1. Introduction
Remote sensing image object detection tasks play a pivotal role in the realm of airborne and satellite remote sensing imagery, representing invaluable applications. Throughout recent decades, remote sensing technology has witnessed remarkable progress, enabling the capture of copious details that inherently reflect the contours, hues, textures, and other distinctive attributes of terrestrial targets [
1]. It has emerged as an indispensable avenue for acquiring comprehensive knowledge about the Earth’s surface. The primary objective of remote sensing image object detection is to precisely identify and locate objects of interest within the vast expanse of remote sensing images. Presently, this task finds extensive implementation across significant domains, including military reconnaissance [
2], urban planning [
3], environmental monitoring [
4], soil science [
5], and maritime vessel surveillance [
6]. With the incessant advancement of observational techniques [
7], the availability of high-quality remote sensing image datasets, encompassing richer and more intricate information, has unlocked immense developmental potential for the ongoing pursuit of remote sensing image object detection.
In the past decade, deep learning has undergone rapid advancements and progressively found applications in diverse fields, including speech recognition, natural language processing, and computer vision. Computer vision technology has been widely implemented in intelligent security, autonomous driving, remote sensing monitoring, healthcare and pharmaceuticals, agriculture, intelligent transportation, and information security [
8,
9,
10,
11,
12,
13,
14]. Within computer vision, tasks can be classified into image classification [
15], object detection [
16], and image segmentation [
17]. Notably, object detection, a pivotal branch of computer vision, has made remarkable strides during this period, largely attributed to the availability of extensive object detection datasets. Datasets such as MS COCO [
18], PASCAL VOC [
19], and Visdrone [
20,
21] have played a crucial role in facilitating breakthroughs in object detection tasks.
Nevertheless, in the realm of optical remote sensing imagery, current object detection algorithms still encounter numerous formidable challenges. These difficulties arise due to disparities between the acquisition methods used for optical remote sensing imagery and those employed for natural images. Remote sensing imagery relies on sensors such as optical, microwave, or laser devices to capture Earth’s surface information by detecting and recording radiation or reflection across different spectral ranges. Conversely, natural images are captured using electronic devices (e.g., cameras) or sensors to record visible light, infrared radiation, and other forms of radiation present in the natural environment, thereby acquiring everyday image data. Unlike natural images captured horizontally by ground cameras, satellite images taken from an aerial perspective provide extensive imaging coverage and comprehensive information. In complex landscapes and urban environments, advanced structures and uneven distribution of background information can pose additional challenges [
22]. Furthermore, due to the imaging method of remote sensing images, they encompass a wealth of information regarding various target objects. Consequently, these images frequently exhibit numerous instances of overlapping and varying-scaled targets, such as ships and ports, which are often arranged in a non-directional manner unnecessarily [
23]. This necessitates that models designed for detecting remote sensing targets possess a highly perceptive ability in terms of accurate positioning [
24] while also being sensitive to capturing informative details during the detection process. Additionally, the prevalence of small target instances in remote sensing images, some of which may consist of only a few pixels, poses significant challenges in feature extraction for the model [
25], thereby resulting in performance degradation. Moreover, certain target instances in remote sensing images, such as flyovers and bridges, share strikingly similar features, intensifying the difficulties encountered in feature extraction for the model [
26], consequently leading to phenomena such as false detections or missed detections. The presence of target instances in remote sensing images with extreme aspect ratios [
27], such as highways and sea-crossing bridges, further exacerbates the challenges faced by the detector. Lastly, the complex background information within remote sensing images often leads to the occlusion of target regions by irrelevant backgrounds, rendering it difficult for the detector to extract target-specific features [
28]. Moreover, the imaging method of remote sensing images is subject to environmental conditions on Earth’s surface [
29], including atmospheric interference, cloud cover, and vegetation obstruction, which may result in target occlusion and overlap, impeding the detector’s ability to accurately delineate object contours [
30] and consequently compromising the precise localization of target information. As a consequence, remote sensing images necessitate calibration and preprocessing measures [
31]. Furthermore, in the current stage, numerous advanced detectors have achieved exceptional performance in remote sensing object detection through the design of neural network models’ depth and width. However, this achievement comes at the cost of a substantial increase in model parameters. For instance, in remote sensing devices such as unmanned aerial vehicles and remote sensing satellites, it is impractical to equip them with mobile devices possessing equivalent computational power. As a result, the lightweight design of remote sensing object detection lags its progress in natural image domains. Hence, effectively addressing the balance between model detection performance and lightweight design becomes an immensely valuable research question.
Deep learning-based object detection algorithms can be broadly classified into two categories. The first category consists of two-stage object detection algorithms that rely on candidate regions. These algorithms generate potential regions [
32,
33] and then perform classification and position regression [
34,
35], achieving high-precision object detection. Representative algorithms in this category include R-CNN [
36], Faster R-CNN [
37], Mask R-CNN [
38], and Sparse R-CNN [
39]. While these algorithms achieve high accuracy, their slower speed prevents real-time detection on all devices. The second category comprises single-stage object detection networks based on regression. These algorithms directly predict the position and class of objects from input images using a single network, avoiding the complex process of generating candidate regions and achieving faster detection speeds. The main representative networks in this category include SSD [
40] and the YOLO [
41,
42,
43,
44,
45,
46] series. Among them, the YOLO series of single-stage detection algorithms is widely used. Currently, YOLOv5 strikes a balanced performance in the YOLO series.
