
Kernel Supervised Ensemble Classifier for the Classification of Hyperspectral Data Using Few Labeled Samples

 ,
,  , and
, and
Abstract
:
1. Introduction
2. Related Works
2.1. Rotation Forest
2.2. Orthonormalized Partial Least Square (OPLS)
| Algorithm 1 Rotation Forest |
Input: : training samples, T: number of classifiers, K: number of subsets (M: number of features in each subset), L: base classifier. The ensemble . : Feature set
|
| Prediction phase |
| Input: The ensemble . A new sample . Rotation matrix:. |
Output: class label
|
3. Proposed Classification Scheme
3.1. Kernel Orthonormalized Partial Least Square (KOPLS)
- Linear Kernel:
- Polynomial Kernel:
- Radial Basis Function Kernel:
3.2. Rotation Forest with OPLS
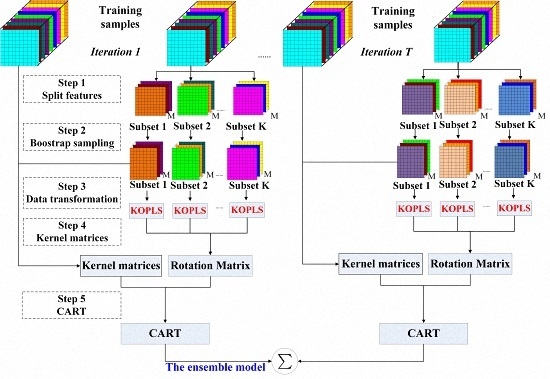
3.3. Rotation Forest with KOPLS
| Algorithm 2 Rotation Forest with KOPLS |
| Training phase |
| Input: : training samples, T: number of classifiers, K: number of subsets, M: number of features in a subset, L: base classifier. The ensemble . : Feature set |
Output: The ensemble
|
| Prediction phase |
| Input: The ensemble . A new sample . Rotation matrix: . |
Output: class label
|
4. Experimental Results
- Overall accuracy (OA) is the percentage of correctly classified pixels.
- Average accuracy (AA) is the average of percentages of classified pixels for individual class.
- Kappa coefficient (κ) is the percentage of agreement corrected by the level of agreement that would be expected by casually [23].
- Average of OA (AOA) is the average of OAs of individual classifiers within the ensemble.
4.1. Results of the AVIRIS Indian Pines Image
4.2. Results of the University of Pavia ROSIS Image
5. Discussion
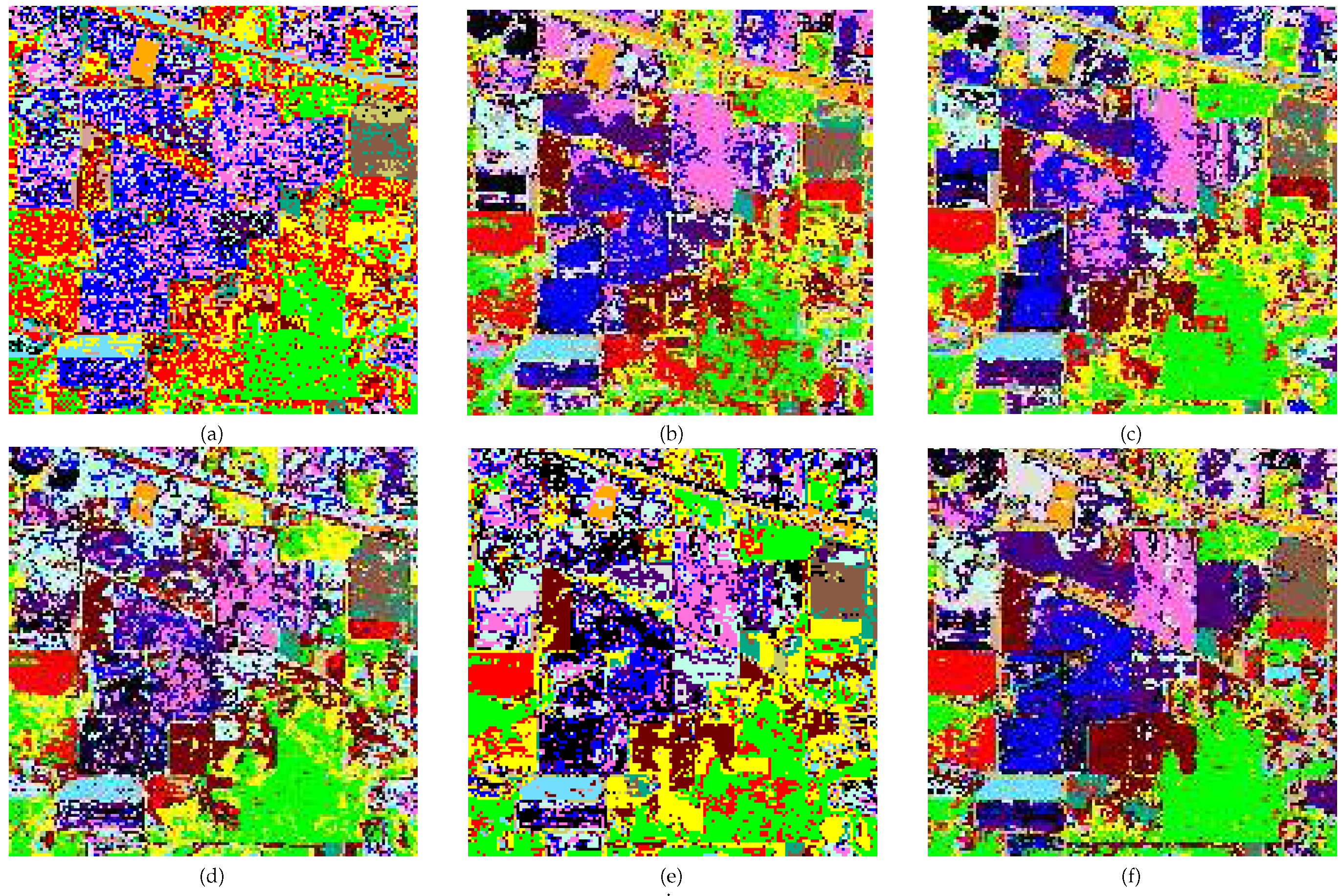
5.1. Discussion on the AVIRIS Indian Pines Image
5.2. Discussion on the University of Pavia ROSIS Image
6. Conclusions
- RoF-KOPLS with RBF kernel yields the best accuracies against the comparative methods above-mentioned due to the ability of improving the accuracy of base classifiers and the diversity within the ensemble, especially for the very limited training set.
- In RoF-KOPLS, the kernel functions can give rise to significant influences on the classification results. Experimental results have shown that RoF-KOPLS with RBF kernel obtained the best performances.
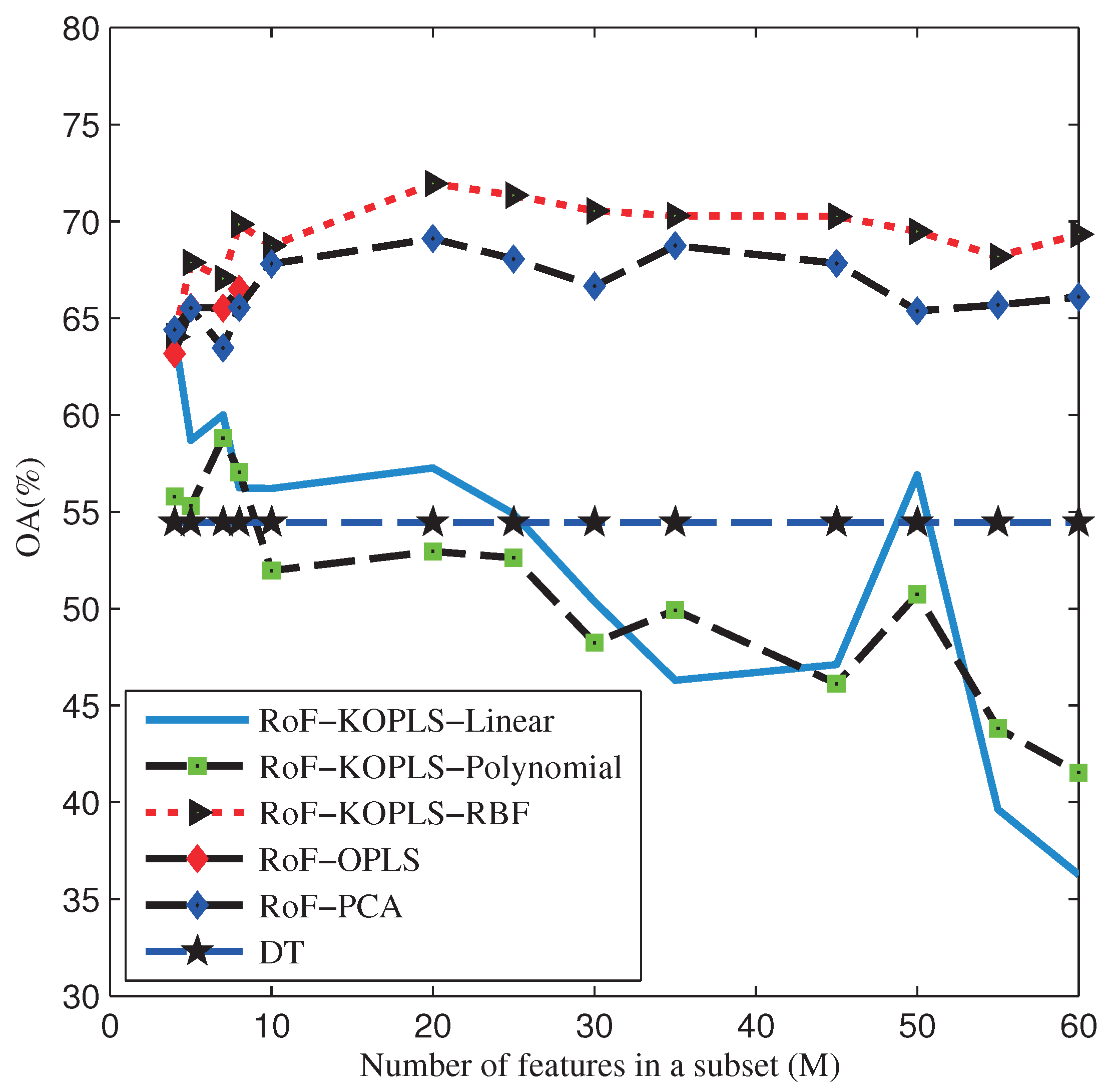
- RoF-KOPLS with RBF kernel is insensitive to the number of features in a subset when compared to other methods.
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| PCA | Principle Component Analysis |
| RBF | Radial Basis Function |
