
Semantic-Layout-Guided Image Synthesis for High-Quality Synthetic-Aperature Radar Detection Sample Generation




Abstract
:1. Introduction
- The synthesis of SAR images often overlooks the correlation between key elements, such as ensuring that objects do not overlap and maintaining logical layouts between objects and backgrounds. This lack of semantic information integration leads to a performance drop in real-world scenarios.
- The generation process of SAR detection samples lacks clear constraints on the range of semantic image transformations. As a result, the quality of generated images is unstable, making it difficult to ensure consistency in object categories. This renders the generated sample less suitable for high-reliability tasks.
2. Related Works
2.1. Basic Methods of Image Augmentation
2.2. Sample Synthesis
2.3. Sample Generation
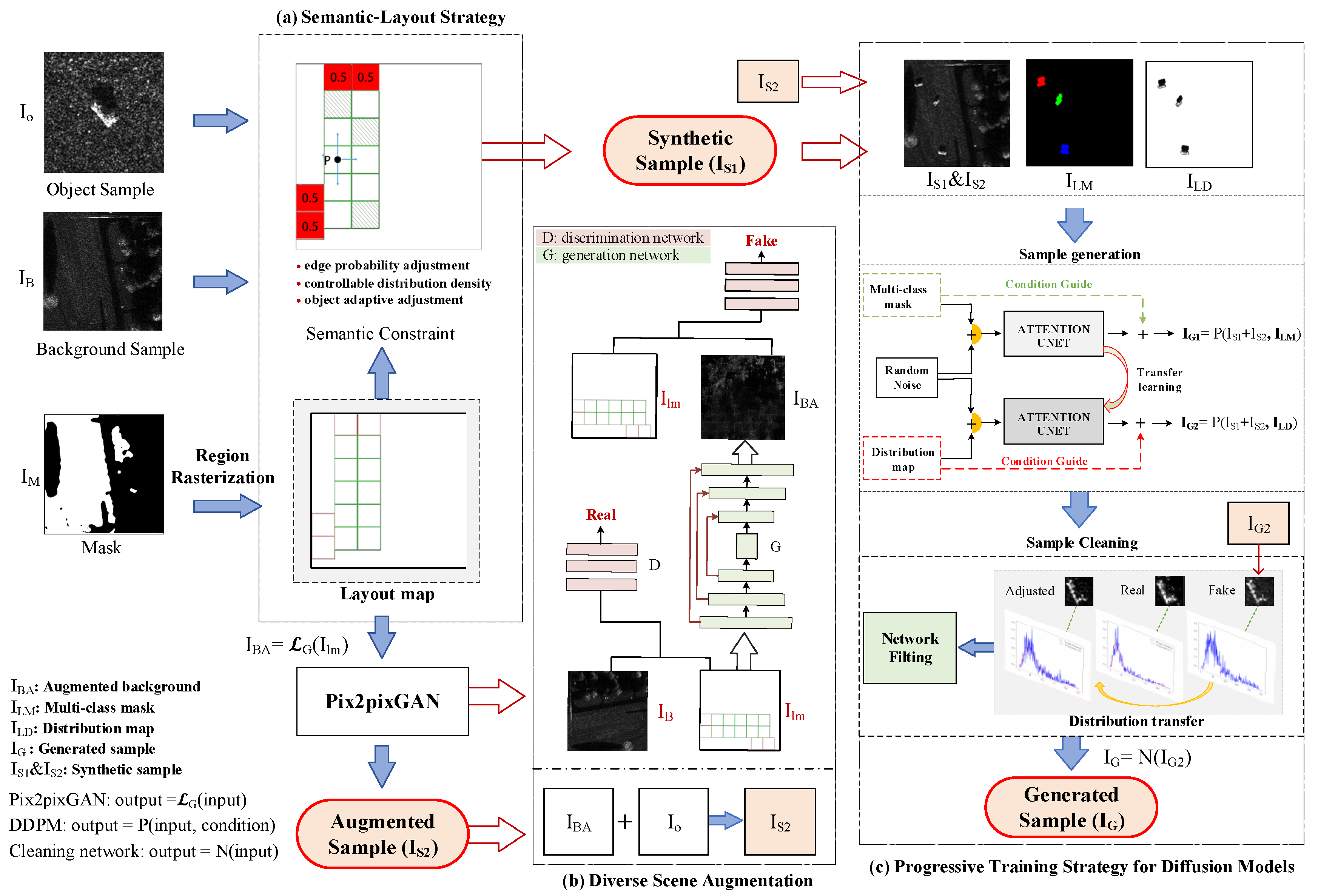
3. Proposed Method
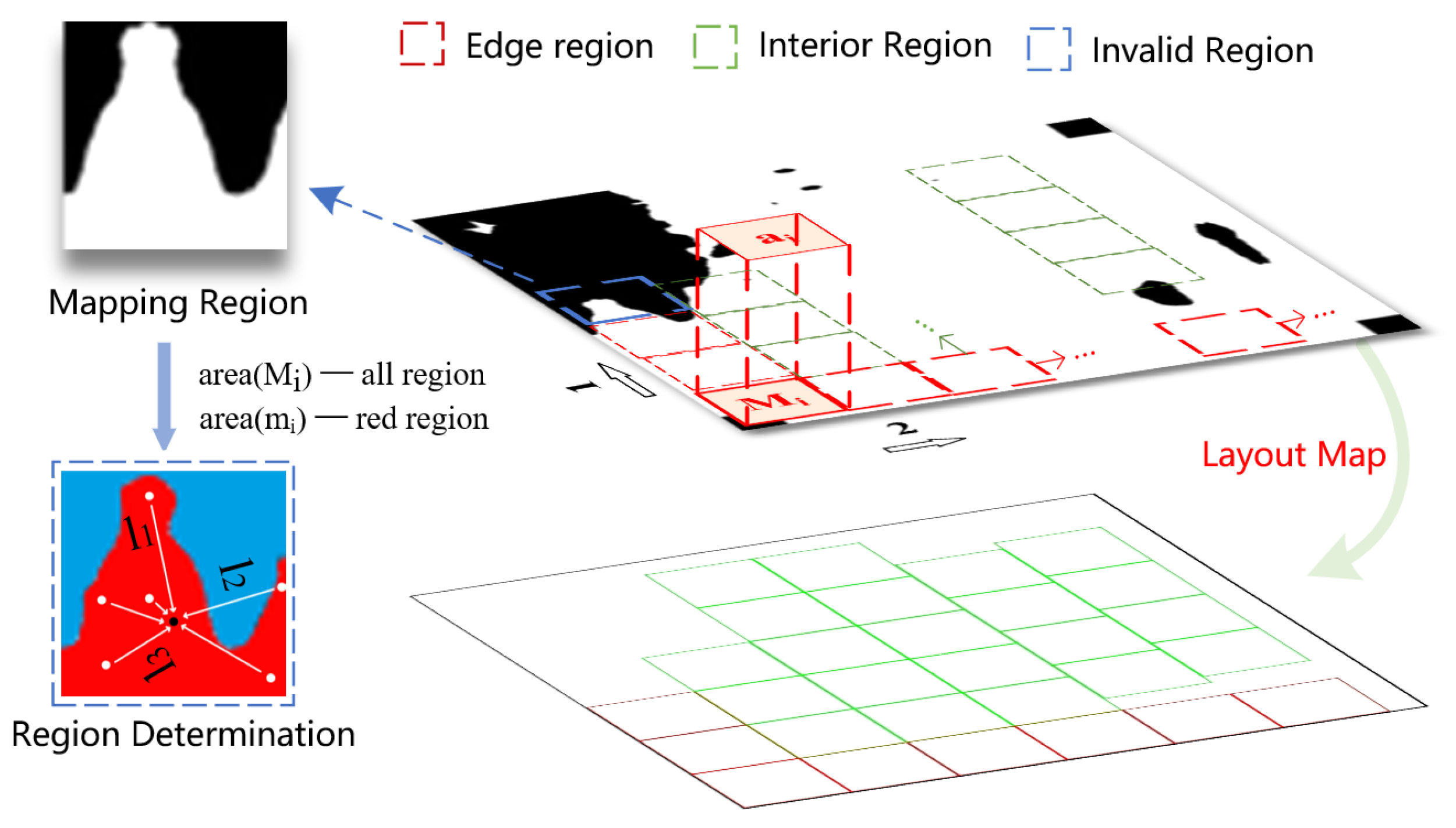
