
A Multi-Phase Based Multi-Application Mapping Approach for Many-Core Networks-on-Chip


Abstract
:1. Introduction
2. Problem Formulation and Definitions
3. Multi-Application Mapping Algorithm
| Algorithm 1 The main procedure of the proposed multi-phase multi-application mapping |
| Input: a set of N applications, a 2D Mesh based NoC architecture Output: mutli-application mapping results 1. for i=1 to N 2. analyze potential rectangles Ri1, Ri2, …Rij…, based on the number of tasks of the application and the bounds of width and height 3. for a single application, under different potential rectangles, a genetic algorithm is used to map tasks onto cores with selected regions on the NoC platform 4. identify the rectangle which performs best as the mapping region for the application 5. end for 6. packet each mapping region as a block and generate initial placement for multiple applications mapping using a B*Tree representation 7. use a simulated annealing algorithm to explore optimal placements 8. output the optimal solution |
3.1. Rectangle Analysis
3.2. Task Mapping
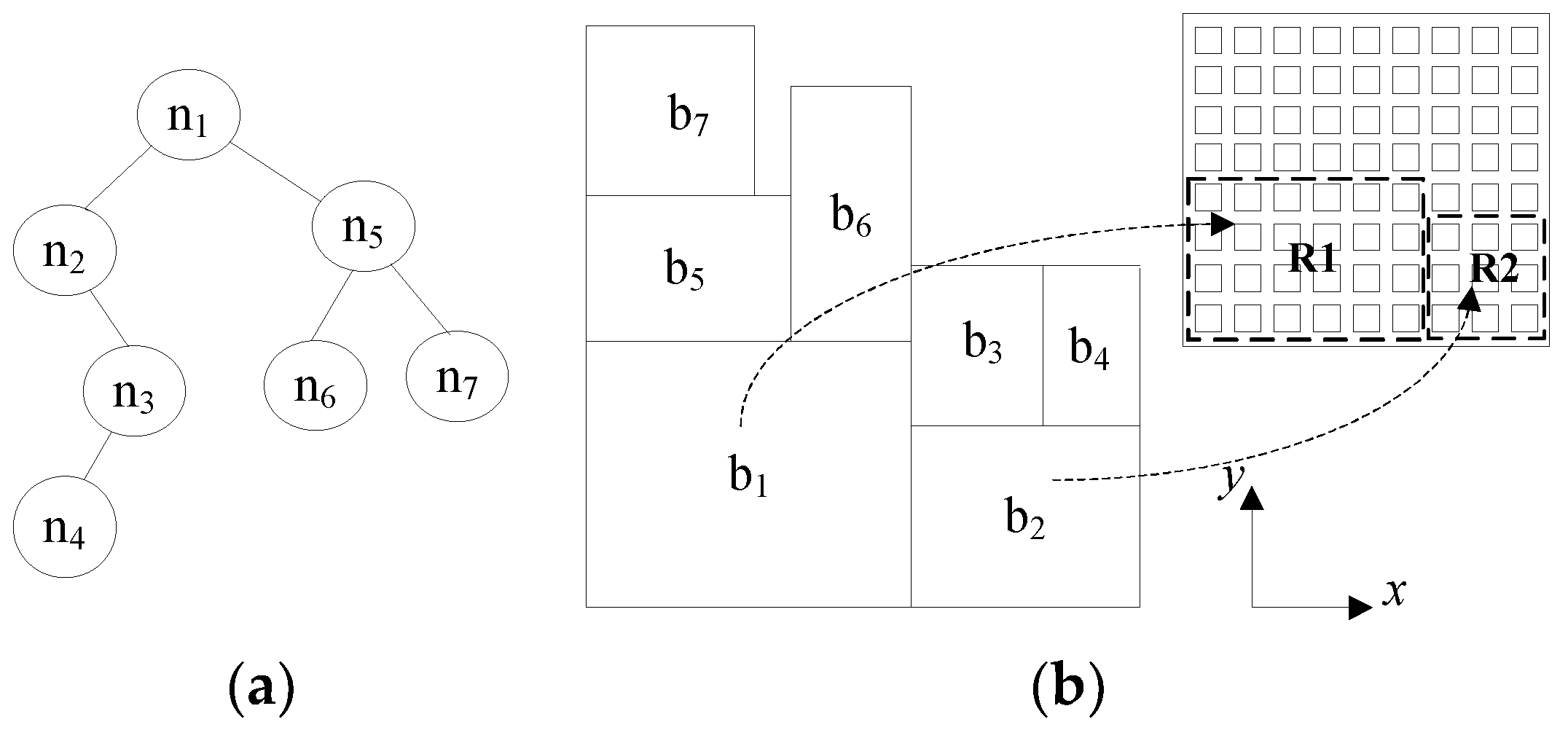
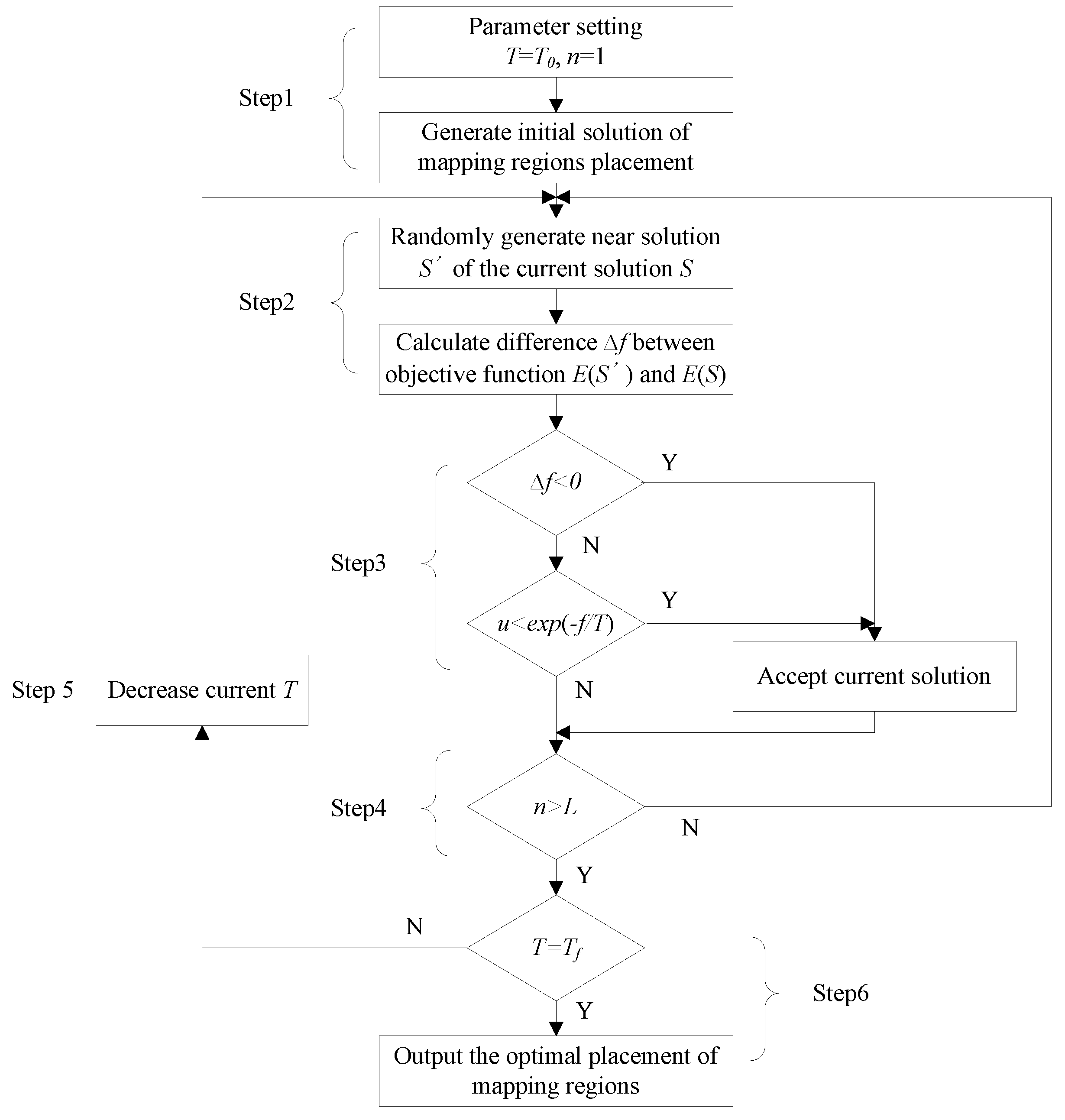
3.3. Application Placement
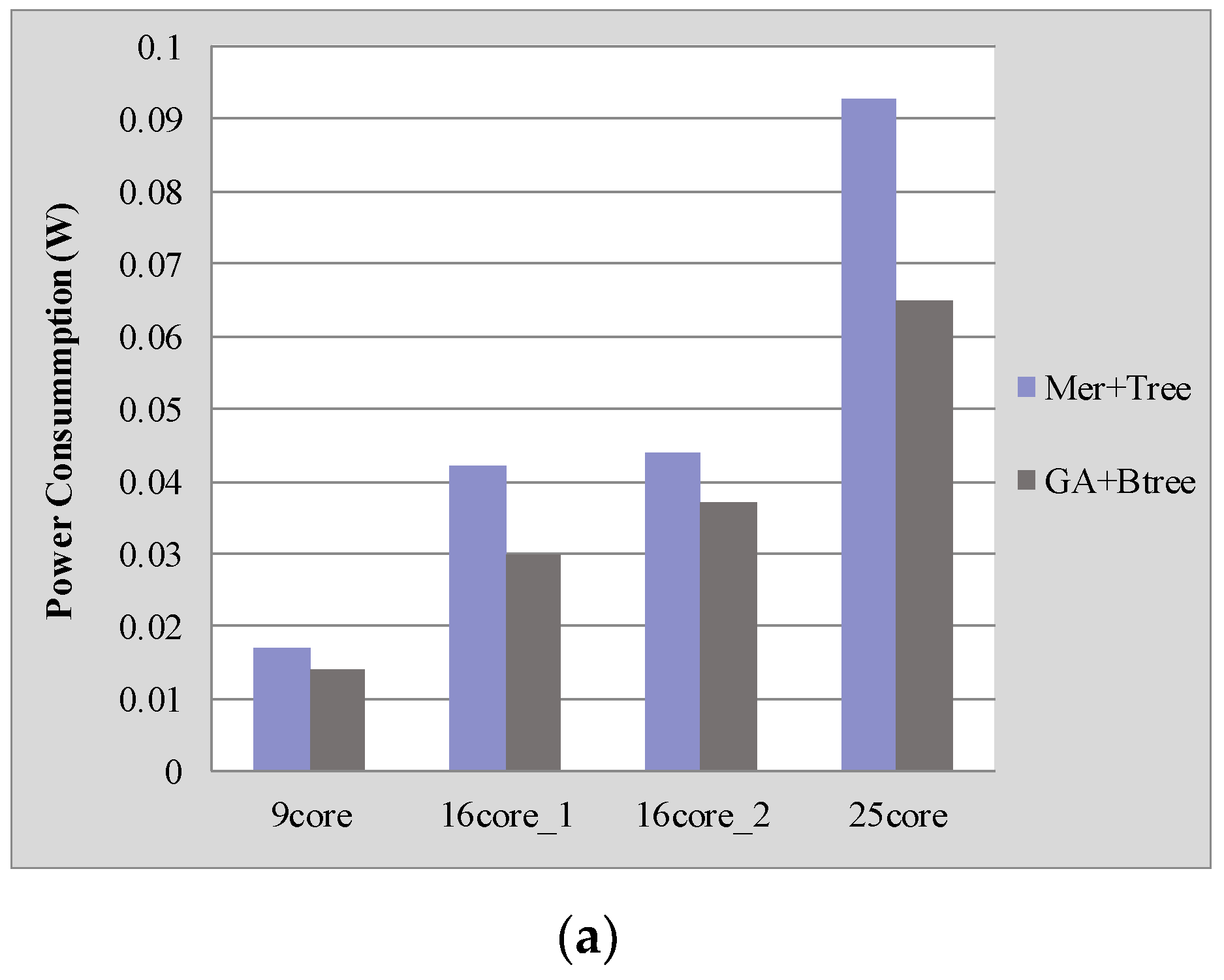
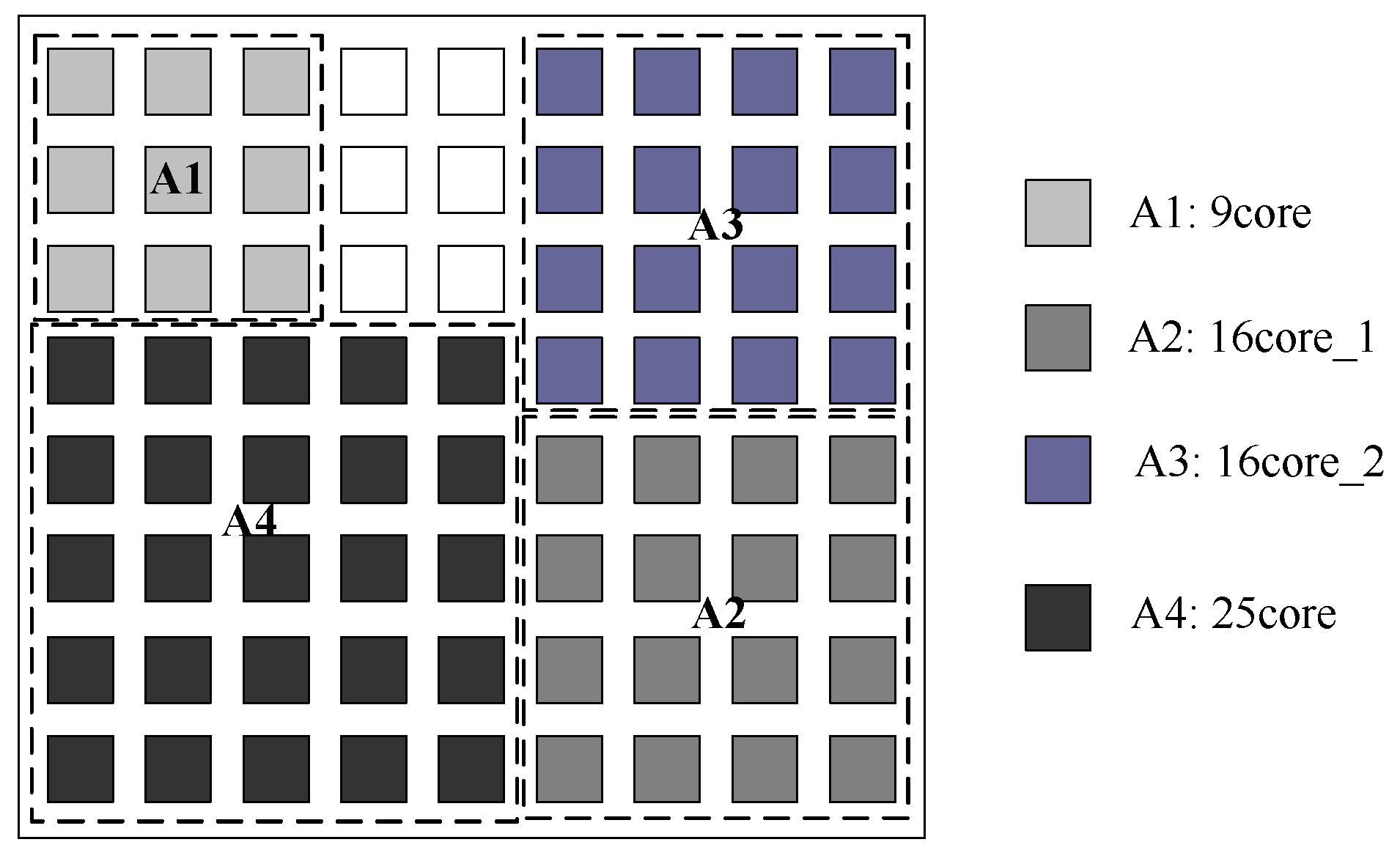
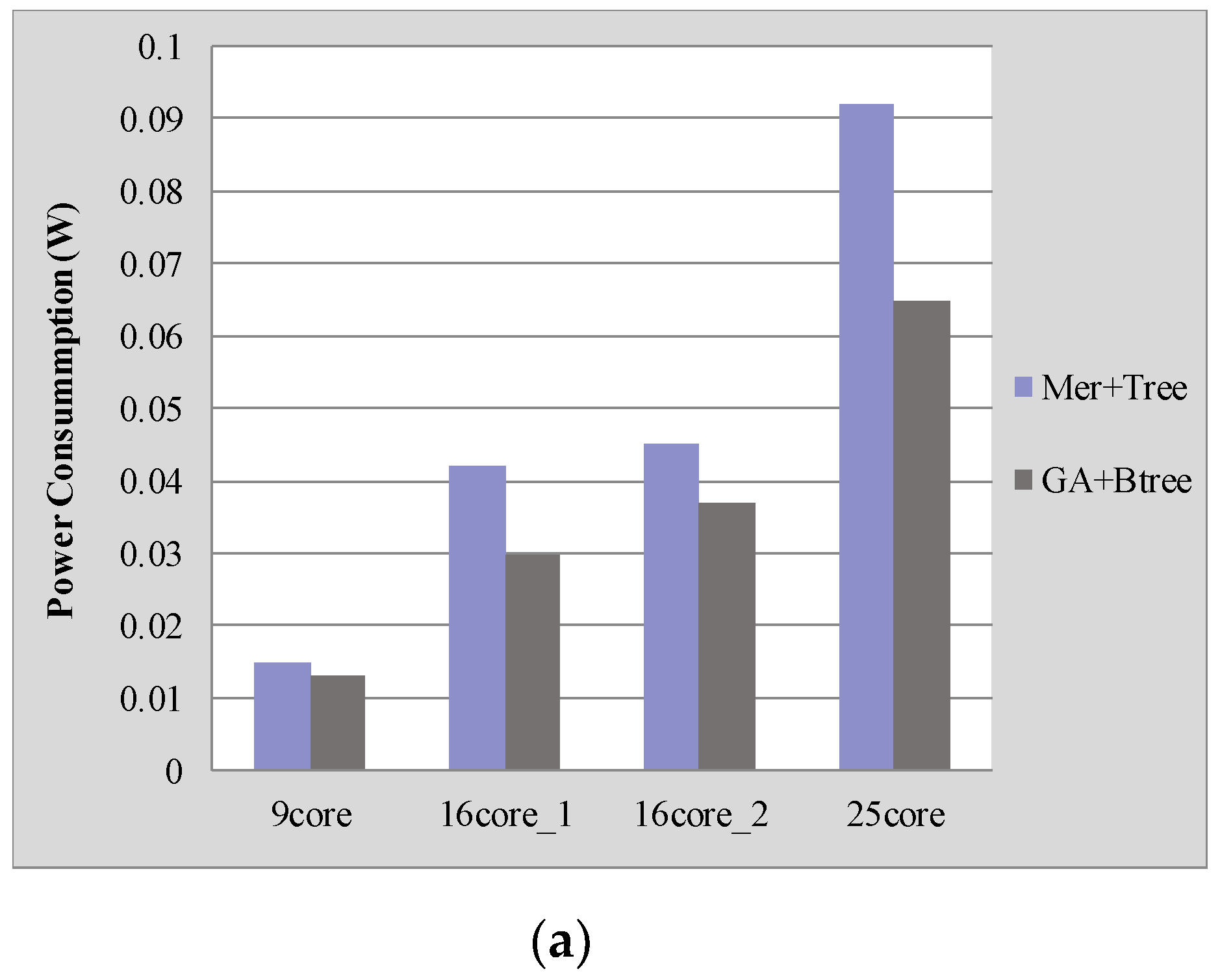
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gomez-Rodriguez, J.R.; Sandoval-Arechiga, R.; Ibarra-Delgado, S.; RodriguezAbdala, V.I.; Vazquez-Avila, J.L.; Parra-Michel, R. A Survey of Software-Defined Networks-on-Chip: Motivations, Challenges and Opportunities. Micromachines 2021, 12, 183. [Google Scholar] [CrossRef] [PubMed]
- Benini, L.; De Micheli, G. Networks on chips: A new SoC paradigm. Computer 2002, 35, 70–78. [Google Scholar] [CrossRef] [Green Version]
- Asanovic, K.; Bodik, R.; Catanzaro, B.C.; Gebis, J.J.; Husbands, P.; Keutzer, K.; Patterson, D.A.; Plishker, W.L.; Shalf, J.; Williams, S.W.; et al. The Landscape of Parallel Computing Research: A View from Berkeley. Technical Report No. UCB/EECS-2006-183. 2006. Available online: https://www2.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-183.html (accessed on 15 October 2020).
