Unmanned Aerial Vehicle Control through Domain-Based Automatic Speech Recognition



Abstract
:1. Introduction
2. Related Works
2.1. Unmanned Aerial Vehicle Control
2.2. Speech Control
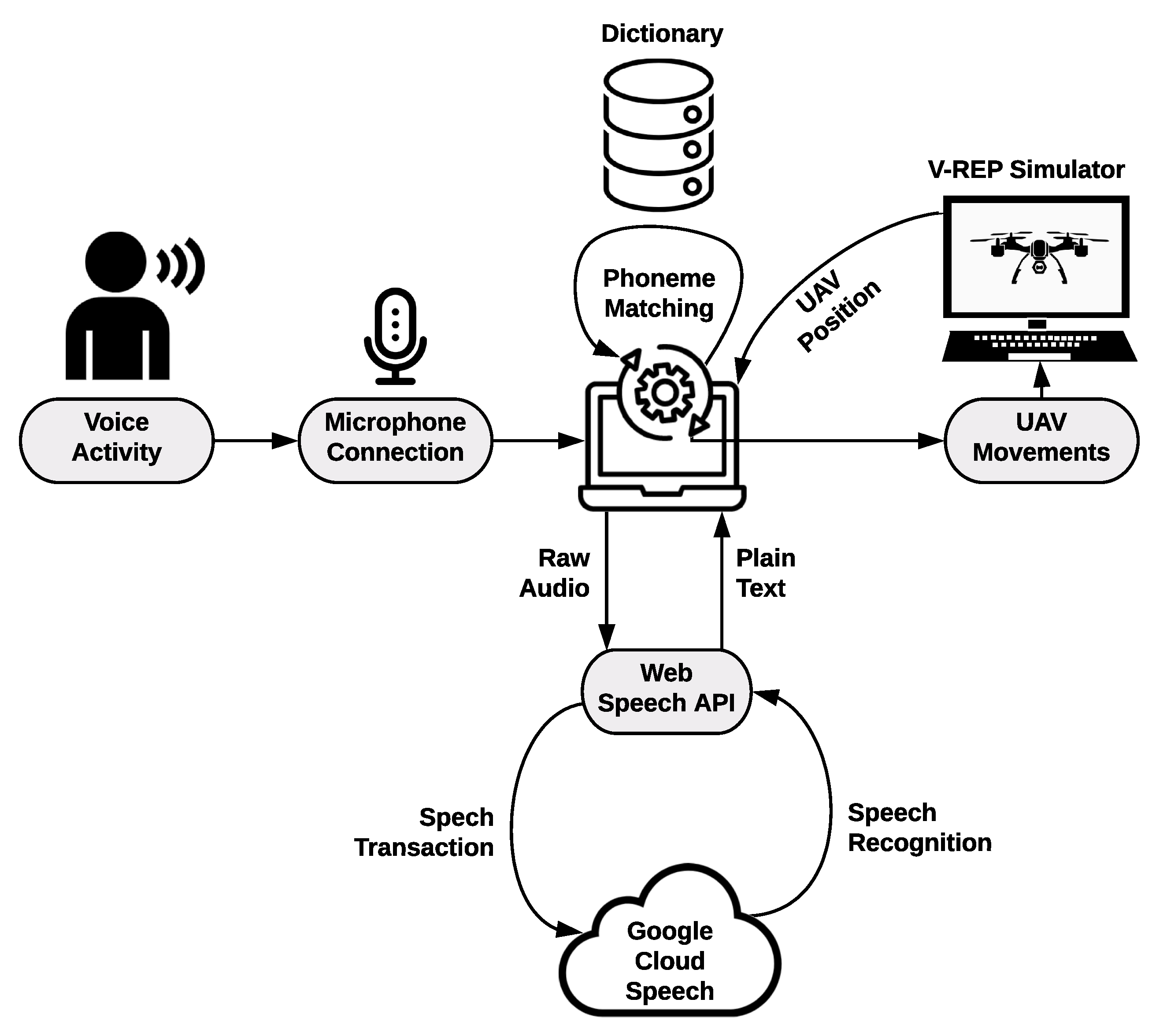
3. Proposed Architecture
- Voice recognition: The interface must be able to recognize instructions through the user’s voice.
- Gesture recognition: The interface can capture gestures from the human body and interpret them.