| FLDA | Fisher’s Linear Discriminant Analysis |
| PLS | Partial Least Square Regression |
| OPLS | Orthonormalized Partial Least Square Regression |
| KOPLS | Kernel Orthonormalized Partial Least Square Regression |
| RF | Random Forest |
| SVMs | Support Vector Machines |
| RoF | Rotation Forest |
| DT | Decision Trees |
| CART | Classification and Regression Tree |
| RoF-OPLS | Rotation Forest with OPLS |
| RoF-KOPLS | Rotation Forest with KOPLS |
| OA | Overall Accuracy |
| AA | Average Accuracy |
| AOA | Average of OA |
| κ | Kappa coefficient |
| CFD | Coincident Failure Diversity |
| RotBoost | Rotation Forest with Adaboost |
| DT-KOPLS | DT with KOPLS |
References
- Plaza, A.; Benediktsson, J.A.; Boardman, J.W.; Brazile, J.; Bruzzone, L.; Camps-Valls, G.; Chanussot, J.; Fauvel, M.; Gamba, P.; Gualtieri, A.; et al. Recent advances in techniques for hyperspectral image processing. Remote Sens. Environ. 2009, 113, S110–S122. [Google Scholar] [CrossRef]
- Shang, X.; Chisholm, L.A. Classification of Australian native forest species using hyperspectral remote sensing and machine-learning classification algorithms. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2481–2489. [Google Scholar] [CrossRef]
- Bioucas-Dias, J.M.; Plaza, A.; Camps-Valls, G.; Scheunders, P.; Nasrabadi, N.M.; Chanussot, J. Hyperspectral remote sensing data analysis and future challenges. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–36. [Google Scholar] [CrossRef]
- Manolakis, D.; Marden, D.; Shaw, G.A. Hyperspectral image processing for automatic target detection applications. Lincoln Lab. J. 2003, 14, 79–116. [Google Scholar]
- Dong, Y.; Zhang, L.; Zhang, L.; Du, B. Maximum margin metric learning based target detection for hyperspectral images. ISPRS J. Photogramm. Remote Sens. 2015, 108, 138–150. [Google Scholar] [CrossRef]
- Hughes, G. On the mean accuracy of statistical pattern recognizers. IEEE Trans. Inf. Theory 1968, 14, 55–63. [Google Scholar] [CrossRef]
- Oza, N.C.; Tumer, K. Classifier ensembles: Select real-world applications. Inf. Fusion 2008, 9, 4–20. [Google Scholar] [CrossRef]
- Benediktsson, J.A.; Chanussot, J.; Fauvel, M. Multiple classifier systems in remote sensing: From basics to recent developments. In Multiple Classifier Systems; Springer: Berlin, Germany, 2007; pp. 501–512. [Google Scholar]
- Du, P.; Xia, J.; Zhang, W.; Tan, K.; Liu, Y.; Liu, S. Multiple classifier system for remote sensing image classification: A review. Sensors 2012, 12, 4764–4792. [Google Scholar] [CrossRef] [PubMed]
