Anomalies Detection Using Isolation in Concept-Drifting Data Streams †

 ,
,
Abstract
:1. Introduction
- We survey the anomaly detection methods in data streams with a deep view of the main approaches in the literature.
- We implement the IForestASD algorithm [3]) on top of the scikit-multiflow streaming framework.
2. Data stream Framework
2.1. Constraints and Synopsis Construction in Data Streams
- Evolving data: the infinite nature of evolving data streams requires real—or near-real—time processing in order to take the evolution and speed of data into account.
- Memory constraint: since data streams are potentially infinite, therefore, stream algorithms need to work within a limited memory by storing as less as possible of incoming observations as well as statistical information regarding the processed data seen so far.
- Time constraint: stream mining has the virtue of being fast. Accordingly, a stream algorithm needs to process incoming observations in limited time, as fast as they arrive.
- Drifts: concept drift is a phenomenon that occurs when the data stream distribution changes in time. The challenge that is posed by concept drift has been subject to multiple research studies, we direct the reader to a survey on drifts [8].
- Single pass: since data stream evolves over time, the stream cannot be examined more that once.
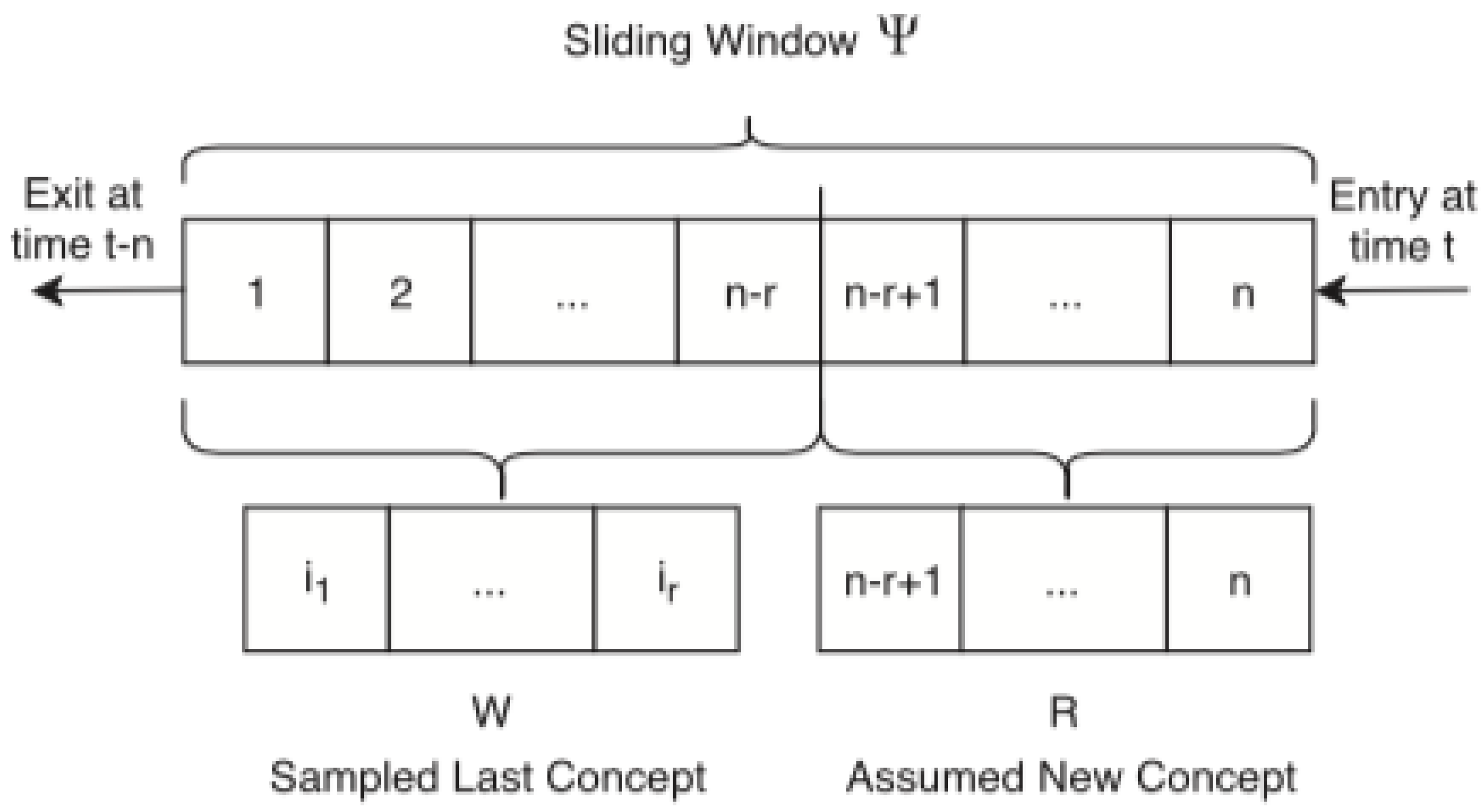
- Windows: window models have been proposed to maintain some of contents the stream in the memory. Different window models exist, such as sliding, landmark, and fading windows [10].
- Synopsis construction: a variety of summarization techniques can be used for synopsis construction in evolving data streams [11], such as sampling methods, histograms, sketching, or dimensionality reduction methods.
2.2. Data Stream Software Packages
- Isolation Forest is a state-of-the-art algorithm for anomaly detection and the only ensemble method in scikit-learn. It is widely used by the community and it can easily be adapted for online and incremental learning.
- Scikit-multiflow (river) is the main streaming framework in Python, which includes a variety of learning algorithms and streaming methods.
