1. Introduction
Synthetic aperture radar (SAR) is a type of active microwave imaging radar. Being an active microwave sensor, SAR is not affected by factors such as daylight and weather conditions, making it capable of conducting observations of the Earth’s surface under all-day and all-weather conditions. Additionally, SAR has the ability to gather information that is concealed beneath the surface and vegetation. SAR finds wide-ranging applications across various fields [
1]. One important application of SAR is object detection based on SAR ships, which is extensively employed in areas including maritime traffic control [
2], ship surveillance [
3], and fishery monitoring [
4].
SAR ship detection can be categorized into two main methods: traditional methods and modern methods based on deep learning. Traditional SAR ship detection methods generally involve several components, including land masking, preprocessing, prescreening, and discrimination [
5]. These methods mainly include constant false alarm rate (CFAR)-based methods [
6], visual saliency-based methods [
7], global threshold-based methods [
8], polarimetry-based methods [
9], and wavelet transform-based methods [
10]. The main characteristic of these methods is that all of them require manual feature extraction, which leads to redundancy and lack of transferability in algorithms, thereby hindering the real-time characteristic and effectiveness of detection. Therefore, traditional SAR ship detection methods cannot adapt to current detection requirements. In recent years, deep learning [
11] has achieved remarkable achievements and significant breakthroughs in areas such as object detection, enabling the extraction of object features for detection without human intervention. The release of multiple SAR ship datasets has promoted the widespread application of deep learning in the field of end-to-end SAR ship detection, and modern detection performance surpasses traditional methods [
12]. This paper investigates ship detection based on SAR images using deep learning as the foundation. The field of object detection, including SAR ship detection, relies on two important indicators [
13]: accuracy and speed. In the field of deep learning, the neural network architectures used for image processing are divided into convolutional neural networks (CNNs) [
14] and transformers [
15].
The high accuracy of detection results is the goal pursued by many researchers in SAR ship detection. In terms of CNN-based algorithms, Li et al. [
16] analyzed the advantages of Faster R-CNN [
17] in computer vision and its limitations in SAR ship detection and proposed improvement strategies. In addition, they also released the first publicly available SAR ship detection dataset, called SSDD. Kang et al. [
18] combined multiple feature layers and introduced a region proposal network to achieve multi-layer fusion based on contextual regions, thereby improving ship detection performance. Fu et al. [
19] proposed the feature-balanced pyramid network and the feature-refined head network, achieving effective detection with the anchor-free method. Zhao et al. [
20] achieved multi-scale feature fusion and calibration by improving the neck and head network, thus realizing high-accuracy ship detection. Li et al. [
21] constructed the long-term dependency relationship between ships and backgrounds using global contextual information, proposed an attention module to reduce noise, and finally reduced the impact of anchor points using a keypoint-based method. In terms of transformer-based algorithms, Xia et al. [
22] were the pioneers in applying a transformer to SAR ship detection. They proposed a transformer framework that incorporates context-aware joint representation learning, combining it with the local representation ability of CNNs to achieve ship detection. Zhou et al. [
23] first introduced the transformer into rotating SAR ship detection. They proposed an improved multi-scale transformer structure which combines feature fusion modules and new loss functions to enhance the detection capability of small ships. Zhao et al. [
24] proposed a domain adaptive transformer to address the matching problem of trained models on new SAR datasets, which differs from traditional supervised learning methods. Zhou et al. [
25] created a new module and integrated it with the feature layer using the transformer, resulting in high-precision detection in nearshore scenes. These mentioned CNN- and transformer-based methods primarily focus on achieving high-precision SAR ship detection. However, the incorporation of complex models in these approaches leads to significant computational costs, which limits their practicality for high-speed ship detection and engineering deployment.
In order to achieve high-speed detection of ship targets in SAR images, researchers have explored some lightweight models. In terms of CNN-based algorithms, Yu et al. [
26] proposed a ship detection scheme that combines multiple attention mechanisms, reducing the model’s complexity while enhancing its applicability. Yang et al. [
27] proposed a scheme based on the YOLOv5 algorithm [
28], improving the backbone and neck networks to reduce the number of model parameters while enhancing feature extraction and fusion capabilities. Ren et al. [
29] also utilized YOLOv5 as the basic framework, designing a lightweight feature enhancement backbone network and multi-scale feature fusion network. In addition, they employed a new loss function to achieve a low computational lightweight model. Zhao et al. [
30] first designed a multi-scale denoising network based on a Laplacian and then connected it with an improved model based on Yolox [
31] to obtain a lightweight detection model. Xiong et al. [
32] proposed a lightweight method based on YOLOv5 which optimizes the pyramid pooling structure and introduces different attention mechanisms to detect rotated multi-class ship targets. The studies that presented the CNN-based methods described above have focused on developing lightweight models to detect horizontal bounding boxes (HBBs) and oriented bounding boxes (OBBs), with many of these approaches being enhancements of the YOLO architecture. However, there has been limited research on lightweight SAR ship detection using transformers. In terms of transformer-based algorithms, Xie et al. [
33] designed a lightweight detector with noise resistance capability by combining YOLOv5 with a transformer encoder. Zhou et al. [
34] used a knowledge distillation technique called teacher–student model to create a global relationship distillation method based on transformers. This method reduces the number of parameters while improving both model accuracy and robustness. Notably, the transformer-based methods mentioned above have only discussed lightweight approaches to detecting HBBs and have not explored strategies for detecting OBBs.
