1. Introduction
Over the past two decades, the environment has suffered extensive damages amounting to billions of dollars due to devastating wildfires. This destructive phenomenon stands out as among the most severe disasters, inflicting ecological harm and causing casualties among both forests and people [
1]. For instance, the 1983 wildfires in Victoria, Australia, resulted in the burning of 392,000 hectares of land and claimed the lives of 75 people [
2]. India experienced wildfires affecting 5.7 million hectares of land from 1985 to 1990, with 17,852 reported incidents [
3]. In Portugal in 2003, 20 people lost their lives, and 420,000 hectares were destroyed due to wildfires [
4]. Spain, in 2006, witnessed the devastation of nearly 150,000 hectares by wildfires [
5]. Canada faces an average of 8000 wildfires annually, consuming an average of 2.5 million hectares of land each year [
6]. A wildfire in the southeast of Australia in September 2019 burned 11.2 million hectares of forests, leading to the tragic deaths of numerous animals [
7]. As the frequency, duration, and intensity of wildfires increase with the impact of climate change, their destructive potential is expected to increase. To mitigate the impacts posed by wildfires on human lives and property, it is imperative to implement management strategies that mitigate these destructive impacts [
8].
Early detection and prediction of wildfires can significantly reduce the destructive impact of wildfires [
9]. It is essential to acknowledge, however, that complete prevention of wildfires in vegetated areas is not possible. Therefore, a crucial tool for accurately predicting the spread of wildfires across diverse geographies, climates, and fuel types is needed.
Researchers worldwide have actively engaged in wildfire research, recognizing the global significance of the issue. Modeling dynamic processes on the Earth’s surface entails a high degree of uncertainty, as the information is either initially known with some error or undergoes changes over time [
10].
Previous studies categorized wildfire spread models into three main types: stochastic, phenomenological, and physical [
11]. In a physical model, equations governing combustion, fluid dynamics, and heat transfer are solved to determine the spatio-temporal distribution of wildfires [
12,
13,
14]. Examples of physics-based models, such as Forbes [
15] and Wildland–Urban Interface Fire Dynamics Simulator (WFDS) [
16], incorporate fuel fundamentals, combustion, and energy transfer. Stochastic wildfire spread models utilize statistics from historical wildfires and prescribed burns. These models summarize wind speed, fuel type, and soil moisture using respective functional forms [
17]. Phenomenological wildfire spread models rely on experimental measurements rather than models based on first principles to develop functional forms [
18]. One of the widely used models for phenomenological time scales is Rothermel’s model [
19]. The abovementioned approaches demand extensive computations at various ignition locations, making it a time-consuming process. For instance, the computational time for a single fire spread simulation could reach 872,000 min (approximately 600 days) on a single processor [
20]. Therefore, new approaches are needed to decrease these computational costs.
Recently, the prediction of wildfire spread has witnessed significant improvements through the utilization of machine learning algorithms [
21,
22,
23,
24]. These algorithms use observed knowledge of previous wildfire patterns to predict future wildfire fronts [
11]. Illustratively, [
25] conducted a study to evaluate the efficacy of Random Forest (RF), Logistic Regression (LR), and convolutional autoencoder models in predicting wildfire spread. They used diverse environmental variables acquired through remote sensing technology in their analysis. The outcomes of their research indicated that the Convolutional Neural Network (CNN) model surpasses the others in terms of performance, showcasing a structural superiority that aligns well with the characteristics of the provided data. In a similar work, Marjani and Mesgari (2023) [
26] introduced a multi-kernel CNN model that integrated diverse data types such as topographical, meteorological, anthropological, fuel, and hydrological data to predict wildfire spread in the United States. Despite its comprehensive approach, the model faced performance challenges when dealing with large pixel-size data (1 km) in real-world scenarios. Furthermore, both studies did not consider the temporal aspect of wildfires. To cover these gaps, [
27] introduced a Convolutional Long Short-Term Memory (ConvLSTM) network to mitigate computational costs associated with predictions. However, their approach involved using simulated data rather than real burn maps as training data. Subsequently, the FirePred [
28] model was proposed using actual wildfire datasets, incorporating both spatial and temporal considerations using various temporal blocks in its architecture. Despite these improvements, a notable challenge arose in real-world scenarios where FirePred struggled to predict future burned maps due to its reliance on initial burn maps—a requirement that is not available during the early stages of a wildfire. The studies mentioned share a common limitation as they rely on an initial burn map from the previous time step to predict wildfire spread in the next steps. In real-world scenarios, the absence of this initial map poses a significant challenge. Therefore, there is a pressing need for additional research to explore innovative approaches that can effectively address this critical gap in existing methodologies.
