
Open-Pit Granite Mining Area Extraction Using UAV Aerial Images and the Novel GIPNet

Abstract
:1. Introduction
2. Methodology
2.1. Motivation
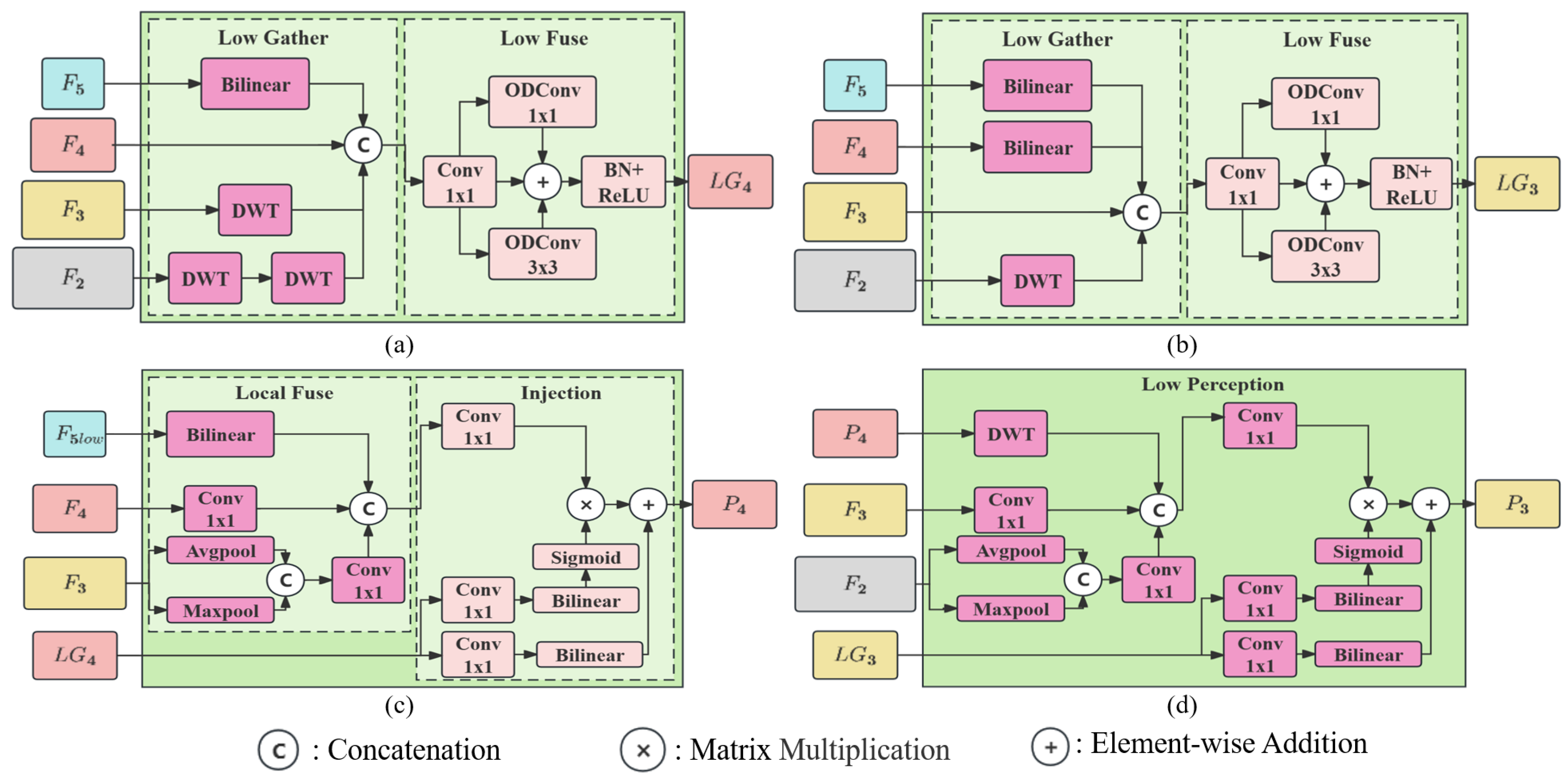
2.2. Gather–Injection–Perception Module
2.2.1. Low Stage Branch
2.2.2. High Stage Branch
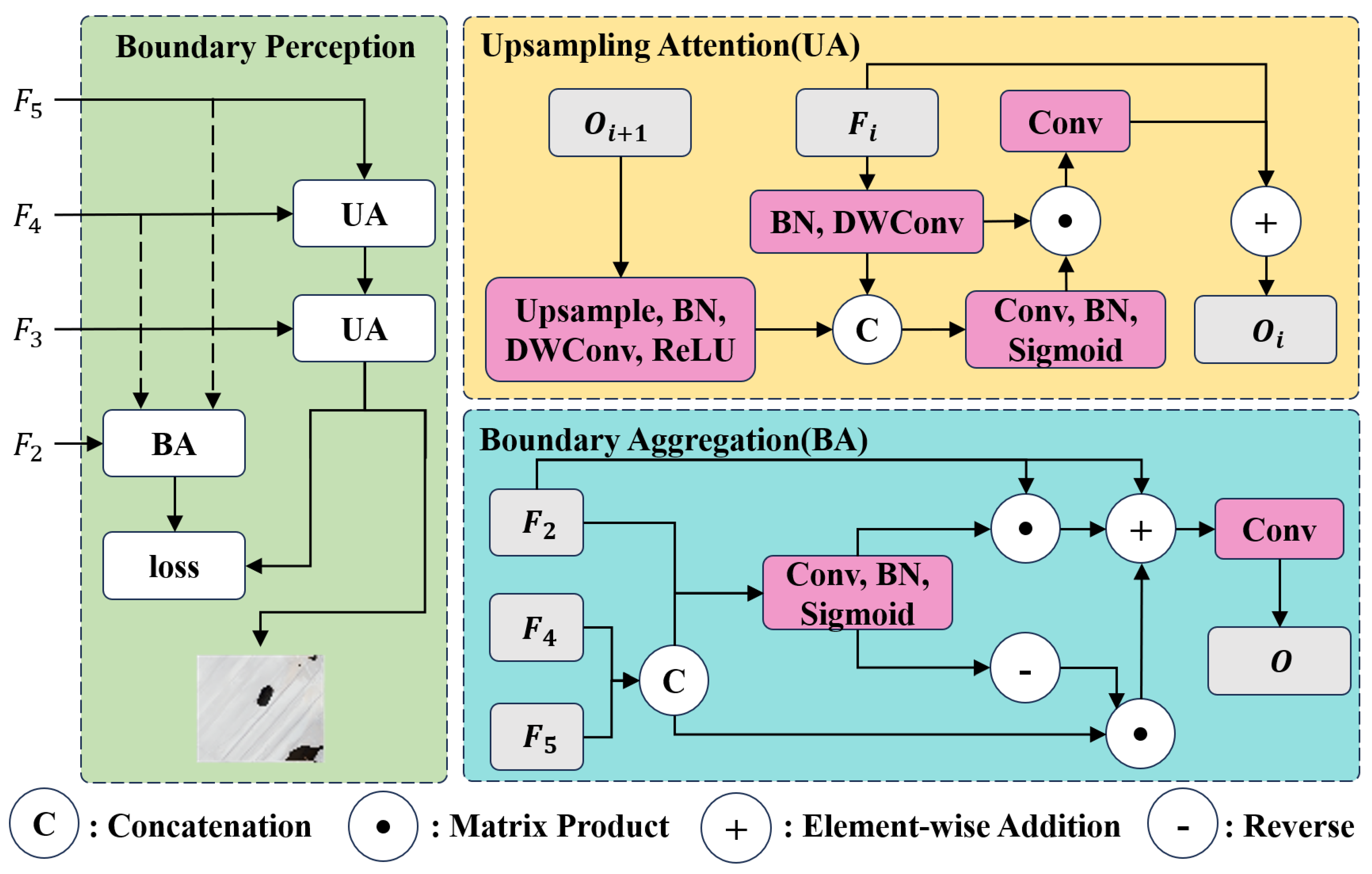
2.3. Boundary Perception Module
2.3.1. Upsampling Attention Branch
2.3.2. Boundary Aggregation Branch
2.4. Loss Function
3. Experiments
3.1. Raw Data
3.2. Dataset
3.3. Experiment Setup
3.4. Evaluation Metrics
4. Results
4.1. Comparison Experiments
4.2. Ablation Experiments
5. Discussion
5.1. Advantages and Disadvantages of Multi-Scale Feature Fusion Methods
5.2. Limitation and Potential Improvements
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nassani, A.A.; Aldakhil, A.M.; Zaman, K. Ecological footprints jeopardy for mineral resource extraction: Efficient use of energy, financial development and insurance services to conserve natural resources. Resour. Policy 2021, 74, 102271. [Google Scholar] [CrossRef]
- Gao, Y.; Wang, J.; Zhang, M.; Li, S. Measurement and prediction of land use conflict in an opencast mining area. Resour. Policy 2021, 71, 101999. [Google Scholar] [CrossRef]
- Li, Y.; Zuo, X.; Xiong, P.; You, H.; Zhang, H.; Yang, F.; Zhao, Y.; Yang, Y.; Liu, Y. Deformation monitoring and analysis of Kunyang phosphate mine fusion with InSAR and GPS measurements. Adv. Space Res. 2022, 69, 2637–2658. [Google Scholar] [CrossRef]
- Ren, Z.; Wang, L.; He, Z. Open-Pit Mining Area Extraction from High-Resolution Remote Sensing Images Based on EMANet and FC-CRF. Remote Sens. 2023, 15, 3829. [Google Scholar] [CrossRef]
- Guo, J.; Li, Q.; Xie, H.; Li, J.; Qiao, L.; Zhang, C.; Yang, G.; Wang, F. Monitoring of Vegetation Disturbance and Restoration at the Dumping Sites of the Baorixile Open-Pit Mine Based on the LandTrendr Algorithm. Int. J. Environ. Res. Public Health 2022, 19, 9066. [Google Scholar] [CrossRef]
- Du, S.; Li, W.; Li, J.; Du, S.; Zhang, C.; Sun, Y. Open-pit mine change detection from high resolution remote sensing images using DA-UNet++ and object-based approach. Int. J. Min. Reclam. Environ. 2022, 36, 512–535. [Google Scholar] [CrossRef]
- Cao, D.; Zhang, B.; Zhang, X.; Yin, L.; Man, X. Optimization methods on dynamic monitoring of mineral reserves for open pit mine based on UAV oblique photogrammetry. Measurement 2023, 207, 112364. [Google Scholar] [CrossRef]
- Fahmy, W.; El-Desoky, H.; Elyaseer, M.; Ayonta Kenne, P.; Shirazi, A.; Hezarkhani, A.; Shirazy, A.; El-Awny, H.; Abdel-Rahman, A.; Khalil, A.; et al. Remote Sensing and Petrological and Geochemical Data for Lithological Mapping in Wadi Kid, Southeast Sinai, Egypt. Minerals 2023, 13, 1160. [Google Scholar] [CrossRef]
