1. Introduction
An urban forest is defined as a forest or a collection of trees that grow within a city, town, or suburb. Urban forests provide a number of benefits such as saving energy and reducing air pollution. To maximize these benefits, an urban forest inventory is often needed for planning and management purposes. However, urban forestry databases are rare, incomplete, and infrequently updated because traditional ground surveys are time-consuming, costly, and labor-intensive. Thus, relatively little is known about urban forest resources. With the emergence of Light Detection and Ranging (LiDAR) techniques, it has been anticipated that the urban forest inventory can be automated.
LiDAR is facilitated with the ability to “see” the ground through openings in canopies and to detect the 3-D structure of trees. Research into the application of LiDAR in forests started in 1980s. Early work mainly focused on the quantification of a forest using profiling LiDAR systems at the stand level [
1,
2]. Stand level measurements are more important than the individual tree level for natural forest management. However, an urban forest is a mosaic of many different species and ages, and commonly has a higher degree of spatial heterogeneity. Thus, more detailed information is usually needed by community managers.
Modern scanning LiDAR technology has allowed for the estimation of inventory elements at the individual tree level due to the great increase in sampling rate. A range of methods have been explored to detect single trees, many of which are based on a LiDAR-derived canopy height model (CHM), a raster surface interpolated from LiDAR points hitting on the tree canopy surface (e.g., [
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17]). These algorithms are favored in many commercial and business environments mainly because of the speed of processing and the accessibility to software that commonly uses regularly spaced data (
i.e., rasters). There are several problems with using these methods. First, the derivation of CHM introduces errors and uncertainties due to both the interpolation methods and the grid spacing chosen [
18]. This will ultimately affect the subsequent estimation of tree metrics [
19]. Second, the Gaussian smoothing step for alleviating the rough surface of the canopy may lead to under- or overestimates of tree height [
20].
Several fundamental tree parameters such as height, base height, crown depth, and crown diameter can actually be estimated from the LiDAR point clouds, as illustrated in
Figure 1. Tree height is the length along the main axis from the treetop to the base of a tree. Crown depth is the length along the main axis from the treetop to the base of the crown. Base height is the length from the base of the crown to the base of the tree. Crown diameter, also known as crown width, is the span of the crown of a tree. Several researchers have developed automated methods for extracting individual trees from the LiDAR point clouds leading to varying degree of success. Mosdorf
et al. (2004) [
21] applied the
k-means clustering algorithm to detect individual trees. Their clustering method depends on seed points extracted from the LiDAR-derived CHM, thus this method is not an approach relying on point clouds only. Reiberger
et al. (2009) [
22] used a normalized-cut segmentation approach that subdivides the tree area into a voxel space and then extracted single trees from identified graphs. Lee
et al. (2010) [
23] developed an adaptive clustering method to segment individual tree crowns. Tittmann
et al. (2011) [
24] developed a RANdom SAmple Consensus (RANSAC)-based approach using a geometric model fitting strategy to identify individual tree crowns. Li
et al. (2012) [
25] proposed a spacing-based tree segmentation algorithm for a mixed conifer forest. Sima and Nüchter (2012) [
26] used a graph-based segmentation approach to LiDAR point clouds. These methods have been tested in natural forests dominated by conifers. Several researchers reported the applicability of LiDAR data in urban forests. Haala and Brenner (1999) [
27] extracted buildings and trees in urban environments by classifying rasterized LiDAR data and multispectral imagery. Wu
et al. (2013) [
28] developed a voxel-based method to identify individual street trees and estimate morphological parameters from mobile laser scanning data. Liu
et al. (2013) [
29] applied a surface growing algorithm to segment individual tree crowns from LiDAR point cloud data. Holopainen
et al. (2013) [
30] evaluated the accuracy and efficiency of airborne, terrestrial, and mobile laser-scanning methods for urban tree mapping. None of these methods were designed to estimate tree metrics for urban forest inventory purposes. Most recently, Saarinen
et al. (2014) [
31] attempted to update urban tree attributes using multisource single tree inventory.
The challenges for urban forest inventory using LiDAR mainly come from three sources: the complexity of urban areas, the spatial heterogeneity of urban forests, and the diverse structure and shape of urban trees. Urban regions are a mosaic of buildings, roads, rivers, trees, and other ground surface features, which makes the LiDAR filtering process (separation of ground points from non-ground LiDAR points) more difficult. The spatial heterogeneity of urban forests is also a challenge. Unlike trees in natural forests, which tend to have similar canopy characteristics when spatially adjacent, trees in urban settings are often single trees or isolated groups with variable heights and crown widths, and multiple treetops. Urban forests are also rich in mixtures of many different tree species and ages with diverse shapes. Broadleaves and conifers are often blended with each other. These combined factors make automated urban forest inventory very difficult.
A few attempts have been made to detect and model forests in an urban environment using LiDAR data alone or a synergy of LiDAR and optical images (e.g., [
27,
28,
29,
30,
31,
32,
33,
34]), but application of LiDAR data for urban forest inventory at the individual tree level is still scarce. To this end, the main objective of this study is to develop new methods to isolate individual trees and estimate tree metrics (tree height, base height, crown depth, and crown diameter) from LiDAR point clouds, which can bring the automated urban forest inventory down to the individual tree level.
Figure 1.
Illustration of tree metrics estimation using raw LiDAR data.
Figure 1.
Illustration of tree metrics estimation using raw LiDAR data.
