1. Introduction
With rapid developments in computer hardware and computer technology, the construction of 3D models has become much easier. This has contributed to an increasing accumulation of 3D models. In the last 20 years, model recognition has become one of the most popular fields of computer science. It has wide application in the fields of Computer Aided Design (CAD)/Computer Aided Manufacturing (CAM) [
1,
2], integrated circuit design [
3], digital city planning [
4], biomedical engineering [
5], military applications [
6], mesh decomposition [
7], virtual reality [
8], education [
9] and animation [
10]. Making full use of the existing resources of 3D model data can greatly reduce the workload of designing new models and promote the flow of 3D data and its application in various fields [
11,
12].
The core content of model recognition is similarity measurement between models. At present, there are a lot of similarity measurement methods:
- (1)
Statistic characteristic-based methods. A classical algorithm is the shape distribution histogram formed by using the sampling function as the shape descriptor. The geometric similarity between shapes can be measured by the histogram [
13]. To calculate the distance histogram between any two points on a shape, the enhanced shape function is used to obtain better experimental results [
14]. The statistic characteristic-based method has a good outcome for global matching of models, but it does not have good performance for local matching.
- (2)
Geometry-based methods. This method is based on various frequency domain features of a model. By using a weighted point set to describe a 3D polyhedral model, the similarity between two shapes can be computed by employing the Earth Mover’s Distance to compare their weighted point sets [
15]. The global properties of a 3D shape can be represented by the reflective value where all planes pass through the shape’s center of mass [
16].
- (3)
Projection-based methods. This method mainly does the projection transform processing of a 3D model in different directions, which can obtain a series of 2D projection images of 3D models for model retrieval. A comparison method has been proposed by Min et al., based on 2D contouring of 3D models [
17]. However, this method can only describe the brightness distribution of models and cannot effectively reflect their topological features.
- (4)
Topology-based methods. Most prior work has focused on skeleton graph or skeleton tree-based methods. The basic idea is as follows: first transform the skeleton or shape axis into an attribute (or relation) graph or a tree structure, called the skeleton tree. Then a graph or tree matching algorithm is used to measure the similarity between models. A detailed review of the skeleton-based method is summarized in the next section.
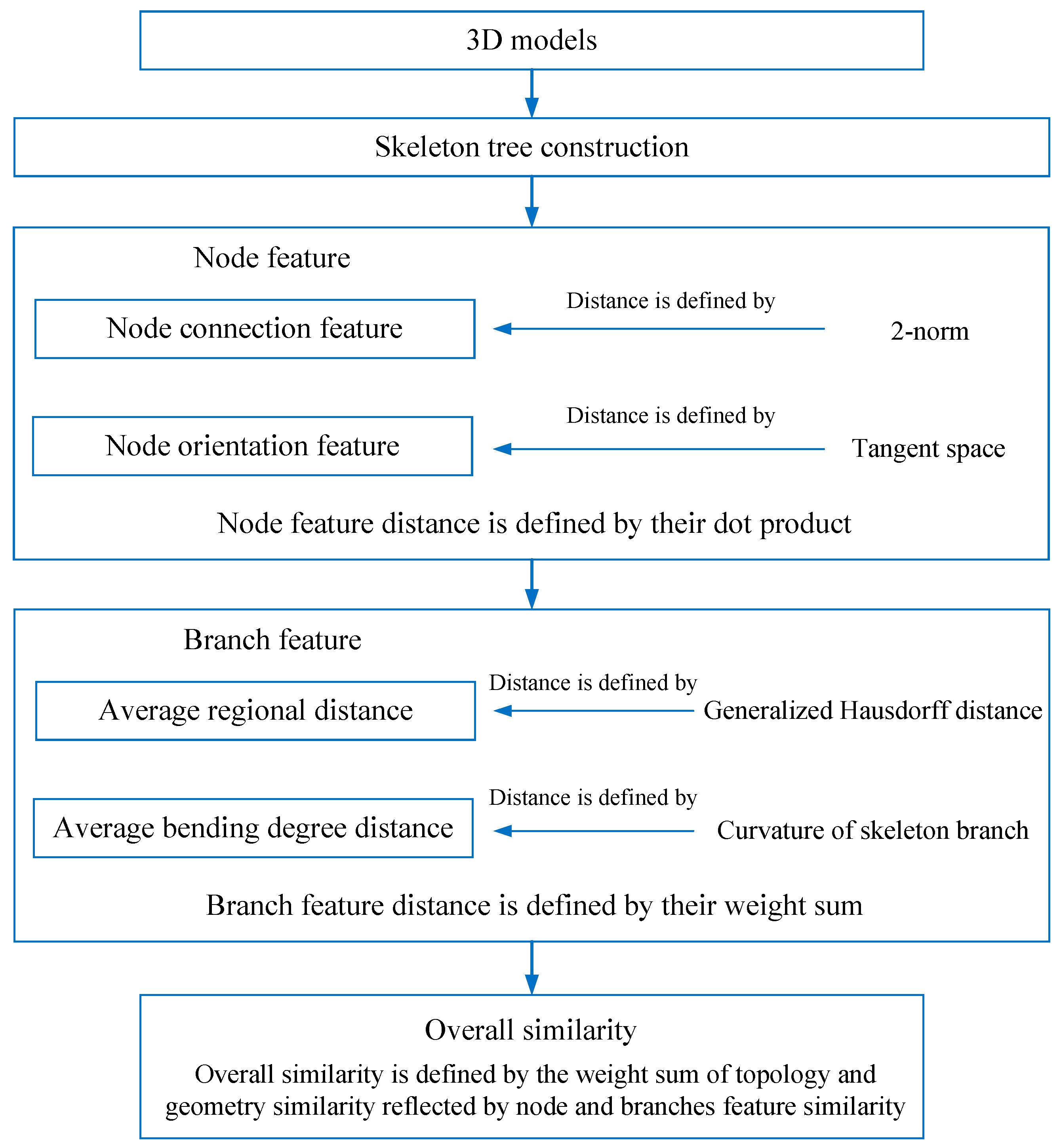
In this paper, we propose a method for measuring the similarity of 3D models. A skeleton tree constructed by a simple rule is used as a descriptor of a 3D model, which can completely retain its topological features. Based on the skeleton tree, we add topological and geometric information deriving from the model to node and branch features, and their respective feature distances are reasonably defined. The final overall similarity is defined by the weighted sum of topologic and geometric similarity, reflected by similarities in the node and branch features. Compared with related existing methods, our method considers the information on topology and geometry more comprehensively because of taking the node connection and orientation features and geometric feature of the skeleton’s points and branches into account, which contributes to high accuracy and good results. Our research work is a significant development in 2/3D model matching, recognition and retrieval.
