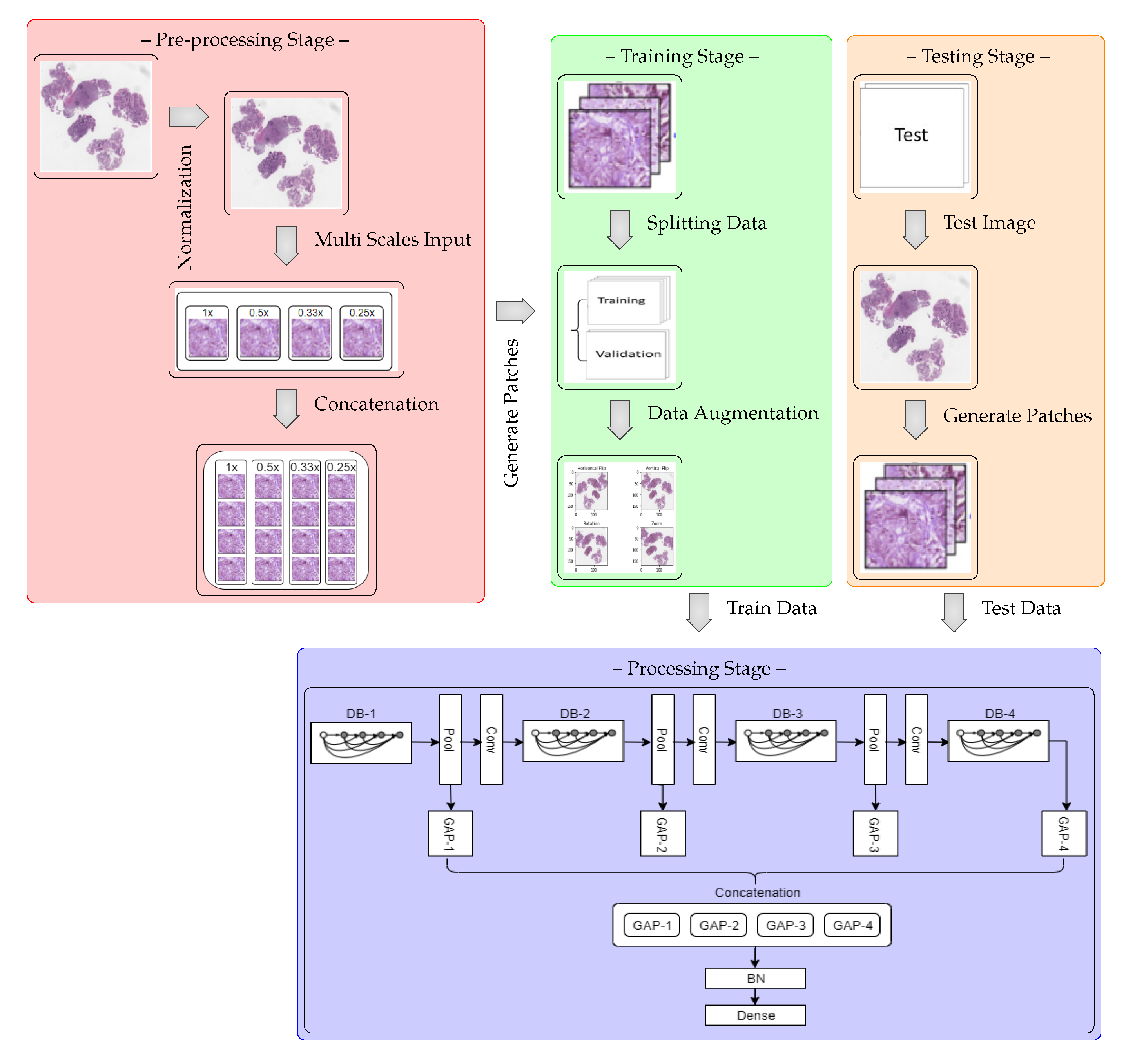
5.1. Classification Results
Table 5 and
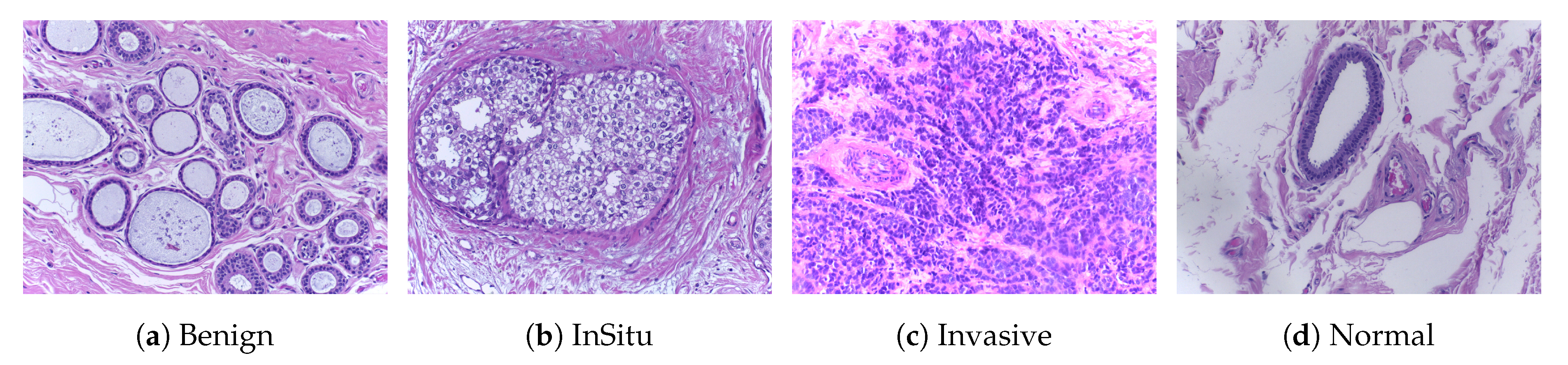
Table 6 show the patch-wise classification results of binary and multi-class classifications for the two augmentation scenarios and for 200× magnification factors, for the two datasets. In terms of accuracy, our model outperformed the DNet model on the ICIAR2018 dataset. The accuracy increased to 83% for the without data augmentation scenario and 82% for the data augmentation scenario when only two classes were considered. Similarly for the BreakHis dataset, our model outperformed the DNet model by a large margin in the binary-class classification; the accuracy reached 90% and 98% for the without data augmentation and with data augmentation scenarios, respectively. However, clinically, multi-class classification results are more important for pathologists. Therefore, for both datasets, the accuracy results of our model were higher for both augmentation scenarios, which indicates that our model works well for this classification. The reason that the multi-class classification accuracy of the ICIAR2018 dataset is as low as 60% is because the distinction between normal and benign is ambiguous. A pathologist who labeled the test data said it was very difficult to distinguish between the two groups. In practice, pathologists often use immunity to accurately differentiate between normal and benign.
Our method demonstrated the highest sensitivity and specificity results for all cases of binary-class classification, compared with the multi-class classification task, while it demonstrated a stable classification performance regardless of the amount of variation (such as rotations and illumination) for the ICIAR2018 dataset. We observed that benign sensitivity is very low because pathologists have difficulty distinguishing benign from