The YOLO object detection model, proposed by Redmon et al. [
47], achieves high-precision object detection performance while ensuring real-time inference. However, the individual training of each module in the YOLO model compromises the model’s inference speed, thus the concept of joint training was introduced in YOLOv2 [
48] to enhance the model’s inference speed. The Darknet-53 backbone network architecture, first introduced in YOLOv3 [
49], combines the strengths of Resnet to ensure highly expressive feature representation while avoiding gradient issues caused by excessive network depth. Additionally, multi-scale prediction techniques were employed to better adapt to objects of various sizes and shapes. In YOLOv4 [
50], the CSPDarknet53 feature extraction backbone network integrated a cross-stage partial network architecture (CSP), effectively addressing information redundancy within the backbone network and significantly reducing the model’s parameter count, thereby improving the overall inference speed. Moreover, the introduced Spatial Pooling Pyramid module in YOLOv4 helps expand the receptive field of the feature maps, further enhancing detection accuracy. As for YOLOv5, it strikes a balance in detection performance within the YOLO series. By employing CSPDarknet as the backbone network for feature extraction and adopting the FPN (Feature Pyramid Network) [
51] approach for semantic transmission in the neck region, YOLOv5 incorporates multiple feature layers with different resolutions at the top of the backbone network. Convolutional and upsampling operations are utilized to fuse the feature maps and align scales. Furthermore, the PANet (Path Aggregation Network) [
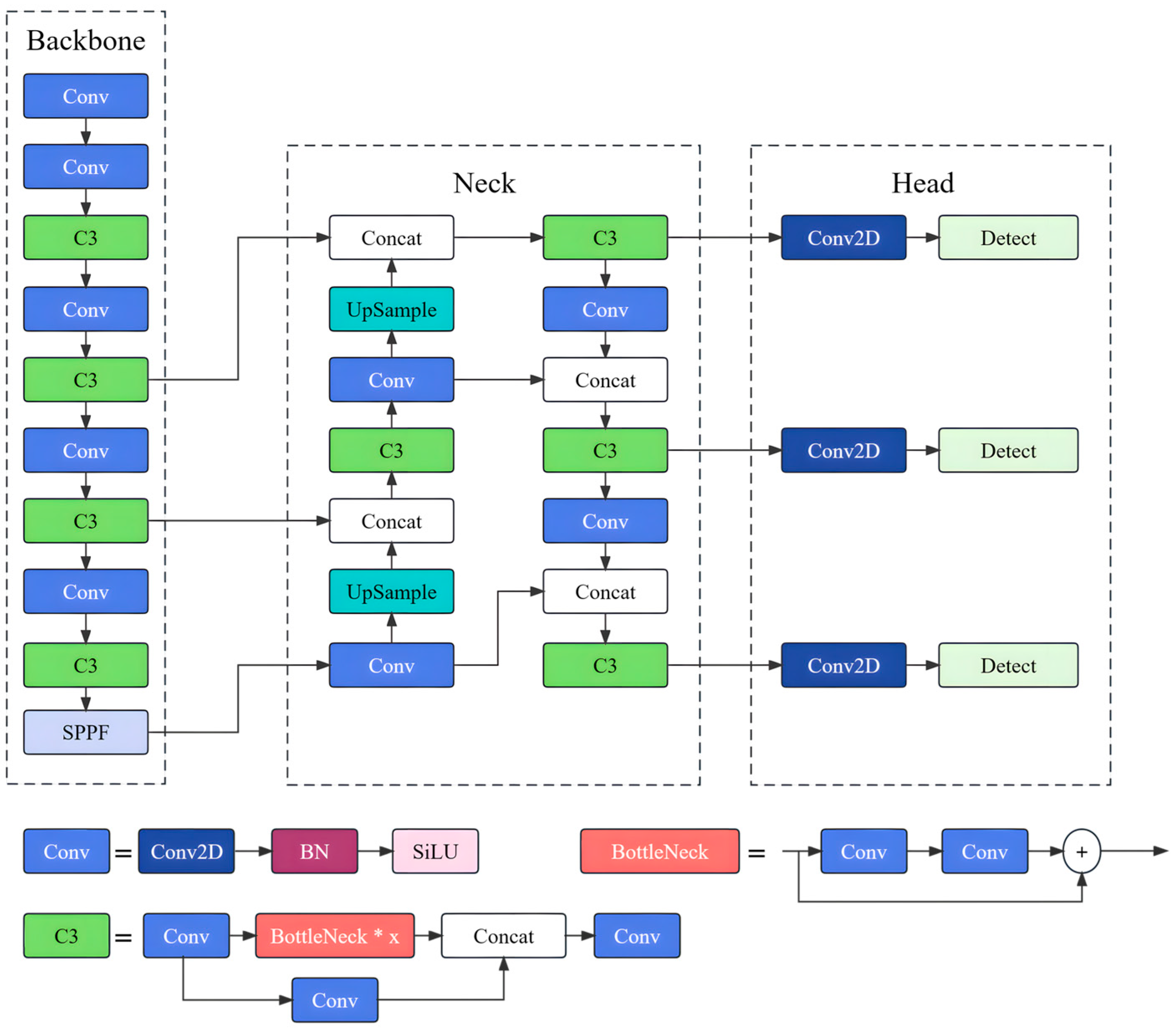
52] facilitates top-down localization. The YOLOv5 model has achieved favorable outcomes in natural image object detection tasks, but its effectiveness diminishes when applied to remote sensing satellite image detection due to challenges in meeting both real-time requirements and accuracy.
