



MRFA-Net: Multi-Scale Receptive Feature Aggregation Network for Cloud and Shadow Detection

Abstract
:1. Introduction
- (1)
- For cloud and cloud shadow detection in remote sensing images, a novel framework called the MRFA-Net is proposed. This model fully utilizes rich features to address the misidentification of blurry features, small objects, and abstract characteristics in detection. The network is end-to-end trainable, significantly simplifying the process of cloud and cloud shadow detection.
- (2)
- Previous methods have overlooked the feature information across different scales. We propose the asymmetric feature extractor module (AFEM) and the multi-scale attention to capture irregular information across multiple scales and to enhance both local and global semantic information. To address the issue of information loss due to direct continuous up-sampling in previous networks, the multi-path decoder module (MDM) and the global feature refinement module (GFRM) are introduced. These modules combine feature information from different receptive fields with the feature fusion module (FFM) and optimize the information before decoding.
- (3)
- We evaluated the model on two remote sensing datasets with diverse environmental scenarios, including tests in challenging conditions. The outcomes demonstrate that the MRFA-Net is quite accurate and reliable when compared to previous deep learning based algorithms.
2. Methods
2.1. Overview
2.2. Asymmertric Feature Extractor Module
2.3. Multi-Scale Attention
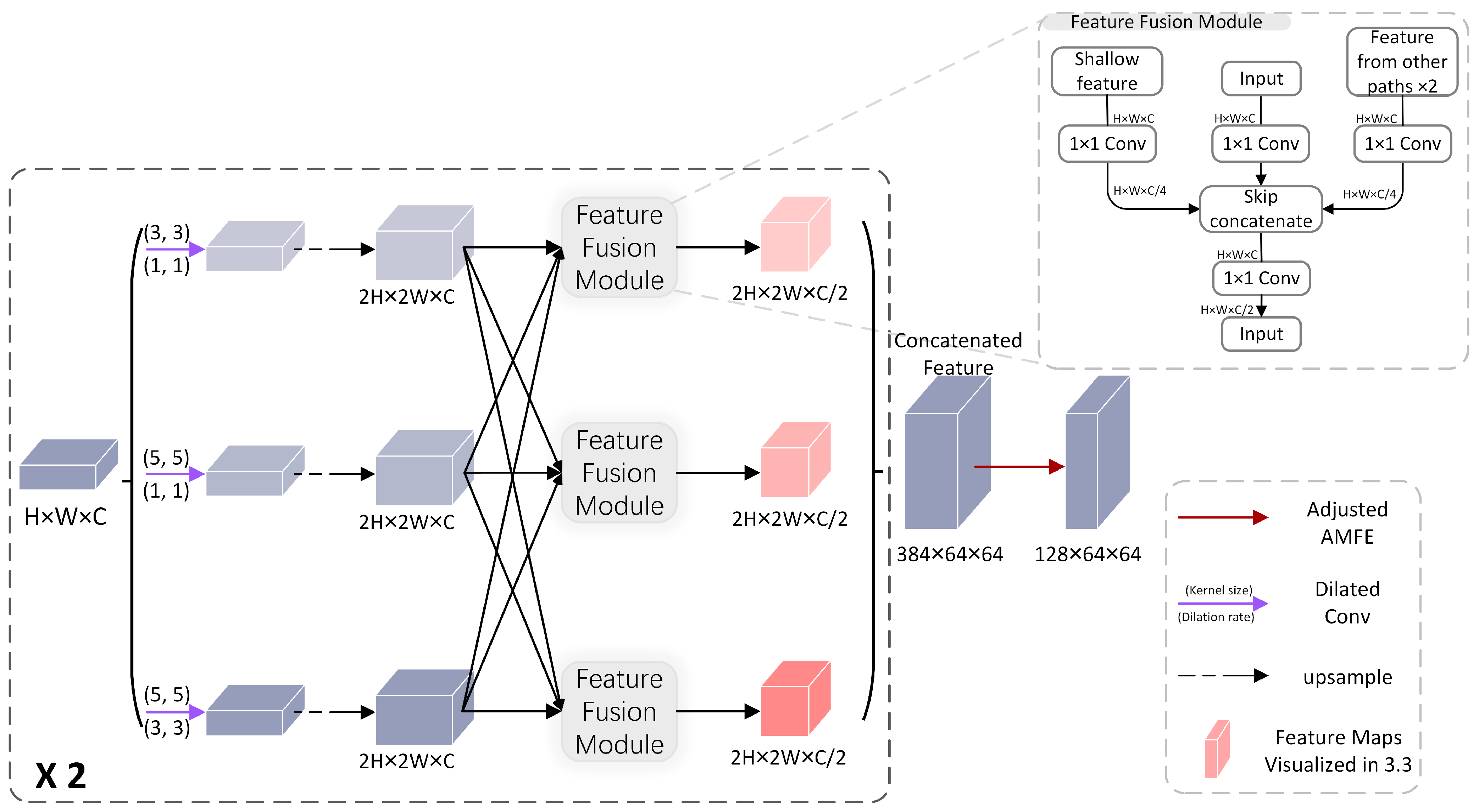
2.4. Multi-Path Decoder Module
2.5. Global Feature Refinement Module
3. Experimental Analysis
3.1. Datasets
3.1.1. Cloud and Cloud Shadow Dataset
3.1.2. HRC_WHU Dataset
3.2. Experiment Details
3.3. Parameter Analysis
3.3.1. Ablation Experiments
3.3.2. Analysis of the Decoder Paths
3.3.3. Parameters of AFEM
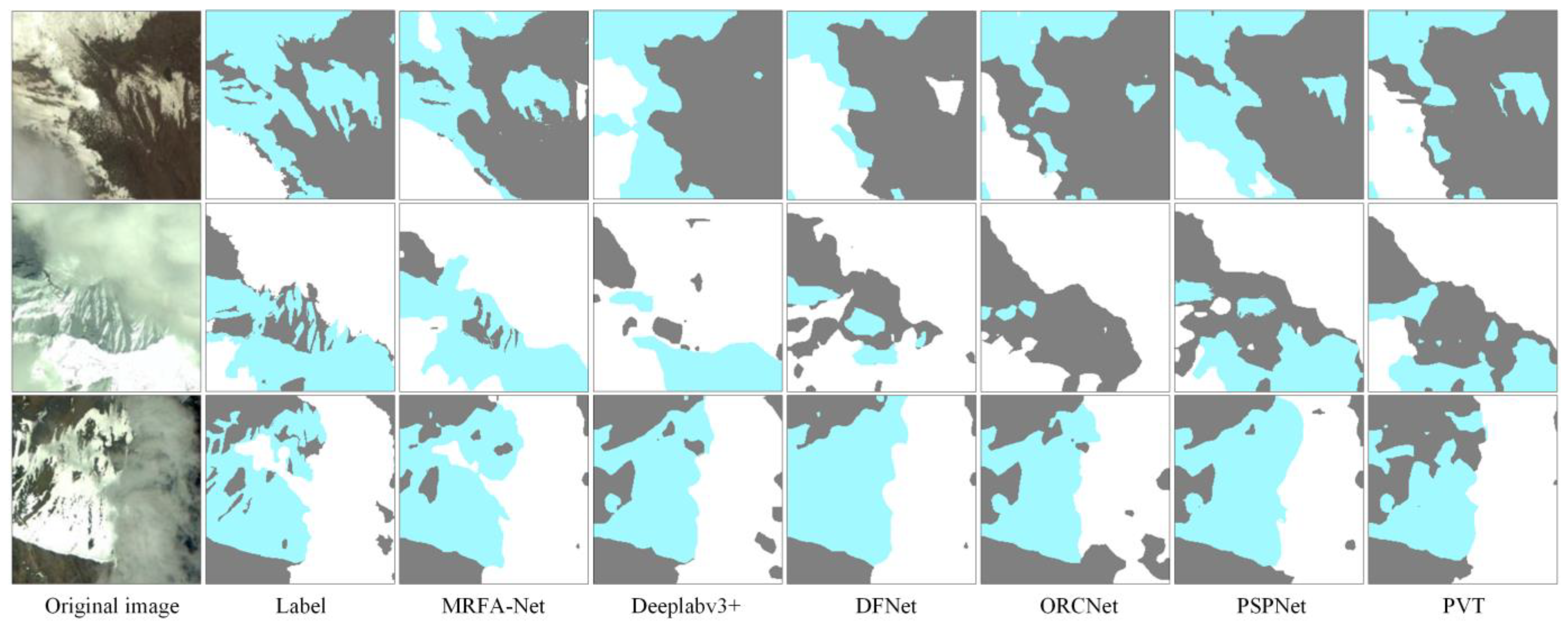
3.4. Comparison Test of the Cloud and Cloud Shadow Dataset
3.5. Comparison Test of the HRC_WHU Dataset
4. Discussion
4.1. Advantages of the Method
4.2. Limitation of the Method
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rossow, W.B.; Schiffer, R.A. Advances in Understanding Clouds from ISCCP. J. Bull. Am. Meteorol. Soc. 1999, 80, 2261–2288. [Google Scholar] [CrossRef]
- Moses, W.J.; Philpot, W.D. Evaluation of atmospheric correction using bi-temporal hyperspectral images. Isr. J. Plant Sci. 2012, 60, 253–263. [Google Scholar] [CrossRef]
