
ERS-HDRI: Event-Based Remote Sensing HDR Imaging


Abstract
:1. Introduction
- Domain Gap. Conventional RGB cameras continuously capture frames by integrating brightness and then generating color frames. In contrast, event cameras operate on a completely different principle, detecting and transmitting changes in luminance, resulting in an asynchronous stream of events [16]. The substantial distinction in imaging mechanisms between conventional cameras and event cameras gives rise to a considerable domain gap between optical images and event streams, preventing their efficient integration. Existing event-guided HDR imaging methods have successfully integrated image frames and event streams by introducing exposure mask attention [18,19]. However, the exposure mask is generated through threshold segmentation and cannot be learned according to different environments, resulting in an inability to perfectly adapt to diverse scenes. Therefore, how to narrow the domain gap and implement adaptive fusion between optical images and event streams is still an open problem in event-guided HDRI tasks.
- Light attenuation. The structures within low dynamic range (LDR) frames typically exhibit weakening in under-/over-exposed regions. Even though event cameras are able to sense structure information at contrast edges, their effectiveness in capturing detailed information diminishes when operating at high altitudes. This limitation arises due to the decrease in light intensity with increasing distance; as a result, the event camera’s perception of brightness changes often fails to reach the event triggering threshold when capturing images at high altitudes [16], making it difficult for the event camera to capture complex details. Therefore, it is challenging to reconstruct informative structures in badly exposed remote sensing images with events captured at high altitudes.
- We introduce an event-based HDRI framework for remote sensing HDR image reconstruction, which integrates LDR frames with event streams.
- We implement a coarse-to-fine strategy that efficiently achieves dynamic range enhancement and structure enhancement, where both the domain gap problem and the light attenuation problem are alleviated.
- We present a hybrid imaging system with a conventional optical camera and an event camera; moreover, we present a novel remote sensing event-based HDRI dataset that contains aligned LDR images, HDR images, and concurrent event streams.
