


Hyperspectral Denoising Using Asymmetric Noise Modeling Deep Image Prior



Abstract
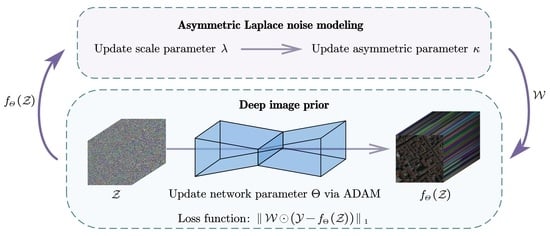
:
1. Introduction
- We propose ALDIP for HSI mixed noise removal. More specifically, we combine a more suitable and reasonable noise model with DIP. Our model hypothesizes real-world HSI noise obeys asymmetric Laplace (AL) distribution.
- ALDIP-SSTV is presented by incorporating the SSTV term to fully utilize spatial–spectral information for performance improvement.
- A variety of experiments are conducted that rigorously validate the effectiveness of our methods. The result shows that our methods outperform many state-of-the-art methods.
2. Related Works
2.1. Low-Rank Models for HSI Denoising
2.2. Deep Learning Based Methods for HSI Denoising
2.3. Noise Modeling for HSI Denoising
2.4. Deep Image Prior
3. Proposed Model
3.1. Model Formulation
3.2. Solving Algorithm
| Algorithm 1: ALDIP or ALDIP-SSTV. |
 |
4. Experiments
- Low-rank methods: fast hyperspectral denoising (FastHyDe) [56], which is based on low-rank and sparse representations.
4.1. Synthetic Data Experiment
- Indian Pines: ground truth of the scene gathered by AVIRIS sensor over the Indian Pines test site in north-western Indiana with pixels and 224 bands.
- Pavia Centre: a cropped HSI with 200 × 200 pixels and 80 bands acquired by the ROSIS sensor during a flight campaign over Pavia, northern Italy.
4.2. Real Data Experiments
- Shanghai: captured by the GaoFen-5 satellite with 300 × 300 pixels and 155 bands.
- Terrain: captured by Hyperspectral Digital Imagery Collection Experiment with 500 × 307 pixels and 210 bands.
- Urban: captured by Hyperspectral Digital Imagery Collection Experiment with 307 × 307 pixels and 210 bands.
4.3. Sensitivity Analysis
4.4. Execution Time
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Nasrabadi, N.M. Hyperspectral target detection: An overview of current and future challenges. IEEE Signal Process. Mag. 2013, 31, 34–44. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep learning-based classification of hyperspectral data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Ding, Y.; Zhang, Z.; Zhao, X.; Hong, D.; Cai, W.; Yu, C.; Yang, N.; Cai, W. Multi-feature fusion: Graph neural network and CNN combining for hyperspectral image classification. Neurocomputing 2022, 501, 246–257. [Google Scholar] [CrossRef]
- Yao, D.; Zhi-li, Z.; Xiao-feng, Z.; Wei, C.; Fang, H.; Yao-ming, C.; Cai, W.W. Deep hybrid: Multi-graph neural network collaboration for hyperspectral image classification. Def. Technol. 2022, in press. [CrossRef]
- Ding, Y.; Zhang, Z.; Zhao, X.; Cai, Y.; Li, S.; Deng, B.; Cai, W. Self-supervised locality preserving low-pass graph convolutional embedding for large-scale hyperspectral image clustering. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5536016. [Google Scholar] [CrossRef]
- Ding, Y.; Zhang, Z.; Zhao, X.; Cai, W.; Yang, N.; Hu, H.; Huang, X.; Cao, Y.; Cai, W. Unsupervised self-correlated learning smoothy enhanced locality preserving graph convolution embedding clustering for hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5536716. [Google Scholar] [CrossRef]
- Ding, Y.; Zhao, X.; Zhang, Z.; Cai, W.; Yang, N.; Zhan, Y. Semi-supervised locality preserving dense graph neural network with ARMA filters and context-aware learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5511812. [Google Scholar] [CrossRef]
- Zhang, Z.; Ding, Y.; Zhao, X.; Siye, L.; Yang, N.; Cai, Y.; Zhan, Y. Multireceptive field: An adaptive path aggregation graph neural framework for hyperspectral image classification. Expert Syst. Appl. 2023, 217, 119508. [Google Scholar] [CrossRef]