3.1. Semantic Layout Strategy
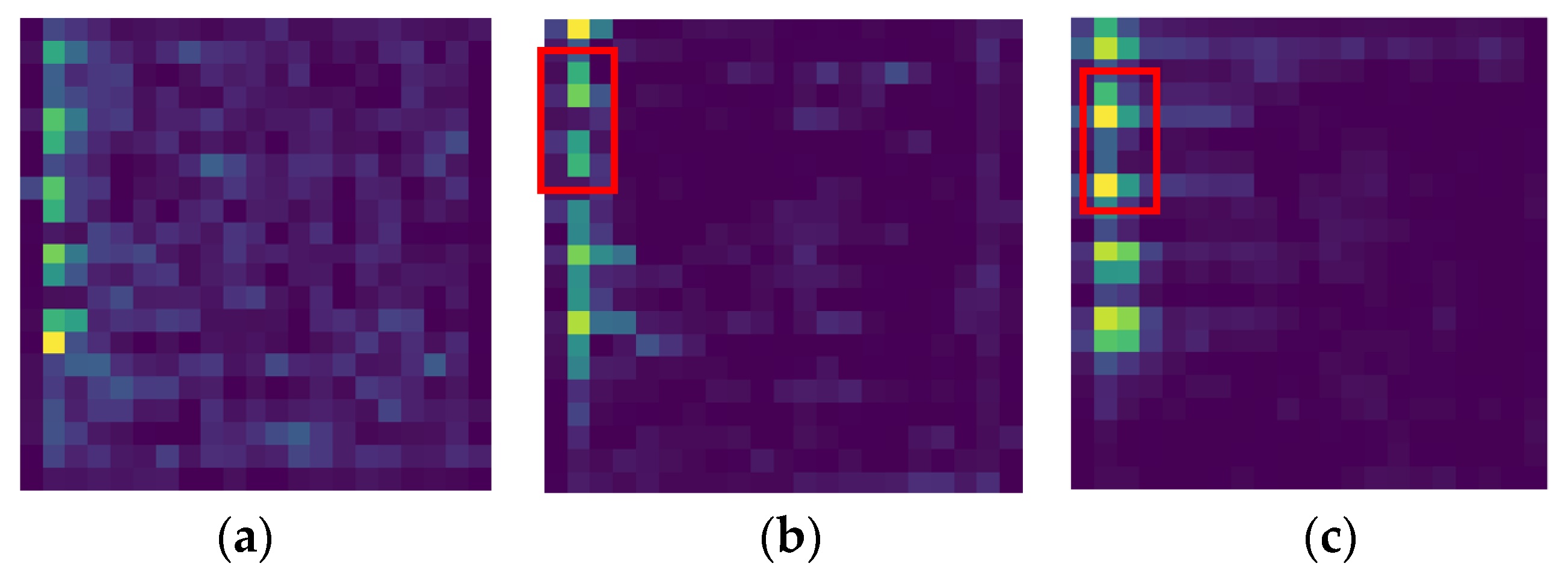
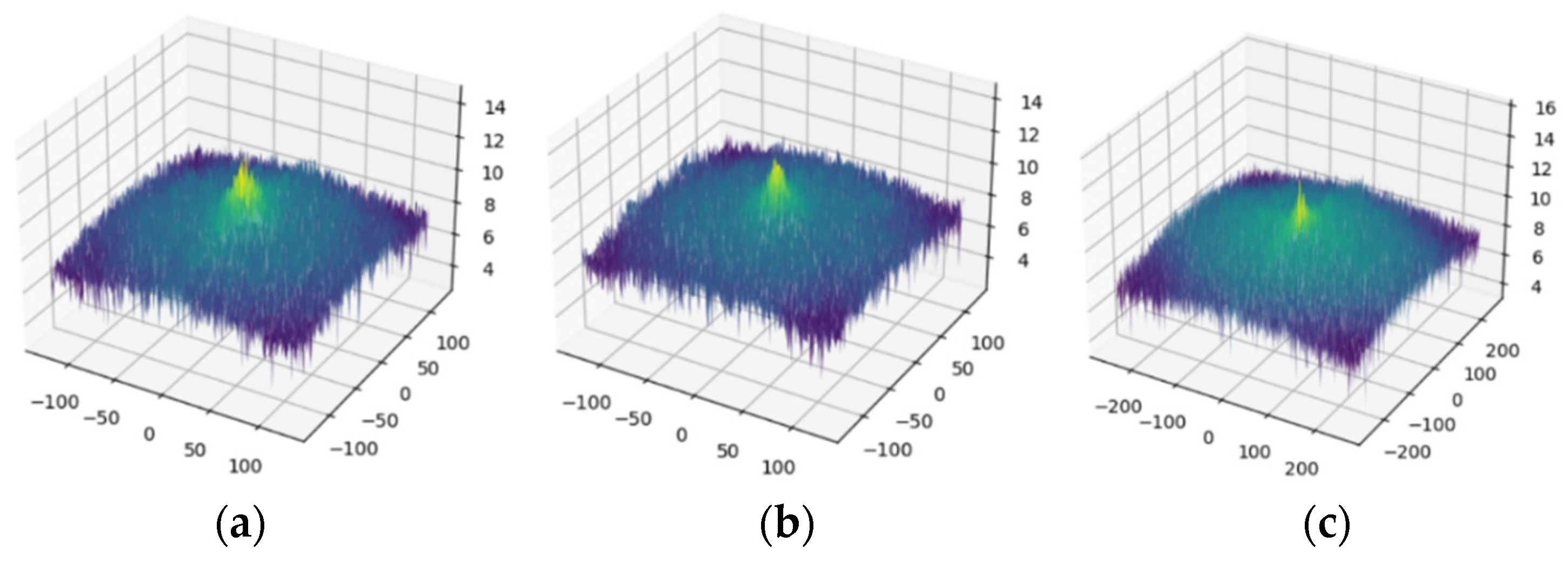
3.1.1. Mask Rasterization
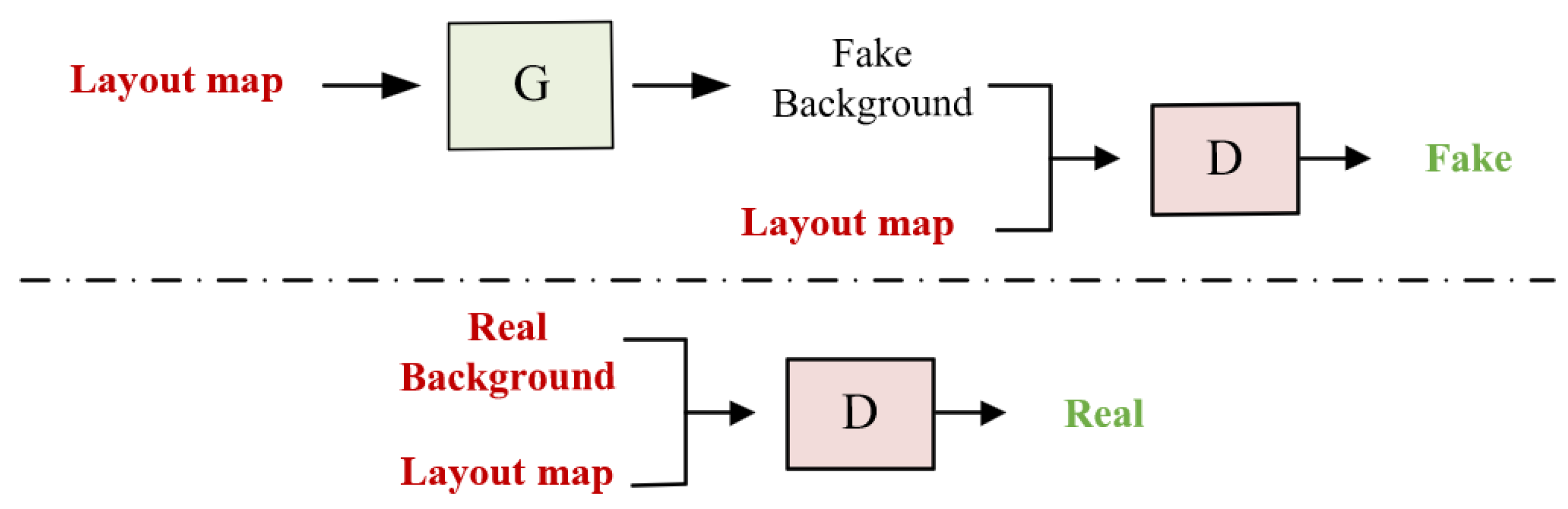
3.1.2. Semantic Constraints
| Algorithm 1: The Semantic-Layout Strategy. |
| Input: background and mask , object slice |
| Output: layout map, position box information |
| Process: |
| 1: The size of M is (w0, h0), perform edge mirroring augmentation to obtain M1(w, h). Preset the size of position boxes as (m, n) and perform grid-based layout on M1: |
| 2: for j in 1, 2, …, w do |
| 3: for k in 1, 2, …, h do |
| 4: Calculate the effective occupancy ratio . |
| 5: if > ε do |
| 6: Calculate the center point (X0, Y0) of the effective region. |
| 7: Calculate the dispersion according to Equation (5). |
| 8: end if |
| 9: Record the rectangular position information , including center (x, y), width–height (h, w), and category (whether it is located on the edge) |
| 10: end for |