To cover the mentioned limitations, this study introduces a novel approach by proposing a hybrid model, CNN and Bidirectional Long Short-Term Memory (BiLSTM) components, referred to as the CNN-BiLSTM model. This model addresses the challenges associated with spatial and temporal patterns in wildfire spread prediction, using Visible Infrared Imaging Radiometer Suite (VIIRS) active fire data as a near-real-time source for generating initial burn maps. The primary contributions of this study include (1) the development of the CNN-BiLSTM model designed for near-real-time wildfire spread prediction, (2) the integration of both spatial and temporal considerations into the wildfire spread prediction task through the fusion of CNN and BiLSTM modules, and (3) analysis of the influences of environmental parameters on the model predictions.
2. Materials and Methods
2.1. Study Area
The research is conducted in Laura, Queensland, Australia, a region known for its substantial rainforest expanses and diverse biological landscapes, featuring 226 national parks. The climate in this area is characterized by hot and humid summers, along with warm and dry winters. The region encounters recurring threats of droughts and bushfires. According to data from the Global Fire Emissions Database (GFED), this particular area experienced the second-longest recorded fire in history until 2016 [
29,
30]. The wildfire persisted for an extensive period, raging from 13 September 2015 to 12 December 2015, spanning a total of 91 days.
Figure 1 shows the extent of the study area.
2.2. Dataset
In this study, we employed the VIIRS dataset [
31] for the specified date. This dataset includes point shapefiles representing active fires on given dates, which are available for daily access. Meteorological data used in this study include precipitation, soil moisture, and runoff. These daily data were collected from the Australian Landscape Water Balance (ALWB) (
https://awo.bom.gov.au/products/ (accessed on 22 September 2021)) between 13 September 2015 and 12 December 2015. Moreover, the daily aggregated temperature was collected from the European Centre for Medium-Range Weather Forecasts (ECMWF) Reanalysis v5 (ERA-5) (
https://cds.climate.copernicus.eu/cdsapp#!/dataset/reanalysis-era5-land?tab=overview (accessed on 12 February 2024)) with the spatial resolution of
using the Google Earth Engine (GEE) platform. It is recognized that the intensity and spread of a wildfire can be mitigated by increased values of each of these variables. Additionally, the wind speed and direction data obtained from the nearest weather station to Laura were incorporated into the dataset (
https://mesonet.agron.iastate.edu/request/daily.phtml# (accessed on 22 September 2021)).
Land cover and vegetation characteristics are important elements in determining wildfire spread dynamics. Certain plant species are highly sensitive to wildfire, and areas devoid of vegetation are less prone to wildfire spread. To consider this information, we utilized the Normalized Difference Vegetation Index (NDVI) and land cover data. The 2015 land cover data, created by the European Space Agency (ESA) for long-term and consistent climate modeling, categorizes the study area into six classes: (1) tree cover—broadleaved, evergreen, closed to open (>15%); (2) tree cover—broadleaved, deciduous, closed to open (>15%); (3) tree cover—broadleaved, deciduous, open (15–40%); (4) mosaic tree and shrub (>50%) and herbaceous cover (<50%); (5) shrubland; and (6) deciduous shrubland.
NDVI data were obtained using the Terra Moderate Resolution Imaging Spectroradiometer (MODIS) sensor called MOD13Q1. These data are generated every 16 days as Level 3 products with a spatial resolution of 250 m (m). Furthermore, we considered earth surface characteristics that influence wildfire spread, including elevation, slope, and aspect. Elevation data were collected from the Shuttle Radar Topography Mission (SRTM) with a 30 m resolution. Slope and aspect data were derived from the elevation data using the Quantum Geographic Information System (QGIS) software (version 3.32.3) by calculating the angle of inclination to the horizontal.
Table 1 indicates an overview of datasets used in this study for wildfire spread prediction.
2.2.1. Data Preparation
The daily wildfire data, acquired from the sensor at a specific time, exhibits movement throughout the day rather than remaining static. As the sensor revisits the area the next day, any new fires are detected. Given the current limitations of sensor technology, which cannot provide temporal resolution finer than a day, a method is required to estimate the burned in a day. This challenge is addressed by employing a fixed radius and the density of points per day. The Global Fire Emissions Database (GFED) provides the average rate per day of fire spread in the area. Equation (1) calculates the constant value of the radius by considering time, which is 24 h.