normal with only a few test images. For the BreakHis dataset, in terms of the sensitivity and specificity of binary classification, our model demonstrated better results than the DNet model. In addition, for multi-class classification, the sensitivity and specificity of our model outperformed that of the DNet model, except for a few cases that are comparable.
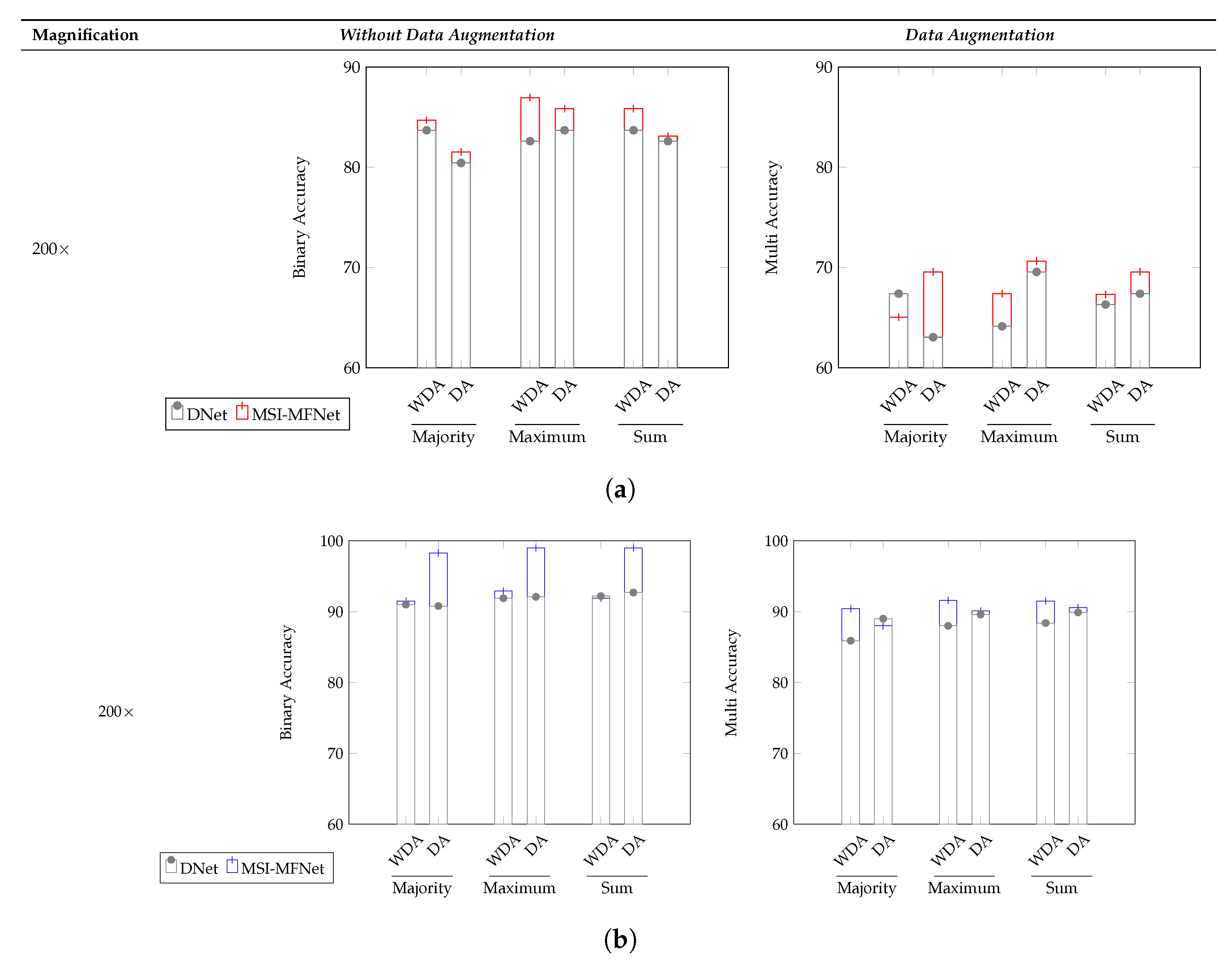
The image-wise classification results for the three different voting criteria (majority, maximum, and sum) is shown in
Figure 4 and in
Table 7 and
Table 8, denoting which are clinically more important and useful. For the ICIAR2018 dataset, the overall accuracy of our model for binary and multi-class classification increased, compared with that of the DNet model. As shown in
Figure 4, the reason why the multi–class classification accuracy of ICIAR2018 data is significantly lower than the others is the same as that described before. Our model exhibited higher accuracy than the DNet model for all three voting criteria.
Table 7 lists the sensitivity and specificity results for the majority voting criterion for the ICIAR2018 dataset. In terms of both metrics, our model outperformed the DNet model with respect to both binary classification and multi-class classification. In the few cases where the model did not outperform DNet, this occurred because various biological structures overlapped in the respective WSI images; feature representations for such regions had no specific general structure, and these few regions varied in appearance compared with normal region variations. However, the sensitivity for the multi-class classification, except for benign classification, showed an average of over 90%.
The sensitivity and specificity results for the BreakHis dataset are reported in
Table 8. Overall, our model outperformed the DNet model [