2. Related Work
2.1. Framed-Based HDR Reconstruction
2.2. Event-Based HDR Reconstruction
2.3. Remote Sensing Image Enhancement
3. Methods
3.1. Problem Formulation
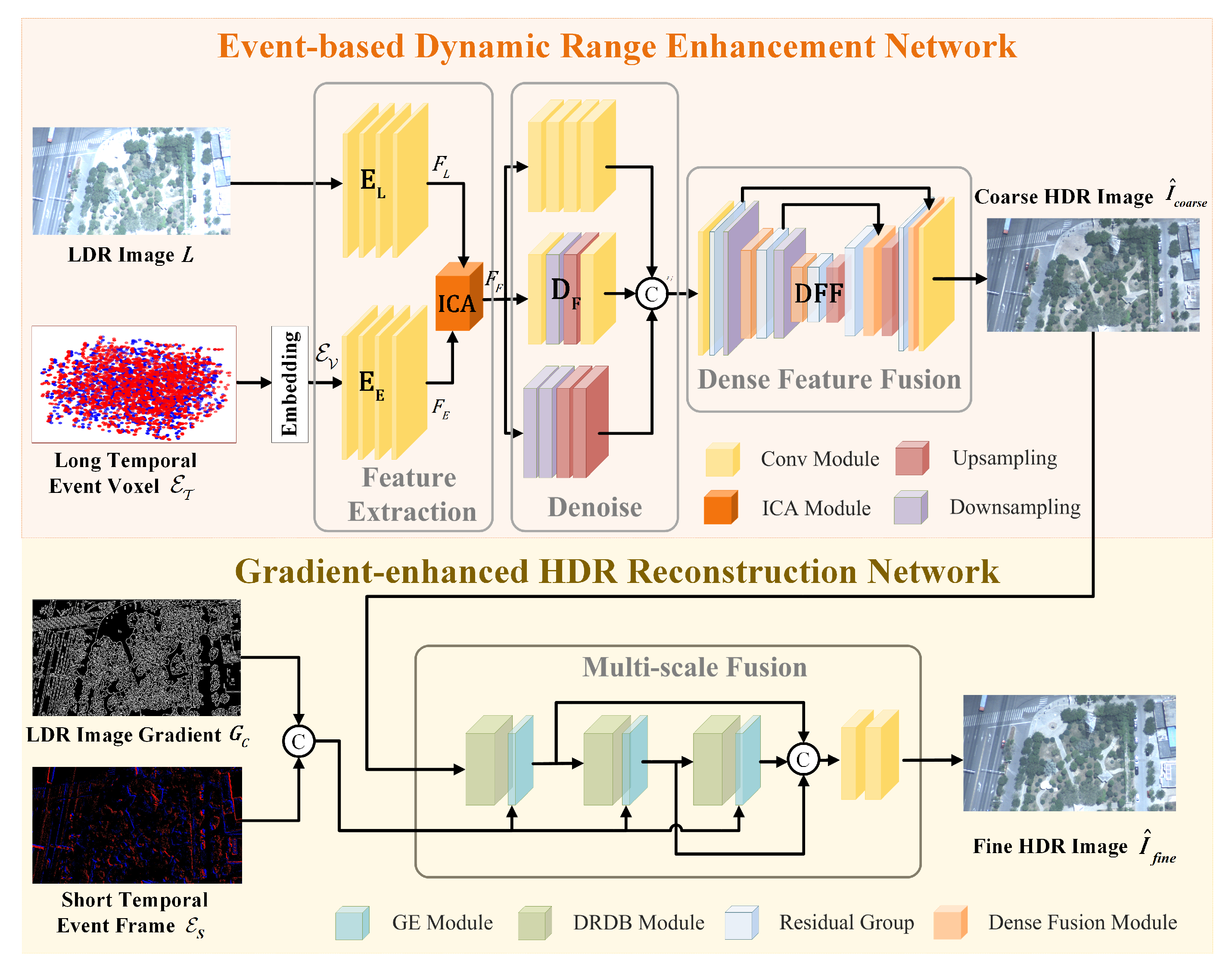
3.2. Network Architecture
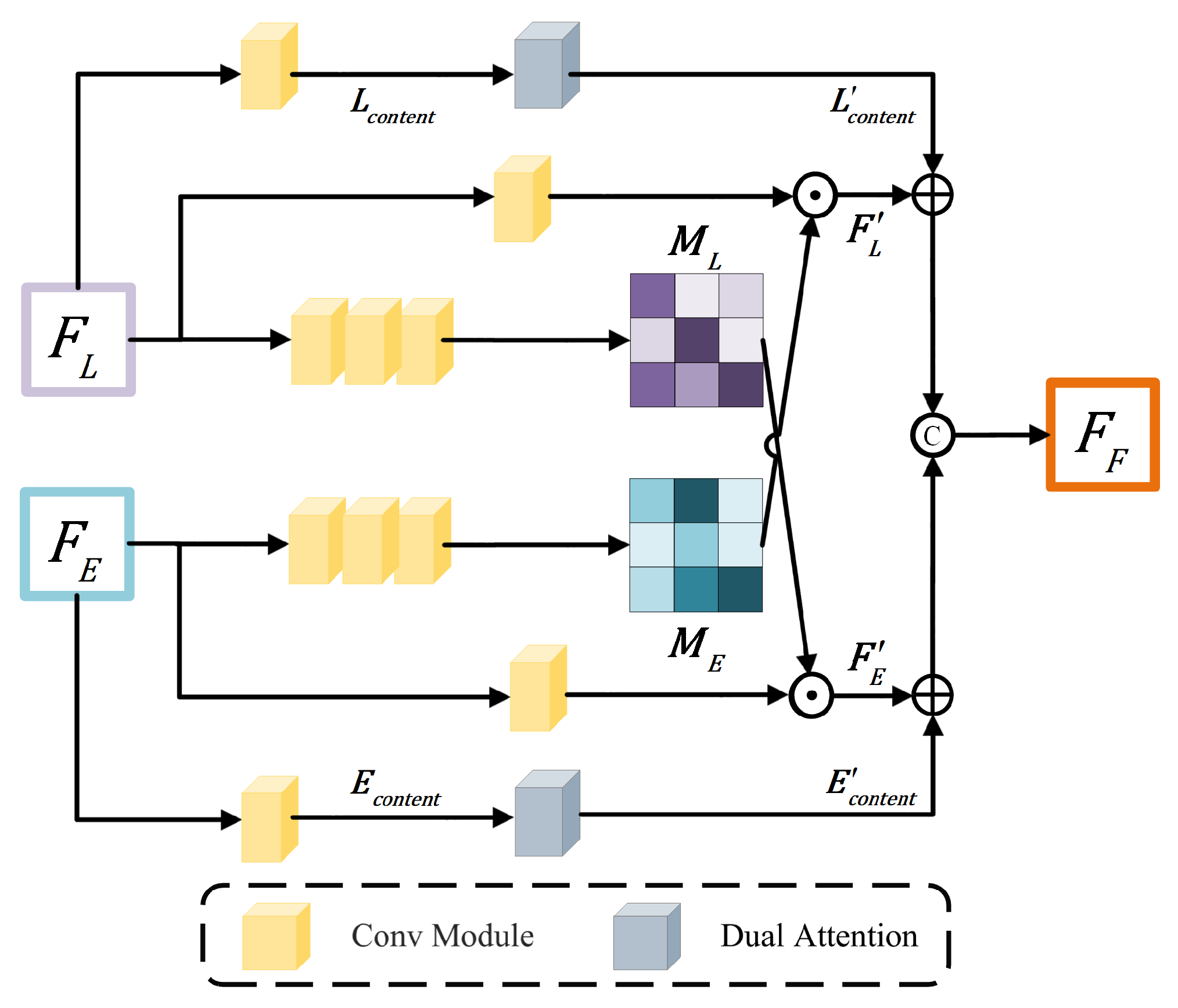
3.2.1. Event-Based Dynamic Range Enhancement Network
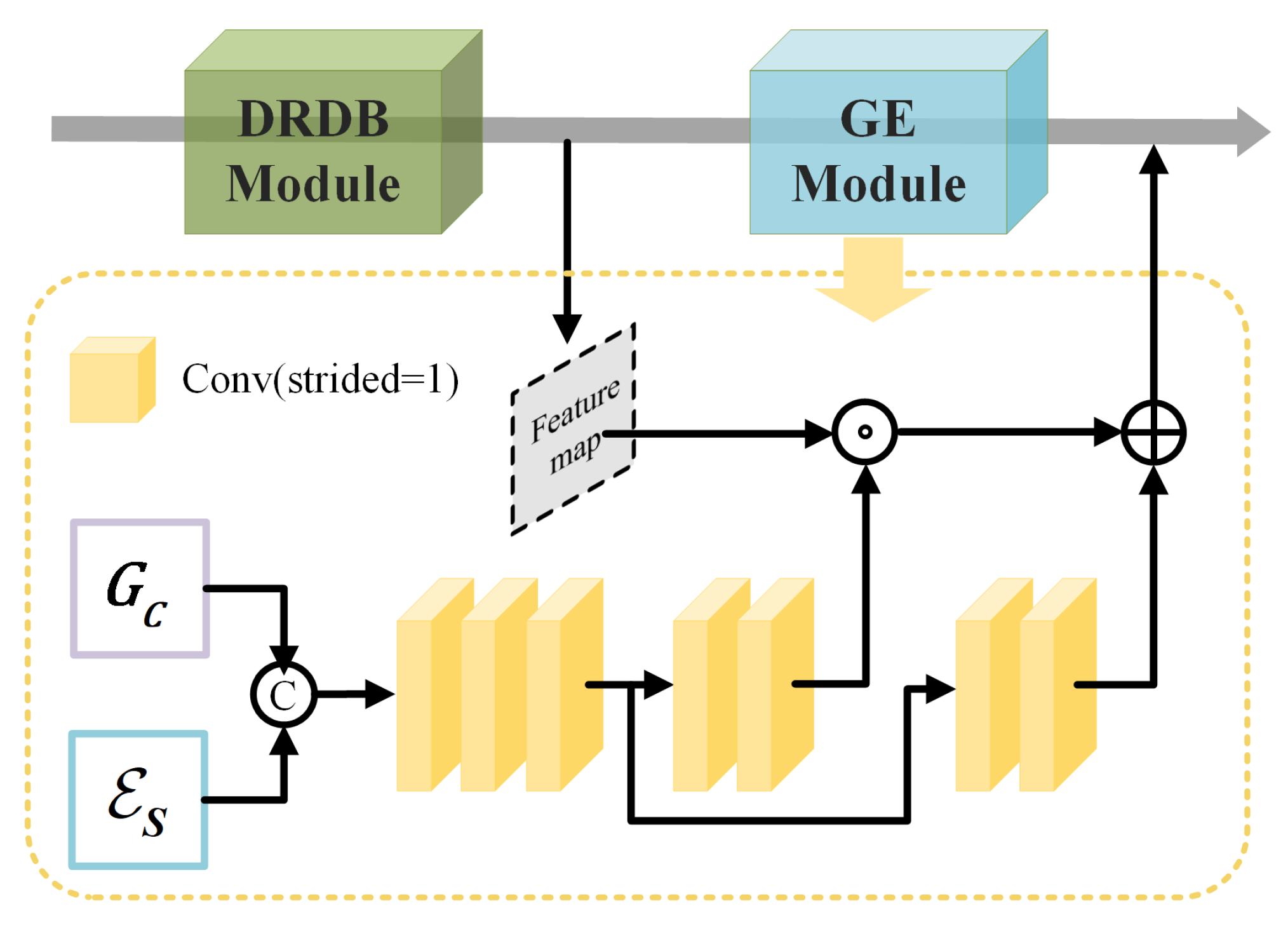
3.2.2. Gradient-Enhanced HDR Reconstruction Module
3.3. Optimization Strategy
4. ERS-HDRD Dataset
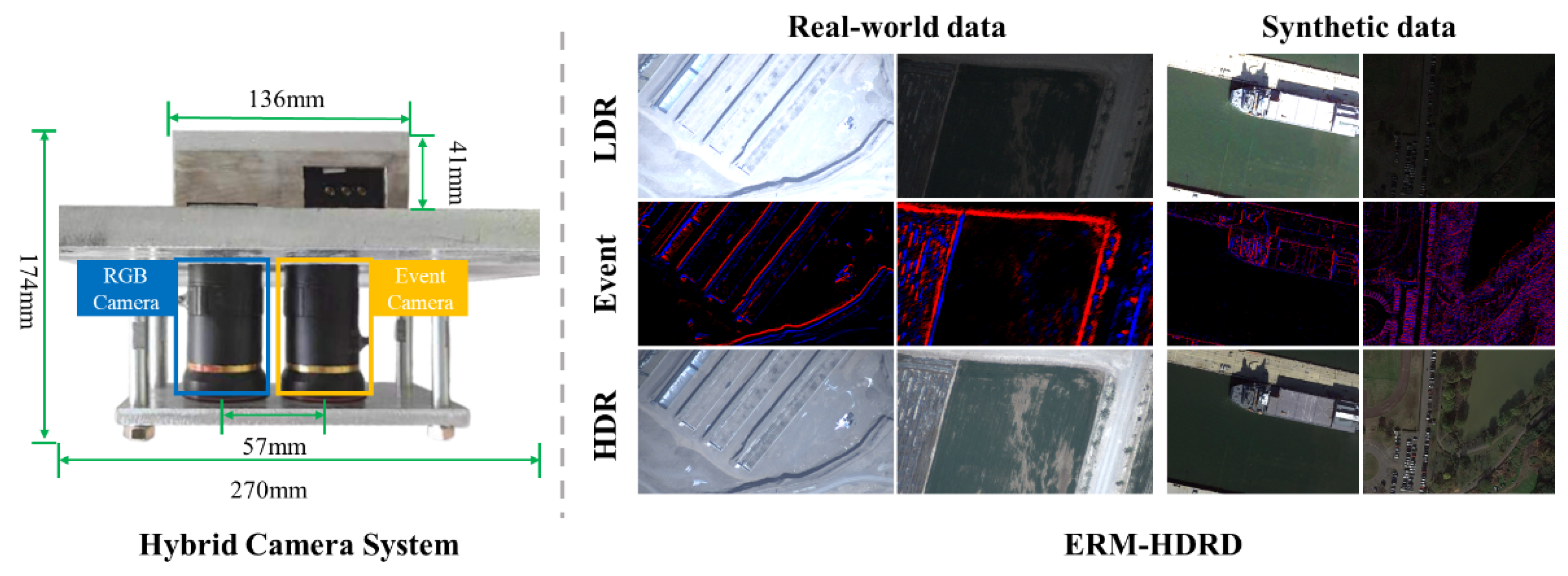
4.1. Real-World Dataset
4.1.1. Hybrid Camera System
4.1.2. Dataset Setup
4.2. Synthetic Dataset
4.3. Comparison with Existing HDRI Datasets
5. Experiments
5.1. Experimental Settings
5.1.1. Comparison Methods and Metrics
5.1.2. Implementation Details
5.2. Comparison with State-of-the-Art Methods
5.2.1. Results on Synthetic Data
5.2.2. Results on Real-World Data
5.3. External Verification on Object Detection
5.4. Efficiency Evaluation
5.5. Ablation Study
6. Conclusions and Discussion
7. Limitations and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 3974–3983. [Google Scholar]
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y.; Xu, H.; Tan, W.; Yang, Q.; Wang, J.; et al. Deep learning in environmental remote sensing: Achievements and challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- Requena-Mesa, C.; Benson, V.; Reichstein, M.; Runge, J.; Denzler, J. EarthNet2021: A large-scale dataset and challenge for Earth surface forecasting as a guided video prediction task. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 1132–1142. [Google Scholar]
- Xiong, Z.; Zhang, F.; Wang, Y.; Shi, Y.; Zhu, X.X. Earthnets: Empowering ai in earth observation. arXiv 2022, arXiv:2210.04936. [Google Scholar]
- Zhang, X.; Zhang, L.; Wei, W.; Ding, C.; Zhang, Y. Dynamic Long-Short Range Structure Learning for Low-Illumination Remote Sensing Imagery HDR Reconstruction. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 859–862. [Google Scholar]
- Xu, H.; Ma, J.; Le, Z.; Jiang, J.; Guo, X. Fusiondn: A unified densely connected network for image fusion. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12484–12491. [Google Scholar]
- Xu, H.; Ma, J.; Zhang, X.P. MEF-GAN: Multi-exposure image fusion via generative adversarial networks. IEEE Trans. Image Process. 2020, 29, 7203–7216. [Google Scholar] [CrossRef]
- Lu, P.Y.; Huang, T.H.; Wu, M.S.; Cheng, Y.T.; Chuang, Y.Y. High dynamic range image reconstruction from hand-held cameras. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 509–516. [Google Scholar]
