
Fine-Tuning Approach for Segmentation of Gliomas in Brain Magnetic Resonance Images with a Machine Learning Method to Normalize Image Differences among Facilities


 ,
,  , , ,
, , ,  , , ,
, , , 
Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Ethics
2.2. JC Dataset
- All four types of images, T1-weighted images (T1), T2-weighted images (T2), fluid-attenuated inversion recovery (FLAIR), and T1-weighted images with gadolinium enhancement (GdT1), were eligible.
- Surgical removal or biopsy was performed.
- Diagnostic tests, including genetic analysis of key biomarkers (IDH mutation and 1p19q), were performed following the WHO 2007 or 2016 classifications of Central Nerves System tumors.
2.3. BraTS Dataset
2.4. Creating VOI
2.5. Image Preparation
2.6. Machine Learning Model
- BraTS model: The BraTS dataset was split into training, validation, and test sets (60% training, 20% validation, and 20% test), and the model was trained for tumor segmentation on the test set.
- JC model: The pre-training part of the JC dataset was further split into training and validation sets (75% training and 25% validation), and the model was trained on the training portion of the JC dataset.
- Fine-tuning model: The BraTS model was fine-tuned to perform an optimized analysis in each facility. A maximum of 20 cases (randomly selected) from the pre-training portion of the JC dataset were used for fine-tuning. Here, if a facility had fewer than 20 training cases, all the training portions in the JC dataset from the facility were used for fine-tuning.
2.7. Finding the Best Fine-Tuning Method
2.8. Overall Workflow
2.9. Performance Evaluation of Segmentation Models
2.10. Statistical Analysis
3. Results
3.1. Performance of Individual Models
3.1.1. BraTS Model
3.1.2. JC Model
3.1.3. Fine-Tuning Models
3.1.4. The Result of Fine-Tuning Models
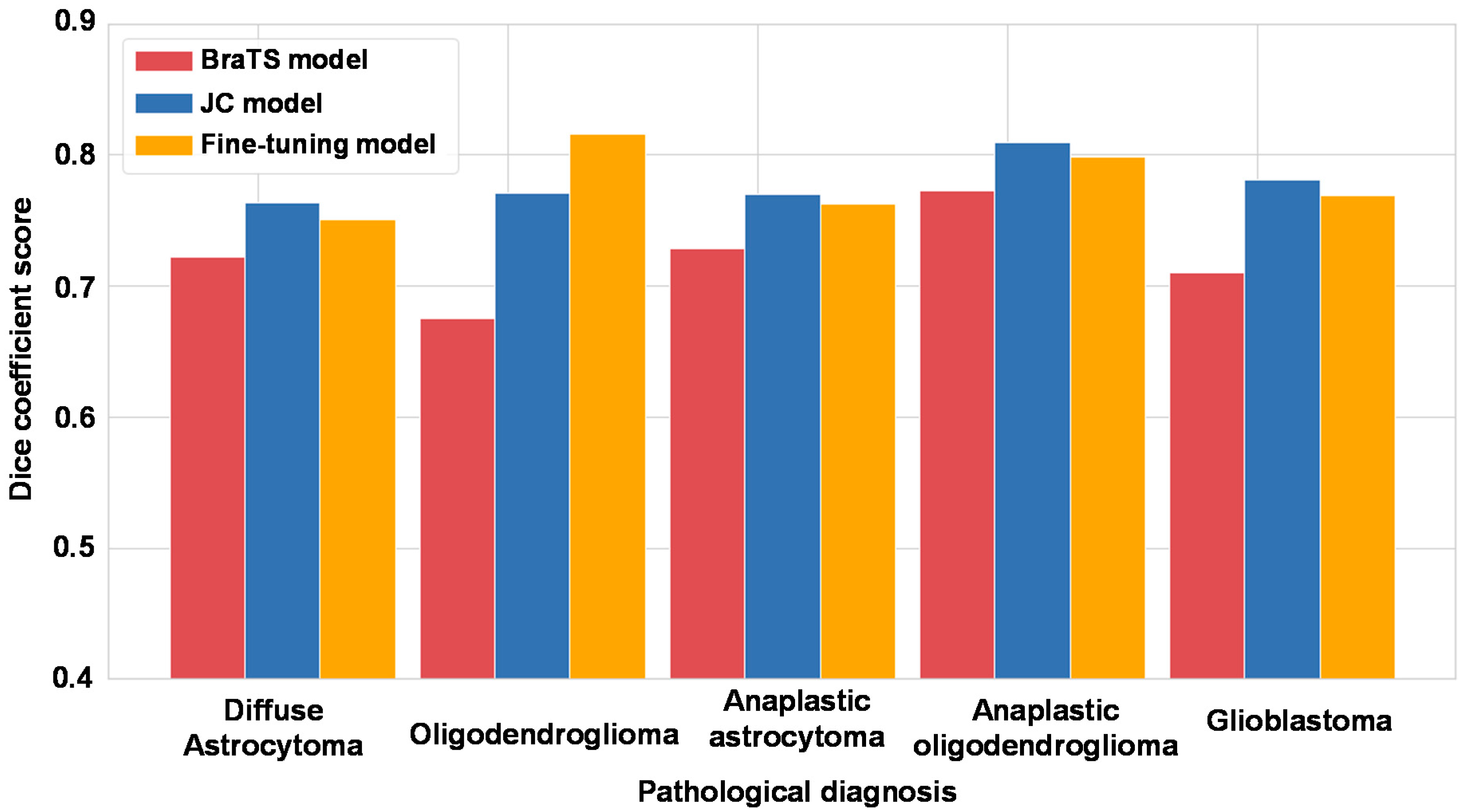
3.2. Comparison of the Three Models
3.3. Comparison of the VOI Obtained with the Three Models
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Meeting Presentation
References
- Rasmussen, B.K.; Hansen, S.; Laursen, R.J.; Kosteljanetz, M.; Schultz, H.; Nørgård, B.M.; Guldberg, R.; Gradel, K.O. Epidemiology of glioma: Clinical characteristics, symptoms, and predictors of glioma patients grade I–IV in the the Danish Neuro-Oncology Registry. J. Neuro-Oncology 2017, 135, 571–579. [Google Scholar] [CrossRef] [PubMed]
- Arita, H.; Narita, Y.; Fukushima, S.; Tateishi, K.; Matsushita, Y.; Yoshida, A.; Miyakita, Y.; Ohno, M.; Collins, V.P.; Kawahara, N.; et al. Upregulating mutations in the TERT promoter commonly occur in adult malignant gliomas and are strongly associated with total 1p19q loss. Acta Neuropathol. 2013, 126, 267–276. [Google Scholar] [CrossRef] [PubMed]
- Ichimura, K.; Nishikawa, R.; Matsutani, M. Molecular markers in pediatric neuro-oncology. Neuro-Oncology 2012, 14, iv90–iv99. [Google Scholar] [CrossRef] [PubMed]
