


SMNet: Symmetric Multi-Task Network for Semantic Change Detection in Remote Sensing Images Based on CNN and Transformer

Abstract
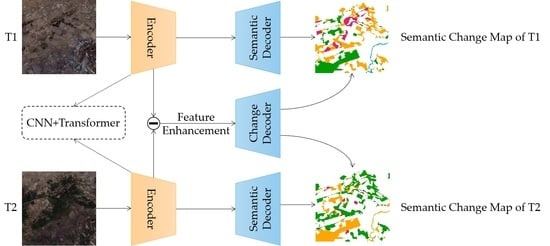
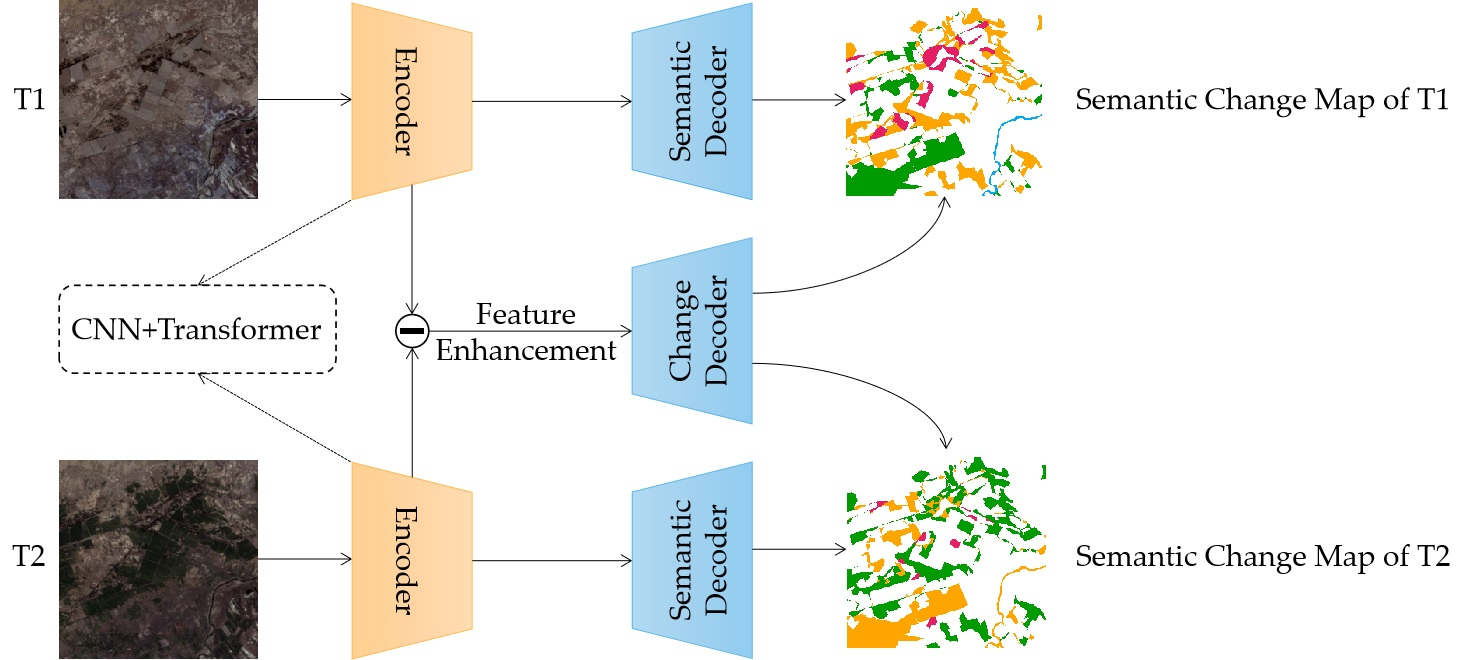
:
1. Introduction
2. Related Work
2.1. Binary Change Detection
2.2. Semantic Change Detection
3. Methodology
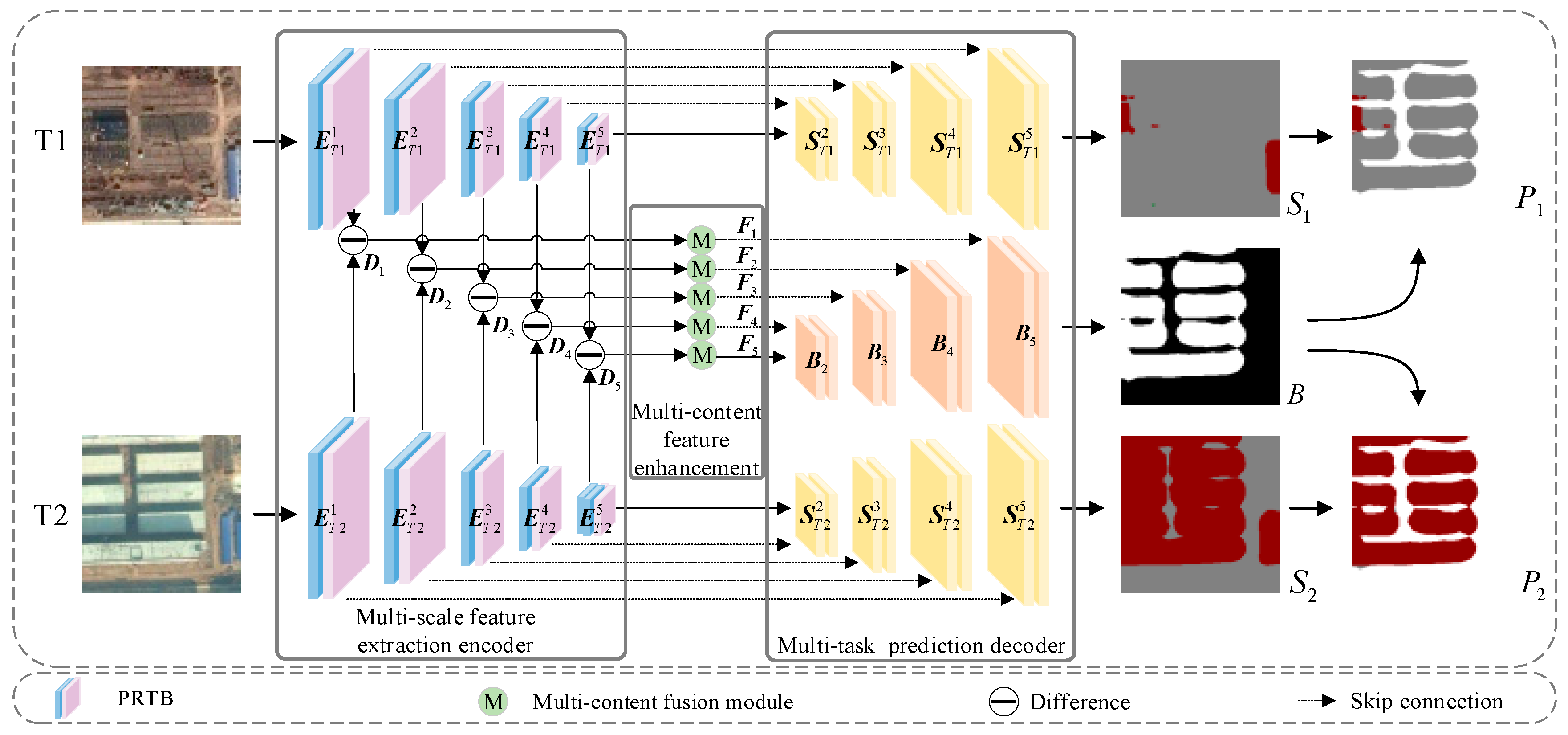
3.1. Overview
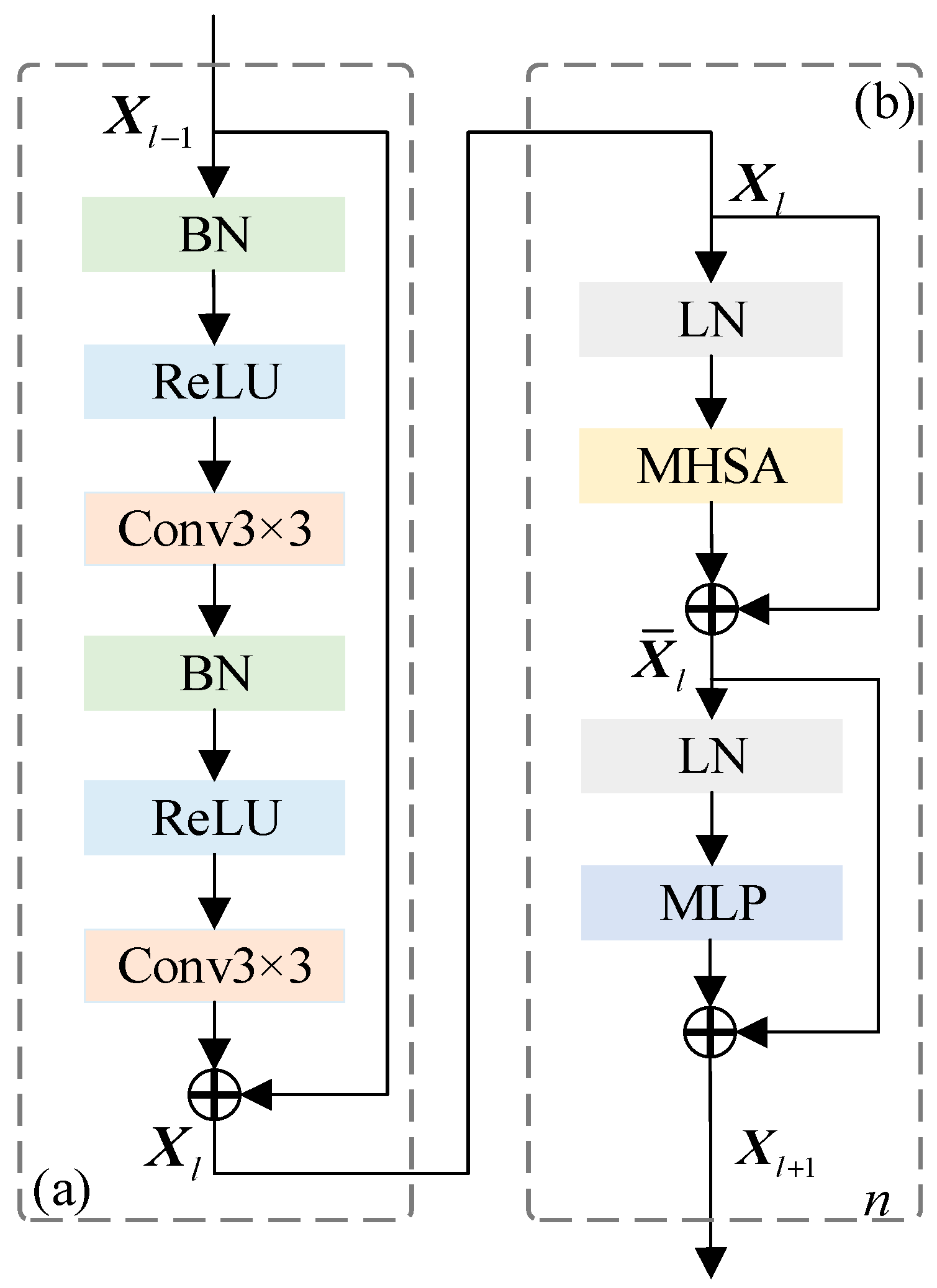
3.2. Multi-Scale Feature Extraction Encoder
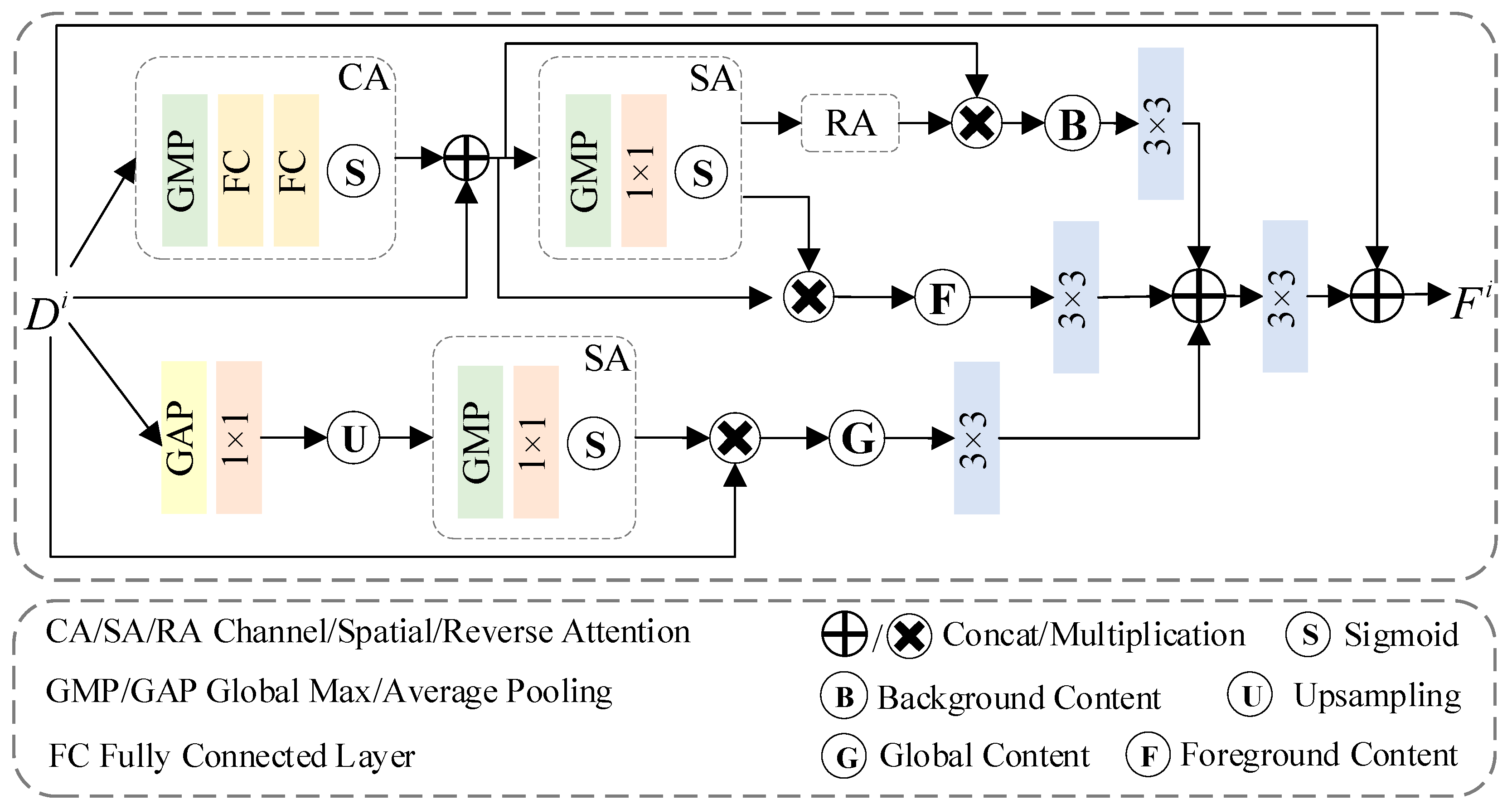
3.3. Multi-Content Fusion Enhancement
3.3.1. Foreground and Background Branches
3.3.2. Global Branch
3.3.3. Feature Fusion
3.4. Multi-Task Prediction Decoder
4. Experimental Data and Evaluation Indices
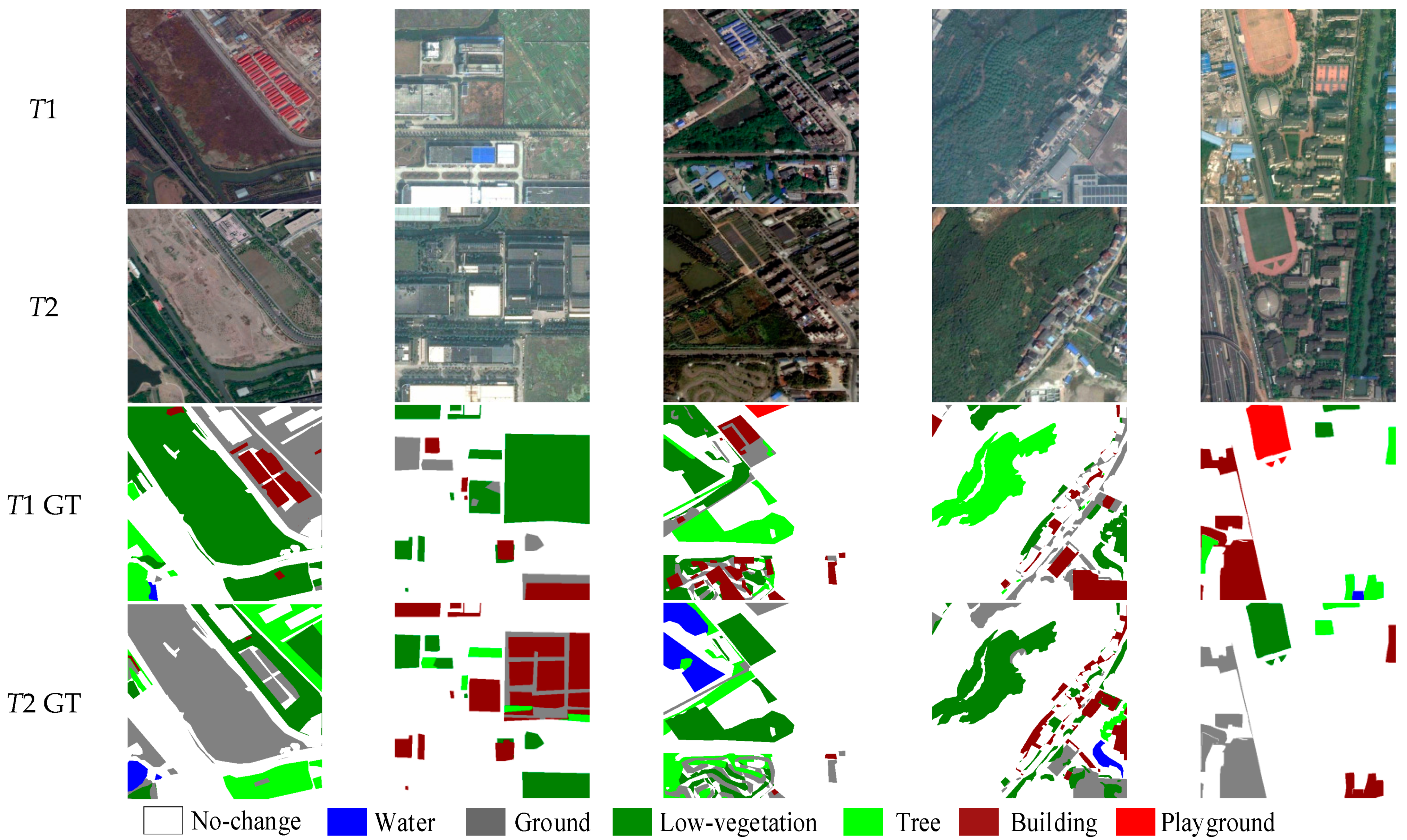
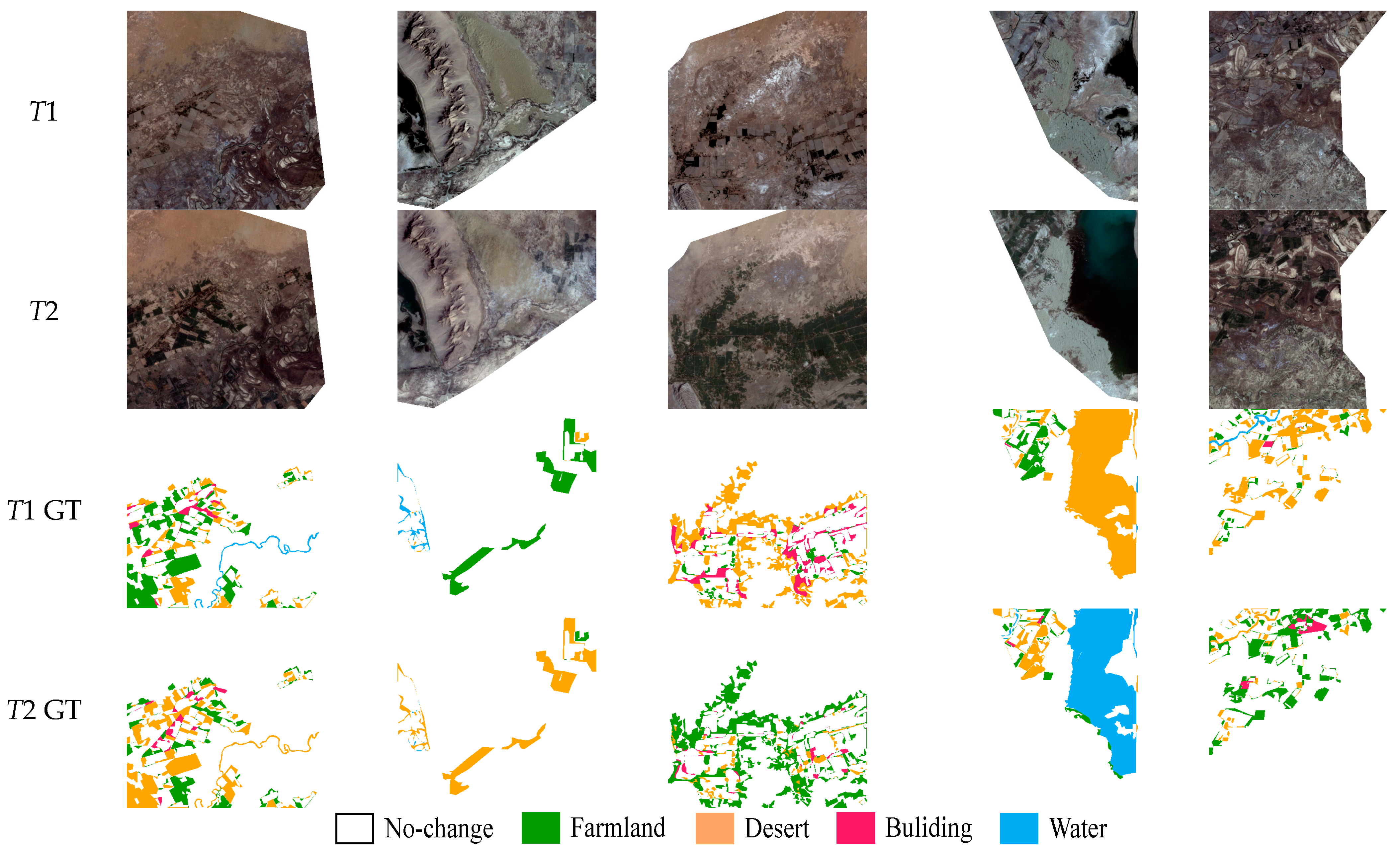
4.1. Datasets
4.2. Evaluation Metrics
4.3. Training Details
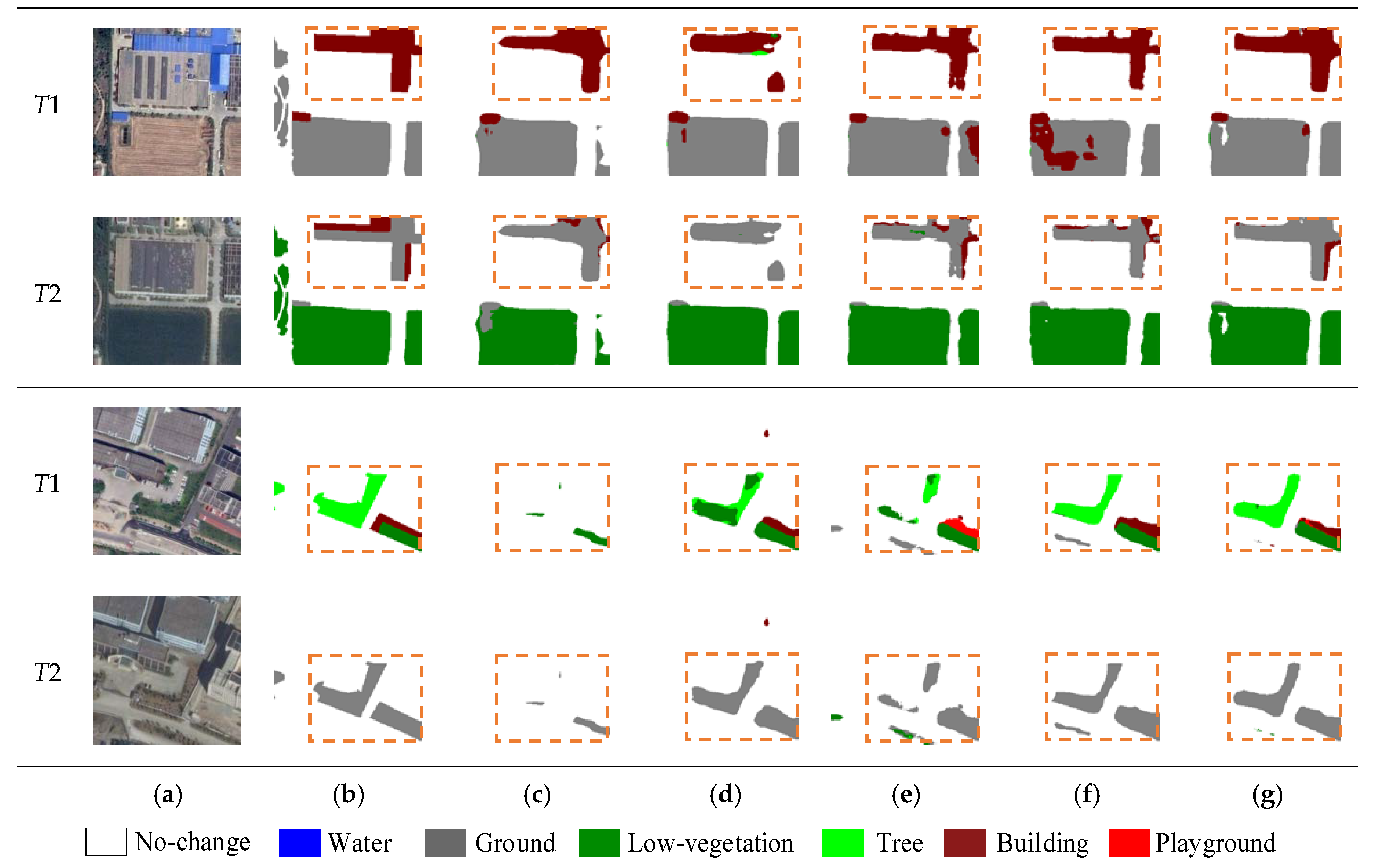
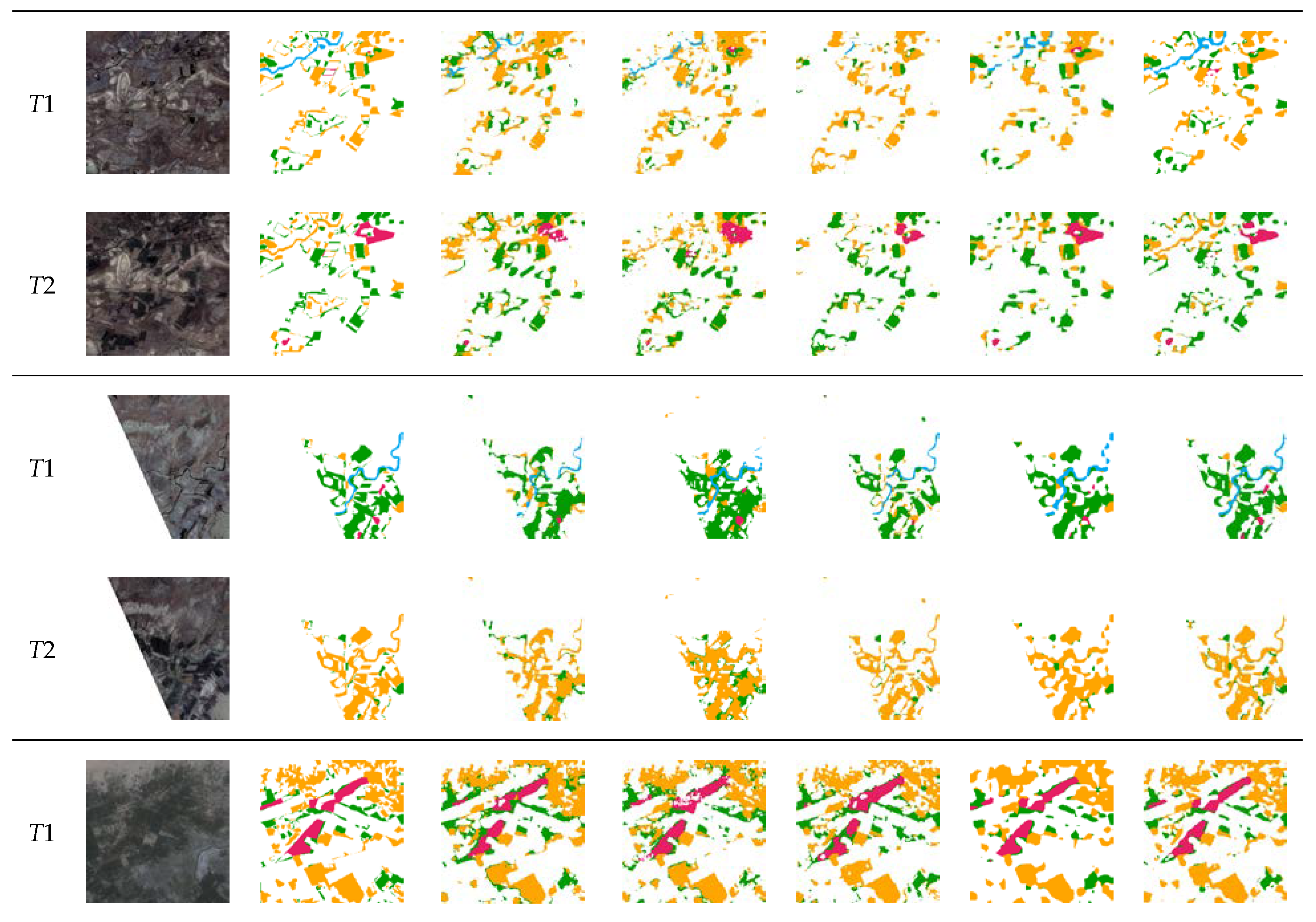
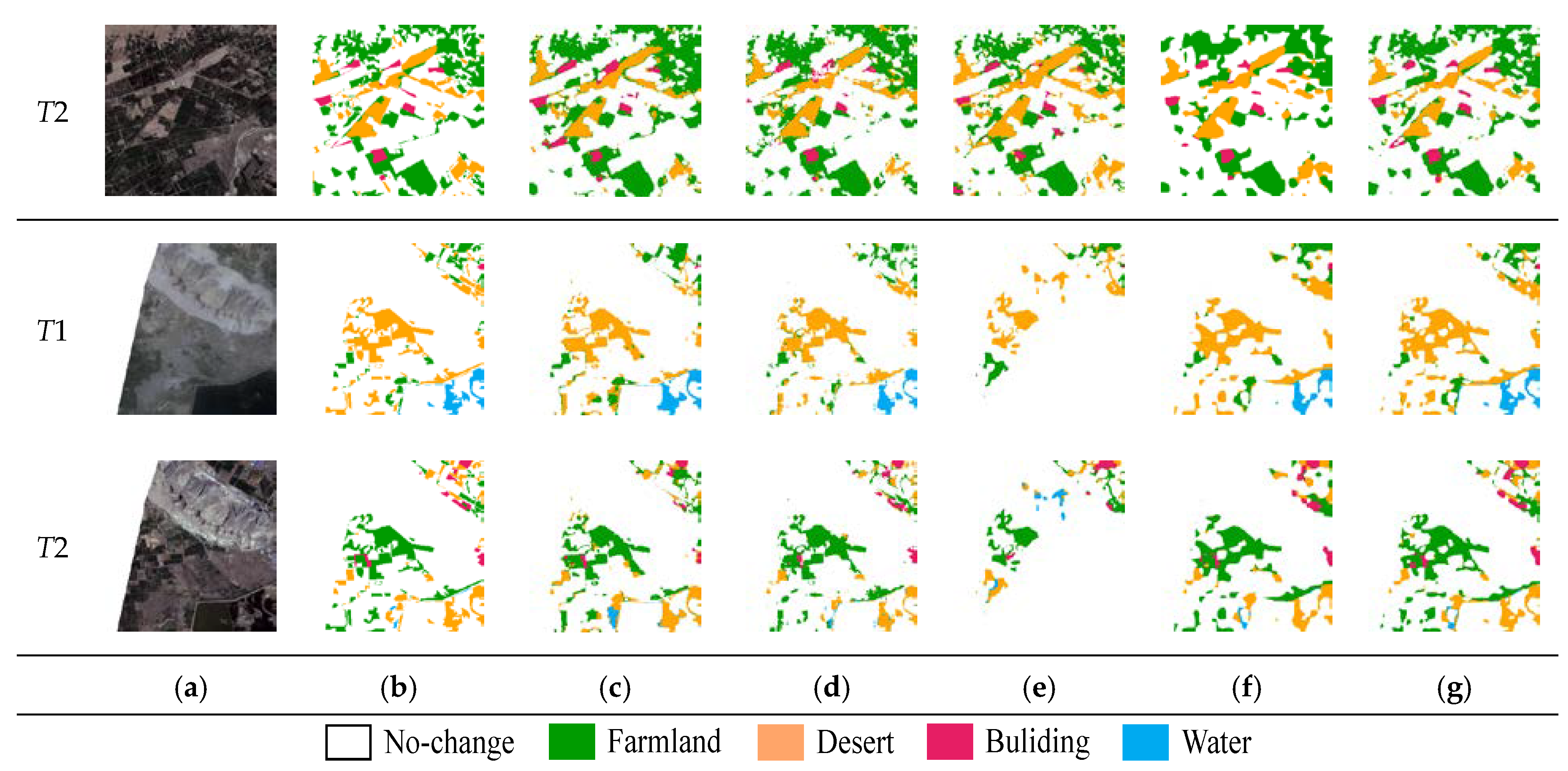
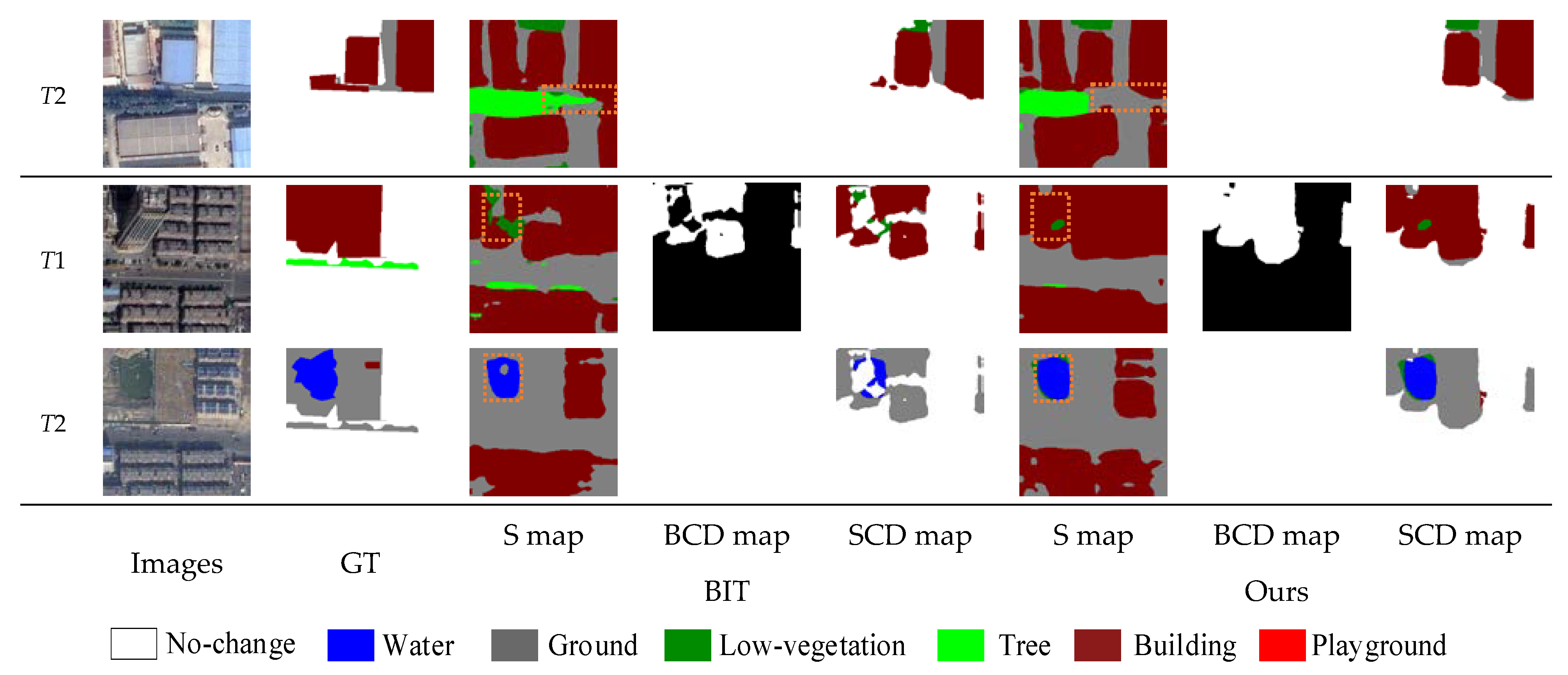
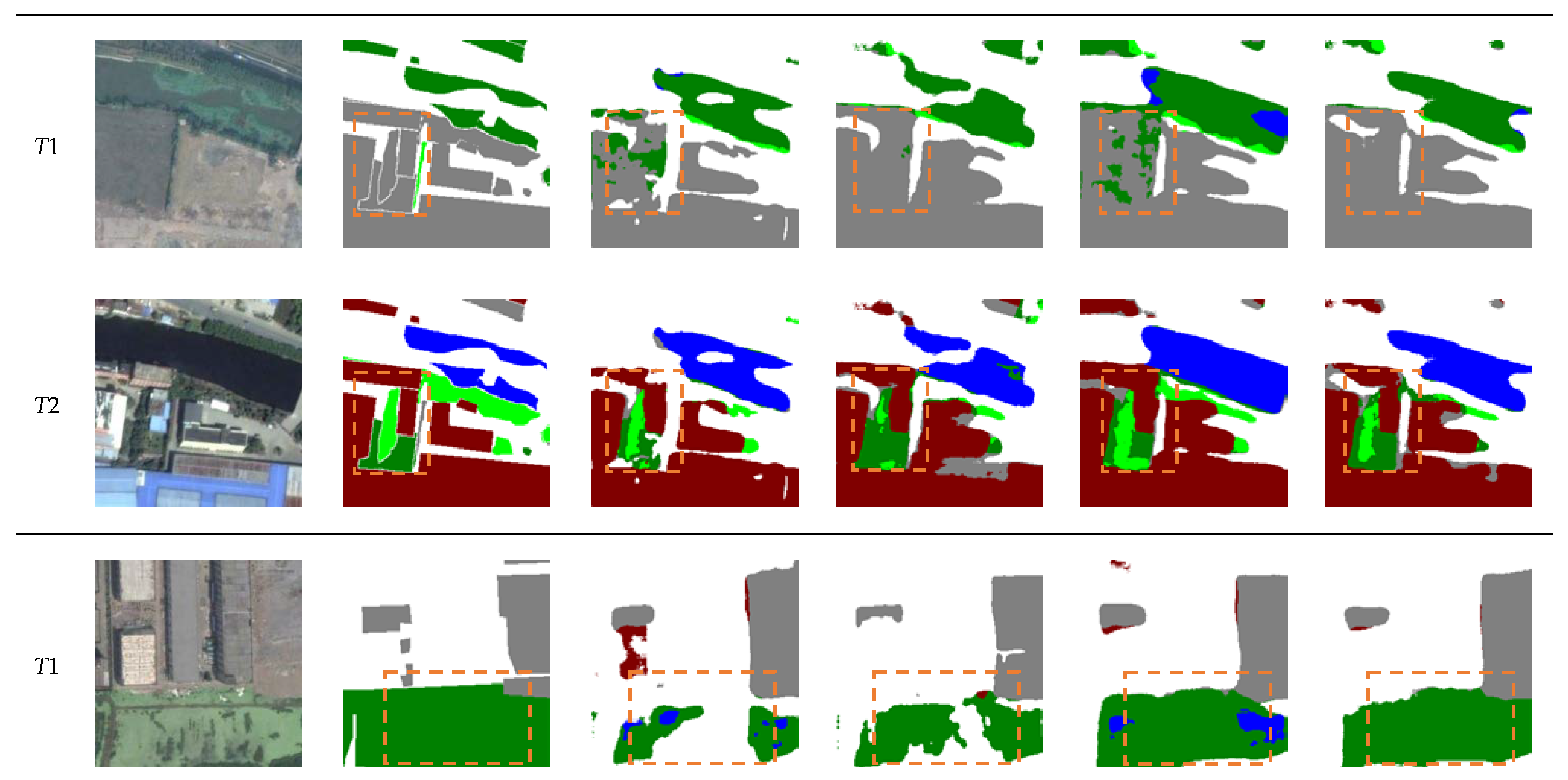
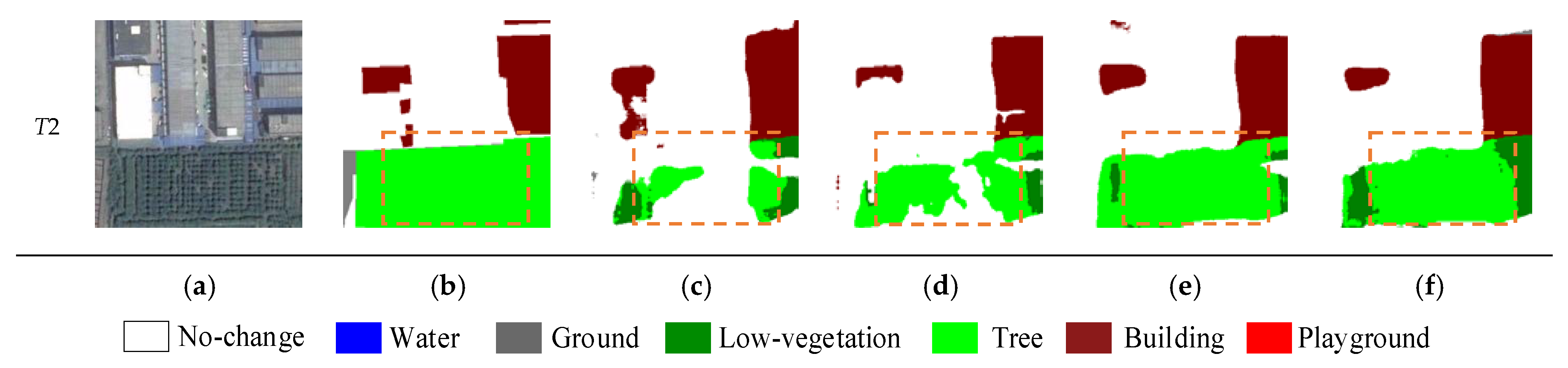
5. Results
5.1. Comparison Experiments
- FC-Siam-conc [12]: A fully convolutional Siamese network that fuses bi-temporal features through skip-connections for CD.
- FC-Siam-diff [12]: A fully convolutional Siamese network that utilizes multi-layer difference features to fuse bi-temporal information.
- DSIFN [40]: A deeply supervised differential network that generates change maps using multi-scale feature fusion.
- HRSCD-str3 [35]: A network that introduces temporal correlation information by constructing a BCD branch.
- HRSCD-str4 [35]: A Siamese network that designs a skip operation to connect Siamese encoders with the decoder of the CD branch.
