
Comparison of Four SVM Classifiers Used with Depth Sensors to Recognize Arabic Sign Language Words †


Abstract
:1. Introduction
2. Related Work
3. Gesture Recognition Pipeline
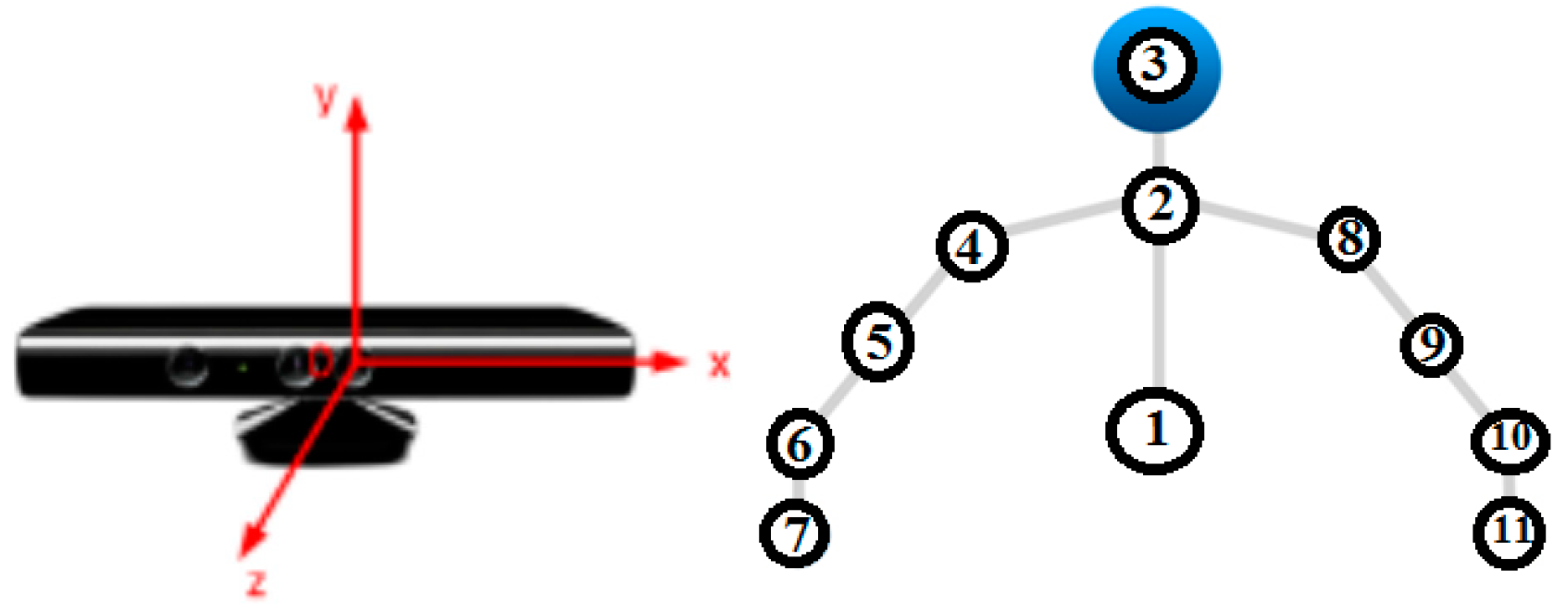
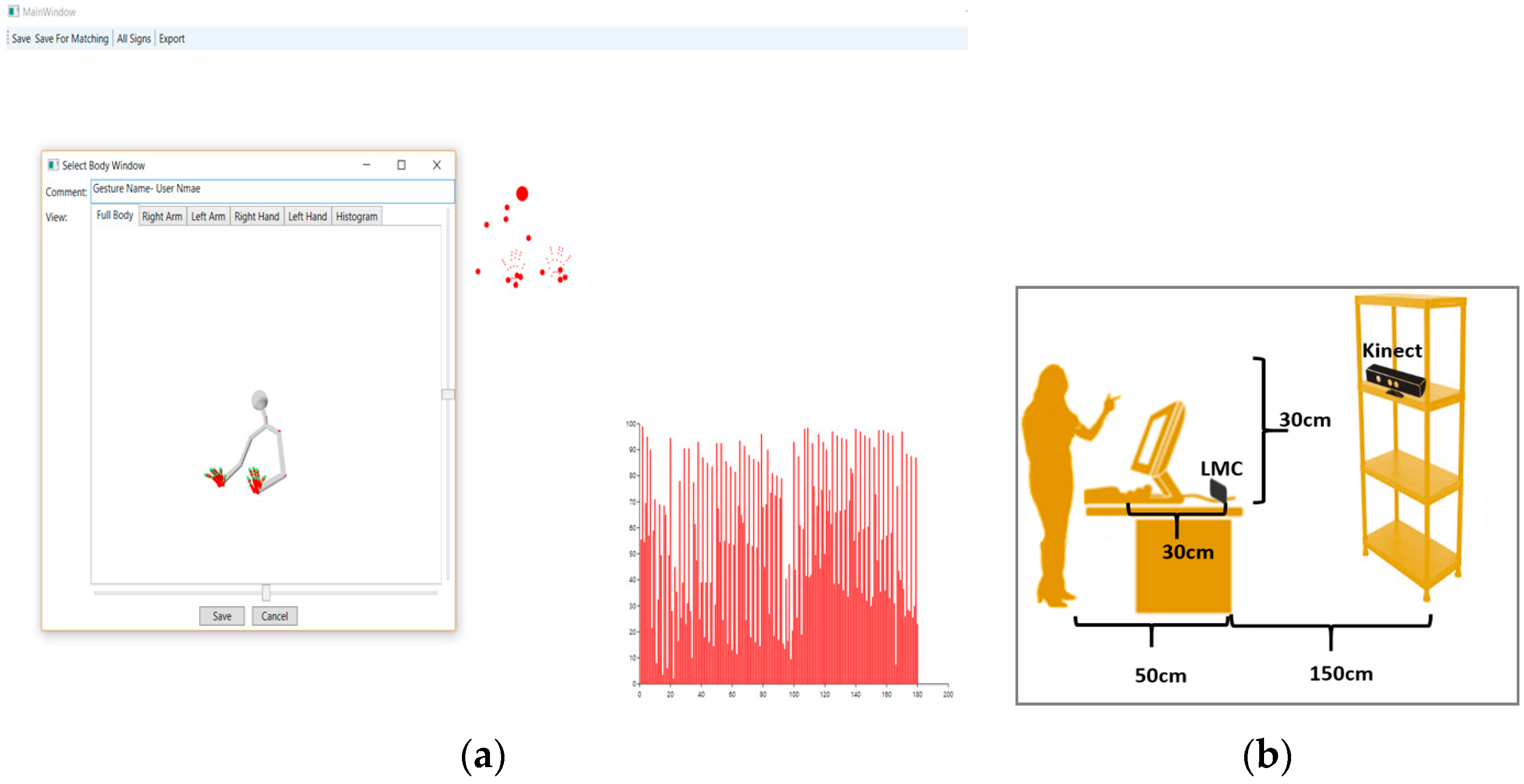
3.1. Input (via Sensors)
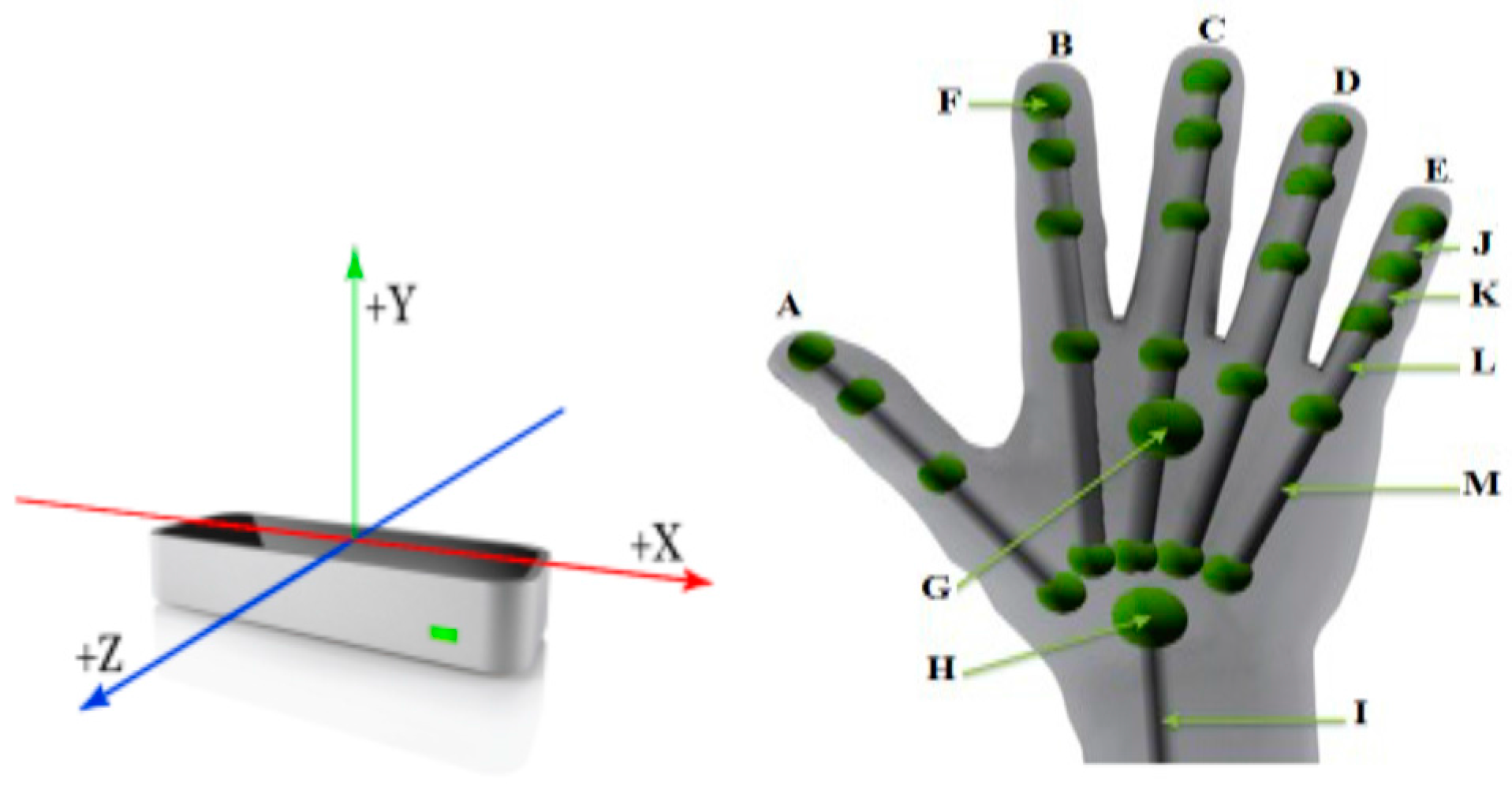
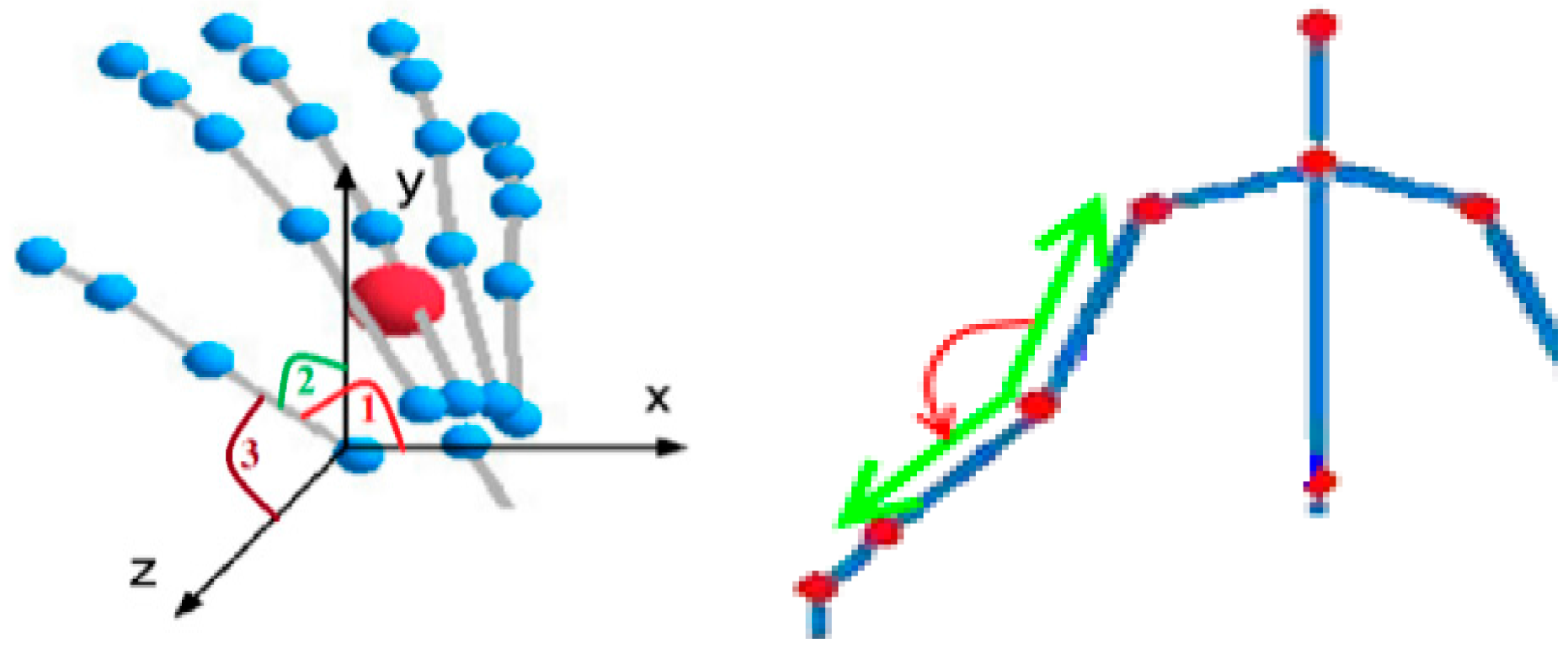
