A Flexible Hybrid BCH Decoder for Modern NAND Flash Memories Using General Purpose Graphical Processing Units (GPGPUs)



Abstract
:1. Introduction
2. Background
2.1. Encoder
2.2. Decoder
2.3. Motivation
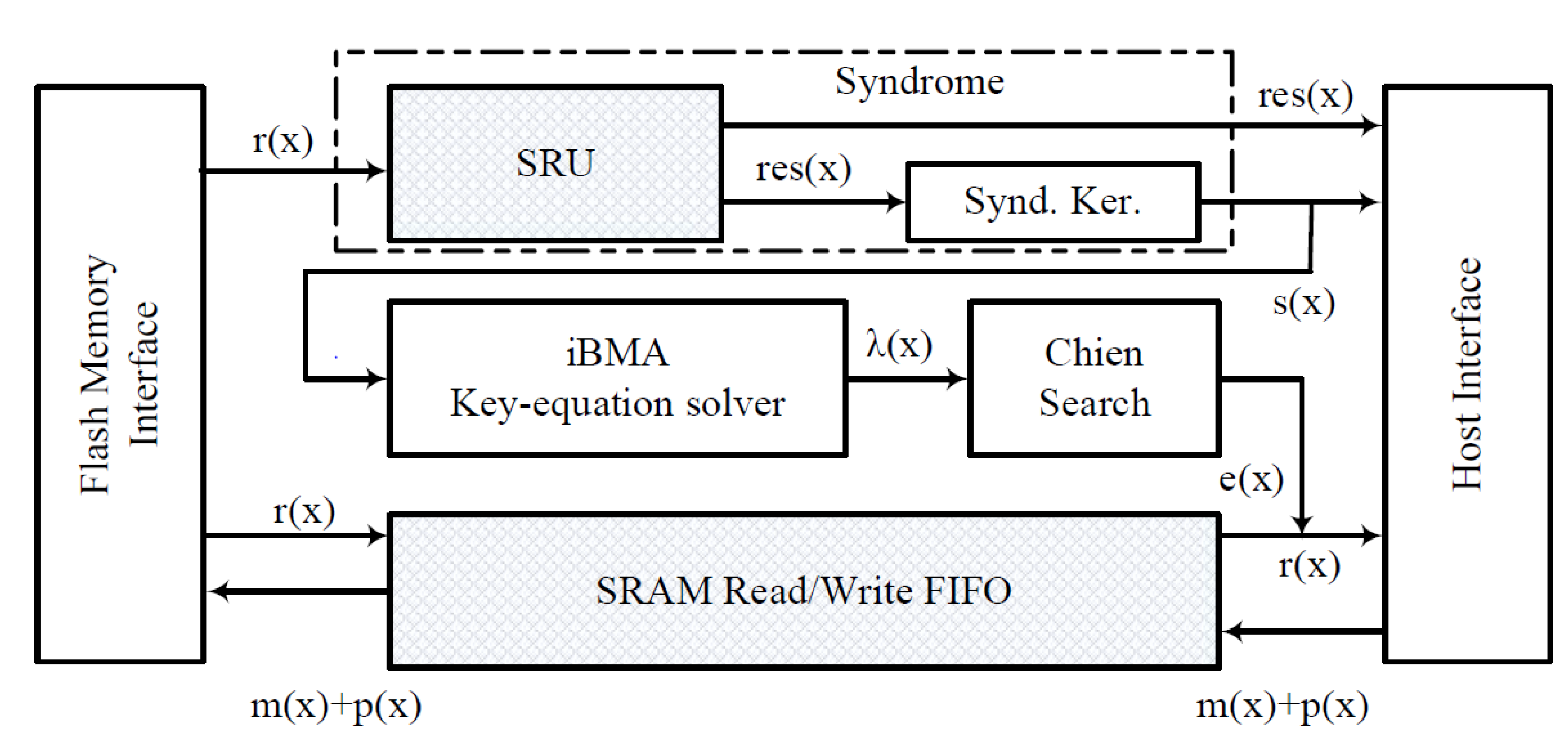
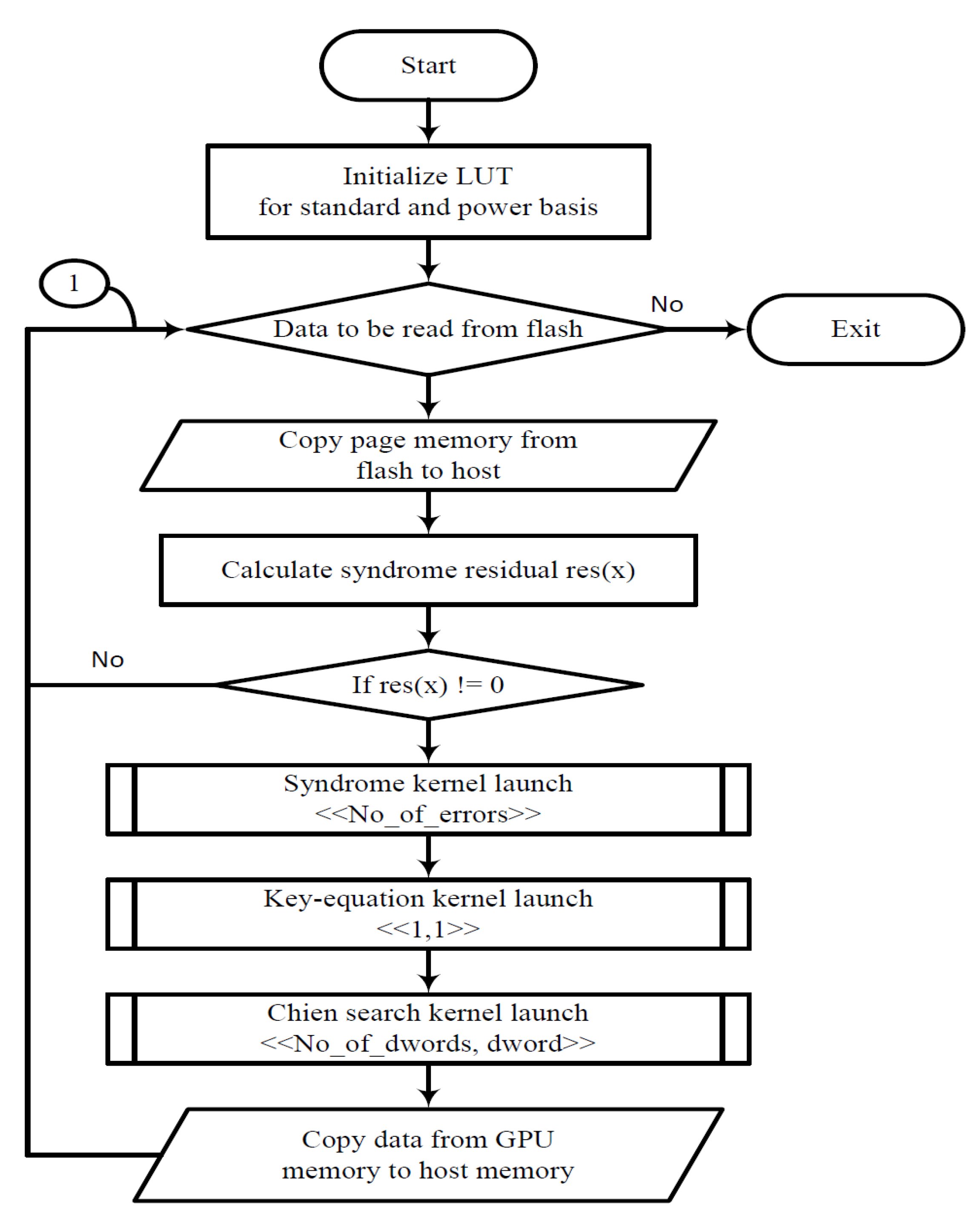
3. Hybrid Method
3.1. Flowchart
3.2. Modified Syndrome Generator
3.3. GPU Kernel Routines
3.3.1. Syndrome Kernel
| Algorithm 1 Syndrome kernel. |
|
3.3.2. Key-Equation Kernel
| Algorithm 2 Key-equation kernel. |
|
3.3.3. Chien Search Kernel
| Algorithm 3 Chien search. Kernel |
|
4. Experimental Results and Analysis
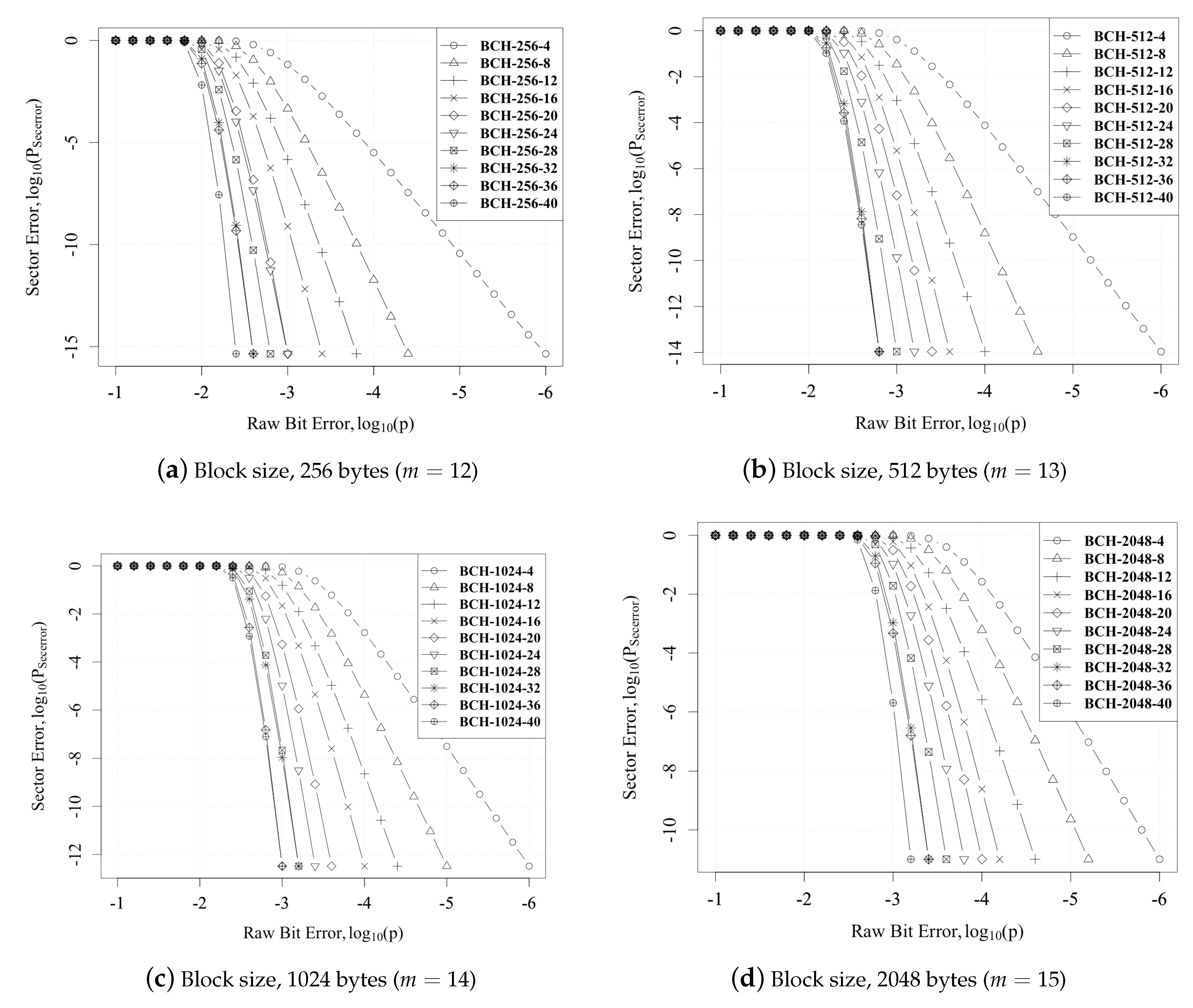
4.1. Error Analysis
4.2. Syndrome Generation Analysis
4.3. VLSI Analysis
4.4. Performance Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| BCH | Bose–Chaudhuri–Hocquenghem |
| iBMA | inversion-less Berlekamp-Massey algorithm |
| CPU | Central Processing Unit |
| CS | Chien Search |
| CSK | Chien Search Kernel |
| KEK | Key Equation Kernel |
| GPU | Graphical Processing Unit |
| GPGPU | General Purpose Graphical Processing Unit |
| LDPC | Low Density Parity Check |
| LFSR | Linear Feedback Shift Register |
| MLC | Multi-Level Cell |
| RS | Reed–Solomon |
| SK | Syndrome calculation Kernel |
| SLC | Single-Level Cell |
| SRU | Syndrome Residual Unit |
| UBER | Uncorrectable Bit Error Rate |
References
- Micheloni, R.; Marelli, A.; Crippa, L. Inside NAND Flash Memories; Springer: New York, NY, USA, 2010. [Google Scholar] [CrossRef]