- Rasti, B.; Sveinsson, J.R.; Ulfarsson, M.O.; Benediktsson, J.A. Hyperspectral image denoising using 3D wavelets. In Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 1349–1352. [Google Scholar]
- Qian, Y.; Ye, M. Hyperspectral imagery restoration using nonlocal spectral-spatial structured sparse representation with noise estimation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 6, 499–515. [Google Scholar] [CrossRef]
- Zelinski, A.; Goyal, V. Denoising hyperspectral imagery and recovering junk bands using wavelets and sparse approximation. In Proceedings of the 2006 IEEE International Symposium on Geoscience and Remote Sensing, Denver, CO, USA, 31 July 31–4 August 2006; pp. 387–390. [Google Scholar]
- Rasti, B.; Sveinsson, J.R.; Ulfarsson, M.O.; Benediktsson, J.A. Hyperspectral image denoising using first order spectral roughness penalty in wavelet domain. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 7, 2458–2467. [Google Scholar] [CrossRef]
- Chen, S.L.; Hu, X.Y.; Peng, S.L. Hyperspectral imagery denoising using a spatial-spectral domain mixing prior. J. Comput. Sci. Technol. 2012, 27, 851–861. [Google Scholar] [CrossRef]
- Rasti, B.; Sveinsson, J.R.; Ulfarsson, M.O.; Benediktsson, J.A. Wavelet based hyperspectral image restoration using spatial and spectral penalties. In Proceedings of the Image and Signal Processing for Remote Sensing XIX, Dresden, Germany, 23–26 September 2013; Volume 8892, pp. 135–142. [Google Scholar]
- Wright, J.; Ganesh, A.; Rao, S.; Peng, Y.; Ma, Y. Robust principal component analysis: Exact recovery of corrupted low-rank matrices via convex optimization. Adv. Neural Inf. Process. Syst. 2009, 22, 5249–5257. [Google Scholar]
- Zhang, H.; He, W.; Zhang, L.; Shen, H.; Yuan, Q. Hyperspectral image restoration using low-rank matrix recovery. IEEE Trans. Geosci. Remote Sens. 2013, 52, 4729–4743. [Google Scholar] [CrossRef]
- Zhu, R.; Dong, M.; Xue, J.H. Spectral nonlocal restoration of hyperspectral images with low-rank property. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 8, 3062–3067. [Google Scholar] [CrossRef]
- Wang, M.; Yu, J.; Xue, J.H.; Sun, W. Denoising of hyperspectral images using group low-rank representation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 4420–4427. [Google Scholar] [CrossRef] [Green Version]
- Xu, S.; Cao, X.; Peng, J.; Ke, Q.; Ma, C.; Meng, D. Hyperspectral Image Denoising by Asymmetric Noise Modeling. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Renard, N.; Bourennane, S.; Blanc-Talon, J. Denoising and dimensionality reduction using multilinear tools for hyperspectral images. IEEE Geosci. Remote Sens. Lett. 2008, 5, 138–142. [Google Scholar] [CrossRef]
- Bai, X.; Xu, F.; Zhou, L.; Xing, Y.; Bai, L.; Zhou, J. Nonlocal similarity based nonnegative tucker decomposition for hyperspectral image denoising. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 701–712. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Peng, J.; Zhao, Q.; Leung, Y.; Zhao, X.L.; Meng, D. Hyperspectral image restoration via total variation regularized low-rank tensor decomposition. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 11, 1227–1243. [Google Scholar] [CrossRef] [Green Version]
- Karami, A.; Yazdi, M.; Asli, A.Z. Noise reduction of hyperspectral images using kernel non-negative tucker decomposition. IEEE J. Sel. Top. Signal Process. 2011, 5, 487–493. [Google Scholar] [CrossRef]
- Dong, W.; Wang, H.; Wu, F.; Shi, G.; Li, X. Deep spatial–spectral representation learning for hyperspectral image denoising. IEEE Trans. Comput. Imaging 2019, 5, 635–648. [Google Scholar] [CrossRef]
