Author Contributions
Conceptualization, S.L.; methodology, S.L.; software, S.L.; validation, S.L. and N.L.; formal analysis, S.L.; investigation, S.L.; resources, S.L. and M.J.; data curation, S.L.; writing— original draft preparation, S.L.; writing—review and editing, C.J.; visualization, S.L. and N.L.; supervision, C.J.; project administration, L.C.; funding acquisition, L.C. All authors have read and agreed to the published version of the manuscript.
Figure 1.
A remote sensing scene classification model trained on a closed dataset tends to encounter challenges when faced with unknown categories in open-world scenarios. In such cases, the model often categorizes them as known ones.
Figure 1.
A remote sensing scene classification model trained on a closed dataset tends to encounter challenges when faced with unknown categories in open-world scenarios. In such cases, the model often categorizes them as known ones.
Figure 2.
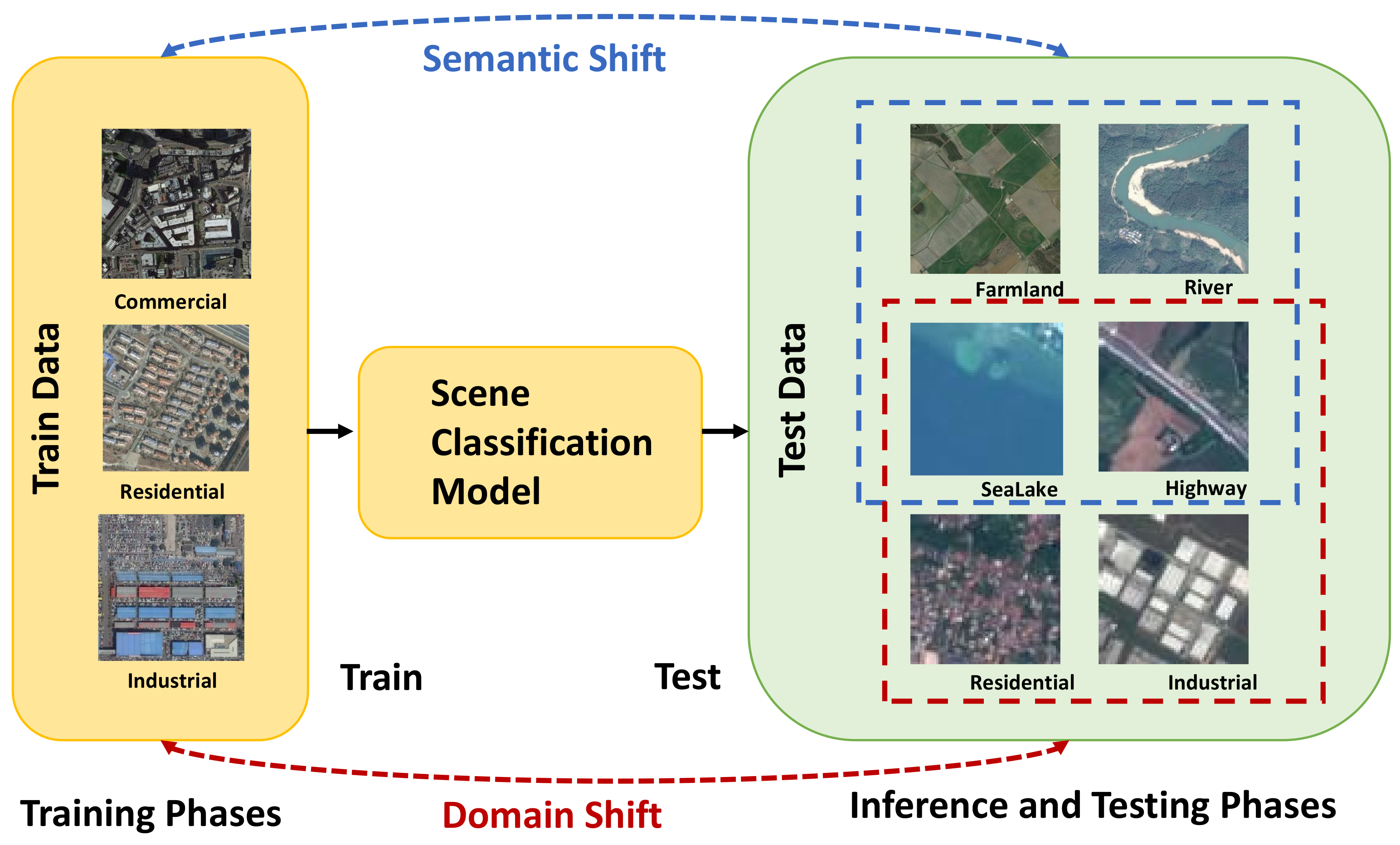
When deploying a remote sensing scene classification model in the real world, challenges arise during inference and testing. These challenges include images with land cover categories not found in the training dataset (referred to as semantic shift) or images with the same categories but differing sensor differences and geographical disparities (referred to as domain shift). Models often tend to classify such images as known categories.