- Visual marker interaction: Visual markers are added. These are captured by a camera and recognized by the machine.
| Algorithm 1 Algorithm implemented for the interpretation of an audio signal into an instruction for the drone. The algorithm comprises two sections for speech recognition with and without phoneme matching. |
|
4. Experimental Setup
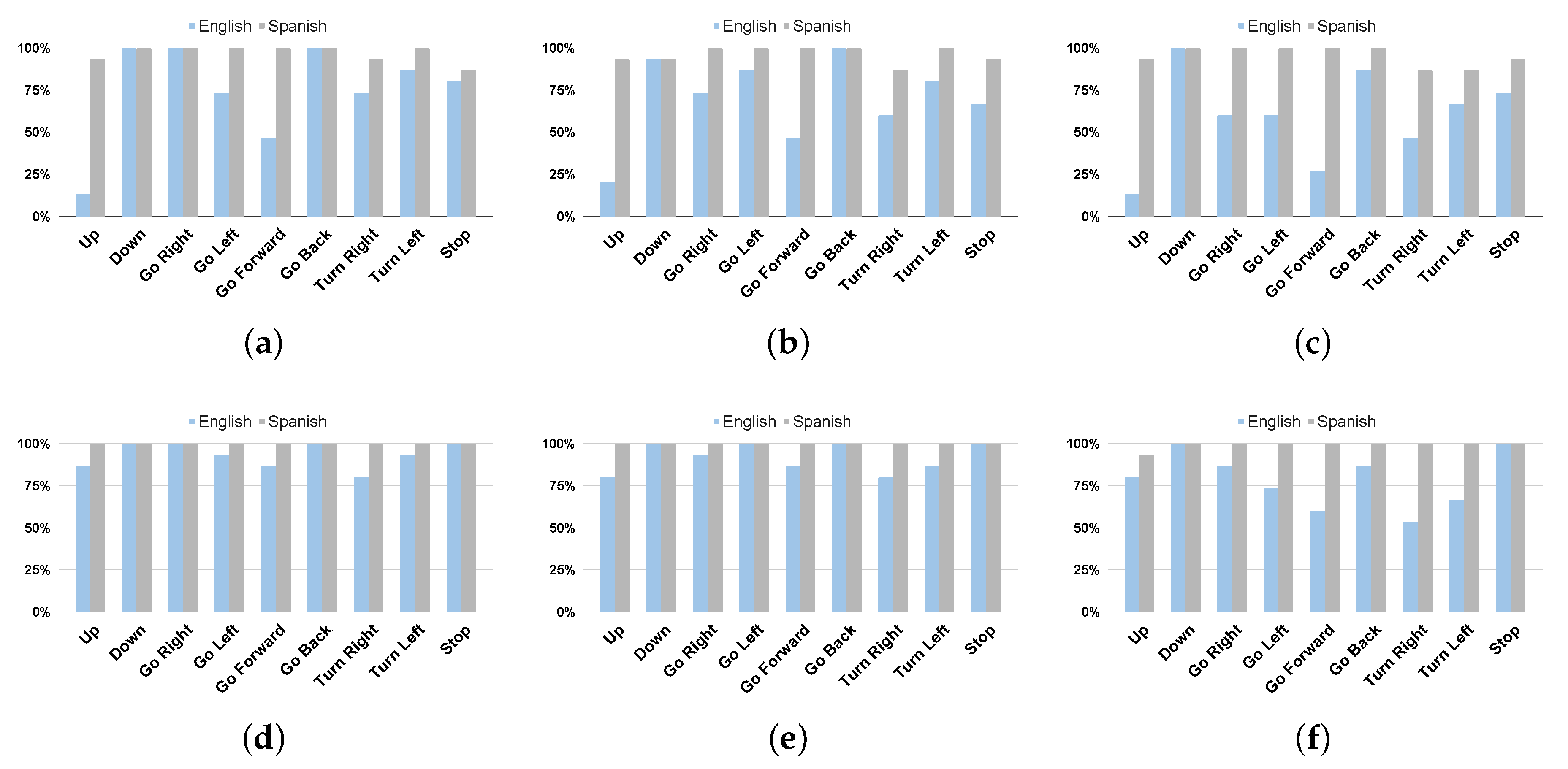
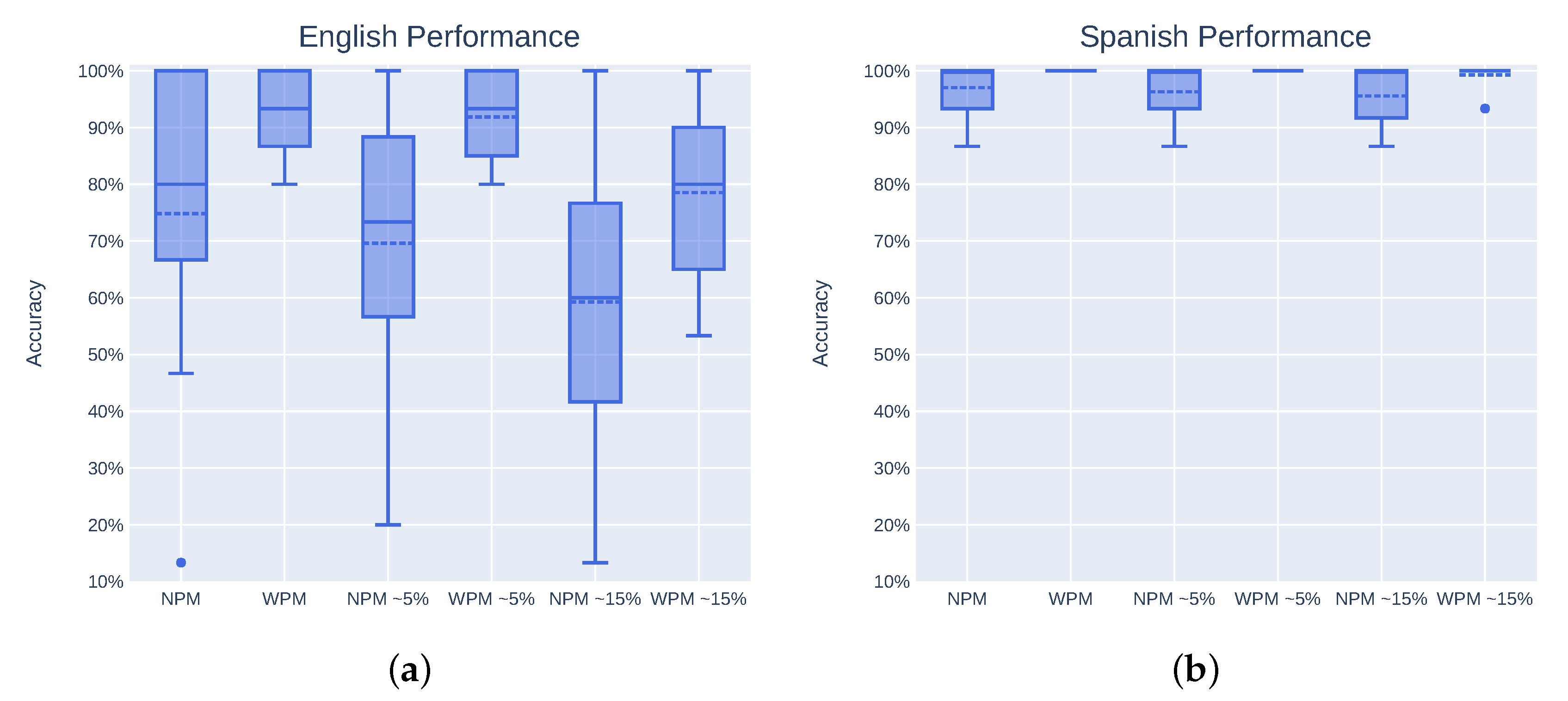
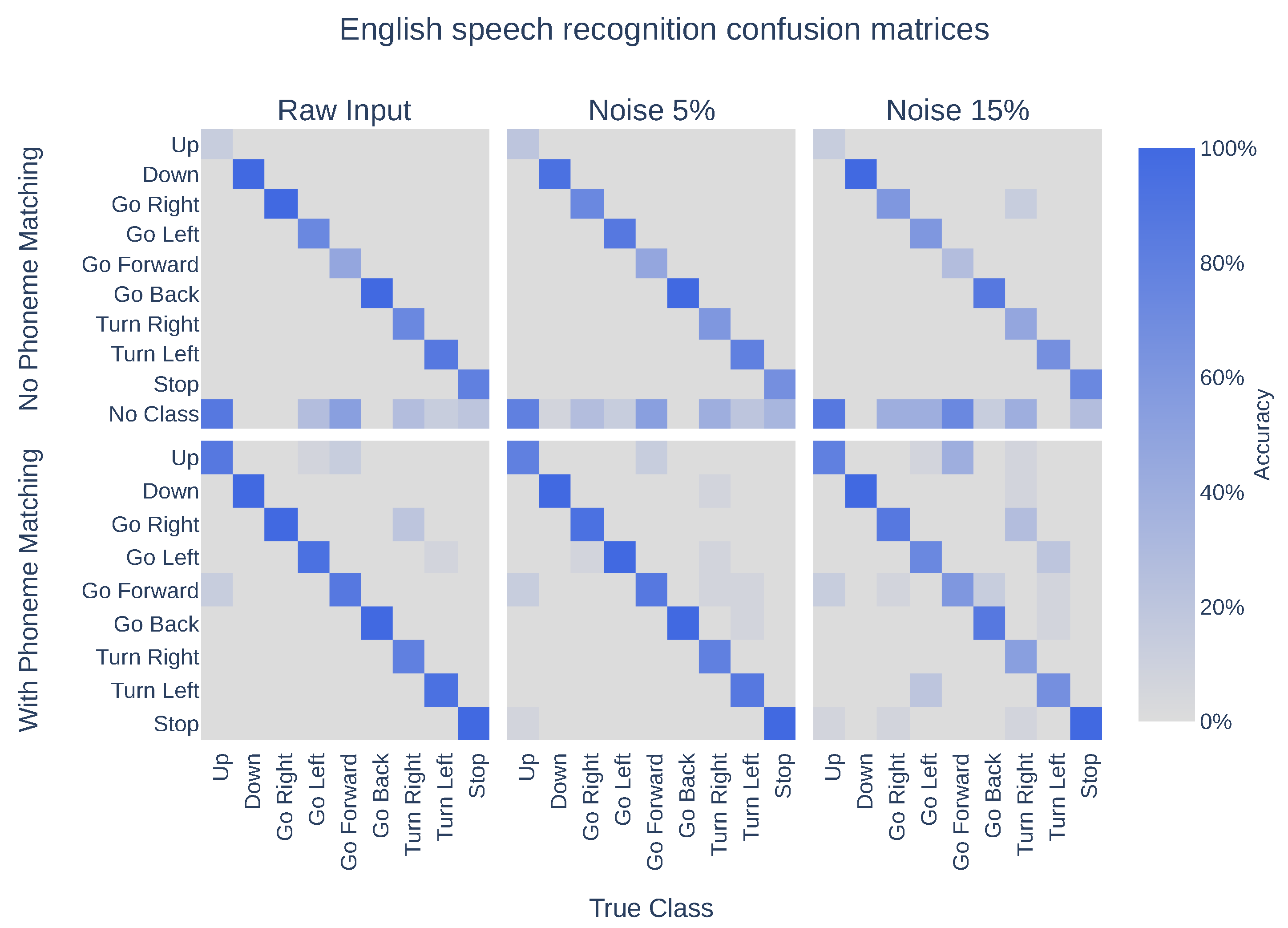
5. Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kardasz, P.; Doskocz, J.; Hejduk, M.; Wiejkut, P.; Zarzycki, H. Drones and possibilities of their using. J. Civ. Environ. Eng. 2016, 6, 1–7. [Google Scholar] [CrossRef]
- Seymour, A.; Dale, J.; Hammill, M.; Halpin, P.; Johnston, D. Automated detection and enumeration of marine wildlife using unmanned aircraft systems (UAS) and thermal imagery. Sci. Rep. 2017, 7, 1–10. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Géza Károly, K.L.; Tokody, D. Radiofrequency Identification by using Drones in Railway Accidents and Disaster Situations. Interdiscip. Descr. Complex Syst. 2017, 15, 114–132. [Google Scholar]
- Fernandez, R.A.S.; Sanchez-Lopez, J.L.; Sampedro, C.; Bavle, H.; Molina, M.; Campoy, P. Natural user interfaces for human-drone multi-modal interaction. In Proceedings of the 2016 International Conference on Unmanned Aircraft Systems (ICUAS), Arlington, VA, USA, 7–10 June 2016; IEEE: Arlington, VA, USA, 2016; pp. 1013–1022. [Google Scholar]
- Schalkwyk, J.; Beeferman, D.; Beaufays, F.; Byrne, B.; Chelba, C.; Cohen, M.; Kamvar, M.; Strope, B. “Your word is my command”: Google search by voice: A case study. In Advances in Speech Recognition. Mobile Environments, Call Centers and Clinics; Springer Science: New York, NY, USA, 2010; pp. 61–90. [Google Scholar]
- Adorf, J. Web Speech API; Technical Report; KTH Royal Institute of Technology: Stockholm, Sweden, 2013. [Google Scholar]