- Tucci, G.; Gebbia, A.; Conti, A.; Fiorini, L.; Lubello, C. Monitoring and computation of the volumes of stockpiles of bulk material by means of UAV photogrammetric surveying. Remote Sens. 2019, 11, 1471. [Google Scholar] [CrossRef]
- Chen, X. Comparison of supervised classification methods based on GF-1 satellite image. Mine Surv. 2017, 23, 8530. [Google Scholar]
- Maxwell, A.; Strager, M.; Warner, T.; Zégre, N.; Yuill, C. Comparison of NAIP orthophotography and RapidEye satellite imagery for mapping of mining and mine reclamation. GIScience Remote Sens. 2014, 51, 301–320. [Google Scholar] [CrossRef]
- Cheng, L. Application of object-oriented combined SVM information extraction of open-pit mine. Qinghai Univ. Xining Qinghai CNKI CDMD 2017, 2, 828168. [Google Scholar]
- Chen, T.; Zheng, X.; Niu, R.; Plaza, A. Open-pit Mine Area Mapping with Gaofen-2 Satellite Images using U-Net+. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 3589–3599. [Google Scholar] [CrossRef]
- Xie, H.; Pan, Y.; Luan, J.; Yang, X.; Xi, Y. Semantic Segmentation of Open Pit Mining Area Based on Remote Sensing Shallow Features and Deep Learning. In Advances in Intelligent Systems and Computing, Big Data Analytics for Cyber-Physical System in Smart City; Springer: Berlin/Heidelberg, Germany, 2021; pp. 52–59. [Google Scholar] [CrossRef]
- Xie, H.; Pan, Y.; Luan, J.; Yang, X.; Xi, Y. Open-pit Mining Area Segmentation of Remote Sensing Images Based on DUSegNet. J. Indian Soc. Remote Sens. 2021, 1257–1270. [Google Scholar] [CrossRef]
- Liu, Y.; Li, C.; Huang, J.; Gao, M. MineSDS: A Unified Framework for Small Object Detection and Drivable Area Segmentation for Open-Pit Mining Scenario. Sensors 2023, 23, 5977. [Google Scholar] [CrossRef]
- Li, J.; Xing, J.; Du, S.; Du, S.; Zhang, C.; Li, W. Change Detection of Open-Pit Mine Based on Siamese Multiscale Network. IEEE Geosci. Remote Sens. Lett. 2023, 20, 2500105. [Google Scholar] [CrossRef]
- Eskandari, A.; Hosseini, M.; Nicotra, E. Application of Satellite Remote Sensing, UAV-Geological Mapping, and Machine Learning Methods in the Exploration of Podiform Chromite Deposits. Minerals 2023, 13, 251. [Google Scholar] [CrossRef]
- Shahmoradi, J.; Talebi, E.; Roghanchi, P.; Hassanalian, M. A Comprehensive Review of Applications of Drone Technology in the Mining Industry. Drones 2020, 4, 34. [Google Scholar] [CrossRef]
- Lev, E.; Arie, M. Unmanned airborne magnetic and VLF investigations: Effective geophysical methodology for the near future. Positioning 2011, 2011. [Google Scholar]