- Spinelli, A.; Compagnoni, C.; Lacaita, A. Reliability of NAND Flash Memories: Planar Cells and Emerging Issues in 3D Devices. Computers 2017, 6, 16. [Google Scholar] [CrossRef]
- Costell, S.L.; Costello, D. Error Control Coding—Fundamentals and Applications, 2nd ed.; Prentice-Hall: Englewood Cliffs, NJ, USA, 2004; pp. 192–233. [Google Scholar]
- Cho, J.; Sung, W. Efficient software-based encoding and decoding of BCH codes. IEEE Trans. Comput. 2009, 58, 878–889. [Google Scholar] [CrossRef]
- Poolakkaparambil, M.; Mathew, J.; Jabir, A. Multiple Bit Error Tolerant Galois Field Architectures over GF (2m). Electronics 2012, 1, 3–22. [Google Scholar] [CrossRef]
- Lee, Y.; Yoo, H.; Yoo, I.; Park, I.C. High-throughput and low-complexity BCH decoding architecture for solid-state drives. IEEE Trans. Very Large Scale Integr. Syst. 2014, 22, 1183–1187. [Google Scholar] [CrossRef]
- Zhang, X. VLSI Architectures for Modern Error-Correcting Codes, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2016; pp. 189–225. [Google Scholar]
- Qi, X.; Ma, X.; Li, D.; Zhao, Y. Implementation of accelerated BCH decoders on GPU. In Proceedings of the 2013 International Conference on Wireless Communications and Signal Processing (WCSP), Hangzhou, China, 24–26 October 2013; pp. 1–6. [Google Scholar] [CrossRef]
- Subbiah, A.K.; Ogunfunmi, T. Efficient implementation of BCH decoders on GPU for flash memory devices using iBMA. In Proceedings of the 2016 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 7–11 January 2016; pp. 275–278. [Google Scholar] [CrossRef]