- BiSRNet [41]: A bi-temporal semantic reasoning (SR) network that applies Siamese and cross-temporal SR to enhance information exchange between temporal and change branches.
- FCCDN [24]: A feature constraint CD network based on a dual encoder–decoder that uses a non-local feature pyramid network to extract and fuse multi-scale features and proposes a densely connected feature fusion module to enhance robustness.
- BIT [42]: A network that combines a CNN and transformer learns a compact set of tokens to represent high-level concepts that reveal change of interest in bi-temporal images. The transformer finds the relationship between semantic concepts in the token-based space-time.
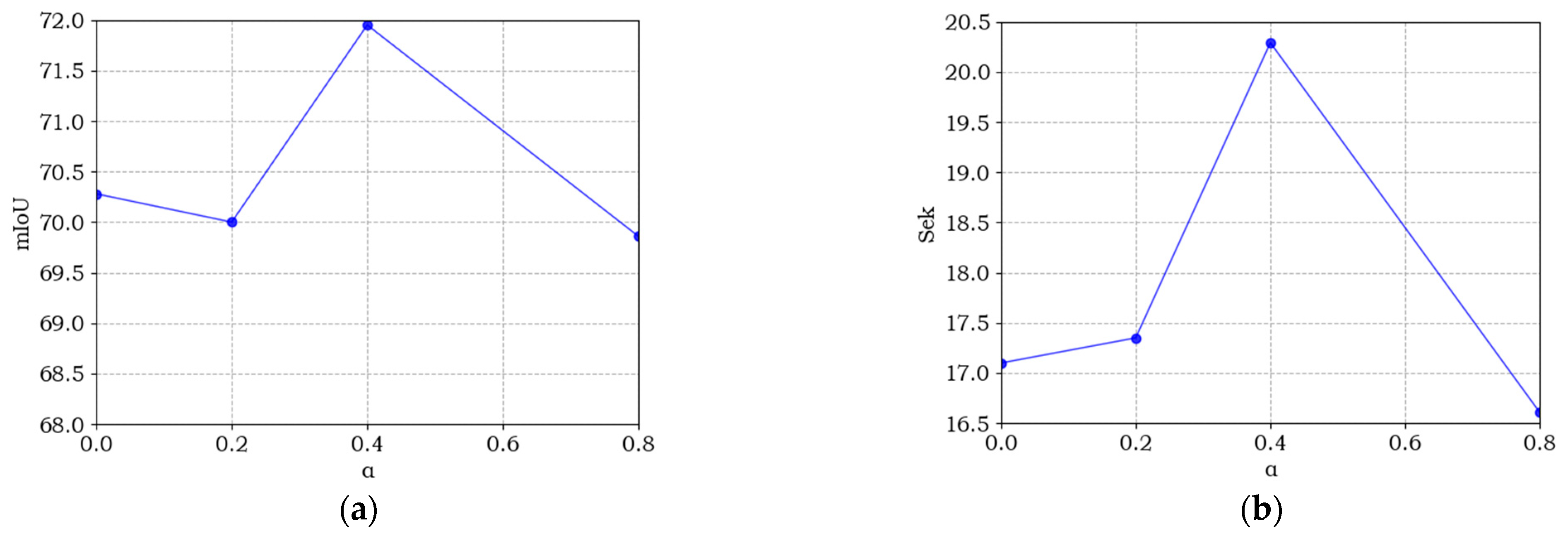
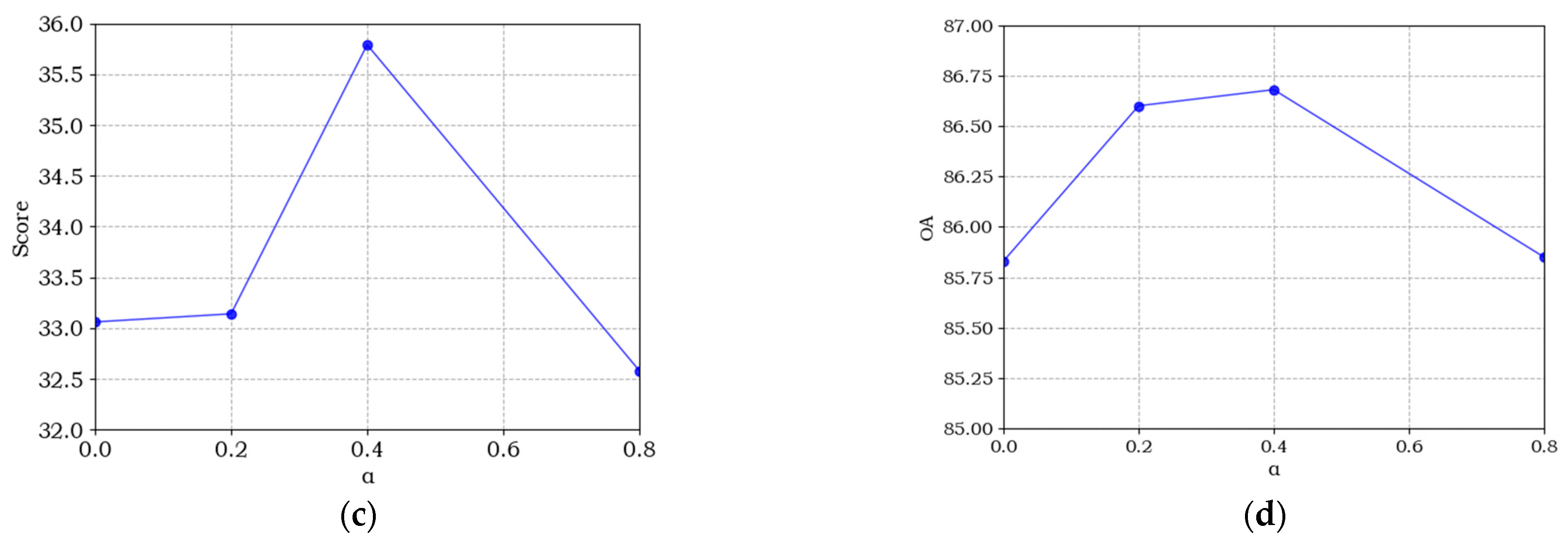
5.2. Ablation Experiments
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Song, X.P.; Hansen, M.C.; Stehman, S.V.; Potapov, P.V.; Tyukavina, A.; Vermote, E.F.; Townshend, J.R. Global land change from 1982 to 2016. Nature 2018, 560, 639–643. [Google Scholar] [CrossRef]
- Huang, X.; Schneider, A.; Friedl, M.A. Mapping sub-pixel urban expansion in China using Modis and DMSP/OLS nighttime lights. Remote Sens. Environ. 2016, 175, 92–108. [Google Scholar] [CrossRef]
- Jin, S.; Yang, L.; Zhu, Z.; Homer, C. A land cover change detection and classification protocol for updating Alaska NLCD 2001 to 2011. Remote Sens. Environ. 2017, 195, 44–55. [Google Scholar] [CrossRef]
- Huang, B.; Zhao, B.; Song, Y. Urban land-use mapping using a deep convolutional neural network with high spatial resolution multispectral remote-sensing imagery. Remote Sens. Environ. 2018, 214, 73–86. [Google Scholar] [CrossRef]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.P.; Gardiner, A.; Hare, J.; Atkinson, P.M. Joint deep learning for land cover and land use classification. Remote Sens. Environ. 2019, 221, 173–187. [Google Scholar] [CrossRef]