- Chen, Y.; Jiang, G.; Yu, M.; Yang, Y.; Ho, Y.S. Learning stereo high dynamic range imaging from a pair of cameras with different exposure parameters. IEEE Trans. Comput. Imaging 2020, 6, 1044–1058. [Google Scholar] [CrossRef]
- Lee, S.H.; Chung, H.; Cho, N.I. Exposure-structure blending network for high dynamic range imaging of dynamic scenes. IEEE Access 2020, 8, 117428–117438. [Google Scholar] [CrossRef]
- Chen, X.; Liu, Y.; Zhang, Z.; Qiao, Y.; Dong, C. Hdrunet: Single image hdr reconstruction with denoising and dequantization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 354–363. [Google Scholar]
- Kalantari, N.K.; Ramamoorthi, R. Deep high dynamic range imaging of dynamic scenes. ACM Trans. Graph. 2017, 36, 144. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, W.; Li, X.; Rao, Q.; Jiang, T.; Han, M.; Fan, H.; Sun, J.; Liu, S. ADNet: Attention-guided deformable convolutional network for high dynamic range imaging. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 463–470. [Google Scholar]
- Vijay, C.S.; Paramanand, C.; Rajagopalan, A.N.; Chellappa, R. Non-uniform deblurring in HDR image reconstruction. IEEE Trans. Image Process. 2013, 22, 3739–3750. [Google Scholar] [CrossRef]
- Lakshman, P. Combining deblurring and denoising for handheld HDR imaging in low light conditions. Comput. Electr. Eng. 2012, 38, 434–443. [Google Scholar] [CrossRef]
- Gallego, G.; Delbrück, T.; Orchard, G.; Bartolozzi, C.; Taba, B.; Censi, A.; Leutenegger, S.; Davison, A.J.; Conradt, J.; Daniilidis, K.; et al. Event-based vision: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 154–180. [Google Scholar] [CrossRef]
- Reinbacher, C.; Munda, G.; Pock, T. Real-time panoramic tracking for event cameras. In Proceedings of the IEEE International Conference on Computational Photography, Stanford, CA, USA, 12–14 May 2017; pp. 1–9. [Google Scholar]
- Han, J.; Zhou, C.; Duan, P.; Tang, Y.; Xu, C.; Xu, C.; Huang, T.; Shi, B. Neuromorphic camera guided high dynamic range imaging. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1730–1739. [Google Scholar]
- Han, J.; Yang, Y.; Duan, P.; Zhou, C.; Ma, L.; Xu, C.; Huang, T.; Sato, I.; Shi, B. Hybrid high dynamic range imaging fusing neuromorphic and conventional images. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 8553–8565. [Google Scholar] [CrossRef]