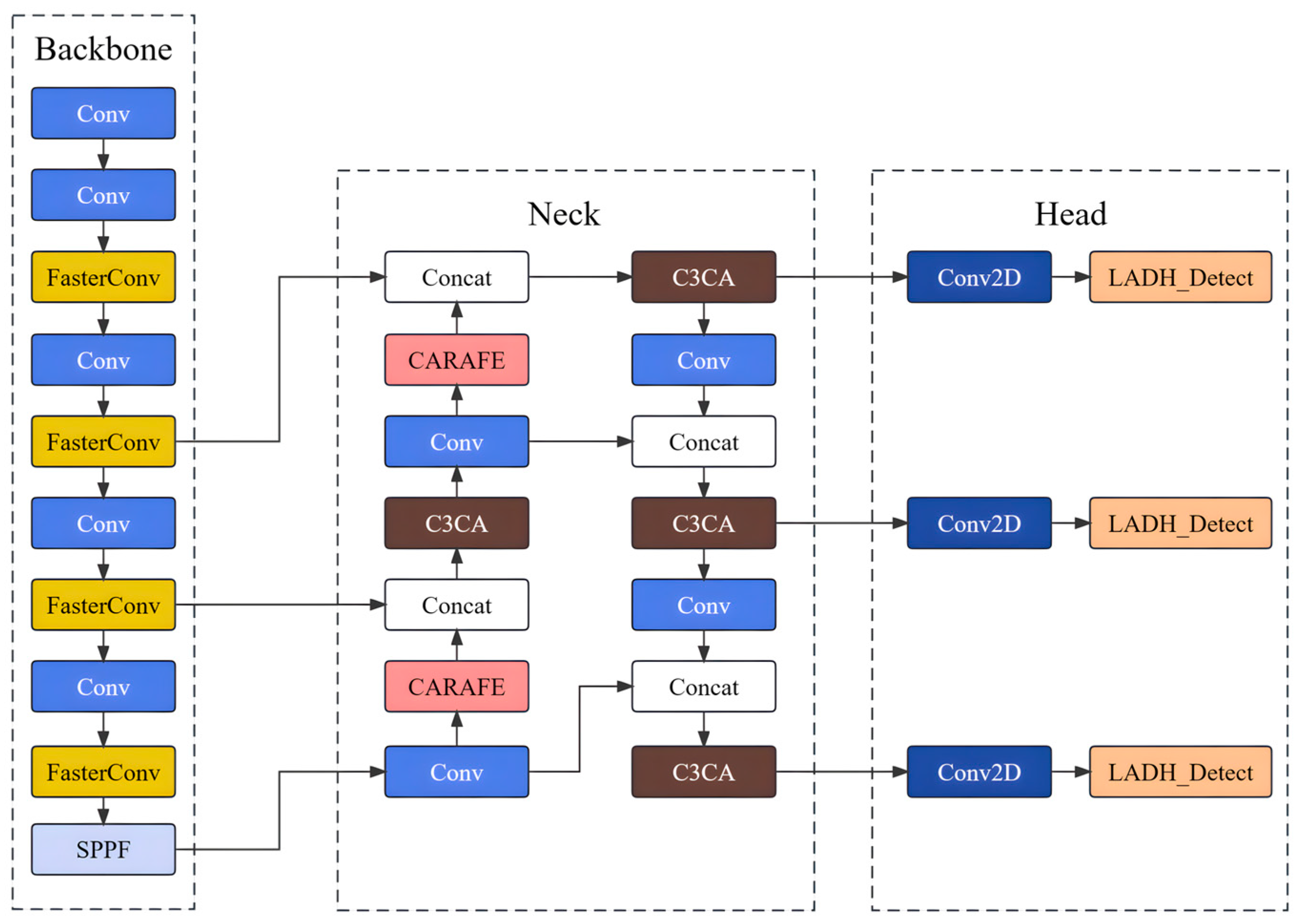
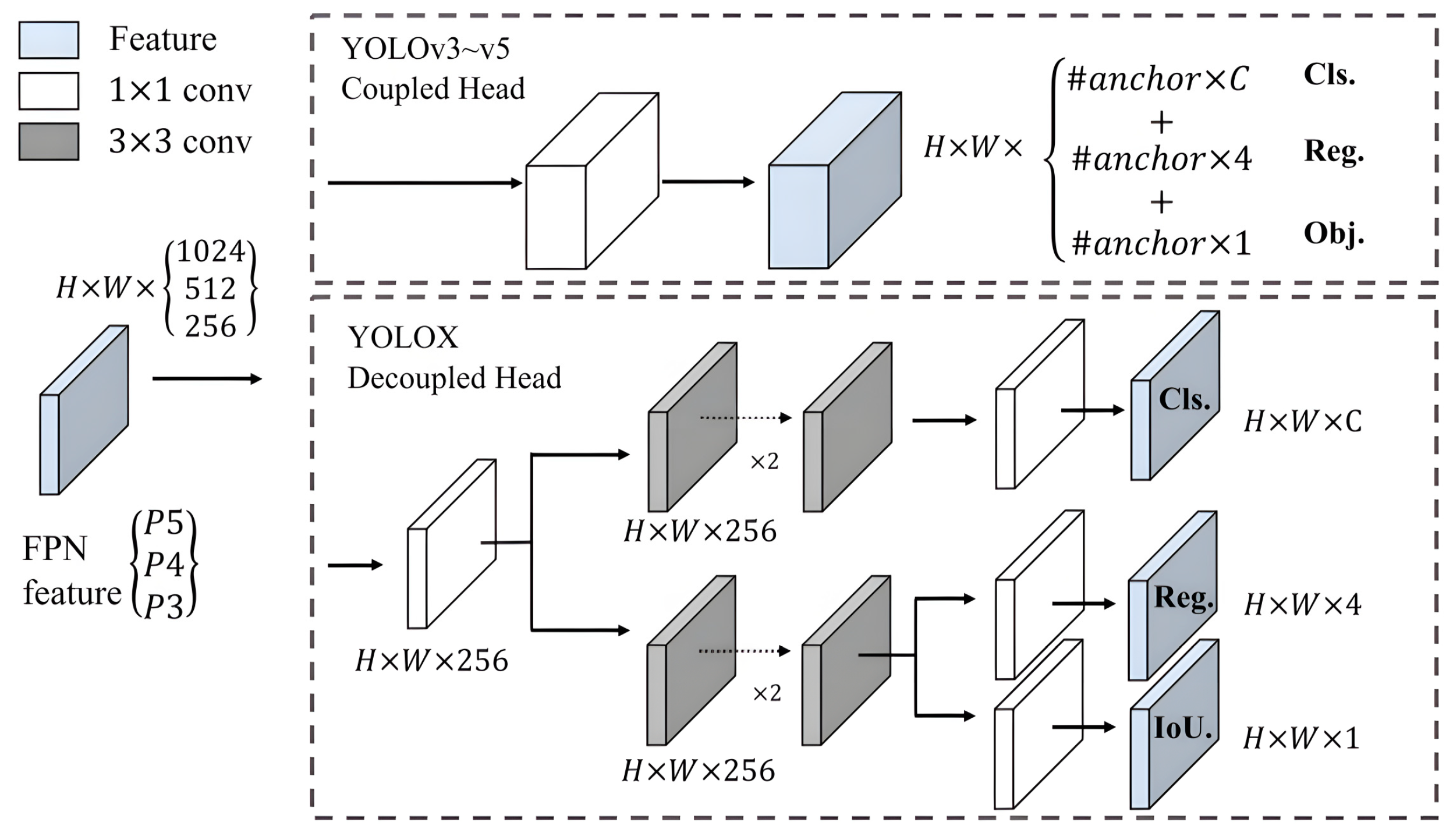
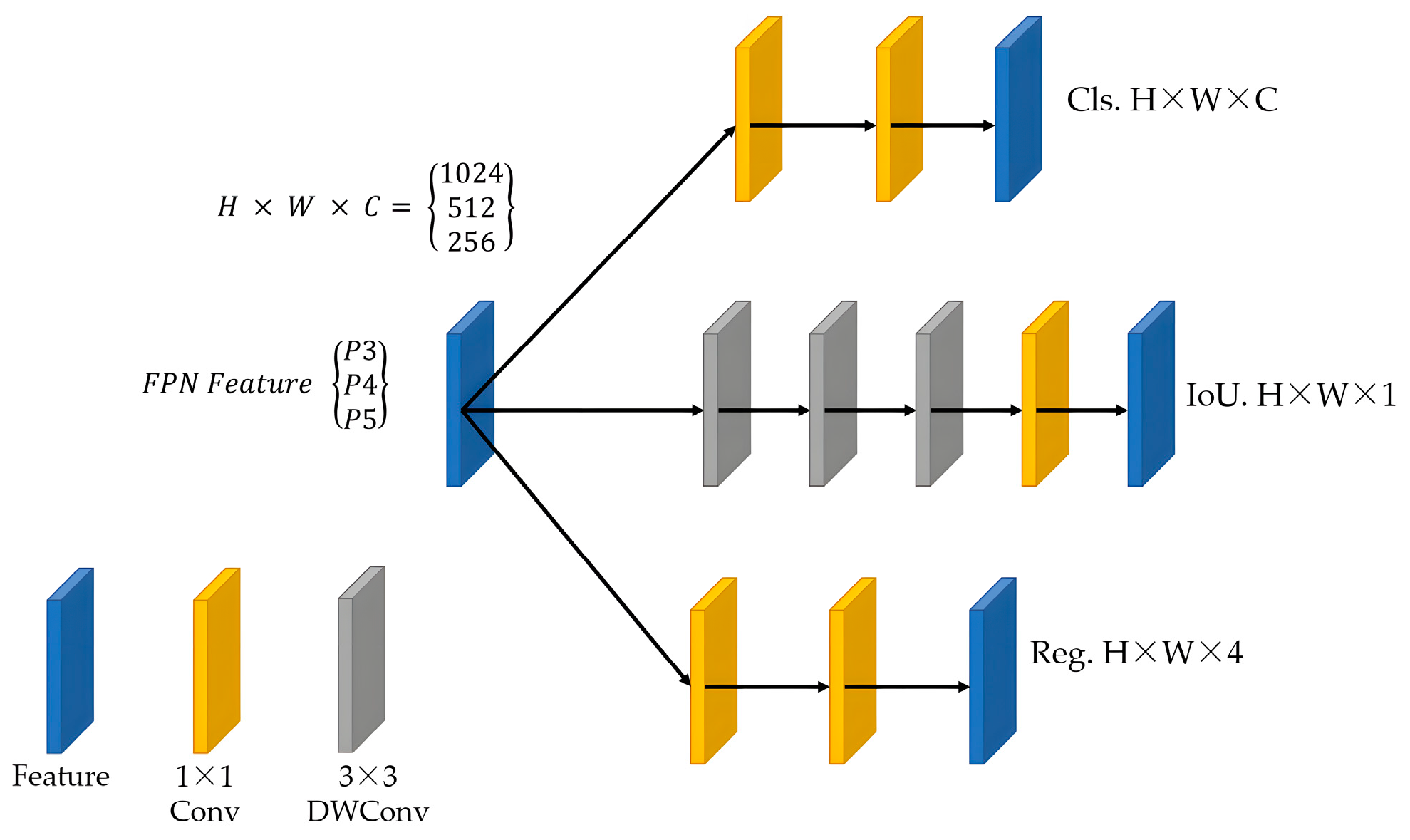
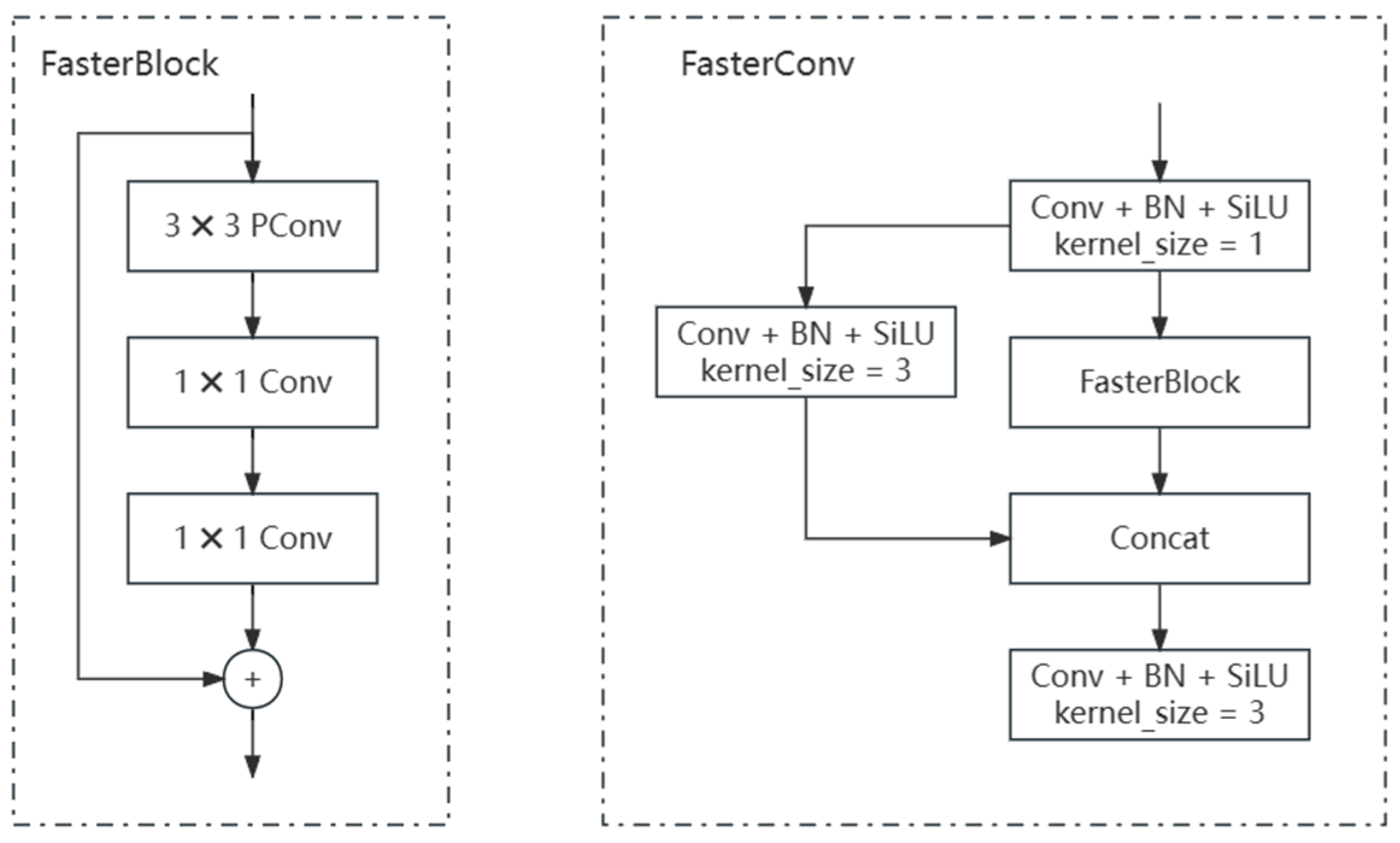
As a result, this study focuses on enhancing the YOLOv5 model for target detection in remote sensing images by proposing a faster and lightweight approach. The improvements include introducing a new backbone module called FasterConv, which replaces the C3 module in the original backbone network. This replacement reduces computational redundancy and optimizes memory access, thereby enhancing the inference speed of YOLOv5 across multiple devices. Additionally, a novel lightweight asymmetric detection head named LADH-Head is designed, inspired by the decoupled heads in YOLOX. By