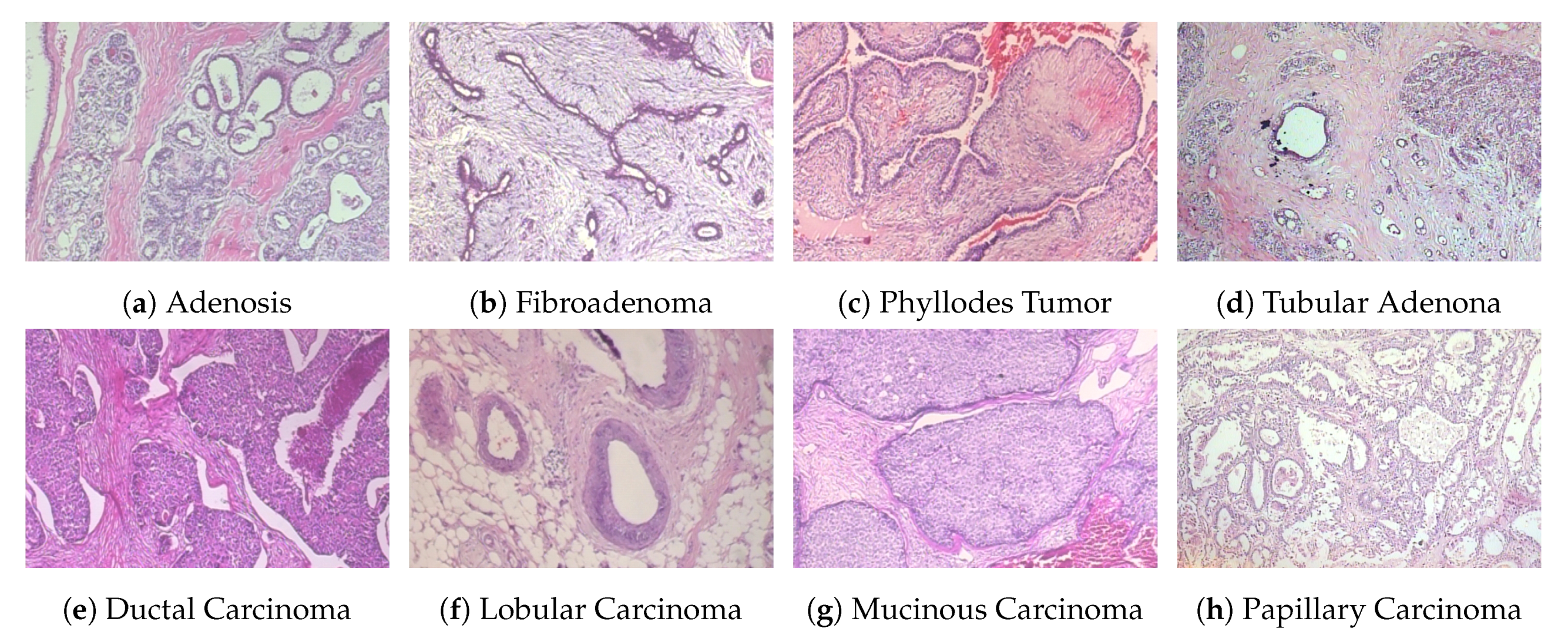
47], except for a few cases. We assumed that this behavior for some cases was due to the scaling magnification images, which can sometimes affect structural information and make it more difficult to pick up relevant information from diseased regions; this is consistent with previous studies. Binary classification yields better results than multi-class classification for 200× and 400× magnification factors. We observed that the learned features are sensitive to variations in the data, which may be reflected in the changes in the selection of relevant regions. In contrast, the BreakHis dataset exhibits considerably large inter- and intra-class sample variations within each class, compared with the ICIAR2018 dataset. Class variations and their relationship to the number of samples in each class also affect the classification results.
For all of the considered criteria, the data augmentation scenario yielded a better performance than that without data augmentation, suggesting that it is a more suitable strategy for classification, as in general, medical images have several unique variants in which patches of images include different non-structural shapes, which can be further increased by augmentation of possible variations because of which general patterns can arise and assist the classification task. This, along with some amount of perspective blurring, improves the overall learning of relevant features. The best accuracy of patch-wise classification is explained by the fact that patch labels are obtained from image labels without any information about the location of abnormalities in medical images. Our approach is optimal as, regardless of the image class, normal tissue regions may be present. As a result, a small amount of noise (blurring) introduced in the training set does not, affect the patch-wise accuracy. Despite