The remainder of the paper is organized as follows. The next section contains a summary of related work.
Section 3 gives an overview of our proposed method.
Section 4 develops the skeleton tree construction.
Section 5 describes the details in node feature similarity.
Section 6 presents the details in branch feature similarity.
Section 7 offers overall similarity measurement.
Section 8 involves experiment and discussion. Finally,
Section 9 concludes and describes future research directions.
2. Related Work
The vast majority of methods in model recognition have concentrated on skeleton-based methods, which are usually based on graph or tree representations of skeletons. These have been well studied by many researchers. Below, we focus on research areas related to the efforts in this paper. For a broad introduction to model recognition method, please refer to any of References [
18,
19,
20,
21,
22].
In early work, a large number of skeleton graph-based recognition methods were proposed and have achieved good performance on object recognition. Blum [
23] transformed the skeleton or medial axis into attribute relation graphs (ARG). The similarity between two objects can be measured by matching their ARGs. Zhu and Yuille [
24] used a branch bounding that is confined to animate objects to match the skeleton graphs of objects. Siddiqi et al. [
25,
26,
27,
28,
29] proposed a kind of ARG, the shock graph, based on shock grammar. The similarity between two 2D objects can be measured by matching their shock graphs. Sundar et al. [
30] first transformed skeletons into skeleton graphs by using a minimum spanning tree (MST) algorithm, then matching it to a skeleton graph. Sebastian et al. [
31,
32] performed the recognition of shapes by editing shock graphs, defining the cost of the least action path deforming one shape to another as the distance between two shapes. Ruberto [
33] took medial axis characteristic points as an attributed skeletal graph (ASG) to model a shape. The matching process for ASGs is based on a revised graduated assignment algorithm. This method can deal with the occlusion problem, but it cannot obtain an optimal matching result due to the heuristic rule. Torsello and Hancock [
34,
35] measured the similarity of 2D shapes with the help of a shock tree by using the rate of change of boundary length with distance along the skeleton to define this measure. Shokoufandeh et al. [
36] described a topological index successfully developed from a shock graph in a large database. The eigenvalues of the adjacency matrices of their subgraphs are used to calculate the similarity between them. Aslan and Tari [
37] developed an unconventional matching scheme for shape recognition using skeletons with disconnected branches in the course level. The presented matching algorithms can find the correct results of correspondences and generate a similarity value. Bai and Latecki [
38] presented skeleton graph matching based on the similarity of the shortest paths between each pair of endpoints of the pruned skeletons. Xu et al. [
39] matched skeleton graphs by comparing the geodesic paths between critical points (junction points and end points). Most of these skeleton graph-based recognition methods are time consuming because of the complexity of the shock grammar, graph matching algorithms, and calculation of eigenvalues. Moreover, these methods do not perform well for for 3D object recognition.