Figure 2.
When deploying a remote sensing scene classification model in the real world, challenges arise during inference and testing. These challenges include images with land cover categories not found in the training dataset (referred to as semantic shift) or images with the same categories but differing sensor differences and geographical disparities (referred to as domain shift). Models often tend to classify such images as known categories.
Figure 3.
Conception of One-Class Classification, Open Set Recognition, Out-of-Distribution Detection and Outlier Detection.
Figure 3.
Conception of One-Class Classification, Open Set Recognition, Out-of-Distribution Detection and Outlier Detection.
Figure 4.
Classes and corresponding examples for the EuroSAT dataset, the UCM dataset, and the AID dataset. For the EuroSAT dataset, only images consisting of the three bands red, green, and blue are shown.
Figure 4.
Classes and corresponding examples for the EuroSAT dataset, the UCM dataset, and the AID dataset. For the EuroSAT dataset, only images consisting of the three bands red, green, and blue are shown.
Figure 5.
We established nine OSR benchmarks and nine OOD benchmarks on the UCM, AID, and EuroSAT datasets. Among them, OSR benchmarks only detect semantic shifts, while OOD benchmarks further detect domain shifts.
Figure 5.
We established nine OSR benchmarks and nine OOD benchmarks on the UCM, AID, and EuroSAT datasets. Among them, OSR benchmarks only detect semantic shifts, while OOD benchmarks further detect domain shifts.
Figure 6.
Performance against OSR Benchmark.
Figure 6.
Performance against OSR Benchmark.
Figure 7.
Performance against OOD benchmark.
Figure 7.
Performance against OOD benchmark.
Table 1.
List of different types of OOD detection methods for remote sensing scene classification tasks.
Table 1.
List of different types of OOD detection methods for remote sensing scene classification tasks.
| | Methodology | Reference |
| OOD detection methods | post hoc | MSP | [17] |
| VIM | [41] |
| KNN | [42] |
| training-time regularization | ConfBranch | [43] |
| LogitNorm | [44] |
| G-ODIN | [45] |
| training with outlier exposure | OE | [28] |
| MCD | [27] |
| model uncertainty | MCDropout | [46] |
| Tempscaling | [47] |
Table 2.
Summary of recent representative model architectures.
Table 2.
Summary of recent representative model architectures.
| Model | Year | Layers | Parameters | FLOPS | Reference |
|---|
| AlexNet | 2012 | 8 | ∼ | 0.72 G | [12] |
| VGG16 | 2014 | 16 | ∼ | 15.47 G | [54] |
| ResNet50 | 2015 | 50 | ∼ | 4.09 G | [53] |
| ResNet152 | 2015 | 152 | ∼ | 11.52 G | [53] |
| DenseNet161 | 2017 | 161 | ∼ | 7.73 G | [55] |
| EfficientNet B0 | 2019 | 237 | ∼ | 0.39 G | [56] |
| Vision Transformer | 2020 | 12 | ∼ | 17.57 G | [57] |
| MLPMixer | 2021 | 12 | ∼ | 12.61 G | [58] |
| ConvNeXt | 2022 | 174 | ∼ | 4.46 G | [59] |
| Swin Transformer | 2022 | 24 | ∼ | 11.55 G | [60] |
Table 3.
The 30 classes in AID, the 21 classes in UCM, and the 10 classes in EuroSAT were divided into closed-set and open-set classes according to defined proportions in various benchmarks. Five randomizations were conducted for AID, UCM, and EuroSAT during the evaluation. Here, we present an example of one random partition.
Table 3.
