
Multi-Sensor Data Fusion for 3D Reconstruction of Complex Structures: A Case Study on a Real High Formwork Project


Abstract
:1. Introduction
- Using learning-based methods to improve image matching accuracy, generate globally consistent 3D point clouds, and enhance the merge quality of the two-point clouds;
- Adopting GNSS information to reduce search space in image matching, provide Exterior Orientation Parameters (EOPs) for the camera, and offer a transformation matrix between the image scene and global reference system;
- Fusing TLS and image data to enhance project digitization with sufficient detail.
2. Literature Review
2.1. Image Processing
2.2. Feature-Based Image Matching
2.3. Multi-Sensor Integration for Developing the 3D Model
3. Methodology
3.1. Overview
3.2. Image Feature Matching
3.3. The Adoption of GNSS Information
Camera Parameters (IOP and EOP)

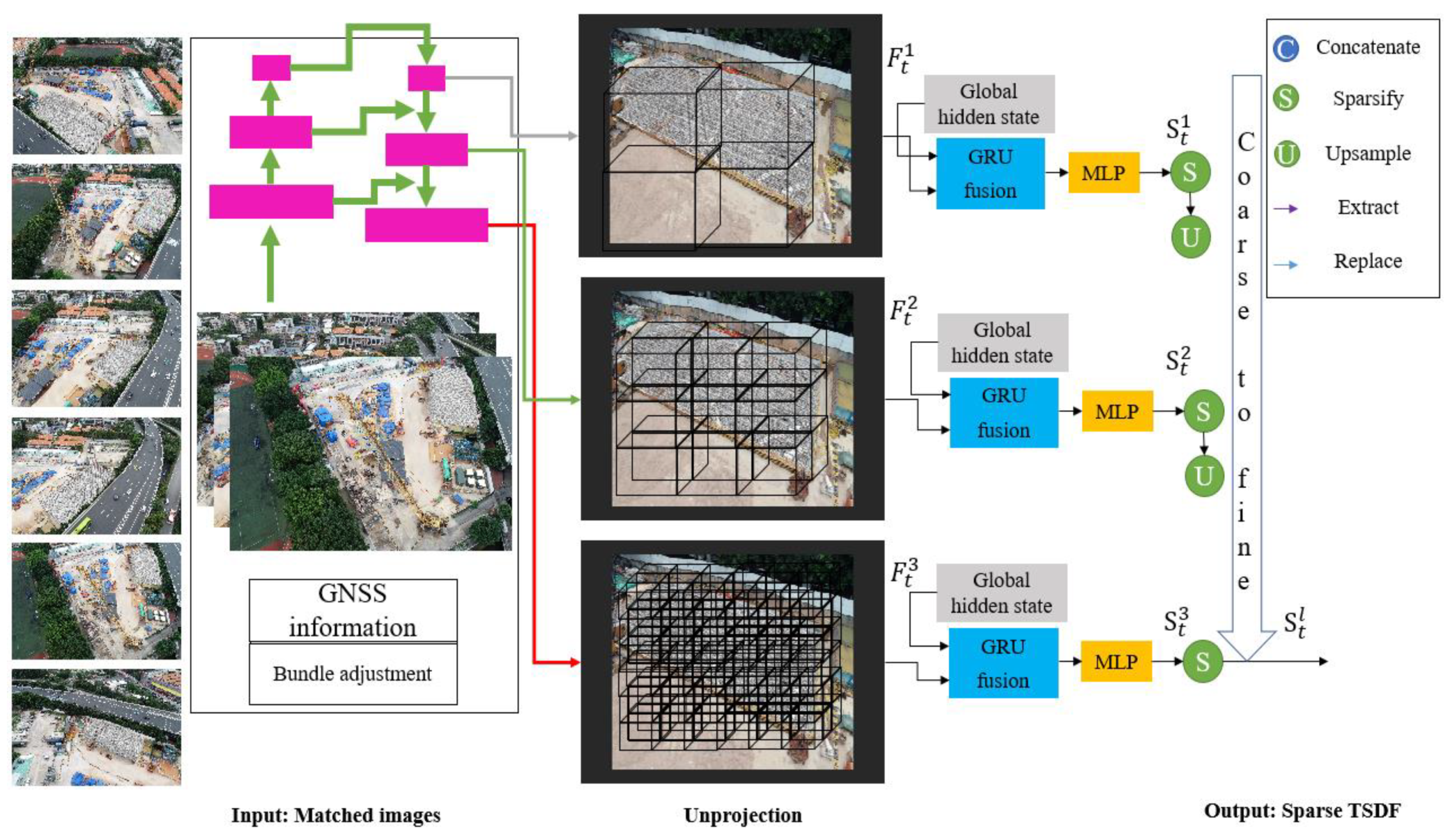
3.4. 3D Image-Based Point Cloud Generation
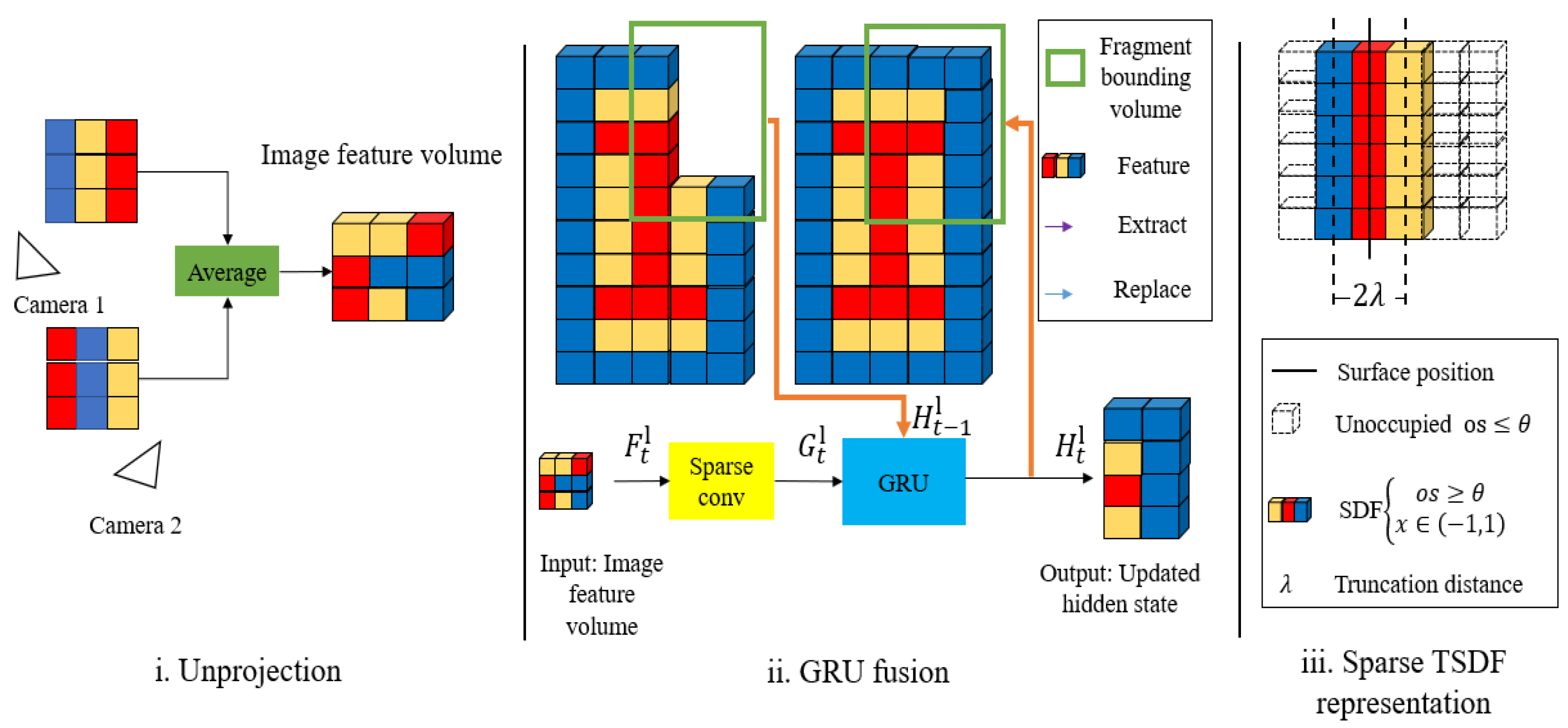
3.4.1. Image Feature Volume Construction
3.4.2. Coarse-to-Fine TSDF Reconstruction
3.5. Processing of TLS Data
3.6. Co-Registration of Image-Based Point Cloud and TLS Point Cloud
3.6.1. Coarse Registration
3.6.2. Fine Registration
3.7. 3D Model Generation
4. Experimental Validation
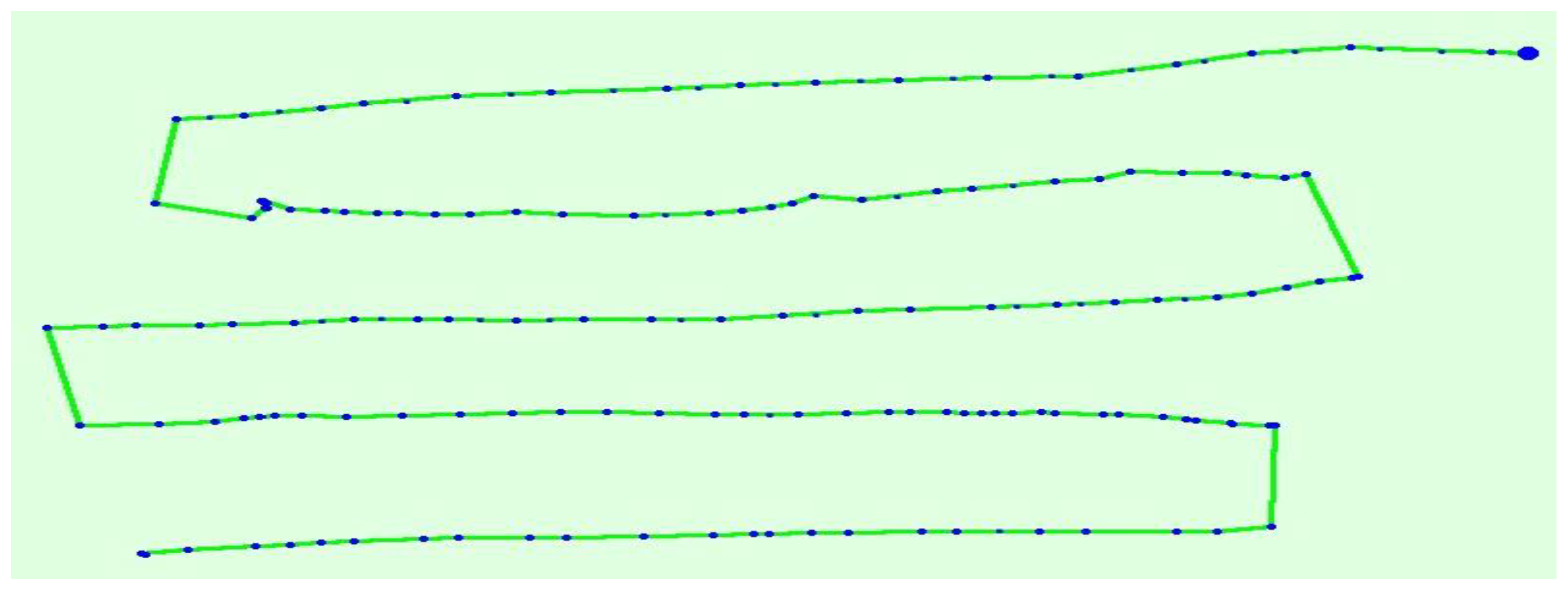
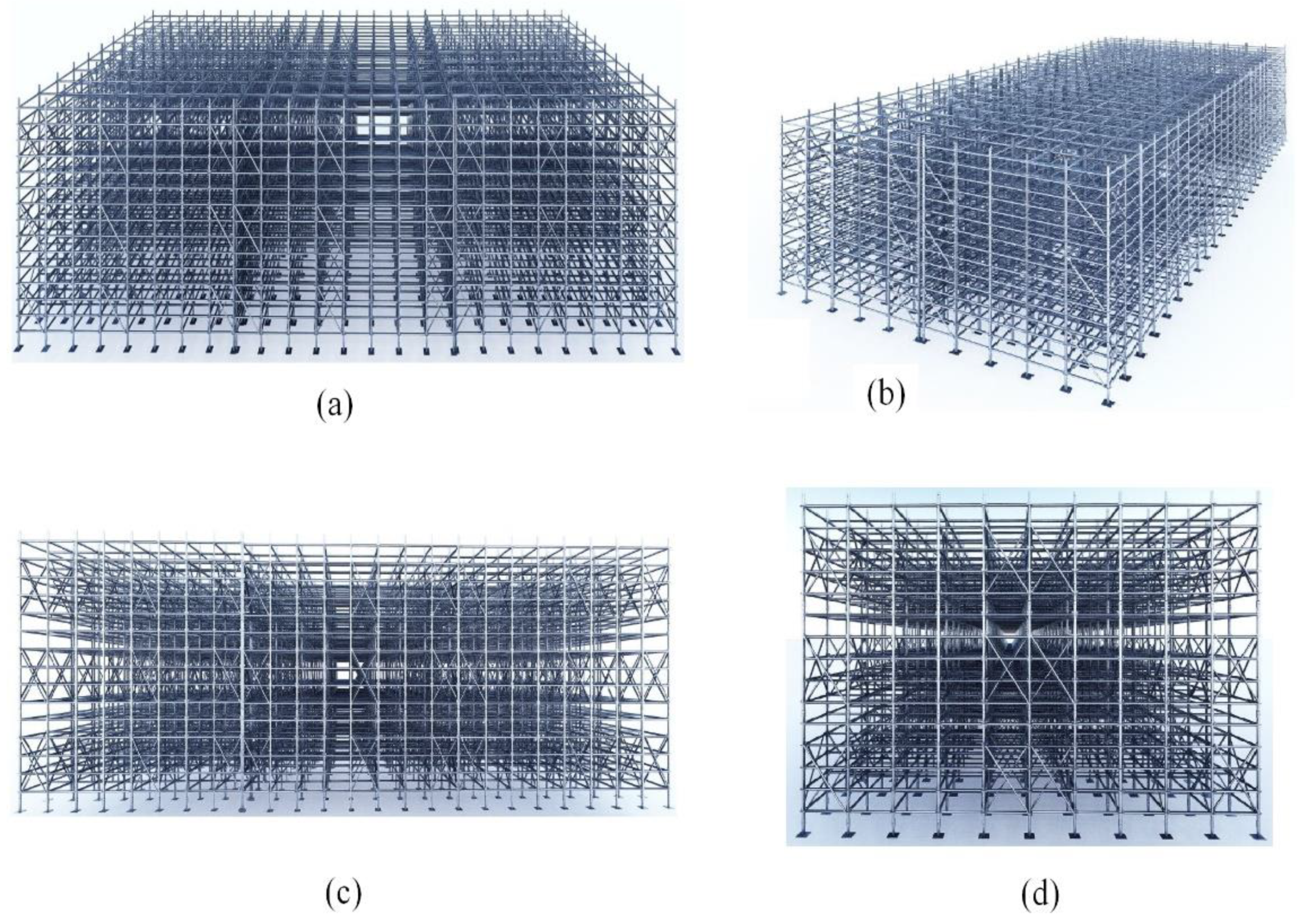
4.1. Dataset and Implementation Details
4.2. Point Cloud Generation from UAV Images
4.3. Data Fusion of Two Point Clouds
5. Model Comparison and Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Acronym | Meaning |
| AEC | Architecture–Engineering–Construction |
| AI | Artificial Intelligence |
| ALS | Airborne Laser Scanning |
| BIM | Building Information Modelling |
| BRIEF | Binary Robust Independent Elementary Features |
| CAD | Computer Aided Design |
| CNNs | Convolutional Neural Networks |
| DL | Deep Learning |
| EOP | Exterior Orientation Parameters |
| FAST | Features from Accelerated Segment Test |
| FPN | Feature Pyramid Network |
| GCP | Ground Control Point |
| GNSS | Global Navigation Satellite System |
| GRU | Gated Recurrent Unit |
| ICP | Iterative Closest Point |
| IMU | Inertial Measurement Unit |
| IOP | Interior Orientation Parameters |
| LoFTR | Local Feature Matching with Transformers |
| LPS | Leica Photogrammetry Suite |
| MEMS | Microelectromechanical Systems |
