
Proposed Method for Statistical Analysis of On-Farm Single Strip Treatment Trials

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Yield Monitor Datasets
2.2. Zone Delineation
2.3. Single Strip Trial Design
2.4. Statistical Modelling
2.5. Explanatory Variables Selection and Model Fitting
2.6. Model Output and Diagnostics
3. Results
3.1. Yield in Control and Nitrogen Strips
3.2. Spatio-Temporal Yield Variation
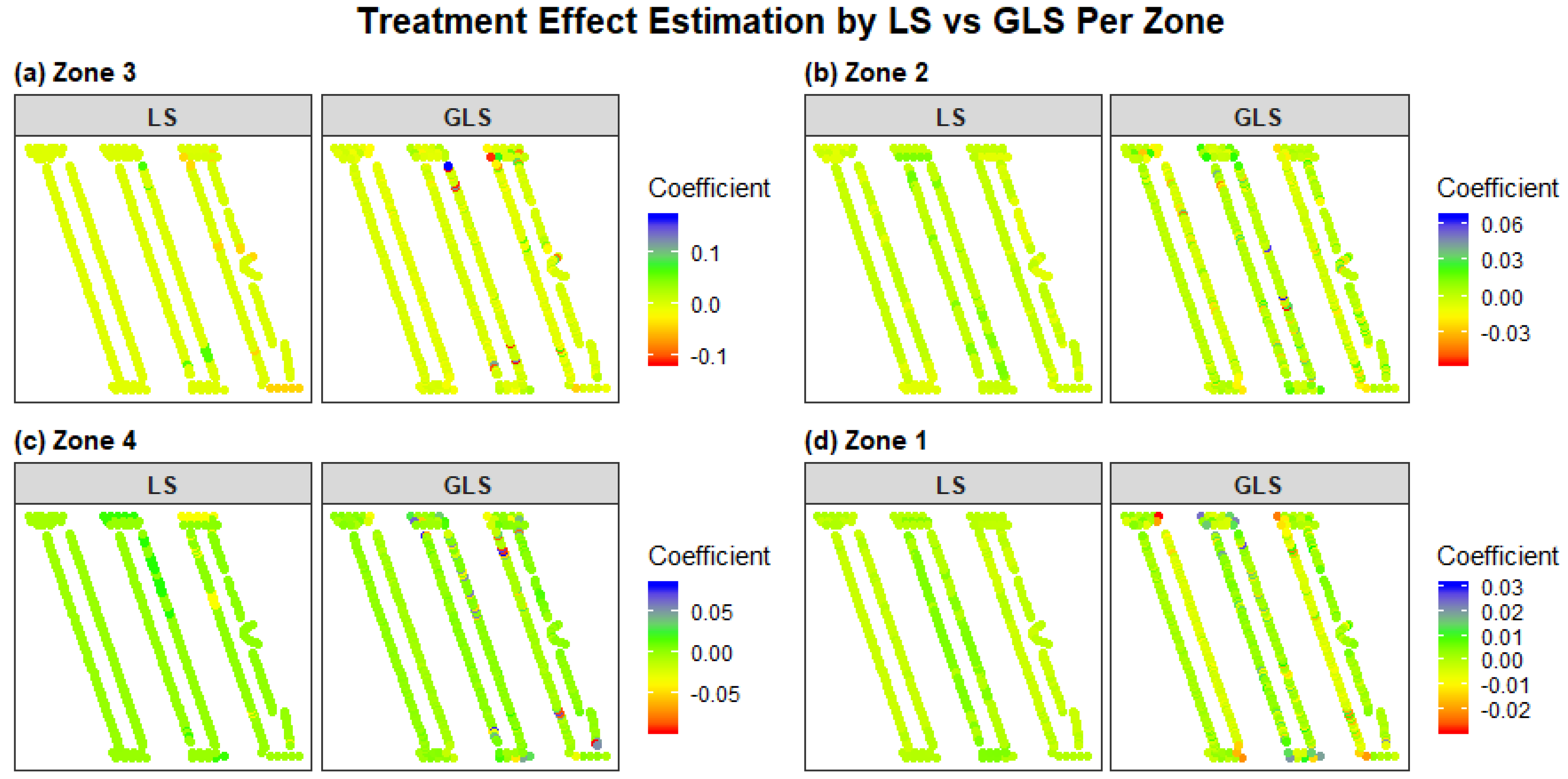
3.3. Model Outputs
3.4. Model Diagnostics
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mutsaers, H.J.W.; Agriculture, I.I.O.T. A Field Guide for On-Farm Experimentation; International Institute of Tropical Agriculture: Ibadan, Nigeria, 1997. [Google Scholar]
- Petersen, R.G. Agricultural Field Experiments: Design and Analysis; Taylor & Francis: London, UK, 1994. [Google Scholar]
- Kyveryga, P.M. On-Farm Research: Experimental Approaches, Analytical Frameworks, Case Studies, and Impact. Agron. J. 2019, 111, 2633–2635. [Google Scholar] [CrossRef] [Green Version]
- Federer, W.T. Experimental Design: Theory and Application; Macmillan: New York, NY, USA, 1955. [Google Scholar]
- Little, T.M.; Hills, F.J. Agricultural Experimentation: Design and Analysis; Wiley: Hoboken, NJ, USA, 1978. [Google Scholar]
- Kyveryga, P.M.; Mueller, T.A.; Mueller, D.S. On-Farm Replicated Strip Trials. In Precision Agriculture Basics; American Society of Agronomy: Madison, WI, USA, 2018; pp. 189–207. [Google Scholar]
- Piepho, H.-P.; Richter, C.; Spilke, J.; Hartung, K.; Kunick, A.; Thöle, H. Statistical aspects of on-farm experimentation. Crop Pasture Sci. 2011, 62, 721–735. [Google Scholar] [CrossRef]
- Gotway Crawford, C.A.; Bullock, D.G.; Pierce, F.J.; Stroup, W.W.; Hergert, G.W.; Eskridge, K.M. Experimental Design Issues and Statistical Evaluation Techniques for Site-Specific Management. In The State of Site Specific Management for Agriculture; American Society of Agronomy: Madison, WI, USA, 1997; pp. 301–335. [Google Scholar]
- Fisher, R.A. The Arrangement of Field Experiments. J. Minist. Agric. 1926, 33, 503–515. [Google Scholar] [CrossRef]
