1. Introduction
In image processing applications such as object recognition, segmentation or Visual Search (VS), a filtering stage is always required. In particular, often the convolution operation has to be performed directly in two dimensions, due to the inherently two-dimensional (2D) nature of the object to process. Moreover, during the last years the computational complexity of designs dedicated to this kind of problems underwent a critical growth, due to more complex architecture designs and an increase in the amount of data to be processed, related to higher resolution images. These kind of issues are typical of any algorithm working on 2D portions of images [
1,
2] and they are relevant in both software (SW) and hardware (HW) applications.
In particular, VS search applications are among those which require most in terms of complexity, due to the high amount of calculations needed for searching and extracting the features in the input frame [
3]. However, in these kind of applications, SW implementations are usually limited in terms of maximum achievable frequency, which does not allow for real-time processing in the case of higher resolution images unless using strong simplifications of the algorithms. Among the most important 2D filtering applications, one of the most important regards the convolution between a tile of the image and several Gaussian kernels to obtain the Difference-of-Gaussian (DoG) scale-space pyramid [
4]. These elaborations are required in the Scale Invariant Feature Transform (SIFT) [
3,
4] algorithm, for example, where they represent the most computationally demanding step. In this case, SW implementations of the algorithm require long elaboration times to process a single image, thus they are not capable of achieving real-time performances, while the problem is worse for images having higher resolutions [
4,
5,
6,
7,
8]. For these reasons, HW implementations of filtering stages are more and more frequent, but it has to be underlined that the effort to obtain optimized designs is not justified by the real-time requirements only. In fact, the diffusion of handheld devices and Internet-of-Things (IoT) applications is leading the research to new designs, capable of achieving better Area-Power-Delay (ADP) trade-offs. Starting from these considerations, during the last years, several HW design have been proposed aiming to obtain optimized filtering architectures dedicated to SIFT and feature extraction [
8,
9,
10].
Another issue arising in applications dealing with image processing is related to the large amount of data to be processed and stored and thus to the memory requirements for frame buffering. At this end, other works have focused on memory management in order to develop architectures capable of optimizing memory designs, together with writing and reading operations. The solution proposed in [
11] exploits custom coding and a partial serialization of the filtering operation to obtain a buffer-less solution. The design is tailored for DoG operations and its method could not be used as presented for other VS applications or other methods not using Gaussian kernels. On the contrary, the design presented in [
12] could be used with kernels different from the Gaussian one, since it does not recur to the separability property of the Gaussian kernels, presenting a complex arrangement of SRAMs modules, row shuffling operations and dedicated logic, which complexity grows with the dimensions of the tile to be processed.
Another huge difference between SW and HW implementations regards the simplification of the operands from IEEE-754 floating point data (FP32) to fixed point (FI) ones. This simplification reduces the accuracy of the design to obtain units capable of performing multiply-accumulate (MAC) operations with better ADP performances, while reaching a trade-off on the accuracy of performances. Meanwhile, very few studies have been conducted to optimize the arithmetic units and improve their performances. Other simplifications of the above-cited methods regard reductions of the algorithm’s complexity, such as the reduction in the number of scales or octaves or a decrease of the value of the standard deviation of the Gaussian filter in the case of SIFT applications [
13,
14].
The aim of the present work is to develop a novel 2D convolutional filter for the processing of images obtaining FP32 results, showing low area occupation and power consumption, while achieving good speed performances. This has been achieved exploiting an ad hoc partitioning method of the operands [
15,
16], dedicated to multimedia applications and to all other applications which present a well-defined integer input range and working on kernels of fixed coefficients. Moreover, the design is capable of working on continuous data streams, which could be provided by either an external memory or an acquisition device, such as an image sensor without using any frame buffer, thanks to a careful organization and management of small intermediate buffers, which allow for on-the-fly calculations. The organization of the data and the management of the memory structures have been favored by the optimized hard macros available in modern Field Programmable Gate Arrays (FPGAs) to implement Block-RAM (BRAM) modules. However, the FPGA implementation has been chosen not only for the availability of hard macros for the memory structures, but also for prototyping purposes, before developing an Application Specific Integrated Circuit (ASIC) design. Avoiding the use of multipliers, the design achieves great area reduction if compared to structures having the same accuracy, allowing to greatly improving the performances to obtain a FP32 compliant result in this case. The implementation of the proposed design on a high-end FPGA board shows a worst delay path of 4.7 ns to elaborate an IEEE-754 FP32 compliant results in the slow/slow corner, considering a 3 × 3 pixels window as input.