- Yang, B.; Guang, L.; Xu, T.C.; Yin, A.W.; Säntti, T.; Plosila, J. Multi-Application Multi-Step Mapping Method for Many-Core Network-on-Chips. In Proceedings of the NORCHIP 2010, Tampere, Finland, 15–16 November 2010. [Google Scholar]
- Hu, J.; Marculescu, R. Energy and performance-aware mapping for regular NoC architectures. IEEE Trans. Comput. Des. Integr. Circuits Syst. 2005, 24, 551–562. [Google Scholar] [CrossRef]
- Murali, S.; De Micheli, G. Bandwidth-constrained mapping of cores onto NoC architectures. In Proceedings of the Design, Automation and Test in Europe Conference and Exhibition, Piscataway, NJ, USA, 16–20 February 2004. [Google Scholar]
- He, O.; Dong, S.; Jang, W.; Bian, J.; Pan, D.Z. UNISM: Unified Scheduling and Mapping for General Networks on Chip. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2011, 20, 1496–1509. [Google Scholar] [CrossRef]
- Xu, C.; Liu, Y.; Zhu, Z.; Yang, Y. An efficient energy and thermal-aware mapping for regular network-on-chip. IEICE Electron. Express 2017, 14. [Google Scholar] [CrossRef] [Green Version]
