Capsule Broad Learning System Network for Robust Synthetic Aperture Radar Automatic Target Recognition with Small Samples


Abstract
:1. Introduction
- Innovative architecture: Introduces CBLS-SARNET, a novel architecture merging CapsNet and BLS in an end-to-end co-training setup, optimized for small-sample SAR ATR. Demonstrated to surpass other methods in recognition accuracy and efficiency, significantly reducing training time and dependency on extensive labeled data.
- The UDC framework: Implements a flexible feature filter through the UDC framework, which enhances feature extraction by segmenting fully connected layers into smaller, co-trainable units. Proven to improve recognition accuracy and operational efficiency over traditional CapsNet and BLS models.
- Enhanced learning via PS network: Features a PS network that promotes secondary learning by sharing weights and biases across BLS node layers, which boosts feature extraction and generalization capabilities. Includes a novel activation function, Uish, tailored for swift SAR classification, outperforming other deep learning models in comparative tests.
- Robustness and generalization: By leveraging the unique designs of the UDC framework and PS network, CBLS-SARNET demonstrates strong spatial feature extraction and adaptability under challenging conditions, including noise, blur, and varying depression angles, ensuring robust performance across diverse operational environments.
2. Preliminary
2.1. Challenges of CNN in SAR ATR
2.2. Basic Theory of CapsNet
2.3. Basic Theory of Broad Learning
2.4. Activation Function
3. Method
3.1. CBLS-SARNET Architecture
3.2. SAR Image Pre-Processing
3.3. From Invariance to Equivalence
3.4. Feature Screening via UDC Framework
3.5. Fast SAR ATR Task via PS Network
3.5.1. PS Network
3.5.2. Uish Function
| Algorithm 1: Pseudo-code of CBLS-SARNET |
 |
4. Experimental Results and Analysis
4.1. Dataset Distribution
4.1.1. MSTAR Datasets
4.1.2. SOC Small-Sample Datasets
4.1.3. EOC Small-Sample Datasets
4.2. Experimental Setup
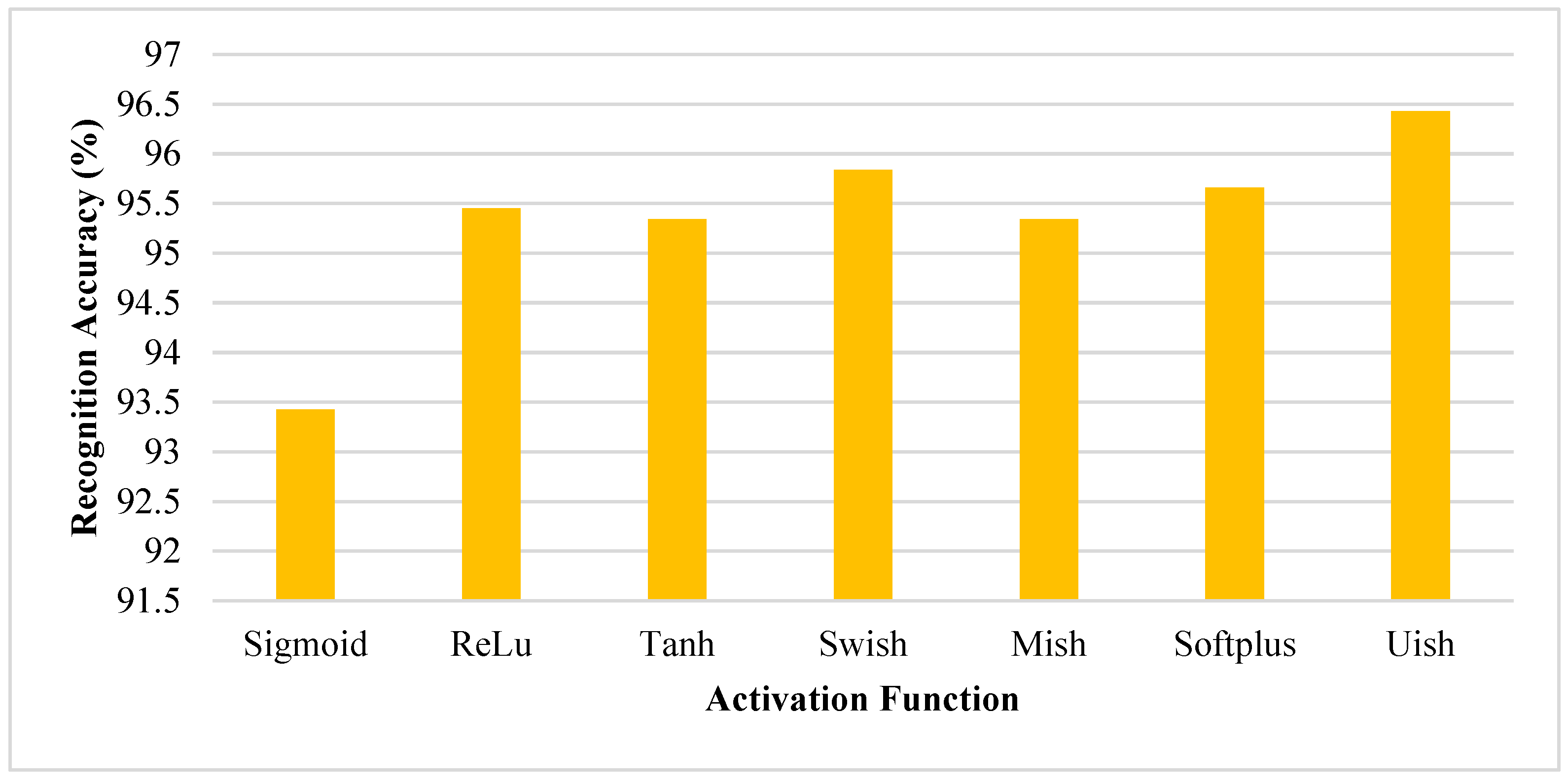
4.3. Activation Function Verification
4.4. Equivalence Verification Experiment of CBLS-SARNET
4.5. Generalization and Robustness of CBLS-SARNET
4.5.1. Blur Analysis
4.5.2. Noise Analysis
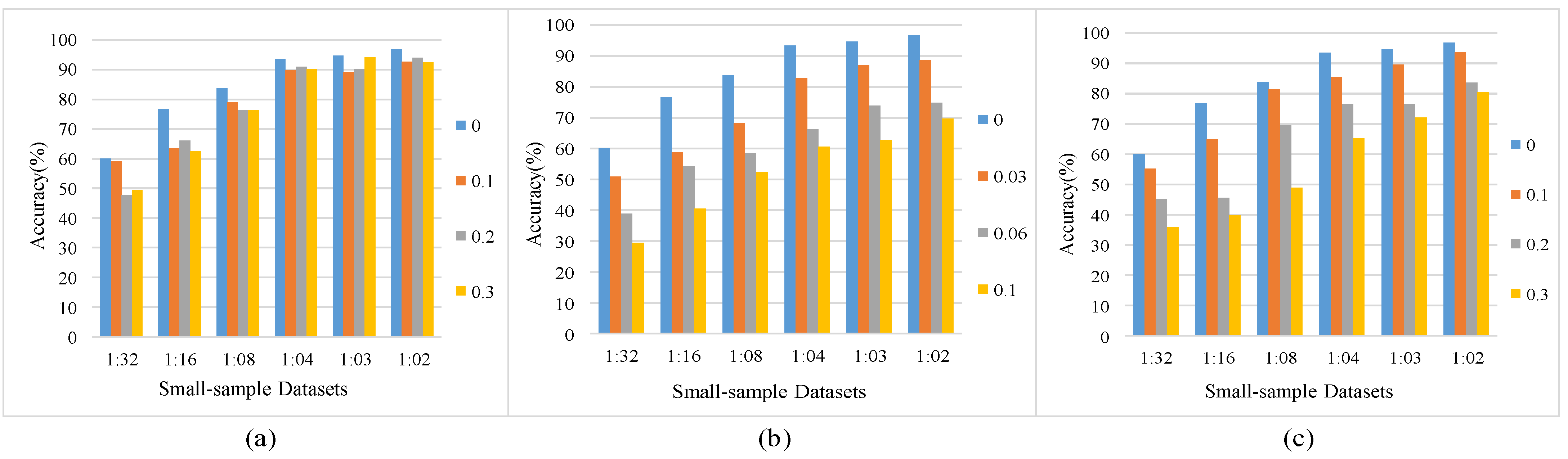
4.5.3. Noisy Labels Analysis
4.6. Efficiency and Effectiveness of CBLS-SARNET
4.6.1. Efficiency Verification
4.6.2. Effectiveness Verification
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, C.; Dong, H.; Deng, B. Improving Pre-Training and Fine-Tuning for Few-Shot SAR Automatic Target Recognition. Remote Sens. 2023, 15, 1709. [Google Scholar] [CrossRef]