3.2. Feature Extraction
3.3. Classification Using Support Vector Machine (SVM)
4. Proposed Model
- Kinect Version 2.0 with voice-recognition and face-tracking capabilities, and an RGB depth camera.
- The two sensors (Kinect and LMC) were connected to a personal computer running a 64-bit Windows 10 operating system, with an Intel® Core (TM) i7 2.5-GHz processor, and 16 GB RAM.
- SDK Version 2 of Kinect and LMC with Windows Media3D to present a three-dimensional model of a human body’s skeleton, which provided three-dimensional object transformation.
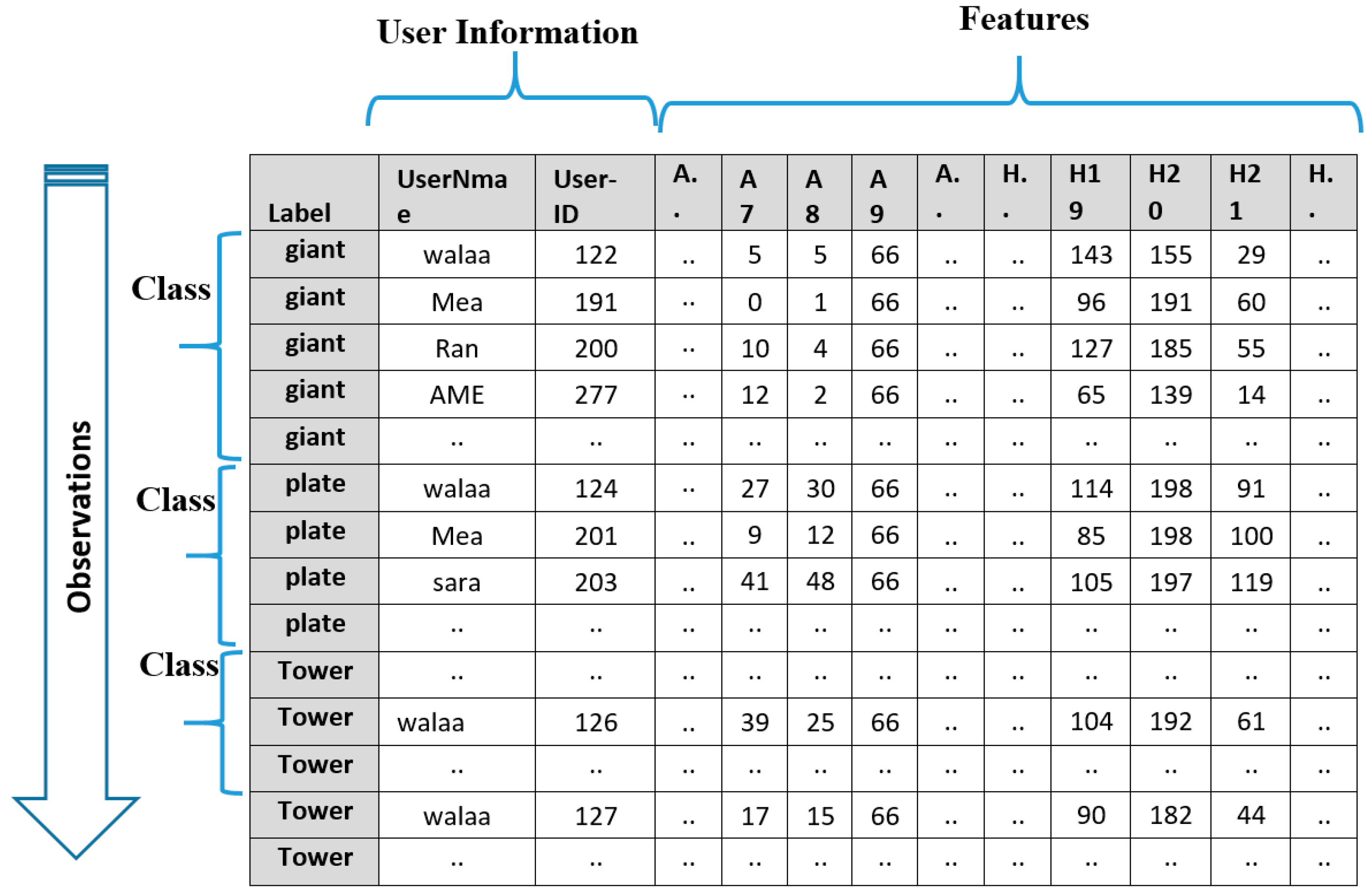
- SQL Server Management Studio to create a relational database to save the data and depth values