

Evaluating the Potential of Sentinel-2 Time Series Imagery and Machine Learning for Tree Species Classification in a Mountainous Forest

 ,
,  ,
,  ,
,  ,
,
Abstract
:1. Introduction
2. Materials and Methods
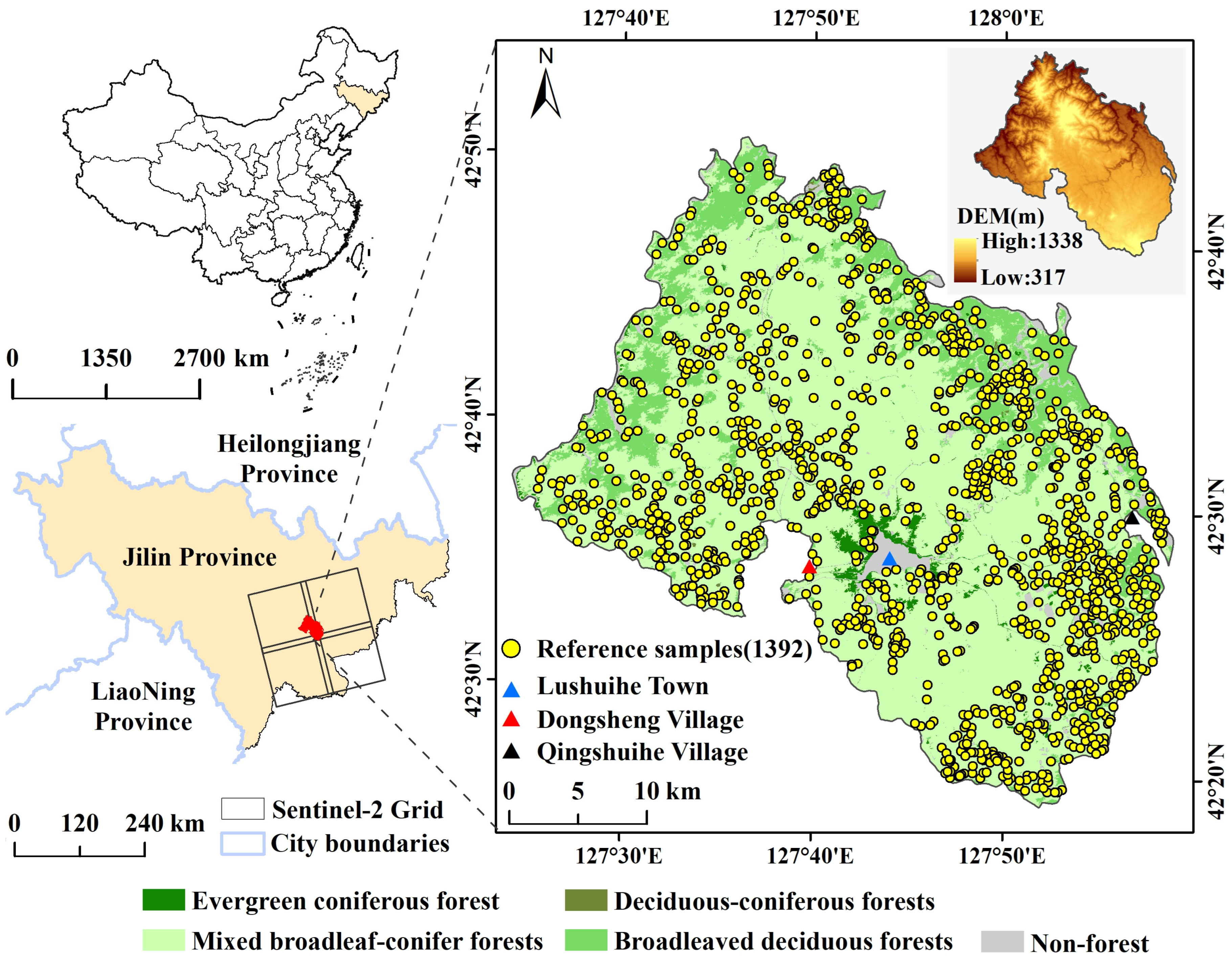
2.1. Study Area
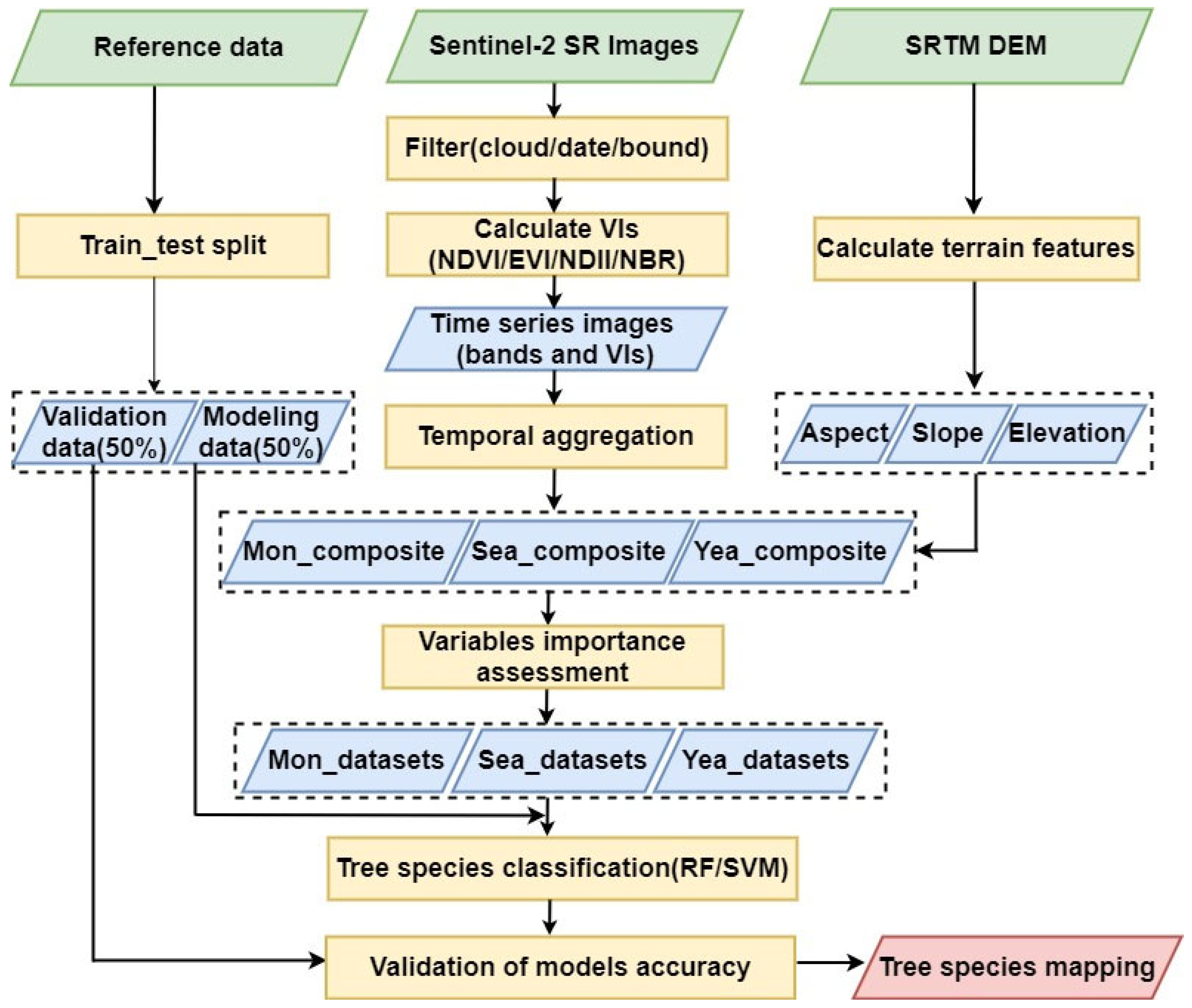
2.2. Methods
2.2.1. Sentinel-2 Data and Topographic Variables
2.2.2. Reference Data
2.2.3. Classification Approach
2.2.4. Accuracy Assessment
3. Results
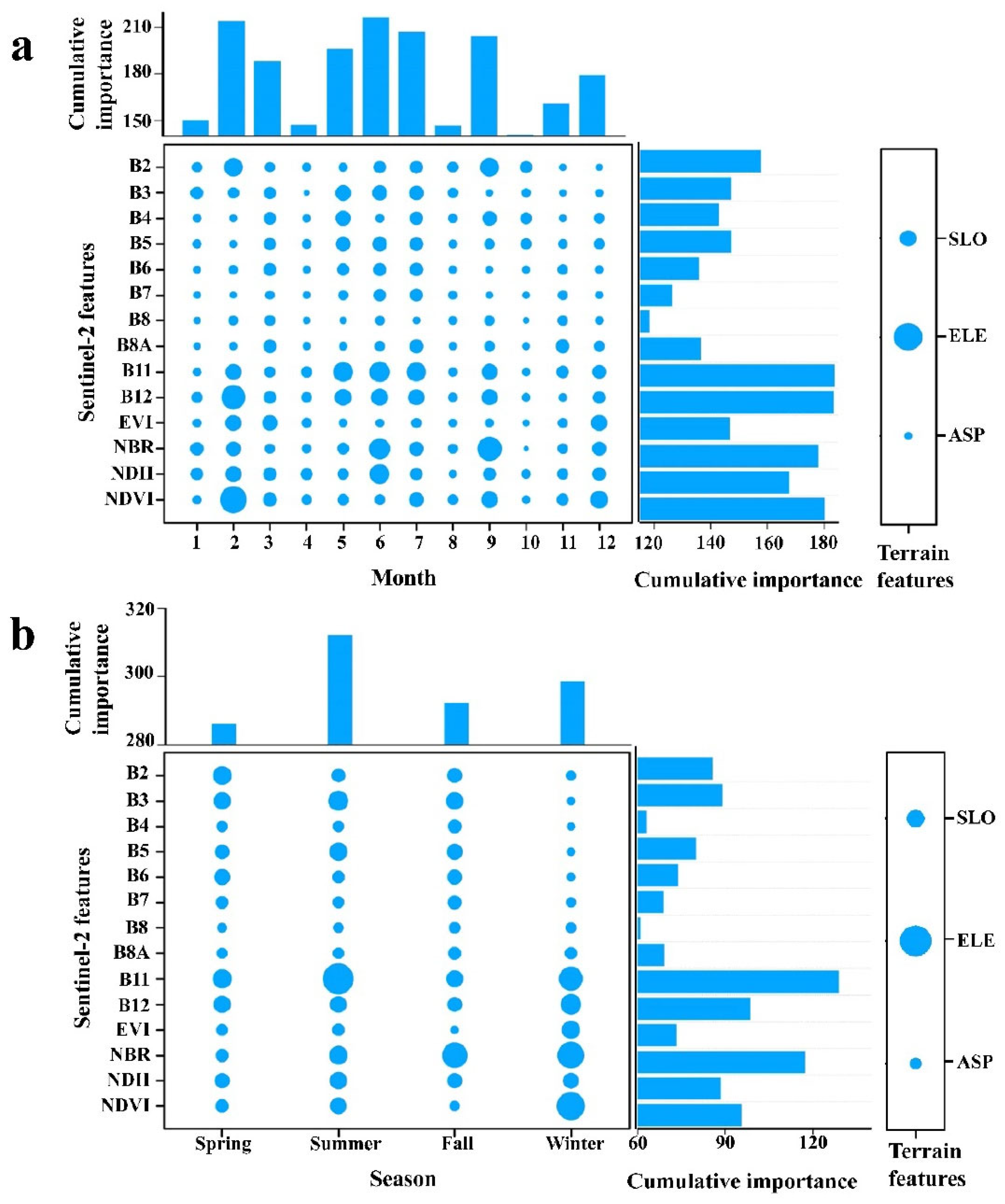
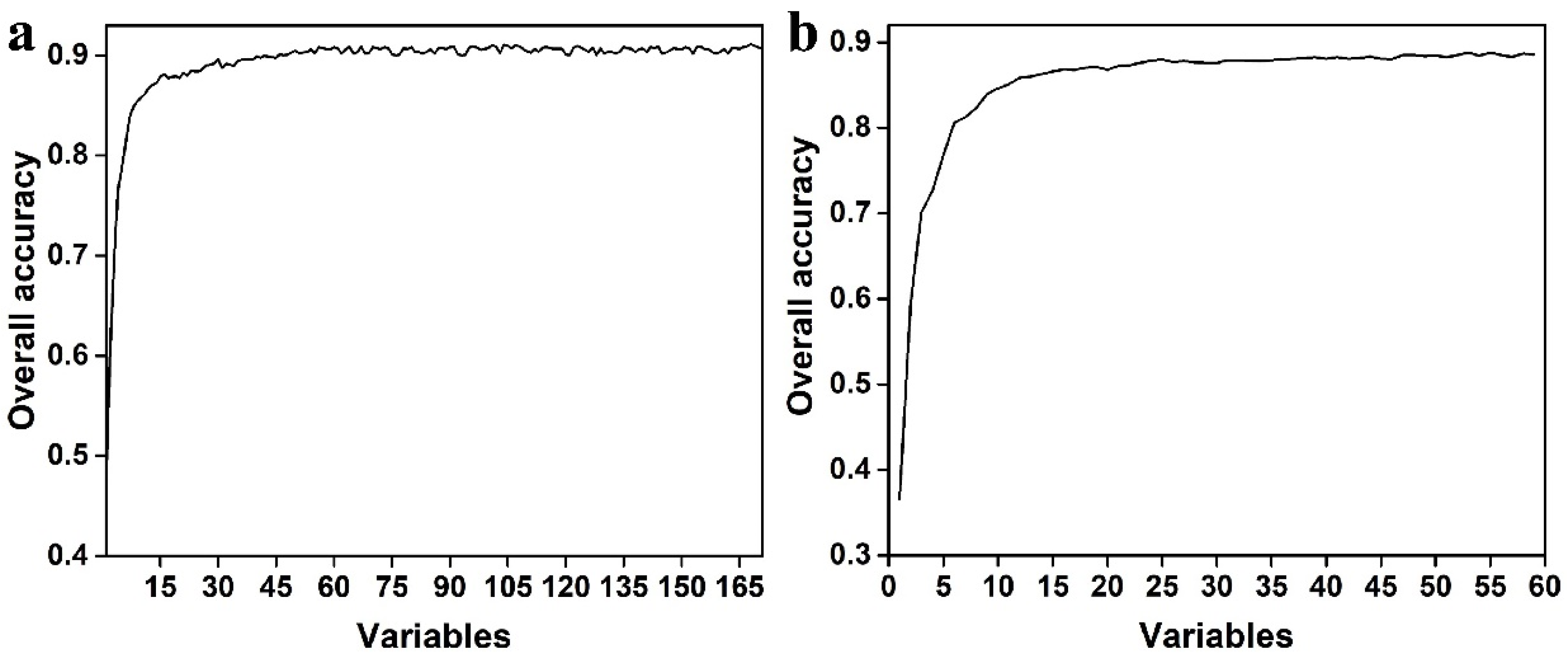
3.1. Conditional Variable Importance Assessment
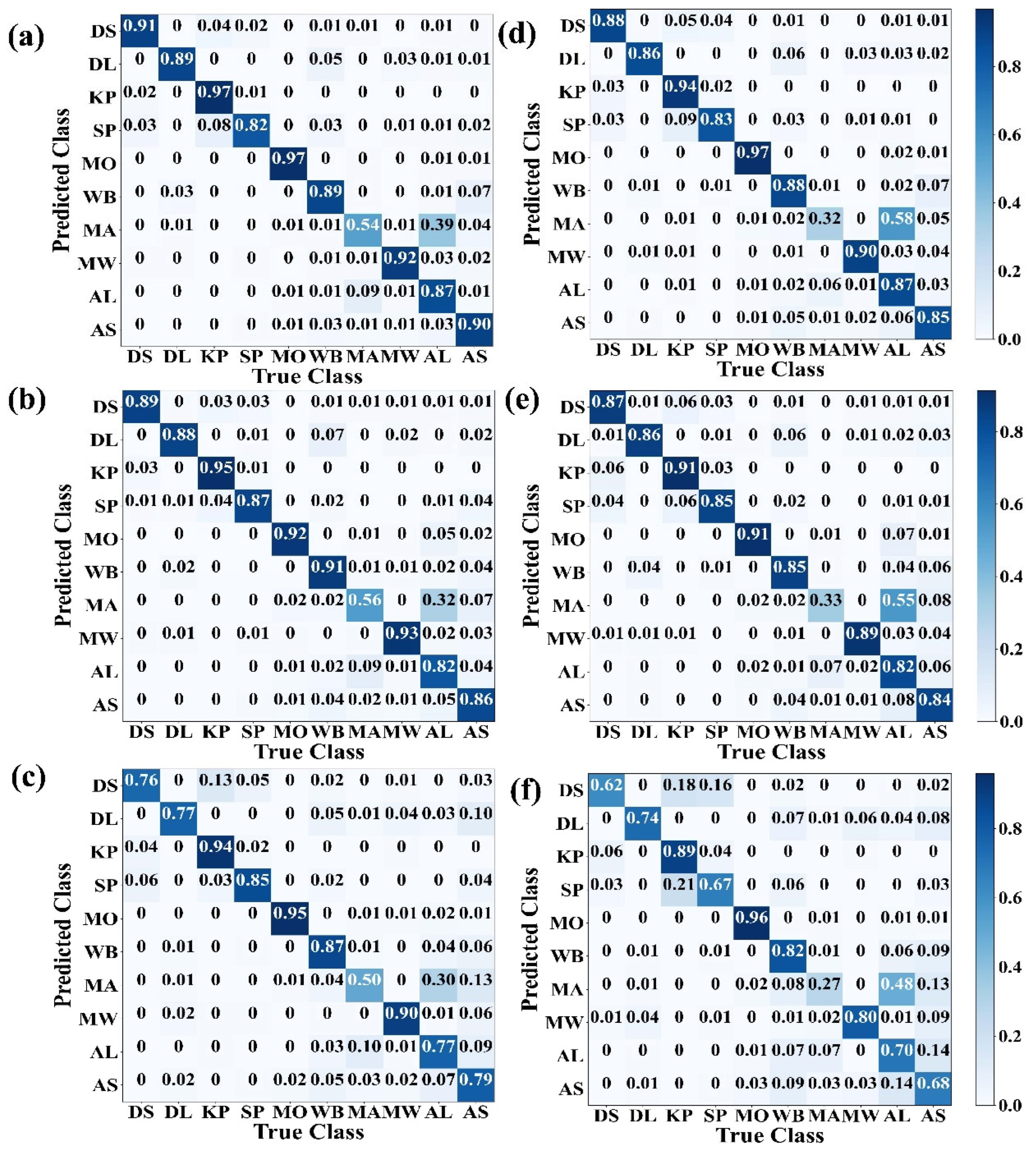
3.2. Tree Species Classification Accuracies
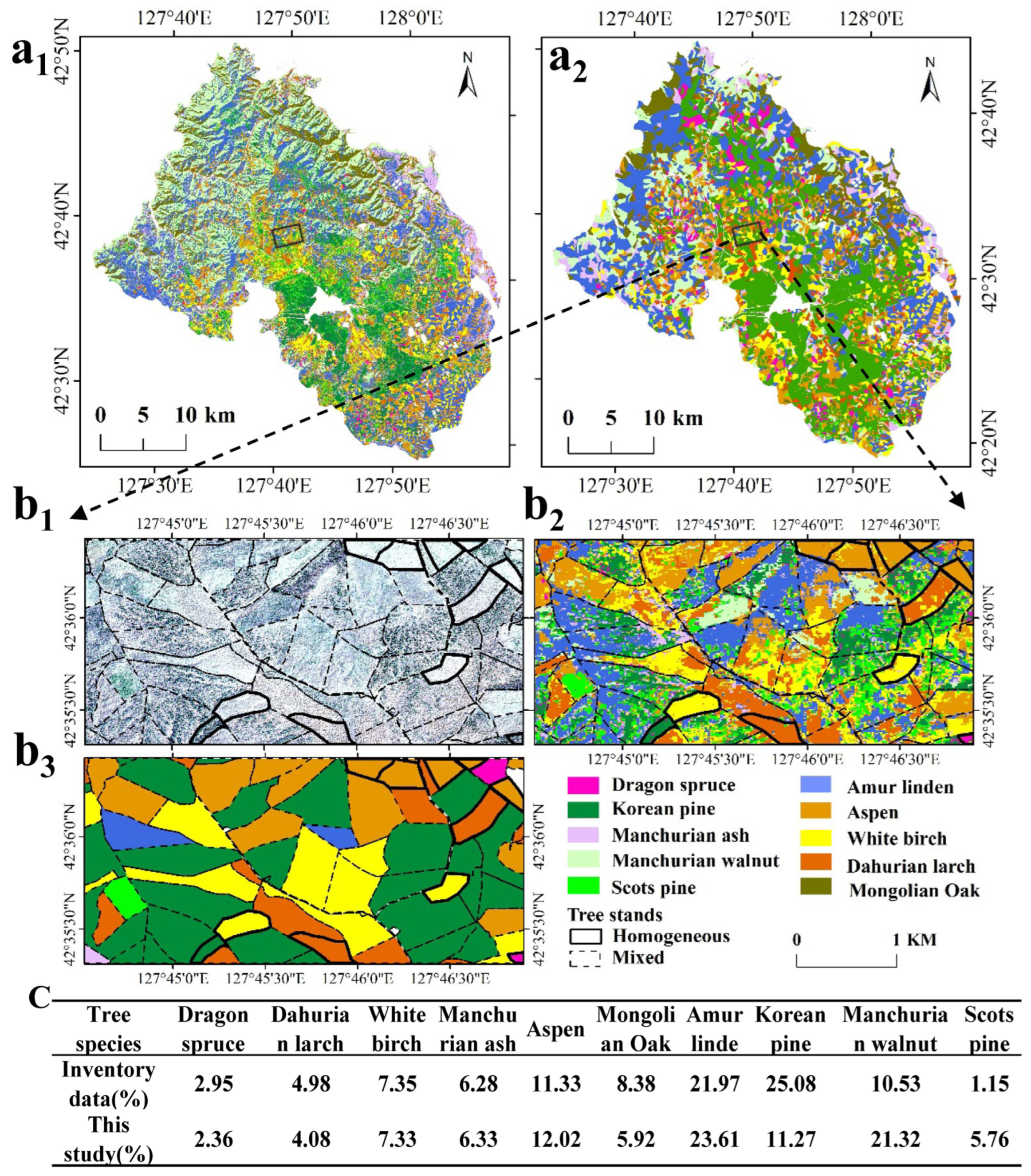
3.3. Tree Species Mapping
4. Discussion
4.1. Monthly Dataset Was Beneficial for Tree Species Classification
4.2. RF Outperformed SVM on Tree Species Classification
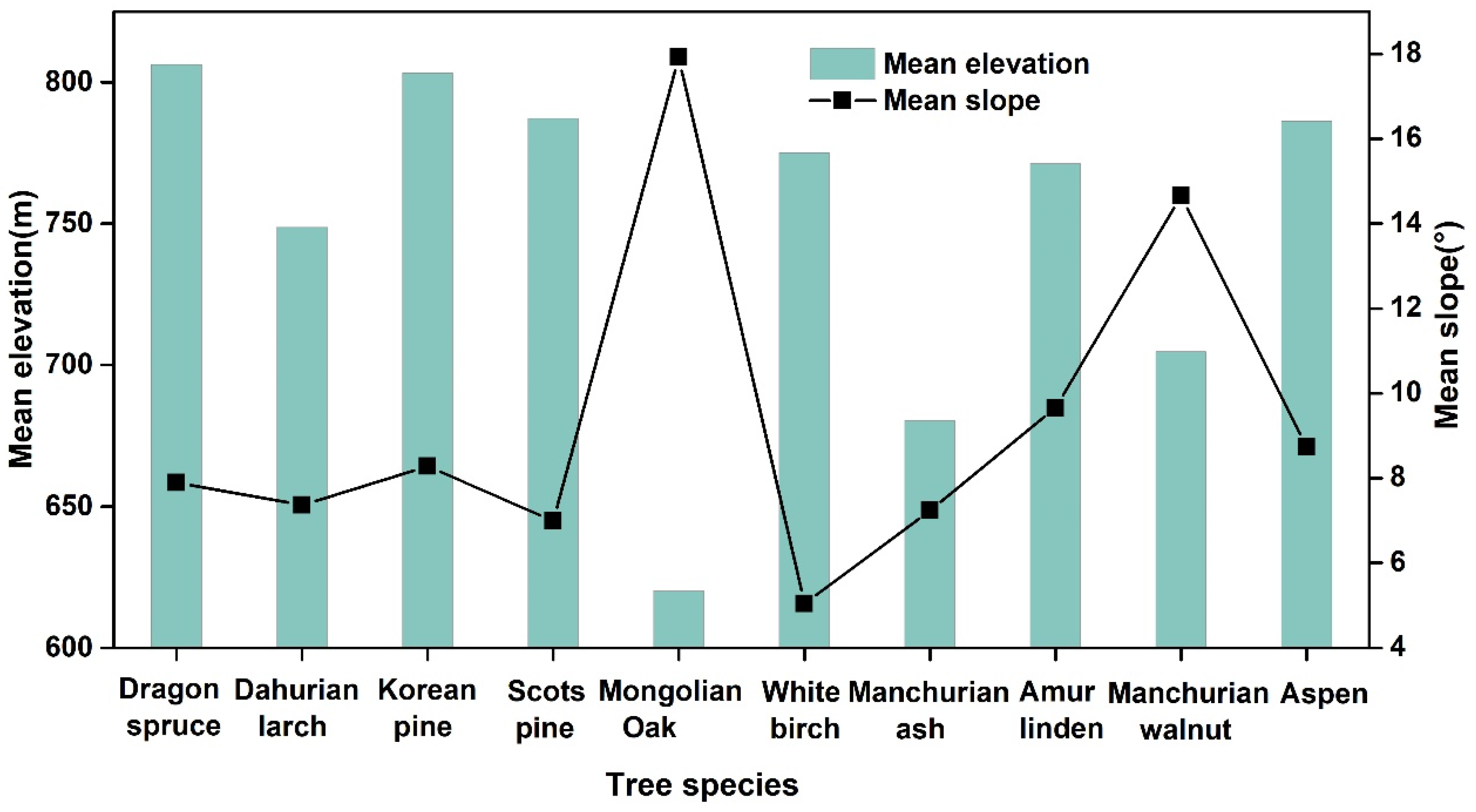
4.3. Great Potential of Sentinel-2 and Topographic Variables for Tree Species Classification
4.4. Classification Accuracy Compared with Forest Inventory Data and Others
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kollert, A.; Bremer, M.; Loew, M.; Rutzinger, M. Exploring the potential of land surface phenology and seasonal cloud free composites of one year of Sentinel-2 imagery for tree species mapping in a mountainous region. Int. J. Appl. Earth Obs. 2021, 94, 102208. [Google Scholar] [CrossRef]
- Hemmerling, J.; Pflugmacher, D.; Hostert, P. Mapping temperate forest tree species using dense Sentinel-2 time series. Remote Sens. Environ. 2021, 267, 112742. [Google Scholar] [CrossRef]
- Grabska, E.; Frantz, D.; Ostapowicz, K. Evaluation of machine learning algorithms for forest stand species mapping using Sentinel-2 imagery and environmental data in the Polish Carpathians. Remote Sens. Environ. 2020, 251, 112103. [Google Scholar] [CrossRef]
- Sheeren, D.; Fauvel, M.; Josipovic, V.; Lopes, M.; Planque, C.; Willm, J.; Dejoux, J.-F. Tree Species Classification in Temperate Forests Using Formosat-2 Satellite Image Time Series. Remote Sens. 2016, 8, 734. [Google Scholar] [CrossRef]
- Vayssieres, M.P.; Plant, R.E.; Allen-Diaz, B.H. Classification trees: An alternative non-parametric approach for predicting species distributions. J. Veg. Sci. 2000, 11, 679–694. [Google Scholar] [CrossRef]
