
Exploration of Machine Learning Approaches for Paddy Yield Prediction in Eastern Part of Tamilnadu



Abstract
:1. Introduction
1.1. Background
1.2. Existing Methods—ML Algorithms for Yield Prediction
1.3. Objectives
- To assess the paddy crop yield data from high potential real-time locations.
- To estimate the crop yield prediction using a statistical model (MLR).
- To demonstrate advanced machine learning techniques such BPNNs, RBFNNs, GRNNs, and SVR for crop yield prediction.
- To analyze the adapted machine learning techniques using evaluation metrics such as R2, RMSE, MAE, MSE, MAPE, CV, and NSME.
- To select and recommend the best accurate prediction technique to evaluate the crop yield.
2. Data Collection
- Step 1: Collect the data using available sources.
- Step 2: Distribute the data into two segments: training data (70%) and testing data (30%).
- Step 3: Develop the machine learning model to assess the crop yield.
- Step 4: Predict the crop yield using adapted techniques.
- Step 5: Determine the evaluation metrics for each model.
- Step 6: Recommend the best-rated technique for crop yield using observed outcomes.
3. Methodology
3.1. Statistical Analysis
3.2. Machine Learning Techniques
3.2.1. Support Vector Machine (SVM)
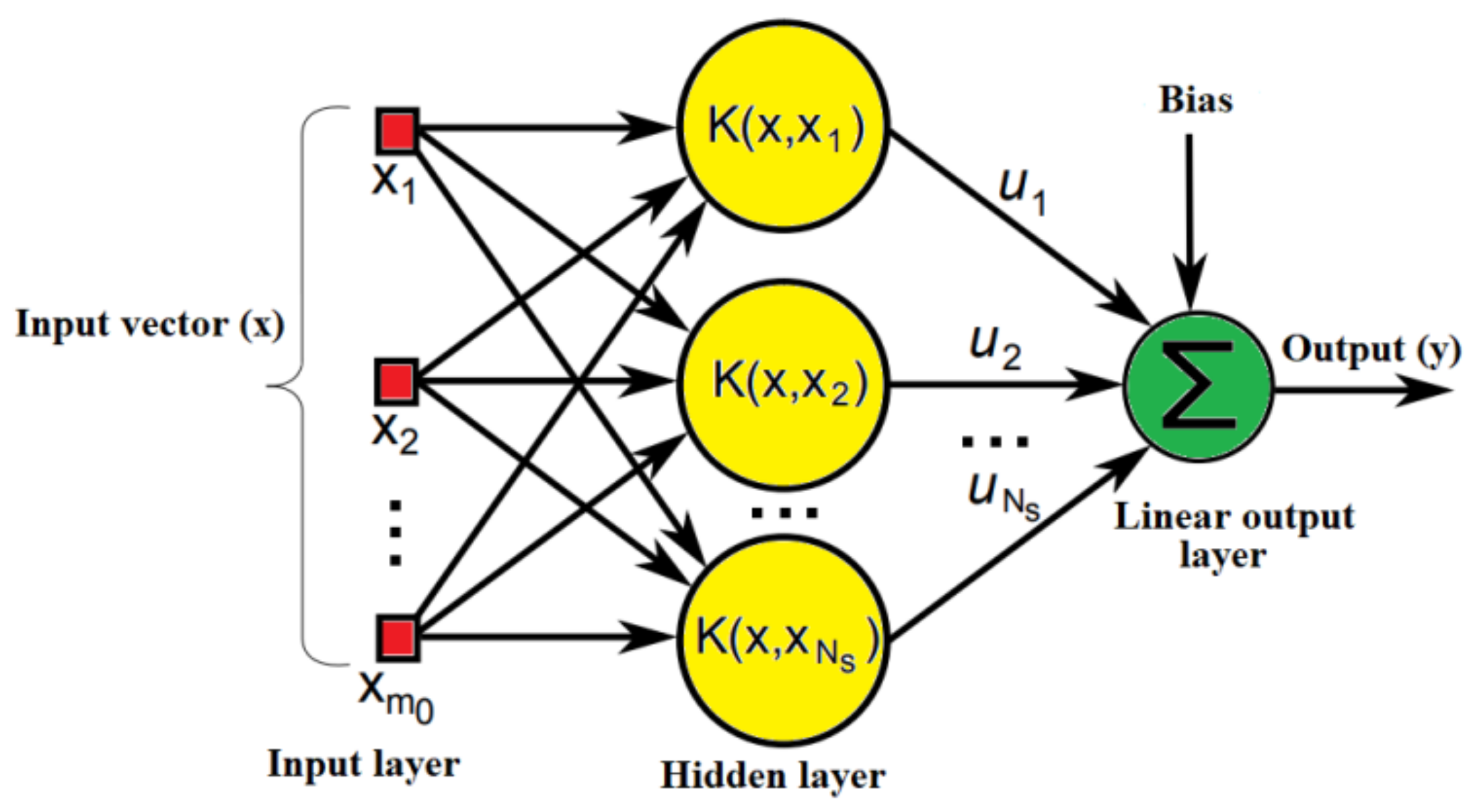
3.2.2. Generalized Regression Neural Network (GRNN)
3.2.3. Radial Basis Functional Neural Network (RBFNN)
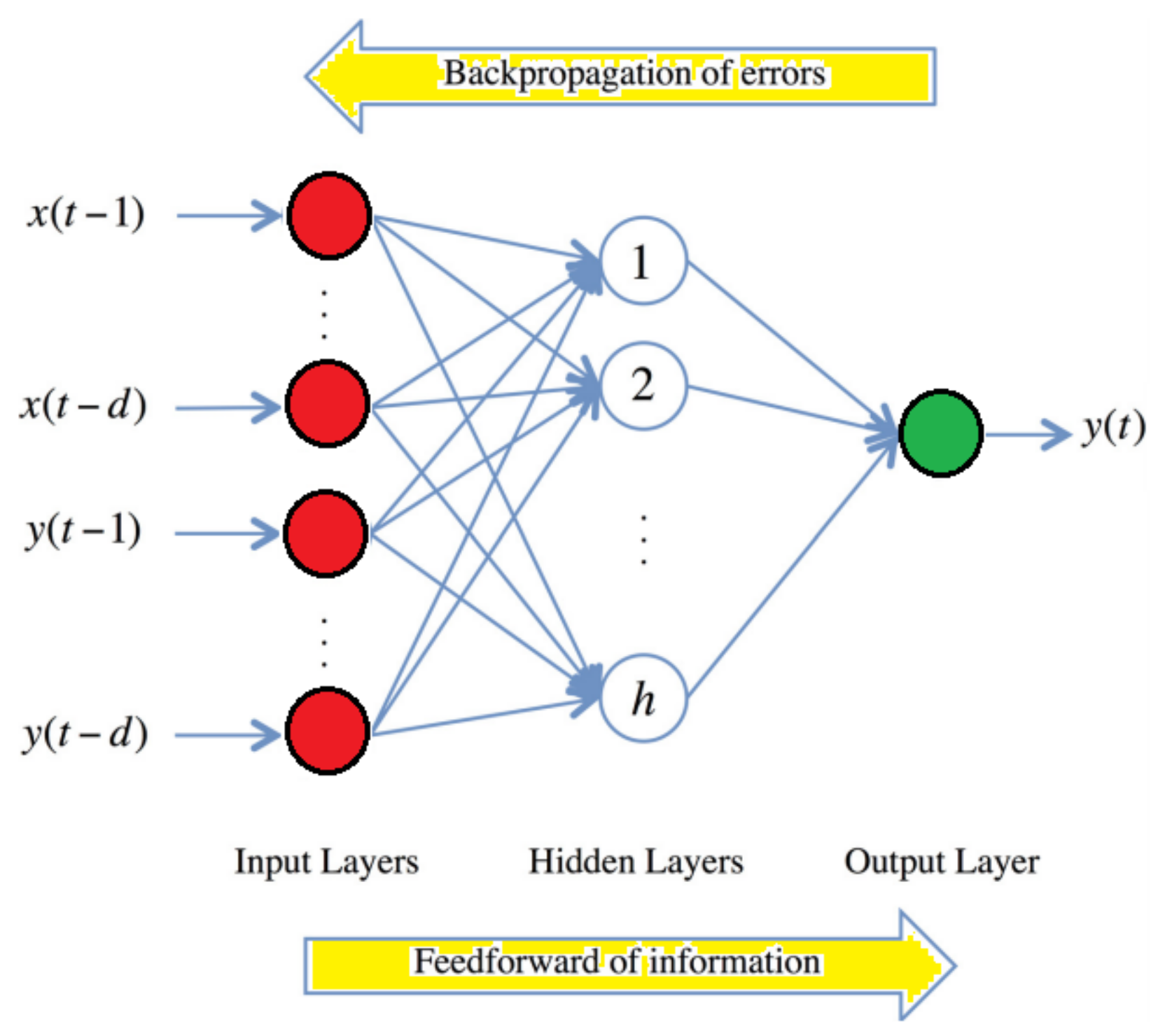
3.2.4. Back Propagation Neural Network (BPNN)
4. Model Performance
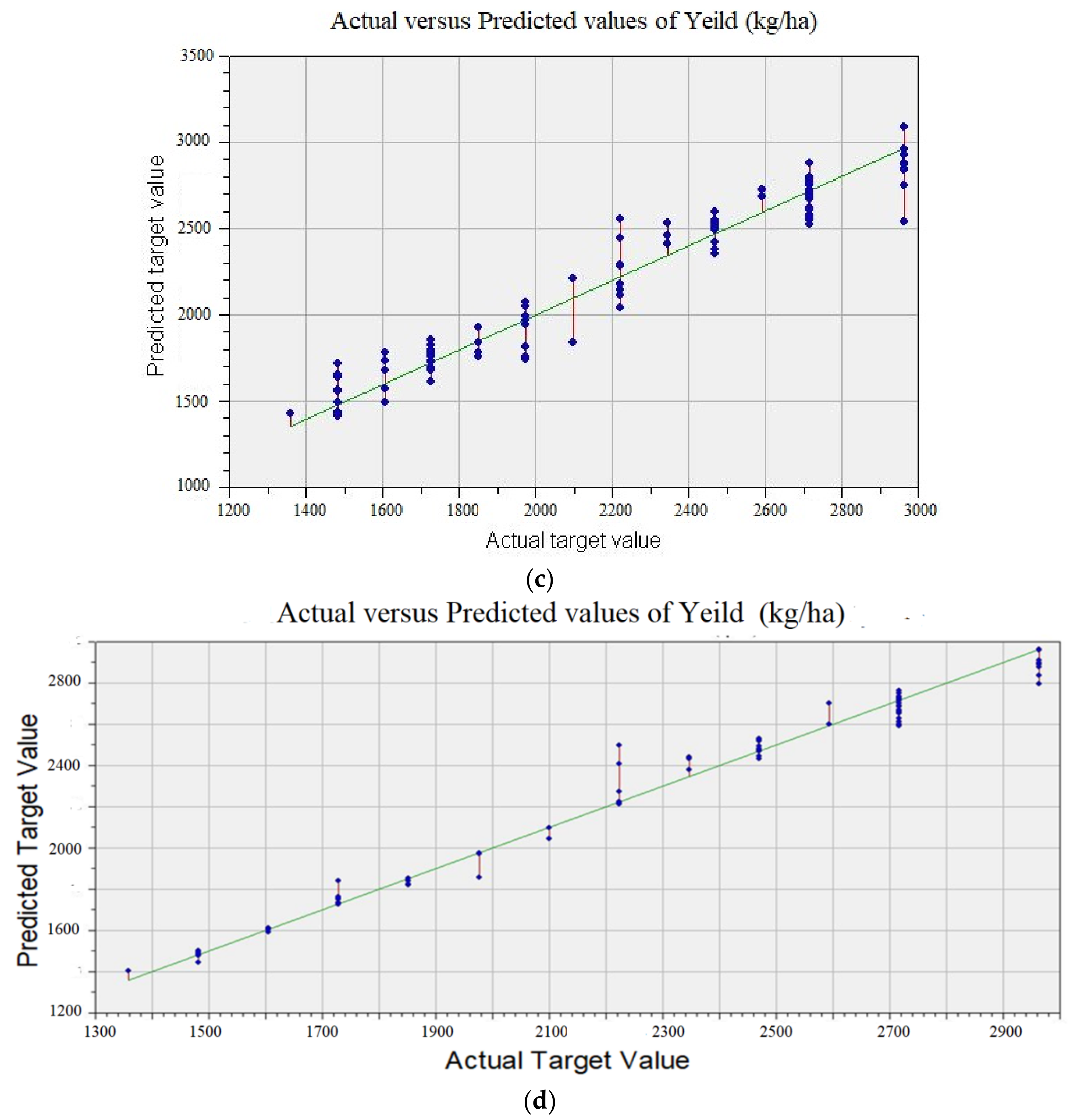
