
ResiDualGAN: Resize-Residual DualGAN for Cross-Domain Remote Sensing Images Semantic Segmentation


Abstract
:1. Introduction
- 1.
- A new architecture of GANs, ResiDualGAN, is implemented based on DualGAN to carry out unpaired RS images cross-domain translation and cross-domain semantic segmentation tasks, in which an in-network resizer module and a residual architecture are used to fully utilize unique features of RS images compared with images used in the CV field. The experiment results show the superiority and stability of the ResiDualGAN. Our source code is available at https://github.com/miemieyanga/ResiDualGAN-DRDG (accessed on 12 January 2023).
- 2.
- To the best of our knowledge, the proposed method reaches state-of-the-art performance when carrying out a cross-domain semantic segmentation task between two open-source datasets: Potsdam and Vaihingen [36]. The mIoU and F1-score are 55.83% and 68.04%, respectively, when carrying out a segmentation task from PotsdamIRRG to Vaihingen, showing increases of 11.71% and 11.09% compared with state-of-the-art methodologies.
- 3.
- On the foundation of thorough experiments and analyses, this paper attempts to explain the reason why such great improvement could be achieved by implementing this kind of simple modification, which should be specially noted when a method from the CV field is applied to RS images processing.
2. Method
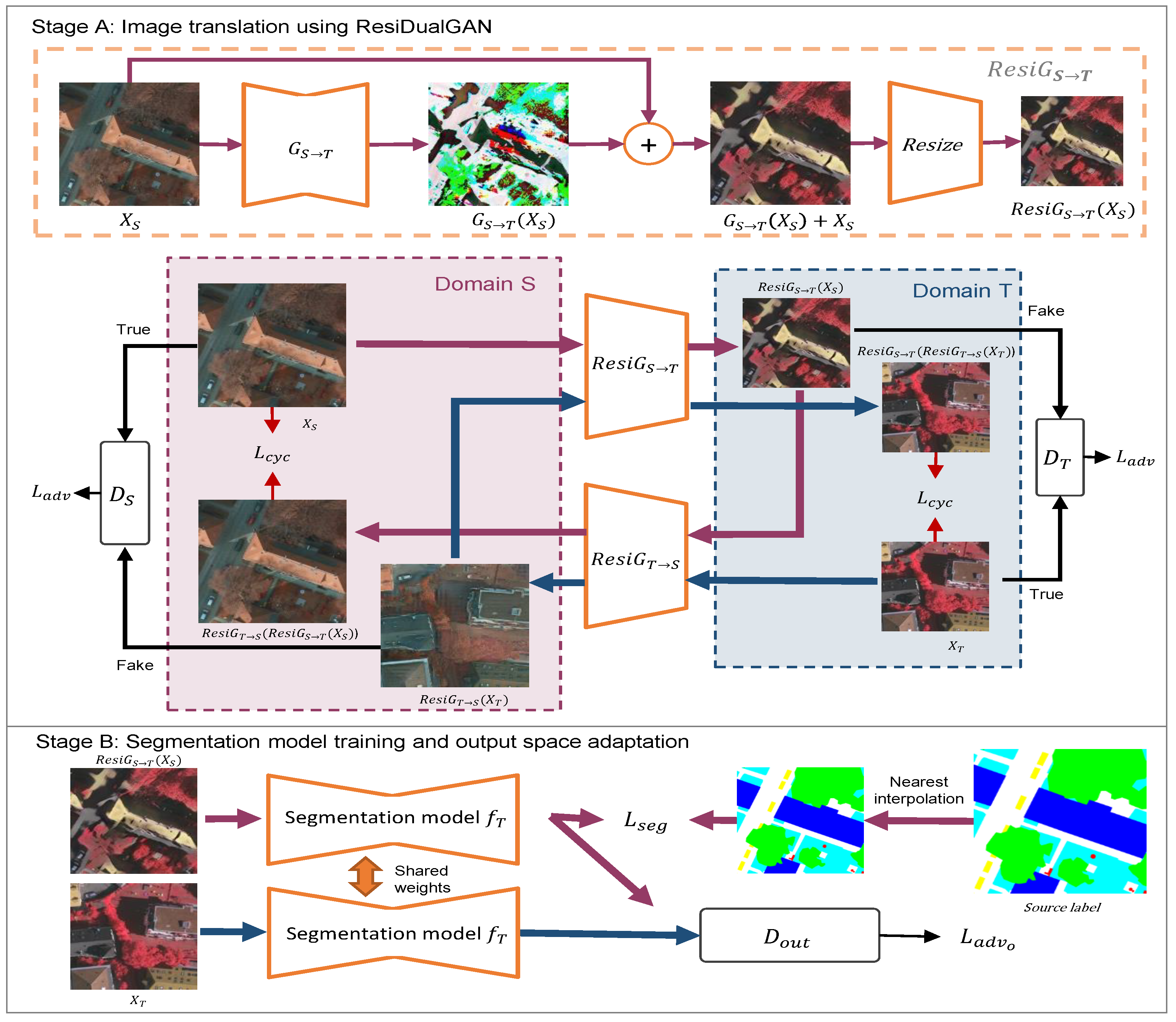
2.1. Stage A: Image Translation Using ResiDualGAN
2.1.1. Overall
2.1.2. ResiGenerator
2.1.3. Adversarial Loss
2.1.4. Reconstruction Loss