- Kyveryga, P.; Mueller, T.; Paul, N.; Arp, A.; Reeg, P. Guide to On-Farm Replicated Strip Trials; Iowa Soybean Association: Ankeny, IA, USA, 2015. [Google Scholar]
- Griffin, T.W.; Lambert, D.M.; Lowenberg-DeBoer, J.M. Testing Appropriate On-Farm Trial Designs and Statistical Methods for Precision Farming: A Simulation Approach; Precision Agriculture Center, University of Minnesota, Department of Soil, Water and Climate: St. Paul, MN, USA, 2004; pp. 1733–1748. [Google Scholar]
- Rudolph, S.; Marchant, P.; Gillingham, V.; Kindred, D.; Sylvester-Bradley, R. Spatial Discontinuity Analysis’a novel geostatistical algorithm for on-farm experimentation. In Proceedings of the 13th International Conference on Precision Agriculture, St. Louis, MO, USA, 31 July–3 August 2016. [Google Scholar]
- Sawyer, J.E. Concepts of Variable Rate Technology with Considerations for Fertilizer Application. J. Prod. Agric. 1994, 7, 195–201. [Google Scholar] [CrossRef]
- Cho, J.B.; Guinness, J.; Kharel, T.P.; Sunoj, S.; Kharel, D.; Oware, E.K.; van Aardt, J.; Ketterings, Q.M. Spatial estimation methods for mapping corn silage and grain yield monitor data. Precis. Agric. 2021, 22, 1501–1520. [Google Scholar] [CrossRef]
- Kharel, T.P.; Maresma, A.; Czymmek, K.J.; Oware, E.K.; Ketterings, Q.M. Combining Spatial and Temporal Corn Silage Yield Variability for Management Zone Development. Agron. J. 2019, 111, 2703–2711. [Google Scholar] [CrossRef]
- Fisher, R.A. Principles of Plot Experimentation in relation to the Statistical Interpretation of the Results. In Proceedings of the Rothamsted Conferences, 13: The Technique of Field Experiments, Harpenden, UK, 7 May 1931; under the Chairmanship of Sir A. D. Hall. Rothamsted Experimental Station: Harpenden, UK, 1931; pp. 11–13. [Google Scholar]
- Oehlert, G.W. A First Course in Design and Analysis of Experiments; W. H. Freeman: New York, NY, USA, 2000. [Google Scholar]
- Gomez, K.A.; Gomez, A.A. Statistical Procedures for Agricultural Research; Wiley: Hoboken, NJ, USA, 1984. [Google Scholar]
- Kim, S.; Daughtry, C.; Russ, A.; Pedrera-Parrilla, A.; Pachepsky, Y. Analysis of Spatiotemporal Variability of Corn Yields Using Empirical Orthogonal Functions. Water 2020, 12, 3339. [Google Scholar] [CrossRef]