- NVIDIA. Cuda C Programming Guide; NVIDIA: Santa Clara, CA, USA, 2015; PMCID:PMC3074485, NIHMSID:Nihms253063. [Google Scholar] [CrossRef]
- Parhi, K.K. Eliminating the fan-out bottleneck in parallel long BCH encoders. IEEE Trans. Circuits Syst. I Regul. Pap. 2004, 51, 512–516. [Google Scholar] [CrossRef]
- Chen, H. CRT-based high-speed parallel architecture for long BCH encoding. IEEE Trans. Circuits Syst. II Express Briefs 2009, 56, 684–686. [Google Scholar] [CrossRef]
- Tang, H.; Jung, G.; Park, J. A hybrid multimode BCH encoder architecture for area efficient re-encoding approach. In Proceedings of the IEEE International Symposium on Circuits and Systems, Lisbon, Portugal, 24–27 May 2015; Volume 2015, pp. 1997–2000. [Google Scholar] [CrossRef]
- Subbiah, A.K.; Ogunfunmi, T. Area-effcient re-encoding scheme for NAND Flash Memory with multimode BCH Error correction. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Zhang, X. An efficient interpolation-based chase BCH decoder. IEEE Trans. Circuits Syst. II: Express Briefs 2013, 60, 212–216. [Google Scholar] [CrossRef]
- Yang, C.H.; Huang, T.Y.; Li, M.R.; Ueng, Y.L. A 5.4 uw soft-decision bch decoder for wireless body area networks. IEEE Trans. Circuits Syst. I: Regul. Pap. 2014, 61, 2721–2729. [Google Scholar] [CrossRef]
- Jamro, E. The Design of a Vhdl Based Synthesis Tool for Bch Codecs. Ph.D. Thesis, University of Huddersfield, Huddersfield, UK, 1997. [Google Scholar]
- Sun, F.; Devarajan, S.; Rose, K.; Zhang, T. Design of on-chip error correction systems for multilevel NOR and NAND flash memories. IET Circuits Devices Syst. 2007, 1, 241–249. [Google Scholar] [CrossRef] [Green Version]