- Messikommer, N.; Georgoulis, S.; Gehrig, D.; Tulyakov, S.; Erbach, J.; Bochicchio, A.; Li, Y.; Scaramuzza, D. Multi-Bracket High Dynamic Range Imaging with Event Cameras. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 547–557. [Google Scholar]
- Akyüz, A.O.; Fleming, R.; Riecke, B.E.; Reinhard, E.; Bülthoff, H.H. Do HDR displays support LDR content? A psychophysical evaluation. ACM Trans. Graph. (TOG) 2007, 26, 38-es. [Google Scholar] [CrossRef]
- Masia, B.; Agustin, S.; Fleming, R.W.; Sorkine, O.; Gutierrez, D. Evaluation of reverse tone mapping through varying exposure conditions. In ACM SIGGRAPH Asia 2009 Papers; Pacifico Yokohama: Yokohama, Japan, 2009; pp. 1–8. [Google Scholar]
- Kovaleski, R.P.; Oliveira, M.M. High-quality reverse tone mapping for a wide range of exposures. In Proceedings of the 2014 27th SIBGRAPI Conference on Graphics, Patterns and Images, Rio de Janeiro, Brazil, 26–30 August 2014; pp. 49–56. [Google Scholar]
- Masia, B.; Serrano, A.; Gutierrez, D. Dynamic range expansion based on image statistics. Multimed. Tools Appl. 2017, 76, 631–648. [Google Scholar] [CrossRef]
- Eilertsen, G.; Kronander, J.; Denes, G.; Mantiuk, R.K.; Unger, J. HDR image reconstruction from a single exposure using deep CNNs. ACM Trans. Graph. 2017, 36, 1–15. [Google Scholar] [CrossRef]
- Santos, M.S.; Ren, T.I.; Kalantari, N.K. Single image HDR reconstruction using a CNN with masked features and perceptual loss. arXiv 2020, arXiv:2005.07335. [Google Scholar] [CrossRef]
- Liu, Y.L.; Lai, W.S.; Chen, Y.S.; Kao, Y.L.; Yang, M.H.; Chuang, Y.Y.; Huang, J.B. Single-image HDR reconstruction by learning to reverse the camera pipeline. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1651–1660. [Google Scholar]
- Akhil, K.; Jiji, C. Single Image HDR Synthesis Using a Densely Connected Dilated ConvNet. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Online, 19–25 June 2021; pp. 526–531. [Google Scholar]
- A Sharif, S.; Naqvi, R.A.; Biswas, M.; Kim, S. A two-stage deep network for high dynamic range image reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 550–559. [Google Scholar]
- Wang, H.; Ye, M.; Zhu, X.; Li, S.; Zhu, C.; Li, X. KUNet: Imaging Knowledge-Inspired Single HDR Image Reconstruction. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, Vienna, Austria, 23–29 July 2022; pp. 1408–1414. [Google Scholar]
- Hu, X.; Shen, L.; Jiang, M.; Ma, R.; An, P. LA-HDR: Light Adaptive HDR Reconstruction Framework for Single LDR Image Considering Varied Light Conditions. IEEE Trans. Multimed. 2022, 25, 4814–4829. [Google Scholar] [CrossRef]