captured by the two sensors. The two feature types in the database were:
- -
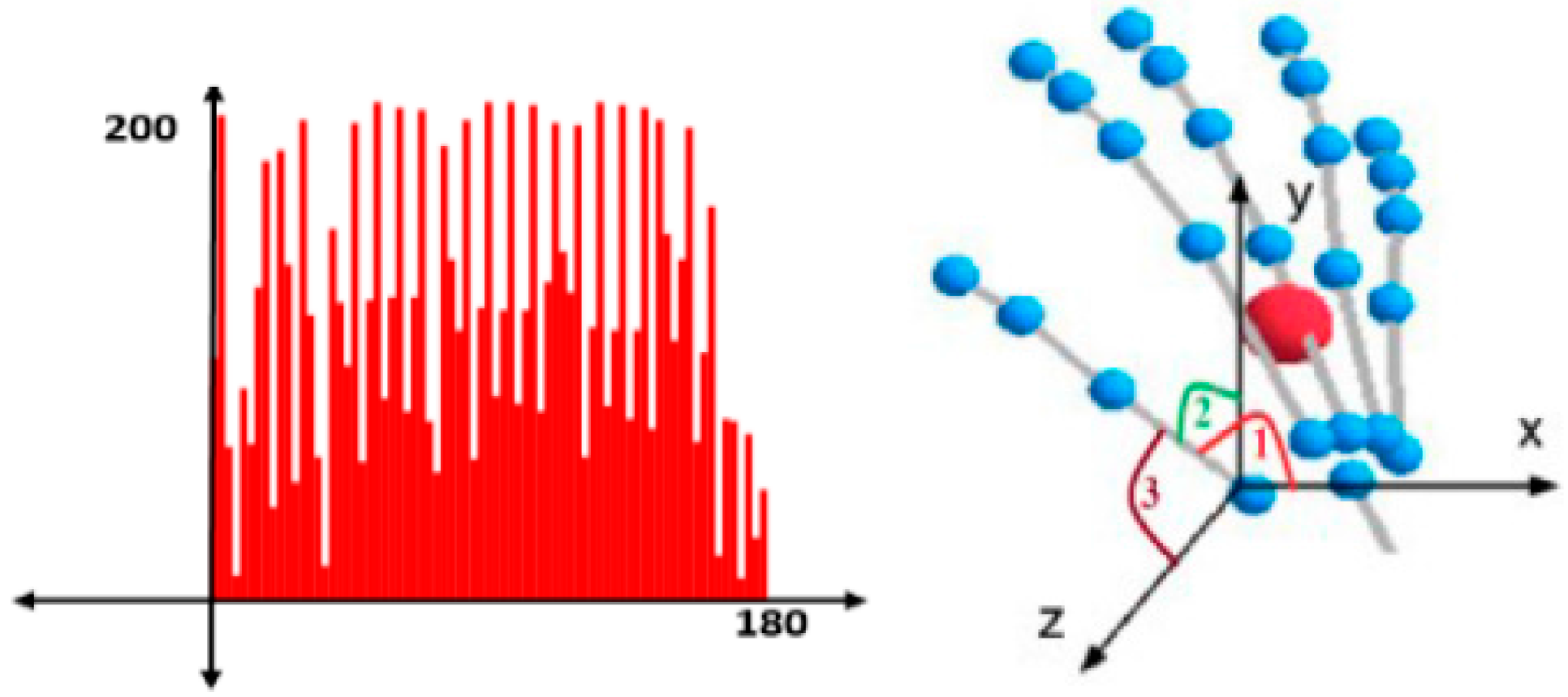
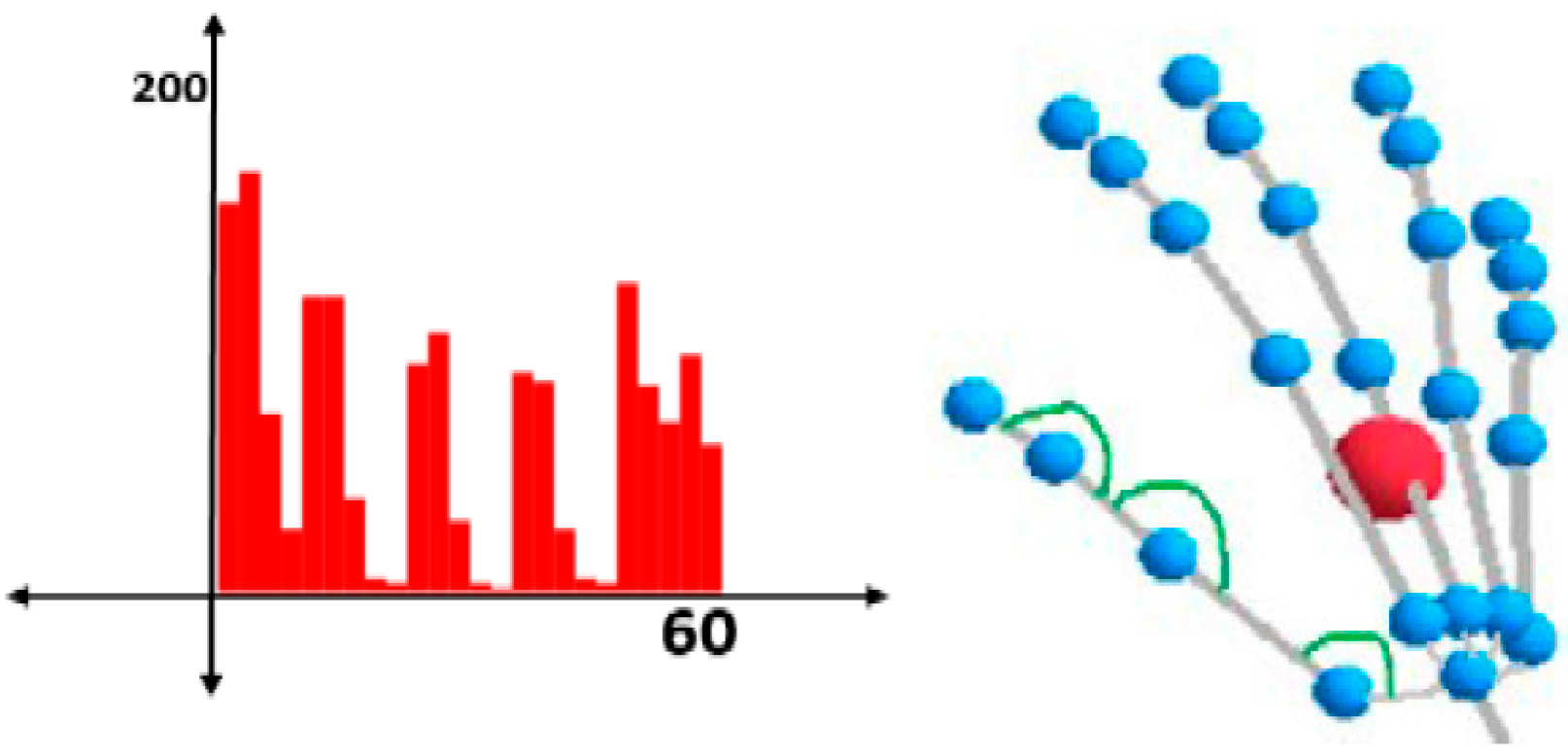
- Type one—denoted as “H” in the database—has three angles for each hand bone, which are angles between the bone and the three axes of the coordinate system (X, Y, Z).
- -
