1. Introduction
In fact, concrete is a widely used construction material in the world. Concrete compressive strength is a criterion employed in specifying the portion of resistance a structural component can deliver to deformation. Compressive strength is a widely used standard to access the performance of a provided concrete mixture. This technique of assessing concrete is essential because it is the primary measure determining how sufficiently concrete can resist loads that impact its measure. It specifically informs us whether a distinct mixture is appropriate for encountering the conditions of a certain venture. Concrete can astoundingly stand up to compressive loading. This is a frequent reason for why it is useful for constructing arches, foundations, dams, columns and tunnel linings among other buildings.
Experimenters from various areas of science may endeavor to represent phenomena of interest, such as high-concrete concrete compressive strength, using probabilistic models. In recent years, many authors have exhibited significant appeal in representing new generalized families of probability distributions by adding one or more additional parameters to well-known distributions to yield new models with more incredible flexibility in modeling. The growth of proposing new statistical distributions is a major study area in the approach of distribution theory. Noteworthy methods include the following: the exponentiated method by Mudholkar and Srivastava [
1], Marshall–Olkin method by Marshall and Olkin [
2], beta-G family by Eugene et al.Olkin [
3], Kumaraswamy-G family by Cordeiro and Castro [
4], T-X family by Alzaatreh et al. [
5], Weibull-G family by Bourguignon et al. [
6], logarithmic transformed (LT) method by Pappas et al. [
7], alpha power (AP) method by Mahdavi and Kundu [
8], Marshall–Olkin AP method by Nassar et al. [
9] and weighted AP transformed method by Alotaibi et al. [
10]. For more details about other methods for generating distributions, one can refer to Lee et al. [
11] and Jones [
12].
Pappas et al. [
7] proposed the LT approach, which uses a cumulative distribution function (CDF) and probability density function to induct a new parameter into well-known distributions (PDF), respectively.
Pappas et al. [
7] considered the modified Weibull extension distribution by Xie et al. [
13] as a baseline distribution
G in (
1) and studied some characteristics of the new distribution. Nassar et al. [
14] used the LT method to propose a new form for the Weibull distribution. Eltehiwy [
15] introduced the LT inverse Lindley distribution. Alotaibi et al. [
16] utilized the CDF in (
1) to introduce a new generalization for the traditional Lomax distribution.
Lately, Mahdavi and Kundu [
8] offered the AP method for yielding new probability distributions by introducing an extra parameter to bring about a more elastic family. The CDF of the AP method is provided as follows:
and the corresponding PDF is the following.
Utilizing the AP method, a new AP Weibull (APW) distribution is proposed by Nassar et al. [
17]. Dey et al. [
18] introduced the AP inverse Lindley distribution. Ihtisham et al. [
19] proposed the AP Pareto distribution. Eghwerido et al. [
20,
21] presented the AP Gompertz and AP Teissier distributions, respectively. Eghwerido et al. [
22] proposed the AP-extended generalized exponential distribution.
The main goal of this article is to present a new method for generating probability distributions by using the AP CDF from (
3) as the baseline CDF in (
1). The logarithmic transformed alpha power (LTAP) family is the name given to the new family. The new LTAP family can be used to produce probability distributions with closed forms CDF and PDF. Firstly, we derive some structural properties of the LTAP family including the mixture representation for the PDF. Secondly, we assume the exponential as a baseline for the LTAP family and develop a new three-parameter LTAP-exponential (LTAPEx) distribution. The hazard rate functions (HRF) of the LTAPEx distribution accommodates monotonic, decreasing, increasing, upside-down bathtub and bathtub-shaped models. Therefore, the LTAPEx distribution can be used as a competitive model for many well-known distributions presented in the literature. Another motivation for the LTAPEx distribution is that it contains some sub-models such as exponential and alpha power exponential (APEx) distributions. Moreover, it can be considered as an appropriate model for modeling positively skewed data, which may not be suitably fitted by other standard distributions. The highly complex materials of high-performance concrete can render modeling its behavior an extremely difficult task. One of our practical objectives in this study is to evaluate the reliability of the high-performance concrete by assuming that the compressive strength of concrete follows the LTAPEx model. We then apply this model to a real high-performance concrete compressive strength dataset to check our findings. The outcomes of this analysis showed that the proposed model can be considered as an appropriate model when compared with some other competitive models to model high-performance concrete. The current study is an attempt to investigate and choose the most suitable model to assess the reliability of high-performance concrete, which we believe would be of outstanding appeal to reliability engineers.
