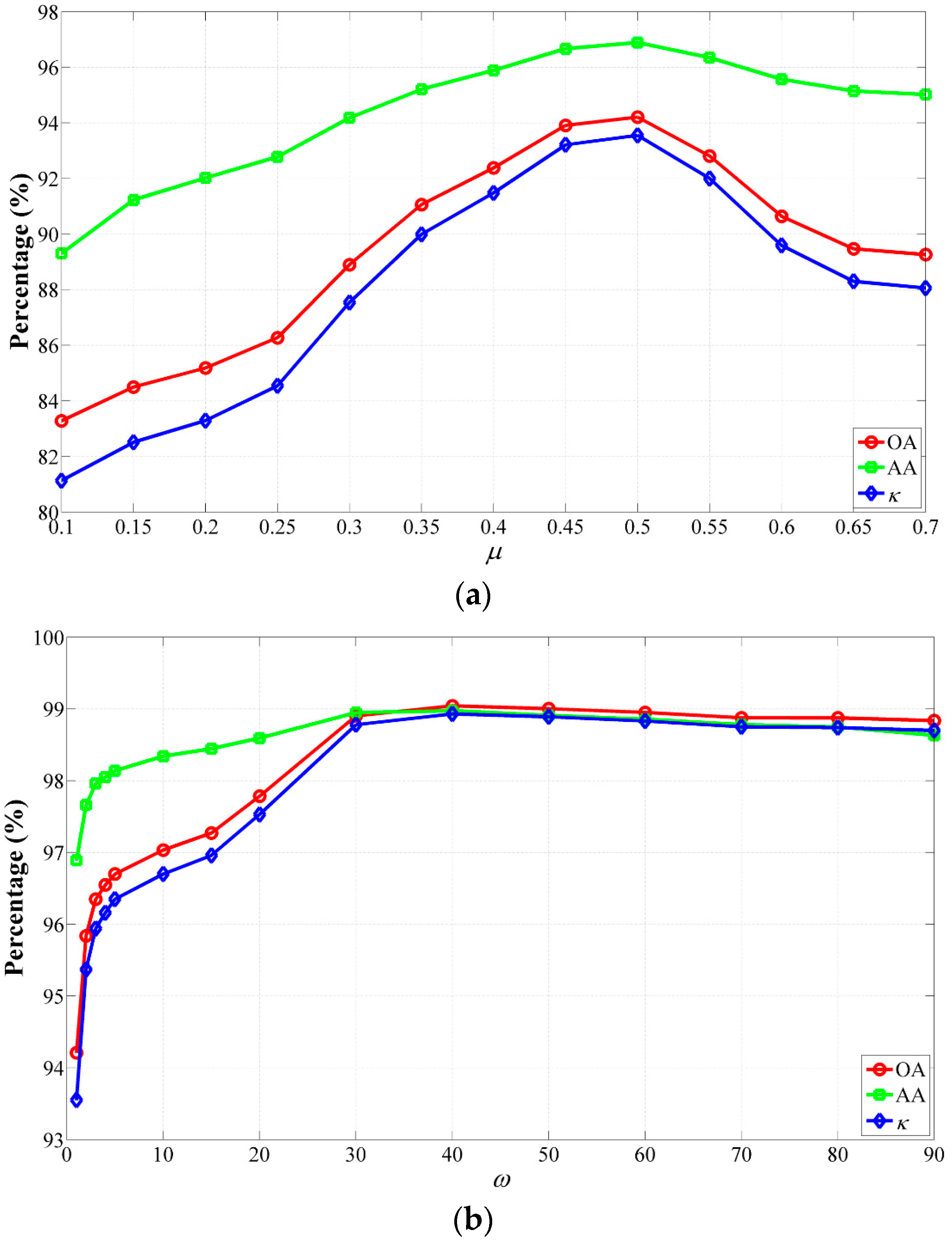
5.1. The Influence of Parameters
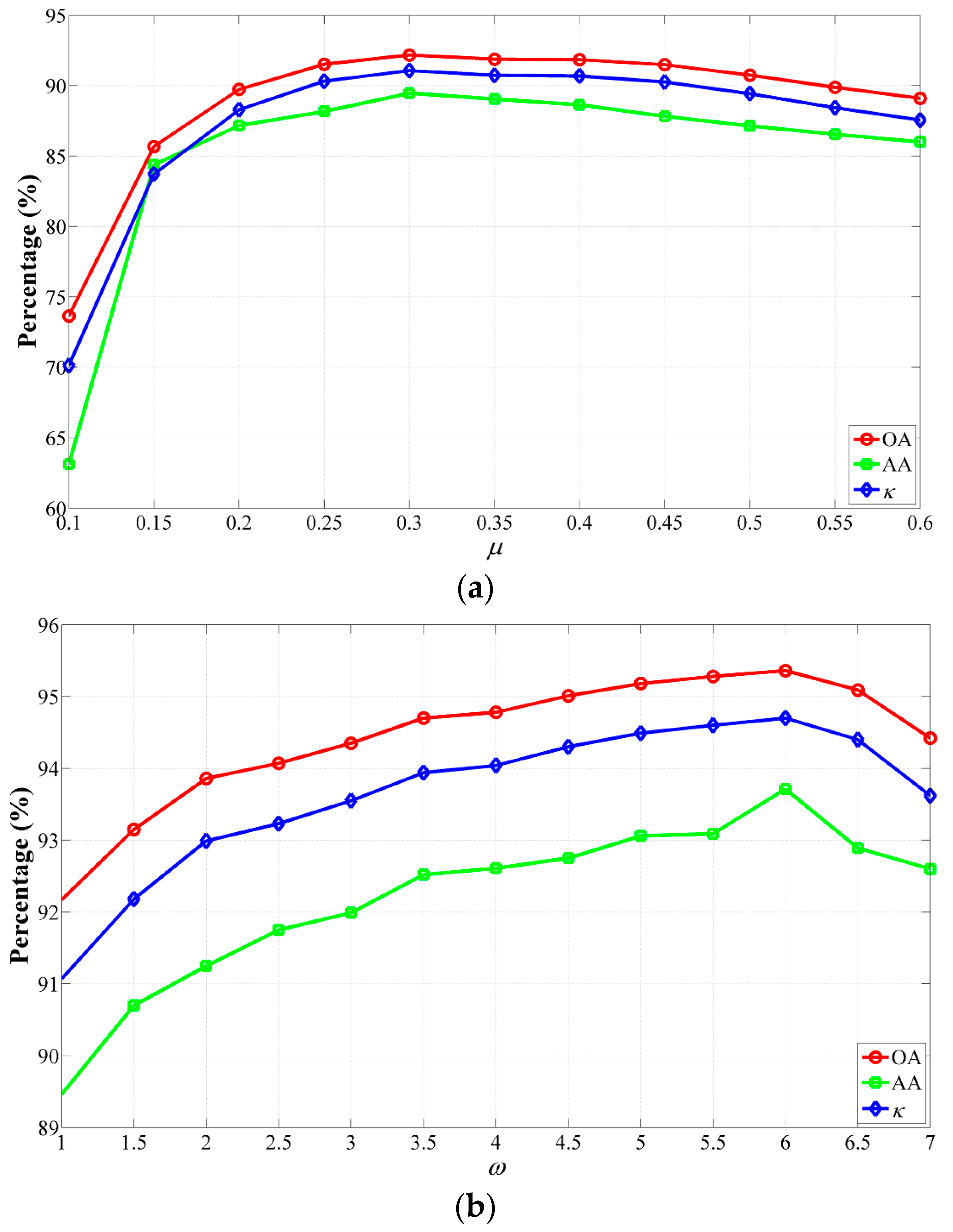
In our method, there are five parameters whose values critically modulate its performance, i.e., μ and ω for the CS-GC model, while n, σs and σr for the JBF. First, we perform the proposed CS-GC method (without the optional JBF step) to analyze the impact of μ and ω on the three hyperspectral datasets used in the last section. The GAs achieved by our method were obtained using different parameter settings.
(1) Influence of μ and ω
The impact of
μ and
ω on classification accuracies using the CS-GC method for the Indian Pines data set is shown in
Figure 8.
Figure 8a demonstrates classification accuracies achieved by the CS-GC method varying
μ from 0.1 to 0.6 with a step size of 0.05, while
ω was set to be one. It can be observed from this figure that the shapes of these plots have a similar global behavior, i.e., the GAs rose rapidly as the increase of
μ from 0.1 to 0.3 and decreased gradually as
μ increased to 0.6. In addition, the highest GAs were obtained when
with
,
and
. Meanwhile,
Figure 8b illustrates the impact of
ω varying from one to seven with a step size of 0.5 on the classification performance of the CS-GC method, while
μ was set to be 0.3. Similarly, the GAs rose gradually as the increase of
ω until the highest GAs were achieved when
. Thus, in this case, the values of the OA, AA and
κ increased from 92.17%, 89.46% and 0.9107 (
) to 95.36%, 93.70% and 0.9470 (
), respectively. However, these values declined to 94.42%, 92.60% and 0.9362 in the case of
.
