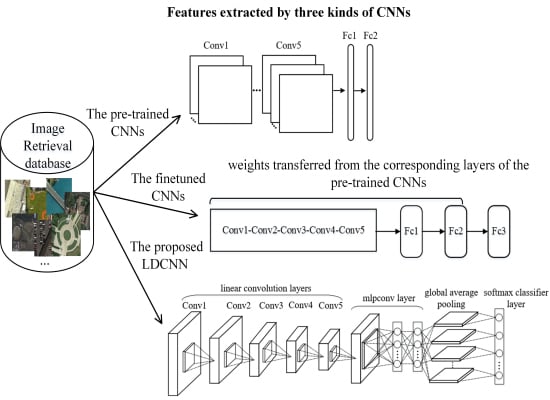
Figure 1.
The typical architecture of convolutional neural networks (CNNs). The rectified linear units (ReLU) layers are ignored here for conciseness.
Figure 1.
The typical architecture of convolutional neural networks (CNNs). The rectified linear units (ReLU) layers are ignored here for conciseness.
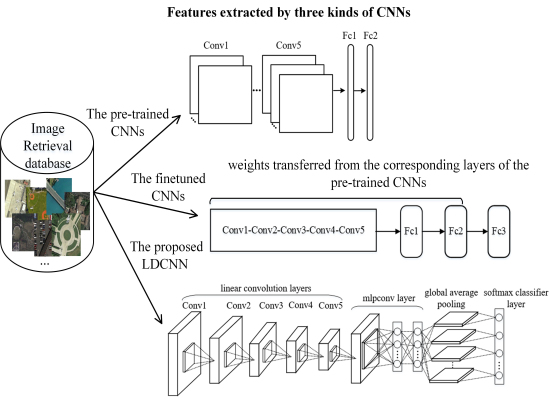
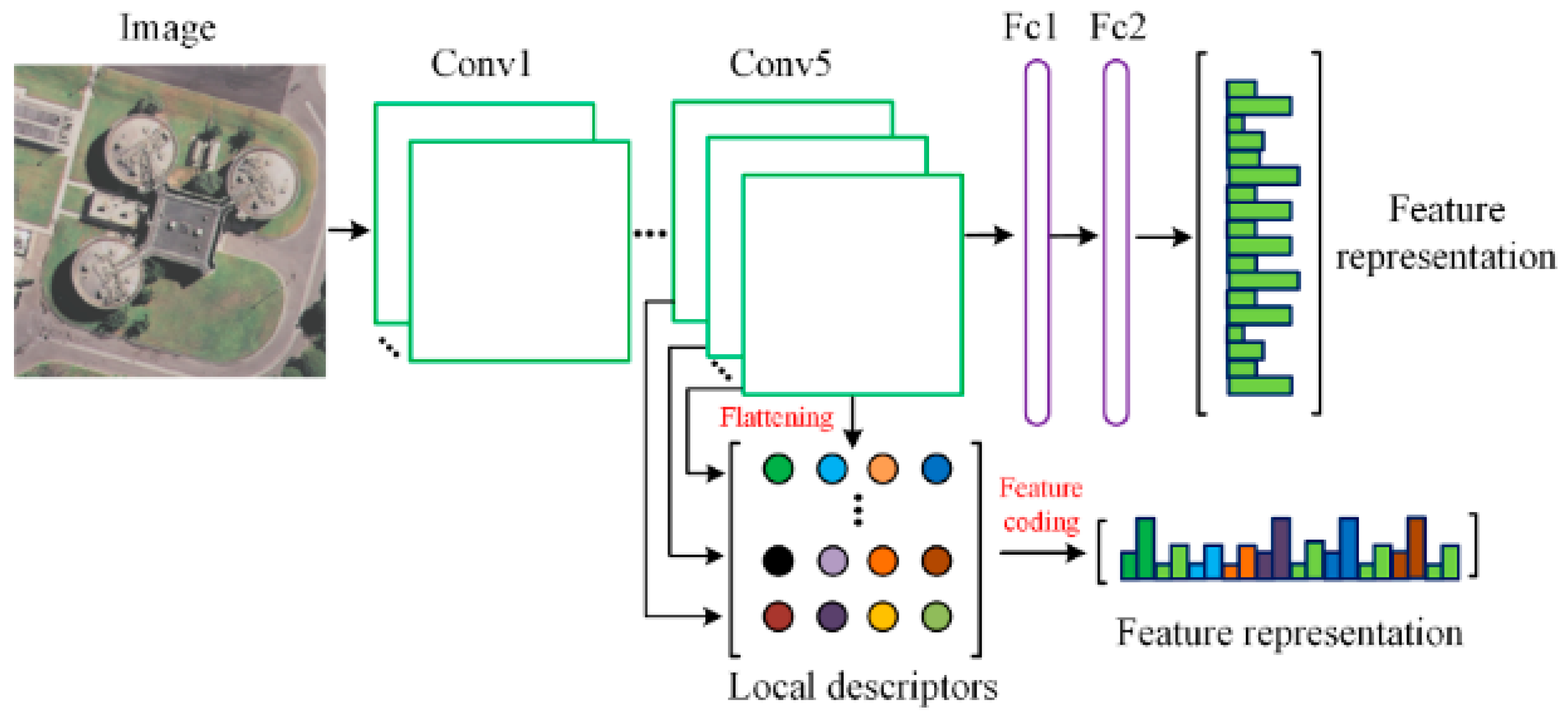
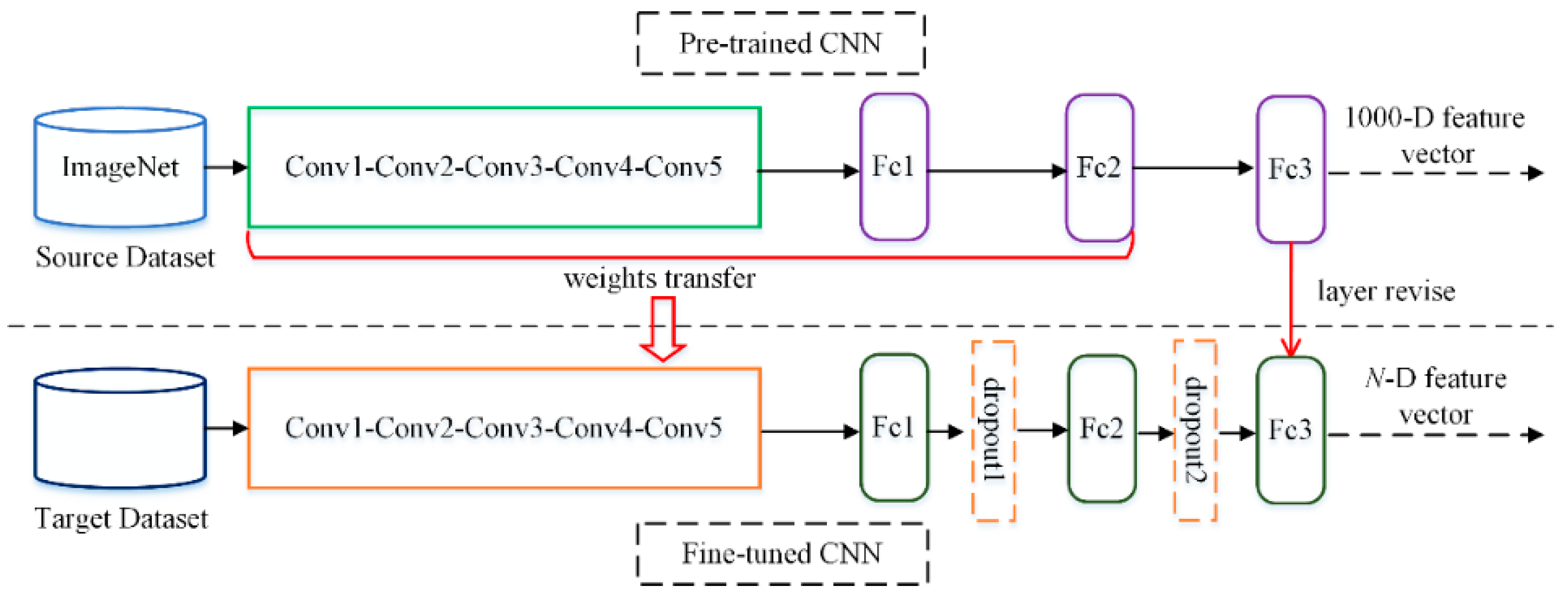
Figure 2.
Flowchart of the first scheme: deep features extracted from Fc2 and Conv5 layers of the pre-trained CNN model. For conciseness, we refer to features extracted from Fc1–2 and Conv1–5 layers as Fc features (Fc1, Fc2) and Conv features (Conv1, Conv2, Conv3, Conv4, Conv5), respectively.
Figure 2.
Flowchart of the first scheme: deep features extracted from Fc2 and Conv5 layers of the pre-trained CNN model. For conciseness, we refer to features extracted from Fc1–2 and Conv1–5 layers as Fc features (Fc1, Fc2) and Conv features (Conv1, Conv2, Conv3, Conv4, Conv5), respectively.
Figure 3.
Flowchart of extracting features from the fine-tuned layers. Dropout1 and dropout2 are dropout layers which are used to control overfitting. N is the number of image classes in the target dataset.
Figure 3.
Flowchart of extracting features from the fine-tuned layers. Dropout1 and dropout2 are dropout layers which are used to control overfitting. N is the number of image classes in the target dataset.
