
The Application of Multiple Linear Regression and Artificial Neural Network Models for Yield Prediction of Very Early Potato Cultivars before Harvest

 ,
,  ,
,  ,
, 
 ,
,  and
and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Experiment Location and Research Material
2.2. Field Experiments
2.3. Building an Experimental Database
2.4. Selecting Variables for Building Predictive Models
2.5. The Method of Building a Linear Forecasting Model (MLR)
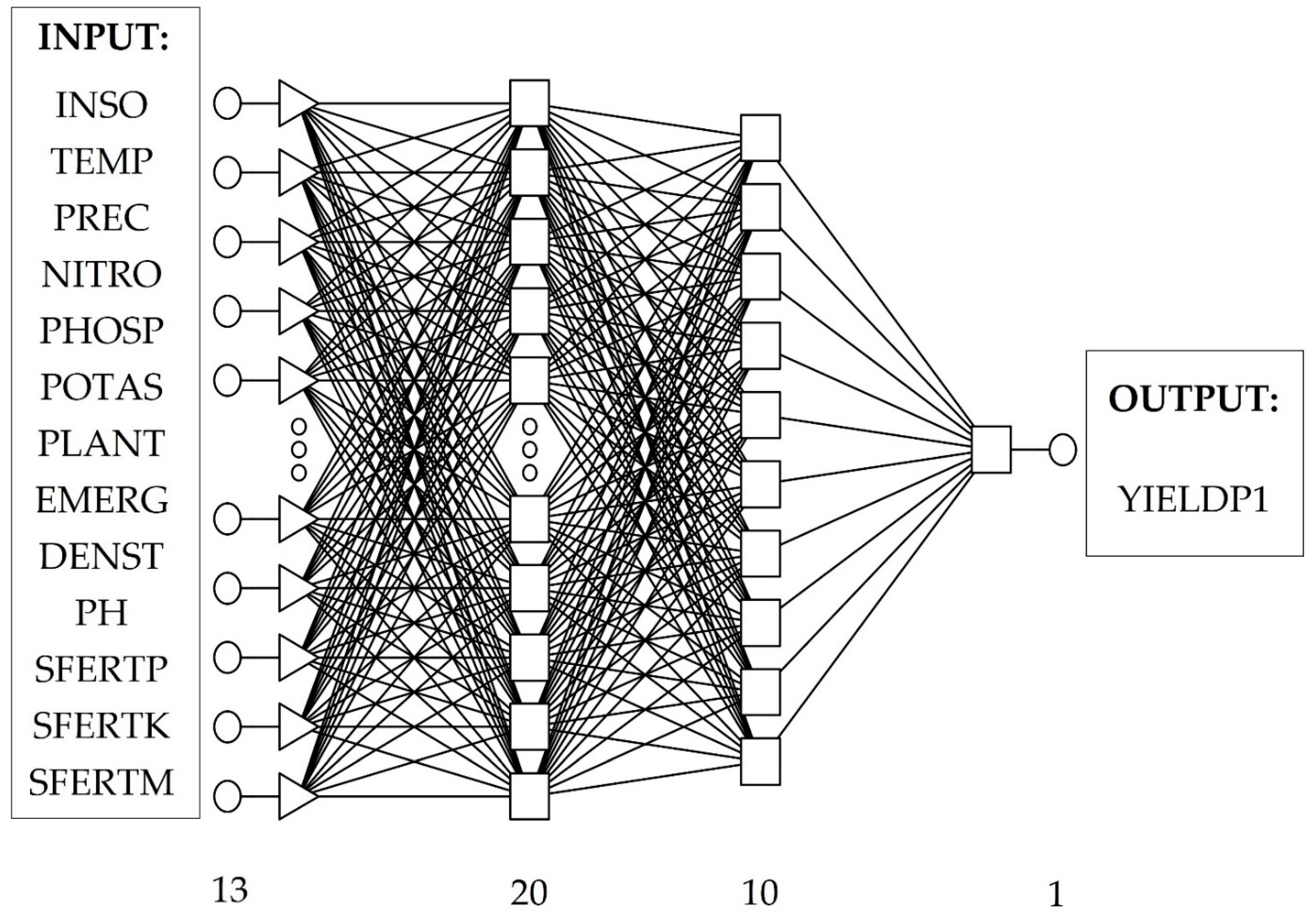
2.6. The Method of Building a Non-Linear Forecasting Model (ANN)
2.7. Neural Network Sensitivity Analysis
3. Results
3.1. Comparing Quality of Forecasting Models of Potato Tuber Yield 40 Days after Full Emergence
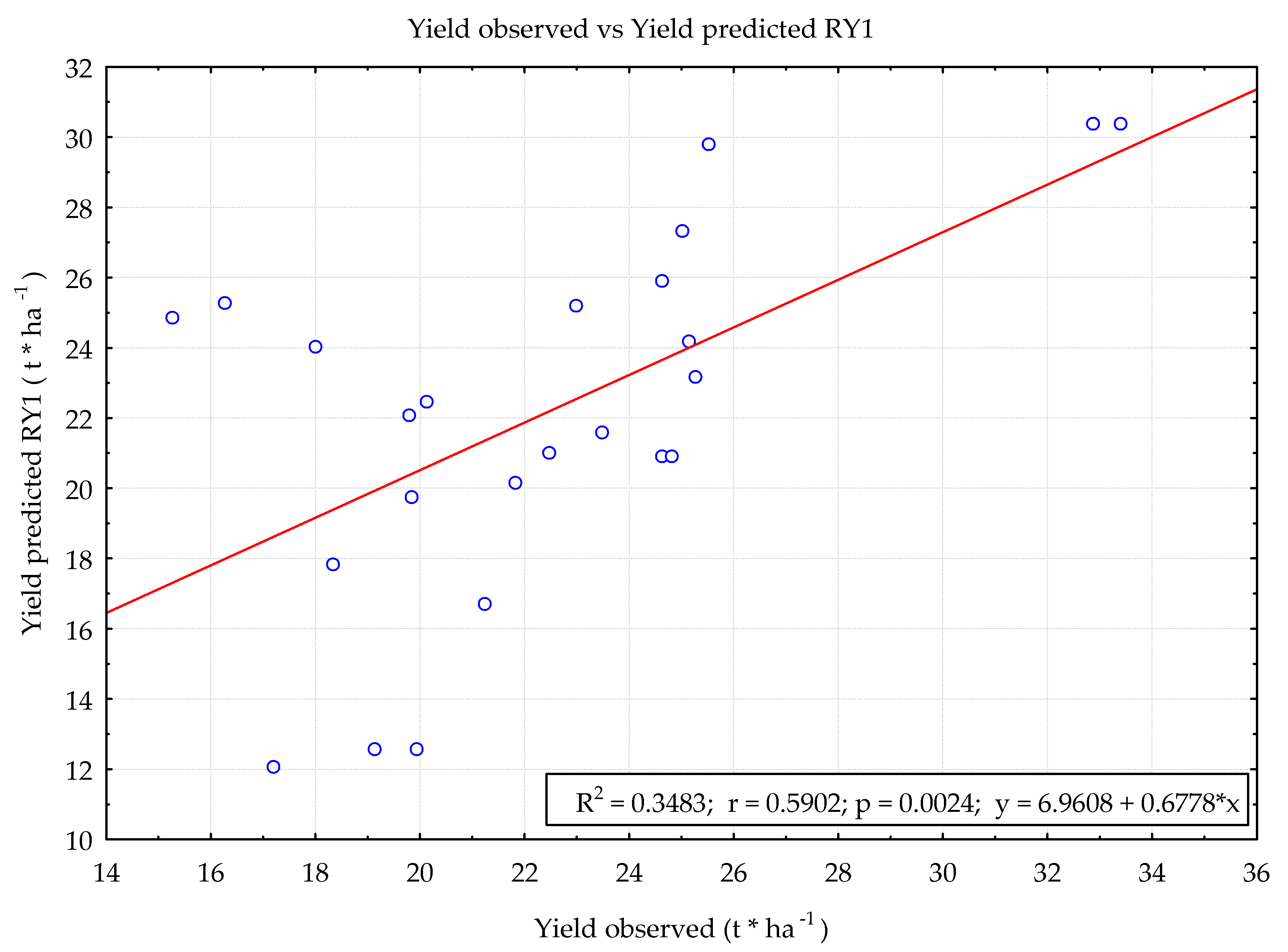
3.2. Forecasting Properties of Linear and Nonlinear Models
3.3. The Results of the Sensitivity Analysis of the MLP 13:13-20-10-1:1 Neural Network
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Basso, B.; Liu, L. Seasonal crop yield forecast: Methods, applications, and accuracies. Adv. Agron. 2019, 201–255. [Google Scholar] [CrossRef]
- Garde, Y.A.; Dhekale, B.S.; Singh, S. Different approaches on pre harvest forecasting of wheat yield. J. Appl. Nat. Sci. 2015, 7, 839–843. [Google Scholar] [CrossRef]
- Niedbała, G.; Piekutowska, M.; Weres, J.; Korzeniewicz, R.; Witaszek, K.; Adamski, M.; Pilarski, K.; Czechowska-Kosacka, A.; Krysztofiak-Kaniewska, A. Application of Artificial Neural Networks for Yield Modeling of Winter Rapeseed Based on Combined Quantitative and Qualitative Data. Agronomy 2019, 9, 781. [Google Scholar] [CrossRef] [Green Version]
- Struik, P.C.; Kuyper, T.W. Sustainable intensification in agriculture: The richer shade of green. A review. Agron. Sustain. Dev. 2017, 37, 39. [Google Scholar] [CrossRef]
- FAO Food and Agriculture Organization of the United Nations (FAO). FAOSTAT Online Statistical Service. 2020. Available online: http://faostat.fao.org (accessed on 15 January 2021).