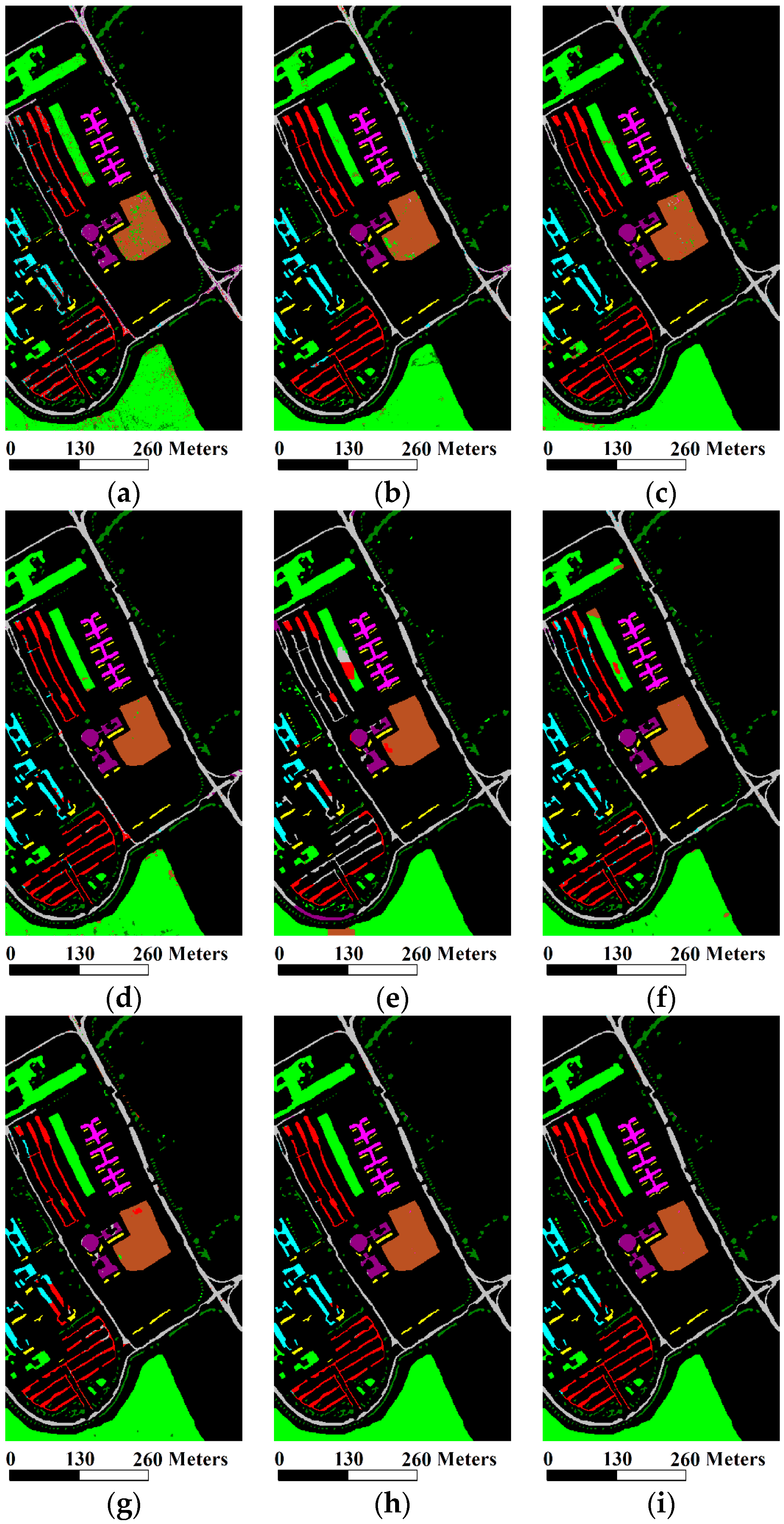
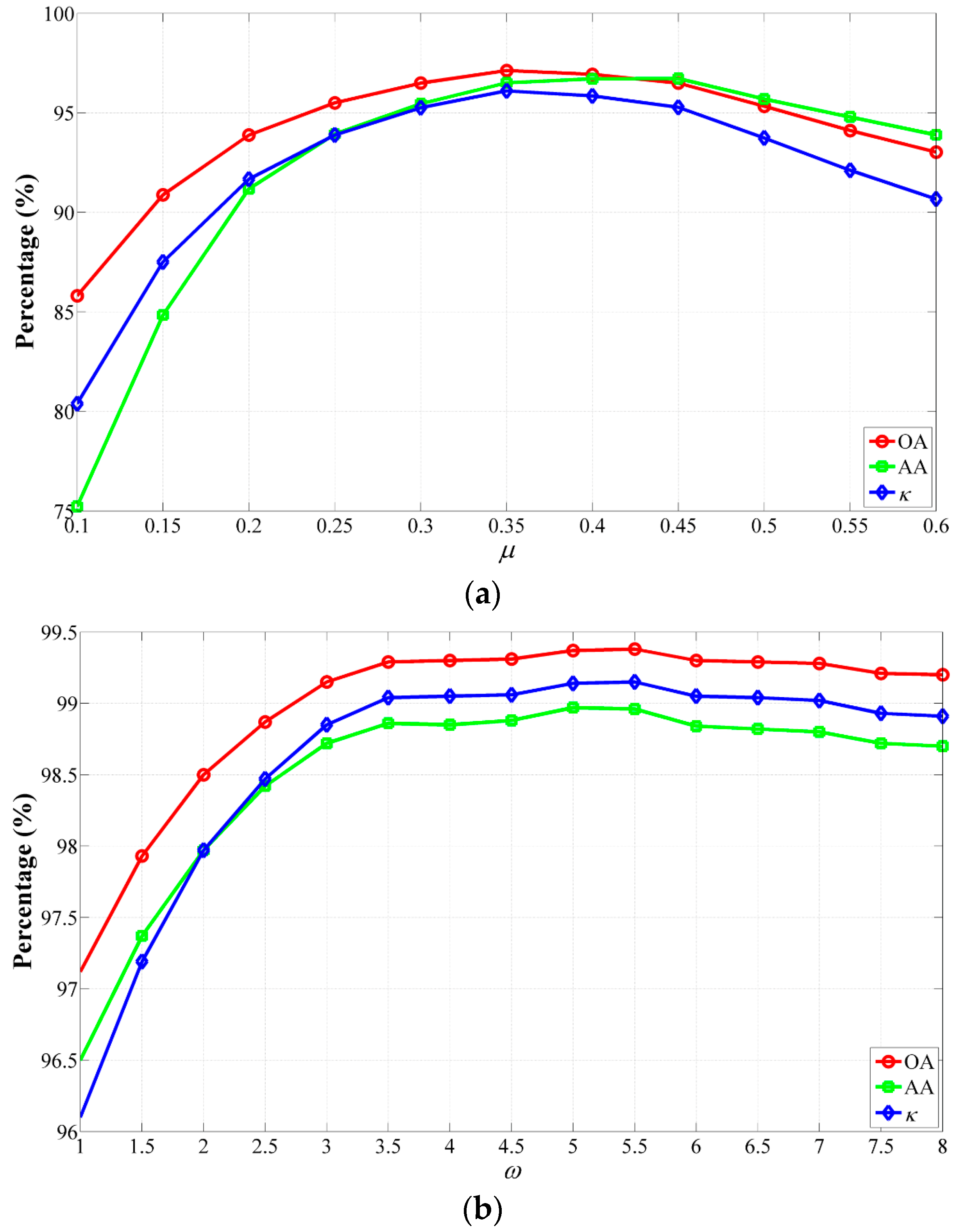
The impact of
μ and
ω on classification accuracies using the CS-GC method for the University of Pavia data set is shown in
Figure 9. (i)
Figure 9a illustrates the GAs obtained using different values of
μ from 0.1 to 0.6 with a step size of 0.05. In this case,
ω was fixed at one. The plots of the GAs as the increase of
μ were considerably similar to parabolas that open downward and the highest GAs were achieved in the case of
with
,
and
.