- Belbachir, A.N.; Schraml, S.; Mayerhofer, M.; Hofstätter, M. A novel hdr depth camera for real-time 3d 360 panoramic vision. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 425–432. [Google Scholar]
- Bardow, P.; Davison, A.J.; Leutenegger, S. Simultaneous optical flow and intensity estimation from an event camera. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 884–892. [Google Scholar]
- Rebecq, H.; Ranftl, R.; Koltun, V.; Scaramuzza, D. Events-to-video: Bringing modern computer vision to event cameras. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3857–3866. [Google Scholar]
- Wang, L.; Ho, Y.S.; Yoon, K.J.; Mohammad Mostafavi, I.S. Event-based high dynamic range image and very high frame rate video generation using conditional generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10081–10090. [Google Scholar]
- Scheerlinck, C.; Rebecq, H.; Gehrig, D.; Barnes, N.; Mahony, R.; Scaramuzza, D. Fast image reconstruction with an event camera. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 156–163. [Google Scholar]
- Zou, Y.; Zheng, Y.; Takatani, T.; Fu, Y. Learning to reconstruct high speed and high dynamic range videos from events. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 2024–2033. [Google Scholar]
- Liang, Q.; Zheng, X.; Huang, K.; Zhang, Y.; Chen, J.; Tian, Y. Event-Diffusion: Event-Based Image Reconstruction and Restoration with Diffusion Models. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 3837–3846. [Google Scholar]
- Shaw, R.; Catley-Chandar, S.; Leonardis, A.; Pérez-Pellitero, E. HDR reconstruction from bracketed exposures and events. arXiv 2022, arXiv:2203.14825. [Google Scholar]
- Yang, Y.; Han, J.; Liang, J.; Sato, I.; Shi, B. Learning event guided high dynamic range video reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 13924–13934. [Google Scholar]
- Gao, T.; Niu, Q.; Zhang, J.; Chen, T.; Mei, S.; Jubair, A. Global to local: A scale-aware network for remote sensing object detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5615614. [Google Scholar] [CrossRef]
- Zhou, X.; Zhou, L.; Gong, S.; Zhong, S.; Yan, W.; Huang, Y. Swin Transformer Embedding Dual-Stream for Semantic Segmentation of Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 17, 175–189. [Google Scholar] [CrossRef]