5. Results and Discussions
5.1. Statistical Analysis
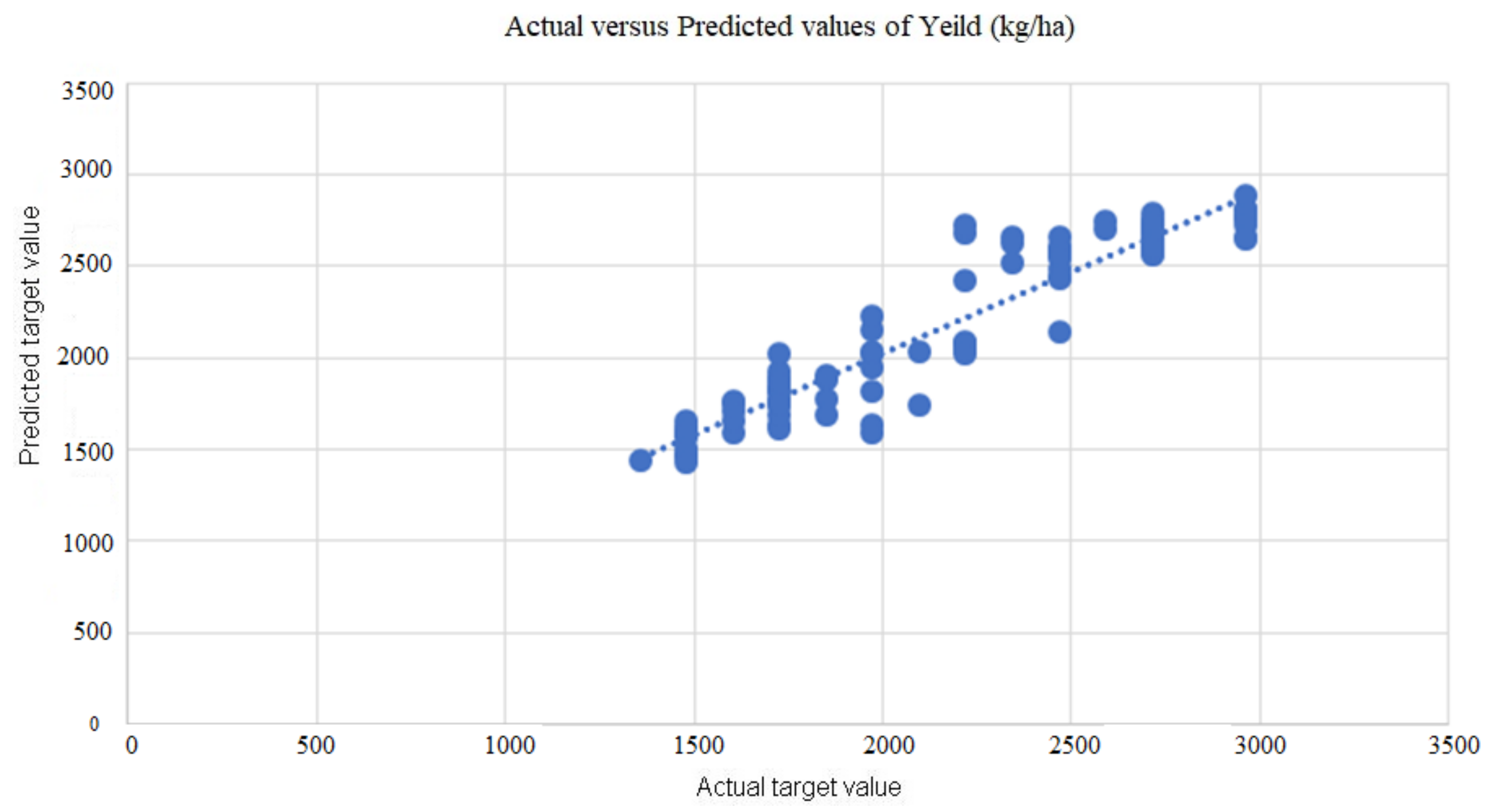
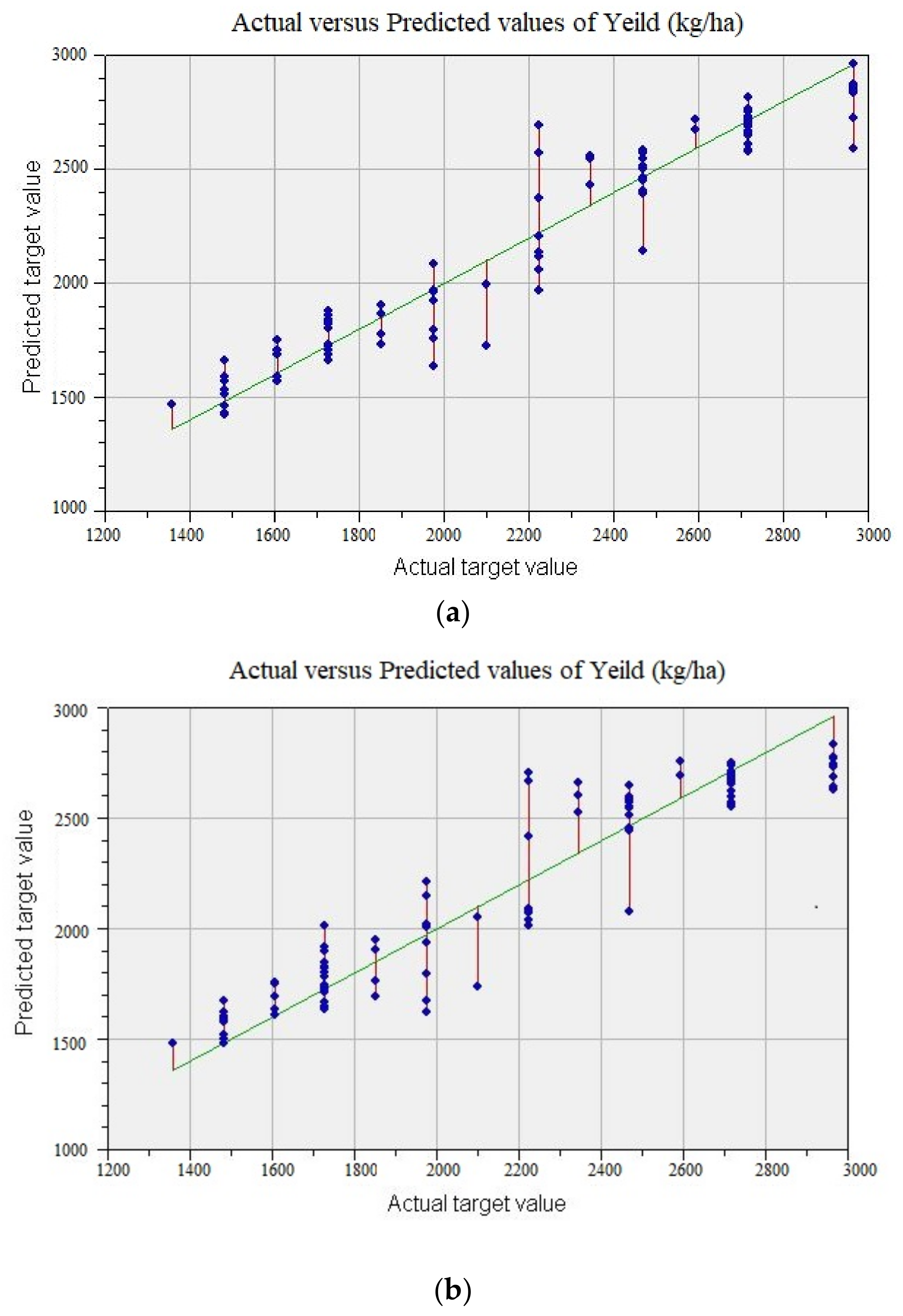
5.2. Machine Learning Techniques
6. Conclusions
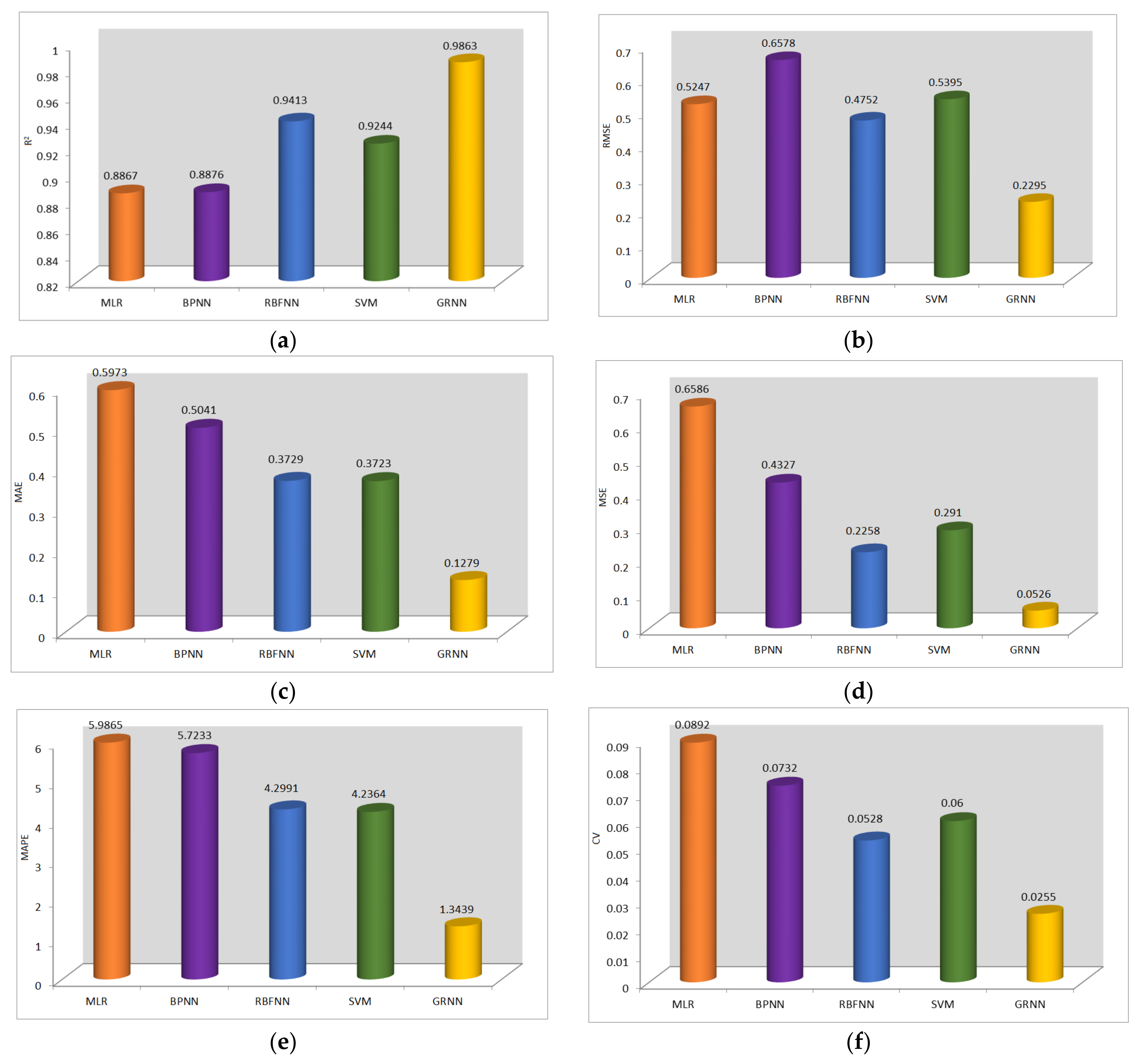
- Machine learning algorithms attained exceptionally greater yield prediction accuracy than statistical methodology based on the results of evaluation metrics.
- Among the four machine learning algorithms such as SVM, RBFNN, GRNN, and BPNN, GRNN predicted the yield more precisely.