- Liu, X.; Xu, J.-M.; Du, B. A bi-channel dynamic thershold algorithm used in automatically identifying clouds on gms-5 imagery. J. Appl. Meteorlog. Sci. 2005, 16, 134–444. [Google Scholar]
- Tapakis, R.; Charalambides, A.G. Equipment and methodologies for cloud detection and classification: A review. Sol. Energy 2013, 95, 392–430. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Object-based cloud and cloud shadow detection in landsat imagery. Remote Sens. Environ. 2012, 118, 83–94. [Google Scholar] [CrossRef]
- Qiu, S.; He, B.; Zhu, Z.; Liao, Z.; Quan, X. Improving fmask cloud and cloud shadow detection in mountainous area for landsats 4–8 images. Remote Sens. Environ. 2017, 199, 107–119. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Automated cloud, cloud shadow, and snow detection in multitemporal landsat data: An algorithm designed specifically for monitoring land cover change. Remote Sens. Environ. 2014, 152, 217–234. [Google Scholar] [CrossRef]
- Wang, Z.; Xia, M.; Lu, M.; Pan, L.; Liu, J. Parameter identification in power transmission systems based on graph convolution network. IEEE Trans. Power Deliv. 2022, 37, 3155–3163. [Google Scholar] [CrossRef]
- Ayala, C.; Sesma, R.; Aranda, C.; Galar, M. A deep learning approach to an enhanced building footprint and road detection in high-resolution satellite imagery. Remote Sens. 2021, 13, 3135. [Google Scholar] [CrossRef]
- Prathap, G.; Afanasyev, I. Deep learning approach for building detection in satellite multispectral imagery. In Proceedings of the 2018 International Conference on Intelligent Systems (IS), Funchal, Portugal, 25–27 September 2018. [Google Scholar]
- Xie, W.; Fan, X.; Zhang, X.; Li, Y.; Sheng, M.; Fang, L. Co-compression via superior gene for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5604112. [Google Scholar] [CrossRef]
- Wieland, M.; Li, Y.; Martinis, S. Multi-sensor cloud and cloud shadow segmentation with a convolutional neural network. Remote Sens. Environ. 2019, 230, 111203. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Wu, X.; Shi, Z. Utilizing multilevel features for cloud detection on satellite imagery. Remote Sens. 2018, 10, 1853. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Jeppesen, J.H.; Jacobsen, R.H.; Inceoglu, F.; Toftegaard, T.S. A cloud detection algorithm for satellite imagery based on deep learning. Remote Sens. Environ. 2019, 229, 247–259. [Google Scholar] [CrossRef]