| MEP | Mechanical, Electrical and Plumbing |
| MLP | Multi-Layer Perceptron |
| MLS | Mobile Laser Scanning |
| MNN | Mutual Nearest Neighbor |
| M3C2 | Multiscale Model-to-Model Cloud Comparison |
| NLOS | Non-Line-of-Sight |
| ORB | Oriented FAST and Rotated BRIEF |
| os | Occupancy score |
| RGB | Red, Green and Blue |
| RPM | Robust Point Matching |
| RTK | Real Time Kinematic |
| RMSE | Root Mean Square Error |
| SDF | Signed Distance Function |
| SfM | Structure from Motion |
| SIFT | Scale Invariant Feature Transform |
| SURF | Speeded Up Robust Features |
| SUSAN | Small Univalue Segment Assimilating Nucleus |
| TLS | Terrestrial Laser Scanning |
| TSDF | Truncated Signed Distance Function |
| UAV | Unmanned Aerial Vehicle |
| 4PCS | 4-Point Congruent Sets |
References
- Hu, Y.; Chen, Y.; Wu, Z. Unmanned aerial vehicle and ground remote sensing applied in 3D reconstruction of hitorical building groups in ancient villages. In Proceedings of the Fifth International Workshop on Earth Observation and Remote Sensing Applications (EORSA), Xi’an, China, 8–20 June 2018. [Google Scholar]
- Fryskowska, A.; Stachelek, J. A no-reference method of geometric content quality analysis of 3D models generated from laser scanning point clouds for hBIM. J. Cult. Herit. 2018, 34, 95–108. [Google Scholar] [CrossRef]
- Talamo, M.; Valentini, F.; Dimitri, A.; Allegrini, I. Innovative technologies for cultural heritage. Tattoo sensors and AI: The new life of cultural assets. Sensors 2020, 20, 1909. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McKinney, K.; Fischer, M. Generating, evaluating and visualizing construction schedules with CAD tools. Autom. Constr. 1998, 7, 433–447. [Google Scholar] [CrossRef]
- Baruch, A.; Filin, S. Detection of gullies in roughly textured terrain using airborne laser scanning data. ISPRS J. Photogramm. Remote Sens. 2011, 66, 564–578. [Google Scholar] [CrossRef]
- Lai, L.; Sordini, M.; Campana, S.; Usai, L.; Condò, F. 4D recording and analysis: The case study of Nuraghe Oes (Giave, Sardinia). Digit. Appl. Archaeol. Cult. Herit. 2015, 2, 233–239. [Google Scholar] [CrossRef]
- Weligepolage, K.; Gieske, A.S.M.; Su, Z. Surface roughness analysis of a conifer forest canopy with airborne and terrestrial laser scanning techniques. Int. J. Appl. Earth Obs. Geoinf. 2012, 14, 192–203. [Google Scholar] [CrossRef]
