
LVI-Fusion: A Robust Lidar-Visual-Inertial SLAM Scheme


Abstract
:1. Introduction
- Based on the issue of inconsistent time frequency between the camera and lidar, we proposed a time alignment module, which divide and merge point clouds according to visual time. This method can effectively solve the problem of time asynchrony in the tight coupling process between vision and lidar sensors.
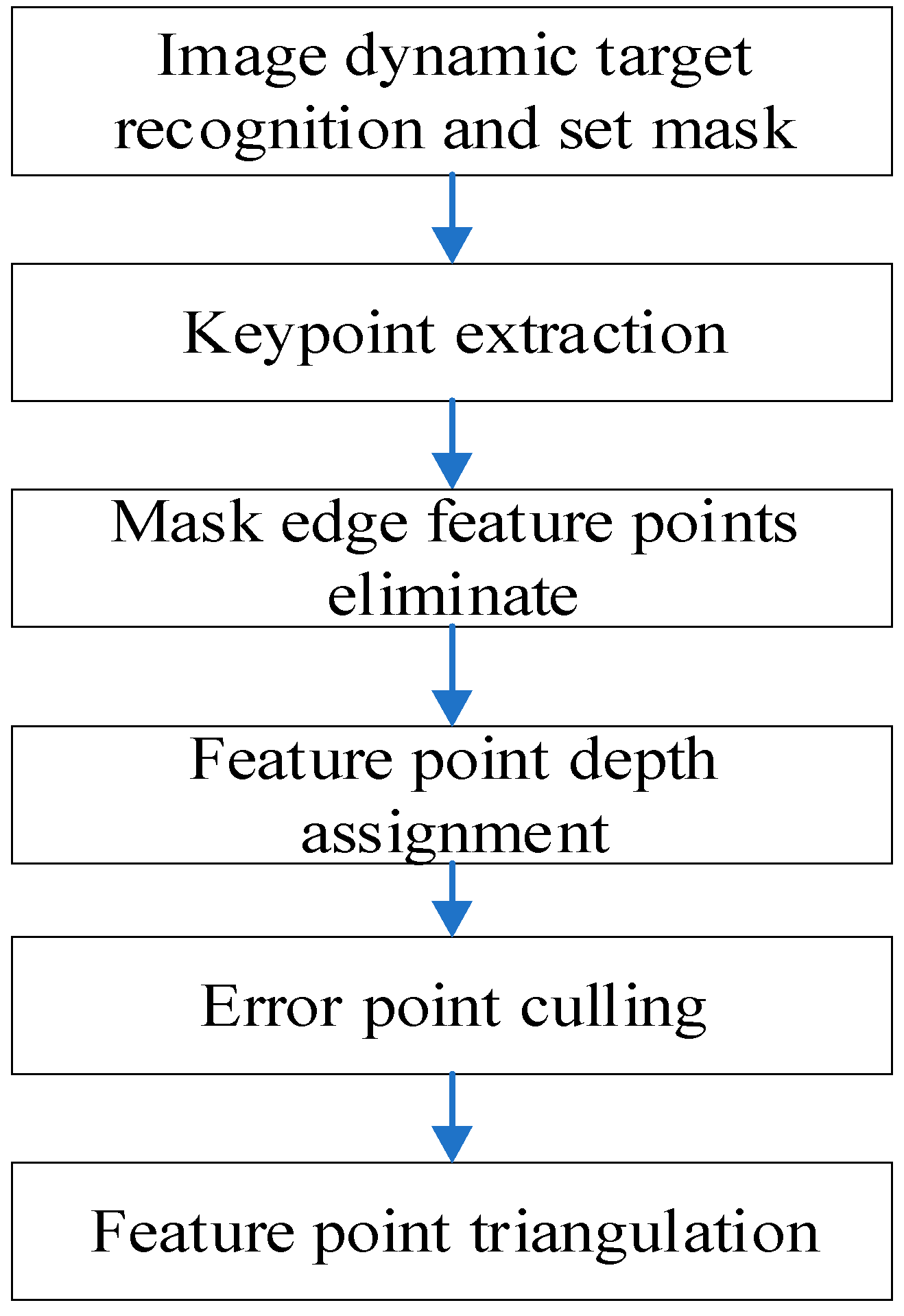
- The image segmentation algorithm is used to segment the dynamic target of the image, eliminating the influence of dynamic objects, and the static key points can be achieved.