| 11: end for |
| 12: Count the number of position boxes (num), calculate the probability based on Equation (2). |
| 13: start composing: |
| 14: for each B in the background dataset do |
| 15: Perform edge mirror augmentation on to match the same augmentation as . |
| 16: Randomly select from the object library, where i ∈ [1,num] |
| 17: Place the objects in the position boxes at random positions based on . |
| 18: Synthesize samples according to Equation (2). |
| 19: Restore by cropping the edges. |
| 20: end for |
3.2. Diverse Scene Generation
3.3. Progressive Training of Synthetic Data-Driven Diffusion Models
3.3.1. Progressive Training of a Diffusion Model
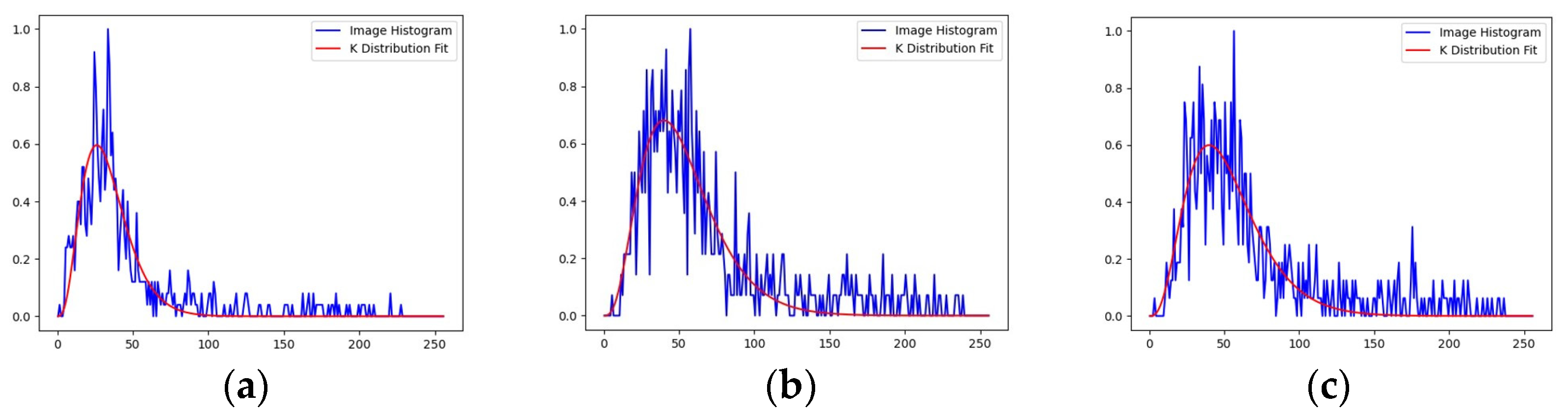
3.3.2. Cleaning Generated SAR Samples
4. Experimental Results and Analysis
4.1. Experimental Data and Evaluation Indexes
