
The Role of Implicit Motives in Strategic Decision-Making: Computational Models of Motivated Learning and the Evolution of Motivated Agents

Abstract
:1. Introduction
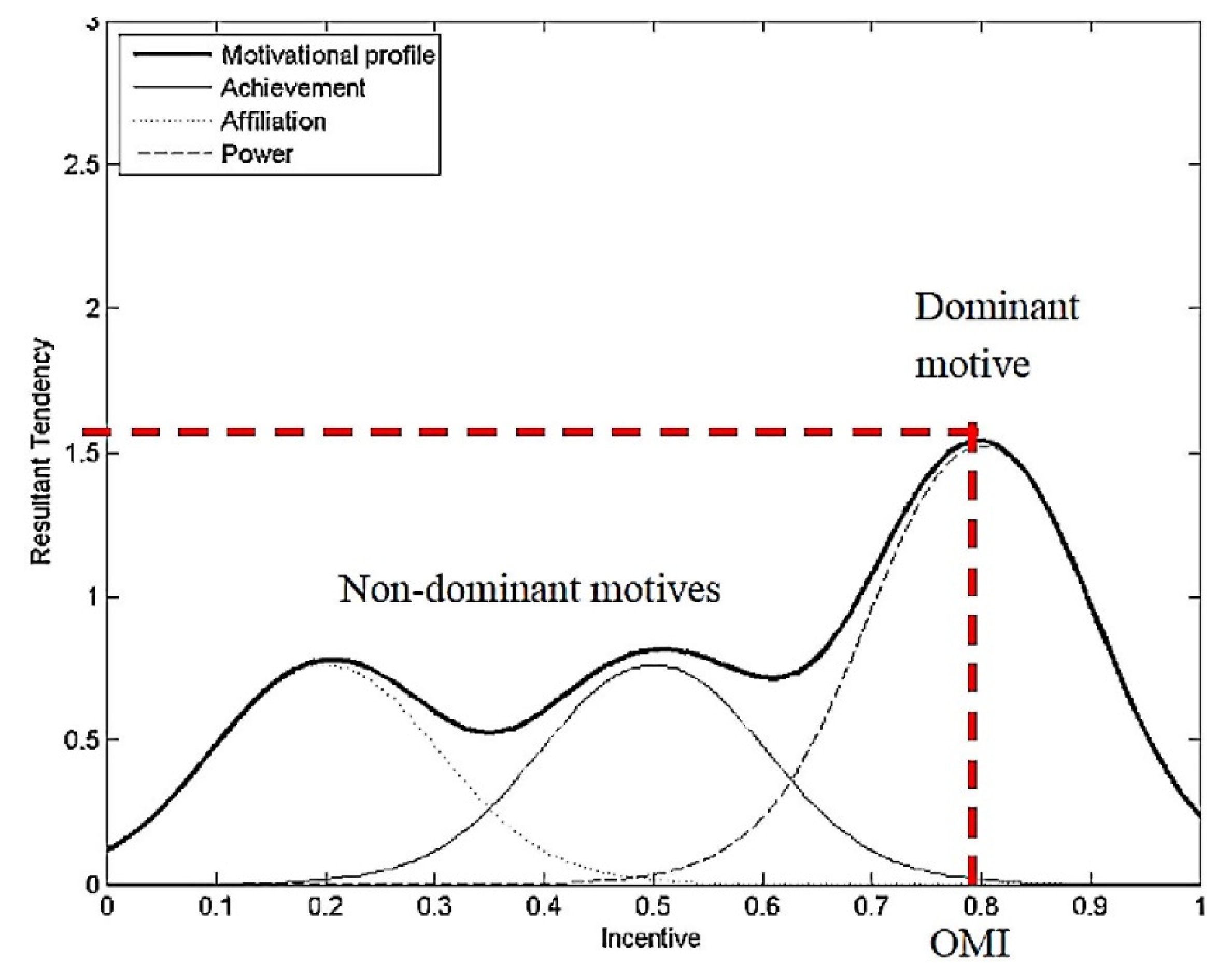
1.1. Achievement, Affiliation and Power Motivation

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dominant Motive | Possible Behavioral Characteristics |
|---|---|
| Achievement | • Prefers moderately challenging goals • Willing to take calculated risks • Likes regular feedback • Often likes to work alone |
| Affiliation | • Wants to belong to a group • Wants to be liked • Prefers collaboration over competition • Does not like high risk or uncertainty |
| Power | • Wants to control and influence others • Likes to win • Likes competition • Likes status and recognition |
1.2. Assumptions and Related Work

2. Materials and Method
2.1. Motivated Learning Agents
| Algorithm 1. Algorithm for a motivated learning agent. |
|
2.2. Evolution of Motivated Agents