In Equation (1), represents the average rate of wildfire spread, and is time. The radius obtained from Equation (1) is then utilized to calculate the density of points. Finally, we used a constant 95th percentile threshold value to extract the estimated burned area for each day from the density analysis output.
Land cover data are typically classified as categorical data, where each class is assigned a unique number. To eliminate the hierarchical nature of these numbers, one-hot encoding is applied. Given the six classes of land cover in the study area, a binary map is generated for each class, assigning a value of one where the desired class exists and zero otherwise.
Considering the limited temporal resolution of available data sources, NDVI is not available for all 91 days of the wildfire. To address this, interpolation is performed for days without NDVI. A procedure is applied where NDVI data over a 16-day time step are combined to calculate NDVI for the second day, using the previous day’s NDVI data (when available) except for pixels burned on that day. For these burned pixels, NDVI is obtained from the next available data. This process is repeated for days without NDVI data.
To collect wind direction and speed data, the two nearest weather stations to the study area are utilized. These stations report daily wind directions and speeds. The weighted average of the values reported by these stations is used to determine wind direction and speed for each pixel. The distance of each pixel from the weather stations is calculated, and the inverse distance is employed to weigh the speed and direction values of the stations. Equation (2) illustrates the wind speed calculation for each pixel, with a similar approach for wind direction.
In Equation (2), represents the wind speed in the i,j pixel, is the inverse distance between the i,j pixel and the first station, is the wind speed reported by the first station, is the inverse distance between the i,j pixel and the second station, and is the wind speed reported by the second station.
2.2.2. Data Resampling and Normalization
In this phase, two preprocessing steps are uniformly applied to all the data, given their diverse sources. Since the spatial resolution of the data varies due to its derivation from different sources, each of the predictor variables on each day was resampled to the spatial resolution of 150 m with the nearest neighbor technique [
32] to create a consistent daily 150 m resolution dataset. In terms of temporal resolution, GEE and ALWB provide aggregated daily products that are aligned with the requirements of this study.
Considering the extensive range of values in the dataset, potential computational complexity, and challenges in prediction [
1], normalization is essential to ensure that all variables carry equal weight. Min–max scaling [