The 30 classes in AID, the 21 classes in UCM, and the 10 classes in EuroSAT were divided into closed-set and open-set classes according to defined proportions in various benchmarks. Five randomizations were conducted for AID, UCM, and EuroSAT during the evaluation. Here, we present an example of one random partition.
| Benchmark | Closed-Set Classes (ID) | Open-Set Classes (OOD) |
|---|
| UCM-7/3 | agricultural airplane baseballdiamond buildings chaparral denseresidential forest freeway golfcourse mobilehomepark overpass parkinglot river sparseresidential tenniscourt | beach harbor intersection mediumresidential runway storagetanks |
| UCM-6/4 | agricultural baseballdiamond beach buildings chaparral forest freeway golfcourse intersection mediumresidential overpass sparseresidential storagetanks | airplane denseresidential harbor mobilehomepark parkinglot river runway tenniscourt |
| UCM-5/5 | agricultural buildings chaparral golfcourse harbor intersection mobilehomepark parkinglot river runway storagetanks | airplane baseballdiamond beach denseresidential forest freeway mediumresidential overpass sparseresidential tenniscourt |
| AID-7/3 | airport baseballfield bareland beach bridge denseresidential desert forest mediumresidential park parking playground pond port railwaystation river school square stadium storagetanks viaduct | center church commercial farmland industrial meadow mountain resort sparseresidentia |
| AID-6/4 | baseballfield bareland bridge center desert denseresidential farmland industrial mediumresidential mountain parking port resort railwaystation school sparseresidential stadium storagetanks | airport beach church commercial forest meadow park playground pond river square viaduct |
| AID-5/5 | baseballfield beach center church desert farmland industrial mediumresidential mountain park parking pond port stadium viaduct | airport bareland bridge commercial denseresidential forest meadow playground
railwaystation resort river school sparseresidential square storagetanks |
| EuroSAT-7/3 | AnnualCrop Industrial Pasture PermanentCrop Residential River SeaLake | HerbaceousVegetation Highway Industrial |
| EuroSAT-6/4 | AnnualCrop HerbaceousVegetation Industrial Residential River SeaLake | Forest Highway Pasture PermanentCrop |
| EuroSAT-5/5 | AnnualCrop Forest Highway Residential River | HerbaceousVegetation Industrial Pasture PermanentCrop SeaLake |
Table 4.
Specific Categorization of Simi-OOD and Near-OOD Classes Across UCM, AID, and EuroSAT.
Table 4.
Specific Categorization of Simi-OOD and Near-OOD Classes Across UCM, AID, and EuroSAT.
| ID Dataset | OOD Dataset | Simi-OOD Classes | Near-OOD Classes |
|---|
| UCM | RSI-CB256 | sea desert snow-mountain mangrove sparse-forest bare-land hirst sandbeach sapling artificial-grassland shrubwood mountain dam pipeline river-protection-forest container stream avenue lakeshore bridge | airport-runway residents marina crossroads green-farmland town parkinglot river forest coastline airplane dry-farm storage-room city-building highway |
| AID | NWPU-RESISC45 | snowberg wetland intersection runway island cloud basketball-court lake golf-course sea-ice roundabout mobile-home-park freeway terrace airplane thermal-power-station ship circular-farmland railway chaparral | parking-lot desert airport tennis-court church mountain medium-residential sparse-residential commercial-area river palace forest dense-residential storage-tank ground-track-field stadium railway-station meadow baseball-diamond overpass harbor industrial-area bridge beach rectangular-farmland |
| EuroSAT | RSI-CB128 | sea sparse-forest residents green-farmland river natural-grassland forest dry-farm city-building highway | turning-circle fork-road desert snow-mountain mangrove airport-runway bare-land hirst sandbeach marina crossroads sapling artificial-grassland shrubwood mountain town dam parkinglot rail city-avenue coastline tower city-green-tree mountain-road pipeline river-protection-forest container stream grave avenue storage-room overpass lakeshore city-road bridge |
Table 5.
Results from nine OSR benchmarks summarized by the top three average AUROC scores (percentage) calculated over seven runs and five random category splits. Bold highlights indicate the top three averages per benchmark.
Table 5.
Results from nine OSR benchmarks summarized by the top three average AUROC scores (percentage) calculated over seven runs and five random category splits. Bold highlights indicate the top three averages per benchmark.
