Efficient Acceleration of Stencil Applications through In-Memory Computing



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Background
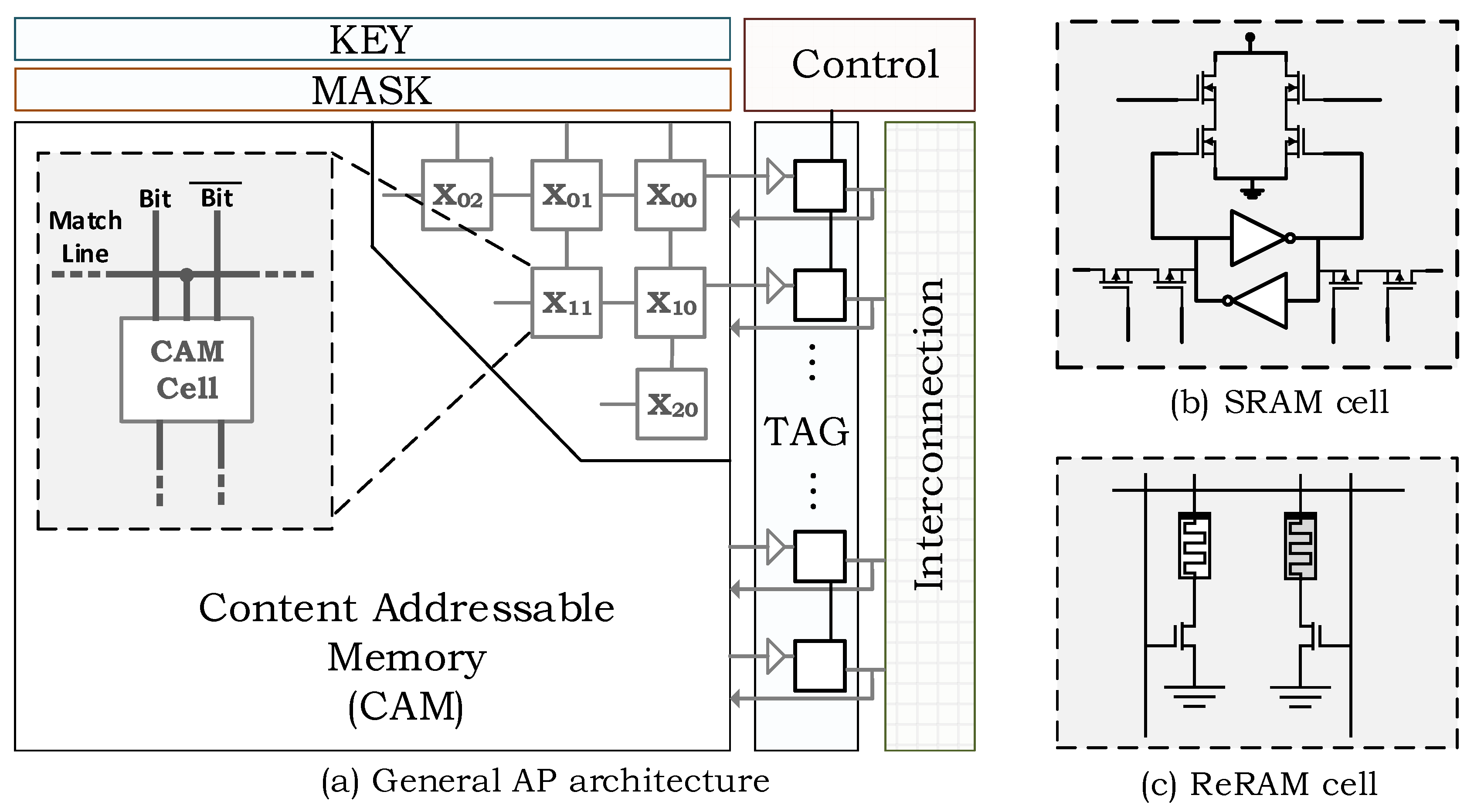
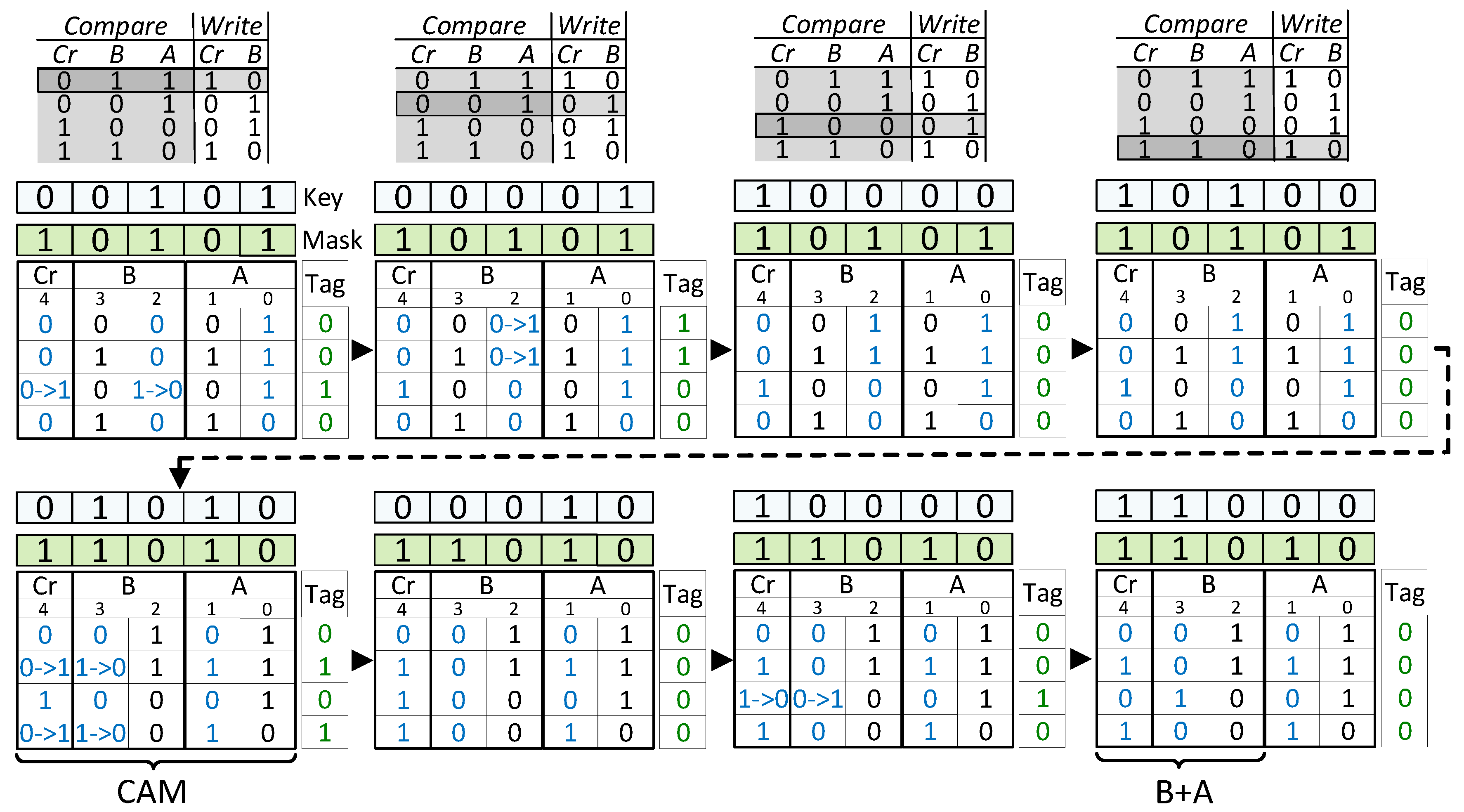
2.1. Associate Processor
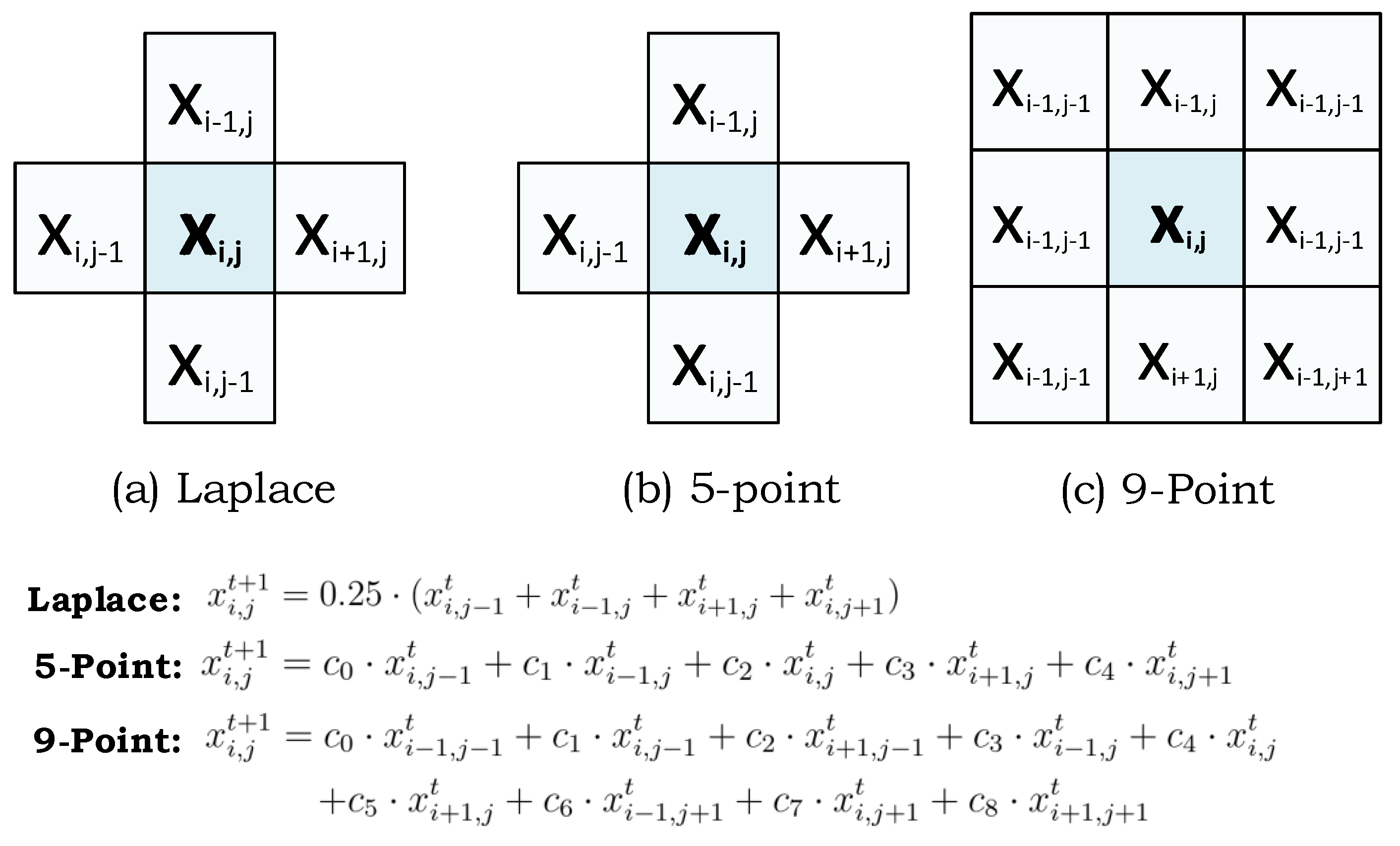
2.2. Stencil Codes
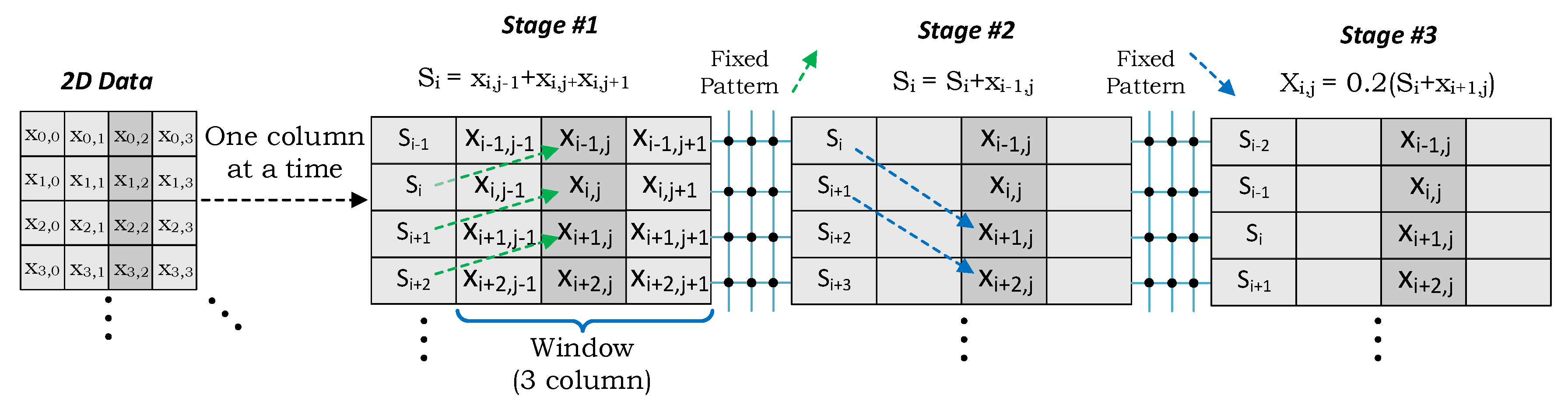
3. Accelerator Architecture for 2D Stencils
4. Evaluation
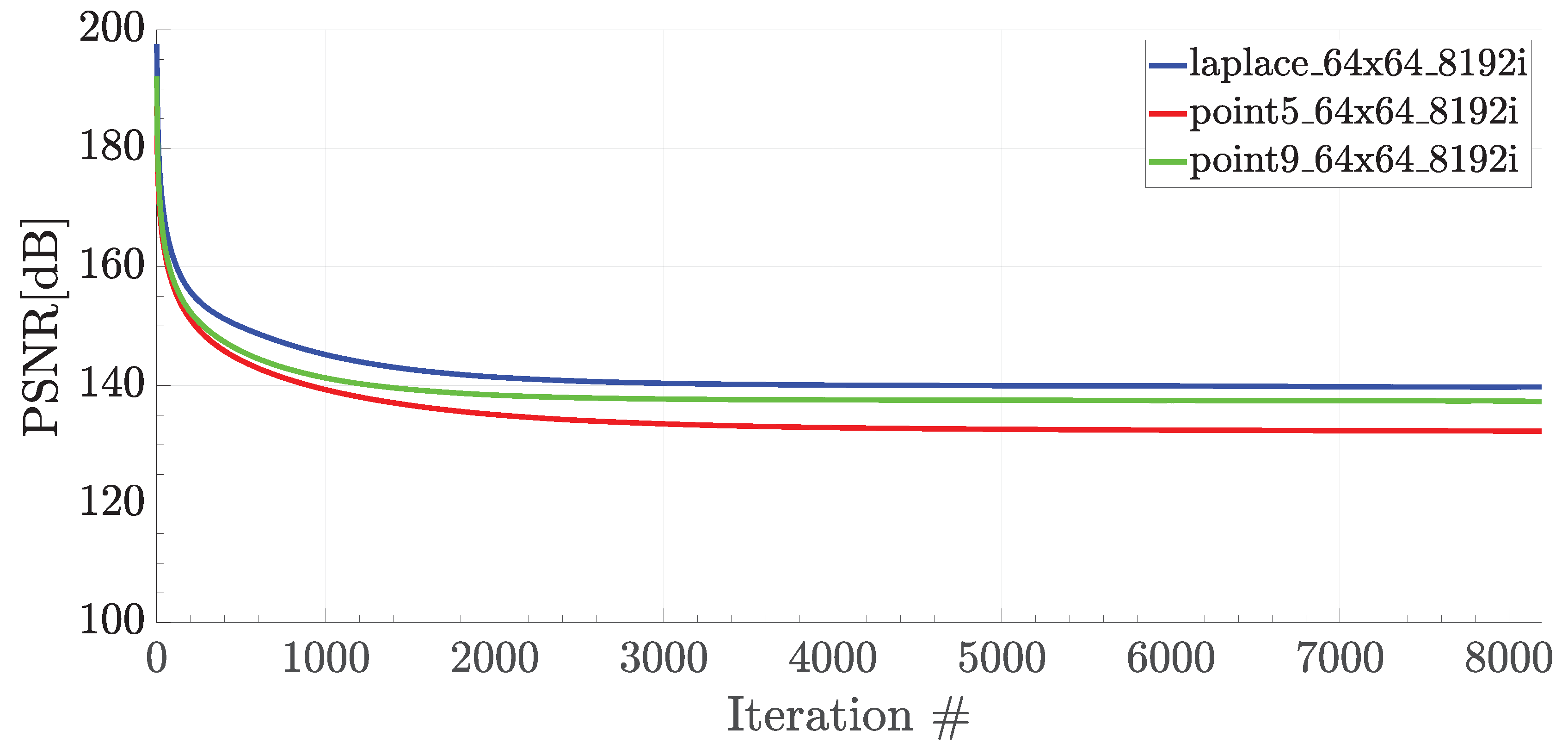
4.1. Fixed-Point Computation
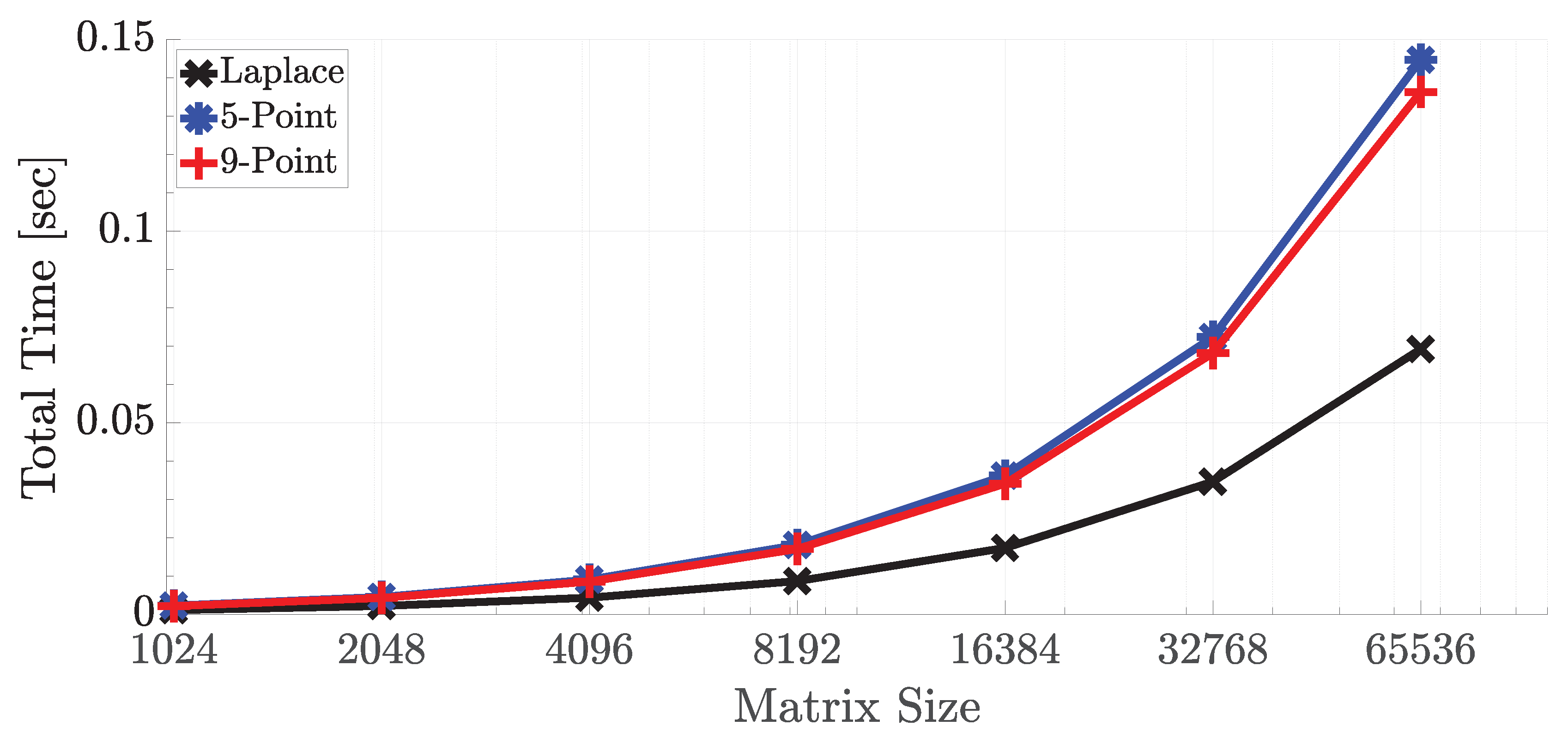
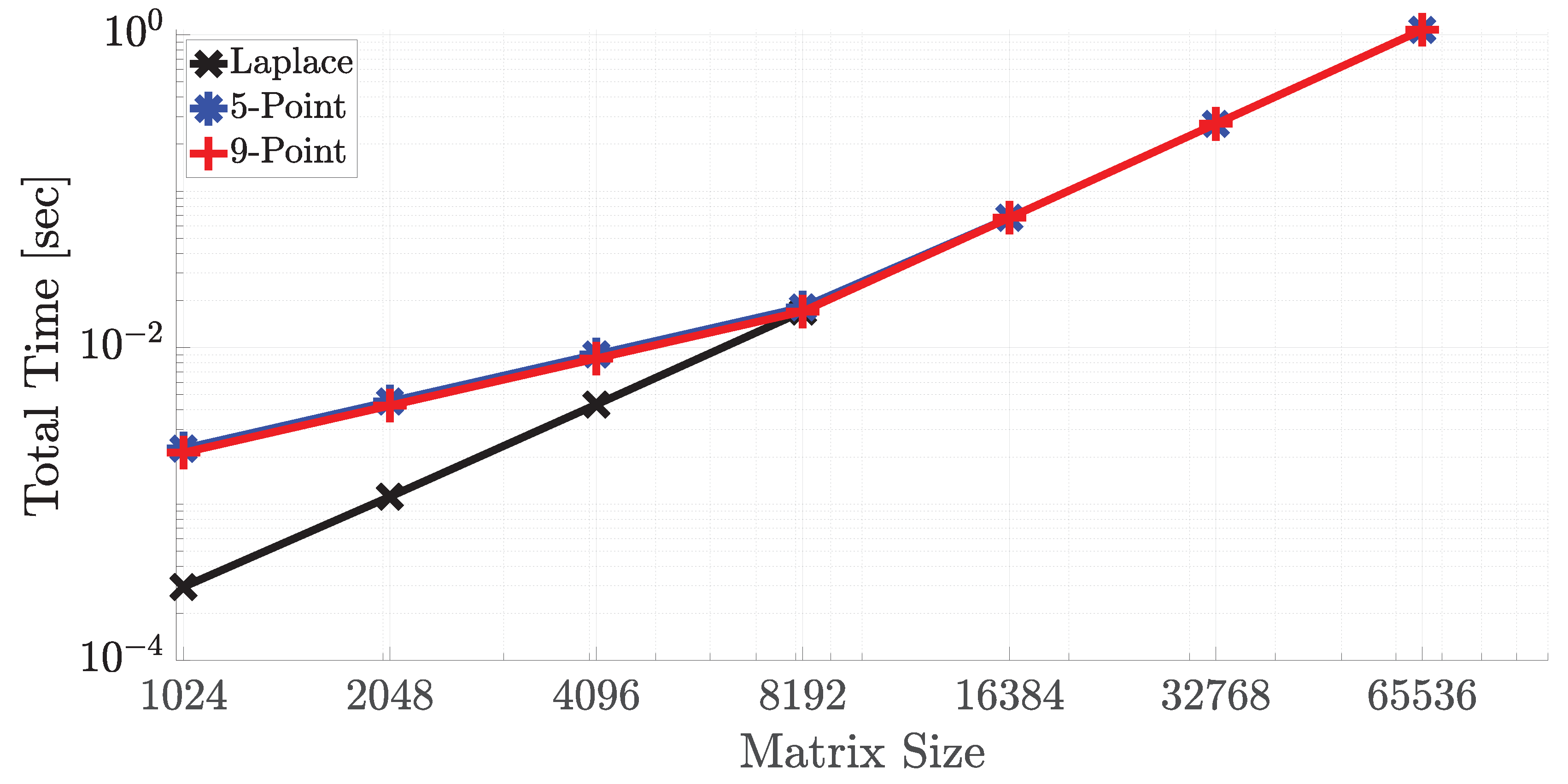
4.2. Comparison of Performance
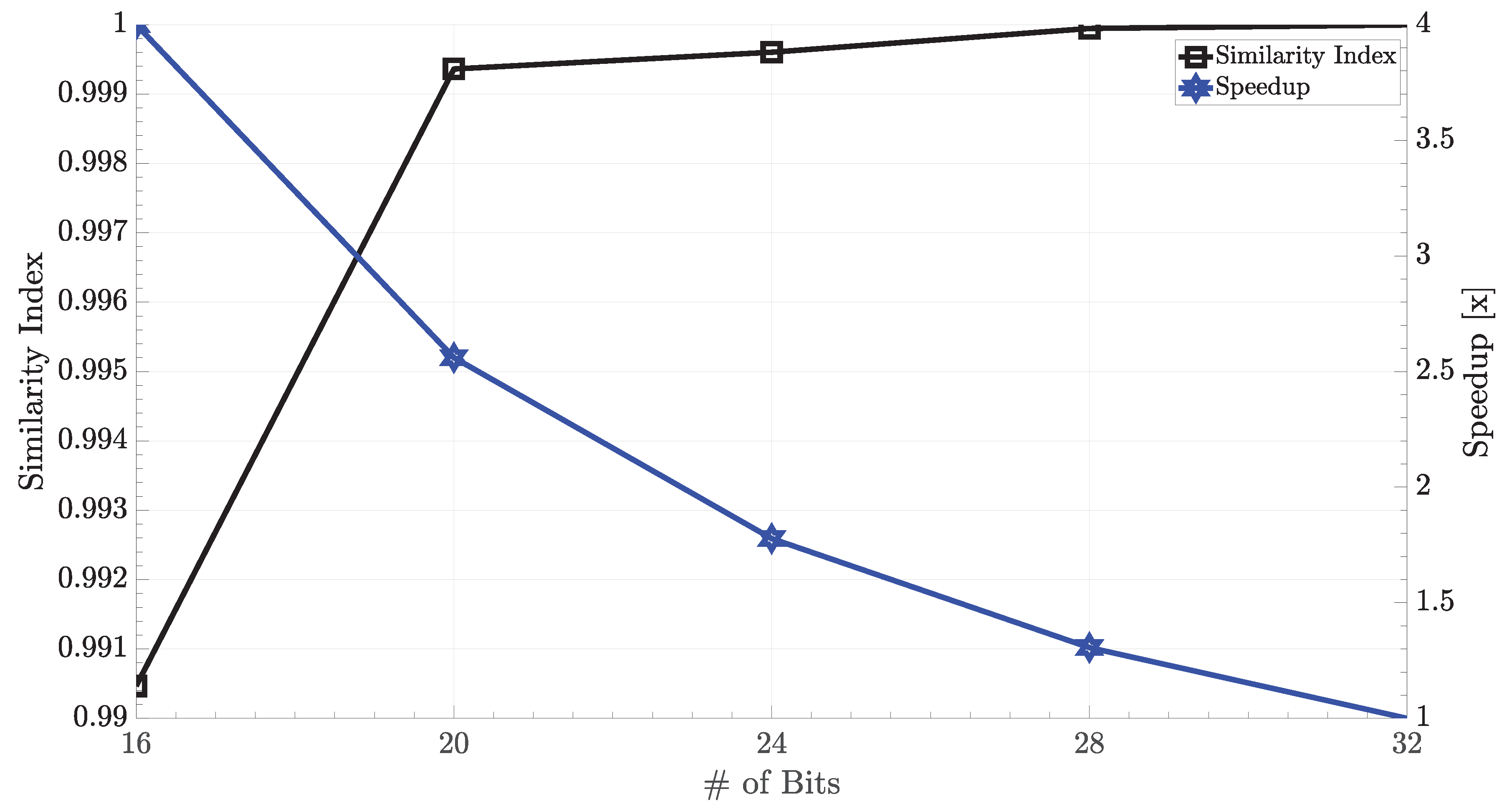
4.3. Approximate Stencil Computing
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| CPU | Central Processing Unit |
| GPU | Graphical Processing Unit |
| AP | Assciative Processor |
| CAM | Content Addressable Memory |
| FFT | Fast Fourier Transform |
| FPGA | Field Programmable Gate Arrays |
| PSNR | Peak Signal-to-Noise Ratio |
| MSE | Mean-squared Error |
References
- Esmaeilzadeh, H.; Blem, E.; Amant, R.S.; Sankaralingam, K.; Burger, D. Dark silicon and the end of multicore scaling. In Proceedings of the 2011 38th Annual International Symposium on Computer Architecture (ISCA), San Jose, CA, USA, 4–8 June 2011; pp. 365–376. [Google Scholar]
- Waldrop, M.M. The chips are down for Moore’s law. Nat. News 2016, 530, 144. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Horowitz, M. 1.1 Computing’s energy problem (and what we can do about it). In Proceedings of the 2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), San Francisco, CA, USA, 9–13 February 2014; pp. 10–14. [Google Scholar] [CrossRef]
