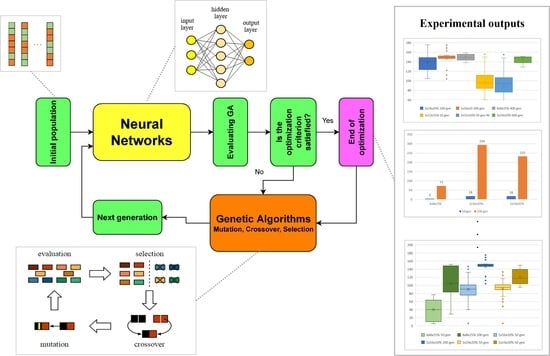
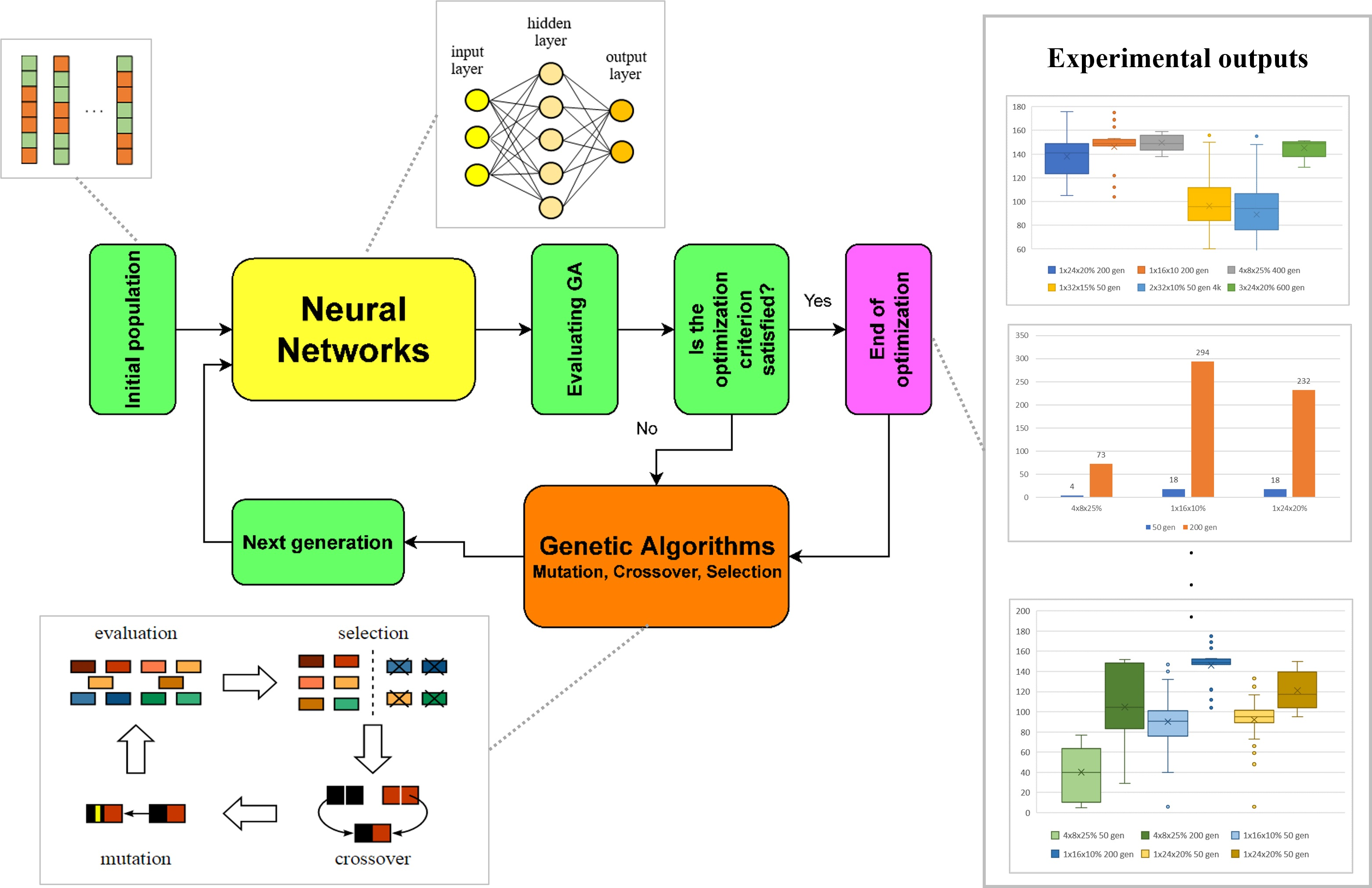
Figure 1.
The schematic process flow.
Figure 1.
The schematic process flow.
Figure 2.
Achieved score according to the number of layers, mutation 5%.
Figure 2.
Achieved score according to the number of layers, mutation 5%.
Figure 3.
Achieved score according to the number of neurons, two hidden layers, mutation 5%.
Figure 3.
Achieved score according to the number of neurons, two hidden layers, mutation 5%.
Figure 4.
Achieved score according to the number of neurons, one hidden layer, mutation 5%.
Figure 4.
Achieved score according to the number of neurons, one hidden layer, mutation 5%.
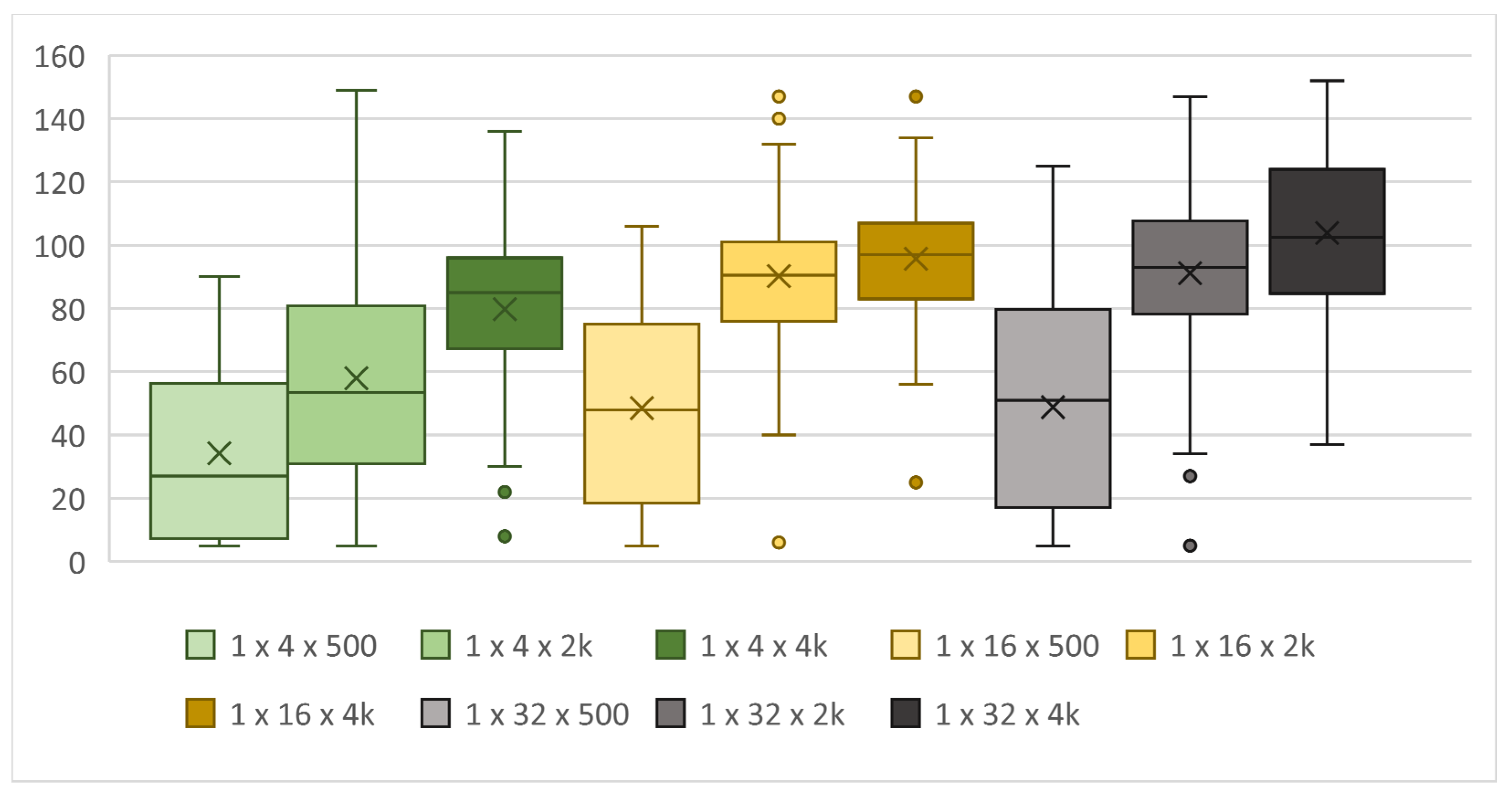
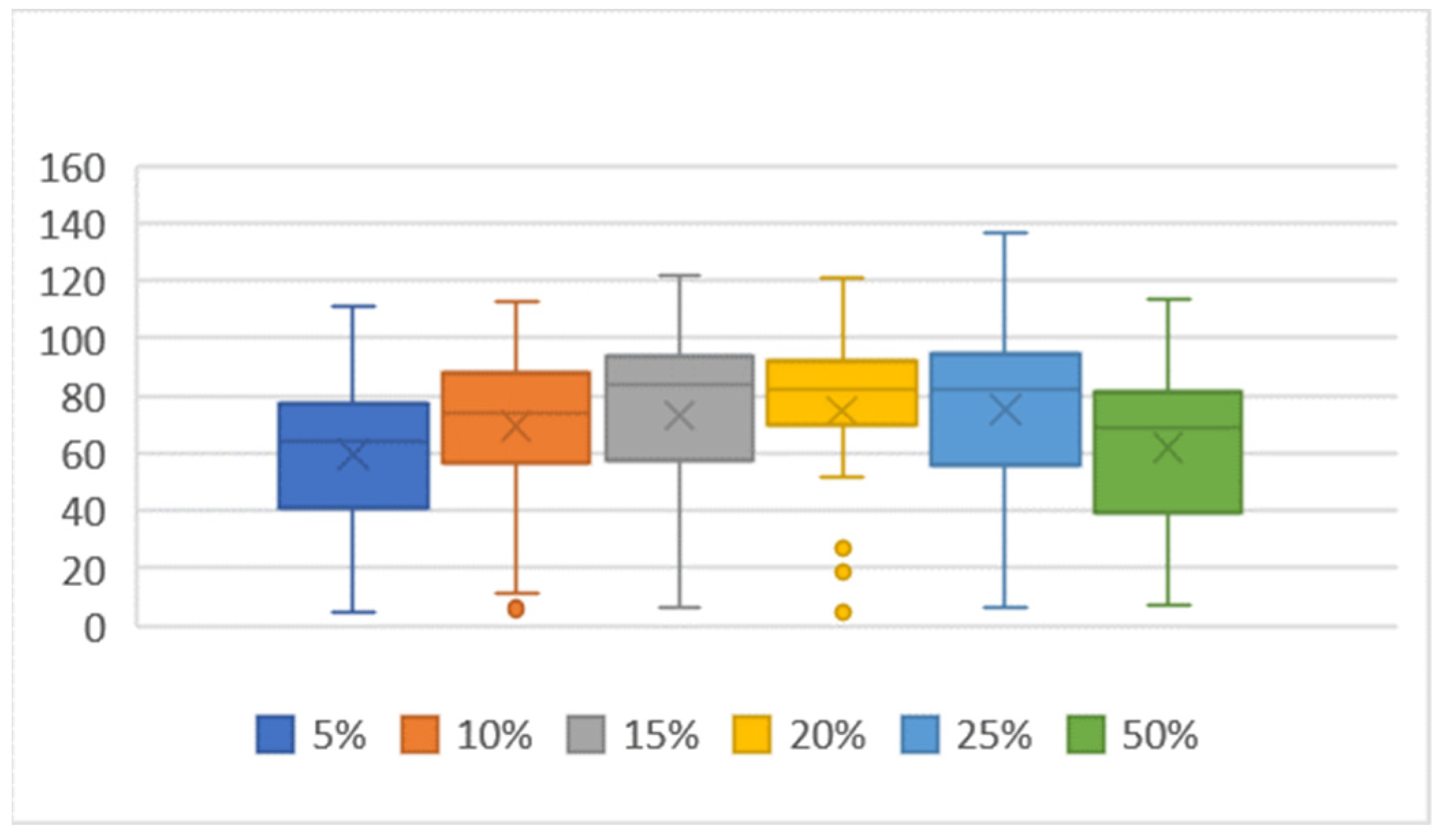
Figure 5.
