
Use of Sub-Aperture Decomposition for Supervised PolSAR Classification in Urban Area


Abstract
:1. Introduction
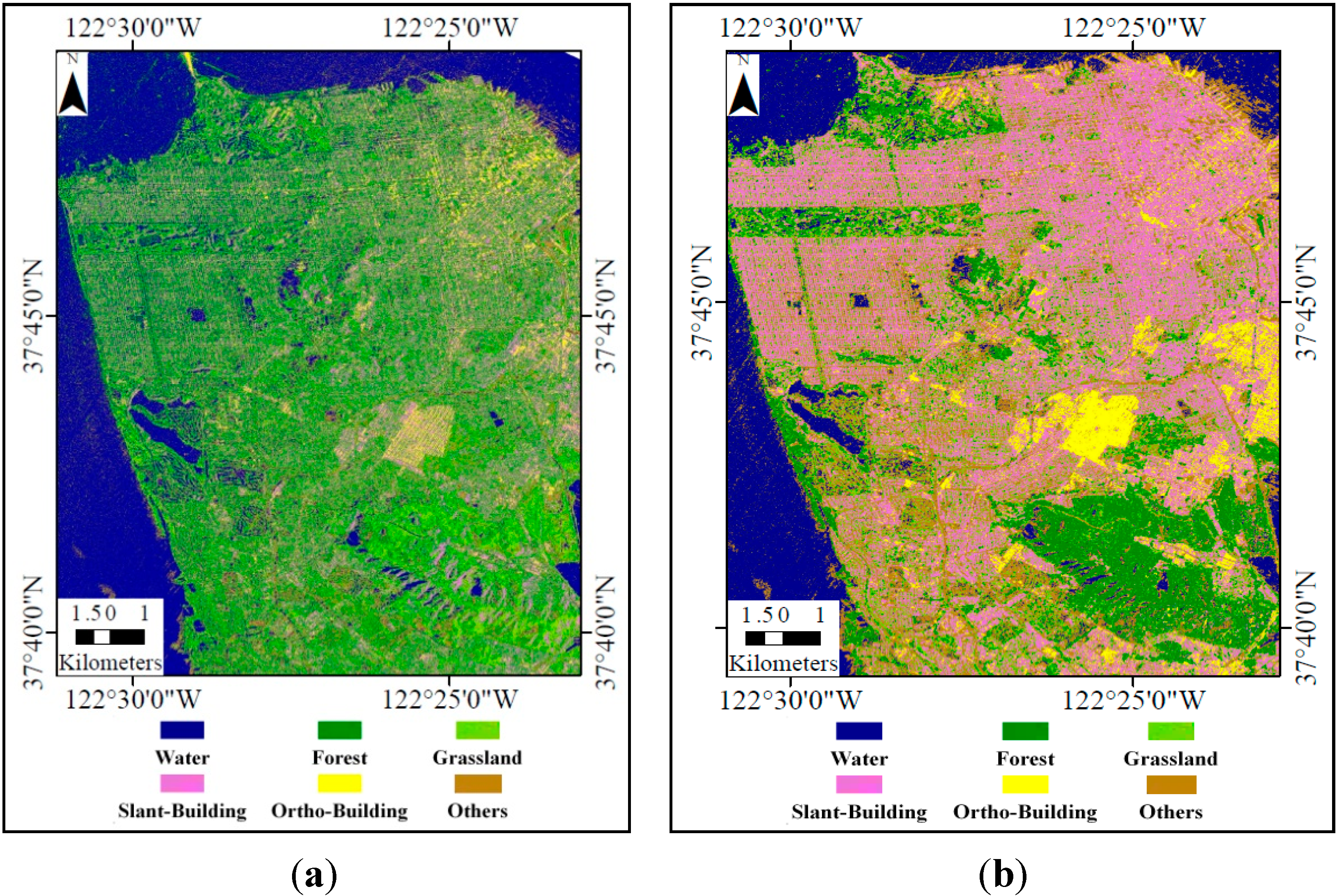
2. Experimental Data



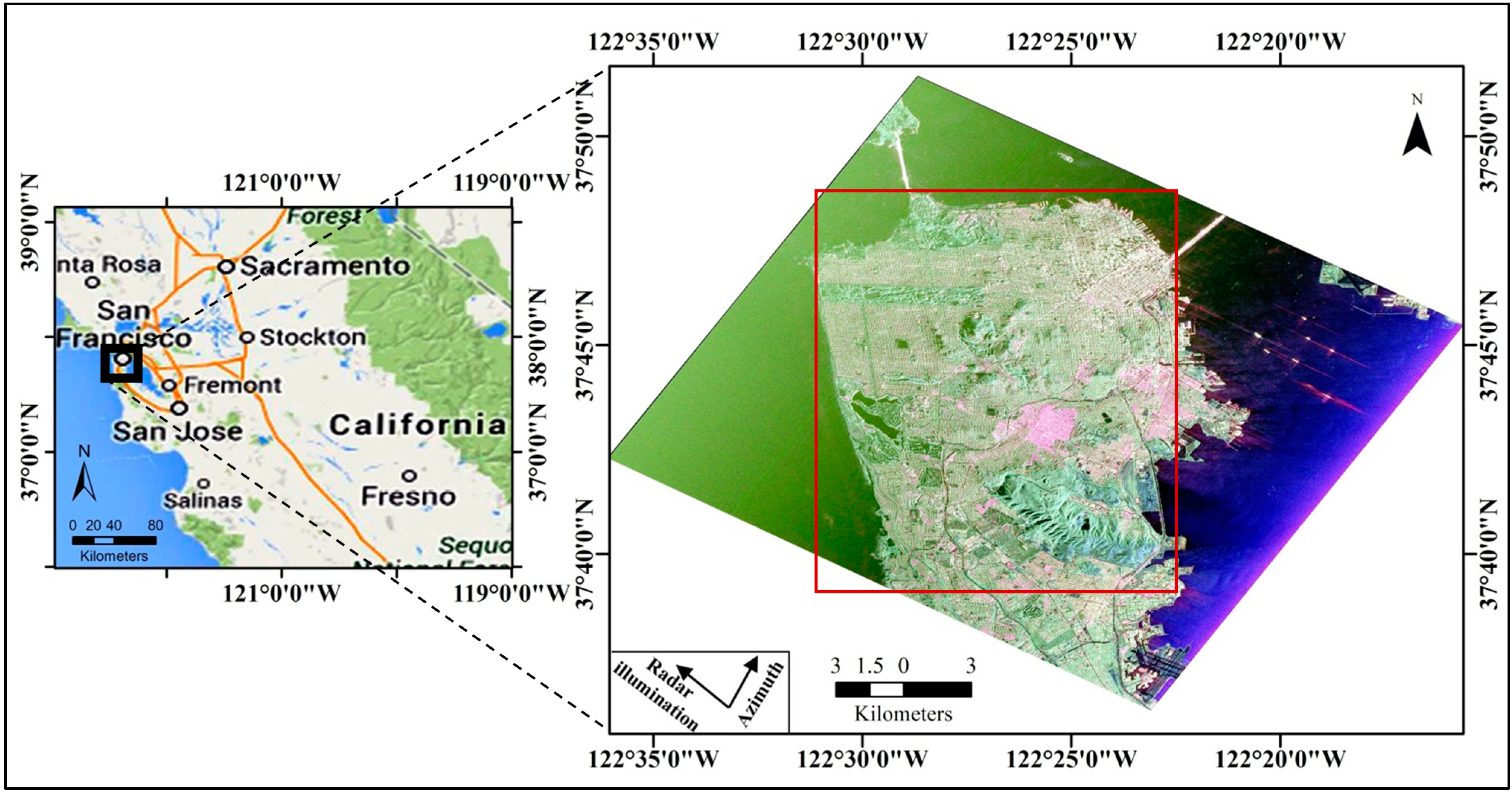{kind=link}
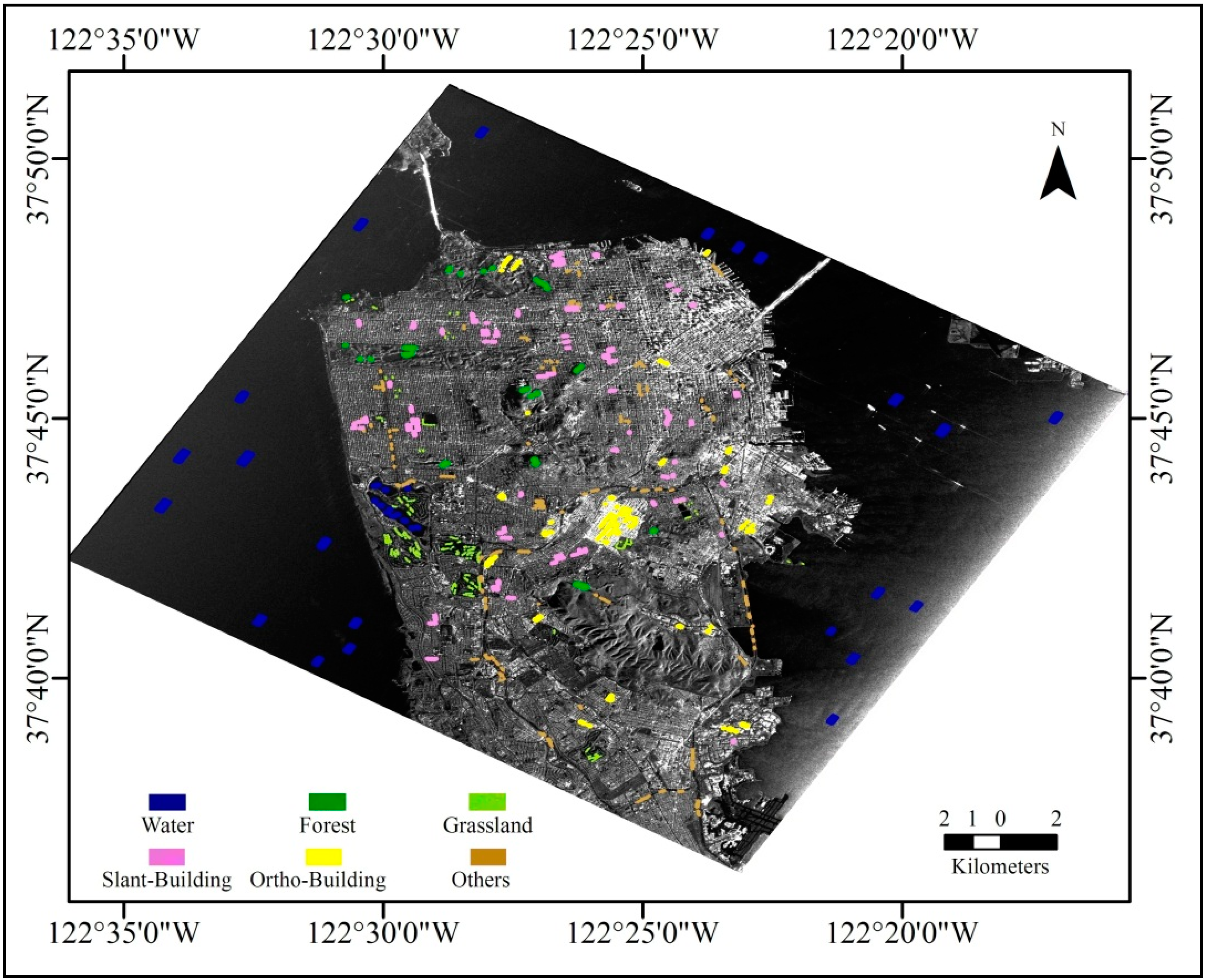{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Training (Pixels) | Validation (Pixels) | Total |
|---|---|---|---|
| Water | 6656 | 6540 | 13,196 |
| Forest | 850 | 884 | 1734 |
| Grassland | 1031 | 1090 | 2121 |
| Ortho-Building | 1373 | 1312 | 2685 |
| Slant-Building | 1563 | 1642 | 3205 |
| Others | 1522 | 1489 | 3011 |
| Total | 12,995 | 12,957 | 25,952 |
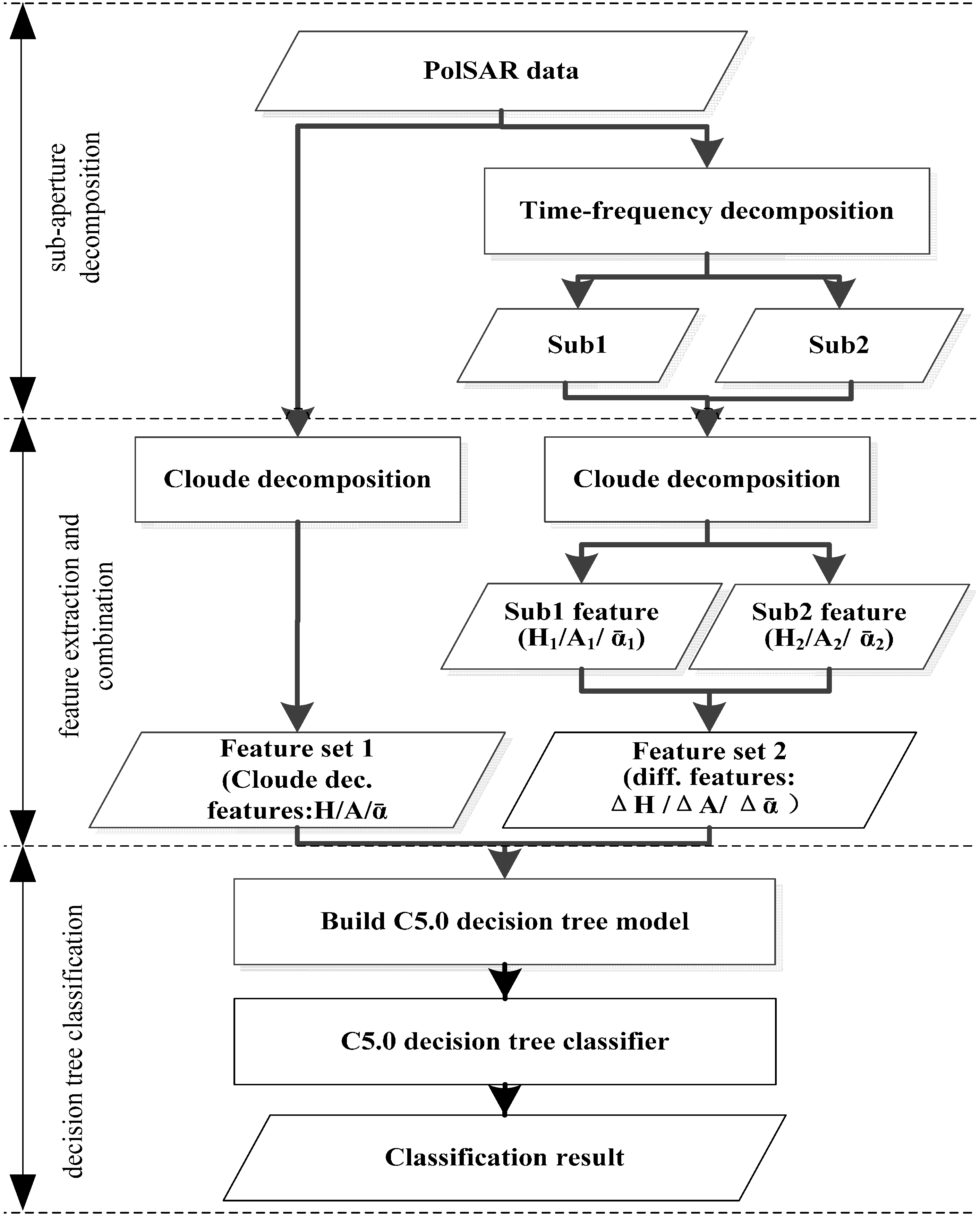
3. Methodology

3.1. Sub-Aperture Decomposition
3.2. Feature Extraction and Combination


3.3. Decision Tree Classification
4. Results and Discussion
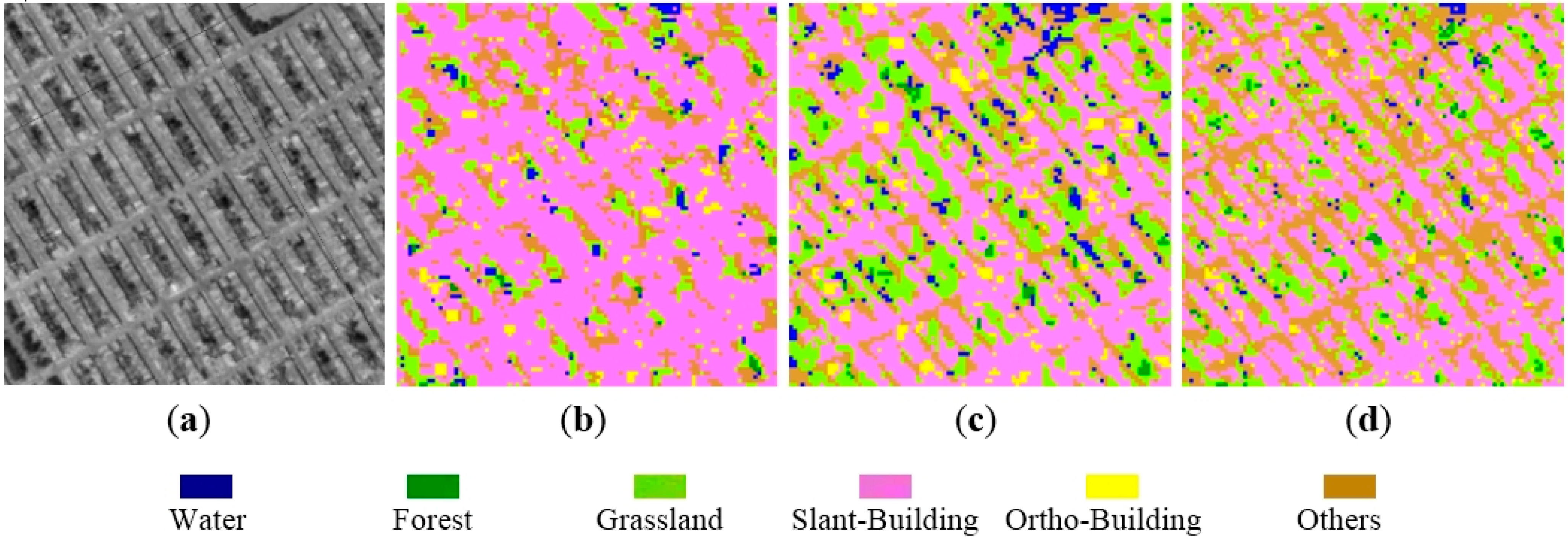
4.1. Comparison between the Proposed Method and the Wishart Supervised Classification

| Class | Water | Forest | Grassland | Ortho-Building | Slant-Building | Others | PA (%) |