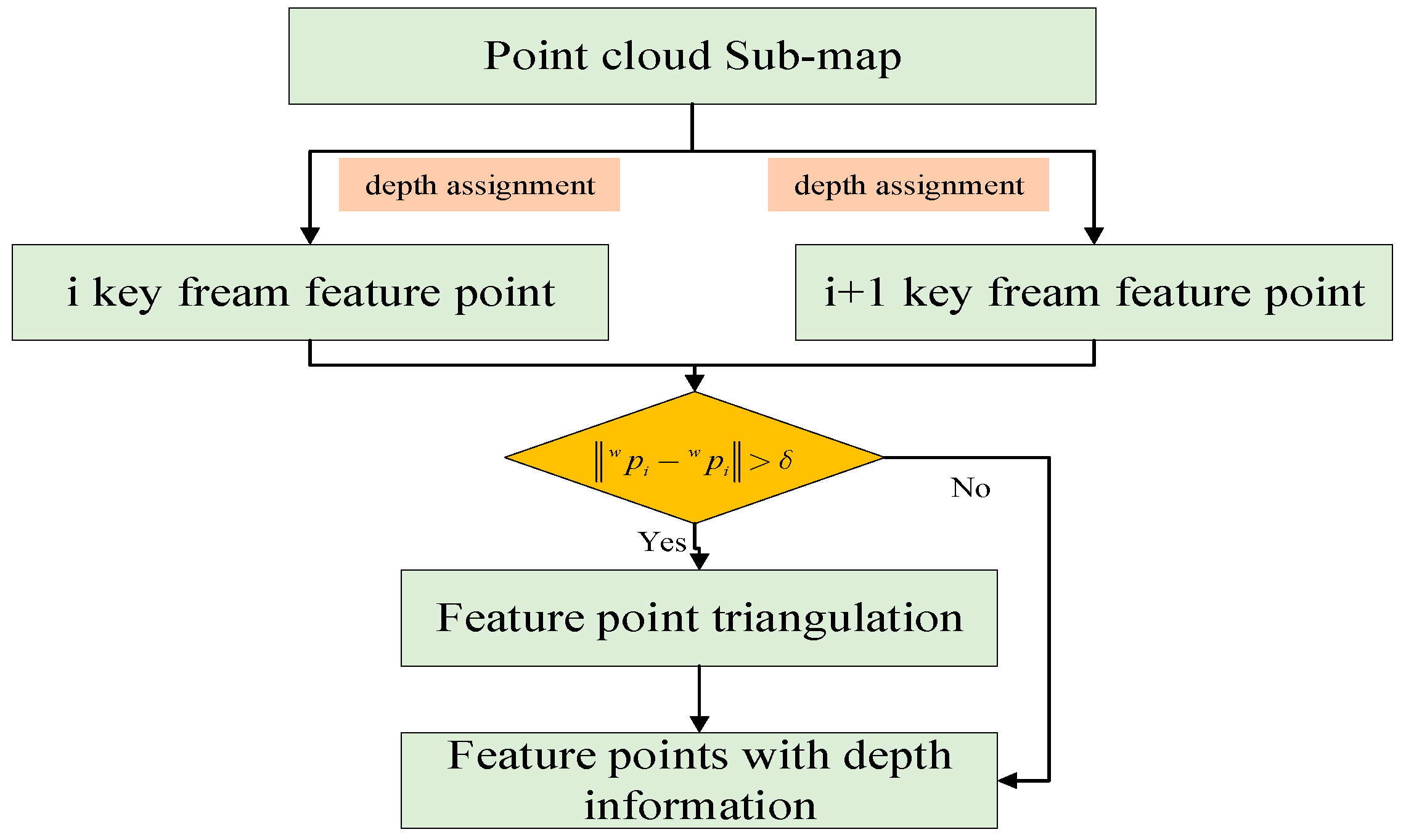
- A robust feature point depth estimation scheme is proposed. The sub-map is used to assign depth to each image key frame feature point, and the 3D world point coordinates are calculated for the same feature point under different camera positions and poses. When the depth estimation is accurate, the world coordinates recovered by the same feature point under different keyframe pose should be consistent. In this way, the depth of feature points can be estimated robustly.
- In order to ensure the real-time performance of the back-end optimization, a sliding window optimization method is adopted for pose calculation, and we implemented a complete multi-sensor fusion SLAM scheme. To extensively validate the positioning accuracy performance of the proposed method, extensive experiments are carried out in the M2DGR dataset [9] and a campus dataset collected by our equipment. The results illustrate that the proposed approach outperforms the state-of-the-art SLAM schemes.
