1. Introduction
Ship recognition based on optical remote sensing images has diverse applications in fishery management, ship traffic surveillance, and maritime warfare [
1]. It has emerged as a significant research field within the field of computer vision. Traditional methods for ship detection relied on geometric elements and artificially designed features to identify ships [
2,
3,
4]. In recent years, advancements in Earth observation technology have significantly enhanced the acquisition capabilities of high-resolution visible remote sensing images [
5]. The inherent interpretability of optical remote sensing images, coupled with their clear and rich texture information, has opened up new avenues for ship target detection and identification techniques. Given high-resolution optical remote sensing images, convolutional neural networks (CNNs) can extract more semantic information than traditional methods, and are also more robust and generalized, thus giving better detection results [
6]. Among them, the coarse-to-fine network structure has excellent results in high-resolution remote sensing images, and it improves the ship detection accuracy by iteratively refining the detection results at different scales, which solves the problem of multi-scale in remote sensing images [
7,
8,
9,
10,
11,
12,
13,
14,
15,
16].
However, remote sensing image ship detection and recognition face challenges arising from the unique shooting angles, scene complexity, and variations in object proportions within a single image [
15]. Currently, the field of ship detection and identification based on remote sensing images primarily encounters difficulties in the two following aspects: rotating the ship detection and fine-grained ship detection.
1. The ship recognition methods based on horizontal bounding boxes (HBBs) aim to produce satisfactory results. Meanwhile, methods based on oriented bounding boxes (OBBs) may require more computational power and time. Most ships in remote sensing images exhibit arbitrary orientation, a high aspect ratio, and dense distribution. Traditional HBB-based methods struggle to accurately capture the true shape of the object, often including background pixels and neighboring targets within the detection box. Additionally, when dealing with high aspect ratios, even slight angular deviations between the predicted frame and the ground truth frame can lead to a rapid decline in the intersection over union (IoU) ratio. This ratio serves as the basis for evaluation metrics and sensitive hyperparameters in non-maximum suppression (NMS).
To further enhance the ship detection accuracy in optical remote sensing images, researchers have proposed target detection methods for arbitrary directions, including both one-stage and two-stage approaches. On the other hand, the two-stage method involves extracting the candidate frames and subsequently classifying and regressing each candidate frame to obtain precise target location and category information [
17,
18,
19,
20]. Included among these, the ROI Transformer [
19] solved the problem of object detection in aerial images, specifically addressing the challenges presented by the bird’s-eye view perspective, highly complex backgrounds, and variant appearances of object. It applies spatial transformations on region of interest (RoIs) and learns transformation parameters under the supervision of oriented bounding box (OBB) annotations, allowing for the detection of oriented and densely packed objects. The proposed method avoids the need for a large number of anchors designed for oriented object detection and is a significant improvement over previous approaches by enabling more accurate object localization and feature extraction. On the other hand, single-stage detectors integrate feature extraction, proposal generation, and subsequent detection steps into a unified network [
9,
21,
22,
23,
24,
25]. The establishment of the rotating boxes introduces additional angular regression. Since angles are periodic, regression at some particular angles will generate abrupt changes in the loss values, interfering with the detection results of the network. Based on this problem, the circular smooth label (CSL) [
21] is proposed, which converts the angular regression approach to a classification approach, since the classification results are limited and do not occur outside the defined range. Converting a regression problem into a classification problem is actually a continuous to discrete problem, and the accuracy is lost in this conversion process. By calculating the maximum loss of accuracy and the average loss, it is concluded that it is feasible to convert the angle prediction approach into a classification problem. The essential problem of rotating target detection is that the detection performance of high-aspect-ratio objects, such as ships, was lower than the overall average [
26]. Currently, the mainstream strategy to solve this problem is to increase the aspect ratio range of the anchor, but this brings a greater amount of calculation and cannot fundamentally solve the problem.
2. The fine-grained recognition method for optical remote sensing ship images faces serious challenges. Ships in remote sensing images exhibit diverse types and complexities. Some classes of ships have significant appearance variations within the class. Additionally, certain ship classes with similar usage may share inter-class similarities.