- Thiruchittampalam, S.; Singh, S.K.; Banerjee, B.P.; Glenn, N.F.; Raval, S. Spoil characterisation using UAV-based optical remote sensing in coal mine dumps. Int. J. Coal Sci. Technol. 2023, 10, 65. [Google Scholar] [CrossRef]
- Kou, X.; Han, D.; Cao, Y.; Shang, H.; Li, H.; Zhang, X.; Yang, M. Acid Mine Drainage Discrimination Using Very High Resolution Imagery Obtained by Unmanned Aerial Vehicle in a Stone Coal Mining Area. Water 2023, 15, 1613. [Google Scholar] [CrossRef]
- Dai, H.; Xu, J. Application of UAV photogrammetry on ecological restoration of abandoned open-pit mines, Northern Anhui province, China. Nat. Environ. Pollut. Technol. 2022, 21, 193–199. [Google Scholar] [CrossRef]
- Aicardi, I.; Chiabrando, F.; Grasso, N.; Lingua, A.M.; Noardo, F.; Spanò, A. UAV photogrammetry with oblique images: First analysis on data acquisition and processing. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41, 835–842. [Google Scholar] [CrossRef]
- Choi, Y. Applications of Unmanned Aerial Vehicle and Artificial Intelligence Technologies in Mining from Exploration to Reclamation. Minerals 2023, 13, 382. [Google Scholar] [CrossRef]
- Wajs, J. Research on surveying technology applied for DTM modelling and volume computation in open pit mines. Min. Sci. 2015, 22, 75–83. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 2017; pp. 2881–2890. [Google Scholar]
- Zhao, H.; Zhang, Y.; Liu, S.; Shi, J.; Loy, C.C.; Lin, D.; Jia, J. Psanet: Point-wise spatial attention network for scene parsing. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 267–283. [Google Scholar]
- Kirillov, A.; Girshick, R.; He, K.; Dollár, P. Panoptic feature pyramid networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6399–6408. [Google Scholar]
- Wang, C.; He, W.; Nie, Y.; Guo, J.; Liu, C.; Han, K.; Wang, Y. Gold-YOLO: Efficient Object Detector via Gather-and-Distribute Mechanism. arXiv 2023, arXiv:2309.11331. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Liu, P.; Zhang, H.; Lian, W.; Zuo, W. Multi-level wavelet convolutional neural networks. IEEE Access 2019, 7, 74973–74985. [Google Scholar] [CrossRef]
- Mallat, S.G. A theory for multiresolution signal decomposition: The wavelet representation. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 11, 674–693. [Google Scholar] [CrossRef]
- Li, C.; Zhou, A.; Yao, A. Omni-dimensional dynamic convolution. arXiv 2022, arXiv:2209.07947. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Zhang, Z.; Zhang, X.; Peng, C.; Xue, X.; Sun, J. Exfuse: Enhancing feature fusion for semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 269–284. [Google Scholar]