2. Related Works
2.1. Visual SLAM
2.2. Lidar SLAM
2.3. SLAM of Vision and Lidar Fusion
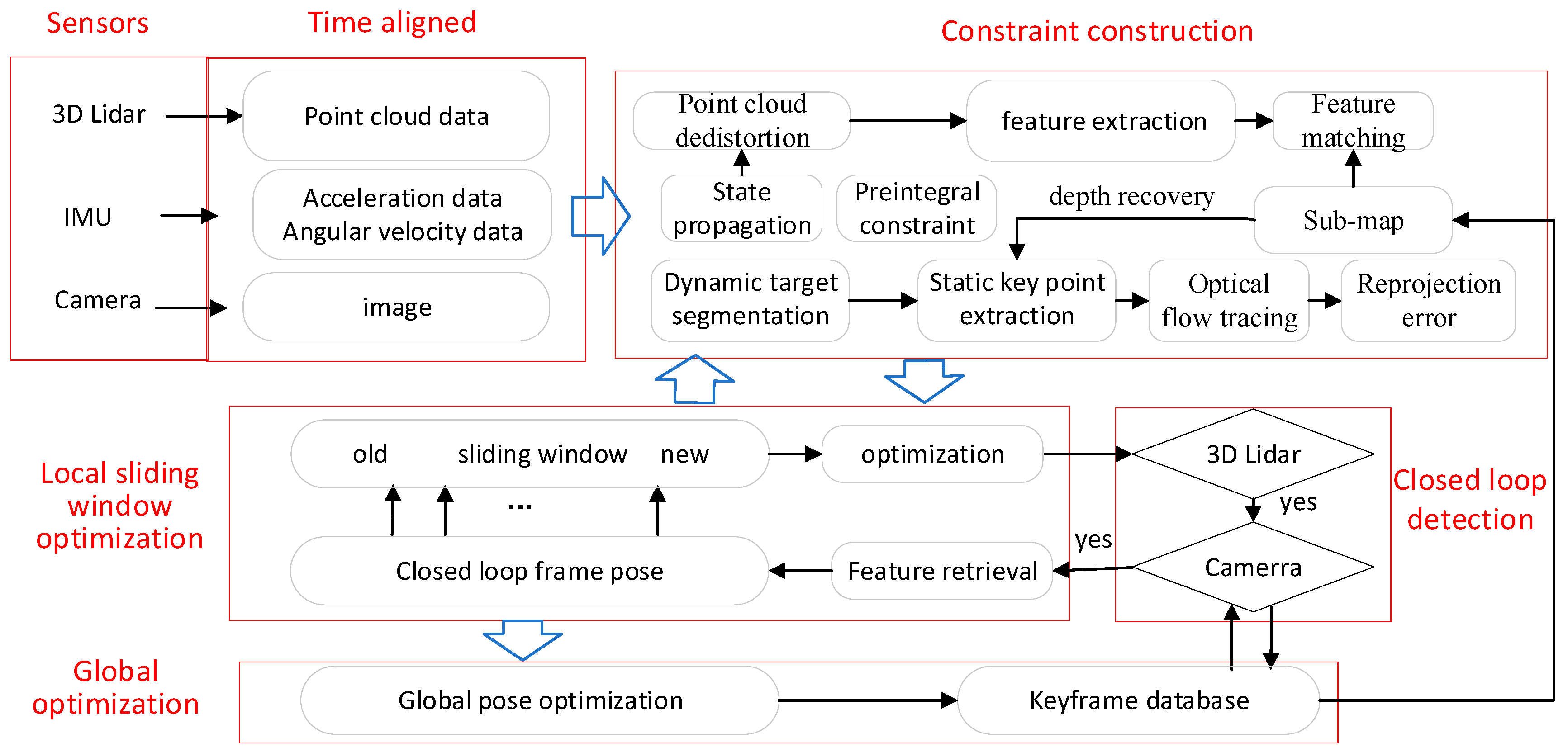
3. System Overview
- (1)
- Time alignment. Regardless of systems triggered by external clocks (such as GNSS), each sensor is collected at a different start time stamp, and different sensors have different data acquisition frequencies. State fusion estimation requires aligning data with different timestamps to the same time node. LVI-fusion takes the camera time stamp as the benchmark, splits the lidar point cloud data according to the camera time stamp, and merges the point cloud data between image frames into one frame point cloud. IMU data is interpolated according to the time stamp of the camera to obtain IMU data aligned with the camera time stamp. Through the above operations, the lidar data, IMU data and camera data can be time-stamped aligned.
- (2)
- Data preprocessing. The state propagation of IMU data between adjacent image frames is carried out, and the point cloud data between two image frames is dedistorted according to the state prediction results, and the point cloud is unified to the end time of the point cloud of the frame. The YOLOv7 dynamic target recognition algorithm [47] is used to segment the dynamic target of the image, eliminate the influence of the dynamic target, obtain the static target image, construct the image pyramid of the deleted dynamic target image, extract the Harris key points from each layer of the image, and use the quadtree to homogenize the feature points to obtain uniformly distributed feature points. The tracked feature points are added to the image queue.