Figure 9b depicts the GAs obtained using different values of
ω from one to eight with a step size of 0.5 while
μ was set to be 0.35. We can observe that the GAs were improved as the increase of
μ. When
ω increased to 5.5, the greatest GAs were obtained with
,
and
, which were 2.26%, 2.46% and 0.0305, respectively, higher than that using
; when
ω increased from 5.5 to eight, the GAs continued to slide. Finally, the GAs of
,
and
were obtained; (ii) To visually analyze the impacts of
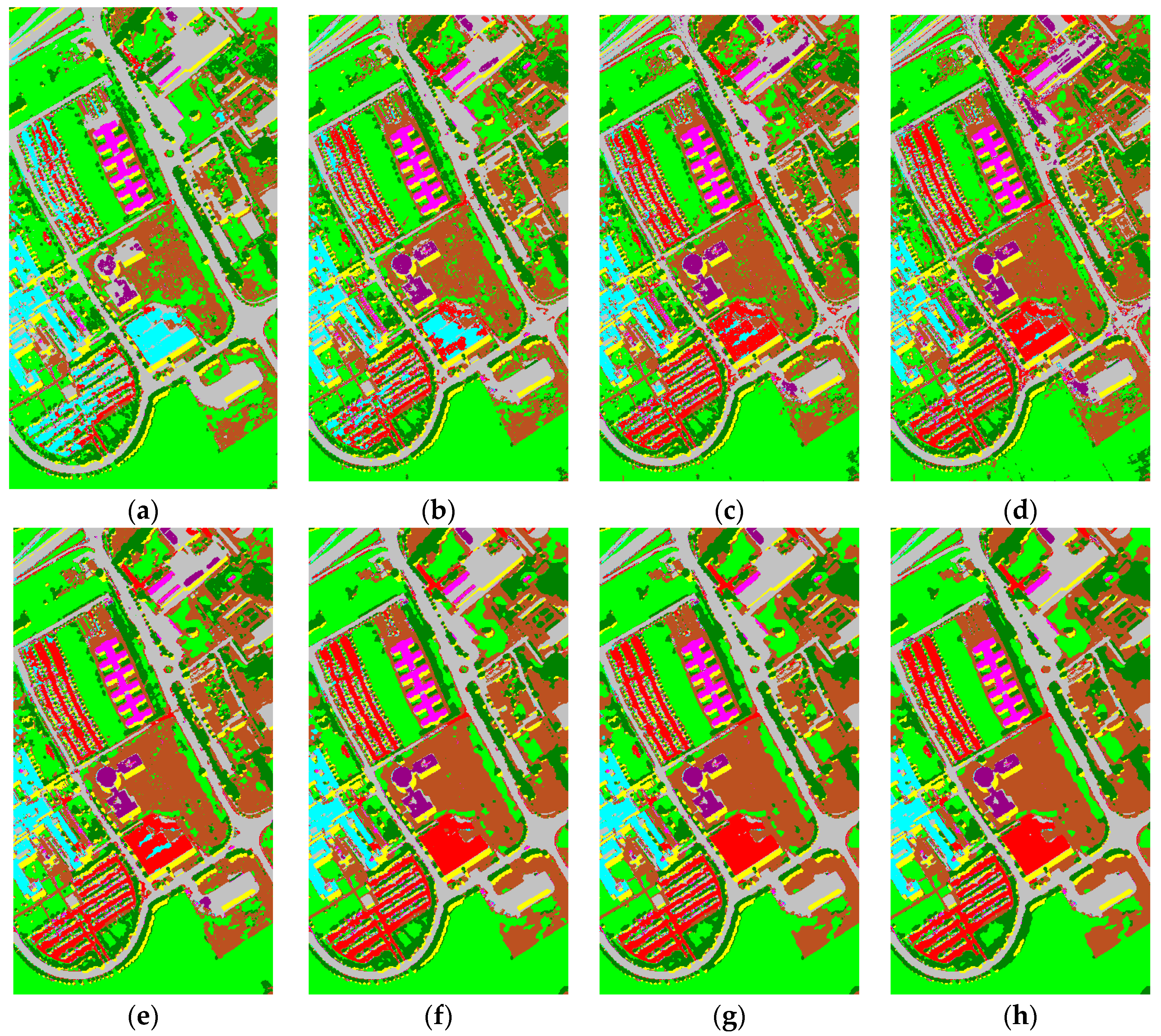
μ, the classification maps with different values of
μ (0.15, 0.25, 0.35, 0.45) and
are shown in
Figure 10a–d, respectively. It can be found that the classes of
Self-Blocking Bricks,
Bitumen and
Bare Soil cannot be effectively extracted if
because smoothed probabilities of those classes were not very large. Meanwhile, some miscellaneous components appeared in the homogeneous regions of the classification maps if
, especially in a region of
Meadows at the bottom of the image. By comparison, we can obtain more accurate classification map when
μ was fixed to be 0.35. To visually analyze the impacts of
ω, the classification maps with different values of
ω (2, 3, 4, and 5) are shown in
Figure 10e–h, respectively. It is clear that salt-and-pepper noise in the classification maps can be well avoided as the increase of