- Yan, Z.; Yan, M.; Sun, H.; Fu, K.; Hong, J.; Sun, J.; Zhang, Y.; Sun, X. Cloud and cloud shadow detection using multilevel feature fused segmentation network. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1600–1604. [Google Scholar] [CrossRef]
- Yang, J.; Guo, J.; Yue, H.; Liu, Z.; Hu, H.; Li, K. CDnet: CNN-based cloud detection for remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6195–6211. [Google Scholar] [CrossRef]
- Li, Z.; Shen, H.; Cheng, Q.; Liu, Y.; You, S.; He, Z. Deep learning based cloud detection for medium and high resolution remote sensing images of different sensors. ISPRS J. Photogramm. Remote Sens. 2019, 150, 197–212. [Google Scholar] [CrossRef]
- Qu, Y.; Xia, M.; Zhang, Y. Strip pooling channel spatial attention network for the segmentation of cloud and cloud shadow. Comput. Geosci. 2021, 157, 104940. [Google Scholar] [CrossRef]
- Zhang, C.; Weng, L.; Ding, L.; Xia, M.; Lin, H. CRSNet: Cloud and cloud shadow refinement segmentation networks for remote sensing imagery. Remote Sens. 2023, 15, 1664. [Google Scholar] [CrossRef]
- Chen, Y.; Tang, L.; Huang, W.; Guo, J.; Yang, G. A novel spectral indices-driven spectral-spatial-context attention network for automatic cloud detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 3092–3103. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV) 2018, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Lu, C.; Xia, M.; Qian, M.; Chen, B. Dual-branch network for cloud and cloud shadow segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5613. [Google Scholar] [CrossRef]
- Hu, K.; Zhang, E.; Xia, M.; Weng, L.; Lin, H. MCANet: A multi-branch network for cloud/snow segmentation in high-resolution remote sensing images. Remote Sens. 2023, 15, 1055. [Google Scholar] [CrossRef]
- Lee, D.D.; Seung, H.S. Learning the parts of objects by non-negative matrix factorization. Nature 1999, 401, 788–791. [Google Scholar] [CrossRef] [PubMed]
- Gregor, K.; LeCun, Y. Learning fast approximations of sparse coding. In Proceedings of the 27th International Conference on International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Liu, J.; Chen, X. ALISTA: Analytic weights are as good as learned weights in LISTA. In Proceedings of the International Conference on Learning Representations (ICLR) 209, New Orleans, LO, USA, 6–9 May 2019. [Google Scholar]
- Xie, X.; Wu, J.; Liu, G.; Zhong, Z.; Lin, Z. Differentiable linearized ADMM. In Proceedings of the International Conference on Machine Learning 2019, Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