- Shi, Y.; Skidmore, A.K.; Wang, T.; Holzwarth, S.; Heiden, U.; Pinnel, N.; Zhu, X.; Heurich, M. Tree species classification using plant functional traits from LiDAR and hyperspectral data. Int. J. Appl. Earth Obs. 2018, 73, 207–219. [Google Scholar] [CrossRef]
- Dalponte, M.; Bruzzone, L.; Gianelle, D. Tree species classification in the Southern Alps based on the fusion of very high geometrical resolution multispectral/hyperspectral images and LiDAR data. Remote Sens. Environ. 2012, 123, 258–270. [Google Scholar] [CrossRef]
- Xi, Y.; Ren, C.; Wang, Z.; Wei, S.; Bai, J.; Zhang, B.; Xiang, H.; Chen, L. Mapping Tree Species Composition Using OHS-1 Hyperspectral Data and Deep Learning Algorithms in Changbai Mountains, Northeast China. Forests 2019, 10, 818. [Google Scholar] [CrossRef]
- Modzelewska, A.; Fassnacht, F.E.; Sterenczak, K. Tree species identification within an extensive forest area with diverse management regimes using airborne hyperspectral data. Int. J. Appl. Earth Obs. 2020, 84, 101960. [Google Scholar] [CrossRef]
- Ferreira, M.P.; Wagner, F.H.; Aragao, L.E.O.C.; Shimabukuro, Y.E.; de Souza Filho, C.R. Tree species classification in tropical forests using visible to shortwave infrared WorldView-3 images and texture analysis. ISPRS J. Photogramm. Remote Sens. 2019, 149, 119–131. [Google Scholar] [CrossRef]
- Mayra, J.; Keski-Saari, S.; Kivinen, S.; Tanhuanpaa, T.; Hurskainen, P.; Kullberg, P.; Poikolainen, L.; Viinikka, A.; Tuominen, S.; Kumpula, T.; et al. Tree species classification from airborne hyperspectral and LiDAR data using 3D convolutional neural networks. Remote Sens. Environ. 2021, 256, 112322. [Google Scholar] [CrossRef]
- Qin, H.; Zhou, W.; Yao, Y.; Wang, W. Individual tree segmentation and tree species classification in subtropical broadleaf forests using UAV-based LiDAR, hyperspectral, and ultrahigh-resolution RGB data. Remote Sens. Environ. 2022, 280, 113143. [Google Scholar] [CrossRef]
- Schiefer, F.; Kattenborn, T.; Frick, A.; Frey, J.; Schall, P.; Koch, B.; Schmidtlein, S. Mapping forest tree species in high resolution UAV-based RGB-imagery by means of convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2020, 170, 205–215. [Google Scholar] [CrossRef]