- Sun, F.; Rose, K.; Zhang, T. On the Use of Strong BCH Codes for Improving Multilevel NAND Flash Memory Storage Capacity. In Proceedings of the IEEE Workshop on Signal Processing, Banff, AB, Canada, 2–4 October 2006; pp. 1–5. [Google Scholar]
- Park, B.; Park, J.; Lee, Y. Area-Optimized Fully-Flexible BCH Decoder for Multiple GF Dimensions. IEEE Access 2018, 6, 14498–14509. [Google Scholar] [CrossRef]
- Wei, L.; Junrye, R.; Wonyong, S. Low-power high-throughput BCH error correction VLSI design for multi-level cell NAND flash memories. In Proceedings of the 2006 IEEE Workshop on Signal Processing Systems Design and Implementation (SIPS), Banff, AB, Canada, 2–4 October 2006; pp. 303–308. [Google Scholar] [CrossRef]
- Park, B.; An, S.; Park, J.; Lee, Y. Novel folded-KES architecture for high-speed and area-efficient BCH decoders. IEEE Trans. Circuits Syst. II: Express Briefs 2017, 64, 535–539. [Google Scholar] [CrossRef]
- Yoo, H.; Lee, Y.; Park, I.C. Low-Power Parallel Chien Search Architecture Using a Two-Step Approach. IEEE Trans. Circuits Syst. II Express Briefs 2016, 63, 269–273. [Google Scholar] [CrossRef]
- Freudenberger, J.; Spinner, J. A Configurable Bose–Chaudhuri–Hocquenghem Codec Architecture for Flash Controller Applications. J. Circuits Syst. Comput. 2013, 23, 1450019. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GPGPU | CPU | |
|---|---|---|
| Platform | Geforce GTX 760. 1152 cores | Intel Xeon i7 |
| Clock Freq. | 1.033 GHz | 3.7 GHz |