- Kuncheva, L.I.; Whitaker, C.J. Measures of diversity in classifier ensembles and their relationship with the ensemble accuracy. Mach. Learn. 2003, 51, 181–207. [Google Scholar] [CrossRef]
- Shipp, C.A.; Kuncheva, L.I. Relationships between combination methods and measures of diversity in combining classifiers. Inf. Fusion 2002, 3, 135–148. [Google Scholar] [CrossRef]
- Kuncheva, L.I. Combining Pattern Classifiers: Methods and Algorithms; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Rokach, L. Pattern Classification Using Ensemble Methods; World Scientific: Singapore, Singapore, 2009; Volume 75. [Google Scholar]
- Waske, B.; Braun, M. Classifier ensembles for land cover mapping using multitemporal SAR imagery. ISPRS J. Photogramm. Remote Sens. 2009, 64, 450–457. [Google Scholar] [CrossRef]
- Briem, G.J.; Benediktsson, J.A.; Sveinsson, J.R. Multiple classifiers applied to multisource remote sensing data. IEEE Trans. Geosci. Remote Sens. 2002, 40, 2291–2299. [Google Scholar] [CrossRef]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Rodriguez, J.J.; Kuncheva, L.I.; Alonso, C.J. Rotation forest: A new classifier ensemble method. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1619–1630. [Google Scholar] [CrossRef] [PubMed]
- Xia, J.; Chanussot, J.; Du, P.; He, X. Rotation-Based Ensemble Classifiers for High-Dimensional Data. In Fusion in Computer Vision; Springer: Berlin, Germany, 2014; pp. 135–160. [Google Scholar]
- Xia, J.; Du, P.; He, X.; Chanussot, J. Hyperspectral remote sensing image classification based on rotation forest. IEEE Geosci. Remote Sens. Lett. 2014, 11, 239–243. [Google Scholar] [CrossRef]
- Xia, J.; Chanussot, J.; Du, P.; He, X. Spectral–Spatial Classification for Hyperspectral Data Using Rotation Forests with Local Feature Extraction and Markov Random Fields. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2532–2546. [Google Scholar] [CrossRef]
- Du, P.; Samat, A.; Waske, B.; Liu, S.; Li, Z. Random Forest and Rotation Forest for fully polarized SAR image classification using polarimetric and spatial features. J. Photogramm. Remote Sens. 2015, 105, 38–53. [Google Scholar] [CrossRef]
- Hsu, P.H. Feature extraction of hyperspectral images using wavelet and matching pursuit. ISPRS J. Photogramm. Remote Sens. 2007, 62, 78–92. [Google Scholar] [CrossRef]
- Richards, J.A. Remote Sensing Digital Image Analysis; Springer: Berlin, Germany, 1999; Volume 3. [Google Scholar]
- Hotelling, H. Analysis of a complex of statistical variables into principal components. J. Educ. Psychol. 1933, 24, 417. [Google Scholar] [CrossRef]