- Martins, V.S.; Kaleita, A.L.; Gelder, B.K.; da Silveira, H.L.; Abe, C.A. Exploring multiscale object-based convolutional neural network (multi-OCNN) for remote-sensing image classification at high spatial resolution. ISPRS J. Photogramm. 2020, 168, 56–73. [Google Scholar] [CrossRef]
- Huang, W.; Zhao, Z.B.; Sun, L.; Ju, M. Dual-branch attention-assisted CNN for hyperspectral image classification. Remote Sens. 2022, 14, 6158. [Google Scholar] [CrossRef]
- Wang, J.; Gong, Z.; Liu, X.; Guo, H.; Yu, D.; Ding, L. Object detection based on adaptive feature-aware method in optical remote sensing images. Remote Sens. 2022, 14, 3616. [Google Scholar] [CrossRef]
- Dong, X.; Qin, Y.; Gao, Y.; Fu, R.; Liu, S.; Ye, Y. Attention-based multi-level feature fusion for object detection in remote sensing images. Remote Sens. 2022, 14, 3735. [Google Scholar] [CrossRef]
- Dong, H.; Yu, B.; Wu, W.; He, C. Enhanced lightweight end-to-end semantic segmentation for high-resolution remote sensing images. IEEE Access 2022, 10, 70947–70954. [Google Scholar] [CrossRef]
- Xiong, J.; Po, L.M.; Yu, W.Y.; Zhou, C.; Xian, P.; Ou, W. CSRNet: Cascaded selective resolution network for real-time semantic segmentation. Expert Sys. Applic. 2021, 211, 118537. [Google Scholar]
- Daudt, R.C.; Le Saux, B.L.; Boulch, A. Fully convolutional Siamese networks for change detection. In Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Zhou, Z.W.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J.M. UNet++: Redesigning skip connections to exploit multiscale features in image segmentation. IEEE Trans. Med. Imaging 2020, 39, 1856–1867. [Google Scholar] [CrossRef]
- Liu, R.; Jiang, D.; Zhang, L.; Zhang, Z. Deep Depthwise separable convolutional network for change detection in optical aerial images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1109–1118. [Google Scholar] [CrossRef]