| Algorithm 2. Algorithm for evolving the proportions of agents with different motives in a society of motivated agents. |
|
3. Results and Discussion
3.1. The Prisoners’ Dilemma and Common Pool Resource Games
3.1.1. Theoretical Results
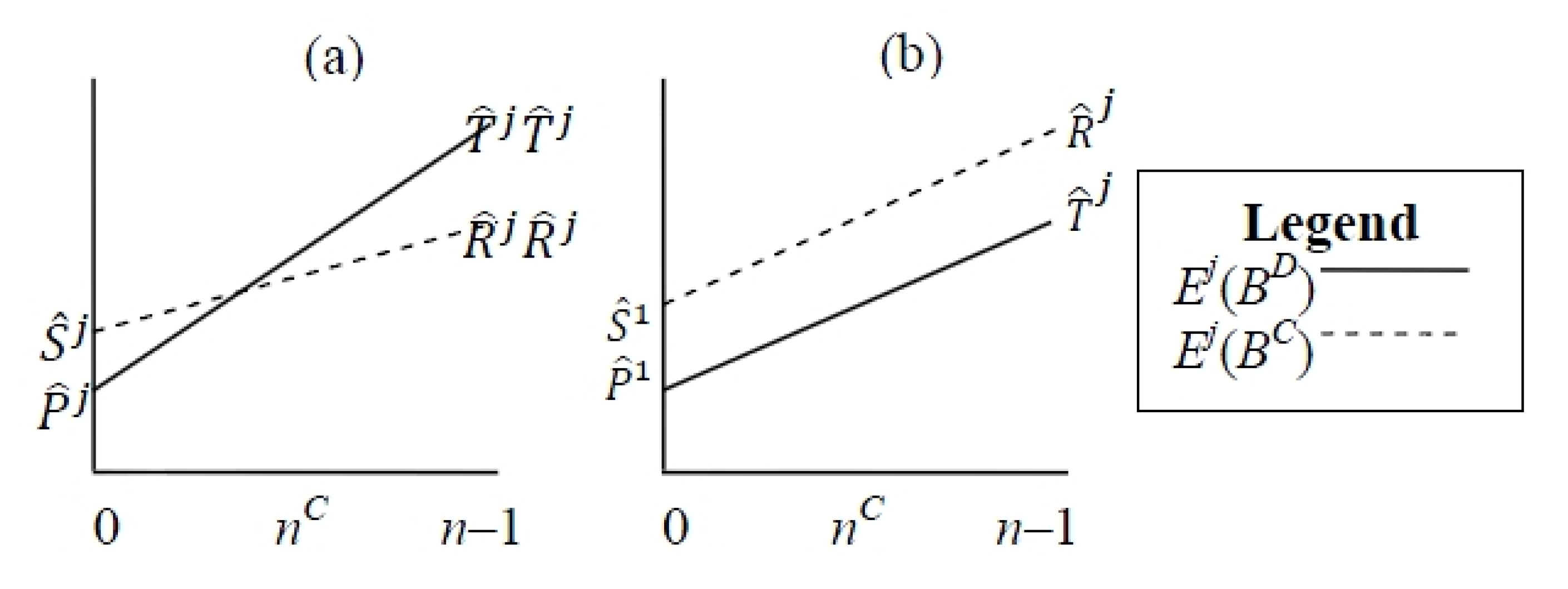
- Power-motivated agents have
- Achievement-motivated agents have
- Affiliation-motivated agents have
Power-Motivated Perception

Achievement-Motivated Perception

Affiliation-Motivated Perception

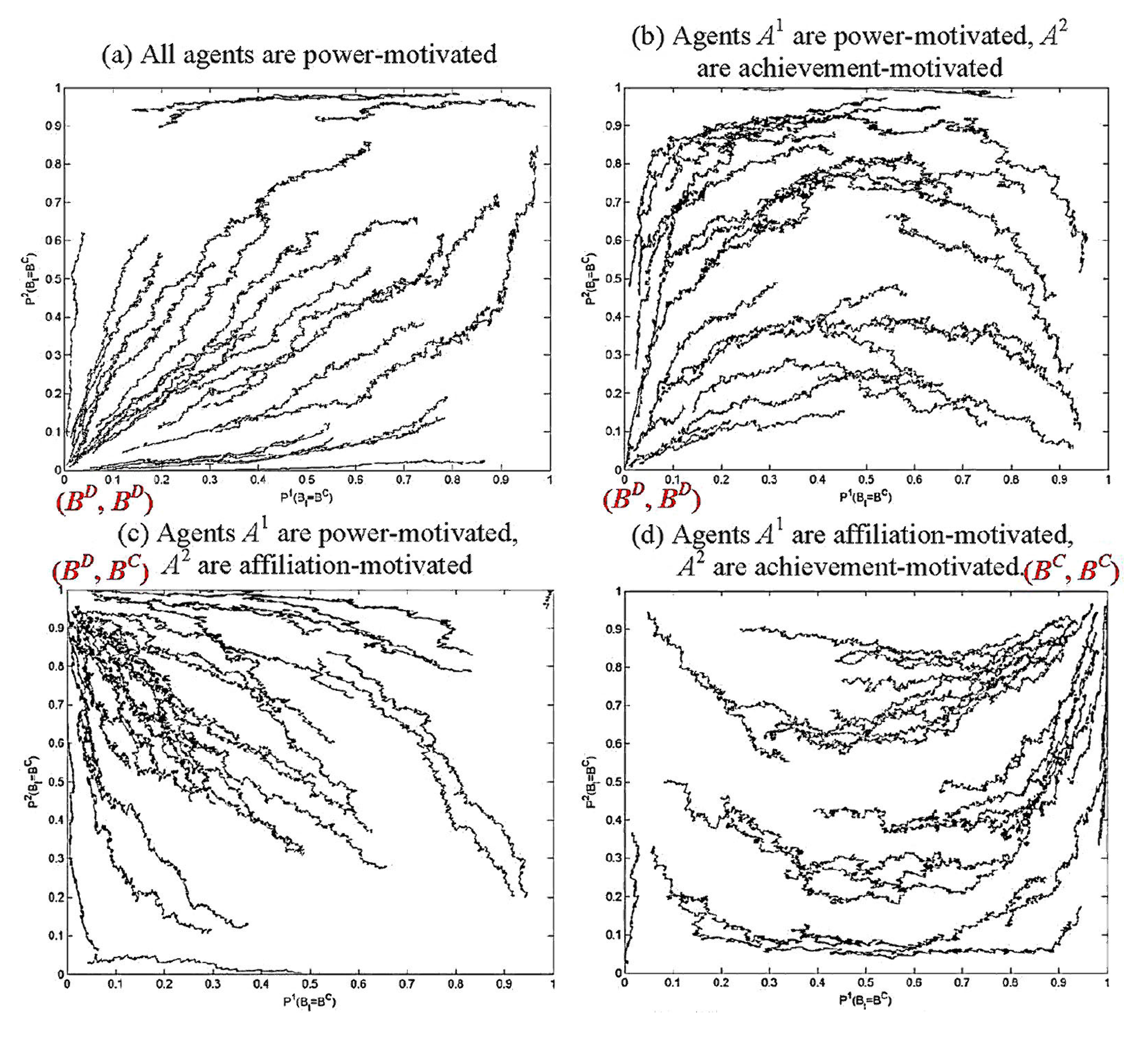
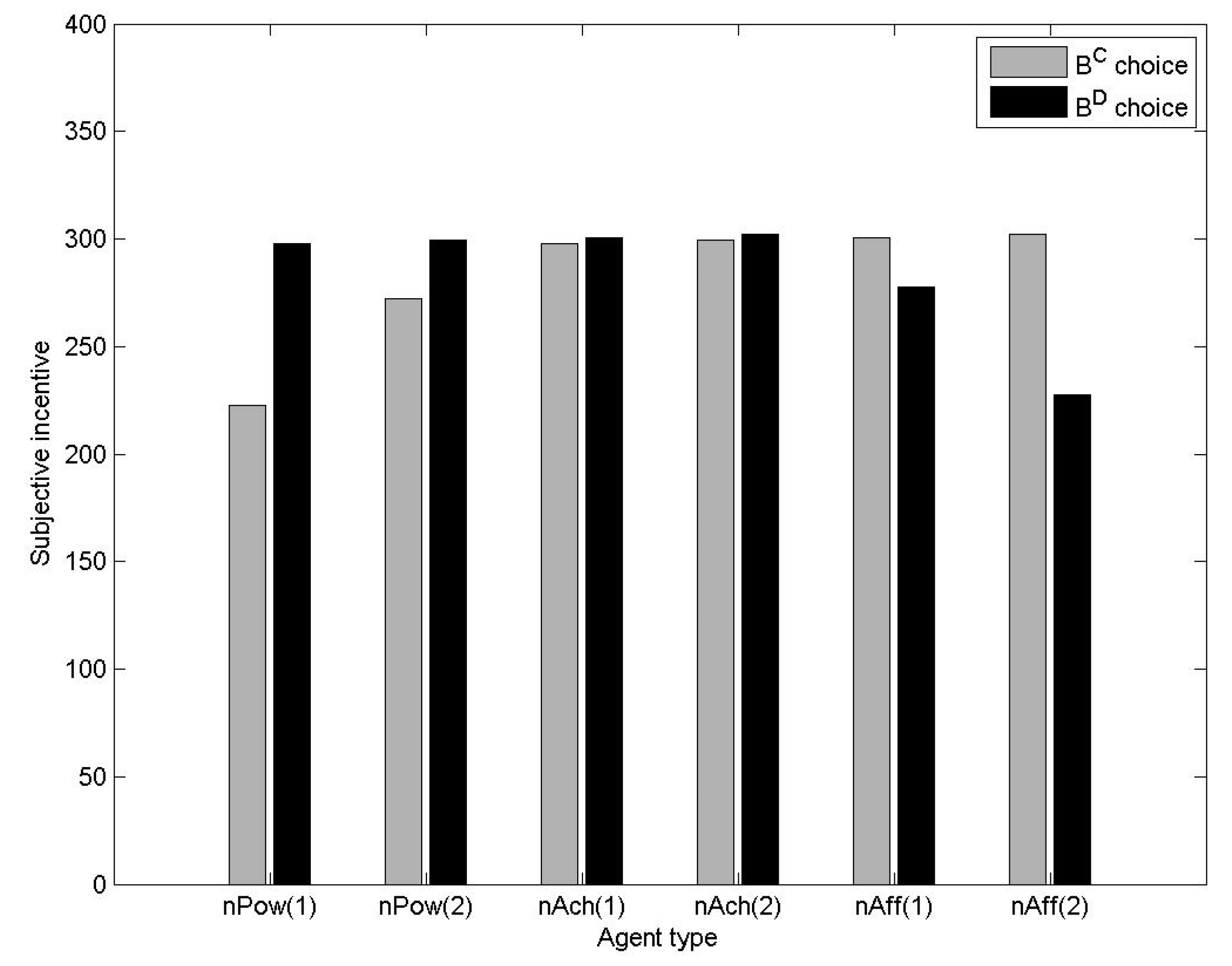
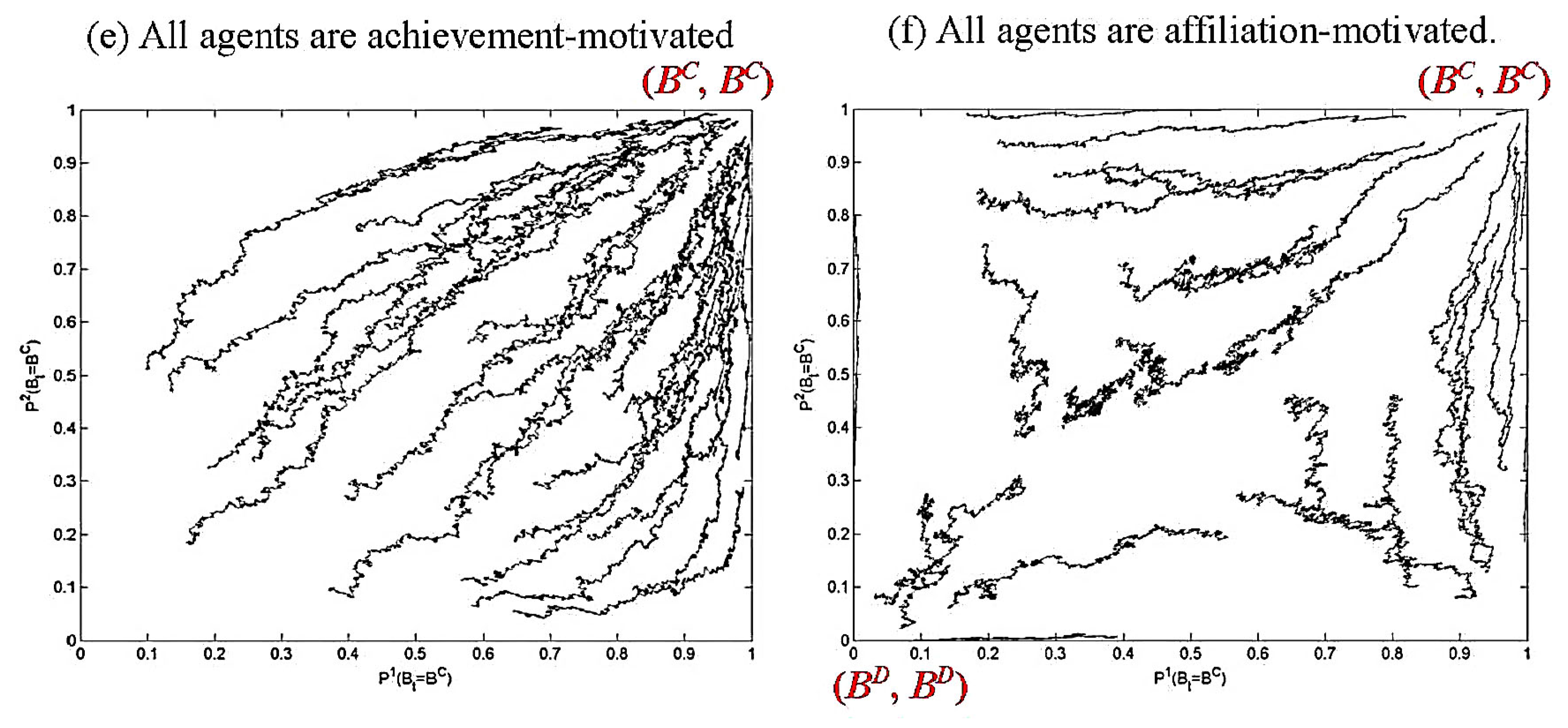
3.1.2. Empirical Study of Motivated Learning in the Prisoners’ Dilemma Game
- Power-motivated: = 3.9
- Achievement-motivated: = 2.6
- Affiliation-motivated: = 1.1



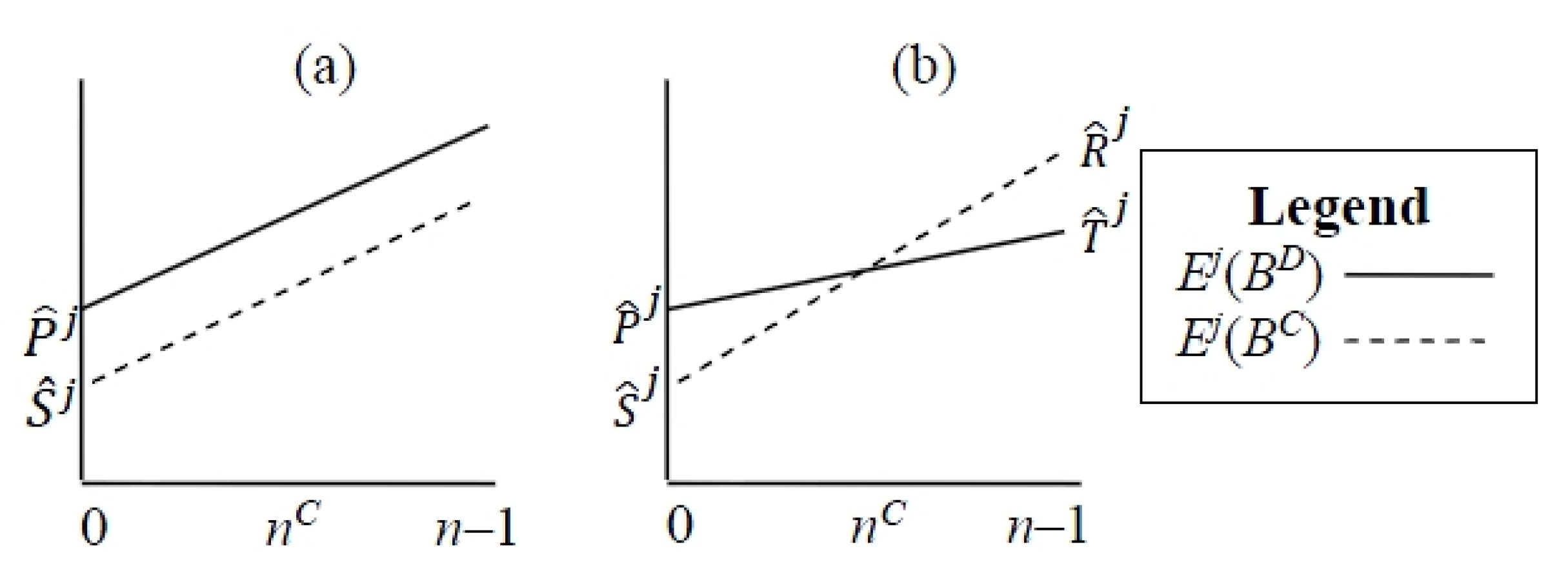
- Power-motivated agents, specifically those with > ½(T + R)(n – 1), will adapt to exploit (choose BD) all opponents. They will exhibit characteristics of competitive behavior.