ω because more spatial information was integrated with spectral features of the hyperspectral data set in the CS-GC method. In addition, the classification map obtained by the CS-GC method using
was better than the remaining resultant maps in terms of visual inspection. Specifically, regions in
Figure 10h were well homogenized to completely remove class errors; (iii) To further analyze the impact of
ω on classification accuracies, we applied the CS-GC + JBF method to the University of Pavia data set. In this experiment,
ω was chosen from one to eight with a step size of 0.5 and the other parameters of the CS-GC + JBF method were set as
,
,
and
.
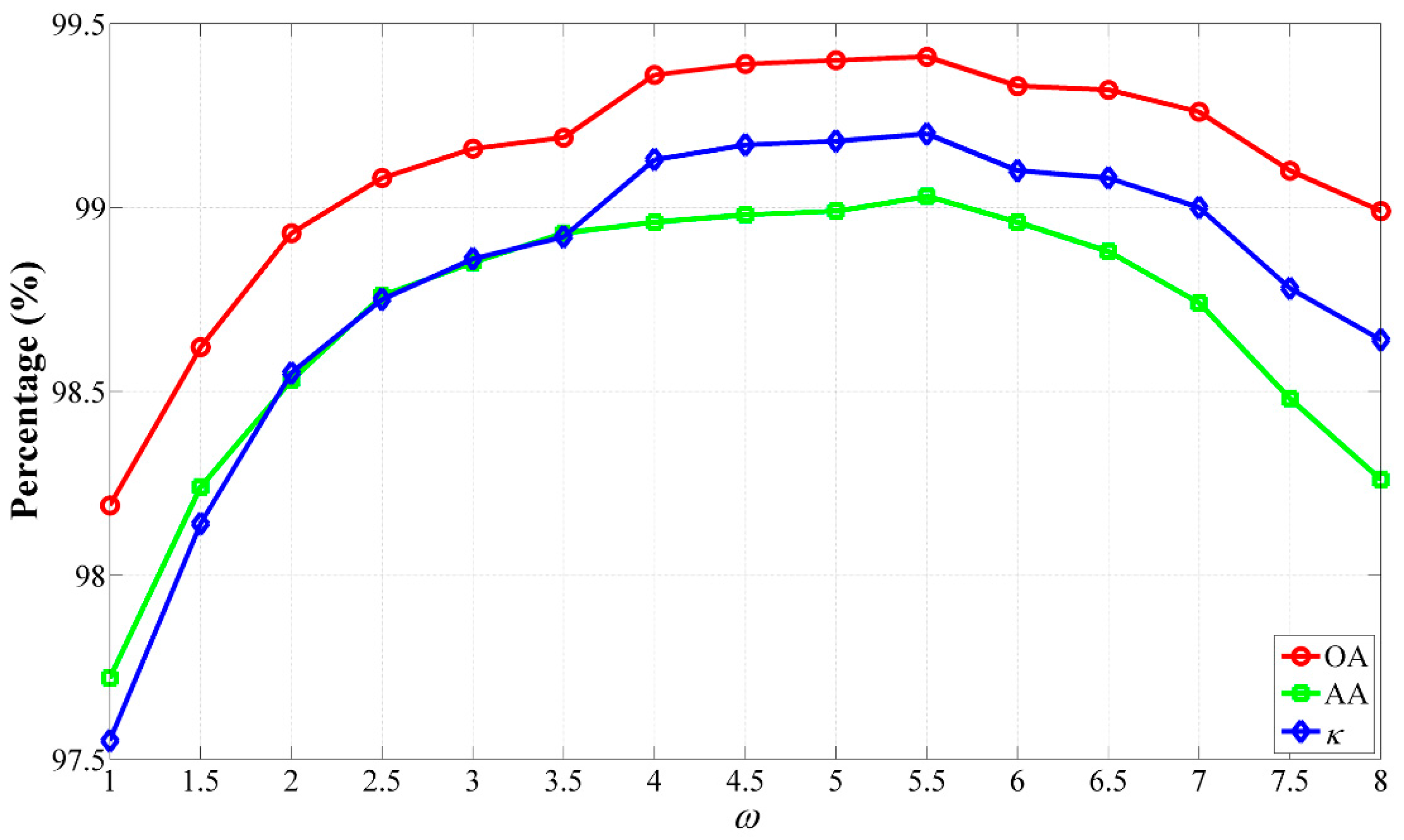
Figure 11 shows the GAs obtained using different values of
ω. It can be found the GAs achieved by the CS-GC + JBF method were improved as the increase of
ω from one to 5.5, and then reduced as the increase of
ω from 5.5 to eight, which is consistent with the conclusion by using the CS-GC methods in terms of different values of
ω. Meanwhile, it should be noted from this figure that the values of OA and
κ are higher than 99% and 0.99, respectively, in the range of
, which further validates the efficiency of the CS-GC + JBF method.