- Zhang, Y.; Fu, L.; Li, Y.; Zhang, Y. HDFNet: Hierarchical dynamic fusion network for change detection in optical aerial images. Remote Sens. 2021, 13, 1440. [Google Scholar] [CrossRef]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A densely connected Siamese network for change detection of VHR images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Ling, J.; Hu, L.; Cheng, L.; Chen, M.H.; Yang, X. IRA-MRSNet: A network model for change detection in high-resolution remote sensing images. Remote Sens. 2022, 14, 5598. [Google Scholar]
- Chen, J.; Yuan, Z.Y.; Peng, J.; Chen, L.; Huang, H.Z.; Zhu, J.W.; Liu, Y.; Li, H. DASNet: Dual attentive fully convolutional Siamese networks for change detection in high-resolution satellite images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1194–1206. [Google Scholar] [CrossRef]
- Peng, X.; Zhong, R.; Li, Z.; Li, Q. Optical remote-sensing image change detection based on attention mechanism and image difference. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7296–7307. [Google Scholar] [CrossRef]
- Guo, E.Q.; Fu, X.S.; Zhu, J.W.; Deng, M.; Liu, Y.; Zhu, Q.; Li, H.F. Learning to measure change: Fully convolutional Siamese metric networks for scene change detection. arXiv 2018, arXiv:1810.09111. [Google Scholar]
- Zhu, Q.; Guo, X.; Deng, W.; Shi, S.; Guan, Q.; Zhong, Y.; Zhang, L.; Li, D. Land-use/land-cover change detection based on a Siamese global learning framework for high spatial resolution remote-sensing imagery. ISPRS J. Photogramm. 2022, 184, 63–78. [Google Scholar] [CrossRef]
- Gao, Y.; Zhou, M.; Metaxas, D.N. UTNet: A hybrid transformer architecture for medical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September–1 October 2021; pp. 61–71. [Google Scholar]