- Hegi, M.E.; Diserens, A.-C.; Gorlia, T.; Hamou, M.-F.; De Tribolet, N.; Weller, M.; Kros, J.M.; Hainfellner, J.A.; Mason, W.; Mariani, L.; et al. MGMTGene Silencing and Benefit from Temozolomide in Glioblastoma. N. Engl. J. Med. 2005, 352, 997–1003. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lassman, A.B.; Iwamoto, F.M.; Cloughesy, T.F.; Aldape, K.D.; Rivera, A.L.; Eichler, A.F.; Louis, D.N.; Paleologos, N.A.; Fisher, B.J.; Ashby, L.S.; et al. International retrospective study of over 1000 adults with anaplastic oligodendroglial tumors. Neuro-Oncology 2011, 13, 649–659. [Google Scholar] [CrossRef]
- Penas-Prado, M.; De Groot, J. CATNON interim results: Another triumph of upfront chemotherapy in glioma. Neuro-Oncology 2017, 19, 1287–1288. [Google Scholar] [CrossRef]
- Stupp, R.; Mason, W.P.; van den Bent, M.J.; Weller, M.; Fisher, B.; Taphoorn, M.J.B.; Belanger, K.; Brandes, A.A.; Marosi, C.; Bogdahn, U.; et al. Radiotherapy plus Concomitant and Adjuvant Temozolomide for Glioblastoma. N. Engl. J. Med. 2005, 352, 987–996. [Google Scholar] [CrossRef]
- Sanai, N.; Berger, M.S. Glioma extent of resection and its impact on patient outcome. Neurosurg. 2008, 62, 753–766. [Google Scholar] [CrossRef] [Green Version]
- Ciçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2016. MICCAI 2016. Lecture Notes in Computer Science; Ourselin, S., Joskowicz, L., Sabuncu, M., Unal, G., Wells, W., Eds.; Springer: Cham, Switzerland, 2016; Volume 9901. [Google Scholar] [CrossRef] [Green Version]
- Akkus, Z.; Galimzianova, A.; Hoogi, A.; Rubin, D.L.; Erickson, B.J. Deep Learning for Brain MRI Segmentation: State of the Art and Future Directions. J. Digit. Imaging 2017, 30, 449–459. [Google Scholar] [CrossRef] [Green Version]
- Havaei, M.; Davy, A.; Warde-Farley, D.; Biard, A.; Courville, A.; Bengio, Y.; Pal, C.; Jodoin, P.-M.; Larochelle, H. Brain tumor segmentation with Deep Neural Networks. Med. Image Anal. 2017, 35, 18–31. [Google Scholar] [CrossRef] [Green Version]
- Kamnitsas, K.; Ledig, C.; Newcombe, V.F.; Simpson, J.P.; Kane, A.D.; Menon, D.K.; Rueckert, D.; Glocker, B. Efficient multi-scale 3D CNN with fully connected CRF for accurate brain lesion segmentation. Med. Image Anal. 2017, 36, 61–78. [Google Scholar] [CrossRef]
- Pereira, S.; Pinto, A.; Alves, V.; Silva, C.A. Brain Tumor Segmentation Using Convolutional Neural Networks in MRI Images. IEEE Trans. Med. Imaging 2016, 35, 1240–1251. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z. Automatic Segmentation of Non-Tumor Tissues in Glioma MR Brain Images Using Deformable Registration with Partial Convolutional Networks. arXiv 2020, in press. [Google Scholar]
- Stawiaski, J. A Multiscale Patch Based Convolutional Network for Brain Tumor Segmentation. arXiv 2017, in press. [Google Scholar]
- Menze, B.H.; Jakab, A.; Bauer, S.; Kalpathy-Cramer, J.; Farahani, K.; Kirby, J.; Burren, Y.; Porz, N.; Slotboom, J.; Wiest, R.; et al. The Multimodal Brain Tumor Image Segmentation Benchmark (BRATS). IEEE Trans. Med. Imaging 2015, 34, 1993–2024. [Google Scholar] [CrossRef]