- Type two—denoted as “A” in the database—has one angle between each pair of bones, as shown in Figure 4. These angles are the main factor for a comparison between two gestures.
4.1. Feature Representation As Histograms
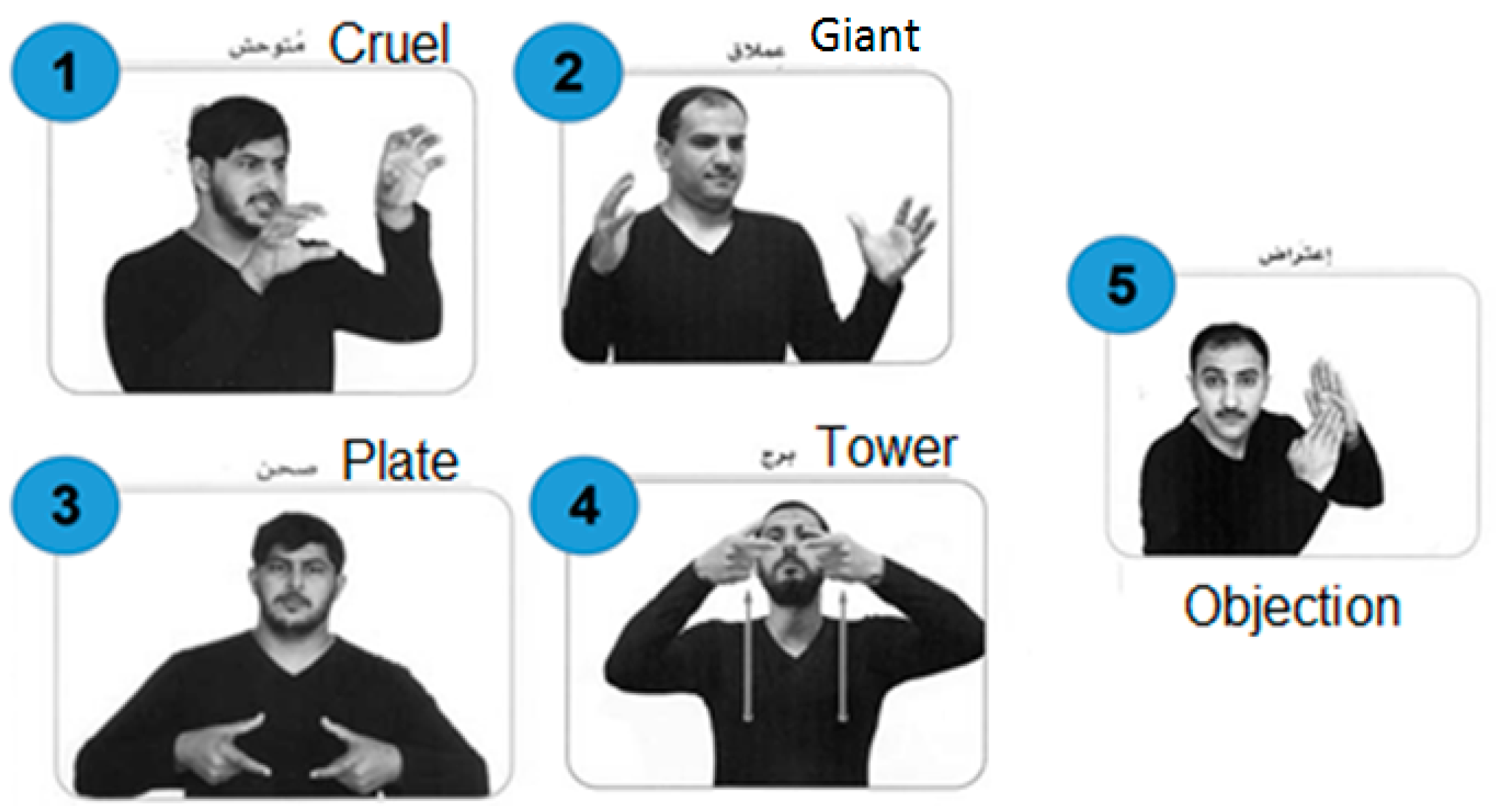
4.2. Dataset Structure
4.3. Classification Implementation
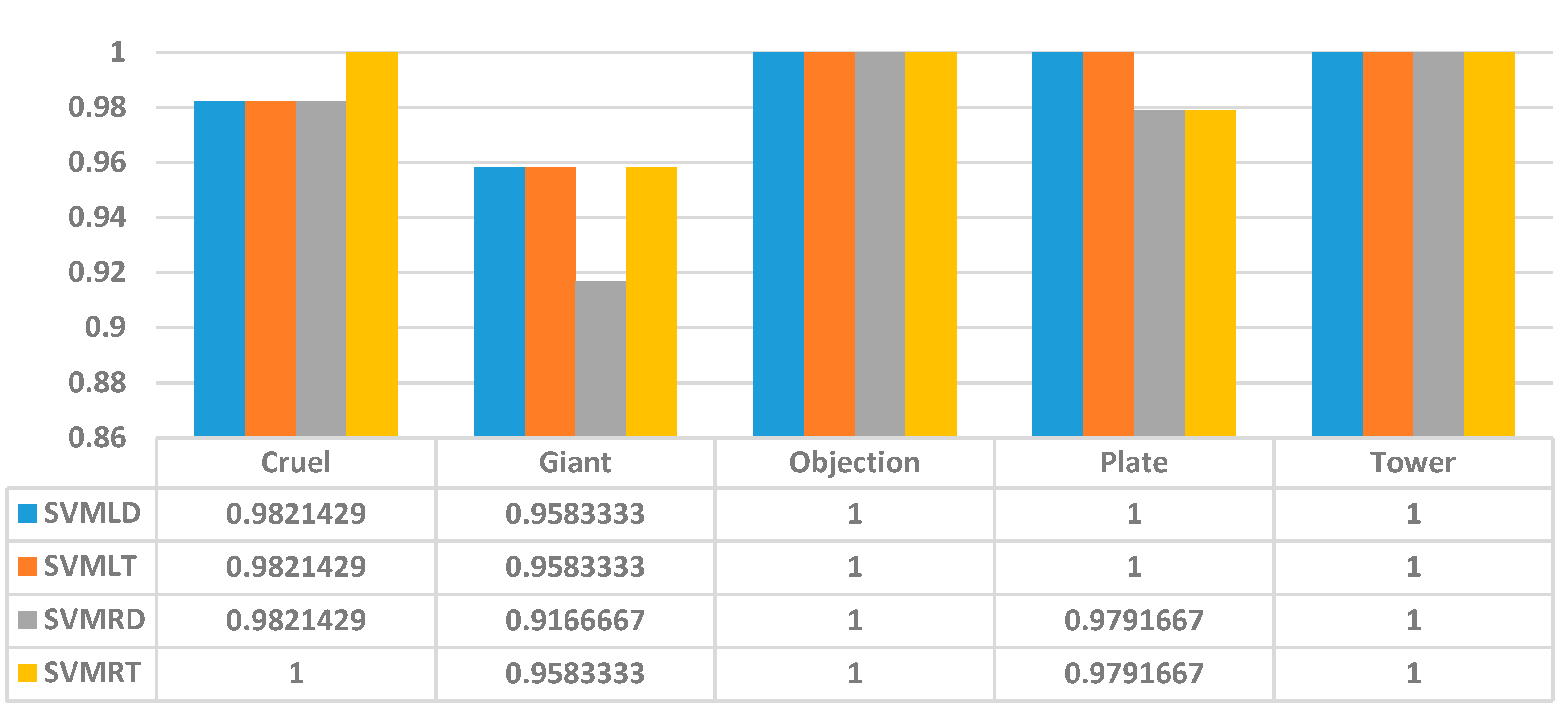
5. Results
- The accuracy performance for the training set differed among the two kernels. The highest accuracy among the four models for the training set was 90.884%, when the radial kernel was set with default parameters or tuned parameters. However, the accuracy was higher—88.92%—when the linear kernel was set with either default parameters or tuned parameters.
