

An Integrated Statistical and Clinically Applicable Machine Learning Framework for the Detection of Autism Spectrum Disorder

 , , , ,
, , , ,  and
and 
Abstract
:1. Introduction
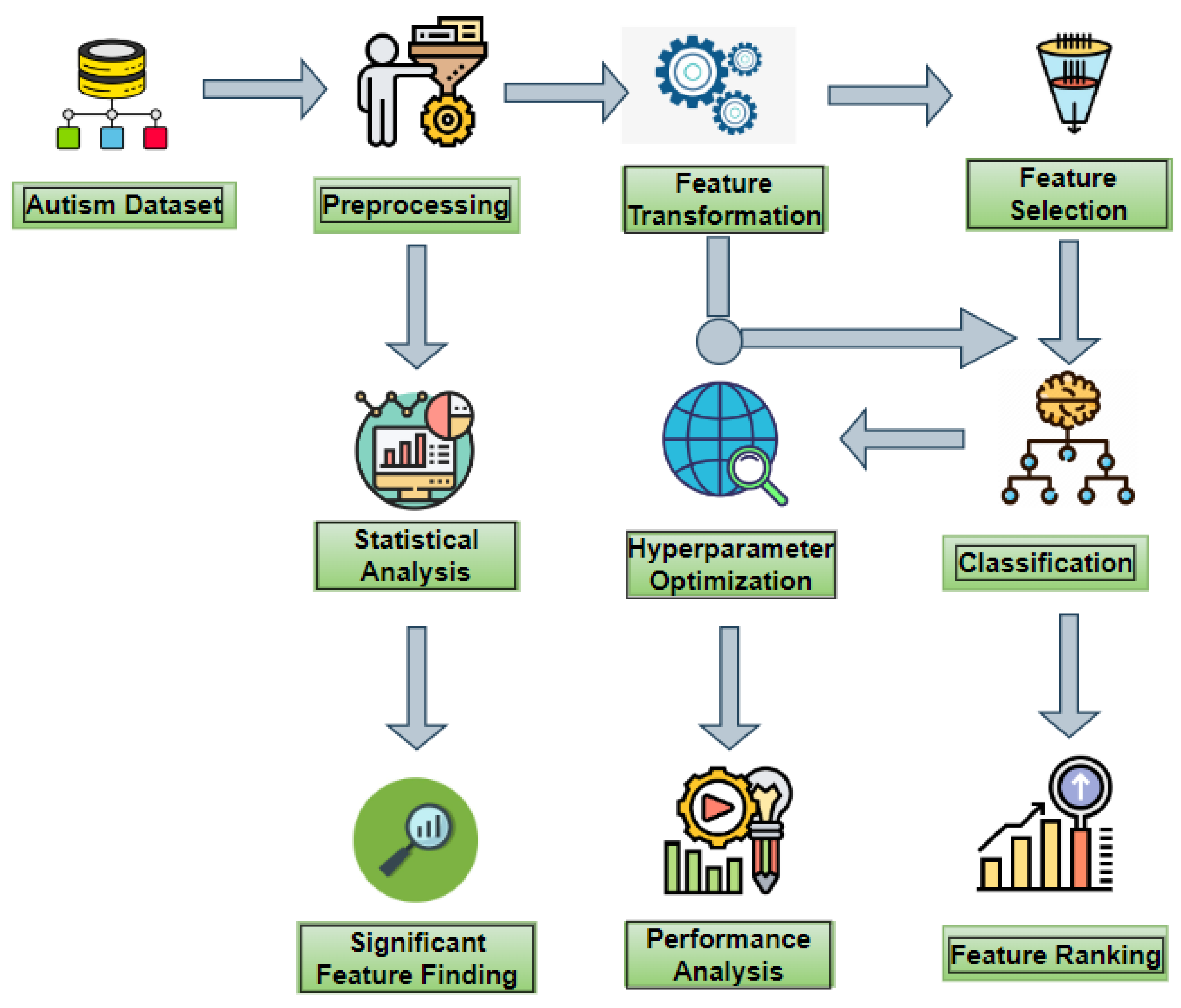
2. Materials and Methods
2.1. Dataset
2.2. Dataset Balancing Technique
2.3. Feature Transformation Method
2.4. Feature Selection Method
- Recursive Feature Elimination: Recursive feature elimination [20], often known as RFE, is a method for selecting features that fits a model and removing the weakest feature (or features) one by one until the necessary number of features has been attained.
- Pearson Correlation Coefficient: A value between −1 and 1 known as a Pearson correlation [21] describes the degree to which two variables are linearly connected. The “product-moment correlation coefficient” (PMCC) or simply “correlation” are other names for the Pearson correlation. Only metric variables are appropriate for Pearson correlations. Values for the correlation coefficient range from −1 to 1. A number that is nearer 0 indicates a weaker association (exact 0 implying no correlation). Values closer to 1 indicate a stronger positive association. A number nearer to −1 denotes a more significant negative correlation metric parameter.
- Mutual Information Gain: Evaluation of the information gain contributed by each variable in relation to the target variable is one method for using information gain in the context of feature selection [22]. When used in this context, the calculation is referred to as the mutual information between the two random variables.
- Boruta: The random forest classification method is the core of the Boruta feature selection algorithm, which is a wrapper constructed around it [23]. It makes an effort to identify all of the significant and intriguing characteristics that our dataset may include in relation to a certain outcome variable. First, it will make a copy of the dataset and then it will randomly reorder the numbers in each column.