- Li, X.; Li, X.; Zhang, L.; Cheng, G.; Shi, J.; Lin, Z.; Tan, S.; Tong, Y. Improving semantic segmentation via decoupled body and edge supervision. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XVII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 435–452. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, L.; Polosukhin, I. Attention is All you Need. Neural Inf. Process. Syst. Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Xu, J.; Xiong, Z.; Bhattacharyya, S.P. PIDNet: A Real-Time Semantic Segmentation Network Inspired by PID Controllers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 19529–19539. [Google Scholar]
- Wei, J.; Wang, S.; Huang, Q. F3Net: Fusion, feedback and focus for salient object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12321–12328. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. Basnet: Boundary-aware salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 7479–7489. [Google Scholar]
- Deng, R.; Shen, C.; Liu, S.; Wang, H.; Liu, X. Learning to predict crisp boundaries. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 562–578. [Google Scholar]
- Wei, X. Development Status and Prospect of Granite Resources Industry in Hezhou City, Guangxi. China Min. Mag. 2022, 31, 51–56. [Google Scholar] [CrossRef]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A database and web-based tool for image annotation. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Zhang, W.; Pang, J.; Chen, K.; Loy, C. K-Net: Towards Unified Image Segmentation. Adv. Neural Inf. Process. Syst. 2021, 34, 10326–10338. [Google Scholar]
- Kirillov, A.; Wu, Y.; He, K.; Girshick, R. Pointrend: Image segmentation as rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9799–9808. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified Perceptual Parsing for Scene Understanding. In Computer Vision – ECCV 2018, Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2018; pp. 432–448. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Guo, M.H.; Lu, C.Z.; Hou, Q.; Liu, Z.; Cheng, M.M.; Hu, S.M. Segnext: Rethinking convolutional attention design for semantic segmentation. Adv. Neural Inf. Process. Syst. 2022, 35, 1140–1156. [Google Scholar]
- Girisha, S.; Verma, U.; Pai, M.M.; Pai, R.M. Uvid-net: Enhanced semantic segmentation of uav aerial videos by embedding temporal information. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4115–4127. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 2117–2125. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Wang, K.; Liew, J.H.; Zou, Y.; Zhou, D.; Feng, J. Panet: Few-shot image semantic segmentation with prototype alignment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 29 October–2 November 2019; pp. 9197–9206. [Google Scholar]