- IS↑: Inception Score. IS consists of two components: the first value is the mean of the KL divergence, where a larger value indicates higher data quality. The second value is the standard deviation of the KL divergence, indicating richer sample diversity as the value increases.
- FID↓: Fréchet Inception Distance. FID is a metric used to measure the difference between generated images and real images. The lower the FID indicates the smaller difference between generated images and real images.
- P↑: Precision. The precision rate refers to the ratio of the truly positive samples among the positive samples detected by the model. The higher the precision rate indicates the lower the probability of the model predicting negative samples as positive samples.
- R↑: Recall. The recall rate refers to the proportion of truly positive samples detected by the model among all positive samples. A higher recall rate indicates a stronger ability of the model to correctly detect positive samples.
- mAP↑: mean Average Precision. The overall performance evaluation index of the model. A higher mAP value indicates superior model performance in object detection tasks.
- F1-score↑: F1-score is a performance metric that provides a comprehensive evaluation of the accuracy of a classification model by considering both precision and recall.
4.2. Comparison with Other Advanced Methods
- Pix2pixGAN [44]: An improved generative adversarial network that achieves real-time transformation from input images to object images by learning the mapping relationship between them.
- CycleGAN [45]: An unsupervised generative adversarial network that maintains the original image’s content using cycle consistency loss.
- BicycleGAN: By introducing additional consistency loss and mutual information loss, it enhances controllability and diversity in image generation tasks.
- DDPM [47]: A generative model that transforms random noise into a coherent image by simulating the reverse of diffusion, providing a unique way to create high-quality and diverse samples.