- Xie, W.; Li, Y. Hyperspectral imagery denoising by deep learning with trainable nonlinearity function. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1963–1967. [Google Scholar] [CrossRef]
- Wei, K.; Fu, Y.; Huang, H. 3-D quasi-recurrent neural network for hyperspectral image denoising. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 363–375. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Maffei, A.; Haut, J.M.; Paoletti, M.E.; Plaza, J.; Bruzzone, L.; Plaza, A. A single model CNN for hyperspectral image denoising. IEEE Trans. Geosci. Remote Sens. 2019, 58, 2516–2529. [Google Scholar] [CrossRef]
- Chang, Y.; Yan, L.; Fang, H.; Zhong, S.; Liao, W. HSI-DeNet: Hyperspectral image restoration via convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2018, 57, 667–682. [Google Scholar] [CrossRef]
- Sidorov, O.; Yngve Hardeberg, J. Deep hyperspectral prior: Single-image denoising, inpainting, super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Luo, Y.S.; Zhao, X.L.; Jiang, T.X.; Zheng, Y.B.; Chang, Y. Hyperspectral mixed noise removal via spatial-spectral constrained unsupervised deep image prior. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 9435–9449. [Google Scholar] [CrossRef]
- Imamura, R.; Itasaka, T.; Okuda, M. Zero-shot hyperspectral image denoising with separable image prior. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Deep image prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9446–9454. [Google Scholar]
- Aggarwal, H.K.; Majumdar, A. Hyperspectral image denoising using spatio-spectral total variation. IEEE Geosci. Remote Sens. Lett. 2016, 13, 442–446. [Google Scholar] [CrossRef]
- Sidiropoulos, N.D.; De Lathauwer, L.; Fu, X.; Huang, K.; Papalexakis, E.E.; Faloutsos, C. Tensor decomposition for signal processing and machine learning. IEEE Trans. Signal Process. 2017, 65, 3551–3582. [Google Scholar] [CrossRef]
- Xue, J.; Zhao, Y.; Liao, W.; Chan, J.C.W. Nonlocal low-rank regularized tensor decomposition for hyperspectral image denoising. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5174–5189. [Google Scholar] [CrossRef]
- Xue, J.; Zhao, Y.; Liao, W.; Kong, S.G. Joint spatial and spectral low-rank regularization for hyperspectral image denoising. IEEE Trans. Geosci. Remote Sens. 2017, 56, 1940–1958. [Google Scholar] [CrossRef]
- He, W.; Yao, Q.; Li, C.; Yokoya, N.; Zhao, Q. Non-local meets global: An integrated paradigm for hyperspectral denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6868–6877. [Google Scholar]
- Yang, Y.; Zheng, J.; Chen, S.; Zhang, M. Hyperspectral image restoration via local low-rank matrix recovery and Moreau-enhanced total variation. IEEE Geosci. Remote Sens. Lett. 2019, 17, 1037–1041. [Google Scholar] [CrossRef]
- He, W.; Zhang, H.; Zhang, L.; Shen, H. Total-variation-regularized low-rank matrix factorization for hyperspectral image restoration. IEEE Trans. Geosci. Remote Sens. 2015, 54, 178–188. [Google Scholar] [CrossRef]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Yuan, Q.; Zhang, Q.; Li, J.; Shen, H.; Zhang, L. Hyperspectral image denoising employing a Spatial–Spectral deep residual convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1205–1218. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Yuan, Q.; Li, J.; Liu, X.; Shen, H.; Zhang, L. Hybrid noise removal in hyperspectral imagery with a Spatial–Spectral gradient network. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7317–7329. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhai, D.; Jiang, J.; Liu, X. ADRN: Attention-based deep residual network for hyperspectral image denoising. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 2668–2672. [Google Scholar]