2. Mathematical Background
The implemented partitioning method derives from a problem stated for the first time by the French mathematician Claude-Gaspard Bachet de Méziriac in the XVII century. The original formulation of the problem regarded how to establish the minimum set of integers to obtain any integer number included in the range [1; 40] using addition and subtraction of the parts composing the set. The problem, known as Bachet’s Weights Problem, concerns theory of numbers and was analytically discussed for the first time by Hardy and Wright in [
17]. However, a solution to the generalized Bachet’s problem, in which 40 could be replaced with any integer number, has been developed in the last years in [
18,
19]. A complete review on the problem, its discussion and on the relative theorems is provided in [
20]. The principal conclusions which are useful in understanding the proposed design are summed up in the following.
Theorem 1. Given a range of integers [0; r], it is possible to define a set of integers of cardinality capable of obtaining all the values in the given range as a combination of the terms , called parts.
Theorem 2. The set is composed by union of the first powers of 3 and the term . The obtained set could then be rewritten as .
Theorem 3. The obtained partition is a unique one and does not exist any other partition, , of the set [0; r] which satisfies the conditions stated in Theorem 1 and Theorem 2 and is composed by fewer than n+1 elements, as .
The reported theorems allow to express any integer number in the input range,
, as a combination of the previously calculated parts
where
is the generic coefficient defined in the set
and used to obtain the correct choice of the parts. The application of the proposed method to obtain any
number is given in
Table 1, in the general case of
parts and.
Equation (2) shows an example in the case of an 8 bits input, in which the partition set is defined as
for the input 42
and the set of values
.
It is now possible to understand how Equation (1) is capable of obtaining a partition of a generic multiplication between an input pixel, representing an integer value, and a value taken from a set and representing a coefficient of a Gaussian kernel. Doing this operation also for the other pixels composing the input tile, having dimensions
, it is then possible to obtain the result of the 2D convolution between the input tile and a generic kernel F, of the same dimensions. The result of the filtering operation for the central pixel of the tile
could be rewritten as
where
and the general input tile
is a matrix in which each element can be decomposed as in (1).
In typical image and video applications working on gray scale images, such as in the case of VS, the input data is coded using 8 bits, representing an integer number in the range
. In these cases, choosing the dimensions of the kernel, it is possible to obtain the coefficients of the filter,
, and precompute all the partial products between all the
and all the parts
. All these pre-calculated products could then be used to rewrite the convolution operation as a summation of the various terms,
P:
where
The minimality property of the set, obtained using the proposed partition method, guarantees a simplified computational complexity to implement Equation (4), if compared to a classical base-2 Distributed Arithmetic (DA) method. Moreover, compared to a base-2 DA decomposition method, the proposed architecture avoids shift operations.
