
AI-Powered Mobile Image Acquisition of Vineyard Insect Traps with Automatic Quality and Adequacy Assessment


Abstract
:1. Introduction
2. Related Work
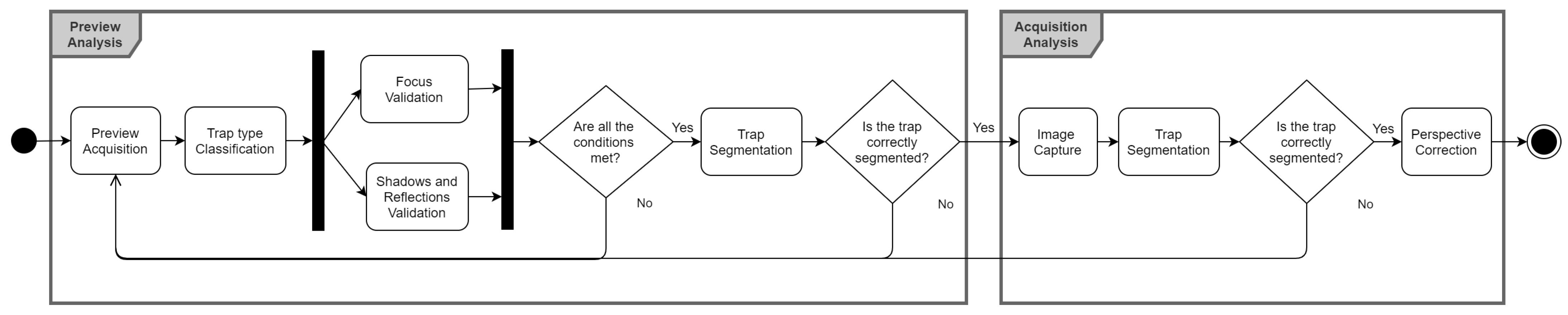
3. System Architecture
3.1. EyesOnTraps Dataset
3.1.1. Image Focus Subset
3.1.2. Reflections and Shadows Subset
3.1.3. Trap Segmentation Subset
3.2. Image Focus Assessment Pipeline
3.2.1. Feature Extraction
3.2.2. Models Training and Optimization
3.3. Shadows & Reflections Assessment Pipeline
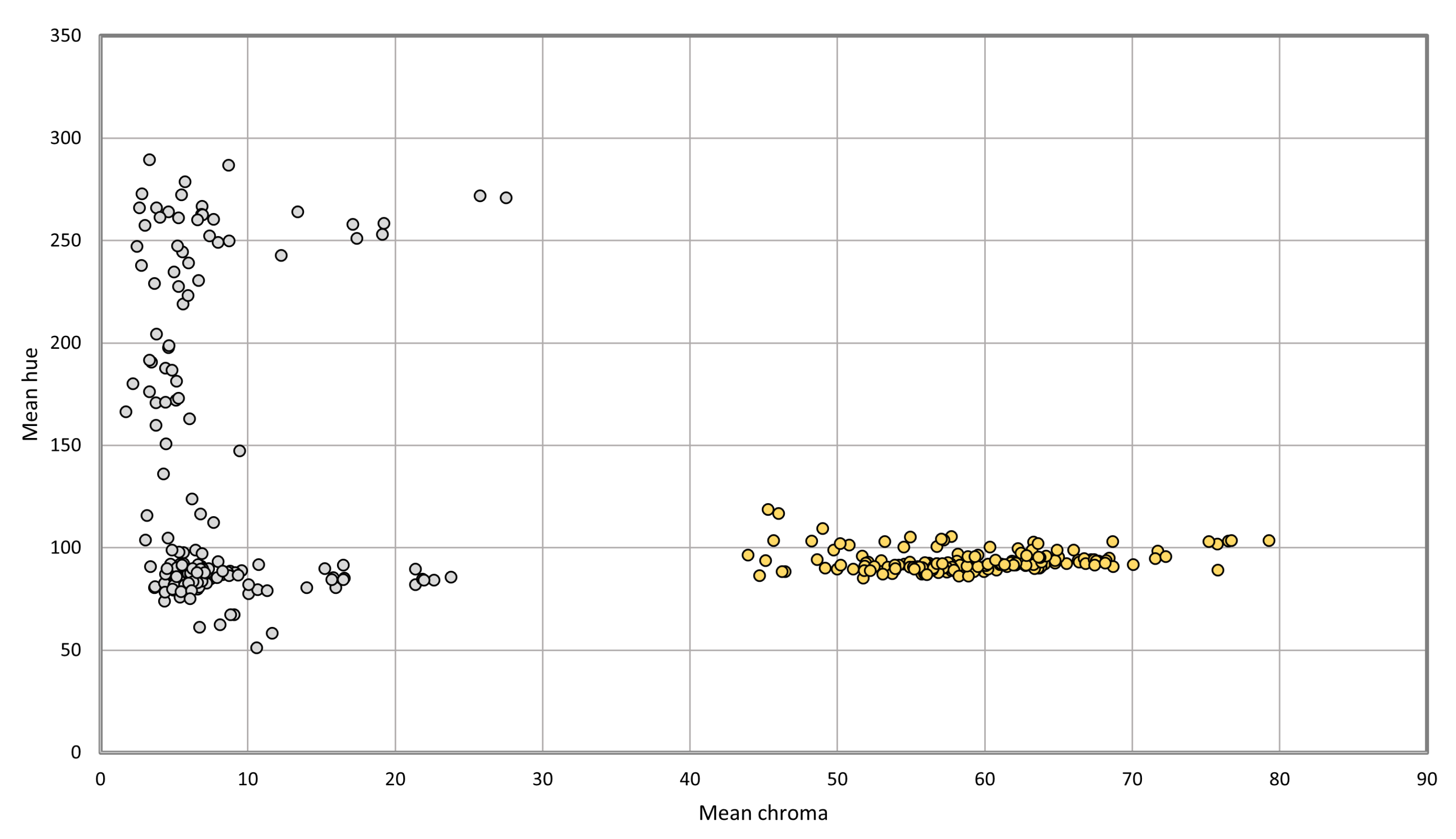
3.4. Trap Type Detection and Segmentation Pipeline
3.5. Trap Perspective Correction Pipeline
4. Results and Discussion
4.1. Image Focus Assessment Results
4.2. Shadows & Reflections Assessment Results
4.3. Trap Type Detection & Segmentation Results
4.4. Trap Perspective Correction Results
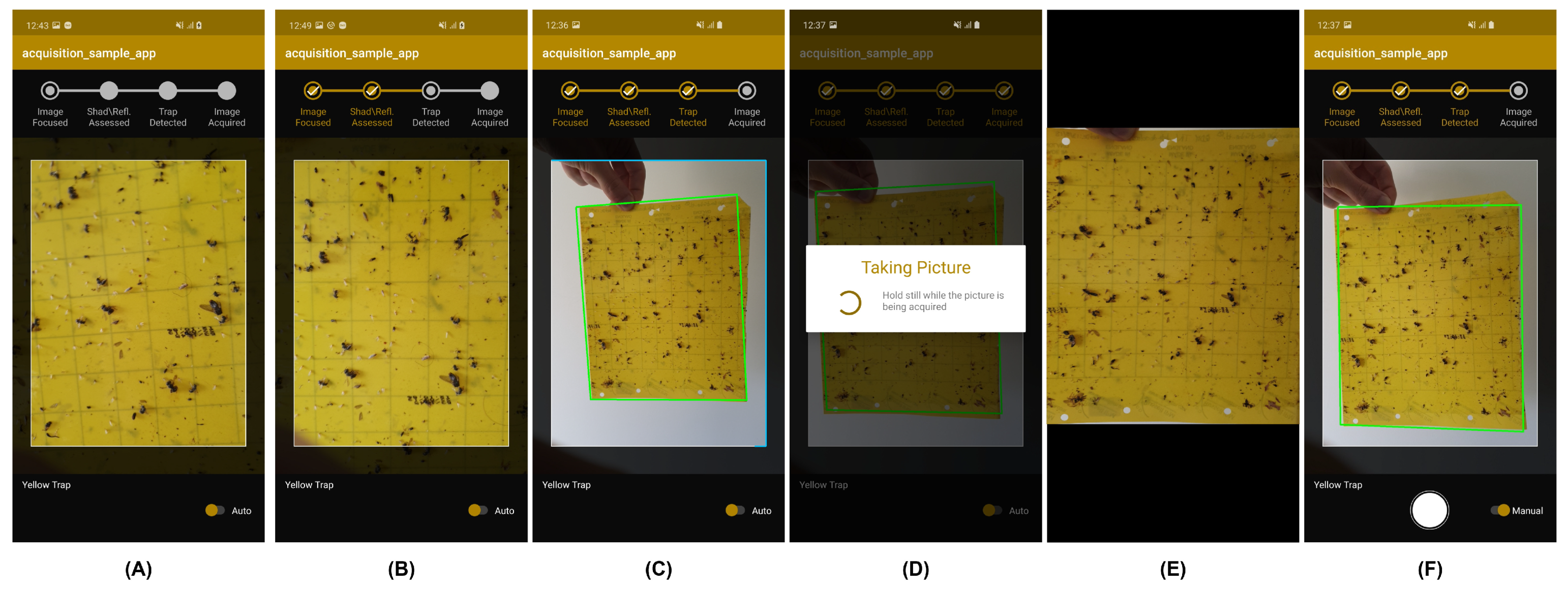
4.5. Mobile Application
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| ML | Machine Learning |
| CT | Chromotropic Traps |
| DT | Delta Traps |
| CtE | Controlled Environment |
| NCtE | Non-Controlled Environment |
References