The rest of the article is divided into the following sections: In
Section 2, we present the LTAP family and provide a linear representation for the LTAP family PDF. In
Section 3, we present the LTAPEx distribution. In
Section 4, we study some properties of the LTAPEx distribution. The maximum likelihood method is considered to obtain the point and interval estimates for the model parameters as well as the corresponding reliability function (RF) in
Section 5. A simulation study is conducted in
Section 6. The investigation of one real dataset is provided in
Section 7. Finally,
Section 8 provides some conclusions.
3. The LTAPEx Distribution
In this section, we explain the LTAPEx distribution and some associated statistical features. By entering
, of the exponential distribution in (
5), one can reach the CDF of the LTAPEx distribution as follows.
By differentiating (
14) with respect to
x, we can obtain the PDF of the LTAPEx distribution as follows:
where
is the scale parameter, and
and
are the shape parameters. Moreover, the RF and the HRF of the LTAPEx distribution are furnished, respectively, by the following.
It can be observed here that when
and
tend to one, the PDF in (
15) reduces to the PDF of the exponential distribution. Moreover, when
, the LTAPEx distribution reduces to the alpha power exponential distribution proposed by Mahdavi and Kundu (2017). Another special case is when
, the LTAPEx distribution reduces to the logarithmic transformed exponential distribution.
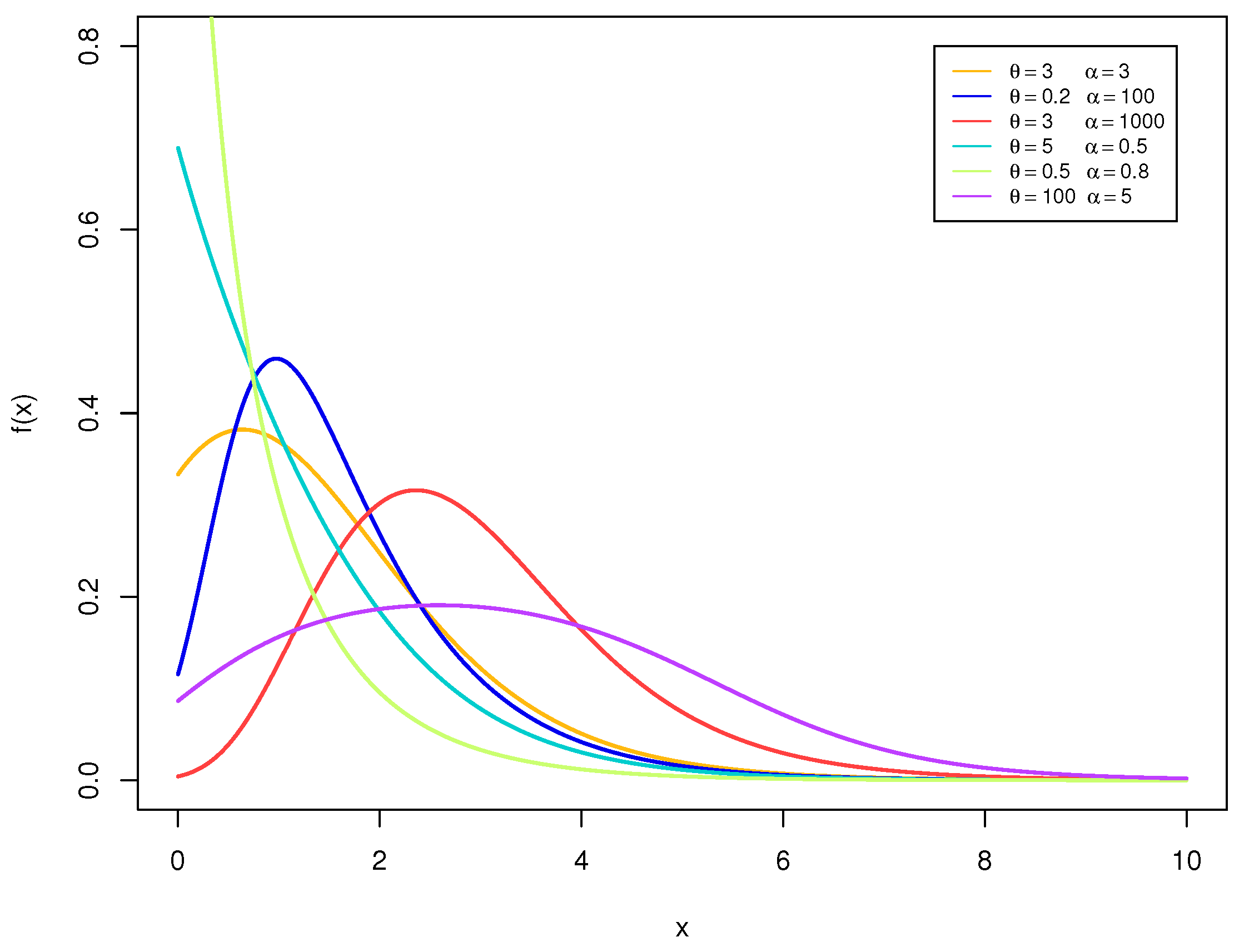
Figure 1 layouts the various plots of the PDF of the LTAPEx distribution applying
in all cases and by considering several values for the shape parameters
and
. In
Figure 1, we can recognize that the new shape parameters
and
afford more flexibility to the PDF of the LTAPEx distribution than the conventional exponential distribution. The LTAPEx distribution is a right-skewed distribution, and this characteristic encourages the use of this distribution to model right-skewed data rather than some other competitive distributions such as Weibull and gamma distributions.