| Memory | GDDR5(2 GB), 6 Gbps | DDR2 (32 GB), 102.4 Gbps |
| Setup | Area for t (m) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | 8 | 12 | 16 | 20 | 24 | 28 | 32 | 36 | 40 | ||
| m =12 | [20] | 606 | 1287 | 2079 | 2871 | 3256 | 3661 | 3959 | 4252 | 4611 | 4917 |
| Prop. | 853 | 1704 | 2550 | 3399 | 4209 | 5061 | 5903 | 6747 | 7592 | 8436 | |
| m =13 | [20] | 858 | 1863 | 2962 | 4043 | 4648 | 5246 | 5814 | 6387 | 6988 | 7573 |
| Prop. | 924 | 1846 | 2767 | 3682 | 4607 | 5532 | 6390 | 7305 | 8308 | 9134 | |
| m =14 | [20] | 916 | 2002 | 3167 | 4330 | 5016 | 5723 | 6375 | 7048 | 7714 | 8390 |
| Prop. | 994 | 1985 | 2976 | 3966 | 4966 | 5959 | 6948 | 7942 | 8935 | 9927 | |
| m =15 | [20] | 988 | 2172 | 3435 | 4707 | 5485 | 6292 | 7043 | 7818 | 8587 | 9367 |
| Prop. | 1064 | 2125 | 3186 | 4249 | 5318 | 6383 | 7448 | 8504 | 9570 | 10,633 | |
| m =12, …, 15 | [20] | 3368 | 7324 | 116,43 | 15,951 | 18,405 | 20,922 | 23,191 | 25,505 | 27,900 | 30,247 |
| Prop. | 1064 | 2125 | 3186 | 4249 | 5318 | 6383 | 7448 | 8504 | 9570 | 10,633 | |
| Setup | Power for t (mW) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | 8 | 12 | 16 | 20 | 24 | 28 | 32 | 36 | 40 | ||
| m =12 | [20] | 0.179 | 0.374 | 0.599 | 0.819 | 0.897 | 0.978 | 1.037 | 1.097 | 1.170 | 1.232 |
| Proposed | 0.167 | 0.336 | 0.499 | 0.673 | 0.841 | 1.014 | 1.185 | 1.354 | 1.524 | 1.695 | |
| m =13 | [20] | 0.226 | 0.491 | 0.773 | 1.054 | 1.178 | 1.304 | 1.426 | 1.546 | 1.674 | 1.797 |
| Proposed | 0.178 | 0.355 | 0.534 | 0.714 | 0.889 | 1.061 | 1.248 | 1.424 | 1.615 | 1.778 | |