- International Organisation of Vine and Wine (OIV). State of the World Vitivinicultural Sector in 2019; International Organisation of Vine and Wine: Paris, France, 2020. [Google Scholar]
- International Organisation of Vine and Wine (OIV). 2019 Statistical Report on World Vitiviniculture; International Organisation of Vine and Wine: Paris, France, 2019. [Google Scholar]
- Plants Vital to Human Diets but Face Growing Risks From Pests and Diseases. 2016. Available online: http://www.fao.org/news/story/en/item/409158/icode/ (accessed on 22 March 2021).
- Monitoring Whitefly and Thrips—Sticky Traps Plus Scouting Delivers Best Results. Available online: https://www.biobestgroup.com/en/news/monitoring-whitefly-and-thrips-sticky-traps-plus-scouting-delivers-best-results (accessed on 24 November 2020).
- Yao, Q.; Xian, D.-X.; Liu, Q.-J.; Yang, B.-J.; Diao, G.-Q.; Tang, J. Automated Counting of Rice Planthoppers in Paddy Fields Based on Image Processing. J. Integr. Agric. 2014, 13, 1736–1745. [Google Scholar] [CrossRef]
- Ünlü, L.; Akdemir, B.; Ögür, E.; Şahin, I. Remote Monitoring of European Grapevine Moth, Lobesia botrana (Lepidoptera: Tortricidae) Population Using Camera-Based Pheromone Traps in Vineyards. Turk. J. Agric. Food Sci. Technol. 2019, 7, 652. [Google Scholar] [CrossRef] [Green Version]
- García, J.; Pope, C.; Altimiras, F. A Distributed K-Means Segmentation Algorithm Applied to Lobesia botrana Recognition. Complexity 2017, 2017, 5137317. [Google Scholar] [CrossRef] [Green Version]
- DTN. DTN Smart Trap for Producer. 2020. Available online: https://www.dtn.com/agriculture/producer/dtn-smart-trap/ (accessed on 24 November 2020).
- TRAPVIEW. 2020. Available online: https://www.trapview.com/en/ (accessed on 24 November 2020).
- Semios. Precision Agriculture Technology that Helps Growers Worry Less. 2020. Available online: https://semios.com/ (accessed on 24 November 2020).
- FARMSENSE. 2020. Available online: https://www.farmsense.io/ (accessed on 24 November 2020).
- TARVOS. 2020. Available online: https://tarvos.ag/ (accessed on 24 November 2020).
- Scoutbox. 2020. Available online: https://www.agrocares.com/en/products/scoutbox/ (accessed on 24 November 2020).