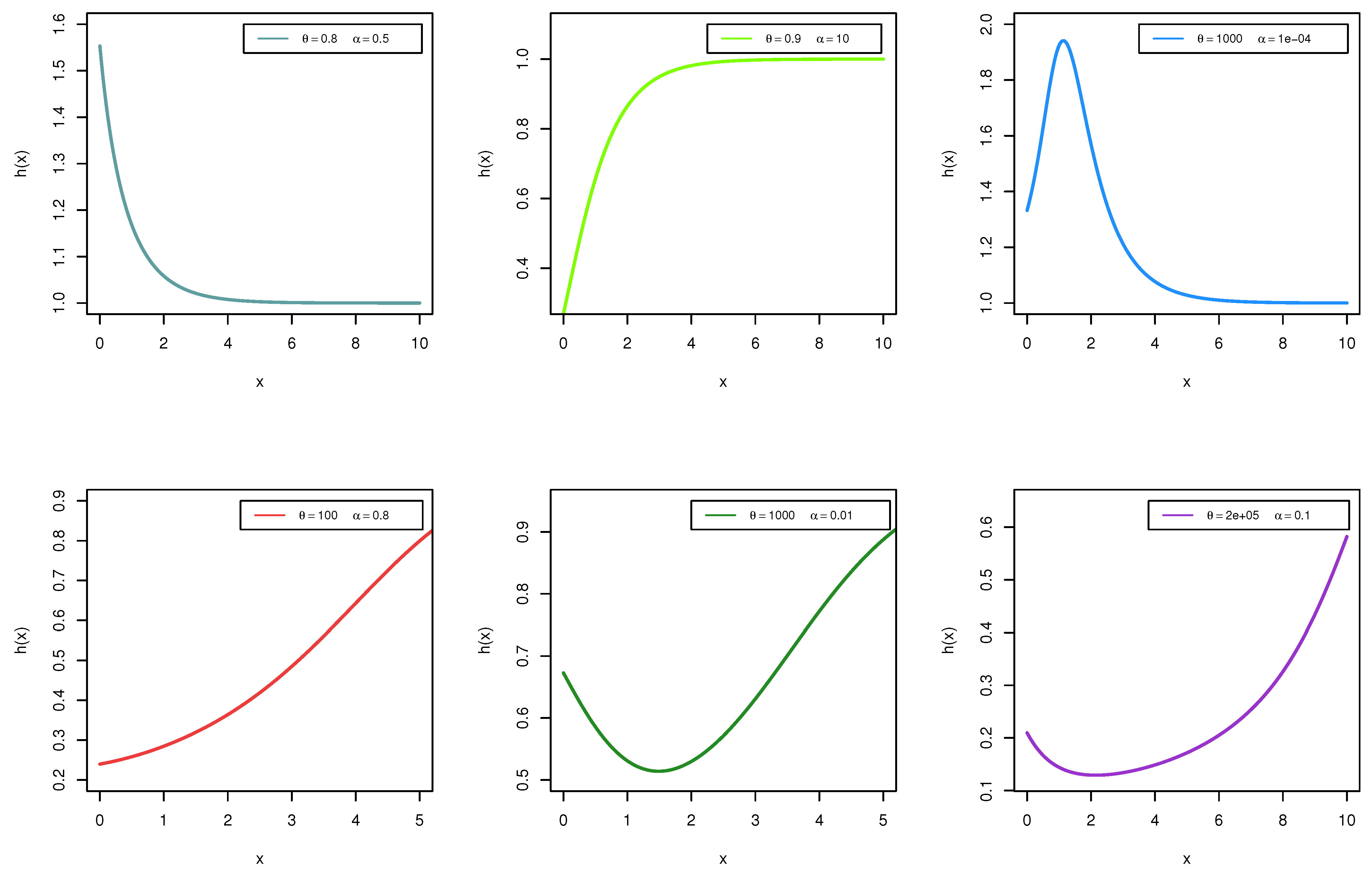
Figure 2 displays the various shapes of the HRF of the LTAPEx distribution.