this, the network is able to focus on those details in the images that are relevant for classification. We also showed that the appearance variability of H&E stained regions can be improved, which is one of the major challenges in the analysis of breast cancer histopathological images [
1].
5.2. Ablation Studies of MSI-MFNet
We performed ablation studies using the MSI-MFNet model to gain deeper insights into the performance improvements associated with the different components of our model. The problem of multi-class classification has been thoroughly studied, with a special emphasis one why we used multi-scale input and multi-feature map modules in our model.
Figure 5 and
Figure 6 show the results of these studies, using four different metrics and varying different combinations (either single or multiple) of inputs and feature maps in each module. Experiments were performed using 400× magnification images from the BreakHis dataset.
MSI (Multi-Scale Inputs) Module:
Figure 5 study shows that metrics can be improved using multi-scale images for classification of pathological images, where we considered different combinations of the MSI (i.e., 1×, 0.5×, 0.33×, and 0.25×), while employing fusion of all MFNet maps. For example, a× corresponds to using only 0.5× magnification images, while abc× corresponds to using 1× 0.5× and 0.33× magnification images. In the present work, we compared the performance of our model to the state-of-the-art DNet [
47] model, because it yields the best performance in the literature. The results of our analysis show that training the models with multi-scale inputs has the benefit of learning the overall structural features and ambiguity regions. The proposed method obtained the highest metric results while maintaining a stable classification using the fusion of all multi-scale input combinations and data augmentation.