2.1.5. Total Loss
2.2. Stage B: Segmentation Model Training
2.2.1. Overall
2.2.2. Discriminator Training
2.2.3. Semantic Segmentation Training
2.2.4. Total Loss
2.3. Networks Settings
2.3.1. ResiGenerators
2.3.2. Discriminators
2.3.3. Output Space Discriminator
2.3.4. Segmentation Baseline
2.4. Training Settings
2.4.1. Stage A
2.4.2. Stage B
3. Experimental Results
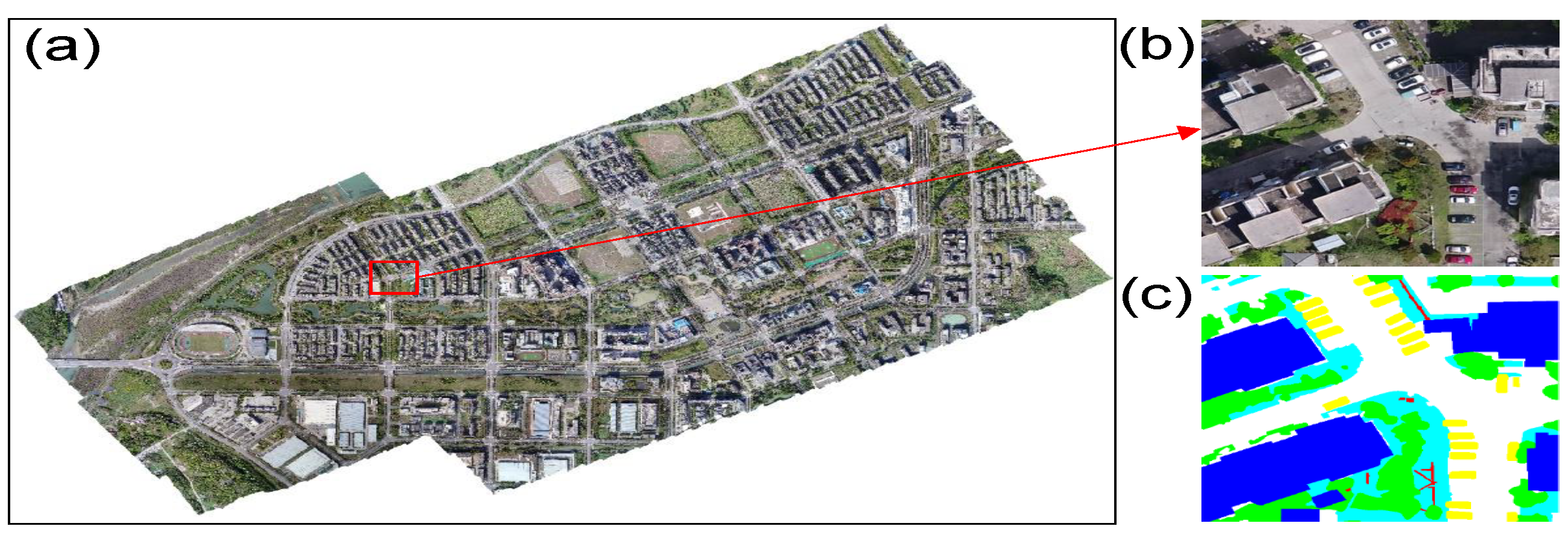
3.1. Datasets
3.2. Experimental Settings
- 1.
- IR-R-G to IR-R-G: PotsdamIRRG to Vaihingen. A commonly used benchmark for evaluating models.
- 2.
- R-G-B to IR-R-G: PotsdamRGB to Vaihingen. Another commonly used benchmark for evaluating models.
- 3.
- IR-R-G to RGB: PotsdamIRRG to BC403. Instead of using PotsdamRGB as the target dataset, where channels of R and G are identical with PotsdamIRRG, we use our annotated BC403 dataset to perform this cross-domain task.
3.3. Evaluation Metrics
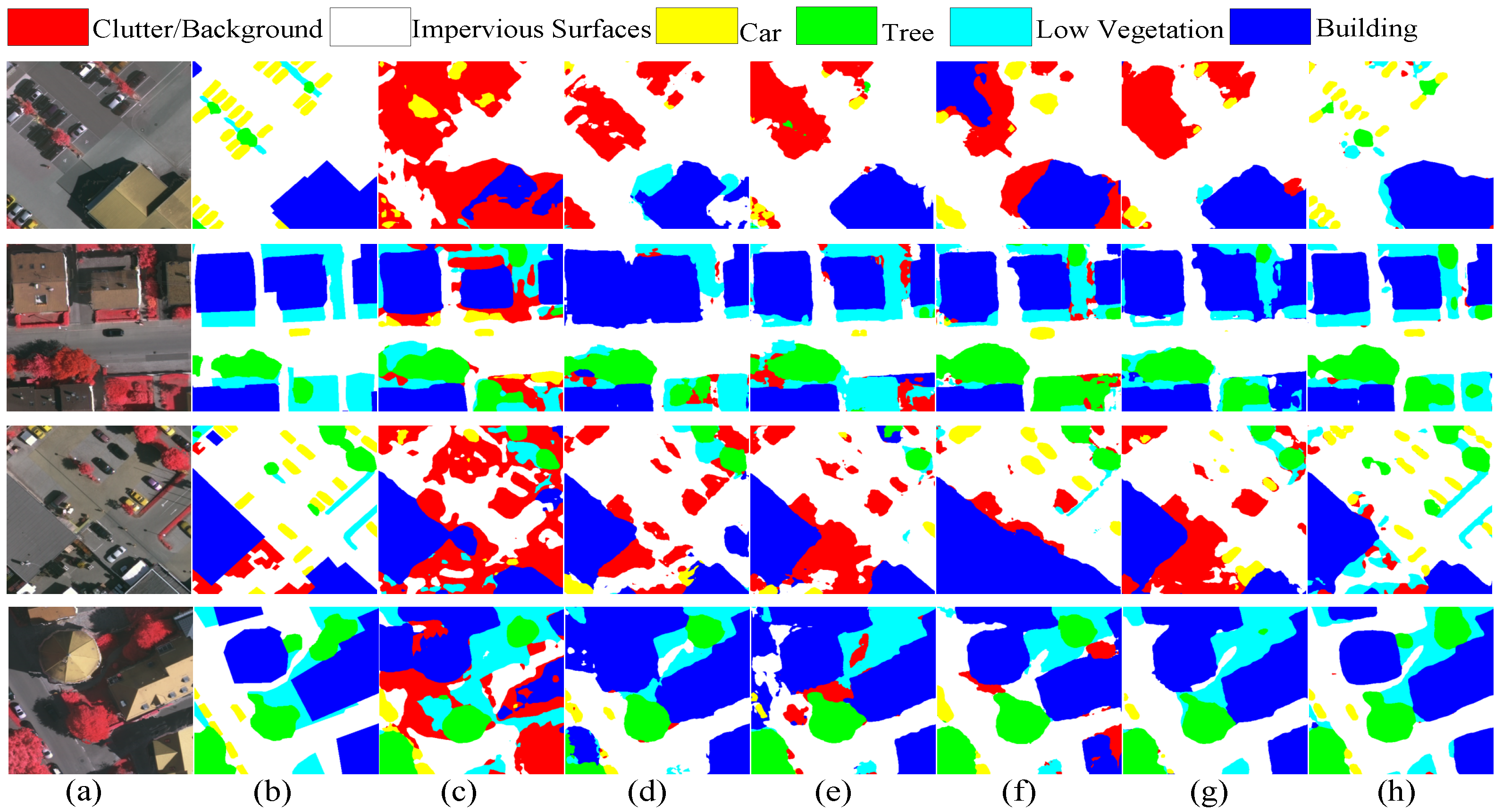
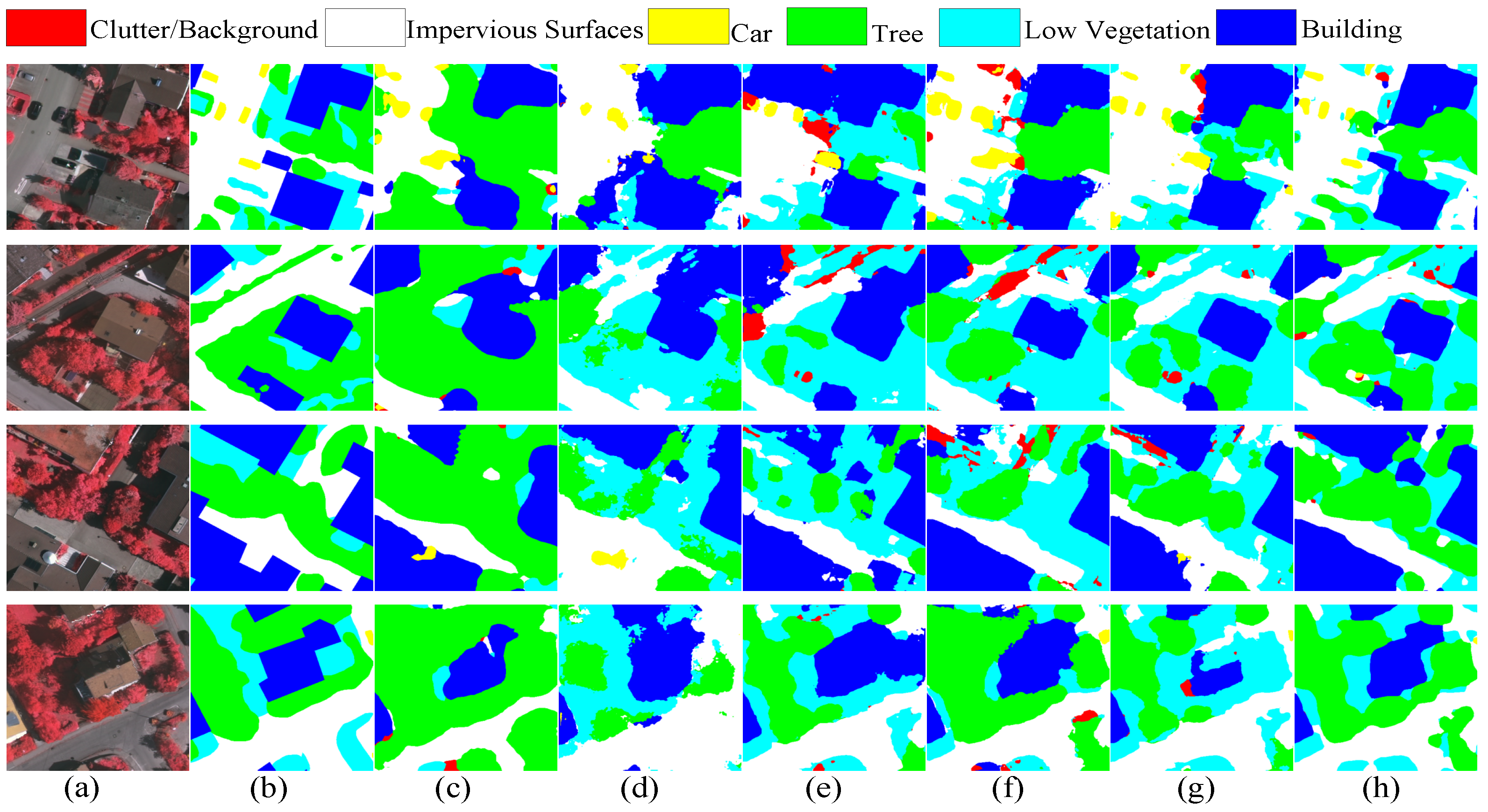
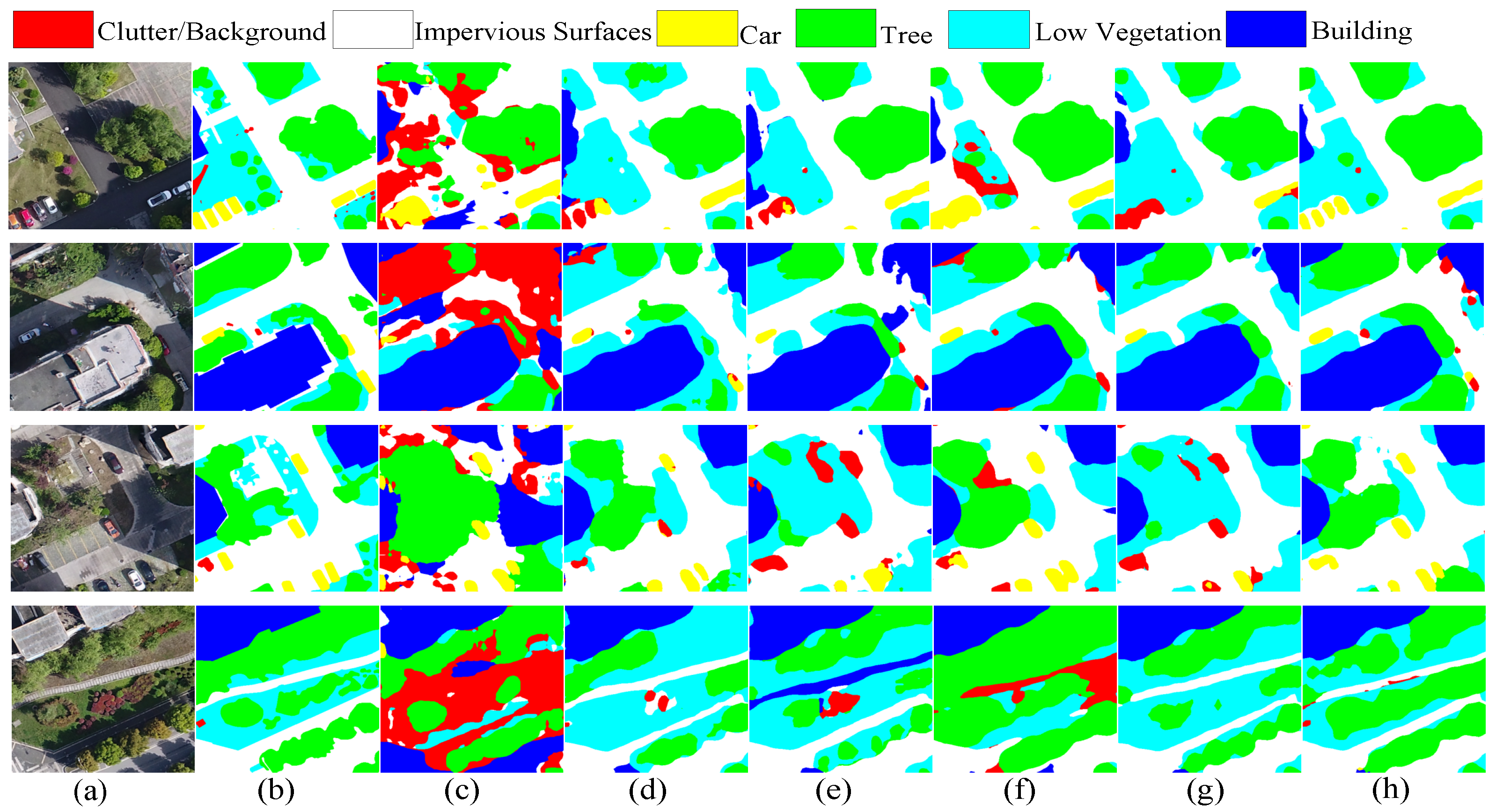
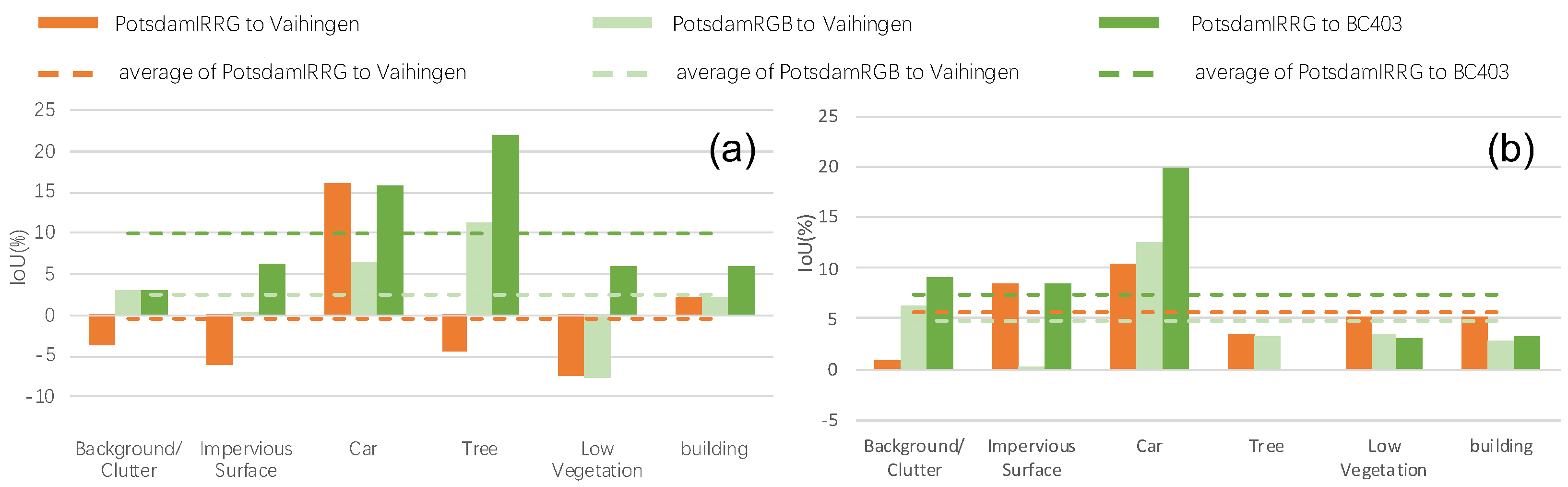
3.4. Compared with the State-of-the-Art Methods
4. Discussion
4.1. Hyperparameters Settings
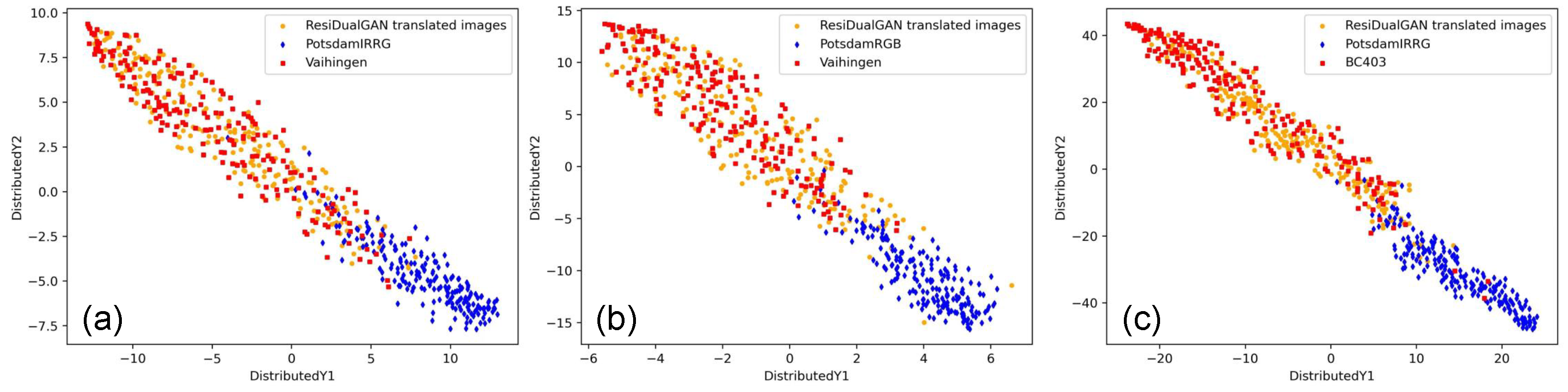
4.2. Image Translation
4.3. Ablation Study
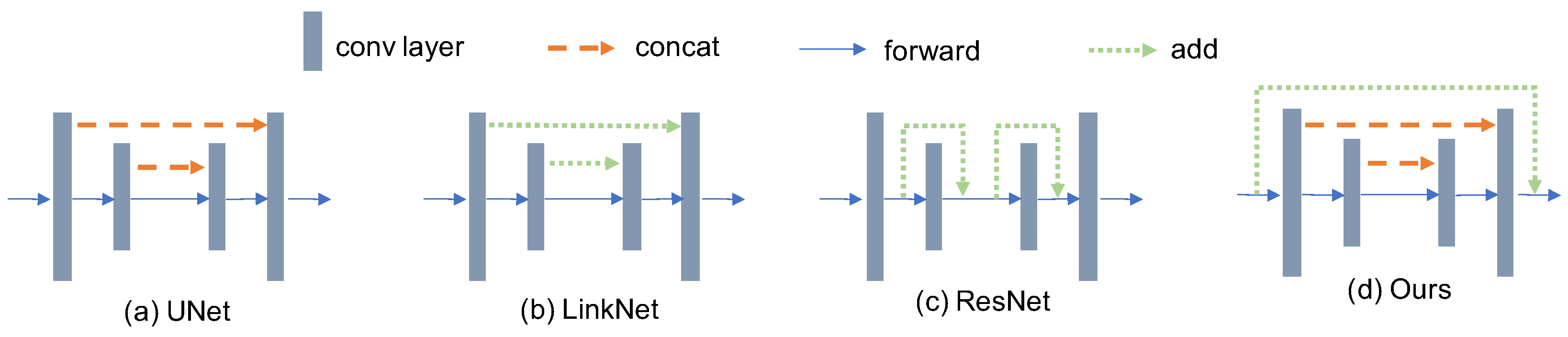
4.3.1. Resizer Module
4.3.2. Resizing Function
4.3.3. Backbone
4.3.4. Residual Connection
4.3.5. Fixed k