- Roy, S.K.; Deria, A.; Hong, D.; Rasti, B.; Plaza, A.; Chanussot, J. Multimodal fusion transformer for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5515620. [Google Scholar] [CrossRef]
- Chen, H.; Qi, Z.; Shi, Z. Remote sensing image change detection with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Cheng, G.; Si, Y.; Hong, H.; Yao, X.; Guo, L. Cross-scale feature fusion for object detection in optical remote sensing images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 431–435. [Google Scholar] [CrossRef]
- Li, J.; Chen, L.; Shen, J.; Xiao, X.; Liu, X.; Sun, X.; Wang, X.; Li, D. Improved neural network with spatial pyramid pooling and online datasets preprocessing for underwater target detection based on side scan sonar imagery. Remote Sens. 2023, 15, 440. [Google Scholar] [CrossRef]
- Han, L.; Zhao, Y.; Lv, H.; Zhang, Y.; Liu, H.; Bi, G. Remote sensing image denoising based on deep and shallow feature fusion and attention mechanism. Remote Sens. 2022, 14, 1243. [Google Scholar] [CrossRef]
- Huang, Z.; Zhu, Z.; Wang, Z.; Shi, Y.; Fang, H.; Zhang, Y. DGDNet: Deep Gradient Descent Network for Remotely Sensed Image Denoising. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Wang, J.; Li, W.; Wang, Y.; Tao, R.; Du, Q. Representation-enhanced status replay network for multisource remote-sensing image classification. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Xi, M.; Li, J.; He, Z.; Yu, M.; Qin, F. NRN-RSSEG: A deep neural network model for combating label noise in semantic segmentation of remote sensing images. Remote Sens. 2022, 15, 108. [Google Scholar] [CrossRef]
- Dong, H.; Pan, J.; Xiang, L.; Hu, Z.; Zhang, X.; Wang, F.; Yang, M.H. Multi-scale boosted dehazing network with dense feature fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2157–2167. [Google Scholar]
- Kim, Y.; Soh, J.W.; Park, G.Y.; Cho, N.I. Transfer learning from synthetic to real-noise denoising with adaptive instance normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3482–3492. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bayraktar, E.; Basarkan, M.E.; Celebi, N. A low-cost UAV framework towards ornamental plant detection and counting in the wild. ISPRS J. Photogramm. Remote Sens. 2020, 167, 1–11. [Google Scholar] [CrossRef]
- Chen, G.; Chen, C.; Guo, S.; Liang, Z.; Wong, K.Y.K.; Zhang, L. HDR video reconstruction: A coarse-to-fine network and a real-world benchmark dataset. In Proceedings of the International Conference on Computer Vision, Online, 11–17 October 2021; pp. 2502–2511. [Google Scholar]