dividing the network paths based on the task type, this design significantly reduces parameters and GFLOPs compared to the original decoupled head module, leading to improved inference speed. Furthermore, the integration of Coordinate Attention into the Neck addresses the relatively high proportion of small objects in remote sensing images. The updated C3CA module models the coordinate information in the image, enabling a better understanding of spatial structure and positional relationships, thus improving performance in detecting small objects. To enhance detail and boundary preservation during upsampling operations, the content-aware reassembly upsampling module (CARAFE) [
53] replaces the nearest-neighbor interpolation upsampling module in the original model. Finally, the original loss function is refined by replacing CIoU with XIoU, resulting in enhanced model robustness, superior regression results, and improved convergence speed. Experimental results validate the outstanding performance of the proposed improved YOLOv5 model in remote sensing image object detection tasks. The paper presents the following contributions and innovations:
- (1)
Asymmetric decoupled detector head with a lightweight structure designed by combining deeply separable convolutions. By incorporating the groundbreaking lightweight asymmetric detection head, commonly referred to as LADH-Head, YOLOv5 achieves a significant reduction in computational complexity and a remarkable enhancement in inference speed. This innovative utilization marks a key milestone in the evolution of YOLOv5, leading to improved efficiency and accelerated performance.
- (2)
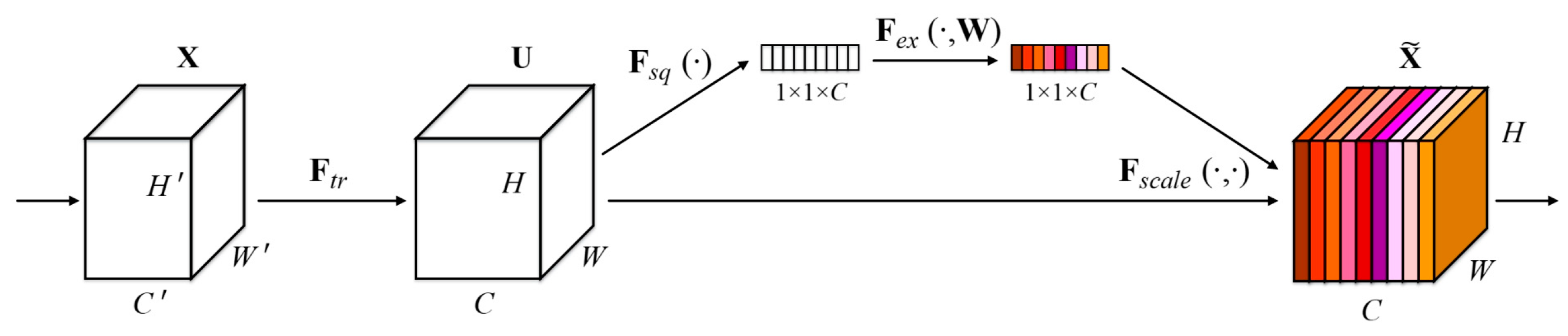
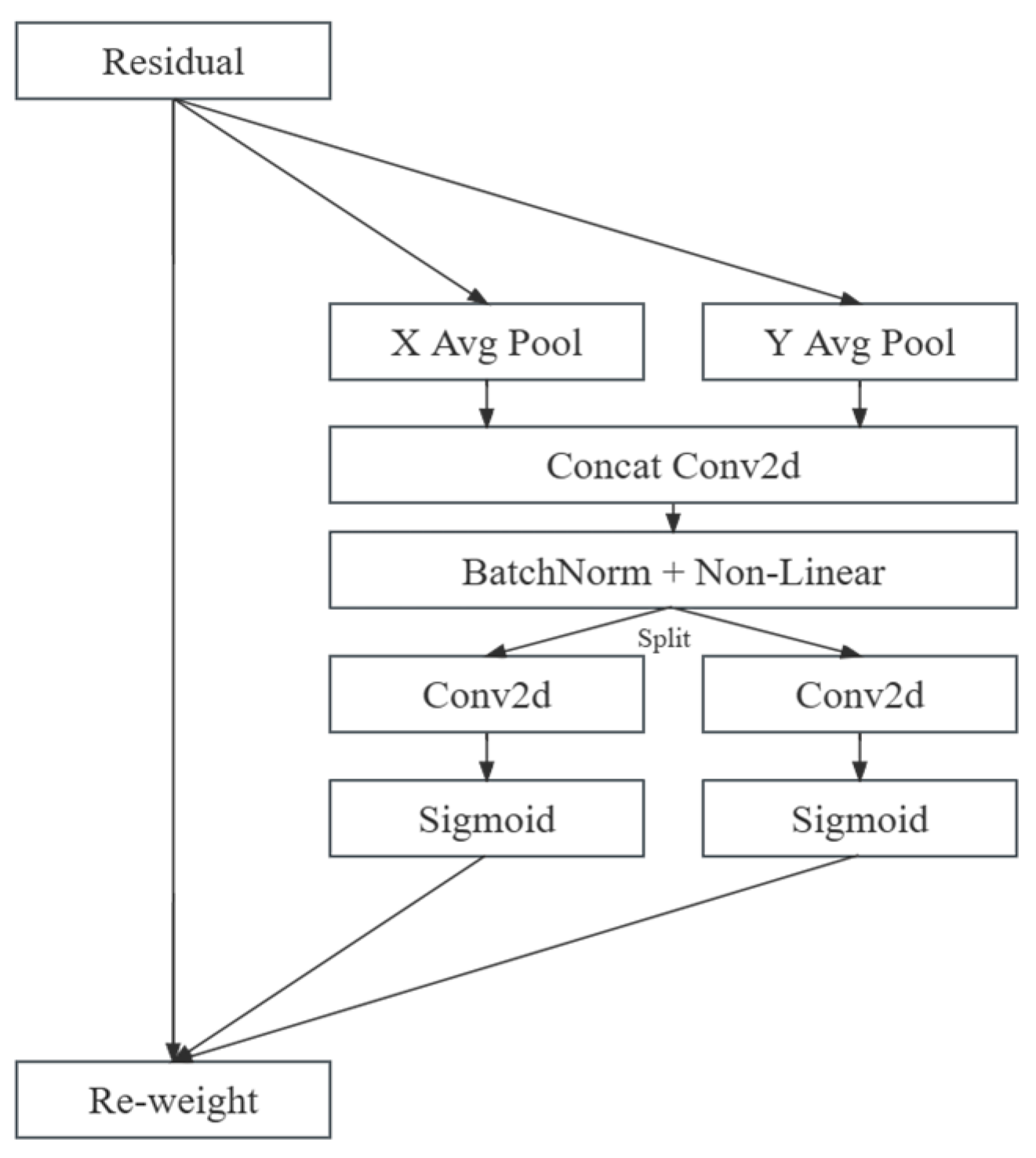
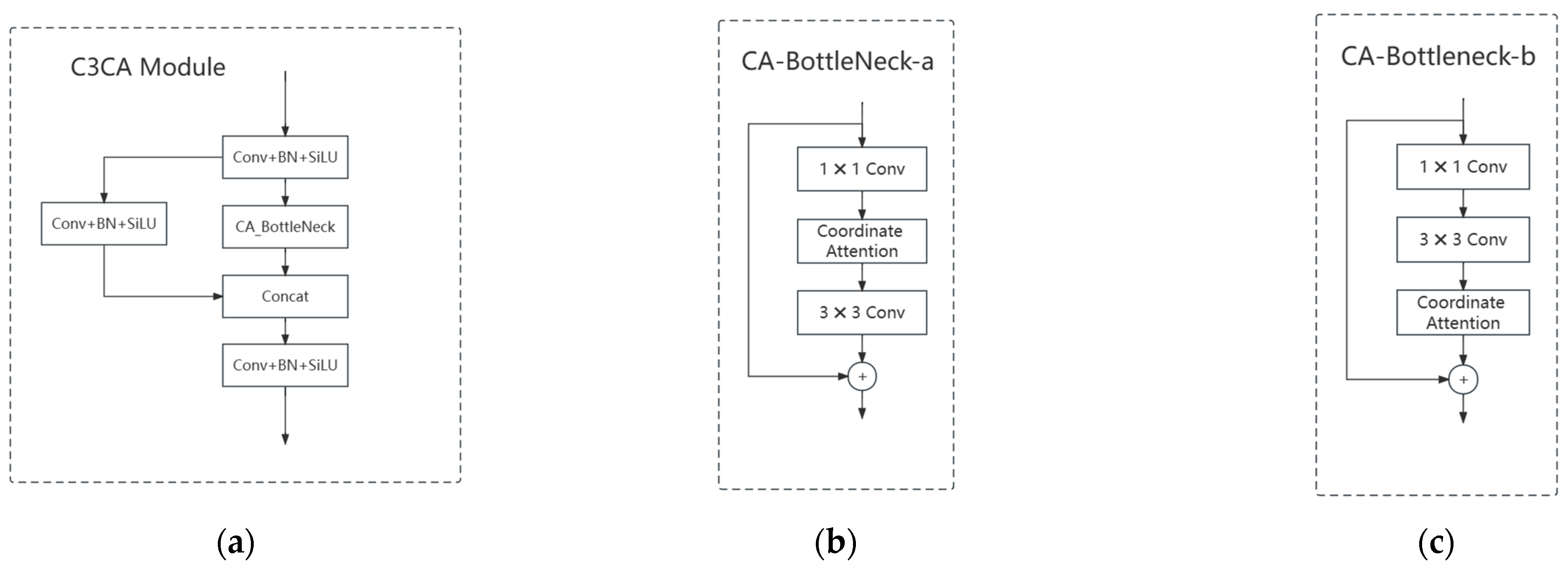
Designing C3CA Modules for Integrated Attention Mechanisms. By seamlessly integrating the Coordinate Attention mechanism into the C3 module of the Neck module within YOLOv5, the model adeptly captures and modeling the intricate spatial information present in the image. This refined approach significantly enhances the detection of object edges, textures, and other salient features, ensuring a heightened focus on diverse positional attributes.