|---|---|---|---|---|---|---|---|
| Water | 6257 | 13 | 168 | 0 | 0 | 102 | 95.67 |
| Forest | 58 | 356 | 422 | 0 | 32 | 16 | 40.27 |
| Grassland | 44 | 306 | 595 | 4 | 110 | 31 | 54.59 |
| Ortho-Building | 0 | 49 | 222 | 499 | 535 | 7 | 38.03 |
| Slant-Building | 35 | 188 | 647 | 91 | 659 | 22 | 40.13 |
| Others | 599 | 34 | 168 | 0 | 7 | 681 | 45.74 |
| UA (%) | 89.48 | 37.63 | 26.78 | 84.01 | 49.07 | 79.28 | |
| OA (%): 69.82 | Kappa Coefficient: 0.56 | ||||||
| Class | Water | Forest | Grassland | Ortho-Building | Slant-Building | Others | PA (%) |
|---|---|---|---|---|---|---|---|
| Water | 6433 | 7 | 14 | 0 | 0 | 86 | 98.36 |
| Forest | 18 | 709 | 121 | 0 | 11 | 25 | 80.20 |
| Grassland | 13 | 138 | 631 | 15 | 190 | 103 | 57.89 |
| Ortho-Building | 0 | 0 | 7 | 1146 | 149 | 10 | 87.35 |
| Slant-Building | 0 | 19 | 180 | 71 | 1286 | 86 | 78.32 |
| Others | 85 | 18 | 55 | 6 | 77 | 1248 | 83.81 |
| UA (%) | 98.23 | 79.57 | 62.60 | 92.57 | 75.07 | 80.10 | |