- Plaza, A.; Martinez, P.; Plaza, J.; Perez, R. Dimensionality reduction and classification of hyperspectral image data using sequences of extended morphological transformations. IEEE Trans. Geosci. Remote Sens. 2005, 43, 466–479. [Google Scholar] [CrossRef]
- Fukunaga, K. Introduction to Statistical Pattern Recognition; Academic Press: New York, NY, USA, 2013. [Google Scholar]
- Wold, S.; Albano, C.; Dunn, W.J., III; Edlund, U.; Esbensen, K.; Geladi, P.; Hellberg, S.; Johansson, E.; Lindberg, W.; Sjöström, M. Multivariate data analysis in chemistry. In Chemometrics; Springer: Berlin, Germany, 1984; pp. 17–95. [Google Scholar]
- Worsley, K.J.; Poline, J.B.; Friston, K.J.; Evans, A. Characterizing the response of PET and fMRI data using multivariate linear models. NeuroImage 1997, 6, 305–319. [Google Scholar] [CrossRef] [PubMed]
- Du, Q. Modified Fisher’s linear discriminant analysis for hyperspectral imagery. IEEE Geosci. Remote Sens. Lett. 2007, 4, 503–507. [Google Scholar] [CrossRef]
- Barker, M.; Rayens, W. Partial least squares for discrimination. J. Chemom. 2003, 17, 166–173. [Google Scholar] [CrossRef]
- Arenas-García, J.; Camps-Valls, G. Efficient kernel orthonormalized PLS for remote sensing applications. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2872–2881. [Google Scholar] [CrossRef]
- Arenas-García, J.; Petersen, K.; Camps-Valls, G.; Hansen, L.K. Kernel multivariate analysis framework for supervised subspace learning: A tutorial on linear and kernel multivariate methods. J. Educ. Psychol. 2013, 30, 16–29. [Google Scholar] [CrossRef]
- Leiva-Murillo, J.M.; Artés-Rodríguez, A. Maximization of mutual information for supervised linear feature extraction. IEEE Trans. Neural Netw. 2007, 18, 1433–1441. [Google Scholar] [CrossRef] [PubMed]
- Arenas-García, J.; Camps-Valls, G. Feature extraction from remote sensing data using Kernel Orthonormalized PLS. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS 2007), Barcelona, Spain, 23–28 July 2007; pp. 258–261.
- Persello, C.; Bruzzone, L. Kernel-Based Domain-Invariant Feature Selection in Hyperspectral Images for Transfer Learning. IEEE Trans. Geosci. Remote Sens. 2016, 54, 2615–2626. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Mooij, J.; Schölkopf, B. Remote sensing feature selection by kernel dependence measures. IEEE Geosci. Remote Sens. Lett. 2010, 7, 587–591. [Google Scholar] [CrossRef]
- Jiménez-Rodríguez, L.O.; Arzuaga-Cruz, E.; Vélez-Reyes, M. Unsupervised linear feature-extraction methods and their effects in the classification of high-dimensional data. IEEE Trans. Geosci. Remote Sens. 2007, 45, 469–483. [Google Scholar] [CrossRef]