- (3)
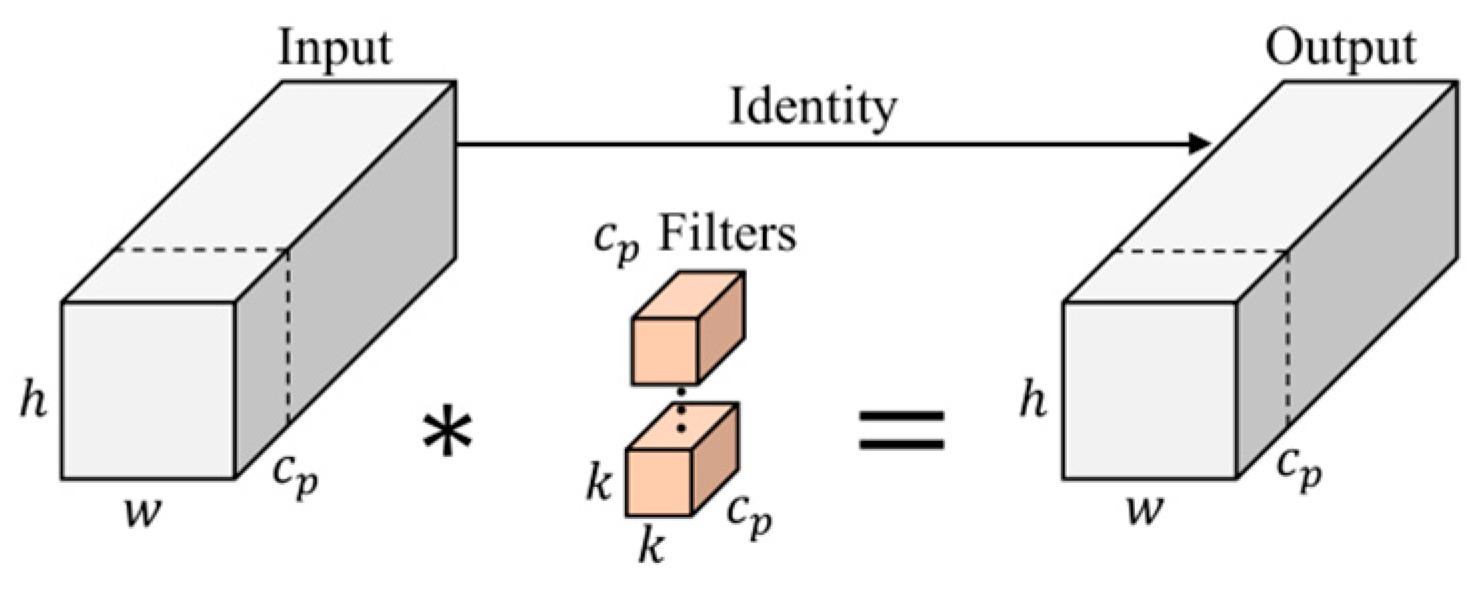
Within the scope of this article, the integration of the FasterConv module, accomplished by seamlessly incorporating PConv [
54] into the backbone network of YOLOv5, guarantees a noteworthy decrease in model parameters and computations while upholding exceptional detection performance.
- (4)
Moreover, the introduction of the content-aware reassembly module (CARAFE) supersedes the conventional nearest-neighbor interpolation upsampling module in the original model. This advanced technique skillfully preserves intricate details and boundary information during upsampling operations, thus elevating the overall detection performance of the model.
- (5)
Substituting the loss function with XIoU in YOLOv5 not only strengthens the resilience of the original CIoU loss function but also accelerates the convergence speed of the model, leading to enhanced performance.
The remaining sections of this article are organized as follows: In
Section 2, we present a comprehensive review of the relevant literature on remote sensing target detection and attention mechanisms.
Section 3 provides a detailed description of the improvements made to our model. In
Section 4, we validate the experimental results and conduct a visual analysis of the detection performance.
Section 5 entails conducting ablation experiments on the proposed model architecture to demonstrate the feasibility of the design modules. Finally, in
Section 6, we draw conclusions and outline prospects for future research endeavors.
5. Discussion
In this section, we shall validate the proposed model on the DIOR dataset through a series of ablation experiments.
Firstly, in order to validate the performance variations in detection resulting from different embedding positions of the Coordinate Attention (CA) module within the Bottleneck, we evaluate the CA-Bottleneck-a and CA-Bottleneck-b configurations. This evaluation aims to verify the superiority of the network’s architectural design. The results of the ablation experiments are presented in
Table 6.
Table 6 illustrates the impact of the two embedding methods on the network’s detection performance. Compared to commonly used embedding techniques, our approach exhibits significant improvements in terms of accuracy, recall rate, mean average precision (mAP), and detection speed. Moreover, it also leads to a reduction in inference time. By embedding the attention mechanism after two convolutional layers, we are able to better preserve and enhance the positional information of small targets amidst complex backgrounds.
Furthermore, we compare the proposed LADH-Head with the Asymmetric Dual-Head (ADH-Head) in terms of detection speed (FPS, inference time), computational complexity (Parameters, GFLOPs), and detection accuracy (mAP). The results are summarized in
Table 7.