- Twiefel, J.; Baumann, T.; Heinrich, S.; Wermter, S. Improving domain-independent cloud-based Speech recognition with domain-dependent phonetic post-processing. In Proceedings of the Association for the Advancement of Artificial Intelligence Conference AAAI, Quebec City, QC, Canada, 27–31 July 2014; AAAI Press: Quebec City, QC, Canada, 2014; pp. 1529–1535. [Google Scholar]
- Cruz, F.; Parisi, G.I.; Wermter, S. Learning contextual affordances with an associative neural architecture. In Proceedings of the European Symposium on Artificial Neural Network, Computational Intelligence and Machine Learning ESANN, UCLouvain, Bruges, Belgium, 27–29 April 2016; pp. 665–670. [Google Scholar]
- Cruz, F.; Wüppen, P.; Magg, S.; Fazrie, A.; Wermter, S. Agent-advising approaches in an interactive reinforcement learning scenario. In Proceedings of the Joint IEEE International Conference on Development and Learning and Epigenetic Robotics ICDL-EpiRob, Lisboa, Portugal, 18–21 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 209–214. [Google Scholar]
- Cruz, F.; Wüppen, P.; Fazrie, A.; Weber, C.; Wermter, S. Action Selection Methods in a Robotic Reinforcement Learning Scenario. In Proceedings of the 2018 IEEE Latin American Conference on Computational Intelligence (LA-CCI), Gudalajara, Mexico, 7–9 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 13–18. [Google Scholar]
- Moreira, I.; Rivas, J.; Cruz, F.; Dazeley, R.; Ayala, A.; Fernandes, B. Deep Reinforcement Learning with Interactive Feedback in a Human–Robot Environment. Appl. Sci. 2020, 10, 5574. [Google Scholar] [CrossRef]
- Cruz, F.; Dazeley, R.; Vamplew, P. Explainable robotic systems: Understanding goal-driven actions in a reinforcement learning scenario. arXiv 2020, arXiv:2006.13615. [Google Scholar]
- Rohmer, E.; Singh, S.P.; Freese, M. V-REP: A versatile and scalable robot simulation framework. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems IROS, Tokyo, Japan, 3–7 November 2013; IEEE: Tokyo, Japan, 2013; pp. 1321–1326. [Google Scholar]