- Zeng, Q.; Mao, J.; Li, X.; Liu, X. Building reconstruction from airborne LiDAR points cloud data. Geomat. Inf. Sci. Wuhan Univ. 2011, 36, 321–324. [Google Scholar]
- Zhang, K.; Sheng, Y.; Meng, W.; Xu, P. Automatic generation of three dimensional colored point clouds based on multi-view image matching. Opt. Precis. Eng. 2013, 21, 1840–1849. [Google Scholar] [CrossRef]
- Akturk, E.; Altunel, A.O. Accuracy assessment of a low-cost uav derived digital elevation model (DEM) in a highly broken and vegetated terrain. Measurement 2018, 136, 382–386. [Google Scholar] [CrossRef]
- Alsadik, B.; Gerke, M.; Vosselman, G. Automated camera network design for 3D modeling of cultural heritage objects. J. Cult. Heritage. 2013, 14, 515–526. [Google Scholar] [CrossRef]
- Huang, J.; Wang, J. Production and application of automatic real 3d modeling of multi-view image. Bull. Surv. Mapp. 2016, 4, 75–78. [Google Scholar]
- Théo, L.; Anthony, P.; Eloi, G.; Thibaut, R.; Livio, D.L.; Franck, R. A shape-adjusted tridimensional reconstruction of cultural heritage artifacts using a miniature quadrotor. Remote Sens. 2016, 8, 858. [Google Scholar]
- Fassi, F.; Fregonese, L.; Ackermann, S.; De Troia, V. Comparison between laser scanning and automated 3d modeling techniques to reconstruct complex and extensive cultural heritage areas. In Proceedings of the 3D-ARCH 2013—3D Virtual Reconstruction and Visualization of Complex Architectures, Trento, Italy, 25–26 February 2013; pp. 73–80. [Google Scholar]
- Guidi, G.; Remondino, F.; Russo, M.; Menna, F.; Rizzi, A. 3D modeling of large and complex site using multi-sensor integration and multi-resolution data. In Proceedings of the 9th International Symposium on Virtual Reality, Archaeology and Cultural Heritage VAST, Braga, Portugal, 2–5 December 2008; pp. 85–92. [Google Scholar]
- Remondino, F. Heritage recording and 3D modelling with photogrammetry and 3D scanning. Remote Sens. 2011, 3, 1104–1138. [Google Scholar] [CrossRef] [Green Version]
- Remondino, F.; El-Hakim, S.; Girardi, S.; Rizzi, A.; Gonzo, L. 3D virtual reconstruction and visualization of complex architectures-the “3D-arch” project. In Proceedings of the ISPRS Working Group V/4 Workshop 3D-ARCH “Virtual Reconstruction and isualization of Complex Architectures”, Virtual, 28 February 2009. [Google Scholar]