The results revealed in
Table 7 exhibit a remarkable enhancement in detection accuracy for our approach compared to the original YOLOv5s. Although there is a slight decrease in detection speed and computational complexity, our method showcases significant advantages over the ADH-Head in these aspects. With only 49% of the parameters of the ADH-Head, we achieve a 3% increase in detection accuracy. This outcome validates the ability of the LADH-Head to effectively balance the exponential growth in computational complexity brought by the ADH-Head while satisfying the demands for lightweight implementation and detection performance.
Finally, we will utilize the original YOLOv5s model as a baseline for verification and experimental control. In the second experiment, we will replace the C3 module in the YOLOv5s model with the FasterConv module to showcase the benefits of FasterConv in terms of inference speed and detection accuracy. Experiment three involves substituting the C3 module in the Neck with the C3CA module to evaluate the lightweight performance and feature extraction ability of the C3CA module. Moving forward, experiment four introduces the LADH-Head module to demonstrate its effectiveness in lightweight models and detecting small targets in remote sensing imagery. In the fifth experiment, we will swap out the upsampling method in the Neck with the CARAFE module to investigate the impact of semantic information on detection performance during the upsampling process. The sixth experiment combines the second and third experiments to assess the combined impact of introducing FasterConv and C3CA on detection performance. Experiment seven integrates experiments two, three, and four to exhibit the effectiveness of incorporating the FasterConv, C3CA, and CARAFE modules on detection performance. In the eighth experiment, we incorporate the LADH-Head on top of experiment seven to evaluate the impact of changing the detection head on detection performance. Finally, in experiment nine, we introduce the XIoU loss function based on experiment eight to evaluate the model’s detection performance on complex backgrounds with small targets.
The results of these nine ablation experiments provide compelling evidence of the effectiveness of our approach in enhancing the performance of remote sensing image object detection. Please refer to
Table 8 for a summary of these ablation experiments. Notably, in experiment two, by employing the FasterConv module to improve the model’s inference speed and introducing PConv and PWConv to enhance focus on the center position of the target receptive field, we observed a 1.4% increase in mAP compared to YOLOv5s, a reduction of 0.6 ms in inference speed, and a 9.0% decrease in parameters. Experiment three introduced the C3CA module, resulting in a 2.4% improvement in mAP compared to experiment one by helping the model better focus on positional information and extract target features more efficiently. Experiment four addressed the conflict between regression and classification tasks within the YOLOv5s detection head, resulting in a 2.2% increase in mAP. Moreover, experiment five incorporated the CARAFE module, leading to a 0.8% increase in detection accuracy by enhancing semantic information extraction and fusion capabilities. Experiments six to nine showcased the effectiveness of combining multiple modules, yielding respective improvements in model accuracy (mAP) by 2.1%, 2.5%, 2.6%, and 3.3%. Additionally, these combined experiments reduced inference speed by 1.3 ms and compared to the original model parameters were reduced by 0.22 M, aligning with the requirements of lightweight network design.
Experiments prove that our method can effectively balance the incongruity between model detection performance and lightweight. In the military field, since detection devices such as UAVs do not have devices similar to GPUs that can perform a large number of computations, our method can be well applied to remote sensing satellites or UAV devices in the military detection field to reduce the weight of the model and redundant computations, and to help military detection devices detect remote sensing targets quickly while guaranteeing detection performance. Meanwhile, in the field of urban planning [
110] and environmental monitoring, our method can provide a new lightweight network design idea to the existing detection methods, through the combination of PConv and lightweight detection head with YOLO series algorithms to better achieve detection performance on mobile devices. In addition, the provided lightweight design can be well ported to the YOLOv8 detection method based on the anchorless frame, and the design of the joint attention mechanism can improve the detection performance degradation of the anchorless frame algorithm due to the change in position during the detection of small targets.
6. Conclusions
In this article, we present a faster and lightweight yet effective model for remote sensing image object detection. Our proposed model, which builds upon the YOLOv5s baseline network, introduces the FasterConv, LADH-Head, and C3CA modules. Additionally, we incorporate the CARAFE upsampling method and XIoU loss function to further enhance the model’s detection capabilities. The FasterConv module significantly improves both the inference and detection speeds of the model while placing greater emphasis on the central receptive field of the target. This targeted focus leads to notable improvements in detection performance. In place of the original coupled head, we employ a lightweight asymmetrical detection head that bifurcates the network based on task type. This innovative approach utilizes three distinct channels to accomplish the associated tasks, effectively resolving any conflicts between classification and regression objectives. Simultaneously, the C3CA module aids the detection network in emphasizing the positional information of the targets, facilitating the model to extract target features more effectively. This enhancement enables the model to focus more precisely on crucial information pertaining to the target objects, particularly in complex backgrounds. By employing the CARAFE module, our model reconstructs feature points with similar semantic information in a content-aware manner. This process facilitates the aggregation of features within a larger receptive field, ultimately enhancing the model’s ability to fuse semantic information. The XIoU loss function plays a crucial role by emphasizing the varying degrees of overlap between targets, thereby improving the robustness of bounding boxes during object detection tasks. Experimental results on the DIOR dataset demonstrate the remarkable performance of our approach. When compared to recent detection methods, our model stands out as a superior choice for achieving optimal detection performance without incurring additional computational costs. The results from our ablation experiments further underscore the effectiveness of each module, showcasing their significant contributions to improving the overall detection performance of the model.
While our approach has yielded advanced results in detecting remote sensing targets, we face the challenge of significant variation in the direction and scale of these targets within the process. Our focus primarily lies on horizontal bounding boxes within the dataset for remote sensing target detection. As a consequence, the detection process is influenced by changes in direction and scale, resulting in potential missed detections or false alarms for overlapping targets. Moreover, the integration of direction and scale detection methods poses difficulties in striking a balance between lightweight design and detection accuracy. In our future endeavors, we will continue to explore the potential of the YOLO model in detecting remote sensing targets that exhibit scale variations. Furthermore, our efforts will be directed towards improving the detection efficiency of the model on real-time devices, enhancing its performance in detecting rotating targets, and achieving a better equilibrium between lightweight design and detection capabilities. Ultimately, our aim is to enhance the real-time detection performance of the model.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}