- Myronenko, A. 3D MRI Brain Tumor Segmentation Using Autoencoder Regularization. In International MICCAI Brainlesion Workshop; Springer: Cham, Switzerland, 2018; pp. 311–320. [Google Scholar]
- Komatsu, M.; Sakai, A.; Komatsu, R.; Matsuoka, R.; Yasutomi, S.; Shozu, K.; Dozen, A.; Machino, H.; Hidaka, H.; Arakaki, T.; et al. Detection of Cardiac Structural Abnormalities in Fetal Ultrasound Videos Using Deep Learning. Appl. Sci. 2021, 11, 371. [Google Scholar] [CrossRef]
- Asada, K.; Kobayashi, K.; Joutard, S.; Tubaki, M.; Takahashi, S.; Takasawa, K.; Komatsu, M.; Kaneko, S.; Sese, J.; Hamamoto, R. Uncovering Prognosis-Related Genes and Pathways by Multi-Omics Analysis in Lung Cancer. Biomolecules 2020, 10, 524. [Google Scholar] [CrossRef] [Green Version]
- Hamamoto, R.; Komatsu, M.; Takasawa, K.; Asada, K.; Kaneko, S. Epigenetics Analysis and Integrated Analysis of Multiomics Data, Including Epigenetic Data, Using Artificial Intelligence in the Era of Precision Medicine. Biomolecules 2019, 10, 62. [Google Scholar] [CrossRef] [Green Version]
- Hamamoto, R.; Suvarna, K.; Yamada, M.; Kobayashi, K.; Shinkai, N.; Miyake, M.; Takahashi, M.; Jinnai, S.; Shimoyama, R.; Sakai, A.; et al. Application of Artificial Intelligence Technology in Oncology: Towards the Establishment of Precision Medicine. Cancers 2020, 12, 3532. [Google Scholar] [CrossRef]
- Jinnai, S.; Yamazaki, N.; Hirano, Y.; Sugawara, Y.; Ohe, Y.; Hamamoto, R. The Development of a Skin Cancer Classification System for Pigmented Skin Lesions Using Deep Learning. Biomolecules 2020, 10, 1123. [Google Scholar] [CrossRef]
- Dozen, A.; Komatsu, M.; Sakai, A.; Komatsu, R.; Shozu, K.; Machino, H.; Yasutomi, S.; Arakaki, T.; Asada, K.; Kaneko, S.; et al. Image Segmentation of the Ventricular Septum in Fetal Cardiac Ultrasound Videos Based on Deep Learning Using Time-Series Information. Biomolecules 2020, 10, 1526. [Google Scholar] [CrossRef] [PubMed]
- Shozu, K.; Komatsu, M.; Sakai, A.; Komatsu, R.; Dozen, A.; Machino, H.; Yasutomi, S.; Arakaki, T.; Asada, K.; Kaneko, S.; et al. Model-Agnostic Method for Thoracic Wall Segmentation in Fetal Ultrasound Videos. Biomolecules 2020, 10, 1691. [Google Scholar] [CrossRef] [PubMed]
- Yamada, M.; Saito, Y.; Imaoka, H.; Saiko, M.; Yamada, S.; Kondo, H.; Takamaru, H.; Sakamoto, T.; Sese, J.; Kuchiba, A.; et al. Development of a real-time endoscopic image diagnosis support system using deep learning technology in colonoscopy. Sci. Rep. 2019, 9, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yasutomi, S.; Arakaki, T.; Matsuoka, R.; Sakai, A.; Komatsu, R.; Shozu, K.; Dozen, A.; Machino, H.; Asada, K.; Kaneko, S.; et al. Shadow Estimation for Ultrasound Images Using Auto-Encoding Structures and Synthetic Shadows. Appl. Sci. 2021, 11, 1127. [Google Scholar] [CrossRef]