4.4. Output Space Adaptation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gao, H.; Guo, J.; Guo, P.; Chen, X. Classification of Very-High-Spatial-Resolution Aerial Images Based on Multiscale Features with Limited Semantic Information. Remote Sens. 2021, 13, 364. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; Curran Associates, Inc.: Red Hook, NY, USA, 2012; Volume 25. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhou, R.; Zhang, W.; Yuan, Z.; Rong, X.; Liu, W.; Fu, K.; Sun, X. Weakly Supervised Semantic Segmentation in Aerial Imagery via Explicit Pixel-Level Constraints. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Saha, S.; Shahzad, M.; Mou, L.; Song, Q.; Zhu, X.X. Unsupervised single-scene semantic segmentation for Earth observation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Pan, X.; Xu, J.; Zhao, J.; Li, X. Hierarchical Object-Focused and Grid-Based Deep Unsupervised Segmentation Method for High-Resolution Remote Sensing Images. Remote Sens. 2022, 14, 5768. [Google Scholar] [CrossRef]
- Yuan, X.; Shi, J.; Gu, L. A review of deep learning methods for semantic segmentation of remote sensing imagery. Expert Syst. Appl. 2021, 169, 114417. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Y.; Georgiou, T.; Lew, M.S. A review of semantic segmentation using deep neural networks. Int. J. Multimed. Inf. Retr. 2018, 7, 87–93. [Google Scholar] [CrossRef] [Green Version]
- Zhang, B.; Chen, T.; Wang, B. Curriculum-Style Local-to-Global Adaptation for Cross-Domain Remote Sensing Image Segmentation. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–12. [Google Scholar] [CrossRef]