- Achievement-motivated agents, specifically those with ½(T + P)(n – 1) > > ½(R + P)(n – 1) will adapt differently to different opponents, choosing BD when exploited, but BC when their opponent does likewise.
- Affiliation-motivated agents, specifically those with < ½(P + S)(n – 1), will choose BC against all opponents. They will exhibit characteristics of cooperative behavior.
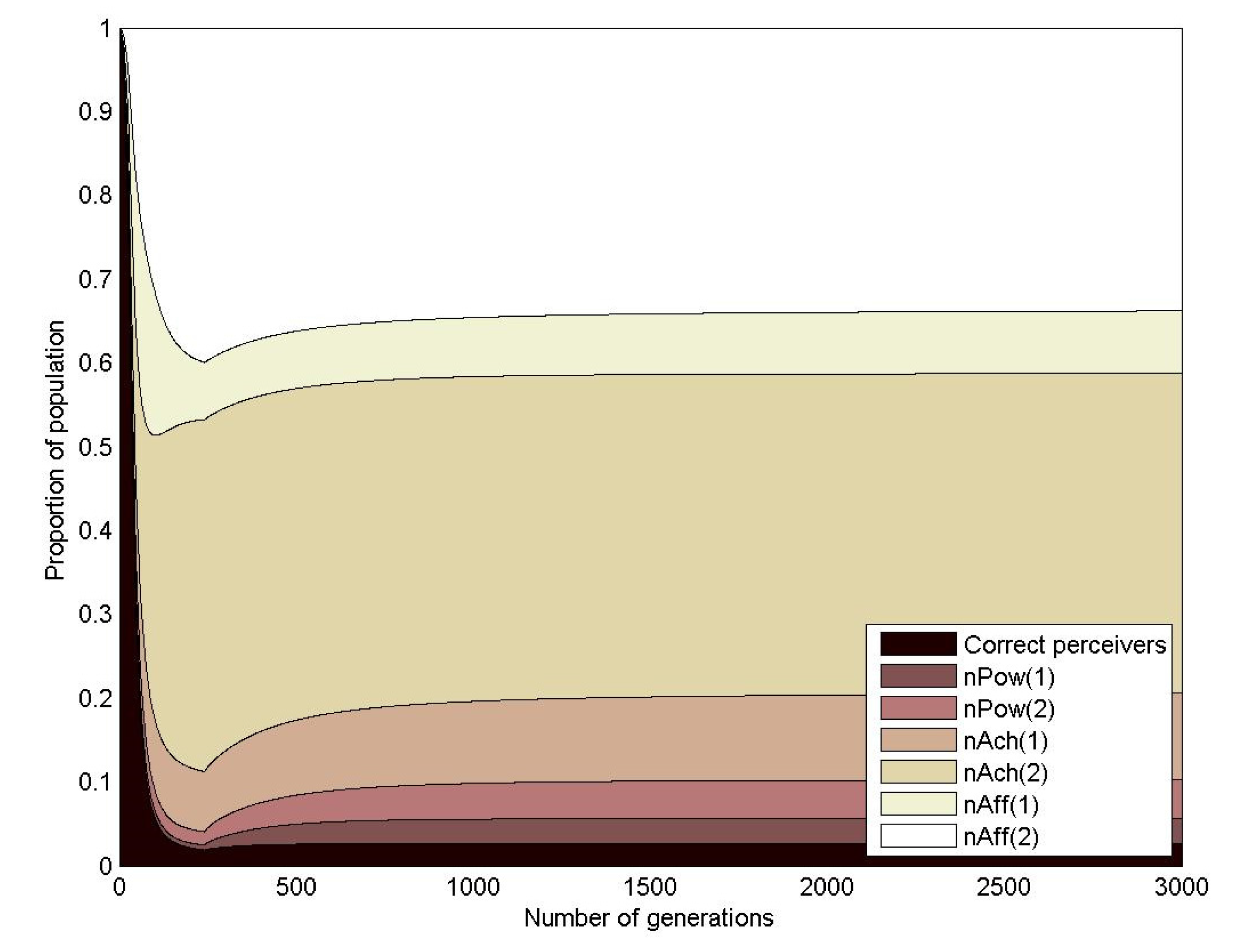
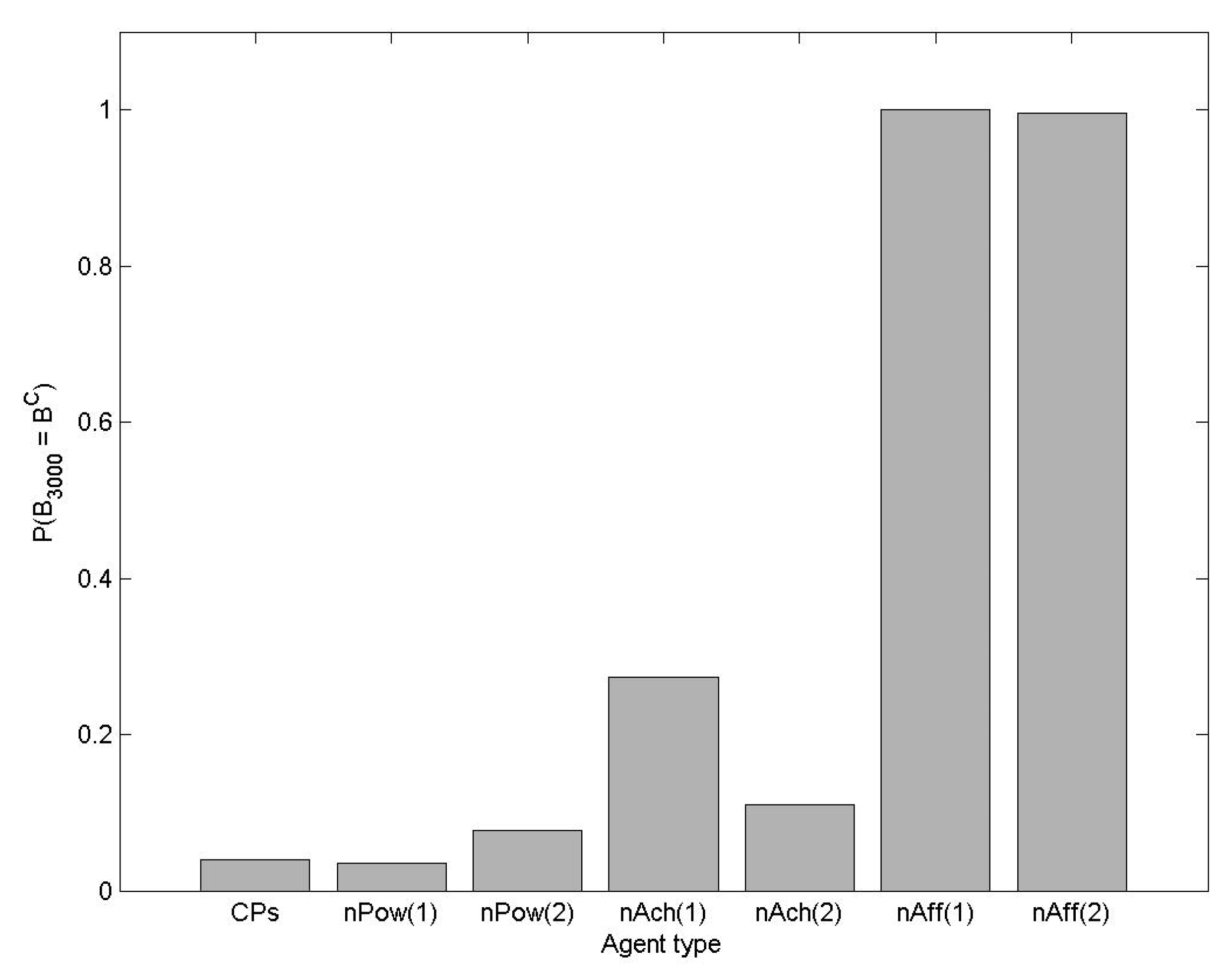
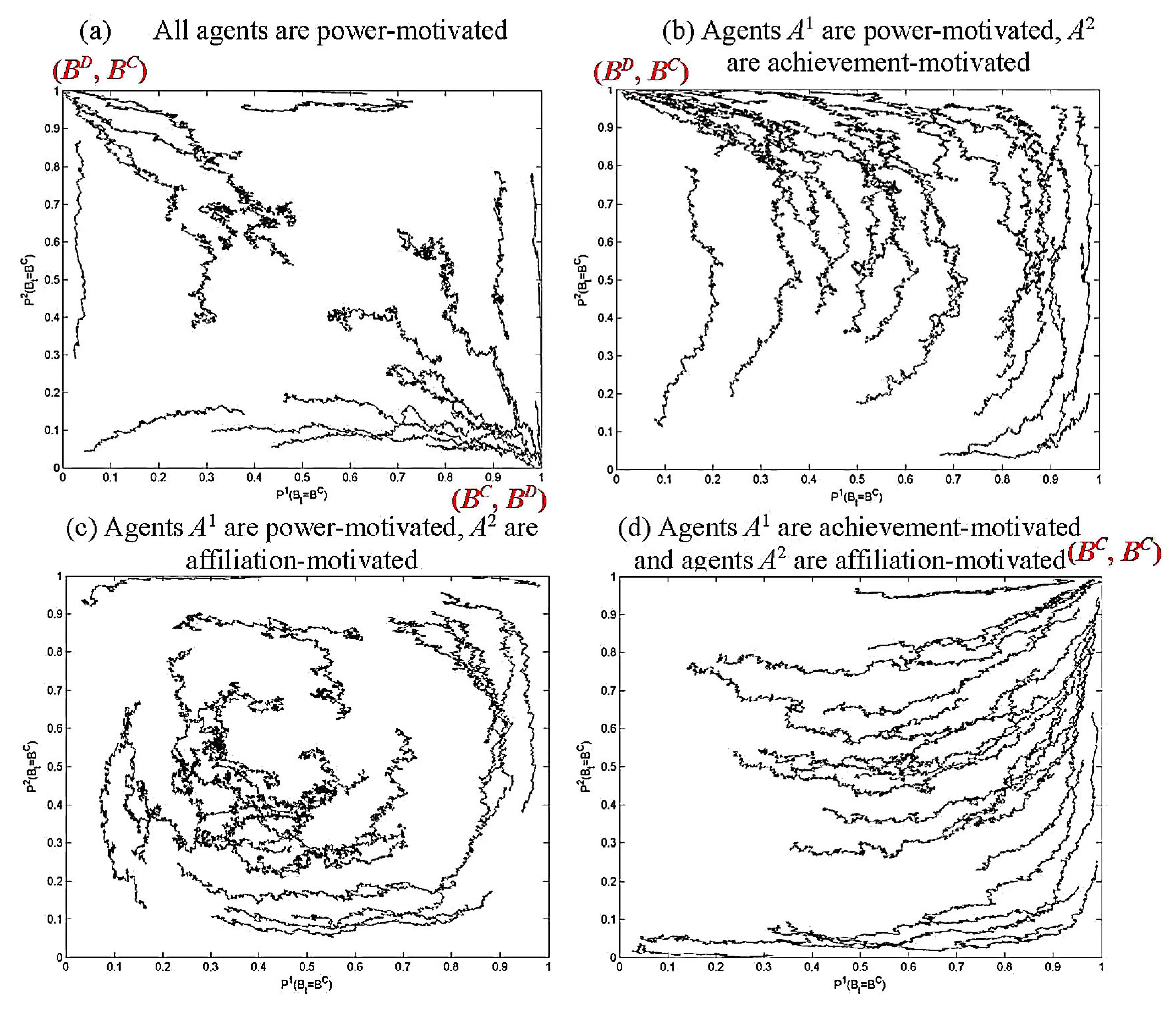
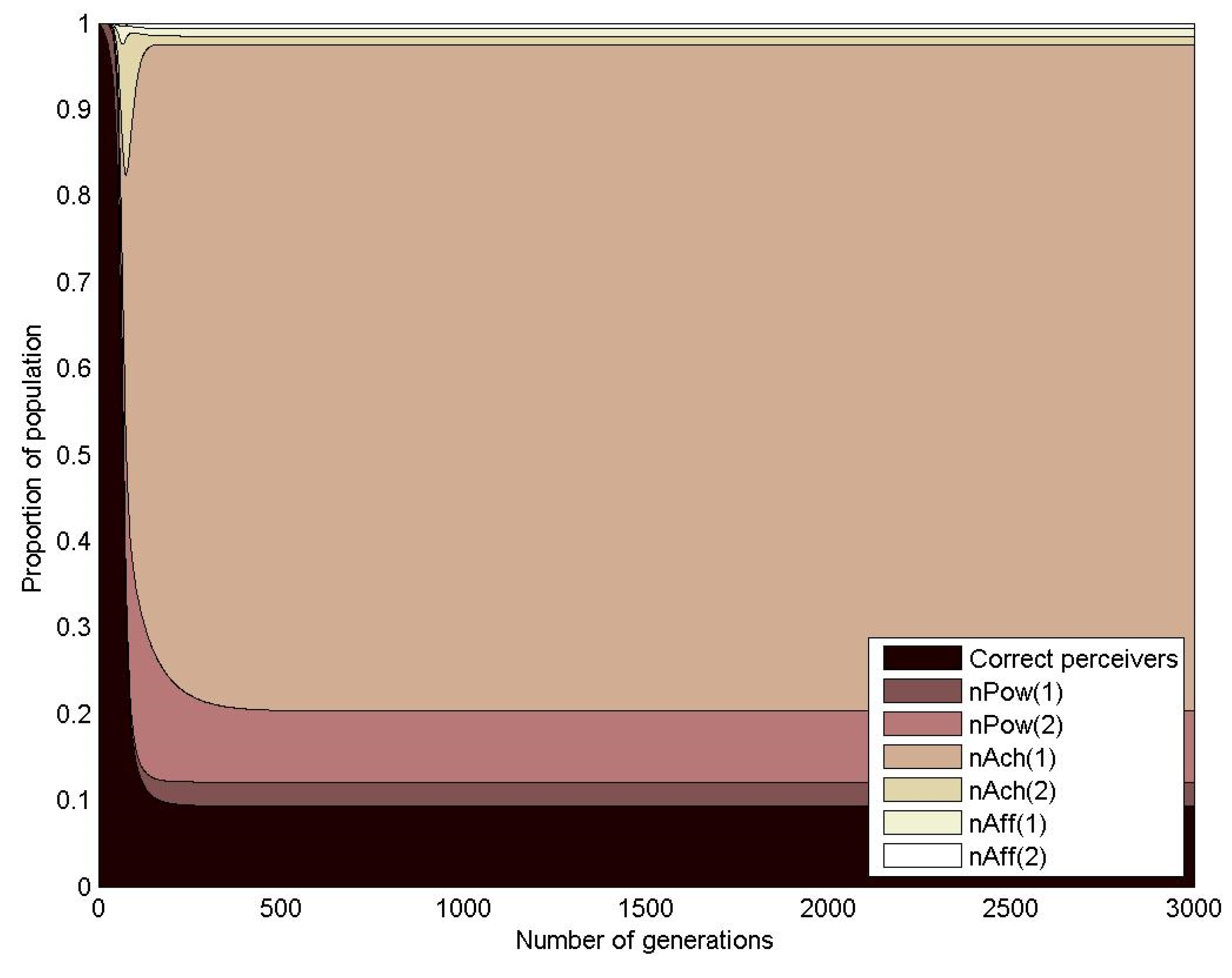