More recent work has developed a method for shape recognition that is relatively simple and efficient compared to the skeleton tree-based method. This method transforms the skeleton into a tree structure, called a skeleton tree, according to the construction rule. Hilaga et al. [
40] constructed a multi-resolution Reeb graph (MRG) representing the skeletal and topological structure of a 3D model based on geodesic distance. The overall similarity calculation between different 3D models is processed using a graph matching algorithm. This method can cope well with loop structures and generates intuitive results. Nevertheless, this method merely depends on topological features when recognizing different shapes, which may fail in distinguishing different shapes with similar topologies. Pelillo et al. [
41] developed a different framework for matching unrooted trees by constructing an association graph with maximal cliques. Liu et al. [
42] constructed a free tree structure and used a tree matching scheme to calculate the similarity between two 2D shapes; their method can deal with articulations, stretching, and occlusions. This method does not require any editing of the skeleton graph, but merge, cut, and merge-and-cut operations are essential before matching the free trees. Liu et al. [
43] proposed a similarity measurement framework by using the skeleton tree represented by tree descriptor. The similarity between two branches is defined as the weighted sum of the average curvature difference (ACD) and the average area difference (AAD). This approach has the time complexity of O(
n3). As this approach only uses a branch to represent geometric features, it may not include all the geometry information of an object, though this limitation can be improved by taking inherent geometry properties into account. Demirci et al. [
44] proposed an accurate matching algorithm by constructing a metric tree representation of the two weighted graphs, which can establish many-to-many correspondences between the nodes of two noisy objects. However, the transformation from graphs to trees has to go through the heuristic rule. In addition, how to choose an optimal root node needs to be considered as this has a great influence on matching results. Xiao [
45] recognized microscopic images of diatom cells by using skeleton tree matching, defining topological and geometric differences to establish a similarity mode for microscopic images of Chaetoceros, but this method is only suitable for diatom cells recognition. Jiang et al. [
46] presented a skeleton graph matching algorithm, namely an order-preserving assignment algorithm, based on a novel tree shape which considers both the positive curvature maxima and the negative curvature minima of the boundary. It has low computational complexity and good performance, but the shape tree does not consider topological structures. Garro and Giachetti [
47] introduced a novel framework for non-rigid and textured 3D shape retrieval and classification with the help of TreeSha-based shape representation, which can offer better similarity recognition and better retrieval results than existing methods on textured and non-textured shape retrieval benchmarks and give effective shape descriptors and graph kernels.