Moreover, results shown in
Figure 5 demonstrate that our method learns representations that are robust to the scale of input, as demonstrated by the results when using multiple inputs. In contrast, for DNet experiments with data augmentation, there are variations in metric results, which are much lower with increasing number of multi-scale inputs as compared with the MSI-MFNet model. We also observed that our method without data augmentation does not outperform DNet (in a few cases) by selecting multi-scale input combinations that are triplets and duplets, which yields lower results according to all the metrics. This trend can be seen in MSI-MFNet and DNet model for without data augmentation scenarios. The accuracy and sensitivity metrics show comparable performance with increasing number of multi-scale inputs for MSI-MFNet as compared with the DNet model.
We believe that, in general, the multi-scale input behavior can improve the model performance because it allows control of the model results with different combinations of multi-scale inputs. By increasing MSI, we can increase the performance, so the model can accurately classify the cancer regions. Note that more combinations of multi-scale input introduce variations for model learning, by introducing diversity in data. Hence, by incorporating this module, the model learns a good decision capability and also demonstrates enhanced functionality to distinguish between the classes that can be too different from trained classes at prediction time, which are in general close enough to the realistic samples. The experimental setup with multi-class data shows the validity of our model utilizing this module, which improves the metrics with respect to the basic flat input approach of traditional CNN’s.
MF (Multi-Feature Maps) Module:
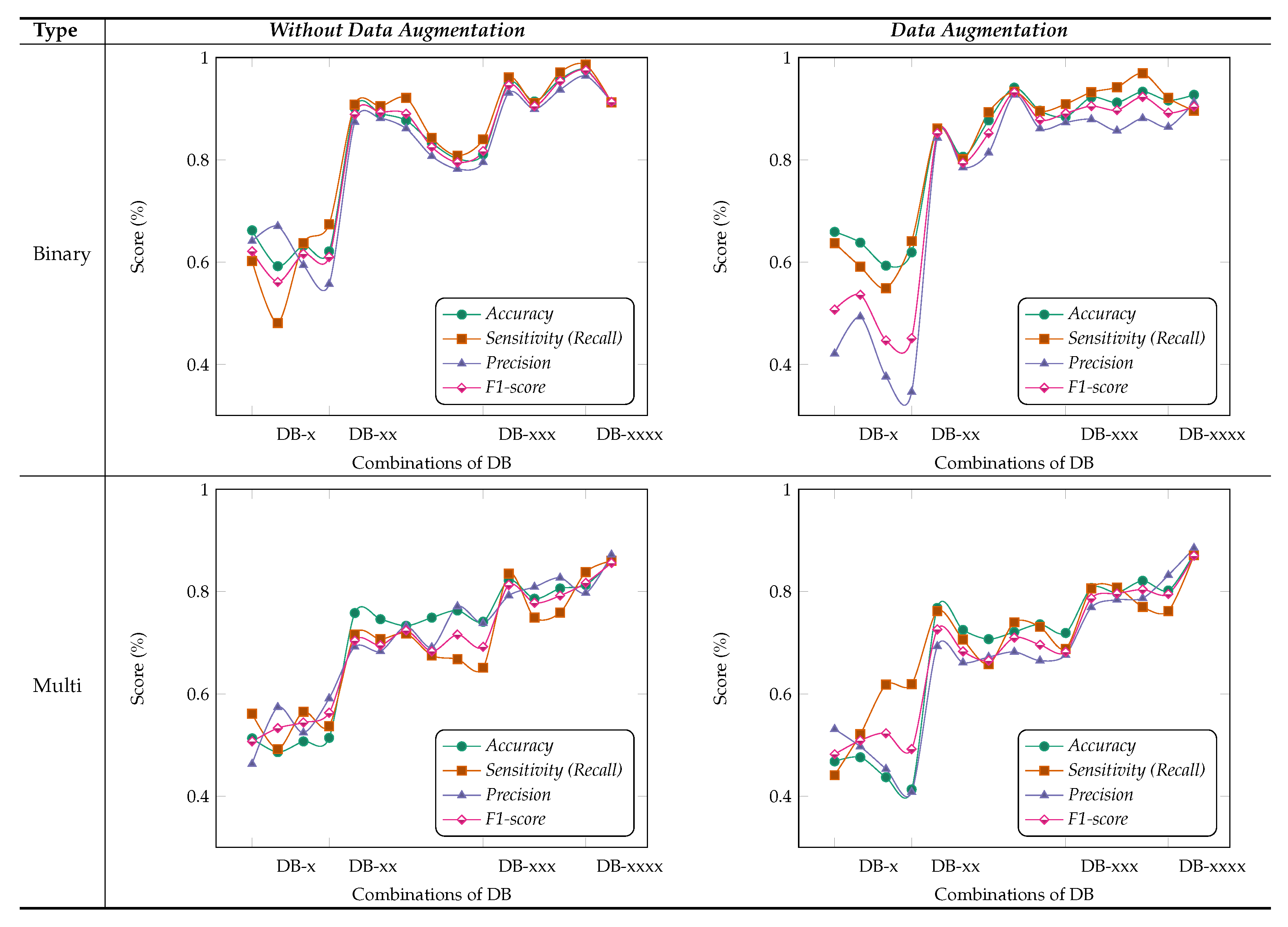
Figure 6 shows the results obtained for different combinations of multi-feature maps in the DB-Depth Block DB-(1–4), where we considered using different numbers of depth blocks in the MSI-MFNet, while using a fusion of all MSI images (i.e., 1×, 0.5×, 0.33×, and 0.25×). For example, DB-× corresponds to using only one depth block (DB-1), while DB-xxx corresponds to using three depth blocks (DB-1, DB-2, and DB-3).