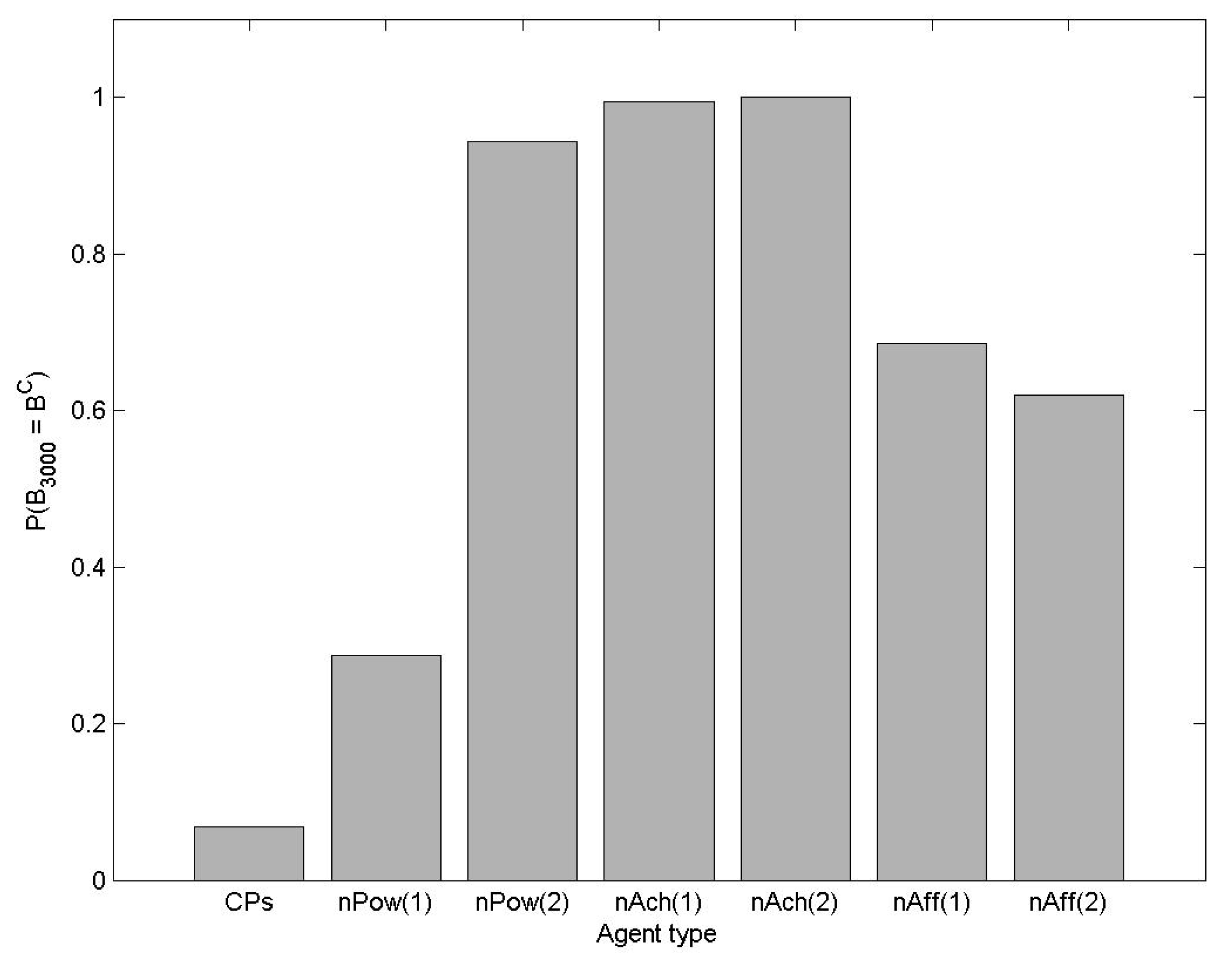
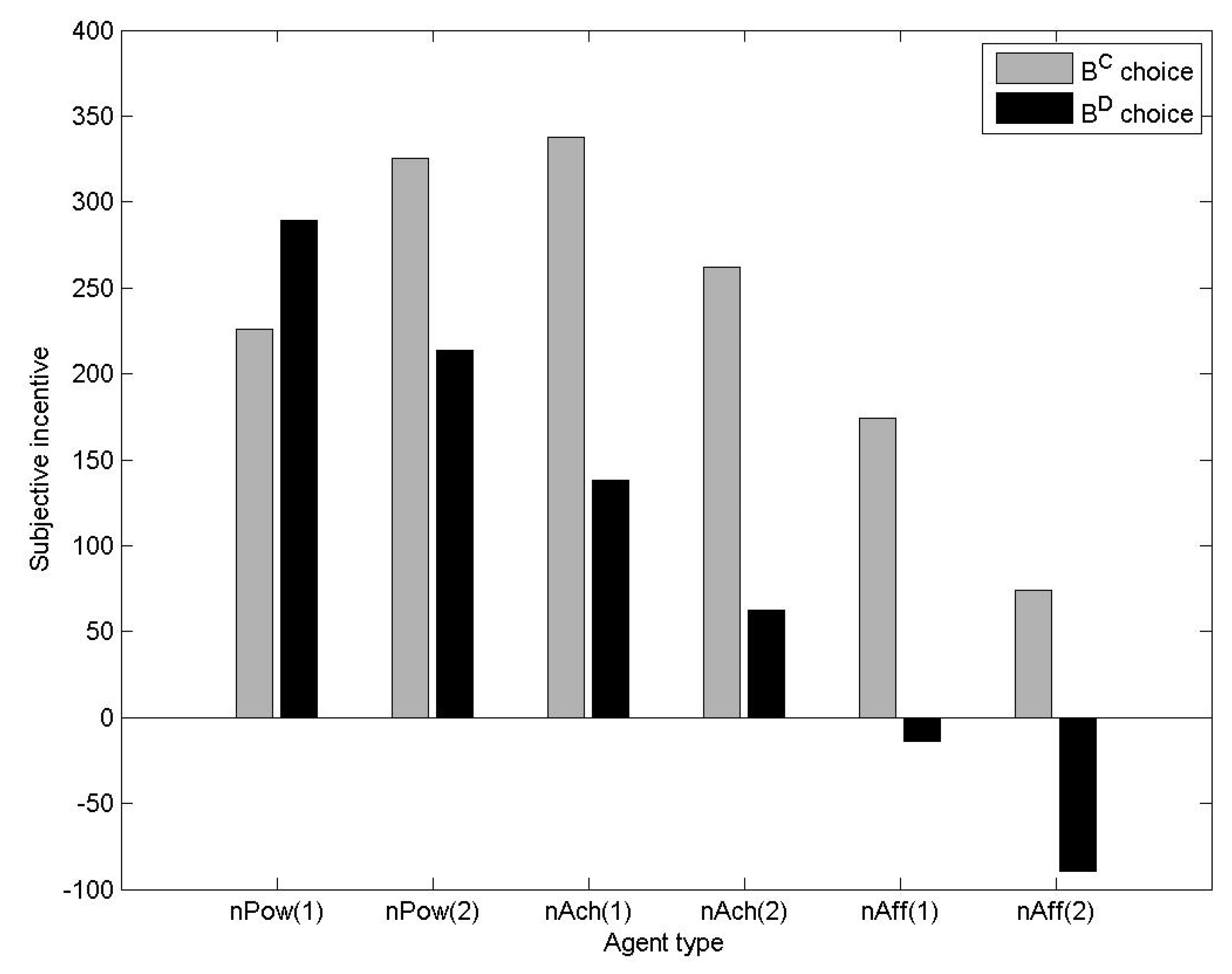
3.1.3. Empirical Study of the Evolution of Motivated Agents during n-Player Common Pool Resource Games
| j | Name | Description | OMI | ||
|---|---|---|---|---|---|
| 1 | CP | Correct perceiver | n/a | 0.5 | 0.5 |
| 2 | nPow(1) | Strong power motivated agent | 375 | 0 | 0 |
| 3 | nPow(2) | Weak power motivated agent | 325 | 0 | 0 |
| 4 | nAch(1) | Achievement motivated agent | 275 | 0 | 0 |
| 5 | nAch(2) | Achievement motivated agent | 225 | 0 | 0 |
| 6 | nAff(1) | Weak affiliation motivated agent | 175 | 0 | 0 |
| 7 | nAff(2) | Strong affiliation motivated agent | 125 | 0 | 0 |



3.2. Snowdrift and the Hawk-Dove Game
- A hawk meets a dove and the hawk gets the full resource. Thus T = U.
- A hawk meets another hawk of equal strength. Each wins half the time and loses half the time. Their average payoff is thus each. Note that P is negative.
- A dove meets a hawk. The dove backs off and gets nothing (that is, S = 0)
- A dove meets a dove and both share the resource ( each).