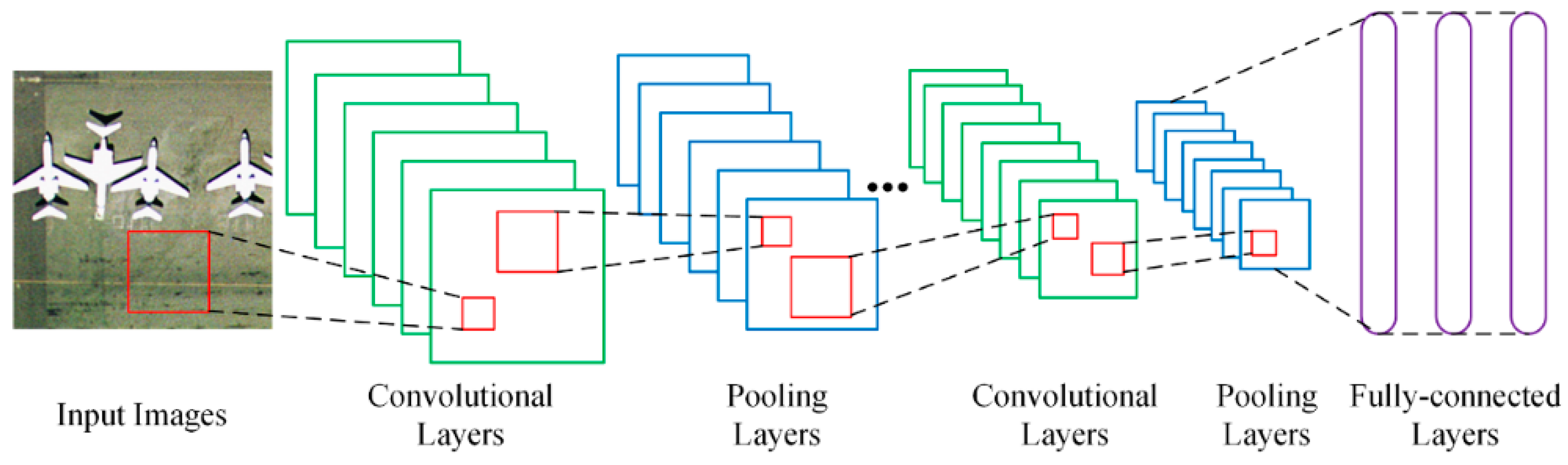
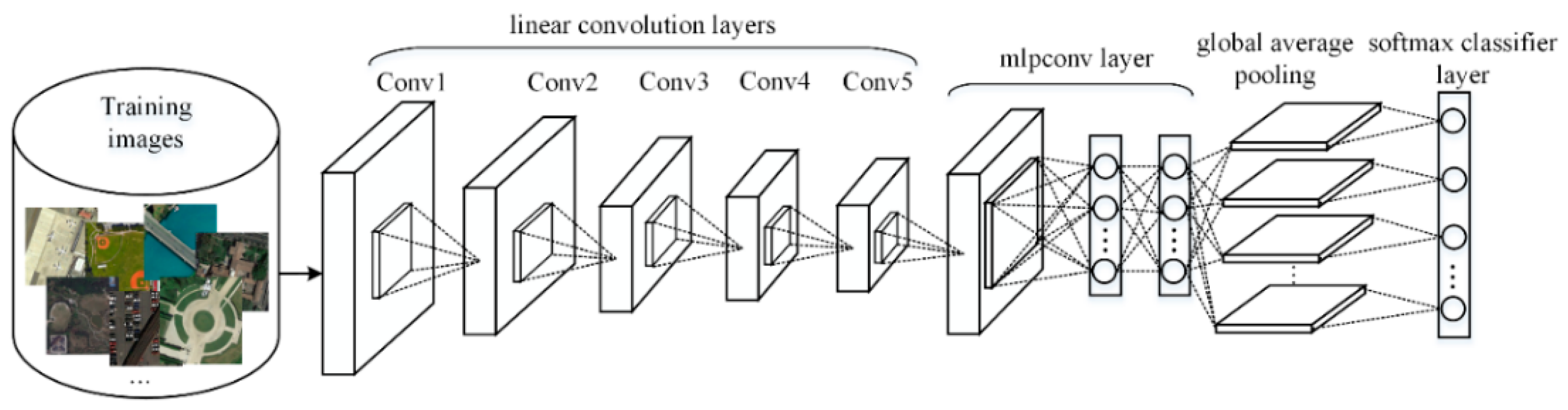
Figure 4.
The overall structure of the proposed, novel CNN architecture. There are five linear convolution layers and an mlpconv layer followed by a global average pooling layer.
Figure 4.
The overall structure of the proposed, novel CNN architecture. There are five linear convolution layers and an mlpconv layer followed by a global average pooling layer.
Figure 5.
Sample images from the University of California, Merced dataset (UCMD) dataset. From the top left to bottom right: agricultural, airplane, baseball diamond, beach, buildings, chaparral, dense residential, forest, freeway, golf course, harbor, intersection, medium density residential, mobile home park, overpass, parking lot, river, runway, sparse residential, storage tanks, and tennis courts.
Figure 5.
Sample images from the University of California, Merced dataset (UCMD) dataset. From the top left to bottom right: agricultural, airplane, baseball diamond, beach, buildings, chaparral, dense residential, forest, freeway, golf course, harbor, intersection, medium density residential, mobile home park, overpass, parking lot, river, runway, sparse residential, storage tanks, and tennis courts.
Figure 6.
Sample images from the remote sensing dataset (RSD). From the top left to bottom right: airport, beach, bridge, commercial area, desert, farmland, football field, forest, industrial area, meadow, mountain, park, parking, pond, port, railway station, residential area, river, and viaduct.
Figure 6.
Sample images from the remote sensing dataset (RSD). From the top left to bottom right: airport, beach, bridge, commercial area, desert, farmland, football field, forest, industrial area, meadow, mountain, park, parking, pond, port, railway station, residential area, river, and viaduct.
Figure 7.
Sample images from the RSSCN7 dataset. From left to right: grass, field, industry, lake, resident, and parking.
Figure 7.
Sample images from the RSSCN7 dataset. From left to right: grass, field, industry, lake, resident, and parking.
Figure 8.
Samples images from the aerial image dataset (AID). From the top left to bottom right: airport, bare land, baseball field, beach, bridge, center, church, commercial, dense residential, desert, farmland, forest, industrial, meadow, medium residential, mountain, park, parking, playground, pond, port, railway station, resort, river, school, sparse residential, square, stadium, storage tanks, and viaduct.
Figure 8.
Samples images from the aerial image dataset (AID). From the top left to bottom right: airport, bare land, baseball field, beach, bridge, center, church, commercial, dense residential, desert, farmland, forest, industrial, meadow, medium residential, mountain, park, parking, playground, pond, port, railway station, resort, river, school, sparse residential, square, stadium, storage tanks, and viaduct.
