1. Introduction
Object detection is an important research topic in the field of remote sensing, which has been widely applied to military and civil tasks, such as geological environment surveys, traffic monitoring, urban planning, precision agriculture, and disaster relief [
1,
2,
3,
4]. Traditional methods of obtaining objects mainly rely on satellites and manned aircraft. In recent years, since unmanned aerial vehicles (UAVs) have the advantages of being small, flexible, and easy to control, they have become more and more popular in various domains, such as civilian, military, and research. Some examples are inspecting power lines in difficult conditions, detecting air quality, rescuing people in danger, spying on the enemy, tracking enemy targets, and searching for information on the battlefield. All these tasks strongly depend on the detection of one or more domain-specific objects. Since the emergence of computer vision, object detection has been extensively researched.
Historically, detecting objects in images captured by cameras is one of the earliest computer vision tasks, dating back to the 1960s. Detecting and recognizing object categories has been viewed as the key element of any artificial intelligence system ever since. Many computer vision methods have been used for this task.
As one of the basic problems for computer vision, traditional object detection adopted statistical-based methods [
5]. However, the massive amount of data has affected the performance of these traditional methods in recent years. Problems such as feature size explosion, requiring larger storage space and time costs, are difficult to solve. With the emergence of deep neural network (deep learning) technology [
6,
7,
8], high-level features of images can be extracted through multiple convolutions and pooling layers, thus achieving object detection. Since 2015, deep neural networks have become the main framework for UAV object detection [
9,
10]. Classical deep neural networks for object detection are divided into two categories: two-stage networks and one-stage networks. Two-stage networks, such as RCNN [
11] and Faster RCNN [
12,
13], first need to generate proposal regions and then classify and locate the proposal regions. Numerous studies have demonstrated that two-stage networks are appropriate for applications with higher detection accuracy requirements [
14,
15]. One-stage networks, such as SSD [
16,
17] and Yolo [
18,
19], directly generate class probabilities and coordinate positions and are faster than two-stage networks. Therefore, one-stage networks have great advantages in UAV practical applications with high-speed requirements. Similarly, there are also some faster lightweight networks, such as MobileNet SSD [
20], Yolov3 [
21], ESPNetv2 [
22], etc.
Object detection for UAVs based on deep learning can acquire and analyze information about the ground scene in real time during flight, thus improving the perception and intelligence of UAVs. However, there are many new challenges regarding UAV object detection compared to ground object detection, such as the low-quality image problem and the complex background problem. Therefore, this paper provides a survey on object detection for UAVs based on deep learning. Firstly, we analyze the types and sensors of UAVs. Then, we point out the main differences between UAV object detection and common object detection, and the main challenges in UAV object detection. On this basis, we focus on the applications of deep learning for UAV object detection from the view of the challenges. Other relevant surveys in the field of object detection based on deep learning can be used as a supplement to this paper (see, e.g., [
23,
24,
25,
26]).
The main contributions of this paper are summarized as follows: (1) the development of UAV object detection is thoroughly analyzed and reviewed. In addition, the differences between UAV object detection and common object detection are analyzed and the challenges in UAV object detection are enumerated. (2) A survey on the applications of deep learning methods in UAV object detection is provided, which focuses on the main challenges in UAV object detection. (3) Some representative methods in the field of UAV object detection based on deep learning are analyzed. At last, some possible future study directions in this field are discussed.
The rest of this paper is organized as follows:
Section 2 briefly outlines the development history of UAV object detection.
Section 3 describes the deep-learning-based object detection algorithms for UAV aerial images.
Section 4 surveys the main public datasets used for UAV object detection.
Section 5 combines the current research status to look forward to the follow-up research direction, and
Section 6 is a conclusion.
2. The Development of UAV Object Detection
The increase in remote sensing systems enables people to collect data regarding any objects on Earth’s surface extensively. With the emergence of UAVs, aerial imaging has become a common method of data acquisition.