- Panten, K.; Bramley, R.G.V.; Lark, R.M.; Bishop, T.F.A. Enhancing the value of field experimentation through whole-of-block designs. Precis. Agric. 2010, 11, 198–213. [Google Scholar] [CrossRef]
- Griffin, T.W.; Florax, R.J.G.M.; Lowenberg-DeBoer, J. Field-Scale Experimental Designs and Spatial Econometric Methods for Precision Farming: Strip-Trial Designs for Rice Production Decision Making. In Proceedings of the 2006 Annual Meeting, Orlando, FL, USA, 5–8 April 2006. [Google Scholar]
- Lambert, D.M.; Lowenberg-Deboer, J.; Bongiovanni, R. A Comparison of Four Spatial Regression Models for Yield Monitor Data: A Case Study from Argentina. Precis. Agric. 2004, 5, 579–600. [Google Scholar] [CrossRef]
- Willers, J.L.; Milliken, G.A.; Jenkins, J.N.; O’Hara, C.G.; Gerard, P.D.; Reynolds, D.B.; Boykin, D.L.; Good, P.V.; Hood, K.B. Defining the experimental unit for the design and analysis of site-specific experiments in commercial cotton fields. Agric. Syst. 2008, 96, 237–249. [Google Scholar] [CrossRef]
- Yan, W.; Hunt, L.A.; Johnson, P.; Stewart, G.; Lu, X. On-Farm Strip Trials vs. Replicated Performance Trials for Cultivar Evaluation. Crop Sci. 2002, 42, 385–392. [Google Scholar] [CrossRef] [Green Version]
- Cox, D.R. Randomization in the Design of Experiments. Int. Stat. Rev. 2009, 77, 415–429. [Google Scholar] [CrossRef]
- Johnson, D.H. The Many Faces of Replication. Crop Sci. 2006, 46, 2486–2491. [Google Scholar] [CrossRef]
- Stroup, W.W.; Hildebrand, P.E.; Francis, C.A. Farmer Participation for More Effective Research in Sustainable Agriculture. In Technologies for Sustainable Agriculture in the Tropics; American Society of Agronomy: Madison, WI, USA, 1993; pp. 153–186. [Google Scholar]
- Lawes, R.A.; Bramley, R.G.V. A Simple Method for the Analysis of On-Farm Strip Trials. Agron. J. 2012, 104, 371–377. [Google Scholar] [CrossRef]
- Andresen, J.A.; Alagarswamy, G.; Rotz, C.A.; Ritchie, J.T.; LeBaron, A.W. Weather Impacts on Maize, Soybean, and Alfalfa Production in the Great Lakes Region, 1895–1996. Agron. J. 2001, 93, 1059–1070. [Google Scholar] [CrossRef] [Green Version]