Conclusions can be drawn from the discussion above regarding different approaches. Firstly, it is noteworthy that there is limited research on lightweight SAR ship detection using the transformer model. Most researchers prefer utilizing CNN-based architectures to extract image features through locality and translation equivariance. However, the receptive field obtained by the CNN-based model is local, which limits the utilization of contextual information [
35]. In contrast, the transformer-based model can effectively capture long-range dependencies [
36] and demonstrate strong robustness against perturbations, occlusions, and domain shifts [
37]. Secondly, there is currently a lack of research on lightweight arbitrarily oriented SAR ship detection using transformers. In coastal and port scenes, SAR ship images often involve densely arranged ships with larger aspect ratios. The use of HBBs may lead to interference from both the neighboring ships and the background. On the contrary, OBBs can accurately reflect the directionality of ship targets, thereby mitigating the aforementioned issues and being more suitable for SAR ship detection. Therefore, it is important to study lightweight arbitrarily oriented methods based on transformers.
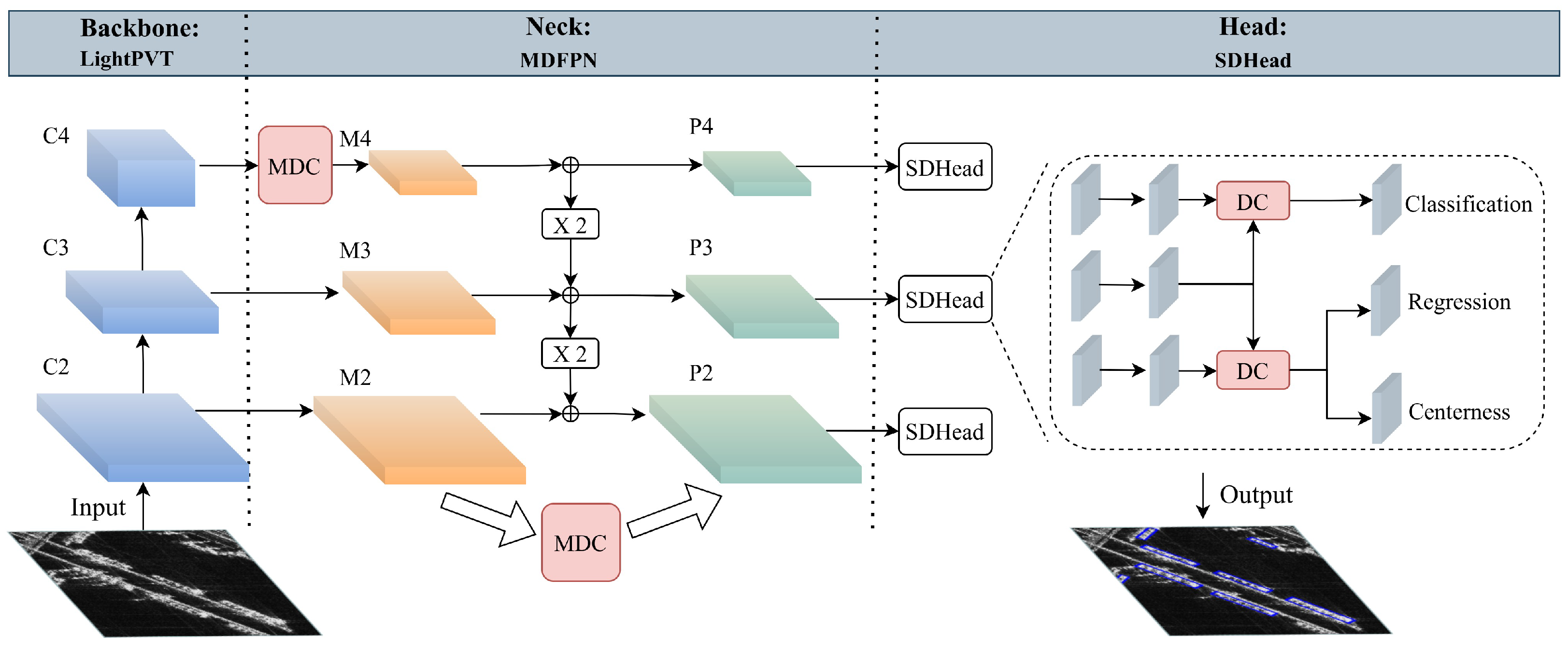
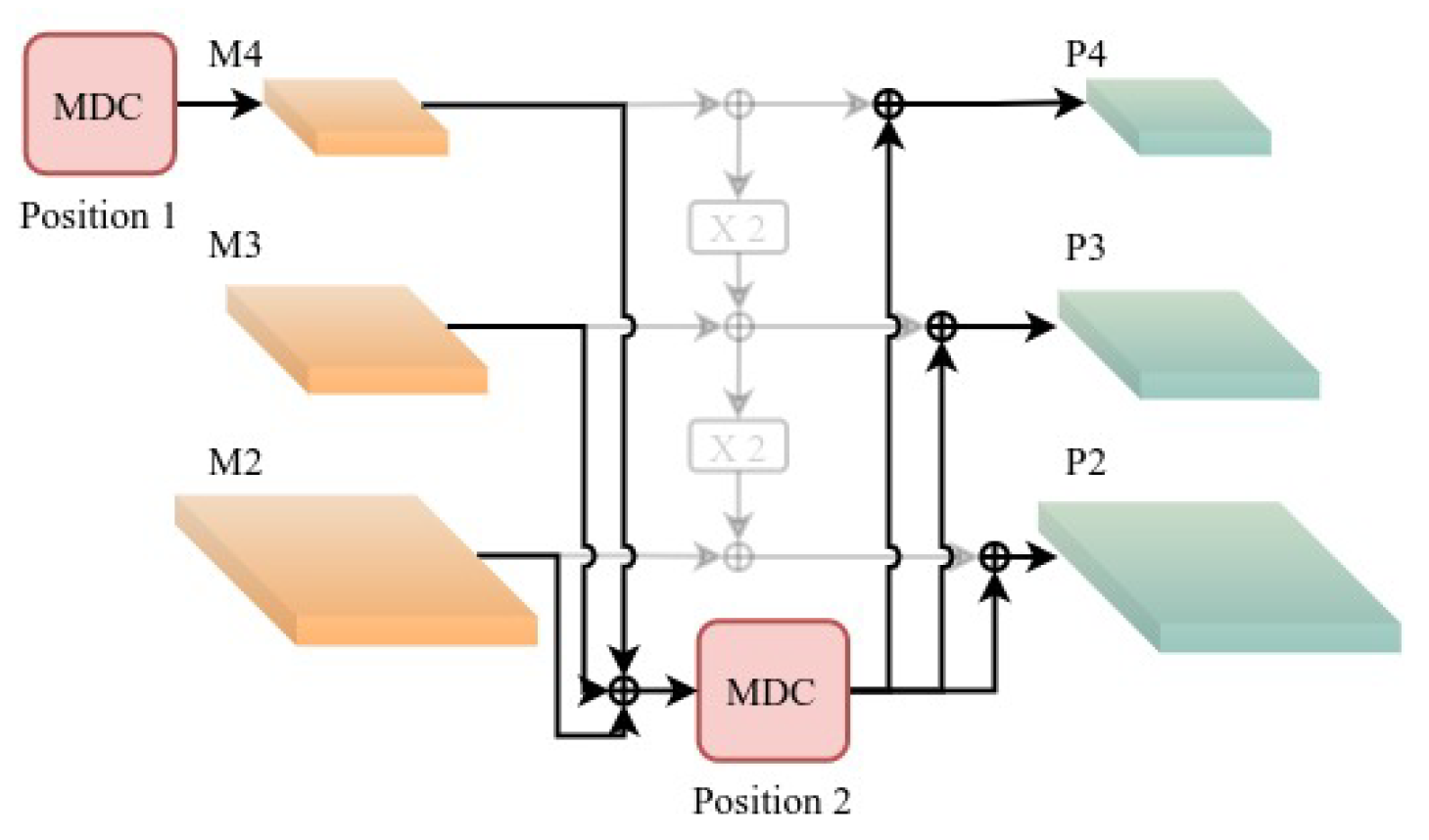
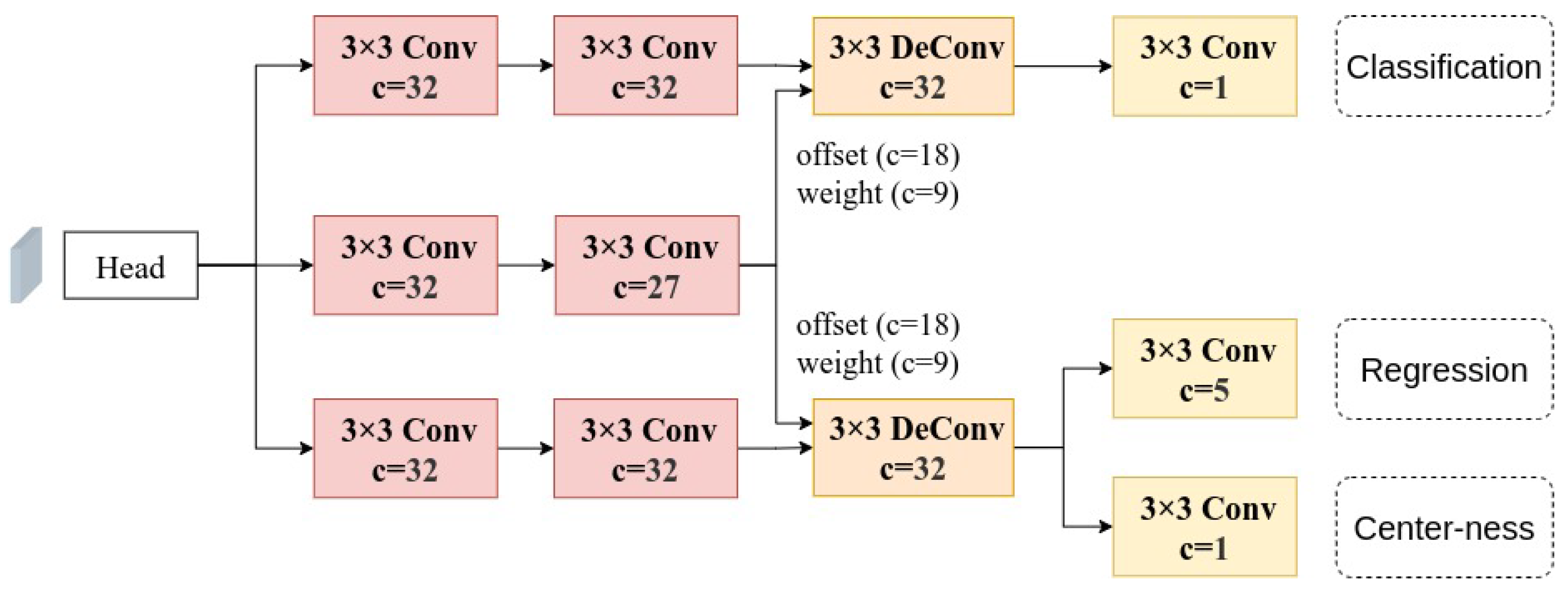
Based on the analysis presented above, this paper proposes LD-Det, a lightweight arbitrarily oriented detector based on transformers and deformable features for ship detection in SAR images. This method introduces a transformer into a lightweight arbitrarily oriented ship detection