2.1. Classification of UAVs
Different criteria can be used to categorize UAVs, such as lift system, payload weight, size, maximum takeoff weight, operational range, operational altitude (above ground level), endurance, operational conditions, or autonomy level [
27]. Based on the lift system, they can be divided into several types, such as lighter-than-air UAVs, fixed-wing UAVs, rotary-wing UAVs, flapping-wing UAVs, etc. [
28]. Fixed-wing UAVs and rotary-wing UAVs are the most common ones. Fixed-wing UAVs have the advantages of fast speed, long range, and large payload, but they require large landing sites and auxiliary equipment. Rotary-wing UAVs have the ability to hover and take off vertically. They are suitable for low-altitude and complex terrain flight but have shorter range and endurance. Rotary-wing UAVs are the widely used type of UAVs in military and civilian applications, and the common types include helicopter-type and multi-rotor-type [
29]. Helicopter-type UAVs have large payloads and high flexibility, but the disadvantages are that the mechanical structure is more complex than multi-rotor, the operation difficulty is high, and the maintenance cost is high. Multi-rotor UAVs, capable of vertical takeoff, landing, and hovering, are particularly suited for missions requiring low-altitude operations and stationary flight. At present, multi-rotor UAVs have become the main type of object detection research and are widely used in environmental protection, precision agriculture, and disaster rescue.
These UAVs develop fast because they are relatively cheap and have the ability to take pictures simply. UAVs can carry high-resolution cameras or other sensors, obtaining clearer and richer object information. Compared with orbital and other aerial sensing acquisition methods, UAV platforms can perform object detection in high-altitude or hazardous areas, avoiding the risk of casualties and cost expenditure. Therefore, UAV-based image acquisition systems are very popular in commercial and scientific exploration. However, visual inspection of objects by UAVs is still biased, inaccurate, and time-consuming. Currently, the real challenge regarding remote sensing methods is to automate the process of obtaining fast and accurate information from data, where detecting objects from UAV images is one of the key tasks.
UAV images for object detection are classified based on flight altitude and application areas at different altitudes: (1) eye-level view: this category, at altitudes between 0 and 5 m, is optimal for ground-level observations. (2) Low and medium height: 5–120 m. It represents the gap between most commercial and industrial applications. (3) Aerial imaging: higher than 120 m, this category is synonymous with high-altitude data capture and often requires special permissions.
2.2. UAV Sensors for Object Detection
UAV sensors are various devices that can measure the motion state, position information, and environmental parameters of UAVs. They are important components for achieving autonomous flight and mission execution. The use of UAVs depends on various factors, such as payload capacity, size, cost, safety, environment, redundancy level, and autonomy level. According to different measurement principles and functions, we will only introduce four sensor technologies that are important for UAV object detection:
Visual sensors: A visual sensor is a device that uses photoelectric sensors to obtain images of objects. From the image, state information such as location and speed of the object can be calculated. The more important thing for visual sensors is the processing algorithm. Recently, the development of deep learning algorithms has brought more extensive applications to visual sensors.
Ultrasonic sensor: Ultrasonic waves are sound waves that exceed the upper limit of human hearing frequency. Due to their good directivity and strong penetration, they are widely used for distance and speed measurement. The ultrasonic sensor emits a signal that is reflected by the object and then received by another ultrasonic sensor. An ultrasonic sensor is generally cheap, but its drawbacks include a low data update rate and a limited measurement range.
Laser sensor: The principle of the laser sensor is basically the same as the ultrasonic sensor, except for the different emitted signal. A laser source is emitted by the laser ranging sensor at the speed of light, which makes the signal frequency much higher than the ultrasonic sensor [
30]. Its disadvantages are high price, small measurement range, and the ability to scan.
Ground-penetrating radar: Ground-penetrating radar (GPR) is a popular nondestructive testing technique for object detection and imaging in geological surveys [
31]. Fast and accurate object detection on the surface can reduce computation time and hardware requirements.
Thermal imager: A thermal imager is a device that can convert invisible infrared radiation into visible images. It can detect the temperature distribution and thermal anomalies of objects in dark or harsh environments [
32].
2.3. The Difference between UAV Object Detection and Common Object Detection
In normal view, the datasets used for object detection algorithms are mostly taken by handheld cameras or fixed positions, so most of the images are side views. However, UAV aerial images have different characteristics from ordinary view images because they are taken from a top-down view. This means that the object detection algorithms in normal view cannot be directly applied to UAV aerial view.