One common approach to address this challenge is to employ attention mechanisms that focus on the discriminative parts of low-discriminative objects to aid recognition. For example, ref. [
27] proposed an interpretable attention network for fine-grained ship classification using remote sensing images. Similarly, ref. [
28] introduced a multi-source regional attention network for fine-grained object recognition in remotely sensed images. This method combines multiple information sources and employs attention mechanisms to recognize fine-grained objects in remote sensing images. Although these methods have introduced new mechanisms for fine-grained target recognition and achieved promising results, the extracted features for fine-grained targets may lack sufficient differentiation, making an accurate distinction challenging. Further research and development are necessary to improve the accuracy and reliability of fine-grained ship recognition in remote sensing imagery.
This paper introduces a ship recognition approach recognizing rotated targets and achieving a fine-grained recognition. The proposed method extends traditional ship detection by incorporating the ship part detection. By simultaneously detecting the ship components and the whole ship, the model leverages the geometric regularity of ship components to extract the key discriminative features more efficiently. The significance of this approach includes:
- 1.
Generalized ship component samples. By selecting commonly found ship components such as the main gun, chimney, vertical launch system, and flight deck, the samples become more generalized. Most ships possess some or all of these components, reducing the need for extensive ship-specific data.
- 2.
The simplified labeling and orientation determination. Ship components often have regular shapes like rounds or squares, with symmetry. This characteristic leads to less background area for labeling and prediction while using horizontal frames. Furthermore, identifying ship components can assist in determining the actual orientation of the ship.
- 3.
The utilization of regular geometric relationships. While ships of different types may share similarities in their outward appearance, the distribution and arrangement of their components exhibit variations. Moreover, there are distinct characteristics in terms of the relative positions and orientations of ship components and the alignment and integration of ship components within the ship’s structure. Exploiting these inherent geometric relationships can significantly contribute to the processes of detection and identification.
The ship recognition method incorporating ship components introduces a new idea and solves the problem of difficult fitting of rotating frame detection. It also introduces more detection content, contributing to the fine-grained detection of ships, and thus enhancing the scope of ship detection applications, which is significant in fishery management, ship traffic surveillance, and maritime warfare. But, it also presents new difficulties and challenges:
- 1.
Smaller and more challenging detection. Ship components are typically smaller than the whole ship in scale, making their detection more difficult. The reduced size increases the complexity of accurately localizing and recognizing these components.
- 2.
Uneven sample distribution. The number of available samples for different ship components may vary significantly, resulting in imbalanced data distributions. This imbalance can pose challenges during training and may impact the performance of the recognition model.
- 3.
Varied difficulty in feature extraction. Different ship components may exhibit varying levels of difficulty in feature extraction. Some components may possess distinctive features, while others may lack clear discriminative characteristics. Addressing these differences in feature extraction complexity is crucial for achieving accurate recognition across all ship components.
This paper proposes a new network structure called Related-YOLO to realize the proposed ship recognition method and overcome the aforementioned difficulties. Additionally, a new dataset is constructed to account for the wide variety of warships with interclass differences and intraclass similarities. The main contributions of this paper are as follows:
- 1.
Geometric relationship constraints and attention mechanism. The paper incorporates the geometric relationship constraints of ship components. This information is utilized to enhance the accuracy and reduce the false alarm rate. Additionally, an attention mechanism is employed to weight the extracted sample features. This mechanism effectively focuses on the most relevant features and improves the overall detection accuracy.
- 2.
Adaptive anchor box generation. A new hierarchical clustering approach is introduced to generate adaptive anchor boxes. This approach helps improve the network’s ability to detect multi-scale samples. By dynamically generating anchor boxes based on the clustering algorithm, the network becomes more effective in handling objects of varying sizes.
- 3.
Small-target detection layer. A novel network structure that incorporates a small target detection layer is designed. This layer specifically focuses on enhancing the network’s capability to detect tiny targets. Small targets often pose challenges due to their limited visual information, and the inclusion of this layer aims to improve the detection performance for such cases.
- 4.
Deformable convolution for feature extraction. This paper utilizes deformable convolution for the feature extraction of input samples. Deformable convolution allows the network to effectively extract features from samples with different shapes. By adapting the convolutional filters to the specific spatial locations, the network becomes more flexible in capturing the informative features from ship images.