2. Study Area and Data
The Turtle Creek Corridor in north Dallas, Texas was selected as our study area (
Figure 2). The topography of the area is dominated by the Turtle Creek, which starts in north central Dallas (at 32°51'N, 96°48'W) and flows southwest five miles through Highland Park and University Park, to its mouth on the Trinity River (at 32°48'N, 96°50'W). Elevation in the study area varies from 112 meters to 156 meters, with the lower elevations found over the creek and higher elevations observed along the bank of the creek. This site is a typical urban area with complex spatial assemblages of vegetation, buildings, roads, creeks, and other man-made features. The Turtle Creek area has a complex ecosystem and has been a center of interest and development in Dallas for over 100 years. To better manage this asset, help understand the current ecosystem, and encourage the development of priorities over this region, the Turtle Creek Association conducted a field survey in August 2008, which was followed by a simultaneous acquisition of small footprint discrete LiDAR data and high spatial resolution hyperspectral images on 24 September 2008.
Figure 2.
Study site shown in a color composite from the collected hyperspectral data. Measured tree locations are shown in green dots.
Figure 2.
Study site shown in a color composite from the collected hyperspectral data. Measured tree locations are shown in green dots.
The field survey was conducted through a contract with Halff Associates, Inc. Only trees with a diameter at breast height (DBH) greater than four inches were measured and tagged with an identification number, resulting in a total of 2602 trees being surveyed in the Turtle Creek Corridor. Tree location, species attributes, DBH, and health condition were recorded for each measured tree.
Figure 2 shows the locations of these surveyed trees in green dots. Unfortunately, tree height, base height, crown depth, and crown radius were not measured during this survey. We thus went to the field and measured 144 trees using a TruPulse 360 Laser Range Finder and a Trimble Geo
XT GPS device in August 2010.
LiDAR data were collected by Terra Remote Sensing Inc. (TRSI) using a proprietary Lightwave Model 110 whisk broom scanning LiDAR system. An average point density of 3.5 p/m
2 was obtained due to an intentional 80% overlap between flights. The raw LiDAR point cloud data were processed by TRSI using Microstation Terrasolid and TRSI proprietary software. Final products were provided in the commonly used LAS LiDAR format with a projection of NAD_1983_UTM_Zone_14N. Additionally, fine spatial resolution optical hyperspectral images were simultaneously acquired with the LiDAR data using an AISA Dual hyperspectral sensor. Hyperspectral images with 492 spectral bands were acquired at a spatial resolution of 1.6 m. Radiometric calibration and geometric correction were performed by the vendor. The original collected images were transformed from raw digital numbers to radiance by applying a pixel by pixel correction using the gain and offset. The offset was extracted from data stored in the “dark” files, which are sensor readings with a closed shutter in order to estimate sensor noise. The gain was extracted from the calibration files supplied by the sensor manufacturer. During the transformation from raw to radiance values, further corrections for dropped lines and spectral shift were also applied. A transformation from radiance to surface reflectance of the entire image dataset was then carried out using ATCOR, a Modtran-based code specifically developed to perform atmospheric correction. For the geometric correction, the vendor used the LiDAR positional information to compute the real world coordinates of each pixel in the dataset, followed by re-sampling of the hyperspectral images. The preprocessed images were then mosaicked and clipped for the study area. A false color composite from the hyperspectral data for the study site is shown in
Figure 2.
3. Methodology
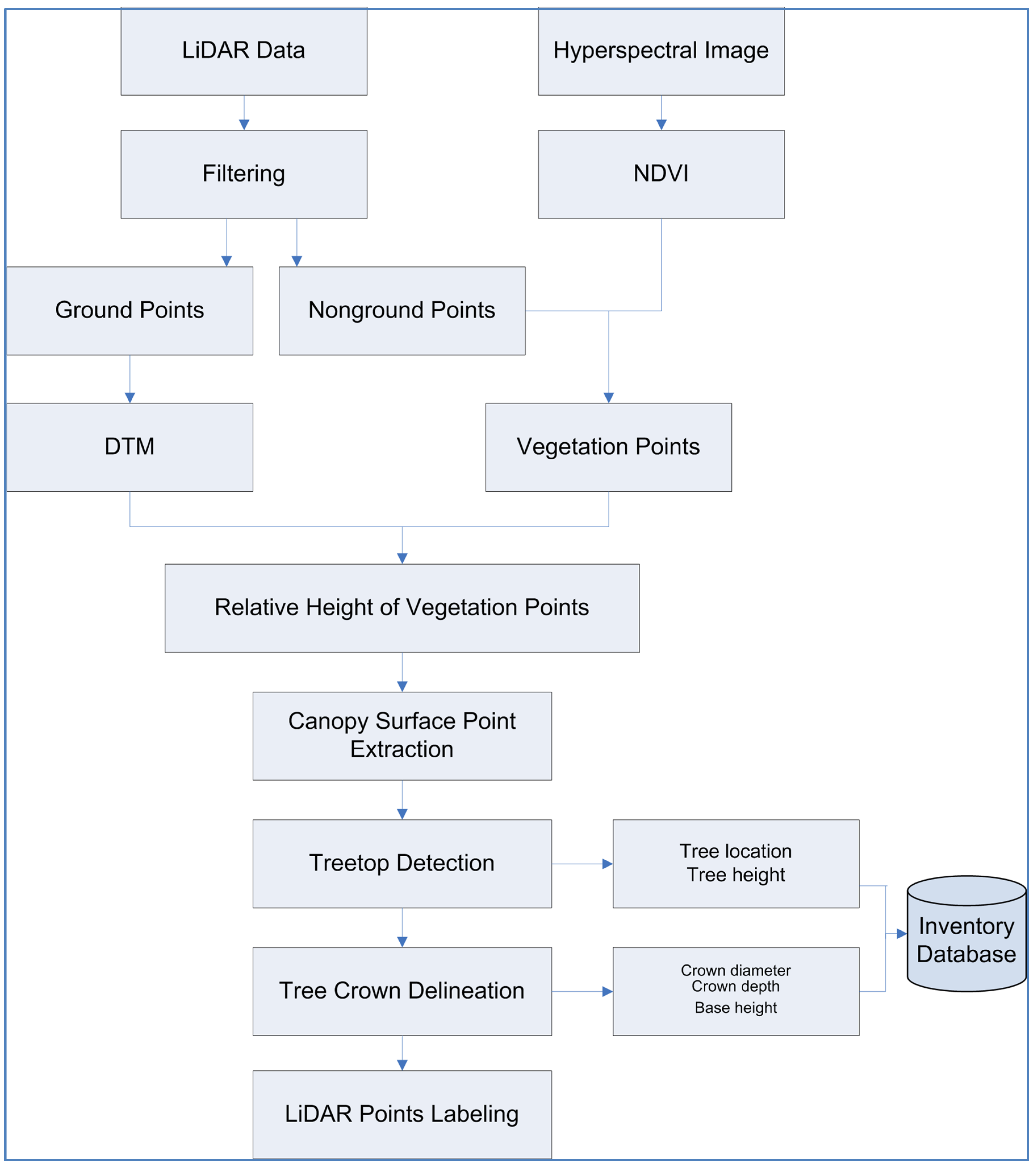
3.1. A Framework to Combine LiDAR and Hyperspectral Data for Urban Forest Inventory
In order to detect each individual tree and estimate its associated metrics (tree height, base height, crown depth, crown diameter), multiple data processing steps are required. These are summarized in
