1. Introduction
There is a maxim that can be helpful when designing AI agents for gaming: that is, what does this agent have the right to know about itself, its environment, and other in-game agents? As a number of standard AI techniques for game-based agents rely on being fed information directly and then making decisions based on the range of values in that information, asking what the agent has the right to know is a pertinent question for designing interesting, immersive, and effective agents. It is self-evident that, in certain circumstances, the greater the range of access an agent has to a larger range of data sources, then the more nuanced and considered the decision-making for that agent can become. This leaves the decision-making in the hands of the behavioural designer, but does not necessarily provide a complete picture, especially if the technique allows some self-learning.
For the purposes of illustration suppose that we have some AI agent as a non-player character in an adventure game. This NPC (non-player character) has a state-machine managed by some FSM (finite state machine) or Markov chain hybrid to process its decision-making and include probability management. A typical behaviour to define might be for the NPC to retreat in the face of danger. The decision-making process to determine whether or not to retreat is, usually, going to be in conflict with a response to stay and confront the danger. The values of certain NPC-internal variables (such as health), danger-external variables (such as strength and location), and environment-external variables (such as locale safety probability ratings) would then be balanced against the expected values and a decision would be made. In such an extreme event the line between dogged determination to stay and confront the danger ahead and a healthy regard for one’s own personal safety is a thin one. What is more important to understand is that the impulse to cross this line is drawn differently by each person. For expedience, however, this kind of tuning is not often taken into consideration on an individual level for NPCs that appear en-masse within a game. Quite often game AI is developed in a generic manner per character type rather than for a particular character.
This is not an unreasonable thing to do, but it does mean that there can exist some instances where an NPC will not act in their best interests, or will fail to step up to a challenge to provide an interesting game experience for the player or players. In either event, judgement that does not align with reasonable expectations will lead to a break in the immersion for the player and a poorer potential game experience.
What we aim to demonstrate in this paper is that some of this tuning could be handled not by a state-machine directly but, rather, with a feed-forward emotional management layer, which we have dubbed the Emotive Effect Layer (EEL). Some of this work has been undertaken previously by Khashman [
1], where the author cites a modified back propagation (BP) learning algorithm modified with emotions of anxiety and confidence, calling this the emotional back propagation (EmBP) learning algorithm. Here, this overlay improves the performance of a neural network yielding higher recognition rates and faster recognition time. In the research executed for this paper, the EEL (see
Section 3.2) manages the incoming data variables and makes alterations to accentuate or diminish their effects within the decision-making method according to predetermined models for emotional behaviour modifications.
In this case study we present preliminary experimentation for this Emotive Effect Layer with specific focus on the effects of frustration whilst an AI agent plays multiple rounds of the card game Love Letter against another AI agent opponent. As this is only an initial exploratory example it is our hope that the outcomes of this case study, coupled with future case studies, may provide the foundations for the creation of a model for emotive effect on AI decision-making in games.
2. Overview of the Love Letter Card Game
In the game of Love Letter players are vying for the affection of a princess of a castle. Taking turns, each player will attempt to eliminate the other(s) from the game by using a special effect written on each of the cards. If there is more than one player remaining at the end of the round, or game, the terms are used interchangeably here, then the winner of the round is determined by the highest printed value written on the card. An overall winner is determined by most rounds won in a single match; each match lasting a number of rounds decided in advance. For each round the central deck of sixteen cards is shuffled, a single card is removed, or burned, from the round entirely and then each player is given a card in secret. Players then take turns to draw a card from the central deck and choose which of their two cards in hand to discard, thus activating the card’s effects and targeting a single player for them to have effect on. When all players but one have been eliminated, or there are no more cards in the central deck to draw from, the game ends and a winner is determined.
Each of the cards can be defined by their purpose into one of four categories. These categories and their descriptions are given as follows:
Eliminating Cards
Cards that can be used, under certain conditions, to eliminate other players from the round.
Information-gathering Cards
Cards that can be used to get information about the card the opponent might hold.
Protection Cards
Cards that are used by players to prevent them being a legal target for other players’ card effects.
Compelling Cards
Cards which serve no other function than that they compel an action of the player in the event that they are required to be discarded.