- Arenas-Garcıa, J.; Petersen, K.B.; Hansen, L.K. Sparse kernel orthonormalized PLS for feature extraction in large data sets. Adv. Neural Inf. Process. Syst. 2007, 19, 33–40. [Google Scholar]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- Roweis, S.; Brody, C. Linear Heteroencoders; Gatsby Computational Neuroscience Unit, Alexandra House: London, UK, 1999. [Google Scholar]
- Shawe-Taylor, J.; Cristianini, N. Kernel Methods for Pattern Analysis; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Camps-Valls, G. Kernel Methods in Bioengineering, Signal and Image Processing; Igi Global: Hershey, PA, USA, 2006. [Google Scholar]
- Rosipal, R.; Trejo, L.J. Kernel partial least squares regression in reproducing kernel hilbert space. J. Mach. Learn. Res. 2002, 2, 97–123. [Google Scholar]
- Ranawana, R.; Palade, V. Multi-Classifier Systems: Review and a roadmap for developers. Inf. Fusion 2006, 3, 1–41. [Google Scholar] [CrossRef]
- Cunningham, P.; Carney, J. Diversity versus quality in classification ensembles based on feature selection. In Machine Learning: ECML 2000; Springer: Berlin, Germany, 2000; pp. 109–116. [Google Scholar]
- Zhang, C.X.; Zhang, J.S. RotBoost: A technique for combining Rotation Forest and AdaBoost. Pattern Recog. Lett. 2008, 29, 1524–1536. [Google Scholar] [CrossRef]
- Li, F.; Xu, L.; Siva, P.; Wong, A.; Clausi, D.A. Hyperspectral Image Classification With Limited Labeled Training Samples Using Enhanced Ensemble Learning and Conditional Random Fields. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2427–2438. [Google Scholar] [CrossRef]
- Blaschko, M.B.; Shelton, J.A.; Bartels, A.; Lampert, C.H.; Gretton, A. Semi-supervised kernel canonical correlation analysis with application to human fMRI. Inf. Fusion 2011, 32, 1572–1583. [Google Scholar] [CrossRef]
- Xia, J.; Mura, M.D.; Chanussot, J.; Du, P.; He, X. Random Subspace Ensembles for Hyperspectral Image Classification with Extended Morphological Attribute Profiles. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4768–4786. [Google Scholar] [CrossRef]
- Foody, G.M. Thematic map comparison. Photogramm. Eng. Remote Sens. 2004, 70, 627–633. [Google Scholar] [CrossRef]
- Li, F.; Wong, A.; Clausi, D.A. Combining rotation forests and adaboost for hyperspectral imagery classification using few labeled samples. In Proceedings of the 2014 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Quebec City, QC, Canada, 13–18 July 2014; pp. 4660–4663.