- The accuracy performance for the testing set also differed among the two kernels. The highest accuracy among the four models for the testing set was 97.059%, when the linear kernel was set with default parameters or tuned parameters. However, the accuracy was higher—at 88.92%—when the linear kernel was set with either default parameters or tuned parameters. The overall accuracy in recognizing the corresponding words in the testing set for the SVMLD, SVMLT, SVMRD, and SVMRT models was 97.059%, 97.059%, 94.118%, and 97.059%, respectively.
- SVM with default parameters and linear kernel (SVMLD): an SVM with a linear kernel has only one parameter that needs to be set: the cost parameter. The default value in the R package is the cost parameter, C = 1, which gave an overall accuracy of 88.92% in the training step.
- SVM with tuned parameters and linear kernel (SVMLT): For an SVM with a linear kernel and tuning for C, trying different cost-parameter values resulted in almost the same training accuracy. When C was set to 0.001, 0.006, 0.011, 0.016, 0.021, 0.026, 0.031, 0.036, 0.041, and 0.046, the accuracy was 78.186%, 88.092%, 89.832%, 88.922%, 88.922%, 88.922%, 88.922%, 88.922%, 88.922%, and 88.922%, respectively. Thus, tuning the cost parameter did not actually increase accuracy, and in many cases the default parameter from the R package was a good choice, especially since the dataset has a large number of features, so the fine-tuning of hyper-parameters in this case was not advantageous.
- SVM with default parameters and radial kernel (SVMRD): The radial kernel needs two parameters to be set (cost and sigma). The default value in the R package for sigma was held constant at a value of 0.002964685, and C = 4, which gave an overall accuracy of 90.884% in the training step.
- SVM with tuned parameters and radial kernel (SVMRT): For an SVM with a radial kernel and the cost and sigma parameters tuned, Table 2 shows the accuracy in the training step for each pair of cost and sigma parameters. High accuracy was achieved when sigma was set to 0.003 and C was set to 3, 3.5, 4, 4.5, and 5.
6. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Capilla, D.M. Sign Language Translator Using Microsoft Kinect XBOX 360 TM; University of Tennesse: Knoxville, TN, USA, 2012. [Google Scholar]
- Almasre, M.A.; Al-Nuaim, H. A Real-Time Letter Recognition Model for Arabic Sign Language Using Kinect and Leap Motion Controller v2. Int. J. Adv. Eng. Manag. Sci. 2016, 2, 514–523. [Google Scholar]
- Liang, H.; Yuan, J. Hand Parsing and Gesture Recognition with a Commodity Depth Camera. In Computer Vision and Machine Learning with RGB-D Sensors; Shao, L., Han, J., Kohli, P., Zhang, Z., Eds.; Springer International Publishing: Cham, Germany, 2014; pp. 239–265. [Google Scholar]
- Han, J.; Shao, L.; Xu, D.; Shotton, J. Enhanced Computer Vision with Microsoft Kinect Sensor: A Review. IEEE Trans. Cybern. 2013, 43, 1318–1334. [Google Scholar] [PubMed]
- Almasre, M.; Al-Nuaim, H. Using the Hausdorff Algorithm to Enhance Kinect’s Recognition of Arabic Sign Language Gestures. Int. J. Exp. Algorithms IJEA 2017, 7, 18. [Google Scholar]
- Almasre, M.A.; Al-Nuaim, H. Recognizing Arabic Sign Language gestures using depth sensors and a KSVM classifier. In Proceedings of the 2016 8th Computer Science and Electronic Engineering (CEEC), Colchester, UK, 28–30 September 2016; pp. 146–151. [Google Scholar]
- Metaxas, D.N.; Liu, B.; Yang, F.; Yang, P.; Michael, N.; Neidle, C. Recognition of Nonmanual Markers in American Sign Language (ASL) Using Non-Parametric Adaptive 2D-3D Face Tracking. In Proceedings of the LREC, Istanbul, Turkey, 21–27 May 2012; pp. 2414–2420. [Google Scholar]
- Abdel-Fattah, M.A. Arabic Sign Language: A Perspective. J. Deaf Stud. Deaf Educ. 2005, 10, 212–221. [Google Scholar] [CrossRef] [PubMed]
- Naqa, I.E.; Murphy, M.J. What Is Machine Learning? In Machine Learning in Radiation Oncology; Naqa, I.E., Li, R., Murphy, M.J., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 3–11. [Google Scholar]
- Munoz, A. Machine Learning and Optimization. Available online: https://www.cims.nyu.edu/~munoz/files/ml_optimization.pdf (accessed on 14 June 2017).