- Werbos, P.J. Backpropagation through time: What it does and how to do it. Proc. IEEE 1990, 78, 1550–1560. [Google Scholar] [CrossRef]
- Amos, B.; Kolter, J.Z. OptNet: Differentiable optimization as a layer in neural networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Bai, S.; Koltun, V.; Kolter, J.Z. Multiscale deep equilibrium models. In Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Li, Z.; Shen, H.; Liu, Y. HRC_WHU: High-resolution cloud cover validation data. ISPRS J. Photogramm. Remote Sens. 2019, 150, 197–212. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar] [CrossRef]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Li, G.; Yun, I.; Kim, J.; Kim, J. Dabnet: Depth-wise asymmetric bottleneck for real-time semantic segmentation. arXiv 2019, arXiv:1907.11357. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, X.; Wei, Y.; Huang, L.; Shi, H.; Liu, W.; Huang, T.S. CCNet: Criss-cross attention for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 6896–6908. [Google Scholar] [CrossRef]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. DenseASPP for semantic segmentation in street scenes. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. Enet: A deep neural network architecture for real-time semantic segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar] [CrossRef]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. BiSeNet V2: Bilateral network with guided aggregation for real-time semantic segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Zhang, F.; Chen, Y.; Li, Z.; Hong, Z.; Liu, J.; Ma, F.; Han, J.; Ding, E. ACFNet: Attentional class feature network for semantic segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Yuan, Y.; Chen, X.; Wang, J. Object-contextual representations for semantic segmentation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Learning a discriminative feature network for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | MIoU on HRC_WHU (%) | MIoU on CCSD (%) | Flops (B) | Param (M) |
|---|---|---|---|---|
| MRFA-Net/AFEM− | 87.12 | 93.96 | 9.18 | 11.07 |
| MRFA-Net/MA− | 86.14 | 93.73 | 6.29 | 7.28 |
| MRFA-Net/Decoder− | 86.95 | 93.79 | 7.44 | 8.39 |
| MRFA-Net/GFRM− | 85.98 | 93.61 | 6.12 | 7.06 |
| MRFA-Net | 87.49 | 94.12 | 9.05 | 10.31 |
| Model | Net-S | Net-L | Net-AS | Net-AL | MRFA-Net |
|---|---|---|---|---|---|
| Input < 64 × 64 | 3, 5, 7 | 3, 6, 10 | 1, 3, 5 | 3, 6, 10 | 3, 5, 7 |