- Li, Y.; Shi, T.; Zhang, Y.; Chen, W.; Wang, Z.; Li, H. Learning deep semantic segmentation network under multiple weakly-supervised constraints for cross-domain remote sensing image semantic segmentation. ISPRS J. Photogramm. Remote Sens. 2021, 175, 20–33. [Google Scholar] [CrossRef]
- Yao, X.; Wang, Y.; Wu, Y.; Liang, Z. Weakly-Supervised Domain Adaptation With Adversarial Entropy for Building Segmentation in Cross-Domain Aerial Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8407–8418. [Google Scholar] [CrossRef]
- Bousmalis, K.; Silberman, N.; Dohan, D.; Erhan, D.; Krishnan, D. Unsupervised pixel-level domain adaptation with generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3722–3731. [Google Scholar]
- Shrivastava, A.; Pfister, T.; Tuzel, O.; Susskind, J.; Wang, W.; Webb, R. Learning from simulated and unsupervised images through adversarial training. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2107–2116. [Google Scholar]
- Yan, Z.; Yu, X.; Qin, Y.; Wu, Y.; Han, X.; Cui, S. Pixel-level Intra-domain Adaptation for Semantic Segmentation. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 404–413. [Google Scholar]
- Ganin, Y.; Lempitsky, V. Unsupervised Domain Adaptation by Backpropagation. In Proceedings of the 32nd International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 1180–1189. [Google Scholar]
- Tsai, Y.H.; Hung, W.C.; Schulter, S.; Sohn, K.; Yang, M.H.; Chandraker, M. Learning to adapt structured output space for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7472–7481. [Google Scholar]
- Wang, H.; Shen, T.; Zhang, W.; Duan, L.Y.; Mei, T. Classes Matter: A Fine-Grained Adversarial Approach to Cross-Domain Semantic Segmentation. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 642–659. [Google Scholar]