- Fauvel, M.; Tarabalka, Y.; Benediktsson, J.A.; Chanussot, J.; Tilton, J.C. Advances in spectral-spatial classification of hyperspectral images. Proc. IEEE 2013, 101, 652–675. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Train | Test | SVM | DT | RotBoost | DT-KOPLS | RoF-PCA | RoF-OPLS | RoF-KOPLS | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| RBF | Linear | Polynomial | |||||||||
| Alfalfa | 10 | 54 | 76.30 | 74.81 | 82.50 | 42.41 | 85.91 | 86.11 | 89.81 | 81.85 | 73.52 |
| Corn-no till | 10 | 1434 | 27.33 | 29.87 | 56.64 | 11.05 | 52.01 | 46.69 | 53.18 | 39.52 | 32.36 |
| Corn-min till | 10 | 834 | 33.39 | 26.62 | 50.85 | 16.94 | 50.69 | 45.30 | 47.28 | 44.44 | 36.02 |
| Bldg-Grass-Tree-Drives | 10 | 234 | 56.37 | 26.79 | 75.00 | 8.550 | 66.16 | 73.55 | 67.31 | 49.15 | 45.68 |
| Grass/pasture | 10 | 497 | 53.76 | 57.24 | 76.18 | 34.35 | 71.17 | 72.72 | 78.17 | 69.72 | 69.72 |
| Grass/trees | 10 | 747 | 60.83 | 40.13 | 83.88 | 26.05 | 81.38 | 74.66 | 88.59 | 69.65 | 64.79 |
| Grass/pasture-mowed | 10 | 26 | 90.77 | 82.69 | 90.63 | 68.08 | 91.87 | 92.31 | 95.00 | 91.54 | 87.31 |
| Corn | 10 | 489 | 51.76 | 49.28 | 82.15 | 25.01 | 78.04 | 64.34 | 87.83 | 67.71 | 62.35 |
| Oats | 10 | 20 | 94.00 | 83.50 | 96.00 | 50.50 | 95.00 | 95.00 | 100.0 | 89.50 | 87.50 |
| Soybeans-no till | 10 | 968 | 45.61 | 31.24 | 67.12 | 17.07 | 62.21 | 54.32 | 55.51 | 52.36 | 40.19 |
| Soybeans-min till | 10 | 2468 | 34.89 | 30.06 | 43.00 | 17.32 | 41.17 | 29.11 | 41.17 | 34.85 | 31.67 |
| Soybeans-clean till | 10 | 614 | 32.98 | 24.92 | 48.66 | 14.66 | 45.15 | 40.54 | 56.81 | 31.89 | 23.21 |
| Wheat | 10 | 212 | 93.54 | 84.95 | 96.63 | 50.09 | 94.70 | 95.61 | 98.49 | 89.25 | 87.36 |
| Woods | 10 | 1294 | 67.67 | 68.63 | 80.02 | 37.33 | 73.75 | 80.02 | 83.79 | 73.22 | 70.83 |
| Hay-windrowed | 10 | 380 | 29.76 | 35.03 | 38.08 | 11.34 | 43.38 | 45.18 | 52.50 | 38.53 | 30.82 |
| Stone-steel towers | 10 | 95 | 88.00 | 89.68 | 97.41 | 64.42 | 95.29 | 92.21 | 90.84 | 91.58 | 92.63 |
| OA | 44.73 | 39.56 | 61.50 | 21.55 | 58.29 | 53.38 | 61.44 | 50.83 | 45.40 | ||
| AA | 58.56 | 52.22 | 72.80 | 30.95 | 70.49 | 67.98 | 74.14 | 63.42 | 58.50 | ||
| κ | 38.65 | 33.17 | 57.03 | 14.62 | 53.52 | 48.21 | 56.98 | 45.38 | 39.53 | ||
| Samples Per Class | SVM | DT | RotBoost | DT-KOPLS | RoF-PCA | RoF-OPLS | RoF-KOPLS | ||
|---|---|---|---|---|---|---|---|---|---|
| RBF | Linear | Polynomial | |||||||
| 10 | 44.73 (58.56) | 39.56 (52.22) | 61.50 (72.80) | 21.55 (30.95) | 58.29 (70.49) | 53.38 (67.98) | 61.44 (74.14) | 50.83 (63.42) | 45.40 (58.50) |