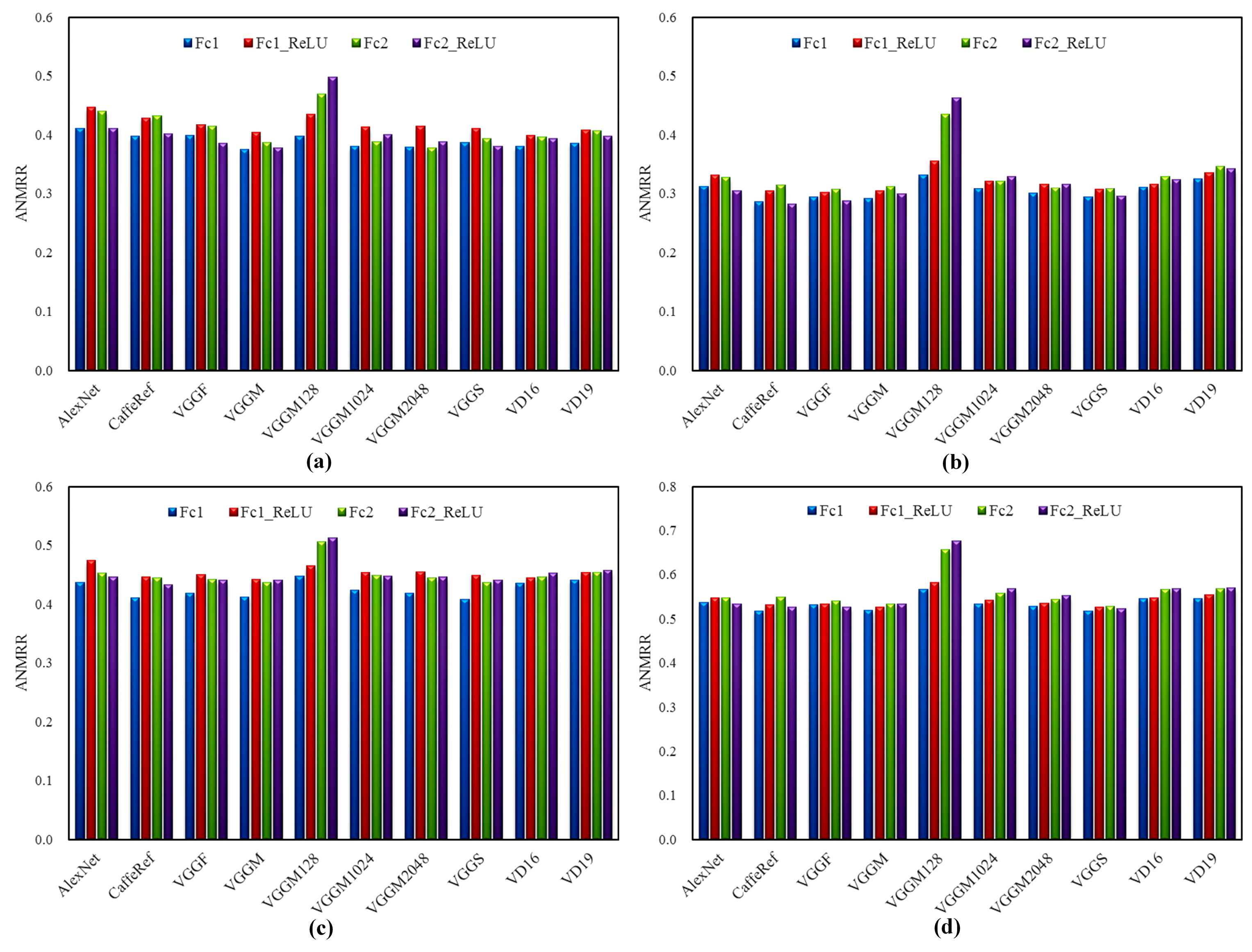
Figure 9.
The effect of ReLU on Fc1 and Fc2 features. (a) Results on UCMD dataset; (b) Results on RSD dataset; (c) Results on RSSCN7 dataset; (d) Results on AID dataset. For Fc1_ReLU and Fc2_ReLU features, ReLU is applied to the extracted Fc features.
Figure 9.
The effect of ReLU on Fc1 and Fc2 features. (a) Results on UCMD dataset; (b) Results on RSD dataset; (c) Results on RSSCN7 dataset; (d) Results on AID dataset. For Fc1_ReLU and Fc2_ReLU features, ReLU is applied to the extracted Fc features.
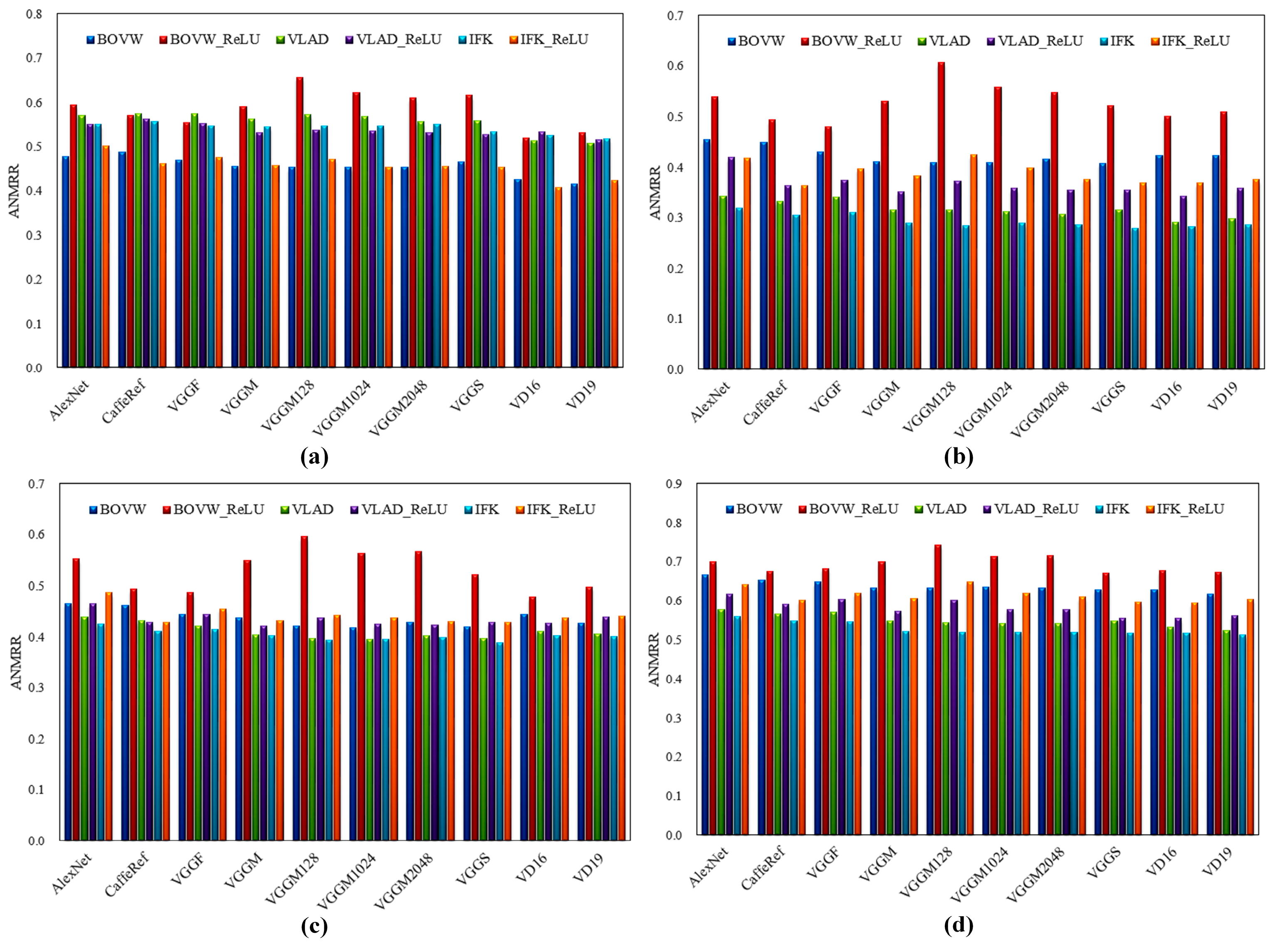
Figure 10.
The effect of ReLU on Conv features. (a) Results on UCMD dataset; (b) Results on RSD dataset; (c) Results on RSSCN7 dataset; (d) Results on AID dataset. For BOVW_ReLU, VLAD_ReLU, and IFK_ReLU features, ReLU is applied to the Conv features before feature aggregation.
Figure 10.
The effect of ReLU on Conv features. (a) Results on UCMD dataset; (b) Results on RSD dataset; (c) Results on RSSCN7 dataset; (d) Results on AID dataset. For BOVW_ReLU, VLAD_ReLU, and IFK_ReLU features, ReLU is applied to the Conv features before feature aggregation.
Figure 11.
Comparison between images of the same class from the four datasets. From left to right, the images are from UCMD, RSSCN7, RSD, and AID respectively.
Figure 11.
Comparison between images of the same class from the four datasets. From left to right, the images are from UCMD, RSSCN7, RSD, and AID respectively.
Figure 12.
The number of parameters contained in VGGM, fine-tuned VGGM, and LDCNN.
Figure 12.
The number of parameters contained in VGGM, fine-tuned VGGM, and LDCNN.
Table 1.
The architectures of the evaluated CNN Models. Conv1–5 are five convolutional layers and Fc1–3 are three fully-connected layers. For each of the convolutional layers, the first row specifies the number of filters and corresponding filter size as “size × size × number”; the second row indicates the convolution stride; and the last row indicates if Local Response Normalization (LRN) is used. For each of the fully-connected layers, its dimensionality is provided. In addition, dropout is applied to Fc1 and Fc2 to overcome overfitting.
Table 1.