| Benchmark | | Post Hoc | Training-Time Regularization | Outlier Exposure | Model Uncertainty |
|---|
| MSP | VIM | KNN | ConfBranch | LogiNorm | G-ODIN | OE | MCD | MCDropout | Tempscaling |
|---|
| UCM | 7/3 | 94.53 | 95.01 | 94.78 | 58.61 | 94.48 | 70.92 | 93.43 | 83.86 | 94.69 | 94.16 |
| 6/4 | 94.84 | 93.85 | 94.15 | 52.31 | 92.25 | 67.85 | 91.78 | 81.95 | 92.67 | 93.18 |
| 5/5 | 93.59 | 92.61 | 93.25 | 50.48 | 90.15 | 65.67 | 90.66 | 80.75 | 92.21 | 91.51 |
| AID | 7/3 | 94.80 | 95.26 | 95.62 | 75.18 | 93.21 | 80.84 | 92.54 | 88.42 | 93.96 | 94.30 |
| 6/4 | 93.51 | 95.28 | 95.76 | 67.22 | 93.72 | 80.50 | 92.78 | 88.97 | 93.88 | 93.59 |
| 5/5 | 91.70 | 94.03 | 94.74 | 59.07 | 92.79 | 79.45 | 92.29 | 88.43 | 93.54 | 92.93 |
| EuroSAT | 7/3 | 94.04 | 94.54 | 92.81 | 73.63 | 96.60 | 83.37 | 94.24 | 91.78 | 92.75 | 94.27 |
| 6/4 | 91.40 | 94.95 | 90.53 | 73.44 | 96.23 | 78.60 | 91.55 | 90.77 | 90.61 | 91.90 |
| 5/5 | 90.25 | 94.56 | 89.65 | 72.98 | 94.38 | 72.87 | 89.49 | 89.66 | 88.46 | 90.96 |
Table 6.
Results from nine OSR benchmarks summarized by the top three average FPR@95 scores (percentage) calculated over seven runs and five random category splits. Bold highlights indicate the top three averages per benchmark.
Table 6.
Results from nine OSR benchmarks summarized by the top three average FPR@95 scores (percentage) calculated over seven runs and five random category splits. Bold highlights indicate the top three averages per benchmark.
| Benchmark | | Post Hoc | Training-Time Regularization | Outlier Exposure | Model Uncertainty |
|---|
|
MSP
|
VIM
|
KNN
|
ConfBranch
|
LogitNorm
|
G-ODIN
|
OE
|
MCD
|
MCDropout
|
Tempscaling
|
|---|
| UCM | 7/3 | 26.33 | 22.15 | 17.33 | 88.00 | 21.00 | 75.67 | 36.67 | 72.33 | 22.67 | 25.33 |
| 6/4 | 32.31 | 23.46 | 25.38 | 89.62 | 28.46 | 72.31 | 41.54 | 75.38 | 41.92 | 29.62 |
| 5/5 | 35.82 | 28.18 | 31.55 | 87.73 | 32.95 | 73.18 | 45.00 | 79.55 | 58.64 | 34.27 |
| AID | 7/3 | 22.20 | 17.58 | 19.07 | 70.52 | 20.44 | 56.89 | 22.70 | 36.00 | 27.92 | 24.30 |
| 6/4 | 24.34 | 22.83 | 23.93 | 87.24 | 23.42 | 60.14 | 24.05 | 33.59 | 25.95 | 23.97 |
| 5/5 | 28.34 | 25.63 | 27.12 | 91.85 | 27.65 | 66.60 | 27.96 | 42.69 | 28.95 | 23.02 |
| EuroSAT | 7/3 | 39.57 | 23.86 | 33.73 | 80.51 | 18.63 | 69.49 | 35.32 | 36.27 | 36.78 | 55.63 |
| 6/4 | 47.74 | 23.47 | 53.44 | 79.91 | 20.91 | 75.76 | 49.53 | 40.26 | 36.15 | 57.59 |
| 5/5 | 53.79 | 22.43 | 78.00 | 83.54 | 26.93 | 80.57 | 67.39 | 61.04 | 46.43 | 61.24 |
Table 7.
Results from nine OSR benchmarks summarized by the top three average AURP-IN scores (percentage) calculated over seven runs and five random category splits. Bold highlights indicate the top three averages per benchmark.
Table 7.
Results from nine OSR benchmarks summarized by the top three average AURP-IN scores (percentage) calculated over seven runs and five random category splits. Bold highlights indicate the top three averages per benchmark.