- Li, G.Y.; Liu, Z.; Lin, W.S.; Ling, H.B. Multi-content complementation network for salient object detection in optical remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar]
- Chen, P.; Zhang, B.; Hong, D.F.; Chen, Z.C.; Yang, X.; Li, B. FCCDN: Feature constraint network for VHR image change detection. ISPRS J. Photogramm. 2022, 187, 101–119. [Google Scholar] [CrossRef]
- Lv, Z.Y.; Wang, F.J.; Cui, G.Q.; Benediktsson, J.A.; Lei, T.; Sun, W. Spatial-spectral attention network guided with change magnitude image for land cover change detection using remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Lei, T.; Xue, D.; Ning, H.; Yang, S.; Lv, Z.; Nandi, A.K. Local and global feature learning with kernel scale-adaptive attention network for VHR remote sensing change detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 7308–7322. [Google Scholar] [CrossRef]
- Wei, H.; Chen, R.; Yu, C.; Yang, H.; An, S. BASNet: A boundary-aware Siamese network for accurate remote-sensing change detection. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Liu, M.X.; Shi, Q.; Andrea, M.; He, D.; Liu, X.P.; Zhang, L.P. Super-resolution-based change detection network with stacked attention module for images with different resolutions. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar]
- Peng, D.; Bruzzone, L.; Zhang, Y.J.; Guan, H.Y.; Ding, H.Y.; Huang, X. SemiCDNet: A semisupervised convolutional neural network for change detection in high resolution remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 5891–5906. [Google Scholar] [CrossRef]
- Tsutsui, S.; Hirakawa, T.; Yamashita, T.; Fujiyoshi, H. Semantic segmentation and change detection by multi-task U-net. In Proceedings of the IEEE International Conference on Image Processing, Anchorage, AK, USA, 19–22 September 2021; pp. 619–623. [Google Scholar] [CrossRef]