- Ferreira, M.P.; de Almeida, D.R.A.; de Almeida Papa, D.; Minervino, J.B.S.; Veras, H.F.P.; Formighieri, A.; Santos, C.A.N.; Ferreira, M.A.D.; Figueiredo, E.O.; Ferreira, E.J.L. Individual tree detection and species classification of Amazonian palms using UAV images and deep learning. For. Ecol. Manag. 2020, 475, 118397. [Google Scholar] [CrossRef]
- Xie, B.; Cao, C.; Xu, M.; Duerler, R.S.; Yang, X.; Bashir, B.; Chen, Y.; Wang, K. Analysis of Regional Distribution of Tree Species Using Multi-Seasonal Sentinel-1&2 Imagery within Google Earth Engine. Forests 2021, 12, 565. [Google Scholar]
- Pasquarella, V.J.; Holden, C.E.; Woodcock, C.E. Improved mapping of forest type using spectral-temporal Landsat features. Remote Sens. Environ. 2018, 210, 193–207. [Google Scholar] [CrossRef]
- Clark, M.L. Comparison of multi-seasonal Landsat 8, Sentinel-2 and hyperspectral images for mapping forest alliances in Northern California. ISPRS J. Photogramm. Remote Sens. 2020, 159, 26–40. [Google Scholar] [CrossRef]
- Wulder, M.A.; Loveland, T.R.; Roy, D.P.; Crawford, C.J.; Masek, J.G.; Woodcock, C.E.; Allen, R.G.; Anderson, M.C.; Belward, A.S.; Cohen, W.B.; et al. Current status of Landsat program, science, and applications. Remote Sens. Environ. 2019, 225, 127–147. [Google Scholar] [CrossRef]
- Vorovencii, I.; Dincă, L.; Crișan, V.; Postolache, R.-G.; Codrean, C.-L.; Cătălin, C.; Greșiță, C.I.; Chima, S.; Gavrilescu, I. Local-scale mapping of tree species in a lower mountain area using Sentinel-1 and -2 multitemporal images, vegetation indices, and topographic information. Front. For. Glob. Chang. 2023, 6, 1220253. [Google Scholar] [CrossRef]
- Immitzer, M.; Neuwirth, M.; Boeck, S.; Brenner, H.; Vuolo, F.; Atzberger, C. Optimal Input Features for Tree Species Classification in Central Europe Based on Multi-Temporal Sentinel-2 Data. Remote Sens. 2019, 11, 2599. [Google Scholar] [CrossRef]
- Wang, M.; Zheng, Y.; Huang, C.; Meng, R.; Pang, Y.; Jia, W.; Zhou, J.; Huang, Z.; Fang, L.; Zhao, F. Assessing Landsat-8 and Sentinel-2 spectral-temporal features for mapping tree species of northern plantation forests in Heilongjiang Province, China. For. Ecosyst. 2022, 9, 100032. [Google Scholar] [CrossRef]