The architectures of the evaluated CNN Models. Conv1–5 are five convolutional layers and Fc1–3 are three fully-connected layers. For each of the convolutional layers, the first row specifies the number of filters and corresponding filter size as “size × size × number”; the second row indicates the convolution stride; and the last row indicates if Local Response Normalization (LRN) is used. For each of the fully-connected layers, its dimensionality is provided. In addition, dropout is applied to Fc1 and Fc2 to overcome overfitting.
| Models | Conv1 | Conv2 | Conv3 | Conv4 | Conv5 | Fc1 | Fc2 | Fc3 |
|---|
| AlexNet | 11 × 11 × 96 | 5 × 5 × 256 | 3 × 3 × 384 | 3 × 3 × 384 | 3 × 3 × 256 | 4096 dropout | 4096 dropout | 1000 softmax |
| stride 4 | stride 1 | stride 1 | stride 1 | stride 1 |
| LRN | LRN | - | - | - |
| CaffeRef | 11 × 11 × 96 | 5 × 5 × 256 | 3 × 3 × 384 | 3 × 3 × 384 | 3 × 3 × 256 | 4096 dropout | 4096 dropout | 1000 softmax |
| stride 4 | stride 1 | stride 1 | stride 1 | stride 1 |
| LRN | LRN | - | - | - |
| VGGF | 11 × 11 × 64 | 5 × 5 × 256 | 3 × 3 × 256 | 3 × 3 × 256 | 3 × 3 × 256 | 4096 dropout | 4096 dropout | 1000 softmax |
| stride 4 | stride 1 | stride 1 | stride 1 | stride 1 |
| LRN | LRN | - | - | - |
| VGGM | 7 × 7 × 96 | 5 × 5 × 256 | 3 × 3 × 512 | 3 × 3 × 512 | 3 × 3 × 512 | 4096 dropout | 4096 dropout | 1000 softmax |
| stride 2 | stride 2 | stride 1 | stride 1 | stride 1 |
| LRN | LRN | - | - | - |
| VGGM-128 | 7 × 7 × 96 | 5 × 5 × 256 | 3 × 3 × 512 | 3 × 3 × 512 | 3 × 3 × 512 | 4096 dropout | 128 dropout | 1000 softmax |
| stride 2 | stride 2 | stride 1 | stride 1 | stride 1 |
| LRN | LRN | - | - | - |
| VGGM-1024 | 7 × 7 × 96 | 5 × 5 × 256 | 3 × 3 × 512 | 3 × 3 × 512 | 3 × 3 × 512 | 4096 dropout | 1024 dropout | 1000 softmax |
| stride 2 | stride 2 | stride 1 | stride 1 | stride 1 |
| LRN | LRN | - | - | - |
| VGGM-2048 | 7 × 7 × 96 | 5 × 5 × 256 | 3 × 3 × 512 | 3 × 3 × 512 | 3 × 3 × 512 | 4096 dropout | 2048 dropout | 1000 softmax |
| stride 2 | stride 2 | stride 1 | stride 1 | stride 1 |
| LRN | LRN | - | - | - |
| VGGS | 7 × 7 × 96 | 5 × 5 × 256 | 3 × 3 × 512 | 3 × 3 × 512 | 3 × 3 × 512 | 4096 dropout | 4096 dropout | 1000 softmax |
| stride 2 | stride 1 | stride 1 | stride 1 | stride 1 |
| LRN | - | - | - | - |
Table 2.