- Torralba, A.; Efros, A.A. Unbiased look at dataset bias. CVPR 2011 2011, 10, 1521–1528. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Arita, H.; Yamasaki, K.; Matsushita, Y.; Nakamura, T.; Shimokawa, A.; Takami, H.; Tanaka, S.; Mukasa, A.; Shirahata, M.; Shimizu, S.; et al. A combination of TERT promoter mutation and MGMT methylation status predicts clinically relevant subgroups of newly diagnosed glioblastomas. Acta Neuropathol. Commun. 2016, 4, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Bakas, S.; Akbari, H.; Sotiras, A.; Bilello, M.; Rozycki, M.; Kirby, J.S.; Freymann, J.B.; Farahani, K.; Davatzikos, C. Advancing The Cancer Genome Atlas glioma MRI collections with expert segmentation labels and radiomic features. Sci. Data 2017, 4, 170117. [Google Scholar] [CrossRef] [Green Version]
- Pei, L.; Vidyaratne, L.; Rahman, M.; Iftekharuddin, K.M. Context aware deep learning for brain tumor segmentation, subtype classification, and survival prediction using radiology images. Sci. Rep. 2020, 10, 1–11. [Google Scholar] [CrossRef]
- Smith, S.M. Fast robust automated brain extraction. Hum. Brain Mapp. 2002, 17, 143–155. [Google Scholar] [CrossRef]
- Isensee, F.; Kickingereder, P.; Wick, W.; Bendszus, M.; Maier-Hein, K.H. Brain Tumor Segmentation and Radiomics Survival Prediction: Contribution to the BRATS 2017 Challenge; Lecture Notes in Computer Science Series; Springer: Cham, Switzerland, 2018; pp. 287–297. [Google Scholar]
- Kayalibay, B.; Jensen, G.; van der Smagt, P. CNN-based segmentation of medical imaging data. arXiv 2017, in press. [Google Scholar]
- Ruxton, G.D. The unequal variance t-test is an underused alternative to Student’s t-test and the Mann–Whitney U test. Behav. Ecol. 2006, 17, 688–690. [Google Scholar] [CrossRef]
- Ruxton, G.D.; Beauchamp, G. Time for some a priori thinking about post hoc testing. Behav. Ecol. 2008, 19, 690–693. [Google Scholar] [CrossRef] [Green Version]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How Transferable Are Features in Deep Neural Networks? arXiv 2014, in press. [Google Scholar]
- Madani, A.; Moradi, M.; Karargyris, A.; Syeda-Mahmood, T. Semi-supervised learning with generative adversarial networks for chest X-ray classification with ability of data domain adaptation. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2018; pp. 1038–1042. [Google Scholar]
- Amiri, M.; Brooks, R.; Rivaz, H. Fine Tuning U-Net for Ultrasound Image Segmentation: Which Layers? Springer International Publishing: Cham, Switzerland, 2019; pp. 235–242. [Google Scholar]
- Chen, C.; Dou, Q.; Chen, H.; Heng, P.-A. Semantic-Aware Generative Adversarial Nets for Unsupervised Domain Adaptation in Chest X-Ray Segmentation; Lecture Notes in Computer Science Series; Springer: Cham, Switzerland, 2018; pp. 143–151. [Google Scholar]
- Pooch, E.H.P.; Ballester, P.L.; Barros, R.C. Can we trust deep learning models diagnosis? The impact of domain shift in chest radiograph classification. arXiv 2020, in press. [Google Scholar]
