




PolSAR Image Classification Based on Relation Network with SWANet

Abstract
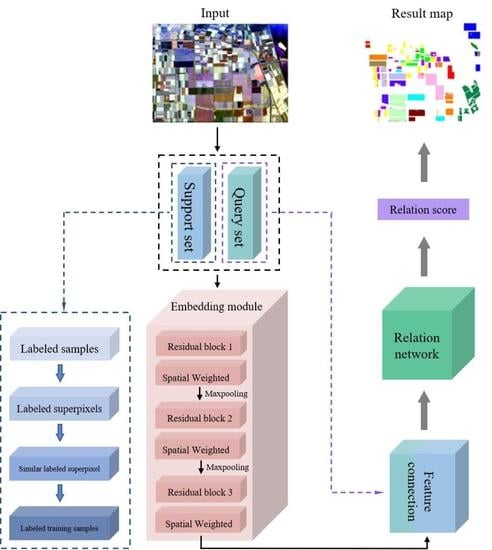
:
1. Introduction
- A new deep network 3D-ARRN is proposed for few-shot PolSAR image classification. This method can automatically select and extract features to achieve end-to-end final classification and effectively improve the classification results with fewer labeled samples.
- According to the properties of a PolSAR image, a spatial weighted attention network (SWANet) is proposed to select important spatial features to improve the network performance.
- We proposed a superpixels-based pseudo-labeled sample generation method, and used the pseudo-labeled sample to learn the transferrable representations. Then, the collected representations are transferred with limited labeled data to perform the few-shot PolSAR classification.
2. The Proposed Method
2.1. Polarimetric Representation
2.2. Feature Selection Based on SWANet
2.3. Relation Network
2.4. Pseudo-Labels Generation Algorithm
- Divide the Pauli image of PolSAR into Ns superpixels by turbopixels algorithm [42], and calculate the clustering center of each superpixel.
- Select the superpixel containing the support sample and give it the same label as the support sample (Figure 3b). Then, calculate the clustering center of these labeled superpixels.
- Among all superpixels, select the superpixel most similar to each class of labeled superpixel by Equation (9) and mark it.
- 4.
- Repeat step 3 until sufficient labeled superpixels are obtained (Figure 3c).
- 5.
- Calculate the distance from all pixels in each labeled superpixel to the center of the superpixel by Equation (13), and calculate the average value of these distances by Equation (14).
- 6.
- If the distance from any pixel in the labeled pixel to the superpixel center is less than the average distance , the label of the pixel is reserved; otherwise, the label of the pixel is removed (Figure 3d).
- 7.
- Output these pseudo-labels sample as the training data.
2.5. Architecture of the 3D-ARRN
| Algorithm 1. Framework of the 3D-ARRN for a training episode |
| Input: Support set , query set . |
| Output: The objective function of the RN in an episode. |
| 1: Obtain the vector representation of each support samples and query samples. |
| 2: The residual network and SWANet are used for feature extraction and selection of the support set and query set, and extracted features are expressed as and , respectively. |
| 3: Connect the feature maps of support set and query set by operator . |
| 4: The combined features are fed into the relational network to calculate the relational score between the query sample and the support samples and calculate the objective function in Equation (8). |
| 5: Return the objective function to be minimized to train the model. |
3. Experimental Design
3.1. Data Sets
3.2. Experimental Design Discussion of Key Parameters