2.5. Statistical Analysis
2.6. Machine Learning Model
2.7. Hyperparameter Optimization Technique
2.8. Performance Evaluation Metrics
3. Results
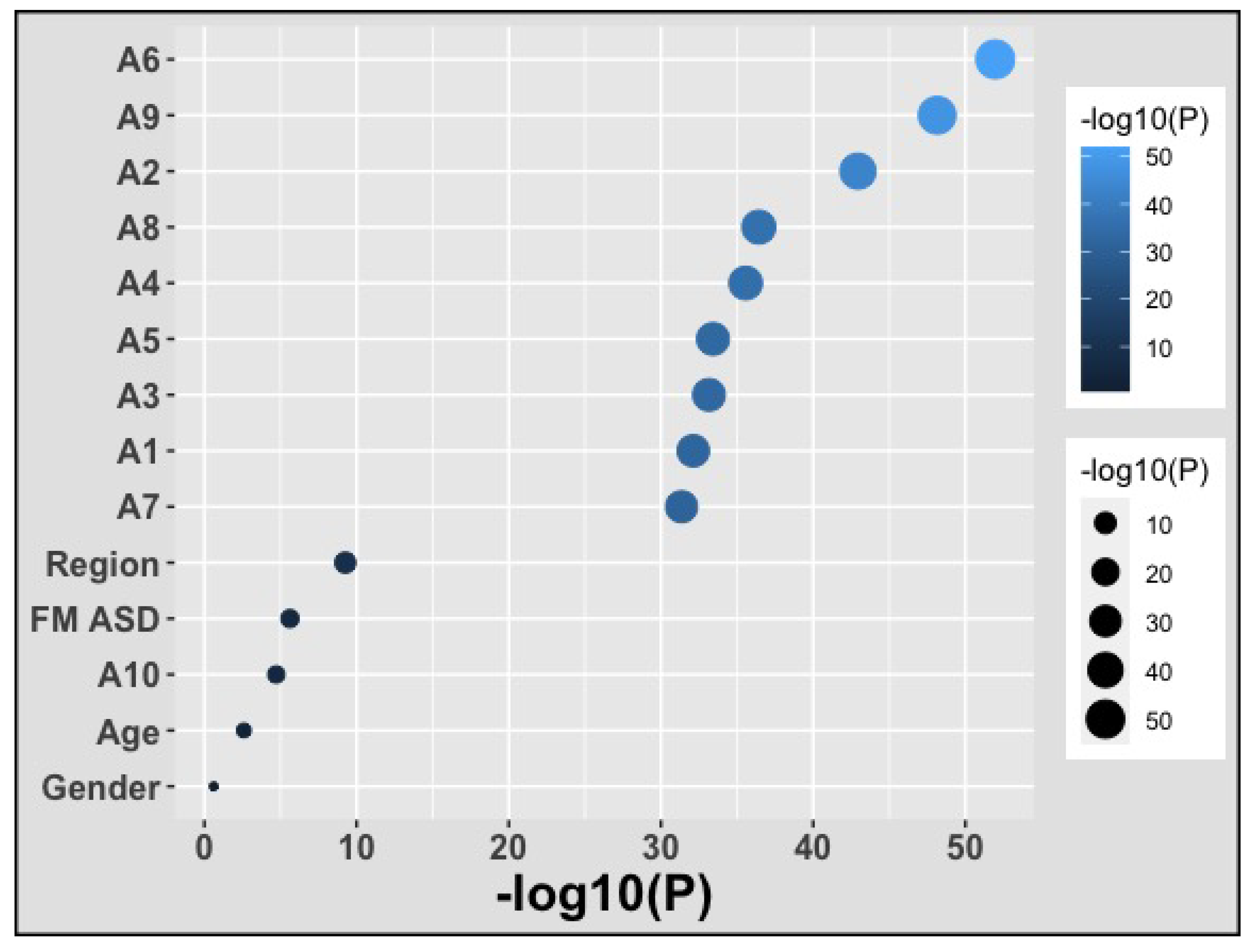
3.1. Finding Significantly Associative Features Using Statistical Methods
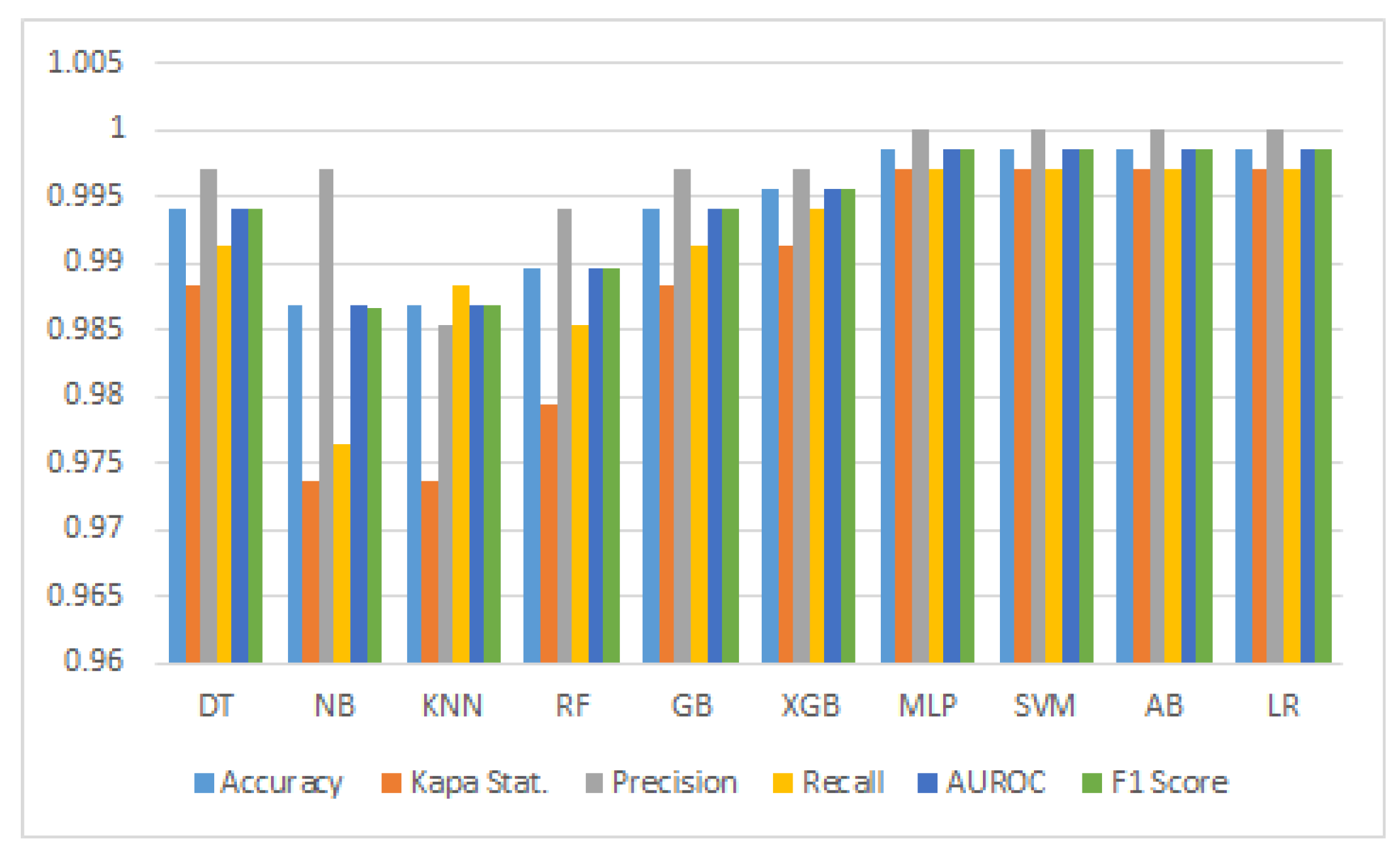
3.2. Analysis of Accuracy
3.3. Result Analysis of Kappa Statistics
3.4. Analysis of Precision
3.5. Analysis of Recall
3.6. Analysis of AUROC
3.7. Analysis of F1 Score
3.8. Analysis of Log loss
3.9. Feature Ranking Using Machine Learning Technique
4. Discussion
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ASD | Autism Spectrum Disorder |
| ML | Machine Learning |
| ML | Machine Learning |
| DT | Decision Tree |
| RF | Random Forest |
| LR | Logistic Regression |
| SVM | Support Vector Machine |
| GBM | Gradient Boosting Machine |
| GB | Gradient Boosting |
| XGB | eXtreme Gradient Boosting |
| MLP | Multi Layer Perceptron |
| NB | Naïve Bayes |
| AB | AdaBoost |
| KNN | K-Nearest Neighbors |
| AUC-ROC | Area under the ROC Curve |
References
- Crane, L.; Batty, R.; Adeyinka, H.; Goddard, L.; Henry, L.A.; Hill, E.L. Autism diagnosis in the United Kingdom: Perspectives of autistic adults, parents and professionals. J. Autism Dev. Disord. 2018, 48, 3761–3772. [Google Scholar] [CrossRef] [PubMed]
- Thabtah, F.; Spencer, R.; Abdelhamid, N.; Kamalov, F.; Wentzel, C.; Ye, Y.; Dayara, T. Autism screening: An unsupervised machine learning approach. Health Inf. Sci. Syst. 2022, 10, 26. [Google Scholar] [CrossRef] [PubMed]
- Thabtah, F.; Kamalov, F.; Rajab, K. A new computational intelligence approach to detect autistic features for autism screening. Int. J. Med. Inform. 2018, 117, 112–124. [Google Scholar] [CrossRef] [PubMed]
- Thabtah, F.; Abdelhamid, N.; Peebles, D. A machine learning autism classification based on logistic regression analysis. Health Inf. Sci. Syst. 2019, 7, 12. [Google Scholar] [CrossRef] [PubMed]
- Roccetti, M.; Delnevo, G.; Casini, L.; Mirri, S. An alternative approach to dimension reduction for pareto distributed data: A case study. J. Big Data 2021, 8, 39. [Google Scholar] [CrossRef] [PubMed]
- Bala, M.; Ali, M.H.; Satu, M.S.; Hasan, K.F.; Moni, M.A. Efficient Machine Learning Models for Early Stage Detection of Autism Spectrum Disorder. Algorithms 2022, 15, 166. [Google Scholar] [CrossRef]