- Wang, C.; Shi, J.; Zhou, Y.; Li, L.; Yang, X.; Zhang, T.; Wei, S.; Zhang, X.; Tao, C. Label Noise Modeling and Correction via Loss Curve Fitting for SAR ATR. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5216210. [Google Scholar] [CrossRef]
- Zhu, M.; Cheng, J.; Lei, T.; Feng, Z.; Zhou, X.; Liu, Y.; Chen, Z. C-RISE: A Post-Hoc Interpretation Method of Black-Box Models for SAR ATR. Remote Sens. 2023, 15, 3103. [Google Scholar] [CrossRef]
- Zhou, X.; Tang, T.; Cui, Y.; Zhang, L.; Kuang, G. Novel Loss Function in CNN for Small Sample Target Recognition in SAR Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4018305. [Google Scholar] [CrossRef]
- Li, Y.; Liu, W.; Qi, R. Multilevel Pyramid Feature Extraction and Task Decoupling Network for SAR Ship Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 3560–3570. [Google Scholar] [CrossRef]
- Cao, C.; Cao, Z.; Cui, Z. LDGAN: A Synthetic Aperture Radar Image Generation Method for Automatic Target Recognition. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3495–3508. [Google Scholar] [CrossRef]
- Inkawhich, N.A.; Davis, E.K.; Inkawhich, M.J.; Majumder, U.K.; Chen, Y. Training SAR-ATR Models for Reliable Operation in Open-World Environments. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3954–3966. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, Y.; Liu, H.; Wang, N.; Wang, J. SAR Target Recognition with Limited Training Data Based on Angular Rotation Generative Network. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1928–1932. [Google Scholar] [CrossRef]
- Molini, A.B.; Valsesia, D.; Fracastoro, G.; Magli, E. Speckle2Void: Deep Self-Supervised SAR Despeckling with Blind-Spot Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5204017. [Google Scholar] [CrossRef]
- Gao, G.; Liu, L.; Zhao, L.; Shi, G.; Kuang, G. An Adaptive and Fast CFAR Algorithm Based on Automatic Censoring for Target Detection in High-Resolution SAR Images. IEEE Trans. Geosci. Remote Sens. 2009, 47, 1685–1697. [Google Scholar] [CrossRef]
- Li, Z.; Li, E.; Samat, A.; Xu, T.; Liu, W.; Zhu, Y. An Object-Oriented CNN Model Based on Improved Superpixel Segmentation for High-Resolution Remote Sensing Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4782–4796. [Google Scholar] [CrossRef]
- Zhang, P.; Tang, J.; Zhong, H.; Ning, M.; Liu, D.; Wu, K. Self-Trained Target Detection of Radar and Sonar Images Using Automatic Deep Learning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4701914. [Google Scholar] [CrossRef]
- Ding, X.; Wang, N.; Gao, X.; Li, J.; Wang, X.; Liu, T. Group Feedback Capsule Network. IEEE Trans. Image Process. 2020, 29, 6789–6799. [Google Scholar] [CrossRef]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic Routing Between Capsules. In Proceedings of the Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Long Beach, CA, USA, 2017. [Google Scholar]