3.2.1. Influence of Sample Window Size on Proposed Method
3.2.2. Influence of Labeled Samples on Proposed Method
3.2.3. Influence of Batch Size on Proposed Method
4. Experimental Results
4.1. Classification Results of the Flevoland I Dataset
4.2. Classification Results of the Flevoland II Dataset
4.3. Classification Results of the San Francisco Datasets
4.4. Classification Results of the Xi’an Datasets
4.5. Comparisons with Other PolSAR Classification Methods
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Parikh, H.; Patel, S.; Patel, V. Modeling PolSAR classification using convolutional neural network with homogeneity based kernel selection. Model. Earth Syst. Environ. 2023, 1–13. [Google Scholar] [CrossRef]
- Chen, J.; Xing, M.; Yu, H.; Liang, B.; Peng, J.; Sun, G.C. Motion Compensation/Autofocus in Airborne Synthetic Aperture Radar: A Review. IEEE Geosci. Remote Sens. Mag. 2022, 10, 185–206. [Google Scholar] [CrossRef]
- Jianlai, C.; Hanwen, Y. Wide-beam SAR autofocus based on blind resampling. Sci. China Inf. Sci. 2022, 66, 140304. [Google Scholar]
- Fang, Z.; Zhang, G.; Dai, Q.; Xue, B.; Wang, P. Hybrid Attention-Based Encoder–Decoder Fully Convolutional Network for PolSAR Image Classification. Remote Sens. 2023, 15, 526. [Google Scholar] [CrossRef]
- Yang, R.; Hu, Z.; Liu, Y.; Xu, Z. A Novel Polarimetric SAR Classification Method Integrating Pixel-Based and Patch-Based Classification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 431–435. [Google Scholar] [CrossRef]
- Jamali, A.; Roy, S.K.; Bhattacharya, A.; Ghamisi, P. Local Window Attention Transformer for Polarimetric SAR Image Classification. IEEE Geosci. Remote Sens. Lett. 2023, 1. [Google Scholar] [CrossRef]
- Chen, S.W.; Li, Y.Z.; Wang, X.S.; Xiao, S.P.; Sato, M. Modeling and Interpretation of Scattering Mechanisms in Polarimetric Synthetic Aperture Radar: Advances and perspectives. IEEE Signal Process. Mag. 2014, 31, 79–89. [Google Scholar] [CrossRef]
- Cloude, S.R.; Pottier, E. A review of target decomposition theorems in radar polarimetry. IEEE Trans. Geosci. Remote Sens. 1996, 34, 498–518. [Google Scholar] [CrossRef]
- Freeman, A.; Durden, S.L. A three-component scattering model for polarimetric SAR data. IEEE Trans. Geosci. Remote Sens. 1998, 36, 963–973. [Google Scholar] [CrossRef] [Green Version]
- Huynen, J.R. Phenomenological Theory of Radar Targets. Ph.D. Thesis, Faculty of Electrical Engineering, Mathematics and Computer Science, Delft, The Netherlands, 1970. [Google Scholar]
- Cloude, S.R.; Pottier, E. An entropy based classification scheme for land applications of polarimetric SAR. IEEE Trans. Geosci. Remote Sens. 1997, 35, 68–78. [Google Scholar] [CrossRef]
- Krogager, E. New decomposition of the radar target scattering matrix. Electron. Lett. 1990, 18, 1525–1527. [Google Scholar] [CrossRef]
- Jong-Sen, L.; Grunes, M.R.; Ainsworth, T.L.; Li-Jen, D.; Schuler, D.L.; Cloude, S.R. Unsupervised classification using polarimetric decomposition and the complex Wishart classifier. IEEE Trans. Geosci. Remote Sens. 1999, 37, 2249–2258. [Google Scholar] [CrossRef]