33] is employed for this purpose, transforming the original variable ranges through a linear transformation. The min–max formula, depicted in Equation (3), quantifies this scaling process:
where Z represents the output variable,
denotes the variables, and min and max stand for the minimum and maximum values, respectively. This normalization ensures that each variable contributes equally to the analysis.
2.2.3. Patch Extraction
The burned area maps and environmental variables for the study area were collected with a daily temporal resolution. For each day, a data cube was created with dimensions of 250 × 400 × 17, where 250 and 400 represent the width and height, respectively, and 17 denotes the number of channels. Due to the substantial size of these data cubes, processing them in their entirety proved to be time-intensive. Consequently, each cube was subdivided into multiple patches along both the x and y dimensions, resulting in a new shape of 50 × 50 × 17. To maintain interaction between patches, a 50% overlap was applied in both the x and y directions during patch extraction (see
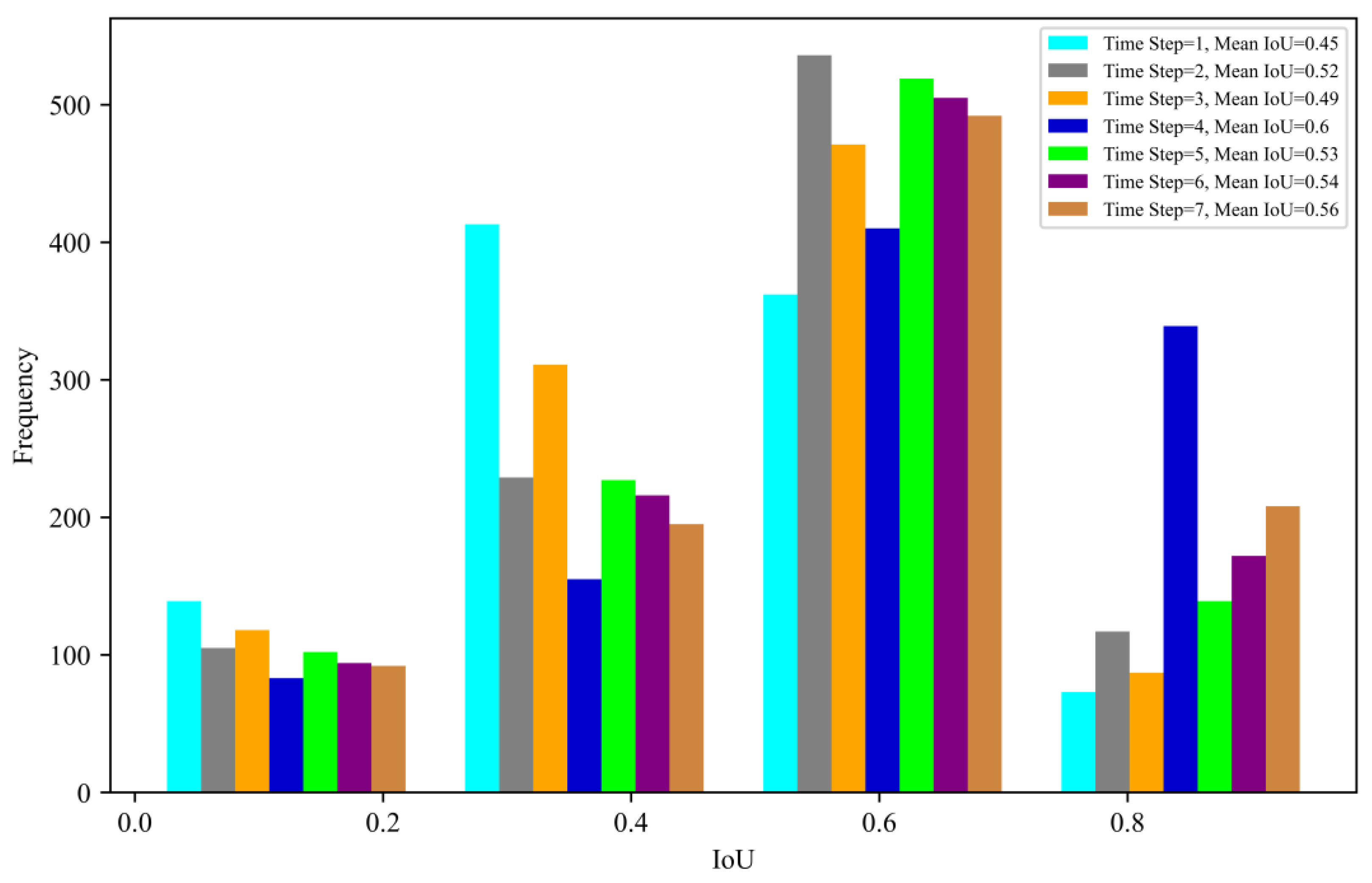
Figure 2C). Subsequently, to preserve the chronological order of the patches, the data were transformed into a tensor with a shape of 4 × 50 × 50 × 17. In this context, the time step represents the number of occurrences in each sample, with 4 designated as the time step value. Therefore, given a series of five tensors, the model will predict the next occurrence (fifth).
Figure 2 visually illustrates the process of patch extraction and the resulting data structure in this study. In total, 1650 patches were extracted using this approach for all 92 days. To prevent an imbalance in the dataset, only the patches containing at least one active fire pixel (within label data) were chosen. Subsequently, this set was partitioned into two new sets, with a validation set accounting for 20% of the samples and a training set including the remaining 80% of samples.
2.3. Time Distributed CNN (TD-CNN)
Recurrent Neural Networks (RNNs) are well-suited for solving time series tasks, while CNNs are effective for extracting features from complex datasets [
34]. The main focus of CNNs is to identify spatial features in a single input image. However, certain tasks, such as predicting video processing, involve multiple images presented chronologically to identify movements and directions. To address this, the TD-CNN approach was employed.
The input for TD-CNN is a 5D tensor consisting of samples, time steps, width, height, and channels. The fundamental concept behind TD-CNNs is to apply a standard CNN architecture independently to each time step of the input sequence. This means that the same set of convolutional filters and pooling operations are applied to each time step, enabling the network to capture both spatial and temporal patterns.
Figure 3 illustrates the process of the TD-CNN approach.