Achieved score according to the number of neurons, two hidden layers, mutation 5%.
Figure 5.
Achieved score according to the number of neurons, two hidden layers, mutation 5%.
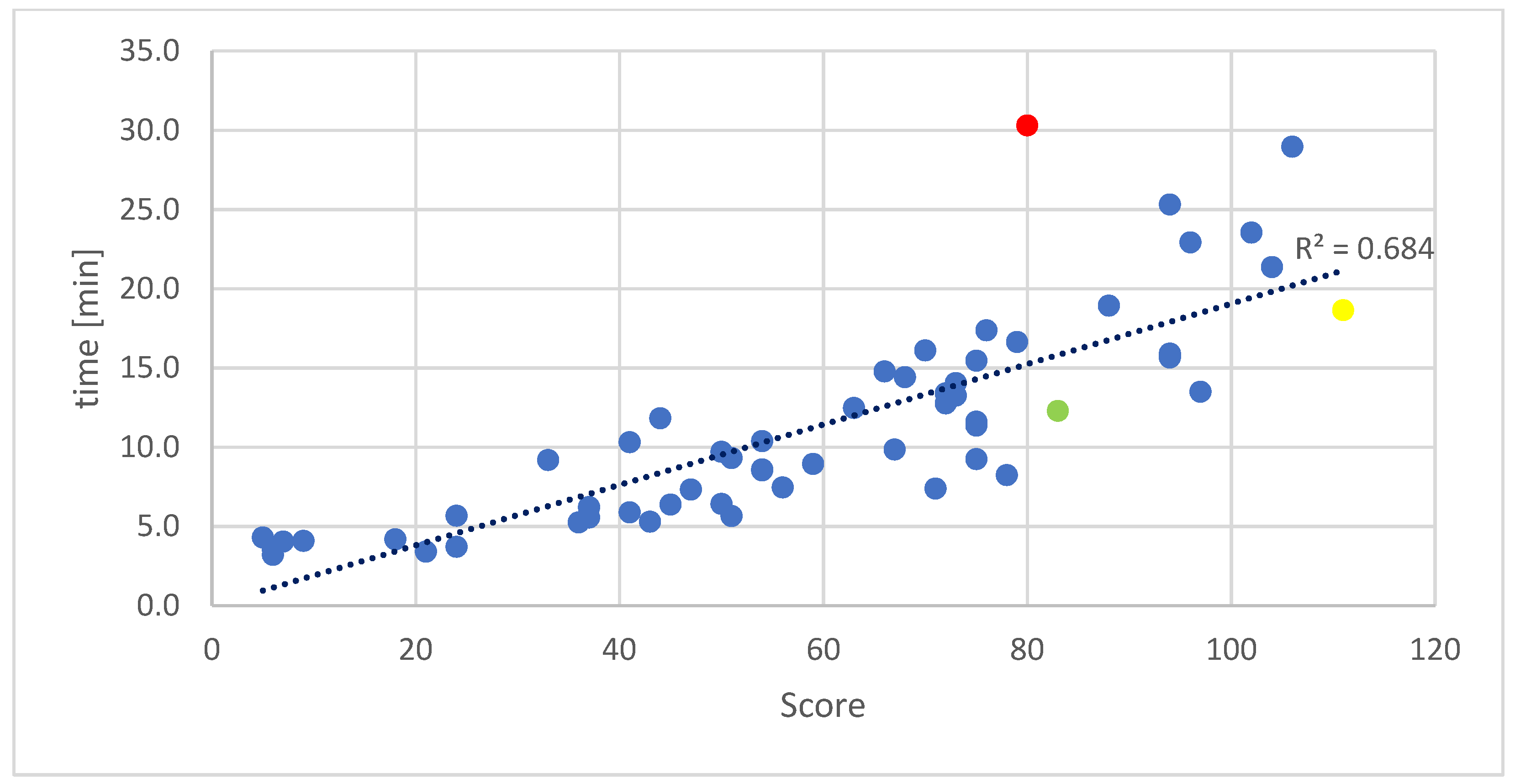
Figure 6.
Time required to compute evolutions according to the achieved score, 2 × 16, mutation 5%. Individuals that are able to achieve high scores in early generations are marked in red, green and yellow.
Figure 6.
Time required to compute evolutions according to the achieved score, 2 × 16, mutation 5%. Individuals that are able to achieve high scores in early generations are marked in red, green and yellow.
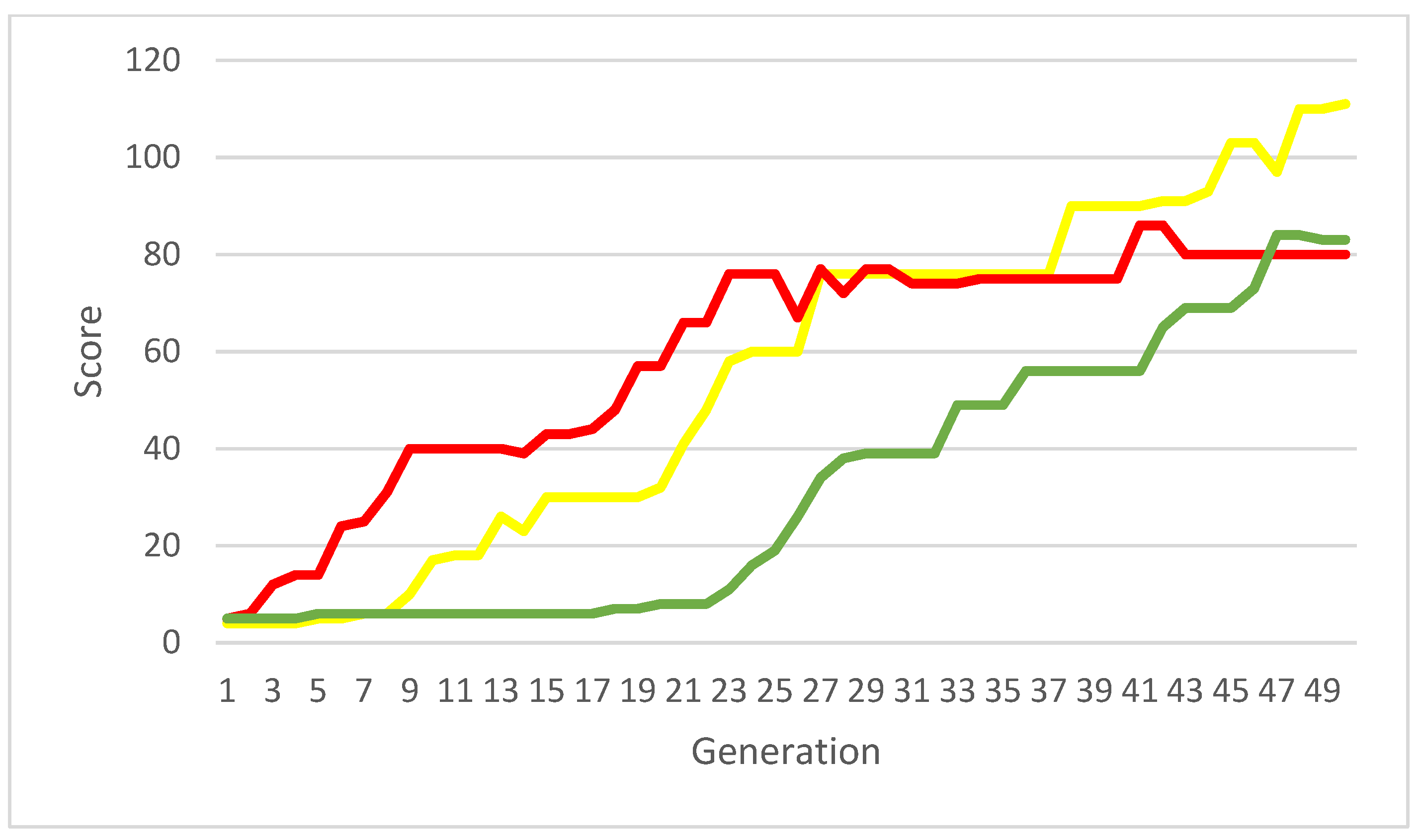
Figure 7.
Evolution of selected measurements in generations from
Figure 6.
Figure 7.
Evolution of selected measurements in generations from
Figure 6.