- Tao, C.; Chen, S.; Li, Y.; Xiao, S. PolSAR Land Cover Classification Based on Roll-Invariant and Selected Hidden Polarimetric Features in the Rotation Domain. Remote Sens. 2017, 9, 660. [Google Scholar] [CrossRef] [Green Version]
- Tao, M.; Zhou, F.; Liu, Y.; Zhang, Z. Tensorial Independent Component Analysis-Based Feature Extraction for Polarimetric SAR Data Classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2481–2495. [Google Scholar] [CrossRef]
- Long, Y.; Liu, X. SVM lithological classification of PolSAR image in Yushigou Area Qilian Mountain. Sci. J. Earth Sci. 2013, 3, 128–132. [Google Scholar]
- Ma, F.; Gao, F.; Sun, J.; Zhou, H.; Hussain, A. Attention Graph Convolution Network for Image Segmentation in Big SAR Imagery Data. Remote Sens. 2019, 11, 2586. [Google Scholar] [CrossRef] [Green Version]
- Xu, H.; Lv, X.; Wang, X.; Ren, Z.; Bodla, N.; Chellappa, R. Deep Regionlets: Blended Representation and Deep Learning for Generic Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1914–1927. [Google Scholar] [CrossRef] [Green Version]
- Geng, J.; Wang, H.; Fan, J.; Ma, X. SAR Image Classification via Deep Recurrent Encoding Neural Networks. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2255–2269. [Google Scholar] [CrossRef]
- Wang, L.; Yang, X.; Tan, H.; Bai, X.; Zhou, F. Few-Shot Class-Incremental SAR Target Recognition Based on Hierarchical Embedding and Incremental Evolutionary Network. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–11. [Google Scholar] [CrossRef]
- Liu, F.; Jiao, L.; Hou, B.; Yang, S. POL-SAR Image Classification Based on Wishart DBN and Local Spatial Information. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3292–3308. [Google Scholar] [CrossRef]
- Hu, Y.; Fan, J.; Wang, J. Classification of PolSAR Images Based on Adaptive Nonlocal Stacked Sparse Autoencoder. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1050–1054. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, H.; Xu, F.; Jin, Y.Q. Polarimetric SAR Image Classification Using Deep Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1935–1939. [Google Scholar] [CrossRef]
- Shang, R.; Wang, J.; Jiao, L.; Yang, X.; Li, Y. Spatial feature-based convolutional neural network for PolSAR image classification. Appl. Soft Comput. 2022, 123, 108922. [Google Scholar] [CrossRef]
- Cui, Y.; Liu, F.; Jiao, L.; Guo, Y.; Liang, X.; Li, L.; Yang, S.; Qian, X. Polarimetric Multipath Convolutional Neural Network for PolSAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Hua, W.; Wang, S.; Liu, H.; Liu, K.; Guo, Y.; Jiao, L. Semisupervised PolSAR Image Classification Based on Improved Cotraining. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4971–4986. [Google Scholar] [CrossRef]