| m =14 | [20] | 0.231 | 0.503 | 0.784 | 1.068 | 1.213 | 1.363 | 1.499 | 1.640 | 1.780 | 1.923 |
| Proposed | 0.187 | 0.373 | 0.561 | 0.747 | 0.938 | 1.122 | 1.309 | 1.493 | 1.678 | 1.863 | |
| m =15 | [20] | 0.235 | 0.512 | 0.812 | 1.110 | 1.270 | 1.438 | 1.593 | 1.755 | 1.915 | 2.078 |
| Proposed | 0.194 | 0.388 | 0.588 | 0.776 | 0.975 | 1.168 | 1.370 | 1.564 | 1.755 | 1.953 | |
| m =12, …, 15 | [20] | 0.692 | 1.506 | 2.369 | 3.232 | 3.661 | 4.105 | 4.518 | 4.941 | 5.369 | 5.798 |
| Proposed | 0.194 | 0.388 | 0.588 | 0.776 | 0.975 | 1.168 | 1.370 | 1.564 | 1.755 | 1.953 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Subbiah, A.; Ogunfunmi, T. A Flexible Hybrid BCH Decoder for Modern NAND Flash Memories Using General Purpose Graphical Processing Units (GPGPUs). Micromachines 2019, 10, 365. https://doi.org/10.3390/mi10060365
Subbiah A, Ogunfunmi T. A Flexible Hybrid BCH Decoder for Modern NAND Flash Memories Using General Purpose Graphical Processing Units (GPGPUs). Micromachines. 2019; 10(6):365. https://doi.org/10.3390/mi10060365
Chicago/Turabian StyleSubbiah, Arul, and Tokunbo Ogunfunmi. 2019. "A Flexible Hybrid BCH Decoder for Modern NAND Flash Memories Using General Purpose Graphical Processing Units (GPGPUs)" Micromachines 10, no. 6: 365. https://doi.org/10.3390/mi10060365
APA StyleSubbiah, A., & Ogunfunmi, T. (2019). A Flexible Hybrid BCH Decoder for Modern NAND Flash Memories Using General Purpose Graphical Processing Units (GPGPUs). Micromachines, 10(6), 365. https://doi.org/10.3390/mi10060365