- Huang, R.; Li, J.; Wang, S.; Li, G.; Li, W. A Robust Weight-Shared Capsule Network for Intelligent Machinery Fault Diagnosis. IEEE Trans. Ind. Inform. 2020, 16, 6466–6475. [Google Scholar] [CrossRef]
- Gong, Z.; Zhong, P.; Yu, Y.; Hu, W. Diversity-Promoting Deep Structural Metric Learning for Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 371–390. [Google Scholar] [CrossRef]
- Zhang, W.; Tan, Z.; Lv, Q.; Li, J.; Zhu, B.; Liu, Y. An Efficient Hybrid CNN-Transformer Approach for Remote Sensing Super-Resolution. Remote Sens. 2024, 16, 880. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Zhang, L.; Li, J.; Lu, G.; Shen, P.; Bennamoun, M.; Shah, S.A.A.; Miao, Q.; Zhu, G.; Li, P.; Lu, X. Analysis and Variants of Broad Learning System. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 334–344. [Google Scholar] [CrossRef]
- Chen, C.L.P.; Liu, Z. Broad Learning System: An Effective and Efficient Incremental Learning System without the Need for Deep Architecture. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 10–24. [Google Scholar] [CrossRef]
- Chen, C.L.P.; Liu, Z.; Feng, S. Universal Approximation Capability of Broad Learning System and Its Structural Variations. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 1191–1204. [Google Scholar] [CrossRef]
- Tang, H.; Dong, P.; Shi, Y. A Construction of Robust Representations for Small Data Sets Using Broad Learning System. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 6074–6084. [Google Scholar] [CrossRef]
- Liu, Z.; Chen, C.L.P.; Feng, S.; Feng, Q.; Zhang, T. Stacked Broad Learning System: From Incremental Flatted Structure to Deep Model. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 209–222. [Google Scholar] [CrossRef]
- Han, M.; Feng, S.; Chen, C.L.P.; Xu, M.; Qiu, T. Structured Manifold Broad Learning System: A Manifold Perspective for Large-Scale Chaotic Time Series Analysis and Prediction. IEEE Trans. Knowl. Data Eng. 2019, 31, 1809–1821. [Google Scholar] [CrossRef]
- Zhao, H.; Zheng, J.; Deng, W.; Song, Y. Semi-Supervised Broad Learning System Based on Manifold Regularization and Broad Network. IEEE Trans. Circuits Syst. Regul. Pap. 2020, 67, 983–994. [Google Scholar] [CrossRef]
- Sharma, J.; Andersen, P.-A.; Granmo, O.-C.; Goodwin, M. Deep Q-Learning with Q-Matrix Transfer Learning for Novel Fire Evacuation Environment. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 7363–7381. [Google Scholar] [CrossRef]