- Bengio, Y.; Courville, A.; Vincent, P. Representation Learning: A Review and New Perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Pisharady, P.K.; Saerbeck, M. Recent methods and databases in vision-based hand gesture recognition: A review. Comput. Vis. Image Underst. 2015, 141, 152–165. [Google Scholar] [CrossRef]
- Erol, A.; Bebis, G.; Nicolescu, M.; Boyle, R.D.; Twombly, X. Vision-based hand pose estimation: A review. Comput. Vis. Image Underst. 2007, 108, 52–73. [Google Scholar] [CrossRef]
- Ionescu, D.; Suse, V.; Gadea, C.; Solomon, B.; Ionescu, B.; Islam, S. An infrared-based depth camera for gesture-based control of virtual environments. In Proceedings of the 2013 IEEE International Conference on Computational Intelligence and Virtual Environments for Measurement Systems and Applications (CIVEMSA), Milan, Italy, 15–17 July 2013; pp. 13–18. [Google Scholar]
- Mohandes, M.; Deriche, M.; Liu, J. Image-Based and Sensor-Based Approaches to Arabic Sign-language recognition. IEEE Trans. Hum.-Mach. Syst. 2014, 44, 551–557. [Google Scholar] [CrossRef]
- Ahmed, H.; Gilani, S.O.; Jamil, M.; Ayaz, Y.; Shah, S.I.A. Monocular Vision-based Signer-Independent Pakistani Sign-language recognition System using Supervised Learning. Indian J. Sci. Technol. 2016, 9. [Google Scholar] [CrossRef]
- Aujeszky, T.; Eid, M. A gesture recognition architecture for Arabic sign language communication system. Multimed. Tools Appl. 2016, 75, 8493–8511. [Google Scholar] [CrossRef]
- Marin, G.; Dominio, F.; Zanuttigh, P. Hand gesture recognition with jointly calibrated Leap Motion and depth sensor. Multimed. Tools Appl. 2016, 75, 14991–15015. [Google Scholar]
- Spiegelmock, M. Leap Motion Development Essentials; Packt Publishing: Birmingham, UK, 2013. [Google Scholar]
- Gavrila, D.M. The Visual Analysis of Human Movement: A Survey. Comput. Vis. Image Underst. 1999, 73, 82–98. [Google Scholar] [CrossRef]
- Srivastava, R. Research Developments in Computer Vision and Image Processing: Methodologies and Applications: Methodologies and Applications; IGI Global: Dauphin County, PA, USA, 2013. [Google Scholar]
- Begg, R.; Kamruzzaman, J. A machine learning approach for automated recognition of movement patterns using basic, kinetic and kinematic gait data. J. Biomech. 2005, 38, 401–408. [Google Scholar] [CrossRef] [PubMed]
- Sayad, S. Model Evaluation. An Introduction to Data Mining. Available online: http://www.saedsayad.com/model_evaluation_c.htm (accessed on 14 August 2016).
- Burges, C.J. A tutorial on support vector machines for pattern recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Ben-Hur, A.; Horn, D.; Siegelmann, H.T.; Vapnik, V. Support vector clustering. J. Mach. Learn. Res. 2002, 2, 125–137. [Google Scholar] [CrossRef]
- Strickland, J. Predictive Analytics Using R; Lulu, Inc.: Raleigh, NC, USA, 2015. [Google Scholar]
- Learning Kernels SVM. Available online: https://www.r-bloggers.com/learning-kernels-svm/ (accessed on 14 June 2017).
- Jana, A. Kinect for Windows SDK Programming Guide: Build Motion-Sensing Applications with Microsoft’s Kinect for Windows SDK Quickly and Easily; Packt Publishing: Birmingham, UK, 2012. [Google Scholar]
- Gravetter, F.J.; Wallnau, L.B. Statistics for the Behavioral Sciences; Cengage Learning: Boston, MA, USA, 2016. [Google Scholar]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; CRC Press: Boca Raton, FL, USA, 1986. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class Name (Words) | # of Observation | Class Proportion |
|---|---|---|
| Objection | 9 | 6% |
| Tower | 18 | 13% |
| Cruel | 25 | 17% |
| plate | 41 | 29% |
| giant | 50 | 35% |
| Total | 143 | 100% |
| C | Sigma | Accuracy | C | Sigma | Accuracy | C | Sigma | Accuracy |
|---|---|---|---|---|---|---|---|---|
| 1 | 0.001 | 0.790951 | 2.5 | 0.001 | 0.827564 | 4 | 0.001 | 0.871833 |
| 1 | 0.002 | 0.801477 | 2.5 | 0.002 | 0.880528 | 4 | 0.002 | 0.898315 |
| 1 | 0.003 | 0.838486 | 2.5 | 0.003 | 0.900146 | 4 | 0.003 | 0.908841 |
| 1.5 | 0.001 | 0.790951 | 3 | 0.001 | 0.854046 | 4.5 | 0.001 | 0.889619 |
| 1.5 | 0.002 | 0.836655 | 3 | 0.002 | 0.889619 | 4.5 | 0.002 | 0.898315 |
| 1.5 | 0.003 | 0.874059 | 3 | 0.003 | 0.908841 | 4.5 | 0.003 | 0.908841 |
| 2 | 0.001 | 0.810173 | 3.5 | 0.001 | 0.871833 | 5 | 0.001 | 0.898315 |
| 2 | 0.002 | 0.871833 | 3.5 | 0.002 | 0.898315 | 5 | 0.002 | 0.898315 |
| 2 | 0.003 | 0.900146 | 3.5 | 0.003 | 0.908841 | 5 | 0.003 | 0.908841 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almasre, M.A.; Al-Nuaim, H. Comparison of Four SVM Classifiers Used with Depth Sensors to Recognize Arabic Sign Language Words. Computers 2017, 6, 20. https://doi.org/10.3390/computers6020020
Almasre MA, Al-Nuaim H. Comparison of Four SVM Classifiers Used with Depth Sensors to Recognize Arabic Sign Language Words. Computers. 2017; 6(2):20. https://doi.org/10.3390/computers6020020
Chicago/Turabian StyleAlmasre, Miada A., and Hana Al-Nuaim. 2017. "Comparison of Four SVM Classifiers Used with Depth Sensors to Recognize Arabic Sign Language Words" Computers 6, no. 2: 20. https://doi.org/10.3390/computers6020020
APA StyleAlmasre, M. A., & Al-Nuaim, H. (2017). Comparison of Four SVM Classifiers Used with Depth Sensors to Recognize Arabic Sign Language Words. Computers, 6(2), 20. https://doi.org/10.3390/computers6020020