- Nasiri, V.; Beloiu, M.; Asghar Darvishsefat, A.; Griess, V.C.; Maftei, C.; Waser, L.T. Mapping tree species composition in a Caspian temperate mixed forest based on spectral-temporal metrics and machine learning. Int. J. Appl. Earth Obs. 2023, 116, 103154. [Google Scholar] [CrossRef]
- Phan, T.N.; Kuch, V.; Lehnert, L.W. Land Cover Classification using Google Earth Engine and Random Forest Classifier—The Role of Image Composition. Remote Sens. 2020, 12, 2411. [Google Scholar] [CrossRef]
- Pratico, S.; Solano, F.; Di Fazio, S.; Modica, G. Machine Learning Classification of Mediterranean Forest Habitats in Google Earth Engine Based on Seasonal Sentinel-2 Time-Series and Input Image Composition Optimisation. Remote Sens. 2021, 13, 586. [Google Scholar] [CrossRef]
- Fang, P.; Ou, G.; Li, R.; Wang, L.; Xu, W.; Dai, Q.; Huang, X. Regionalized classification of stand tree species in mountainous forests by fusing advanced classifiers and ecological niche model. GISci. Remote Sens. 2023, 60, 2211881. [Google Scholar] [CrossRef]
- Xi, Y.; Ren, C.; Tian, Q.; Ren, Y.; Dong, X.; Zhang, Z. Exploitation of Time Series Sentinel-2 Data and Different Machine Learning Algorithms for Detailed Tree Species Classification. IEEE J.—STARS 2021, 14, 7589–7603. [Google Scholar] [CrossRef]
- Hoscilo, A.; Lewandowska, A. Mapping Forest Type and Tree Species on a Regional Scale Using Multi-Temporal Sentinel-2 Data. Remote Sens. 2019, 11, 929. [Google Scholar] [CrossRef]
- Abdollahnejad, A.; Panagiotidis, D.; Shataee Joybari, S.; Surový, P. Prediction of Dominant Forest Tree Species Using QuickBird and Environmental Data. Forests 2017, 8, 42. [Google Scholar] [CrossRef]
- Pittman, R.C.; Hu, B. Contribution of topographic features and categorization uncertainty for a tree species classification in the boreal biome of Northern Ontario. GISci. Remote Sens. 2023, 60, 2214994. [Google Scholar] [CrossRef]
- Pimple, U.; Sitthi, A.; Simonetti, D.; Pungkul, S.; Leadprathom, K.; Chidthaisong, A. Topographic Correction of Landsat TM-5 and Landsat OLI-8 Imagery to Improve the Performance of Forest Classification in the Mountainous Terrain of Northeast Thailand. Sustainability 2017, 9, 258. [Google Scholar] [CrossRef]