- Hasan, S.M.; Uddin, M.P.; Al Mamun, M.; Sharif, M.I.; Ulhaq, A.; Krishnamoorthy, G. A Machine Learning Framework for Early-Stage Detection of Autism Spectrum Disorders. IEEE Access 2022, 11, 15038–15057. [Google Scholar] [CrossRef]
- Rodrigues, I.D.; de Carvalho, E.A.; Santana, C.P.; Bastos, G.S. Machine Learning and rs-fMRI to Identify Potential Brain Regions Associated with Autism Severity. Algorithms 2022, 15, 195. [Google Scholar] [CrossRef]
- Raj, S.; Masood, S. Analysis and detection of autism spectrum disorder using machine learning techniques. Procedia Comput. Sci. 2020, 167, 994–1004. [Google Scholar] [CrossRef]
- Hossain, M.D.; Kabir, M.A.; Anwar, A.; Islam, M.Z. Detecting autism spectrum disorder using machine learning techniques. Health Inf. Sci. Syst. 2021, 9, 386. [Google Scholar] [CrossRef]
- Akter, T.; Shahriare Satu, M.; Khan, M.I.; Ali, M.H.; Uddin, S.; Lió, P.; Quinn, J.M.W.; Moni, M.A. Machine Learning-Based Models for Early Stage Detection of Autism Spectrum Disorders. IEEE Access 2019, 7, 166509–166527. [Google Scholar] [CrossRef]
- Pietrucci, D.; Teofani, A.; Milanesi, M.; Fosso, B.; Putignani, L.; Messina, F.; Pesole, G.; Desideri, A.; Chillemi, G. Machine Learning Data Analysis Highlights the Role of Parasutterella and Alloprevotella in Autism Spectrum Disorders. Biomedicines 2022, 10, 2028. [Google Scholar] [CrossRef] [PubMed]
- Omar, K.S.; Mondal, P.; Khan, N.S.; Rizvi, M.R.K.; Islam, M.N. A Machine Learning Approach to Predict Autism Spectrum Disorder. In Proceedings of the 2019 International Conference on Electrical, Computer and Communication Engineering (ECCE), Cox’s Bazar, Bangladesh, 7–9 February 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Akter, T.; Ali, M.H.; Satu, M.; Khan, M.; Mahmud, M. Towards autism subtype detection through identification of discriminatory factors using machine learning. In International Conference on Brain Informatics; Springer: Cham, Switzerland, 2021; pp. 401–410. [Google Scholar]
- ASD Screening Data for Toddlers in Saudi. Kaggle. Available online: https://www.kaggle.com/datasets/asdpredictioninsaudi/asd-screening-data-for-toddlers-in-saudi-arabia (accessed on 20 March 2023).