4.3. Ablation Analysis of Different Sample Augmentation Strategies
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ma, F.; Sun, X.; Zhang, F.; Zhou, Y.; Li, H.C. What Catch Your Attention in SAR Images: Saliency Detection Based on Soft-Superpixel Lacunarity Cue. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5200817. [Google Scholar] [CrossRef]
- Zhou, Y.; Liu, H.; Ma, F.; Pan, Z.; Zhang, F. A Sidelobe-Aware Small Ship Detection Network for Synthetic Aperture Radar Imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5205516. [Google Scholar] [CrossRef]
- Zhang, F.; Yao, X.; Tang, H.; Yin, Q.; Hu, Y.; Lei, B. Multiple Mode SAR Raw Data Simulation and Parallel Acceleration for Gaofen-3 Mission. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2115–2126. [Google Scholar] [CrossRef]
- Lyu, Y.; Wang, Z.; Wang, P.; Li, S.; Tan, H.; Chen, K.; Zhao, L.; Sun, X. Scattering information and meta-learning based SAR images interpretation for aircraft target recognition. J. Radars 2022, 11, 652–665. [Google Scholar]
- Wangiyana, S.; Samczyński, P.; Gromek, A. Data augmentation for Building Footprint Segmentation in SAR Images: An Empirical Study. Remote Sens. 2022, 14, 2012. [Google Scholar] [CrossRef]
- Ma, Q. Improving SAR Object Recognition Performance Using Multiple Preprocessing Techniques. Comput. Intell. Neurosci. 2021, 2021, 6572362. [Google Scholar] [CrossRef] [PubMed]
- Yang, R. Rethinking the Random Cropping Data augmentation Method Used in the Training of CNN-Based SAR Image Ship Detector. Sensors 2021, 13, 34. [Google Scholar] [CrossRef]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Jiang, T.; Cui, Z.; Zhou, Z.; Cao, Z. Data augmentation with Gabor Filter in Deep Convolutional Neural Networks for Sar Object Recognition. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 689–692. [Google Scholar] [CrossRef]
- Tang, G.; Zhao, H.; Claramunt, C.; Men, S. FLNet: A Near-shore Ship Detection Method Based on Image Enhancement Technology. Remote Sens. 2022, 14, 4857. [Google Scholar] [CrossRef]
- Gong, C.; Wang, D.; Li, M.; Chandra, V.; Liu, Q. Keep augment: A simple information-preserving data augmentation approach. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–21 June 2021; pp. 1055–1064. [Google Scholar]
- Jiang, X.; Huang, B. Unmixing-Based Spatiotemporal Image Fusion Accounting for Complex Land Cover Changes. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5623010. [Google Scholar] [CrossRef]
- Sengupta, S.; Jayaram, V.; Curless, B.; Seitz, S.M.; Kemelmacher-Shlizerman, I. Background Matting: The World Is Your Green Screen. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2291–2300. [Google Scholar]
- Wang, J.; Li, J.; Sun, B.; Zuo, Z. SAR image synthesis based on conditional generative adversarial networks. J. Eng. 2019, 2019, 8093–8097. [Google Scholar] [CrossRef]
- Wang, R.; Zhang, H.; Han, B.; Zhang, Y.; Guo, J.; Hong, W.; Sun, W.; Hu, W. Multiangle SAR dataset construction of aircraft targets based on angle interpolation simulation. J. Radars 2022, 11, 637–651. [Google Scholar]
- Geng, Z.; Xu, Y.; Wang, B.-N.; Yu, X.; Zhu, D.Y.; Zhang, G. Object Recognition in SAR Images by Deep Learning with Training Data augmentation. Sensors 2023, 23, 941. [Google Scholar] [CrossRef]
- Bao, W.; Hu, J.; Huang, M.; Xu, Y.; Ji, N.; Xiang, X. Detecting Fine-Grained Airplanes in SAR Images with Sparse Attention-Guided Pyramid and Class-Balanced Data augmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 8586–8599. [Google Scholar] [CrossRef]
- Suo, Z.; Zhao, Y.; Chen, S.; Hu, Y. BoxPaste: An Effective Data augmentation Method for SAR Ship Detection. Remote Sens. 2022, 14, 5761. [Google Scholar] [CrossRef]
- Lv, J.T.; Liu, Y. Data augmentation Based on Attributed Scattering Centers to Train Robust CNN for SAR ATR. IEEE Access 2019, 7, 25459–25473. [Google Scholar] [CrossRef]
- Ding, B.; Wen, G.; Huang, X.; Huang, X.; Ma, C.; Yang, X. Data augmentation by Multilevel Reconstruction Using Attributed Scattering Center for SAR Object Recognition. IEEE Geosci. Remote Sens. Lett. 2017, 14, 979–983. [Google Scholar] [CrossRef]