Figure 2 reveals that the HRF of the LTAPEx distribution has different shapes, including decreasing, increasing, upside-down and bathtub-shaped hazard rates.
Using the linear representation for the PDF in (
8), one can write the PDF of the LTAPEx distribution given by (
15) as follows:
where
is the PDF of the exponential distribution with scale parameter
and the following.
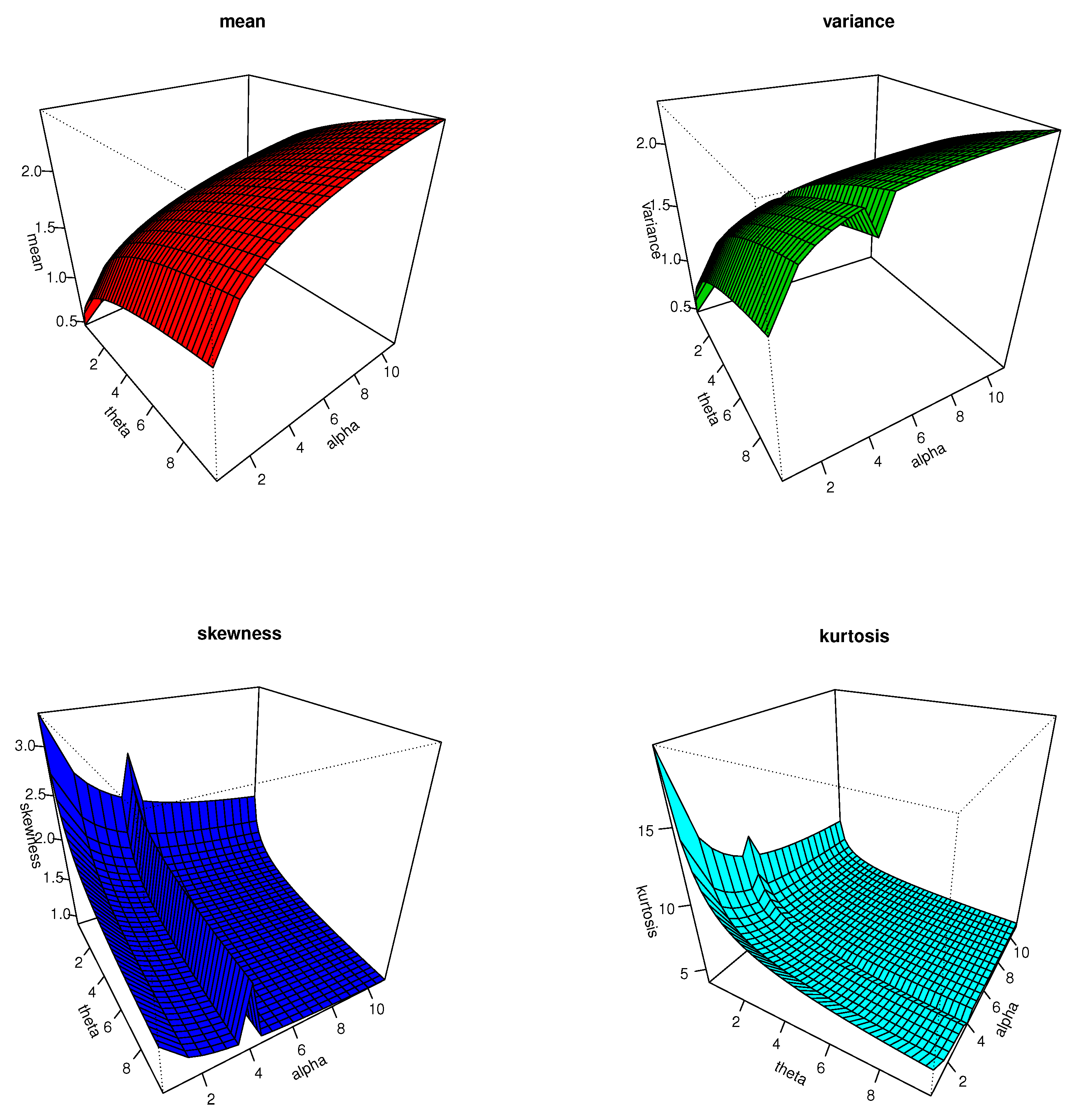
Various structural properties of the LTAPEx distribution can be acquired directly from (
18) based on the well-known properties of exponential distribution. Integrating (
18), one can write the expansion of the CDF of the LTAPEx distribution as follows:
where
is the CDF of the exponential distribution.