- Fang, J.; Zong, H.; Zhao, H.; Cai, H. Intelligent Mapping Method for Power Consumption and Delay Optimization Based on Heterogeneous NoC Platform. Electronics 2019, 8, 912. [Google Scholar] [CrossRef] [Green Version]
- Fang, J.; Yu, T.; Wei, Z. Improved Ant Colony Algorithm Based on Task Scale in Network on Chip (NoC) Mapping. Electronics 2019, 9, 6. [Google Scholar] [CrossRef] [Green Version]
- Murali, S.; Coenen, M.; Radulescu, A.; Goossens, K.; De Micheli, G. Mapping and Configuration Methods for Multi-Use-Case Networks on Chips. In Proceedings of the Asia and South Pacific Conference on Design Automation (ASPDAC 2006), Yoko-hama, Japan, 24–27 January 2006; pp. 146–151. [Google Scholar]
- Sepulveda, J.; Strum, M.; Chau, W.J.; Gogniat, G. A multi-Objective Approach for Multi-Application NoC Mapping. In Proceedings of the IEEE Second Latin American Symposium on Circuits and Systems (LASCAS 2011), Bogota, Colombia, 23–25 February 2011. [Google Scholar]
- Khalili, F.; Zarandi, H.R. A Fault-Tolerant Low-Energy Multi-Application Mapping onto NoC-based Multiprocessors. In Proceedings of the 2012 IEEE 15th International Conference on Computational Science and Engineering, Nicosia, Cyprus, 5–7 December 2013; pp. 421–428. [Google Scholar]
- Zhu, D.; Chen, L.; Yue, S.; Pinkston, T.M.; Pedram, M. Balancing On-Chip Network Latency in Multi-application Mapping for Chip-Multiprocessors. In Proceedings of the 2014 IEEE 28th International Parallel and Distributed Processing Symposium, Phoenix, AZ, USA, 19–23 May 2014; pp. 872–881. [Google Scholar]
- Khasanov, R.; Castrillon, J. Energy-efficient Runtime Resource Management for Adaptable Multi-application Mapping. In Proceedings of the 2020 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2020; pp. 909–914. [Google Scholar]
- Chang, Y.; Chang, Y.; Wu, G.; Wu, S. B*-Tree: A New Representation for Non-Slicing Floorplans. In Proceedings of the 37th Design Automation Conference (DAC 2000), Los Angeles, CA, USA, 5–9 June 2000; pp. 458–463. [Google Scholar]