Figure 3. LiDAR data filtering is the first step to separate ground points from aboveground points. Ground points are then used to build a Digital Terrain Model (DTM), which will assist with the elimination of local terrain impact on tree metrics estimation. Among all the aboveground points, vegetation points then need to be separated from non-vegetation points. This is achieved by using the Normalized Difference Vegetation Index (NDVI) derived from the hyperspectral data. To extract individual trees, LiDAR points hitting on the tree canopy surface need to be extracted by isolating them from the points that penetrate into the canopy. After this, a treetop detection algorithm (referred to as the
tree climbing method) is applied to identify the treetop of each individual tree, and then a tree boundary extraction algorithm (referred to as the
donut expanding and sliding method) is used to isolate individual trees. All individual tree level attributes including tree location, height, base height, crown depth, and crown diameter are stored in a tree inventory database. Species for each LiDAR-detected tree can be identified using the hyperspectral data, which has been reported in Zhang and Qiu (2012) [
35]. There are three major steps in the framework: LiDAR data filtering, treetop detection, and individual tree extraction. They are described in the following subsections.
Figure 3.
The designed framework to combine LiDAR and hyperspectral data for urban forest inventory at the individual tree level.
Figure 3.
The designed framework to combine LiDAR and hyperspectral data for urban forest inventory at the individual tree level.
3.2. LiDAR Data Filtering and Canopy Points Separation
Various methods have been developed to automate LiDAR data filtering procedures. Sithole and Vosselman (2004) [
36] compared eight filters and found that these filters performed well in smooth rural landscapes, but they produced larger errors in complex urban areas and rough terrain with vegetation. Since a variety of feature types are present in our study area, none of these eight filters is likely to achieve satisfactory results. In this study, a vector-based filtering technique known as the
k mutual nearest neighborhood clustering algorithm [
37] was used. The idea of this algorithm is that points in a neighborhood sharing similar LiDAR attributes should belong to the same cluster which represents either ground or aboveground. A main advantage of this algorithm is that there is no loss of information by working directly with the raw LiDAR point clouds. More details of this algorithm can be found in Chang (2011) [
37]. The accuracy of the filtering result was assessed using the commonly adopted omission and commission error approaches based on randomly selected reference points. After data filtering, the ground derived points were used to generate the DTM that normalized the original LiDAR elevation data to eliminate the terrain effects.
To extract individual trees in the aboveground LiDAR point cloud, points hitting tree crowns need to be identified so that non-tree points will not interfere with individual tree isolation. The NDVI derived from the narrow-band hyperspectral data can be used for this purpose. We derived an NDVI image from the hyperspectral data (bands: 860 nm and 660 nm) and then spatially overlaid the aboveground LiDAR point cloud on it. The NDVI value at the cell in which the LiDAR point falls was then extracted as an additional attribute for the point. A LiDAR point with an NDVI value of more than zero was then considered as the vegetation point.
3.3. Treetop Detection
To effectively and efficiently find treetops, the LiDAR points hitting the tree canopy surface need to be extracted by isolating them from the points that penetrate into the canopy. This was accomplished by moving a square window over the study area in a non-overlapping manner and preserving the highest first-return pulse within it. After this, a treetop detection algorithm, tree climbing algorithm, was applied to identify the highest point (i.e. the treetop) of each individual tree.
Local maximum algorithms have been commonly used for treetop detection by finding the local maxima within a fixed or variable-sized window in a LiDAR-derived CHM (e.g., [
5,
8,
12]). The main problem of this approach is that large commission errors are generated, that is, non-treetop local maxima may be incorrectly classified as treetops [
12]. The local maximum method with a variable-sized window for treetop detection using LiDAR point cloud data suffers the same problem as the CHM-based methods [
20].