2. Materials and Methods
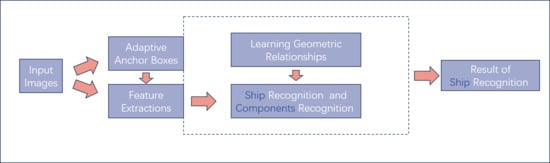
The workflow of this study is shown in
Figure 1. In the beginning, the detection network needs to be trained. We first input the training image and its annotation, obtain the extracted features through the backbone, and then calculate the geometric position relationship between the targets to weight the extracted features. The weighted features complete feature fusion in the neck part, and finally complete label matching and loss function calculation in the head part, and obtain the geometric relationship constraints between the targets. In the testing and inference stages, after we input the image to be detected, we obtained the final result of ship recognition through the detection network and geometric relationship constraints.
In this paper, a new neural network called related-YOLO is developed to improve ship detection by incorporating the geometric relationships of ship components in remote sensing images. The network structure is shown in
Figure 2, which consists of four main components: input, backbone, neck, and head. The Related-YOLO network builds upon the YOLO v5 [
29] algorithm, enhancing it with adaptive anchor boxes, deformable convolution, and the relational attention module. These modifications enable the better detection of ship components in remote sensing images, particularly in terms of small and irregular objects, and improve the overall accuracy of the ship recognition system.
Data augmentation techniques are first applied to enhance the training data including ship components and ships. Additionally, the adaptive anchor boxes are generated using a hierarchical clustering algorithm. Thus, boxes are better suited for detecting small and irregular objects, such as ship components.
The backbone is responsible for downsampling the input image and extracting multi-scale features. We innovatively modified the network structure of the backbone by adding a small target detection layer to enhance the multi-scale capability of the network. Additionally, the convolutional layer of the backbone is improved by incorporating deformable convolution. This enhances the feature extraction capability, particularly for irregular targets like the main gun of the warship. Another notable improvement in the Related-YOLO network is the addition of the relational attention module at the tail of the backbone. This module introduces geometric relational constraints, leveraging the relationships between ship components. By incorporating these constraints, the network achieves a significantly improved detection accuracy.
The neck fuses the extracted features from different scales to generate semantic features. This fusion process helps capture more comprehensive information about the ship components and improves the overall understanding of the image.
At the Head of the network, the positional regression and classification are performed based on the predictive feature mappings generated in the neck section. This process outputs detection boxes for each object of interest, i.e., the ship and ship components, in the image.
2.1. A Hierarchical Clustering Algorithm to Implement Adaptive Anchor Boxes
In the detection network, the anchor-based mechanism generates a set of anchor boxes that serve as reference templates for target classification and bounding box regression [
17]. This mechanism improves the recall ability of the network, especially for detecting small targets. However, setting the hyperparameters for anchor generation requires prior knowledge and can be challenging [
30].
To address this issue, adaptive anchor box generation is introduced, which eliminates the need for manual hyperparameter tuning. In the original YOLO v5 framework [
29], the adaptive anchor boxes are generated using the K-means clustering algorithm. The algorithm works as follows:
Step 1: Randomly select K initial center values.
Step 2: Group the samples into clusters based on the distance between each sample and the center value.
Step 3: Update the center value of each cluster by calculating the mean of the values contained in the cluster.
Repeat steps 2 and 3 until the positions of the cluster centers no longer change.
The K-means algorithm, although capable of solving the problem of generating adaptive anchor boxes, has some problems in our study:
- 1.
The number of clusters needs to be specified in advance: for the task of ship detection based on ship parts in remote sensing imagery, the size distribution of the samples is not uniform, and selecting the appropriate number of clusters may be difficult without a priori knowledge.
- 2.
Sensitivity to initial centroid selection: different initial centroid selections may lead to different clustering results. A poor initial selection may cause the algorithm to fall into a local optimum solution.
- 3.
Sensitive to outliers: outliers may disturb the clustering results, causing some clusters to be affected or even split into multiple clusters.
As a result, the K-means clustering algorithm is not fully applicable to our kind of multi-target and multi-size tasks with large-scale differences.