- Kołodziejczyk, M.; Oleksy, A.; Kulig, B.; Lepiarczyk, A. Early potato cultivation using synthetic and biodegradable covers. Plant Soil Environ. 2019, 65, 97–103. [Google Scholar] [CrossRef] [Green Version]
- De Cicco, A.; Jeanty, J.-C. The EU Potato Sector-Statistics on Production, Prices and Trade. Available online: https://ec.europa.eu/eurostat/statistics-explained/index.php/The_EU_potato_sector_-_statistics_on_production,_prices_and_trade (accessed on 15 January 2021).
- Cholakov, T.L.; Nacheva, E.K. Results from using polypropylene cover in production of early potatoes. Acta Hortic. 2009, 603–608. [Google Scholar] [CrossRef]
- Wadas, W.; Kosterna, E.; Sawicki, M. Effect of Perforated Film And Polypropylene Nonwoven Covering On The Marketable Value of Early Potato Yield. Veg. Crop. Res. Bull. 2008, 69. [Google Scholar] [CrossRef]
- Jiang, D.; Yang, X.; Clinton, N.; Wang, N. An artificial neural network model for estimating crop yields using remotely sensed information. Int. J. Remote Sens. 2004, 25, 1723–1732. [Google Scholar] [CrossRef]
- Heremans, S.; Dong, Q.; Zhang, B.; Bydekerke, L.; Van Orshoven, J. Potential of ensemble tree methods for early-season prediction of winter wheat yield from short time series of remotely sensed normalized difference vegetation index and in situ meteorological data. J. Appl. Remote Sens. 2015, 9. [Google Scholar] [CrossRef]
- Niedbała, G.; Nowakowski, K.; Rudowicz-Nawrocka, J.; Piekutowska, M.; Weres, J.; Tomczak, R.J.; Tyksiński, T.; Pinto, A.Á. Multicriteria prediction and simulation of winter wheat yield using extended qualitative and quantitative data based on artificial neural networks. Appl. Sci. 2019, 9, 2773. [Google Scholar] [CrossRef] [Green Version]
- Chipanshi, A.; Zhang, Y.; Kouadio, L.; Newlands, N.; Davidson, A.; Hill, H.; Warren, R.; Qian, B.; Daneshfar, B.; Bedard, F.; et al. Evaluation of the Integrated Canadian Crop Yield Forecaster (ICCYF) model for in-season prediction of crop yield across the Canadian agricultural landscape. Agric. For. Meteorol. 2015, 206, 137–150. [Google Scholar] [CrossRef] [Green Version]
- Bustos-Korts, D.; Malosetti, M.; Chapman, S.; van Eeuwijk, F. Modelling of Genotype by Environment Interaction and Prediction of Complex Traits across Multiple Environments as a Synthesis of Crop Growth Modelling, Genetics and Statistics. In Crop Systems Biology; Springer International Publishing: Cham, Switzerland, 2016; pp. 55–82. [Google Scholar]
- Shahhosseini, M.; Hu, G.; Archontoulis, S.V. Forecasting Corn Yield With Machine Learning Ensembles. Front. Plant Sci. 2020, 11. [Google Scholar] [CrossRef] [PubMed]
- Bala, S.K.; Islam, A.S. Correlation between potato yield and MODIS-derived vegetation indices. Int. J. Remote Sens. 2009, 30, 2491–2507. [Google Scholar] [CrossRef]
- Abrougui, K.; Gabsi, K.; Mercatoris, B.; Khemis, C.; Amami, R.; Chehaibi, S. Prediction of organic potato yield using tillage systems and soil properties by artificial neural network (ANN) and multiple linear regressions (MLR). Soil Tillage Res. 2019, 190, 202–208. [Google Scholar] [CrossRef]
- Reynolds, C.A.; Yitayew, M.; Slack, D.C.; Hutchinson, C.F.; Huete, A.; Petersen, M.S. Estimating crop yields and production by integrating the FAO Crop Specific Water Balance model with real-time satellite data and ground-based ancillary data. Int. J. Remote Sens. 2000, 21, 3487–3508. [Google Scholar] [CrossRef]
- Matsumura, K.; Gaitan, C.F.; Sugimoto, K.; Cannon, A.J.; Hsieh, W.W. Maize yield forecasting by linear regression and artificial neural networks in Jilin, China. J. Agric. Sci. 2015, 153, 399–410. [Google Scholar] [CrossRef]
- MacKerron, D.K.L. Mathematical Models of Plant Growth and Development. In Potato Biology and Biotechnology; Elsevier: New York, NY, USA, 2007; pp. 753–776. [Google Scholar]
- Daccache, A.; Weatherhead, E.K.; Stalham, M.A.; Knox, J.W. Impacts of climate change on irrigated potato production in a humid climate. Agric. For. Meteorol. 2011, 151, 1641–1653. [Google Scholar] [CrossRef]