- Boyle, M.J. The race for drones. Orbis 2015, 59, 76–94. [Google Scholar] [CrossRef]
- Marshall, D.M.; Barnhart, R.K.; Hottman, S.B.; Shappee, E.; Most, M.T. Introduction to Unmanned Aircraft Systems; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Muchiri, N.; Kimathi, S. A review of applications and potential applications of UAV. In Proceedings of the Sustainable Research and Innovation Conference, Nairobi, Kenya, 4–6 May 2016; Open Journal Systems: Nairobi, Kenya, 2016; pp. 280–283. [Google Scholar]
- Amin, R.; Aijun, L.; Shamshirband, S. A review of quadrotor UAV: Control methodologies and performance evaluation. Int. J. Autom. Control 2016, 10, 87–103. [Google Scholar] [CrossRef]
- Clough, B. Metrics, Schmetrics! How Do You Track a UAV’s Autonomy? In Proceedings of the 1st UAV Conference, Portsmouth, VA, USA, 20–23 May 2002; p. 3499. [Google Scholar]
- Peng, Z.; Li, B.; Chen, X.; Wu, J. Online route planning for UAV based on model predictive control and particle swarm optimization algorithm. In Proceedings of the 10th World Congress on Intelligent Control and Automation, Beijing, China, 6–8 July 2012; pp. 397–401. [Google Scholar]
- Al-Madani, B.; Svirskis, M.; Narvydas, G.; Maskeliūnas, R.; Damaševičius, R. Design of Fully Automatic Drone Parachute System with Temperature Compensation Mechanism for Civilian and Military Applications. J. Adv. Transp. 2018, 1–11. [Google Scholar] [CrossRef]
- Ivanovas, A.; Ostreika, A.; Maskeliūnas, R.; Damaševičius, R.; Połap, D.; Woźniak, M. Block matching based obstacle avoidance for unmanned aerial vehicle. In Proceedings of the International Conference on Artificial Intelligence and Soft Computing, Zakopane, Poland, 3–7 June 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 58–69. [Google Scholar]
- Pham, H.X.; La, H.M.; Feil-Seifer, D.; Nguyen, L.V. Autonomous UAV navigation using reinforcement learning. arXiv 2018, arXiv:1801.05086. [Google Scholar]