5. Estimation of the Parameters and Reliability Function
In this section, we consider the maximum likelihood estimation method for estimating parameters
and
as well as the reliability function of the LTAPEx distribution. Let
be a random sample obtained from the LTAPEx distribution with PDF given by (
15), then the likelihood function can be formulated as follows.
Taking the natural logarithm of (
37), one can obtain the log-likelihood function, denoted by
, as follows.
Hence, the maximum likelihood estimates (MLEs) of
and
, denoted by
and
, can be computed by maximizing the objective log-likelihood function in (
38) with respect to
and
. Another useful approach to obtain these estimates is to solve the following three normal equations simultaneously.
It is observed from (
39)–(
41) that there are no ended forms for the MLEs of
and
. Therefore, to reach these estimates, we should adopt an iterative procedure for determining the numerical solution of (
39)–(
41). Now, based on the invariance property of MLEs, the MLEs of the RF at
can be computed from (
16) as follows.
The ACIs of
and
are instantly obtained based on the asymptotic properties of the MLEs. It is known that
, where
is the asymptotic variance–covariance matrix of MLEs. Actually, it is not easy to reach
; hence, the approximate asymptotic variance–covariance matrix of the MLEs expressed by
can be used alternatively as follows
The elements
and
are the second derivatives of the log-likelihood function in (
38), and they can be expressed as follows:
where
,
and
. Now, the
ACIs of parameters
and
can be computed as follows:
where
is the upper
th percentile point of the standard normal distribution.
In order to obtain the ACIs of the reliability function, we are required to obtain its variance. One of the common significant adopted procedures for approximating the variance is the delta method. To practice this approach, suppose that
, where the following is the case:
where
. Then, the approximate estimate for the variance of the reliability function is as follows, respectively:
Therefore, the two-sided ACI for the reliability function is provided by the following.
6. Simulation Study
In this section, a simulation analysis is accomplished to assess the performance of the MLEs of the unknown parameters and the reliability function. The efficiency of the estimates is evaluated using their mean squared errors (MSEs) and the confidence interval lengths. We employ Equation (
22) to yield samples from the LTAPEx distribution. The simulation experiment is replicated 1000 times, each for samples of 25, 50 and 100. These sample sizes are selected to reflect the impact of small, intermediate and large sample sizes on the estimates. Moreover, different values for the unknown parameters
and
are considered. The selected values are
,
and
. In a separate setting, we have acquired the MLE, MSE and confidence interval lengths (CILs). The simulation study is carried out based on following the steps:
Decide the values of and the distinct time ;
Generate
n observations from the LTAPEx distribution using (
22);
Use the generated sample to compute the MLEs of , and ;
Obtain the MSEs of , and ;
Obtain the confidence interval bounds of , and ;
Redo steps 2–5 M times;
Compute the the average values (AVs) of MLEs, MSEs, confidence interval bounds (CIBs) and CILs of the parameter
as follows:
where
and
are the lower and upper CIBs, respectively.
The simulation outcomes are presented in
Table 1,
Table 2,
Table 3,
Table 4,
Table 5 and
Table 6. From these Tables, we can observe that as the sample size grows, the AV-MLEs of the different parameters and the reliability function are stable and relatively close to the actual parameter values. This implies that the MLEs act asymptotically unbiased estimators. Furthermore, the AV-MSEs reduce as the sample size increases in all issues, which indicate that the MLEs are consistent. Finally, one can observe that, as the sample size increases, CILs decrease in all the cases, as expected. This is because as the sample size raises, more additional information is collected.
7. Real Data Analysis
In this section, one real dataset is considered to explain the flexibility of our offered LTAPEx distribution. We compare the results of the LTAPEx distribution with some competitive distributions, such as exponential (Ex), generalized exponential (GEx) by Gupta and Kundu [
24], APEx by Mahdavi and Kundu [
8], APW by Nassar et al. [
17] and Marshall–Olkin alpha power exponential (MOAPEx) by Nassar et al. [
9]. The PDFs of these distributions are shown in
Table 7 (for
). To compare the suitability of the different competitive models to fit the real datasets, we consider employing some different statistics including the following: The log-likelihood function is evaluated at the MLEs
, Anderson–Darling (
) and Cramér–Von Mises (
). Moreover, we use the Kolmogorov–Smirnov (KS) statistic in addition to the corresponding
p-value.