In this study, a treetop detection algorithm using LiDAR point clouds was developed based on an improvement to the local maximum method. The algorithm involves several steps. The first step is to select the first LiDAR point of the study area. The second step is to obtain the local maximum that is the highest point within a circle centered at the selected point. The third step is to designate the local maximum point as the new center and repeat steps two and three if the elevation at the local maximum point is higher than the elevation at the currently selected point (i.e., the current center); otherwise, flag the currently selected point as a potential treetop and stop searching the local maximum point. This process will continue for the remaining point clouds until all treetops are identified. This tree finding process is referred to as a tree climbing algorithm because a treetop can be reached from any direction.
The tree climbing algorithm described above may work for trees with a single well-defined apex, such as most conifers. However, for trees with multiple tops or a concave crown shape, commission errors may again occur. This is often the case for urban trees because most of them are broadleaves with complex shapes. False treetops may be detected in these situations. A simple and effective solution to this problem is to use a horizontal threshold (H) to remove the false treetops. Among all the treetops detected using the tree climbing algorithm, if the horizontal Euclidean distance of two treetops is less than the defined threshold, then the lower treetop is dropped and the higher one will be preserved for further analysis. This improved treetop detection method is referred to as the constrained tree climbing algorithm because it incorporates a horizontal threshold. Also note that the aboveground LiDAR vegetation points may come from shrubs; thus, if the height of the detected trees is less than 1.5 m, then the detected trees are considered as shrubs to be dropped.
4. Results and Discussion
4.1. Filtering Results
A total of 4,310,395 original LiDAR points were first filtered by the
k mutual nearest neighborhood clustering algorithm, leading to the identification of 969,836 ground points and 3,340,559 aboveground points, as shown in
Figure 4. A zoomed view of the filtering results or a selected region is also displayed (see
Figure 4, right panel). As can be seen, the LiDAR points falling on roads, bare soil, and lawns were filtered as ground points (
Figure 4a), while those hitting buildings and tree canopies were filtered as aboveground points (
Figure 4b). A digital surface model (DSM) was generated using all LiDAR points (
Figure 5a) and the DTM was generated (
Figure 5b). The complexity of this urban view arises from the variety of aboveground features depicted on the DSM. The DTM effectively reveals the bare earth topography and preserves linear features such as roads. The bases of buildings can also be easily detected in the DTM once the aboveground points are removed. Visual comparison of the DSM and DTM illustrates that aboveground features were successfully separated from the bare earth beneath them, suggesting that the filtering algorithm performed well in this complex urban area. Accuracy assessment of the filtering results for the study site showed an omission error of 3.9% and commission error of 1.4% based on randomly selected reference points [
37].
Figure 4.
(a) Separated ground points in blue dots. (b) Separated non-ground points in green dots for the study area.
Figure 4.
(a) Separated ground points in blue dots. (b) Separated non-ground points in green dots for the study area.
Figure 5.
LiDAR-derived (a) DSM and (b) DTM for the study site (unit: meters; cell size: 1 m).
Figure 5.
LiDAR-derived (a) DSM and (b) DTM for the study site (unit: meters; cell size: 1 m).
The vertical accuracy of LiDAR-derived DTM was assessed using 370 field-surveyed elevation points, which are randomly distributed over the study area. In the literature, Root Mean Square Error (RMSE) has often been used to evaluate the accuracy of a LiDAR estimated DTM. An RMSE of 0.4 m was obtained for the DTM, suggestive of a reliable DTM. An accurate DTM is critical for tree parameter extraction because it provides the base from which the relative height of each LiDAR point is calculated, thus the accuracy of the DTM is reflected indirectly in the accuracy of the estimated tree heights.
4.2. Detected Tree Numbers
The detection of individual trees from a vegetation point cloud is one of the most difficult estimation tasks using airborne LiDAR. To achieve this, the top of each tree was first identified using the proposed
tree climbing algorithm, assuming that each tree has only one highest point. The number of trees was then estimated by counting the number of treetops identified by the algorithm. To assess the accuracy of the LiDAR-derived tree numbers, 17 spatially homogenous subareas were selected in the study site. A total of 11,434 trees were estimated for the entire area. The tree count was severely overestimated for each subarea from the original
tree climbing algorithm. To better detect individual trees and obtain a more accurate tree count, we applied the
constrained tree climbing algorithm, leading to a total of 2652 detected trees and an average agreement of 93.5%. The number of LiDAR-detected, field-surveyed trees, as well as the calculated agreement for the 17 subareas, are shown in
Table 1. The best results were observed in subareas 3 and 17, where a 99.1% agreement was achieved. Subarea 10 had the least agreement, with 32 out of 41 trees being detected. To further assess the commission and omission errors in LiDAR tree detection, a revised tree matching scheme was used based on the strategy in Kaartinen
et al. (2012) [
15]. When a LiDAR-detected tree was within a distance of 5 m to a field tree or a field tree was within a LiDAR-estimated tree crown, this field tree was assumed to be found in LiDAR-detected trees. In this way, a total of 2360 field trees found their corresponding LiDAR trees, leading to an omission error of 9.4%. Any LiDAR-detected trees without corresponding field references were assumed to be extra trees. This led to a total of 633 unmatched trees, resulting in a commission error of 24.3%.
There is one parameter in the tree climbing algorithm, the radius of the circle (r) for searching local maximum. Values that are too small or too large will lead to commission errors or omission errors, respectively. For the constrained tree climbing algorithm, a small value is preferred because false treetops can be removed by applying the horizontal threshold (H) in the subsequent procedure of the algorithm. The value of H can be empirically set based on field data. For this study, a heuristic method was designed to optimally set this value through a training process using the field survey data. This method involves several steps. Begin with a small value for this threshold such as one equal to the point spacing (d). Next, run the false treetop removal algorithm and obtain the number of newly estimated treetops. If the new number of treetops is more than that of the field survey trees, then the value set for this threshold will be gradually increased and the treetop removal algorithm will be repeated until an expected number for detected trees is obtained for the testing area. Both parameters (r and H) can be locally adjusted based on prior knowledge of the study area, such as whether the area is characterized by well-separated single trees or severely overlapping trees, to obtain better results.