- Fang, Y.; Zhu, H.; Zeng, Y.; Ma, K.; Wang, Z. Perceptual Quality Assessment of Smartphone Photography. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Robisson, P.; Jourdain, J.B.; Hauser, W.; Viard, C.; Guichard, F. Autofocus measurement for imaging devices. Electron. Imaging 2017, 2017, 209–218. [Google Scholar] [CrossRef] [Green Version]
- Tiwari, A.; Singh, P.; Amin, S. A survey on Shadow Detection and Removal in images and video sequences. In Proceedings of the 2016 6th International Conference—Cloud System and Big Data Engineering, Noida, India, 14–15 January 2016; pp. 518–523. [Google Scholar] [CrossRef]
- Morgand, A.; Tamaazousti, M. Generic and real-time detection of specular reflections in images. In Proceedings of the 2014 International Conference on Computer Vision Theory and Applications (VISAPP), Lisbon, Portugal, 5–8 January 2014; pp. 274–282. [Google Scholar]
- Jiddi, S.; Robert, P.; Marchand, E. Detecting Specular Reflections and Cast Shadows to Estimate Reflectance and Illumination of Dynamic Indoor Scenes. IEEE Trans. Vis. Comput. Graph. 2020. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Al-amri, S.S.; Kalyankar, N.V.; Khamitkar, S.D. Image segmentation by using edge detection. Int. J. Comput. Sci. Eng. 2010, 2, 804–807. [Google Scholar]
- Mukherjee, S.; Mukherjee, D. Segmentation of Circular and Rectangular Shapes in an Image Using Helmholtz Principle. In Proceedings of the 2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing, Bhubaneswar, India, 16–19 December 2008; pp. 657–664. [Google Scholar] [CrossRef]
- Guerzhoy, M.; Zhou, H. Segmentation of Rectangular Objects Lying on an Unknown Background in a Small Preview Scan Image. In Proceedings of the 2008 Canadian Conference on Computer and Robot Vision, Windsor, ON, Canada, 28–30 May 2008; pp. 369–375. [Google Scholar] [CrossRef]
- Moreira, D.; Alves, P.; Veiga, F.; Rosado, L.; Vasconcelos, M.J.M. Automated Mobile Image Acquisition of Macroscopic Dermatological Lesions. In Proceedings of the 14th International Joint Conference on Biomedical Engineering Systems and Technologies, Online Streaming, 11–13 February 2021. [Google Scholar]
- Faria, J.; Almeida, J.; Vasconcelos, M.J.M.; Rosado, L. Automated Mobile Image Acquisition of Skin Wounds Using Real-Time Deep Neural Networks. In Medical Image Understanding and Analysis: Proceedings of the 23rd Conference, MIUA 2019, Liverpool, UK, 24–26 July 2019; Zheng, Y., Williams, B.M., Chen, K., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 61–73. [Google Scholar]
- Alves, J.; Moreira, D.; Alves, P.; Rosado, L.; Vasconcelos, M.J.M. Automatic focus assessment on dermoscopic images acquired with smartphones. Sensors 2019, 19, 4957. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rosado, L.; Silva, P.T.; Faria, J.; Oliveira, J.; Vasconcelos, M.J.M.; da Costa, J.M.C.; Elias, D.; Cardoso, J.S. μSmartScope: Towards a Fully Automated 3D-printed Smartphone Microscope with Motorized Stage. In Biomedical Engineering Systems and Technologies: 10th International Joint Conference, BIOSTEC 2017, Porto, Portugal, 21–23 February 2017; Communications in Computer and Information Science Book Series; Springer: Cham, Switzerland, 2018; Volume 881. [Google Scholar]
- Pertuz, S.; Puig, D.; García, M. Analysis of focus measure operators in shape-from-focus. Pattern Recognit. 2013, 46, 1415–1432. [Google Scholar] [CrossRef]