Firstly, the quality of UAV aerial images is affected by many factors, such as the instability of equipment causing jitter, blur, low resolution, light change, image distortion, etc. These problems need to be preprocessed for the video to improve the detection effect of methods [
33].
Secondly, the object density in the aerial view is inconsistent and the size is very small. For example, pedestrians and cars may occupy many pixels in normal view but only a few pixels in aerial view, and they are distributed irregularly, causing object deformation, increasing the difficulty of multi-object detection, and requiring special network modules to extract features [
34].
Finally, the occlusion in aerial view is also different from that in normal view. In normal view, the object may be occluded by other objects, such as a person in front of a car. However, in an aerial view, the object may be occluded by the environment, such as buildings and trees [
35]. Therefore, it is not possible to directly apply the multi-object detection algorithms trained on normal view video datasets to UAV aerial images. It is necessary to design corresponding algorithms, which can meet the UAV object detection task requirements according to the features of UAV images.
2.4. Challenges in UAV Object Detection
The object detection task in UAV remote sensing images faces many challenges, such as object rotation, complex background, an increase in small object issues, low detection efficiency caused by scale changes, and sparse and uneven distribution of object categories. Detailed explanations of the different challenges are as follows:
Small objects increasing problem: The scale range of objects in UAV images is large. Buildings, pedestrians, mountains, and animals often appear in the same image. Small objects have a very small proportion in the image, which makes detection difficult [
36,
37]. The multiscale feature fusion method can effectively solve the problem of small objects increasing by detecting objects of different sizes through different levels of features.
Background complexity problem: The dense object areas in UAV images contain many identical items, which increases the probability of false detection. In addition, a large amount of noise information in the background of UAV images can also weaken or obscure the object, making it difficult to detect continuously and completely [
38]. In order to improve detection accuracy and robustness in the complex background, attention mechanisms and graph neural networks can be used to enhance the relationships between objects.
Category imbalance problem: The objects in the images captured by UAVs may have category imbalance problems, such as having a large number of objects in one category and a small number of objects in the other category, resulting in the detector leaning towards predicting categories with a large number [
39]. Generative adversarial networks or autoencoders can be used to enhance data diversity and quality, which will alleviate issues regarding data imbalance and noise.
Object rotation problem: In UAV images, objects can appear in any position and direction [
40]. Traditional object detection algorithms usually assume that the object is horizontal, but, in UAV images, the object may be rotated at any angle. In addition, rotating objects may change their shape and appearance in the image, which makes the object detection algorithm based on shape and appearance not work accurately [
41]. Use a rotation box or polygon box to represent the object that can adapt to any angle of the object.
4. Public Datasets for UAV Object Detection
Data-driven deep learning methods have been rapidly developed in recent years, providing powerful tools for object detection (images and videos) in the UAV remote sensing domain. To facilitate the research progress and performance evaluation of these tasks, many researchers have contributed various open-source and classic UAV-based remote sensing datasets. These datasets have a large scale and good generalization ability, which can reduce the characteristics of the dataset itself. In this section, we will introduce some of the most commonly used and influential datasets for UAV object detection.
Stanford Drone dataset [
103]: This dataset was released by Stanford University’s Computer Vision and Geometry Laboratory (CVGL) for studying human trajectory prediction and multi-object tracking in crowded scenes. The dataset contains eight different outdoor scenes, such as bookstores, cafes, campus squares, etc., each with multiple videos, totaling about 20,000 object trajectories. Each object’s trajectory is annotated with a unique ID, containing 10 types of objects, more than 19,000 objects. Although this dataset only collects videos from a university campus, it can be applied to different application scenarios due to the diversity of scenes and the complexity of objects.
UAV123 dataset [
104]: This dataset contains 123 video sequences captured from low-altitude UAVs, totaling more than 110,000 frames. These video sequences cover a variety of different scenes, such as urban areas, parks, beaches, and campuses, as well as different types of objects, such as pedestrians, bicycles, cars, and boats. Each video sequence has a corresponding bounding box annotation file that records the position and size of the object in each frame. In addition, each video sequence also has an attribute file that describes the features of the sequence.