- Big Data: Big Challenge or Big Opportunity. Available online: https://www.ibm.com/watson/infographic/discovery/big-data-challenge-opportunity/ (accessed on 2 February 2020).
- Schäfer, A.; Fey, D. High Performance Stencil Code Algorithms for GPGPUs. Procedia Comput. Sci. 2011, 4, 2027–2036. [Google Scholar] [CrossRef] [Green Version]
- Wellein, G.; Hager, G.; Zeiser, T.; Wittmann, M.; Fehske, H. Efficient Temporal Blocking for Stencil Computations by Multicore-Aware Wavefront Parallelization. In Proceedings of the 2009 33rd Annual IEEE International Computer Software and Applications Conference, Seattle, WA, USA, 20–24 July 2009; Volume 1, pp. 579–586. [Google Scholar] [CrossRef]
- Gil, D.; Green, W.M.J. 1.4 The Future of Computing: Bits + Neurons + Qubits. In Proceedings of the 2020 IEEE International Solid- State Circuits Conference—(ISSCC), San Francisco, CA, USA, 16–20 February 2020; pp. 30–39. [Google Scholar]
- Singh, G.; Chelini, L.; Corda, S.; Javed Awan, A.; Stuijk, S.; Jordans, R.; Corporaal, H.; Boonstra, A. A Review of Near-Memory Computing Architectures: Opportunities and Challenges. In Proceedings of the 2018 21st Euromicro Conference on Digital System Design (DSD), Prague, Czech Republic, 29–31 August 2018; pp. 608–617. [Google Scholar]
- Mittal, S. A Survey of ReRAM-Based Architectures for Processing-In-Memory and Neural Networks. Mach. Learn. Knowl. Extr. 2018, 1, 75–114. [Google Scholar] [CrossRef] [Green Version]