- Van der Zaag, D.E. Simulation of growth and yield of the potato crop. Potato Res. 1984, 27, 305–306. [Google Scholar] [CrossRef]
- Aguiar Pinto, P. Computer Simulation Modeling of the Growth and Development of the Potato Crop Under Different Water Regimes; University of California: Los Angeles, CA, USA, 1988. [Google Scholar]
- Arora, V.K.; Nath, J.C.; Singh, C.B. Analyzing potato response to irrigation and nitrogen regimes in a sub-tropical environment using SUBSTOR-Potato model. Agric. Water Manag. 2013, 124, 69–76. [Google Scholar] [CrossRef]
- Raymundo, R.; Asseng, S.; Prassad, R.; Kleinwechter, U.; Concha, J.; Condori, B.; Bowen, W.; Wolf, J.; Olesen, J.E.; Dong, Q.; et al. Performance of the SUBSTOR-potato model across contrasting growing conditions. Field Crop. Res. 2017, 202, 57–76. [Google Scholar] [CrossRef] [Green Version]
- Griffin, T.S.; Bradley, S.J.; Ritchie, J.T. A Simulation Model for Potato Growth and Development: Substor-Potato Version 2.0; University of Honolulu: Honolulu, HI, USA, 1993. [Google Scholar]
- Kooman, P.L.; Haverkort, A.J. Modelling Development and Growth of the Potato Crop Influenced by Temperature and Daylength: LINTUL-POTATO; Kluwer Academic Publishers: Amsterdam, The Netherlands, 1995; pp. 41–59. [Google Scholar]
- Wolf, J. Comparison of two potato simulation models under climate change. I. Model calibration and sensitivity analyses. Clim. Res. 2002, 21, 173–186. [Google Scholar] [CrossRef] [Green Version]
- Alva, A.K.; Marcos, J.; Stockle, C.; Reddy, V.R.; Timlin, D. A Crop Simulation Model for Predicting Yield and Fate of Nitrogen in Irrigated Potato Rotation Cropping System. J. Crop Improv. 2010, 24, 142–152. [Google Scholar] [CrossRef]
- MacKerron, D.K.L.; Haverkort, A.J. Decision Support Systems in Potato Production; MacKerron, D.K.L., Haverkort, A.J., Eds.; Wageningen Academic Publishers: Wageningen, The Netherlands, 2004; ISBN 978-90-76998-30-5. [Google Scholar]
- Pentoś, K. The methods of extracting the contribution of variables in artificial neural network models—Comparison of inherent instability. Comput. Electron. Agric. 2016, 127, 141–146. [Google Scholar] [CrossRef]
- Niazian, M.; Niedbała, G. Machine Learning for Plant Breeding and Biotechnology. Agriculture 2020, 10, 436. [Google Scholar] [CrossRef]
- van Klompenburg, T.; Kassahun, A.; Catal, C. Crop yield prediction using machine learning: A systematic literature review. Comput. Electron. Agric. 2020, 177. [Google Scholar] [CrossRef]
- Kujawa, S.; Dach, J.; Kozłowski, R.J.; Przybył, K.; Niedbała, G.; Mueller, W.; Tomczak, R.J.; Zaborowicz, M.; Koszela, K. Maturity classification for sewage sludge composted with rapeseed straw using neural image analysis. In Proceedings of the SPIE—The International Society for Optical Engineering, San Diego, CA, USA, 28 August 2016; Volume 10033, p. 100332H. [Google Scholar] [CrossRef]
- Wojciechowski, T.; Niedbala, G.; Czechlowski, M.; Nawrocka, J.R.; Piechnik, L.; Niemann, J. Rapeseed seeds quality classification with usage of VIS-NIR fiber optic probe and artificial neural networks. In Proceedings of the 2016 International Conference on Optoelectronics and Image Processing, ICOIP 2016, Warsaw, Poland, 10–12 June 2016. [Google Scholar] [CrossRef]
- Pandey, A.; Mishra, A. Application of artificial neural networks in yield prediction of potato crop. Russ. Agric. Sci. 2017, 43, 266–272. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, S.; Chen, X.; Wang, J. Artificial Combined Model Based on Hybrid Nonlinear Neural Network Models and Statistics Linear Models—Research and Application for Wind Speed Forecasting. Sustainability 2018, 10, 4601. [Google Scholar] [CrossRef] [Green Version]
- Niedbała, G. Simple model based on artificial neural network for early prediction and simulation winter rapeseed yield. J. Integr. Agric. 2019, 18, 54–61. [Google Scholar] [CrossRef] [Green Version]
- Research Centre for Cultivar Testing (COBORU). Available online: https://coboru.gov.pl/ (accessed on 20 April 2021).