- Santos, A.; Ortiz-de Solorzano, C.; Vaquero, J.J.; Peña, J.; Malpica, N.; Del Pozo, F. Evaluation of autofocus functions in molecular cytogenetic analysis. J. Microsc. 1998, 188, 264–272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Frank, E.; Hall, M.A.; Holmes, G.; Kirkby, R.; Pfahringer, B.; Witten, I.H. Weka: A machine learning workbench for data mining. In Data Mining and Knowledge Discovery Handbook: A Complete Guide for Practitioners and Researchers; Maimon, O., Rokach, L., Eds.; Springer: Berlin, Germany, 2005; pp. 1305–1314. [Google Scholar]
- Wang, S.; Zheng, H. Clustering-based shadow edge detection in a single color image. In Proceedings of the 2013 International Conference on Mechatronic Sciences, Electric Engineering and Computer (MEC), Shenyang, China, 20–22 December 2013; pp. 1038–1041. [Google Scholar] [CrossRef]
- Xu, L.; Qi, F.; Jiang, R. Shadow Removal from a Single Image. In Proceedings of the Sixth International Conference on Intelligent Systems Design and Applications, Jian, China, 16–18 October 2006; pp. 1049–1054. [Google Scholar] [CrossRef]
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Douglas, D.; Peucker, T. Algorithms for the reduction of the number of points required to represent a digitized line or its caricature. Cartogr. Int. J. Geogr. Inf. Geovis. 1973, 10, 112–122. [Google Scholar] [CrossRef] [Green Version]
- Szeliski, R. Computer Vision: Algorithms and Applications, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Zhang, Z.; He, L.-W. Whiteboard scanning and image enhancement. Digit. Signal Process. 2007, 17, 414–432. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Trap Type | #Images Controlled Environment | #Images Non-Controlled Environment | Total |
|---|---|---|---|
| DT | 141 | 90 | 231 |
| CT | 253 | 32 | 285 |
| All | 394 | 122 | 516 |
| Trap Type | #Images Focused | #Images Unfocused | Total |
|---|---|---|---|
| DT | 33 | 27 | 60 |
| CT | 76 | 69 | 145 |
| All | 102 | 103 | 205 |
| Trap Type | #Control Images | #Images with Reflections | #Images with Shadows | Total |
|---|---|---|---|---|
| DT | 51 | 5 | 22 | 78 |
| CT | 53 | 37 | 48 | 138 |
| All | 104 | 42 | 70 | 216 |
| Group | Feature Name | Extracted Metrics |
|---|---|---|
| Gradient | Gaussian Derivative | max, std, min, max, sum, L2norm, skew, kurt |
| Squared Gradient | max, std, min, max, sum, L2norm, skew, kurt | |
| Thresholded Abs. Grad. | max, std, min, max, sum, L2norm, skew, kurt | |
| Gradient Energy | max, std, min, max, sum, L2norm, skew, kurt | |
| Tenengrad | max, std, min, max, sum, L2norm, skew, kurt | |
| Tenengrad Variance | max, std, min, max, sum, L2norm, skew, kurt | |
| Statistic | Gray Level Variance | max, std, min, max, sum, L2norm, skew, kurt |
| Norm. Gray L. Variance | max, std, min, max, sum, L2norm, skew, kurt | |
| Histogram Range | Range (grey, blue, green, red) | |
| Histogram Entropy | Entropy (blue, green, red) | |
| Laplacian | Modified Laplacian | max, std, min, max, sum, L2norm, skew, kurt |
| Energy of Laplacian | max, std, min, max, sum, L2norm, skew, kurt | |
| Diagonal of Laplacian | max, std, min, max, sum, L2norm, skew, kurt | |
| Variance of Laplacian | max, std, min, max, sum, L2norm, skew, kurt | |
| Laplacian Filter | max, std, min, max, sum, L2norm, skew, kurt | |
| DCT | DCT Energy Ratio | max, std, min, max, sum, L2norm, skew, kurt |
| DCT Reduced Energy Ratio | max, std, min, max, sum, L2norm, skew, kurt | |
| Modified DCT | max, std, min, max, sum, L2norm, skew, kurt | |
| Other | Brenner’s Measure | max, std, min, max, sum, L2norm, skew, kurt |