- Shiri, H.; Park, J.; Bennis, M. Remote UAV Online Path Planning via Neural Network-Based Opportunistic Control. IEEE Wirel. Commun. Lett. 2020, 9, 861–865. [Google Scholar] [CrossRef] [Green Version]
- Kusyk, J.; Uyar, M.U.; Ma, K.; Samoylov, E.; Valdez, R.; Plishka, J.; Hoque, S.E.; Bertoli, G.; Boksiner, J. Artificial intelligence and game theory controlled autonomous UAV swarms. Evol. Intell. 2020, 1–18. [Google Scholar] [CrossRef]
- Chen, H.; Wang, X.; Li, Y. A Survey of Autonomous Control for UAV. In Proceedings of the 2009 International Conference on Artificial Intelligence and Computational Intelligence, Shanghai, China, 7–8 November 2009; Volume 2, pp. 267–271. [Google Scholar]
- Quigley, M.; Goodrich, M.A.; Beard, R.W. Semi-autonomous human-UAV interfaces for fixed-wing mini-UAVs. In Proceedings of the 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Sendai, Japan, 28 September–2 October 2004; IEEE: Chicago, IL, USA, 2004; Volume 3, pp. 2457–2462. [Google Scholar]
- Wopereis, H.W.; Fumagalli, M.; Stramigioli, S.; Carloni, R. Bilateral human-robot control for semi-autonomous UAV navigation. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; pp. 5234–5240. [Google Scholar]
- Perez-Grau, F.J.; Ragel, R.; Caballero, F.; Viguria, A.; Ollero, A. Semi-autonomous teleoperation of UAVs in search and rescue scenarios. In Proceedings of the 2017 International Conference on Unmanned Aircraft Systems (ICUAS), Miami, FL, USA, 13–16 June 2017; pp. 1066–1074. [Google Scholar]
- Imdoukh, A.; Shaker, A.; Al-Toukhy, A.; Kablaoui, D.; El-Abd, M. Semi-autonomous indoor firefighting UAV. In Proceedings of the 2017 18th International Conference on Advanced Robotics (ICAR), Hong Kong, China, 10–12 July 2017; pp. 310–315. [Google Scholar]