Car Parking Lot dataset (CARPK) dataset [
105]: The CARPK dataset is a dataset for vehicle detection and counting on UAV platforms. It was designated as a public dataset by National Taiwan University in 2017. Specifically, it is the largest and first parking dataset that UAV view has collected. The dataset was acquired by a UAV flying at an altitude of 40 m and includes images of nearly 90,000 vehicles taken from four different parking lots. The maximum number of vehicles in a single scene is 188. The label information of each vehicle is a horizontal bounding box.
UAV-ROD dataset [
64]: In this dataset, 2806 aerial images were gathered using various platforms and sensors. Each image has items with sizes, shapes, and orientations and is roughly 4000 × 4000 pixels. These DOTA images are then annotated by aerial image interpretation experts using 15 common object categories. The fully annotated DOTA image contains 188,282 instances, each marked with an arbitrary (8d.o.F) quadrilateral.
Okutama-Action dataset [
106]: The Okutama-Action Dataset is a video dataset for concurrent human action detection from a UAV perspective. It consists of 43 fully annotated sequences with a duration of one minute and contains 12 action categories. This dataset has many challenges that are lacking in current datasets, such as dynamic action transitions, significant scale and aspect ratio changes, sudden camera movements, and multi-label actors1. Therefore, this dataset is more challenging than existing datasets and will help advance the field and achieve real-world applications.
UAV Detection and Tracking (UAVDT) dataset [
68]: The UAVDT dataset is a benchmark test for object detection and tracking on UAV platforms. It contains about 80,000 frames extracted from 10 h of videos involving three basic tasks, namely object detection (DET), single-object tracking (SOT), and multi-object tracking (MOT). The images in this dataset are taken by UAVs in various complex environments, with the main focus on vehicles. These images are manually annotated, including bounding boxes and some attributes that help analysis, such as vehicle category and occlusion. The UAVDT dataset consists of 100 video sequences that are filtered out from more than 10 h of videos taken at different locations in urban areas covering various common scenarios, such as square road toll stations, highway intersections, and T-junctions. The framerate of these videos is 30 frames per second (fps), and the resolution of the JPEG images is 1080 × 540 pixels.
DAC-SDC dataset [
107]: The DAC-SDC dataset is a video dataset for object detection and classification on UAV platforms. It is provided by the System Design Contest (SDC) hosted by the IEEE/ACM Design Automation Conference (DAC) in 2019. The dataset is provided by Baidu and contains 95 categories and 150,000 images. These images are taken by UAVs in various complex scenarios, and each extracted frame contains 640 × 360 pixels.
Moving Object Recognition (MOR-UAV) dataset [
108]: The Moving Object Recognition (MOR-UAV) dataset is a benchmark dataset for moving object recognition in UAV videos. The dataset contains 89,783 cars or heavy vehicle instances collected from 30 UAV videos, covering 10,948 frames. These videos are taken in different scenarios, such as occlusion, weather conditions, flying altitude changes, and multiple camera angles. The feature of this dataset is to use axis-aligned bounding boxes to annotate moving objects, which saves more computational resources than generating pixel-level estimates.
DroneVehicle dataset [
108]: The DroneVehicle dataset is a benchmark dataset for vehicle detection and counting in UAV aerial images. The shooting environment covers from day to night, with real environment occlusion and scale changes. The dataset contains 15,532 pairs (31,064 images), half of which are RGB images and the other half are infrared images. It contains 441,642 annotated instances, divided into five categories: car, truck, bus, van, and cargo truck. Tilted bounding boxes are used to annotate vehicles to adapt to different angles and directions.
AU-AIR dataset [
109]: The AU-AIR dataset is a large-scale object detection dataset of multimodal sensors captured by UAVs. It has 32,823 extracted frames from eight video sequences with different lighting and weather situations. The dataset contains eight types of objects, including people, cars, buses, vans, trucks, bicycles, motorcycles, and trailers. Each frame contains 1920 × 1080 pixels.
UVSD dataset [
110]: The UVSD dataset is a large-scale benchmark dataset for vehicle detection, counting, and segmentation in UAV aerial images. The dataset consists of 5874 images with resolutions ranging from 960 × 540 to 5280 × 2970 pixels. The 98,600 vehicle instances in this dataset have accurate instance-level semantic annotations including three formats: pixel-level semantics, horizontal bounding boxes, and tilted bounding boxes. The dataset covers various complex scenarios, such as viewpoint changes, scale changes, occlusion dense distribution, and lighting changes, which result in great challenges for UAV vision tasks.