The dataset presents the high-performance concrete compressive strength, which is originally provided by Yeh [
25] and analyzed recently by Alam and Nassar [
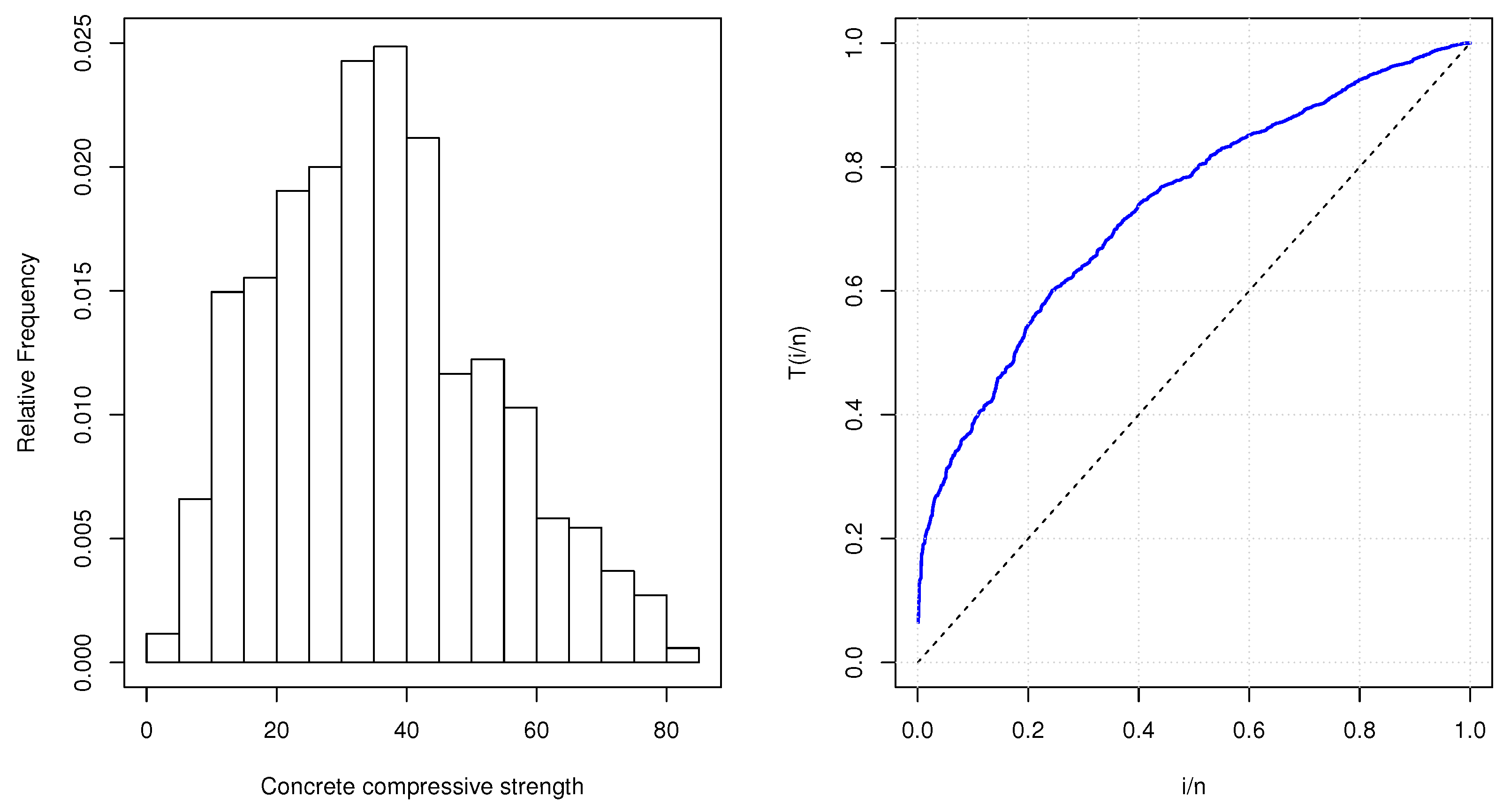
26]. The dataset was established from 17 various sources to inspect the reliability of a proposed strength model. The data collected concrete comprising cement alongside fly ash, blast furnace slag and superplasticizer. The dataset consisted of a single dependent variable, namely the compressive strength of concrete (in MPa), and eight independent variables. The data contain 1030 instances. Our purpose here is to find a suitable model to fit the compressive strength of the concrete variable in order to evaluate reliability using some concrete compressive strength. Before analyzing this dataset, we first plot the corresponding histogram as well as the TTT plot.
Figure 4 shows the corresponding histogram and the TTT plot. From this Figure, we can notice that the dataset is positively skewed. Furthermore, the TTT plot demonstrates that the empirical hazard rate function is an increasing function. Consequently, we can conclude that the LTAPEx distribution is appropriate to model this dataset.