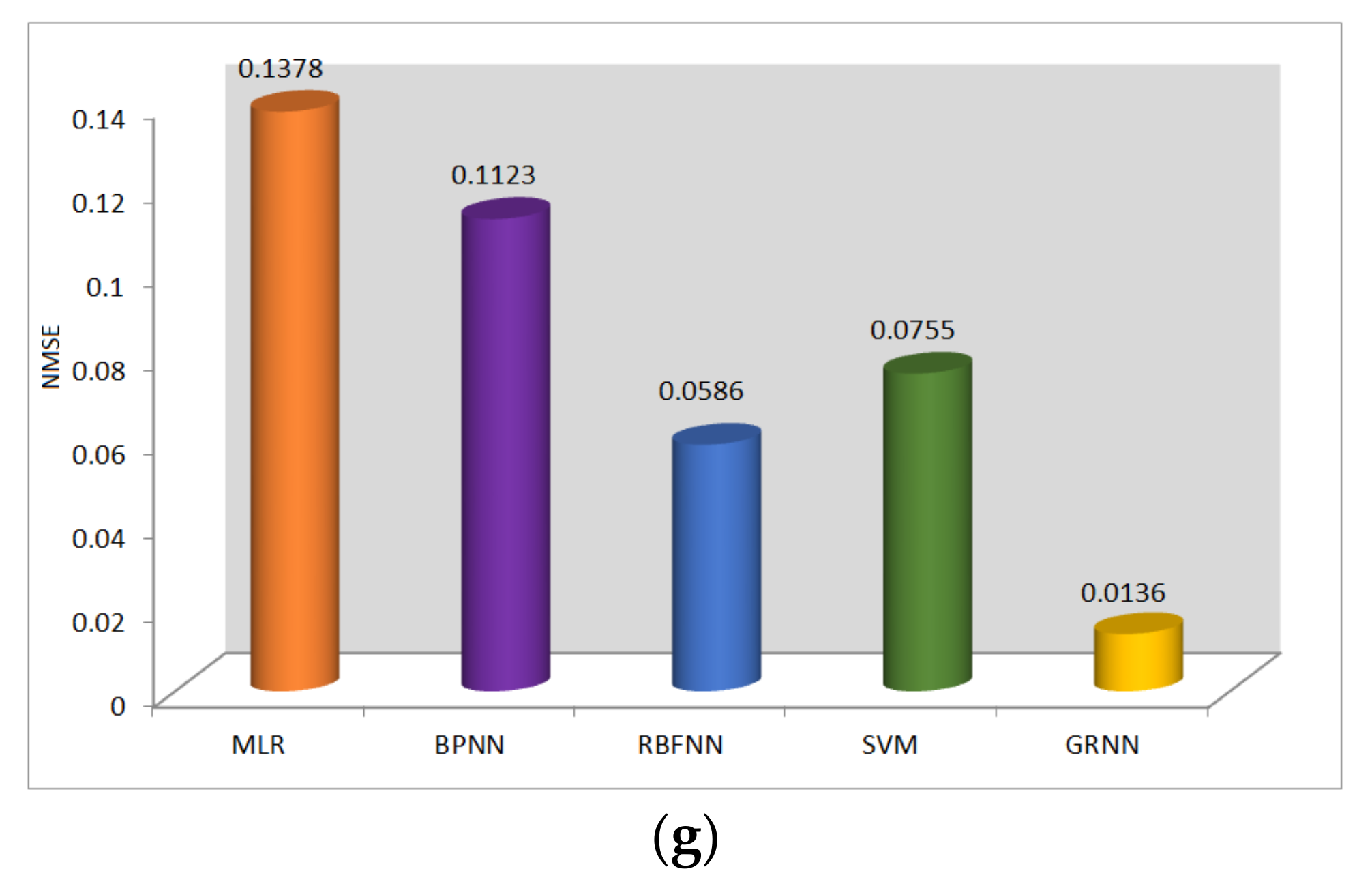
- R2, RMSE, MAE, MSE, MAPE, CV, and NSME performance metrics of GRNN showed a better scale of 0.9863, 0.2295, 0.1290, 0.0526, 1.3439, 0.0255, and 0.0136, respectively.
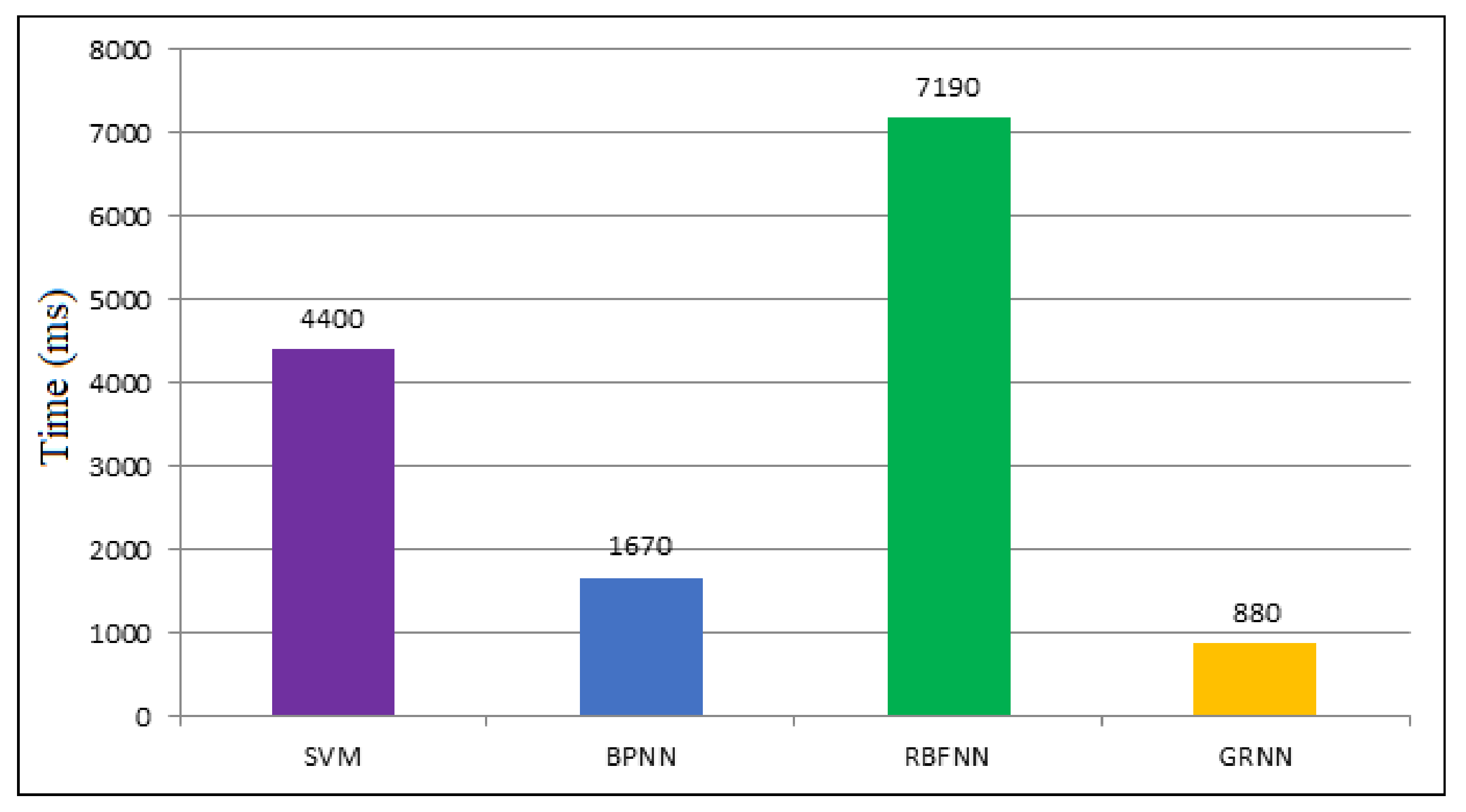
- Run time of the GRNN model shows a superior scale of 880 ms, which is comparatively less than that of the other ANN models.