The impact of
μ and
ω on classification accuracies using the CS-GC method for the Salinas data set is shown in
Figure 12. The GAs plots obtained by using different values of
μ from 0.1 to 0.7 with a step size of 0.05 and
are shown in
Figure 12a. From this figure, we can observe that the GAs kept increasing until
μ increased to 0.5. However, when
μ increased from 0.5 to 0.7, the GAs continued to slide. Therefore, the highest GAs were achieved in the case of
with
,
and
. Meanwhile, the GAs plots obtained by using different values of
ω from 0 to 90 with unequal steps and
are demonstrated in
Figure 12b. In this figure, the OA, AA and
κ increased from 94.21%, 96.89% and 0.9355 (
) to 99.04%, 98.97% and 0.9893 (
), respectively, as the increase of
ω from one to 40. In contrast, the GAs reduced very slowly in the range of
. Based on our experiments on the Salinas data set, including those not reported here, the GAs achieved by the CS-GC method were lower and can still maintain at high values even if
ω was set very large. It should be noted that the range of
ω for the Salinas data set was greatly different from that for the above two hyperspectral data sets, because the distribution of objects in the Salinas data set is more regular and all of regions in the ground truth data are quite large.
Based on the above experiments on the impact analysis of μ and ω, we can draw conclusions as follows:
(1) Since the strength of spectral weights in the procedure of image classification is modulated by
μ, we can consider this parameter as a spectral weight regulator. As mentioned in
Section 3, the proposed method performs segmentation based on the competition between object (each class) and background in the energy functional Equation (13). If the value of
μ is close to one, the “background” is dominant in the competition. Otherwise, if the value of
μ is close to 0, the energy functional is apt to superiorly separate targets of a certain class from backgrounds. Therefore, the appropriate setting of the spectral weight regulator plays an important role for exacting information classes from hyperspectral images. Experiments on the three hyperspectral datasets demonstrated that the plots of the GAs as the increase of
μ were approximately a concave shape and the highest GAs can be achieved using an appropriate setting of
μ.
(2) The parameter ω is used to balance the data and smoothness terms. In this work, it is also employed as a spatial weight regulator. For instance, the increase of ω contributes to accurately extracting spatial information and improving classification accuracies due to similarities between the central pixel and its neighborhoods. However, if the value of ω is set too large, the smoothness term plays a major role in the energy functional. Therefore, some information class regions always contain small-scale regions belonging to other classes, which leads to the reduction of classification accuracies.
(3) We can observe that our method can achieve the highest classification accuracies on the Indian Pines data set with a relatively small value of
μ, by comparing
Figure 8a with
Figure 9a and
Figure 12a, due to the fact that the ground objects in the Indian Pines data set are mainly the corps and this image includes more small-scale homogeneous regions that are spatially and spectrally similar. Although the other two data sets are composed of different types of ground objects, the distribution of all the different objects in the Salinas data set is much more regular and the corresponding homogeneous regions are quite large, compared to the University of Pavia data set. As a consequence, a relative large value of
μ is required for our method to achieve the best classification accuracies on the Salinas data set. Therefore, for classification of unlabeled data,
μ should be a data-dependent parameter. (i) If the unlabeled data include many small-scale homogeneous regions that are spatially and spectrally close like the Indian Pines data set, a small value of
μ is recommended. For instance, the default value of
μ can be set as
μ = 0.3; (ii) If the unlabeled data contain different types of ground objects and shapes of these objects are very regular,
μ can be set as a large value, e.g.,
μ = 0.5; (iii) If there is no prior knowledge, considering the classification performance, we recommend selecting a relatively moderate value of
μ as
μ = 0.4. Similarly,
ω should be a data-dependent parameter as well. (i) If the unlabeled data are spatially and spectrally close like the University of Pavia image, i.e., the unlabeled data contain different types of ground objects and the distribution of those objects in the unlabeled data is unbalanced, a small value of
ω is recommended, e.g.,
ω = 3; (ii) If the unlabeled data mainly include the ground objects with quite regular boundaries and the distribution of all the ground objects is relatively uniform like the Salinas image,
ω can be set as a relatively small value to obtain satisfactory results, e.g.,
ω = 30; (iii) If there is no prior knowledge, considering the classification performance, we recommend selecting a relatively moderate value of
ω as
.
(2) Influence of n, σs and σr
Then, we perform the proposed CS-GC + JBF method to analyze the impact of the parameters in the JBF. As mentioned in
Section 3.2, our JBF can greatly avoid unstable distribution of class membership probabilities caused by a pixel-wise classifier only taking spectral features in the image into account. Not only does the proposed JBF well preserve important edges in the image, but also spatially optimize class membership probabilities. Therefore, we may not achieve the highest GAs using the optimal parameter setting of
μ and
ω obtained from
Figure 9, especially for the spatial weight regulator
ω. Based on our experiments on the Indian Pines data set, including those not reported here, these two parameters for the CS-GC + JBF method were set as
and
.