approach for SAR images for the first time. Firstly, we propose light pyramid vision transformer (LightPVT) as a lightweight backbone network. It effectively captures long-range dependencies of ships in SAR images and enhances detection performance by obtaining sufficient contextual information. Secondly, we introduce multi-scale deformable feature pyramid network (MDFPN), which integrates our proposed multi-scale deformable convolution (MDC) module into the feature pyramid network (FPN) [
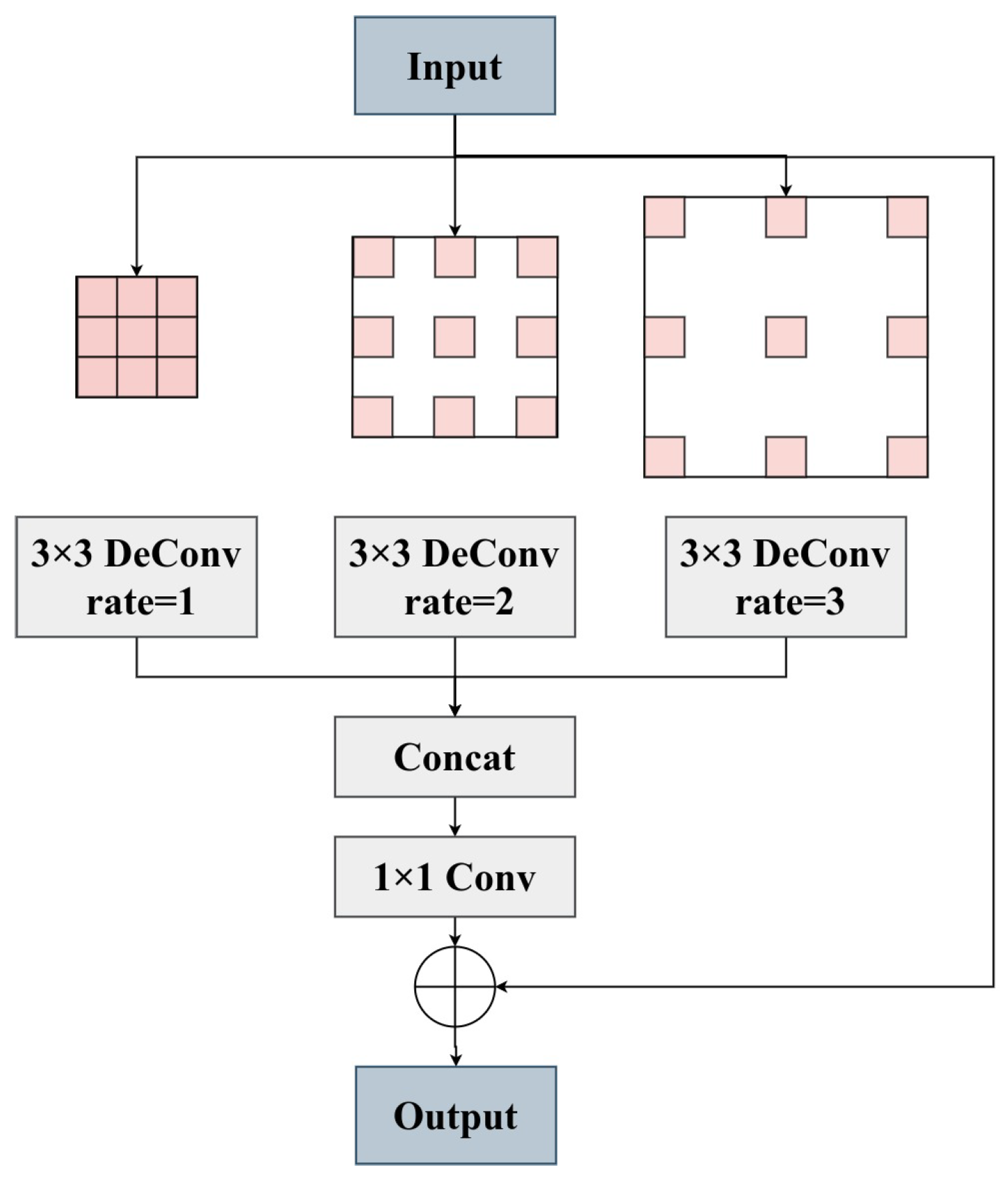
38]. This network adjusts the receptive field area for ship features in SAR images, improving the extraction of ship features. Thirdly, we design shared deformable head (SDHead), which optimizes ship feature extraction by combining deformable convolution and shared parameters. We validate