The performances of Fc features (ReLU is used) extracted by different CNN models on the four datasets. For average normalized modified retrieval rank (ANMRR), lower values indicate better performance, while for mean average precision (mAP), larger is better. The best result for each dataset is reported in bold.
Table 2.
The performances of Fc features (ReLU is used) extracted by different CNN models on the four datasets. For average normalized modified retrieval rank (ANMRR), lower values indicate better performance, while for mean average precision (mAP), larger is better. The best result for each dataset is reported in bold.
| Features | UCMD | RSD | RSSCN7 | AID |
|---|
| ANMRR | mAP | ANMRR | mAP | ANMRR | mAP | ANMRR | mAP |
|---|
| AlexNet_Fc1 | 0.447 | 0.4783 | 0.332 | 0.5960 | 0.474 | 0.4120 | 0.548 | 0.3532 |
| AlexNet_Fc2 | 0.410 | 0.5113 | 0.304 | 0.6206 | 0.446 | 0.4329 | 0.534 | 0.3614 |
| CaffeRef_Fc1 | 0.429 | 0.4982 | 0.305 | 0.6273 | 0.446 | 0.4381 | 0.532 | 0.3692 |
| CaffeRef_Fc2 | 0.402 | 0.5200 | 0.283 | 0.6460 | 0.433 | 0.4474 | 0.526 | 0.3694 |
| VGGF_Fc1 | 0.417 | 0.5116 | 0.302 | 0.6283 | 0.450 | 0.4346 | 0.534 | 0.3674 |
| VGGF_Fc2 | 0.386 | 0.5355 | 0.288 | 0.6399 | 0.440 | 0.4400 | 0.527 | 0.3694 |
| VGGM_Fc1 | 0.404 | 0.5235 | 0.305 | 0.6241 | 0.442 | 0.4479 | 0.526 | 0.3760 |
| VGGM_Fc2 | 0.378 | 0.5444 | 0.300 | 0.6255 | 0.440 | 0.4412 | 0.533 | 0.3632 |
| VGGM128_Fc1 | 0.435 | 0.4863 | 0.356 | 0.5599 | 0.465 | 0.4176 | 0.582 | 0.3145 |
| VGGM128_Fc2 | 0.498 | 0.4093 | 0.463 | 0.4393 | 0.513 | 0.3606 | 0.676 | 0.2183 |
| VGGM1024_Fc1 | 0.413 | 0.5138 | 0.321 | 0.6052 | 0.454 | 0.4380 | 0.542 | 0.3590 |
| VGGM1024_Fc2 | 0.400 | 0.5165 | 0.330 | 0.5891 | 0.447 | 0.4337 | 0.568 | 0.3249 |
| VGGM2048_Fc1 | 0.414 | 0.5130 | 0.317 | 0.6110 | 0.455 | 0.4365 | 0.536 | 0.3662 |
| VGGM2048_Fc2 | 0.388 | 0.5315 | 0.316 | 0.6053 | 0.446 | 0.4357 | 0.552 | 0.3426 |
| VGGS_Fc1 | 0.410 | 0.5173 | 0.307 | 0.6224 | 0.449 | 0.4406 | 0.526 | 0.3761 |
| VGGS_Fc2 | 0.381 | 0.5417 | 0.296 | 0.6288 | 0.441 | 0.4412 | 0.523 | 0.3725 |
| VD16_Fc1 | 0.399 | 0.5252 | 0.316 | 0.6102 | 0.444 | 0.4354 | 0.548 | 0.3516 |
| VD16_Fc2 | 0.394 | 0.5247 | 0.324 | 0.5974 | 0.452 | 0.4241 | 0.568 | 0.3272 |
| VD19_Fc1 | 0.408 | 0.5144 | 0.336 | 0.5843 | 0.454 | 0.4243 | 0.554 | 0.3457 |
| VD19_Fc2 | 0.398 | 0.5195 | 0.342 | 0.5736 | 0.457 | 0.4173 | 0.570 | 0.3255 |
Table 3.
The precision at k (P@k) values of Fc features that achieve inconsistent results on the RSSCN7 and AID datasets for the ANMRR and mAP measures.
Table 3.
The precision at k (P@k) values of Fc features that achieve inconsistent results on the RSSCN7 and AID datasets for the ANMRR and mAP measures.
| Measures | RSSCN7 | AID |
|---|
| VGGF_Fc2 | VGGM_Fc1 | VGGM_Fc2 | VGGS_Fc1 | VGGS_Fc2 |
|---|
| P@5 | 0.7974 | 0.8098 | 0.8007 | 0.7754 | 0.7685 |
| P@10 | 0.7645 | 0.7787 | 0.7687 | 0.7415 | 0.7346 |
| P@50 | 0.6618 | 0.6723 | 0.6626 | 0.6265 | 0.6214 |
| P@100 | 0.5940 | 0.6040 | 0.5943 | 0.5550 | 0.5521 |
| P@1000 | 0.2960 | 0.2915 | 0.2962 | 0.2069 | 0.2097 |
Table 4.