- Albahri, A.; Hamid, R.A.; Zaidan, A.; Albahri, O. Early automated prediction model for the diagnosis and detection of children with autism spectrum disorders based on effective sociodemographic and family characteristic features. Neural Comput. Appl. 2022, 35, 921–947. [Google Scholar] [CrossRef]
- Yassin, W.; Nakatani, H.; Zhu, Y.; Kojima, M.; Owada, K.; Kuwabara, H.; Gonoi, W.; Aoki, Y.; Takao, H.; Natsubori, T.; et al. Machine-learning classification using neuroimaging data in schizophrenia, autism, ultra-high risk and first-episode psychosis. Transl. Psychiatry 2020, 10, 278. [Google Scholar] [CrossRef] [PubMed]
- Ahsan, M.M.; Mahmud, M.P.; Saha, P.K.; Gupta, K.D.; Siddique, Z. Effect of data scaling methods on machine learning algorithms and model performance. Technologies 2021, 9, 52. [Google Scholar] [CrossRef]
- Zhang, Y.; Yu, Q. What is the best article publishing strategy for early career scientists? Scientometrics 2020, 122, 397–408. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L.; Wang, B.; Li, F.; Zhang, Z. Feature clustering based support vector machine recursive feature elimination for gene selection. Appl. Intell. 2018, 48, 594–607. [Google Scholar] [CrossRef]
- Hu, C.C.; Xu, X.; Xiong, G.L.; Xu, Q.; Zhou, B.R.; Li, C.Y.; Qin, Q.; Liu, C.X.; Li, H.P.; Sun, Y.J.; et al. Alterations in plasma cytokine levels in chinese children with autism spectrum disorder. Autism Res. 2018, 11, 989–999. [Google Scholar] [CrossRef]
- Battiti, R. Using mutual information for selecting features in supervised neural net learning. IEEE Trans. Neural Netw. 1994, 5, 537–550. [Google Scholar] [CrossRef]
- Chang, J.M.; Zeng, H.; Han, R.; Chang, Y.M.; Shah, R.; Salafia, C.M.; Newschaffer, C.; Miller, R.K.; Katzman, P.; Moye, J.; et al. Autism risk classification using placental chorionic surface vascular network features. BMC Med. Inform. Decis. Mak. 2017, 17, 162. [Google Scholar] [CrossRef]
- Belaoued, M.; Mazouzi, S. A real-time pe-malware detection system based on Chi-square test and pe-file features. In Computer Science and Its Applications, Proceedings of the 5th IFIP TC 5 International Conference, CIIA 2015, Saida, Algeria, 20–21 May 2015; Springer: Cham, Switzerland, 2015; pp. 416–425. [Google Scholar]
- Shrestha, U.; Alsadoon, A.; Prasad, P.; Al Aloussi, S.; Alsadoon, O.H. Supervised machine learning for early predicting the sepsis patient: Modified mean imputation and modified Chi-square feature selection. Multimed. Tools Appl. 2021, 80, 20477–20500. [Google Scholar] [CrossRef]
- Oh, D.H.; Kim, I.B.; Kim, S.H.; Ahn, D.H. Predicting autism spectrum disorder using blood-based gene expression signatures and machine learning. Clin. Psychopharmacol. Neurosci. 2017, 15, 47. [Google Scholar] [CrossRef] [PubMed]
- Magboo, V.P.C.; Magboo, M.; Sheila, A. Classification Models for Autism Spectrum Disorder. In International Conference on Artificial Intelligence and Data Science; Springer: Cham, Switzerland, 2022; pp. 452–464. [Google Scholar]
- Sujatha, R.; Aarthy, S.; Chatterjee, J.; Alaboudi, A.; Jhanjhi, N. A machine learning way to classify autism spectrum disorder. Int. J. Emerg. Technol. Learn. (iJET) 2021, 16, 182–200. [Google Scholar]
- Retico, A.; Giuliano, A.; Tancredi, R.; Cosenza, A.; Apicella, F.; Narzisi, A.; Biagi, L.; Tosetti, M.; Muratori, F.; Calderoni, S. The effect of gender on the neuroanatomy of children with autism spectrum disorders: A support vector machine case-control study. Mol. Autism 2016, 7, 5. [Google Scholar] [CrossRef] [PubMed]
- Lohar, M.; Chorage, S. Automatic Classification of Autism Spectrum Disorder (ASD) from Brain MR Images Based on Feature Optimization and Machine Learning. In Proceedings of the 2021 International Conference on Smart Generation Computing, Communication and Networking (SMART GENCON), Pune, India, 29–30 October 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Negin, F.; Ozyer, B.; Agahian, S.; Kacdioglu, S.; Ozyer, G.T. Vision-assisted recognition of stereotype behaviors for early diagnosis of Autism Spectrum Disorders. Neurocomputing 2021, 446, 145–155. [Google Scholar] [CrossRef]
- Ismail, E.; Gad, W.; Hashem, M. HEC-ASD: A hybrid ensemble-based classification model for predicting autism spectrum disorder disease genes. BMC Bioinform. 2022, 23, 554. [Google Scholar] [CrossRef]