- Studnicki, M.; Lenartowicz, T.; Noras, K.; Wójcik-Gront, E.; Wyszyński, Z. Assessment of Stability and Adaptation Patterns of White Sugar Yield from Sugar Beet Cultivars in Temperate Climate Environments. Agronomy 2019, 9, 405. [Google Scholar] [CrossRef] [Green Version]
- Sellam, V.; Poovammal, E. Prediction of Crop Yield using Regression Analysis. Ind. J. Sci. Technol. 2016, 9. [Google Scholar] [CrossRef]
- TIBCO Statistica® Automated Neural Networks. Available online: https://community.tibco.com/wiki/tibco-statistica-automated-neural-networks (accessed on 21 March 2021).
- Boozarjomehry, R.B.; Svrcek, W.Y. Automatic design of neural network structures. Comput. Chem. Eng. 2001, 25, 1075–1088. [Google Scholar] [CrossRef]
- Qi, A.; Kenter, C.; Hoffmann, C.; Jaggard, K.W. The Broom’s Barn sugar beet growth model and its adaptation to soils with varied available water content. Eur. J. Agron. 2005, 23, 108–122. [Google Scholar] [CrossRef]
- Sharifi, A. Yield prediction with machine learning algorithms and satellite images. J. Sci. Food Agric. 2021, 101, 891–896. [Google Scholar] [CrossRef]
- Šťastná, M.; Toman, F.; Dufková, J. Usage of SUBSTOR model in potato yield prediction. Agric. Water Manag. 2010, 97, 286–290. [Google Scholar] [CrossRef]
- Travasso, M.I.; Caldiz, D.O.; Saluzzo, J.A. Yield prediction using the SUBSTOR-potato model under Argentinian conditions. Potato Res. 1996, 39, 305–312. [Google Scholar] [CrossRef]
- Machakaire, A.T.B.; Steyn, J.M.; Caldiz, D.O.; Haverkort, A.J. Forecasting Yield and Tuber Size of Processing Potatoes in South Africa Using the LINTUL-Potato-DSS Model. Potato Res. 2016, 59, 195–206. [Google Scholar] [CrossRef] [Green Version]
- Babyak, M.A. What You See May Not Be What You Get: A Brief, Nontechnical Introduction to Overfitting in Regression-Type Models. Psychosom. Med. 2004, 66, 411–421. [Google Scholar] [CrossRef] [Green Version]
- Guo, W.W.; Xue, H. Crop yield forecasting using artificial neural networks: A comparison between spatial and temporal models. Math. Probl. Eng. 2014, 2014. [Google Scholar] [CrossRef]
- Bhojani, S.H.; Bhatt, N. Wheat crop yield prediction using new activation functions in neural network. Neural Comput. Appl. 2020, 32, 13941–13951. [Google Scholar] [CrossRef]
- Niazian, M.; Sadat-Noori, S.A.; Abdipour, M.; Tohidfar, M.; Mortazavian, S.M.M. Image Processing and Artificial Neural Network-Based Models to Measure and Predict Physical Properties of Embryogenic Callus and Number of Somatic Embryos in Ajowan (Trachyspermum ammi (L.) Sprague). Vitr. Cell. Dev. Biol. Plant 2018, 54, 54–68. [Google Scholar] [CrossRef]