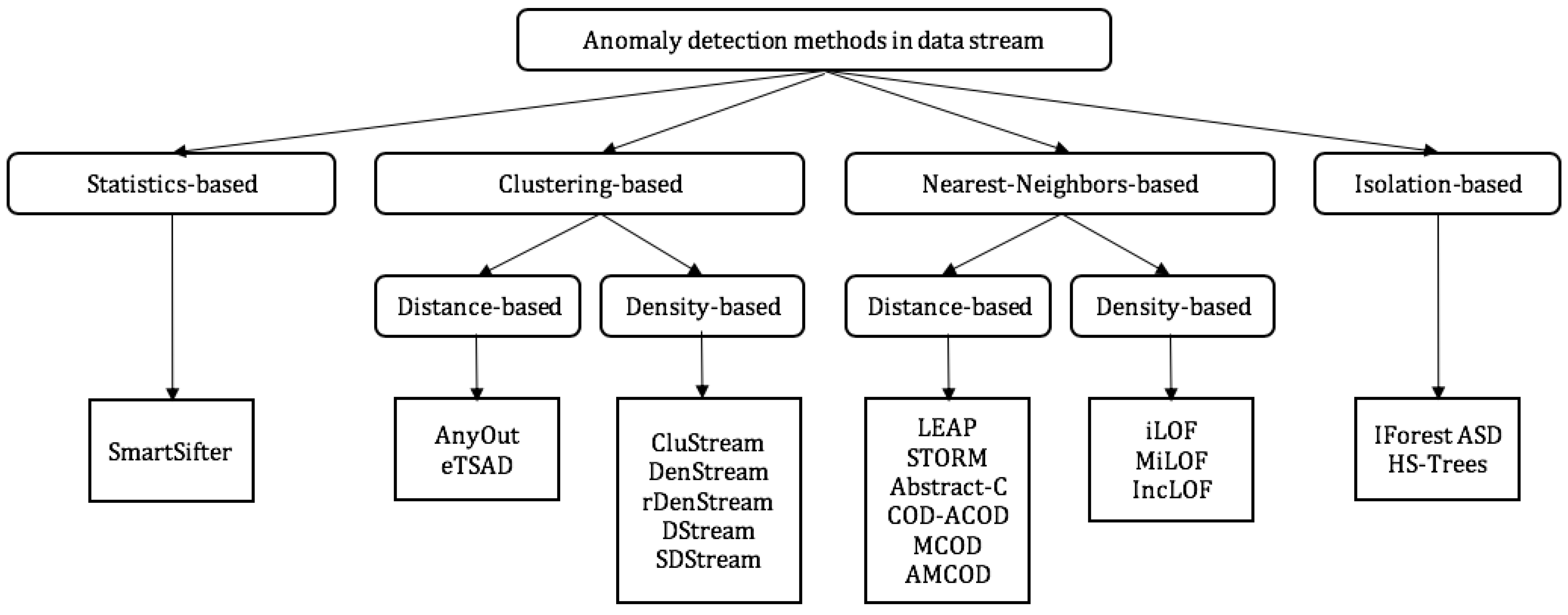
3. Anomaly Detection in Data Streams: Survey
3.1. Existing Methods
3.2. Approaches and Methods Classification
3.2.1. Statistics-Based
3.2.2. Clustering-Based and Nearest-Neighbors-Based
3.2.3. Isolation-Based
4. Isolation Forest, IForestASD and HSTrees Methods
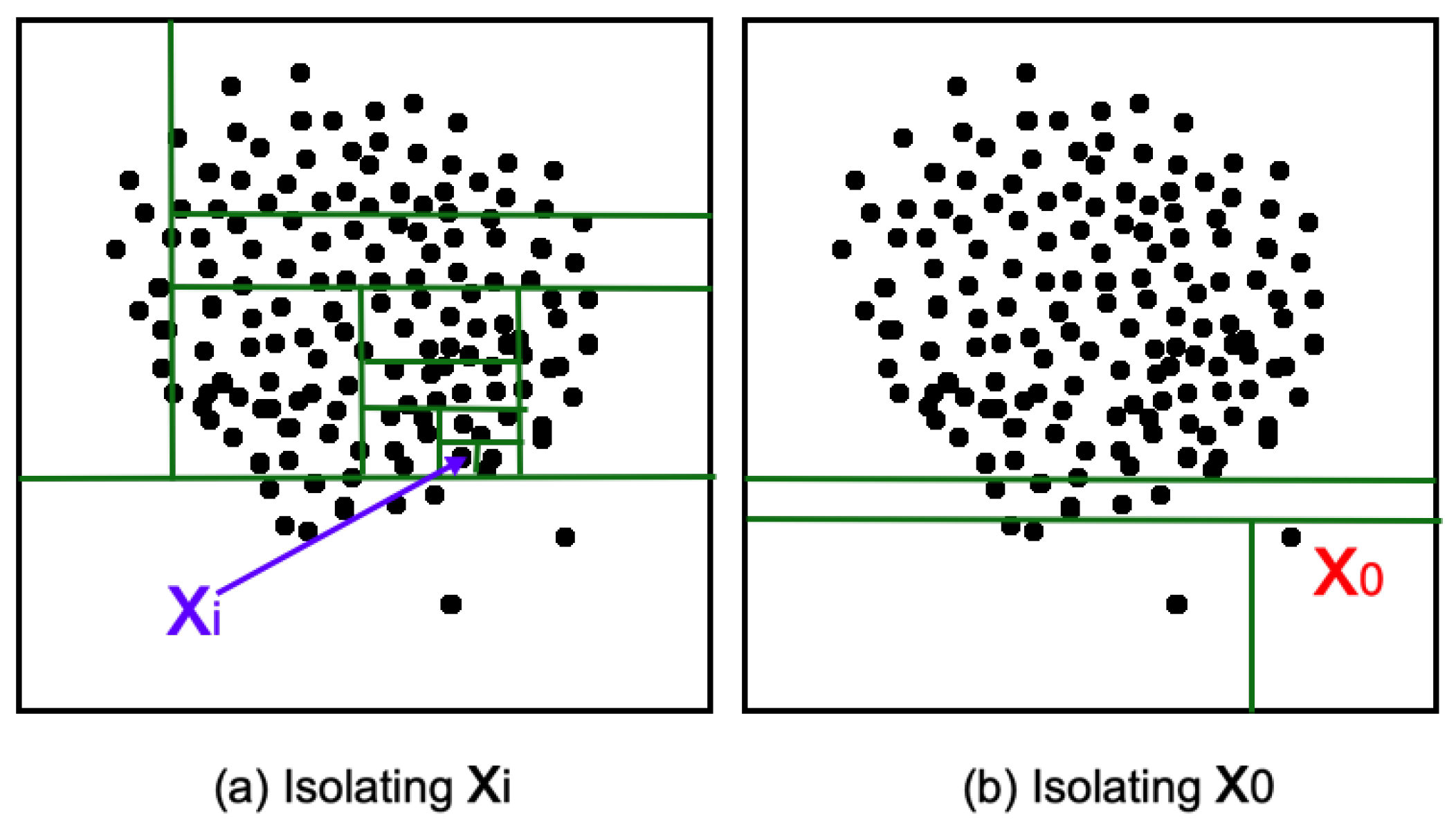
4.1. Isolation Forest Method
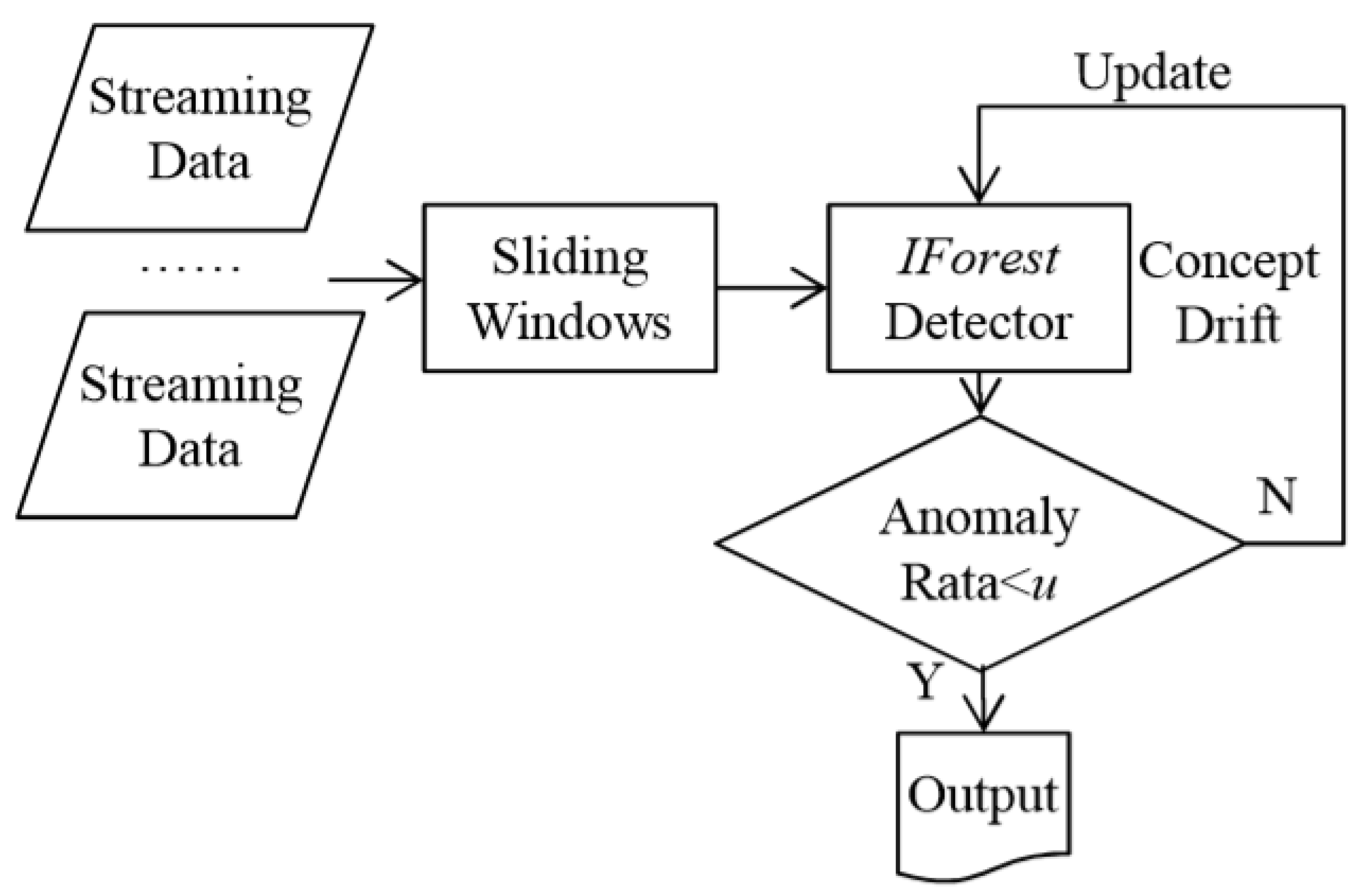
4.2. IForestASD: Isolation Forest Algorithm for Stream Data Method
4.3. Streaming Half-Space Trees
4.4. Main Differences between HSTrees and IForestASD
- The training phase: before the trees are built, while IForestASD chooses from the original dataset a sample of data without replacement for each tree planned for the forest, HSTrees creates a fictitious data space. Indeed, for each dimension of the original dataset, HSTrees creates a minimum and maximum value:being a random value in .IForestASD needs a sample of the original dataset to build the ensemble, while HSTrees can build trees structures without any data. During the construction of the trees, to split a node, while IForest ASD chooses a random split value v between and , for HSTrees v is the average of the (fictitious) values of the node, . Note that the maximum size of a tree () with IForestASD is a function of the sample size () while it is a user-defined parameter for HSTrees. Accordingly, to build the trees in the forest, HSTrees has no knowledge of what dataset to use, except the number of attributes. While IForestASD is closely dependent of the dataset.
- Score’s computation: to calculate the score of a given data, IForestASD is based on the length of the path of this data in each tree (as described in Section 4.1) then HSTrees is based on the score of the data for each tree. The overall score of the data is therefore for IForestASD based on the average of the path covered in all the trees in the forest, whereas it will be a sum of the scores that were obtained at the level of each tree in the forest for HSTrees. Unlike IForestASD, which normalizes the average length with when calculating the score, HSTrees limits the number of instances that a node can have in a tree, i.e., sizeLimit. This is a parameter that is predefined by the user.
- Drift Handling approach: the concept drift consists of the normal change of the values of the observations. Both of the methods update the base model (the forest) in order to handle the concept drift. However, while IForestASD updates its model on the condition that the anomaly rate in a window is greater than the preset u parameter, HSTrees automatically updates its model for each new incoming window.
- Model Updates policies: HSTrees updates the model after the completion of each batch by resetting, to 0, the mass value of each node in each tree. However, IForestASD updates the model when the rate of anomalies in the window is greater than a predefined parameter u by retraining a new Isolation Forest model on the last window.