It is possible for two or more players to tie the round as there exist multiple copies of the same card in the central deck, however, this is a very unlikely outcome. For the purposes of our experimentation we limited each match to only two AI agent players so as to keep a strategy for play as simple as possible.
2.1. Developing a Default Strategy for Play
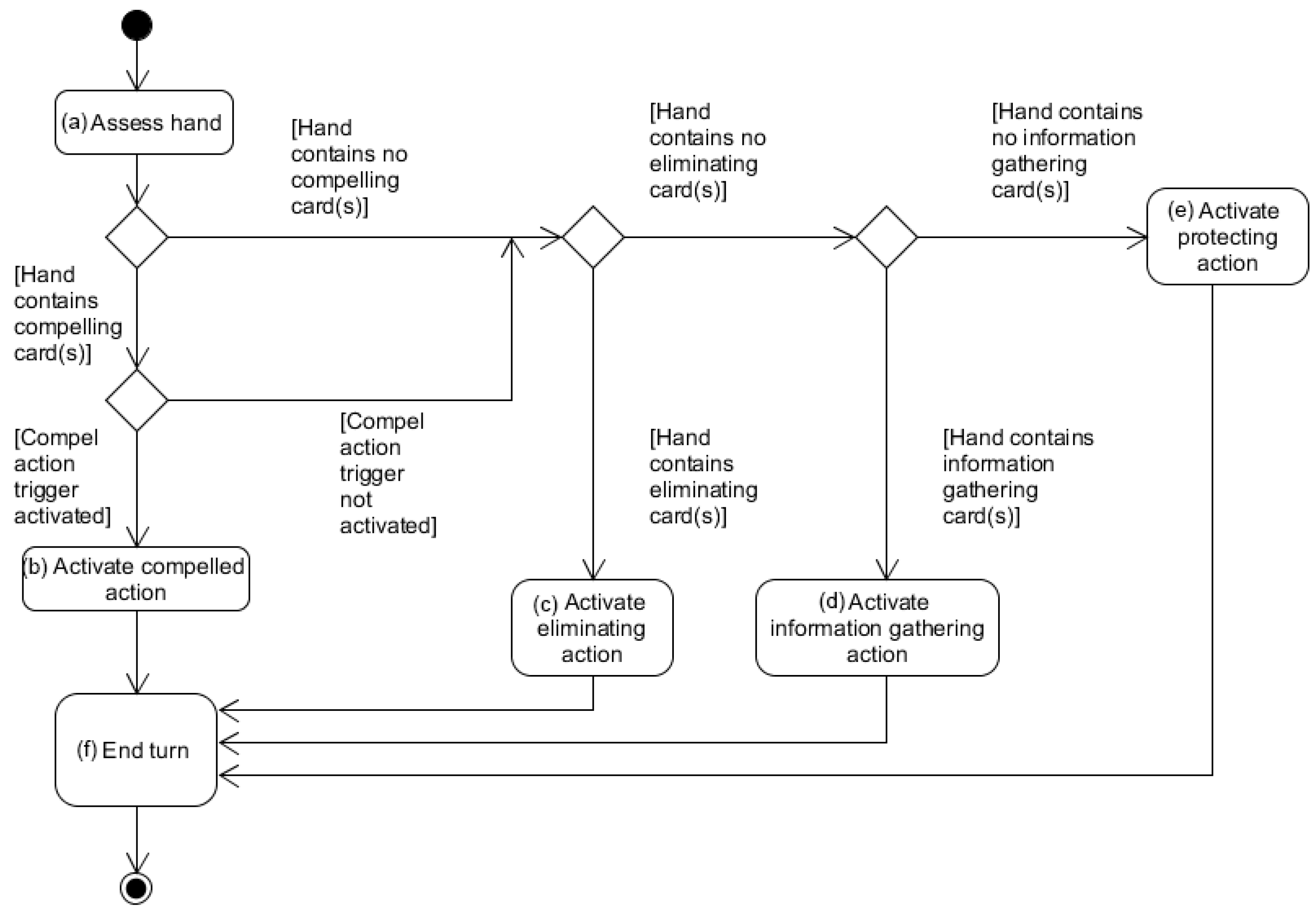
To begin, we developed a simple default strategy for the AI agents to use on their turn. The diagram below (
Figure 1) shows a simple overview of the strategy play order that was used for default reasoning by the agent during play. The flow of
Figure 1 shows, after analysing if any compelled actions need to be activated, a preference for playing eliminating cards, then information gathering cards, then protection cards. As a game strategy this preference follows a simple logical path of the player preferring to activate cards that are most likely to increase that player’s chances of winning.