2.4. Dilated CNN (DCNN)
The wildfire spread prediction is similar to the image segmentation task. The concept of an image pyramid was introduced to enhance segmentation precision [
35]. In this pyramid-based approach, features are extracted from various scales, and subsequently, they are interpolated and merged. However, extracting features separately for each scale can increase the network’s size and potentially lead to overfitting [
36]. To overcome these limitations, the DCNNs were introduced. This approach inserts holes between pixels with a rate called the dilation rate (DR). By adjusting the DR of an atrous convolutional kernel, varying receptive fields can be achieved. This mechanism can address the diverse shapes and sizes of wildfires, especially those of different sizes.
2.5. Bidirectional LSTM (BiLSTM)
LSTM, known for its efficacy in capturing long-term temporal dependencies [
37], comprises two fundamental components: a memory cell capable of preserving its state over time and gating units that regulate the flow of information. The LSTM architecture includes three gates within its elemental cell structure: input, output, and forget. For a given time series
where
∈
, the LSTM unit updates according to the following formal expressions:
Here, , , and denote the input gate, output gate, and forget gate, respectively. represents the hidden state at time t with size q over the entire hidden state. The weight matrices , , , ∈ , and biases , , , ∈ are integral components. The sigmoid function, denoted by , and × representing the element-wise multiplication operator, contribute to the formal expressions.
BiLSTM is an extension of the traditional LSTM architecture that enhances the model’s ability to capture temporal dependencies by processing input sequences in both forward and backward directions [
38]. In a standard LSTM, information flows only in one direction, from past to future. However, BiLSTM introduces a bidirectional approach, allowing the model to consider past and future contexts simultaneously.
In a BiLSTM, the network is split into two components: one processes the input sequence in the forward direction, while the other processes it in the backward direction. Each component has its own set of memory cells and gates. The forward and backward hidden states at each time step are then concatenated or combined to provide a more comprehensive understanding of the input sequence.
2.6. CNN-BiLSTM Architecture
The proposed CNN-BiLSTM model, illustrated in
Figure 4, processes a tensor input with dimensions 50 × 50 × 17 for each time step. The model uses two convolution layers with filter sizes of 64 and 128, followed by a DCNN module with DRs of 1, 3, 6, 12, and 18, all using a consistent filter size of 64. Extracted features are concatenated along the channel axis, followed by a pair of CNN and max-pooling operations with filter sizes of 16 and 32 and kernel sizes of 1 and 3, respectively. Next, the batch normalization layer normalizes the extracted features, which are then flattened in preparation for three BiLSTM layers with 16, 32, and 64 neurons. The output from the last BiLSTM layer is processed through a dense layer with 32 neurons, followed by a final dense layer with 2500 neurons and a sigmoid activation function, determining the burn probability for each pixel in the next time step. A reshape layer transforms the output vector into a 2D map with the shape of 50 × 50 × 1. The rectified linear unit (ReLU) activation function is used in the CNN and dense layers, except for the last dense layer, which employs a sigmoid activation function. In this study, an experimental threshold value was employed for post-processing to convert probability values to a binary value.
2.7. Validation Metrics
Evaluation of a wildfire spread model involves the application of various statistical metrics. Precision, recall, F1-score, and Intersection over Union (IoU) were employed in this study for validation analysis and comprehensive model evaluation (Equations (10)–(13)).
Figure 5 provides a visual representation of True Positive (TP), False Negative (FN), False Positive (FP), and True Negative (TN). Beyond the mathematical formulation of these evaluation metrics,
Figure 6 offers a visual depiction of the fundamental definitions of precision and recall. In this study, the Binary Cross-Entropy (BCE) was employed as the loss function, chosen for its superior performance compared to other loss functions in previous studies [
28].
5. Conclusions
This study introduces the CNN-BiLSTM model as a novel approach for near-real-time daily wildfire spread prediction, addressing the increasing threat of wildfires and the limitations of existing models. The CNN-BiLSTM model was trained using different environmental variables, including topography, land cover, temperature, NDVI, wind data, precipitation, soil moisture, and runoff. These variables and VIIRIS active fire data were prepared for the wildfire spread prediction. Then, the proposed CNN-BiLSTM model was trained using different configurations and settings.