- (3)
- Constraint construction. The IMU data between adjacent image key frames are pre-integrated, the pre-integral increment of adjacent image key frames is obtained, and the Jacobian matrix and covariance of the pre-integral error matrix are constructed. The local point cloud map near the current key frame is used to assign depth to the image feature points, and the image feature points with depth are obtained. The reprojection error constraints are constructed according to the 3D coordinates of the feature points and the image frames tracked to their coordinates. Due to the high frequency of the camera, the field of view Angle of the lidar data with the camera time is less than half of the original, and the key frame is selected according to the pose result obtained by the VIO odometer. When it is a key frame, the lidar data of the current frame and the lidar data of the previous two frames are combined into one frame point cloud data. Line features and surface features are extracted from key frame point cloud data and matched with a local map to construct pose constraint based on lidar. According to IMU pre-integral constraints, visual reprojection constraints and lidar matching constraints, the nonlinear optimization objective function can be constructed, and the real-time pose calculation can be performed by using the sliding window optimization method, and the optimization results are fed back to the visual inertial odometer.
- (4)
- Closed loop detection. The closed-loop detection algorithm based on 3D lidar, and the visual-based bag of words model were used for closed-loop detection. When the constraints of both methods are met, the closed-loop constraints between visual and lidar are added to the global optimization.
- (5)
- Global optimization. Opens a separate thread for global optimization of keyframe-based pose.
3.1. Symbolic Description
3.2. Time Aligned
3.3. Key Point Depth Association
3.3.1. Image Target Detection
3.3.2. Key Point Depth Recovery
3.4. Constraint Construction
3.4.1. Pre-Integration Factor
3.4.2. Vision Factor
3.4.3. Lidar Factor
3.5. Local Sliding Window Optimization
3.6. Loopback Detection
4. Experimental Setup and Evaluation
4.1. M2DGR Dataset
4.1.1. Mapping Effect
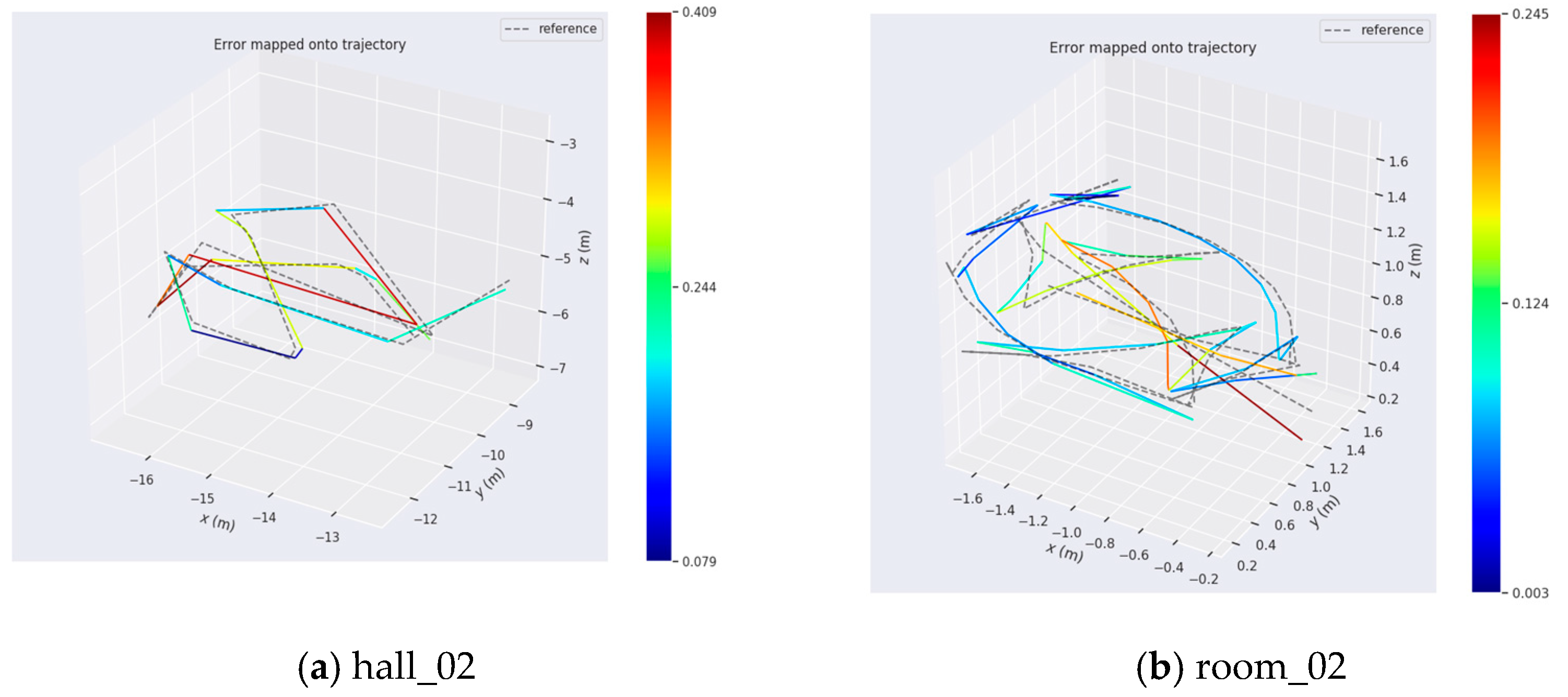
4.1.2. Precision Analysis
4.2. Low-Dynamic Environment
4.2.1. Mapping Effect
4.2.2. Precision Analysis
4.3. High-Dynamic Environment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef]
- Li, J.; Pei, L.; Zou, D. Attention-SLAM: A Visual Monocular SLAM Learning From Human Gaze. IEEE Sens. J. 2021, 21, 6408–6420. [Google Scholar] [CrossRef]
- Debeunne, C.; Vivet, D. A review of visual-Lidar fusion based simultaneous localization and mapping. Sensors 2020, 20, 2068. [Google Scholar] [CrossRef] [PubMed]
- Forster, C.; Carlone, L.; Dellaert, F. On-Manifold Preintegration for Real-Time Visual—Inertial Odometry. IEEE Trans. Robot. 2017, 33, 1–21. [Google Scholar] [CrossRef]
- Tao, Y.; He, Y.; Ma, X. SLAM Method Based on Multi-Sensor Information Fusion. In Proceedings of the 2021 International Conference on Computer Network, Electronic and Automation (ICCNEA), Xi’an, China, 24–26 September 2021; pp. 289–293. [Google Scholar] [CrossRef]