As well as performing the initial phase calculations for the turn we additionally, during the assess hand state, provided the agents with the ability to override the default reasoning for the standard play strategy in two general circumstances. The first occurred if a probability analysis suggested that an alternative play would increase the chance of winning. The second occurred in the event that previously-gained information suggested that an alternative play would guarantee the agent protection from losing. In most cases, however, deviations from this standard play strategy were unnecessary and, using this strategy enabled the possibility of one agent eliminating their opponent in the first turn. This put the range for round length using the standard play strategy at between one and thirteen turns for full completion; the full possible range for the game.
Figure 2 shows the output from a typical game between the two agents using the default reasoning.
2.2. Phase-I Testing
To see the extent of the likely outcomes of a game between two agents using the standard play strategy, 10
6 games were played to test a number of initial hypotheses. It was reasoned, firstly, that the likelihood of a draw or tie between the two agents was so remote that it would be statistically insignificant. Secondly, assuming this to be true, it was thus reasoned that as it was possible to eliminate one opponent in the first round or, that by going first, the second player was to have access to more information for their first turn that there may be some advantage to one player or another dependent on the turn order. Our hypotheses are, thus, stated more formally below:
Hypothesis 1 (H1).
The probability of a game ending in a tie, on average, would be so unlikely as to be insignificant in comparison to winning or losing.
Hypothesis 2 (H2).
There is some statistically significant advantage to taking the first turn.
Hypothesis 3 (H3).
There is some statistically significant disadvantage to taking the first turn.
After the full run of 106 games only 101 games were identified to have been a draw. The probability of a draw using the standard play strategy was then calculated using a Poisson distribution as P(D, X = 1) = 0.0001. At one-percent of one-percent we concluded that the results supported the expectations of H1.
The next analysis required that H1 had been fulfilled and, therefore, in order to provide for statistical significance in the next hypotheses tests, we could assume that, all other things being equal bar the turn order, that the likelihood of winning or losing was equally as likely. This being the case, both H2 and H3 could be reduced to probability statements; P(W, X = 1) ≥ 0.5 and P(W, X = 1) ≤ 0.5, respectively. The results of the completed 106 games concluded with 537,128 player one wins to 462,771 player one losses. Using Chi-squared to compare with the reasoned expected outcomes being close to one win for one loss, X2(1, N = 106) = 512, the resultant p-value of less than 0.00001 confirmed that this trend was statistically significant and reflected an accurate likelihood of performance based on turn order. On the basis of these results we were able to confirm H2 and reject H3 suggesting that, under ordinary circumstances, the standard play strategy yielded a probability of approximately 54% likelihood that the first player would win the round or game.
3. Modelling Frustration for Agent Manipulation
3.1. Frustration as It Has Been Observed in Human Players
Our first-stage research in frustration effects on gameplay was devoted to frustration factor identification. In terms of outcomes frustration manifests in one of two ways, each of those ways being relative to certain identified factors and existing within a range. The first outcome is that the effects of frustration will cause the player to become more determined in their pursuit of victory [
2,
3]. The second outcome is that the effects of frustration will cause the player to give-up, and, accepting their imminent defeat, the player will no longer make serious attempts towards victory, either quitting the game then and there, or continuing to play in a tokenistic fashion [
4].
This, albeit generalised, depiction of the effects of frustration does point towards a major impact factor for frustration modelling: a determination index. As with ordinary human players, the determination index represents the cumulative effects of the process factors associated with frustration, mimicked by the agent [
5,
6]. In practical terms within the EEL, the determination index is used as a pointer to a subset of coefficients within a set of larger modelled emotive behaviours. The purpose of these subsets is to make alterations to the data variables that any such state machine might use and alter them in a way that is comparable to human emotive responses on reasoning and reaction to in-game events.