The detection of individual trees is one of the most challenging but at the same time most important tasks for a LiDAR-based urban forest inventory. It is anticipated that errors may occur in attempting to estimate individual trees because of the complex crown shapes of urban trees. However, the estimations demonstrated that the results are in good agreement with the field data. This may be attributed to the higher degree of spatial homogeneity of trees within each subarea than within the entire study areas. As far as the algorithm is concerned, potential sources of error remain. Underestimations might occur if small trees are located next to big ones because lower trees could be considered as the branches of big trees, and thus incorrectly removed during the treetop removal procedure. Overestimations could also occur if tree crowns are so big that some branches extend far from the crown. The algorithm may fail to identify these far-extending branches as false treetops, thus leading to overestimation.
Table 1.
The number of LiDAR-detected, field-surveyed trees, and agreement of LiDAR detection for 17 selected testing subareas.
Table 1.
The number of LiDAR-detected, field-surveyed trees, and agreement of LiDAR detection for 17 selected testing subareas.
| Subarea | No. of LiDAR-Detected Trees | No. of Field-Surveyed Trees | Agreement |
|---|
| 1 | 69 | 68 | 98.5% |
| 2 | 196 | 186 | 94.6% |
| 3 | 117 | 116 | 99.1% |
| 4 | 45 | 42 | 92.9% |
| 5 | 235 | 242 | 97.1% |
| 6 | 502 | 488 | 97.1% |
| 7 | 97 | 93 | 95.7% |
| 8 | 215 | 227 | 94.8% |
| 9 | 131 | 128 | 97.7% |
| 10 | 41 | 32 | 71.9% |
| 11 | 191 | 163 | 82.8% |
| 12 | 161 | 170 | 94.8% |
| 13 | 68 | 72 | 94.4% |
| 14 | 52 | 48 | 91.7% |
| 15 | 41 | 46 | 90.1% |
| 16 | 263 | 257 | 97.7% |
| 17 | 228 | 226 | 99.1% |
| Total | 2652 | 2604 | 93.5% |
4.3. Tree Height Estimation
Tree height is one of the most important variables in forest inventory and can be estimated from LiDAR-detected treetops. Tree height for each individual tree is estimated by subtracting the elevation of the terrain from the elevation of treetops. To assess the accuracy of the estimation, field measurements for 144 trees were taken using a Laser Range Finder and then compared with the LiDAR-derived estimations. The summary statistics of the datasets for estimations and field measurements are listed in
Table 2. The field-measured heights range from 5.18 m to 26.49 m, with an average of 14.07 m and a standard deviation of 3.95 m, while the LiDAR-estimated tree heights range from 5.43 m to 23.05 m, with an average of 13.9 m and a standard deviation of 3.85 m. These values suggest general agreement between the two datasets. The largest discrepancy between LiDAR-estimated and field-measured heights is 5.97 m, and the difference between their means is 0.17 m. In the literature, RMSE has been used to evaluate the accuracy of LiDAR estimated tree heights. A RMSE of 1.7 m was obtained using 144 field measured tree heights as reference. A linear regression was conducted with the LiDAR-estimated height as the independent variable and the field-measured height as the dependent variable. An R-square value of 0.93 was obtained for the regression (
Table 3). A scatter plot (not shown here) of these two variables revealed a few outliers. These outliers were further detected using the statistical studentized residual test, a widely used technique for the diagnosis of outliers. The occurrence of outliers may be attributed to several factors, including the mismatch between the LiDAR-detected treetops and ground-surveyed treetops, as well as errors caused by inappropriate operation of the Laser Range Finder during the field survey procedure. Outliers are most likely to occur where the terrain is rough and in neighborhoods where trees significantly overlap each other. For example, the surveyors may miss a treetop when using the Laser Ranger Finder to measure tree heights and record the readings from nearby trees instead. To minimize the influence of the outliers, a new regression was conducted with the outliers removed from the dataset. Subsequently, the R-square value increases from 0.93 to 0.98 and the RMSE is decreased from 1.11 m to 0.57 m (
Table 3).
Table 2.
Summary statistics of field-measured vs. LiDAR-estimated tree height, crown diameter, base height, and crown depth.
Table 2.
Summary statistics of field-measured vs. LiDAR-estimated tree height, crown diameter, base height, and crown depth.
| | Field (meter) | LiDAR (meter) |
|---|
| | Max. | Min. | Mean | Std. | Max. | Min. | Mean | Std. |
| Tree Height | 26.49 | 5.18 | 14.07 | 3.95 | 23.05 | 5.43 | 13.90 | 3.85 |
| Crown Diameter | 28.02 | 4.12 | 13.37 | 5.84 | 25.96 | 3.86 | 11.70 | 4.75 |
| Base Height | 8.32 | 1.49 | 4.13 | 1.20 | 8.50 | 1.12 | 4.54 | 1.53 |
| Crown Depth | 21.61 | 2.38 | 9.86 | 3.51 | 21.36 | 2.25 | 8.93 | 3.25 |
Table 3.
Statistics for regressions of field-measured and LiDAR-estimated tree height, crown diameter, base height, and crown depth with and without outliers.
Table 3.