- Madeira, T.; Oliveira, M.; Dias, P. Enhancement of RGB-D image alignment using fiducial markers. Sensors 2020, 20, 1497. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rodríguez-Martín, M.; Rodríguez-Gonzálvez, P. Suitability of automatic photogrammetric reconstruction configurations for small archaeological remains. Sensors 2020, 20, 2936. [Google Scholar] [CrossRef] [PubMed]
- Zhao, L.L.; Mbachu, J.; Wang, B.; Liu, Z.S.; Zhang, H.R. Installation quality inspection for high formwork using terrestrial laser scanning technology. Symmetry 2022, 14, 377. [Google Scholar] [CrossRef]
- Spencer Jr, B.F.; Hoskere, V.; Narazaki, Y. Advances in Computer Vision-Based Civil Infrastructure Inspection and Monitoring. Engineering 2019, 5, 199–222. [Google Scholar] [CrossRef]
- Feng, D.; Feng, M.Q. Computer vision for SHM of civil infrastructure: From dynamic response measurement to damage detection—A review. Eng. Struct. 2018, 156, 105–117. [Google Scholar] [CrossRef]
- Koch, C.; Georgieva, K.; Kasireddy, V.; Akinci, B.; Fieguth, P. A review on computer vision-based defect detection and condition assessment of concrete and asphalt civil infrastructure. Adv. Eng. Inf. 2015, 29, 196–210. [Google Scholar] [CrossRef] [Green Version]
- Sharifi, M.; Fathy, M.; Mahmoudi, M.T. A classified and comparative study of edge detection algorithms. In Proceedings of the International Conference on Information Technology: Coding and Computing, Las Vegas, NV, USA, 8–10 April 2002. [Google Scholar]
- Kuruvilla, J.; Sukumaran, D.; Sankar, A.; Joy, S.P. A review on image processing and image segmentation. In Proceedings of the International Conference on Data Mining and Advanced Computing (SAPIENCE), Ernakulam, India, 16–18 March 2016. [Google Scholar]
- Morala-Argüello, P.; Joaquín Barreiro, J.; Alegre, E. A evaluation of surface roughness classes by computer vision using wavelet transform in the frequency domain. Int. J. Adv. Manuf. Technol. 2012, 59, 213–220. [Google Scholar] [CrossRef]
- Nixon, M.; Aguado, A. Feature Extraction and Image Processing for Computer Vision, 4th ed; Elsevier: London, UK, 2019. [Google Scholar]
- Abdul Raof, A.N.; Setan, H.; Chong, A.; Majid, Z. Three dimensional modeling of archaeological artifact using PhotoModeler scanner. J. Teknol. 2015, 75, 143–153. [Google Scholar] [CrossRef] [Green Version]
- Metashape. Available online: https://www.agisoft.com/ (accessed on 15 September 2022).