5. Drift Detection Methods
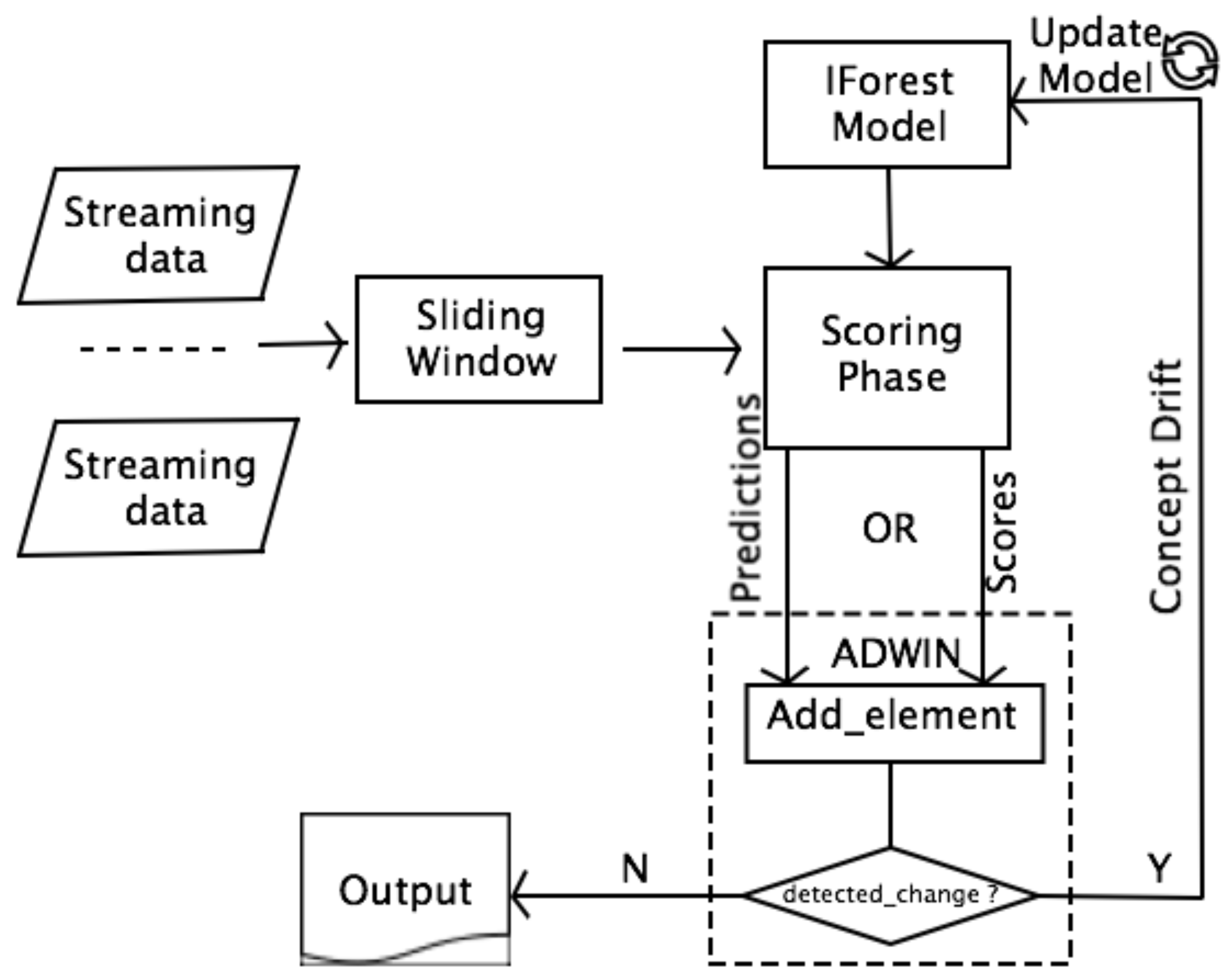
5.1. ADWIN for IFA
5.1.1. PADWIN IFA
5.1.2. SADWIN IFA
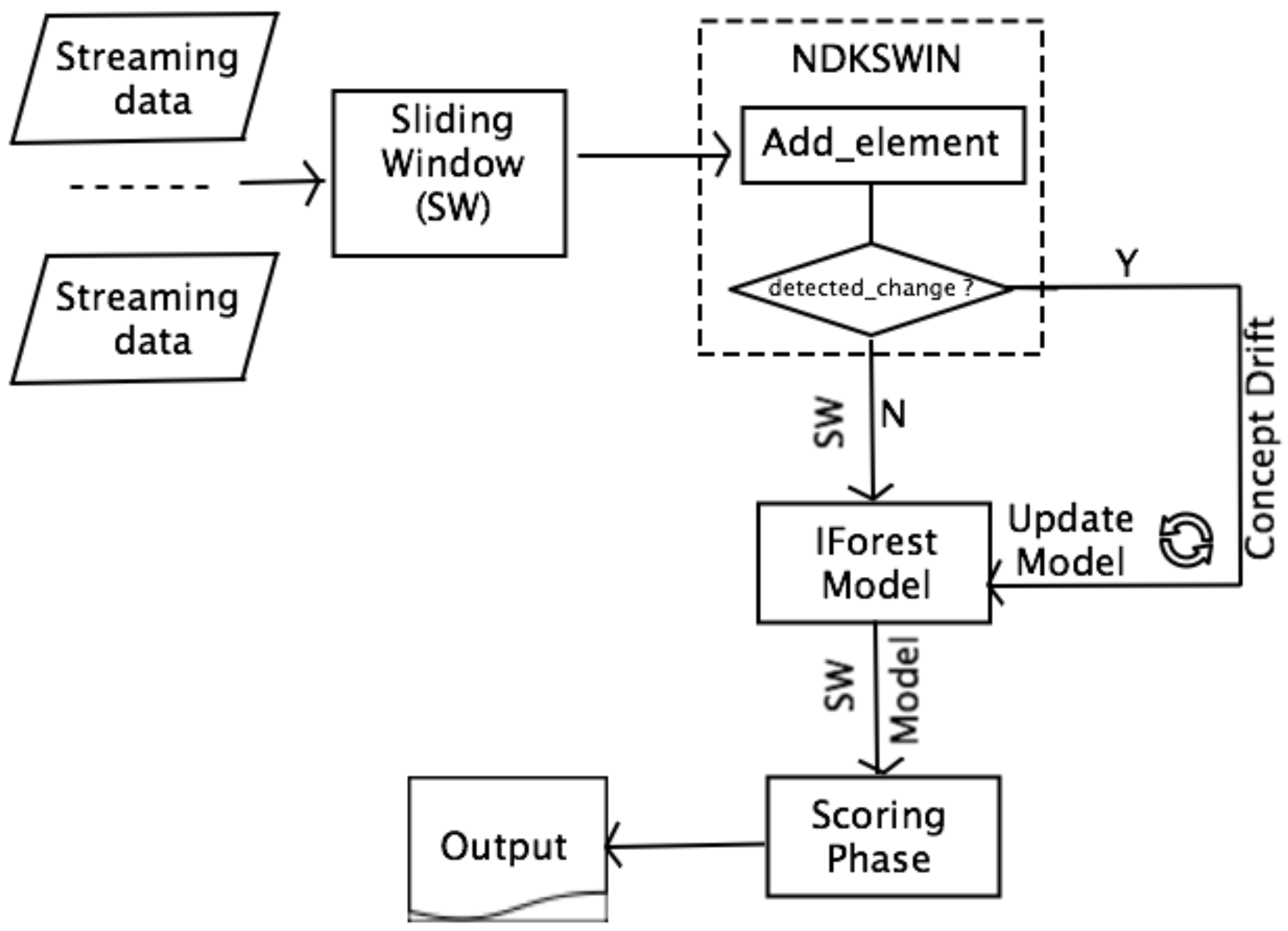
5.2. KSWIN for IForestASD
KSWIN and NDKSWIN IForestASD
6. Experimental Evaluation
- explain the experiments set up and material used to reproduce the work;
- provide the results of our implementation with a deep comparison with half-space trees; and,
- compare of the novel proposed algorithms and their performance related to the original version.