- Kravchenko, A.N.; Robertson, G.P.; Thelen, K.D.; Harwood, R.R. Management, Topographical, and Weather Effects on Spatial Variability of Crop Grain Yields. Agron. J. 2005, 97, 514–523. [Google Scholar] [CrossRef] [Green Version]
- Mallory, E.B.; Porter, G.A. Potato Yield Stability under Contrasting Soil Management Strategies. Agron. J. 2007, 99, 501–510. [Google Scholar] [CrossRef]
- Smith, R.G.; Menalled, F.D.; Robertson, G.P. Temporal Yield Variability under Conventional and Alternative Management Systems. Agron. J. 2007, 99, 1629–1634. [Google Scholar] [CrossRef] [Green Version]
- Dobermann, A.; Ping, J.L. Geostatistical Integration of Yield Monitor Data and Remote Sensing Improves Yield Maps. Agron. J. 2004, 96, 285–297. [Google Scholar] [CrossRef]
- Kharel, T.P.; Swink, S.N.; Maresma, A.; Youngerman, C.; Kharel, D.; Czymmek, K.J.; Ketterings, Q.M. Yield Monitor Data Cleaning is Essential for Accurate Corn Grain and Silage Yield Determination. Agron. J. 2019, 111, 509–516. [Google Scholar] [CrossRef]
- Vega, A.; Córdoba, M.; Castro-Franco, M.; Balzarini, M. Protocol for automating error removal from yield maps. Precis. Agric. 2019, 20, 1030–1044. [Google Scholar] [CrossRef]
- Sudduth, K.A.; Drummond, S.T. Yield Editor: Software for Removing Errors from Crop Yield Maps. Agron. J. 2007, 99, 1471–1482. [Google Scholar] [CrossRef]
- Sudduth, K.A.; Drummond, S.T.; Brenton Myers, D. Yield Editor 2.0: Software for Automated Removal of Yield Map Errors. In 2012 Dallas, Texas, July 29–August 1, 2012; American Society of Agricultural and Biological Engineers: St. Joseph, MI, USA, 2012. [Google Scholar]
- Kharel, T.P.; Swink, S.N.; Youngerman, C.; Maresma, A.; Czymmek, K.J.; Ketterings, Q.M.; Kyveryga, P.; Lory, J.; Musket, T.A.; Hubbard, V. Processing/Cleaning Corn Silage and Grain Yield Monitor Data for Standardized Yield Maps across Farms, Fields, and Years; Cornell University, Nutrient Management Spear Program, Department of Animal Science: Ithaca, NY, USA, 2018. [Google Scholar]
- Guinness, J.; Katzfuss, M. GpGp: Fast Gaussian Process Computation Using Vecchia’s Approximation. R package 0.3.2. 2019. Available online: https://CRAN.R-project.org/package=GpGp (accessed on 1 October 2021).