Statistics for regressions of field-measured and LiDAR-estimated tree height, crown diameter, base height, and crown depth with and without outliers.
| | With Outliers | Without Outliers |
|---|
| | R2 | RMSE (meter) | R2 | RMSE (meter) |
| Tree Height | 0.93 | 1.11 | 0.98 | 0.57 |
| Crown Diameter | 0.70 | 2.58 | 0.84 | 1.90 |
| Base Height | 0.63 | 1.79 | 0.84 | 0.94 |
| Crown Depth | 0.71 | 2.39 | 0.84 | 1.61 |
Overall, the results demonstrate that tree height can be accurately estimated using LiDAR point cloud data. LiDAR estimations for tree heights can explain 98% of the variance of field measurement after the outliers were detected and removed. The findings are particularly important given that tree heights on the ground are more difficult and costly to collect than species types, especially in densely forested areas. As suggested in the literature, it was anticipated that LiDAR-based estimation tends to underestimate tree heights, which was evidenced by the smaller mean of LiDAR-estimated tree height compared to that of the field-measured height. This is because there is a high probability for the LiDAR pulse to miss a treetop, especially when average spacing of the LiDAR point cloud is large. The LiDAR-estimated tree heights have an average only 0.17 m lower than that of the field measurements. This may be attributed to the fact that most trees in this study area are broadleaved and have a wider top than conifers, increasing the probability that laser pulses hit the vicinity of the treetops. Also note that there is around a two-year time gap between LiDAR and field data collection, which may partially explain the errors in the estimation.
When evaluating the accuracy of LiDAR-estimated tree heights using Laser Range Finder measurements as reference data, one should bear in mind that both LiDAR point cloud data and reference data have measurement uncertainties. When measuring tree heights using the Laser Range Finder, the operators may not be able to locate a treetop exactly, but can often find an approximate location close to the top when firing the device to record its elevation. It was also noted earlier that the error of the Laser Range Finder itself is ± 0.3 m in its distance measurements. The LiDAR point cloud data also has a vertical measurement uncertainty of ± 0.15 m. Leaving out operator-caused uncertainty, the combined uncertainty for LiDAR and Laser Range Finder measurement can be as high as ± 0.45 m. If the 0.45 m measurement uncertainty were able to be excluded, the RMSE of LiDAR-estimated tree heights would be reduced to 0.66 m and 0.12 m with and without the outliers, respectively.
4.4. Crown Size Estimation and Individual Tree Extraction
In forestry, crown size is usually represented by the maximum diameter of a crown. In this study, crown diameters were estimated using the
donut expanding and sliding method, which determines the diameter of the outermost donut and uses it as the estimated crown diameter. A total of 93 trees with field-measured crown diameters from the Laser Range Finder were used to assess the LiDAR estimations. The summary statistics for estimated and field-measured crown diameter are also listed in
Table 2. The crown diameters measured by the Laser Range Finder vary from 4.12 m to 28.02 m, with an average of 13.37 m and a standard deviation of 5.84 m. Comparatively, LiDAR-estimated crown diameters vary from 3.86 m to 25.96 m, with an average of 11.70 m and a standard deviation of 4.75 m. The scatter plot with the regression line between the estimated and the measured again reveals the existence of several outliers and seven were diagnosed by the statistical studentized residual test. After deleting these seven outliers, the R-square value increased from 0.7 to 0.84, and the RMSE decreased from 3.58 m to 1.9 m (
Table 3). By subtracting the combined uncertainties of the Laser Range Finder and LiDAR, the RMSE could be reduced to 1.45 m.
Crown size is not always measured in urban forest inventories, but it is needed if the canopy cover is to be determined as a parameter for urban ecosystem modeling. When needed, crown size is usually either obtained through field sampling or estimated from other parameters. According to the literature, crown diameter estimated from LiDAR is usually less accurate than tree height. In estimating crown diameters, Gill
et al. (2000) [
38] obtained R-square values in the range of 0.27 to 0.61 for several conifer species. Popescu
et al. (2003) [
39] obtained R-square values of 0.62 and 0.63 for pines and deciduous trees, respectively, and Heurich
et al. (2004) [
40] reported R-square values of 0.48 for conifers and 0.31 for deciduous trees. In this study, an R-square value of 0.84 was achieved. This higher accuracy may be attributed to the use of the original LiDAR point cloud instead of derived raster surface as in the other studies. The challenges in estimating crown diameters using LiDAR include the complexity of crown shapes and the low density of LiDAR sampling. Our method may underestimate the crown size for overlapping trees and produce relatively better results for single trees.
A total of 20,736 trees were detected and segmented. Their treetops and delineated tree crowns using the
isotropic donut expanding and sliding algorithm are shown in
Figure 6. The complexity of this urban forest is well presented with varying crown size, high spatial heterogeneity, and both well-separated and overlapping trees.
Figure 6.
Detected trees shown in green dots for the study area (left) and delineated crowns for a zoomed region (right).
Figure 6.
Detected trees shown in green dots for the study area (left) and delineated crowns for a zoomed region (right).
The donut expanding and sliding method assumes that the tree crown is symmetrical in shape and its projection on the ground is a circle, which may not be true in the real world, especially for urban trees that usually have complex geometric shapes. An improvement on this method is to incorporate the concept of anisotropy into the algorithm. Anisotropy is the property of being directionally dependent, as opposed to isotropy, which exhibits homogeneity in all directions. In the improved tree segmentation method, each tree crown boundary is searched from the treetop outward in four or more directions. In the case of searching in four directions, a Cartesian coordinate system from a selected treetop needs to be built first. The tree crown boundary is then searched separately in each quadrant in a similar manner to the donut expanding and sliding algorithm but only using LiDAR points falling into that quadrant. The anisotropic donut expanding and sliding method delineates crowns in more detail by searching multiple directions in order to model more effectively the complexity of tree crown shapes.