- Rebecq, H.; Gehrig, D.; Scaramuzza, D. ESIM: An open event camera simulator. In Proceedings of the Conference on Robot Learning, Zürich, Switzerland, 29–31 October 2018; pp. 969–982. [Google Scholar]
- Ying, Z.; Li, G.; Ren, Y.; Wang, R.; Wang, W. A new image contrast enhancement algorithm using exposure fusion framework. In Proceedings of the International Conference on Computer Analysis of Images and Patterns, Ystad, Sweden, 22–24 August 2017; pp. 36–46. [Google Scholar]
- Li, M.; Liu, J.; Yang, W.; Sun, X.; Guo, Z. Structure-revealing low-light image enhancement via robust retinex model. IEEE Trans. Image Process. 2018, 27, 2828–2841. [Google Scholar] [CrossRef]
- Dhara, S.K.; Sen, D. Exposedness-based noise-suppressing low-light image enhancement. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 3438–3451. [Google Scholar] [CrossRef]
- Li, X.; Fan, C.; Zhao, C.; Zou, L.; Tian, S. NIRN: Self-supervised noisy image reconstruction network for real-world image denoising. Appl. Intell. 2022, 52, 16683–16700. [Google Scholar] [CrossRef]
- Kalantari, N.K.; Shechtman, E.; Barnes, C.; Darabi, S.; Goldman, D.B.; Sen, P. Patch-based high dynamic range video. ACM Trans. Graph. 2013, 32, 202. [Google Scholar] [CrossRef]
- Pérez-Pellitero, E.; Catley-Chandar, S.; Leonardis, A.; Timofte, R. NTIRE 2021 challenge on high dynamic range imaging: Dataset, methods and results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 691–700. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Li, Y.; Hou, Q.; Zheng, Z.; Cheng, M.M.; Yang, J.; Li, X. Large Selective Kernel Network for Remote Sensing Object Detection. arXiv 2023, arXiv:2303.09030. [Google Scholar]
- Lv, X.; Zhang, S.; Liu, Q.; Xie, H.; Zhong, B.; Zhou, H. BacklitNet: A dataset and network for backlit image enhancement. Comput. Vis. Image Underst. 2022, 218, 103403. [Google Scholar] [CrossRef]
- Fang, J.; Cao, X.; Wang, D.; Xu, S. Multitask learning mechanism for remote sensing image motion deblurring. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 2184–2193. [Google Scholar] [CrossRef]
- Sheng, Z.; Shen, H.L.; Yao, B.; Zhang, H. Guided colorization using mono-color image pairs. IEEE Trans. Image Process. 2023, 32, 905–920. [Google Scholar] [CrossRef]
- Kang, X.; Lin, X.; Zhang, K.; Hui, Z.; Xiang, W.; He, J.Y.; Li, X.; Ren, P.; Xie, X.; Timofte, R.; et al. NTIRE 2023 video colorization challenge. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 1570–1581. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