- Compared with other existing models from the literature reports, the R2 metrics of the proposed model (GRNN) are improved by 7.53%.
- The absolute yield of Tamilnadu and other Indian states are compared, and it is found that Tamilnadu acquired the highest yield, about 3191 kg/ha, and the same is attained with the proposed GRNN prediction model with higher accuracy.
- It is also concluded that Tamilnadu consists of optimum parameters (rainfall, temperature, and pH value) for paddy cultivation that enable the farmers to attain higher yield.
- The recommended machine learning algorithm, notably GRNN, reduces the risk factor for paddy yield due its superior performance metrics.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Feng, P.; Wang, B.; Liu, D.L.; Waters, C.; Yu, Q. Incorporating machine learning with biophysical model can improve the evaluation of climate extremes impacts on wheat yield in south-eastern Australia. Agric. For. Meteorol. 2019, 275, 100–113. [Google Scholar] [CrossRef]
- Frei, U.; Sporri, S.; Stebler, O.; Holecz, F. Rice field mapping in Sri Lanka using ERS SAR data. Earth Observ. Q. 1999, 63, 30–35. [Google Scholar]
- Rashid, M.; Bari, B.S.; Yusup, Y.; Kamaruddin, M.A.; Khan, N. A Comprehensive Review of Crop Yield Prediction Using Machine Learning Approaches with Special Emphasis on Palm Oil Yield Prediction. IEEE Access 2021, 9, 63406–63439. [Google Scholar] [CrossRef]
- Schlenker, W.; Roberts, M.J. Nonlinear temperature effects indicate severe damages to US crop yields under climate change. Proc. Natl. Acad. Sci. USA 2009, 106, 15594–15598. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Folberth, C.; Baklanov, A.; Balkovič, J.; Skalský, R.; Khabarov, N.; Obersteiner, M. Spatio-temporal downscaling of gridded crop model yield estimates based on machine learning. Agric. For. Meteorol. 2019, 264, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Innes, P.J.; Tan, D.K.Y.; Ogtrop, F.V.; Amthor, J.S. Effects of high-temperature episodes on wheat yields in New South Wales, Australia. Agric. For. Meteorol. 2015, 208, 95–107. [Google Scholar] [CrossRef]
- Lamb, D.W.; Brown, R.B. PA—Precision agriculture. J. Agric. Eng. Res. 2001, 78, 117–125. [Google Scholar] [CrossRef]
- Chlingaryan, A.; Sukkarieh, S.; Whelan, B. Machine learning approaches for crop yield prediction and nitrogen status estimation in precision agriculture: A review. Comput. Electron. Agric. 2018, 151, 61–69. [Google Scholar] [CrossRef]
- Mishra, S.; Mishra, D.; Santra, G.H. Applications of Machine Learning Techniques in Agricultural Crop Production: A Review Paper. Indian J. Sci. Technol. 2016, 9, 1–14. [Google Scholar] [CrossRef]
- Marko, O.; Brdar, S.; Panic, M.; Lugonja, P.; Crnojevic, V. Soybean varieties portfolio optimisation based on yield prediction. Comput. Electron. Agric. 2016, 127, 467–474. [Google Scholar] [CrossRef]
- Sellam, V.; Poovammal, E. Prediction of Crop Yield using Regression Analysis. Indian J. Sci. Technol. 2016, 9, 1–5. [Google Scholar] [CrossRef]
- You, J.; Li, X.; Low, M.; Lobell, D.; Ermon, S. Deep Gaussian Process for Crop Yield Prediction Based on Remote Sensing Data. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17), San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Gu, J.; Yin, G.; Huang, P.; Guo, J.; Chen, L. An improved back propagation neural network prediction model for subsurface drip irrigation system. Comput. Electr. Eng. 2017, 60, 58–65. [Google Scholar] [CrossRef]
- Kosari-Moghaddam, A.; Rohani, A.; Kosari-Moghaddam, L.; Esmaeipour-Troujeni, M. Developing a Radial Basis Function Neural Networks to Predict the Working Days for Tillage Operation in Crop Production. Int. J. Agric. Manag. Dev. 2018, 9, 119–133. [Google Scholar]
- Khosla, E.; Dharavath, R.; Priya, R. Crop yield prediction using aggregated rainfall-based modular artificial neural networks and Support vector regression. Environ. Dev. Sustain. 2019, 22, 5687–5708. [Google Scholar] [CrossRef]
- Esfandiarpour-Boroujeni, I.; Karimi, E.; Shirani, H.; Esmaeilizadeh, M.; Mosleh, Z. Yield prediction of apricot using a hybrid particle swarm optimization-imperialist competitive algorithm- support vector regression (PSO-ICA-SVR) method. Sci. Hortic. 2019, 257, 108756. [Google Scholar] [CrossRef]
- Maya Gopal, P.S.; Bhargavi, R. Performance Evaluation of Best Feature Subsets for Crop Yield Prediction Using Machine Learning Algorithms. Appl. Artif. Intell. 2019, 33, 621–642. [Google Scholar] [CrossRef]
- Kim, N.; Ha, K.J.; Park, N.W.; Cho, J.; Hong, S.; Lee, Y.W. A Comparison Between Major Artificial Intelligence Models for Crop Yield Prediction: Case Study of the Midwestern United States, 2006–2015. ISPRS Int. J. Geo-Inf. 2019, 8, 240. [Google Scholar] [CrossRef] [Green Version]
- Khaki, S.; Wang, L. Crop Yield Prediction Using Deep Neural Networks. Front. Plant Sci. 2019, 10, 621. [Google Scholar] [CrossRef] [Green Version]
- Abdipour, M.; Younessi-Hmazekhanlu, M.; Ramazani, S.H.R.; Omidi, A.H. Artificial neural networks and multiple linear regression as potential methods for modeling seed yield of safflower (Carthamus tinctorius L.). Ind. Crop. Prod. 2019, 127, 185–194. [Google Scholar] [CrossRef]
- Palanivel, K.; Surianarayanan, C. An Approach for Prediction Of Crop Yield Using Machine Learning And Big Data Techniques. Int. J. Comput. Eng. Technol. 2019, 10, 110–118. [Google Scholar] [CrossRef]
- Cai, Y.; Guan, K.; Lobell, D.; Potgieter, A.B.; Wang, S.; Peng, J.; Xu, T.; Asseng, S.; Zhang, Y.; You, L.; et al. Integrating satellite and climate data to predict wheat yield in Australia using machine learning approaches. Agric. For. Meteorol. 2019, 274, 144–159. [Google Scholar] [CrossRef]
- Wang, L.; Wang, P.; Liang, S.; Zhu, Y.; Khan, J.; Fang, S. Monitoring maize growth on the North China Plain using a hybrid genetic algorithm-based back-propagation neural network model. Comput. Electron. Agric. 2020, 170, 105238. [Google Scholar] [CrossRef]
- Abbas, F.; Afzaal, H.; Farooque, A.A.; Tang, S. Crop Yield Prediction through Proximal Sensing and Machine Learning Algorithms. Agronomy 2020, 10, 1046. [Google Scholar] [CrossRef]
- Xiong, Y.; Ohashi, S.; Nakano, K.; Jiang, W.; Takizawa, K.; Iijima, K.; Maniwara, P. Application of the radial basis function neural networks to improve the nondestructive Vis/NIR spectrophotometric analysis of potassium in fresh lettuces. J. Food Eng. 2021, 298, 110417. [Google Scholar] [CrossRef]
- Available online: https://mausam.imd.gov.in/ (accessed on 5 August 2021).