the effectiveness of the proposed method using two publicly available datasets and a large-scene SAR image. Compared with other methods for detecting rotated objects, our approach achieves optimal detection accuracy while maintaining a low level of spatial and temporal complexity in the model.
The main contributions of this paper are as follows:
A lightweight arbitrarily oriented detector for ship detection in SAR images based on transformers and deformable features called LD-Det is proposed. LD-Det is a hybrid structure of a transformer and a CNN, introducing a transformer into a lightweight arbitrarily oriented ship detection approach for SAR images for the first time. LD-Det achieves state-of-the-art detection performance when compared with other lightweight methods for detecting rotated targets.
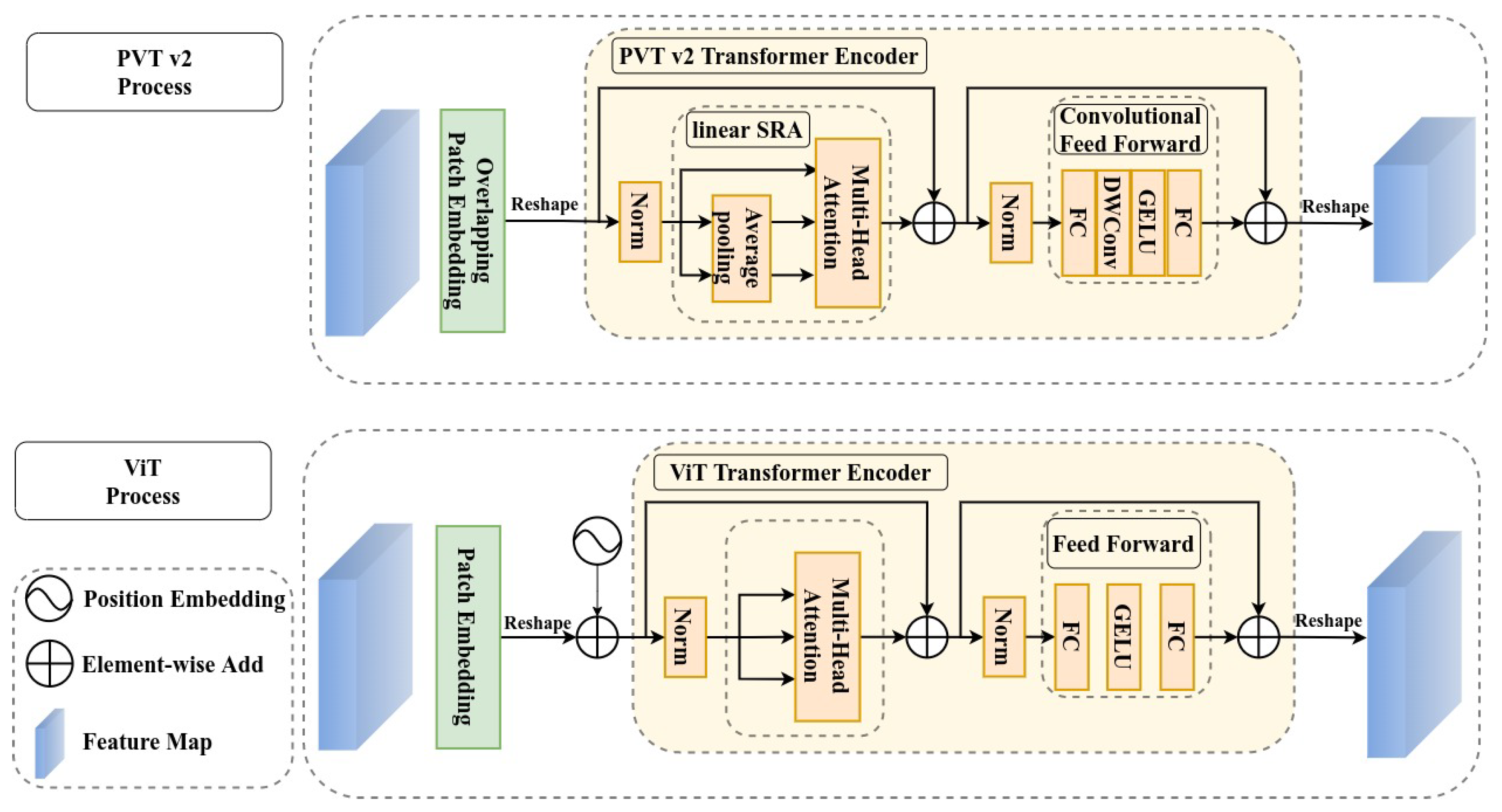
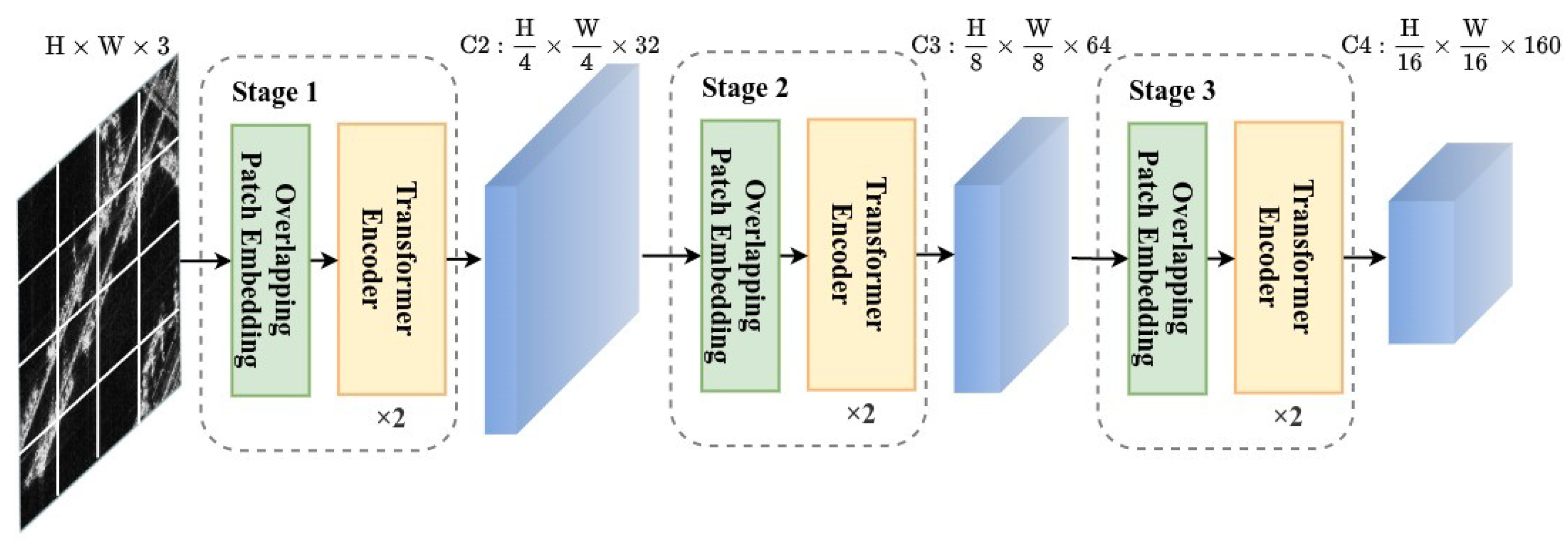
Firstly, we introduce light pyramid vision transformer (LightPVT) by modifying PVT v2-B0-Li and discarding the highest-level feature map. This modification results in a lightweight backbone network capable of capturing long-range dependencies of ships in SAR images. We then propose multi-scale deformable feature pyramid network (MDFPN), which incorporates our proposed multi-scale deformable convolution (MDC) module into two positions of the FPN. This allows the detector to adjust the receptive field regions for ship features in SAR images and improve the extraction of ship features. Finally, we present shared deformable head (SDHead), which combines deformable convolution and shared parameter structure design to optimize the feature extraction of ships.