- Santoro, G.; Turvani, G.; Graziano, M. New Logic-In-Memory Paradigms: An Architectural and Technological Perspective. Micromachines 2019, 10, 368. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Li, K.; Lin, W.; Hsu, K.; Li, P.; Yang, C.; Xue, C.; Yang, E.; Chen, Y.; Chang, Y.; et al. A 65 nm 1 Mb nonvolatile computing-in-memory ReRAM macro with sub-16ns multiply-and-accumulate for binary DNN AI edge processors. In Proceedings of the 2018 IEEE International Solid—State Circuits Conference—(ISSCC), San Francisco, CA, USA, 11–15 February 2018; pp. 494–496. [Google Scholar]
- Halawani, Y.; Mohammad, B.; Al-Qutayri, M.; Al-Sarawi, S. A Re-configurable Memristor Array Structure for In-Memory Computing Applications. In Proceedings of the 2018 30th International Conference on Microelectronics (ICM), Sousse, Tunisia, 16–19 December 2018; pp. 160–163. [Google Scholar]
- Zidan, M.A.; Strachan, J.P.; Lu, W.D. The future of electronics based on memristive systems. Nat. Electron. 2018, 1, 22–29. [Google Scholar] [CrossRef]
- Gokmen, T.; Vlasov, Y. Acceleration of Deep Neural Network Training with Resistive Cross-Point Devices: Design Considerations. Front. Neurosci. 2016, 10, 333. [Google Scholar] [CrossRef] [Green Version]
- Seshadri, V.; Lee, D.; Mullins, T.; Hassan, H.; Boroumand, A.; Kim, J.; Kozuch, M.A.; Mutlu, O.; Gibbons, P.B.; Mowry, T.C. Ambit: In-Memory Accelerator for Bulk Bitwise Operations Using Commodity DRAM Technology. In Proceedings of the 2017 50th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Boston, MA, USA, 14–18 October 2017; pp. 273–287. [Google Scholar]
- Foster, C.C. Content Addressable Parallel Processors; John Wiley & Sons, Inc.: New York, NY, USA, 1976. [Google Scholar]
- Potter, J.L. Associative Computing: A Programming Paradigm for Massively Parallel Computers; Perseus Publishing: New York, NY, USA, 1991. [Google Scholar]