- Meshroom. Available online: https://alicevision.github.io/ (accessed on 15 September 2022).
- Yang, L. Lunar Reconnaissance Orbiter Topographic Mapping Using Leica Photogrammetry Suite. Ph.D. Thesis, The Ohio State University, Columbus, OH, USA, 2009. [Google Scholar]
- Pix4D. Available online: https://www.pix4d.com/ (accessed on 10 September 2022).
- Reality Capture. Available online: https://www.capturingreality.com/ (accessed on 15 September 2022).
- Snavely, N. Bundler. 2008. Available online: http://phototour.cs.washington.edu/bundler/ (accessed on 15 September 2022).
- Pierrot-Deseilligny, M.; Cléry, I. APERO, an open source bundle adjustment software for automatic calibration and orientation of a set of images. In Proceedings of the ISPRS Symposium, Trento, Italy, 2–4 March 2011. [Google Scholar]
- COLMAP. Available online: http://colmap.github.io/ (accessed on 22 October 2022).
- Wu, C. VisualSFM. 2011. Available online: http://www.cs.washington.edu/homes/ccwu/vsfm/ (accessed on 22 October 2022).
- Uricchio, W. The algorithmic turn: Photosynth, augmented reality and the changing implications of the image. Vis. Stud. 2011, 26, 25–35. [Google Scholar] [CrossRef]
- Vergauwen, M.; Van Gool, L. Web-based 3D reconstruction service. Mach. Vis. Appl. 2006, 17, 411–426. [Google Scholar] [CrossRef]
- 3DF Zephyr. Available online: https://www.3dflow.net/3df-zephyr-photogrammetry-software/ (accessed on 22 October 2022).
- 123D-Catch. Available online: http://www.123dapp.com/catch (accessed on 15 September 2022).
- Li, X.; Chen, Z.; Zhang, L.; Jia, D. Construction and Accuracy Test of a 3D Model of Non-Metric Camera Images Using Agisoft PhotoScan. In Proceedings of the International Conference on Geographies of Health and Living in Cities: Making Cities Healthy for All, Pokfulam, Hong Kong, 21–24 June 2016. [Google Scholar]
- Jebur, A.; Abed, F.; Mohammed, M. Assessing the performance of commercial Agisoft PhotoScan software to deliver reliable data for accurate 3D modelling. In Proceedings of the Materials Science, Engineering and Chemistry (MATEC) Web of Conferences 2018, Aachen, Germany.
- Szeliski, R. Computer Vision: Algorithms and Applications; Springer: Berlin, Germany, 2010. [Google Scholar]
- Westoby, M.J.; Brasington, J.; Glasser, N.F.; Hambrey, M.J.; Reynolds, J.M. Structure-from-Motion’ photogrammetry: A low-cost, effective tool for geoscience applications. Geomorphology 2012, 179, 300–314. [Google Scholar] [CrossRef] [Green Version]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Cronje, J. BFROST: Binary features from robust orientation segment tests accelerated on the GPU. In Proceedings of the 22nd Annual Symposium of the Pattern Recognition Association of South Africa (PRASA), Vanderbijlpark, South Africa, 22–25 November 2011. [Google Scholar]
- ezSIFT. Available online: https://github.com/robertwgh/ezSIFT2013 (accessed on 15 September 2022).