3.2.1. Theoretical Evaluation
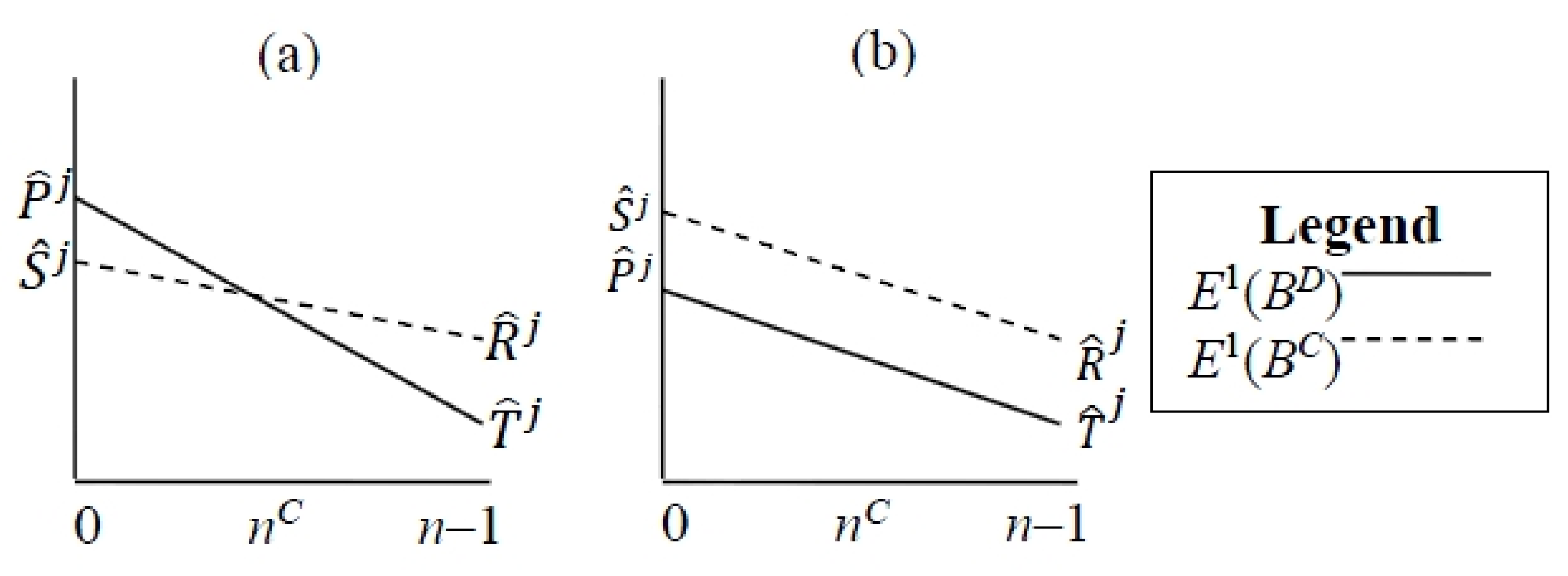
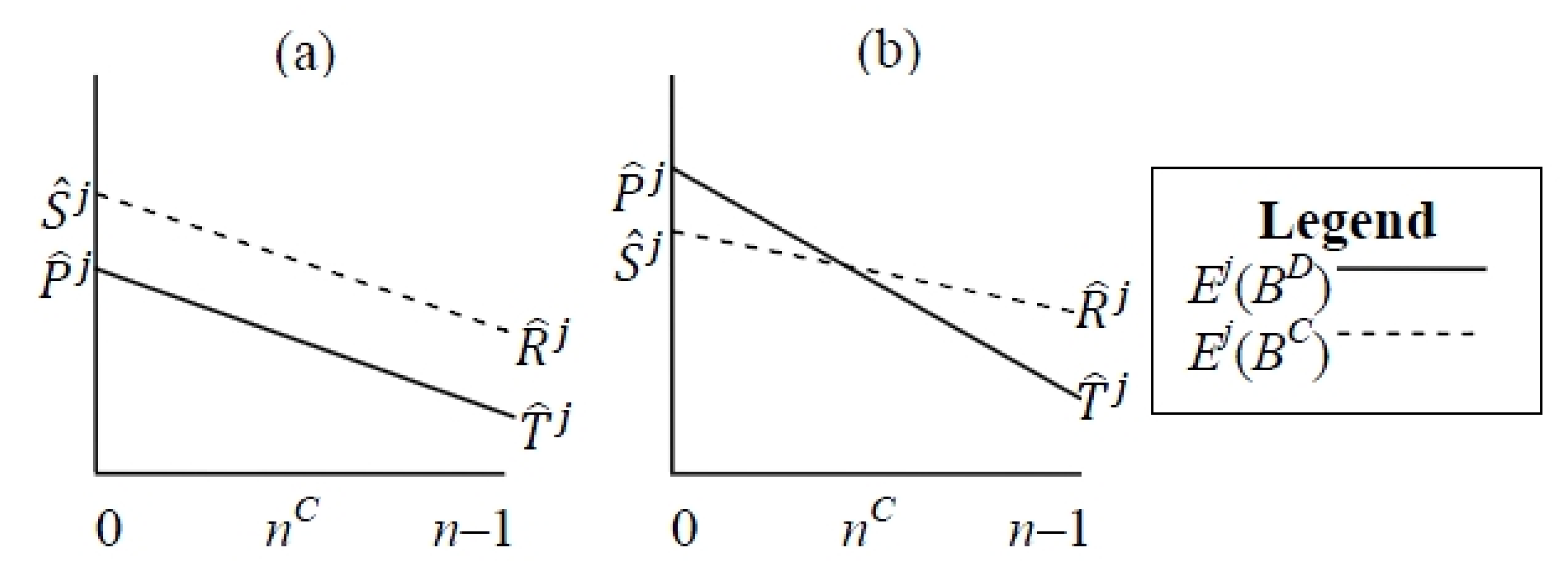
- Power-motivated agents have T(n – 1) > > ½(T + S)(n – 1)
- Achievement-motivated agents have ½(T + S)(n – 1) > > ½(R + P)(n – 1)
- Affiliation-motivated agents have ½(R + P)(n – 1) > > P(n – 1)
Power-Motivated Perception

Achievement-Motivated Perception
Affiliation-Motivated Perception

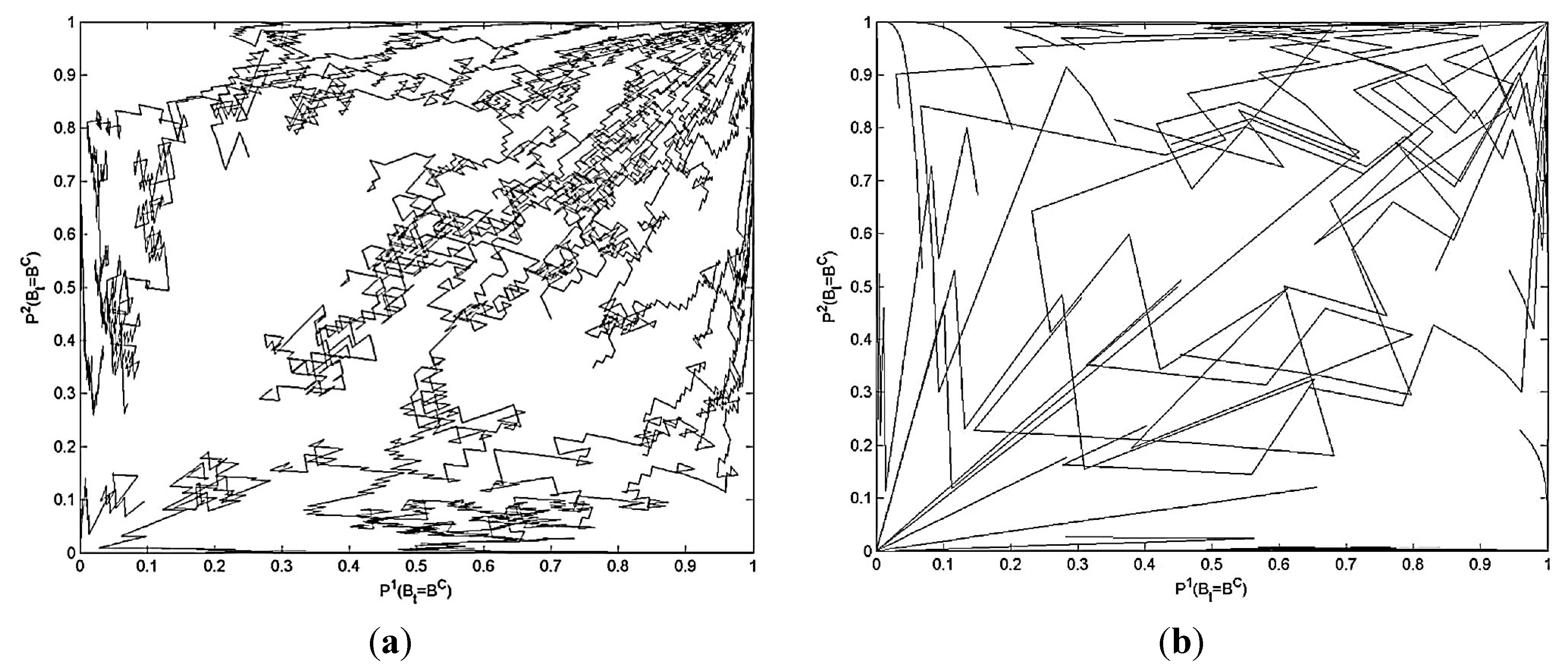
3.2.2. Learning in the Snowdrift Game


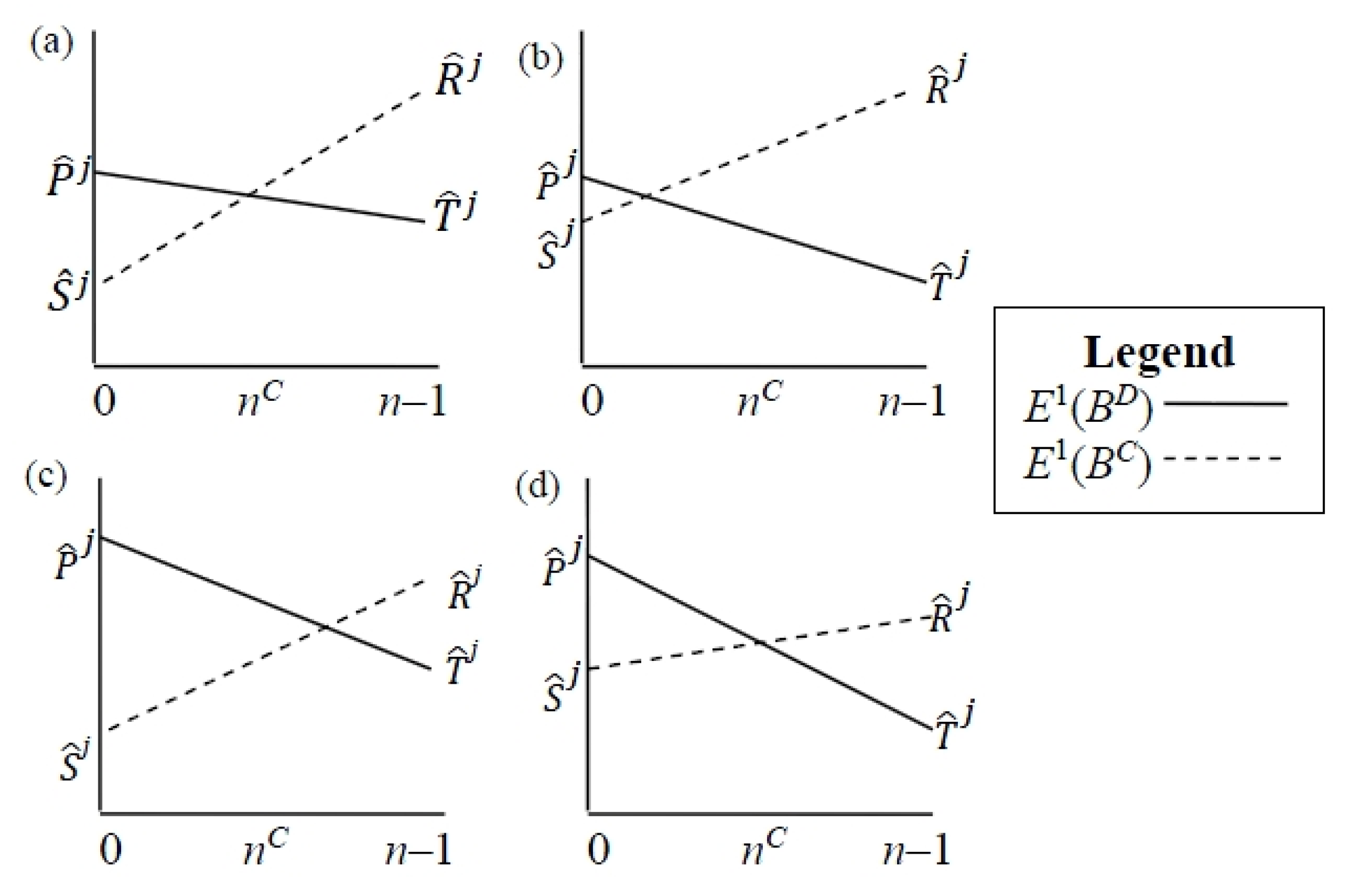
- Power-motivated agents, specifically those with > ½(T + R)(n – 1), prefer outcomes in which one player refuses to dig (either (BC, BD) or (BD, BC)). If one player is not power-motivated then the power-motivated agent will be the one that refuses to dig. That is, the power-motivated agent will gain the benefit from the digging without exerting themselves. This is consistent with the preference for competitive behavior identified in Table 1.