3. The Proposed Architecture
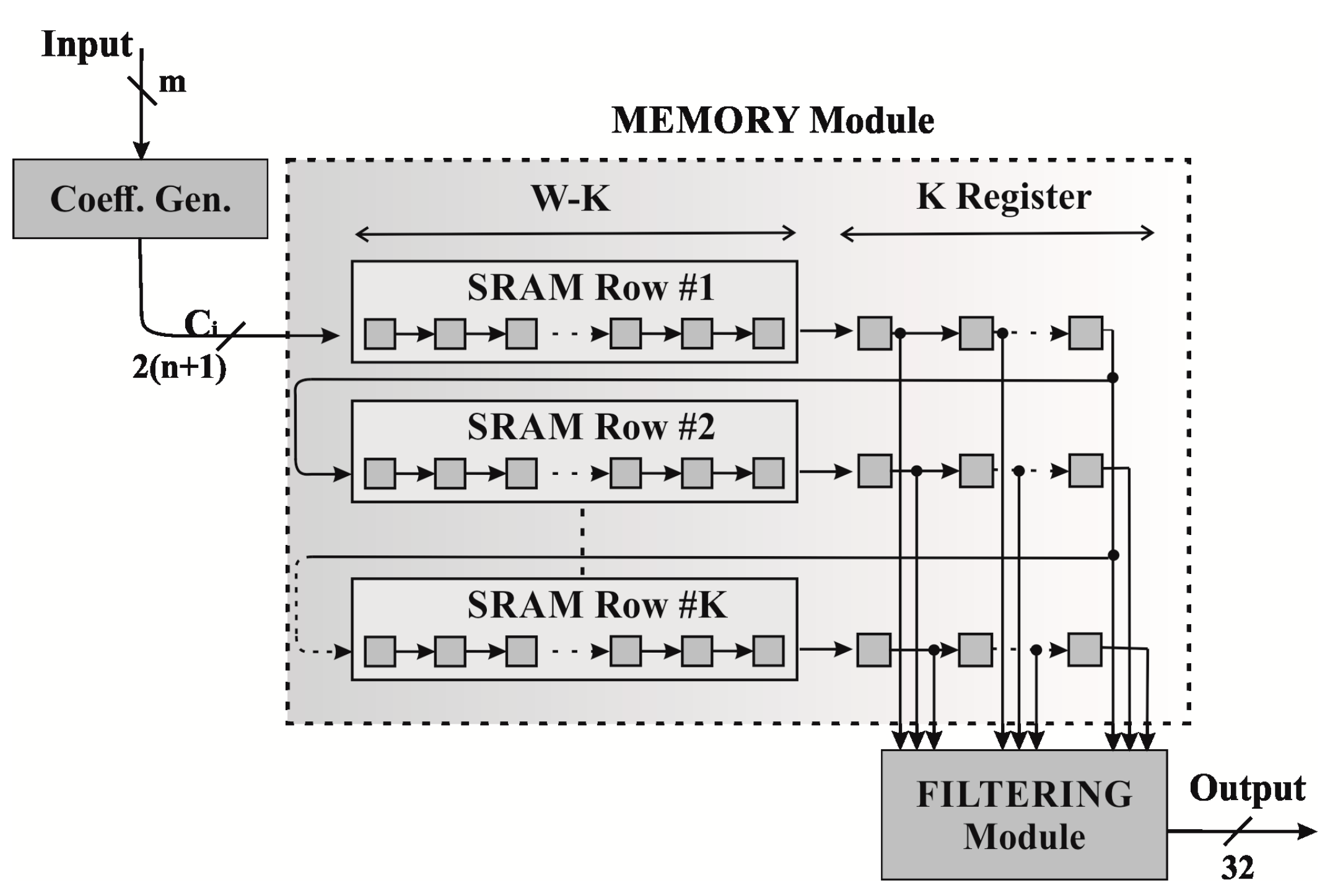
The proposed method has been used to implement a 2D filter, starting from a single FP32 multiplier unit developed using the Bachet decomposition. The input pixels are, in general, coded on m bits, representing unsigned integer data, and they are acquired in raster-scan mode, without using input frame buffers or caching apparatus, except from the one provided by the input acquisition device itself. The main units composing the architecture are:
A block scheme of the proposed implementation is depicted in
Figure 1.
3.1. Coefficient Generator Unit
In order to calculate the combination of the various
parts, a unit capable of generating the various
coefficients for any
of the input range is needed. This unit, called Coefficient Generator Unit, takes as input the Uint-m data and returns a
bits string as output, since every sign coefficient
is coded on 2 bits. The unit is principally made up by a Read-Only Memory (ROM) implementing the coding reported in
Table 1, where the input range, i.e. the value of the input length in bits,
m, establishes the size of the ROM needed to store all the coefficients, which value is
Obviously, after this operation the input pixel value is no longer needed, since this information is coded in the associated coefficients that are sent to the Memory Module.