To solve these problems, this paper uses a hierarchical clustering algorithm [
31]. This algorithm connects objects to form clusters based on distance. The clusters can be roughly described by the maximum distance required to connect the components. Different clusters are formed at different distances, which can be presented using a dendrogram in
Figure 3. Distinguishing from the K-means algorithm, hierarchical clustering does not require the number of clusters to be pre-specified, it automatically constructs the cluster hierarchy; and it does not require an explicit initial selection—it constructs the cluster hierarchy by gradually merging or splitting data points; in addition to this, hierarchical clustering can be used to detect outliers by treating them as separate clusters, or by characterizing the cluster hierarchy according to outlier detection and elimination.
The algorithm connects objects to form clusters based on distance. The clusters can be roughly described by the maximum distance required to connect the components. At different distances, different clusters are formed, which can be presented using a tree diagram. The specific algorithm steps are:
Step 1. Initially each sample is a cluster and the distance matrix
D is computed:
iterate through the distance matrix
D to find out the minimum distance in it except the diagonal and obtain the number of the two clusters having the minimum distance, merging the two clusters into a new cluster and updating the distance matrix
D.
Step 3. The merging process of clustering is repeated until all objects finally satisfy the number of clusters set by the termination condition.
2.2. Deformable Convolution
In detection networks, convolutional kernels are commonly used to extract features from the input data. However, traditional convolutional kernels have fixed shapes and sizes, which restrict their adaptability and generalizability when dealing with targets of varying shapes [
6]. To address this limitation, deformable convolution [
32] is introduced. It is shown in the
Figure 4.
Deformable convolution extends the capabilities of traditional convolutional kernels by incorporating learnable offsets within the receptive field. These offsets are parameters that can be adjusted during training through backpropagation. By introducing these offsets, deformable convolution allows the receptive field to be dynamically adjusted and aligned with the actual shape of the target.
During the forward pass of deformable convolution, the offsets are learned and used to sample input features in a grid-like manner. This sampling process enables the receptive field to be deformed and adapt to the shape of the target being detected. As a result, deformable convolution can capture more fine-grained details and better represent the spatial characteristics of objects with irregular shapes.
The learning of offsets in deformable convolution is performed jointly with the other network parameters during backpropagation. This means that the network can learn to adjust the offsets to align the receptive field with the target shape which maximizes the detection performance.
By introducing deformable convolution, the detection network becomes more flexible and capable of handling targets with varying shapes. It improves the network’s ability to capture object details and enhances the generalization of the model to different shape variations within the target class.
Overall, deformable convolution addresses the limitations of traditional fixed-shape convolutional kernels by introducing learnable offsets that allow the receptive field to be deformed and aligned with the actual shape of the target. This adaptive mechanism improves the detection network’s ability to handle objects with different shapes, enhancing performance in shape-sensitive tasks like object detection.
The traditional convolution operation can be represented by Equation (
1), where
represents each point in the output feature map corresponding to the center point of the convolution kernel, and
represents the offset of
within the range of the convolution kernel [
6].
In deformable convolution, an offset is introduced for each point in the output feature map. This offset is generated from the input feature map using another convolution operation, typically resulting in decimal values. The convolution kernel used to obtain the offsets is the same as a regular convolution kernel. The dimensions of the output offsets are the same as the dimensions of the input feature map, and the channel dimension is 2N, where N represents the number of offsets. These two convolutional kernels are learned simultaneously using the backward propagation algorithm with bilinear interpolation.
The regression process for the offsets is as follows:
Initially, a feature map is obtained by applying a regular convolutional kernel to the input image, similarly to a normal convolutional neural network. The obtained feature map is then fed into another convolutional layer to regress the offsets for deformable convolution. These offsets represent the deformation of the receptive field and are learned through backpropagation. The dimension of the offset layer is 2N because we need to account for translations in both the x and y directions. During training, both the convolutional kernel used for generating the output features and the convolutional kernel used for generating the offsets are learned simultaneously. Since the positions after adding the offsets are non-integer and do not correspond to actual pixel points on the feature map, interpolation is required to obtain the offset pixel values. Bilinear interpolation is commonly used for this purpose.