6.1. Datasets and Evaluation Metrics
6.1.1. Datasets Description
6.1.2. Experimental Setup
6.1.3. Evaluation Metrics
6.1.4. F1 Metric
6.1.5. Model Size Ratio (HSTrees Coefficient Ratio)—HRa
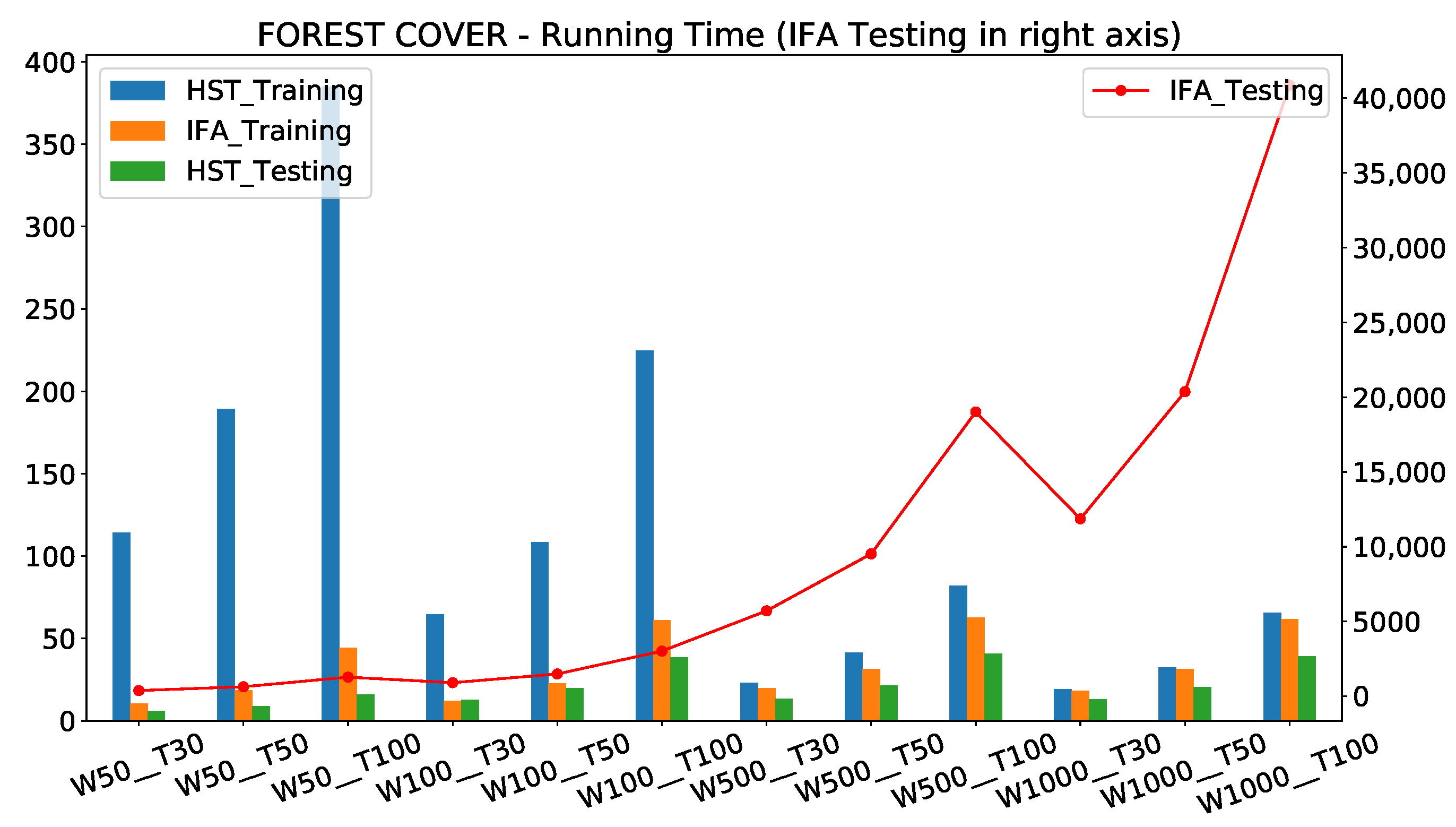
6.1.6. Running Time Ratio (IForestASD Coefficient Ratio)—IRa
6.2. Comparison of Original IForestASD (IFA) and Streaming Half-Space Trees (HST)
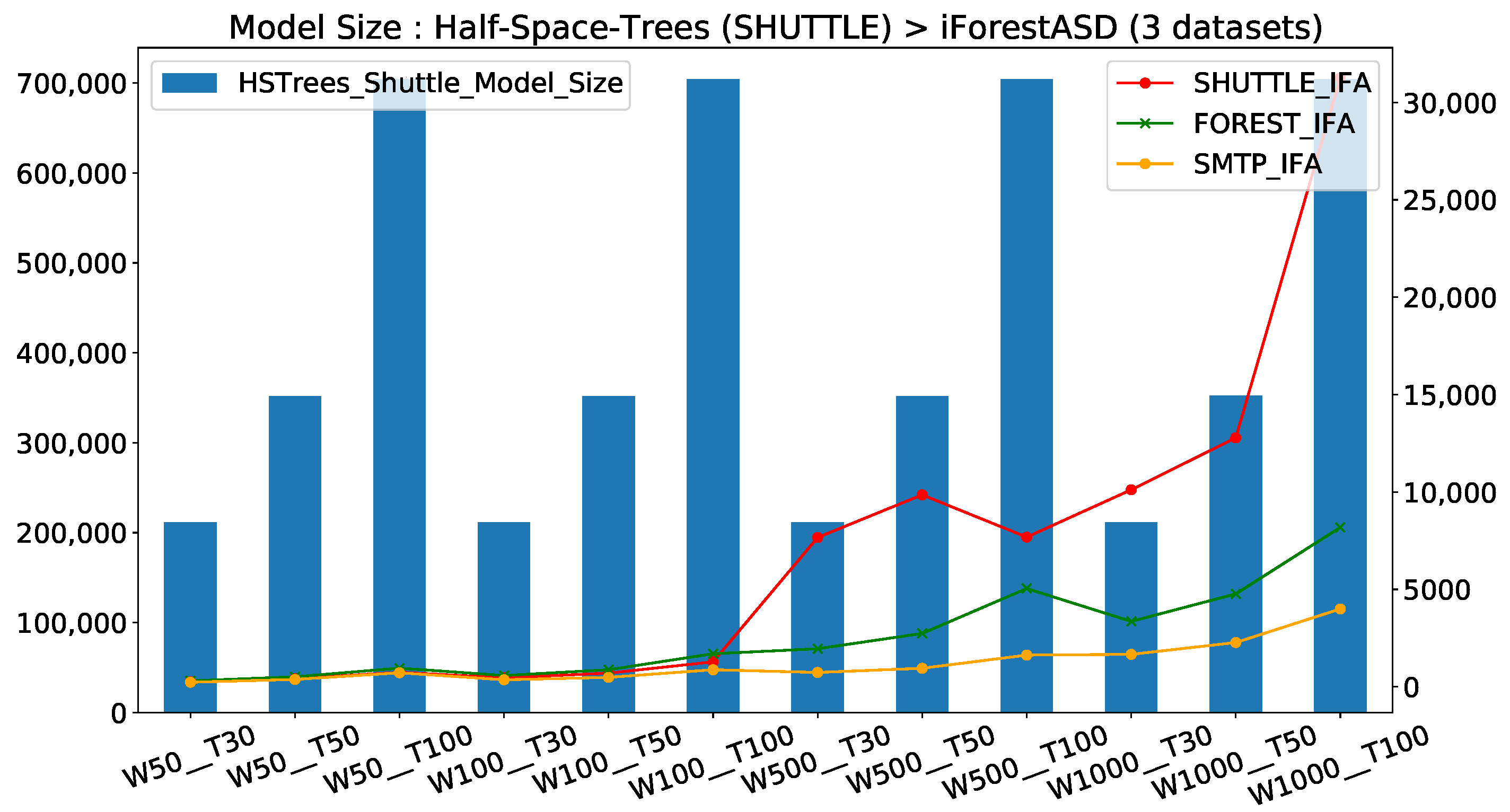
Models Memory Consumption Comparison
- IForestASD used less memory than HSTrees (≈20× less); this is explained by the fact that with IForestASD, update policy consists on discarding completely old model when drift anomaly rate in sliding window (updates by replacement), while HSTrees continuously updates the model at each observation
- For HSTrees, the window size W has no impact on the model size, only the number of trees T increases the memory used (barplots). This is consistent with the HSTrees update policy, which consists of updating statistics in Tree nodes with a fixed ensemble size.
- For IForestASD, both window size w and the number of trees T have a positive impact on model size, for three datasets (in three linesplot). This is due to the fact that IForestASD uses all of the instances in the window (W) to build the ensemble with T trees.
6.3. Proposed Algorithms to Deal with Drift Detection: SADWIN, PADWIN and NDKSWIN
6.3.1. Experiments Results
6.3.2. Discussion
- IForestASD does not have a real drift detection method as the model updates policy depends on a user-defined threshold (anomaly-rate), which is not available for real application.
- Integrating a drift detection method in conjunction with the vanilla IForestASD reduces the training time while maintaining similar performance.
7. Conclusions and Future Research Direction
7.1. Concluding Remarks
7.2. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| IForest | Isolation Forest |
| IForestASD | Isolation Forest Anomaly detection in Streaming Data |
| HSTrees | half-space trees |
| ADWIN | ADaptive WINdowing |
| SADWIN IFA | Score based ADWIN with IForestASD |
| PADWIN IFA | Prediction based ADWIN for IForestASD |
| KSWIN | Kolmogorov-Smirnov WINdowing |
| NDKSWIN | N-Dimensional Kolmogorov-Smirnov WINdowing |
| NDKSWIN IFA | NDKSWIN for IForestASD |
References
- Montiel, J.; Read, J.; Bifet, A.; Abdessalem, T. Scikit-Multiflow: A Multi-output Streaming Framework. J. Mach. Learn. Res. 2018, 19, 1–5. [Google Scholar]