- Zhang, D.; Zhang, H.; Tang, J.; Wang, M.; Hua, X.; Sun, Q. Feature pyramid transformer. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXVIII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 323–339. [Google Scholar]
- Zhang, W.; Huang, Z.; Luo, G.; Chen, T.; Wang, X.; Liu, W.; Yu, G.; Shen, C. TopFormer: Token pyramid transformer for mobile semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12083–12093. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Park, S.; Choi, Y. Applications of unmanned aerial vehicles in mining from exploration to reclamation: A review. Minerals 2020, 10, 663. [Google Scholar] [CrossRef]
- Fu, Y.; Aldrich, C. Deep learning in mining and mineral processing operations: A review. IFAC-PapersOnLine 2020, 53, 11920–11925. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Camera | UAV | ||
|---|---|---|---|
| Type | ILCE-5100 | Type | M300RTK |
| Sensor | 23.5 mm | Flight time | 55 min |
| Millimeter focal length | 6.56287 mm | Maximum take-off weight | 9 kg |
| Focal length in pixel | 1675.63 pixel | Maximum load | 2.7 kg |
| Network | Characteristic | Backbone | Optimizer |
|---|---|---|---|
| K-Net [46] | K-Net enhances segmentation core by dynamically updating instance kernels and mask predictions. | ResNet-50 | AdamW |
| PointRend [47] | PointRend achieves denser sampling in boundary regions and predicts point-based segmentations at adaptively chosen positions. | ResNet-50 | SGD |
| PSPNet [27] | PSPNet introduces the Pyramid Pooling Module, replacing global pooling operations and collecting information from diverse scales and sub-regions. | ResNet-50 | SGD |
| UNet [48] | UNet features a U-shaped network structure for precise localization and enhances segmentation accuracy. | 5 layers of BasicConvBlock (Conv+BN+ReLU) | SGD |
| UPerNet [49] | UPerNet enhances global prior representation by applying the Pyramid Pooling module and predict texture labels through additional convolution layers. | ResNet-50 | SGD |
| HRNet [50] | HRNet incrementally adds high to low-resolution subnetworks, connecting them to exchange information and generates rich high-resolution representations. | HRNet | SGD |
| FCN [51] | FCN replaces fully connected layers with convolutional layers for direct pixel-level predictions. | ResNet-50 | SGD |
| DeepLabv3 [31] | DeepLabv3 utilizes dilated convolutions to extract dense feature maps capturing long-range contextual information and introduces the Atrous Spatial Pyramid Pooling module to improve accuracy. | ResNet-50 | SGD |
| DANet [52] | DANet introduces spatial and channel attention for integration of global information to captures pixel-level spatial relationships and inter-channel correlations. | ResNet-50 | SGD |