The agent investment shift in light of the win/loss ratio is significant in that frustration does not merely manifest itself in negative ways. It can focus a player to improve their performance, particularly if the match is a close one [
7]. Thus, the significance of the EEL not completely hampering an agent’s chances is that one might expect an EEL focused on frustration to only demonstrate negative effects. Instead, as described in the evaluation, the EEL functions insofar as it allows the frustration effects to be more nuanced than the AI simply losing hope. The mean shift therefore, represents a multitude of different frustrated emotive responses.
Defining the process factors for modelling purposes requires a better understanding of the causes of frustration. There is good support for the idea that emotional responses can be linked more to a cultural, than a biological, origin [
8,
9]. It is worth exploring this idea in terms of views to the contrary. It is often said that emotions are the antithesis of reason, however, here the physiological and emotional state are intertwined. One such example, for instance, could be the way in which an actor in a horror movie fumbles with the keys in trying to escape in a car while zombies chase him. In this case it might seem apparent that the character is not frustrated at his inability to locate the ignition slot because the zombies chasing him are triggering an adrenal response for his own personal safety rather than any cultural connotations with regards to zombie behaviour. Is this character frustrated? Yes. Are the rampaging hordes of zombies the cause for the frustration in this example? No, or rather at least not directly. It would present a fuller picture to make a case that the frustration occurred due to a failure of the character to perform to expectation rather than the fear factor. This matches what has been observed in human-players when they become noticeably frustrated in other gaming or social instances [
6,
10,
11,
12,
13]. Fear, instead, is the cause of the failure to perform. This may seem an arbitrary distinction, however, to suppose a more direct link would be to suppose that it would always naturally follow that fear would lead to frustration.
This effect has been seen before in instances where players have been in direct competition with others in video games. In these events frustration was found to be derived from personal performance failing to live up to reasonable expectations, such as a win/loss ratio, or from a failure of the game components to adhere to the players’ general expectations [
1,
6]. This puts frustration, as an emotive reaction, squarely in the context of the game and the cultural expectations the player has for this game. If we were to take, again, the horror example of our character’s attempted escape by way of illustration, then the flow of the reaction follows an interesting and telling path for emotive effect.
Fear, as a process of biological stimuli, affects the capability of the person, leading to a diminished performance and a failure to meet expectations, is really a manifestation of frustration.
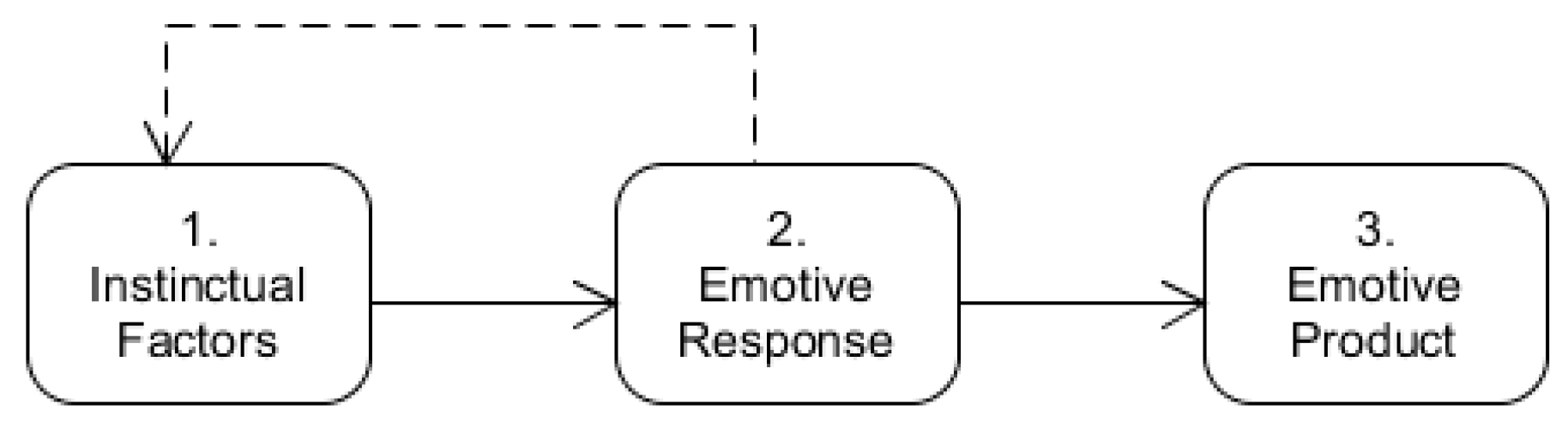
That frustration will then manifest itself in a number of ways, one of which might be lashing out in anger. Anger, in this case, is not an emotive response, itself, but rather the product of an emotive response recognisable by an exhibited behaviour. Therefore, if, instead, one were to consider fear an instinctual reaction of biological stimuli rather than a cultural-emotional reaction to a failure of expectation, then it is possible for the two instances to exist within distinct categories without contradiction. This allows the flow of information, such that it exists in this abstraction, to follow the form given below (
Figure 3):
Instinctual factors as the basis of an initial subset of data feed with other data sources into an emotive response. It should be noted that these factors can run the gambit between simple fact gathering within the game-world, the state of play, environmental factors, etc., and predetermined interpretations of values as artificial biological stimuli.