- Chen, W.; Xie, X.; Wang, J.; Pradhan, B.; Hong, H.; Bui, D.T.; Duan, Z.; Ma, J. A comparative study of logistic model tree, random forest, and classification and regression tree models for spatial prediction of landslide susceptibility. Catena 2017, 151, 147–160. [Google Scholar] [CrossRef]
- Li, B.; Sharma, A.; Meng, J.; Purushwalkam, S.; Gowen, E. Applying machine learning to identify autistic adults using imitation: An exploratory study. PLoS ONE 2017, 12, e0182652. [Google Scholar] [CrossRef]
- Chen, J.; Huang, H.; Cohn, A.G.; Zhang, D.; Zhou, M. Machine learning-based classification of rock discontinuity trace: SMOTE oversampling integrated with GBT ensemble learning. Int. J. Min. Sci. Technol. 2022, 32, 309–322. [Google Scholar] [CrossRef]
- Akter, T.; Ali, M.H.; Khan, M.I.; Satu, M.S.; Uddin, M.J.; Alyami, S.A.; Ali, S.; Azad, A.; Moni, M.A. Improved transfer-learning-based facial recognition framework to detect autistic children at an early stage. Brain Sci. 2021, 11, 734. [Google Scholar] [CrossRef]
- Nehm, R.H.; Ha, M.; Mayfield, E. Transforming biology assessment with machine learning: Automated scoring of written evolutionary explanations. J. Sci. Educ. Technol. 2012, 21, 183–196. [Google Scholar] [CrossRef]
- Ahamad, M.M.; Aktar, S.; Uddin, M.J.; Rahman, T.; Alyami, S.A.; Al-Ashhab, S.; Akhdar, H.F.; Azad, A.; Moni, M.A. Early-Stage Detection of Ovarian Cancer Based on Clinical Data Using Machine Learning Approaches. J. Pers. Med. 2022, 12, 1211. [Google Scholar] [CrossRef] [PubMed]
- Ahamad, M.M.; Aktar, S.; Uddin, M.J.; Rashed-Al-Mahfuz, M.; Azad, A.; Uddin, S.; Alyami, S.A.; Sarker, I.H.; Khan, A.; Liò, P.; et al. Adverse effects of COVID-19 vaccination: Machine learning and statistical approach to identify and classify incidences of morbidity and postvaccination reactogenicity. Healthcare 2022, 11, 31. [Google Scholar] [CrossRef] [PubMed]
- Gao, Y.; Hasegawa, H.; Yamaguchi, Y.; Shimada, H. Malware detection using LightGBM with a custom logistic loss function. IEEE Access 2022, 10, 47792–47804. [Google Scholar] [CrossRef]
- Vovk, V. The fundamental nature of the log loss function. In Fields of Logic and Computation II: Essays Dedicated to Yuri Gurevich on the Occasion of His 75th Birthday; Springer: Cham, Switzerland, 2015; pp. 307–318. [Google Scholar]
- Lu, H.J.; Zou, N.; Jacobs, R.; Afflerbach, B.; Lu, X.G.; Morgan, D. Error assessment and optimal cross-validation approaches in machine learning applied to impurity diffusion. Comput. Mater. Sci. 2019, 169, 109075. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Type | Values/Count/Statistics | Description | |
|---|---|---|---|---|
| 1 | Does your child look at you when youcall his/her name (A1)? | Categorical | Yes = 285 No = 221 | Yes, No |
| 2 | How easy is it for you to get eye contact with your child (A2)? | Categorical | Yes = 247 No = 259 | Yes, No |
| 3 | Does your child point to indicate that s/he wants something (A3)? | Categorical | Yes = 259 No = 247 | Yes, No |
| 4 | Does your child point to share interest with you (A4)? | Categorical | Yes = 266 No = 240 | Yes, No |
| 5 | Does your child pretend (A5)? (e.g., care for dolls‚ talk on a toy phone) | Categorical | Yes = 283 No = 223 | Yes, No |
| 6 | Does your child follow where you’re looking (A6)? | Categorical | Yes = 278 No = 228 | Yes, No |
| 7 | If you or someone else in the family is visibly upset‚ does your child show signs of wanting to comfort them (A7)? | Categorical | Yes = 280 No = 226 | Yes, No |
| 8 | Would you describe your child’s first words as (A8): | Categorical | Yes = 291 No = 215 | Yes, No |
| 9 | Does your child use simple gestures (A9)? (e.g., wave goodbye) | Categorical | Yes = 275 No = 231 | Yes, No |
| 10 | Does your child stare at nothing with no apparent purpose (A10)? | Categorical | Yes = 314 No = 192 | Yes, No |
| 11 | Region | Categorical | Al Baha = 7 Najran = 9, Tabuk = 18 Jizan = 19 Makkah = 217 Northern Borders = 15 Aseer = 13 Riyadh = 85 Ha’il = 16 Madinah = 23 Eastern = 50 Al Jawf = 12 Qassim = 22 | List of regions |
| 12 | Age | Number | Mean = 24.445, Standard deviation = 8.35 | Toddlers (Months) |
| 13 | Gender | Categorical | Female = 349 Male = 157 | Male or Female |