| SegNeXt [53] | SegNeXt presents a multi-scale convolutional attention module within the conventional encoder–decoder framework, substituting the traditional self-attention mechanism. | MSCAN | AdamW |
| Method | Precision | Recall | F1-Score | IoU |
|---|---|---|---|---|
| SegNeXt | 85.35 | 89.66 | 87.45 | 77.70 |
| UNet | 90.37 | 87.31 | 88.81 | 79.88 |
| DeepLabv3 | 86.64 | 91.56 | 89.03 | 80.23 |
| FCN | 90.68 | 87.74 | 89.19 | 80.48 |
| UPerNet | 88.70 | 90.10 | 89.39 | 80.82 |
| DANet | 89.27 | 90.40 | 89.83 | 81.54 |
| PSPNet | 89.64 | 90.20 | 89.91 | 81.68 |
| HRNet | 89.76 | 90.49 | 90.13 | 82.03 |
| K-Net | 89.42 | 90.91 | 90.06 | 82.09 |
| Pointrend | 89.91 | 90.55 | 90.23 | 82.20 |
| GIPNet | 90.67 | 92.00 | 91.33 | 84.04 |
| Method | Precision | Recall | F1-Score | IoU |
|---|---|---|---|---|
| Baseline | 90.37 | 87.31 | 88.81 | 79.88 |
| Baseline + FPN | 89.82 | 89.28 | 89.55 | 81.08 |
| Baseline + GD | 88.62 | 90.46 | 89.53 | 81.05 |
| Baseline + GIP | 90.98 | 89.66 | 90.31 | 82.34 |
| Baseline + BA | 90.12 | 87.60 | 88.84 | 79.92 |
| Baseline + GIP + BA | 90.67 | 92.00 | 91.33 | 84.04 |
| Backbone | Precision | Recall | F1-Score | IoU |
|---|---|---|---|---|
| ResNet-18 | 90.94 | 87.40 | 89.14 | 80.04 |
| ResNet-34 | 88.71 | 89.98 | 89.34 | 80.74 |
| ResNet-50 | 89.16 | 90.99 | 90.07 | 81.93 |
| ResNet-101 | 84.95 | 92.90 | 88.75 | 79.78 |
| ResNet-152 | 84.63 | 89.39 | 86.95 | 76.91 |
| : | Precision | Recall | F1-Score | IoU |
|---|---|---|---|---|
| 4:1 | 88.00 | 92.49 | 90.19 | 82.13 |
| 3:2 | 83.70 | 93.48 | 88.32 | 79.08 |
| 1:1 | 87.97 | 90.66 | 89.29 | 80.66 |
| 2:3 | 90.33 | 88.62 | 89.47 | 80.94 |
| 1:4 | 90.67 | 92.00 | 91.33 | 84.04 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meng, X.; Zhang, D.; Dong, S.; Yao, C. Open-Pit Granite Mining Area Extraction Using UAV Aerial Images and the Novel GIPNet. Remote Sens. 2024, 16, 789. https://doi.org/10.3390/rs16050789
Meng X, Zhang D, Dong S, Yao C. Open-Pit Granite Mining Area Extraction Using UAV Aerial Images and the Novel GIPNet. Remote Sensing. 2024; 16(5):789. https://doi.org/10.3390/rs16050789
Chicago/Turabian StyleMeng, Xiaoliang, Ding Zhang, Sijun Dong, and Chunjing Yao. 2024. "Open-Pit Granite Mining Area Extraction Using UAV Aerial Images and the Novel GIPNet" Remote Sensing 16, no. 5: 789. https://doi.org/10.3390/rs16050789
APA StyleMeng, X., Zhang, D., Dong, S., & Yao, C. (2024). Open-Pit Granite Mining Area Extraction Using UAV Aerial Images and the Novel GIPNet. Remote Sensing, 16(5), 789. https://doi.org/10.3390/rs16050789