This emotive response, which is the positioning of the Emotive Effect Layer, in turn manipulates this data so as to condition a desired behavioural effect in the state-machine.
This behavioural effect is, itself, in the form of an emotive product, a description of an exhibited behaviour. This is achieved through use of the determination index, as described previously, and the selection of a subset of modifying coefficients.
Thus, instinctual factors are, themselves, fed into emotive mapping rather than being declared emotions themselves and, indeed, there is the possibility that the instinctual factors can, themselves, be altered by the changes made within the Emotive Effect Layer. This being the case, then the determination index, as an end product of this emotive process, must represent more than simply a range of values; it must represent the design element of the character’s personality and their will to partake in the game-play experience.
3.2. Implementing Frustration Modifiers through the Emotive Effect Layer
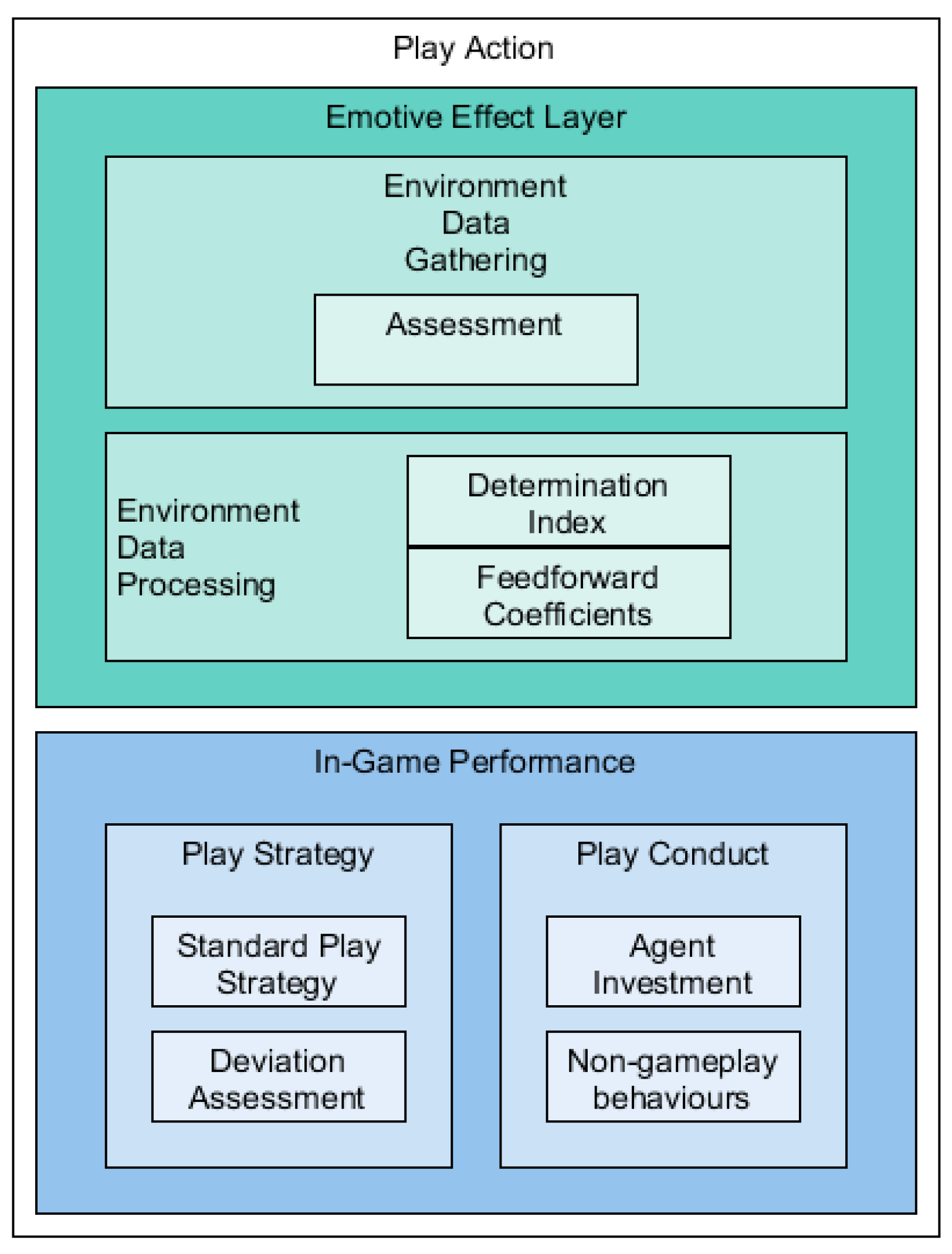
Using the data flow model described in
Figure 3 and taken from the background research of the emotional effects of frustration detailed in the previous section, a revised-play model (
Figure 4) was developed and implemented into the experimental prototype.
As
Figure 4 shows, much of the in-game performance remained the same from the original standard play strategy, including the capacity to deviate from that strategy when specific conditions allowed the agent to do so. The new factors found in Play Conduct provide part of the mechanism for determining how the agent is to react according to the state of the game rather than to specific plays in the game. In this way the non-gameplay behaviours are directly linked to the idea of an emotive product (as illustrated in
Figure 3).
This might mean, for example, that an agent abandons a match after a number of successive failures. However, in this particular example, that reaction might be triggered by an overall lack of investment in the agent over the course of a number of games or a sudden number of “bad beats” causing the agent to become “tilted” [
14,
15]. This would serve as a comparable input to the instinctual factors found in the model of the data flow of
Figure 3 for the purposes of playing a card game.