- Yavits, L.; Kvatinsky, S.; Morad, A.; Ginosar, R. Resistive Associative Processor. IEEE Comput. Archit. Lett. 2015, 14, 148–151. [Google Scholar] [CrossRef]
- Yantir, H.E. Efficient Acceleration of Computation Using Associative In-Memory Processing. Ph.D. Thesis, University of California, Irvine, CA, USA, 2018. [Google Scholar]
- Yantır, H.E.; Eltawil, A.M.; Kurdahi, F.J. A Hybrid Approximate Computing Approach for Associative In-Memory Processors. IEEE J. Emerg. Sel. Top. Circuits Syst. 2018, 8, 758–769. [Google Scholar] [CrossRef]
- Yavits, L.; Morad, A.; Ginosar, R. Computer Architecture with Associative Processor Replacing Last-Level Cache and SIMD Accelerator. IEEE Trans. Comput. 2015, 2, 368–381. [Google Scholar] [CrossRef]
- Roth, G.; Mellor-Crummey, J.; Kennedy, K.; Brickner, R.G. Compiling Stencils in High Performance Fortran. In Proceedings of the 1997 ACM/IEEE Conference on Supercomputing, SC ’97, San Jose, CA, USA, 15–21 November 1997; Association for Computing Machinery: New York, NY, USA, 1997; pp. 1–20. [Google Scholar] [CrossRef]
- Pereira, A.D.; Ramos, L.; Góes, L.F.W. PSkel: A stencil programming framework for CPU-GPU systems. Concurr. Comput. Pract. Exp. 2015, 27, 4938–4953. [Google Scholar] [CrossRef]
- Datta, K.; Kamil, S.; Williams, S.; Oliker, L.; Shalf, J.; Yelick, K. Optimization and Performance Modeling of Stencil Computations on Modern Microprocessors. SIAM Rev. 2009, 51, 129–159. [Google Scholar] [CrossRef] [Green Version]
- Rahman, S.M.F.; Yi, Q.; Qasem, A. Understanding Stencil Code Performance on Multicore Architectures. In Proceedings of the 8th ACM International Conference on Computing Frontiers, CF’11, Ischia, Italy, 18–21 May 2011; Association for Computing Machinery: New York, NY, USA, 2011. [Google Scholar] [CrossRef]