The performance of the Conv features (ReLU is used) aggregated using bag of visual words (BOVW), vector of locally aggregated descriptors (VLAD), and improved fisher kernel (IFK) on the four datasets. For ANMRR, lower values indicate better performance, while for mAP, larger is better. The best result for each dataset is reported in bold.
Table 4.
The performance of the Conv features (ReLU is used) aggregated using bag of visual words (BOVW), vector of locally aggregated descriptors (VLAD), and improved fisher kernel (IFK) on the four datasets. For ANMRR, lower values indicate better performance, while for mAP, larger is better. The best result for each dataset is reported in bold.
| Features | UCMD | RSD | RSSCN7 | AID |
|---|
| ANMRR | mAP | ANMRR | mAP | ANMRR | mAP | ANMRR | mAP |
|---|
| AlexNet_BOVW | 0.594 | 0.3240 | 0.539 | 0.3715 | 0.552 | 0.3403 | 0.699 | 0.2058 |
| AlexNet_VLAD | 0.551 | 0.3538 | 0.419 | 0.4921 | 0.465 | 0.4144 | 0.616 | 0.2793 |
| AlexNet_IFK | 0.500 | 0. 4217 | 0.417 | 0.4958 | 0.486 | 0.4007 | 0.642 | 0.2592 |
| CaffeRef_BOVW | 0.571 | 0.3416 | 0.493 | 0.4128 | 0.493 | 0.3858 | 0.675 | 0.2265 |
| CaffeRef_VLAD | 0.563 | 0.3396 | 0.364 | 0.5552 | 0.428 | 0.4543 | 0.591 | 0.3047 |
| CaffeRef_IFK | 0.461 | 0.4595 | 0.364 | 0.5562 | 0.428 | 0.4628 | 0.601 | 0.2998 |
| VGGF_BOVW | 0.554 | 0.3578 | 0.479 | 0.4217 | 0.486 | 0.3926 | 0.682 | 0.2181 |
| VGGF_VLAD | 0.553 | 0.3483 | 0.374 | 0.5408 | 0.444 | 0.4352 | 0.604 | 0.2895 |
| VGGF_IFK | 0.475 | 0.4464 | 0.397 | 0.5141 | 0.454 | 0.4327 | 0.620 | 0.2769 |
| VGGM_BOVW | 0.590 | 0.3237 | 0.531 | 0.3790 | 0.549 | 0.3469 | 0.699 | 0.2054 |
| VGGM_VLAD | 0.531 | 0.3701 | 0.352 | 0.5640 | 0.420 | 0.4621 | 0.572 | 0.3200 |
| VGGM_IFK | 0.458 | 0.4620 | 0.382 | 0.5336 | 0.431 | 0.4516 | 0.605 | 0.2955 |
| VGGM128_BOVW | 0.656 | 0.2717 | 0.606 | 0.3120 | 0.596 | 0.3152 | 0.743 | 0.1728 |
| VGGM128_VLAD | 0.536 | 0.3683 | 0.373 | 0.5377 | 0.436 | 0.4411 | 0.602 | 0.2891 |
| VGGM128_IFK | 0.471 | 0.4437 | 0.424 | 0.4834 | 0.442 | 0.4388 | 0.649 | 0.2514 |
| VGGM1024_BOVW | 0.622 | 0.2987 | 0.558 | 0.3565 | 0.564 | 0.3393 | 0.714 | 0.1941 |
| VGGM1024_VLAD | 0.535 | 0.3691 | 0.358 | 0.5560 | 0.425 | 0.4568 | 0.577 | 0.3160 |
| VGGM1024_IFK | 0.454 | 0.4637 | 0.399 | 0.5149 | 0.436 | 0.4490 | 0.619 | 0.2809 |
| VGGM2048_BOVW | 0.609 | 0.3116 | 0.548 | 0.3713 | 0.566 | 0.3378 | 0.715 | 0.1939 |
| VGGM2048_VLAD | 0.531 | 0.3728 | 0.354 | 0.5591 | 0.423 | 0.4594 | 0.576 | 0.3150 |
| VGGM2048_IFK | 0.456 | 0.4643 | 0.376 | 0.5387 | 0.430 | 0.4535 | 0.610 | 0.2907 |
| VGGS_BOVW | 0.615 | 0.3021 | 0.521 | 0.3843 | 0.522 | 0.3711 | 0.670 | 0.2347 |
| VGGS_VLAD | 0.526 | 0.3763 | 0.355 | 0.5563 | 0.428 | 0.4541 | 0.555 | 0.3396 |
| VGGS_IFK | 0.453 | 0.4666 | 0.368 | 0.5497 | 0.428 | 0.4574 | 0.596 | 0.3054 |
| VD16_BOVW | 0.518 | 0.3909 | 0.500 | 0.3990 | 0.478 | 0.3930 | 0.677 | 0.2236 |
| VD16_VLAD | 0.533 | 0.3666 | 0.342 | 0.5724 | 0.426 | 0.4436 | 0.554 | 0.3365 |
| VD16_IFK | 0.407 | 0.5102 | 0.368 | 0.5478 | 0.436 | 0.4405 | 0.594 | 0.3060 |
| VD19_BOVW | 0.530 | 0.3768 | 0.509 | 0.3896 | 0.498 | 0.3762 | 0.673 | 0.2253 |
| VD19_VLAD | 0.514 | 0.3837 | 0.358 | 0.5533 | 0.439 | 0.4310 | 0.562 | 0.3305 |
| VD19_IFK | 0.423 | 0.4908 | 0.375 | 0.5411 | 0.440 | 0.4375 | 0.604 | 0.2965 |
Table 5.