- Shi, Q.; Tang, X.; Yang, T.; Liu, R.; Zhang, L. Hyperspectral image denoising using a 3-D attention denoising network. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10348–10363. [Google Scholar] [CrossRef]
- Wang, Z.; Shao, Z.; Huang, X.; Wang, J.; Lu, T. SSCAN: A spatial–spectral cross attention network for hyperspectral image denoising. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Pan, E.; Ma, Y.; Mei, X.; Fan, F.; Huang, J.; Ma, J. Sqad: Spatial-spectral quasi-attention recurrent network for hyperspectral image denoising. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Meng, D.; De La Torre, F. Robust matrix factorization with unknown noise. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1337–1344. [Google Scholar]
- Han, Z.; Wang, Y.; Zhao, Q.; Meng, D.; Lin, L.; Tang, Y. A generalized model for robust tensor factorization with noise modeling by mixture of Gaussians. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5380–5393. [Google Scholar]
- Luo, Q.; Han, Z.; Chen, X.; Wang, Y.; Meng, D.; Liang, D.; Tang, Y. Tensor rpca by bayesian cp factorization with complex noise. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5019–5028. [Google Scholar]
- Chen, Y.; Cao, X.; Zhao, Q.; Meng, D.; Xu, Z. Denoising hyperspectral image with non-iid noise structure. IEEE Trans. Cybern. 2017, 48, 1054–1066. [Google Scholar] [CrossRef] [Green Version]
- Cao, X.; Chen, Y.; Zhao, Q.; Meng, D.; Wang, Y.; Wang, D.; Xu, Z. Low-rank matrix factorization under general mixture noise distributions. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 1493–1501. [Google Scholar]
- Cao, X.; Zhao, Q.; Meng, D.; Chen, Y.; Xu, Z. Robust low-rank matrix factorization under general mixture noise distributions. IEEE Trans. Image Process. 2016, 25, 4677–4690. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, J.; Sun, Y.; Xu, X.; Kamilov, U.S. Image restoration using total variation regularized deep image prior. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 7715–7719. [Google Scholar]
- Mataev, G.; Milanfar, P.; Elad, M. DeepRED: Deep image prior powered by RED. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Cascarano, P.; Sebastiani, A.; Comes, M.C.; Franchini, G.; Porta, F. Combining weighted total variation and deep image prior for natural and medical image restoration via ADMM. In Proceedings of the 2021 21st International Conference on Computational Science and Its Applications (ICCSA), Cagliari, Italy, 13–16 September 2021; pp. 39–46. [Google Scholar]
- Zhuang, L.; Bioucas-Dias, J.M. Fast hyperspectral image denoising and inpainting based on low-rank and sparse representations. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 730–742. [Google Scholar] [CrossRef]
- Peng, J.; Wang, Y.; Zhang, H.; Wang, J.; Meng, D. Exact decomposition of joint low rankness and local smoothness plus sparse matrices. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 5766–5781. [Google Scholar] [CrossRef] [PubMed]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case | Gaussian Noise | Impulse Noise | Deadline | Stripe | ||||
|---|---|---|---|---|---|---|---|---|
| Bands | Bands | p | Bands | q | Bands | q | ||
| Case 1 | all bands | 0.05 | - | - | - | - | - | - |
| Case 2 | all bands | 0.01∼0.05 * | - | - | - | - | - | - |
| Case 3 | all bands | 0.01 | all bands | 0.1 | - | - | - | - |
| Case 4 | all bands | 0.01 | all bands | 0.1 | 10% bands | 35 | - | - |