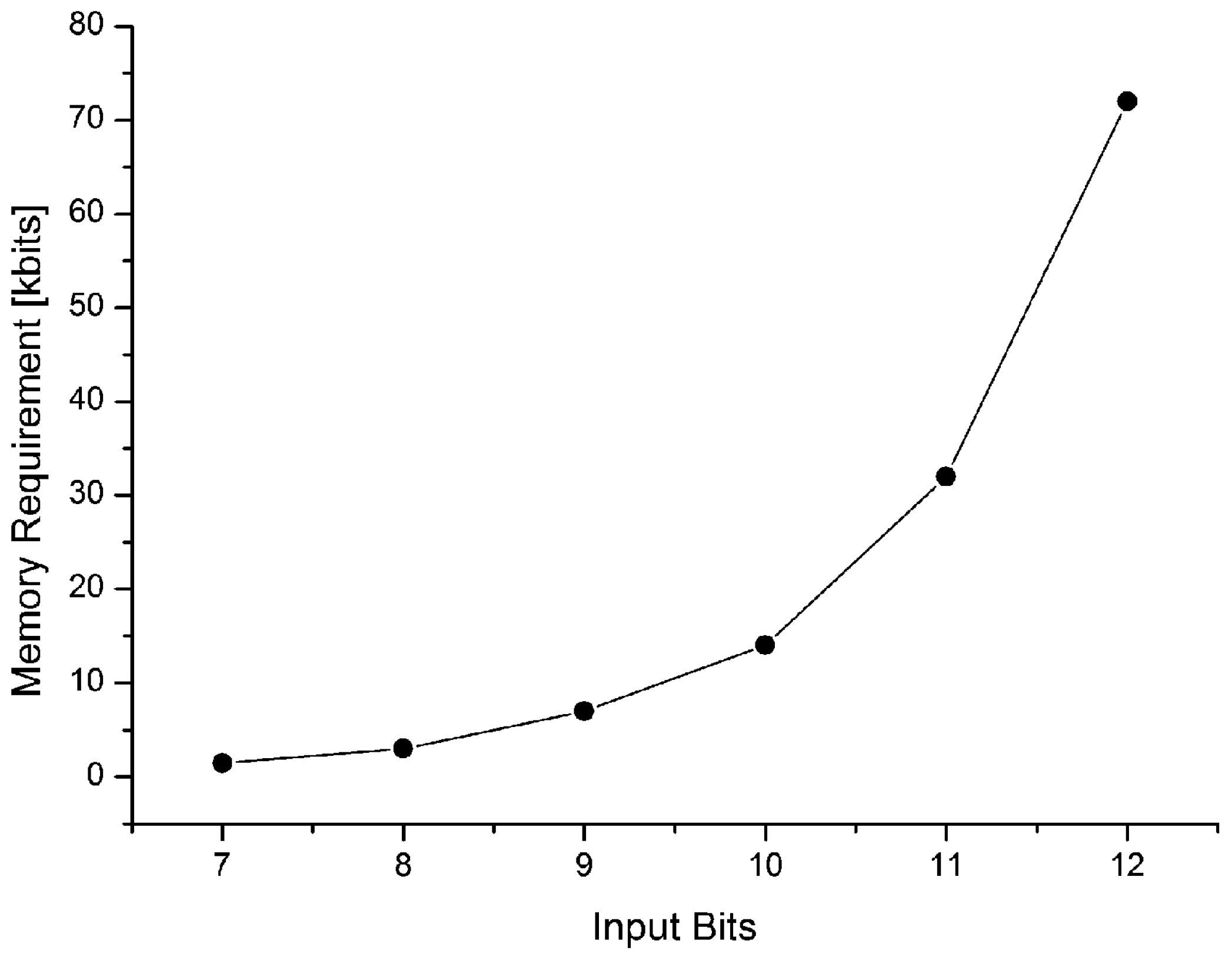
Figure 2 reports the memory requirement for the Coefficient Generator ROM varying the number of the input bits.
3.2. Memory Module
The data coming from the Coefficient Generator Unit are stored in a Serial Input Parallel Output (SIPO) unit. The SIPO takes the input pixels in raster scan order and could be represented as a stripe buffer having dimensions , to store the first rows of the frame to be elaborated. Only when the first values of the last row arrive to the buffer, the data related to the tile to be processed are ready to be sent to the filtering stage. In this way, after the Memory Module stored values it is possible to process one pixel per cycle, due to the organization of the memory described above. In fact, the insertion of a new data in the Memory Module, causes the shift of those stored in a way that data to be filtered result naturally aligned in the new tile, without any additional operation.