The above dataset is mainly used for urban environmental object detection. In recent years, natural disasters have had a profound impact on various regions around the world. The use of UAV geological object detection can make a significant contribution to accurate damage assessment. Here are some datasets for geological post-disaster object detection:
Maduo dataset [
111]: Firstly, a UAV was used to capture the entire scene of the Maduo earthquake disaster area, and then photogrammetry technology was used to process individual images into a large digital orthophoto map (DOM) for further use. Finally, all cracks in the DOM are depicted through extensive manual annotations. Seismologists use these cracks to evaluate the stability of faults in the area and serve as samples for supervised deep learning methods. This dataset contains 382 DOMs, covering the entire area affected by the Maduo earthquake.
UNFSI dataset [
112]: UNFSI is a dataset of road crack images captured by UAVs. Considering the effectiveness of the input image, the collected images were cleaned as follows: (1) they do not belong to common crack types. (2) They have severe interference crack features. (3) They have indistinguishable pixels. (4) They do not contain cracks. The total number of images is 5705, with a size of 4000 × 2250 pixels. To ensure the original size of crack feature values and facilitate the adaptation of target detection algorithms to actual UAV detection processes, all the original images were cropped into 640 × 640.
RescueNet dataset [
113]: RescueNet is a high-resolution post-disaster dataset that includes detailed classification and semantic segmentation annotations. This dataset aims to facilitate comprehensive scene understanding after natural disasters. RescueNet comprises post-disaster images collected after Hurricane Michael, obtained using UAVs from multiple impacted regions.
In the past few years, with the development of precision agriculture, accurate counting and measurement can improve the accuracy of activities such as crop monitoring, precision fertilization, and yield prediction. However, manual counting in the field is both labor-intensive and time-consuming. UAVs equipped with RGB cameras can quickly and accurately facilitate this task. The datasets used for UAV agricultural object detection are as follows:
Zenodo dataset [
114]: The Zenodo dataset was recorded using the UAV platform DJI Matrice 210 at a flight altitude of 3 m above the vineyard. Every flight records one side of the vineyard row. Grape berries are in the pea size (BBCH75) and string closure (BBCH79) stages. Two annotation types were used: MOTS to detect and track grape bunches, and COCO to detect berries. All the annotations were labeled using CVAT software. This dataset can be used for object detection and tracking on UAV RGB videos for early extraction of grape phenotypic traits.
Grape-Internet dataset [
115]: The grape images in the Grape-Internet dataset are all from the network, including various red grape varieties, totaling 787 grape images. After data cleaning, all images are randomly cropped to different resolutions (from 514 × 460 pixels to 4160 × 3120 pixels) and manually annotated using LabelImg. The images have differences in shooting angle and shooting distance, as well as varying degrees of occlusion and overlap. The above differences greatly increase the difficulty of detection and bring greater challenges to the detection network.
MangoYOLO dataset [
116]: The MangoYOLO dataset consists of 1730 images for mango object detection. The size of each image is 612 × 512 pixels, and each image contains at least one annotated mango. The annotation file contains the bounding box coordinates and mango variety names for each mango in XML format.
5. Future Directions
At present, the interest in UAV object detection algorithms is increasing, and the existing algorithms have achieved good detection results, but there are still issues that need to be addressed. The interference caused by complex backgrounds to the object detection task has been effectively suppressed, but the existing algorithms still have false alarms and missed detection problems in a dense environment or an environment with a large number of similar objects. The object detection algorithms based on the two-stage method have advantages in the accuracy of classification and regression. However, on the UAV platform, in order to meet the real-time requirements of image processing, the object detection algorithm needs to have a high processing speed, which places higher demands on the parameter size and computational complexity of the network. Shadow appears when the object is disturbed by direct light from the light source. This increases the difficulty of object recognition and limits object detection. Due to differences in shape and position, objects may move differently or exhibit multiple postures based on their real-world rules. For example, pedestrians can walk, run, stand, or sit. At the same time, the height variation in UAVs can easily cause changes in the scale of the same object in the visual image, which can interfere with object detection.