The MLEs of the unknown parameters of the LTAPEx model and the other competitive models are obtained and displayed in
Table 8. Moreover, the standard errors and the different goodness-of-fit statistics are computed and presented also in
Table 8. From
Table 8, one can observe that the LTAPEx model has the lowest values of
,
and KS distance with the highest
p-value compared to all other competitive models. Consequently, we can deduce that the LTAPEx model is the most acceptable model to fit concrete compressive strength data.
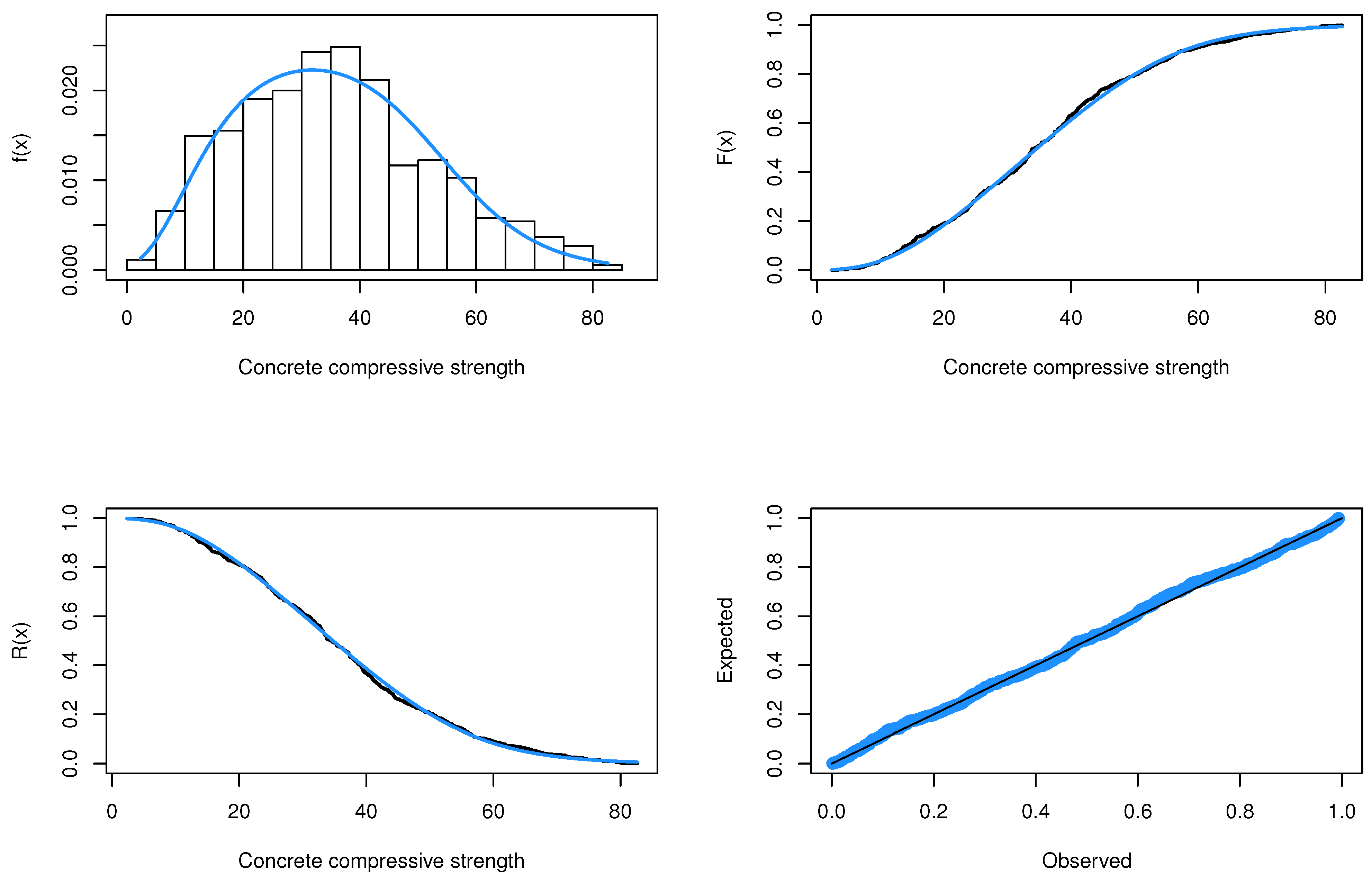
Figure 5 shows the fitted density and the estimated CDF, RF and probability–probability (PP) plots of the LTAPEx model for concrete compressive strength data.