- Wang, S.; Guo, Y.; Hua, W.; Liu, X.; Song, G.; Hou, B.; Jiao, L. Semi-Supervised PolSAR Image Classification Based on Improved Tri-Training with a Minimum Spanning Tree. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8583–8597. [Google Scholar] [CrossRef]
- Fang, Z.; Zhang, G.; Dai, Q.; Kong, Y.; Wang, P. Semisupervised Deep Convolutional Neural Networks Using Pseudo Labels for PolSAR Image Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Guo, J.; Wang, L.; Zhu, D.; Zhang, G. Semisupervised Classification of PolSAR Images Using a Novel Memory Convolutional Neural Network. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1199–1208. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one shot learning. Adv. Neural Inf. Process. Syst. 2016, 29, 1–12. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Chen, Z.; Fu, Y.; Wang, Y.-X.; Ma, L.; Liu, W.; Hebert, M. Image deformation meta-networks for one-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 8680–8689. [Google Scholar]
- Liu, B.; Yu, X.; Yu, A.; Zhang, P.; Wan, G.; Wang, R. Deep Few-Shot Learning for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2290–2304. [Google Scholar] [CrossRef]
- Gao, K.; Liu, B.; Yu, X.; Qin, J.; Zhang, P.; Tan, X. Deep Relation Network for Hyperspectral Image Few-Shot Classification. Remote Sens. 2020, 12, 923. [Google Scholar] [CrossRef] [Green Version]
- Tong, X.; Yin, J.; Han, B.; Qv, H. Few-Shot Learning with Attention-Weighted Graph Convolutional Networks for Hyperspectral Image Classification. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 25–28 October 2020; pp. 1686–1690. [Google Scholar]
- Zuo, X.; Yu, X.; Liu, B.; Zhang, P.; Tan, X. FSL-EGNN: Edge-Labeling Graph Neural Network for Hyperspectral Image Few-Shot Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, S.; Zou, B.; Dong, H. Unsupervised Deep Representation Learning and Few-Shot Classification of PolSAR Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, B.; Lu, R.; Zhang, H.; Liu, H.; Varshney, P.K. FusionNet: An Unsupervised Convolutional Variational Network for Hyperspectral and Multispectral Image Fusion. IEEE Trans. Image Process. 2020, 29, 7565–7577. [Google Scholar] [CrossRef]
- Levinshtein, A.; Stere, A.; Kutulakos, K.N.; Fleet, D.J.; Dickinson, S.J.; Siddiqi, K. TurboPixels: Fast Superpixels Using Geometric Flows. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 2290–2297. [Google Scholar] [CrossRef] [Green Version]
- Liu, L.; Hu, F.; Zhao, J. Action Recognition Based on Features Fusion and 3D Convolutional Neural Networks. In Proceedings of the 2016 9th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 10–11 December 2016; pp. 178–181. [Google Scholar]
- Zhang, L.; Chen, Z.; Zou, B.; Gao, Y. Polarimetric SAR Terrain Classification Using 3D Convolutional Neural Network. In Proceedings of the 2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 4551–4554. [Google Scholar]
- Jong-Sen, L.; Grunes, M.R.; Grandi, G.d. Polarimetric SAR speckle filtering and its implication for classification. IEEE Trans. Geosci. Remote Sens. 1999, 37, 2363–2373. [Google Scholar] [CrossRef]