- Peng, D.F.; Bruzzone, L.; Zhang, Y.J.; Guan, H.Y.; He, P.F. SCDNET: A novel convolutional network for semantic change detection in high resolution optical remote sensing imagery. Int. J. Appl. Earth Obs. Geoinf. 2021, 103, 102465. [Google Scholar] [CrossRef]
- Liu, Y.I.; Pang, C.; Zhan, Z.; Zhang, X.; Yang, X. Building change detection for remote sensing images using a dual-task constrained deep Siamese convolutional network model. IEEE Geosci. Remote Sens. Lett. 2021, 18, 811–815. [Google Scholar] [CrossRef]
- Mou, L.C.; Bruzzone, L.; Zhu, X.X. Learning spectral-spatial-temporal features via a recurrent convolutional neural network for change detection in multispectral imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 924–935. [Google Scholar] [CrossRef]
- Papadomanolaki, M.; Vakalopoulou, M.; Karantzalos, K. A deep multitask learning framework coupling semantic segmentation and fully convolutional LSTM networks for urban change detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7651–7668. [Google Scholar]
- Daudt, R.C.; Le, S.B.; Boulch, A.; Gousseau, Y. Multitask learning for large-scale semantic change detection. Comput. Vis. Image Understand. 2019, 187, 102783. [Google Scholar]
- Yang, K.P.; Xia, G.S.; Liu, Z.C.; Du, B.; Yang, W.; Pelillo, M.; Zhang, L.P. Asymmetric Siamese networks for semantic change detection in aerial images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–18. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhong, Y.; Tian, S.; Ma, A.L.; Zhang, L. ChangeMask: Deep multitask encoder-transformer-decoder architecture for semantic change detection. ISPRS J. Photogramm. 2022, 183, 228–239. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Identity mappings in deep residual networks, Computer Vision—ECCV 2016. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 1995; Volume 9908. [Google Scholar] [CrossRef]