An implementation of the described Memory Module could be carried out using registers to compose the entire stripe buffer, but this kind of solution has the major drawback of requiring a large amount of physical resources. In fact, for an 8 bit input, in the case of working on VGA frames (640 × 480 pixels), would require, in the case of a kernel having , values; considering that each value is coded on 12 bits, the total amount of memory to be implemented has to store 188 Kbits. A much more fitting solution consists of using embedded BRAMs modules, emulating the SIPO structure behavior, to store a complete frame row, with the exception of the data to be sent to the Filtering Module which are stored in registers instead. On the contrary, the tile has to be stored in registers, in order to preserve the data stream and to allow the transfer of all the tile to the final filtering structure. It is important to note that, due to the use of RAM structures, the shifting operations do not involve any data transfer, but only a careful management of the generation of the addresses to emulate the shift operations and maintain the correct alignment of the data. The solution is also advantageous due to the availability of hard macros in modern FPGA boards, which are optimized for data transferring and storing operations. Using a partial tile buffer, the proposed implementation is always better in terms of resource requirements if compared to a buffer-based one in terms of amount of memory to be stored.
3.3. Filtering Module
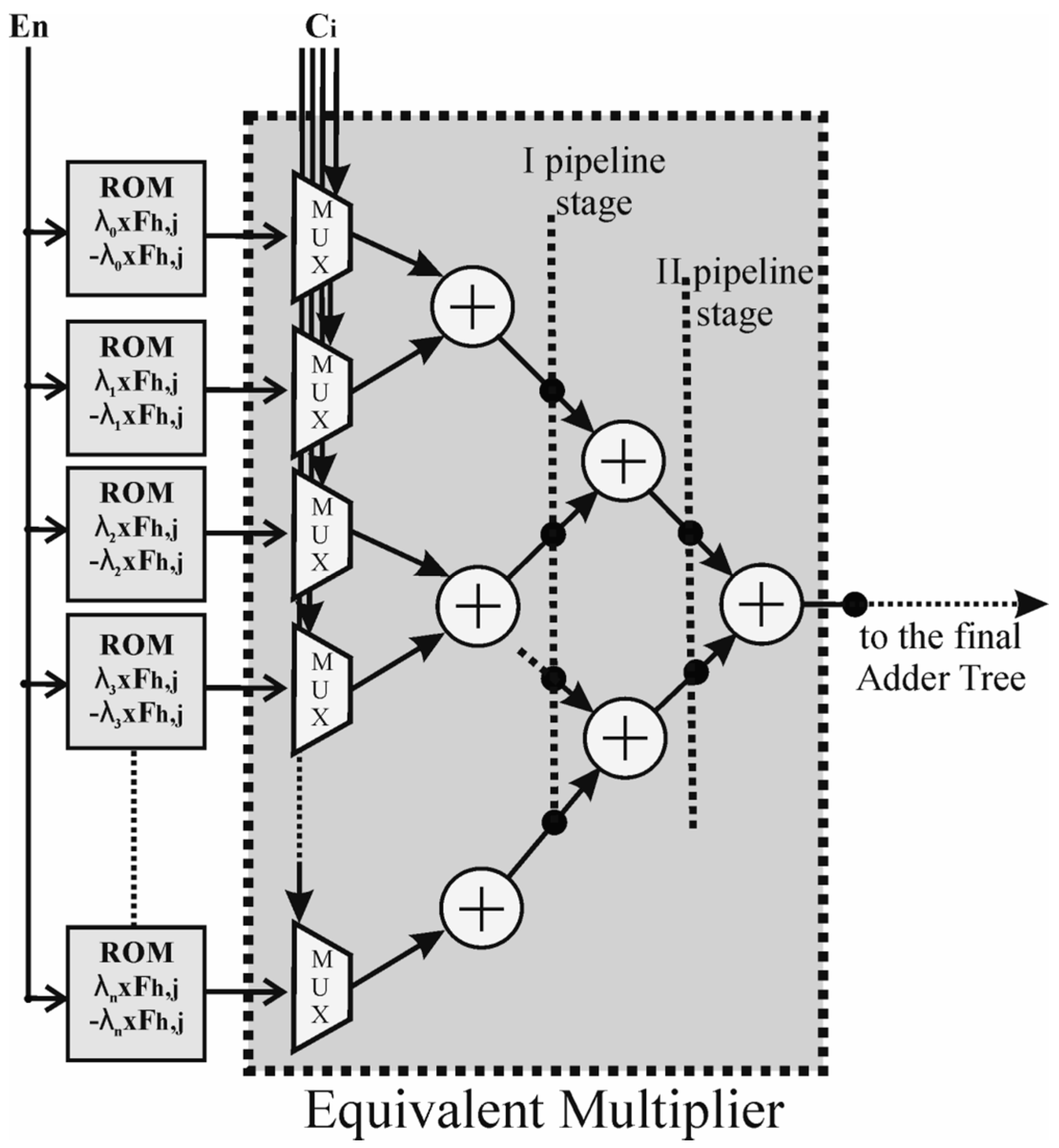
In order to calculate (3), the pre-calculated products
are stored in
small ROMs, one for each part, whose dimensions are reduced to
words for the symmetry of the kernel. A further simplification of the operation to be performed could be achieved storing also the 2’s complements of the pre-multiplied coefficients in the ROMs. In this way, when the generic
, any further logic circuitry to complement the operands for the subtraction operation is not needed. The outputs of the ROMs together with the coefficients bits coming from the Memory Module are sent to the Bachet multiplier units. It is important to note that all the ROMs must be read at the same time. The structure of the developed equivalent FP32 multiplier unit is depicted in