- Inoue, H. Data augmentation by pairing samples for images classification. arXiv 2018, arXiv:1801.02929. [Google Scholar]
- Sun, Y.; Wang, Y.; Hu, L.; Huang, Y.; Liu, H.; Wang, S.; Zhang, C. Attribute-Guided Generative Adversarial Network with Improved Episode Training Strategy for Few-Shot SAR Image Generation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 1785–1801. [Google Scholar] [CrossRef]
- Wang, C.; Pei, J.; Liu, X.; Huang, Y.; Mao, D.; Zhang, Y.; Yang, J. SAR Object Image Generation Method Using Azimuth-Controllable Generative Adversarial Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 9381–9397. [Google Scholar] [CrossRef]
- Baier, G.; Deschemps, A.; Schmitt, M.; Yokoya, N. Synthesizing Optical and SAR Imagery from Land Cover Maps and Auxiliary Raster Data. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4701312. [Google Scholar] [CrossRef]
- Lou, X.; Liu, Y.; Xiong, Z.; Wang, H. Generative knowledge transfer for ship detection in SAR images. Comput. Electr. Eng. 2022, 101, 108041. [Google Scholar] [CrossRef]
- Huang, H.; Zhang, F.; Zhou, Y.; Yin, Q.; Hu, W. High Resolution SAR Image Synthesis with Hierarchical Generative Adversarial Networks. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 2782–2785. [Google Scholar] [CrossRef]
- Serrà, J.; Álvarez, D.; Gómez, V.; Slizovskaia, O.; Núñez, J.F.; Luque, J. Input complexity and out-of-distribution detection with likelihood-based generative models. arXiv 2019, arXiv:1909.11480. [Google Scholar]
- Mohamed, S.; Lakshminarayanan, B. Learning in implicit generative models. arXiv 2016, arXiv:1610.03483. [Google Scholar]
- Chung, Y.A.; Hsu, W.N.; Tang, H.; Glass, J. An unsupervised autoregressive model for speech representation learning. arXiv 2019, arXiv:1904.03240. [Google Scholar]
- Boutsidis, C.; Woodruff, D.P.; Zhong, P. Optimal principal component analysis in distributed and streaming models. In Proceedings of the 48th Annual ACM Symposium on Theory of Computing, Cambridge, MA, USA, 19–21 June 2016; pp. 236–249. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Niu, L.; Cong, W.; Liu, L.; Hong, Y.; Zhang, B.; Liang, J.; Zhang, L. Making Images Real Again: A Comprehensive Survey on Deep Image Composition. arXiv 2021, arXiv:2106.14490. [Google Scholar]
- Fu, Y.; Hu, Y. A survey on image matting methods based on deep learning. Front. Econ. Manag. 2022, 3, 497–502. [Google Scholar]
- Xu, N.; Price, B.; Cohen, S.; Huang, T. Deep image matting. In Proceedings of the EEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2970–2979. [Google Scholar]
- Cong, W.; Zhang, J.; Niu, L.; Liu, L.; Ling, Z.; Li, W.; Zhang, L. DoveNet: Deep image harmonization via domain verification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 8394–8403. [Google Scholar]
- Cun, X.; Pun, C.-M. Improving the harmony of the composite image by spatial-separated attention module. IEEE Trans. Image Process. 2020, 29, 4759–4771. [Google Scholar] [CrossRef]
- Azadi, S.; Pathak, D.; Ebrahimi, S.; Darrell, T. Compositional GAN: Learning image conditional binary composition. Int. J. Comput. Vis. 2020, 128, 2570–2585. [Google Scholar] [CrossRef]
- Zhang, L.; Wen, T.; Min, J.; Wang, J.; Han, D.; Shi, J. Learning object placement by inpainting for compositional data augmentation. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; pp. 566–581. [Google Scholar]
- Katsumata, K.; Nakayama, H. Semantic image synthesis from inaccurate and coarse masks. In Proceedings of the IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2285–2289. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Audebert, N.; Le Saux, B.; Lefevre, S. Generative Adversarial Networks for Realistic Synthesis of Hyperspectral Samples. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 4359–4362. [Google Scholar] [CrossRef]