- Tan, S.C.; Ting, K.M.; Liu, F.T. Fast Anomaly Detection for Streaming Data. In Proceedings of the Twenty-Second international joint conference on Artificial Intelligence, Catalonia, Spain, 16–22 July 2011. [Google Scholar]
- Ding, Z.; Fei, M. An anomaly detection approach based on isolation forest algorithm for streaming data using sliding window. IFAC Proc. Vol. 2013, 46, 12–17. [Google Scholar] [CrossRef]
- Bifet, A.; Gavaldà, R. Adaptive learning from evolving data streams. In Proceedings of the Intelligent Data Analysis (IDA), Lyon, France, 31August–2 September 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 249–260. [Google Scholar]
- Raab, C.; Heusinger, M.; Schleif, F.M. Reactive Soft Prototype Computing for Concept Drift Streams. arXiv 2020, arXiv:2007.05432. [Google Scholar]
- Aggarwal, C.C.; Philip, S.Y. Aggarwal, C.C.; Philip, S.Y. A survey of synopsis construction in data streams. In Data Streams; Springer: Berlin/Heidelberg, Germany, 2007; pp. 169–207. [Google Scholar]
- Gama, J.; Gaber, M.M. Learning from Data Streams: Processing Techniques in Sensor Networks; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Gama, J.; Žliobaitė, I.; Bifet, A.; Pechenizkiy, M.; Bouchachia, A. A survey on concept drift adaptation. Comput. Surv. (CSUR) 2014, 46, 44. [Google Scholar] [CrossRef]
- Ikonomovska, E.; Loskovska, S.; Gjorgjevik, D. A survey of stream data mining. In Proceedings of the 8th National Conference with International Participation, Philadelphia, PA, USA, 20–23 May 2007; pp. 19–25. [Google Scholar]
- Ng, W.; Dash, M. Discovery of frequent patterns in transactional data streams. In Transactions on Large-Scale Data-and Knowledge-Centered Systems II; Springer: Berlin/Heidelberg, Germany, 2010; pp. 1–30. [Google Scholar]
- Aggarwal, C.C. Data Streams: Models and Algorithms; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2007; Volume 31. [Google Scholar]
- Gomes, H.M.; Read, J.; Bifet, A.; Barddal, J.P.; Gama, J. Machine learning for streaming data: State of the art, challenges, and opportunities. ACM SIGKDD Explor. Newsl. 2019, 21, 6–22. [Google Scholar] [CrossRef]
- Bifet, A.; Holmes, G.; Kirkby, R.; Pfahringer, B. MOA: Massive Online Analysis. J. Mach. Learn. Res. 2010, 11, 1601–1604. [Google Scholar]
- Bifet, A.; Gavaldà, R.; Holmes, G.; Pfahringer, B. Machine Learning for Data Streams with Practical Examples in MOA; MIT Press: Cambridge, MA, USA, 2018; Available online: https://moa.cms.waikato.ac.nz/book/ (accessed on 18 January 2021).