There are other new methods in shape recognition. Chen and Ming [
48] proposed a 3D model retrieval system based on the Reeb graph, linked with preprocessing that can accelerate the graph-matching step. Biasotti et al. [
49] presented an efficient method for partial shape-matching based on Reeb graphs. Goh [
50] described some useful strategies for 2D shape retrieval. These strategies include dynamic part decomposition, local and global measurement, and weighting skeletal segments. The incorporation of these strategies significantly improves shape database retrieval accuracy. Biasotti et al. [
51] devised an original framework for 3D model retrieval and classification. Similarity between shapes is measured by attractive features of size functions computed from skeletal signatures. Experimental results demonstrate that this method is efficient and effective. Tierny et al. [
52] used a Reeb graph to represent shapes and developed a fast and efficient framework for partial shape retrieval, where partial similarity between two shapes is evaluated by computing their maximum common sub-graph. Zhang et al. [
53] achieved 3D non-rigid object retrieval by utilizing integral geodesic distance. Their proposed coarse-to-fine process can reduce the large computational cost of matching. Barra and Biasotti [
54] developed a new unsupervised method for 3D shape retrieval based on the extended Reeb graphs. Using kernels as descriptions to measure the similarity between pairs of extended Reeb graphs, their method has been tested on three databases to verify its good performance. Usai et al. [