- Sanders, B.; Shen, Y.; Vincenzi, D. Design and Validation of a Unity-Based Simulation to Investigate Gesture Based Control of Semi-autonomous Vehicles. In Proceedings of the International Conference on Human-Computer Interaction, Copenhagen, Denmark, 19–24 July 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 325–345. [Google Scholar]
- Wuth, J.; Correa, P.; Núñez, T.; Saavedra, M.; Yoma, N.B. The Role of Speech Technology in User Perception and Context Acquisition in HRI. Int. J. Soc. Robot. 2020, 1–20. [Google Scholar] [CrossRef]
- Lavrynenko, O.; Konakhovych, G.; Bakhtiiarov, D. Method of voice control functions of the UAV. In Proceedings of the 2016 IEEE 4th International Conference on Methods and Systems of Navigation and Motion Control (MSNMC), Kyiv, Ukraine, 18–20 October 2016; IEEE: Kyiv, Ukraine, 2016; pp. 47–50. [Google Scholar]
- Fayjie, A.R.; Ramezani, A.; Oualid, D.; Lee, D.J. Voice enabled smart drone control. In Proceedings of the 2017 Ninth International Conference on Ubiquitous and Future Networks (ICUFN), Milan, Italy, 4–7 July 2017; IEEE: Milan, Italy, 2017; pp. 119–121. [Google Scholar]
- Landau, M.; van Delden, S. A System Architecture for Hands-Free UAV Drone Control Using Intuitive Voice Commands. In Proceedings of the Companion of the 2017 ACM/IEEE International Conference on Human-Robot Interaction, Vienna, Austria, 6–9 March 2017; Association for Computing Machinery: New York, NY, USA, 2017. HRI’17. pp. 181–182. [Google Scholar] [CrossRef]
- Chandarana, M.; Meszaros, E.L.; Trujillo, A.; Allen, B.D. ‘Fly Like This’: Natural Language Interface for UAV Mission Planning. In Proceedings of the 10th International Conference on Advances in Computer-Human Interactions (ACHI 2017), Nice, France, 19–23 March 2017; IARIA XPS Press: Nice, France, 2017; pp. 40–46. [Google Scholar]
- Jones, G.; Berthouze, N.; Bielski, R.; Julier, S. Towards a situated, multimodal interface for multiple UAV control. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–8 May 2010; IEEE: Anchorage, AK, USA, 2010; pp. 1739–1744. [Google Scholar]