We observed that the model achieved the highest metric performance when we used a fusion of more combinations of multi-feature maps, which classify samples more accurately using rich information learned when data augmentation is applied to patches, compared with the scenario in which no data augmentation is employed, as shown in
Figure 6. The data augmentation scenario of binary classification shows better performance compared with multi-class classification, with an overall average score of over
. We also noticed that there are several dips and changes in the metric scores for both augmentation scenarios and types of classification when fewer combinations of feature maps are used. We attribute this behavior to two factors: pair and individual feature maps learned are not useful for medical image classification because of large structural variations in images, and intra-class variations of samples also affect the model feature learning functionality.
Interestingly, we consistently obtained higher sensitivity scores for both types of classification with higher combinations of feature maps, which shows the capability of our model to correctly classify the patches with their respective classes. Nevertheless, our method still achieves a comparable performance with both scenarios of data augmentation when we used combinations of feature maps with more than pair combinations. Hence, in general, we can say that the classification models with more combinations of feature maps are more suitable and accurate for feature learning and to address multi-class task problems associated with medical images. However, from the experiments, we can state that the selection of multi-feature maps affects the results in various ways, but as already explained, in general, higher combinations show an improvement.
Importance of MSI-MFNet: Our model has two important characteristics. First, it has a powerful ability to transform raw data into high-level representation using different-scale image patches, which automatically bridges the semantic gap through image abstraction. This can be inferred by inspecting the results for two different models, as shown in
Figure 5. The models’ performance is affected by input combinations; omitting one or more inputs from fusing reduces the models’ performance, that is, having more combinations of input scales is better. This trend was observed for all combinations for the both models. The results of our experiments demonstrate the need to fuse MSI for the classification of medical images. Second,
Figure 6 shows the fusion results for different combinations of feature maps. These variations are reflected in the changes in the trends of different metrics, which also exhibit significant drops. These observations provide the rationale for fusing multi-resolution hierarchical feature maps at different layers. Such fusion allows the extraction of more distinct and salient information while retaining coarse-scale features. Fusing larger combinations of feature maps allows us to learn more robust and effective features for classification.
Fusing the feature maps from learning layers explicitly quantifies the fusion weights of the features used for classification, which is different from previous CNN-based methods [
47,
48,
49] that typically fuse same-size feature maps and use encoding methods, which can corrupt the original spatial structure of the data features. A few studies have also proposed methods for designing parameters for generalization to arbitrary sizes, which means that information contained in different-size feature maps is not exploited to the fullest. We do not assume any input modalities that are explicitly fused or encoded using specific types of encoding operations. Instead, we rely only on raw multi-scale inputs, and later fuse feature maps from different layers. Unlike previous tightly coupled traditional methods [
27,
28,
29], the present approach consists of separable modules: processing multi-scale inputs, feature learning with dense connectivity, fusing multi-scale feature maps, and classification layers. This modularity increases the method’s portability and applicability; consequently, the method can be used by other researchers for various medical image analysis tasks, such as visualization, classification, and segmentation.
Based on these ablation studies, we conclude that our results align with the objective of fusing multi-scale inputs before the feature learning stage and subsequent fusing of multiple feature map stages. Our general observation is that removing the fusion of combinations significantly affects the results, regardless of data augmentation, type of classification (binary or multi-class), or classification model, as shown in
Figure 5 and
Figure 6, respectively.