| Benchmark | | Post Hoc | Training-Time Regularization | Outlier Exposure | Model Uncertainty |
|---|
|
MSP
|
VIM
|
KNN
|
ConfBranch
|
LogitNorm
|
G-ODIN
|
OE
|
MCD
|
MCDropout
|
Tempscaling
|
|---|
| UCM | 7/3 | 85.62 | 90.23 | 89.61 | 36.27 | 85.95 | 47.19 | 91.81 | 68.33 | 87.00 | 85.75 |
| 6/4 | 88.20 | 92.51 | 91.14 | 35.96 | 87.01 | 55.95 | 96.97 | 71.52 | 89.47 | 90.35 |
| 5/5 | 89.88 | 94.65 | 92.89 | 48.28 | 85.84 | 64.18 | 97.14 | 76.46 | 92.09 | 93.90 |
| AID | 7/3 | 86.91 | 90.90 | 92.46 | 44.47 | 87.29 | 63.03 | 87.91 | 77.78 | 88.78 | 86.98 |
| 6/4 | 90.09 | 94.44 | 94.04 | 38.67 | 90.62 | 68.71 | 89.22 | 80.97 | 91.92 | 90.25 |
| 5/5 | 93.68 | 94.13 | 94.72 | 58.60 | 93.31 | 71.54 | 92.11 | 84.45 | 93.55 | 94.63 |
| EuroSAT | 7/3 | 81.03 | 85.80 | 86.77 | 57.06 | 88.37 | 54.39 | 78.98 | 75.54 | 77.33 | 82.13 |
| 6/4 | 88.20 | 88.92 | 87.31 | 65.75 | 92.87 | 69.26 | 86.07 | 81.82 | 84.39 | 87.57 |
| 5/5 | 94.01 | 93.56 | 89.95 | 72.54 | 92.24 | 78.51 | 93.98 | 90.59 | 90.99 | 93.74 |
Table 8.
Results from nine OSR benchmarks summarized by the top three average AURP-OUT scores (percentage) calculated over seven runs and five random category splits. Bold highlights indicate the top three averages per benchmark.
Table 8.
Results from nine OSR benchmarks summarized by the top three average AURP-OUT scores (percentage) calculated over seven runs and five random category splits. Bold highlights indicate the top three averages per benchmark.
| Benchmark | | Post Hoc | Training-Time Regularization | Outlier Exposure | Model Uncertainty |
|---|
|
MSP
|
VIM
|
KNN
|
ConfBranch
|
LogitNorm
|
G-ODIN
|
OE
|
MCD
|
MCDropout
|
Tempscaling
|
|---|
| UCM | 7/3 | 97.72 | 96.80 | 98.09 | 76.77 | 97.67 | 85.40 | 97.10 | 89.70 | 97.72 | 97.54 |
| 6/4 | 94.64 | 95.91 | 96.37 | 67.40 | 94.17 | 74.69 | 95.84 | 86.45 | 94.52 | 94.44 |
| 5/5 | 90.31 | 93.54 | 94.70 | 57.14 | 90.77 | 68.95 | 91.54 | 81.83 | 90.57 | 91.30 |
| AID | 7/3 | 96.90 | 97.18 | 97.51 | 76.81 | 96.97 | 91.83 | 97.23 | 95.12 | 96.92 | 97.04 |
| 6/4 | 94.70 | 96.49 | 95.26 | 69.28 | 94.75 | 85.55 | 95.05 | 92.73 | 94.63 | 94.68 |
| 5/5 | 94.89 | 94.72 | 94.58 | 60.37 | 94.07 | 78.22 | 93.65 | 90.10 | 92.94 | 95.19 |
| EuroSAT | 7/3 | 93.95 | 97.44 | 96.43 | 83.25 | 97.68 | 84.46 | 94.48 | 91.68 | 95.69 | 94.02 |
| 6/4 | 93.97 | 95.77 | 93.26 | 80.07 | 94.67 | 82.32 | 94.41 | 91.06 | 92.66 | 94.64 |
| 5/5 | 94.36 | 94.53 | 91.76 | 75.12 | 92.41 | 81.14 | 94.88 | 91.82 | 93.47 | 93.96 |
Table 9.
Results from nine OSR benchmarks summarized by the top three average ID-ACC scores (percentage) calculated over seven runs and five random category splits. Bold highlights indicate the top three averages per benchmark.
Table 9.
Results from nine OSR benchmarks summarized by the top three average ID-ACC scores (percentage) calculated over seven runs and five random category splits. Bold highlights indicate the top three averages per benchmark.