- Abdipour, M.; Younessi-Hmazekhanlu, M.; Ramazani, S.H.R.; Omidi, A.H. Artificial neural networks and multiple linear regression as potential methods for modeling seed yield of safflower (Carthamus tinctorius L.). Ind. Crops Prod. 2019, 127, 185–194. [Google Scholar] [CrossRef]
- Al-Gaadi, K.A.; Hassaballa, A.A.; Tola, E.; Kayad, A.G.; Madugundu, R.; Alblewi, B.; Assiri, F. Prediction of potato crop yield using precision agriculture techniques. PLoS ONE 2016, 11, 1–16. [Google Scholar] [CrossRef]
- Cillis, D.; Maestrini, B.; Pezzuolo, A.; Marinello, F.; Sartori, L. Modeling soil organic carbon and carbon dioxide emissions in different tillage systems supported by precision agriculture technologies under current climatic conditions. Soil Tillage Res. 2018, 183, 51–59. [Google Scholar] [CrossRef]
- Nevavuori, P.; Narra, N.; Lipping, T. Crop yield prediction with deep convolutional neural networks. Comput. Electron. Agric. 2019, 163. [Google Scholar] [CrossRef]
- Niedbała, G.; Kozłowski, R.J. Application of Artificial Neural Networks for Multi-Criteria Yield Prediction of Winter Wheat. J. Agric. Sci. Technol. 2019, 21, 51–61. [Google Scholar]
- Zhang, G.P.; Qi, M. Neural network forecasting for seasonal and trend time series. Eur. J. Oper. Res. 2005, 160, 501–514. [Google Scholar] [CrossRef]
- Peng, J.; Kim, M.; Kim, Y.; Jo, M.; Kim, B.; Sung, K.; Lv, S. Constructing Italian ryegrass yield prediction model based on climatic data by locations in South Korea. Grassl. Sci. 2017, 63, 184–195. [Google Scholar] [CrossRef]
- Kouadio, L.; Newlands, N.; Davidson, A.; Zhang, Y.; Chipanshi, A. Assessing the Performance of MODIS NDVI and EVI for Seasonal Crop Yield Forecasting at the Ecodistrict Scale. Remote Sens. 2014, 6, 10193–10214. [Google Scholar] [CrossRef] [Green Version]
- Khoshnevisan, B.; Rafiee, S.; Omid, M.; Mousazadeh, H. Prediction of potato yield based on energy inputs using multi-layer adaptive neuro-fuzzy inference system. Measurement 2014, 47, 521–530. [Google Scholar] [CrossRef]
- Kawakami, J.; Iwama, K.; Jitsuyama, Y. Effects of Planting Date on the Growth and Yield of Two Potato Cultivars Grown from Microtubersand Conventional Seed Tubers. Plant Prod. Sci. 2005, 8, 74–78. [Google Scholar] [CrossRef]
- Muleta, H.D.; Aga, M.C. Role of nitrogen on potato production: A review. J. Plant Sci. 2019, 7, 36–42. [Google Scholar]
- Kołodziejczyk, M. Effect of nitrogen fertilization and microbial preparations on potato yielding. Plant Soil Environ. 2014, 60, 379–386. [Google Scholar] [CrossRef] [Green Version]
- Olivier, M.; Goffart, J.-P.; Ledent, J.-F. Threshold Value for Chlorophyll Meter as Decision Tool for Nitrogen Management of Potato. Agron. J. 2006, 98, 496–506. [Google Scholar] [CrossRef]