- Cressie, N.; Wikle, C.K. Statistics for Spatio-Temporal Data; Wiley: Hoboken, NJ, USA, 2011. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2019. [Google Scholar]
- Sunoj, S.; Kharel, D.; Kharel, T.; Cho, J.; Czymmek, K.J.; Ketterings, Q.M. Impact of headland area on whole field and farm corn silage and grain yield. Agron. J. 2021, 113, 147–158. [Google Scholar] [CrossRef]
- White, T.L.; Hodge, G.R. Best Linear Unbiased Prediction: Applications. In Predicting Breeding Values with Applications in Forest Tree Improvement; Springer: Dordrecht, The Netherlands, 1989; pp. 300–327. [Google Scholar]
- Jin, H.; Shuvo Bakar, K.; Henderson, B.L.; Bramley, R.G.V.; Gobbett, D.L. An efficient geostatistical analysis tool for on-farm experiments targeted at localised treatment. Biosyst. Eng. 2021, 205, 121–136. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Unit | Grain Operation | Dairy Farm | |||||
|---|---|---|---|---|---|---|---|
| Field name | Field A | Field B | Field C | Field D | Field E | Field F | |
| Crop type | Grain | Grain | Grain | Silage | Silage | Silage | |
| Year | 2018 | 2018 | 2019 | 2018 | 2018 | 2019 | |
| Field size | ha | 2.59 | 2.02 | 2.99 | 22.74 | 42.41 | 33.63 |
| Average yield * | Mg ha−1 | 13.07 | 11.99 | 12.84 | 40.80 | 39.90 | 54.47 |
| Number of data points | 827 | 753 | 553 | 3557 | 3229 | 5220 | |
| Nitrogen strip | |||||||
| Source | UAN | UAN | UAN | Urea | Urea | Urea | |
| Method | Injected | Injected | Injected | Broadcast | Broadcast | Broadcast | |
| Rate | kg ha−1 | 56 | 56 | 56 | 121 | 121 | 121 |
| Width | m | 9 | 9 | 9 | 24 | 24 | 24 |
| Most common soil type | Honeoye (fine-loamy, mixed, semiactive, mesic glossic hapludalfs) | Honeoye (fine-loamy, mixed, semiactive, mesic glossic hapludalfs) | Lima (fine-loamy, mixed, semiactive, mesic oxyaquic hapludalfs) | Ontario (fine-loamy, mixed, active, mesic glossic hapludalfs) | Ovid (fine-loamy, mixed, active, mesic aeric endo-aqualfs) | Honeoye (fine-loamy, mixed, semiactive, mesic glossic hapludalfs) | |
| Second most common soil type | Lima (fine-loamy, mixed, semiactive, mesic oxyaquic hapludalfs) | Lima (fine-loamy, mixed, semiactive, mesic oxyaquic hapludalfs) | Kendaia (fine-loamy, mixed, semi-active, nonacid, mesic aeric endoaquepts) | Benson (loamy-skeletal, mixed, active, mesic lithic eutrudepts) | Cazenovia (fine-loamy, mixed, active, mesic glossoboric hapludalfs) | Ontario (fine-loamy, mixed, active, mesic glossic hapludalfs) | |
| Distribution of management zones (%) | |||||||
| Zone 1 | 76.09 | 35.99 | 78.12 | 11.46 | 24.82 | 28.56 | |
| Zone 2 | 23.91 | 0.00 | 0.00 | 88.54 | 38.78 | 0.00 | |
| Zone 3 | 0.00 | 30.81 | 21.88 | 0.00 | 6.99 | 5.76 | |
| Zone 4 | 0.00 | 33.20 | 0.00 | 0.00 | 29.41 | 65.68 | |
| Field/Model | N-Effect in Zone 1 | N-Effect in Zone 2 | N-Effect in Zone 3 | N-Effect in Zone 4 | |||||
|---|---|---|---|---|---|---|---|---|---|
| Estimate | SE | Estimate | SE | Estimate | SE | Estimate | SE | ||