| Benchmark | | Post Hoc | Training-Time Regularization | Outlier Exposure | Model Uncertainty |
|---|
|
MSP
|
VIM
|
KNN
|
ConfBranch
|
LogitNorm
|
G-ODIN
|
OE
|
MCD
|
MCDropout
|
Tempscaling
|
|---|
| UCM | 7/3 | 98.67 | 98.67 | 98.67 | 99.00 | 99.00 | 83.00 | 98.00 | 92.00 | 98.67 | 99.00 |
| 6/4 | 99.23 | 99.23 | 99.23 | 98.46 | 98.46 | 81.15 | 98.46 | 92.31 | 99.23 | 98.85 |
| 5/5 | 99.55 | 99.55 | 99.55 | 98.64 | 98.64 | 82.27 | 97.73 | 89.09 | 99.09 | 98.64 |
| AID | 7/3 | 97.08 | 97.08 | 97.08 | 96.80 | 96.24 | 86.21 | 96.10 | 91.57 | 96.52 | 97.14 |
| 6/4 | 97.25 | 97.25 | 97.25 | 97.08 | 97.25 | 84.88 | 95.96 | 93.30 | 96.39 | 96.99 |
| 5/5 | 98.81 | 98.81 | 98.81 | 99.11 | 98.91 | 89.53 | 98.42 | 95.45 | 98.91 | 99.01 |
| EuroSAT | 7/3 | 98.84 | 98.84 | 98.84 | 98.95 | 98.70 | 95.68 | 98.51 | 97.51 | 97.22 | 98.92 |
| 6/4 | 99.62 | 99.62 | 99.62 | 99.62 | 99.41 | 96.56 | 99.03 | 98.03 | 96.65 | 99.56 |
| 5/5 | 99.54 | 99.54 | 99.54 | 99.43 | 99.46 | 95.82 | 99.25 | 98.71 | 99.32 | 99.50 |
Table 10.
Results from nine OSR benchmarks summarized by the top three average computation time (seconds) calculated over seven runs and five random category splits. Bold highlights indicate the top three averages per benchmark.
Table 10.
Results from nine OSR benchmarks summarized by the top three average computation time (seconds) calculated over seven runs and five random category splits. Bold highlights indicate the top three averages per benchmark.
| Benchmark | | Post Hoc | Training-Time Regularization | Outlier Exposure | Model Uncertainty |
|---|
|
MSP
|
VIM
|
KNN
|
ConfBranch
|
LogitNorm
|
G-ODIN
|
OE
|
MCD
|
MCDropout
|
Tempscaling
|
|---|
| UCM | Avg. | 4 | 4 | 4 | 668 | 744 | 638 | 2930 | 1572 | 736 | 5 |
| AID | Avg. | 10 | 10 | 10 | 2570 | 2682 | 2397 | 10205 | 7370 | 2644 | 12 |
| EuroSAT | Avg. | 5 | 5 | 5 | 698 | 810 | 732 | 4832 | 5699 | 4021 | 6 |
Table 11.
Results from nine OOD benchmarks summarized by the top three average AUROC scores (percentage) calculated over seven runs. Bold highlights indicate the top three averages per benchmark.
Table 11.
Results from nine OOD benchmarks summarized by the top three average AUROC scores (percentage) calculated over seven runs. Bold highlights indicate the top three averages per benchmark.
| Benchmark | | Post Hoc | Training-Time Regularization | Outlier Exposure | Model Uncertainty |
|---|
|
MSP
|
VIM
|
KNN
|
ConfBranch
|
LogitNorm
|
G-ODIN
|
OE
|
MCD
|
MCDropout
|
Tempscaling
|
|---|
| UCM | Semi-OOD | 79.46 | 85.43 | 45.41 | 66.07 | 79.70 | 66.13 | 77.43 | 68.03 | 79.46 | 78.93 |
| Near-OOD | 89.68 | 87.11 | 66.92 | 83.27 | 89.96 | 67.10 | 93.07 | 83.69 | 88.13 | 88.80 |
| Far-OOD | 97.03 | 99.54 | 14.72 | 54.75 | 97.14 | 78.02 | 98.48 | 76.07 | 97.98 | 97.22 |
| AID | Semi-OOD | 78.60 | 82.68 | 37.73 | 52.28 | 78.76 | 66.98 | 76.64 | 70.63 | 75.50 | 78.95 |
| Near-OOD | 91.66 | 96.08 | 30.81 | 55.04 | 92.05 | 77.01 | 88.47 | 85.22 | 91.10 | 91.90 |
| Far-OOD | 95.88 | 99.64 | 26.36 | 54.85 | 96.58 | 82.10 | 91.35 | 91.25 | 96.60 | 95.72 |
| EuroSAT | Semi-OOD | 93.43 | 98.54 | 96.40 | 86.89 | 93.98 | 90.73 | 99.55 | 91.84 | 84.60 | 92.79 |
| Near-OOD | 89.12 | 97.70 | 95.37 | 85.24 | 89.39 | 87.44 | 98.84 | 94.95 | 71.20 | 90.72 |
| Far-OOD | 95.59 | 99.95 | 99.35 | 65.29 | 96.06 | 95.52 | 99.98 | 97.26 | 44.76 | 82.26 |
Table 12.