| 14 | Screening Score | Number | Mean = 5.49, Standard deviation = 3.18 | From 1 to 10 |
| 15 | Family member with ASD history | Boolean | Yes = 122 No = 384 | Family members has ASD traits or not |
| 16 | Who is completing test | Categorical | Family member = 414 Other = 92 | Parents or other |
| 17 | Class | Boolean | ASD = 346 No ASD = 160 | No ASD traits or ASD traits |
| EM | Dataset | DT | NB | KNN | RF | GB | XGB | MLP | SVM | AB | LR |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | Main | 0.9407 | 0.9506 | 0.8992 | 0.9585 | 0.9664 | 0.9743 | 0.9704 | 0.8854 | 0.9941 | 0.9901 |
| Balanced | 0.9545 | 0.9428 | 0.9223 | 0.9633 | 0.9707 | 0.978 | 0.9692 | 0.937 | 0.9956 | 0.9912 | |
| Kapa Stat. | Main | 0.8643 | 0.886 | 0.778 | 0.9051 | 0.9232 | 0.9415 | 0.9329 | 0.7342 | 0.9866 | 0.9777 |
| Balanced | 0.9091 | 0.8856 | 0.8446 | 0.9267 | 0.9413 | 0.956 | 0.9384 | 0.8739 | 0.9912 | 0.9824 | |
| Precision | Main | 0.9507 | 0.9514 | 0.9531 | 0.9651 | 0.9709 | 0.9795 | 0.9822 | 0.9008 | 1.000 | 1.000 |
| Balanced | 0.9613 | 0.9016 | 0.9706 | 0.954 | 0.9679 | 0.9766 | 0.9678 | 0.9776 | 1.000 | 1.000 | |
| Recall | Main | 0.9619 | 0.9765 | 0.8944 | 0.9736 | 0.9795 | 0.9824 | 0.9736 | 0.9326 | 0.9912 | 0.9853 |
| Balanced | 0.9472 | 0.9941 | 0.871 | 0.9736 | 0.9736 | 0.9795 | 0.9707 | 0.8944 | 0.9912 | 0.9824 | |
| AUC-ROC | Main | 0.9294 | 0.9368 | 0.9018 | 0.9504 | 0.9594 | 0.97 | 0.9686 | 0.8602 | 0.9956 | 0.9927 |
| Balanced | 0.9545 | 0.9428 | 0.9223 | 0.9633 | 0.9707 | 0.978 | 0.9692 | 0.937 | 0.9956 | 0.9912 | |
| F1 score | Main | 0.9563 | 0.9638 | 0.9228 | 0.9693 | 0.9752 | 0.981 | 0.9779 | 0.9164 | 0.9956 | 0.9926 |
| Balanced | 0.9542 | 0.9456 | 0.9181 | 0.9637 | 0.9708 | 0.978 | 0.9693 | 0.9342 | 0.9956 | 0.9911 | |
| Log loss | Main | 2.0478 | 1.7065 | 3.4812 | 1.4334 | 1.1604 | 0.8874 | 1.0239 | 3.959 | 0.2048 | 0.3413 |
| Balanced | 1.57 | 1.9751 | 2.6841 | 1.2661 | 1.0129 | 0.7597 | 1.0635 | 2.1777 | 0.1519 | 0.3039 |
| EM | Dataset | DT | NB | KNN | RF | GB | XGB | MLP | SVM | AB | LR |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | Standard Scalar | 0.9589 | 0.9428 | 0.9663 | 0.9663 | 0.9765 | 0.9809 | 0.9941 | 0.9795 | 0.9985 | 0.9956 |
| Unit Vector | 0.9428 | 0.9267 | 0.9575 | 0.9663 | 0.9677 | 0.9736 | 0.9428 | 0.9238 | 0.9897 | 0.8314 | |
| Yeo-Johnson | 0.9604 | 0.9428 | 0.9663 | 0.9736 | 0.9721 | 0.978 | 0.9941 | 0.9824 | 0.9941 | 0.9956 | |
| Robust Scalar | 0.9633 | 0.9428 | 0.9575 | 0.9692 | 0.9736 | 0.9809 | 0.9927 | 0.9795 | 0.9985 | 0.9941 | |
| Kapa Stat. | Standard Scalar | 0.9179 | 0.8856 | 0.9326 | 0.9326 | 0.9531 | 0.9619 | 0.9883 | 0.9589 | 0.9971 | 0.9912 |
| Unit Vector | 0.8856 | 0.8534 | 0.915 | 0.9326 | 0.9355 | 0.9472 | 0.8856 | 0.8475 | 0.9795 | 0.6628 | |
| Yeo-Johnson | 0.9208 | 0.8856 | 0.9326 | 0.9472 | 0.9443 | 0.956 | 0.9883 | 0.9648 | 0.9883 | 0.9912 | |
| Robust scalar | 0.9267 | 0.8856 | 0.915 | 0.9384 | 0.9472 | 0.9619 | 0.9853 | 0.9589 | 0.9971 | 0.9883 | |
| Precision | Standard Scalar | 0.9672 | 0.9016 | 0.9877 | 0.9543 | 0.971 | 0.9795 | 1.0000 | 0.9712 | 1.0000 | 1.0000 |
| Unit Vector | 0.9415 | 0.9076 | 0.9588 | 0.9543 | 0.9544 | 0.9681 | 0.9415 | 0.9446 | 0.9912 | 0.8717 | |
| Yeo-Johnson | 0.9673 | 0.9016 | 0.9969 | 0.9654 | 0.9708 | 0.9766 | 0.9971 | 0.9768 | 1.0000 | 1.0000 | |
| Robust scalar | 0.9731 | 0.9016 | 0.9937 | 0.9598 | 0.9681 | 0.9795 | 0.9941 | 0.9767 | 1.0000 | 1.0000 | |
| Recall | Standard Scalar | 0.9501 | 0.9941 | 0.9443 | 0.9795 | 0.9824 | 0.9824 | 0.9883 | 0.9883 | 0.9971 | 0.9912 |
| Unit Vector | 0.9443 | 0.9501 | 0.956 | 0.9795 | 0.9824 | 0.9795 | 0.9443 | 0.9003 | 0.9883 | 0.7771 | |
| Yeo-Johnson | 0.9531 | 0.9941 | 0.9355 | 0.9824 | 0.9736 | 0.9795 | 0.9912 | 0.9883 | 0.9883 | 0.9912 | |
| Robust scalar | 0.9531 | 0.9941 | 0.9208 | 0.9795 | 0.9795 | 0.9824 | 0.9912 | 0.9824 | 0.9971 | 0.9883 | |
| AUC-ROC | SST | 0.9589 | 0.9428 | 0.9663 | 0.9663 | 0.9765 | 0.9809 | 0.9941 | 0.9795 | 0.9985 | 0.9956 |
| Unit Vector | 0.9428 | 0.9267 | 0.9575 | 0.9663 | 0.9677 | 0.9736 | 0.9428 | 0.9238 | 0.9897 | 0.8314 | |
| Yeo-Johnson | 0.9604 | 0.9428 | 0.9663 | 0.9736 | 0.9721 | 0.978 | 0.9941 | 0.9824 | 0.9941 | 0.9956 | |