Figure 3.
It is basically composed of an adder tree structure, having depth and made up by adder units. The operation performed by the architecture is the one presented in Equation (3): the pre-multiplied coefficients are selected using a multiplexer and the coefficients coming from the stripe buffer as selection inputs. The partial results of the multiplications then have to be added together with the products calculated for the other pixels, to complete the convolution operation.
Moreover, the operands have been custom recoded to obtain further simplifications of the complexity of the proposed architecture, without accuracy losses. In fact, starting from considerations of the FP32 format it is possible to code the starting coefficients and the partial results as FI data, establishing the appropriate codelength in order to not undermine the accuracy of the result of the single multiplication and of the overall convolution operation. To obtain this implementation, first a careful study of the IEEE-754 coding of the product between the kernel coefficients and the parts set has to be conducted. Then, all the exponents of the pre-multiplied coefficients have to be reported to the greatest exponent among all the used coefficients and the significands have to be shifted according to the difference between the maximum exponent value and the significand exponent. Hence, to obtain the correct FI coding, the codelength of each operand has to be increased to avoid any truncation of the operands that could undermine the accuracy of the result. Given the minimum and maximum kernel coefficients,
and
, it is possible to obtain an analytical formula to choose the adequate codelength,
, as
where 23 bits are the length of the standard FP32 significand while
and
represents the minimum and maximum element of the calculated part set, respectively. Using this type of coding, the mantissas of the partial results do not need any normalization operation and the exponents are not taken into account in these operations, causing a resource and thus an area saving. The normalization operations on both the mantissa and exponent of the final results will be then performed in order to obtain a FP32 compliant format, allowing to correctly reuse the outputs of the Filtering Module for further elaborations.