In the Emotive Effect Layer, itself, the actions are divided into two processes. The first, and simplest, is the environment data gathering which takes data from the game-world itself and, in effect, normalises it for use in the second process: environment data processing. In this instance the data that was gathered was limited to information regarding the state of play which encompassed, the agent’s success rate, games remaining, likelihood for match success, the spread of game loss, etc. In other game settings these points of reference would alter according to the context of the interaction.
During the environment data processing tasks a value for the determination index is derived as a product of the agent’s investment value, previous determination index score, and a controlling coefficient, referred to as the valence spike coefficient. This calculation is, therefore, reminiscent of the derivative calculation used in gradient descent for certain machine learning techniques and was modelled purposely so as to match extreme models of behavioural change. The determination index and the agent investment value are somewhat linked in that they are ascribed values given to the agent at initialisation to numerically represent, respectively, the agent’s will to succeed and its understanding of the stakes of the venture; fundamental cultural aspects for the framing of emotive reactions [
6,
9]. So, for example, an agent will have a greater investment value in a card game if that card game has stakes, such as in betting, than a card game that does not. In our example the stakes were increased artificially by calculating the win-loss ratio of the games of a match and interpreting a critical point for that ratio as being representative of either imminent success or failure.
The valence spike coefficient is a secondary calculated value, which is an influencing value modelled on behavioural outbursts attributed to specific events during the game [
16,
17]. These values were used to affect a dramatic shift in the determination index to represent the emotive effects of certain events. Such sudden spikes of pique are commonly found in observations of frustration in human players [
8,
10,
18,
19]. Consequently, these values act as a means to shift from specific sets of feed-forward coefficients to other extreme values that were chosen to represent a better-suited altered emotive state.