- Albadawy, E.A.; Saha, A.; Mazurowski, M.A. Deep learning for segmentation of brain tumors: Impact of cross-institutional training and testing. Med. Phys. 2018, 45, 1150–1158. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | All Dataset | Facility A | Facility B | Facility C | Facility D | Facility E | Facility F | Facility G | Facility H | Facility I | Facility J |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Median age (range) | 60 (86–17) | 54 (81–28) | 64.5 (84–26) | 64.5 (85–25) | 66 (85–51) | 59 (80–25) | 57 (86–17) | 60 (79–22) | 55.5 (80–21) | 54 (76–28) | 61 (81–19) |
| Sex | |||||||||||
| Male | 293 | 92 | 20 | 50 | 8 | 32 | 17 | 21 | 23 | 16 | 23 |
| Female | 251 | 65 | 20 | 44 | 5 | 27 | 14 | 21 | 21 | 13 | 12 |
| LrGG or GBM | |||||||||||
| LrGG | 218 | 71 | 18 | 0 | 0 | 31 | 18 | 25 | 23 | 18 | 14 |
| GBM | 326 | 86 | 22 | 94 | 13 | 28 | 13 | 17 | 21 | 11 | 21 |
| WHO grade | |||||||||||
| II | 91 | 34 | 12 | 0 | 0 | 7 | 5 | 10 | 10 | 7 | 6 |
| III | 127 | 37 | 6 | 0 | 0 | 24 | 13 | 15 | 13 | 11 | 8 |
| IV | 326 | 86 | 22 | 94 | 13 | 28 | 13 | 17 | 21 | 11 | 21 |
| Pathological diagnosis | |||||||||||
| Diffuse astrocytoma | 66 | 27 | 9 | 0 | 0 | 4 | 3 | 9 | 7 | 4 | 3 |
| Anaplastic astrocytoma | 88 | 25 | 3 | 0 | 0 | 16 | 6 | 14 | 10 | 7 | 7 |
| Oligodendroglioma | 25 | 7 | 3 | 0 | 0 | 3 | 2 | 1 | 3 | 3 | 3 |
| Anaplastic oligodendroglioma | 39 | 12 | 3 | 0 | 0 | 8 | 7 | 1 | 3 | 4 | 1 |
| Glioblastoma | 326 | 86 | 22 | 94 | 13 | 28 | 13 | 17 | 21 | 11 | 21 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Takahashi, S.; Takahashi, M.; Kinoshita, M.; Miyake, M.; Kawaguchi, R.; Shinojima, N.; Mukasa, A.; Saito, K.; Nagane, M.; Otani, R.; et al. Fine-Tuning Approach for Segmentation of Gliomas in Brain Magnetic Resonance Images with a Machine Learning Method to Normalize Image Differences among Facilities. Cancers 2021, 13, 1415. https://doi.org/10.3390/cancers13061415
Takahashi S, Takahashi M, Kinoshita M, Miyake M, Kawaguchi R, Shinojima N, Mukasa A, Saito K, Nagane M, Otani R, et al. Fine-Tuning Approach for Segmentation of Gliomas in Brain Magnetic Resonance Images with a Machine Learning Method to Normalize Image Differences among Facilities. Cancers. 2021; 13(6):1415. https://doi.org/10.3390/cancers13061415
Chicago/Turabian StyleTakahashi, Satoshi, Masamichi Takahashi, Manabu Kinoshita, Mototaka Miyake, Risa Kawaguchi, Naoki Shinojima, Akitake Mukasa, Kuniaki Saito, Motoo Nagane, Ryohei Otani, and et al. 2021. "Fine-Tuning Approach for Segmentation of Gliomas in Brain Magnetic Resonance Images with a Machine Learning Method to Normalize Image Differences among Facilities" Cancers 13, no. 6: 1415. https://doi.org/10.3390/cancers13061415
APA StyleTakahashi, S., Takahashi, M., Kinoshita, M., Miyake, M., Kawaguchi, R., Shinojima, N., Mukasa, A., Saito, K., Nagane, M., Otani, R., Higuchi, F., Tanaka, S., Hata, N., Tamura, K., Tateishi, K., Nishikawa, R., Arita, H., Nonaka, M., Uda, T., ... Hamamoto, R. (2021). Fine-Tuning Approach for Segmentation of Gliomas in Brain Magnetic Resonance Images with a Machine Learning Method to Normalize Image Differences among Facilities. Cancers, 13(6), 1415. https://doi.org/10.3390/cancers13061415