| Field A | LS 1 | −0.23 | 0.06 | 0.16 | 0.11 | - | - | - | - |
| LS 2 | −0.23 | 0.24 | 0.16 | 0.34 | - | - | - | - | |
| GLS | 0.45 | 0.16 | 0.52 | 0.18 | - | - | - | - | |
| Field B | LS 1 | 0.20 | 0.06 | - | - | 0.36 | 0.09 | 0.38 | 0.07 |
| LS 2 | 0.20 | 0.18 | - | - | 0.36 | 0.26 | 0.38 | 0.17 | |
| GLS | 0.14 | 0.13 | - | - | 0.35 | 0.16 | 0.24 | 0.13 | |
| Field C | LS 1 | −0.16 | 0.07 | - | - | 1.13 | 0.14 | - | - |
| LS 2 | −0.16 | 0.24 | - | - | 1.13 | 0.41 | - | - | |
| GLS | 0.00 | 0.18 | - | - | 0.93 | 0.24 | - | - | |
| Field D | LS 1 | 0.38 | 0.74 | 1.62 | 0.25 | - | - | - | - |
| LS 2 | 0.38 | 3.31 | 1.62 | 1.78 | - | - | - | - | |
| GLS | 0.53 | 1.05 | 0.07 | 0.97 | - | - | - | - | |
| Field E | LS 1 | 3.48 | 0.56 | 4.12 | 0.44 | 7.51 | 1.01 | 4.70 | 0.56 |
| LS 2 | 3.48 | 2.22 | 4.12 | 2.37 | 7.51 | 2.98 | 4.70 | 2.36 | |
| GLS | 1.01 | 1.22 | 1.00 | 1.22 | 1.89 | 1.32 | 1.68 | 1.24 | |
| Field F | LS 1 | −3.29 | 0.52 | - | - | −9.70 | 1.35 | −4.46 | 0.37 |
| LS 2 | −3.29 | 3.14 | - | - | −9.70 | 6.54 | −4.46 | 2.58 | |
| GLS | −0.42 | 1.14 | - | - | 0.18 | 1.43 | −0.57 | 1.10 | |
| Field A | Field B | Field C | Field D | Field E | Field F | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LS | GLS | LS | GLS | LS | GLS | LS | GLS | LS | GLS | LS | GLS | |
| -------------------------------------------------------------- Mg ha−1-------------------------------------------------------------- | ||||||||||||
| Zone 1 | 0.038 | 0.688 | 0.044 | 0.232 | 0.069 | 0.840 | 0.921 | 2.748 | 0.470 | 2.341 | 0.293 | 2.427 |
| Zone 2 | 0.099 | 0.551 | - | - | - | - | 0.176 | 1.443 | 0.307 | 2.243 | - | - |
| Zone 3 | - | - | 0.066 | 0.347 | 0.140 | 0.954 | - | - | 0.926 | 5.143 | 1.415 | 3.259 |
| Zone 4 | - | - | 0.055 | 0.306 | - | - | - | - | 0.474 | 4.645 | 0.316 | 2.672 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cho, J.B.; Guinness, J.; Kharel, T.; Maresma, Á.; Czymmek, K.J.; van Aardt, J.; Ketterings, Q.M. Proposed Method for Statistical Analysis of On-Farm Single Strip Treatment Trials. Agronomy 2021, 11, 2042. https://doi.org/10.3390/agronomy11102042
Cho JB, Guinness J, Kharel T, Maresma Á, Czymmek KJ, van Aardt J, Ketterings QM. Proposed Method for Statistical Analysis of On-Farm Single Strip Treatment Trials. Agronomy. 2021; 11(10):2042. https://doi.org/10.3390/agronomy11102042
Chicago/Turabian StyleCho, Jason B., Joseph Guinness, Tulsi Kharel, Ángel Maresma, Karl J. Czymmek, Jan van Aardt, and Quirine M. Ketterings. 2021. "Proposed Method for Statistical Analysis of On-Farm Single Strip Treatment Trials" Agronomy 11, no. 10: 2042. https://doi.org/10.3390/agronomy11102042
APA StyleCho, J. B., Guinness, J., Kharel, T., Maresma, Á., Czymmek, K. J., van Aardt, J., & Ketterings, Q. M. (2021). Proposed Method for Statistical Analysis of On-Farm Single Strip Treatment Trials. Agronomy, 11(10), 2042. https://doi.org/10.3390/agronomy11102042