- Tamiminia, H.; Salehi, B.; Mahdianpari, M.; Quackenbush, L.; Brisco, B. Google Earth Engine for geo-big data applications: A meta-analysis and systematic review. ISPRS J. Photogramm. Remote Sens. 2020, 164, 152–170. [Google Scholar] [CrossRef]
- Jia, M.; Wang, Z.; Mao, D.; Ren, C.; Song, K.; Zhao, C.; Wang, C.; Xiao, X.; Wang, Y. Mapping global distribution of mangrove forests at 10-m resolution. Sci. Bull. 2023, 68, 1306–1316. [Google Scholar] [CrossRef]
- Silveira, E.M.O.; Radeloff, V.C.; Martinuzzi, S.; Martinez Pastur, G.J.; Bono, J.; Politi, N.; Lizarraga, L.; Rivera, L.O.; Ciuffoli, L.; Rosas, Y.M.; et al. Nationwide native forest structure maps for Argentina based on forest inventory data, SAR Sentinel-1 and vegetation metrics from Sentinel-2 imagery. Remote Sens. Environ. 2023, 285, 113391. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Yu, D.Y.; Shi, P.J.; Han, G.Y.; Zhu, W.Q.; Du, S.Q.; Xun, B. Forest ecosystem restoration due to a national conservation plan in China. Ecol. Eng. 2011, 37, 1387–1397. [Google Scholar] [CrossRef]
- Kan, B.; Wang, Q.; Wu, W. The influence of selective cutting of mixed Korean pine (Pinus koraiensis Sieb. et Zucc.) and broad-leaf forest on rare species distribution patterns and spatial correlation in Northeast China. J. For. Res. 2015, 26, 833–840. [Google Scholar] [CrossRef]
- ESA. Sentinel-2 User Handbook, Revision 2; ESA Standard Document; ESA: Paris, France, 2015. [Google Scholar]
- Huete, A.R.; Liu, H.Q.; Batchily, K.; van Leeuwen, W. A Comparison of Vegetation Indices over a Global Set of TM Images for EOS-MODIS. Remote Sens. Environ. 1997, 59, 440–451. [Google Scholar] [CrossRef]
- Tucker, C.J. Red and photographic infrared linear combinations for monitoring vegetation. Remote Sens. Environ. 1979, 8, 127–150. [Google Scholar] [CrossRef]
- García, M.J.L.; Caselles, V. Mapping burns and natural reforestation using thematic Mapper data. Geocarto Int. 1991, 6, 31–37. [Google Scholar] [CrossRef]
- GB/T 26424-2010; Technical Regulations for Inventory for Forest Management Planning and Design. Standards Press of China: Beijing, China, 2011.
- Fang, F.; McNeil, B.E.; Warner, T.A.; Maxwell, A.E.; Dahle, G.A.; Eutsler, E.; Li, J. Discriminating tree species at different taxonomic levels using multi-temporal WorldView-3 imagery in Washington DC, USA. Remote Sens. Environ. 2020, 246, 111811. [Google Scholar] [CrossRef]