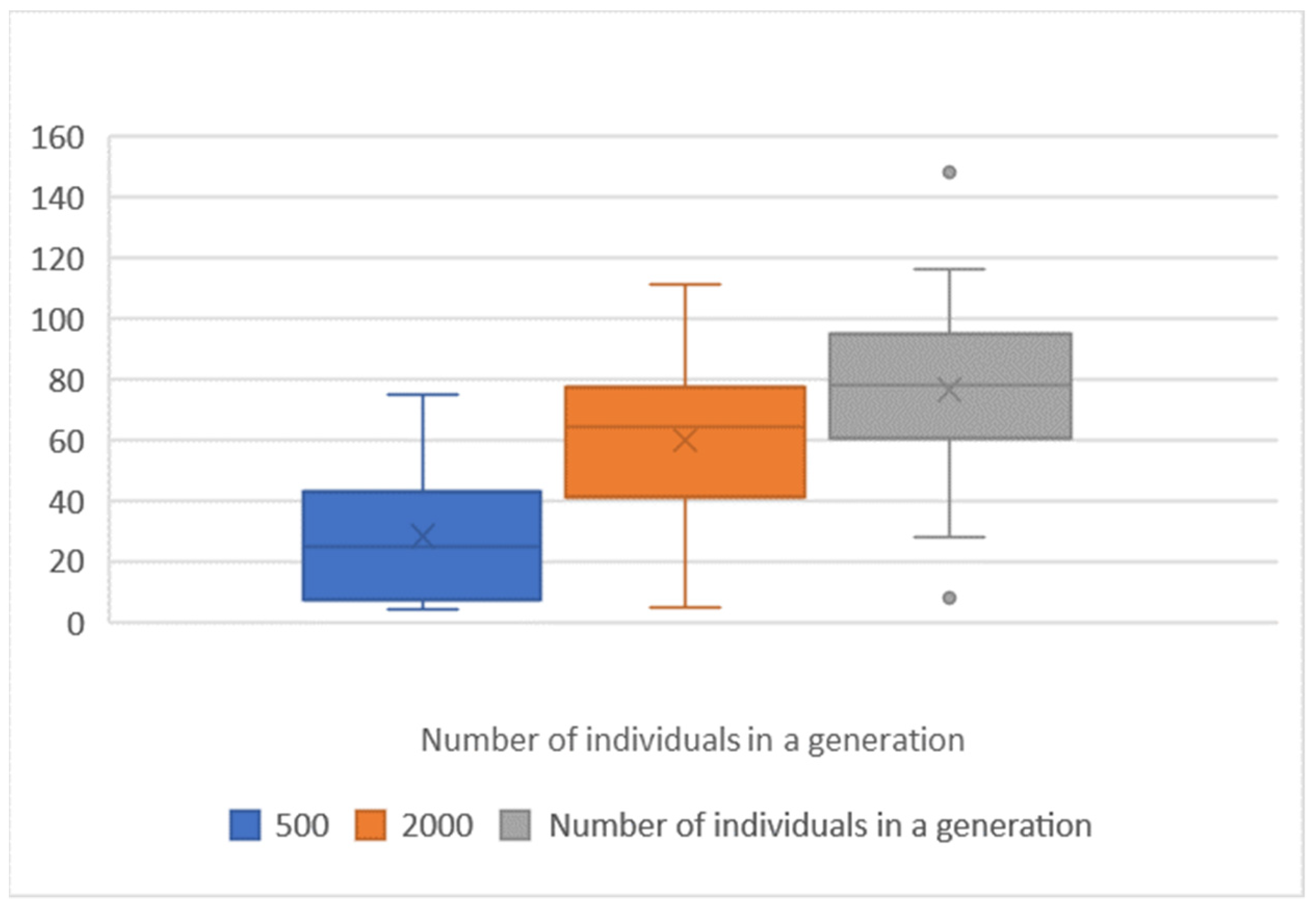
Figure 8.
Achieved score according to the number of individuals in the generation, topology 2 × 16, mutation 5%.
Figure 8.
Achieved score according to the number of individuals in the generation, topology 2 × 16, mutation 5%.
Figure 9.
Time in hours necessary to compute 60 evolutions based on the number of individuals in the generation, topology 2 × 16, mutation 5%.
Figure 9.
Time in hours necessary to compute 60 evolutions based on the number of individuals in the generation, topology 2 × 16, mutation 5%.
Figure 10.
Influence of the number of individuals on the achieved score in topologies with one hidden layer, mutation 10%.
Figure 10.
Influence of the number of individuals on the achieved score in topologies with one hidden layer, mutation 10%.
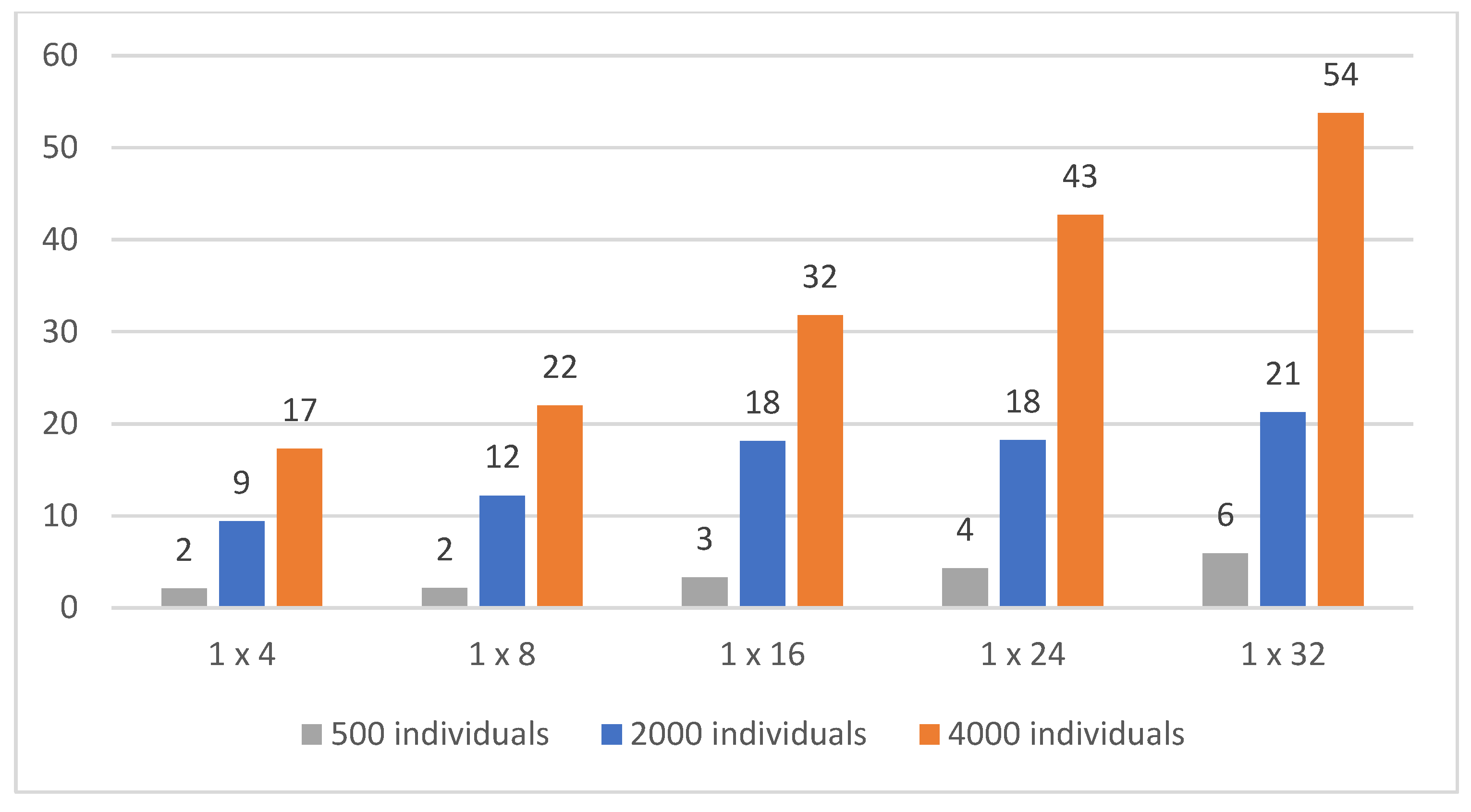
Figure 11.
Time in hours necessary for the computation based on the number of individuals, one hidden layer.
Figure 11.
Time in hours necessary for the computation based on the number of individuals, one hidden layer.
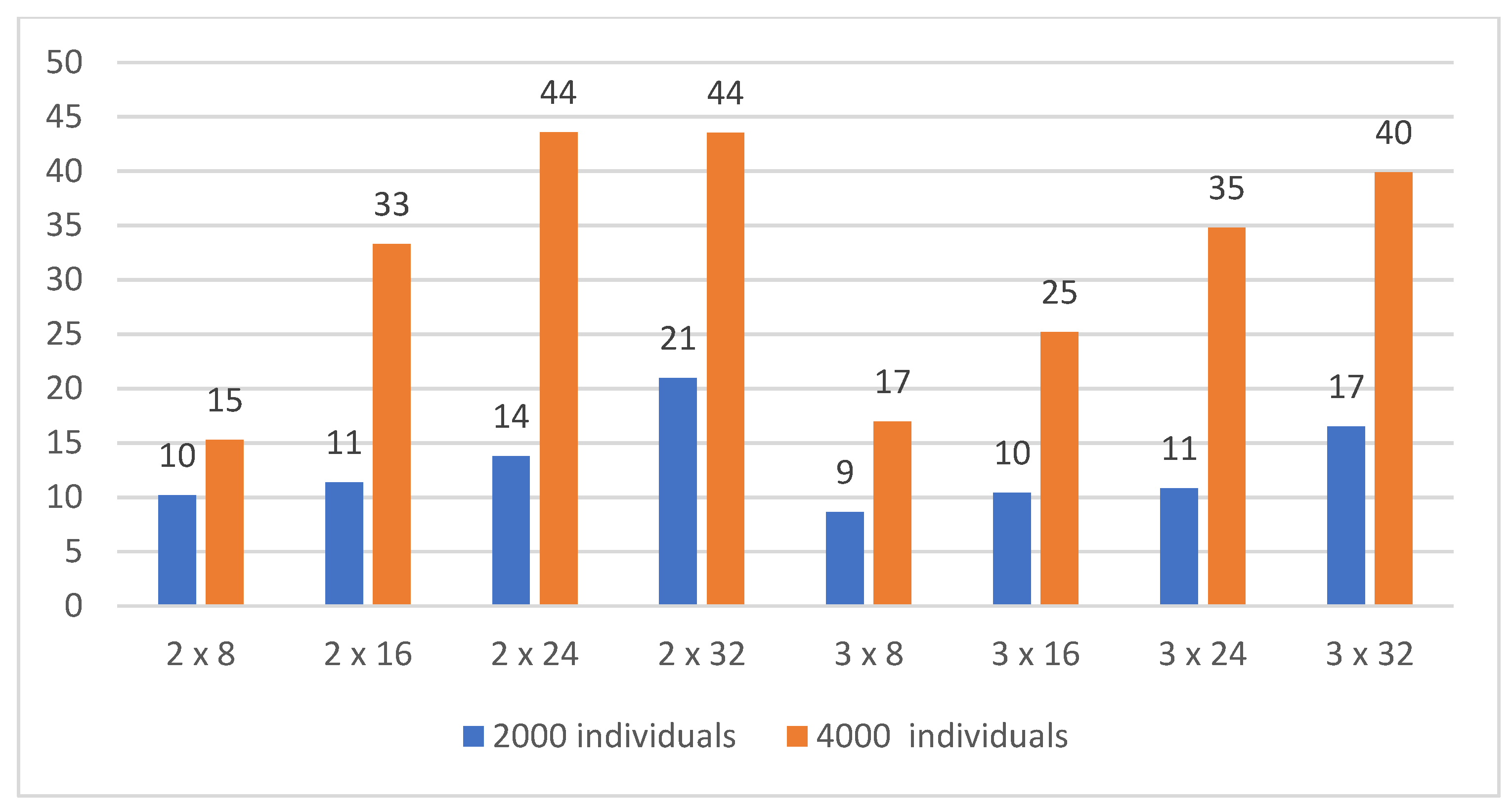
Figure 12.