The impact of
n,
σs and
σr on classification accuracies using the proposed CS-GC + JBF method for the Indian Pines data set is shown in
Table 5. (i) To analyze the impact of the size of local window on classification accuracies, we applied the CS-GC + JBF method to classify the Indian Pines image by setting different values of
n from one to five and the corresponding window sizes and GAs are listed in
Table 5. In our method, the other parameters were set as
and
. It should be noted that the GAs in
Table 5 at the value of “0” in terms of different parameters mean that they were achieved by our CS-GC method (without the optional JBF step) for the Indian Pines image. In addition, it can be seen from this table that the highest OA and
κ can be reached when the size of local window was 7 × 7, i.e.,
. If
n is too large, small-scale regions belonging to a certain class are always smoothed out by the JBF, which may cause the decrease of classification accuracies; while if
n is too small, our method cannot considerably smooth out salt-and-pepper classification noise caused by the pixel-wise classification and avoid unstable distribution of class membership probabilities; (ii) To analyze the impact of
on classification accuracies, we applied the CS-GC + JBF method to classify the Indian Pines image by selecting different values (0.5, 1, 2, 4, and 8) and the corresponding GAs are listed in
Table 5 as well. In our method, the other parameters were set as
and
. A similar conclusion can be drawn that
should not be set to be too large or small and the highest OA and
κ were achieved in the case of
; (iii) It can be observed from Equation (8) that the setting of
σr is vitally important to the performance of our JFB. To analyze the impact of
σr on classification accuracies, we provided an example of probability smoothing by selecting different values of
σr (0.001, 0.005, 0.01, 0.02, 0.04, and 0.1). The corresponding smoothed probability maps in terms of
Corn-no till are shown in
Figure 13. The other parameters for the JBF were set as
and
. We can observe from this figure that the smoothing effect was very limited when
σr was equal to 0.001. As
σr increased, the salt-and-pepper classification noise in the probability map was gradually removed while edges were well preserved. However, the proposed JBF leaded to oversmoothing on the probability map and edges of
Corn-no till were seriously blurred in the case of
. To better analyze the impact of
σr on classification accuracies, this parameter was set from 0.005 to 0.03 with a step size of 0.005 and the other parameters were the same as that used in
Figure 9. It can be easily observed from
Table 5 that the GAs shared the same tendency as the above experiments when analyzing the impacts of
n and
σs. For instance, the OA and
κ increased in the case of
and the highest OA and
κ can be achieved when
σr was equal to 0.015. However, these two measures decreased in the case of
. Meanwhile, the extremum value of
σr was 0.02 in terms of the AA.
Then, we performed the CS-GC + JBF method on the University of Pavia data set to analyze the impact of
n,
and
on classification accuracies. To analyze the impact of
n, we provided a set of
n (1, 2, 3, 4, and 5) and the other parameters were fixed as
,
,
and
; to analyze the impact of
on classification accuracies, we gave a set of
(0, 0.5, 1, 2, 4, and 8) and the other parameters were fixed as
,
,
and
; and to analyze the impact of
on classification accuracies, we presented a set of
from 0 to 0.03 with a step size of 0.005 and the other parameters were fixed as
,
,
and
. The corresponding GAs in terms of different parameter settings are reported in
Table 6. It can be seen that the trend of the GAs, as the increase of
n,
or
, was similar to that in the first experiment for the Indian Pines data set.