The process of bilinear interpolation can be expressed by the following equation:
where
represents the pixel value at the interpolated position
represents the pixel value at the nearest existing pixel points in the feature map, and the summation is performed over the four neighboring pixel points. The weights for each point are determined based on their distances to the interpolation position’s vertical and horizontal coordinates. The final term, max (0, 1, …), ensures that the interpolated point does not deviate by more than one pixel from the neighboring points.
In summary, deformable convolution introduces learnable offsets to adapt the receptive field, and these offsets are generated from the input feature map using convolutional operations. The regression of offsets is performed by applying a separate convolutional layer. Bilinear interpolation is used to obtain the pixel values for the offset positions. This mechanism allows the receptive field to deform and align with the target shape, improving the adaptability of the network in capturing fine-grained details and handling objects with varying shapes.
2.3. Mechanisms of Relational Attention
This paper introduces geometric constraints into the network structure to improve the performance of ship component detection algorithms. These geometric constraints are incorporated using a relational attention module [
33].
In this paper, the relational attention module utilizes the self-attention mechanism to model the regular geometric relationships between ship components. Each target is considered to have two features: geometric features and appearance features , which they obtain using the self-attention mechanism. The geometric features capture the relationships between targets, while the appearance features represent the visual appearance of each target.
The self-attention [
34] mechanism is a common attention mechanism used in many models. The core formula of self-attention is
where
Q represents the query,
K represents the key, and
V represents the value.
In the self-attention mechanism,
Q,
K, and
V are linearly transformed from the same input matrix
X. The input matrix
X is the same as the input feature map. The linear transformations are defined as follows:
Here, and are trainable parameter matrices.
The self-attention mechanism calculates the correlation between every two input vectors using Q and K. The resulting similarity matrix is then divided by to stabilize the gradient during training. After normalization using softmax, each value becomes a weight coefficient between 0 and 1, summing to 1. This weight matrix is then multiplied with V to compute a weighted summation.
To handle the translation and scale transformations, a normalized four-dimensional geometric feature
is used to represent the relative geometric relationship between targets m and n. This geometric feature includes the logarithm of the relative distances and sizes of the targets.
Using the geometric features, a geometric weight
is computed to constrain the geometric relationship between the different targets. The geometric features are transformed by a matrix
, and the resulting weights are pruned at 0, indicating that the geometric weights are only applied to pairs of targets with specific geometric relationships.
Similarly, the appearance features
are used to compute an appearance weight
. This is achieved using a dot product between the appearance features and a trainable matrix
, and applying softmax to obtain the weights.
By incorporating the geometric weights and appearance weights into the network, the relational attention module considers both the geometric relationships and appearance information of the ship components, enhancing the detection performance and reducing false alarms by combining them with the NMS algorithm.
And, it is possible to compute the relational characteristics of each target with respect to the other targets
.
Finally, the appearance features of the input target are augmented by summation:
2.4. Datasets
On the field of ship detection and fine-grained recognition, several challenges related to datasets have been identified. These challenges include:
- 1.
Limited open source datasets and small data volume: There is a scarcity of open source datasets, particularly for ship fine-grained recognition. The available datasets are often small in size, which limits the amount of training data.
- 2.
Confusing dataset labeling: Existing datasets, such as the HRSC-2016 [
35] dataset, suffer from confusing multilevel labeling. This includes missing the labeling of small ships and incorrectly labeled ship classes, which can affect the accuracy of ship recognition algorithms.
- 3.
Imbalance in ship classes and appearance features: Current ship class datasets suffer from an imbalance in the number of ship classes and appearance features. The majority of datasets have a larger number of civilian ships, while warships, which are strategically significant and more challenging to identify due to inter-class similarities and intra-class differences have limited samples.
To address these challenges, we collected samples from various publicly available datasets, including Google Earth, and reclassified and annotated them. This effort resulted in the creation of a new fine-grained warship dataset called FGWC-18. The FGWC-18 dataset includes 18 ship classes, namely Arleigh Burke class; Whitby Island class; Perry class; San Antonio class; Ticonderoga class; Abukuma class; Tarawa class; Austen class; Wasp class; Freedom class; Independence class; Horizon class; Atago class; Maestrale class; Akizuki class; Asagiri class; Kidd class; and Kongo-class. Specific types and the number distribution are shown in
Figure 5 and
Figure 6. The dataset also includes annotations for ship components, including main guns, vertical launch systems, chimneys, and flight decks. For the convenience of subsequent research, we included ship components in a separate dataset named FGWC-components. As can be observed in
Figure 5, our dataset covers most of the common types of warships, and these have greater detection significance and little presence in other datasets. As shown in
Figure 6, the distribution of the number of different warship types has a long-tailed distribution, which is widely present in remote sensing imagery. Smaller ship types are often not detected well. Therefore, the detection results of the smaller ship types are a judgment criterion for the detection algorithm.