Time in hours necessary for the computation based on the number of individuals, two and three hidden layers.
Figure 12.
Time in hours necessary for the computation based on the number of individuals, two and three hidden layers.
Figure 13.
Influence of the number of individuals on the achieved score in a topology with two hidden layers, mutation 10%.
Figure 13.
Influence of the number of individuals on the achieved score in a topology with two hidden layers, mutation 10%.
Figure 14.
Influence of the number of individuals on the achieved score in a topology with three hidden layers, mutation 10%.
Figure 14.
Influence of the number of individuals on the achieved score in a topology with three hidden layers, mutation 10%.
Figure 15.
Influence of the 2 × 16 topology.
Figure 15.
Influence of the 2 × 16 topology.
Figure 16.
Influence of mutation on the achieved results, 1 × 16 topology.
Figure 16.
Influence of mutation on the achieved results, 1 × 16 topology.
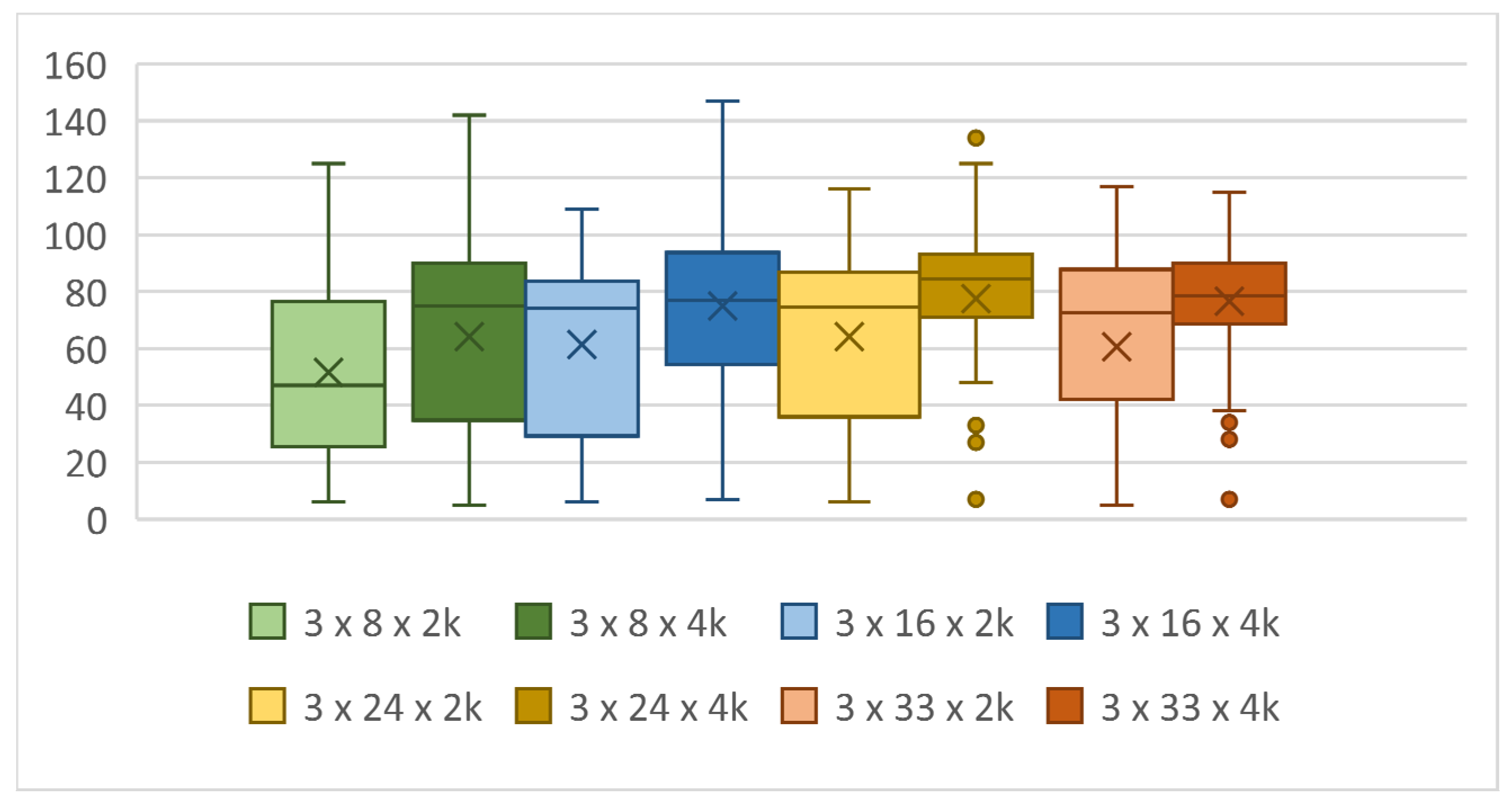
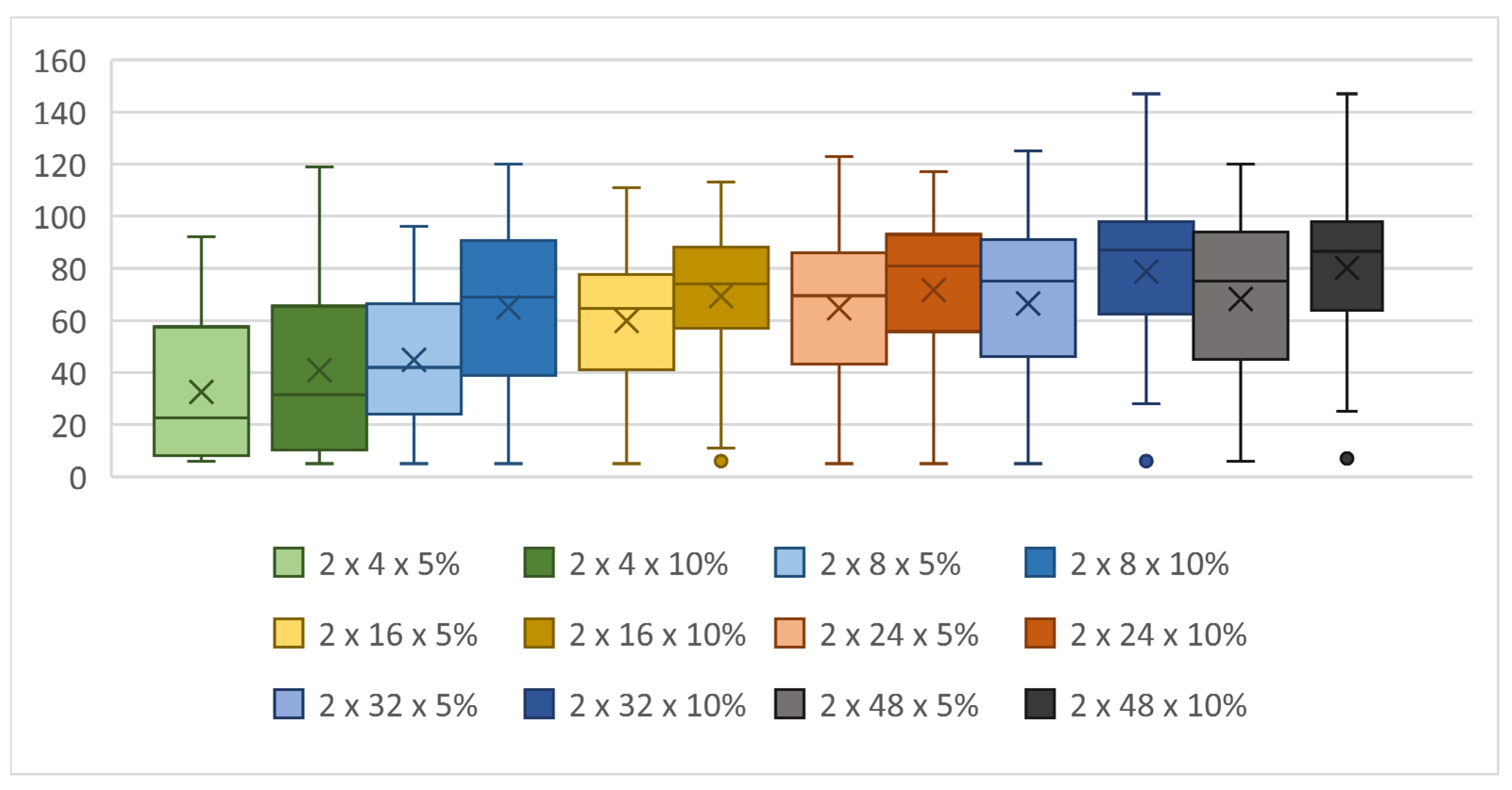
Figure 17.
Achieved score based on a mutation in topologies with two hidden layers.
Figure 17.
Achieved score based on a mutation in topologies with two hidden layers.
Figure 18.
Computation time of topologies with two hidden layers based on the mutation level.
Figure 18.
Computation time of topologies with two hidden layers based on the mutation level.