- Available online: https://www.tnagrisnet.tn.gov.in/ (accessed on 5 August 2021).
- Available online: https://tn.data.gov.in/statedepartment/department-economics-and-statistics (accessed on 5 August 2021).
- Piekutowska, M.; Niedbała, G.; Piskier, T.; Lenartowicz, T.; Pilarski, K.; Wojciechowski, T.; Pilarska, A.A.; Czechowska-Kosacka, A. The Application of Multiple Linear Regression and Artificial Neural Network Models for Yield Prediction of Very Early Potato Cultivars before Harvest. Agronomy 2021, 11, 885. [Google Scholar] [CrossRef]
- Pandey, A.; Mishra, A. Application of artificial neural networks in yield prediction of potato crop. Russ. Agric. Sci. 2017, 43, 266–272. [Google Scholar] [CrossRef]
- Son, N.T.; Chen, C.F.; Chen, C.R.; Guo, H.Y.; Cheng, Y.S.; Chen, S.L.; Lin, H.S.; Chen, S.H. Machine learning approaches for rice crop yield predictions using time-series satellite data in Taiwan. Int. J. Remote. Sens. 2020, 41, 7868–7888. [Google Scholar] [CrossRef]
- Granata, F. Evapotranspiration evaluation models based on machine learning algorithms—A comparative study. Agric. Water Manag. 2019, 217, 303–315. [Google Scholar] [CrossRef]
- Han, L.; Yang, G.; Dai, H.; Xu, B.; Yang, H.; Feng, H.; Li, Z.; Yang, X. Modeling maize above-ground biomass based on machine learning approaches using UAV remote-sensing data. Plant Methods 2019, 15, 10. [Google Scholar] [CrossRef] [Green Version]
- Ramesh, D.; Vardhan, B.V. Analysis Of Crop Yield Prediction Using Data Mining Techniques. Int. J. Res. Eng. Technol. 2015, 4, 470–473. [Google Scholar]
- Elavarasan, D.; Vincent, P.M.D. Crop yield prediction using deep reinforcement learning model for sustainable agrarian applications. IEEE Access 2020, 8, 8688686901. [Google Scholar]
- Gopal, P.S.M.; Bhargavi, R. A novel approach for efcient crop yield prediction. Comput. Electron. Agric. 2019, 165, 104968. [Google Scholar] [CrossRef]
- Shiu, Y.-S.; Chuang, Y.-C. Yield estimation of paddy rice based on satellite imagery: Comparison of global and local regression models. Remote Sens. 2019, 11, 111. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.; Fu, Y.; Hao, F.; Zhang, X.; Wu, W.; Jin, X.; Bryant, C.R.; Senthilnath, J. Integrated phenology and climate in rice yields prediction using machine learning methods. Ecol. Indic. 2021, 120, 106935. [Google Scholar] [CrossRef]
- Elavarasan, D.; Vincent, P.M.D.R.; Srinivasan, K.; Chang, C.Y. A hybrid CFS lter and RF-RFE wrapper-based feature extraction for enhanced agricultural crop yield prediction modeling. Agriculture 2020, 10, 400. [Google Scholar] [CrossRef]
- Khaki, S.; Wang, L.; Archontoulis, S.V. A CNN-RNN framework for crop yield prediction. Front. Plant Sci. 2020, 10, 1750. [Google Scholar] [CrossRef] [PubMed]
- Yalcin, H. An approximation for a relative crop yield estimate from field images using deep learning. In Proceedings of the 2019 8th International Conference on Agro-Geoinformatics (Agro-Geoinformatics), Istanbul, Turkey, 16–19 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Hilal, Y.Y.; Ishak, W.; Yahya, A.; Asha’ari, Z.H. Development of genetic algorithm for optimization of yield models in oil palm production. Chil. J. Agric. Res. 2018, 78, 228–237. [Google Scholar] [CrossRef] [Green Version]
- Nevavuori, P.; Narra, N.; Lipping, T. Crop yield prediction with deep convolutional neural networks. Comput. Electron. Agric. 2019, 163, 104859. [Google Scholar] [CrossRef]
- Government of India. A Status Note on Rice in India, National Food Security Mission. Available online: https://www.nfsm.gov.in (accessed on 5 August 2021).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref No | Year | Methodologies | Inferences |
|---|---|---|---|
| [10] | 2016 | Weighted histograms regression |
|
| [11] | 2016 | Regression Analysis (RA) |
|
| [12] | 2017 | Gaussian process component and spatio-temporal structure |
|
| [8] | 2017 | Generalized regression neural network and radial basis function neural network |
|
| [13] | 2017 | Improved genetic algorithm-back propagation neural network prediction algorithm |
|
| [8] | 2018 | Remote sensing and machine learning algorithms |
|
| [14] | 2018 | Multiple linear regression and radial basis function artificial networks |
|
| [15] | 2019 | Aggregated rainfall-based modular artificial neural networks and support vector regression |
|
| [16] | 2019 | Hybrid particle swarm optimization imperialist competitive algorithm, support vector regression |
|
| [17] | 2019 | Support vector regression, K-nearest neighbor, random forest, and artificial neural network |