- Bifet, A.; Morales, G.D.F. Big Data Stream Learning with SAMOA. In Proceedings of the 2014 IEEE International Conference on Data Mining Workshop, Shenzhen, China, 14 December 2014; pp. 1199–1202. [Google Scholar] [CrossRef]
- Bifet, A.; Maniu, S.; Qian, J.; Tian, G.; He, C.; Fan, W. StreamDM: Advanced Data Mining in Spark Streaming. In Proceedings of the International Conference on Data Mining Workshops (ICDMW), Atlantic City, NJ, USA, 14–17 November 2015. [Google Scholar] [CrossRef] [Green Version]
- Behera, R.K.; Das, S.; Jena, M.; Rath, S.K.; Sahoo, B. A Comparative Study of Distributed Tools for Analyzing Streaming Data. In Proceedings of the International Conference on Information Technology (ICIT), Singapore, 27–29 December 2017; pp. 79–84. [Google Scholar]
- Inoubli, W.; Aridhi, S.; Mezni, H.; Maddouri, M.; Nguifo, E. A comparative study on streaming frameworks for big data. In Proceedings of the Very Large Data Bases (VLDB), Rio de Janeiro, Brazil, 27–31 August 2018. [Google Scholar]
- Hodge, V.; Austin, J. A survey of outlier detection methodologies. Artif. Intell. Rev. 2004, 22, 85–126. [Google Scholar] [CrossRef] [Green Version]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. (CSUR) 2009, 41, 15. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Outlier Analysis, 2nd ed.; Springer International Publishing AG: Cham, Switzerland, 2017. [Google Scholar] [CrossRef]
- Gupta, M.; Gao, J.; Aggarwal, C.C.; Han, J. Outlier detection for temporal data: A survey. IEEE Trans. Knowl. Data Eng. 2014, 26, 2250–2267. [Google Scholar] [CrossRef]
- Thakkar, P.; Vala, J.; Prajapati, V. Survey on outlier detection in data stream. Int. J. Comput. Appl. 2016, 136, 13–16. [Google Scholar] [CrossRef]
- Tellis, V.M.; D’Souza, D.J. Detecting Anomalies in Data Stream Using Efficient Techniques: A Review. In Proceedings of the 2018 International Conference ICCPCCT, Kerala, India, 23–24 March 2018. [Google Scholar]
- Salehi, M.; Rashidi, L. A survey on anomaly detection in evolving data: [with application to forest fire risk prediction]. ACM SIGKDD Explor. Newsl. 2018, 20, 13–23. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar]
- Yamanishi, K.; Takeuchi, J.I.; Williams, G.; Milne, P. On-line unsupervised outlier detection using finite mixtures with discounting learning algorithms. Data Min. Knowl. Discov. 2004, 8, 275–300. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Han, J.; Wang, J.; Yu, P.S. A framework for clustering evolving data streams. In Proceedings of the 29th International Conference on Very Large Data Bases-Volume 29, VLDB Endowment, Berlin, Germany, 9–12 September 2003; pp. 81–92. [Google Scholar]
- Assent, I.; Kranen, P.; Baldauf, C.; Seidl, T. Anyout: Anytime outlier detection on streaming data. In International Conference on Database Systems for Advanced Applications; Springer: Berlin/Heidelberg, Germany, 2012; pp. 228–242. [Google Scholar]
- Angiulli, F.; Fassetti, F. Detecting distance-based outliers in streams of data. In Proceedings of the Sixteenth ACM Conference on Conference on Information and Knowledge Management, ACM, Lisbon, Portugal, 6–10 November 2007; pp. 811–820. [Google Scholar]
- Pokrajac, D.; Lazarevic, A.; Latecki, L.J. Incremental local outlier detection for data streams. In Proceedings of the 2007 IEEE Symposium on Computational Intelligence and Data Mining, Honolulu, HI, USA, 1–5 April 2007; pp. 504–515. [Google Scholar]
- Togbe, M.U.; Chabchoub, Y.; Boly, A.; Chiky, R. Etude comparative des méthodes de détection d’anomalies. Rev. Des. Nouv. Technol. L’Inf. 2020, RNTI-E-36, 109–120. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation-based anomaly detection. ACM Trans. Knowl. Discov. Data (TKDD) 2012, 6, 3. [Google Scholar] [CrossRef]
- Hariri, S.; Kind, M.C.; Brunner, R.J. Extended Isolation Forest. arXiv 2018, arXiv:1811.02141. [Google Scholar] [CrossRef] [Green Version]
- Staerman, G.; Mozharovskyi, P.; Clémençon, S.; d’Alché Buc, F. Functional Isolation Forest. arXiv 2019, arXiv:stat.ML/1904.04573. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. On detecting clustered anomalies using SCiForest. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Barcelona, Spain, 20–24 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 274–290. [Google Scholar]
- Marteau, P.F.; Soheily-Khah, S.; Béchet, N. Hybrid Isolation Forest-Application to Intrusion Detection. arXiv 2017, arXiv:1705.03800. [Google Scholar]
- Cortes, D. Distance approximation using isolation forests. arXiv 2019, arXiv:1910.12362. [Google Scholar]
- Liao, L.; Luo, B. Entropy isolation forest based on dimension entropy for anomaly detection. In Proceedings of the International Symposium on Intelligence Computation and Applications, Guangzhou, China, 16–17 November 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 365–376. [Google Scholar]
- Zhang, X.; Dou, W.; He, Q.; Zhou, R.; Leckie, C.; Kotagiri, R.; Salcic, Z. LSHiForest: A generic framework for fast tree isolation based ensemble anomaly analysis. In Proceedings of the 2017 IEEE 33rd International Conference on Data Engineering (ICDE), San Diego, CA, USA, 19–22 April 2017; pp. 983–994. [Google Scholar]