Aiming at the above problems and the research in recent years, this paper undertakes the following discussions on the future research directions of UAV object detection based on deep learning.
- (1)
Rely on unsupervised or semi-supervised training. The existing multi-object detection datasets for UAVs are small, and the labeling cost is high. Unsupervised learning and semi-supervised deep learning network training methods can learn useful features and knowledge from unlabeled or a small amount of labeled data to achieve UAV object detection. In addition, pre-trained models from other fields or tasks can be used, such as image classification or object detection in natural scenes, to initialize or fine-tune UAV object detection models, thereby utilizing knowledge from the source domain or task to improve model performance.
- (2)
Data preprocessing algorithm. The effect of the deep learning method depends on the quality of the input data but cannot distinguish the data. The computational efficiency of the deep learning model can be improved by starting with data enhancement and reducing redundant features. Due to the limitations of UAV flight altitude and payload, problems such as object overlap, coverage, and displacement are inevitable. Generative adversarial networks and instance segmentation can effectively address these issues before object detection.
- (3)
Multimodal data. Multimodal data refers to data obtained from different sensors, such as visible light, infrared, and radar. Multimodal data can provide richer and more complete information, which helps to overcome the limitations and deficiencies of single-modal data. The application of multimodal data fusion is very wide, and there are some challenges in the data fusion process. Firstly, there are various problems with the data source: data quality issues, errors, formatting errors, incompleteness, etc. Secondly, there is also the problem of noise. Noise is not unique to multimodal data, but it creates new problems as each method can generate noise and potentially affect each other. There are also problems such as large data volume and inconsistent data. To address these issues, it is necessary to convert data from different sources into a unified format and resolution, thus promoting data fusion and processing.
- (4)
Introducing models with lower computational power requirements. Deep learning can achieve adaptive optimization by adjusting the learning rate, but, when the data or sample size is large, or when there are high requirements for convergence, a suitable algorithm can be chosen to optimize the structure and parameters of the net to improve the detection effect. As a data-driven approach, deep learning is not the best solution to solve a particular problem. A more targeted algorithm and reasonably allocated weights can be selected to accomplish the task flexibly and efficiently.