- Yu, H.; Wang, Q.; Yan, C.; Feng, Y.; Sun, Y.; Li, L. DLD-SLAM: RGB-D Visual Simultaneous Localisation and Mapping in Indoor Dynamic Environments Based on Deep Learning. Remote Sens. 2024, 16, 246. [Google Scholar] [CrossRef]
- Huletski, A.; Kartashov, D.; Krinkin, K. Evaluation of the modern visual SLAM methods. In Proceedings of the 2015 Artificial Intelligence and Natural Language and Information Extraction, Social Media and Web Search FRUCT Conference (AINL-ISMW FRUCT), St. Petersburg, Russia, 9–14 November 2015; pp. 19–25. [Google Scholar] [CrossRef]
- Shan, T.; Englot, B.; Ratti, C. LVI-SAM: Tightly-Coupled Lidar-Visual-Inertial Odometry via Smoothing and Mapping. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May 2021–5 June 2021; pp. 5692–5698. [Google Scholar] [CrossRef]
- Yin, J.; Li, A.; Li, T. M2DGR: A Multi-Sensor and Multi-Scenario SLAM Dataset for Ground Robots. IEEE Robot. Auto Let. 2022, 7, 2266–2273. [Google Scholar] [CrossRef]
- Chghaf, M.; Rodriguez, S.; Ouardi, A.E. Camera, LiDAR and Multi-modal SLAM Systems for Autonomous Ground Vehicles: A Survey. J. Intell. Robot. Syst. 2022, 105, 2. [Google Scholar] [CrossRef]
- Davison, A.J.; Reid, I.D.; Molton, N.D. MonoSLAM: Real-Time Single Camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef]
- Klein, G.; Murray, D. Parallel Tracking and Mapping for Small AR Workspaces. In Proceedings of the 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Nara, Japan, 13–16 November 2007; pp. 225–234. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Montiel, J.M. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2017, 31, 1147–1163. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2011, Barcelona, Spain, 6–13 November 2011. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 15–22. [Google Scholar] [CrossRef]
- Engel, J.; Thomas, S.; Cremers, D. Lsd-Salm: Large-Scale Direct Monocular Salm. In Proceedings of the European Conference on Computer Vision, Cham, Switzerland, 6–12 September 2014; pp. 834–849. [Google Scholar] [CrossRef]
- Engel, J.; Koltun, V.; Cremers, D. Direct Sparse Odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 611–625. [Google Scholar] [CrossRef] [PubMed]
- Mourikis, A.I.; Roumeliotis, S.I. A Multi-State Constraint Kalman Filter for Vision-aided Inertial Navigation. In Proceedings of the 2007 IEEE International Conference on Robotics and Automation, Rome, Italy, 10–14 April 2007; pp. 3565–3572. [Google Scholar] [CrossRef]
- Leutenegger, S.; Lynen, S.; Bosse, M. Keyframe-based visual–inertial odometry using nonlinear optimization. Int. J. Robot. Res. 2015, 34, 314–334. [Google Scholar] [CrossRef]
- Qin, T.; Li, P.; Shen, S.T. VINS-Mono: A Robust and Versatile Monocular Visual-Inertial State Estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef]
- Qin, T.; Pan, J.; Cao, S. A general optimization-based framework for local odometry estimation with multiple sensors. arXiv 2019, arXiv:1901.03638. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Hess, W.; Kohler, D.; Rapp, H. Real-time loop closure in 2D LIDAR SLAM. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 1271–1278. [Google Scholar] [CrossRef]
- Zhang, J.; Singh, S. LOAM: Lidar Odometry and Mapping in Real-time. Robot. Sci. Syst. 2014, 2, 1–9. [Google Scholar]
- Qin, T.; Cao, S. A-LOAM. 2018. Available online: https://github.com/HKUST-Aerial-Robotics/A-LOAM (accessed on 23 April 2024).