- Xu, D.; Wang, Y.; Meng, Y.; Zhang, Z. An Improved Data Anomaly Detection Method Based on Isolation Forest. In Proceedings of the2017 10th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 9–10 December 2017; Volume 2, pp. 287–291. [Google Scholar]
- Bandaragoda, T.R.; Ting, K.M.; Albrecht, D.; Liu, F.T.; Zhu, Y.; Wells, J.R. Isolation-based anomaly detection using nearest-neighbor ensembles. Comput. Intell. 2018, 34, 968–998. [Google Scholar] [CrossRef]
- Bifet, A.; Gavalda, R. Learning from time-changing data with adaptive windowing. In Proceedings of the 2007 SIAM International Conference on Data Mining, SIAM, Minneapolis, MN, USA, 26–28 April 2007; pp. 443–448. [Google Scholar]
- Gomes, H.M.; Barddal, J.P.; Enembreck, F.; Bifet, A. A survey on ensemble learning for data stream classification. Comput. Surv. (CSUR) 2017, 50, 23. [Google Scholar] [CrossRef]
- Massey, F.J., Jr. The Kolmogorov-Smirnov test for goodness of fit. J. Am. Stat. Assoc. 1951, 46, 68–78. [Google Scholar] [CrossRef]
- Lopes, R.H.C. Kolmogorov-Smirnov Test. In International Encyclopedia of Statistical Science; Lovric, M., Ed.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 718–720. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI Machine Learning Repository; UCI: Irvine, CA, USA, 2017. [Google Scholar]
- Street, W.N.; Kim, Y. A streaming ensemble algorithm (SEA) for large-scale classification. In Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 26–29 August 2001; pp. 377–382. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approaches | Advantages | Disadvantages |
|---|---|---|
| Statistics-based | Non-parametric methods are adapted to data stream context |
|
| Nearest-neighbors | Distance-based methods
| Distance-based methods
|
Density-based methods
| Density-based methods
| |
| Clustering-based | Adapted for clusters identification | Not optimized for individual anomaly identification |
| Isolation-based |
|
|
| Shuttle | Forest-Cover | SMTP | SEA | |
|---|---|---|---|---|
| Attributes, Number of features | 9 | 10 | 3 | 3 |
| u—Drift Rate = Anomaly rate | 7.15% | 0.96% | 0.03% | 0.1% |
| Number of samples | 49,097 | 286,048 | 95,156 | 10,000 |
| W—Window size range | [50, 100, 500, 1000] | |||
| T—Number of Trees | [30, 50, 100] |
| Forest Cover | Shuttle | SMTP | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Time | Size | 1 | Time | Size | 1 | Time | Size | |||||
| HST | IFA | IRa | HRa | HST | IFA | IRa | HRa | HST | IFA | IRa | HRa | ||
| 50 | 30 | 0.36 | 0.22 | 3 | 702 | 0.13 | 0.64 | 3 | 817 | 0 | 0.34 | 3 | 926 |
| 50 | 50 | 0.36 | 0.23 | 3 | 694 | 0.13 | 0.64 | 3 | 854 | 0 | 0.34 | 3 | 940 |
| 50 | 100 | 0.36 | 0.22 | 3 | 737 | 0.13 | 0.64 | 3 | 950 | 0 | 0.34 | 3 | 986 |
| 100 | 30 | 0.39 | 0.30 | 12 | 367 | 0.14 | 0.71 | 12 | 461 | 0 | 0.36 | 9 | 596 |
| 100 | 50 | 0.39 | 0.29 | 12 | 404 | 0.13 | 0.72 | 14 | 505 | 0 | 0.36 | 9 | 734 |
| 100 | 100 | 0.39 | 0.30 | 12 | 416 | 0.13 | 0.71 | 16 | 551 | 0 | 0.36 | 9 | 808 |
| 500 | 30 | 0.39 | 0.49 | 158 | 108 | 0.14 | 0.80 | 519 | 28 | 0 | 0.39 | 106 | 288 |
| 500 | 50 | 0.39 | 0.47 | 152 | 129 | 0.13 | 0.80 | 393 | 36 | 0 | 0.40 | 111 | 372 |
| 500 | 100 | 0.39 | 0.47 | 156 | 140 | 0.15 | 0.80 | 363 | 92 | 0 | 0.40 | 111 | 434 |
| 1000 | 30 | 0.54 | 0.40 | 372 | 63 | 0.17 | 0.78 | 1757 | 21 | 0 | 0.39 | 264 | 127 |
| 1000 | 50 | 0.54 | 0.40 | 387 | 74 | 0.14 | 0.78 | 1175 | 28 | 0 | 0.39 | 272 | 155 |
| 1000 | 100 | 0.55 | 0.40 | 391 | 86 | 0.14 | 0.77 | 1678 | 23 | 0 | 0.39 | 272 | 176 |
| Shuttle | SMTP | SEA | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metrics | W | IFA | SAd | PAd | KSi | IFA | SAd | PAd | KSi | IFA | SAd | PAd | KSi |
| 1 | 100 | 0.72 | 0.74 | 0.73 | 0.70 | 0.37 | 0.33 | 0.33 | 0.34 | 0.41 | 0.39 | 0.42 | 0.41 |
| 500 | 0.80 | 0.81 | 0.80 | 0.80 | 0.41 | 0.40 | 0.39 | 0.39 | 0.39 | 0.40 | 0.39 | 0.38 | |
| Model updated | 100 | 0 | 0 | 0 | 3 | 88 | 6 | 10 | 11 | 99 | 0 | 0 | 7 |
| 500 | 0 | 0 | 0 | 2 | 15 | 3 | 5 | 2 | 19 | 0 | 0 | 2 | |
| Time Ratio | 100 | - | 0.99 | 1.01 | 1.05 | - | 1.09 | 1.03 | 1.08 | - | 1.03 | 1.05 | 1.05 |
| 500 | - | 1.00 | 1.00 | 1.00 | - | 1.07 | 1.09 | 1.10 | - | 1.01 | 1.02 | 1.02 | |
| Size Ratio | 100 | - | 0.94 | 0.97 | 0.94 | - | 1.32 | 1.12 | 1.24 | - | 0.96 | 0.93 | 1.06 |
| 500 | - | 0.97 | 0.98 | 0.98 | - | 0.89 | 1.39 | 1.31 | - | 0.98 | 0.96 | 1.03 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Togbe, M.U.; Chabchoub, Y.; Boly, A.; Barry, M.; Chiky, R.; Bahri, M. Anomalies Detection Using Isolation in Concept-Drifting Data Streams . Computers 2021, 10, 13. https://doi.org/10.3390/computers10010013
Togbe MU, Chabchoub Y, Boly A, Barry M, Chiky R, Bahri M. Anomalies Detection Using Isolation in Concept-Drifting Data Streams . Computers. 2021; 10(1):13. https://doi.org/10.3390/computers10010013
Chicago/Turabian StyleTogbe, Maurras Ulbricht, Yousra Chabchoub, Aliou Boly, Mariam Barry, Raja Chiky, and Maroua Bahri. 2021. "Anomalies Detection Using Isolation in Concept-Drifting Data Streams " Computers 10, no. 1: 13. https://doi.org/10.3390/computers10010013
APA StyleTogbe, M. U., Chabchoub, Y., Boly, A., Barry, M., Chiky, R., & Bahri, M. (2021). Anomalies Detection Using Isolation in Concept-Drifting Data Streams . Computers, 10(1), 13. https://doi.org/10.3390/computers10010013