- Culjak, I.; Abram, D.; Pribanic, T.; Dzapo, H.; Cifrek, M. A brief introduction to OpenCV. In Proceedings of the 35th International Convention MIPRO, Opatija, Croatia, 21–25 May 2012. [Google Scholar]
- Liang, S.; Zhu, Q.; Wang, Z. Research and Application of 3D Map Modelling for Indoor Environment Based on Siftgpu. In Proceedings of the 2nd International Conference on Multimedia and Image Processing (ICMIP), Wuhan, China, 17–19 March 2017. [Google Scholar]
- Paleo, P.; Pouyet, E.; Kieffer, J. Image stack alignment in full-field X-ray absorption spectroscopy using SIFT_PyOCL. J. Synchrotron Radiat. 2014, 21, 456–461. [Google Scholar] [CrossRef]
- Guo, F.; Yang, J.; Chen, Y.; Yao, B. Research on image detection and matching based on SIFT features. In Proceedings of the 3rd International Conference on Control and Robotics Engineering (ICCRE), Nagoya, Japan, 20–23 April 2018. [Google Scholar]
- Li, Z.; Jia, H.; Zhang, Y.; Liu, S.; Li, S.; Wang, X.; Zhang, H. Efficient parallel optimizations of a high-performance SIFT on GPUs. J. Parallel Distrib. Comput. 2019, 124, 78–91. [Google Scholar] [CrossRef]
- Mouats, T.; Aouf, N.; Nam, D.; Vidas, S. Performance Evaluation of Feature Detectors and Descriptors Beyond the Visible. J. Intell. Robot. Syst. 2018, 92, 33–63. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, M.A. Neural Networks and Deep Learning; Determination Press: San Francisco, CA, USA, 2015. [Google Scholar]
- Ali, M.; Clausi, D. Using the Canny edge detector for feature extraction and enhancement of remote sensing images. In Proceedings of the International Geoscience and Remote Sensing Symposium, Sydney, NSW, Australia, 9–13 July 2001. [Google Scholar]
- Perez, M.M.; Dennis, T.J. An adaptive implementation of the SUSAN method for image edge and feature detection. In Proceedings of the International Conference on Image Processing, Santa Barbara, CA, USA, 26–29 October 1997. [Google Scholar]
- Sipiran, I.; Bustos, B. Harris 3D: A robust extension of the Harris operator for interest point detection on 3D meshes. Vis. Comput. 2011, 27, 963–976. [Google Scholar] [CrossRef]
- Li, Y.; Zheng, W.; Liu, X.; Mou, Y.; Yin, L.; Yang, B. Research and improvement of feature detection algorithm based on FAST. Rend. Lincei. Sci. Fis. E Nat. 2021, 32, 775–789. [Google Scholar] [CrossRef]
- Li, Y.; Wu, H.Y. Adaptive building edge detection by combining LiDAR data and aerial images. In Proceedings of the 21th ISPRS Congress, Commission I on Standards, Calibration and Validation, Beijing, China, 2–4 July 2008. [Google Scholar]
- Koch, A. An approach for the semantically correct integration of a DTM and 2D GIS vector data. In Proceeding of the 20th ISPRS Congress, Commission IV on Geo-Imagery Bridging Continents, Istanbul, Turkey, 12–23 July 2004. [Google Scholar]
- Suveg, I.; Vosselman, G. Reconstruction of 3D building models from aerial images and maps. ISPRS J. Photogramm. Remote Sens. 2004, 58, 202–224. [Google Scholar] [CrossRef] [Green Version]
- Remondino, F.; El-Hakim, S.F.; Gruen, A.; Zhang, L. Turning images into 3-D models. Signal Process. Mag. IEEE 2008, 25, 55–65. [Google Scholar] [CrossRef]
- Ressl, C.; Haring, A.; Briese, C.; Rottensteiner, F. A concept for adaptive mono-plotting using images and laserscanner data. In Proceedings of the Symposium of ISPRS Commission III-Photogrammetric Computer Vision-PCV, Bonn, Germany, 20–22 September 2006. [Google Scholar]
- Wendt, A. A concept for feature based data registration by simultaneous consideration of laser scanner data and photogrammetric images. ISPRS J. Photo-gramm. Remote Sens. 2007, 62, 122–134. [Google Scholar] [CrossRef]
- Kang, Z.; Zlatanova, S.; Gorte, B. Automatic registration of terrestrial scanning data based on registered imagery. In Proceedings of the XXX FIG Working Week 2007, Hong Kong, China, 13–17 May 2007. [Google Scholar]
- Becker, S.; Haala, N. Refinement of Building Facades by Integrated Processing of LiDAR and Image Data. In Proceedings of the ISPRS Workshop on Photogrammetric Image Analysis, Munich, Germany, 18–20 September 2007. [Google Scholar]
- Demir, N.; Poli, D.; Baltsavias, E. Detection of buildings at airport sites using images & LiDAR data and a combination of various methods. In Proceedings of the ISPRS Workshop CMRT09 on Object Extraction for 3D City Models, Road Databases and Traffic Monitoring—Concepts, Algorithms and Evaluation, Paris, France, 3–4 September 2009. [Google Scholar]
- Rottensteiner, F.; Briese, C. A New Method for Building Extraction in Urban Areas from High-Resolution LiDAR Data. In Proceedings of the ISPRS Commission III Symposium on Photogrammetric Computer Vision, Graz, Austria, 10–13 September 2002. [Google Scholar]
- Abdelhafiz, A. Integrating Digital Photogrammetry and Terrestrial Laser Scanning; Techn. Univ., Inst. für Geodäsie und Photogrammetrie: Braunschweig, Germany, 2009; pp. 1–118. ISBN 978-392-614-618-2. [Google Scholar]
- Alshawabkeh, Y.; Haala, N. Integration of Laser Scanning and Photogrammetry for Heritage Documentation; Universität Stuttgart: Stuttgart, Germany, 2006; p. 98. [Google Scholar] [CrossRef]
- El-Hakim, S.F.; Beraldin, J.A. On the integration of range and intensity data to improve vision-based three-dimensional measurements. Videometrics III 1994, 2350, 306–327. [Google Scholar]
- Yang, M.Y.; Cao, Y.; McDonald, J. Fusion of camera images and laser scans for wide baseline 3D scene alignment in urban environments. ISPRS J. Photogramm. Remote Sens. 2011, 66, 52–61. [Google Scholar] [CrossRef] [Green Version]