| OA (%): 88.39 | Kappa Coefficient: 0.83 | ||||||
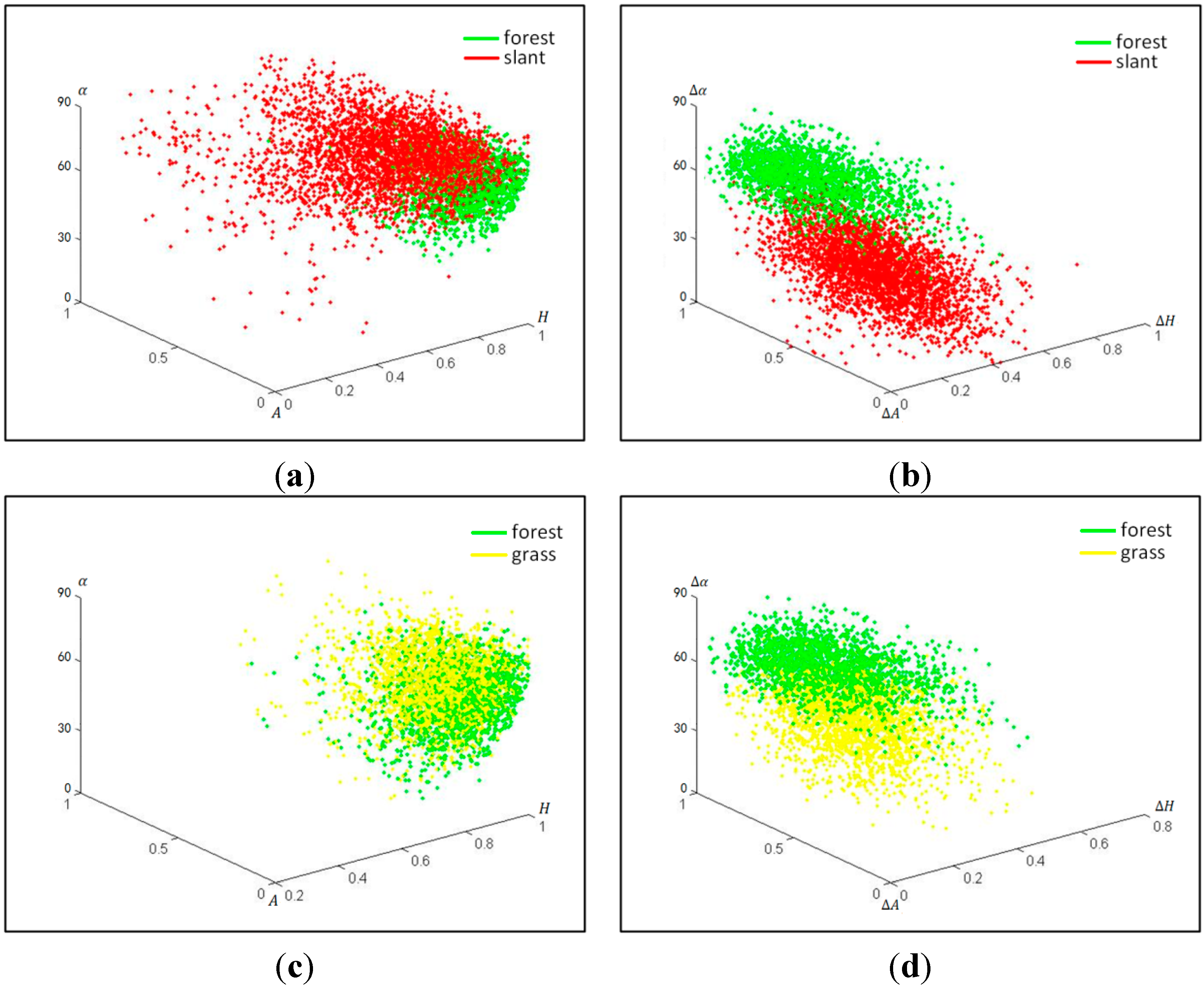
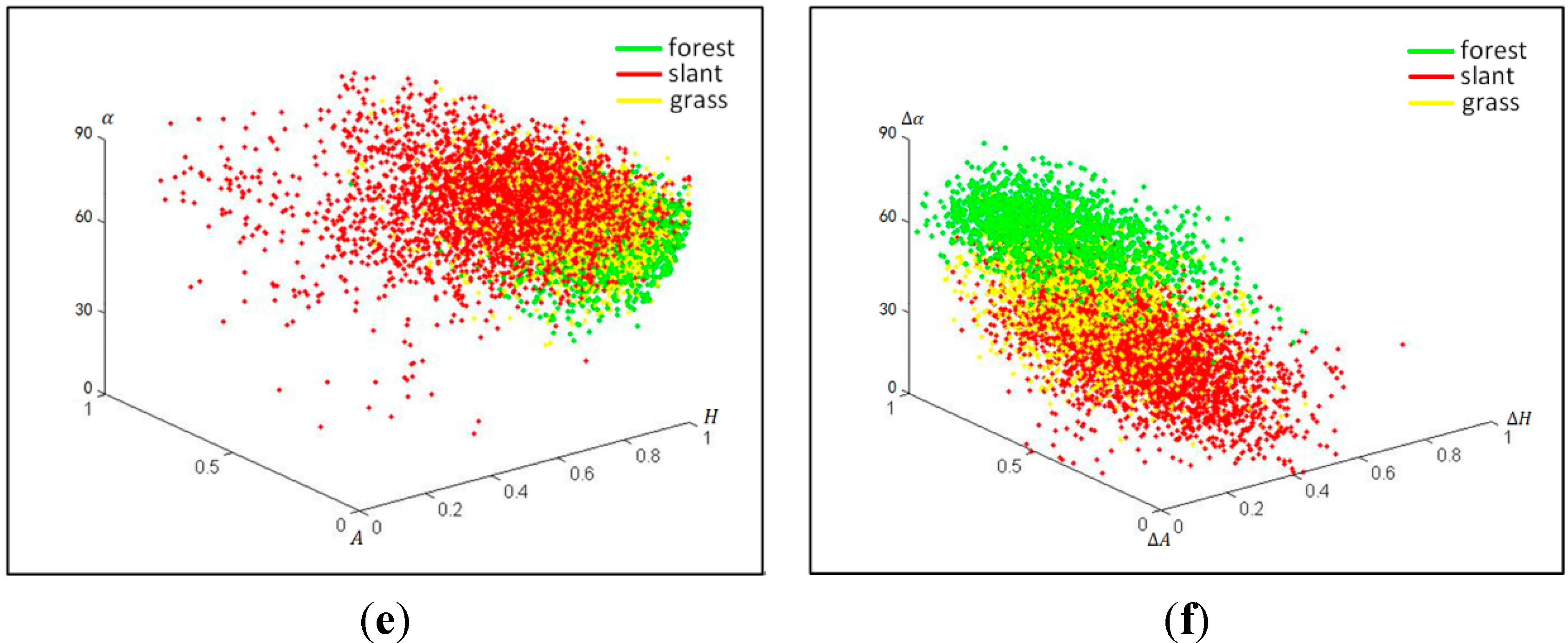
4.2. Influence of Sub-Aperture Decomposition

| Class | Water | Forest | Grassland | Ortho-Building | Slant-Building | Others | PA (%) |
|---|---|---|---|---|---|---|---|
| Water | 6429 | 11 | 5 | 0 | 0 | 95 | 98.3 |
| Forest | 15 | 599 | 174 | 0 | 43 | 53 | 67.76 |
| Grassland | 25 | 254 | 470 | 8 | 258 | 75 | 43.12 |
| Ortho-Building | 0 | 0 | 4 | 1143 | 162 | 3 | 87.12 |
| Slant-Building | 4 | 51 | 174 | 85 | 1290 | 38 | 78.56 |
| Others | 146 | 38 | 89 | 9 | 97 | 1110 | 74.55 |
| UA (%) | 97.13 | 62.85 | 51.31 | 91.81 | 69.73 | 80.79 | |
| OA (%): 85.21 | Kappa Coefficient: 0.79 | ||||||
4.3. Comparison among Different Classifiers

| Class | Water | Forest | Grassland | Ortho-Building | Slant-Building | Others | PA (%) |
|---|---|---|---|---|---|---|---|
| Water | 6350 | 85 | 60 | 0 | 8 | 37 | 97.09 |
| Forest | 114 | 624 | 63 | 0 | 0 | 83 | 70.59 |
| Grassland | 170 | 84 | 509 | 3 | 207 | 117 | 46.70 |