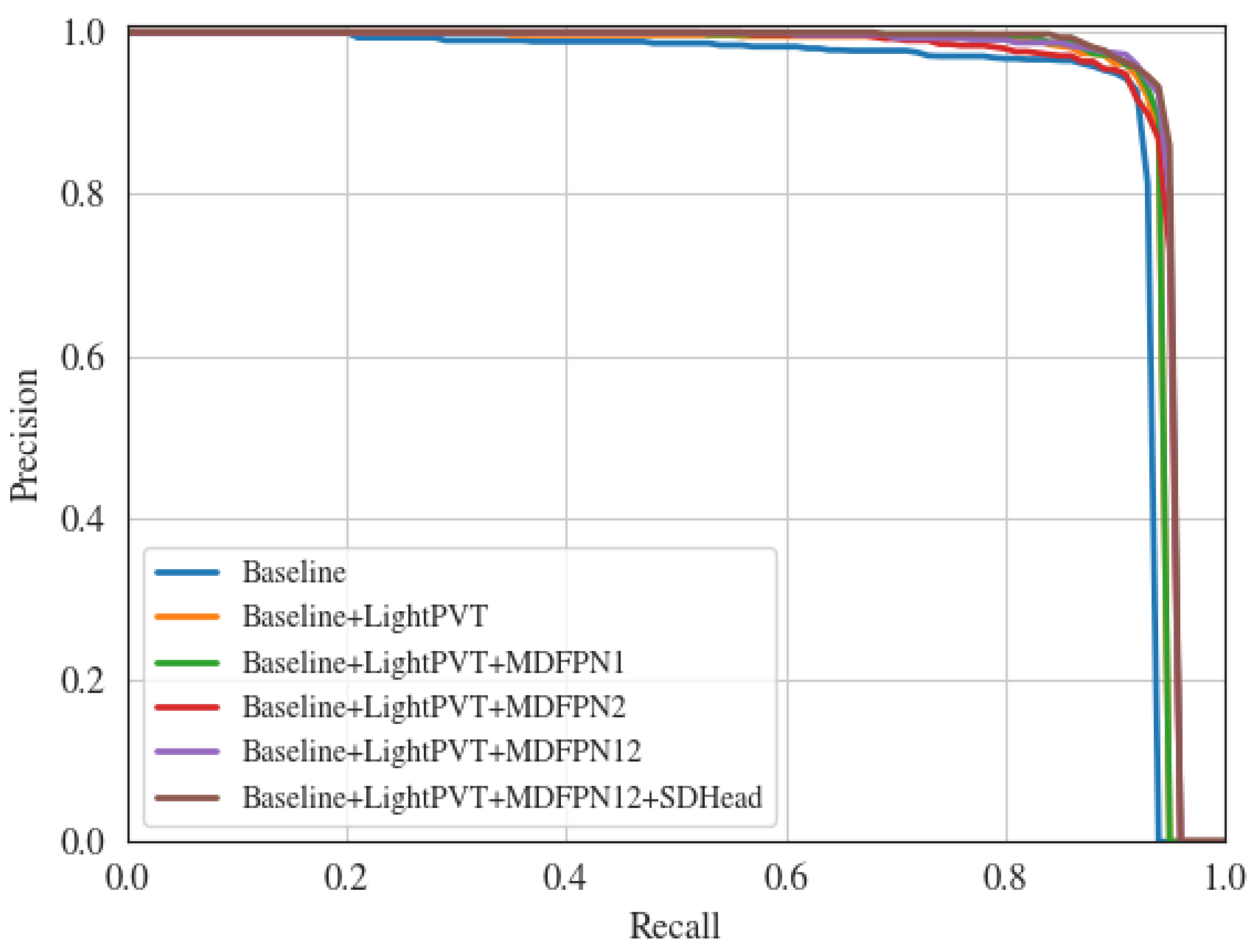
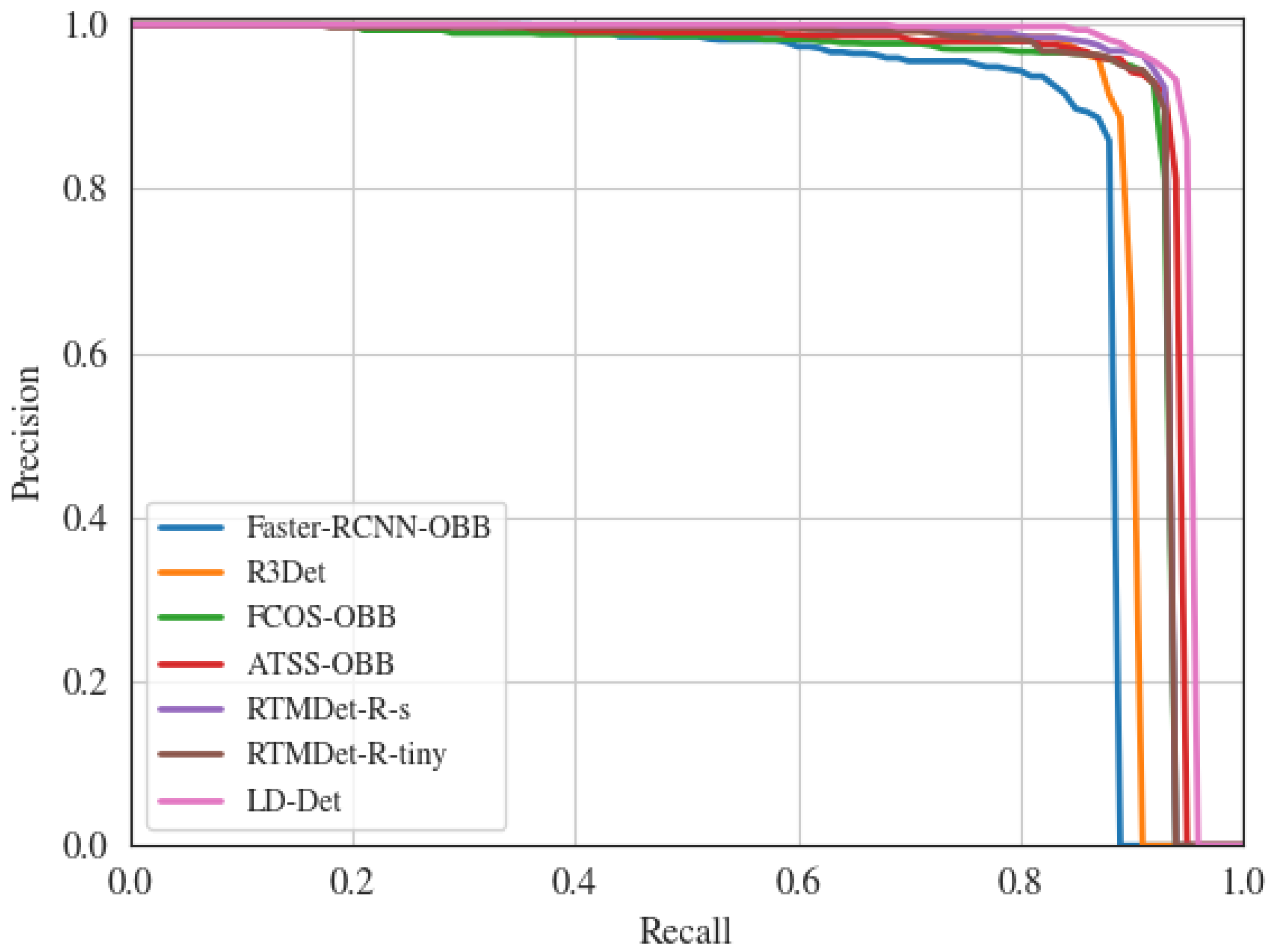
Extensive experiments on SAR ship detection dataset (SSDD) and rotated ship detection dataset in SAR images (RSDD-SAR) are conducted to demonstrate the effectiveness of our proposed modules. The comparative analysis with other arbitrarily oriented object detection methods shows that LD-Det achieves optimal performance.
The remaining parts of this paper are as follows: In
Section 2, the proposed method is described in detail. In
Section 3, extensive experiments are conducted with the proposed method. In
Section 4, the impact of the three proposed modules is discussed. In
Section 5, a conclusion is summarized.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}