- Achievement-motivated agents, specifically those with = ½(R + S)(n – 1) will dig regardless of the motive profile of the other player. They do not mind working alone, consistent with the suggestion in Table 1.
- Affiliation-motivated agents, specifically those with < ½(P + S) (n – 1), prefer the outcomes where both players do the same thing. This is consistent with wanting to belong to a (peer) group, as in Table 1.
3.2.3. Empirical Study of Evolution in the Hawk-Dove Game
| j | Name | Description | OMI | ||
|---|---|---|---|---|---|
| 1 | CP | Correct perceiver | n/a | 0.5 | 0.5 |
| 2 | nPow(1) | Strong power motivated agent | 350 | 0 | 0 |
| 3 | nPow(2) | Weak power motivated agent | 250 | 0 | 0 |
| 4 | nAch(1) | Achievement motivated agent | 150 | 0 | 0 |
| 5 | nAch(2) | Achievement motivated agent | 50 | 0 | 0 |
| 6 | nAff(1) | Weak affiliation motivated agent | –50 | 0 | 0 |
| 7 | nAff(2) | Strong affiliation motivated agent | –150 | 0 | 0 |



4. Conclusions and Future
- Power-motivated agents learn competitive behavior.
- Achievement-motivated agents will adapt differently to different opponents and different games.
- Affiliation-motivated agents will exhibit characteristics of cooperative behavior and prefer outcomes where both players do the same thing.
- Different types of motivated agents thrive in different scenarios
- Diversity of agents is achieved
- Evolutionary benefit can be observed in the form of higher average explicit incentive (payoff) achieved by the society than we would expect of a society of objectively rational agents without motivation.
Conflicts of Interest
Appendix A—Proofs
Appendix B

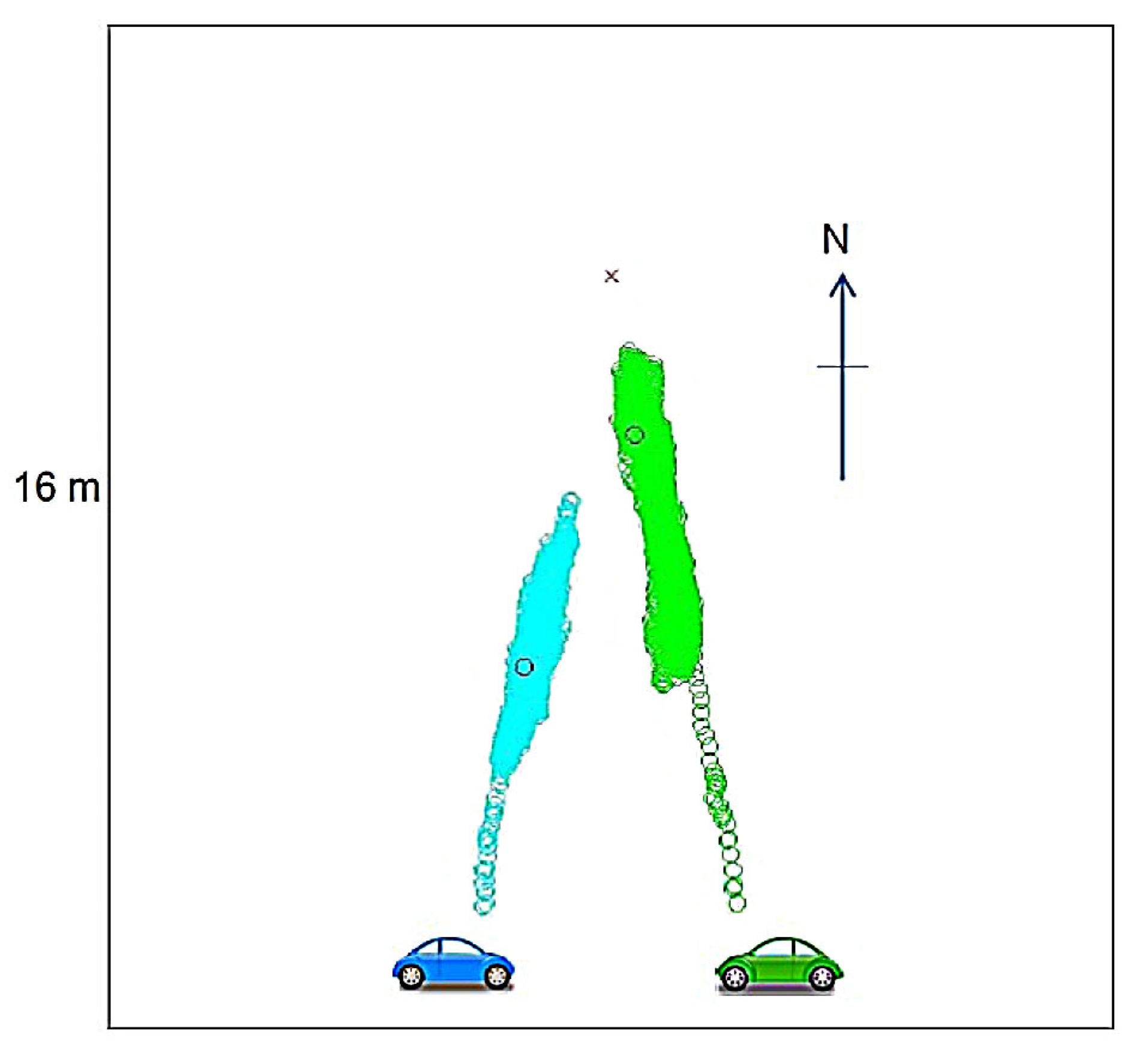
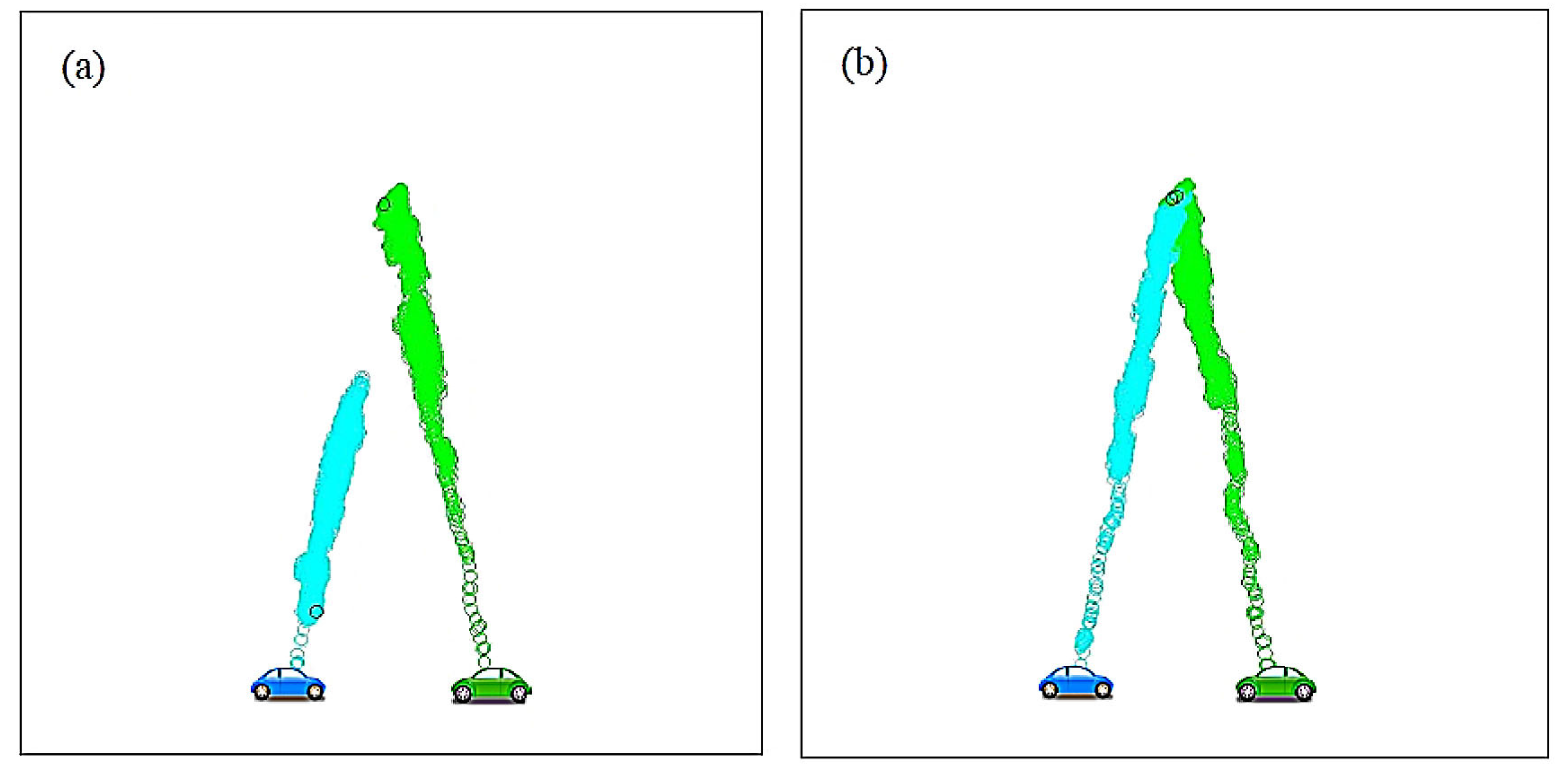
- BC moves the motivated agent towards the snowdrift according to:
- BD moves the motivated agent towards position of their own car:

References
- Heckhausen, J.; Heckhausen, H. Motivation and Action; Cambridge University Press: New York, NY, USA, 2010. [Google Scholar]
- Terhune, K.W. Motives, situation and interpersonal conflict within prisoner’s dilemma. J. Personal. Soc. Psychol. Monogr. Suppl. 1968, 8, 1–24. [Google Scholar] [CrossRef]
- Kuhlman, D.; Marshello, A. Individual differences in game motivation as moderators of preprogrammed strategy effects in prisoner’s dilemma. J. Personal. Soc. Psychol. 1975, 32, 922–931. [Google Scholar] [CrossRef]
- Kuhlman, D.; Wimberley, D. Expectations of choice behavior held by cooperators, competitors and individualists across four classes of experimental game. J. Personal. Soc. Psychol. 1976, 34, 69–81. [Google Scholar] [CrossRef]
- Van Run, G.; Liebrand, W. The effects of social motives on behavior in social dilemmas in two cultures. J. Exp. Soc. Psychol. 1985, 21, 86–102. [Google Scholar]
- Atkinson, J.W.; Litwin, G.H. Achievement motive and test anxiety conceived as motive to approach success and motive to avoid failure. J. Abnorm. Soc. Psychol. 1960, 60, 52–63. [Google Scholar] [CrossRef] [PubMed]
- Merrick, K.; Maher, M.L. Motivated Reinforcement Learning: Curious Characters for Multiuser Games; Springer: Berlin, Germany, 2009. [Google Scholar]
- Merrick, K.; Shafi, K. A game theoretic framework for incentive-based models of intrinsic motivation in artificial systems. Front. Cogn. Sci. Spec. Issue Intrinsic Motiv. Open-End. Dev. Anim. Hum. Robot. 2013, 4, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, M.; Oudeyer, P.-Y. Socially guided intrinsic motivation for robot learning of motor skills. Auton. Robot. 2014, 36, 273–394. [Google Scholar] [CrossRef]
- Baldassare, G.; Mannella, F.; Fiore, V.; Redgrave, P.; Gurney, K.; Mirolli, M. Intrinsically motivated action-outcome learning and goal-based action recall: A system-level bio-constrained computational model. Neural Netw. 2013, 41, 168–187. [Google Scholar] [CrossRef] [PubMed]
- Baldassarre, G.; Mirolli, M. Intrinsically Motivated Learning in Natural and Artificial Systems; Springer: Berlin, Heidelberg, Germany, 2013. [Google Scholar]
- Oudeyer, P.-Y.; Kaplan, F. Intelligent Adaptive Curiosity: A Source of Self-Development; Fourth International Workshop on Epigenetic Robotics, Lund University: Lund, Sweden, 2004; pp. 127–130. [Google Scholar]
- Merrick, K.; Shafi, K. Achievement, affiliation and power: Motive profiles for artificial agents. Adapt. Behav. 2011, 19, 40–62. [Google Scholar] [CrossRef]
- McClelland, D. The Achieving Society; The Free Press: New York, NY, USA, 2010. [Google Scholar]
- Sirota, D.; Mischkind, L.; Meltzer, M. The Enthusiastic Employee; Pearson Education Inc: Upper Saddle River, NJ, USA, 2005. [Google Scholar]
- Atkinson, J.W. Motivational determinants of risk-taking behavior. Psychol. Rev. 1957, 64, 359–372. [Google Scholar] [CrossRef] [PubMed]