| Case 5 | all bands | 0.01 | all bands | 0.1 | 20% bands | 35 | 20% bands | 35 |
| Case 6 | all bands | 0.01 | all bands | 0.15 | 30% bands | 35 | 30% bands | 35 |
| Case 7 | all bands | 0.01 | all bands | 0.25 | 40% bands | 35 | 40% bands | 35 |
| Case 8 | all bands | 0.01 | all bands | 0.3 | 50% bands | 35 | 50% bands | 35 |
| Case 9 | all bands | 0.01 | all bands | 0.35 | 50% bands | 40 | 50% bands | 40 |
| Case 10 | all bands | 0.01 | all bands | 0.4 | 50% bands | 45 | 50% bands | 45 |
| Case 11 | all bands | 0.01 | all bands | 0.3 | 60% bands | 35 | 60% bands | 35 |
| Case 12 | all bands | 0.01 | all bands | 0.3 | 70% bands | 3 5 | 70% bands | 35 |
| Cases | Metrics | Noisy | FastHyDe | LRTV | LRTDTV | NMoG | BALMF | CTV | DIP2D- | DIP2D- | S2DIP | ALDIP | ALDIP-SSTV |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Case 1 | PSNR | 26.03 | 39.23 | 43.76 | 43.44 | 39.05 | 36.13 | 40.08 | 41.04 | 40.10 | 44.91 | 40.10 | 41.84 |
| SSIM | 0.6036 | 0.9590 | 0.9929 | 0.9956 | 0.9583 | 0.9092 | 0.9721 | 0.9780 | 0.9699 | 0.9971 | 0.9669 | 0.9816 | |
| SAM | 5.8973 | 1.1306 | 0.6230 | 0.6513 | 1.2091 | 1.7804 | 1.05 | 0.8983 | 0.9976 | 0.6930 | 0.9892 | 0.7755 | |
| ERGAS | 116.62 | 26.80 | 16.08 | 17.16 | 27.32 | 37.87 | 24.41 | 21.18 | 23.74 | 15.70 | 23.66 | 20.46 | |
| Case 2 | PSNR | 30.84 | 41.78 | 47.28 | 44.80 | 44.10 | 39.98 | 42.25 | 44.67 | 44.05 | 47.02 | 46.03 | 47.07 |
| SSIM | 0.7569 | 0.9812 | 0.9968 | 0.9973 | 0.9865 | 0.9561 | 0.9812 | 0.9904 | 0.9888 | 0.9981 | 0.9921 | 0.9947 | |
| SAM | 3.9517 | 0.8090 | 0.3974 | 0.5323 | 0.6781 | 1.2462 | 0.862 | 0.5932 | 0.6510 | 0.5345 | 0.5022 | 0.4529 | |
| ERGAS | 78.13 | 20.29 | 11.09 | 15.24 | 15.61 | 26.88 | 19.56 | 14.01 | 15.15 | 12.42 | 12.12 | 11.39 | |
| Case 3 | PSNR | 18.52 | 28.06 | 48.47 | 44.62 | 46.80 | 47.19 | 47.84 | 30.46 | 49.45 | 48.11 | 49.82 | 50.40 |
| SSIM | 0.4557 | 0.8076 | 0.9988 | 0.9980 | 0.9948 | 0.9947 | 0.9944 | 0.9133 | 0.9978 | 0.9993 | 0.9980 | 0.9984 | |
| SAM | 13.1936 | 2.7764 | 0.2494 | 0.4344 | 0.3999 | 0.4128 | 0.4319 | 1.8306 | 0.3375 | 0.2903 | 0.3218 | 0.3047 | |
| ERGAS | 273.80 | 92.08 | 8.96 | 15.68 | 16.75 | 11.03 | 10.24 | 69.44 | 8.74 | 9.41 | 7.86 | 7.48 | |
| Case 4 | PSNR | 17.10 | 24.74 | 37.09 | 39.96 | 35.24 | 41.96 | 44.11 | 30.27 | 48.99 | 48.06 | 49.76 | 50.31 |
| SSIM | 0.4073 | 0.7181 | 0.9655 | 0.9845 | 0.9809 | 0.9743 | 0.9692 | 0.9061 | 0.9978 | 0.9992 | 0.9979 | 0.9982 | |
| SAM | 17.9269 | 8.6414 | 2.8213 | 1.5948 | 5.6250 | 3.6964 | 1.5977 | 1.9643 | 0.2914 | 0.2979 | 0.3245 | 0.3057 | |
| ERGAS | 371.64 | 213.74 | 75.18 | 45.80 | 117.76 | 87.57 | 36.52 | 70.96 | 8.35 | 9.47 | 7.89 | 7.50 | |
| Case 5 | PSNR | 16.89 | 24.59 | 36.78 | 39.45 | 36.01 | 41.19 | 41.23 | 29.77 | 48.00 | 47.72 | 48.81 | 49.62 |
| SSIM | 0.3937 | 0.7089 | 0.9602 | 0.9792 | 0.9805 | 0.9662 | 0.9354 | 0.8975 | 0.9972 | 0.9991 | 0.9977 | 0.9981 | |
| SAM | 18.3366 | 8.7609 | 3.0209 | 1.6783 | 5.3124 | 3.2847 | 2.8146 | 2.3404 | 0.3566 | 0.3564 | 0.3558 | 0.3234 | |
| ERGAS | 377.49 | 217.16 | 81.72 | 51.00 | 111.17 | 84.29 | 61.26 | 76.72 | 10.06 | 10.31 | 9.28 | 8.18 | |
| Case 6 | PSNR | 16.06 | 22.94 | 36.18 | 38.91 | 40.04 | 39.93 | 37.91 | 29.72 | 47.24 | 47.55 | 48.66 | 49.54 |
| SSIM | 0.3622 | 0.6569 | 0.9584 | 0.9817 | 0.9830 | 0.9592 | 0.9880 | 0.8838 | 0.9968 | 0.9990 | 0.9973 | 0.9980 | |
| SAM | 20.8171 | 10.6067 | 2.5872 | 1.5086 | 5.0481 | 3.8595 | 1.0938 | 2.6751 | 0.4134 | 0.3835 | 0.3713 | 0.3334 | |
| ERGAS | 423.77 | 258.33 | 76.07 | 48.55 | 106.80 | 88.84 | 36.42 | 77.99 | 10.98 | 10.39 | 9.24 | 8.25 | |