3.4. Memory Reduced Bachet Multiplier Architecture
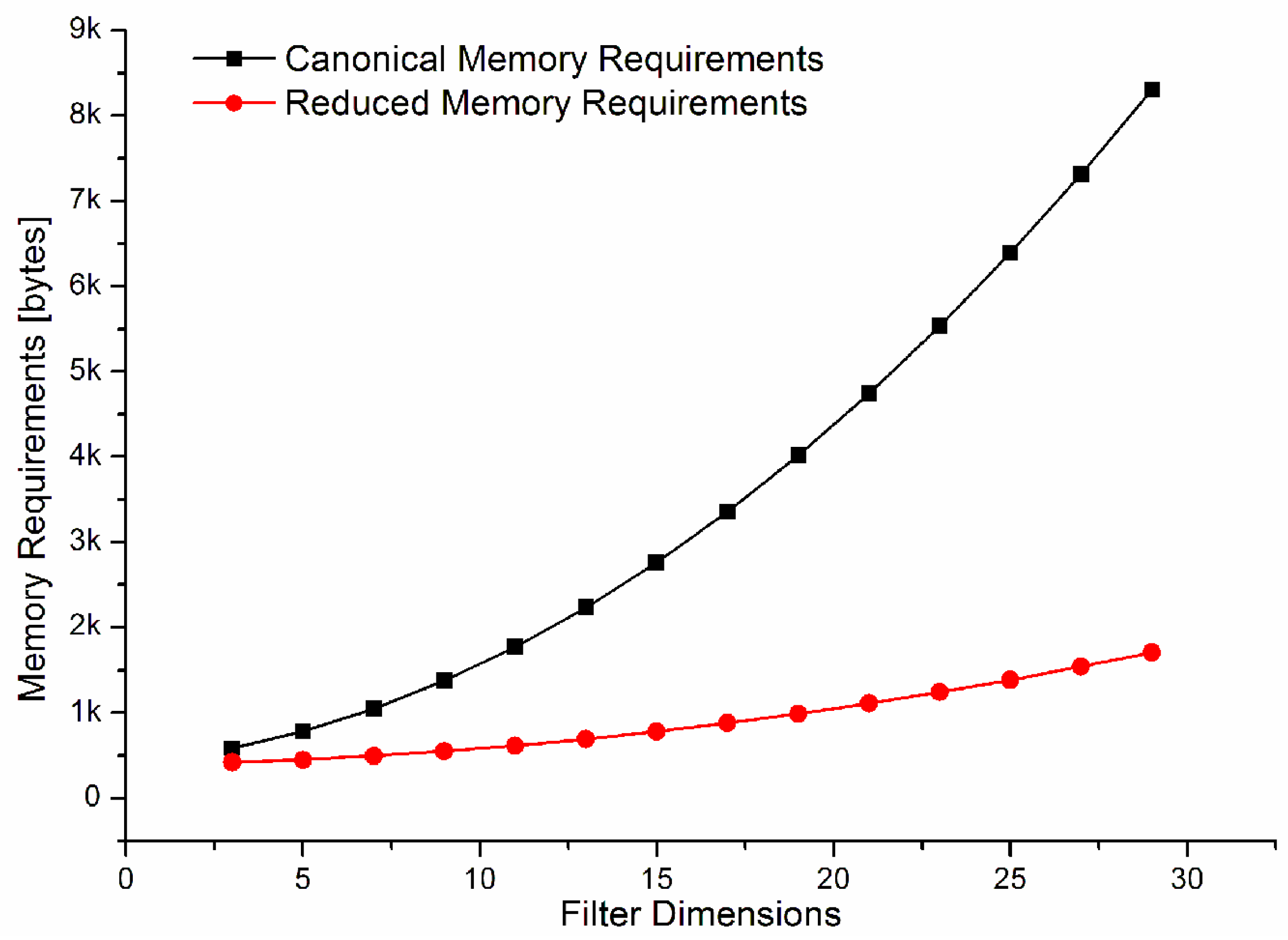
A study on the amount of memory to be stored, increasing the dimensions of the tile to be processed, has been conducted. The results are shown in
Figure 4.
Given an input range, the amount of memory to be stored related to the
does not increase with the filter, as showed in Equation (5). On the contrary, the number of bits to be stored that are dedicated to the pre-multiplied coefficients undergoes a huge increase with the filter size. Analytically the number of bits,
, increases as
where
is the coefficient codelength,
is the number of parts and
is the number of coefficients to be considered.
This could result in unacceptable memory requirements in the case of memory-constrained applications. We developed a memory-reduced implementation of the Bachet multiplier, which is capable of obtaining the other
coefficients starting from
and their 2’s complement counterparts. The other coefficients are obtained by shift and add operations on the stored
and
stored terms.
Table 2 reports the shift and add operations in the case of an 8 bit input. In this case, Equation (6) could be rewritten as
This approach reduces the number of embedded ROMs to be implemented on the targeted FPGA at the cost of allocating more logic and algebraic elements. We have to underline that in the 8 bit input case there is no need to store the 2’s complements of and , since the related pre-multiplied coefficients are never used in the decomposition operations for the given input range.