- Cecilia, J.M.; García, J.M.; Ujaldón, M. CUDA 2D Stencil Computations for the Jacobi Method. In Applied Parallel and Scientific Computing; Jónasson, K., Ed.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 173–183. [Google Scholar]
- Su, H.; Wu, N.; Wen, M.; Zhang, C.; Cai, X. On the GPU performance of 3D stencil computations implemented in OpenCL. In International Supercomputing Conference; Springer: Berlin/Heidelberg, Germany, 2013; pp. 125–135. [Google Scholar]
- Malas, T.; Hager, G.; Ltaief, H.; Stengel, H.; Wellein, G.; Keyes, D. Multicore-Optimized Wavefront Diamond Blocking for Optimizing Stencil Updates. SIAM J. Sci. Comput. 2015, 37, C439–C464. [Google Scholar] [CrossRef]
- Waidyasooriya, H.M.; Takei, Y.; Tatsumi, S.; Hariyama, M. OpenCL-Based FPGA-Platform for Stencil Computation and Its Optimization Methodology. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 1390–1402. [Google Scholar] [CrossRef]
- Nacci, A.A.; Rana, V.; Bruschi, F.; Sciuto, D.; di Milano, P.; Beretta, I.; Atienza, D. A high-level synthesis flow for the implementation of iterative stencil loop algorithms on FPGA devices. In Proceedings of the 2013 50th ACM/EDAC/IEEE Design Automation Conference (DAC), Austin, TX, USA, 2–6 June 2013; pp. 1–6. [Google Scholar]
- Sano, K.; Hatsuda, Y.; Yamamoto, S. Multi-FPGA Accelerator for Scalable Stencil Computation with Constant Memory Bandwidth. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 695–705. [Google Scholar] [CrossRef]