| Case 7 | PSNR | 15.30 | 21.85 | 34.35 | 37.80 | 39.61 | 37.16 | 36.63 | 29.63 | 46.30 | 47.03 | 48.11 | 49.71 |
| SSIM | 0.3310 | 0.6335 | 0.9457 | 0.9763 | 0.9845 | 0.9369 | 0.9857 | 0.8871 | 0.9960 | 0.9987 | 0.9966 | 0.9975 | |
| SAM | 22.6722 | 11.0750 | 3.3362 | 1.3765 | 4.5066 | 3.9360 | 1.1551 | 2.9089 | 0.4594 | 0.4495 | 0.3846 | 0.3577 | |
| ERGAS | 461.45 | 278.01 | 84.80 | 43.50 | 94.44 | 98.32 | 40.56 | 80.22 | 12.44 | 11.48 | 9.77 | 8.37 | |
| Case 8 | PSNR | 14.52 | 19.96 | 32.80 | 36.49 | 39.31 | 35.02 | 35.66 | 29.18 | 46.01 | 46.61 | 47.95 | 49.32 |
| SSIM | 0.3012 | 0.5566 | 0.9300 | 0.9750 | 0.9849 | 0.9128 | 0.9838 | 0.8668 | 0.9959 | 0.9985 | 0.9969 | 0.9973 | |
| SAM | 24.6293 | 13.6830 | 3.2331 | 1.3849 | 4.3261 | 3.2084 | 1.2382 | 3.2743 | 0.4792 | 0.4933 | 0.4013 | 0.3914 | |
| ERGAS | 497.95 | 323.77 | 89.67 | 51.52 | 92.30 | 94.75 | 44.59 | 85.39 | 12.86 | 12.28 | 9.95 | 9.19 | |
| Case 9 | PSNR | 14.29 | 19.70 | 28.54 | 33.94 | 34.15 | 33.31 | 34.65 | 28.81 | 44.48 | 46.08 | 47.10 | 50.20 |
| SSIM | 0.2916 | 0.6960 | 0.9171 | 0.9444 | 0.9216 | 0.8749 | 0.9811 | 0.8525 | 0.9937 | 0.9981 | 0.9962 | 0.9981 | |
| SAM | 25.6182 | 12.3029 | 4.7091 | 2.6407 | 8.0042 | 5.0992 | 1.2395 | 3.6646 | 0.6310 | 0.5571 | 0.4811 | 0.3556 | |
| ERGAS | 518.06 | 313.29 | 123.04 | 80.01 | 180.95 | 132.82 | 48.79 | 91.31 | 16.00 | 13.39 | 11.94 | 8.18 | |
| Case 10 | PSNR | 14.08 | 19.12 | 27.13 | 31.01 | 29.21 | 29.56 | 33.66 | 28.84 | 42.70 | 46.14 | 46.99 | 49.79 |
| SSIM | 0.2831 | 0.6754 | 0.8783 | 0.9047 | 0.8376 | 0.8267 | 0.9777 | 0.8502 | 0.9919 | 0.9983 | 0.9959 | 0.9978 | |
| SAM | 26.8287 | 13.9469 | 5.8248 | 4.0121 | 10.7548 | 7.0674 | 1.4748 | 3.7119 | 0.7584 | 0.5570 | 0.4909 | 0.3923 | |
| ERGAS | 538.55 | 342.07 | 139.38 | 107.30 | 259.88 | 167.56 | 55.69 | 91.63 | 20.07 | 13.53 | 12.52 | 9.32 | |
| Case 11 | PSNR | 13.80 | 18.62 | 31.58 | 34.60 | 37.87 | 32.87 | 35.23 | 27.67 | 43.95 | 45.67 | 47.37 | 48.79 |
| SSIM | 0.2796 | 0.5233 | 0.9714 | 0.9615 | 0.9811 | 0.9003 | 0.9821 | 0.8369 | 0.9936 | 0.9982 | 0.9956 | 0.9972 | |
| SAM | 26.4903 | 14.6744 | 2.3998 | 2.0343 | 5.0204 | 4.4053 | 1.2945 | 3.9564 | 0.6378 | 0.5478 | 0.4563 | 0.4067 | |
| ERGAS | 531.88 | 349.84 | 79.30 | 63.94 | 104.89 | 108.83 | 47.07 | 101.46 | 16.17 | 13.65 | 10.70 | 9.56 | |
| Case 12 | PSNR | 13.14 | 17.55 | 31.01 | 33.62 | 35.51 | 31.37 | 34.6 | 27.31 | 43.29 | 45.44 | 45.54 | 48.05 |
| SSIM | 0.2576 | 0.4994 | 0.9706 | 0.9600 | 0.9657 | 0.8594 | 0.9804 | 0.8235 | 0.9931 | 0.9982 | 0.9949 | 0.9966 | |
| SAM | 28.0145 | 15.0541 | 2.4515 | 2.1039 | 6.0969 | 4.8016 | 1.4321 | 4.0036 | 0.6207 | 0.5570 | 0.4942 | 0.4582 | |
| ERGAS | 561.12 | 372.75 | 79.56 | 65.50 | 131.85 | 122.80 | 50.42 | 103.93 | 17.03 | 13.88 | 13.13 | 11.05 |
| Cases | Metrics | Noisy | FastHyDe | LRTV | LRTDTV | NMoG | BALMF | CTV | DIP2D- | DIP2D- | S2DIP | ALDIP | ALDIP-SSTV |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Case 1 | PSNR | 26.30 | 39.20 | 39.48 | 35.86 | 39.51 | 37.43 | 38.8 | 39.17 | 39.00 | 40.04 | 37.45 | 38.69 |
| SSIM | 0.7424 | 0.9800 | 0.9829 | 0.9620 | 0.9811 | 0.9680 | 0.9794 | 0.9809 | 0.9805 | 0.9845 | 0.9814 | 0.9840 | |
| SAM | 17.0067 | 3.7325 | 3.8531 | 4.6013 | 3.5918 | 5.3550 | 3.7128 | 3.7796 | 4.0133 | 3.0926 | 4.3570 | 4.0333 | |
| ERGAS | 175.10 | 40.62 | 39.03 | 58.34 | 39.22 | 50.16 | 41.83 | 40.37 | 41.22 | 36.22 | 49.91 | 43.81 | |
| Case 2 | PSNR | 31.65 | 41.78 | 42.08 | 37.46 | 44.68 | 41.65 | 41.78 | 41.98 | 42.59 | 43.80 | 43.47 | 44.10 |
| SSIM | 0.8729 | 0.9902 | 0.9912 | 0.9734 | 0.9938 | 0.9868 | 0.9902 | 0.9891 | 0.9907 | 0.9928 | 0.9943 | 0.9949 | |