| Robust scalar | 0.9633 | 0.9428 | 0.9575 | 0.9692 | 0.9736 | 0.9809 | 0.9927 | 0.9795 | 0.9985 | 0.9941 | |
| F1 score | Standard Scalar | 0.9586 | 0.9456 | 0.9655 | 0.9667 | 0.9767 | 0.981 | 0.9941 | 0.9797 | 0.9985 | 0.9956 |
| Unit Vector | 0.9429 | 0.9284 | 0.9574 | 0.9667 | 0.9682 | 0.9738 | 0.9429 | 0.9219 | 0.9897 | 0.8217 | |
| Yeo-Johnson | 0.9601 | 0.9456 | 0.9652 | 0.9738 | 0.9722 | 0.978 | 0.9941 | 0.9825 | 0.9941 | 0.9956 | |
| Robust scalar | 0.963 | 0.9456 | 0.9559 | 0.9695 | 0.9738 | 0.981 | 0.9927 | 0.9795 | 0.9985 | 0.9941 | |
| Log loss | Standard Scalar | 1.418 | 1.9751 | 1.1648 | 1.1648 | 0.8103 | 0.6584 | 0.2026 | 0.709 | 0.0506 | 0.1519 |
| Unit Vector | 1.9751 | 2.5322 | 1.4687 | 1.1648 | 1.1142 | 0.9116 | 1.9751 | 2.6335 | 0.3545 | 5.824 | |
| Yeo-Johnson | 1.3674 | 1.9751 | 1.1648 | 0.9116 | 0.9622 | 0.7597 | 0.2026 | 0.6077 | 0.2026 | 0.1519 | |
| Robust scalar | 1.2661 | 1.9751 | 1.4687 | 1.0635 | 0.9116 | 0.6584 | 0.2532 | 0.709 | 0.0506 | 0.2026 |
| EM | Feature Selection Technique | DT | NB | KNN | RF | GB | XGB | MLP | SVM | AB | LR |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | Boruta | 0.9604 | 0.9428 | 0.9677 | 0.9648 | 0.9707 | 0.9721 | 0.9765 | 0.9721 | 0.9765 | 0.9765 |
| Pearson Correlation Coefficient | 0.9633 | 0.9501 | 0.9604 | 0.9736 | 0.9707 | 0.9692 | 0.9751 | 0.9677 | 0.9765 | 0.9736 | |
| Mutual Information Gain | 0.9648 | 0.9531 | 0.9604 | 0.9721 | 0.9824 | 0.9839 | 0.9941 | 0.9927 | 0.9956 | 0.9956 | |
| Recursive Feature Elimination | 0.9721 | 0.9457 | 0.9663 | 0.9736 | 0.9839 | 0.9839 | 0.9956 | 0.9839 | 0.9956 | 0.9956 | |
| Kapa Stat. | Boruta | 0.9208 | 0.8856 | 0.9355 | 0.9296 | 0.9413 | 0.9443 | 0.9531 | 0.9443 | 0.9531 | 0.9531 |
| Pearson Correlation Coefficient | 0.9267 | 0.9003 | 0.9208 | 0.9472 | 0.9413 | 0.9384 | 0.9501 | 0.9355 | 0.9531 | 0.9472 | |
| Mutual Information Gain | 0.9296 | 0.9062 | 0.9208 | 0.9443 | 0.9648 | 0.9677 | 0.9883 | 0.9853 | 0.9912 | 0.9912 | |
| Recursive Feature Elimination | 0.9443 | 0.8915 | 0.9326 | 0.9472 | 0.9677 | 0.9677 | 0.9912 | 0.9677 | 0.9912 | 0.9912 | |
| Precision | Boruta | 0.9701 | 0.9016 | 0.9878 | 0.9621 | 0.9707 | 0.9763 | 0.9794 | 0.9708 | 0.9794 | 0.9765 |
| Pearson Correlation Coefficient | 0.9675 | 0.9183 | 0.9846 | 0.9681 | 0.9707 | 0.9678 | 0.9737 | 0.9623 | 0.9765 | 0.9792 | |
| Mutual Information Gain | 0.9648 | 0.921 | 0.9968 | 0.9653 | 0.9853 | 0.9882 | 1.0000 | 0.9941 | 1.0000 | 1.0000 | |
| Recursive Feature Elimination | 0.9735 | 0.9086 | 0.9938 | 0.9681 | 0.9882 | 0.9853 | 1.0000 | 0.9882 | 1.0000 | 1.0000 | |
| Recall | Boruta | 0.9501 | 0.9941 | 0.9472 | 0.9677 | 0.9707 | 0.9677 | 0.9736 | 0.9736 | 0.9736 | 0.9765 |
| Pearson Correlation Coefficient | 0.9589 | 0.9883 | 0.9355 | 0.9795 | 0.9707 | 0.9707 | 0.9765 | 0.9736 | 0.9765 | 0.9677 | |
| Mutual Information Gain | 0.9648 | 0.9912 | 0.9238 | 0.9795 | 0.9795 | 0.9795 | 0.9883 | 0.9912 | 0.9912 | 0.9912 | |
| Recursive Feature Elimination | 0.9707 | 0.9912 | 0.9384 | 0.9795 | 0.9795 | 0.9824 | 0.9912 | 0.9795 | 0.9912 | 0.9912 | |
| AUC-ROC | Boruta | 0.9604 | 0.9428 | 0.9677 | 0.9648 | 0.9707 | 0.9721 | 0.9765 | 0.9721 | 0.9765 | 0.9765 |
| Pearson Correlation Coefficient | 0.9633 | 0.9501 | 0.9604 | 0.9736 | 0.9707 | 0.9692 | 0.9751 | 0.9677 | 0.9765 | 0.9736 | |
| Mutual Information Gain | 0.9648 | 0.9531 | 0.9604 | 0.9721 | 0.9824 | 0.9839 | 0.9941 | 0.9927 | 0.9956 | 0.9956 | |
| Recursive Feature Elimination | 0.9721 | 0.9457 | 0.9663 | 0.9736 | 0.9839 | 0.9839 | 0.9956 | 0.9839 | 0.9956 | 0.9956 | |
| F1 score | Boruta | 0.96 | 0.9456 | 0.9671 | 0.9649 | 0.9707 | 0.972 | 0.9765 | 0.9722 | 0.9765 | 0.9765 |
| Pearson Correlation Coefficient | 0.9632 | 0.952 | 0.9594 | 0.9738 | 0.9707 | 0.9693 | 0.9751 | 0.9679 | 0.9765 | 0.9735 | |
| Mutual Information Gain | 0.9648 | 0.9548 | 0.9589 | 0.9723 | 0.9824 | 0.9838 | 0.9941 | 0.9927 | 0.9956 | 0.9956 | |
| Recursive Feature Elimination | 0.9721 | 0.9481 | 0.9653 | 0.9738 | 0.9838 | 0.9838 | 0.9956 | 0.9838 | 0.9956 | 0.9956 | |
| Log loss | Boruta | 1.3674 | 1.9751 | 1.1142 | 1.2155 | 1.0129 | 0.9622 | 0.8103 | 0.9622 | 0.8103 | 0.8103 |
| Pearson Correlation Coefficient | 1.2661 | 1.7219 | 1.3674 | 0.9116 | 1.0129 | 1.0635 | 0.8609 | 1.1142 | 0.8103 | 0.9116 | |