- Shan, T.; Englot, B. LeGO-LOAM: Lightweight and Ground-Optimized Lidar Odometry and Mapping on Variable Terrain. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 4758–4765. [Google Scholar] [CrossRef]
- Kimm, G. SC-LeGO-LOAM. 2020. Available online: https://gitee.com/zhankun3280/lslidar_c16_lego_loam (accessed on 23 April 2024).
- Kim, G.; Kim, A. Scan Context: Egocentric Spatial Descriptor for Place Recognition within 3D Point Cloud Map. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 4802–4809. [Google Scholar] [CrossRef]
- Zhao, S.; Fang, Z.; Li, H. A Robust Laser-Inertial Odometry and Mapping Method for Large-Scale Highway Environments. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 1285–1292. [Google Scholar] [CrossRef]
- Ye, H.; Chen, Y.; Liu, M. Tightly Coupled 3D Lidar Inertial Odometry and Mapping. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 3144–3150. [Google Scholar] [CrossRef]
- Shan, T.; Englot, B.; Meyers, D. LIO-SAM: Tightly-coupled Lidar Inertial Odometry via Smoothing and Mapping. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 5135–5142. [Google Scholar] [CrossRef]
- Qin, C.; Ye, H.; Pranata, C.E. LINS: A Lidar-Inertial State Estimator for Robust and Efficient Navigation. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 8899–8906. [Google Scholar] [CrossRef]
- Xu, W.; Zhang, F. FAST-LIO: A Fast, Robust Lidar-Inertial Odometry Package by Tightly-Coupled Iterated Kalman Filter. IEEE Robot. Autom. Let. 2020, 6, 3317–3324. [Google Scholar] [CrossRef]
- Xu, W.; Cai, Y.; He, D. FAST-LIO2: Fast Direct Lidar-Inertial Odometry. IEEE Trans. Robot. 2022, 38, 2053–2073. [Google Scholar] [CrossRef]
- Bai, C.; Xiao, T.; Chen, Y. Faster-LIO: Lightweight Tightly Coupled Lidar-Inertial Odometry Using Parallel Sparse Incremental Voxels. IEEE Robot. Autom. Let. 2022, 7, 4861–4868. [Google Scholar] [CrossRef]
- Graeter, J.; Wilczynski, A.; Lauer, M. LIMO: Lidar-Monocular Visual Odometry. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 7872–7879. [Google Scholar] [CrossRef]
- Zhang, J.; Singh, S. Visual-Lidar odometry and mapping: Low-drift, robust, and fast. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 2174–2181. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar]
- Shao, W.; Vijayarangan, S.; Li, C. Stereo Visual Inertial Lidar Simultaneous Localization and Mapping. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 370–377. [Google Scholar] [CrossRef]
- Zuo, X.; Geneva, P.; Lee, W. LIC-Fusion: Lidar-Inertial-Camera Odometry. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 5848–5854. [Google Scholar] [CrossRef]
- Zuo, X. LIC-Fusion 2.0: Lidar-Inertial-Camera Odometry with Sliding-Window Plane-Feature Tracking. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 5112–5119. [Google Scholar] [CrossRef]
- Wisth, D.; Camurri, M.; Das, S. Unified Multi-Modal Landmark Tracking for Tightly Coupled Lidar-Visual-Inertial Odometry IEEE Robot. Autom. Let. 2021, 6, 1004–1011. [Google Scholar] [CrossRef]
- Lin, J.; Zheng, C.; Xu, W. R2 LIVE: A Robust, Real-Time, Lidar-Inertial-Visual Tightly-Coupled State Estimator and Mapping. IEEE Robot. Autom. Let. 2021, 6, 7469–7476. [Google Scholar] [CrossRef]
- Lin, J.; Zheng, C. R3LIVE: A Robust, Real-time, RGB-colored, Lidar-Inertial-Visual tightly-coupled state Estimation and mapping package. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 10672–10678. [Google Scholar] [CrossRef]
- Zheng, C. FAST-LIVO: Fast and Tightly-coupled Sparse-Direct Lidar-Inertial-Visual Odometry. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar] [CrossRef]
- Lin, J.; Chen, W.M.; Lin, Y.; Cohn, J.; Han, S. MCUNet: Tiny Deep Learning on IoT Devices. arXiv 2007, arXiv:2007.10319. [Google Scholar] [CrossRef]
- Lyu, R. Nanodet-Plus: Super Fast and High Accuracy Lightweight Anchor-Free Object Detection Model. 2021. Available online: https://github.com/RangiLyu/nanodet (accessed on 23 April 2024).