Finally, we performed the CS-GC + JBF method on the Salinas data set to analyze the impact of
n,
and
on classification accuracies with
,
and the corresponding GAs in terms of different parameter settings are reported in
Table 7. To analyze the impact of
n,
n was set from one to five with a step size of one and the other parameters were fixed as
and
. In
Table 7, the GAs were improved as the increase of
n due to the fact that a very large local window is required for smoothing out the noise in large-scale regions in the image. To analyze the impact of
,
was chosen from (0, 0.5, 1, 2, 4, and 8) and the other parameters were fixed as
and
; to analyze the impact of
,
was set from 0.01 to 0.035 with a step size of 0.005 and the other parameters were fixed as
and
. It can be observed that the trend of the GAs, as the increase of
or
, is completely consistent with the previous experiments. In addition, the highest GAs can be obtained using the CS-GC + JBF method with
when varying
from 0 to eight; the highest GAs can be obtained using the CS-GC + JBF method with
when varying
from 0.01 to 0.035, as shown in
Table 7. To further analyze the impact of
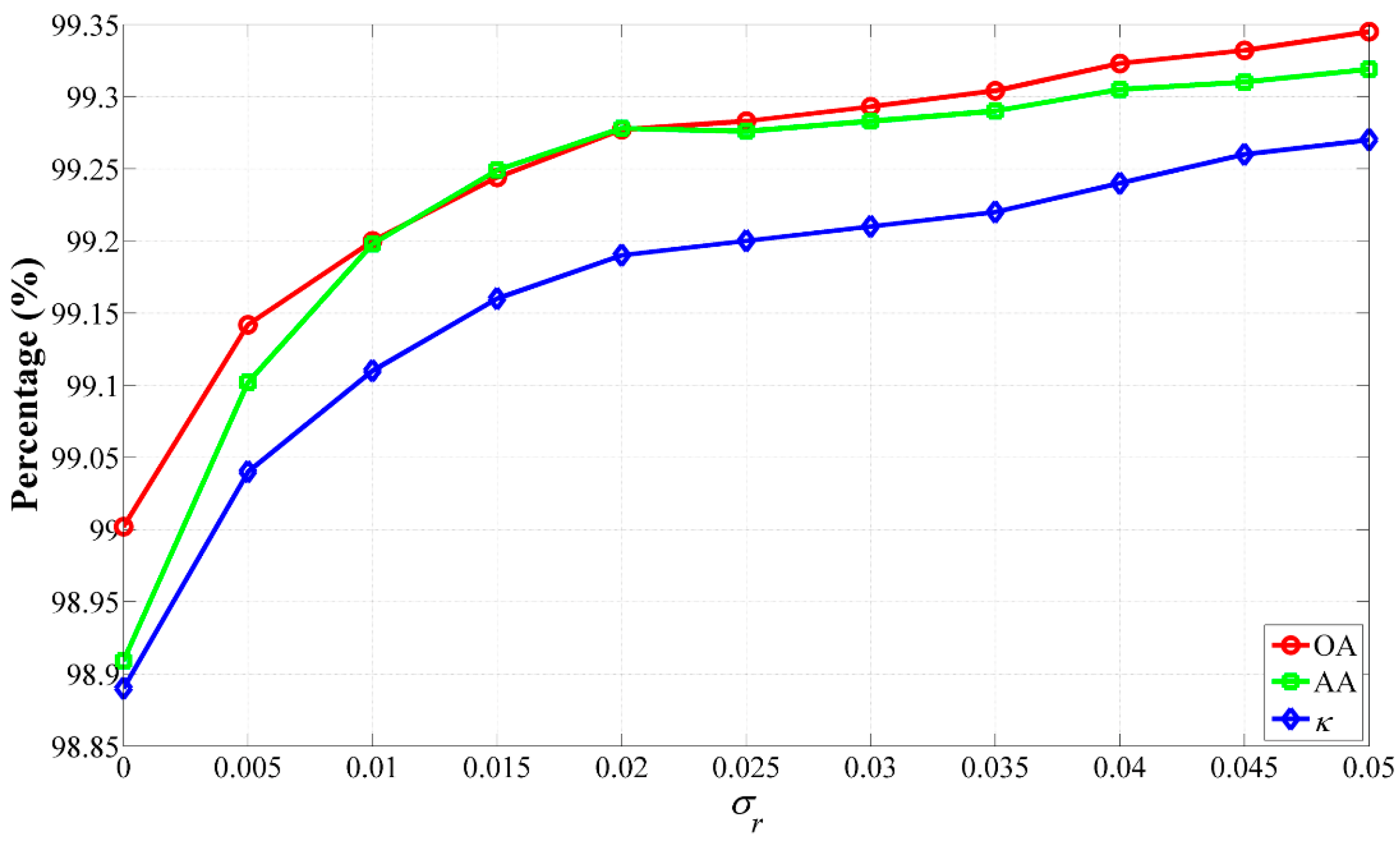
on classification accuracies, we applied the CS-GC + JBF method to the Salinas data set. In this experiment,
was chosen from 0 to 0.05 with a step size of 0.005 and the other parameters of the CS-GC + JBF method were set as
,
,
and
. The GAs plots obtained by the CS-GC + JBF method using different values of
(
) are demonstrated in
Figure 14. We observed that the GAs achieved by the CS-GC + JBF method increased fast as the rising of
from 0 to 0.02, while if
was larger than 0.02, the increase of the GAs slowed down. Finally, the highest OA, AA and
κ achieved by the CS-GC + JBF method with
can reach 99.35%, 99.32% and 0.9927, respectively. It is noteworthy that the main difference between the impacts of
in
Figure 14 and
Table 7 on classification accuracies stems from the different ranges of
ω.
It can be seen in
Table 5,
Table 6 and
Table 7 that the CS-GC + JBF method is not very sensitive to
and
performs the best for our method on all of the three data sets. In addition, it should be noted that the University of Pavia data set is composed of different types of ground objects. Furthermore, those objects on the image are unevenly distributed. As a consequence, edge strengths of the object boundaries vary in a wide range. To better preserve most important edge features of this data set for the subsequent classification, a relatively small value of
is preferred. As mentioned above, the ground objects are mainly the corps in the Indian Pines data set, thus edge strengths of the object boundaries change very little, a slightly large value of
can ensure that noise in the probability maps is thoroughly removed while edges are effectively preserved. Since the Salinas data set is composed by mainly different types of vegetation and the object boundaries are very regular for observation, a relatively large value of
is required for our method to achieve the best classification performance.
In conclusion, for classification of unlabeled data, can be the same as for our method to achieve the best classification accuracies, while should be a data-dependent parameter. (i) If the unlabeled data contain different types of ground objects and edge strengths of the object boundaries are very different, a small value of is recommended. For instance, the default value of can be set as ; (ii) If boundaries of ground objects in the unlabeled data are obvious and their shapes are very regular, can be set as a large value, ; (iii) If there is no prior knowledge, considering the classification performance, we recommend selecting a relatively moderate value of as .




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}