- Schmidt, M.; Reichenbach, M.; Fey, D. A Generic VHDL Template for 2D Stencil Code Applications on FPGAs. In Proceedings of the 2012 IEEE 15th International Symposium on Object/Component/Service-Oriented Real-Time Distributed Computing Workshops, Shenzhen, China, 11–13 April 2012; pp. 180–187. [Google Scholar]
- Patterson, D. 50 Years of computer architecture: From the mainframe CPU to the domain-specific tpu and the open RISC-V instruction set. In Proceedings of the 2018 IEEE International Solid—State Circuits Conference—(ISSCC), San Francisco, CA, USA, 11–15 February 2018; pp. 27–31. [Google Scholar]
- Waidyasooriya, H.M.; Hariyama, M. Multi-FPGA Accelerator Architecture for Stencil Computation Exploiting Spacial and Temporal Scalability. IEEE Access 2019, 7, 53188–53201. [Google Scholar] [CrossRef]
- Yantır, H.E.; Eltawil, A.M.; Niar, S.; Kurdahi, F.J. Power optimization techniques for associative processors. J. Syst. Archit. 2018, 90, 44–53. [Google Scholar] [CrossRef]
- Pagiamtzis, K.; Sheikholeslami, A. Content-addressable memory (CAM) circuits and architectures: A tutorial and survey. IEEE J. Solid-State Circuits 2006, 41, 712–727. [Google Scholar] [CrossRef]
- Li, J.; Montoye, R.K.; Ishii, M.; Chang, L. 1 Mb 0.41 um2 2T-2R Cell Nonvolatile TCAM With Two-Bit Encoding and Clocked Self-Referenced Sensing. IEEE J. Solid-State Circuits 2014, 49, 896–907. [Google Scholar] [CrossRef]
- Zidan, M.A.; Omran, H.; Sultan, A.; Fahmy, H.A.H.; Salama, K.N. Compensated Readout for High-Density MOS-Gated Memristor Crossbar Array. IEEE Trans. Nanotechnol. 2015, 14, 3–6. [Google Scholar] [CrossRef]