- (5)
Phenotype analysis. With the development of UAV technology in precision agriculture [
114], high-precision real-time detection of crops is of great significance. Here, phenotype analysis refers to the use of UAVs, deep learning, and object detection to measure and evaluate the morphological, structural, physiological, and biochemical characteristics of crops, which can optimize planting management and improve crop quality [
115]. Traditional yield estimation relies on manual experience, with low efficiency and accuracy, and cannot meet the fast and accurate prediction needs of large-scale planting enterprises. Considering the significant differences in shape and size among crop varieties, designing an end-to-end lightweight UAV object detection algorithm can improve the speed, accuracy, and reliability of phenotype analysis while reducing costs and errors.


























{kind=link}
{kind=link}
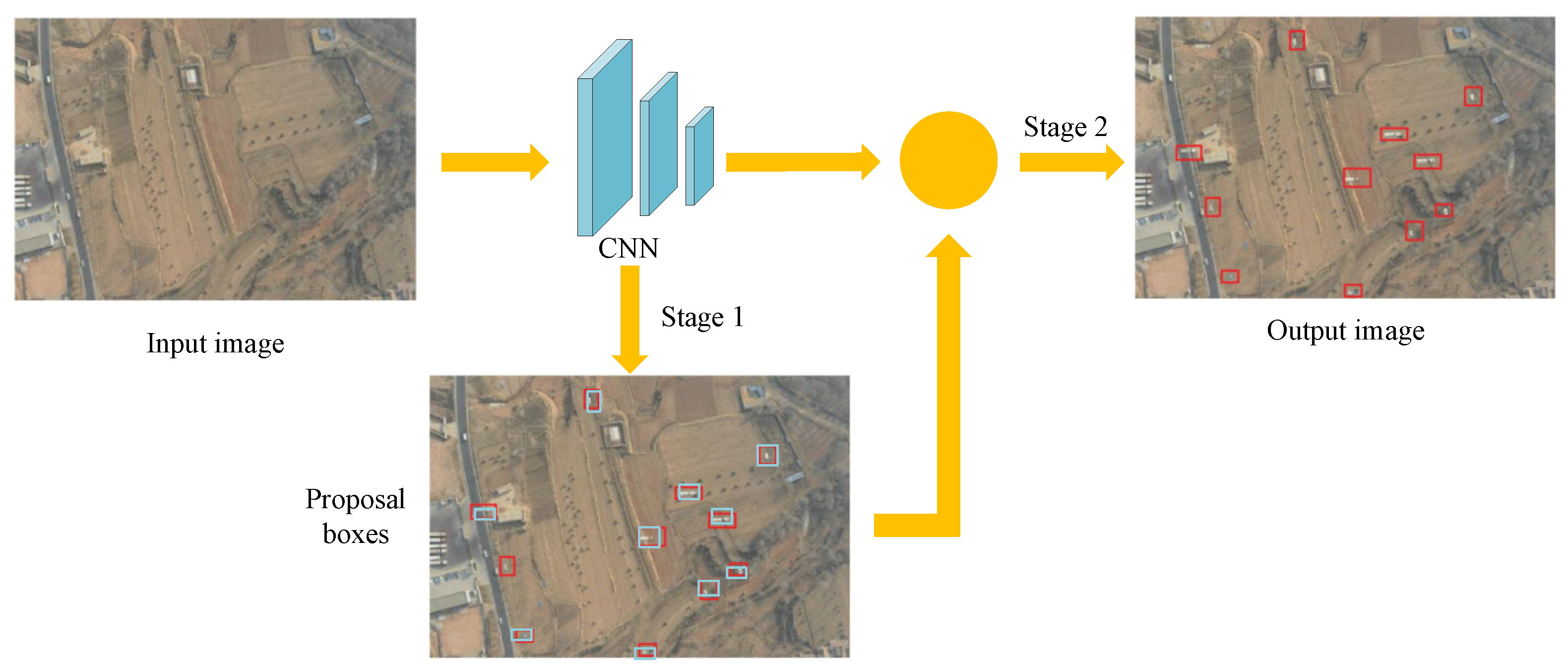{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
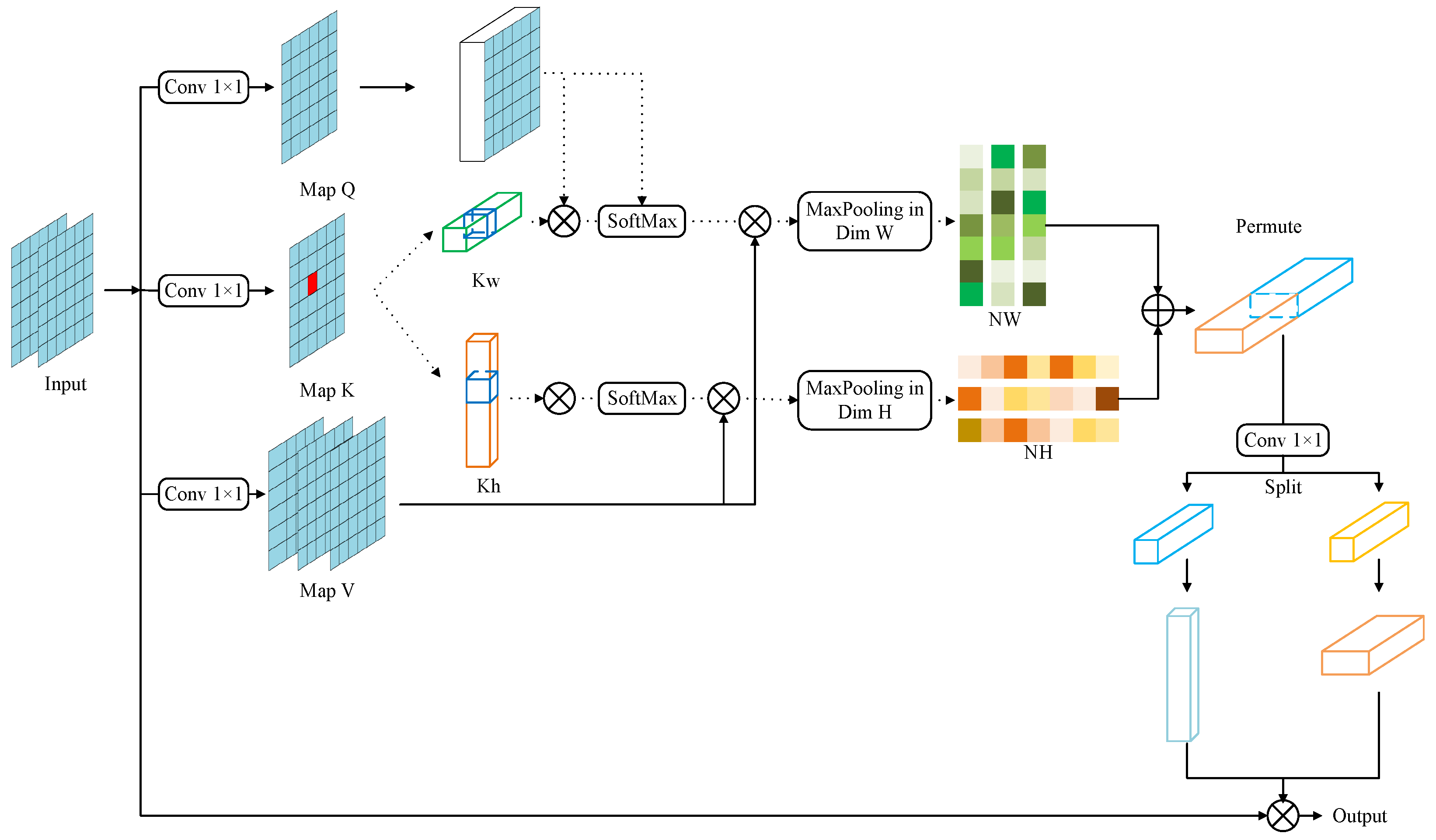{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
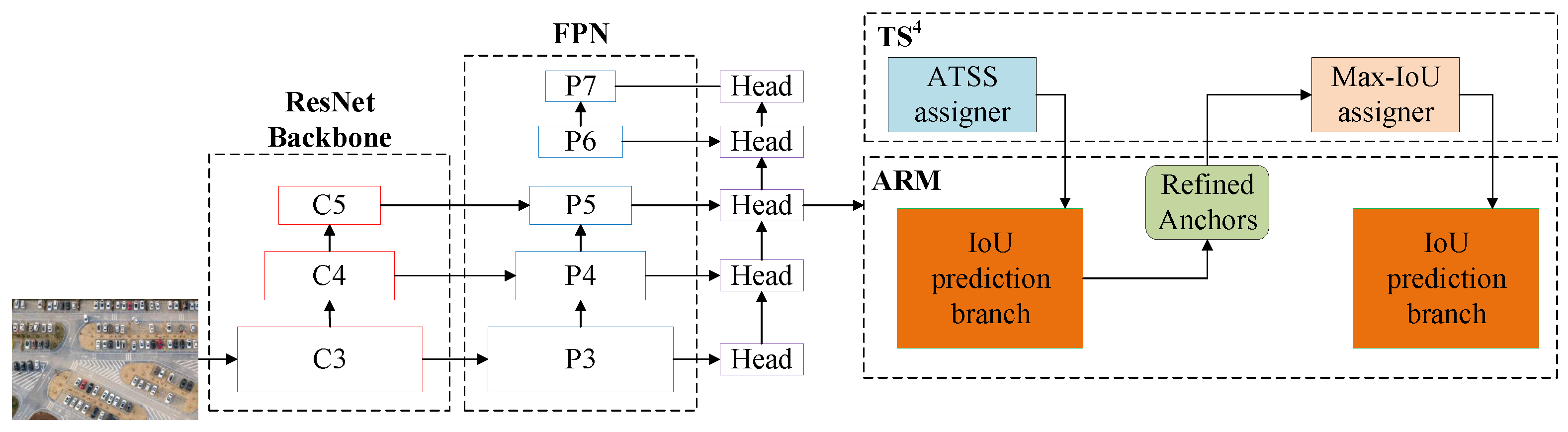{kind=link}
{kind=link}