- Lavrynenko, O.; Taranenko, A.; Machalin, I.; Gabrousenko, Y.; Terentyeva, I.; Bakhtiiarov, D. Protected Voice Control System of UAV. In Proceedings of the 2019 IEEE 5th International Conference Actual Problems of Unmanned Aerial Vehicles Developments (APUAVD), Kyiv, Ukraine, 22–24 October 2019; IEEE: Kyiv, Ukraine, 2019; pp. 295–298. [Google Scholar]
- López, G.; Quesada, L.; Guerrero, L.A. Alexa vs. Siri vs. Cortana vs. Google Assistant: A comparison of speech-based natural user interfaces. In Proceedings of the International Conference on Applied Human Factors and Ergonomics, Los Angeles, CA, USA, 17–21 July 2017; Springer: Los Angeles, CA, USA, 2017; pp. 241–250. [Google Scholar]
- Glonek, G.; Pietruszka, M. Natural user interfaces (NUI). J. Appl. Comput. Sci. 2012, 20, 27–45. [Google Scholar]
- Cruz, F.; Twiefel, J.; Magg, S.; Weber, C.; Wermter, S. Interactive reinforcement learning through speech guidance in a domestic scenario. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–16 July 2015; IEEE: Killarney, Ireland, 2015; pp. 1341–1348. [Google Scholar]
- Levenshtein, V.I. Binary codes capable of correcting deletions, insertions, and reversals. Sov. Phys. Dokl. 1966, 10, 707–710. [Google Scholar]
- Ayala, A.; Cruz, F.; Campos, D.; Rubio, R.; Fernandes, B.; Dazeley, R. A Comparison of Humanoid Robot Simulators: A Quantitative Approach. In Proceedings of the IEEE International Joint Conference on Development and Learning and Epigenetic Robotics ICDL-EpiRob, Valparaiso, Chile, 26–30 October 2020; p. 6. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Action Classes | Description |
|---|---|---|
| 1 | Up | Increase the UAV’s altitude |
| 2 | Down | Decrease the UAV’s altitude |
| 3 | Go right | Move the UAV to the right |
| 4 | Go left | Move the UAV to the left |
| 5 | Go forward | Move the UAV forward |
| 6 | Go back | Move the UAV backward |
| 7 | Turn right | Turn the UAV 90° clockwise |
