 | 0 | 0 | 9 | 651 | 0 | 1 | 0 | 1 | 0 | 2 | 8 | 0 | 0 | 0 | 0 | 672 |
| 6 | 0 | 0 | 0 | 5 | 1 | 432 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 440 |
| 7 | 43 | 6 | 0 | 2 | 3 | 1 | 540 | 241 | 30 | 0 | 0 | 0 | 0 | 0 | 4 | 1 | 871 |
| 8 | 106 | 30 | 0 | 8 | 15 | 3 | 87 | 1921 | 43 | 0 | 0 | 6 | 0 | 0 | 1 | 1 | 2221 |
| 9 | 90 | 31 | 15 | 1 | 2 | 1 | 26 | 94 | 287 | 0 | 0 | 0 | 4 | 0 | 1 | 0 | 552 |
| 10 | 0 | 0 | 0 | 0 | 5 | 0 | 1 | 0 | 0 | 164 | 0 | 20 | 0 | 0 | 0 | 0 | 190 |
| 11 | 0 | 0 | 0 | 20 | 7 | 0 | 0 | 0 | 0 | 1 | 1104 | 32 | 0 | 0 | 0 | 0 | 1164 |
| 12 | 0 | 0 | 0 | 11 | 87 | 0 | 0 | 0 | 0 | 15 | 96 | 131 | 1 | 0 | 0 | 1 | 342 |
| 13 | 0 | 1 | 0 | 0 | 0 | 0 | 2 | 10 | 2 | 0 | 0 | 1 | 69 | 0 | 0 | 0 | 85 |
| 14 | 0 | 0 | 0 | 5 | 0 | 28 | 1 | 4 | 0 | 0 | 0 | 0 | 0 | 10 | 0 | 0 | 48 |
| 15 | 0 | 0 | 0 | 2 | 0 | 12 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 9 | 0 | 23 |
| 16 | 0 | 0 | 0 | 0 | 12 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 4 | 18 |
| RN | 1304 | 472 | 97 | 434 | 808 | 487 | 757 | 2744 | 476 | 180 | 1238 | 212 | 75 | 12 | 20 | 7 | 9323 |
| TP | 888 | 369 | 58 | 366 | 651 | 432 | 540 | 1921 | 287 | 164 | 1104 | 131 | 69 | 10 | 9 | 4 | 7003 |
| accuracy | 0.68 | 0.78 | 0.60 | 0.84 | 0.81 | 0.89 | 0.71 | 0.70 | 0.60 | 0.91 | 0.89 | 0.62 | 0.92 | 0.83 | 0.45 | 0.57 | 0.75(OA) |
| Type | IE | IG | SR |
|---|---|---|---|
| 1 | 0.67 | 0.68 | 0.67 |
| 2 | 0.77 | 0.78 | 0.76 |
| 3 | 0.61 | 0.60 | 0.62 |
| 4 | 0.86 | 0.84 | 0.86 |
| 5 | 0.81 | 0.81 | 0.79 |
| 6 | 0.87 | 0.89 | 0.88 |
| 7 | 0.70 | 0.71 | 0.71 |
| 8 | 0.70 | 0.70 | 0.70 |
| 9 | 0.58 | 0.60 | 0.57 |
| 10 | 0.90 | 0.91 | 0.89 |
| 11 | 0.90 | 0.89 | 0.89 |
| 12 | 0.62 | 0.62 | 0.55 |
| 13 | 0.92 | 0.92 | 0.96 |
| 14 | 0.88 | 0.83 | 0.75 |
| 15 | 0.80 | 0.45 | 1.00 |
| 16 | 0.67 | 0.57 | 0.67 |
| AA | 0.77 | 0.74 | 0.77 |
| Classifiers | KNN | RF | SVM-RBF | CNN | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BS | OA | AA | Kappa | OA | AA | Kappa | OA | AA | Kappa | OA | AA | Kappa | |
| PCA | 0.6731 | 0.6536 | 0.6272 | 0.7212 | 0.7430 | 0.6764 | 0.7527 | 0.7393 | 0.7172 | 0.9478 | 0.9178 | 0.9328 | |
| mvPCA | 0.6734 | 0.6409 | 0.6283 | 0.7275 | 0.7142 | 0.6841 | 0.7616 | 0.7525 | 0.7270 | 0.9517 | 0.9027 | 0.9422 | |
| ICA | 0.6171 | 0.5839 | 0.5622 | 0.6851 | 0.7019 | 0.6334 | 0.6997 | 0.6986 | 0.6543 | 0.9069 | 0.8421 | 0.9226 | |
| WaLuDi | 0.6474 | 0.6102 | 0.5980 | 0.7396 | 0.7760 | 0.6995 | 0.7390 | 0.7371 | 0.7118 | 0.9619 | 0.9323 | 0.9565 | |
| RLSBS-A | 0.6707 | 0.6537 | 0.6250 | 0.7249 | 0.7839 | 0.6820 | 0.6896 | 0.6849 | 0.6391 | 0.9406 | 0.8621 | 0.9322 | |
| DRL-Mou | 0.6790 | 0.6688 | 0.6338 | 0.7542 | 0.7657 | 0.7167 | 0.7042 | 0.6388 | 0.6565 | 0.9617 | 0.9154 | 0.9563 | |
| Proposed | 0.7114 | 0.6828 | 0.6704 | 0.7547 | 0.7733 | 0.7176 | 0.7457 | 0.7428 | 0.7041 | 0.9578 | 0.9138 | 0.9518 | |