| Mutual Information Gain | 1.2155 | 1.6206 | 1.3674 | 0.9622 | 0.6077 | 0.5571 | 0.2026 | 0.2532 | 0.1519 | 0.1519 | |
| Recursive Feature Elimination | 0.9622 | 1.8738 | 1.1648 | 0.9116 | 0.5571 | 0.5571 | 0.1519 | 0.5571 | 0.1519 | 0.1519 |
| Classifier | DT | NB | KNN | RF | GB | XGB | MLP | SVM | AB | LR |
|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | 0.9941 | 0.9868 | 0.9868 | 0.9897 | 0.9941 | 0.9956 | 0.9985 | 0.9985 | 0.9985 | 0.9985 |
| Kapa Stat. | 0.9883 | 0.9736 | 0.9736 | 0.9795 | 0.9883 | 0.9912 | 0.9971 | 0.9971 | 0.9971 | 0.9971 |
| Precision | 0.9971 | 0.997 | 0.9854 | 0.9941 | 0.9971 | 0.9971 | 1.000 | 1.000 | 1.000 | 1.000 |
| Recall | 0.9912 | 0.9765 | 0.9883 | 0.9853 | 0.9912 | 0.9941 | 0.9971 | 0.9971 | 0.9971 | 0.9971 |
| AUC-ROC | 0.9941 | 0.9868 | 0.9868 | 0.9897 | 0.9941 | 0.9956 | 0.9985 | 0.9985 | 0.9985 | 0.9985 |
| F1 Score | 0.9941 | 0.9867 | 0.9868 | 0.9897 | 0.9941 | 0.9956 | 0.9985 | 0.9985 | 0.9985 | 0.9985 |
| Log Loss | 0.2026 | 0.4558 | 0.4558 | 0.3545 | 0.2026 | 0.1519 | 0.0506 | 0.0506 | 0.0506 | 0.0506 |
| Feature | DT | NB | KNN | RF | GB | XGB | MLP | SVM | AB | LR | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|
| A10 | 0.039 | 0.000 | 0.325 | 0.380 | 0.319 | 0.353 | 0.687 | 0.101 | 0.833 | 0.107 | 0.314 |
| A9 | 0.135 | 0.016 | 0.662 | 0.155 | 0.028 | 0.073 | 0.707 | 0.815 | 0.833 | 0.803 | 0.423 |
| A8 | 0.036 | 1.000 | 0.587 | 1.000 | 1.000 | 1.000 | 0.867 | 0.135 | 0.833 | 0.148 | 0.661 |
| A7 | 0.017 | 0.674 | 0.238 | 0.821 | 0.521 | 0.507 | 0.675 | 1.000 | 1.000 | 1.000 | 0.645 |
| A6 | 1.000 | 0.258 | 1.000 | 0.357 | 0.301 | 0.484 | 0.707 | 0.726 | 0.667 | 0.720 | 0.622 |
| A5 | 0.050 | 0.044 | 0.538 | 0.004 | 0.003 | 0.064 | 0.663 | 0.526 | 0.833 | 0.507 | 0.323 |
| A4 | 0.021 | 0.052 | 0.263 | 0.019 | 0.018 | 0.047 | 0.491 | 0.542 | 0.667 | 0.543 | 0.266 |
| A3 | 0.029 | 0.052 | 0.238 | 0.000 | 0.015 | 0.000 | 1.000 | 0.527 | 0.833 | 0.542 | 0.324 |
| A2 | 0.280 | 0.078 | 0.650 | 0.159 | 0.052 | 0.249 | 0.809 | 0.606 | 0.833 | 0.590 | 0.431 |
| A1 | 0.043 | 0.721 | 0.450 | 0.570 | 0.267 | 0.432 | 0.641 | 0.431 | 0.833 | 0.454 | 0.484 |
| Region | 0.000 | 0.164 | 0.000 | 0.300 | 0.000 | 0.043 | 0.000 | 0.727 | 0.167 | 0.724 | 0.213 |
| Age | 0.011 | 0.253 | 0.075 | 0.526 | 0.380 | 0.344 | 0.203 | 0.181 | 0.000 | 0.178 | 0.215 |
| Gender | 0.026 | 0.068 | 0.100 | 0.013 | 0.010 | 0.076 | 0.110 | 0.631 | 0.000 | 0.657 | 0.169 |
| FM ASD | 0.000 | 0.661 | 0.275 | 0.539 | 0.165 | 0.269 | 0.020 | 0.000 | 0.000 | 0.000 | 0.193 |
| Reference | Feature Selection | Accuracy | Kapa Stat. | Precision | Recall | AUROC | F1 Score | Log Loss |
|---|---|---|---|---|---|---|---|---|
| Akter et al. [14] | No | 98.77 | 97.1 | 99.98 | 3.01 | |||
| Bala et al. [6] | Yes | 97.82 | 94.87 | 99.7 | 97.8 | |||
| Hasan et al. [7] | No | 99.25 | 98.97 | 99.89 | 98.45 | 99.1 | 0.0802 | |
| Proposed Model | Yes | 99.85 | 99.71 | 1.00 | 1.00 | 99.85 | 99.85 | 0.0506 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Uddin, M.J.; Ahamad, M.M.; Sarker, P.K.; Aktar, S.; Alotaibi, N.; Alyami, S.A.; Kabir, M.A.; Moni, M.A. An Integrated Statistical and Clinically Applicable Machine Learning Framework for the Detection of Autism Spectrum Disorder. Computers 2023, 12, 92. https://doi.org/10.3390/computers12050092
Uddin MJ, Ahamad MM, Sarker PK, Aktar S, Alotaibi N, Alyami SA, Kabir MA, Moni MA. An Integrated Statistical and Clinically Applicable Machine Learning Framework for the Detection of Autism Spectrum Disorder. Computers. 2023; 12(5):92. https://doi.org/10.3390/computers12050092
Chicago/Turabian StyleUddin, Md. Jamal, Md. Martuza Ahamad, Prodip Kumar Sarker, Sakifa Aktar, Naif Alotaibi, Salem A. Alyami, Muhammad Ashad Kabir, and Mohammad Ali Moni. 2023. "An Integrated Statistical and Clinically Applicable Machine Learning Framework for the Detection of Autism Spectrum Disorder" Computers 12, no. 5: 92. https://doi.org/10.3390/computers12050092
APA StyleUddin, M. J., Ahamad, M. M., Sarker, P. K., Aktar, S., Alotaibi, N., Alyami, S. A., Kabir, M. A., & Moni, M. A. (2023). An Integrated Statistical and Clinically Applicable Machine Learning Framework for the Detection of Autism Spectrum Disorder. Computers, 12(5), 92. https://doi.org/10.3390/computers12050092