- Zou, Y.; Yu, Z.; Kumar, B.; Wang, J. Unsupervised domain adaptation for semantic segmentation via class-balanced self-training. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 289–305. [Google Scholar]
- Tranheden, W.; Olsson, V.; Pinto, J.; Svensson, L. Dacs: Domain adaptation via cross-domain mixed sampling. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 1379–1389. [Google Scholar]
- Hoyer, L.; Dai, D.; Van Gool, L. Daformer: Improving network architectures and training strategies for domain-adaptive semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9924–9935. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 139–144. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Benjdira, B.; Bazi, Y.; Koubaa, A.; Ouni, K. Unsupervised Domain Adaptation Using Generative Adversarial Networks for Semantic Segmentation of Aerial Images. Remote Sens. 2019, 11, 1369. [Google Scholar] [CrossRef] [Green Version]
- Ji, S.; Wang, D.; Luo, M. Generative Adversarial Network-Based Full-Space Domain Adaptation for Land Cover Classification From Multiple-Source Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 3816–3828. [Google Scholar] [CrossRef]
- Shi, L.; Wang, Z.; Pan, B.; Shi, Z. An End-to-End Network for Remote Sensing Imagery Semantic Segmentation via Joint Pixel- and Representation-Level Domain Adaptation. IEEE Geosci. Remote Sens. Lett. 2021, 18, 1896–1900. [Google Scholar] [CrossRef]