Results from nine OOD benchmarks summarized by the top three average FPR@95 scores (percentage) calculated over seven runs. Bold highlights indicate the top three averages per benchmark.
Table 12.
Results from nine OOD benchmarks summarized by the top three average FPR@95 scores (percentage) calculated over seven runs. Bold highlights indicate the top three averages per benchmark.
| Benchmark | | Post Hoc | Training-Time Regularization | Outlier Exposure | Model Uncertainty |
|---|
|
MSP
|
VIM
|
KNN
|
ConfBranch
|
LogitNorm
|
G-ODIN
|
OE
|
MCD
|
MCDropout
|
Tempscaling
|
|---|
| UCM | Semi-OOD | 76.90 | 59.29 | 98.33 | 89.05 | 75.95 | 82.62 | 100.00 | 88.10 | 72.38 | 76.90 |
| Near-OOD | 36.19 | 57.86 | 95.24 | 54.76 | 35.00 | 80.71 | 24.52 | 53.10 | 43.33 | 40.95 |
| Far-OOD | 12.06 | 1.98 | 100.00 | 85.87 | 11.03 | 68.17 | 6.27 | 96.83 | 9.37 | 10.95 |
| AID | Semi-OOD | 75.70 | 59.20 | 98.80 | 93.60 | 75.65 | 86.30 | 81.70 | 88.20 | 78.55 | 76.55 |
| Near-OOD | 31.50 | 16.35 | 98.85 | 90.60 | 31.90 | 65.95 | 51.90 | 52.85 | 38.35 | 30.30 |
| Far-OOD | 14.78 | 1.48 | 96.22 | 87.15 | 13.30 | 57.47 | 35.23 | 32.30 | 14.72 | 15.52 |
| EuroSAT | Semi-OOD | 24.48 | 6.39 | 16.31 | 51.20 | 22.31 | 30.91 | 3.07 | 33.07 | 100.00 | 34.48 |
| Near-OOD | 100.00 | 12.19 | 23.74 | 61.78 | 100.00 | 56.15 | 6.37 | 17.43 | 100.00 | 100.00 |
| Far-OOD | 15.34 | 0.14 | 3.70 | 81.74 | 13.75 | 18.25 | 1.06 | 8.28 | 100.00 | 52.31 |
Table 13.
Results from nine OOD benchmarks summarized by the top three average AUPR-IN scores (percentage) calculated over seven runs. Bold highlights indicate the top three averages per benchmark.
Table 13.
Results from nine OOD benchmarks summarized by the top three average AUPR-IN scores (percentage) calculated over seven runs. Bold highlights indicate the top three averages per benchmark.
| Benchmark | | Post Hoc | Training-Time Regularization | Outlier Exposure | Model Uncertainty |
|---|
|
MSP
|
VIM
|
KNN
|
ConfBranch
|
LogitNorm
|
G-ODIN
|
OE
|
MCD
|
MCDropout
|
Tempscaling
|
|---|
| UCM | Semi-OOD | 98.85 | 99.18 | 96.10 | 97.77 | 98.86 | 97.75 | 98.80 | 97.94 | 98.87 | 98.83 |
| Near-OOD | 99.61 | 99.53 | 98.52 | 99.33 | 99.62 | 98.45 | 99.73 | 99.32 | 99.56 | 99.58 |
| Far-OOD | 99.67 | 99.98 | 85.68 | 91.82 | 99.68 | 96.86 | 99.86 | 97.44 | 99.79 | 99.70 |
| AID | Semi-OOD | 96.56 | 97.17 | 86.78 | 90.85 | 96.65 | 94.18 | 96.28 | 94.88 | 96.14 | 96.66 |
| Near-OOD | 98.37 | 99.29 | 80.06 | 88.46 | 98.51 | 95.04 | 97.82 | 97.02 | 98.40 | 98.48 |
| Far-OOD | 97.90 | 99.91 | 68.70 | 77.29 | 98.29 | 91.47 | 96.28 | 95.69 | 98.49 | 97.92 |
| EuroSAT | Semi-OOD | 95.79 | 99.15 | 98.05 | 91.52 | 96.16 | 93.32 | 99.78 | 94.80 | 90.30 | 95.68 |
| Near-OOD | 96.86 | 99.36 | 98.67 | 95.25 | 96.94 | 95.63 | 98.71 | 98.14 | 90.72 | 97.25 |
| Far-OOD | 98.59 | 99.99 | 99.86 | 88.94 | 98.74 | 98.30 | 98.89 | 98.86 | 65.43 | 96.77 |
Table 14.