- Yuan, P.; Zhao, Q.; Zhao, X.; Wang, X.; Long, X.; Zheng, Y. A transformer-based Siamese network and an open-optical dataset for semantic-change detection of remote sensing images. Int. J. Digit. Earth 2022, 15, 1506–1525. [Google Scholar]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A deeply supervised image fusion network for change detection in high-resolution bitemporal remote-sensing images. ISPRS J. Photogramm. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- Ding, L.; Guo, H.T.; Liu, S.C.; Mou, L.C.; Zhang, J.; Lorenzo, B. Bi-temporal semantic reasoning for the semantic change detection in HR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar]
- Chen, H.; Qi, Z.; Shi, Z. Remote sensing image change detection with transformers. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions, and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions, or products referred to in the content. |
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | mIoU/% | SeΚ/% | Score/% | OA/% |
|---|---|---|---|---|
| FC-Siam-conc | 66.38 | 10.60 | 27.33 | 84.11 |
| FC-Siam-diff | 66.65 | 9.57 | 26.69 | 84.01 |
| DSIFN | 66.28 | 9.37 | 26.44 | 83.20 |
| HRSCD-str3 | 65.85 | 11.89 | 28.08 | 82.85 |
| HRSCD-str4 | 69.69 | 16.91 | 32.74 | 84.81 |
| BiSRNet | 69.13 | 15.08 | 31.30 | 83.90 |
| FCCDN | 69.38 | 17.06 | 32.75 | 86.44 |
| BIT | 70.17 | 18.06 | 33.69 | 86.01 |
| SMNet (ours) | 71.95 | 20.29 | 35.79 | 86.68 |
| Method | mIoU/% | SeΚ/% | Score/% | OA/% |
|---|---|---|---|---|
| FC-Siam-conc | 64.66 | 5.70 | 23.39 | 80.09 |
| FC-Siam-diff | 69.22 | 10.25 | 27.94 | 84.25 |
| DSIFN | 70.37 | 20.67 | 35.58 | 85.66 |
| HRSCD-str3 | 78.23 | 32.70 | 46.36 | 90.65 |
| HRSCD-str4 | 80.33 | 36.68 | 49.78 | 91.79 |
| BiSRNet | 80.44 | 37.65 | 50.49 | 92.16 |