| Image Curvature | max, std, min, max, sum, L2norm, skew, kurt | |
| Image Contrast | max, std, min, max, sum, L2norm, skew, kurt | |
| Spatial Frequency | max, std, min, max, sum, L2norm, skew, kurt | |
| Vollath’s Autocorrelation | max, std, min, max, sum, L1norm, L2norm, skew, kurt | |
| Vollath’s Standard Deviation | max, std, min, max, sum, L1norm, L2norm, skew, kurt | |
| Helmli and Scheres Mean Method | max, std, min, max, sum, L2norm, skew, kurt | |
| Marziliano Metric | sumX, meanX, sumY, meanY |
| Model | Accuracy | Recall | Precision | F1 | #Features |
|---|---|---|---|---|---|
| Linear SVM | 0.884 | 0.884 | 0.887 | 0.882 | 788 |
| Random Forest | 0.895 | 0.895 | 0.899 | 0.894 | 495 |
| Decision Tree | 0.855 | 0.855 | 0.855 | 0.853 | 4 |
| Decision Tree | 0.843 | 0.843 | 0.843 | 0.843 | 1 |
| #Classes | Model | Accuracy | Recall | Precision | F1 | #Features |
|---|---|---|---|---|---|---|
| 3-class problem | Decision Tree | 0.857 | 0.857 | 0.868 | 0.857 | 2 |
| 3-class problem | Random Forest | 0.929 | 0.929 | 0.928 | 0.928 | 185 |
| 2-class problem | Random Forest | 0.894 | 0.894 | 0.894 | 0.894 | 587 |
| 2-class problem | Decision Tree | 0.822 | 0.822 | 0.823 | 0.822 | 1 |
| Train Conditions | Model | Accuracy | Recall | Precision | F1 | #Features |
|---|---|---|---|---|---|---|
| 3-class problem | Random Forest | 0.946 | 0.946 | 0.951 | 0.946 | 403 |
| 3-class problem | Decision Tree | 0.957 | 0.957 | 0.957 | 0.957 | 3 |
| 2-class problem | Decision Tree | 0.962 | 0.962 | 0.963 | 0.962 | 1 |
| Train Conditions | Model | Accuracy | Recall | Precision | F1 | #Features |
|---|---|---|---|---|---|---|
| 3-class problem | Random Forest | 0.846 | 0.846 | 0.804 | 0.823 | 210 |
| 3-class problem | Decision Tree | 0.795 | 0.795 | 0.795 | 0.770 | 2 |
| 2-class problem | Random Forest | 0.833 | 0.833 | 0.845 | 0.832 | 237 |
| 2-class problem | Decision Tree | 0.796 | 0.796 | 0.793 | 0.796 | 2 |
| Entire Dataset | CT-CtE Subset | CT-NCtE Subset | DT-CtE Subset | DT-NCtE Subset | |
|---|---|---|---|---|---|
| JA Mean | 0.967 | 0.989 | 0.936 | 0.990 | 0.936 |
| JA STD | 0.076 | 0.029 | 0.108 | 0.012 | 0.109 |
| CT | DT | ||||
|---|---|---|---|---|---|
| High-End | Low-End | High-End | Low-End | ||
| Preview Analysis Time (ms) | mean | 556 | 1508 | 802 | 1784 |
| std | 36 | 183 | 135 | 195 | |
| Perspective Correction Time (ms) | mean | 5091 | 14,922 | 21,409 | 44,581 |
| std | 592 | 1574 | 12,055 | 7665 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Faria, P.; Nogueira, T.; Ferreira, A.; Carlos, C.; Rosado, L. AI-Powered Mobile Image Acquisition of Vineyard Insect Traps with Automatic Quality and Adequacy Assessment. Agronomy 2021, 11, 731. https://doi.org/10.3390/agronomy11040731
Faria P, Nogueira T, Ferreira A, Carlos C, Rosado L. AI-Powered Mobile Image Acquisition of Vineyard Insect Traps with Automatic Quality and Adequacy Assessment. Agronomy. 2021; 11(4):731. https://doi.org/10.3390/agronomy11040731
Chicago/Turabian StyleFaria, Pedro, Telmo Nogueira, Ana Ferreira, Cristina Carlos, and Luís Rosado. 2021. "AI-Powered Mobile Image Acquisition of Vineyard Insect Traps with Automatic Quality and Adequacy Assessment" Agronomy 11, no. 4: 731. https://doi.org/10.3390/agronomy11040731
APA StyleFaria, P., Nogueira, T., Ferreira, A., Carlos, C., & Rosado, L. (2021). AI-Powered Mobile Image Acquisition of Vineyard Insect Traps with Automatic Quality and Adequacy Assessment. Agronomy, 11(4), 731. https://doi.org/10.3390/agronomy11040731