Validation experiments were conducted on the FGWC-18 dataset for ship recognition as a whole and ship components. Additionally, to evaluate the generalization ability and robustness of the proposed algorithm, experimental validation was performed on two ship fine-grained datasets with more labeled categories, namely FGSC-23 [
36] and FGSCR-42 [
37]. The results of these experiments demonstrate the significant potential of the proposed method in ship detection and fine-grained recognition tasks.
2.4.1. HRSC2016
The HRSC2016 dataset, released by the Northwestern Polytechnical University in 2016, was extracted from six important ports in Google Earth and consists of a total of 1680 images. However, only 1061 of these images were valid for annotation. The dataset was classified at multiple levels, with a total of 28 defined categories. The first level of classification is based on ship types, while the second level provides coarse classification into the four major categories: aircraft carriers, warships, merchant ships, and submarines. The third level of classification further refines the ship models.
This dataset poses several challenges for ship detection and classification tasks. Some of these difficulties include:
- 1.
Dense arrangement of ships along the shore: Ships are often densely arranged along the shore in the dataset, resulting in a high degree of overlap in the labeling frames. This can make it challenging to accurately detect and classify individual ships.
- 2.
Complex background in remote sensing images: The background of the remote sensing images in the dataset is complex, and there is a significant degree of similarity between the ships to be detected and the nearby shore textures. This adds to the difficulty of distinguishing ships from the background.
- 3.
Variation in ship scales: The dataset contains ships of various scales, with a wide range of sizes present in the same image. Detecting and classifying ships with varying scales adds complexity to the task.
- 4.
Numerous ship categories: The dataset includes dozens of different ship categories, making classification detection a challenging task. Each category may have distinct visual characteristics that need to be learned and recognized.
- 5.
Within-category ship variations: Each ship category in the dataset contains multiple different ships, which further complicate the classification detection task. The variations within each category require the model to be robust and capable of distinguishing between different ships within the same category.
- 6.
Small sample size and insufficient learning: The number of ships in each category is not large, leading to a small sample size for training. Insufficient learning and training data can result in reduced model performance and poor robustness.
- 7.
Cloud masking issues: The dataset may also have challenges related to cloud masking, where clouds obstruct the components of the ships or introduce additional visual noise.
These difficulties and challenges highlight the complexity of ship detection and classification tasks using the HRSC2016 dataset.
2.4.2. FGSC-23
The FGSC-23 dataset consists of images that were primarily derived from publicly available Google Earth data and panchromatic remote sensing images captured by the GF-2 satellite. The images have a resolution ranging from 0.4 to 2 m. This dataset includes a total of 4052 foreign ship slices.
The dataset comprises 23 categories, including 22 ship target categories and 1 non-ship target category that resembles a ship. The ship target categories encompass various types of ships such as container ships, bulk carriers, fishing boats, passenger ships, and more. Each ship category is labeled with a number ranging from 0 to 22. The number of samples for each category may vary, resulting in an imbalanced distribution.
The FGSC-23 dataset exhibits several characteristics:
Category diversity: The dataset provides a fine-grained categorization of ship samples within the images. For instance, the cargo ship category is further subdivided into five fine-grained categories, including container ships, bulk carriers, car carriers, oil tankers, and liquefied gas ships. This level of category diversity allows for more detailed and precise ship recognition.
Image diversity: The FGSC-23 dataset encompasses both panchromatic and synthetic color images. The dataset captures a variety of imaging weather conditions, lighting conditions, ship backgrounds (such as offshore and alongside), and varying ship orientations. Additionally, the dataset features a range of image resolutions between 0.4 and 2 m. The diverse nature of the images, including different backgrounds, lighting conditions, and resolutions, increases the complexity and difficulty of ship recognition tasks. However, this diversity also contributes to training recognition models with better generalization ability, as the models learn to handle various real-world scenarios.