- Wen, Z.; Liu, Z.; Zhang, S.; Pan, Q. Rotation Awareness Based Self-Supervised Learning for SAR Target Recognition with Limited Training Samples. IEEE Trans. Image Process. 2021, 30, 7266–7279. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.L.P.; Wan, J.Z. A Rapid Learning and Dynamic Stepwise Updating Algorithm for Flat Neural Networks and the Application to Time-Series Prediction. IEEE Trans. Syst. Man Cybern. Part B Cybern. 1999, 29, 62–72. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.L.P. A Rapid Supervised Learning Neural Network for Function Interpolation and Approximation. IEEE Trans. Neural Netw. 1996, 7, 1220–1230. [Google Scholar] [CrossRef] [PubMed]
- Gadiraju, K.K.; Vatsavai, R.R. Remote Sensing Based Crop Type Classification Via Deep Transfer Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 4699–4712. [Google Scholar] [CrossRef]
- Zhao, S.; Zhou, L.; Wang, W.; Cai, D.; Lam, T.L.; Xu, Y. Toward Better Accuracy-Efficiency Trade-Offs: Divide and Co-Training. IEEE Trans. Image Process. 2022, 31, 5869–5880. [Google Scholar] [CrossRef]
- Zhao, X.; Zhang, Y.; Zhang, T.; Zou, X. Channel Splitting Network for Single MR Image Super-Resolution. IEEE Trans. Image Process. 2019, 28, 5649–5662. [Google Scholar] [CrossRef]
- Qiao, S.; Shen, W.; Zhang, Z.; Wang, B.; Yuille, A. Deep Co-Training for Semi-Supervised Image Recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Chu, F.; Liang, T.; Chen, C.L.P.; Wang, X.; Ma, X. Weighted Broad Learning System and Its Application in Nonlinear Industrial Process Modeling. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 3017–3031. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Zhang, L.; Zuo, W.; Zhang, B. Class-Specific Reconstruction Transfer Learning for Visual Recognition Across Domains. IEEE Trans. Image Process. 2020, 29, 2424–2438. [Google Scholar] [CrossRef] [PubMed]
- Feng, S.; Ji, K.; Zhang, L.; Ma, X.; Kuang, G. SAR Target Classification Based on Integration of ASC Parts Model and Deep Learning Algorithm. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10213–10225. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-Style ConvNets Great Again. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Chen, W.; Xie, D.; Zhang, Y.; Pu, S. All You Need Is a Few Shifts: Designing Efficient Convolutional Neural Networks for Image Classification. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Bi, Q.; Qin, K.; Li, Z.; Zhang, H.; Xu, K.; Xia, G.-S. A Multiple-Instance Densely-Connected ConvNet for Aerial Scene Classification. IEEE Trans. Image Process. 2020, 29, 4911–4926. [Google Scholar] [CrossRef] [PubMed]
- Bi, Q.; Zhou, B.; Qin, K.; Ye, Q.; Xia, G.-S. All Grains, One Scheme (AGOS): Learning Multigrain Instance Representation for Aerial Scene Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5629217. [Google Scholar] [CrossRef]
- Chen, S.; Wang, H.; Xu, F.; Jin, Y.-Q. Target Classification Using the Deep Convolutional Networks for SAR Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4806–4817. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Target | Training Datasets | Test Datasets | ||