- Nagel, J. A Review and Application of the Finite-Difference Time-Domain Algorithm Applied to the Schrodinger Equation. Appl. Comput. Electromagn. Soc. J. 2009, 24. [Google Scholar] [CrossRef]
- Abdelaal, R.A.; Yantır, H.E.; Eltawil, A.M.; Kurdahi, F.J. Power Performance Tradeoffs Using Adaptive Bit Width Adjustments on Resistive Associative Processors. IEEE Trans. Circuits Syst. I Regul. Pap. 2019, 66, 302–312. [Google Scholar] [CrossRef]
- Zha, Y.; Li, J. Hyper-AP: Enhancing Associative Processing Through A Full-Stack Optimization. In Proceedings of the 47th International Symposium on Computer Architecture, ISCA ’20, Valencia, Spain, 30 May–3 June 2020; Association for Computing Machinery: New York, NY, USA, 2020. [Google Scholar]
- Kaplan, R.; Yavits, L.; Ginosar, R.; Weiser, U. A Resistive CAM Processing-in-Storage Architecture for DNA Sequence Alignment. IEEE Micro 2017, 37, 20–28. [Google Scholar] [CrossRef] [Green Version]
- Yantır, H.E.; Eltawil, A.M.; Kurdahi, F.J. A Two-Dimensional Associative Processor. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2018, 26, 1659–1670. [Google Scholar] [CrossRef]
- Yantır, H.E.; Guo, W.; Eltawil, A.M.; Kurdahi, F.J.; Salama, K.N. An Ultra-Area-Efficient 1024-Point In-Memory FFT Processor. Micromachines 2019, 10, 509. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, W.; Cao, Y. Predictive Technology Model for Nano-CMOS Design Exploration. J. Emerg. Technol. Comput. Syst. 2007, 3, 1-es. [Google Scholar] [CrossRef]
- Yakopcic, C.; Taha, T.M.; Subramanyam, G.; Pino, R.E. Generalized Memristive Device SPICE Model and its Application in Circuit Design. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2013, 32, 1201–1214. [Google Scholar] [CrossRef]