4. Results
At the end of obtaining an implementation that could be easily compared to the ones presented in literature related to VS applications, we decided to implement a 2D Gaussian kernel, working on 8 bit inputs. In typical VS applications a minimum size is fixed for the kernel, thus this size has been chosen for the Gaussian kernel. The input range fixes the parameter, , and thus from Theorem 1 and Theorem 2 it is possible to state that parts are needed, while the parts set is given by and the codelength requirement to code the sign coefficients for each input pixel is bits.
In order to obtain the codelength on which to code the pre-calculated coefficients, further considerations have to be developed on the filter. A standard 2D symmetric Gaussian kernel function is analytically represented by
and starting from that it is possible to obtain the
and
values
Since
and
, substituting these values in (5) we obtain a length of the significands
bits. An example of the custom recoding is given in
Table 3.
The results related to the implementation of the proposed filter are instead presented in
Table 4, together with a comparison with architectures using conventional FP32 multipliers and a one using Modified Booth (MB) multipliers, used to compare the proposed design with DA related techniques.
All the implementations have been targeted to the same FPGA board, considering the multiplication between a FP32 and an 8 bits integer data at the end of a fair comparison. Moreover, to obtain results which are as reproducible as possible, Xilinx IPs have been used in the comparisons to implement the multiplier and adder units. In particular, the multiplier units have been implemented using a 3-stage pipeline design. We imposed not too aggressive constraints, always to obtain a fair comparison between the various designs. With this in mind, we forced the system to use BRAM modules and we do not allow the use of Digital Signal Processors (DSP), aiming to obtain a good estimation for future std_cell implementation, towards an ASIC realization of the proposed design.
As it is possible to notice from the data reported in
Table 4, the proposed design is very fit to be implemented on an FPGA board, since it is possible to obtain good speed and area performances exploiting the availability of hard macros to implement both BRAMs and ROMs. The structure developed is capable of processing one pixel per cycle in 4.700 ns. This represents a 371% increase in speed compared to a conventional FP32 multiplier and a 187% increase compared to a MB multiplier. A Floating-Point (FP) implementation on 16 bits of the proposed design has been also developed at the end of comparing the proposed architecture with the one presented in [
21]. This design has been implemented on a Xilinx Spartan 6 board, using Nexys 3, in order to obtain a fair comparison with the design in [
21]. The results are also reported in
Table 4. The number of LUTs required for the proposed implementation are approximately 38.6% and 44.8% lower than in the conventional FP32 and MB cases, respectively. However, in the case of memory-constrained applications, it is possible to use the Memory Reduced implementation of the Bachet multiplier described in
Section 3.4. To briefly recall, this solution reduces the number of stored coefficients and, hence, of the related memory, deriving a large number of coefficients by shift and add operations. For these reasons, it shows a small increase in the number of occupied LUTs with respect to the conventional FP32 filter design, while having approximately the same delay path of the classical Bachet filter. Furthermore, it has to be underlined that, since almost the totality of the LUTs considered in
Table 4 are used to implement the multipliers, it is correct to say that increasing the size of the tile,
, the LUTs occupation will increase approximately as
2, while the memory requirements will scale as shown in
Figure 4. The performances for the various architectures in terms of frames-per-second, by varying the resolution of the processed frames are reported in
Table 5.
Furthermore, VS applications usually require great amounts of memory; for this reason the amount of memory required to implement the proposed architecture does not represent an actual problem in most VS applications. In fact, due to the implementation of frame buffers [
22] or partial data storage [
23,
24,
25], in these designs usually the memory requirements are in the order of Mbits, making the additional memory required to store the coefficients negligible.
Finally, it is important to notice that implementations regarding Gaussian filters are some of the most demanding applications in terms of resource usage. For this reason, it has been employed in the proposed design. However, the proposed design can be very easily adapted to different kernel filters, by simply changing the stored coefficients. This modification, in general, causes a favourable reduction of the amount of mapped memory. Meanwhile, the arithmetic complexity of the convolution operation does not vary, depending only on the number of additions to be performed and thus on the dimensions of the kernels of the filters. For example, in the use of a weighted average filter or a Sobel filter it is possible to store fewer coefficients than in the Gaussian case. This results in a simpler implementation and allows for better performances, even on semi-custom devices [
26].









{kind=link}
{kind=link}
{kind=link}
{kind=link}