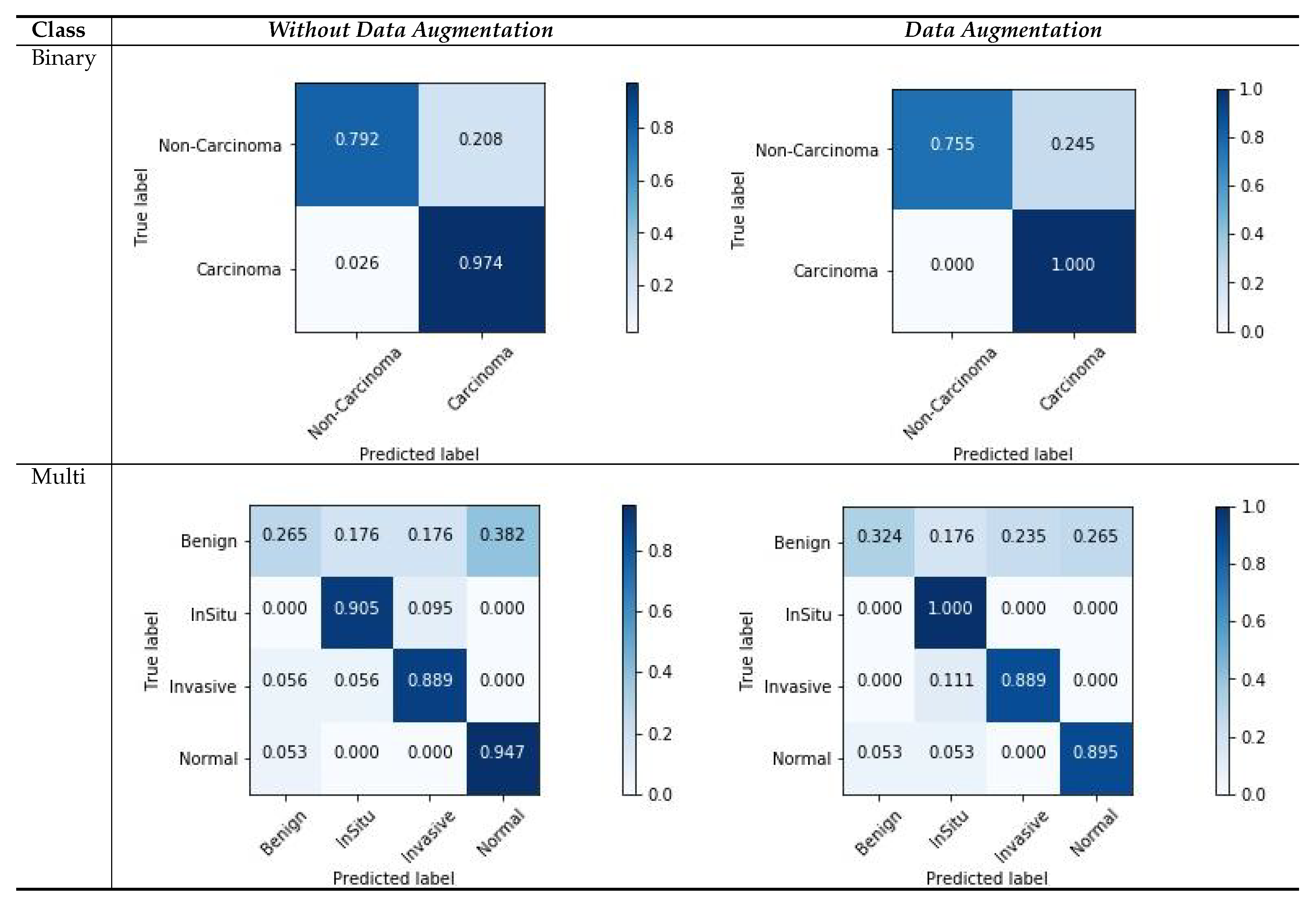
5.3. Confusion Matrix Visualization
Figure 7 shows the confusion matrix results for the ICIAR2018 dataset with a magnification factor of 200×. From the visualization results, we can observe that the data augmentation scenario demonstrated better results than that without data augmentation. For both scenarios, there were several changes in the multi-class scores. This is due to the ambiguous distinction between normal and benign classes, as well as large intra-class sample variations within each class. The variations in the classes and their relationship to the number of samples in each class can also affect the classification results, and consequently, the image patches that are used for learning. However, the results of two classes of samples (In situ and Invasive) are more accurately classified. Moreover, our results demonstrate that the carcinoma classes were more precisely classified using binary classification with a data-augmentation scenario, as compared with non-carcinoma classes. This behavior reflects a smaller amount of data and weaker variations in the dataset. However, from these experiments, we can summarize that the use of data augmentation affects the results considerably, as demonstrated by the improved results.