Figure 5 demonstrates that the LTAPEx model can deliver a tight fit to the dataset. Generally, we can infer that the LTAPEx model is appropriate for modeling concrete compressive strength data rather than some traditional and some recently proposed distributions.
Practically, the concrete compressive strength can vary from 17 MPa to 28 MPa for residential constructions, while it can be increased as 70 MPa in the case of commercial buildings. Accordingly, based on the results of the LTAPEx distribution in
Table 8, reliability is estimated at 17 MPa, 28 MPa and 70 MPa.
Table 9 shows the input and output values of the proposed model. The different estimates and the associated CIBs are displayed in
Table 10.
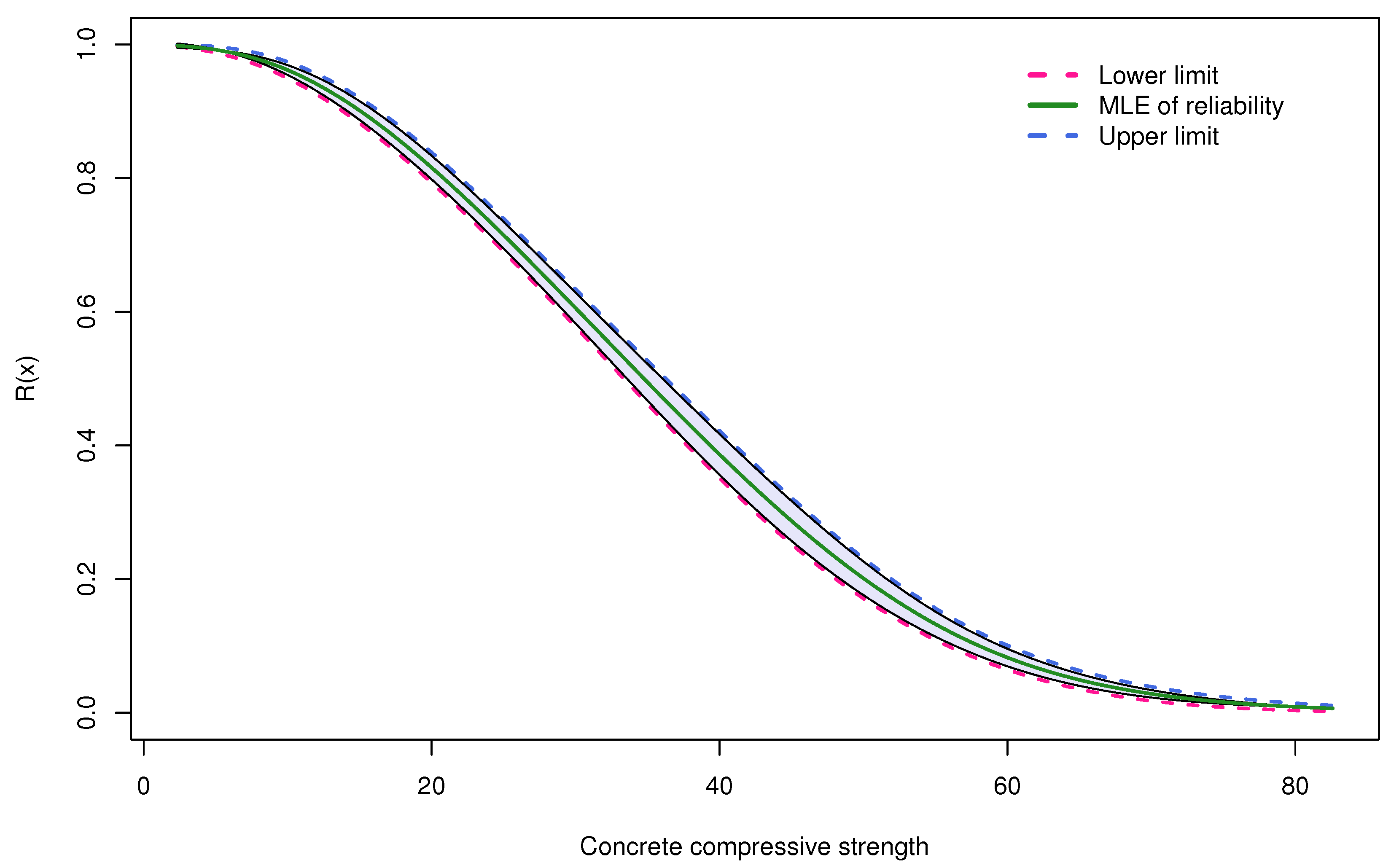
Figure 6 shows the ACIs of the reliability function at each point of the real dataset. Based on the reliability probabilities displayed in
Table 10, one can infer that the tested instances were appropriate for commercial constructions.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}