|
| [18] | 2019 | Deep neural network (DNN) |
|
| [19] | 2019 | Deep neural network (DNN) |
|
| [20] | 2019 | Artificial neural network |
|
| [21] | 2019 | Machine learning and big data |
|
| [22] | 2019 | Support vector machine, random forest, and neural network |
|
| [23] | 2020 | Hybrid genetic algorithm-based back-propagation neural network (GA-BPNN) model |
|
| [24] | 2020 | Proximal Sensing (PS) and machine learning algorithms |
|
| [25] | 2021 | Partial least squares and radial basis function neural network. |
|
| Parameters | Tiruchirappalli | Pudukkottai | Perambalur |
|---|---|---|---|
| pH range | 8.2–9.6 | 6.8–8.5 | 8.09–8.6 |
| Temperature | 24–38 | 24–33 | 25–34 |
| Mean annual rainfall | 761 | 821 | 861 |
| SW monsoon (June–September): mm | 273.3 | 351.9 | 270 |
| NE monsoon (October–December): mm | 394.8 | 394.1 | 466 |
| Field | 16 | 21 | 13 |
| Variables | Rows | Minimum | Maximum | Mean | Std. Deviation |
|---|---|---|---|---|---|
| Mean Rainfall (mm) | 100 | 266.0 | 464.0 | 366.4 | 75.59 |
| Temperature (°C) | 24.0 | 38.0 | 31.5 | 4.40 | |
| Fertilizer(urea) (kg/ha) | 123.50 | 197.6 | 166.62 | 24.86 | |
| Nitrogen (N) (kg/ha) | 143.26 | 197.6 | 174.13 | 16.66 | |
| Phosphorus (P)(kg/ha) | 44.46 | 61.75 | 52.04 | 4.75 | |
| Potassium (K) (kg/ha) | 37.05 | 54.34 | 44.48 | 4.49 | |
| pH value | 6.90 | 8.93 | 8.12 | 0.48 | |
| Yeild (kg/ha) | 2358.0 | 3189.0 | 2773.5 | 207.7 |
| Parameters | Descriptions/Values |
|---|---|
| Type of SVM model | Epsilon-SVR |
| SVM kernel function | Radial basis function (RBF) |
| Search criterion | Minimize total error |
| Number of points evaluated during search | 1093 |
| Minimum error found by search | 0.462196 |
| Epsilon | 0.001 |
| C | 34.5930771 |
| Gamma | 0.41179479 |
| P | 0.21545292 |
| Number of support vectors | 73 |
| Parameters | Ranges/Values |
|---|---|
| No. of neurons | 25 |
| Minimum radius | 0.019 |
| Maximum radius | 395.265 |
| Minimum lambda | 0.06458 |
| Maximum lambda | 8.64019 |
| Regularization lambda (final weights) | 1.549 × 10−5 |
| Layer | Neurons | Activation |
|---|---|---|
| Input | 7 | Pass through |
| Hidden | 15 | Logistic |
| Output | 1 | Linear |
| Regression Statistics | ||||||||
| Multiple R | 0.942762 | |||||||
| R Square | 0.8888 | |||||||
| Adjusted R Square | 0.88034 | |||||||
| Standard Error | 0.682364 | |||||||
| Observations | 100 | |||||||
| ANOVA | ||||||||
| df | SS | MS | F | Significance F | ||||
| Regression | 7 | 8.1039 | 1.15770 | 105.0487 | 4.69E–41 | |||
| Residual | 92 | 1.0138 | 0.01102 | |||||
| Total | 99 | 9.1178 | ||||||
| Coefficients | Standard Error | t Stat | p-Value | Lower 95% | Upper 95% | Lower 95.0% | Upper 95.0% | |
| Intercept | 0.439148 | 0.11923 | 3.683201 | 0.000389 | 0.202347 | 0.675948 | 0.202347 | 0.675948 |
| Mean Rainfall (mm) | 0.04361 | 0.109511 | 0.398225 | 0.691387 | −0.17389 | 0.261109 | −0.17389 | 0.261109 |
| Temperature (°C) | −0.36972 | 0.106524 | −3.47074 | 0.000792 | −0.58128 | −0.15815 | −0.58128 | −0.15815 |
| Fertilizer(urea) (kg/ha) | −0.13005 | 0.092188 | −1.41074 | 0.161694 | −0.31314 | 0.05304 | −0.31314 | 0.05304 |
| Nitrogen (N) (kg/ha) | 0.343809 | 0.094175 | 3.650756 | 0.000434 | 0.15677 | 0.530848 | 0.15677 | 0.530848 |
| Phosphorus (P) (kg/ha) | 0.112423 | 0.072317 | 1.554591 | 0.123477 | −0.0312 | 0.256051 | −0.0312 | 0.256051 |
| Potassium (K) (kg/ha) | 0.304443 | 0.079279 | 3.840153 | 0.000226 | 0.146988 | 0.461897 | 0.146988 | 0.461897 |
| pH value | −0.04314 | 0.049602 | −0.86974 | 0.386708 | −0.14165 | 0.055373 | −0.14165 | 0.055373 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Joshua, V.; Priyadharson, S.M.; Kannadasan, R. Exploration of Machine Learning Approaches for Paddy Yield Prediction in Eastern Part of Tamilnadu. Agronomy 2021, 11, 2068. https://doi.org/10.3390/agronomy11102068
Joshua V, Priyadharson SM, Kannadasan R. Exploration of Machine Learning Approaches for Paddy Yield Prediction in Eastern Part of Tamilnadu. Agronomy. 2021; 11(10):2068. https://doi.org/10.3390/agronomy11102068
Chicago/Turabian StyleJoshua, Vinson, Selwin Mich Priyadharson, and Raju Kannadasan. 2021. "Exploration of Machine Learning Approaches for Paddy Yield Prediction in Eastern Part of Tamilnadu" Agronomy 11, no. 10: 2068. https://doi.org/10.3390/agronomy11102068
APA StyleJoshua, V., Priyadharson, S. M., & Kannadasan, R. (2021). Exploration of Machine Learning Approaches for Paddy Yield Prediction in Eastern Part of Tamilnadu. Agronomy, 11(10), 2068. https://doi.org/10.3390/agronomy11102068