- Liu, H.; Wang, Z.; Shang, F.; Yang, S.; Gou, S.; Jiao, L. Semi-Supervised Tensorial Locally Linear Embedding for Feature Extraction Using PolSAR Data. IEEE J. Sel. Top. Signal Process. 2018, 12, 1476–1490. [Google Scholar] [CrossRef]
- Wang, Y.; Cheng, J.; Zhou, Y.; Zhang, F.; Yin, Q. A Multichannel Fusion Convolutional Neural Network Based on Scattering Mechanism for PolSAR Image Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Wang, J.; Hou, B.; Jiao, L.; Wang, S. POL-SAR Image Classification Based on Modified Stacked Autoencoder Network and Data Distribution. IEEE Trans. Geosci. Remote Sens. 2020, 58, 1678–1695. [Google Scholar] [CrossRef]
- Zhang, P.; Tan, X.; Li, B.; Jiang, Y.; Song, W.; Li, M.; Wu, Y. PolSAR Image Classification Using Hybrid Conditional Random Fields Model Based on Complex-Valued 3-D CNN. IEEE Trans. Aerosp. Electron. Syst. 2021, 57, 1713–1730. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Description |
|---|---|
| H, a, A, , , | Cloude decomposition [9] |
| , , | Freeman–Durden decomposition [10] |
| , , | Krogager decomposition [12] |
| , , , , , , , , | Huynen decomposition [11] |
| , , | Pauli decomposition [8] |
| , | Roll-Invariant Polarimetric Features [7] |
| , , , , , | Elements from the coherency matrix |
| Proposed Method | ||||||
|---|---|---|---|---|---|---|
| Layer Name | Embedding Module | |||||
| Support Samples | Query Samples | |||||
| Output Shape | Filter Size | Padding | Output Shape | Filter Size | Padding | |
| Input | K × 1 × 9 × 15 × 15 | N/A | N | Q × 1 × 9 × 15 × 15 | N/A | N |
| Convolution1 | K × 9 × 9 × 15 × 15 | 1 × 9 × 3 × 3 × 3 | Y | Q × 9 × 9 × 15 × 15 | 1 × 9 × 3 × 3 × 3 | Y |
| Convolution2 | K × 9 × 9 × 15 × 15 | 9 × 9 × 3 × 3 × 3 | Y | Q × 9 × 9 × 15 × 15 | 9 × 9 × 3 × 3 × 3 | Y |
| Convolution3 | K × 9 × 9 × 15 × 15 | 9 × 9 × 3 × 3 × 3 | Y | Q × 9 × 9 × 15 × 15 | 9 × 9 × 3 × 3 × 3 | Y |
| Shortcut | Convolution1 + Convolution3 | Convolution1 + Convolution3 | ||||
| Spatial Weight | K × 9 × 9 × 15 × 15 | N/A | N | Q × 9 × 9 × 15 × 15 | N/A | N |
| Max pooling1 | K × 9 × 9 × 7 × 7 | 1 × 2 × 2 | N | Q × 9 × 9 × 7 × 7 | 1 × 2 × 2 | N |
| Convolution4 | K × 32 × 9 × 7 × 7 | 9 × 32 × 3 × 3 × 3 | Y | Q × 32 × 9 × 7 × 7 | 9 × 32 × 3 × 3 × 3 | Y |
| Convolution5 | K × 32 × 9 × 7 × 7 | 9 × 32 × 3 × 3 × 3 | Y | Q × 32 × 9 × 7 × 7 | 9 × 32 × 3 × 3 × 3 | Y |
| Convolution6 | K × 32 × 9 × 7 × 7 | 9 × 32 × 3 × 3 × 3 | Y | Q × 32 × 9 × 7 × 7 | 9 × 32 × 3 × 3 × 3 | Y |
| Short cut | Convolution4 + Convolution6 | Convolution4 + Convolution6 | ||||
| Spatial Weight | K × 32 × 9 × 7 × 7 | N/A | N | Q × 32 × 9 × 7 × 7 | N/A | N |
| Max pooling2 | K × 32 × 9 × 3 × 3 | 1 × 2 × 2 | N | Q × 32 × 9 × 3 × 3 | 1 × 2 × 2 | N |
| Convolution7 | K × 64 × 9 × 3 × 3 | 32 × 64 × 3 × 3 × 3 | Y | Q × 64 × 9 × 3 × 3 | 32 × 64 × 3 × 3 × 3 | Y |