- Dalponte, M.; Orka, H.O.; Gobakken, T.; Gianelle, D.; Naesset, E. Tree Species Classification in Boreal Forests with Hyperspectral Data. IEEE Geosci. Remote 2013, 51, 2632–2645. [Google Scholar] [CrossRef]
- Zhong, L.; Hu, L.; Zhou, H. Deep learning based multi-temporal crop classification. Remote Sens. Environ. 2019, 221, 430–443. [Google Scholar] [CrossRef]
- Tigges, J.; Lakes, T.; Hostert, P. Urban vegetation classification: Benefits of multitemporal RapidEye satellite data. Remote Sens. Environ. 2013, 136, 66–75. [Google Scholar] [CrossRef]
- Hartling, S.; Sagan, V.; Maimaitijiang, M. Urban tree species classification using UAV-based multi-sensor data fusion and machine learning. GISci. Remote Sens. 2021, 58, 1250–1275. [Google Scholar] [CrossRef]
- Bénard, C.; Da Veiga, S.; Scornet, E. Mean decrease accuracy for random forests: Inconsistency, and a practical solution via the Sobol-MDA. Biometrika. 2022, 109, 881–900. [Google Scholar] [CrossRef]
- Xu, Z.; Liu, Q.; Du, W.; Zhou, G.; Qin, L.; Sun, Z. Modelling leaf phenology of some trees with accumulated temperature in a temperate forest in northeast China. For. Ecol. Manag. 2021, 489, 119085. [Google Scholar] [CrossRef]
- Shi, D.; Yang, X. An Assessment of Algorithmic Parameters Affecting Image Classification Accuracy by Random Forests. Photogramm. Eng. Remote Sens. 2016, 82, 407–417. [Google Scholar] [CrossRef]
- Pelletier, C.; Valero, S.; Inglada, J.; Champion, N.; Dedieu, G. Assessing the robustness of Random Forests to map land cover with high resolution satellite image time series over large areas. Remote Sens. Environ. 2016, 187, 156–168. [Google Scholar] [CrossRef]
- Ferreira, M.P.; Zortea, M.; Zanotta, D.C.; Shimabukuro, Y.E.; de Souza Filho, C.R. Mapping tree species in tropical seasonal semi-deciduous forests with hyperspectral and multispectral data. Remote Sens. Environ. 2016, 179, 66–78. [Google Scholar] [CrossRef]
- Pu, R.; Liu, D. Segmented canonical discriminant analysis of in situ hyperspectral data for identifying 13 urban tree species. Int. J. Remote Sens. 2011, 32, 2207–2226. [Google Scholar] [CrossRef]
- Immitzer, M.; Vuolo, F.; Atzberger, C. First Experience with Sentinel-2 Data for Crop and Tree Species Classifications in Central Europe. Remote Sens. 2016, 8, 166. [Google Scholar] [CrossRef]