| 8 | Turn left | Turn the UAV 90° counterclockwise |
| 9 | Stop | Stop the UAV |
| Class | English | Spanish | Average |
|---|---|---|---|
| Up | −4.21 × 10−4 | 5.33 × 10−4 | 5.57 × 10−5 |
| Down | −9.06 × 10−4 | −2.37 × 10−5 | −4.65 × 10−4 |
| Go Right | −6.93 × 10−4 | −2.09 × 10−4 | −4.51 × 10−4 |
| Go Left | −8.03 × 10−4 | −3.16 × 10−5 | −4.18 × 10−4 |
| Go Forward | −3.85 × 10−4 | −1.36 × 10−4 | −2.60 × 10−4 |
| Go Back | −6.86 × 10−4 | −9.70 × 10−6 | −3.48 × 10−4 |
| Turn Left | −9.54 × 10−4 | −5.55 × 10−5 | −5.05 × 10−4 |
| Turn Right | −7.79 × 10−4 | 2.68 × 10−4 | −2.55 × 10−4 |
| Stop | −2.94 × 10−4 | 3.02 × 10−5 | −1.32 × 10−4 |
| Average | −6.58 × 10−4 | 4.06 × 10−5 | −3.09 × 10−4 |
| Approach | Language | Raw Input | Noise 5% | Noise 15% |
|---|---|---|---|---|
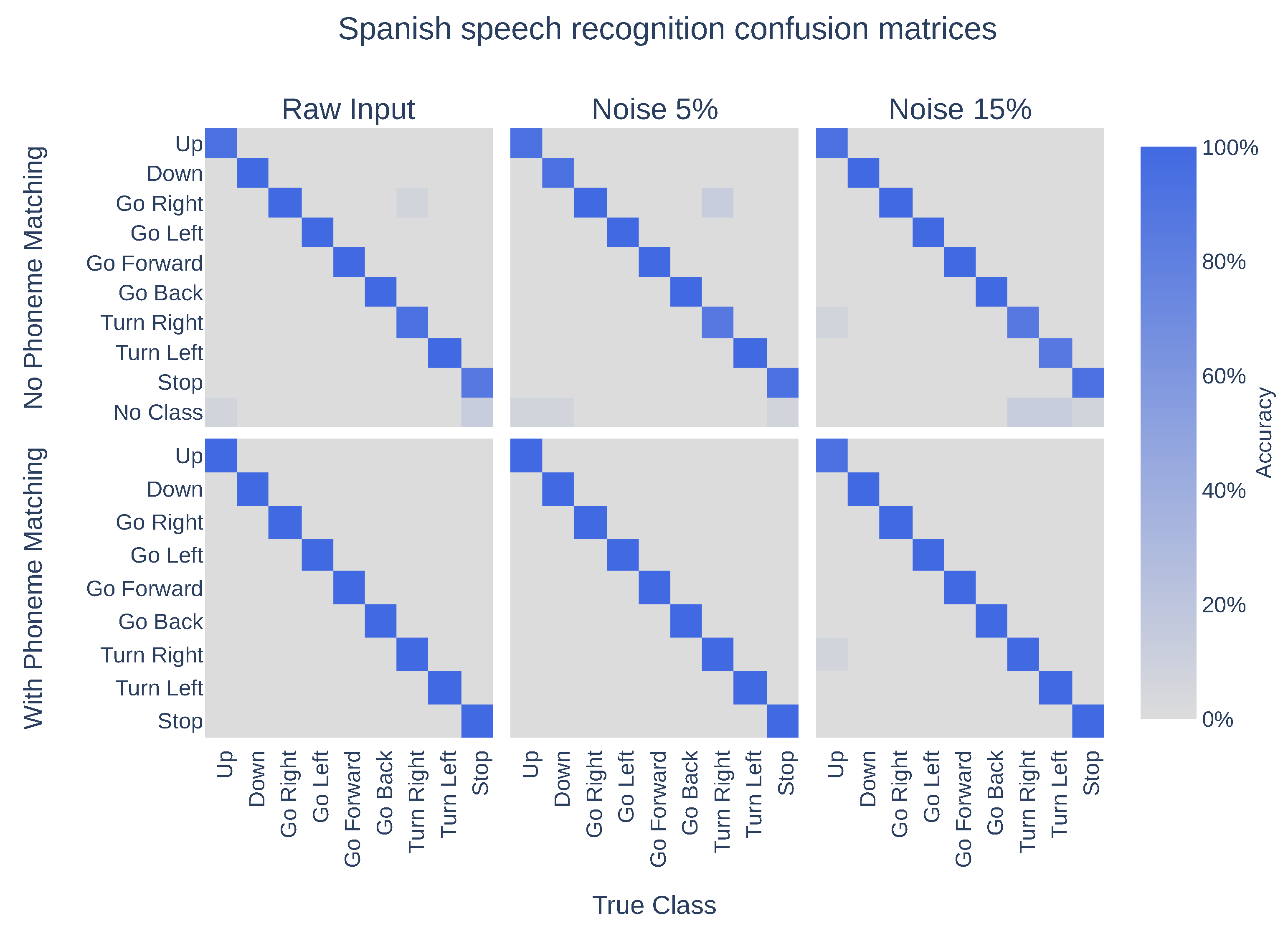
| No phoneme matching | Spanish | 97.04% | 96.30% | 95.56% |
| English | 74.81% | 69.63% | 59.26% | |
| Both | 85.93% | 82.96% | 77.41% | |
| With phoneme matching | Spanish | 100.00% | 100.00% | 99.26% |
| English | 93.33% | 91.85% | 78.52% | |
| Both | 96.67% | 95.93% | 88.89% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Contreras, R.; Ayala, A.; Cruz, F. Unmanned Aerial Vehicle Control through Domain-Based Automatic Speech Recognition. Computers 2020, 9, 75. https://doi.org/10.3390/computers9030075
Contreras R, Ayala A, Cruz F. Unmanned Aerial Vehicle Control through Domain-Based Automatic Speech Recognition. Computers. 2020; 9(3):75. https://doi.org/10.3390/computers9030075
Chicago/Turabian StyleContreras, Ruben, Angel Ayala, and Francisco Cruz. 2020. "Unmanned Aerial Vehicle Control through Domain-Based Automatic Speech Recognition" Computers 9, no. 3: 75. https://doi.org/10.3390/computers9030075
APA StyleContreras, R., Ayala, A., & Cruz, F. (2020). Unmanned Aerial Vehicle Control through Domain-Based Automatic Speech Recognition. Computers, 9(3), 75. https://doi.org/10.3390/computers9030075