The determination index, when calculated using these values, produced a single decimal figure between the values of zero and one. It should be noted, however, that this determination index value was not thought of, and nor should it be thought of as representing some percentage of frustration. The determination index value was used only as an index, within a range of acceptable values, for a table of different configurations of feed-forward coefficients to pass into the play strategy of the agent. These feed-forward coefficients were modelled to be indicative of emotive products taking effect on the agent’s ability to make decisions according to the strategy it used. So, for example, two of these coefficients were placed to affect the agent’s ability to calculate probabilities relating to play strategy; the first affecting the value of remembered cards of only the agent themselves, and the second affecting the value of played cards by both agents. The configuration of these feed-forward coefficients used in this example is meant to simulate frustration-induced forgetfulness in deliberation as seen in human players [
2,
20,
21]. Similar configurations were then modelled based on the supporting literature we had researched and we created an implementation of the EEL to pipe in to an agent’s standard strategy for use in our second phase testing. The process algorithm for the EEL as it exists in the
Love Letter experiment is as follows:
- (1)
The agent, as part of the normal default strategy, first calculates the probability assessments for their own hand, the opponent’s hand in light of previous plays, and performs an analysis of what their play should be in light of this information.
In order to perform these calculations the agent has knowledge of how many of each specific card exist within the game deck, how many of that card have already been played, as well as prior information gained from information-seeking cards.
The probability calculations can be split into two activities. Raw calculations which occur first from knowledge of the game, and override calculations which come from turn-by-turn acquired knowledge. Thus a base probability is first calculated, and then adjusted where appropriate.
The base, or raw, calculations are subject to alteration by associated coefficients. These coefficients represent gameplay reaction values, such as tilting effects or successive loss effects. Each of these coefficients are represented as value from 0 to 1, with 1 being the initial state and are subject to alteration. Thus this represents the agent’s ability to have their reasoning altered by gameplay events, the base probabilities becoming either more or less accurate as the case may be.
- (2)
The agent performs their turn action.
- (3)
Steps 1 and 2 are repeated until game end.
- (4)
There is a game evaluation analysis.
This analysis reviews the state of the match in terms of win/loss for the agent, the length of the game by number of terms, the trend of expected behaviour as seen in frustration profiles taken from human player observations.
This analysis is then used to calculate agent investment and valence spike values which are, themselves, values between 0 and 1, as per the expectations of behavioural shifts seen in the real world. In effect, these are normalised values taken from data taken from the frustration, gameplay, and motivation studies cited in this paper.
The shift of investment and valence spikes are then compared to their previous values, or 0 in the event of a first calculation.
The determination index value is calculated as a product of these shifts in the same way as a multi-variable chain differential as used to calculate error gradients in back propagation techniques.
- (5)
The newly-determination index value points towards a specific subset of probability affecting coefficients or behaviours, as described in Step 1, which are fed as new replacement values for those probability coefficients or describe some game action, such as ending the match before a full ten games have been completed.
4. Phase-II Testing
Before the second phase testing began we first decided upon a number of predicate statements by which we were able to assess the performance of the agent affected by the implementation. These predicates served as guidelines for the types of reactions we expected to see from the affected agent. For the purposes of clarity there are a few terms that ought to be introduced. Play between EEL-affected and non-affected agents was divided into matches, each match being the best of ten games. Matches were completed when one agent or another had reached a majority of six wins.
The critical play moments of match play were, therefore, defined as moments where one agent or another was likely to achieve a majority of wins in either the current or next game. Other terms used in the predicates refer directly to components of the EEL. These predicates are:
Agent investment should steadily increase in value during match play IF the win-loss ratio for the agent remains close to one [
6]. Other negative consequence effects during this eventuality should have lesser impact, as well.
Agent investment should increase rapidly IF the game concludes with a loss, but took greater than 10 turns to complete.
Agent investment should decrease rapidly IF the win-loss ratio for the agent reaches towards a critical point for match play.
Agent investment should decrease rapidly IF the game concludes with a loss and in fewer than 3 turns.
The agent’s ability to calculate probability should reduce IF the agent suffers a number of losses in quick succession, comparable with effects of “tilting” [
15].
The agent will end the match IF the agent investment value is sufficiently low (<0.15) and the win-loss ratio suggests that match play is reaching a critical point.