| Classifiers | KNN | RF | SVM-RBF | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| BS | OA | AA | Kappa | OA | AA | Kappa | OA | AA | Kappa | |
| PCA | 0.9842 | 0.9685 | 0.9794 | 0.9845 | 0.9746 | 0.9797 | 0.9857 | 0.9751 | 0.9813 | |
| mvPCA | 0.9815 | 0.9242 | 0.9693 | 0.9820 | 0.9650 | 0.9355 | 0.9832 | 0.9660 | 0.9799 | |
| WaLuDi | 0.9722 | 0.9628 | 0.9767 | 0.9772 | 0.9567 | 0.9701 | 0.9730 | 0.9650 | 0.9778 | |
| RLSBS-A | 0.9843 | 0.9647 | 0.9795 | 0.9835 | 0.9656 | 0.9785 | 0.9831 | 0.9662 | 0.9778 | |
| DRL-Mou | 0.9838 | 0.9506 | 0.9788 | 0.9833 | 0.9634 | 0.9781 | 0.9835 | 0.9725 | 0.9785 | |
| Proposed | 0.9850 | 0.9804 | 0.9655 | 0.9837 | 0.9563 | 0.9787 | 0.9857 | 0.9763 | 0.9812 | |
| Classifiers | KNN | RF | SVM-RBF | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| BS | OA | AA | Kappa | OA | AA | Kappa | OA | AA | Kappa | |
| PCA | 0.8518 | 0.8573 | 0.8346 | 0.9072 | 0.9155 | 0.8963 | 0.7325 | 0.7790 | 0.7172 | |
| mvPCA | 0.8581 | 0.8630 | 0.8417 | 0.9151 | 0.9227 | 0.9052 | 0.6348 | 0.6926 | 0.6259 | |
| WaLuDi | 0.8436 | 0.8526 | 0.8255 | 0.8646 | 0.8526 | 0.8488 | 0.8997 | 0.9053 | 0.8880 | |
| RlSBS-A | 0.8274 | 0.8328 | 0.8074 | 0.8804 | 0.9013 | 0.8849 | 0.8869 | 0.8889 | 0.8738 | |
| DRL-Mou | 0.8611 | 0.8646 | 0.8450 | 0.9049 | 0.9105 | 0.8953 | 0.9030 | 0.9102 | 0.8917 | |
| Proposed | 0.8678 | 0.8715 | 0.8526 | 0.9044 | 0.9094 | 0.8932 | 0.9072 | 0.9140 | 0.8964 | |
| PRISMA Band | 3 | 5 | 23 | 29 | 52 | 62 | 76 | 91 | 102 | 195 |
|---|---|---|---|---|---|---|---|---|---|---|
| Center Wavelength (nm) | 419 | 434 | 571 | 623 | 855 | 962 | 1008 | 1163 | 1284 | 2175 |
| Sentinel-2 band | 3 | 8 | 12 |
| OA | AA | Kappa | |
|---|---|---|---|
| Sentinel-2 (10 bands) | 0.8755 | 0.8787 | 0.8610 |
| PRISMA (10 selected bands) | 0.9037 | 0.9108 | 0.8925 |
| Sentinel-2-like (10 simulated bands) | 0.9702 | 0.9700 | 0.9668 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, H.; Chen, M.; Wu, G.; Wang, J.; Wang, Y.; Hong, Z. Double Deep Q-Network for Hyperspectral Image Band Selection in Land Cover Classification Applications. Remote Sens. 2023, 15, 682. https://doi.org/10.3390/rs15030682
Yang H, Chen M, Wu G, Wang J, Wang Y, Hong Z. Double Deep Q-Network for Hyperspectral Image Band Selection in Land Cover Classification Applications. Remote Sensing. 2023; 15(3):682. https://doi.org/10.3390/rs15030682
Chicago/Turabian StyleYang, Hua, Ming Chen, Guowen Wu, Jiali Wang, Yingxi Wang, and Zhonghua Hong. 2023. "Double Deep Q-Network for Hyperspectral Image Band Selection in Land Cover Classification Applications" Remote Sensing 15, no. 3: 682. https://doi.org/10.3390/rs15030682
APA StyleYang, H., Chen, M., Wu, G., Wang, J., Wang, Y., & Hong, Z. (2023). Double Deep Q-Network for Hyperspectral Image Band Selection in Land Cover Classification Applications. Remote Sensing, 15(3), 682. https://doi.org/10.3390/rs15030682