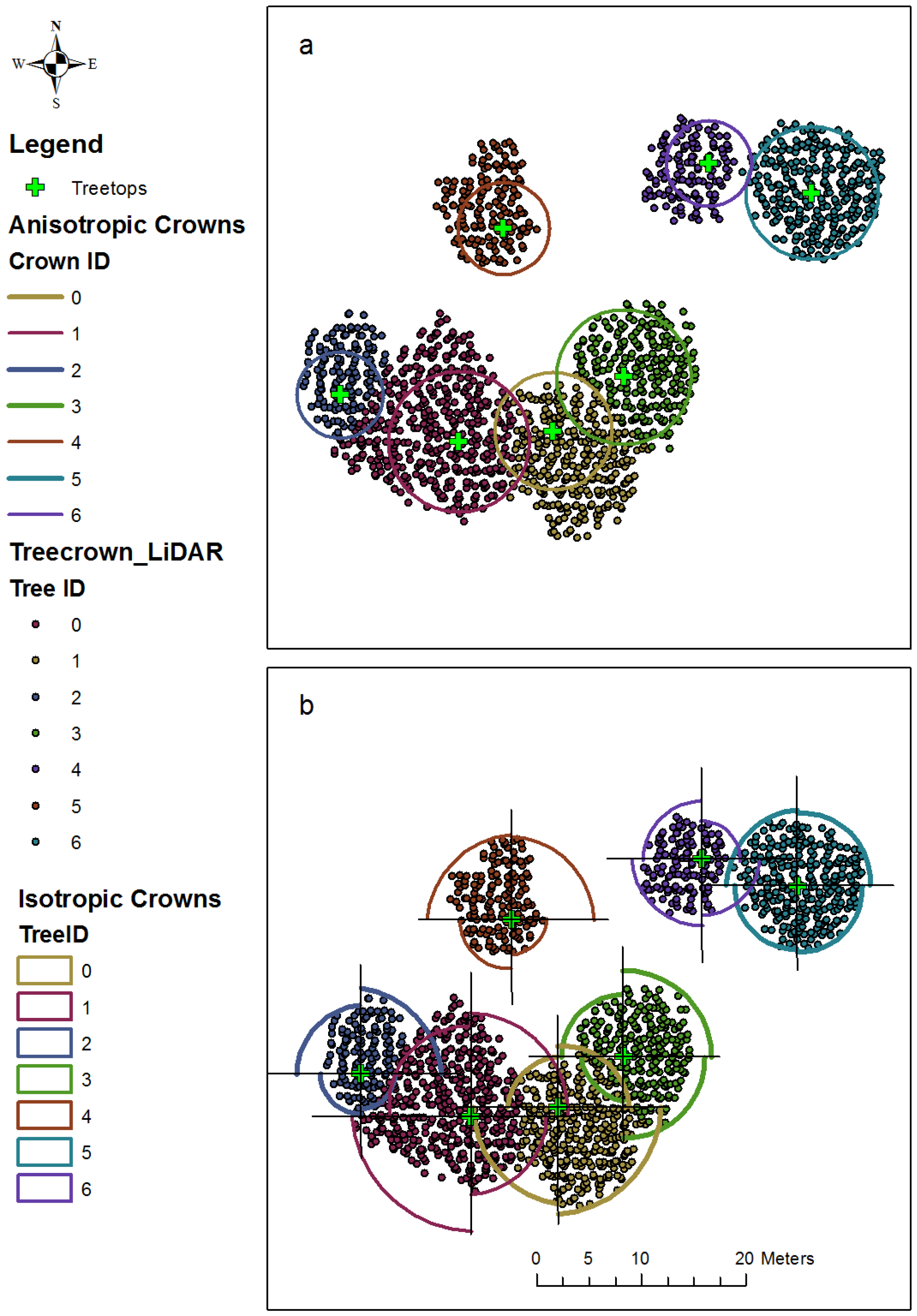
A testing of the isotropic and anisotropic
donut expanding and sliding algorithms is displayed for a portion of the study area in
Figure 7a and
Figure 7b, respectively. A total of seven trees were detected, three well separated and four overlapped. The diverse size and complex crown shapes of this testing area are well exhibited by the LiDAR point cloud data. The estimated crown boundary is a circle when the isotropic
donut expanding and sliding method is applied (
Figure 7a), which assumes that the shape of tree crowns is symmetrical. The crown boundary defined for each tree is irregular with quadrants of different radii when four directions are considered in the algorithm (
Figure 7b).
Two parameters need to be specified in the donut expanding and sliding algorithm: the initial radius of the circle (r) and the expanding radius (). The initial radius was set as the smallest crown size in the ground inventory. The expanding radius cannot be too small or too big. A value that is too small will lead to a small number of points within the donut, which may not be enough to indicate the declining of tree crowns. A value that is too large may include points hitting on neighboring trees. Our experiments, by gradually increasing at an interval of half of the point spacing (d), indicate that = 1.5d can produce the best result for crown size estimation.
Figure 7.
Defined crown boundary and extracted individual trees for a portion of the study area from (a) the isotropic and (b) anisotropic donut expanding and sliding method.
Figure 7.
Defined crown boundary and extracted individual trees for a portion of the study area from (a) the isotropic and (b) anisotropic donut expanding and sliding method.