During testing agent investment was initialised to 0.5 for each match and changes to agent investment were recorded for each game of the match, as well as cumulatively for the entire match. As Phase-I testing had revealed that, using the standard play strategy, the second player was noticeably disadvantaged for taking the second turn, it was decided that the second player ought to be the agent affected by the EEL implementation, as it was reasoned that this increased the likelihood of observing the frustration effects of the EEL.
Given this disadvantage, and the likely negative cumulative effects of the EEL on the second agent’s performance, it was hypothesised that the affected agent should, on average, have a smaller investment value after a match than before it. This outcome would, thus, represent a strategy affected by frustration and sudden behavioural shifts associated with negative gaming outcomes. The negative shift would not, however, be absolute as the above predicates allow frustration as an emotive response to, instead, focus the agent to become more determined to win.
The table below (
Table 1) shows results from the second phase test results from the data collected from 10
5 matches.
The results shown in
Table 1 provide some interesting perspectives on the effects of an EEL implementation on the standard play strategy. The first, and most striking, is that the number of match losses suggest that the deleterious effects of frustration provided for via the EEL have hampered the agent’s in-game abilities, but not entirely eradicated the agent’s chances of winning. However, the win-loss ratio breakdown does show that the affected agent secured only 12.82% of total match wins during the entirety of the tests.
The win-loss breakdown shows that the most likely result of the EEL frustration-affected agent is losing a match three games to six. This is simple to explain if one understands the behaviour of the agent in light of the predicates given above. In this instance it is likely that the agent, having lost some early games to its opponent, would instead refocus their efforts on redressing a balance between gameplay results.
It is likely, also, that, unlike a match scenario for a win-loss ratio of 0.67 instead, that the agent would likely have suffered a number of losses in quick succession which would have an effect on the agent’s ability to return the ratio nearer to 1. As the agent suffered further losses, and noting that the match was reaching a critical point, the agent may well invoke the behaviour described in predicate six and end the match.
As was hypothesised, the final agent investment value was, on average, lower after match play than its initial value. This aligns with what would be expected given the structure of the Emotive-Effect Layer’s influence on the agent’s strategy and the behaviours modelled by the effects of the feed-forward coefficients; stated within the given predicates for expected agent behaviours. Surprisingly, the mean agent investment shift per game was much higher than expected. The explanation given here is that the factor of the valence spike coefficient was too great an influence on the EEL’s effect on the calculation of the determination index values. This would help to explain the overall negative gameplay experience trend found in the match play results of the affected agent when compared with the game results described in the first-phase tests.
5. Conclusions
The results of the second phase tests with an EEL implementation demonstrate what might be described as a partial success for EEL as a model for managing the emotive-effect in decision-making for AI agents. However, this partial success is tempered by some limitations. Firstly, the structure of the EEL requires a complex integration with the key components of an agent’s strategy in order to take an effect on that agent’s ability to reason under emotional stresses. The nature of this complexity may present the Emotive-Effect Layer as being unwieldy and convoluted to make it of practical use in the design of in-game agents. This could be true also in that the integration of the EEL may not be abstract enough to make it suitable for as wide a range of gameplay settings and behaviours as we might wish. Secondly, the output of these tests have been text-based and between two AI agents. Consequently, the Emotive-Effect Layer has no direct provision for animated behavioural responses, which might lead to a more interesting gameplay experience. Nor, indeed, has the EEL been endowed with the ability to assess environmental information derived from a human player, such as completion time, micro-movements of controls, patterns of activity, etc.
Lastly, as a rudimentary effect layer focused only on frustration derives effects, the EEL has not accounted for the management of data flow when processing different emotive states. As discussed above, the self is also influenced by visual cues and this is something that is available in a face-to-face situation or in a virtual game, but not through an algorithm based on non-visual cues.
These are, perhaps, ambitious quibbles for the foundation of a larger model of emotive-effect. However, it is important to note that it is realised that the EEL does not give an entire picture of what might be achieved in this area. Further experimentation will need to be undertaken to address the limitations described above, and only when, and if, the EEL can be said to have surpassed these issues, it can it be said to have begun to present a workable model for emotive-effect on AI agent strategy.








{kind=link}
{kind=link}
{kind=link}
{kind=link}