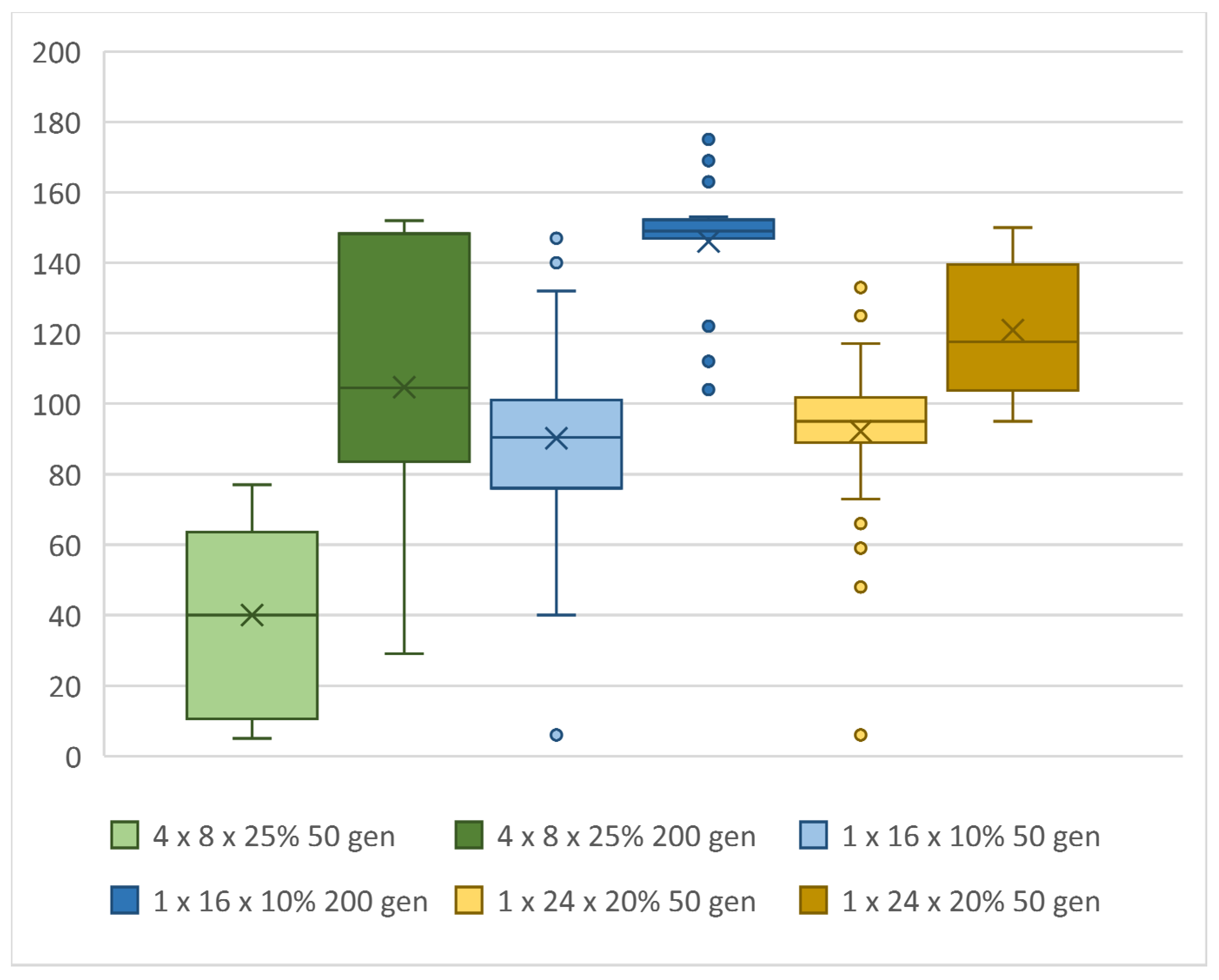
Figure 19.
Influence of the number of generations in the evolution of the final score.
Figure 19.
Influence of the number of generations in the evolution of the final score.
Figure 20.
Time in minutes necessary to train an NN based on the number of generations in the evolution.
Figure 20.
Time in minutes necessary to train an NN based on the number of generations in the evolution.
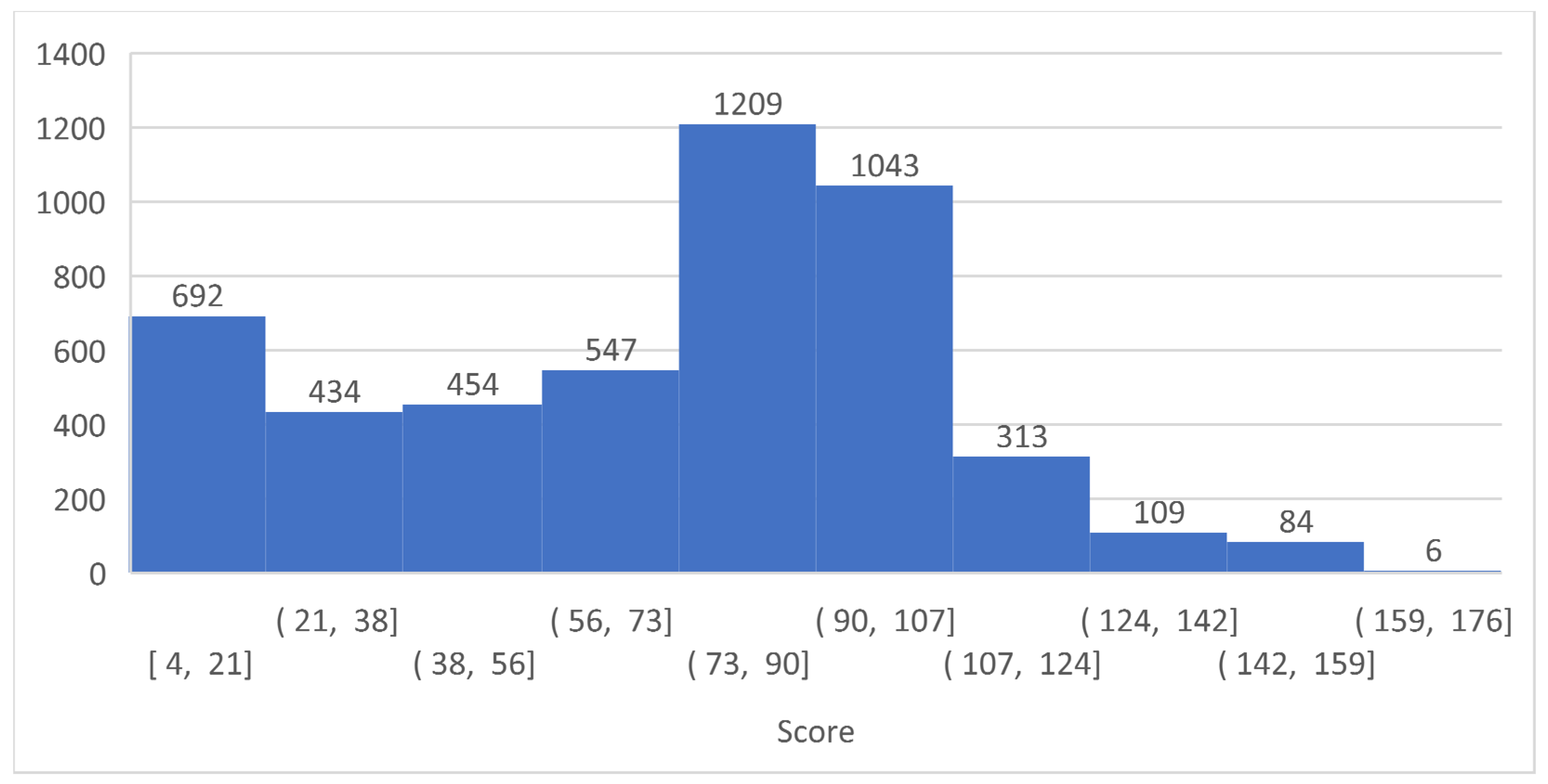
Figure 21.
Frequency of the achieved results of evolutions of all topologies.
Figure 21.
Frequency of the achieved results of evolutions of all topologies.
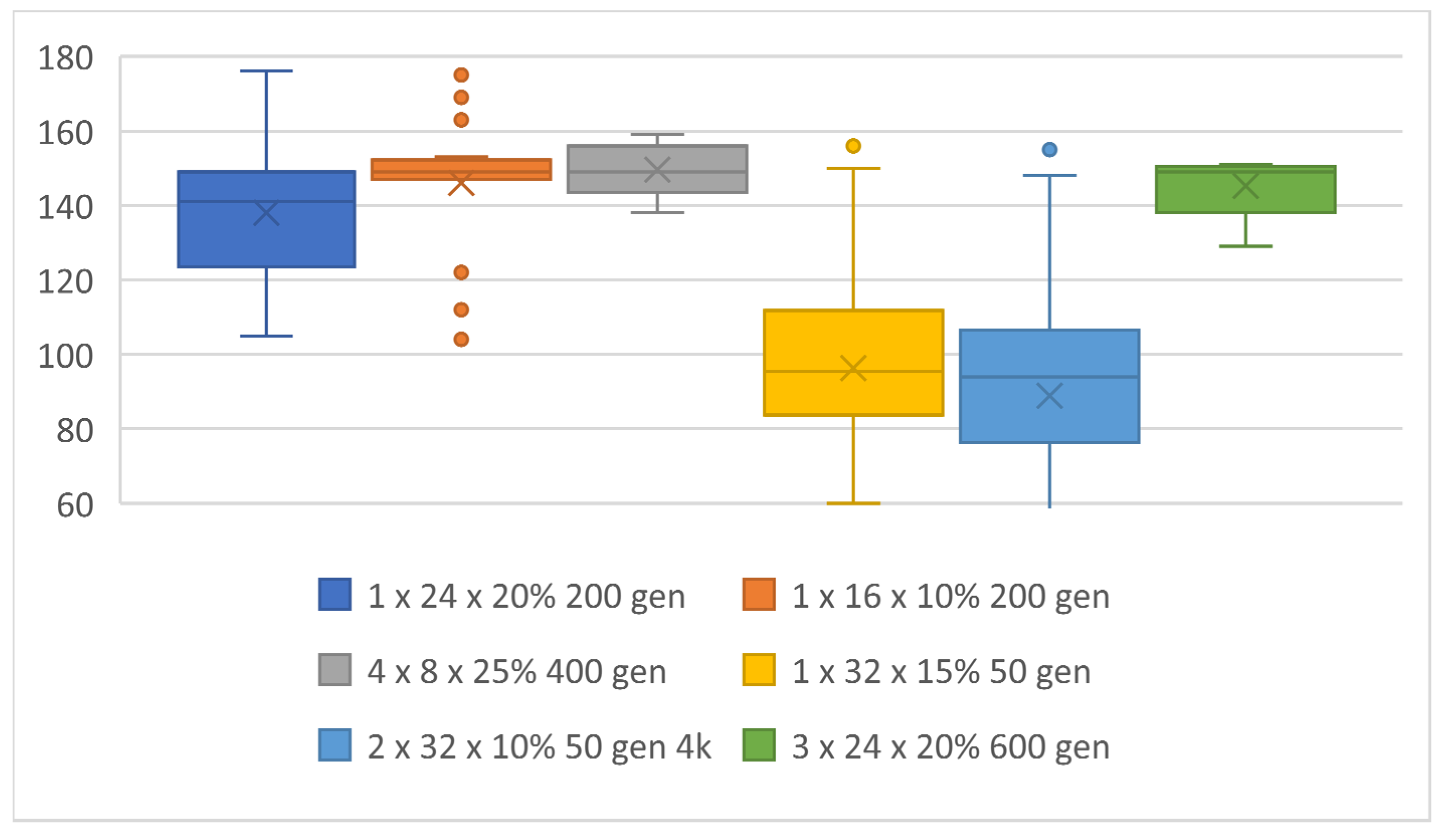
Figure 22.