- Lucas, R.; Bunting, P.; Paterson, M.; Chisholm, L. Classification of Australian forest communities using aerial photography, CASI and HyMap data. Remote Sens. Environ. 2008, 112, 2088–2103. [Google Scholar] [CrossRef]
- Wolter, P.T.; Townsend, P.A. Multi-sensor data fusion for estimating forest species composition and abundance in northern Minnesota. Remote Sens. Environ. 2011, 115, 671–691. [Google Scholar] [CrossRef]
- Isaacson, B.N.; Serbin, S.P.; Townsend, P.A. Detection of relative differences in phenology of forest species using Landsat and MODIS. Landscape Ecol. 2012, 27, 529–543. [Google Scholar] [CrossRef]
- Du, E.; Fang, J. Linking belowground and aboveground phenology in two boreal forests in Northeast China. Oecologia 2014, 176, 883–892. [Google Scholar] [CrossRef]
- Ahmadi, K.; Mahmoodi, S.; Pal, S.C.; Saha, A.; Chowdhuri, I.; Nguyen, T.T.; Jarvie, S.; Szostak, M.; Socha, J.; Thai, V.N. Improving species distribution models for dominant trees in climate data-poor forests using high-resolution remote sensing. Ecol. Model. 2023, 475, 110190. [Google Scholar] [CrossRef]
- Soleimannejad, L.; Ullah, S.; Abedi, R.; Dees, M.; Koch, B. Evaluating the potential of sentinel-2, landsat-8, and irs satellite images in tree species classification of hyrcanian forest of iran using random forest. J. Sustain. Forest. 2019, 38, 615–628. [Google Scholar] [CrossRef]
- Ma, M.; Liu, J.; Liu, M.; Zeng, J.; Li, Y. Tree Species Classification Based on Sentinel-2 Imagery and Random Forest Classifier in the Eastern Regions of the Qilian Mountains. Forests. 2021, 12, 1736. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Formula/Description |
|---|---|
| Enhanced vegetation index (EVI) | EVI = 2.5 × (B8 − B4)/(B8 + 6 × B4 − 7.5 × B2 + 1) |
| Normalized Burn Ratio (NBR) | NBR = (B8 − B12)/(B8 + B12) |
| Normalized difference vegetation index (NDVI) | NDVI = (B8 − B4)/(B8 + B4) |
| Normalized Difference Infrared Index (NDII) | NDII = (B8 − B11)/(B8 + B11) |
| Species | No. of Plots | No. of Pixels | Species | No. of Plots | No. of Pixels |
|---|---|---|---|---|---|
| Dragon spruce | 63 | 964 | Aspen | 274 | 2475 |
| Dahurian larch | 100 | 1014 | Amur linden | 229 | 1984 |