| 20 | 55.45 (68.76) | 44.48 (58.01) | 68.34 (77.97) | 22.74 (32.89) | 65.32 (77.01) | 61.28 (74.67) | 67.40 (79.38) | 59.44 (71.25) | 53.31 (66.80) |
| 30 | 60.81 (73.23) | 49.39 (61.94) | 71.58 (80.62) | 26.38 (32.49) | 69.06 (78.67) | 65.81 (77.20) | 71.88 (82.52) | 63.74 (75.35) | 59.31 (71.40) |
| 50 | 65.69 (77.39) | 53.81 (65.11) | 75.83 (83.40) | 54.33 (64.49) | 73.54 (82.88) | 69.65 (80.24) | 75.55 (85.86) | 67.84 (78.21) | 63.98 (74.97) |
| 60 | 69.53 (79.64) | 55.61 (66.13) | 77.24 (83.39) | 58.62 (68.30) | 75.46 (82.91) | 71.17 (80.97) | 76.99 (86.66) | 70.37 (79.56) | 66.36 (76.58) |
| 80 | 72.58 (80.81) | 58.11 (68.27) | 78.83 (84.76) | 66.43 (74.52) | 77.02 (83.34) | 74.05 (82.66) | 79.70 (88.27) | 73.49 (81.26) | 70.32 (78.57) |
| 100 | 73.50 (79.48) | 60.67 (69.70) | 79.82 (84.71) | 67.90 (74.97) | 78.12 (84.00) | 75.72 (83.48) | 82.56 (89.51) | 74.36 (81.49) | 71.51 (79.79) |
| 120 | 78.04 (85.35) | 62.95 (70.77) | 81.00 (85.36) | 71.01 (77.23) | 79.48 (84.99) | 76.93 (83.76) | 83.97 (90.39) | 75.98 (82.93) | 74.56 (81.16) |
| Classifiers | RoF-PCA | RoF-OPLS | RoF-KOPLS | ||
|---|---|---|---|---|---|
| RBF | Linear | Polynomial | |||
| OA | 58.29 | 53.38 | 61.44 | 50.83 | 45.40 |
| AOA | 45.76 | 42.75 | 48.16 | 41.13 | 40.01 |
| Diversity | 47.76 | 44.19 | 48.84 | 40.95 | 37.75 |
| Class | Train | Test | SVM | DT | RotBoost | DT-KOPLS | RoF-PCA | RoF-OPLS | RoF-KOPLS | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| RBF | Linear | Polynomial | |||||||||
| Bricks | 10 | 3682 | 74.40 | 55.89 | 69.16 | 33.58 | 66.55 | 67.47 | 71.94 | 69.70 | 65.17 |
| Shadows | 10 | 947 | 99.97 | 94.19 | 99.98 | 84.09 | 99.54 | 99.95 | 99.88 | 99.86 | 99.80 |
| Metal Sheets | 10 | 1345 | 99.20 | 96.88 | 99.70 | 56.27 | 99.40 | 99.30 | 98.70 | 96.60 | 95.97 |
| Bare Soil | 10 | 5029 | 69.70 | 49.81 | 71.32 | 22.81 | 71.94 | 73.81 | 67.69 | 61.44 | 48.88 |
| Trees | 10 | 3064 | 88.18 | 72.11 | 94.38 | 42.28 | 90.42 | 90.16 | 89.67 | 86.06 | 72.40 |
| Meadows | 10 | 18649 | 62.26 | 46.63 | 61.65 | 35.81 | 63.05 | 56.47 | 68.44 | 54.60 | 52.70 |
| Gravel | 10 | 2099 | 63.60 | 37.81 | 68.64 | 37.63 | 61.02 | 54.82 | 66.83 | 48.99 | 37.85 |
| Asphalt | 10 | 6631 | 64.90 | 58.93 | 63.43 | 38.95 | 64.83 | 67.92 | 67.35 | 70.68 | 63.83 |
| Bitumen | 10 | 1330 | 86.66 | 70.75 | 90.48 | 57.97 | 81.63 | 76.90 | 80.58 | 74.34 | 74.41 |
| OA | 69.27 | 54.46 | 69.34 | 37.51 | 69.06 | 66.49 | 71.95 | 64.11 | 58.81 | ||
| AA | 78.76 | 64.78 | 79.86 | 45.49 | 77.60 | 76.31 | 79.01 | 73.59 | 67.89 | ||