Overall, the FGSC-23 dataset offers a wide range of ship categories and diverse images, providing researchers with valuable data for ship recognition and classification tasks.
2.4.3. FGSCR-42
The FGSCR-42 dataset consists of images collected from various sources, including Google Earth and popular remote sensing imagery datasets like DOTA, HRSC2016, and NWPU VHR-10. This dataset focuses on the most common ship types and contains a total of 9320 images.
The images in the FGSCR-42 dataset have varying sizes, ranging from approximately 50 × 50 to 1500 × 1500 pixels. Different subclasses within the same parent class may exhibit different aspect ratios, leading to significant intraclass variations. This means that ships of the same category can have diverse appearances due to variations in their aspect ratios, further challenging the ship recognition task. On the other hand, interclass variations, or the differences between different ship categories, may be relatively small.
One important aspect of the FGSCR-42 dataset is its representation of real-world scenarios. In reality, the different types of ships can be docked together, resulting in images where multiple ships appear simultaneously. This scenario can introduce additional complexity and potential interference in ship recognition algorithms.
Compared to other fine-grained visual classification (FGVC) datasets, the FGSCR-42 dataset is particularly suitable for fine-grained ship classification. Its inclusion of realistic scene representations, with variations in ship types, aspect ratios, and the presence of multiple ships in an image, provides a challenging and representative dataset for fine-grained ship classification tasks.
By utilizing the FGSCR-42 dataset, researchers can develop and evaluate ship recognition models capable of handling real-world ship classification scenarios.
2.5. Evaluation Metrics
In our evaluation of RS ship recognition methods, we primarily utilize the intersection over union (IoU) metric to distinguish detection results. IoU is calculated by dividing the overlap area between the predicted bounding box and the ground truth bounding box by their combined area. By comparing the IoU value against a threshold, we can determine whether a detection is considered a true positive (TP) or a false positive (FP). If a ground truth box does not have a corresponding detection, it is labeled a false negative (FN).
To evaluate the overall performance of the RS ship recognition method, we employ the widely used mean average precision (mAP) as the evaluation metric. mAP is derived from calculating the precision (P) and recall (R) values. Precision is defined as the ratio of true positives to the sum of true positives and false positives (P = TP/(TP + FP)), while recall is defined as the ratio of true positives to the sum of true positives and false negatives (R = TP/(TP + FN)).
mAP is then computed by averaging the precision–recall curves across all categories, and can be expressed as:
Here, A denotes the total number of categories, and and represent the precision and recall for each category a, respectively. The mAP value provides an overall assessment of the model’s performance across all categories, considering both precision and recall.
4. Discussion
This paper proposes a new network called Related-YOLO to solve the problem of difficult detection of rotating targets and difficult fine-grained detection in remote sensing images. To evaluate the performance of Related-YOLO, we conduct experiments on three datasets: FGWC-18, FGSC-23, and FGSCR-42. The results demonstrate the superiority of our algorithm compared to popular object detectors. On the FGWC-18 dataset, Related-YOLO achieves an impressive mAP of 88.8%. Furthermore, on the FGSC-23 and FGSCR-42 datasets, Related-YOLO outperforms other methods and achieves a state-of-the-art performance with mAP values of 92.1% and 95.5%, respectively.
Ablation experiments were also conducted to validate the effectiveness of the proposed modules in Related-YOLO. The results of these experiments further confirm the significance of the introduced components in achieving a superior detection performance.
In summary, our method effectively addresses the challenges of detecting rotating targets and performing fine-grained detection in ship detection, which greatly enhances the applicability of remotely sensed images in the marine field. However, it should be noted that our algorithm introduces additional parameters, which slightly reduces the detection speed of the model.
In future work, we aim to design algorithms that make better use of the internal geometric features of ships. The goal is to develop an end-to-end network for ship detection and recognition, which will provide a more balanced trade-off between model performance and speed. By leveraging the internal geometric features of ships, we anticipate achieving improved efficiency in ship detection and recognition tasks. This will further enhance the overall performance of the model while maintaining a reasonable detection speed.








 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}