| Korean pine | 122 | 2104 | White birch | 170 | 1621 |
| Scots pine | 44 | 688 | Manchurian ash | 145 | 1301 |
| Mongolian Oak | 125 | 1206 | Manchurian walnut | 120 | 1019 |
| Metrics | RF | SVM | |||||
|---|---|---|---|---|---|---|---|
| Mon | Sea | Yea | Mon | Sea | Yea | ||
| RF_Mon | RF_Sea | RF_Yea | SVM_Mon | SVM_Sea | SVM_Yea | ||
| OA (%) | 87.45 | 85.91 | 81.7 | 83.38 | 81.39 | 72.38 | |
| Kappa | 0.86 | 0.84 | 0.79 | 0.81 | 0.79 | 0.69 | |
| F1 score (%) | Dragon spruce | 91.61 | 90.40 | 79.83 | 89.44 | 84.77 | 69.55 |
| Dahurian larch | 91.05 | 91.00 | 81.85 | 89.84 | 87.50 | 80.53 | |
| Korean pine | 95.58 | 96.00 | 92.87 | 93.44 | 92.71 | 86.94 | |
| Scots pine | 87.38 | 87.52 | 83.82 | 84.21 | 83.99 | 63.96 | |
| Mongolian Oak | 97.04 | 92.21 | 94.95 | 95.80 | 91.84 | 93.37 | |
| White birch | 88.64 | 87.33 | 83.75 | 86.0 | 85.64 | 75.04 | |
| Manchurian ash | 62.99 | 63.37 | 57.86 | 44.49 | 44.60 | 37.01 | |
| Manchurian walnut | 90.91 | 91.51 | 88.5 | 89.18 | 89.92 | 82.39 | |
| Amur linden | 78.55 | 76.34 | 72.62 | 71.91 | 68.45 | 61.43 | |
| Aspen | 89.61 | 85.99 | 76.27 | 85.96 | 83.22 | 67.25 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, P.; Ren, C.; Wang, Z.; Jia, M.; Yu, W.; Ren, H.; Xia, C. Evaluating the Potential of Sentinel-2 Time Series Imagery and Machine Learning for Tree Species Classification in a Mountainous Forest. Remote Sens. 2024, 16, 293. https://doi.org/10.3390/rs16020293
Liu P, Ren C, Wang Z, Jia M, Yu W, Ren H, Xia C. Evaluating the Potential of Sentinel-2 Time Series Imagery and Machine Learning for Tree Species Classification in a Mountainous Forest. Remote Sensing. 2024; 16(2):293. https://doi.org/10.3390/rs16020293
Chicago/Turabian StyleLiu, Pan, Chunying Ren, Zongming Wang, Mingming Jia, Wensen Yu, Huixin Ren, and Chenzhen Xia. 2024. "Evaluating the Potential of Sentinel-2 Time Series Imagery and Machine Learning for Tree Species Classification in a Mountainous Forest" Remote Sensing 16, no. 2: 293. https://doi.org/10.3390/rs16020293
APA StyleLiu, P., Ren, C., Wang, Z., Jia, M., Yu, W., Ren, H., & Xia, C. (2024). Evaluating the Potential of Sentinel-2 Time Series Imagery and Machine Learning for Tree Species Classification in a Mountainous Forest. Remote Sensing, 16(2), 293. https://doi.org/10.3390/rs16020293