55] presented a novel method for extracting the quad layout of a triangle mesh guided by its accurate curve skeleton; t this quad layout is able to reflect the intrinsic characteristics of the shape. Also, this method has applications to semiregular quad meshing and UV mapping, which may provide good shape representation for 2/3D shape matching. Guler et al. [
56] presented a SIFT-based image matching framework for 2D planar shape retrieval. Their shape similarity measurement is based on the number of matching internal regions. Yang et al. [
57] proposed a novel 2D object matching method based on a hierarchical skeleton capturing the object’s topology and geometry, where determining similarity considers both single skeletons and skeleton pairs. Yasseen et al. [
58] developed a 2D shape matching method, which can perform a part-to-part matching analysis between two objects’ visual protruding parts to measure the distance between them. Yang et al. [
59] mentioned a new shape matching method based on the interesting point detector and high-order graph matching. It can consider geometrical relations and reduce computational costs for point matching. Shakeri et al. [
60] devised a groupwise shape analysis framework for subcortical surfaces based on spectral marching theory. This spectral matching process can build reliable correspondences between different surface meshes and is likely to help to investigate groupwise structural differences between two study groups. Yang et al. [
61] proposed a novel invariant multi-scale descriptor that can capture both local and global information simultaneously for shape representation, matching, and retrieval by adopting the dynamic programming algorithm to conduct shape matching. Since most of these new methods are applied to 2D object recognition, they do not have good applicability and performance on 3D object recognition.
To summarize: many previous methods either have operational complexity or cannot be well used for 3D models because they develop complicated rules for graphing (or tree definition) or pay more attention to 2D modeling. The motivation behind our work is to present a simple method of similarity measurement with high accuracy for 3D model matching, recognition, and retrieval.
4. Skeleton Tree Construction
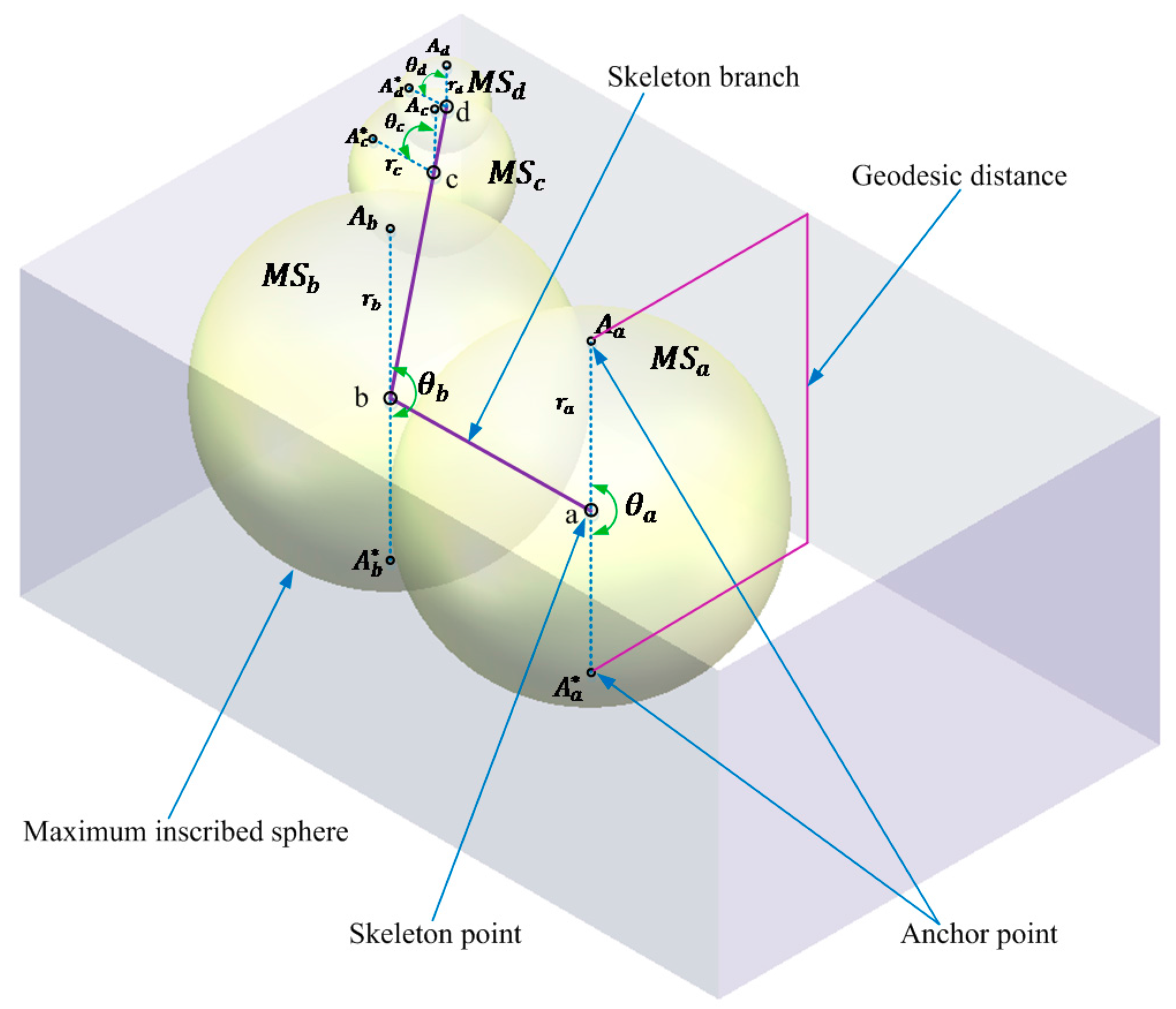
The skeleton is an important foundation for skeleton tree construction. An extracted skeleton should retain the key topological information of model. Here, we use the mesh contraction method proposed by Au et al. [
47] to effectively extract a smooth curve-skeleton with correct connectivity and topology. This method is simple to perform and insensitive to noise. The extraction of 3D model skeletons in both experiments uses this method. Next, we map the skeleton to a tree structure named the skeleton tree.
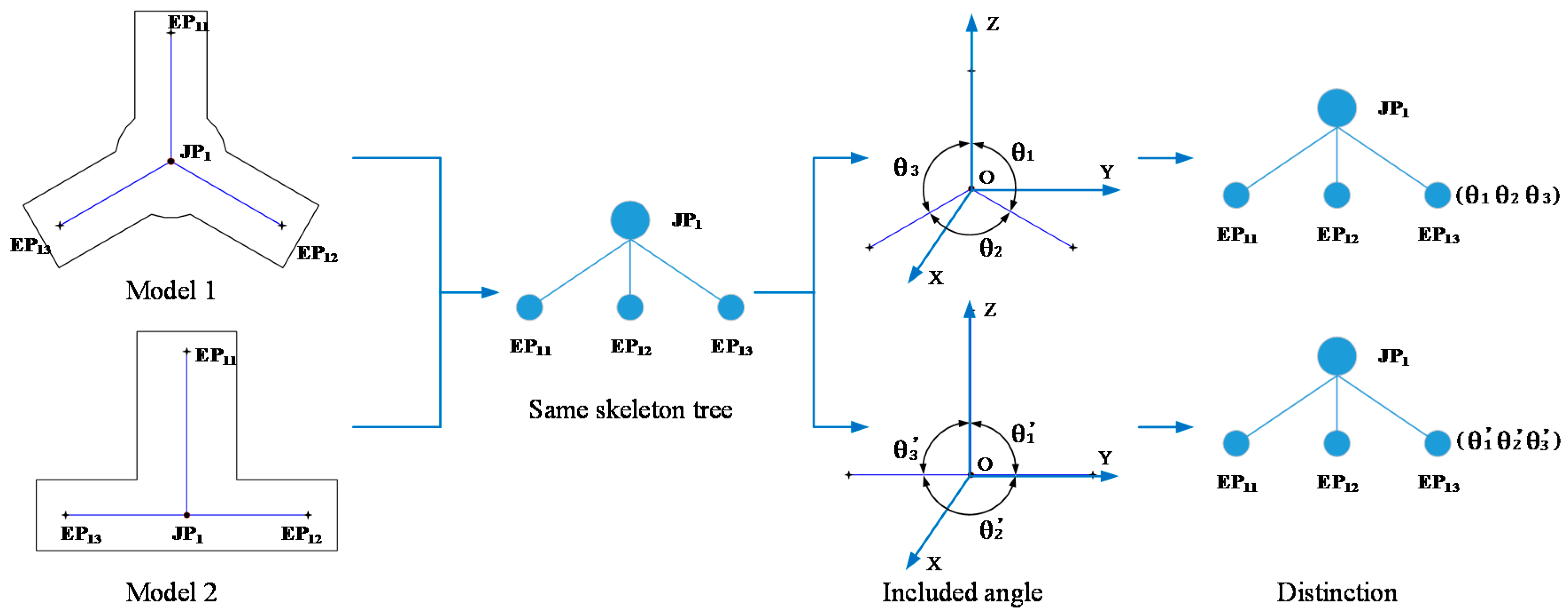
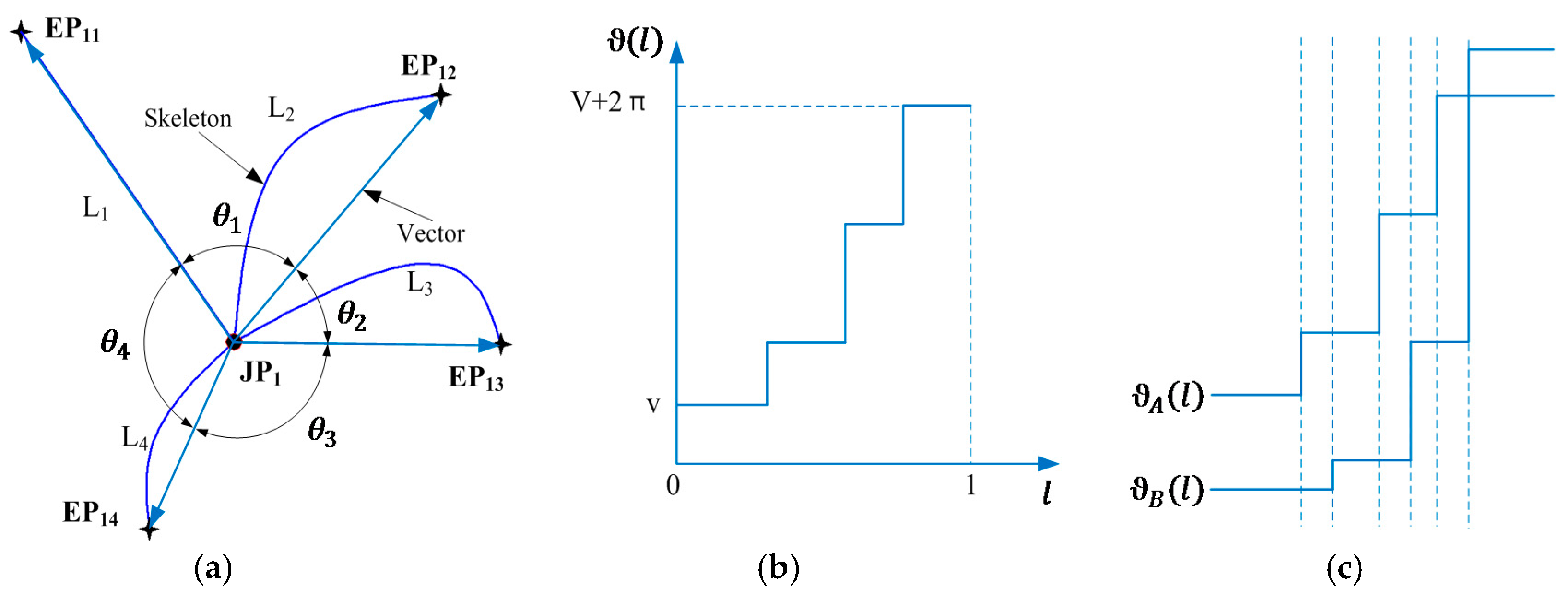
Definition 1. If a skeleton point is only adjacent to one point on the skeleton, it is considered as an endpoint (EP); if a skeleton exists two or more adjacent points on the skeleton, it is considered as a junction point (JP).
Definition 2. Linking any two connected skeleton points to form the sequence constitutes a skeleton branch.