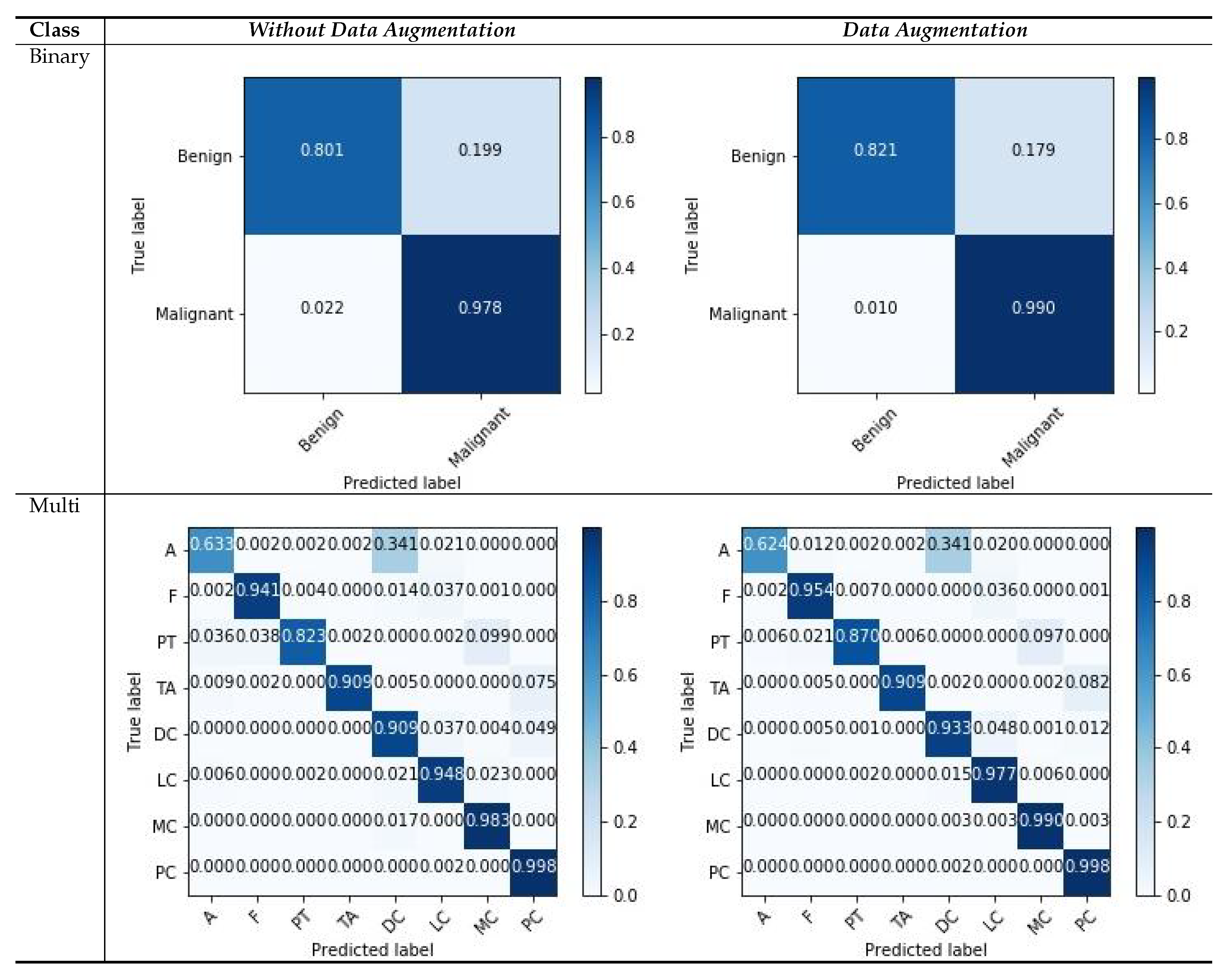
Similarly, we show the confusion matrices of the BreakHis dataset with a magnification factor of 400× in
Figure 8. We observe that our models tend to approximate good samples with deep layered networks, and input images with magnifications that are greater than 100× yield better results. From the visualization of the confusion matrix results, we can observe that the binary cases have superior performance compared with multi-classification cases, because of the rich and relevant regions, with data augmentation scenarios as compared to those without data augmentation. The features with higher magnification have good structural information, which helps the model to learn good representation between patches with respective labels. There are a few classes that consists of more patches without diseased regions and which deviate in appearance as compared with the normal region; such variations in patches can affect the classification capability, and the multi-classification results vary. Even with challenging variations in datasets, the visualization results suggest that data augmentation is a more suitable strategy for both types of classification. The overall result indicates that our model is useful for classifying histology images.
A factor that strongly improved the results was the application of data augmentation to patches, rather than the complete images, which sometimes exhibited no general patterns for feature learning. Carefully selecting each patch individually from WSI images and then applying data augmentation can further improve the model’s performance. However, such results are not useful for multi-scale networks and deviates from our objective of feature learning and the consequent fusion of feature maps from random patches. The overall results reported for both datasets and for the data augmentation scenarios suggest that our model performs well, regardless of the number of generated patches from WSIs, and using the fusion of combinations at the two modules of the MSI-MFNet model.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}