Topologies with individuals that achieved the top-six best scores.
Figure 22.
Topologies with individuals that achieved the top-six best scores.
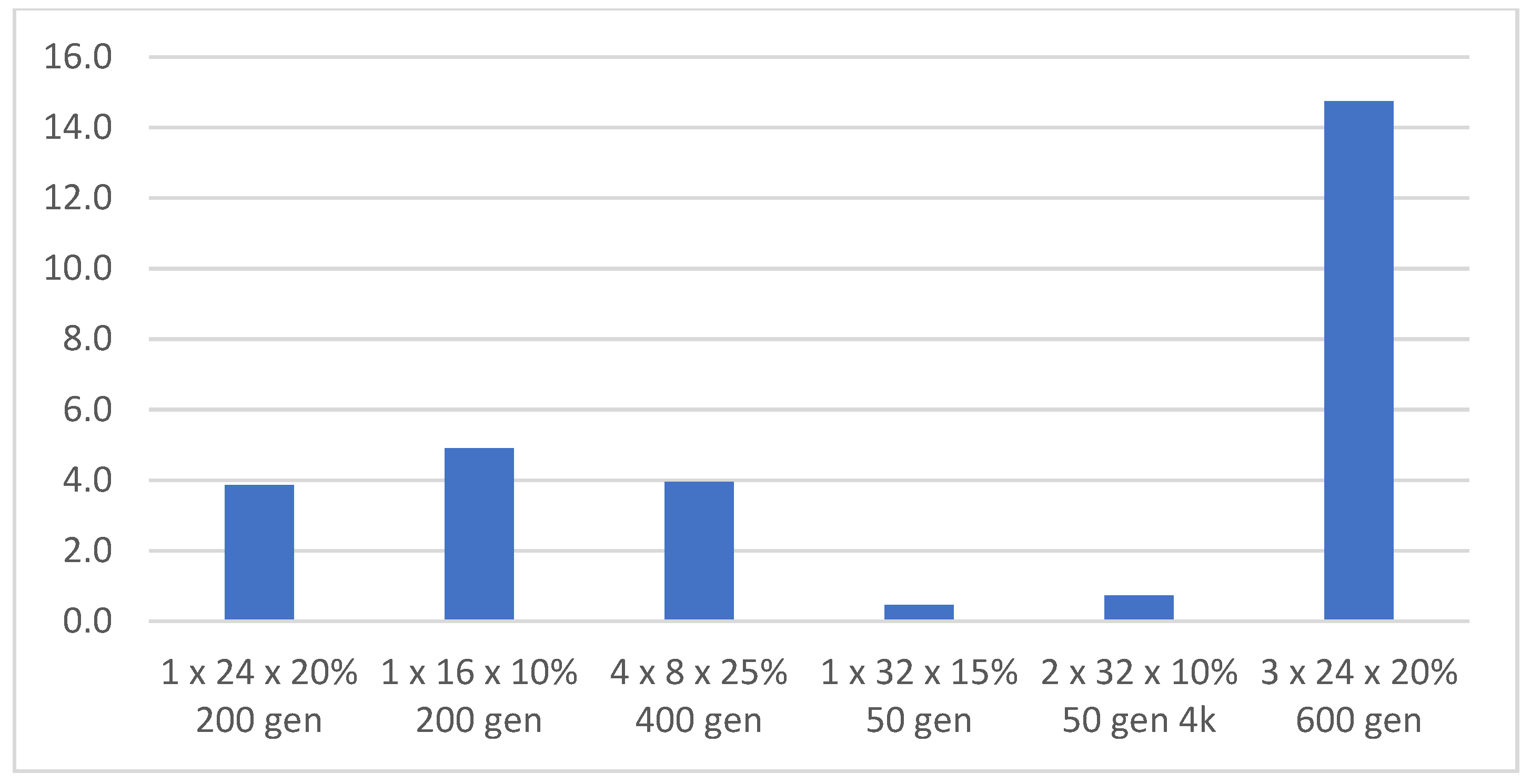
Figure 23.
Time in hours necessary to train one evolution, top score.
Figure 23.
Time in hours necessary to train one evolution, top score.
Table 1.
Achieved score according to the number of layers, each of 16 neurons, mutation 5%.
Table 1.
Achieved score according to the number of layers, each of 16 neurons, mutation 5%.
| Topology: | 1 × 16 | 2 × 16 | 3 × 16 | 4 × 16 |
|---|
| Max score: | 142 | 111 | 123 | 98 |
| Min score: | 5 | 5 | 6 | 6 |
| Average: | 72 | 60 | 49 | 41 |
| Median: | 75.5 | 64.5 | 52 | 27 |
| 25th percentile: | 51 | 41 | 23 | 11 |
| 75th percentile: | 96 | 77 | 73 | 74 |
| Total processing time [h] | 17 | 11 | 11 | 4 |
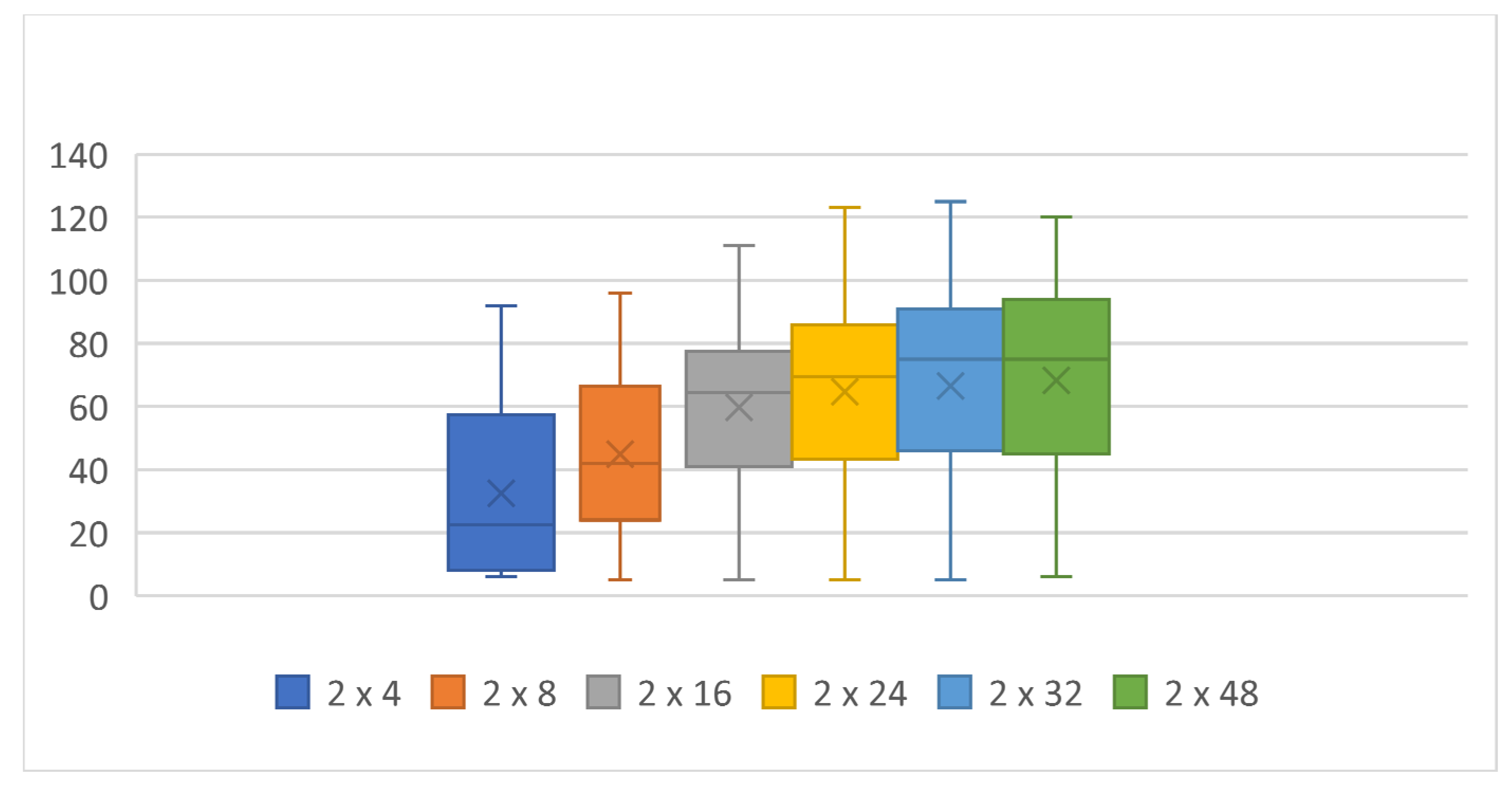
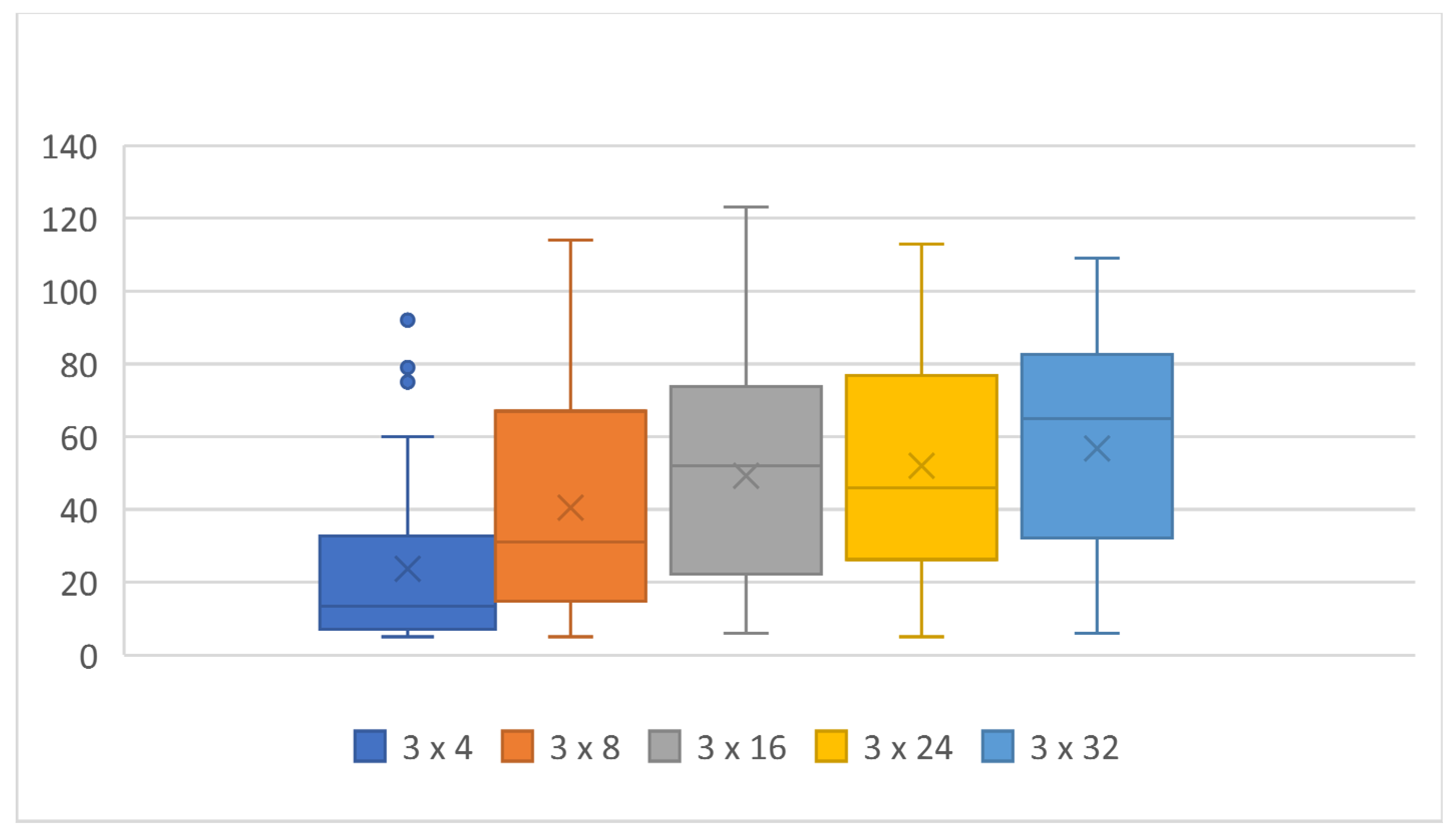
Table 2.