- El-Hakim, S.; Gonzo, L.; Picard, M.; Girardi, S.; Simoni, A. Visualization of Frescoed Surfaces: Buonconsiglio Castle-Aquila Tower, “Cycle of The Months. In Proceedings of the International Workshop on Visualisation and Animation of Reality-Based 3D Models, Tarasp-Vulpera, Switzerland, 24–28 February 2003. [Google Scholar]
- Nex, F.; Remondino, F. Range and image data integration for man-made object reconstruction. In Proceedings of the International Archives of Photogrammetry, Remote Sensing and Spatial Information Sciences, Munich, Germany, 5–7 October 2011. [Google Scholar]
- Baik, A.; Boehm, J. Building information modelling for historical building Historic Jeddah-Saudi Arabia. Digital Herit. 2015, 2, 125–128. [Google Scholar]
- Oreni, D.; Brumana, R.; Georgopoulos, A.P.; Cuca, B. HBIM for conservation and management of built heritage: Towards a library of vaults and wooden bean floors. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, 2, 215–221. [Google Scholar] [CrossRef] [Green Version]
- Bagnolo, V.; Argiolas, R.; Cuccu, A. HBIM for archaeological sites: From sfm based survey to algorithmic modeling. ISPRS-Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 42, 57–63. [Google Scholar] [CrossRef] [Green Version]
- Barrile, V.; Fotia, A.; Candela, G.; Bernardo, E. Integration of 3D model from UAV survey in BIM environment. ISPRS-Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 42, 195–199. [Google Scholar] [CrossRef] [Green Version]
- Remondino, F.; Rizzi, A. Reality-based 3D documentation of natural and cultural heritage sites—Techniques, problems, and examples. Appl. Geomat. 2010, 2, 85–100. [Google Scholar] [CrossRef] [Green Version]
- Banfi, F.; Brumana, R.; Stanga, C. Extended reality and informative models for the architectural heritage: From scan-to-BIM process to virtual and augmented reality. Virtual Archaeol. Rev. 2019, 10, 14–30. [Google Scholar] [CrossRef]
- López, F.J.; Lerones, P.M.; Llamas, J.; Gómez-García-Bermejo, J.; Zalama, E. A framework for using point cloud data of Heritage buildings towards geometry modeling in a BIM context: A case study on Santa Maria la Real de Mave Church. Int. J. Arch. Herit. 2017, 11, 965–986. [Google Scholar] [CrossRef]
- Sztwiertnia, D.; Ochałek, A.; Tama, A.; Lewi’nska, P. HBIM (heritage Building Information Modell) of the Wang Stave Church in Karpacz—Case Study. Int. J. Arch. Herit. 2019, 15, 5238. [Google Scholar] [CrossRef]
- Moon, D.; Chung, S.; Kwon, S.; Seo, J.; Shin, J. Comparison and utilization of point cloud generated from photogrammetry and laser scanning: 3D world model for smart heavy equipment planning. Autom. Constr. 2019, 98, 322–331. [Google Scholar] [CrossRef]
- Son, H.; Bosche, F.; Kim, C. As-built data acquisition and its use in production monitoring and automated layout of civil infrastructure: A survey. Adv. Eng. Inf. 2015, 29, 172–183. [Google Scholar] [CrossRef]
- Turkan, Y.; Bosché, F.; Haas, C.T.; Haas, R. Tracking of secondary and temporary objects in structural concrete work. Constr. Innov. 2014, 14, 145–167. [Google Scholar] [CrossRef]
- Riveiro, B.; González-Jorge, H.; Varela, M.; Jauregui, D.V. Validation of terrestrial laser scanning and photogrammetry techniques for the measurement of vertical underclearance and beam geometry in structural inspection of bridges. Measurement 2013, 46, 784–794. [Google Scholar] [CrossRef]
- Lagüela, S.; Solla, M.; Puente, I.; Prego, F.J. Joint use of GPR, IRT and TLS techniques for the integral damage detection in paving. Constr. Build. Mater. 2018, 174, 749–760. [Google Scholar] [CrossRef]
- Wang, B.; Wang, Q.; Cheng, J.C.P.; Song, C.; Yin, C. Vision-assisted BIM reconstruction from 3D LiDAR point clouds for MEP scenes. Autom. Constr. 2022, 133, 1–28. [Google Scholar] [CrossRef]
- Sun, J.; Shen, Z.; Wang, Y.; Bao, H.; Zhou, X. LoFTR: Detector-Free Local Feature Matching with Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Sasiadek, J.Z. Sensor fusion. Annu. Rev. Control. 2002, 26, 203–228. [Google Scholar] [CrossRef]
- Hosseinyalamdary, S. Deep Kalman Filter: Simultaneous Multi-Sensor Integration and Modelling; A GNSS/IMU Case Study. Sensors 2018, 18, 1316. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, C.; Shi, W.; Chen, W. Correlational inference-based adaptive unscented Kalman filter with application in GNSS/IMU-integrated navigation. GPS Solut. 2018, 22, 100. [Google Scholar] [CrossRef]
- Lee, J.; Kim, M.; Lee, J.; Pullen, S. Integrity assurance of Kalman-filter based GNSS/IMU integrated systems against IMU faults for UAV applications. In Proceedings of the 31st International Technical Meeting of the Satellite Division of The Institute of Navigation, Miami, FL, USA, 24–28 September 2018. [Google Scholar]
- Tominaga, T.; Kubo, N. Adaptive estimation of measurement noise to improve the performance of GNSS single point positioning in dense urban environment. J. Inst. Position. Navig. Timing Jpn. 2017, 8, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Diesel, J.W.; Huddle, J.R. Advantage of Autonomous Integrity Monitored Extrapolation Technology for precision Approach. In Proceedings of the 10th International Technical Meeting of the Satellite Division of The Institute of Navigation, Kansas City, MO, USA, 16–19 September 1997. [Google Scholar]
- Przybilla, H.J.; Bäumker, M.; Luhmann, T.; Hastedt, H.; Eilers, M. Interaction between direct georeferencing, control point configuration and camera self-calibration for rtk-based uav photogrammetry. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2020, 43, 485–492. [Google Scholar] [CrossRef]
- Ji, M.; Gall, J.; Zheng, H.; Liu, Y.; Fang, L. SurfaceNet: An end-to-end 3D neural network for multiview stereopsis. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Kar, A.; Hane, C.; Malik, J. Learning a multi-view stereo machine. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Murez, Z.; van As, T.; Bartolozzi, J.; Sinha, A.; Badrinarayanan, V.; Rabinovich, A. Atlas: End to-end 3D scene reconstruction from posed images. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 8–14 September 2020. [Google Scholar]