| Ortho-Building | 3 | 0 | 5 | 1163 | 113 | 28 | 88.64 |
| Slant-Building | 42 | 3 | 135 | 64 | 1259 | 139 | 76.67 |
| Others | 97 | 136 | 153 | 68 | 416 | 619 | 41.57 |
| UA (%) | 93.71 | 66.95 | 55.03 | 89.6 | 62.86 | 60.51 | |
| OA (%): 81.22 | Kappa Coefficient: 0.73 | ||||||
| Class | Water | Forest | Grassland | Ortho-Building | Slant-Building | Others | PA (%) |
|---|---|---|---|---|---|---|---|
| Water | 6274 | 78 | 0 | 0 | 0 | 188 | 95.93 |
| Forest | 34 | 696 | 112 | 1 | 28 | 13 | 78.76 |
| Grassland | 60 | 156 | 497 | 6 | 290 | 81 | 45.60 |
| Ortho-Building | 0 | 15 | 7 | 1125 | 165 | 7 | 85.75 |
| Slant-Building | 5 | 13 | 25 | 88 | 1301 | 210 | 79.23 |
| Others | 527 | 36 | 38 | 12 | 125 | 751 | 50.44 |
| UA (%) | 90.93 | 70.02 | 73.20 | 91.31 | 68.15 | 60.41 | |
| OA (%): 82.03 | Kappa Coefficient: 0.74 | ||||||
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Yu, J.; Yan, Q.; Zhang, Z.; Ke, H.; Zhao, Z.; Wang, W. Unsupervised classification of polarimetric synthetic aperture radar images using kernel fuzzy c-means clustering. Int. J. Image Data Fusion 2012, 3, 319–332. [Google Scholar] [CrossRef]