|---|---|---|---|---|
| Depre. | Number | Depre. | Number | |
| BMP2 | 17° | 233 | 15° | 587 |
| BTR70 | 233 | 196 | ||
| T72 | 232 | 582 | ||
| ZSU23/4 | 299 | 274 | ||
| ZIL131 | 299 | 274 | ||
| T62 | 299 | 273 | ||
| BTR60 | 256 | 195 | ||
| D7 | 299 | 274 | ||
| BDRM2 | 298 | 274 | ||
| 2S1 | 299 | 274 | ||
| Total | 2747 | 3203 | ||
| Dataset | Depre. | 2S1 | BDRM2 | ZSU23/4 | Total |
|---|---|---|---|---|---|
| Training dataset | 17° | 299 | 298 | 299 | 896 |
| Test dataset | 30° | 288 | 287 | 288 | 863 |
| 45° | 303 | 303 | 303 | 909 |
| Parameters | Setting |
|---|---|
| Feature nodes | 500 |
| Enhancement nodes | 500 |
| Batch sizes | 128 |
| Capsule number | 8 |
| Learning rate | 0.0003 |
| Epochs | 300 |
| Optimizer | Adam |
| k | Accuracy (%) | k | Accuracy (%) |
|---|---|---|---|
| 1 | 90.23 | 0.1 | 95.64 |
| 0.1 | 95.98 | 0.2 | 96.01 |
| 0.001 | 94.32 | 0.3 | 98.34 |
| 0.0001 | 96.79 | 0.4 | 95.98 |
| Method | 1:32 | 1:16 | 1:08 | 1:04 | 1:03 | 1:02 |
|---|---|---|---|---|---|---|
| VGG | 14.00 | 31.40 | 39.20 | 46.10 | 55.50 | 62.40 |
| InceptionV3 | 17.70 | 43.50 | 49.80 | 60.20 | 71.10 | 82.02 |
| DenseNet | 17.00 | 50.00 | 60.00 | 82.00 | 87.50 | 84.20 |
| ResNet50 | 20.10 | 25.10 | 28.50 | 35.60 | 59.70 | 69.00 |
| Xception | 22.50 | 34.10 | 41.60 | 70.40 | 78.50 | 84.00 |
| LeNet | 31.60 | 48.00 | 63.00 | 80.90 | 84.10 | 87.40 |
| AlexNet | 38.20 | 60.50 | 80.90 | 89.70 | 92.40 | 93.20 |
| CNN-TL | 52.33 | 61.47 | 71.42 | 84.38 | 89.45 | 91.13 |
| A-ConvNets | 63.54 | 72.12 | 76.80 | 88.73 | 87.23 | 94.38 |
| CBLS-SARNET | 68.05 | 80.70 | 86.77 | 94.48 | 96.06 | 98.78 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, C.; Zhai, Y.; Huang, H.; Wang, Q.; Zhou, W. Capsule Broad Learning System Network for Robust Synthetic Aperture Radar Automatic Target Recognition with Small Samples. Remote Sens. 2024, 16, 1526. https://doi.org/10.3390/rs16091526
Yu C, Zhai Y, Huang H, Wang Q, Zhou W. Capsule Broad Learning System Network for Robust Synthetic Aperture Radar Automatic Target Recognition with Small Samples. Remote Sensing. 2024; 16(9):1526. https://doi.org/10.3390/rs16091526
Chicago/Turabian StyleYu, Cuilin, Yikui Zhai, Haifeng Huang, Qingsong Wang, and Wenlve Zhou. 2024. "Capsule Broad Learning System Network for Robust Synthetic Aperture Radar Automatic Target Recognition with Small Samples" Remote Sensing 16, no. 9: 1526. https://doi.org/10.3390/rs16091526
APA StyleYu, C., Zhai, Y., Huang, H., Wang, Q., & Zhou, W. (2024). Capsule Broad Learning System Network for Robust Synthetic Aperture Radar Automatic Target Recognition with Small Samples. Remote Sensing, 16(9), 1526. https://doi.org/10.3390/rs16091526