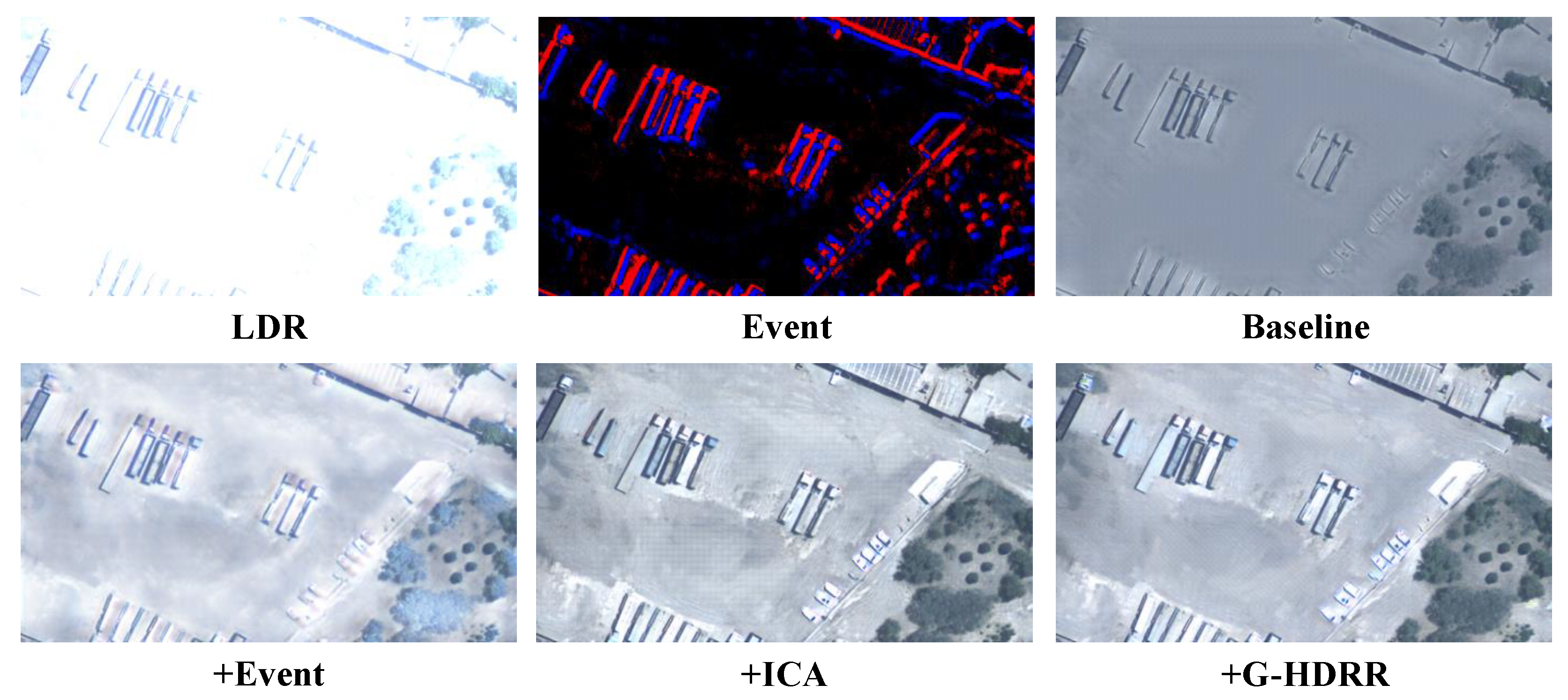{kind=link}
{kind=link}
| Dataset | Data Pairs | Remote | Event | Resolution (Image, Event) |
|---|---|---|---|---|
| Kalantari13 [63] | 976 | × | × | 1280 × 720, NA |
| HDM-HDR-2014 [64] | 15,087 | × | × | 1920 × 1080, NA |
| VHR-10-LI [5] | 650 | ✓ | × | 1100 × 1100, NA |
| HES-HDR [19] | 3071 | × | ✓ | 2448 × 2048, 346 × 260 |
| ERS-HDRD (Real-world) | 20,000 | ✓ | ✓ | 1280 × 720, 1280 × 720 |
| ERS-HDRD (Synthetic) | 38,400 | ✓ | ✓ | 640 × 480, 640 × 480 |
| Metrics | Frame-Based Methods | Event-Based Methods | |||
|---|---|---|---|---|---|
| DeepHDR [26] | HDRUnet [11] | KUnet [30] | HDRev [40] | Ours | |
| PSNR ↑ | 16.865 | 11.837 | 11.448 | 12.766 | 29.128 |
| SSIM ↑ | 0.627 | 0.668 | 0.659 | 0.560 | 0.886 |
| LPIPS ↓ | 0.293 | 0.229 | 0.242 | 0.362 | 0.055 |
| Metrics | Frame-Based Methods | Event-Based Methods | |||
|---|---|---|---|---|---|
| DeepHDR [26] | HDRUnet [11] | KUNet [30] | HDRev [40] | Ours | |
| PSNR ↑ | 20.183 | 17.693 | 17.514 | 16.368 | 26.226 |
| SSIM ↑ | 0.678 | 0.716 | 0.728 | 0.540 | 0.792 |
| LPIPS ↓ | 0.284 | 0.273 | 0.278 | 0.471 | 0.111 |
| DeepHDR [26] | HDRUnet [11] | KUnet [30] | HDRev [40] | Ours | |
|---|---|---|---|---|---|
| # Param (M) | 51.54 | 1.65 | 1.14 | 57.93 | 10.06 |
| FLOPs () | 75.77 | 203.11 | 217.66 | 748.47 | 194.41 |
| Runtime (s) | 0.0161 | 0.0215 | 0.0273 | 0.4661 | 0.0209 |
| Baseline | +Events | +ICA | +G-HDRR | PSNR ↑ | SSIM ↑ | LPIPS ↓ |
|---|---|---|---|---|---|---|
| ✓ | 21.241 | 0.729 | 0.255 | |||
| ✓ | ✓ | 23.662 | 0.763 | 0.149 | ||
| ✓ | ✓ | ✓ | 25.791 | 0.787 | 0.124 | |
| ✓ | ✓ | ✓ | ✓ | 26.226 | 0.792 | 0.111 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Cheng, S.; Zeng, Z.; Zhao, C.; Fan, C. ERS-HDRI: Event-Based Remote Sensing HDR Imaging. Remote Sens. 2024, 16, 437. https://doi.org/10.3390/rs16030437
Li X, Cheng S, Zeng Z, Zhao C, Fan C. ERS-HDRI: Event-Based Remote Sensing HDR Imaging. Remote Sensing. 2024; 16(3):437. https://doi.org/10.3390/rs16030437
Chicago/Turabian StyleLi, Xiaopeng, Shuaibo Cheng, Zhaoyuan Zeng, Chen Zhao, and Cien Fan. 2024. "ERS-HDRI: Event-Based Remote Sensing HDR Imaging" Remote Sensing 16, no. 3: 437. https://doi.org/10.3390/rs16030437
APA StyleLi, X., Cheng, S., Zeng, Z., Zhao, C., & Fan, C. (2024). ERS-HDRI: Event-Based Remote Sensing HDR Imaging. Remote Sensing, 16(3), 437. https://doi.org/10.3390/rs16030437