- Aiger, D.; Mitra, N.J.; Cohen-Or, D. 4-points congruent sets for robust pairwise surface registration. ACM Trans. Graph. 2008, 27, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Deng, Y.; Yu, K.; Yao, X.; Xie, Q.; Hsieh, Y.; Liu, J. Estimation of Pinus massoniana leaf area using terrestrial laser scanning. Forests 2019, 10, 660. [Google Scholar] [CrossRef] [Green Version]
- Yew, Z.J.; Lee, G.H. PRN-Net: Robust point matching using learned features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Będkowski, J.; Pełka, M.; Majek, K.; Fitri, T.; Naruniec, J. Open source robotic 3D mapping framework with ROS—Robot Operating System, PCL—Point Cloud Library and CloudCompare. In Proceedings of the International Conference on Electrical Engineering and Informatics (ICEEI), Denpasar, Indonesia, 10–11 August 2015. [Google Scholar]
- Liu, R.; Duan, W.; Zhang, Y. Study on Close Computation of Parameters of Bursa Transformation Model. Resour. Environ. Eng. 2010, 24, 416–418. [Google Scholar]
- Beinat, A.; Crosilla, F. Generalized procrustes analysis for size and shape 3D object reconstructions. In Proceedings of the 10th Conference of Optical 3-D Measurement Techniques, Vienna, Austria, 1–4 October 2001; pp. 345–353. [Google Scholar]
- Cucchiaro, S.; Maset, E.; Cavalli, M.; Crema, S.; Marchi, L.; Beinat, A.; Cazorzi, F. How does co-registration affect geomorphic change estimates in multi-temporal surveys? GIScience Remote Sens. 2020, 45, 1–22. [Google Scholar] [CrossRef]
- Rajendra, Y.D.; Mehrotra, S.C.; Kale, K.V.; Manza, R.R.; Dhumal, R.K.; Nagne, A.D.; Vibhute, A.D. Evaluation of partially overlapping 3D point cloud’s registration by using ICP variant and CloudCompare. In Proceedings of the ISPRS Technical Commission VIII Symposium, Hyderabad, India, 9–12 December 2014. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Point net++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 10–13 November 2017. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image | Altitude (m) | Distance (m) | Image Scale | |
|---|---|---|---|---|
| Nadir | 156 | 20–30 | 15–20 | 4600–6500 |
| Oblique | 83 | 10–20 | 10–15 | 5500–6800 |
| Overlap | Camera Angles | |||
| Camera images | 90/90 or 70/70 | Nadir + oblique camera angles |
| Scanner Specifications | Leica Scan Station P50 |
|---|---|
| Scan rate | 976,000 points/s |
| Range | 0.6–120 m |
| Range error | 2 mm at 10 m (90% reflectivity) |
| Range noise | 0.6 mm at 10 m (90% reflectivity) |
| Total image resolution | Up to 70 Mpix |
| Leica Scan Station P50 | |
|---|---|
| Stations | 6 |
| 3D points | 1,001,065 |
| Scan durations | 5 h |
| Mean resolution (mm) | 3–5 |
| Reg.prec.Register (mm) | 6 |
| Reg.prec.Cyclone(mm) | 4 |
| Step | Overlap | Camera Angles |
|---|---|---|
| Initial processing | Keypoint image scale Matching image pairs Calibration | Full Aerial grid or corridor Standard ( camera self-calibration) |
| Point cloud densification | Image scale Point density Minimum number of matches Matching window size | Original image size (slow) Multiscale Optimal 4 9 9 pixels |
| Alignment | Photogrammetry | TLS | Data Fusion 1 | Data Fusion 2 |
|---|---|---|---|---|
| Total input data size | 2.74 G | 2.88 G | 5.6 G | 5.2 G |
| Number of registered images | 239/239 | 239/239 | 239/239 | |
| Number of registered laser scans | 6/6 | 6/6 | 6/6 | |
| Number of points | 1,804,180 | 1,001,065 | 2,805,245 | 2,504,328 |
| Metric scale | No | Yes | Yes | |
| Reconstruction | ||||
| Number of vertices | 15,328,689 | 13,306,254 | 27,025,188 | 23,058,878 |
| Number of faces | 31,058,214 | 27,258,687 | 55,557,121 | 51,028.339 |
| Photogrammetry | TLS | Data Fusion 1 | Data Fusion 2 | |
|---|---|---|---|---|
| GCP RMSE (cm) | 14.9 | 2.5 | 13 | 5 |
| Image-Based | TLS | Data Fusion 1 | Data Fusion 2 | |
|---|---|---|---|---|
| Pre-processed time | 20 min | 2 h: 30 min | 3 h: 10 min | 30 min |
| Meshing time | 10 min | 2 h: 15 min | 3 h: 45 min | 3 h: 10 min |
| Texturing time | 10 min | 3 h: 20 min | 5 h: 10 min | 4 h |
| Total time | 40 min | 8 h: 05 min | 12 h: 05 min | 7 h: 40 min |
| Photogrammetry | TLS | Data Fusion 1 | Data Fusion 2 | |
|---|---|---|---|---|
| Mean | 71 | 111 | 100 | 81 |
| Std.dev. | 32 | 48 | 42 | 36 |
| Number of black pixels | 1436 | 1,768,325 | 4015 | 3867 |
| Number of white pixels | 1568 | 3,664,783 | 916,487 | 803,721 |
| Percentage of black pixels | 0.00089% | 1.02% | 0.0028% | 0.0019% |
| Percentage of white pixels | 0.00093% | 2.23% | 0.52% | 0.47% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, L.; Zhang, H.; Mbachu, J. Multi-Sensor Data Fusion for 3D Reconstruction of Complex Structures: A Case Study on a Real High Formwork Project. Remote Sens. 2023, 15, 1264. https://doi.org/10.3390/rs15051264
Zhao L, Zhang H, Mbachu J. Multi-Sensor Data Fusion for 3D Reconstruction of Complex Structures: A Case Study on a Real High Formwork Project. Remote Sensing. 2023; 15(5):1264. https://doi.org/10.3390/rs15051264
Chicago/Turabian StyleZhao, Linlin, Huirong Zhang, and Jasper Mbachu. 2023. "Multi-Sensor Data Fusion for 3D Reconstruction of Complex Structures: A Case Study on a Real High Formwork Project" Remote Sensing 15, no. 5: 1264. https://doi.org/10.3390/rs15051264
APA StyleZhao, L., Zhang, H., & Mbachu, J. (2023). Multi-Sensor Data Fusion for 3D Reconstruction of Complex Structures: A Case Study on a Real High Formwork Project. Remote Sensing, 15(5), 1264. https://doi.org/10.3390/rs15051264