A simple and intuitive method of constructing the skeleton tree follows:
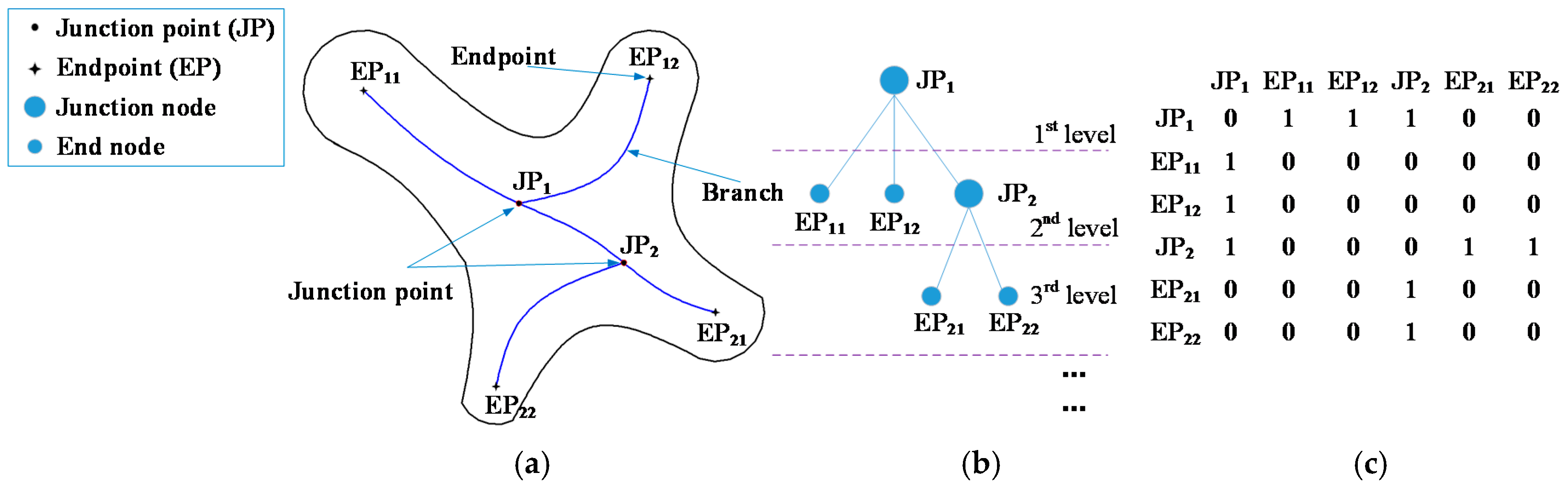
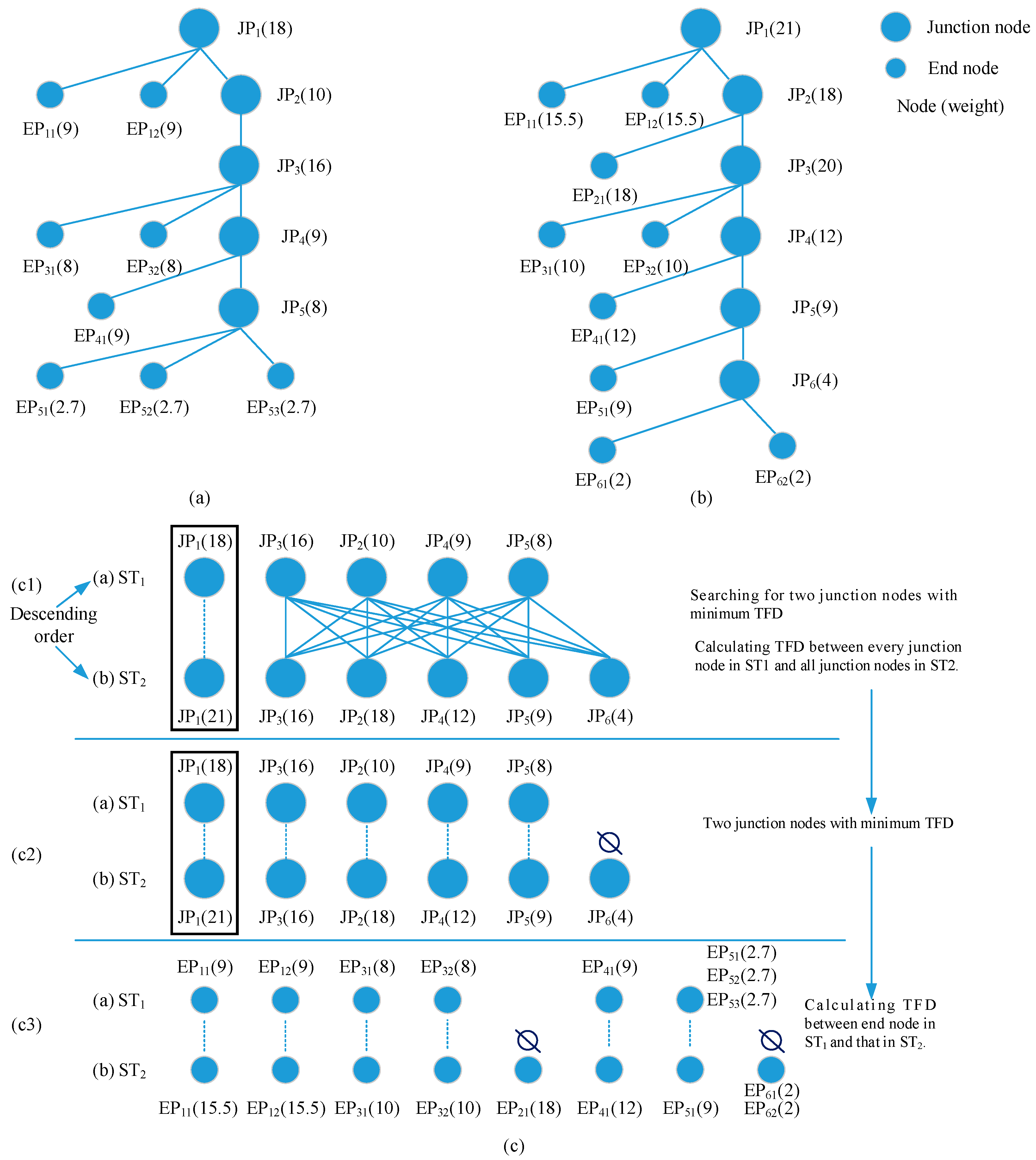
The endpoint and the junction point are selected as the nodes of the skeleton tree. The skeleton branch is a branch of the skeleton tree. We select a skeleton point located as close as possible to the center of model as the top node of skeleton tree, because there is usually important location and shape information in the center of a model. For example, in
Figure 2, according to Definition 1, skeleton points (
JP1,
JP2) are both junction points, and skeleton points (
EP11,
EP12,
EP21 and
EP22) are all endpoints. Selecting
JP1 as the top node of skeleton tree and according to the skeleton’s topology, the corresponding skeleton tree can be constructed.
Before constructing the skeleton tree, we mark the endpoint and junction point by sign and number. The junction point is marked first, by a solid circle and is numbered JPi (i = 1, 2, …, n, n is the total number of junction points). Then, the endpoint is marked by the star shape and is numbered by EPij (i = 1, 2, …, n; j = 1, 2, …, k, k is the total number of endpoints connected with i-th junction point). In the skeleton tree, the number of nodes are the same as for the skeleton. The large solid circle represents the junction node and the small circle represents an end node.
Definition 3. In a skeleton tree, the endpoint is considered an end node and the junction point is considered the junction node.
Definition 4. In a skeleton tree, the junction node is considered a root node and an end node is considered a leaf node. From the top node, the level of the top node is 1, its next level is 2, and so on. The nodes belonging to the same layer have the same level number. The upper node is considered the root node of the lower node.
In
Figure 2b,
JP1 is the 1st level root node,
JP2 is the 2nd level root node,
EP11 and
EP22 are both 2nd level leaf nodes, and
EP21 and
EP22 are both 3rd level leaf nodes.
Definition 5. A skeleton tree is described by ST = (N, B), where N is the node set of the tree and B is the branch set of the tree.
Ideally, skeleton trees are linear and open. However, according to the method described in Definition 2, a skeleton tree is likely to be closed. For a ring skeleton tree, at least one node exists for every two or more root nodes. Such a node needs special treatment: assuming that node P has n (n > 1) root nodes, copy P to be n duplicates (P1, P2, ……, Pn), then connecting Pi with the i-th root node of P. Simultaneously, P1 inherits all the leaf nodes of P and it and Pi are both set as leaf nodes. After treating all such nodes by this approach, one open and linear skeleton tree can be obtained.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













