Achieved score according to the number of neurons, two hidden layers, mutation 5%.
Table 2.
Achieved score according to the number of neurons, two hidden layers, mutation 5%.
| Topology: | 1 × 4 | 1 × 8 | 1 × 16 | 1 × 24 | 1 × 32 | 1 × 48 | 2 × 4 | 2 × 8 | 2 × 16 | 2 × 24 | 2 × 32 | 2 × 48 | 3 × 4 | 3 × 8 | 3 × 16 | 3 × 24 | 3 × 32 |
|---|
| Max score: | 99 | 117 | 142 | 130 | 128 | 140 | 92 | 96 | 111 | 123 | 125 | 120 | 92 | 114 | 123 | 113 | 109 |
| Min score: | 6 | 7 | 5 | 6 | 6 | 6 | 6 | 5 | 5 | 5 | 5 | 6 | 5 | 5 | 6 | 5 | 6 |
| Average: | 54 | 60 | 72 | 82 | 76 | 87 | 33 | 45 | 60 | 65 | 67 | 68 | 24 | 41 | 49 | 52 | 57 |
| Median | 53 | 63 | 75.5 | 81 | 80 | 91.5 | 22.5 | 42 | 64.5 | 69.5 | 75 | 75 | 13.5 | 31 | 52 | 46 | 65 |
| 25th percentile | 33 | 35 | 51 | 71 | 59 | 77 | 8 | 24 | 41 | 46 | 46 | 47 | 7 | 16 | 23 | 27 | 33 |
| 75th percentile | 75 | 82 | 96 | 97 | 98 | 101 | 57 | 66 | 77 | 86 | 91 | 94 | 32 | 65 | 73 | 76 | 82 |
| Time [h] | 9 | 13 | 17 | 16 | 25 | 30 | 6 | 8 | 11 | 14 | 16 | 29 | 4 | 8 | 11 | 12 | 14 |
Table 3.
Kruskal–Wallis Test for data distribution normality.
Table 3.
Kruskal–Wallis Test for data distribution normality.
| Factor | Statistic | df | p |
|---|
| Topology | 14.621 | 2 | <0.001 |
Table 4.
Dunn Post Hoc comparison test–Topologies.
Table 4.
Dunn Post Hoc comparison test–Topologies.
| Comparison | z | Wi | Wj | p | pbonf | pholm |
|---|
| 1 × 16–2 × 16 | 2.064 | 109.150 | 89.525 | 0.020 | 0.059 | 0.039 |
| 1 × 16–3 × 16 | 3.820 | 109.150 | 72.825 | <0.001 | <0.001 | <0.001 |
| 2 × 16–3 × 16 | 1.756 | 89.525 | 72.825 | 0.040 | 0.119 | 0.040 |
Table 5.
Achieved score according to the number of individuals in the generation, topology 2 × 16, mutation 5%.
Table 5.
Achieved score according to the number of individuals in the generation, topology 2 × 16, mutation 5%.
| Topology: | 2 × 16 | 2 × 16 | 2 × 16 |
|---|
| Individuals in a generation | 500 | 2000 | 4000 |
| Max score: | 75 | 111 | 149 |
| Min score: | 4 | 5 | 8 |
| Average: | 28 | 60 | 76 |
| Median: | 24.5 | 64.5 | 78 |
| 25th percentile: | 7 | 41 | 64 |
| 75th percentile: | 42 | 77 | 94 |
| Total processing time [h] | 2 | 11 | 24 |
Table 6.
Influence of the number of individuals on the achieved score in topologies with one hidden layer, mutation 10%.
Table 6.
Influence of the number of individuals on the achieved score in topologies with one hidden layer, mutation 10%.
| Topology: | 1 × 4 | 1 × 4 | 1 × 4 | 1 × 16 | 1 × 16 | 1 × 16 | 1 × 32 | 1 × 32 | 1 × 32 |
|---|
| Number of individuals: | 500 | 2000 | 4000 | 500 | 2000 | 4000 | 500 | 2000 | 4000 |
| Max score: | 90 | 149 | 136 | 106 | 147 | 147 | 125 | 147 | 152 |
| Min score: | 5 | 5 | 8 | 5 | 6 | 25 | 5 | 5 | 37 |
| Average: | 34 | 58 | 80 | 49 | 90 | 96 | 49 | 91 | 104 |
| Median: | 27 | 53.5 | 85 | 48 | 90.5 | 97 | 51 | 93 | 102.5 |
| 25th percentile: | 8 | 31 | 70 | 20 | 76 | 83 | 17 | 79 | 88 |
| 75th percentile: | 55 | 80 | 96 | 75 | 101 | 107 | 79 | 107 | 122 |
| Total processing time [h] | 2 | 9 | 17 | 3 | 18 | 32 | 6 | 21 | 54 |
Table 7.
Influence of mutation on the achieved results, topologies 1 × 16 and 2 × 16.
Table 7.
Influence of mutation on the achieved results, topologies 1 × 16 and 2 × 16.
| Topology: | 1 × 16 | 1 × 16 | 1 × 16 | 1 × 16 | 1 × 16 | 2 × 16 | 2 × 16 | 2 × 16 | 2 × 16 | 2 × 16 | 2 × 16 |
|---|
| Mutation: | 5% | 10% | 15% | 20% | 25% | 5% | 10% | 15% | 20% | 25% | 50% |
|---|
| Max score: | 142 | 147 | 150 | 150 | 156 | 111 | 113 | 122 | 121 | 137 | 114 |
| Min score: | 5 | 6 | 6 | 6 | 6 | 5 | 6 | 6 | 5 | 6 | 7 |
| Average: | 72 | 90 | 88 | 93 | 91 | 60 | 69 | 73 | 75 | 75 | 62 |
| Median: | 75.5 | 90.5 | 89 | 96 | 94 | 64.5 | 74 | 83.5 | 82.5 | 82.5 | 69 |
| 25th percentile: | 51 | 76 | 76 | 89 | 77 | 41 | 57 | 58 | 70 | 62 | 41 |
| 75th percentile: | 96 | 101 | 98 | 105 | 105 | 77 | 87 | 94 | 91 | 94 | 81 |
| Total processing time [h] | 17 | 18 | 16 | 19 | 17 | 11 | 11 | 13 | 13 | 12 | 7 |
Table 8.
Achieved score based on a mutation in topologies with two hidden layers.
Table 8.
Achieved score based on a mutation in topologies with two hidden layers.
| Topology: | 2 × 4 | 2 × 4 | 2 × 8 | 2 × 8 | 2 × 16 | 2 × 16 |
|---|
| Mutation: | 5% | 10% | 5% | 10% | 5% | 10% |
|---|
| Max score: | 92 | 119 | 96 | 120 | 111 | 113 |
| Min score: | 6 | 5 | 5 | 5 | 5 | 6 |
| Average: | 33 | 41 | 45 | 65 | 60 | 69 |
| Median: | 22.5 | 31.5 | 42 | 69 | 64.5 | 74 |
| 25th percentile: | 8 | 13 | 24 | 40 | 41 | 57 |
| 75th percentile: | 57 | 65 | 66 | 90 | 77 | 87 |
| Total processing time [h] | 6 | 5 | 8 | 10 | 11 | 11 |
| Topology: | 2 × 24 | 2 × 24 | 2 × 32 | 2 × 32 | 2 × 48 | 2 × 48 |
| Mutation: | 5% | 10% | 5% | 10% | 5% | 10% |
| Max score: | 123 | 117 | 125 | 147 | 120 | 147 |
| Min score: | 5 | 5 | 5 | 6 | 6 | 7 |
| Average: | 65 | 72 | 67 | 79 | 68 | 80 |
| Median: | 69.5 | 81 | 75 | 87 | 75 | 86.5 |
| 25th percentile: | 46 | 57 | 46 | 66 | 47 | 66 |
| 75th percentile: | 86 | 93 | 91 | 98 | 94 | 98 |
| Total processing time [h] | 14 | 14 | 16 | 21 | 29 | 28 |
Table 9.
Influence of the number of generations on the final score.
Table 9.
Influence of the number of generations on the final score.
| Topology: | 4 × 8 | 4 × 8 | 1 × 16 | 1 × 16 | 1 × 24 | 1 × 24 |
|---|
| Mutation: | 25% | 25% | 10% | 10% | 20% | 20% |
|---|
| Number of generations: | 50 | 200 | 50 | 200 | 50 | 200 |
| Number of evolutions: | 20 | 10 | 60 | 20 | 60 | 10 |
| Max score: | 77 | 152 | 147 | 175 | 133 | 150 |
| Min score: | 5 | 29 | 6 | 104 | 6 | 95 |
| Average: | 40 | 105 | 90 | 146 | 92 | 121 |
| Median: | 40 | 104.5 | 90.5 | 149 | 95 | 117.5 |
| 25th percentile: | 12 | 95 | 76 | 147 | 89 | 106 |
| 75th percentile: | 63 | 141 | 101 | 151 | 101 | 133 |
| Total processing time [h] | 1 | 12 | 18 | 98 | 18 | 39 |
Table 10.
Topologies with individuals that achieved the top-six best scores.
Table 10.