| SAM | 12.1869 | 3.0119 | 3.0857 | 4.0471 | 2.5040 | 3.9117 | 2.7267 | 3.2144 | 2.9836 | 2.4591 | 2.5291 | 2.4204 | |
| ERGAS | 113.60 | 30.25 | 29.25 | 49.42 | 22.24 | 33.56 | 30.44 | 29.99 | 27.94 | 23.97 | 25.83 | 24.08 | |
| Case 3 | PSNR | 22.36 | 35.48 | 43.90 | 38.49 | 47.64 | 46.40 | 42.71 | 35.64 | 47.25 | 47.43 | 46.36 | 47.29 |
| SSIM | 0.6967 | 0.9662 | 0.9948 | 0.9806 | 0.9970 | 0.9964 | 0.9942 | 0.9673 | 0.9967 | 0.9969 | 0.9974 | 0.9975 | |
| SAM | 20.0879 | 4.1047 | 2.6064 | 3.3883 | 1.9752 | 2.0972 | 2.1413 | 4.9394 | 1.9686 | 1.8505 | 1.7034 | 1.7181 | |
| ERGAS | 273.22 | 60.78 | 24.40 | 43.81 | 15.86 | 18.88 | 30.51 | 59.42 | 16.09 | 15.74 | 17.51 | 16.00 | |
| Case 4 | PSNR | 21.57 | 32.82 | 43.60 | 36.12 | 47.52 | 45.64 | 42.07 | 35.53 | 47.20 | 47.39 | 46.40 | 47.35 |
| SSIM | 0.6549 | 0.9493 | 0.9946 | 0.9565 | 0.9969 | 0.9962 | 0.9942 | 0.9660 | 0.9967 | 0.9969 | 0.9974 | 0.9975 | |
| SAM | 23.0573 | 7.4007 | 2.6426 | 7.9608 | 2.0154 | 2.1448 | 2.1413 | 5.0382 | 1.9759 | 1.8543 | 1.7262 | 1.6897 | |
| ERGAS | 308.95 | 101.51 | 25.14 | 90.77 | 16.03 | 20.30 | 30.51 | 60.22 | 16.16 | 15.81 | 17.43 | 15.94 | |
| Case 5 | PSNR | 21.30 | 32.67 | 43.51 | 36.14 | 47.37 | 45.61 | 42.07 | 34.40 | 46.93 | 46.88 | 46.22 | 46.97 |
| SSIM | 0.6343 | 0.9471 | 0.9945 | 0.9560 | 0.9969 | 0.9960 | 0.9937 | 0.9583 | 0.9965 | 0.9966 | 0.9972 | 0.9973 | |
| SAM | 24.7838 | 7.5769 | 2.6701 | 8.1455 | 2.0495 | 2.2043 | 2.2856 | 5.6935 | 2.0375 | 1.9416 | 1.8048 | 1.8292 | |
| ERGAS | 319.28 | 103.08 | 25.37 | 86.62 | 16.29 | 20.43 | 33.02 | 69.52 | 16.67 | 16.75 | 17.93 | 16.75 | |
| Case 6 | PSNR | 20.12 | 31.57 | 43.27 | 36.53 | 46.95 | 45.47 | 41.82 | 34.04 | 46.42 | 46.74 | 46.67 | 47.21 |
| SSIM | 0.5786 | 0.9312 | 0.9943 | 0.9584 | 0.9967 | 0.9957 | 0.9934 | 0.9524 | 0.9963 | 0.9965 | 0.9966 | 0.9974 | |
| SAM | 27.9489 | 8.3278 | 2.6936 | 7.9102 | 2.0806 | 2.2514 | 2.2472 | 5.9020 | 2.1359 | 1.9748 | 2.0690 | 1.7600 | |
| ERGAS | 363.07 | 116.00 | 26.00 | 85.87 | 17.06 | 21.18 | 33.27 | 72.71 | 17.71 | 16.98 | 17.24 | 16.34 | |
| Case 7 | PSNR | 19.02 | 30.37 | 43.12 | 36.30 | 47.03 | 45.47 | 41.4 | 33.53 | 46.04 | 46.00 | 46.40 | 46.95 |
| SSIM | 0.5223 | 0.9210 | 0.9941 | 0.9593 | 0.9966 | 0.9954 | 0.9929 | 0.9466 | 0.9960 | 0.9961 | 0.9963 | 0.9972 | |
| SAM | 31.2914 | 8.8795 | 2.7314 | 7.6461 | 2.1179 | 2.3055 | 2.2937 | 6.0722 | 2.1985 | 2.1082 | 2.1499 | 1.8355 | |
| ERGAS | 408.59 | 127.06 | 26.27 | 80.63 | 16.91 | 21.26 | 35.1 | 77.29 | 18.60 | 18.61 | 18.15 | 17.15 | |
| Case 8 | PSNR | 18.45 | 29.59 | 42.69 | 35.64 | 46.79 | 45.08 | 41.08 | 32.85 | 45.62 | 45.90 | 46.12 | 46.48 |
| SSIM | 0.4854 | 0.9076 | 0.9935 | 0.9538 | 0.9965 | 0.9950 | 0.9927 | 0.9386 | 0.9956 | 0.9960 | 0.9961 | 0.9971 | |
| SAM | 32.6879 | 9.3407 | 2.7869 | 8.3467 | 2.1769 | 2.4255 | 2.3561 | 6.4693 | 2.2487 | 2.0995 | 2.1969 | 1.8739 | |
| ERGAS | 436.01 | 133.66 | 27.50 | 89.53 | 17.59 | 22.48 | 35.61 | 83.97 | 19.73 | 18.76 | 18.84 | 18.20 | |
| Case 9 | PSNR | 17.85 | 28.79 | 41.96 | 34.91 | 44.94 | 43.03 | 40.73 | 31.97 | 44.18 | 44.20 | 44.57 | 45.20 |
| SSIM | 0.4520 | 0.8932 | 0.9927 | 0.9506 | 0.9951 | 0.9909 | 0.9919 | 0.9294 | 0.9943 | 0.9946 | 0.9949 | 0.9952 | |
| SAM | 34.6958 | 10.5187 | 3.0950 | 8.1836 | 2.8347 | 3.3299 | 2.4071 | 6.8319 | 2.8962 | 2.7547 | 2.8309 | 2.7075 | |
| ERGAS | 466.46 | 148.92 | 31.78 | 91.92 | 24.96 | 33.94 | 37.9 | 92.21 | 26.54 | 25.90 | 25.74 | 24.12 | |
| Case 10 | PSNR | 17.41 | 28.42 | 41.50 | 34.22 | 44.23 | 42.53 | 39.48 | 31.32 | 43.95 | 44.28 | 44.42 | 45.00 |