| Convolution8 | K × 64 × 9 × 3 × 3 | 32 × 64 × 3 × 3 × 3 | Y | Q × 64 × 9 × 3 × 3 | 32 × 64 × 3 × 3 × 3 | Y |
| Convolution9 | K × 64 × 9 × 3 × 3 | 32 × 64 × 3 × 3 × 3 | Y | Q × 64 × 9 × 3 × 3 | 32 × 64 × 3 × 3 × 3 | Y |
| Shortcut | Convolution7 + Convolution9 | Convolution7 + Convolution9 | ||||
| Spatial Weight | K × 64 × 9 × 3 × 3 | N/A | N | Q × 64 × 9 × 3 × 3 | N/A | N |
| Relation module | ||||||
| Output Shape | Filter Size | Padding | ||||
| Convolution10 | Nm × 128 × 9 × 3 × 3 | 128 × 64 × 1 × 3 × 3 | Y | |||
| Max pooling3 | Nm × 64 × 11 × 1 × 1 | 1 × 2 × 2 | N | |||
| Convolution11 | Nm × 64 × 13 × 1 × 1 | 64 × 64 × 1 × 3 × 3 | Y | |||
| Flatten | Nm × 832 | N/A | N | |||
| Flatten | Nm × 8 | N/A | N | |||
| Output | Nm × 1 | N/A | N | |||
| Method | RN | RN-SWANet | RRN | RRN-SWANet | 3D-RRN | 3D-ARRN | |
|---|---|---|---|---|---|---|---|
| Region | |||||||
| Stem beans | 97.19 | 96.05 | 97.27 | 98.10 | 96.73 | 96.54 | |
| Rapeseed | 79.25 | 86.14 | 90.24 | 92.75 | 88.94 | 93.20 | |
| Bare soil | 99.71 | 99.98 | 100 | 99.49 | 99.96 | 99.71 | |
| Potatoes | 74.64 | 91.15 | 86.02 | 95.27 | 95.81 | 99.16 | |
| Beet | 88.38 | 89.42 | 95.21 | 97.77 | 93.12 | 93.76 | |
| Wheat 2 | 84.24 | 88.24 | 96.02 | 92.40 | 95.06 | 91.58 | |
| Peas | 91.28 | 92.88 | 98.59 | 99.82 | 99.70 | 98.68 | |
| Wheat 3 | 90.92 | 88.82 | 97.58 | 94.78 | 98.43 | 98.86 | |
| Lucerne | 97.39 | 93.61 | 96.35 | 94.04 | 96.94 | 98.24 | |
| Barley | 93.57 | 96.28 | 96.63 | 97.51 | 99.14 | 98.22 | |
| Wheat | 81.83 | 77.32 | 81.96 | 88.74 | 86.73 | 97.07 | |
| Grasses | 87.72 | 91.09 | 91.36 | 95.02 | 94.58 | 92.00 | |
| Forest | 93.87 | 96.20 | 96.16 | 94.95 | 97.12 | 97.71 | |
| Water | 77.52 | 83.97 | 83.83 | 87.91 | 96.52 | 90.45 | |
| Building | 88.60 | 91.07 | 93.54 | 97.66 | 95.74 | 98.35 | |
| OA | 87.05 | 89.70 | 92.57 | 94.22 | 95.23 | 96.22 | |
| Method | RN | RN-SWANet | RRN | RRN-SWANet | 3D-RRN | 3D-ARRN | |
|---|---|---|---|---|---|---|---|
| Region | |||||||
| Urban | 88.22 | 95.03 | 93.17 | 89.01 | 95.46 | 96.19 | |
| Water | 99.21 | 98.11 | 98.65 | 98.56 | 97.50 | 98.86 | |
| Forest | 92.78 | 91.69 | 94.04 | 92.26 | 91.09 | 92.78 | |
| Cropland | 80.23 | 84.16 | 84.13 | 89.95 | 92.41 | 93.20 | |
| OA | 89.98 | 91.55 | 92.08 | 92.79 | 93.84 | 95.03 | |
| Method | RN | RN-SWANet | RRN | RRN-SWANet | 3D-RRN | 3D-ARRN | |
|---|---|---|---|---|---|---|---|
| Region | |||||||
| Water | 93.07 | 98.80 | 99.79 | 99.43 | 99.75 | 99.98 | |
| Vegetation | 94.14 | 87.50 | 75.33 | 72.94 | 83.37 | 90.28 | |
| Low-Density Urban | 73.67 | 67.43 | 95.52 | 93.48 | 79.99 | 90.00 | |
| High-Density Urban | 84.86 | 89.97 | 90.78 | 96.61 | 95.15 | 92.73 | |
| Developed | 87.17 | 89.21 | 96.05 | 96.92 | 92.99 | 97.53 | |
| OA | 89.62 | 92.22 | 93.78 | 94.30 | 94.39 | 96.09 | |
| Method | RN | RN-SWANet | RRN | RRN-SWANet | 3D-RRN | 3D-ARRN | |
|---|---|---|---|---|---|---|---|
| Region | |||||||
| Bench land | 77.16 | 80.82 | 80.69 | 82.26 | 82.36 | 84.19 | |