The P@k values of Conv features that achieve inconsistent results on the RSSCN7 and AID datasets for the ANMRR and mAP measures.
Table 5.
The P@k values of Conv features that achieve inconsistent results on the RSSCN7 and AID datasets for the ANMRR and mAP measures.
| Measures | RSSCN7 | AID |
|---|
| CaffeRef_IFK | VGGM_VLAD | VGGS_VLAD | VD16_VLAD |
|---|
| P@5 | 0.7741 | 0.7997 | 0.7013 | 0.6870 |
| P@10 | 0.7477 | 0.7713 | 0.6662 | 0.6577 |
| P@50 | 0.6606 | 0.6886 | 0.5649 | 0.5654 |
| P@100 | 0.6024 | 0.6294 | 0.5049 | 0.5081 |
| P@1000 | 0.2977 | 0.2957 | 0.2004 | 0.1997 |
Table 6.
The models that achieve the best results in terms of Fc and Conv features on each dataset. The numbers are ANMRR values.
Table 6.
The models that achieve the best results in terms of Fc and Conv features on each dataset. The numbers are ANMRR values.
| Features | UCMD | RSD | RSSCN7 | AID |
|---|
| Fc1 | VGGM | 0.375 | Caffe_Ref | 0.286 | VGGS | 0.408 | VGGS | 0.518 |
| Fc1_ReLU | VD16 | 0.399 | VGGF | 0.302 | VGGM | 0.442 | VGGS | 0.526 |
| Fc2 | VGGM2048 | 0.378 | VGGF | 0.307 | VGGS | 0.437 | VGGS | 0.528 |
| Fc2_ReLU | VGGM | 0.378 | Caffe_Ref | 0.283 | Caffe_Ref | 0.433 | VGGS | 0.523 |
| Conv | VD19 | 0.415 | VGGS | 0.279 | VGGS | 0.388 | VD19 | 0.512 |
| Conv_ReLU | VD16 | 0.407 | VD16 | 0.342 | VGGM | 0.420 | VD16 | 0.554 |
Table 7.
The results of the combined features on each dataset. For the UCMD dataset, Fc1, Fc2_ReLU, and Conv_ReLU features are selected; for the RSD dataset, Fc1, Fc2_ReLU, and Conv features are selected; for the RSSCN7 dataset, Fc1, Fc2_ReLU, and Conv features are selected; for the AID dataset, Fc1, Fc2_ReLU, and Conv features are selected. “+” means the combination of two features. The numbers are ANMRR values.
Table 7.
The results of the combined features on each dataset. For the UCMD dataset, Fc1, Fc2_ReLU, and Conv_ReLU features are selected; for the RSD dataset, Fc1, Fc2_ReLU, and Conv features are selected; for the RSSCN7 dataset, Fc1, Fc2_ReLU, and Conv features are selected; for the AID dataset, Fc1, Fc2_ReLU, and Conv features are selected. “+” means the combination of two features. The numbers are ANMRR values.
| Features | UCMD | RSD | RSSCN7 | AID |
|---|
| Fc1 + Fc2 | 0.374 | 0.286 | 0.407 | 0.517 |
| Fc1 + Conv | 0.375 | 0.286 | 0.408 | 0.518 |
| Fc2 + Conv | 0.378 | 0.283 | 0.433 | 0.523 |
Table 8.
Comparisons of deep features with state-of-the-art methods on the UCMD dataset. The numbers are ANMRR values.
Table 8.
Comparisons of deep features with state-of-the-art methods on the UCMD dataset. The numbers are ANMRR values.
| Deep Features | Local Features [9] | VLAD-PQ [32] | Morphological Texture [5] | IRMFRCAMF [14] |
|---|
| 0.375 | 0.591 | 0.451 | 0.575 | 0.715 |
Table 9.
Comparisons of deep features with state-of-the-art methods on RSD, RSSCN7, and AID datasets. The numbers are ANMRR values.
Table 9.
Comparisons of deep features with state-of-the-art methods on RSD, RSSCN7, and AID datasets. The numbers are ANMRR values.
| Features | RSD | RSSCN7 | AID |
|---|
| Deep features | 0.279 | 0.388 | 0.512 |
| LBP | 0.688 | 0.569 | 0.848 |
| GIST | 0.725 | 0.666 | 0.856 |
| BOVW | 0.497 | 0.544 | 0.721 |
Table 10.
Results of the pre-trained CNN, the fine-tuned CNN, and the proposed LDCNN on the UCMD, RSD, and RSSCN7 datasets. For the pre-trained CNN, we choose the best results, as shown in
Table 6 and
Table 7; for the fine-tuned CNN, VGGM, CaffeRef, and VGGS are fine-tuned on AID and then applied to UCMD, RSD, and RSSCN7, respectively. The numbers are ANMRR values.
Table 10.
Results of the pre-trained CNN, the fine-tuned CNN, and the proposed LDCNN on the UCMD, RSD, and RSSCN7 datasets. For the pre-trained CNN, we choose the best results, as shown in
Table 6 and
Table 7; for the fine-tuned CNN, VGGM, CaffeRef, and VGGS are fine-tuned on AID and then applied to UCMD, RSD, and RSSCN7, respectively. The numbers are ANMRR values.
| Datasets | Pre-Trained CNN | Fine-Tuned CNN | LDCNN |
|---|
| Fc1 | Fc1_ReLU | Fc2 | Fc2_ReLU |
|---|
| UCMD | 0.375 | 0.349 | 0.334 | 0.329 | 0.340 | 0.439 |
| RSD | 0.279 | 0.185 | 0.062 | 0.044 | 0.036 | 0.019 |
| RSSCN7 | 0.388 | 0.361 | 0.337 | 0.304 | 0.312 | 0.305 |
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}