- Brook, A.; Ben-Dor, E.; Richter, R. Modelling and monitoring urban built environment via multi-source integrated and fused remote sensing data. Int. J. Image Data Fusion 2013, 4, 2–32. [Google Scholar] [CrossRef]
- Dickinson, C.; Siqueira, P.; Clewley, D.; Richard, L. Classification of forest composition using polarimetric decomposition in multiple landscapes. Remote Sens. Environ. 2013, 131, 206–214. [Google Scholar] [CrossRef]
- Boerner, W.M.; Yan, W.-L.; Xi, A.Q.; Yamaguchi, Y. On the basic principles of radar polarimetry: The target characteristic polarization state theory of kennaugh, huynen’s polarization fork concept, and its extension to the partially polarized case. IEEE Proc. 1991, 79, 1538–1550. [Google Scholar] [CrossRef]
- Del Frate, F.; Latini, D.; Pratola, C.; Palazzo, F. Pcnn for automatic segmentation and information extraction from x-band sar imagery. Int. J. Image Data Fusion 2013, 4, 75–88. [Google Scholar]
- Vanzyl, J.J. Unsupervised classification of scattering behavior using radar polarimetry data. IEEE Trans. Geosci. Remote Sens. 1989, 27, 36–45. [Google Scholar] [CrossRef]
- Park, S.E.; Moon, W.M. Unsupervised classification of scattering mechanisms in polarimetric sar data using fuzzy logic in entropy and alpha plane. IEEE Trans. Geosci. Remote Sens. 2007, 45, 2652–2664. [Google Scholar] [CrossRef]
- Kourgli, A.; Ouarzeddine, M.; Oukil, Y.; Belhadj-Aissa, A. Texture modelling for land cover classification of fully polarimetric sar images. Int. J. Image Data Fusion 2012, 3, 129–148. [Google Scholar] [CrossRef]
- Cloude, S.R.; Pottier, E. A review of target decomposition theorems in radar polarimetry. IEEE Trans. Geosci. Remote Sens. 1996, 34, 498–518. [Google Scholar] [CrossRef]
- Trisasongko, B.H. The use of polarimetric SAR data for forest disturbance monitoring. Sens. Imaging: Int. J. 2010, 11, 1–13. [Google Scholar] [CrossRef]
- Potier, E.; Lee, J.S. Unsupervised classification scheme of polSAR images based on the complex Wishart distribution and the “H/A/alpha” polarimetric decomposition theorem. In Proceedings of the EUSAR 2000, Munich, Germany, 23–25 May 2000; pp. 265–268.
- Conradsen, K.; Nielsen, A.A.; Sehou, J.; Skriver, H. A test statistic in the complex wishart distribution and its application to change detection in polarimetric sar data. IEEE Trans. Geosci. Remote Sens. 2003, 41, 4–19. [Google Scholar] [CrossRef]
- Lee, J.S.; Grunes, M.R. Classification of multi-look polarimetric SAR data based on complex Wishart distribution. In Proceedings of the 1992 IEEE National Telesystems Conference, George Washington University, Virginia Campus, Washington, DC, USA, 19–20 May 1992; pp. 21–24.
- Ainsworth, T.L.; Lee, J.S. Polarimetric SAR image classification employing subaperture polarimetric analysis. In Proceedings of the 2005 IEEE International Geoscience and Remote Sensing Symposium, Seoul, Korea, 25–29 July 2005; pp. 41–43.