Topologies with individuals that achieved the top-six best scores.
| Topology: | 1 × 24 × 20% | 1 × 16 × 10% | 4 × 8 × 25% | 1 × 32 × 15% | 2 × 32 × 10% | 3 × 24 × 20% |
|---|
| Number of generations: | 200 | 200 | 400 | 50 | 50 | 600 |
| Number of individuals | 2000 | 2000 | 2000 | 2000 | 4000 | 2000 |
| Number of evolutions: | 10 | 20 | 5 | 60 | 60 | 5 |
| Max score: | 176 | 175 | 159 | 156 | 155 | 151 |
| Min score: | 105 | 104 | 138 | 5 | 6 | 129 |
| Average: | 138 | 146 | 150 | 96 | 89 | 145 |
| Median: | 141 | 149 | 149 | 95.5 | 94 | 149 |
| 25th percentile: | 125 | 147 | 149 | 85 | 77 | 147 |
| 75th percentile: | 149 | 151 | 153 | 111 | 106 | 150 |
| Total processing time [h] | 39 | 98 | 20 | 27 | 44 | 74 |
| Processing time of evolution [h] | 3.9 | 4.9 | 4.0 | 0.5 | 0.7 | 14.7 |
Table 11.
Best achieved results across topologies.
Table 11.
Best achieved results across topologies.
| File Name | Topology | GA Parameters | Score | Time |
|---|
| H | N | Mut | Gen | Individ. | min |
|---|
| T1×24m20G200R6bestSnake_176.csv | 1 | 24 | 20 | 200 | 2000 | 176 | 210 |
| T1×16m10G200R12bestSnake_175.csv | 1 | 16 | 10 | 200 | 2000 | 175 | 353 |
| T4×8m25G400R1bestSnake_159.csv | 4 | 8 | 25 | 400 | 2000 | 159 | 252 |
| T1×32m15G50R47bestSnake_156.csv | 1 | 32 | 15 | 50 | 2000 | 156 | 42 |
| T1×16m25G50R28bestSnake_156.csv | 1 | 16 | 25 | 50 | 2000 | 156 | 28 |
| T2×32m10G50R35bestSnake4000_155.csv | 2 | 32 | 10 | 50 | 4000 | 155 | 96 |
| T4×8m25G200R1bestSnake_152.csv | 4 | 8 | 25 | 200 | 2000 | 152 | 109 |
| T1×32m10G50R14bestSnake4000_152.csv | 1 | 32 | 10 | 50 | 4000 | 152 | 73 |
| T3×24m20G600R5bestSnake_151.csv | 3 | 24 | 20 | 600 | 2000 | 151 | 914 |
| T1×4m10G50R16bestSnake_149.csv | 1 | 4 | 10 | 50 | 2000 | 149 | 28 |
| T2×16m15G50R43bestSnake4000_149.csv | 2 | 16 | 15 | 50 | 4000 | 149 | 41 |
| T2×24m10G50R9bestSnake4000_149.csv | 2 | 24 | 10 | 50 | 4000 | 149 | 60 |
| T3×48m10G50R5bestSnake4000_147.csv | 3 | 48 | 10 | 50 | 4000 | 147 | 107 |
| T3×16m10G50R46bestSnake4000_147.csv | 3 | 16 | 10 | 50 | 4000 | 147 | 58 |




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
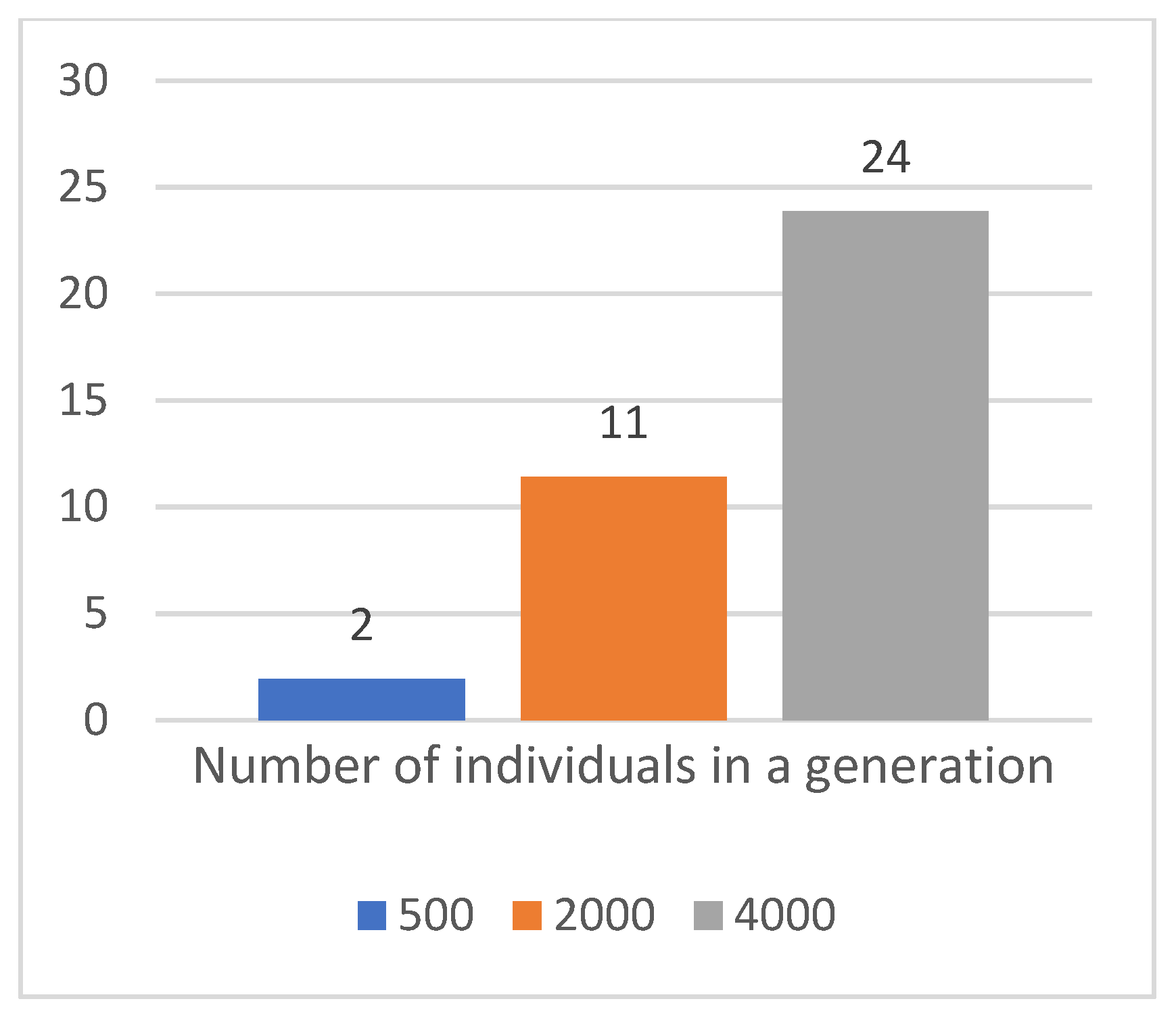{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
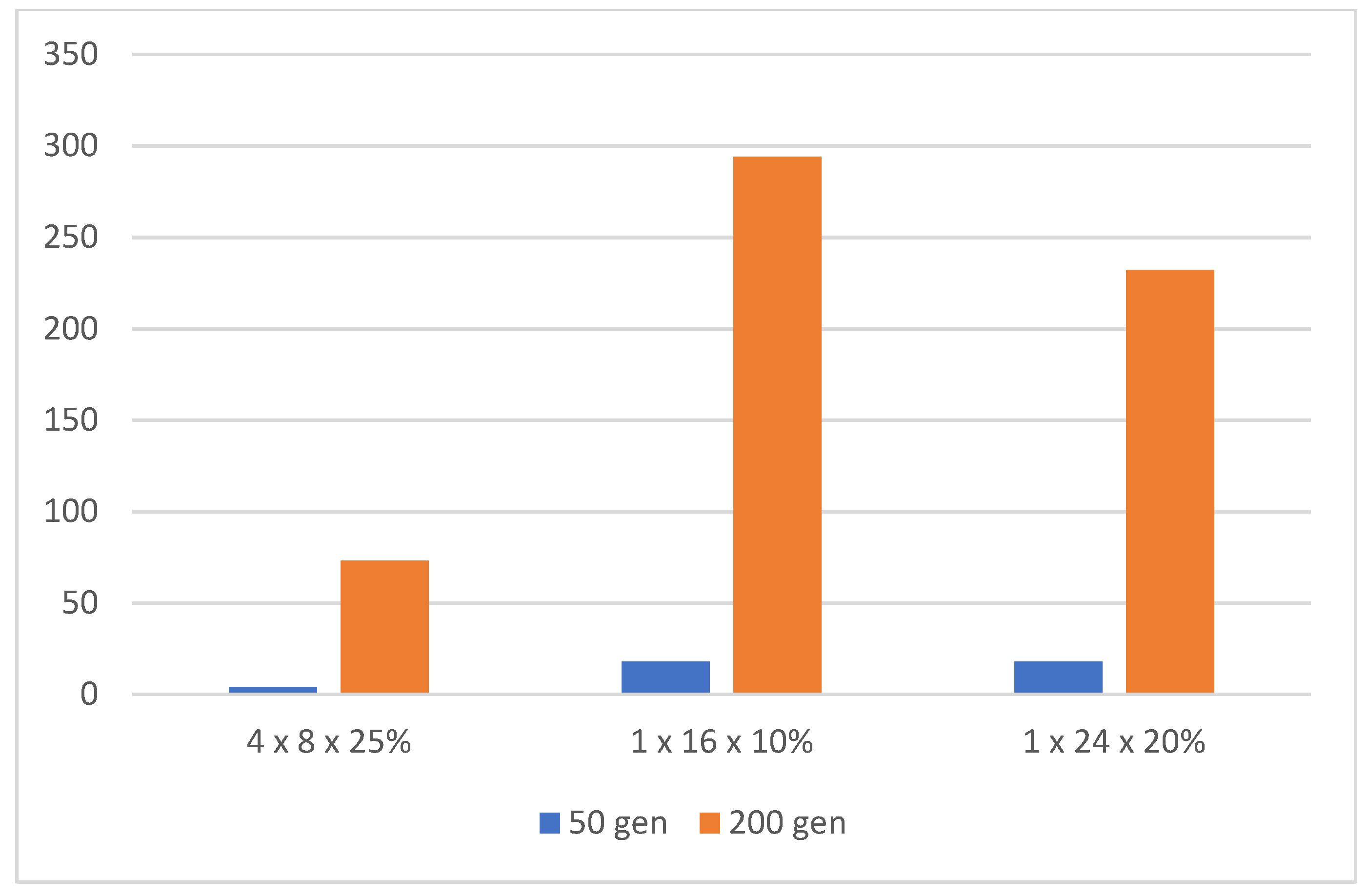{kind=link}
{kind=link}
{kind=link}
{kind=link}