| SSIM | 0.4261 | 0.8847 | 0.9922 | 0.9413 | 0.9944 | 0.9876 | 0.9902 | 0.9215 | 0.9939 | 0.9946 | 0.9948 | 0.9950 | |
| SAM | 35.8854 | 11.0685 | 3.1327 | 8.8384 | 3.0609 | 3.6675 | 3.2593 | 7.3129 | 2.9434 | 2.7617 | 2.8315 | 2.7416 | |
| ERGAS | 491.22 | 155.12 | 33.31 | 102.06 | 30.26 | 42.02 | 46.45 | 101.00 | 27.08 | 25.80 | 26.27 | 24.69 | |
| Case 11 | PSNR | 18.18 | 28.73 | 42.45 | 34.97 | 46.36 | 43.93 | 39.43 | 32.50 | 45.50 | 45.71 | 46.00 | 46.71 |
| SSIM | 0.4617 | 0.8992 | 0.9932 | 0.9522 | 0.9962 | 0.9933 | 0.9896 | 0.9354 | 0.9955 | 0.9958 | 0.9961 | 0.9963 | |
| SAM | 33.8180 | 9.6114 | 2.8141 | 7.3038 | 2.2481 | 2.6948 | 3.2593 | 6.6250 | 2.2602 | 2.1392 | 2.1863 | 2.0957 | |
| ERGAS | 449.56 | 144.97 | 28.39 | 84.59 | 18.79 | 26.89 | 46.45 | 87.30 | 19.79 | 19.19 | 18.89 | 17.47 | |
| Case 12 | PSNR | 17.81 | 27.76 | 41.79 | 34.73 | 45.43 | 42.80 | 39.3 | 32.02 | 44.92 | 45.07 | 45.67 | 46.52 |
| SSIM | 0.4357 | 0.8871 | 0.9924 | 0.9540 | 0.9959 | 0.9936 | 0.9896 | 0.9305 | 0.9951 | 0.9954 | 0.9959 | 0.9962 | |
| SAM | 35.8303 | 9.4789 | 2.8691 | 7.1715 | 2.3083 | 2.6295 | 3.1511 | 6.9558 | 2.3550 | 2.2468 | 2.2371 | 2.1170 | |
| ERGAS | 469.43 | 157.33 | 30.54 | 80.55 | 20.99 | 28.06 | 45.64 | 91.81 | 21.20 | 20.57 | 19.59 | 17.91 |
| Datasets | Metrics | Case 1 | Case 2 | Case 3 | Case 4 | Case 5 | Case 6 | Case 7 | Case 8 | Case 9 | Case 10 | Case 11 | Case 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Indian Pines | PSNR | −0.01 | 1.98 | 0.37 | 0.77 | 0.81 | 1.42 | 1.81 | 1.94 | 2.61 | 4.29 | 3.43 | 2.25 |
| SSIM | 0.0030 | 0.0033 | 0.0003 | 0.0001 | 0.0004 | 0.0005 | 0.0006 | 0.0010 | 0.0025 | 0.0040 | 0.0020 | 0.0018 | |
| SAM | 0.0084 | 0.1487 | 0.0157 | 0.0331 | 0.0008 | 0.0421 | 0.0748 | 0.0779 | 0.1499 | 0.2675 | 0.1815 | 0.1265 | |
| ERGAS | 0.09 | 3.03 | 0.89 | 0.46 | 0.78 | 1.74 | 2.67 | 2.91 | 4.06 | 7.55 | 5.47 | 3.90 | |
| Pavia Centre | PSNR | −1.55 | 0.87 | −0.89 | −0.80 | −0.71 | 0.25 | 0.37 | 0.50 | 0.39 | 0.47 | 0.50 | 0.75 |
| SSIM | 0.0009 | 0.0035 | 0.0007 | 0.0007 | 0.0007 | 0.0003 | 0.0002 | 0.0006 | 0.0006 | 0.0009 | 0.0006 | 0.0008 | |
| SAM | −0.3436 | 0.4545 | 0.2652 | 0.2496 | 0.2327 | 0.0669 | 0.0486 | 0.0519 | 0.0654 | 0.1119 | 0.9014 | 0.1179 | |
| ERGAS | −8.6971 | 2.1089 | −1.4204 | −1.2677 | −1.2612 | 0.4747 | 0.4451 | 0.8953 | 0.8005 | 0.8074 | 0.9014 | 1.6018 |
| Datasets | Metrics | DIP2D- | DIP2D- | S2DIP | ALDIP | ALDIP-SSTV |
|---|---|---|---|---|---|---|
| Indian Pines | Exe. time | 72.29 | 123.74 | 341.27 | 114.23 | 660.58 |
| PSNR | 29.27 | 45.75 | 46.61 | 47.44 | 50.00 | |
| Pavia Centre | Exe. time | 42.75 | 109.48 | 128.90 | 74.59 | 231.91 |
| PSNR | 32.03 | 44.91 | 44.95 | 45.74 | 46.46 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Xu, S.; Cao, X.; Ke, Q.; Ji, T.-Y.; Zhu, X. Hyperspectral Denoising Using Asymmetric Noise Modeling Deep Image Prior. Remote Sens. 2023, 15, 1970. https://doi.org/10.3390/rs15081970
Wang Y, Xu S, Cao X, Ke Q, Ji T-Y, Zhu X. Hyperspectral Denoising Using Asymmetric Noise Modeling Deep Image Prior. Remote Sensing. 2023; 15(8):1970. https://doi.org/10.3390/rs15081970
Chicago/Turabian StyleWang, Yifan, Shuang Xu, Xiangyong Cao, Qiao Ke, Teng-Yu Ji, and Xiangxiang Zhu. 2023. "Hyperspectral Denoising Using Asymmetric Noise Modeling Deep Image Prior" Remote Sensing 15, no. 8: 1970. https://doi.org/10.3390/rs15081970
APA StyleWang, Y., Xu, S., Cao, X., Ke, Q., Ji, T. -Y., & Zhu, X. (2023). Hyperspectral Denoising Using Asymmetric Noise Modeling Deep Image Prior. Remote Sensing, 15(8), 1970. https://doi.org/10.3390/rs15081970