- Wang, G.; Dong, G.; Li, H.; Han, L.; Tao, X.; Ren, P. Remote Sensing Image Synthesis via Graphical Generative Adversarial Networks. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 10027–10030. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.Y.; Zhou, T. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Sohl-Dickstein, J.; Weiss, E.; Maheswaranathan, N.; Ganguli, S. Deep unsupervised learning using nonequilibrium thermodynamics. In Proceedings of the International Conference on Machine Learning 2015, Lille, France, 6–11 July 2015; Volume 19, pp. 2256–2265. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Song, J.; Meng, C.; Ermon, S. Denoising diffusion implicit models. arXiv 2020, arXiv:2010.02502. [Google Scholar]
- Yuan, Z.; Hao, C.; Zhou, R.; Chen, J.; Yu, M.; Zhang, W.; Wang, H.; Sun, X. Efficient and Controllable Remote Sensing Fake Sample Generation Based on Diffusion Model. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5615012. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Transformations | Introduction |
|---|---|---|
| Information Transformation | Translation | Moving the image horizontally or vertically |
| Rotation | Rotating the image at a certain angle | |
| Scaling | Stretching or compressing the image in a ratio | |
| Mirroring | Flipping the image horizontally or vertically | |
| Noise Addition | Adding noise to the image | |
| Cropping | Cropping different regions from the image | |
| Overlay | Overlaying multiple images together | |
| Illumination | Adjusting the brightness, contrast, and color of the image | |
| Information Fusion | Image Stitching | Seamlessly merging multiple images together |
| Image Blending | Blending two or more different images together | |
| Image Fusion | Fusing two or more different images together |
| Platform | Windows 11 |
|---|---|
| CPU | Intel Core i7-12700 k |
| Memory | 16 G |
| GPU | Nvidia GeForce RTX 3070 |
| Video memory | 8 G |
| Method | KL (Mean)↑ | FID↓ | KL (Std)↑ | Matching Degree (%)↑ |
|---|---|---|---|---|
| Original | 1.866 | - | 0.163 | 92.9 |
| CycleGAN | 1.349 | 28.42 | 0.070 | 18.5 |
| Pix2pixGAN | 1.252 | 28.47 | 0.038 | 15.1 |
| BicycleGAN | 1.126 | 32.07 | 0.056 | 10.2 |
| DDPM | 1.871 | 25.93 | 0.084 | 48.6 |
| Ours-SL | 1.782 | - | 0.010 | 92.7 |
| Ours-BA | 1.300 | 30.17 | 0.042 | 87.8 |
| Ours-GE | 1.774 | 25.54 | 0.090 | 78.2 |
| Ours-all | 1.884 | 18.83 | 0.180 | 81.8 |
| Network | Method | P (%) | R (%) | mAP (%) | F1 (%) |
|---|---|---|---|---|---|
| Yolov5 | Baseline | 78.8 | 79.8 | 66.6 | 79.30 |
| Random | 80 | 80.3 | 67.3 | 80.15 | |
| Ours-SL | 81.1 | 80.1 | 68.7 | 80.60 | |
| Ours-SL+ BA | 82.9 | 81.5 | 69.7 | 82.19 | |
| Ours-all | 85.5 | 86.3 | 73.6 | 85.90 | |
| RetinaNet | Baseline | 69.2 | 78.9 | 54.3 | 73.73 |
| Random | 70.2 | 79.5 | 54.8 | 74.56 | |
| Ours-SL | 70.5 | 79.8 | 55.2 | 74.86 | |
| Ours-SL+ BA | 71.9 | 81.9 | 57.1 | 76.57 | |
| Ours-all | 73.2 | 83 | 58.3 | 77.79 | |
| VarifocalNet | Baseline | 74.4 | 81.9 | 59.5 | 77.97 |
| Random | 76.7 | 82.6 | 61.6 | 79.54 | |
| Ours-SL | 81.7 | 83.4 | 66.4 | 82.54 | |
| Ours-SL+ BA | 82.2 | 83.8 | 67 | 82.99 | |
| Ours-all | 85.6 | 84.6 | 70.4 | 85.10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kuang, Y.; Ma, F.; Li, F.; Liu, Y.; Zhang, F. Semantic-Layout-Guided Image Synthesis for High-Quality Synthetic-Aperature Radar Detection Sample Generation. Remote Sens. 2023, 15, 5654. https://doi.org/10.3390/rs15245654
Kuang Y, Ma F, Li F, Liu Y, Zhang F. Semantic-Layout-Guided Image Synthesis for High-Quality Synthetic-Aperature Radar Detection Sample Generation. Remote Sensing. 2023; 15(24):5654. https://doi.org/10.3390/rs15245654
Chicago/Turabian StyleKuang, Yi, Fei Ma, Fangfang Li, Yingbing Liu, and Fan Zhang. 2023. "Semantic-Layout-Guided Image Synthesis for High-Quality Synthetic-Aperature Radar Detection Sample Generation" Remote Sensing 15, no. 24: 5654. https://doi.org/10.3390/rs15245654
APA StyleKuang, Y., Ma, F., Li, F., Liu, Y., & Zhang, F. (2023). Semantic-Layout-Guided Image Synthesis for High-Quality Synthetic-Aperature Radar Detection Sample Generation. Remote Sensing, 15(24), 5654. https://doi.org/10.3390/rs15245654