Results from nine OOD benchmarks summarized by the top three average AUPR-OUT scores (percentage) calculated over seven runs. Bold highlights indicate the top three averages per benchmark.
Table 14.
Results from nine OOD benchmarks summarized by the top three average AUPR-OUT scores (percentage) calculated over seven runs. Bold highlights indicate the top three averages per benchmark.
| Benchmark | | Post Hoc | Training-Time Regularization | Outlier Exposure | Model Uncertainty |
|---|
|
MSP
|
VIM
|
KNN
|
ConfBranch
|
LogitNorm
|
G-ODIN
|
OE
|
MCD
|
MCDropout
|
Tempscaling
|
|---|
| UCM | Semi-OOD | 11.92 | 31.86 | 3.33 | 6.86 | 12.23 | 9.89 | 15.55 | 8.02 | 12.93 | 11.85 |
| Near-OOD | 56.90 | 31.53 | 4.24 | 28.11 | 57.85 | 9.44 | 54.23 | 23.58 | 47.50 | 45.08 |
| Far-OOD | 75.01 | 95.94 | 4.00 | 9.40 | 76.33 | 19.47 | 85.98 | 12.90 | 80.50 | 76.94 |
| AID | Semi-OOD | 28.93 | 45.53 | 7.56 | 11.12 | 28.48 | 17.83 | 24.81 | 18.65 | 25.26 | 29.37 |
| Near-OOD | 69.64 | 86.17 | 8.41 | 15.60 | 68.22 | 39.14 | 54.57 | 53.09 | 64.15 | 69.76 |
| Far-OOD | 86.77 | 98.28 | 17.69 | 26.50 | 87.83 | 53.38 | 67.37 | 74.31 | 85.86 | 84.70 |
| EuroSAT | Semi-OOD | 89.32 | 97.56 | 93.67 | 75.92 | 90.19 | 84.58 | 99.12 | 86.12 | 77.53 | 87.34 |
| Near-OOD | 67.80 | 92.70 | 87.99 | 60.92 | 67.47 | 66.33 | 95.29 | 88.96 | 51.45 | 72.84 |
| Far-OOD | 83.78 | 99.64 | 95.82 | 26.40 | 85.04 | 85.67 | 98.77 | 93.42 | 38.47 | 59.12 |
Table 15.
Results from nine OOD benchmarks summarized by the top three average ID-ACC scores (percentage), calculated over seven runs. Bold highlights indicate the top three averages per benchmark.
Table 15.
Results from nine OOD benchmarks summarized by the top three average ID-ACC scores (percentage), calculated over seven runs. Bold highlights indicate the top three averages per benchmark.
| Benchmark | | Post Hoc | Training-Time Regularization | Outlier Exposure | Model Uncertainty |
|---|
|
MSP
|
VIM
|
KNN
|
ConfBranch
|
LogitNorm
|
G-ODIN
|
OE
|
MCD
|
MCDropout
|
Tempscaling
|
|---|
| UCM | ID | 98.33 | 98.33 | 98.33 | 98.10 | 98.33 | 83.81 | 97.38 | 90.24 | 98.10 | 98.33 |
| AID | ID | 96.35 | 96.35 | 96.35 | 96.85 | 96.45 | 84.75 | 95.40 | 92.00 | 96.25 | 96.50 |
| EuroSAT | ID | 98.28 | 98.28 | 98.28 | 98.39 | 98.30 | 94.54 | 97.81 | 96.85 | 71.48 | 98.26 |
Table 16.
Results from nine OOD benchmarks summarized by the top three average computation time (seconds) calculated over seven runs. Bold highlights indicate the top three averages per benchmark.
Table 16.
Results from nine OOD benchmarks summarized by the top three average computation time (seconds) calculated over seven runs. Bold highlights indicate the top three averages per benchmark.
| Benchmark | | Post Hoc | Training-Time Regularization | Outlier Exposure | Model Uncertainty |
|---|
|
MSP
|
VIM
|
KNN
|
ConfBranch
|
LogitNorm
|
G-ODIN
|
OE
|
MCD
|
MCDropout
|
Tempscaling
|
|---|
| UCM | Semi+Near+Far | 112 | 123 | 142 | 1191 | 987 | 1244 | 4116 | 2940 | 1266 | 114 |
| AID | Semi+Near+Far | 118 | 158 | 221 | 3705 | 3525 | 765 | 17,885 | 12,310 | 3822 | 117 |
| EuroSAT | Semi+Near+Far | 44 | 62 | 161 | 1268 | 1128 | 1253 | 6763 | 5699 | 1218 | 44 |











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}