| κ | 61.76 | 44.63 | 62.12 | 26.42 | 61.55 | 58.81 | 64.69 | 55.72 | 49.36 | ||
| Samples Per Class | SVM | DT | RotBoost | DT-KOPLS | RoF-PCA | RoF-OPLS | RoF-KOPLS | ||
|---|---|---|---|---|---|---|---|---|---|
| RBF | Linear | Polynomial | |||||||
| 10 | 69.27 (78.76) | 54.46 (64.78) | 69.34 (79.86) | 37.51 (45.49) | 69.06 (77.60) | 66.49 (76.31) | 71.95 (79.01) | 64.11 (73.59) | 58.81 (67.89) |
| 30 | 78.30 (84.06) | 62.88 (72.96) | 79.22 (85.31) | 61.56 (67.88) | 75.75 (82.68) | 78.92 (83.91) | 80.25 (86.28) | 70.04 (79.33) | 61.85 (74.01) |
| 40 | 81.69 (86.50) | 64.03 (73.45) | 81.40 (87.21) | 65.61 (72.69) | 79.68 (84.63) | 80.47 (85.03) | 81.96 (87.10) | 71.74 (81.39) | 64.62 (75.97) |
| 50 | 83.36 (87.84) | 64.71 (74.04) | 83.71 (88.13) | 73.08 (77.40) | 81.71 (86.45) | 80.97 (85.87) | 83.56 (88.35) | 73.52 (83.06) | 66.91 (77.59) |
| 60 | 84.22 (88.39) | 66.64 (75.15) | 84.61 (88.89) | 72.07 (79.04) | 82.48 (87.31) | 81.58 (86.52) | 84.47 (89.17) | 74.51 (82.91) | 68.05 (77.99) |
| 80 | 85.65 (89.39) | 68.58 (76.87) | 85.06 (89.42) | 73.54 (78.37) | 83.66 (87.83) | 82.62 (87.33) | 86.20 (90.22) | 76.47 (84.64) | 69.96 (79.47) |
| 100 | 87.28 (90.17) | 69.77 (77.56) | 86.05 (90.37) | 80.05 (83.56) | 85.56 (89.55) | 83.38 (88.05) | 87.33 (90.93) | 77.59 (85.33) | 71.49 (81.0) |
| Classifiers | RoF-PCA | RoF-OPLS | RoF-KOPLS | ||
|---|---|---|---|---|---|
| RBF | Linear | Polynomial | |||
| OA | 69.06 | 66.49 | 71.95 | 64.11 | 58.81 |
| AOA | 57.48 | 57.16 | 58.09 | 56.42 | 56.81 |
| Diversity | 55.78 | 57.86 | 59.00 | 53.56 | 46.99 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Xia, J.; Du, P.; Chanussot, J.; Xue, Z.; Xie, X. Kernel Supervised Ensemble Classifier for the Classification of Hyperspectral Data Using Few Labeled Samples. Remote Sens. 2016, 8, 601. https://doi.org/10.3390/rs8070601
Chen J, Xia J, Du P, Chanussot J, Xue Z, Xie X. Kernel Supervised Ensemble Classifier for the Classification of Hyperspectral Data Using Few Labeled Samples. Remote Sensing. 2016; 8(7):601. https://doi.org/10.3390/rs8070601
Chicago/Turabian StyleChen, Jike, Junshi Xia, Peijun Du, Jocelyn Chanussot, Zhaohui Xue, and Xiangjian Xie. 2016. "Kernel Supervised Ensemble Classifier for the Classification of Hyperspectral Data Using Few Labeled Samples" Remote Sensing 8, no. 7: 601. https://doi.org/10.3390/rs8070601
APA StyleChen, J., Xia, J., Du, P., Chanussot, J., Xue, Z., & Xie, X. (2016). Kernel Supervised Ensemble Classifier for the Classification of Hyperspectral Data Using Few Labeled Samples. Remote Sensing, 8(7), 601. https://doi.org/10.3390/rs8070601