- Guo, P.N.; Cheng, C.K.; Yoshimura, T. An O-Tree Representation of Non-Slicing Floorplan and Its Application. In Proceedings of the 1999 Design Automation Conference (DAC 1999), New Orleans, LA, USA, 21–25 June 1999; pp. 268–273. [Google Scholar]
- Dick, R.; Rhodes, D.; Wolf, W. TGFF: Task graphs for free. In Proceedings of the Sixth International Workshop on Hardware/Software Codesign. (CODES/CASHE’98), Seattle, WA, USA, 18 March 1998. [Google Scholar]
- Jain, L.; Al-Hashimi, B.M.; Gaur, M.S.; Laxmi, V.; Narayanan, A. NIRGAM: A Simulator for NoC Interconnect Routing and Application Modeling. In Proceedings of the 2007 Design, Automation and Test in Europe Conference and Exhibition (DATE 2007), Nice, France, 16–20 April 2007. [Google Scholar]
- Wang, H.-S.; Zhu, X.; Peh, L.-S.; Malik, S. Orion: A power-performance simulator for interconnection networks. In Proceedings of the 35th Annual IEEE/ACM International Symposium on Microarchitecture, 2002 (MICRO-35), Istanbul, Turkey, 18–22 November 2002. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Name | Value |
|---|---|
| Topology | 10 × 7 Mesh, 9 × 8 Mesh |
| Routing algorithm | XY |
| Packet size (flit) | 2 |
| Router buffer (flit) | 5 |
| Clock frequency (GHz) | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ge, F.; Cui, C.; Zhou, F.; Wu, N. A Multi-Phase Based Multi-Application Mapping Approach for Many-Core Networks-on-Chip. Micromachines 2021, 12, 613. https://doi.org/10.3390/mi12060613
Ge F, Cui C, Zhou F, Wu N. A Multi-Phase Based Multi-Application Mapping Approach for Many-Core Networks-on-Chip. Micromachines. 2021; 12(6):613. https://doi.org/10.3390/mi12060613
Chicago/Turabian StyleGe, Fen, Chenchen Cui, Fang Zhou, and Ning Wu. 2021. "A Multi-Phase Based Multi-Application Mapping Approach for Many-Core Networks-on-Chip" Micromachines 12, no. 6: 613. https://doi.org/10.3390/mi12060613
APA StyleGe, F., Cui, C., Zhou, F., & Wu, N. (2021). A Multi-Phase Based Multi-Application Mapping Approach for Many-Core Networks-on-Chip. Micromachines, 12(6), 613. https://doi.org/10.3390/mi12060613