| Urban | 79.66 | 76.92 | 84.93 | 82.43 | 85.08 | 92.41 | |
| River | 93.94 | 94.14 | 82.51 | 91.26 | 93.04 | 88.97 | |
| OA | 80.56 | 81.44 | 82.86 | 84.24 | 85.27 | 88.12 | |
| Method | 3D- ARRN | SVM | Wishart | 3D- CNN | SF- CNN | CNN +PL | 3D-CNN +PL | STLLE | MC- CNN | MAE | CV-3D- CNN | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Region | ||||||||||||
| Sample Number | Labeled Sample Per Class (The Total Number Is 105) | Training Ratio (The Total Number Is 1682) | ||||||||||
| 7 | 1% | |||||||||||
| Stem beans | 96.54 | 66.23 | 89.72 | 81.11 | 87.52 | 99.16 | 98.28 | 97.35 | 97.01 | 95.91 | 98.63 | |
| Rapeseed | 93.20 | 56.91 | 71.13 | 11.42 | 91.26 | 91.22 | 86.47 | 86.87 | 91.94 | 84.11 | 97.48 | |
| Bare soil | 99.71 | 79.51 | 98.04 | 94.03 | 100 | 100 | 99.86 | 97.46 | 91.70 | 92.62 | 92.74 | |
| Potatoes | 99.16 | 48.05 | 74.99 | 64.92 | 93.53 | 85.89 | 91.51 | 93.35 | 96.04 | 89.64 | 93.60 | |
| Beet | 93.76 | 68.66 | 91.32 | 85.25 | 96.25 | 96.82 | 96.95 | 96.99 | 93.26 | 95.77 | 95.21 | |
| Wheat 2 | 91.58 | 31.63 | 64.17 | 73.13 | 89.84 | 88.29 | 92.81 | 83.85 | 98.14 | 81.02 | 95.73 | |
| Peas | 98.68 | 70.41 | 94.64 | 38.38 | 97.78 | 95.25 | 98.33 | 97.61 | 97.76 | 96.42 | 87.65 | |
| Wheat 3 | 98.86 | 59.97 | 76.77 | 69.91 | 84.84 | 96.98 | 97.32 | 95.06 | 97.60 | 95.06 | 99.44 | |
| Lucerne | 98.24 | 65.57 | 93.69 | 81.22 | 94.79 | 94.37 | 90.18 | 94.65 | 97.77 | 95.34 | 84.81 | |
| Barley | 98.22 | 55.10 | 91.89 | 82.14 | 94.18 | 97.95 | 94.39 | 89.37 | 99.39 | 95.98 | 84.14 | |
| Wheat | 97.07 | 46.85 | 79.85 | 53.02 | 92.54 | 89.33 | 83.35 | 88.32 | 86.24 | 91.57 | 98.79 | |
| Grasses | 92.00 | 61.21 | 64.72 | 55.68 | 84.61 | 88.43 | 95.29 | 81.68 | 97.82 | 86.41 | 72.39 | |
| Forest | 97.71 | 82.51 | 51.10 | 58.17 | 95.24 | 96.77 | 95.83 | 90.19 | 99.14 | 91.13 | 99.85 | |
| Water | 90.45 | 69.49 | 81.31 | 74.42 | 90.80 | 83.81 | 92.89 | 98.87 | 98.15 | 98.02 | 99.95 | |
| Building | 98.35 | 61.77 | 83.94 | 58.77 | 88.71 | 98.08 | 98.63 | 86.81 | 98.38 | 84.09 | 96.22 | |
| OA | 96.22 | 61.59 | 80.49 | 65.44 | 92.13 | 92.63 | 93.14 | 92.33 | 95.83 | 92.01 | 93.42 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hua, W.; Zhang, Y.; Zhang, C.; Jin, X. PolSAR Image Classification Based on Relation Network with SWANet. Remote Sens. 2023, 15, 2025. https://doi.org/10.3390/rs15082025
Hua W, Zhang Y, Zhang C, Jin X. PolSAR Image Classification Based on Relation Network with SWANet. Remote Sensing. 2023; 15(8):2025. https://doi.org/10.3390/rs15082025
Chicago/Turabian StyleHua, Wenqiang, Yurong Zhang, Cong Zhang, and Xiaomin Jin. 2023. "PolSAR Image Classification Based on Relation Network with SWANet" Remote Sensing 15, no. 8: 2025. https://doi.org/10.3390/rs15082025
APA StyleHua, W., Zhang, Y., Zhang, C., & Jin, X. (2023). PolSAR Image Classification Based on Relation Network with SWANet. Remote Sensing, 15(8), 2025. https://doi.org/10.3390/rs15082025