- Shi, T.; Li, Y.; Zhang, Y. Rotation Consistency-Preserved Generative Adversarial Networks for Cross-Domain Aerial Image Semantic Segmentation. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 8668–8671. [Google Scholar]
- Tasar, O.; Happy, S.; Tarabalka, Y.; Alliez, P. ColorMapGAN: Unsupervised domain adaptation for semantic segmentation using color mapping generative adversarial networks. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7178–7193. [Google Scholar] [CrossRef] [Green Version]
- Bai, L.; Du, S.; Zhang, X.; Wang, H.; Liu, B.; Ouyang, S. Domain Adaptation for Remote Sensing Image Semantic Segmentation: An Integrated Approach of Contrastive Learning and Adversarial Learning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Wittich, D.; Rottensteiner, F. Appearance based deep domain adaptation for the classification of aerial images. ISPRS J. Photogramm. Remote Sens. 2021, 180, 82–102. [Google Scholar] [CrossRef]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. Dualgan: Unsupervised dual learning for image-to-image translation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2849–2857. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Richter, S.R.; Vineet, V.; Roth, S.; Koltun, V. Playing for Data: Ground Truth from Computer Games. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science. Springer International Publishing: Cham, Switzerland, 2016; pp. 102–118. [Google Scholar] [CrossRef] [Green Version]
- ISPRS WG III/4. ISPRS 2D Semantic Labeling Contest. Available online: https://www2.isprs.org/commissions/comm2/wg4/benchmark/semantic-labeling (accessed on 3 January 2023).