- Jamaati-e-Somarin, S.; Zabihi-e-Mahmoodabad, R.; Yari, A. Yield and yield components of potato (Solanum Tuberosum L.) tuber as affected by nitrogen fertilizer and plant density. Aust. J. Basic Appl. Sci. 2010, 4, 3128–3131. [Google Scholar]
- Kleinkopf, G.E.; Westermann, D.T.; Dwelle, R.B. Dry Matter Production and Nitrogen Utilization by Six Potato Cultivars. Agron. J. 1981, 73, 799–802. [Google Scholar] [CrossRef]
- Westermann, D.T.; Kleinkopf, G.E. Nitrogen Requirements of Potatoes. Agron. J. 1985, 77, 616–621. [Google Scholar] [CrossRef]
- Millard, P.; Marshall, B. Growth, nitrogen uptake and partitioning within the potato (Solatium tuberosum L.) crop, in relation to nitrogen application. J. Agric. Sci. 1986, 107, 421–429. [Google Scholar] [CrossRef]
- Westermann, D.T.; Kleinkopf, G.E.; Porter, L.K. Nitrogen fertilizer efficiencies on potatoes. Am. Potato J. 1988, 65, 377–386. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Quantitative Yield Forecast | ||
|---|---|---|
| Models RY1 and NY1 | Yield Forecast before Harvest (40 Days from Full Emergence) | Data Range |
| INSO | insolation sum [h] in the periods: planting—June 20, | 275.3–711.7 |
| TEMP | average daily air temperature [°C] in the periods: planting—20 June | 10.8–15.7 |
| PREC | precipitation [mm] in the periods: planting—20 June | 38.7–258.2 |
| NITRO | sum of nitrogen fertilization [kg∙ha−1] in the periods: planting—20 June | 80–155 |
| PHOSP | sum of phosphorus fertilization [kg∙ha−1] | 28.2–150 |
| POTAS | sum of potassium fertilization [kg∙ha−1] | 80–306.5 |
| PLANT | planting date [number of days since the beginning of the year] | 107–127 |
| EMERG | date of emergence [number of days since the beginning of the year], yield forecast 20th of June | 130–151 |
| DENST | densification [plants/plot], yield forecast June 20 | 35–60 |
| PH | Soil pH [in 1 mol KCl] | 5.8–7 |
| SFERTP | soil fertility in phosphorus [mg P2O5∙100 g−1 soil] | 14–26.2 |
| SFERTK | soil fertility in potassium [mg K2O∙100 g−1 soil] | 11.7–19.2 |
| SFERTM | soil fertility in magnesium [mg Mg∙100 g−1 soil] | 3–9.1 |
| YIELDP1 | tuber yield [t∙ha−1 ], harvest 40 days from full emergence | 11.6–41.3 |
| Factor | RY1: r = 0.729 R2 = 0.532 Free Term = −151.714 | |||||
|---|---|---|---|---|---|---|
| b | Standard Error b | Beta | Standard Error Beta | p | Significance | |
| PREC | 0.038 | 0.009 | 0.195 | 0.049 | 0.000103 | + |
| INSO | 0.025 | 0.004 | 0.339 | 0.064 | 0.000000 | + |
| TEMP | −0.541 | 0.332 | −0.097 | 0.059 | 0.105023 | − |
| NITRO | 0.087 | 0.016 | 0.257 | 0.048 | 0.000000 | + |
| PHOSP | 0.016 | 0.017 | 0.057 | 0.061 | 0.347699 | − |
| POTAS | 0.004 | 0.005 | 0.032 | 0.052 | 0.522928 | − |
| PLANT | 1.604 | 0.138 | 0.859 | 0.074 | 0.000000 | + |
| EMERG | −0.509 | 0.096 | −0.341 | 0.064 | 0.000000 | + |