- Ge, Z.; Liu, S.; Wang, F. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar] [CrossRef]
- Michele, A.; Colin, V.; Santika, D.D. Mobilenet convolutional neural networks and support vector machines for palmprint recognition. Procedia Comput. Sci. 2019, 157, 110–117. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, X.; Lin, M. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar] [CrossRef]
- Targ, S.; Almeida, D.; Lyman, K. Resnet in resnet: Generalizing residual architectures. arXiv 2016, arXiv:1603.08029. [Google Scholar] [CrossRef]
- Yu, F.; Wang, D.; Shelhamer, E. Deep layer aggregation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2403–2412. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar] [CrossRef]
- Sol’a, J. Quaternion kinematics for the error-state Kalman filter. arXiv 2017, arXiv:1711.02508. [Google Scholar] [CrossRef]
- Teunissen, P.J.G.; Khodabandeh, A. Review and principles of PPP-RTK methods. J. Geod. 2015, 89, 217–240. [Google Scholar] [CrossRef]



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scheme | Release Time | Sensor Form | Characteristic |
|---|---|---|---|
| MonoSLAM [11] | 2007 | a | EKF + Feature point method |
| PTAM [12] | 2007 | a | Feature point method |
| ORB-SLAM [13] | 2011 | a | ORB feature point method |
| ORB-SLAM2 [15] | 2015 | b | ORB feature + multiple mode cameras |
| SVO [16] | 2014 | a | Semi-direct method |
| LSD-SLAM [17] | 2014 | a | Direct method + semi-dense reconstruction |
| DSO [18] | 2020 | b | Direct method+ Sparse reconstruction |
| MSCKF [19] | 2020 | c | IESKF (iterative error state Kalman filter) |
| OKVIS [20] | 2020 | c | Key frame + graph optimization |
| VINS-mono [21] | 2017 | c | Optical flow + graph optimization |
| VINS-fusion [22] | 2019 | c | Optical flow + multimode |
| ORB-SLAM3 [23] | 2021 | c | ORB feature+ multimode |
| Scheme | Release Time | Sensor Form | Characteristic |
|---|---|---|---|
| LOAM [25] | 2014 | a | Milestone, based on feature matching |
| A-LOAM [26] | 2018 | a | Streamline LOAM code with optimization library |
| LeGO-LOAM [27] | 2018 | a | Ground point filtering, point cloud clustering |
| SC-LeGO-LOAM [28] | 2020 | a | Add loopback detection based on Scan Context |
| LIOM [30] | 2020 | b | CNN dynamic target elimination; ESKF filtering |
| LIO-Mapping [31] | 2019 | b | Graph optimization method |
| LIO-SAM [32] | 2020 | b | Factor graph optimization method |
| LINS [33] | 2020 | b | IESKF (iterative error state Kalman filter) |
| FAST-LIO [34] | 2020 | b | IEKF (Iterative Extended Kalman Filtering) |
| FAST-LIO2 [35] | 2021 | b | Incremental KD data structure (fast efficiency) |
| Faster-LIO [36] | 2022 | b | Use iVox data structure based on FAST-LIO2 to further improve efficiency |
| Scheme | Release Time | Sensor Form | Characteristic |
|---|---|---|---|
| LIMO [37] | 2018 | a | lidar-assisted visual recovery of feature point depth |
| V-LOAM [38] | 2018 | a | Match from high frequency to low frequency |
| VIL-SLAM [40] | 2019 | b | VIO assisted lidar positioning |
| LIC_Fusion [41] | 2019 | b | MSCKF filter (sensor online calibration) |