| FCCDN | 77.10 | 29.72 | 43.94 | 90.29 |
| BIT | 82.60 | 43.98 | 55.56 | 93.45 |
| SMNet (ours) | 85.65 | 51.14 | 61.49 | 94.53 |
| Model | mIoU/% | SeΚ/% | Score/% | OA/% |
|---|---|---|---|---|
| Base | 70.28 | 17.10 | 33.06 | 85.83 |
| Base + mul | 70.62 | 17.83 | 33.67 | 85.38 |
| Base + PRTB | 70.64 | 18.74 | 34.31 | 86.25 |
| Base + mul + PRTB | 71.50 | 19.45 | 35.10 | 86.44 |
| Base + mul + PRTB + MCFM | 71.95 | 20.29 | 35.79 | 86.68 |
| Layers | mIoU/% | SeΚ/% | Score/% | OA/% | Flops/G | Params/M |
|---|---|---|---|---|---|---|
| (1,1,1,1,1) | 70.54 | 18.17 | 33.91 | 85.86 | 67.63 | 36.87 |
| (2,2,2,2,2) | 70.62 | 18.59 | 34.17 | 86.30 | 70.35 | 38.63 |
| (1,2,4,2,1) | 71.95 | 20.29 | 35.79 | 86.68 | 71.05 | 37.48 |
| (4,4,4,4,4) | 70.72 | 18.66 | 34.28 | 86.50 | 75.79 | 42.16 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Niu, Y.; Guo, H.; Lu, J.; Ding, L.; Yu, D. SMNet: Symmetric Multi-Task Network for Semantic Change Detection in Remote Sensing Images Based on CNN and Transformer. Remote Sens. 2023, 15, 949. https://doi.org/10.3390/rs15040949
Niu Y, Guo H, Lu J, Ding L, Yu D. SMNet: Symmetric Multi-Task Network for Semantic Change Detection in Remote Sensing Images Based on CNN and Transformer. Remote Sensing. 2023; 15(4):949. https://doi.org/10.3390/rs15040949
Chicago/Turabian StyleNiu, Yiting, Haitao Guo, Jun Lu, Lei Ding, and Donghang Yu. 2023. "SMNet: Symmetric Multi-Task Network for Semantic Change Detection in Remote Sensing Images Based on CNN and Transformer" Remote Sensing 15, no. 4: 949. https://doi.org/10.3390/rs15040949
APA StyleNiu, Y., Guo, H., Lu, J., Ding, L., & Yu, D. (2023). SMNet: Symmetric Multi-Task Network for Semantic Change Detection in Remote Sensing Images Based on CNN and Transformer. Remote Sensing, 15(4), 949. https://doi.org/10.3390/rs15040949