4.5. Crown Base Height and Depth Estimation
The base height and crown depth were measured for 140 trees in the field using the Laser Range Finder, which were then used to assess the accuracy of the LiDAR estimations for these two variables. The summary statistics of the two datasets show that the field-measured base heights vary from 1.49 m to 8.32 m, with an average of 4.13 m and a standard deviation of 1.2 m, while LiDAR-estimated base heights range from 1.12 m to 8.5 m, with an average of 4.54 m and a standard deviation of 1.53 m (
Table 2). These values are again similar in magnitude. A regression was conducted with the field-measured base height as the dependent variable and LiDAR-estimated base height as the independent variable. The results show that the LiDAR estimations can explain 63% of the field-measured base height variance (
Table 3). Six outliers were observed in the regression scatter plot and they were again diagnosed using the statistical studentized residual test. After deleting these diagnosed outliers, the R-square value increases to 0.84 from 0.63, and the RMSE decreases to 0.94 m from 1.79 m (
Table 3). Similarly, if the combined uncertainty of 0.45 m from LiDAR and Laser Range Finder measurement was excluded, the RMSE of LiDAR-estimated base heights could be reduced to 0.49 m without the outliers.
The accuracy of the LiDAR-estimated crown depths was analyzed using the Laser Range Finder measured depths for 140 trees. The LiDAR-estimated
vs. field-measured crown depths and the difference between them are given in
Table 2. Large variation of crown depth is observed in this area, with a range from 2.38 m to 21.61 m for the field measurements, and a range from 2.25 m to 21.36 m for the LiDAR estimations. The average crown depth for field measurements is 9.86 m, and the average crown depth for LiDAR estimations is 8.93 m. The standard deviation of crown depth for field measurements is 3.51 m and for the LiDAR estimations the standard deviation is 3.25 m (
Table 2). On average, LiDAR underestimated the crown depth by 0.94 m but overall the estimates exhibit a close correspondence to the field data. Regression results demonstrate that LiDAR can explain 71% of the variance of the field measurements (
Table 3). The scatter plot reveals the existence of a few outliers falling far away from the regression line. A statistical studentized residual test detected a total of 10 outliers. After deleting these outliers, the RMSE decreases from 2.39 m to 1.61 m, and the R-square value increases from 0.71 to 0.84. The RMSE could be further reduced to 1.16 m if the combined measurement uncertainty of 0.45 m from the LiDAR and Laser Range Finder devices were able to be removed. Again, the time gap between LiDAR data and field data collection may explain part of the disagreement in the estimation.
The results for the base height and crown depth estimation are encouraging. Similar to the tree height, these two parameters are also difficult to measure in the field, especially for densely forested areas. Part of the unexplained variance may be attributed to the ground irregularities of the bare earth surface, which may lead to uncertainties in measuring the elevation of tree base using the Laser Range Finder. Furthermore, the lowest point of a canopy used to determine the canopy base height may be blocked by thick foliage cover above it and missed by any LiDAR pulse, especially for broadleaved trees with complex crown shape. Higher LiDAR sampling density may lead to better estimation of base height accuracy because more LiDAR echoes from lower branches could be received and the probability of hitting the lowest branches would be increased. Also note that the errors in tree height estimations are the propagated estimations of base height and crown depth since the latter is derived partly based on the former.
By jointly analyzing the LiDAR tree detection and tree metrics estimation results and the tree species map produced from hyperspectral data [
28], we found that better results were produced for areas with relatively homogeneous characteristics (
i.e., similar species and tree height), or regions where trees are well-separated such as street trees. This is expected given that heterogeneous areas are more complex in tree size, structure, and shape or dominated by overlapping trees. Increasing of LiDAR point density may produce better results. In addition, availability of more prior information for each specific region in the study area could improve the performance of the algorithms.
5. Conclusions
In this study, we developed new algorithms for detecting individual trees and estimating related tree metrics from LiDAR point clouds for urban forest inventory purpose. These algorithms were tested in a typical urban forest. The results illustrated that individual trees can be detected from LiDAR point cloud data using the proposed tree climbing algorithm, and tree crowns can be delineated using the donut expanding and sliding method. Tree metrics (tree height, crown diameter, crown depth, and base height) can be estimated from original LiDAR data and the accuracy is reasonable. Seeing individual trees in a forest is important and should be the first step in the urban forest inventory. LiDAR point cloud data provide the possibility of effectively estimating the number of trees and their locations for a forest. The ability of the proposed algorithms to automatically and effectively estimate tree metrics is important because they are key variables for the prediction of other forest parameters. The research proved that LiDAR is a suitable technology in determining these parameters.
Note that only the NDVI imagery produced from the hyperspectral data was used in the LiDAR tree processing. A further integration of LiDAR and hyperspectral data using data fusion techniques may improve the accuracy of individual tree delineation, metrics estimation, and species classification. For example, the spectral information may be used to provide a better tree extraction by excluding LiDAR points with very different spectra at the edge of the tree. This could bring striking gains in characterizing urban forests, which would consequently accelerate the application of LiDAR and hyperspectral in their respective fields from scientific interests to commercial operational implementations. A complete fusion of the two data sources for forest applications is one of the major directions for future research.
Similar to other LiDAR algorithms using point cloud data, the proposed methods for treetop detection and individual tree extraction are time-consuming because a large volume of point cloud data needs to be processed. To address this problem, two solutions could be adopted in the future. The first one is software-based optimization of the LiDAR algorithm. The other solution is hardware-based. Using a graphics processing unit (GPU)-based computation systems to parallelize the proposed algorithms should greatly reduce the processing time. Indeed, combining these software and hardware solutions may, in fact, completely solve the computational bottle-neck problem for raw LiDAR data-based tree inventory.
The designed algorithms have so far only been tested over the Dallas urban area. Considerable additional research is needed in other urban areas with different species, forest compositions, and sensors in order to examine the robustness and extensibility of these techniques. It is also anticipated that the algorithm may work in non-urban forests with modifications to adapt to the natural environment, which would be a major task for future studies.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