- Jia, X.; Song, S.; He, W.; Wang, Y.; Rong, H.; Zhou, F.; Xie, L.; Guo, Z.; Yang, Y.; Yu, L.; et al. Highly Scalable Deep Learning Training System with Mixed-Precision: Training ImageNet in Four Minutes. arXiv 2018, arXiv:1807.11205. [Google Scholar]
- Naous, R.; AlShedivat, M.; Neftci, E.; Cauwenberghs, G.; Salama, K.N. Memristor-based neural networks: Synaptic versus neuronal stochasticity. Aip Adv. 2016, 6, 111304. [Google Scholar] [CrossRef] [Green Version]
- Hassan, S.; Attia, S.; Salama, K.N.; Mostafa, H. EANN: Energy Adaptive Neural Networks. Electronics 2020, 9, 746. [Google Scholar] [CrossRef]
- Barua, H.B.; Mondal, K.C. Approximate Computing: A Survey of Recent Trends–Bringing Greenness to Computing and Communication. J. Inst. Eng. (India) Ser. B 2019, 100, 619–626. [Google Scholar] [CrossRef]








© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yantır, H.E.; Eltawil, A.M.; Salama, K.N. Efficient Acceleration of Stencil Applications through In-Memory Computing. Micromachines 2020, 11, 622. https://doi.org/10.3390/mi11060622
Yantır HE, Eltawil AM, Salama KN. Efficient Acceleration of Stencil Applications through In-Memory Computing. Micromachines. 2020; 11(6):622. https://doi.org/10.3390/mi11060622
Chicago/Turabian StyleYantır, Hasan Erdem, Ahmed M. Eltawil, and Khaled N. Salama. 2020. "Efficient Acceleration of Stencil Applications through In-Memory Computing" Micromachines 11, no. 6: 622. https://doi.org/10.3390/mi11060622
APA StyleYantır, H. E., Eltawil, A. M., & Salama, K. N. (2020). Efficient Acceleration of Stencil Applications through In-Memory Computing. Micromachines, 11(6), 622. https://doi.org/10.3390/mi11060622