| LIC_Fusion2 [42] | 2020 | b | Sliding window filter |
| ULVIO [43] | 2021 | b | Factor Graph Optimization |
| R2live [44] | 2021 | b | ESKF filtering + factor graph optimization |
| R3live [45] | 2021 | b | Minimize the photometric error from frame to map |
| LVI-SAM [8] | 2021 | b | Factor Graph Optimization |
| FAST-LIVO [46] | 2022 | b | IESKF filtering |
| Sequence Name | Duration (s) | Features |
|---|---|---|
| hall_02 | 128 | random walk, indoor, day |
| room_02 | 75 | room, bright, indoor, day |
| door_02 | 127 | outdoor to indoor, short-term, day |
| gate_03 | 283 | outdoor, day |
| walk_01 | 291 | back and forth, outdoor, day |
| street_05 | 469 | straight line, outdoor, night, |
| Approach | Hall_02 | Room_02 | Door_02 | Gate_03 | Walk_01 | Street_05 |
|---|---|---|---|---|---|---|
| VINS-Mono | fail | 0.462 | 1.653 | 5.838 | 9.976 | fail |
| A-LOAM | 0.208 | 0.121 | 0.168 | 0.246 | 3.303 | 0.657 |
| LIO-SAM | 0.399 | 0.125 | 0.124 | 0.111 | 0.891 | 0.407 |
| LVI-SAM | 0.279 | 0.123 | 0.186 | 0.113 | 0.885 | 0.394 |
| LVI-fusion | 0.214 | 0.103 | 0.117 | 0.104 | 0.627 | 0.371 |
| Approach | Hall_02 | Room_02 | Door_02 | Gate_03 | Walk_01 | Street_05 |
|---|---|---|---|---|---|---|
| VINS-Mono | fail | 0.311 | 1.522 | 5.838 | 9.976 | fail |
| LIO-SAM | 0.291 | 0.125 | 0.106 | 0.111 | 0.830 | 0.405 |
| LVI-SAM | 0.270 | 0.120 | 0.171 | 0.114 | 0.888 | 0.395 |
| LVI-fusion | 0.181 | 0.101 | 0.099 | 0.105 | 0.631 | 0.370 |
| Parameter | RS-LiDAR-16 | |
|---|---|---|
| Ranging range | 20 cm~150 m | |
| Distance measurement accuracy | ±2 cm | |
| Field of view angle | horizontal | 360° |
| Vertical | +15°~−15° | |
| Angle resolution | horizontal | 0.2° |
| Vertical | 2° | |
| Collect points per second | 28,800 | |
| scan period | 0.1 s | |
| Parameter | Index | |
|---|---|---|
| Accelerometer | Speed Random Walk () | 57 |
| Zero bias instability () | 14 | |
| gyroscope | angle random walk() | 0.18 |
| Zero bias instability () | 8 | |
| magnetometer | Noise (m Gauss) | 3 |
| Zero bias stability (m Gauss) | 1 |
| Approach | Road Scene (m) | Square Scene (m) |
|---|---|---|
| LIO-SAM | 1.16 | 1.09 |
| LVI-SAM | 1.04 | 0.98 |
| LVI-fusion | 0.80 | 0.79 |
| Representative SLAM Scheme | LIO-SAM | LVI-SAM | LVI-Fusion |
|---|---|---|---|
| RMSE(m) | 1.201 | 1.548 | 0.890 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Li, Z.; Liu, A.; Shao, K.; Guo, Q.; Wang, C. LVI-Fusion: A Robust Lidar-Visual-Inertial SLAM Scheme. Remote Sens. 2024, 16, 1524. https://doi.org/10.3390/rs16091524
Liu Z, Li Z, Liu A, Shao K, Guo Q, Wang C. LVI-Fusion: A Robust Lidar-Visual-Inertial SLAM Scheme. Remote Sensing. 2024; 16(9):1524. https://doi.org/10.3390/rs16091524
Chicago/Turabian StyleLiu, Zhenbin, Zengke Li, Ao Liu, Kefan Shao, Qiang Guo, and Chuanhao Wang. 2024. "LVI-Fusion: A Robust Lidar-Visual-Inertial SLAM Scheme" Remote Sensing 16, no. 9: 1524. https://doi.org/10.3390/rs16091524
APA StyleLiu, Z., Li, Z., Liu, A., Shao, K., Guo, Q., & Wang, C. (2024). LVI-Fusion: A Robust Lidar-Visual-Inertial SLAM Scheme. Remote Sensing, 16(9), 1524. https://doi.org/10.3390/rs16091524