| DENST | 0.414 | 0.176 | 0.104 | 0.044 | 0.019452 | + |
| PH | 3.349 | 0.632 | 0.291 | 0.054 | 0.000000 | + |
| SFERTP | 0.287 | 0.059 | 0.225 | 0.046 | 0.000002 | + |
| SFERTK | −0.224 | 0.086 | −0.141 | 0.054 | 0.009887 | + |
| SFERTM | −0.418 | 0.163 | −0.188 | 0.074 | 0.011268 | + |
| NY1 | |
|---|---|
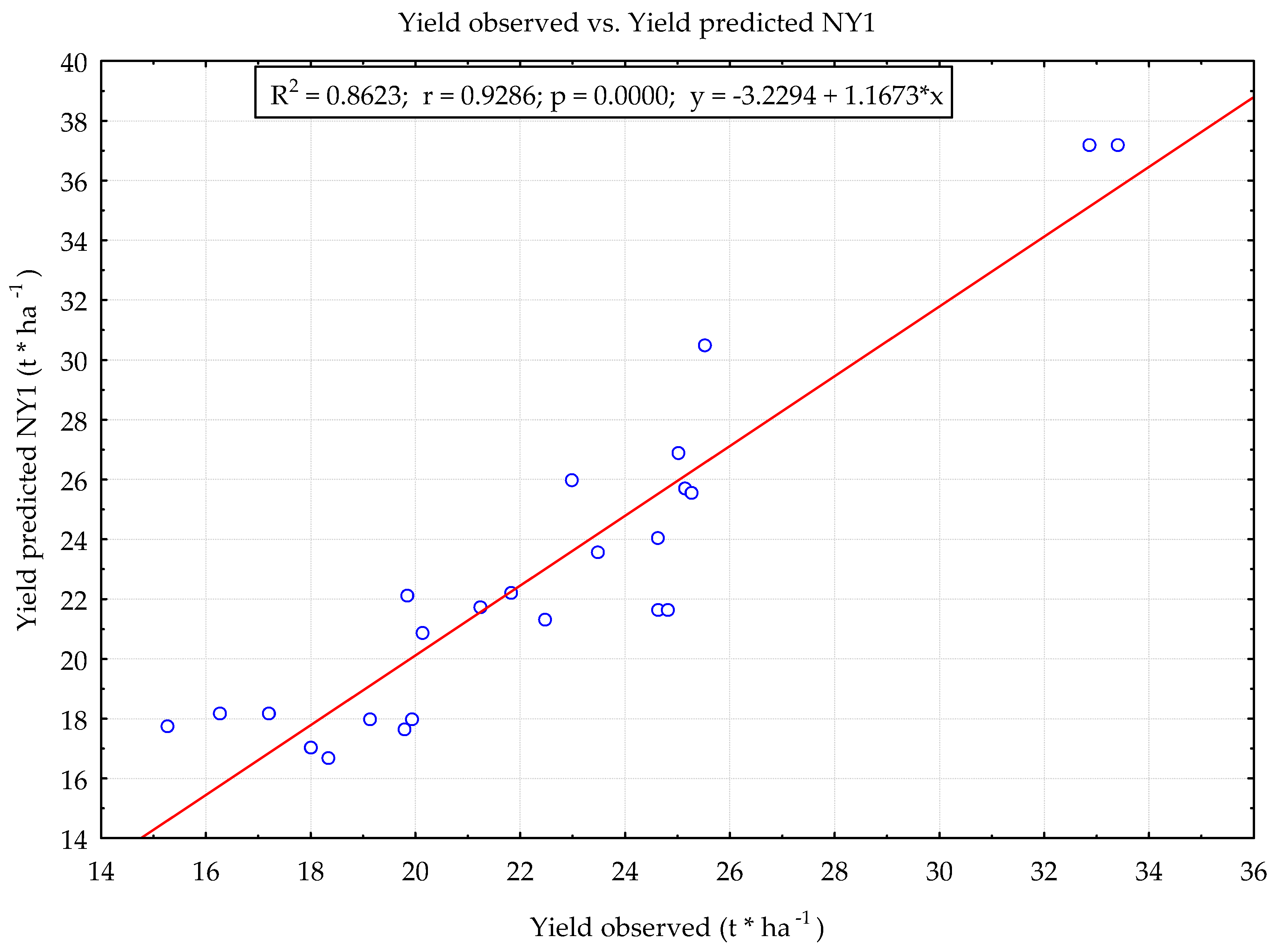
| Neural network structure | MLP 13:13-20-10-1:1 |
| Learning error | 0.065 |
| Validation error | 0.084 |
| Test error | 0.104 |
| Mean | 23.417 |
| Standard deviation | 6.541 |
| Average error | −0.008 |
| Deviation error | 2.978 |
| Mean Absolute error | 2.241 |
| Quotient deviations | 0.455 |
| Correlation coefficient—r Determination coefficient—R2 | 0.891 0.793 |
| Error Type | Model | |
|---|---|---|
| RY1 | NY1 | |
| RAE [–] | 0.995 | 0.099 |
| RMS [t∙ha−1] | 21.407 | 2.121 |
| MAE [t∙ha−1] | 3.137 | 1.626 |
| MAPE [%] | 15.667 | 7.203 |
| VARIABLE | PREC | INSO | TEMP | NITRO | PHOSP | POTAS | PLANT | EMERG | DENST | PH | SFERTP | SFERTK | SFERTM |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| QUOTIENT | 1.2 | 1.24 | 1.21 | 1.41 | 1.13 | 1.07 | 1.79 | 1.57 | 1.01 | 1.20 | 1.16 | 1.291 | 1.23 |
| RANK | 7 | 5 | 9 | 3 | 11 | 12 | 1 | 2 | 13 | 8 | 10 | 4 | 6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Piekutowska, M.; Niedbała, G.; Piskier, T.; Lenartowicz, T.; Pilarski, K.; Wojciechowski, T.; Pilarska, A.A.; Czechowska-Kosacka, A. The Application of Multiple Linear Regression and Artificial Neural Network Models for Yield Prediction of Very Early Potato Cultivars before Harvest. Agronomy 2021, 11, 885. https://doi.org/10.3390/agronomy11050885
Piekutowska M, Niedbała G, Piskier T, Lenartowicz T, Pilarski K, Wojciechowski T, Pilarska AA, Czechowska-Kosacka A. The Application of Multiple Linear Regression and Artificial Neural Network Models for Yield Prediction of Very Early Potato Cultivars before Harvest. Agronomy. 2021; 11(5):885. https://doi.org/10.3390/agronomy11050885
Chicago/Turabian StylePiekutowska, Magdalena, Gniewko Niedbała, Tomasz Piskier, Tomasz Lenartowicz, Krzysztof Pilarski, Tomasz Wojciechowski, Agnieszka A. Pilarska, and Aneta Czechowska-Kosacka. 2021. "The Application of Multiple Linear Regression and Artificial Neural Network Models for Yield Prediction of Very Early Potato Cultivars before Harvest" Agronomy 11, no. 5: 885. https://doi.org/10.3390/agronomy11050885
APA StylePiekutowska, M., Niedbała, G., Piskier, T., Lenartowicz, T., Pilarski, K., Wojciechowski, T., Pilarska, A. A., & Czechowska-Kosacka, A. (2021). The Application of Multiple Linear Regression and Artificial Neural Network Models for Yield Prediction of Very Early Potato Cultivars before Harvest. Agronomy, 11(5), 885. https://doi.org/10.3390/agronomy11050885