- Ainsworth, T.L.; Jansen, R.W.; Lee, J.S.; Fiedler, R. Sub-aperture analysis of high-resolution polarimetric SAR data. In Proceedings of the 1999 IEEE International Geoscience and Remote Sensing Symposium, Hamburg, Germany, 28 June–2 July 1999; pp. 41–43.
- Ferro-Famil, L.; Reigber, A.; Pottier, E.; Boerner, W.M. Analysis of anisotropic behavior using sub-aperture polarimetric SAR data. In Proceedings of the 2003 IEEE International Geoscience and Remote Sensing Symposium, Toulouse, France, 21–25 July 2003; pp. 434–436.
- Ferro-Famil, L.; Reigber, A.; Pottier, E. Nonstationary natural media analysis from polarimetric sar data using a two-dimensional time-frequency decomposition approach. Can. J. Remote Sens. 2005, 31, 21–29. [Google Scholar]
- Reigber, A.; Jager, M.; He, W.; Ferro-Famil, L.; Hellwich, O. Detection and classification of urban structures based on high-resolution SAR imagery. In Proceedings of the 2005 IEEE International Urban Remote Sensing Joint Event, Paris, France, 11–13 April 2007; pp. 1–6.
- Runkle, P.; Nguyen, L.H.; McClellan, J.H.; Carin, L. Multi-aspect target detection for sar imagery using hidden markov models. IEEE Trans. Geosci. Remote Sens. 2001, 39, 46–55. [Google Scholar]
- Chen, M. Comparing traditional statistics, decision tree classification and support vector machine techniques for financial bankruptcy prediction. Intell. Autom. Soft Comput. 2012, 18, 65–73. [Google Scholar]
- Kimura, H. Radar polarization orientation shifts in built-up areas. IEEE Trans. Geosci. Remote Sens. 2008, 5, 217–221. [Google Scholar]
- Cloude, S.R. Target decomposition theorems in radar scattering. Electron. Lett. 1985, 21, 22–24. [Google Scholar] [CrossRef]
- Cloude, S.R.; Pottier, E. An entropy based classification scheme for land applications of polarimetric sar. IEEE Trans. Geosci. Remote Sens. 1997, 35, 68–78. [Google Scholar]
- Wang, Y.Y.; Li, J. Feature-selection ability of the decision-tree algorithm and the impact of feature-selection/extraction on decision-tree results based on hyperspectral data. Int. J. Remote Sens. 2008, 29, 2993–3010. [Google Scholar]
- Pang, S.L.; Gong, J.Z. C5.0 classification algorithm and application on individual credit evaluation of banks. Syst. Eng.—Theory Pract. 2009, 29, 94–104. [Google Scholar]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Story, M.; Congalton, R.G. Accuracy assessment-a user’s perspective. Photogramm. Eng. Remote Sens. 1986, 52, 397–399. [Google Scholar]
- Qia, Z.; Yeh, A.G.O.; Li, X.; Zheng, L. A novel algorithm for land use and land cover classification using RADARSAT-2 polarimetric SAR data. Remote Sens. Environ. 2012, 118, 21–39. [Google Scholar] [CrossRef]
- Lee, J.S.; Ainsworth, T.L. The effect of orientation angle compensation on coherency matrix and polarimetric target decompositions. IEEE Trans. Geosci. Remote Sens. 2011, 49, 53–64. [Google Scholar]
- Lardeux, C.; Frison, P.L.; Rudant, J.P.; Souyris, J.C. Use of the SVM classification with polarimetric SAR data for land use cartography. In Proceedings of the 2006 IEEE International Geoscience and Remote Sensing Symposium, Denver, CO, USA, 31 July–4 August 2006; pp. 493–496.
- Lim, T.S.; Loh, W.Y.; Shih, Y.S. A comparison of prediction accuracy, complexity, and training time of thirty-three old and new classification algorithms. Machine Learning 2000, 40, 203–228. [Google Scholar] [CrossRef]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, L.; Yan, Y.-n.; Sun, C. Use of Sub-Aperture Decomposition for Supervised PolSAR Classification in Urban Area. Remote Sens. 2015, 7, 1380-1396. https://doi.org/10.3390/rs70201380
Deng L, Yan Y-n, Sun C. Use of Sub-Aperture Decomposition for Supervised PolSAR Classification in Urban Area. Remote Sensing. 2015; 7(2):1380-1396. https://doi.org/10.3390/rs70201380
Chicago/Turabian StyleDeng, Lei, Ya-nan Yan, and Chen Sun. 2015. "Use of Sub-Aperture Decomposition for Supervised PolSAR Classification in Urban Area" Remote Sensing 7, no. 2: 1380-1396. https://doi.org/10.3390/rs70201380
APA StyleDeng, L., Yan, Y. -n., & Sun, C. (2015). Use of Sub-Aperture Decomposition for Supervised PolSAR Classification in Urban Area. Remote Sensing, 7(2), 1380-1396. https://doi.org/10.3390/rs70201380