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the 34th International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved Training of Wasserstein GANs. arXiv 2017, arXiv:1704.00028v3. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance normalization: The missing ingredient for fast stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 17–19 June 2013; Volume 30, p. 3. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Diederik, P.K.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Tieleman, T.; Hinton, G. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Hu, X.; Xu, X.; Xiao, Y.; Chen, H.; He, S.; Qin, J.; Heng, P.A. SINet: A scale-insensitive convolutional neural network for fast vehicle detection. IEEE Trans. Intell. Transp. Syst. 2018, 20, 1010–1019. [Google Scholar] [CrossRef] [Green Version]
- Gao, Y.; Guo, S.; Huang, K.; Chen, J.; Gong, Q.; Zou, Y.; Bai, T.; Overett, G. Scale optimization for full-image-CNN vehicle detection. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 785–791. [Google Scholar]
- Chaurasia, A.; Culurciello, E. Linknet: Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Talebi, H.; Milanfar, P. Learning to Resize Images for Computer Vision Tasks. arXiv 2021, arXiv:2103.09950. [Google Scholar]
- Zheng, C.; Cham, T.J.; Cai, J. T2net: Synthetic-to-realistic translation for solving single-image depth estimation tasks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 767–783. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Background/Clutter | Impervious Surface | Car | Tree | Low Vegetation | Building | Overall | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IoU | F1Score | IoU | F1Score | IoU | F1Score | IoU | F1Score | IoU | F1Score | IoU | F1Score | IoU | F1Score | |
| Baseline (DeeplabV3 [43]) | 2.12 | 4.01 | 47.68 | 64.47 | 20.39 | 33.62 | 51.37 | 67.81 | 30.25 | 46.38 | 65.74 | 79.28 | 36.26 | 49.26 |
| Benjdira’s [26] | 6.93 | 9.95 | 57.41 | 72.67 | 20.74 | 33.46 | 44.31 | 61.08 | 35.60 | 52.17 | 65.71 | 79.12 | 38.45 | 51.41 |
| DualGAN [33] | 7.70 | 11.12 | 57.98 | 73.04 | 25.20 | 39.43 | 46.12 | 62.79 | 33.77 | 50.00 | 64.24 | 78.02 | 39.17 | 52.40 |
| AdaptSegNet [18] | 5.84 | 9.01 | 62.81 | 76.88 | 29.43 | 44.83 | 55.84 | 71.45 | 40.16 | 56.87 | 70.64 | 82.66 | 44.12 | 56.95 |
| MUCSS [12] | 10.82 | 14.35 | 65.81 | 79.03 | 26.19 | 40.67 | 50.60 | 66.88 | 39.73 | 56.39 | 69.16 | 81.58 | 43.72 | 56.48 |
| ResiDualGAN | 8.20 | 13.71 | 68.15 | 81.03 | 49.50 | 66.06 | 61.37 | 76.03 | 40.82 | 57.86 | 75.50 | 86.02 | 50.59 | 63.45 |
| ResiDualGAN + OSA | 11.64 | 18.42 | 72.29 | 83.89 | 57.01 | 72.51 | 63.81 | 77.88 | 49.69 | 66.29 | 80.57 | 89.23 | 55.83 | 68.04 |
| Methods | Background/Clutter | Impervious Surface | Car | Tree | Low Vegetation | Building | Overall | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IoU | F1Score | IoU | F1Score | IoU | F1Score | IoU | F1Score | IoU | F1Score | IoU | F1Score | IoU | F1Score | |
| Baseline ((DeeplabV3 [43]) | 1.81 | 3.43 | 46.29 | 63.17 | 13.53 | 23.70 | 40.23 | 57.27 | 14.57 | 25.39 | 60.78 | 75.56 | 29.53 | 41.42 |
| Benjdira’s [26] | 2.03 | 3.14 | 48.48 | 64.99 | 25.99 | 40.57 | 41.97 | 58.87 | 23.33 | 37.50 | 64.53 | 78.26 | 34.39 | 47.22 |
| DualGAN [33] | 3.97 | 6.67 | 49.94 | 66.23 | 20.61 | 33.18 | 42.08 | 58.87 | 27.98 | 43.40 | 62.03 | 76.35 | 34.44 | 47.45 |
| AdaptSegNet [18] | 6.49 | 9.82 | 55.70 | 71.24 | 33.85 | 50.05 | 47.72 | 64.31 | 22.86 | 36.75 | 65.70 | 79.15 | 38.72 | 51.89 |