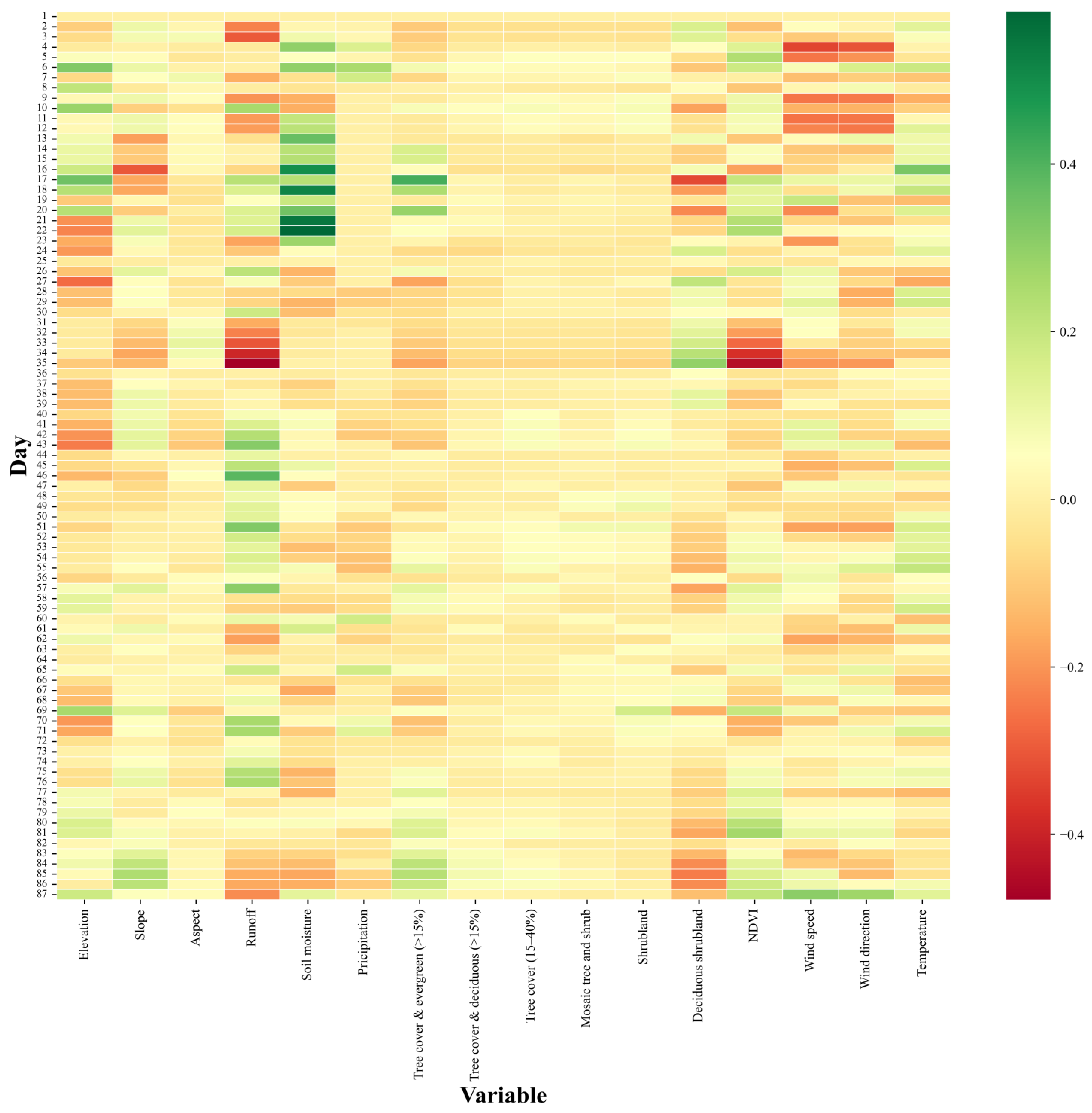
Through extensive experimentation and comparison with other state-of-the-art architectures, the CNN-BiLSTM model demonstrates superior predictive capabilities, showcasing its potential as an effective approach in the field of wildfire spread prediction. The results highlighted the importance of model configuration, such as the impact of threshold values and time steps on the model performance. Optimal configurations, determined through evaluation and experimentation, contribute significantly to the model’s accuracy in predicting wildfire spread. Furthermore, the study investigated the correlation analysis between the CNN-BiLSTM model predictions and environmental variables, with notable findings regarding the positive correlation of soil moisture with wildfire spread. The next step of this study involves the implementation of advanced deep-learning methodologies, including the incorporation of attention mechanisms. Additionally, to enhance the model’s ability to adapt to diverse scenarios, an augmentation of historical wildfire data will be conducted to train the deep learning model.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}