- Elliot, A.; Eder, A.; Harmon-Jones, E. Approach-avoidance motivation and emotion: Convergence and divergence. Emot. Rev. 2013, 5, 308–311. [Google Scholar] [CrossRef]
- Atkinson, J.W.; Raynor, J.O. Motivation and Achievement; V.H. Winston: Washington, DC, USA, 1974. [Google Scholar]
- Nikitin, J.; Freund, A. When wanting and fearing go together: The effect of co-occurring social approach and avoidance motivation on behavior, affect and cognition. Eur. J. Soc. Psychol. 2009, 40, 783–804. [Google Scholar] [CrossRef]
- Elliot, A. Handbook of Approach and Avoidance Motivation; Taylor and Francis: New York, NY, USA, 2008. [Google Scholar]
- McClelland, J.; Watson, R.I. Power motivation and risk-taking behaviour. J. Personal. 1973, 41, 121–139. [Google Scholar] [CrossRef]
- McClelland, J.; Boyatzis, R.E. The leadership motive pattern and long term success in management. J. Appl. Psychol. 1982, 67, 737–743. [Google Scholar] [CrossRef]
- Merrick, K. Evolution of intrinsic motives in a multi-player common pool resource game. In Proceedings of the IEEE Symposium Series on Computational Intelligence for Human-like Intelligence, Orlando, FL, USA; 2014; pp. 36–43. [Google Scholar]
- Acemoglu, D.; Yildiz, M. Evolution of Perceptions and Play; Massachusetts Institute of Technology, Department of Economics: Cambridge, MA, USA, 2001. [Google Scholar]
- Dekel, E.; Ely, J.; Ylankaya, O. Evolution of preferences. Rev. Econ. Stud. 2007, 74, 685–704. [Google Scholar] [CrossRef]
- Colman, A. Game theory and experimental games: The study of strategic interaction. In International Series in Experimental Social Psychology; Pergamon Press: Oxford, UK, 1982. [Google Scholar]
- Wang, M.; Hipel, K.; Fraser, N. Modeling misperceptions in games. Behav. Sci. 1988, 33, 207–223. [Google Scholar] [CrossRef]
- Givigi, S.N.; Schwartz, H.M. Swarm robot systems based on the evolution of personality traits. Turk. J. Electr.Eng. 2007, 15, 257–282. [Google Scholar]
- Nowak, M.; Sigmund, K. Evolution of indirect reciprocity. Nature 2005, 437, 1291–1298. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Kokubo, S.; Jusup, M.; Tanimoto, J. Universal scaling for the dilemma strength in evolutionary games. Phys. Life Rev. 2015, 14, 1–30. [Google Scholar] [CrossRef] [PubMed]
- Bennett, E. The aspiration approach to predicting coalition formation and payoff distribution in sidepayment games. Int. J. Game Theory 1983, 12, 1–28. [Google Scholar] [CrossRef]
- Brumley, L. Misperception and Its Evolutionary Value; Monash University: Melbourne, Australia, 2014. [Google Scholar]
- Fudenberg, D.; Levine, D. Learning and evolution: Where to we stand? Learning in games. Eur. Econ. Rev. 1998, 42, 631–639. [Google Scholar] [CrossRef]
- Chakraborty, D.; Stone, P. Multiagent learning in the presence of memory-bounded agents. Auton. Agents Multi-Agent Syst. 2014, 28, 182–213. [Google Scholar] [CrossRef]
- Borgers, T.; Sarin, R. Learning through reinforcement and replicator dynamics. J. Econ. Theory 1997, 77, 1–14. [Google Scholar] [CrossRef]
- Schembri, M.; Mirolli, M.; Baldassarre, G. Evolution and learning in an intrinsically motivated reinforcement learning robot. In Advances in Artificial Life; Springer: Berlin, Heidelberg, Germany, 2007; Volume 4648, pp. 294–303. [Google Scholar]
- Singh, S.; Lewis, R.; Barto, A.G.; Sorg, J. Intrinsically motivated reinforcement learning: An evolutionary perspective. IEEE Trans. Auton. Ment. Dev. 2010, 2, 70–82. [Google Scholar] [CrossRef]
- Rapoport, A.; Chammah, A. Prisoner’s Dilemma, A Study in Conflict and Cooperation; University of Michigan Press: Ann Arbor, MI, USA, 1965. [Google Scholar]
- Maynard-Smith, J.; Price, G.R. The logic of animal conflict. Nature 1973, 246, 15–18. [Google Scholar] [CrossRef]
- 1While in nature these are two different species that cannot cross-breed, the spirit of this game model is such that the terms “hawk” and “dove” refer to strategies used in the contest rather than species of bird.
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Merrick, K. The Role of Implicit Motives in Strategic Decision-Making: Computational Models of Motivated Learning and the Evolution of Motivated Agents. Games 2015, 6, 604-636. https://doi.org/10.3390/g6040604
Merrick K. The Role of Implicit Motives in Strategic Decision-Making: Computational Models of Motivated Learning and the Evolution of Motivated Agents. Games. 2015; 6(4):604-636. https://doi.org/10.3390/g6040604
Chicago/Turabian StyleMerrick, Kathryn. 2015. "The Role of Implicit Motives in Strategic Decision-Making: Computational Models of Motivated Learning and the Evolution of Motivated Agents" Games 6, no. 4: 604-636. https://doi.org/10.3390/g6040604
APA StyleMerrick, K. (2015). The Role of Implicit Motives in Strategic Decision-Making: Computational Models of Motivated Learning and the Evolution of Motivated Agents. Games, 6(4), 604-636. https://doi.org/10.3390/g6040604