| MUCSS [12] | 8.78 | 12.78 | 57.85 | 73.04 | 16.11 | 26.65 | 38.20 | 54.87 | 34.43 | 50.89 | 71.91 | 83.56 | 37.88 | 50.30 |
| ResiDualGAN | 8.80 | 13.90 | 52.01 | 68.35 | 42.58 | 59.58 | 59.88 | 74.87 | 31.42 | 47.69 | 69.61 | 82.04 | 44.05 | 57.74 |
| ResiDualGAN +OSA | 9.76 | 16.08 | 55.54 | 71.36 | 48.49 | 65.19 | 57.79 | 73.21 | 29.15 | 44.97 | 78.97 | 88.23 | 46.62 | 59.84 |
| Methods | Background/Clutter | Impervious Surface | Car | Tree | Low Vegetation | Building | Overall | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IoU | F1Score | IoU | F1Score | IoU | F1Score | IoU | F1Score | IoU | F1Score | IoU | F1Score | IoU | F1Score | |
| Baseline (DeeplabV3 [43]) | 2.74 | 5.26 | 27.35 | 42.44 | 35.68 | 52.22 | 43.18 | 60.02 | 11.43 | 19.99 | 60.51 | 75.20 | 30.15 | 42.52 |
| Benjdira’s [26] | 4.79 | 6.54 | 68.37 | 79.65 | 47.99 | 54.76 | 22.69 | 45.76 | 22.68 | 42.05 | 72.57 | 80.85 | 39.85 | 51.60 |
| DualGAN [33] | 3.52 | 8.78 | 66.48 | 80.97 | 39.26 | 64.35 | 30.58 | 36.68 | 28.03 | 35.73 | 68.53 | 83.63 | 39.40 | 51.69 |
| AdaptSegNet [18] | 4.57 | 8.17 | 56.37 | 72.03 | 50.90 | 66.95 | 52.01 | 67.87 | 14.70 | 25.06 | 74.38 | 85.17 | 42.15 | 54.21 |
| MUCSS [12] | 3.13 | 5.86 | 71.83 | 83.35 | 27.72 | 41.62 | 32.53 | 48.17 | 27.95 | 42.08 | 78.82 | 87.82 | 40.33 | 51.48 |
| ResiDualGAN | 13.79 | 23.72 | 72.26 | 83.64 | 61.06 | 75.69 | 46.56 | 62.76 | 33.73 | 49.67 | 76.08 | 86.15 | 50.58 | 63.61 |
| ResiDualGAN + OSA | 13.25 | 23.03 | 75.51 | 85.95 | 61.32 | 75.87 | 51.22 | 67.18 | 35.35 | 51.33 | 82.51 | 90.24 | 53.19 | 65.60 |
| Hyperparameters Settings | mIoU | F1 | |
|---|---|---|---|
| 53.29 | 66.09 | ||
| 56.80 | 68.46 | ||
| 55.10 | 67.39 | ||
| 56.00 | 68.24 | ||
| 56.71 | 69.10 | ||
| 1, 10) | 56.80 | 68.46 | |
| 54.79 | 67.34 | ||
| 54.43 | 67.33 | ||
| 52.69 | 65.02 | ||
| 55.73 | 68.26 | ||
| 53.39 | 65.51 | ||
| 55.12 | 67.10 | ||
| 54.98 | 67.56 | ||
| Experiment | Method | mIoU | F1 |
|---|---|---|---|
| Resize | No Resize | 44.97 | 58.51 |
| Pre-resize | 53.46 | 66.10 | |
| In-network Resize | 55.83 | 68.04 | |
| Resizing Function | Nearest | 53.86 | 66.30 |
| Bilinear | 55.83 | 68.04 | |
| Resizer model | 52.97 | 65.88 | |
| Backbone | ResNet [44] | 52.51 | 65.33 |
| LinkNet [51] | 52.22 | 64.84 | |
| U-Net [4] | 55.83 | 68.04 | |
| Residual Connection | No Residual | 38.67 | 52.37 |
| Residual (fixed k) | 55.83 | 68.04 | |
| k | Learnable | 54.05 | 67.02 |
| Fixed | 55.83 | 68.04 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Guo, P.; Sun, Z.; Chen, X.; Gao, H. ResiDualGAN: Resize-Residual DualGAN for Cross-Domain Remote Sensing Images Semantic Segmentation. Remote Sens. 2023, 15, 1428. https://doi.org/10.3390/rs15051428
Zhao Y, Guo P, Sun Z, Chen X, Gao H. ResiDualGAN: Resize-Residual DualGAN for Cross-Domain Remote Sensing Images Semantic Segmentation. Remote Sensing. 2023; 15(5):1428. https://doi.org/10.3390/rs15051428
Chicago/Turabian StyleZhao, Yang, Peng Guo, Zihao Sun, Xiuwan Chen, and Han Gao. 2023. "ResiDualGAN: Resize-Residual DualGAN for Cross-Domain Remote Sensing Images Semantic Segmentation" Remote Sensing 15, no. 5: 1428. https://doi.org/10.3390/rs15051428
APA StyleZhao, Y., Guo, P., Sun, Z., Chen, X., & Gao, H. (2023). ResiDualGAN: Resize-Residual DualGAN for Cross-Domain Remote Sensing Images Semantic Segmentation. Remote Sensing, 15(5), 1428. https://doi.org/10.3390/rs15051428