| Input ≥ 64 × 64 | 3, 5, 7 | 3, 6, 10 | 3, 5, 7 | 5, 8, 12 | 3, 7, 11 |
| Model | PA (%) | MAP (%) | MIoU |
|---|---|---|---|
| Net-S | 95.93 | 95.37 | 92.56 |
| Net-L | 96.12 | 95.66 | 92.81 |
| Net-AS | 96.88 | 96.32 | 93.47 |
| Net-AL | 97.21 | 96.69 | 93.84 |
| MRFA-Net | 97.53 | 97.00 | 94.12 |
| Class Pixel Accuracy (%) | Overall Results (%) | |||||
|---|---|---|---|---|---|---|
| Model | Cloud | Shadow | Background | PA | MPA | MIoU |
| FCN | 96.87 | 94.11 | 97.12 | 96.42 | 96.03 | 90.69 |
| U-Net | 96.12 | 92.53 | 96.31 | 95.39 | 94.98 | 90.18 |
| SegNet | 94.16 | 91.32 | 95.21 | 94.47 | 93.56 | 87.91 |
| PSPNet | 96.95 | 94.52 | 97.79 | 97.61 | 96.42 | 93.37 |
| ShuffleNetv2 | 96.76 | 94.27 | 97.18 | 96.37 | 96.07 | 91.85 |
| Deeplabv3+ | 96.13 | 92.52 | 96.87 | 95.87 | 95.17 | 90.51 |
| DABNet | 97.12 | 94.85 | 97.32 | 97.31 | 96.43 | 93.59 |
| CCNet | 96.59 | 93.71 | 96.89 | 96.42 | 95.73 | 92.08 |
| CSAMNet | 96.87 | 94.52 | 97.73 | 97.10 | 96.37 | 93.13 |
| DBNet | 96.46 | 94.23 | 97.42 | 96.78 | 96.04 | 92.59 |
| MRFA-Net | 97.42 | 95.37 | 98.21 | 97.53 | 97.00 | 94.12 |
| Model | PA (%) | MPA (%) | MIoU |
|---|---|---|---|
| DenseASPP [41] | 91.21 | 89.71 | 82.86 |
| Enet [42] | 91.85 | 90.35 | 83.44 |
| BiSeNetV2 [43] | 91.75 | 90.36 | 83.19 |
| SegNet | 91.97 | 90.23 | 83.79 |
| PVT [44] | 91.37 | 91.15 | 84.85 |
| PSPNet | 92.30 | 90.69 | 84.52 |
| ACFNet [45] | 92.20 | 91.11 | 84.79 |
| OCRNet [46] | 92.78 | 91.56 | 85.21 |
| DFNet [47] | 92.67 | 92.14 | 86.22 |
| Deeplabv3+ | 93.49 | 92.23 | 86.92 |
| MRFA-Net | 94.09 | 93.72 | 87.54 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Li, Y.; Fan, X.; Zhou, X.; Wu, M. MRFA-Net: Multi-Scale Receptive Feature Aggregation Network for Cloud and Shadow Detection. Remote Sens. 2024, 16, 1456. https://doi.org/10.3390/rs16081456
Wang J, Li Y, Fan X, Zhou X, Wu M. MRFA-Net: Multi-Scale Receptive Feature Aggregation Network for Cloud and Shadow Detection. Remote Sensing. 2024; 16(8):1456. https://doi.org/10.3390/rs16081456
Chicago/Turabian StyleWang, Jianxiang, Yuanlu Li, Xiaoting Fan, Xin Zhou, and Mingxuan Wu. 2024. "MRFA-Net: Multi-Scale Receptive Feature Aggregation Network for Cloud and Shadow Detection" Remote Sensing 16, no. 8: 1456. https://doi.org/10.3390/rs16081456
APA StyleWang, J., Li, Y., Fan, X., Zhou, X., & Wu, M. (2024). MRFA-Net: Multi-Scale Receptive Feature Aggregation Network for Cloud and Shadow Detection. Remote Sensing, 16(8), 1456. https://doi.org/10.3390/rs16081456